
Abstract
The Web of Data, and in particular Linked Data, has seen tremendous growth over the past years. However, reuse and take-up of these rich data sources is often limited and focused on a few well-known and established RDF datasets. This can be partially attributed to the lack of reliable and up-to-date information about the characteristics of available datasets. While RDF datasets vary heavily with respect to the features related to quality, provenance, interlinking, licenses, statistics and dynamics, reliable information about such features is essential to enable dataset discovery and selection in tasks such as entity linking, distributed query, search or question answering. Even though there exists a wealth of works contributing to the task of dataset profiling in general, these works are spread across a wide range of communities. In this survey, we provide a first comprehensive overview of the RDF dataset profiling features, methods, tools and vocabularies. We organize these building blocks of dataset profiling in a taxonomy and illustrate the links between the dataset profiling and feature extraction approaches and several application domains. This survey is aimed towards data practitioners, data providers and scientists, spanning a large range of communities and drawing from different fields such as dataset profiling, assessment, summarization and characterization. Ultimately, this work is intended to facilitate the reader to identify the relevant features for building a dataset profile for intended applications together with the methods and tools capable of extracting these features from the datasets as well as vocabularies to describe the extracted features and make them available.
Introduction
The Web of Data, and in particular Linked Data [8], has seen tremendous growth over the past number of years, leading up to the availability of a large amount of RDF datasets1
For readability, we use the terms “RDF dataset” and “dataset” interchangeably within this survey.
Given this scale, the discovery of suitable RDF datasets, which satisfy specific criteria, has become a challenging problem for a variety of applications including entity linking, entity retrieval, distributed search, query federation, and question answering, just to name a few. This prevalent problem is underlined by the strong bias towards using established and well-known reference knowledge graphs such as DBpedia [3], YAGO [70] or Wikidata,3
In the context of this survey, an RDF dataset is defined in accordance with the dataset definition in the Vocabulary of Interlinked Datasets (VoID),4
A number of popular dataset registries have emerged, which tackle the problem of dataset discovery through the curation of lightweight dataset descriptions, often also exposing structured metadata according to the state-of-the-art vocabularies such as DCAT6
On the one hand, as the Web of Data as a whole is evolving along with the constant evolution of individual datasets, manual assessment and representation of a large variety of dataset features is neither feasible nor sustainable. On the other hand, a wide variety of competing as well as complementary approaches exist, aimed at automatic assessment and description of arbitrary datasets. This body of work is spanning several research communities and includes works in fields such as dataset characterisation, data summarisation, dataset assessment or dataset profiling. While the problem of dataset profiling is of particular importance in the context of the Web of Data, it has been identified and approached already in other related fields, such as general database and data management research. Emerging from the aforementioned works, a wealth of tools, methods, vocabularies and applications for assessing, describing and profiling datasets has become available throughout the past few years, where a comprehensive overview and classification is still missing. Myriads of terms and notions do co-exist, whereas a clear distinction, classification and comparison is still required. Only recently, some first efforts have been made to bring together such disparate yet closely related fields, e.g. in [20].
The aim of this survey is to provide researchers, dataset providers and application developers with an overview of dataset profiling and closely related approaches, including dataset profile features, feature extraction methods and tools, vocabularies, and example applications to encourage experimentation and facilitate the broader use of RDF datasets. Being the first comprehensive study in this area, we provide a thorough analysis and definition of related terms and typical dataset profile features. Furthermore, we provide a systematic study of the available methods and tools for assessing and profiling structured datasets, and survey state-of-the-art vocabularies for representing dataset profiles.
While some of the discussed works are dedicated to profiling RDF datasets in particular, works of relevance from other related fields are also discussed. In this survey we address domain-agnostic dataset profiling approaches (e.g., the Linked Data Observatory [25]) as described in Section 4, and RDF-based vocabularies for representing resource metadata, such as general metadata, quality, provenance, links, licensing, statistics and dynamics, which are applicable to datasets as a particular kind of resource on the Web as described in Section 5. It should be noted that domain-specific vocabularies (e.g., Medical Subject Headings (MESH)10
In summary, in this survey we provide the following contributions:
A taxonomy of dataset profile features, including “general”, “qualitative”, “provenance”, “links”, “licensing”, “statistical” and “dynamics” feature categories;
A systematic overview of dataset profile feature extraction approaches and tools and their discussion in the context of the taxonomy;
An overview and a classification of available vocabularies for representing dataset features and profiles according to the taxonomy;
An illustration of the use of dataset profiles in several application scenarios.
The remainder of the survey is organized as follows: In Section 2, we present the methodology adopted to collect and organise the publications included in this survey. Next, we provide a comprehensive set of commonly investigated dataset features (Section 3), based on the existing literature and organize these features into a taxonomy. Then, we provide an overview of the existing approaches and tools for the automatic extraction of dataset profile features (Section 4), followed by an overview of existing RDF vocabularies for the representation of certain dataset profiles and features (Section 5). Where feasible, we also provide suggestions on vocabulary use and offer vocabulary recommendations suitable for representing particular dataset profile features. We conclude by exemplifying subsets of features considered relevant in selected application scenarios in Section 6, and have a final discussion in Section 7.

Survey methodology workflow.
In this section, we present the methodology adopted to select the publications discussed in this survey. The stages of the survey process are depicted in Fig. 1 and described in the following.
Terminology, taxonomy and search process
As a starting point, we identified a basic terminology of dataset profile features, from which we extracted keywords that were potentially relevant for the scope of this survey, such as profiling, dynamicity, quality, index, etc. These keywords were defined and embedded into a taxonomy, which guided the overall study. The taxonomy was iteratively refined throughout the process. During the review process, we updated the taxonomy and consequently further modified the keywords by both including or excluding relevant features. The extracted keywords from the taxonomy were used individually and in combination to query several online databases and search engines (Fig. 1). For example, we used keywords and multiword expressions to build the following combinations: {Semantic Web, Linked Data, Linked Open Data (LOD), …} × {profiling, dynamicity, quality, index, …}.
Literature review
Each category of the resulting taxonomy covers a range of works in the Semantic Web and related fields and would potentially deserve a dedicated survey. In this survey, we provide a pivotal guide for readers to obtain a global view on the various dataset profile features illustrated by examples. For this purpose, we focused our review on key approaches established in each category of the taxonomy, while providing examples for: (i) The identification of the feature extraction methods and tools (Section 4); (ii) The identification of vocabularies for dataset profile representation (Section 5); and (iii) The illustration of some application-driven profiles (Section 6).
Overview of selected publications
By applying the selection and review procedure described in Section 2.1, we obtained a list of 85 publications ranging from 1993 to 2017 with about
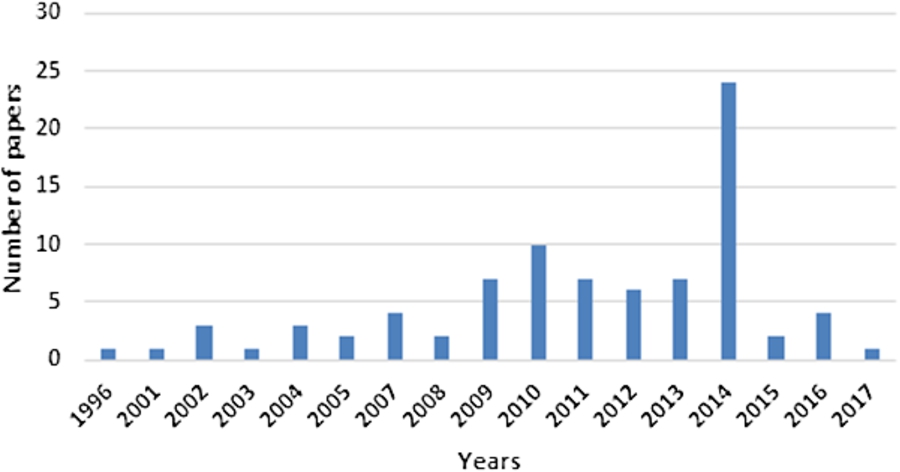
Referenced papers per year.
Information Processing and Management (IPM) [5]. Australasian Medical Journal (AMJ) [48]. Transactions of the Association for Computational Linguistics (TACL) [52]. International Journal on Semantic Web and Information Systems (IJSWIS) [8,20,60]. Foundations and Trends in Web Science (FTWEB) [51]. Journal of Management Information Systems (JMIS) [80]. Cybernetics and Systems (CAS) [74]. Journal of Data and Information Quality (JDIQ) [54].
Conference Proceedings
International Semantic Web Conference (ISWC) [3,26,33,38,41,55,67,72,83]. International World Wide Web Conference (WWW) [10,13,15,35,47,62,69,70]. International Conference on Knowledge Engineering and Knowledge Management (EKAW) [4,28,30]. IEEE International Conference on Data Engineering (ICDE) [1]. Extended Semantic Web Conference (ESWC) [22,25,32,40,44,65,68,79,81]. Conference on Spatial Information Theory (COSIT) [43]. International Conference on eDemocracy and eGovernment (EGOV) [49]. Association for the Advancement of Artificial Intelligence (AAAI) [71]. IEEE International Conference on Future Internet of Things and Cloud (FiCloud) [76]. Joint International Conference on Extending Database Technology and International Conference on Database Theory (EDBT/ICDT) [50]. Annual Meeting of the Association for Computational Linguistics (ACL) [64]. International Conference on Web Intelligence, Mining and Semantics (WIMS) [56].
Workshop Proceedings
Workshop on Linked Data on the Web (LDOW) at WWW [2,17,19,37,45,77]. International Conference on Data Engineering Workshops (ICDEW) [12]. Workshop on PROFIling & fEderated Search for Linked Data (PROFILES) at ESWC [23,27,78]. International Workshop on Consuming Linked Data (COLD) [21,31]. International Workshop on Linked Web Data Management (LWDM) [29]. Workshop on Linked Data Quality (LDQ) at I-Semantics [34]. STI Berlin & CSW PhD Workshop (STI&CSW) [36]. Workshop on Ontology and Semantic Web Patterns (WOP) [39]. Workshop on Scripting and Development for the Semantic Web (SFSW) [58]. International Workshop on Debugging Ontologies and Ontology Mappings (WoDOOM) at ESWC [59]. On the Move to Meaningful Internet Systems Workshops (OTM) [73].
Magazines
Communications of the ACM [61].
Books
Felix Naumann. Quality-driven Query Answering for Integrated Information Systems. Springer-Verlag. 2002. [53].
PhD theses
W3C recommendations
OWL Web Ontology Language Reference:
RDF Schema 1.1: https://www.w3.org/TR/rdf-schema.
Data Catalog Vocabulary (DCAT):
SKOS Simple Knowledge Organization System Reference:
The RDF Data Cube Vocabulary:
PROV-O: The PROV Ontology:
PROV-DM: The PROV Data Model:
Overall, in this survey, we aim to give the reader a bird’s-eye view of the RDF datasets profiling problem (whether or not referred to explicitly by using this term), while providing some examples of a worm’s-eye view, especially in terms of feature extraction methods, vocabularies for dataset profile representations and application-driven profiles.
Dataset profiling: Features and taxonomy
This section provides an inventory of dataset features of relevance to dataset profiling. The features identified in the literature are grouped in an extensible feature taxonomy, which provides a categorization system for the purpose of this survey. This taxonomy reflects the authors’ consensus and provides one way (of several feasible ones) to structure the profiling features.
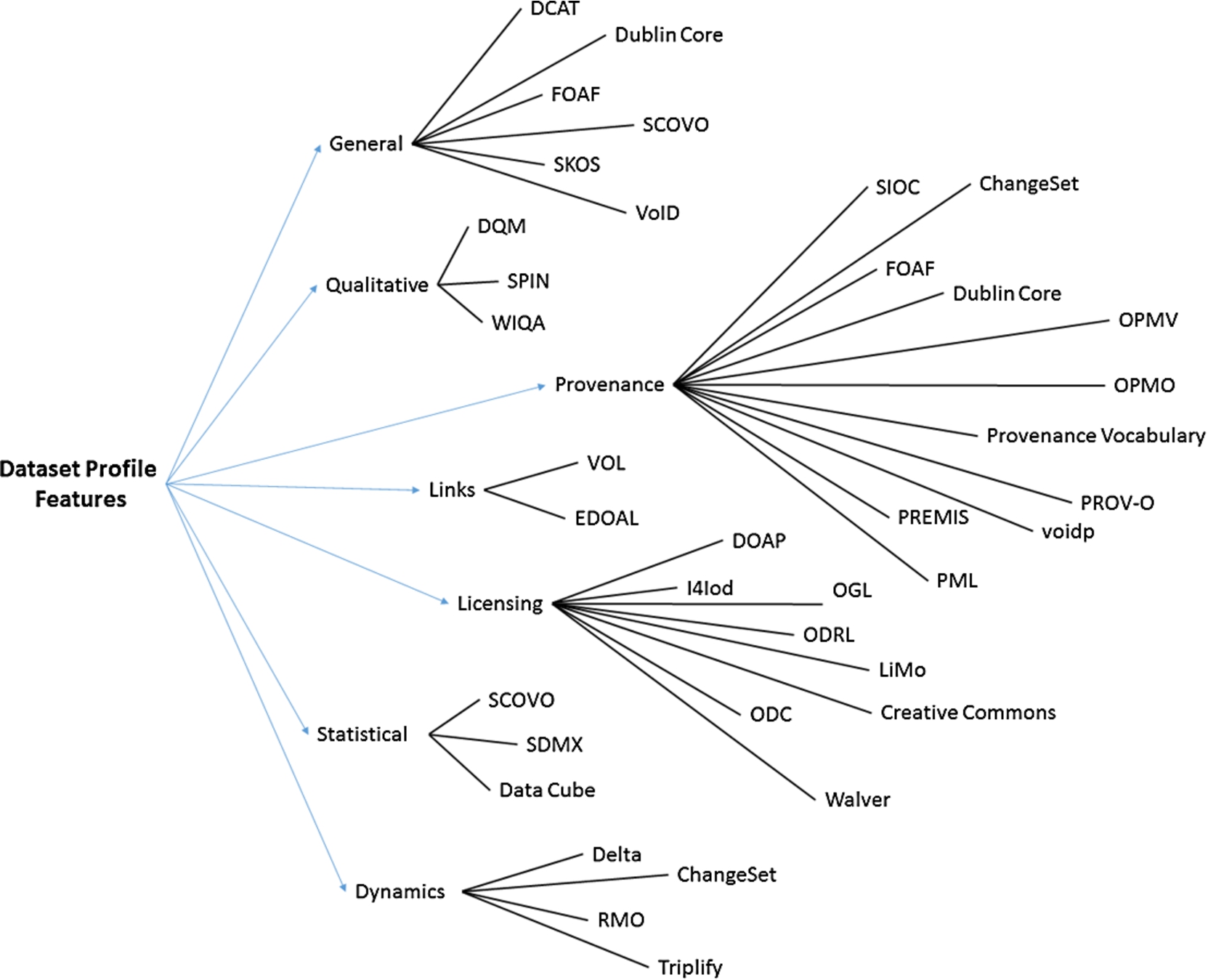
In particular, we propose to organise the features into the following top-level categories: “General”, “Qualitative”, “Provenance”, “Links”, “Licensing”, “Statistical” and “Dynamics”. This feature categorization guides the categorization of profiling tools and vocabularies in the subsequent sections.
Fig. 3 depicts the resulting taxonomy including references to instances of feature extraction systems (discussed in more detail following the taxonomy structure in Section 4). Although we do not discuss the measurements for the different dataset features in detail within this survey, they partially follow from the definition of a particular feature (e.g., in case of statistical features) or have been extensively discussed in the literature (e.g., qualitative features in [85]).

A taxonomy including dataset profile features organized into General, Qualitative, Provenance, Links, Licensing, Statistical and Dynamics categories (arrows) as well as links to the corresponding feature extraction systems (lines).
General features are dataset profile features carrying high-level semantic information (e.g., domain and topic of the dataset) that do not fit into any of the more specific categories defined in this survey.
Qualitative features
The study of data quality has a strong and ongoing tradition in the computer science community at large, and in particular, with respect to Web data and data reuse. According to [80], data quality is generally conceived as fitness for use, i.e. the capability of data to respond to the demands of a specific user given a specific use case. Data quality has multiple dimensions, and many of them cannot be evaluated in a task-independent manner.
In the context of Linked Data, Bizer et al. [7] classified data quality metrics into three groups according to the type of information that is used as a quality dimension: (i) Content-based metrics – analyzing the information content or comparing information to related information; (ii) Context-based metrics – employing meta-information about the information content and the circumstances in which information was claimed; and (iii) Rating-based metrics – relying on explicit ratings about the information itself, information sources, or information providers. Zaveri et al. [85] identified further dimensions and reorganized the quality dimension into four groups: (i) Accessibility; (ii) Intrinsic; (iii) Contextual; and (iv) Representational. Another approach to assess metadata quality can be found in [54], monitoring the quality of 259 Open Data portals (as of May 2017) classified in five quality dimensions: existence, conformance, retrievability, accuracy and openness.
In this work, we collected commonly used qualitative features and re-arranged them into the following categories: (1) Trust; (2) Accessibility; (3) Representativity; and (4) Context/Task Specificity.
Provenance features
A variety of definitions have been given for provenance over the past number of years. One very pragmatic definition comes from the W3C Provenance Working Group,12
“Links” here is understood as the number of datasets with which a dataset is interlinked, or as the number of triples in a dataset, in which the subject and the object refer to different datasets. Two datasets can be linked through: (i) explicit links when they have linked instances, for example when sharing instances by using owl:sameAs13
Here, we adopt the recommendation of Heath et al. [41]: “in order to enable information consumers to use your data under clear legal terms, each RDF document should contain a license, under which the content can be used”. In other words, the type of license, under which a dataset is published, indicates whether reproduction, distribution, modification or redistribution are permitted. This can have a direct impact on data quality, both in terms of trust and accessibility. Hence the availability of license information is important in both human-readable and machine-readable profiles (i.e. including the description in a license vocabulary, Section 5.5).
Statistical features
This group of features comprises a set of statistical features, such as size, coverage, average number of triples, property co-occurrence and others [4,27].
Dynamics features
This class of features concerns the dynamicity of a dataset. In principle, every dataset feature can be dynamic, i.e. changing over time (think, for example, of data quality). Inversely, the dynamics of a dataset can be seen as a separate feature describing data (take the example of the dynamics of data quality). For that reason, this family of features is seen as transversal (spanning over the groups of features described above). Käfer et al. [45] provide a study of LOD dynamicity use cases, based on which we identify the following sub-categories:
Dataset profiling and feature extraction methods & tools
The field of dataset profiling and feature extraction is comprised of a broad range of tools, and is much too extensive to fully cover here. Therefore, we provide examples of relevant dataset profiling approaches for each category of features, as introduced in the previous section (Fig. 3). We describe these approaches according to their respective categories below.
General features
General features, presented in Section 3.1, include “Domain/Topic”, “Contextual Connectivity”, “Index Elements” and “Representative Elements”. In the following, we present a selection of tools that support feature extraction in this category.
As discussed in Section 3, in this survey we focus on selected groups of qualitative features such as trust, accessibility, representativity, and context, which are most relevant in the context of dataset profiling. In the following, we discuss a selection of relevant tools for these groups. Note that a broader overview of the quality assessment approaches in the context of Linked Data in general is provided by Zaveri et al. [85], who conducted an extensive survey of 21 works.
Annotation Canonicalization through Expression synthesis.
Links features
Licensing features
In this survey we consider statistical feature extraction approaches at both schema and instance level, as defined in Section 3.6.
PubSubHubbub is a decentralized real-time web protocol that delivers data to subscribers when they become available. Parties (servers) speaking the PubSubHubbub protocol can get near-instant notifications when a topic (resource URL) they are interested in is updated.
Dataset profile feature extraction methods: Homepages (checked on February 2017); Accessibility that can be Open Source (O.S.) or Online (via SPARQL Endpoint or via HTTP API, etc.); and Human readability (H) vs. Machine readability (M)
We would like to highlight several issues regarding the dataset profile extraction methods that we observed in the survey process. First, for “General” features, these typically require domain knowledge with respect to the content of the dataset. As a best practice, we recommend that the general category should be provided by the data domain experts (e.g., data providers or maintainers) to ensure a high quality profile. Second, profile features like “Provenance” and “License” are meant to be augmented manually by the data provider and cannot be derived automatically. Third, we consider that “Qualitative”, “Links”, “Statistical” and “Dynamics” profile features would in general require less domain expertise and can be extracted automatically by applications in many cases. Furthermore, we observe an obvious need for more general profile extraction tools, notably for the “Domain/Topic” and “Contextual Connectivity” general features, where only a few automatic extraction approaches exist.
Regarding the dynamics aspects of a dataset, in order to ensure that profiles are not out of date, they need to be regenerated periodically and regularly, according to the dataset dynamicity. Dataset versioning and archiving also requires versioning and archiving of the corresponding profiles in order to ensure coherence between the dataset snapshots and their profile versions.
Finally, we emphasize the fact that RDF dataset profiles need to provide representations for both human and machine readability. Hence, in Table 1, we provide an overview of the dataset profiling methods with respect to their representation formats and we verify for each method if the extracted profile features are designed for humans or machines (or both). In addition, the table provides links to the webpages for each method.
Vocabularies for representation of dataset profiles and features
This section introduces vocabularies for the representation of dataset profiles, structured according to the profiles feature categories. These vocabularies are depicted in Fig. 4, ranging from general dataset metadata to vocabularies dedicated to one or more of the features introduced in Section 3. Note that general-purpose vocabularies such as Dublin Core22
A range of vocabularies exist, which can be used to provide more general metadata about datasets or ontologies, where Dublin Core is an obvious candidate to represent metadata about any resource, including datasets.
While the Ontology Metadata Vocabulary (OMV) [39] is aimed at providing descriptive information about ontologies – specifically their creators, contributors, reviewers, and creation/modification dates – here we focus specifically on dataset metadata vocabularies.
Adoption of VoID across LOD Datasets per Category
*
Adoption of VoID across LOD Datasets per Category *
Taken from the 30/08/2014 snapshot of the LOD cloud available at
The Vocabulary of Interlinked Datasets (VoID) [2] provides a core vocabulary for describing datasets and their links. The schema23
The Data Catalog vocabulary (DCAT)27
Early works by Supelar et al. in [71] define a set of knowledge quality features applicable for knowledge graphs, respectively ontologies, and a corresponding ontology. Their features are classified into quantifiable and non-quantifiable characteristics and include characteristics such as usability, availability, accuracy, or complexity. The suggested ontology, however, only includes a higher level taxonomy, but neither a fully fledged vocabulary for annotation nor a specific set of metrics to quantify the quantifiable metrics.
Fürber et al. [29] describe the DQM Ontology,28
Data Quality Assessment as an abstract container of scores and metrics describing class/property quality aspects.
Completeness, derived into: Property Completeness as a measure of the degree to which properties are consistently populated; and Population Completeness as the degree to which all objects of a certain reference are represented in a specific class.
Accuracy as a notion representing the degree to which a statement captures the intended semantics and syntax (subtypes are Syntactic Accuracy and Semantic Accuracy).
Uniqueness of properties and entities is introduced to capture the existence of duplicates.
Timeliness captures the recency of a specific statement/entity.
The authors also introduce a preliminary classification for data quality problems.
In addition, the Web Information Quality Assessment (WIQA) Framework29
Another one worth mentioning is the work in [28], where the authors use the SPARQL Inferencing Notation (SPIN) – a vocabulary that allows the representation of SPARQL queries – to represent data quality rules.
Additionally, the Dataset Quality vocabulary (daQ)30
Finally, while provenance information often provides indicators about timeliness, currency and update cycles of datasets, Section 5.3 introduces additional vocabularies of relevance.
A provenance record is essentially a record of metadata that details the entities and processes that were involved in creating, modifying and delivering a resource, be it physical or digital. Such records include details about when an item was created, what were the original sources of information used in its creation, what kind of evolution has the resource undergone (e.g., what were the other entities or processes that may have modified the resulting piece of information). Moreau [51] states that “the provenance of a piece of data is the process that led to that piece of data”.
This section describes some of the main provenance models used on the Web, some of which have specific applicability in terms of whole datasets.
From the perspective of archiving and long-term preservation of data, the
Inspired by the notion of changesets in code or document revisions, the
The
The
The
The
The
As well as the above vocabularies that are specifically designed to facilitate provenance and related primitives, there are a number of commonly-used vocabularies and de-facto standards on the Web that also contain terms of relevance to provenance derivation and definition. These include Dublin Core (DC), Friend-of-a-Friend (FOAF), and Semantically Interlinked Online Communities (SIOC). Some of these terms were highlighted by [37], and we outline these and others below. Since a dataset can be identified by a resource, we can use many of the properties described below with full datasets as well as individual resources or pieces of data in those datasets.
In addition to the “SIOC Core” ontology terms, there are also SIOC modules which can be used in provenance descriptions for datasets. The most relevant is the
Overview of relevant vocabularies as classified by type of dataset profile features. The figure is based on January 2017 statistics.
Links as important features of Linked Data datasets are represented through a variety of means, covering both schema-level and entity-level links. VoID, for instance, includes specific linksets which can be instantiated to define metadata about a dataset’s links. SKOS,40
A more specific approach is followed by the Vocabulary of Links (VoL),41
The Expressive and Declarative Ontology Alignment Language (EDOAL)42
This section examines vocabularies available to assist with representing licenses of data and datasets. These include RDF versions of common licensing frameworks and alignments of multiple licensing frameworks into a combined vocabulary. In addition to the dedicated licensing vocabularies stated below, general resource metadata vocabularies provide basic features to indicate licensing information. This includes the DCMI Metadata Terms,43
The
The
The
A range of vocabularies exist, which partially support the representation of dataset statistics and can be used in conjunction with general dataset metadata vocabularies such as VoID or DCAT. These include, for instance, the RDF Data Cube vocabulary,54
The VoID guidelines, for instance, recommend the use of SCOVO to share statistical dataset features [2]. There can be statistics concerning the whole dataset or linkset, such as triple count, and others attributing statistics to a source, to capture where a statistical datum stems from. SCOVO, also described by Hausenblas et al. [40], is an earlier, native RDF vocabulary for statistical data, consisting of three main classes, Dataset, Dimension, and Item. While there exist efforts to merge SCOVO and SDMX-RDF [17], both approaches are superseded by the Data Cube vocabulary, which represents the state of the art in representing statistical data on the Web.
The RDF Data Cube vocabulary,57
While the Data Cube vocabulary builds on SKOS, its Data Cubes approach originates from and is compatible with the cube structure underlying the SDMX (Statistical Data and Metadata eXchange) information model. The latter is an ISO standard, describing an information model for exchanging statistical data and metadata which has been serialised into XML, EDI and recently, RDF. SDMX-RDF59
Auer et al. present LODStats [4], a framework for dataset analytics, which introduces a set of 32 statistical features and uses the most recommended combination of VoID and the Data Cube vocabulary. Links between the Data Cube class qb:Observation and the void:Dataset class are represented using a native property (void-ext:observation). While VoID already represents properties for several statistically described objects (triples, classes, distinctSubjects, etc.), additional features were represented using void:classPartition and void:propertyPartition. While this approach combines two state of the art vocabularies for general dataset metadata (VoID) and statistical data (Data Cube), it turns out to be quite a future-proof approach to capture statistical dataset metadata.
While there does exist a wealth of methods for assessing characteristics related to the dynamics and evolution of datasets, as illustrated in earlier sections of this survey, most vocabularies in this area are dedicated to representing the actual evolution of a dataset, rather than higher level observations about dynamics.
The Dataset Dynamics group60
In a similar direction is the recent work of Graube et al. [34] on R43ples, a revision management approach for RDF datasets using named graphs for capturing revisions and SPARQL for manipulation of the latter. Authors introduce the so-called Revision Management Ontology (RMO) based on PROV-O (Section 5.3). While RMO implements baseline revision management notions for data graphs, it is of lesser relevance for the purposes of this section.
A more abstract approach is offered by the Dataset Dynamics (DaDy) vocabulary,64
For capturing specific features and observations related to dynamics and evolution, beyond the ones covered by the vocabularies above, some of the vocabularies mentioned in Section 5.6 (for representing statistical dataset features) may also be closely related to dynamics.
We use the LOD2 Stats service65
Where multiple entries exist for a vocabulary on LOD2 Stats, we use the numbers from the largest entry rather than adding usage figures together, as modules in a vocabulary may be used together in the same dataset, e.g., DC Terms and DC Elements, or SDMX Dimension and SDMX Measure).
Overall usage and dataset counts for the aforementioned vocabularies, sorted by number of datasets in February 2015. Those numbers in
While our quantitative assessment indicates mere usage of a particular vocabulary, it does not provide any insights into the way a vocabulary has been used in particular scenarios. In addition, it is worth noting that particular features, for instance, license information, are often represented through a variety of means, which may not be captured by the vocabularies identified here [42,67].
While we were unable to filter the instances of dataset profiling-specific terms from our suggested vocabularies while examining their usage statistics in LOD2, we can gain some insight into which ones may be more widely adopted by looking at the existing overall statistics and dataset usages, especially over time, i.e., from 2015 to 2017, we can see which vocabularies are consistently being used and are growing in usage). It is reasonable to assume that users will be more willing to adopt terms from widely-used vocabularies for representing dataset profiles, as long as they are fit for purpose. We note that for many of the vocabularies that have changing numbers of datasets and triples over time, there can be somewhat conflicting numbers (e.g. for SKOS, VoID, etc. where the number of datasets increases but the number of triples decreases, sometimes by an order of magnitude). We consider that this can be explained by the removal of a particular dataset/website that has a particularly high number of triples of a particular type, or by the adoption of a new vocabulary/removal of a particular vocabulary for a set of triples on a website.
251 datasets used RDF syntax in 2015 (increasing to 1,718 in 2017), giving us an overall total. From the data in Table 3, we observe that general metadata about the datasets is readily provided, but that more specific information on provenance and statistics using specialised vocabularies is only available in somewhere around 22% (55) and 10% (25) of datasets in 2015 respectively (in 2017, these numbers reduced to 2% (36) and 5% (87) for provenance and statistics respectively).
Another observation is that none of the quality or dynamics and evolution vocabularies appear in LOD2 Stats. That points to a significant under-utilization of terms relating to dataset quality, the evolution of a dataset, or the dynamics involved in a changing dataset. The assumption is that dataset creators are more interested in providing the datasets themselves without giving assurances to others who may want to use them about their quality or how they have changed over time.
It does not seem from Table 3 that many datasets are explicitly licensed via some machine-readable form, with just 5% (12) in 2015 and 1% (21) in 2017 containing Creative Commons metadata. However, according to work by [33], 95% of the datasets in the LOD cloud67
Dataset profiles are highly important for a wide variety of cross-domain applications, for example, data linking and curation, schema inference, federated query and search, as well as question answering. In this section, we highlight important applications from these domains that use dataset profiles along with their relevant profile features. Some of these applications can use, verify and update dataset profile features (e.g., including statistical characteristics of datasets) and may in turn generate additional statistics that can become part of the dataset profile. The list of the applications and relevant features presented in this section aims to illustrate the use of dataset profiles by state-of-the-art tools and is not exhaustive.
Data linking applications
Data linking applications aim to annotate, disambiguate and interlink entities and events in text using Natural Language Processing (NLP) techniques and external sources including Linked Data. In this context, popular services include DBpedia Spotlight [18], Illinois Wikifier [64] as well as Babelfy [52].
Example features for data linking applications: Data linking applications typically use the general features discussed in Section 3.1 such as topics, domains, as well as representative schema elements and instances.
Data curation, cleansing and maintenance
As linked datasets are often generated from semi-structured or unstructured sources using automated extraction approaches, these datasets vary heavily with respect to quality, currentness and completeness of the contained information [84].
A number of recent works focus on statistical methods for: (1) outlier detection to detect errors in numerical values [26,60,81]; (2) automatic prediction of missing types of instances [60]; and (3) the identification of incorrect links between datasets [59]. A further line of research in Linked Data quality is related to the discovery of errors in the data based on existing interlinkings (e.g., [13,83]). Thereby some works go beyond error detection and attempt to automatically determine correct data values in case of inconsistencies [13]. As mentioned above, additional statistics generated by these approaches that can become part of the dataset profile.
Example features for error detection in numerical values: In [26] the authors detect errors in numerical values using outlier detection. To identify the properties to which numerical outlier detection can be applied, the following statistical characteristics (discussed in Section 3.6) are used:
total number of instances,
names of the properties used in the dataset,
frequency of usage with numerical values in the object position for each property, and
total number of distinct numerical values for each property.
Example features for conflict resolution in multilingual DBpedia: The features used in conflict resolution in [13] include provenance metadata at the statement, property and author levels. The temporal dataset profile includes in particular:
Recency of the specific statement (measured using the time of the last edit); Overall editing frequency of the property in the dataset; and The overall number of edits performed by the specific editor.
Schema inference
Many existing Linked Data sources do not explicitly specify schemas, or only provide incomplete specifications. However, many real-world applications (e.g., answering queries over distributed data [9]) rely on the schema information. Recently, approaches aimed at the automatic inference of missing schema information have been developed (e.g., [46,60]).
Example features for type inference: Statistical characteristics of datasets (see Section 3.6) play an important role in type inference applications. For example, in [60] statistics on the completeness of type statements as well as property-specific type distributions are required (i.e. the types of resources appearing in subject and object positions of each property including their frequencies).
Distributed query applications
The Linked Data Cloud can be queried either through direct HTTP URI lookups or using distributed SPARQL endpoints [35] that can include full-text search extensions (see e.g., [55]). Also combinations of both query paradigms are possible [38]. Typically, the first step of query answering over distributed data is the generation of ordered query plans against the mediated schema on a number of data sources [82]; In this step, dataset profiling plays an important role.
In order to guide distributed query processing, existing applications rely on indexes of varying granularity including Schema-level Indexes and Data Summaries. Schema-level Indexes contain information about properties and classes occurring at certain sources. Data Summaries use a combined description of instance- and schema-level elements to summarise the content of data sources [35]. The majority of existing federated query approaches for LOD (e.g., [31,35,38,79]) aim to optimize efficient query processing and do not (yet) take the quality parameters of LOD sources into account. Therefore, existing Data Summaries mostly contain frequencies and interlinking statistics of varying granularity.
Example features for efficient and quality-aware query applications: The majority of existing query applications rely on general and statistical characteristics (see Sections 3.1 and 3.6) at the schema-level, i.e. properties and classes occurring at certain sources for effective query interpretation. In addition, applications that optimize for efficient query processing require data-level statistics (including frequency and interlinking) either on triple level or for each subject, object and predicate individually [35]. Finally, quality-aware query applications also take into account qualitative characteristics (see Section 3.2) (e.g., completeness and accuracy) at different granularity levels. This includes overall data source statistics [53], as well as property-specific [66] and type-specific statistics [82].
Information retrieval (IR) applications
In IR, Linked Data is mostly used in the context of semantic search, a typical demonstration of which can be found in [24]. The majority of semantic search applications are domain-oriented; a large number of practical cases have been shown for repositories related to biomedical sciences. For example, the concept-based search mechanism [48] allows biologists to describe the topics of interest in a search more specifically and retrieve information with higher precision (in comparison to the usage of keywords only). It should be stressed here that concept-based search requires linking to high-quality external resources (such as, e.g. Unified Medical Language System – UMLS), which involves features related to trust, especially verifiability and believability.
Datasets providing semantic features enable us to go beyond the standard bag of words representation [74]. A wide range of methods based on linking to external, domain-oriented resources has been proposed, e.g., [64]. They also employ statistical features extracted from large-scale text corpora and allow one to expand the user queries to increase recall [5]. In addition, geographical and temporal contexts play an increasingly important role in IR applications. These contexts enable the retrieval of information that is relevant with respect to the spatial [43] and temporal [14] dimensions of the query.
Example features for Information Retrieval applications: IR involves qualitative profile features related to trust (i.e., verifiability and believability) and the accessibility of data. In addition, to facilitate semantic search, IR implies general profile features like topical domains and context.
Discussion
Overall, we observe that although existing applications make use of the whole spectrum of the dataset profile feature categories, including general, qualitative, statistical and dynamics features discussed in this survey, the concrete set of features is application-dependent and the whole set is rarely used within any single application. Whereas some applications rely on existing metadata, many applications compute dataset profile features as part of their own processing pipelines. These applications can thus directly contribute to the dataset profile generation.
Summary and conclusions
The availability of dataset profiles has the potential to improve data discovery and reuse on the Web. Remaining challenges and obstacles include the lack of Web-scale adoption of general standards, e.g., for representing profile features, and the lack of automated means for interpreting and using profile information as part of large-scale data reuse scenarios. This survey hence aims at raising the awareness and uptake of profiling techniques and vocabularies.
In this survey, we provided a comprehensive overview of dataset profiling features, methods, tools, vocabularies and applications. Given the complexity of the topic, we first focused on organizing the different dataset profile features in a taxonomy. We then provided a systematic overview of a large set of approaches and tools for assessing and extracting such features from RDF datasets. We reviewed the vocabularies for representing these features, preferably as Linked Data, and finally we discussed several prominent applications of dataset profiles.
Wherever feasible, we also provided insights into the adoption and impact of the discussed works; for instance, based on the profile extraction tools distribution in the provided taxonomy, we proposed that certain profile features, notably in the general category, should be provided by domain experts to ensure high quality profiles. Another observation concerned the vocabulary usage where some features, such as the quality or the dynamicity of vocabularies did not appear in the evaluated statistics. That led us to recommend that dataset providers need to guarantee a high confidence with respect to these profile features in order to ensure better access to their quality and dynamics.
We observed that although existing applications made use of the whole spectrum of the discussed feature categories, including general, qualitative, statistical and temporal features, the concrete set of features was application-dependent and the whole set was rarely used within any single application. Furthermore, we discussed the fact that many applications generated dataset profile features as a part of their own processing pipelines.
Finally, we strongly recommended that dataset profiles should provide representations readable for both humans and machines to open up the Web of Data to a wider variety of users and applications. Given the continuous evolution and expansion of the Web of Data, we assume that the problem of dataset profiling will become an even more prominent one, and corresponding methods will form a crucial building block for enabling the reuse and take-up of datasets beyond established and well-understood knowledge bases and reference graphs.
Footnotes
Acknowledgements
This paper was partially supported by COST (European Cooperation in Science and Technology) under Action IC1302 (KEYSTONE), Science Foundation Ireland under Grant Number SFI/12/RC/2289 (INSIGHT), the German Federal Ministry of Education and Research (BMBF) under Data4UrbanMobility (02K15A040), the Datalyse project![]()