
Abstract
RDF dataset profiling is the task of extracting a formal representation of a dataset’s features. Such features may cover various aspects of the RDF dataset ranging from information on licensing and provenance to statistical descriptors of the data distribution and its semantics. In this work, we focus on the characteristics sets profile features that capture both structural and semantic information of an RDF dataset, making them a valuable resource for different downstream applications. While previous research demonstrated the benefits of characteristic sets in centralized and federated query processing, access to these fine-grained statistics is taken for granted. However, especially in federated query processing, computing this profile feature is challenging as it can be difficult and/or costly to access and process the entire data from all federation members. We address this shortcoming by introducing the concept of a profile feature estimation and propose a sampling-based approach to generate estimations for the characteristic sets profile feature. In addition, we showcase the applicability of these feature estimations in federated querying by proposing a query planning approach that is specifically designed to leverage these feature estimations. In our first experimental study, we intrinsically evaluate our approach on the representativeness of the feature estimation. The results show that even small samples of just
Introduction
In recent years, the amount of information published as Linked Open Data has steadily increased as new RDF datasets are published and existing datasets are growing.1
In this work, we focus on the Characteristic Sets Profile Feature (CSPF) [17], which is a statistical feature of RDF datasets that includes the characteristic sets, their occurrence distribution, and the multiplicity of their predicates. We focus on this particular profile features as an informative statistical characterization of RDF datasets due to the following reasons. First, CSPFs implicitly captures structural features of the data, such as the mean out-degree, distinct number of subjects, and the set of predicates including their counts. Second, characteristic sets implicitly reflect the schema of an RDF dataset as they capture semantic information on its entities. Finally, CSPFs are well suited to be leveraged by (decentralized) query planning approaches for cardinality estimations and other downstream tasks as they provide insights into the predicate co-occurrence. While the CSPFs provide rich information that is beneficial for various applications, obtaining the profile feature can be a challenging task. For instance, the federated query planning approach Odyssey [26] exploits information on the characteristic sets and how they are linked across datasets to estimate intermediate results when optimizing query plans. Yet, especially in federated query processing, it can be difficult and/or costly to access the entire RDF datasets of all members in the federation and, subsequently, compute these fine-grained statistics. First, data dumps are not always available in federated querying as data publisher may choose different Linked Data Fragments (LDFs) to publish their data [40]. For example, the datasets may only be partially accessed via SPARQL endpoints or Triple Pattern Fragment servers. Moreover, in the case of public resources, the statistics need to be obtained while respecting the fair use policies of the publisher [39]. Second, to build the characteristic sets for an RDF dataset requires scanning the entire dataset. This computational effort can be an additional restriction, especially for very large and evolving datasets, such as DBpedia2
Addressing these limitations, we propose an approach that estimates accurate statistical profile features based on characteristic sets and that relies only on a small sample of the original dataset. Our sample-based approach alleviates the necessity of having access to the entire dataset and also reduces the cost of computing the profile feature. Given an RDF dataset, our approach employs an entity-enteric sampling method and computes the characteristic sets of the entities to build the CSPF of the sample. Then, we apply a projection function to extrapolate the statistics observed in the sample to estimate the original dataset’s CSPF. As the statistics of the characteristic sets are sensitive to the structure of the datasets and the sample, this extrapolation step can be challenging. Take for example the following characteristic sets
In the remainder of this work, we assume prefixes as given in
LinkedMDB: Example characteristic sets
We observe that the characteristic set
RQ 1 Which steps are sufficient for accurately estimating RDF dataset profile features? First, we want to investigate how we can estimate profile features without requiring access to the entire dataset. In particular, we study which sampling methods are suitable to obtain a representative sample for the specific characteristic sets profile feature. Based on samples, we investigate how the information captured in the sample can be extrapolated to the original dataset. The goal of this research question is, therefore, to understand the impact of different sampling methods, sample sizes, and extrapolation techniques on the profile feature estimation.
RQ 2 How can we assess the effectiveness of estimated profile features? Given the original profile feature and an estimation, we need means to assess the accuracy of the estimation. As we focus on the characteristic sets profile features that capture various characteristics of the dataset, we investigate how the representativeness of an estimation with respect to those characteristics can be measured. Moreover, with this question, we also want to understand which characteristics are more difficult to estimate and how the structure of the original dataset impacts the estimations.
RQ 3 How can we leverage estimated profile features to support downstream applications such as federated query processing? This question aims to investigate how estimated profile features still support applications that rely on these features. As we focus on the characteristic sets profile feature, we consider applications that leverage this information and where the computation of the complete statistics may not be feasible. Therefore, we investigate how a federated query planning approach can leverage the estimated profile features. Specifically, we study how source selection, query decomposition, and join ordering is affected by different estimations. Finally, we want to understand to which extent the effectiveness of the estimation (c.f. ) is reflected in the performance of the query plans.
Contributions This paper builds on a previous work of ours [17], which focuses on a sampling-based approach for estimating characteristic sets for RDF dataset profiles. We extend this work regarding two major aspects. First, we expand our experimental evaluation about CSPF estimations by studying additional datasets and providing a more fine-grained analysis of the results. Second, we address a central aspect of the profile feature estimations, which is their application in downstream tasks. Particularly, we propose a novel federated query planning approach based on the profile feature estimations. Finally, we evaluate this approach in an experimental study. In summary, the novel contributions of this work are as follows.
An extensive experimental study of our Characteristic Sets Profile Feature estimation approach on eight new datasets,
a fine-grained analysis of the results to understand the effectiveness of our CSPF estimation approach and its components,
a new estimations-based query planner to showcase the application of the estimations in federated query processing,
an experimental study of our query planner on the well-known FedBench benchmark, and
a detailed evaluation of the results to understand the benefits and limitations of the query planner.
Structure of this paper The remainder of this work is organized as follows. In Section 2, we introduce RDF dataset profiling and present our problem definition for estimating profile features. We define characteristic sets profile features and present our sampling-based approach to estimate them in Section 3. In Section 4, we present an application of the estimated profile features in federated query planning. We evaluate our profile feature estimation and estimation-based query approaches in Section 5. Related work on statistical profiling, graph sampling, and federated query processing is discussed in Section 6. Finally, we conclude our work with remarks on future work in Section 7.
The Resource Description Framework (RDF) is a graph-based data model. The atomic elements in RDF are triples, which are statements represented as 3-tuple of RDF terms:
RDF datasets are summarized in RDF dataset profiles that consist of profile features describing the characteristics and entities of the dataset. In the area of traditional relational database theory, a statistical profile is defined as a “complex object composed of quantitative descriptors” that “summarizes the instances of a database” [23]. These quantitative descriptors can cover different characteristics of the instances, for example:
central tendency (e.g., mean),
dispersion, (e.g., coefficient of variation),
size (e.g., number of instances), and
frequency distribution (e.g., uniformity).
The specific characteristics covered in such profiles depend on the downstream application, for example, the statistical features required by a query optimizer that uses the profile to devise efficient query plans. Similar to relational databases, statistic profiles are also commonly used for a variety of applications in the realm of RDF datasets. These applications range from centralized RDF data management solutions [28] and RDF graph compression [14] to query optimization for both centralized and federated query processing [16,24,26]. For instance, a common application of such statistical profiles in query optimization is the estimation of join cardinalities for subqueries.
The terminology for such statistical profiles varies according to their application [9,13,43]. In this work, we follow the terminology introduced by Ellefi et al. [13]: An RDF dataset profile is a formal representation of a set of dataset profile features. Moreover, we focus on statistical profile features and define them as follows.
(Profile Feature [17]).
Given an RDF graph G, a profile feature
As previously mentioned, computing these profile features can be challenging because accessing and processing the entire datasets is difficult and/or costly. Therefore, we investigate profile feature estimation without requiring access to the complete RDF graph.
Profile feature estimation
Addressing the limitation of requiring access to the entire RDF dataset for computing statistical profile features, we propose the concept of Profile Feature Estimation. Profile feature estimations aim to estimate a statistical profile features of RDF datasets using a subset of the data only. The goal is to generate a profile feature estimation that is as similar as possible to the original profile feature while requiring access to a subset of the dataset only. In particular, we propose an approach that relies on a sample from the original RDF graph in combination with a projection function to extrapolate the true profile feature. Consequently, we define a profile feature estimation as follows.
(Profile Feature Estimation [17]).
Given an RDF graph G, a projection function ϕ, a subgraph
In an ideal situation, the estimated profile feature is identical to the true original profile feature (computed over the complete RDF graph). However, the profile feature to be estimated and the properties of both the subgraph H and the projection function ϕ may affect the differences between the true and the estimated feature. For example, given a larger subgraph, the estimation might be more accurate than for a smaller subgraph, as the larger subgraph potentially covers more characteristics of the original graph. The problem is finding an estimation for the profile feature which maximizes the similarity to the profile feature of the original RDF graph. To this aim, we introduce the concept of a similarity function δ that maps two profile features to a similarity value. The profile feature estimation problem is given as finding a profile feature estimation that maximizes the similarity to the original profile feature.
(Profile Feature Estimation Problem [17]).
Given an RDF graph G and a profile feature
In order to maximize the similarity, the sampling algorithm for obtaining H and the projection function ϕ need to be chosen appropriately. The particular method to measure the similarity δ depends on the actual profile feature to be estimated with potentially several similarity functions for the same profile feature. Take for example a profile feature
Characteristic sets profile feature estimation
We now present our sampling-based approach to estimate profile features based on the characteristics sets of RDF graphs. In this section, we first introduce the concept of characteristics sets and define the corresponding Characteristic Sets Profile Feature. Thereafter, we present our approach that combines RDF graph sampling with projection functions to estimate the Characteristic Sets Profile Feature. Finally, we propose structural and statistical similarity measures to assess the representativeness of these estimations.
Characteristic sets profile feature
The concept of characteristic sets for RDF graphs was introduced by Neumann et al. [27]. In their work, the authors used characteristics sets for query planning as they capture the co-occurrences of predicates in RDF graphs. The idea of characteristic sets is describing semantically similar entities by grouping them according to the set of predicates the entities share. Furthermore, the number of entities in each group are counted as well as the average usage of their predicates. As a result, the characteristic sets capture both statistical information on the data distribution as well as semantic information on the entities in an RDF graph.
(Characteristic Sets [27]).
The characteristic set of an entity s in an RDF graph G is given by:
In an RDF graph, the statistical information determined for the characteristic sets typically includes the number of occurrences (count) of a given characteristic set as well as the multiplicities of the predicates within each characteristic set. These statistics are used in both centralized triple stores and federated query engines because they allow to determine exact join cardinalities for specific
In addition, in this work, we focus on the occurrences of predicates in characteristic sets by considering their mean multiplicity. The mean multiplicity
In other words, for a given characteristic set, the multiplicity measures how often each predicate occurs on average. Combining the count and mean multiplicity statistics of a characteristic set, we can compute the number of triples that are covered by it. The relative coverage
For example, consider the characteristic set
The statistics indicate that 9838 entities in the LinkedMDB graph belong to
Finally, we introduce the notion of exclusive characteristic sets. An exclusive characteristic set occurs only once in an RDF graph and is defined as the following.
(Exclusive Characteristic Sets [17]).
Given the characteristic sets
For example, in the LinkedMDB graph there exists only one entity with the predicates
Based on these definitions, the statistical aspects of characteristics sets can be combined to formally define the characteristic sets profile feature (CSPF) as follows.
(Characteristic Sets Profile Feature (CSPF) [17]).
Given a RDF graph G, the characteristic sets profile feature
We now present the individual steps of our approach for estimating the CSPF of a given RDF graph.
Overview of the approach We propose a sampling-based approach that is shown in Fig. 1. Given a graph G, the approach generates a sample

Overview of the approach: a sample H is taken from the original graph G. The profile feature
The first step of our approach is obtaining a representative sample of the original RDF graph that provides a suitable foundation for estimating the profile feature. Before collecting data from a population in a sample, an appropriate sampling method needs to be chosen. Accordingly, we focus on sampling methods suitable for estimating the CSPF. Since characteristic sets capture the attributes of the entities in an RDF graph, we focus on entity-centered sampling methods in the following. Each entity (i.e., subject) is associated with exactly one characteristic set, thus, we define the population to be sampled from as the set of entities in the given graph:
Unweighted sampling The unweighted sampling method selects
Weighted sampling The weighted sampling method is a biased sampling method, where the probability of an entity to be part of the sample is proportional to its out-degree. As a result, the more central an entity is in the graph with respect to its out-degree centrality [29], the more likely it is part of the sample. In this way, entities that appear in many triples of the graph in the subject position, have a higher probability of being selected. The out-degree of each entity e given by
Hybrid sampling The hybrid sampling method combines the previous two sampling methods. From the original graph,
The β parameter allows for favoring either the weighted or the unweighted method.
Profile feature creation
After obtaining a subgraph H using a sampling method, the characteristic sets profile feature
Profile feature projection
Given the profile feature
We now present two classes of projection functions for the count values of the characteristic sets in the sample. The first class, which we denote basic projection functions, only relies on information contained within the sample and the size of the original graph. The second class, which we denote as statistics-enhanced projection functions also relies on high-level information on the original dataset in addition to the information contained in the sample.
Basic projection function The basic projection function extrapolates the count values for the given characteristic sets profile feature
The assumption of the basic projection function is that the characteristic sets observed in a sample occur proportionally more often in the original graph. However, as exemplified in the introduction, the distributions of the counts may be potentially skewed which is not considered by this projection function. Moreover, this function neglects the fact that some characteristics sets might not have been sampled and merely distributes the proportional counts across the characteristic sets in the sample. As a result, it is likely that the counts for the characteristic sets is overestimated, especially if just a small portion of characteristics sets from the original graph are captured. To address this shortcoming, we introduce two statistic-enhanced projection functions that leverage high-level information to reduce the probability of overestimating the counts.
Statistics-enhanced projection functions The second class of projection functions incorporates additional high-level information about the original graph. In particular, we consider the number of triples per predicate in the original graph as this high-level statistic. The rationale for this particular statistic is that it potentially yields a good trade-off between the effort to obtain the statistic and the benefit it provides for the projection function. The number of triples for predicate
The first statistic-enhanced projection function,
The idea of this projection function is that the predicate occurrence statistics of the original graph allows for limiting the estimated counts for characteristic sets containing that predicate. If a predicate
The projection function
In contrast to
Concluding this section on the projection functions, we want to note that further functions may be applied to potentially improve the estimation of the profile feature. For example, the characteristic sets sizes or additional statistics about the predicate distribution in the sample could be considered. However, we chose not to include them since they are likely to just produce accurate estimation under certain conditions and, therefore, do not generalize well for other datasets. Moreover, further improvements in the estimations do not necessarily imply the same improvements in the downstream applications that use the feature estimations.
Sampling RDF graphs in practice
The presented sampling approaches define the process for selecting entities to be sampled from the original graph but they do not encode how the samples are generated in practice. The implementation of the sampling approaches depends on the access methods to the given RDF graph. In the case of centralized RDF graphs, the sampling approach has access to the entire dataset and could potentially exploit existing data structures (e.g., indices) to efficiently access the entities in the graph. However, in decentralized scenarios as federations, the sampling methods have only access to parts of the RDF graphs and their implementation depends on the expressivity, capabilities, and configuration of the access interfaces. While it is out of the scope of this work to present specific implementations for each access interface, in the following, we provide insights into the considerations when implementing these sampling methods over remote SPARQL endpoints and Triple Pattern Fragments (TPF) servers.
SPARQL endpoints The expressivity of endpoints allows for selecting the entities to be sampled and then obtaining the subgraph induced by those entities.
The unweighted sampling method can be implemented over a SPARQL endpoint as follows. (i) Query all unique subjects (i.e., with
In the weighted sampling method, the out-degree of an entity determines its probability to be sampled. To avoid computing the out-degree for each entity, it is possible to implement a simple heuristic that relies on the following assumption: The higher an entity’s out-degree, the more triples with it in the subject positions are present in the graph. Therefore, to obtain a weighted sample, the approach can randomly select triples from the graph and obtain the subjects of those triples. This can be achieved in endpoints using a query that matches any triple in the graph, a
Finally, after the entities have been selected, the induced subgraph of the entities can be obtained using either a
Triple pattern fragments (TPF) TPF servers support triple pattern-based querying of RDF graphs. Since TPF servers do not provide the same expressivity as SPARQL endpoint for accessing the RDF graphs, the sampling methods need to be implemented accordingly.
Because TPF servers do not support
For implementing the weighted sampling method, a similar heuristic to the one presented for SPARQL endpoints can be followed. Instead of computing the out-degrees of each entity, the approach can randomly select triples from the RDF graph: entities with higher out-degrees have a higher probability of being chosen with this approach, as they appear more frequently in the triples. Random selection of triples is implemented over TPF servers by randomly selecting a page from the range 1 to the number of pages in the fragment, which can be obtained from the metadata
Finally, the induced subgraph of the entities can be obtained by querying all the triples where the subject corresponds to each selected entity.
Overview of the similarity measures: the structural similarity measure capture the degree to which structural features of the original graph are represented. The statistical similarity measures focus on the
Finally, we define similarity measures that quantify the similarity between the estimated profile feature and the feature of the original graph. A higher similarity value indicates a more representative feature estimation. According to our problem definition (Definition 2.3) in Section 2.2, the goal is obtaining an estimator
Structural similarity measures The first category of similarity measures focuses on the structural information captured in the characteristic sets. We propose four measures that consider the mean out-degree, the predicates covered, and the absolute and relative number of covered characteristics sets. The out-degree similarity measure
Note that
The second structural measure focuses on the predicates captured in the characteristic sets of the CSPF. The predicate coverage similarity
The final two structural measures address characteristic sets themselves and determine how many of them are covered in the CSPF
However, this measure does not reflect the importance of the characteristic sets captured in estimated CSPF with respect to their
Note that the characteristic sets of the estimation
Statistical similarity measures The second category of similarity measures focuses on the statistical aspects covered in the feature estimations, namely the counts of the characteristic sets and the multiplicity of predicates. Depending on the distribution of the characteristics sets in the original graph, an accurate estimation of both counts and multiplicity values can be challenging. As a consequence, for some characteristic sets, the estimations can be accurate, while for others large estimation errors can occur. We propose statistical similarity measures that capture the estimation accuracy on the level of individual characteristics sets. To better understand the estimation error distribution across all characteristic sets in a sample, different aggregation functions, such as mean or median, may be applied afterward.
We propose a similarity measure for the count values that is the inverse of the count estimation q-errors. The q-error [25] is the maximum of the ratios between true and estimated count and vice versa. Given a profile feature
Higher q-errors indicate a higher discrepancy between the true value and the estimation, and a q-error of 1 indicates that the estimation is correct. We take the inverse of the q-error to map it to the similarity measure range
Note that the q-error only measures the magnitude of the estimation error but does not indicate whether values are over- or underestimated. As a result, when aggregating the similarity measures across all characteristic sets of a given feature estimation
The proposed similarity measure for the predicate multiplicities is also based on the q-error and is defined on the level of characteristic sets. Given a profile feature
Analogously, to the count values, the similarity measure for the multiplicities is the inverse of the q-error
In summary, the characteristic sets in a CSPF captures various characteristics of RDF graphs, ranging from out-degree distribution to predicate co-occurrence. As a result, a combination of similarity measures needs to be taken into account to assess the representativeness of an estimation of a CSPF. To this end, we have proposed four structural and two statistical similarity measures. The importance of the individual measures depends on the application. In the following section, we present one potential application of the CSPF estimations in federated query planning.
Federated query planning using characteristic sets profile feature estimations
We investigate the applicability and effectiveness of the characteristic set profile feature (CSPF) estimations in a downstream application. In particular, we focus on federated SPARQL query planning motivated by previous works, which studied how characteristic sets can be exploited in query plan optimization in both centralized and decentralized scenarios. In decentralized query processing, it has been shown how characteristic sets can be leveraged to obtain efficient federated query execution plans that outperform existing state-of-the-art federated query plan optimizers in terms of query execution time and data transfer [26]. However, the computation of the complete characteristics sets profile feature can be challenging in such decentralized scenarios as it requires obtaining the entire datasets of all members in the federation and, subsequently, computing the profile feature. Consequently, we study how federated query planning approaches can benefit from the proposed characteristic sets profile feature estimations that are based on samples from the original graphs.
We propose a novel heuristic for federated query planning to obtain efficient federated query plans based on estimated CSPFs. We cannot directly apply an existing approach, such as Odyssey [26], due to the following reason. First, Odyssey relies on having access to the entire datasets to obtain the complete characteristic sets and the query planner assumes complete information. Hence, the planner relies on complete statistics for query decomposition, join ordering, and cardinality estimation and it does not handle potentially missing statistics in those steps. Second, the Odyssey approach additionally leverages both the characteristic pair (CP) and the federated characteristic pair (FCP) statistics to capture how characteristic sets are linked within and entities are linked across the datasets of the members in the federation [26]. In this work, we focus only on characteristic sets and assume estimated statistics. Therefore, we propose a novel query planner based on these restrictions. Still, our query planner is based on existing approaches for characteristic sets-based cardinality estimation and query planning [25–27].
We begin by introducing the necessary concepts and notation from SPARQL, which is the recommended query language for RDF graphs. Following the notation of Schmidt et al. [38], where V is the set of variables that is disjoint with I, B, and L, we can define a SPARQL expression as follows.
(SPARQL Expression [38]).
A SPARQL expression is an expression that is build recursively as follows.
A triple pattern If
In our query planning approach, we focus on Basic Graph Patterns which we define as follows.
(Basic Graph Pattern (BGP)).
Let
Next, we denote the set of predicates in a BGP P as
Moreover, we denote the evaluation of an expression P over a graph G by
CSPF estimation-based federated query planner
We propose a heuristic-based query planner to determine efficient query plans based on CSPF estimations. We adapt the notation from [2] and define a federation of SPARQL endpoints (sources) as
Source selection and query decomposition The source selection and query decomposition step determine which subexpressions of a given BGP P should be evaluated at which members of the federation
(Query Decomposition).
Given a BGP P and a federation
The challenge of query decomposition based on estimated statistics is the fact that the planner does not know what is not captured in the estimations. For example, this is the case when determining the relevant sources. In the following, we assume a source
The source selection and query decomposition process are shown in Algorithm 1. The goal of the approach is to merge multiple triple patterns into larger subexpressions to reduce the number of subexpressions to be evaluated over the sources. Our planner focuses on subject-based star-shaped basic graph pattern. That is, BGPs where all triple patterns share the same RDF term or variable in the subject position [41]. These subject-based star-shaped basic graph patterns are obtained by the function
Alternatively, the planner could use

Query decomposer
Cardinality estimation Given a query decomposition, the query planner estimates the cardinalities of all subexpressions in the decomposition. Given these estimations, the planner determines an efficient join order for the subexpressions. To this end, the subexpressions are ordered by increasing cardinality to minimize the number of intermediate results to be transferred during query execution. For a given subexpression
For the first case, we apply the
We then sum up the estimations to aggregate the cardinalities across all sources:
In the second case (
If both subject and predicate are bound in the triple pattern, we estimate the cardinality as the mean multiplicity values for all predicates and characteristic sets in all sources of the federation
If just the subject is bound, we estimate the cardinality as the mean of the mean out-degrees
If just the predicate is bound, we assume that the predicate occurs less frequently than the least frequent predicate in all estimated CSPF. The rationale for this is, if predicate p would occur more frequently, it would be very likely to be sampled. Thus, it can be assumed to be less frequent than any predicate that was sampled.
(?s, ?p, ?o)
The estimated cardinality, is the sum of the sizes of the graphs in the federation:
For all remaining types of triple patterns, we estimate the cardinality to be 1.
Join ordering and query plan generation After estimating the cardinalities of all subexpressions in the decomposition, the query planner iteratively builds a left-deep plan by joining subexpressions ordered by increasing cardinality. In this query plan, each tuple
Limitations Note that the proposed query planner does not guarantee to obtain query plans that produce complete answers. This is due to two main reasons. First, the planner may fail to identify a source as relevant in the case that the relevant characteristic set is missing in the CSPF estimation. While the planner assumes all sources to be relevant in the case that none of the estimations include a matching predicate, it might be the case that the a CSPF estimation for one source is missing the relevant information and for another sources it does not.
Second, the greedy nature of our query decomposition approach presented in Algorithm 1 may produce query decompositions that yield incomplete results. For example, the decomposer may find a star-shaped subquery
Characterization of the FedBench RDF graphs studied in the experiments
We empirically evaluate our contributions in two experimental studies. The first study focuses on analyzing the different components of our proposed approach to estimate the Characteristic Sets Profile Feature (CSFP) presented in Section 3. The second study aims to evaluate our CSPF estimations-based federated query planner which we presented in Section 4. We use the well-known federated querying benchmark FedBench [37] to investigate the effectiveness of our query planner and therefore, investigate the RDF graphs from FedBench in the first part of the evaluation as well. All raw experimental results are provided online under the DOI 10.5281/zenodo.4507242. The source code is provided on GitHub: (i) the sampling implementation,8
We first empirically evaluate the different components of our approach to estimate the Characteristic Sets Profile Feature (CSPF). In the evaluation, we focus on the following core questions:
How do different sampling sizes influence the similarity measures?
What is the impact of different sampling methods on the similarity measures?
What are the effects of leveraging additional statistics in the projection functions?
How do different characteristics of the RDF graph influence the estimation?
We first present the setup of our experiments and analyze the results in Sections 5.1.1 and 5.1.2. Based on our findings, we answer the core questions in the final discussion in Section 5.1.3.
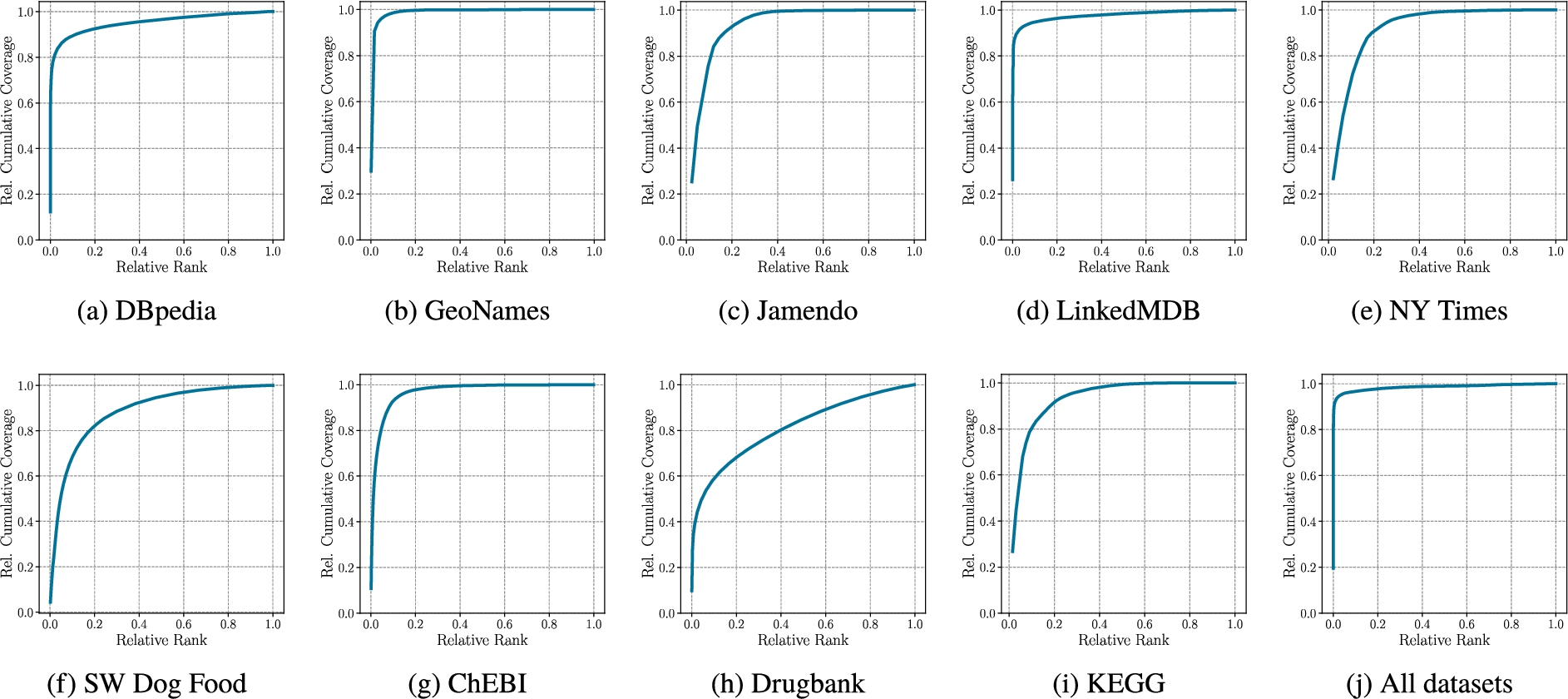
The cumulative relative coverage curve shows the ratio of triples covered with respect to the characteristic sets ordered by decreasing relative coverage.
RDF graphs We select the six cross-domain and three Life Science RDF graphs from the FedBench benchmark [37] for our evaluation. An overview of the graphs’ properties is given in Table 3. The graphs differ in their general properties: the number of triples, the number of distinct subjects, predicates, and objects as well as the out-degree distribution. Moreover, the graphs differ with respect to their characteristic sets. The number of characteristic sets ranges from 42 to more than 160000. Theoretically, the number of potential characteristic sets in a graph is bound by the power set of its predicates. In practice, however, the number of distinct subjects in the graph is a stricter upper bound. Therefore, we provide the ratio of characteristic sets and distinct subjects (
Figure 2 shows the cumulative coverage curve of the characteristic sets for all graphs. The curve plots the cumulative coverage of the characteristics sets in a graph sorted by decreasing coverage (c.f. Equation (3)).
Sampling methods We study the presented unweighted, weighted, and hybrid sampling methods. We chose
Mean similarity values

Table 4 shows the structural similarity measures out-degree
Interestingly, there are also few cases where a higher sample size yields worse similarity results. For instance, the out-degree similarity
The two graphs KEGG and ChEBI have a high dispersion of the out-degree distribution with
Considering the absolute (
Comparing the different sampling methods (

Sampled characteristic sets for Drugbank for one sample with a
Except for LinkedMDB, the unweighted sampling method exhibits the lowest predicate coverage similarity (
The degree of a characteristic set is given by the average degree of the entities belonging to it. The degree is therefore a combination of its size (number of predicates) and the predicates’
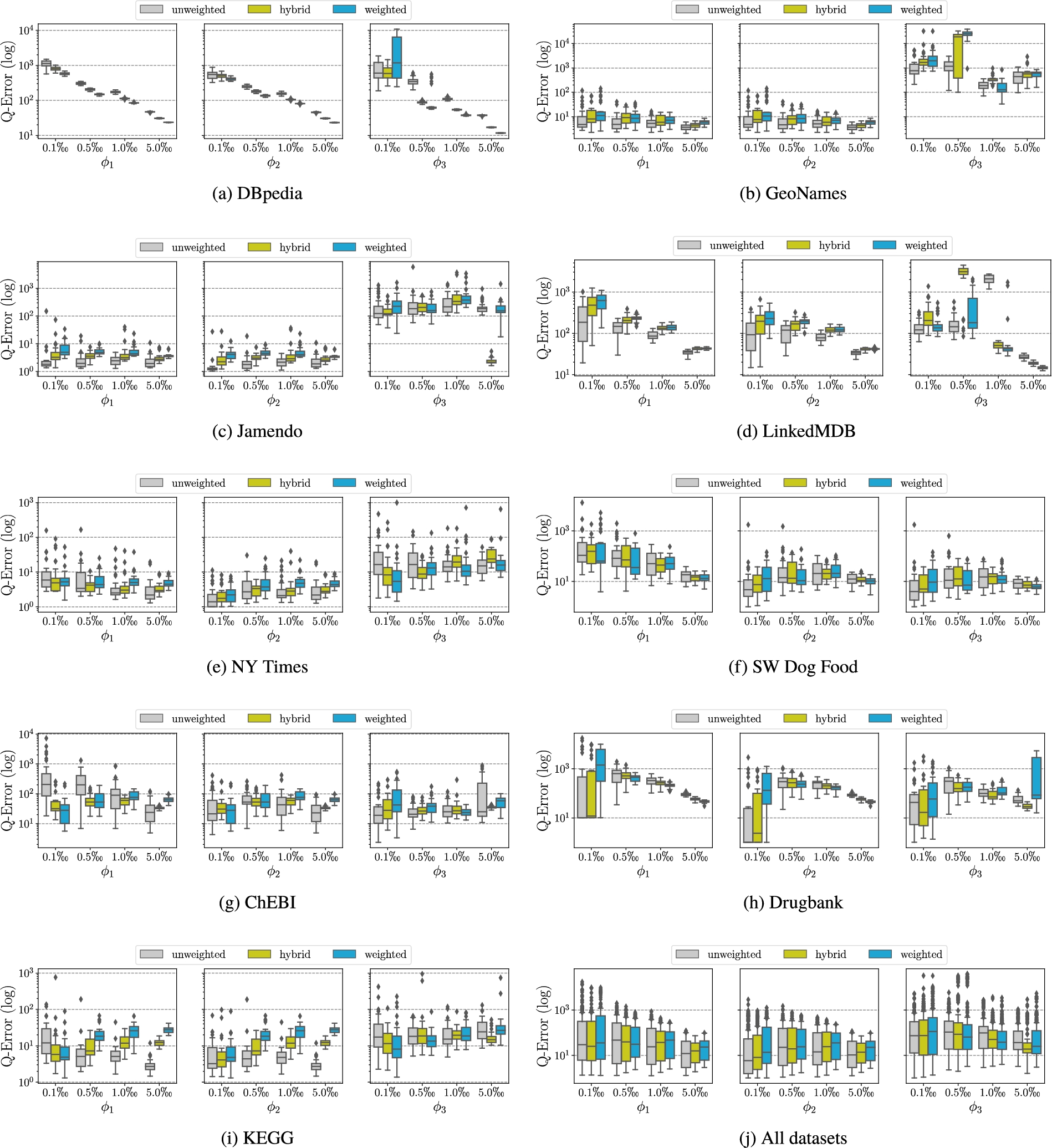
Box plots of the count estimation q-errors (lower is better) for each dataset, projection function, sample size and sampling method.
We now focus on the statistical similarity measures that assess the accuracy of the count and multiplicity estimations. In this evaluation, we concentrate on the q-errors due to their more natural interpretation, rather than the proposed similarity measures

Box plots of the q-errors (lower is better) of the predicate multiplicity estimations for each dataset, sample size and sampling method.
Similar to the structural similarity measures, the results indicate an improvement in the estimations with larger sample sizes (
Comparing the different sampling methods (
Considering the characteristic set diversity of the graphs
Summarizing the results across all datasets for the count q-errors (cf. Fig. 4j), we observe that an increase in sample size (
Next, we focus on the estimations of the predicate multiplicities within the characteristic sets. Analogous to the count statistic, we concentrate on the q-errors in the evaluation and aggregate the values per sample by computing the mean over all its characteristic sets:
The box plots of the samples’ mean q-errors are shown in Fig. 5 for all graphs, sample sizes, and sampling methods. The first obvious observation is the substantially lower q-errors in comparison to the count statistic. This is because the range of the value to be estimated is lower. Typically, the same predicate is only used a few times for the same subject, with some exceptions that occur multiple times, such as
Concluding, as the summarized results in Fig. 5j show, the multiplicity statistic are estimated more accurately than count statistic with improving estimations for larger sample sizes (
After providing a detailed presentation of our experimental results, we conclude the evaluation by providing answers to our core questions.
Concluding all findings, a variety of factors, ranging from the sampling method to the structure of the RDF graphs, impact the quality of the characteristic sets profile feature estimation. Therefore, in our second evaluation, we investigate how the CSPF estimation can be leveraged in a specific application and how the estimations impact the performance of the application.
Federated query planner evaluation
After investigating the effectiveness of our approach to estimate profile features according to the similarity measures, we now focus on a particular application of the estimated features. We, therefore, study the performance of the proposed federated query planning approach that relies on CSPF estimations. In particular, we want to study the following core questions.
How do the CSPF estimations obtained from the unweighted and weighted sampling methods impact the effectiveness of federated query planning?
How do the CSPF estimations from different sample sizes impact the effectiveness of the plans?
What is the effect of the different projection functions on the query plan effectiveness?
How well do the structural similarity measures reflect the performance of the query plans?
We begin by introducing our experimental setup. We then provide a detailed evaluation and discussion of our experimental results in Section 5.2.1, which we conclude by answering our core questions in Section 5.2.2.
Benchmark and sampled statistics We study the effectiveness of the proposed query planning approach using the FedBench benchmark [37]. The benchmark consist of the 9 interlinked RDF graphs that are listed in Table 3, and which were also investigated in the previous evaluation. We selected 25 queries from the Cross Domain (CD1-CD7), Life Science (LS1-LS7), and Linked Data (LD1-LD11) queries. We used a subset of the estimated CSPF generated from the samples of the previous evaluation. In particular, we only considered the weighted and unweighted sampling methods, leading to a total of 2160 estimated CSPF.11
The previous experimental results suggest that the hybrid sampling method balances the two opposing (weighted and unweighted) sampling methods. We therefore assume that the estimated CSPF based on the hybrid samples will exhibit a similar performance in the following experiments. As a result, we only focus on the edge cases, that is weighted and unweighted samples.
As a baseline, we additionally computed the complete CSPF for all RDF graphs. In accordance with previous approaches [26,27], we reduce the number of characteristics sets in the profile feature to a maximum of 10000 characteristic sets per RDF graph.
Implementation We implemented the proposed federated query planning approach based on CROP [18] and nLDE [3]. We extended the query engine with an access operator for SPARQL endpoints and implemented our source selection, query decomposition, and left-linear query plan optimizer to create query execution plans. The RDF graphs in the federation are deployed with a single SPARQL endpoint per graph using Virtuoso v7.2..12
We study the performance on each of the 30 samples for the 2 sampling methods (weighted and unweighted), 4 sample sizes (
Evaluation metrics We study the following metrics:
Execution Time: Elapsed time spent by the engine to complete the evaluation of a query in seconds. This includes time spent on query planning. Number of requests: Number of requests performed by the engine to the SPARQL endpoints during the query execution. Answer completeness: Percentage of total answers produced. We computed the complete answers by executing the queries over the union of all graphs. Number of subexpressions: Number of subexpressions in the query decomposition to assess how well the predicate co-occurrence of the graphs is captured in the estimated CSPF.
An overview of the experimental results is provided in Table 5. The table shows the mean and median execution times, the mean number of requests, the mean percentage of answers produced, and the mean percentage of query executions reaching the timeout. We start with the results for the unweighted sampling method (
Overview for the FedBench Queries. Mean and median execution times, mean number of requests, mean percentage of answers produces, and mean percentage of queries reaching the timeout. Best values per table are indicated in bold
Overview for the FedBench Queries. Mean and median execution times, mean number of requests, mean percentage of answers produces, and mean percentage of queries reaching the timeout. Best values per table are indicated in bold
In contrast, the performance results differ for the weighted sampling method (
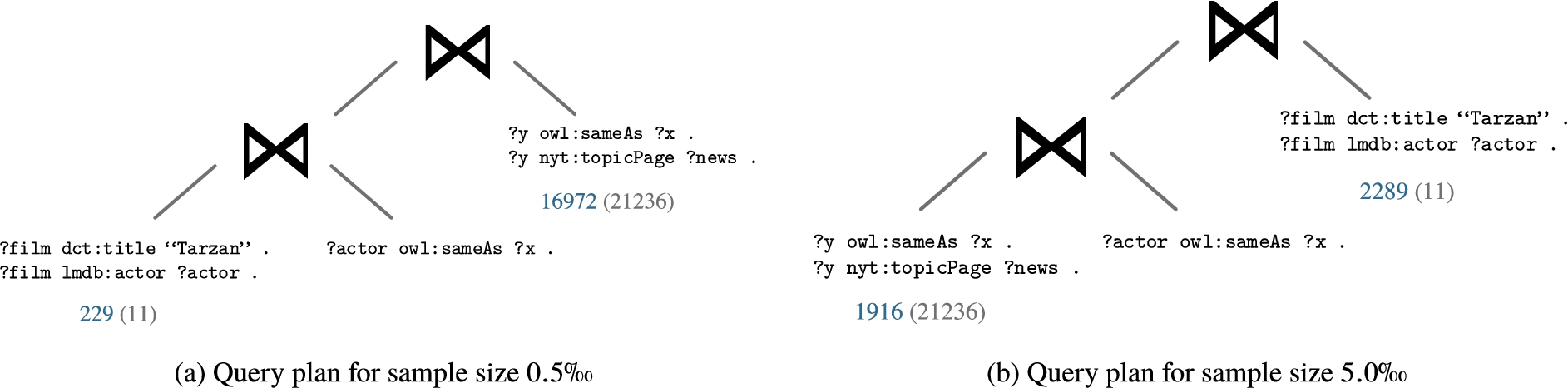
Hence, we focus on the results for the weighted sampling method in more detail to investigate the following observations: (i) a larger sample size in the weighted sampling does not entail better query execution performance, and (ii) the query planner with complete statistics is outperformed by the majority of configurations with estimated statistics. The mean execution times and mean number of requests (both log scale) per query and sample size for the weighted sampling method (all projection functions) are shown in Fig. 6. The trend of an increase in execution time with larger samples sizes is observable especially for the queries
Note that the query planner is designed to handle estimated statistics. Therefore, a query planner that fully leverages the complete statistics, e.g., with the (federated) characteristic pairs, would potentially obtain a more efficient query plan.
This is due to the fact that the number of relevant characteristic sets for a triple pattern

Mean performances for all FedBench queries for the weighted sampling method and averaged across all projection functions.

Relation between the answer completeness and the number of subexpression of the query plans and the structural similarity measures for the estimated CSPF. Sample size are indicated in color.
Finally, we want to examine whether the proposed structural similarity measures (c.f. Section 3.6) reflect the performance of the query plans obtained by our planning approach (
Similar to this observation, the results in Fig. 8b show that, there is no correlation between the answer completeness and the out-degree similarity
Concluding the evaluation of the experimental results for our query planning approach, we summarize the findings by providing answers to our core question.
Summarizing the evaluation, we demonstrated the successful application of characteristics sets profile feature estimations to federated query planning. Overall, the unweighted sampling method with the largest sample size showed the best average performance. The experiments show that the proposed query planner provides a foundation to further develop query planning approaches that leverage estimated profile features obtained from RDF graph samples. For instance, future research could investigate source selection techniques as proposed in [35], but relying on samples to get the authority of subjects and objects in the graphs.
Limitations Finally, we want to discuss the limitations of the proposed query planner and experiments. The first limitation is the heuristic nature of the planner. As a result, there are no theoretical guarantees for the answer completeness of the query decomposition. For example, in case the planner finds at least one relevant source for a triple pattern in the estimated statistics, it assumes there are no additional relevant sources, which are not captured in the statistics. In other words, the query planner does not know what it does not know about. This limitation could potentially be overcome by obtaining additional information from the RDF graph, such as its distinct predicates, in the case that the expressivity of the query interface supports this. Secondly, our evaluation focuses on an implementation that combines query planning and execution based on CROP. Therefore, our insights are currently limited to this setup and future work should investigate our planner with other query execution engines (e.g. using SPARQL 1.1 queries). This would also allow for a direct comparison to Odyssey. Finally, additional federated benchmarks could be investigated to gain further insights.
Regardless, our experimental results still provide valuable insights into the potential of using sample-based statistics and summaries to support federated querying approaches without requiring access to the entire datasets of the federation members.
Related work
We now discuss related work on statistical profiling (Section 6.1), graph sampling (Section 6.2) and federated query processing (Section 6.3).
Statistical profiling
In the realm of statistical feature profiling for RDF graphs, a variety features and tools to assess them have been proposed. Zloch et al. [44] investigate statistical features of RDF graphs with the focus on the topological graph structure including degree-based, edge-based, centrality, and descriptive statistical measures. Consequently, these measures are not specific to RDF graphs and, in contrast to our work, do not capture the semantics on the instance or schema level of the data. Complementary, Fernández et al. [14] focus on RDF-specific measures. They propose various schema- and instance-level metrics to characterize RDF datasets that incorporate the particularities of RDF graphs. The metrics and the resulting statistics are tailored to the development of better RDF data storage solutions including data structures, indexes, and compression techniques by considering RDF data characteristics.
LODStats [6] is a statement-stream-based approach for gathering comprehensive statistics of RDF datasets. They present 32 instance- and schema-level statistical criteria covering both RDF-specific metrics as well as topological graph metrics. The authors aim to improve reuse, linking, revising, or querying Linked Open Data sources but do not discuss specific applications.
ProLOD
Finally, ExpLOD [20] is a tool for generating summaries of RDF datasets combining text labels and bisimulation contractions. These summaries include schema-level statistical information such as the class, predicate, and interlinking usage in the dataset. Similar to ProLOD
In this work, we propose a novel schema-level statistical profile feature based on characteristic sets that captures both the topological structure of the graph as well as its semantics. This statistical feature has not yet been addressed in related work. We demonstrate an application of estimations of this feature in federated query planning.
Graph sampling
Next, we focus on sampling approaches for graphs. We start by introducing related work on sampling large graphs and networks. Thereafter, we analyze RDF-specific sampling approaches and their applications.
Graph sampling A variety of approaches for sampling large non-RDF graphs have been proposed. Leskovec et al. [21] provide an overview of approaches suitable for obtaining representative samples from large graphs for scale-down sampling for static graphs and back-in-time sampling for evolving graphs. They consider the distributions of different structural properties of the graphs, denoted static graph patterns, as the criteria for evaluating the representativeness of the samples for scale-down sampling. These static graph patterns include, among others, the in-degree, out-degree, and cluster coefficient distributions. As a similarity measure to assess the representativeness of samples, they use the Kolmogorov-Smirnov D-statistic of the graph patterns’ distribution. They present three major categories of sampling approaches: (i) random node selection, (ii) random edge selection, and (iii) graph exploration. The results of their evaluation reveal that there is no single best solution and the authors conclude that an appropriate sampling algorithm and sample size depends on the specific application.
Ahmed et al. [5] present a detailed framework for the problem of graph sampling that focuses on large scale graphs. They identify two models of computation that are relevant when sampling from large graphs. The static model of computation allows for randomly accessing any location in the graph. The streaming model of computation merely allows for accessing edges in a sequential stream of edges. In their evaluation, the authors show that the proposed methods preserve key graph statistics of the graph (e.g., degree distributions, cluster coefficient distribution). Moreover, they demonstrate low space- and runtime-complexity that is in the order of edges in the sample for these methods.
Our sampling methods are a special case scale-down sampling of random node selection approaches according to [21], that only sample specific nodes, the entities of an RDF graph. However, in contrast to traditional graph sampling, we aim to generate representative samples for our specific statistical graph feature. Hence, the representativeness of a sample is given by the accuracy of the profile feature estimation.
RDF graph sampling Sampling approaches for RDF graphs have been proposed and applied to different problems as well. In the following, we will analyze example applications and show how sampling approaches are chosen according to those applications.
Debattista et al. [11] propose approximating specific quality metrics for large, evolving datasets based on samples. They argue that the exact computation of some quality metrics is too time-consuming and that an approximation is usually sufficient. In particular, they apply a sampling-based approach for the quality metrics (i) dereferenceability of URIs, and (ii) links to external data providers. They use the reservoir sampling approach [42] which randomly selects n items from a set of N elements with the equal probability
In their work, Rietveld et al. [34] aim to obtain samples that entail as many of the original answers to typical SPARQL queries. They use query logs from SPARQL endpoints to determine such typical queries. The sampling pipeline proposed by the authors consists of four steps and aims to obtain the parts of the graph that are relevant for answering the queries. First, they rewrite the original RDF graph as a directed unlabeled graph. On the resulting graph, they then compute the structural graph metrics PageRank, in-degree, and out-degree for all nodes. Thereafter, they use the structural graph metrics to rank the triples in the graph and generate the sample by selecting the top-k percent of all triples. The authors aim to obtain samples with a “more manageable size” [34] that produce answers to common SPARQL queries and hence, the samples’ representativeness is measured by the recall for those queries. As a result, the resulting samples may be biased towards more prominent entities in the graphs and less suitable to capture long-tail entities [8]. Different from our work, the goal is obtaining relevant samples which allow answering common queries. Therefore, these samples are not representative in our sense with regards to the semantic and statistical features.
Soulet et al. [39] focus on analytical queries, which are typically too expensive to be executed directly over public SPARQL endpoints. They propose separating the computation of such expensive queries by executing them over random samples of the RDF graph. Due to the properties of the queries, the values for the aggregations converge as they are executed over increasingly larger portions of the graph. As a result, the authors do not rely on the necessity of each sample to be representative according to the aggregates, but rely on the convergence of the aggregates towards the true value with an increasing number of samples. Similar to Soulet et al. [39], our work is motivated by the restrictions that occur especially in decentralized scenarios with large, evolving datasets where it is not feasible to have local access to every dataset. Different from [39], we aim to sample the data in such a fashion that a single sample can be used to estimate the statistical profile feature and do not rely on the convergence properties induced by increasing sample sizes.
Profiling-based federated query processing
We demonstrate how the profile features estimations can be applied to federated query processing. Therefore, in this section, we analyze other types of pre-computed statistics leveraged by federated query engines to determine efficient plans.
ANAPSID [4] is an adaptive federated query engine that leverages a Catalog with high-level statistics on the members in the federation. This catalog contains a list of the predicates present in each data member in the federation and is used by the engine to perform the source selection and query decomposition.
More fine-grained statistics are leveraged by the following approaches. SPLENDID [15] uses indexes built from VoID descriptions for query planning. These indexes additionally hold information on the occurrences of predicates within the classes of the sources. In combination with
Our approach also uses statistics to perform source selection, query decomposition, and join ordering to obtain efficient query plans. Specifically, our approach leverages characteristics sets similar to Odyssey [26]. In contrast to the aforementioned approaches, however, our approach does not require the complete statistics but is specifically designed to handle estimated statistics from RDF graph samples. As a result, our approach aims to leverage the estimated statistics as much as possible and is also able to cope with potentially misestimated or missing statistics.
Conclusion
In this work, we presented an approach to estimate RDF dataset profile features and an application of those estimations in federated SPARQL query planning. Specifically, we focused on the characteristic set profile features as it captures not only structural but also semantic properties of RDF graphs. We proposed a sampling-based approach that utilizes a projection function to estimate characteristic set profile feature statistics (). Furthermore, we introduced four structural and two statistical similarity measures that allow for assessing the representativeness of the generated feature estimations. In our experimental study, we investigated the effectiveness of the proposed estimation approach using these similarity measures (). The evaluation showed that our approach obtains representative feature estimations according to the structural similarity measure. In contrast, the lower statistical similarity values showed that the count distributions of characteristics sets in the RDF graphs are more challenging to estimate. These results highlight that the samples capture structural aspects while it is difficult to capture the distribution of the characteristic sets.
The second main contribution of this work focused on an application of the proposed feature estimations to better understand the practical implications of their representativeness (). We proposed a federated query planning approach that leverages the estimated characteristic set profile features to perform source selection, query decomposition, and join ordering. The query planner is based on insights from existing characteristic set-based query planning strategies. However, it is adapted such that it can handle limited and potentially inaccurate information in the profile feature estimations. The results of our experiments on the FedBench benchmark illustrated the feasibility of using estimated profile features. Overall, we found the best query plans are obtained for the feature estimations using the unweighted sampling method with improvements for larger sample sizes. Moreover, the results revealed that the capability of obtaining more efficient query plans with respect to the number of subexpressions and answer completeness is also reflected in the structural similarity measures ().
Future work will focus on two directions. The first direction is extending our profile feature estimation approach with further sampling approaches that make use of additional information, such as query logs, to better capture the relevant parts of the RDF graphs. Besides, our approach can be extended to estimate other profile features. The second area of research is the application of the feature estimations to other problems. It would be worth investigating how other applications can benefit from the estimated profile features. Furthermore, we aim to improve the query planning approach by (i) leveraging further information that can be obtained from the samples, and (ii) implementing a hybrid planning strategy that not only relies on the estimated statistics. Finally, an evaluation of our query planner in additional federations will support a better understanding of the advantages and limitations of our approach.
Footnotes
Acknowledgements
This work was supported by the grant QUOCA (FKZ 01IS17042) from the German Federal Ministry of Education and Research (BMBF).
Efficiency of CSPF computation
Part of the motivation of this work is the fact that computing and estimating CSPF over samples of the original graph reduces the computational effort. As discussed in Section 3.5, the computation method needs to be tailored to the access methods of the RDF graph. To showcase the reduction in computational effort when computing CSPF from samples, we focus on a single, general case and we assume the RDF graphs to be given as edge lists (i.e.,
Algorithm The algorithm first sorts the triples in the graph G by subject. Thereafter, it iterates the sorted list of triples, determining the characteristic set per subject and storing the corresponding statistics in a hash table or dictionary. This process is detailed in Algorithm 2.
Central to the computation are dictionaries
Efficiency results In Fig. 9, the mean runtimes for computing the CSPF are summarized per sample size and for the entire original graph. For the sake of comparability, the triples were randomly shuffled before computing the CSPF. For each of the 90 samples per dataset and sample size, the CSPF was computed once and the runtimes averaged across the 90 measurements. For the original graphs, this process was repeated 10 times to obtain an average runtime value. The results indicate a substantial reduction in the runtimes for computing the CSPF for the samples than the original graphs (note the log-scale for the runtimes). In addition, the gain in efficiency also depends on the structure of the RDF graph, such as its out-degree dispersion.