
Abstract
Quality is a complicated and multifarious topic in contemporary Linked Data research. The aspect of literal quality in particular has not yet been rigorously studied. Nevertheless, analyzing and improving the quality of literals is important since literals form a substantial (one in seven statements) and crucial part of the Semantic Web. Specifically, literals allow infinite value spaces to be expressed and they provide the linguistic entry point to the LOD Cloud. We present a toolchain that builds on the LOD Laundromat data cleaning and republishing infrastructure and that allows us to analyze the quality of literals on a very large scale, using a collection of quality criteria we specify in a systematic way. We illustrate the viability of our approach by lifting out two particular aspects in which the current LOD Cloud can be immediately improved by automated means: value canonization and language tagging. Since not all quality aspects can be addressed algorithmically, we also give an overview of other problems that can be used to guide future endeavors in tooling, training, and best practice formulation.
Introduction
In this paper we investigate the quality of literals in the Linked Open Data (LOD) Cloud. A lot of work has focused on assessing and improving the quality of Linked Data. However, the particular topic of literal quality has not yet been thoroughly addressed. The quality of literals is particularly important because (i) they provide a concise notation for large (and possibly infinite) value spaces and (ii) they allow text-based information to be integrated into the RDF data model. Also, one in seven RDF statements contains a literal as object term.1
A statistic derived from the LOD Laundromat data collection on 2016-05-18.
Our approach consists of the following steps. We create a toolchain that allows billions of literals to be analyzed efficiently by using a stream-based approach. The toolchain is made available as Open Source code to the community. We show that the toolchain is easy to integrate into existing approaches and can be used in a sustainable manner: Firstly, important parts of the toolchain are integrated into the ClioPatria triple store and RDF library. Secondly, important parts of the toolchain are integrated into the LOD Laundromat infrastructure, and are used for clearning RDF content that is scraped from the web. Thirdly, the toolchain is used by Luzzu: a state-of-the-art Linked Data quality framework. We will use the here presented toolchain in order perform an analysis of the quality of literals in the LOD Cloud. Finally, we present automated procedures and concrete suggestions for improving the quality of literals in today’s Web of Data. An important property of the here presented approach is that it can be applied to web-scale data, and ultimately to the LOD Cloud as a whole.
This paper focuses on a relatively isolated and restricted part of quality: the syntactic, semantic and linguistic aspects of literal terms. As such, it does not cover quality issues that may arise once more expressive vocabularies such as OWL are interpreted as well. Specifically, the problem of missing values may occur in this context, as may constraint violations, e.g., uniqueness constraints. These are considered to be future work.
This paper is structured as follows. Section 2 discusses related efforts on quality assessment and improvement. In Section 3 we give our motivation for performing this work. In Section 4 we define a set of quality criteria for literals. The next section describes the toolchain and its role in supporting the defined quality criteria. Section 6 reports our analysis in terms of the quality criteria defined in the previous section. In Section 7 we enumerate opportunities for improving the quality of literals based on our observations in the previous section. We implement two of those opportunities and evaluate their precision and recall. Section 8 concludes the paper and discusses further opportunities for research on literals quality.2
This paper uses the following RDF prefixes for brevity:
.
Quality assessment for Linked Data is a difficult and multifarious topic. A taxonomy of problem categories for data quality has been developed by [23]. Not all categories are applicable to Linked Data quality. Firstly, due to its fluid schema and the Open World Assumption, the absence of an RDF property assertion does not imply a missing value. Secondly, because RDF does not enforce the Unique Names Assumption, the problem of value uniqueness does not arise.3
For comparison, if distinct resources are described with the same value for one of the primary key attributes, then this is considered a schema violation in relational databases.
Empirical observations. The large-scale aspects of Linked Data quality have been quantified in various ‘LOD Observatory’ studies: [2,16,17]. These studies, while focusing on Linked Data quality overall, have only included cursory analyses of quality issues for RDF literals. In [17], Hogan et al. conduct an empirical study on Linked Data conformance, assessing RDF documents against a number of Linked Data best practices and principles. They specifically cover (i) how resources are named, (ii) how data providers link their resources to external sources, (iii) how resources are described, and (iv) how resources are dereferenced.
Metadata. Various metadata descriptions for expressing Linked Data quality have been proposed. In Assaf et al. [2], the authors give insight into existing metadata descriptions. This assessment checks the metadata of each RDF document for generic information, access information, ownership information and provenance information. No vocabulary for expressing literal quality metadata exists today. However, the taxonomy of literal quality in Section 4.3 may serve as a starting point for such a vocabulary. There are already several data quality vocabularies that can be extended, e.g. [12,15]. The W3C has recently standardized a vocabulary (DQV) for expressing Linked Data quality.4
See
Quality Frameworks. A number of tools have been developed for assessing the quality of Linked data documents [7,11,20,22]. The authors in [20] present RDFUnit, a SPARQL based approach towards assessing the quality of Linked Data. Their framework uses SPARQL query templates to express quality metrics. The benefit of this tool is that it uses SPARQL as an extensibility framework for formulating new quality criteria. The drawback of this framework is that metrics that cannot be expressed in SPARQL, such as checking the correctness of language tags, cannot be assessed in RDFUnit. In [22], the authors make use of metadata of named graphs to assess data quality. Their framework, Sieve, allows for custom quality metrics based on an XML configuration. WIQA [7] is another quality assessment framework that enables users to create policies on indicators such as provenance. Luzzu [11] is an extensible Linked Data quality assessment framework that enables users to create their own quality metrics either procedurally, through Java classes, or declaratively, through a quality metric DSL.
Crowdsourcing. Some aspects of quality are highly subjective and cannot be determined by automated means alone. In order to improve these quality aspects a human data curator is required. [1] present a crowdsourcing approach that allows data quality to be improved. Quality is not a static property of data but something that can change over time as the data gets updated. The dynamic aspects of data quality are observed in [19].
This section gives motivation for analyzing and improving the quality of literals. We first explain the importance of literals overall. We then distinguish three perspectives from which the assessment and improvement of literal quality is important. We also enumerate the concrete benefits of improving literal quality.
The importance of literals
Literals have a crucial syntactic and semantic role within the Semantic Web’s data model. Firstly, they introduce a concise notation for infinite value spaces. While one of the main Linked Data principles is to “use URIs as names for things” [6], URIs/IRIs are not a viable option for expressing values from infinite value spaces. The Linked Data principle of using URIs for everything is carried through to the absurd in Linked Open Numbers,5
See
See
The second main benefit of literals is that they allow linguistic or text-based information to be expressed complementary to RDF’s graph-based data model. While IRIs are (also) intended to be human-readable [14], a literal can contain natural language or textual content without syntactic constraints. This allows literals to be used in order to convey human-readable information about resources. Also, in some datasets, IRIs are intentionally left opaque as the human-readability of universal identifiers may negatively affect their permanence [5]. Since the Semantic Web is a universally shared knowledge base, natural language annotations are particularly important in order to ease the human processability of information in different languages.
Improving the quality of literals has (at least) the following concrete benefits for the consumption of Linked Data:
Efficient computation
If a data consumer wants to check whether two literals are identical she first has to interpret their values and apply a datatype-specific comparator operator [9]. For example,
Data enrichment
The availability of reliable language tags that indicate the language of a textual string is an enabler for data enrichment. Language-informed parsing and comparing of string literals is an important part of existing instance matching approaches [13]. Having language tags associated with string literals allows various notions of similarity to be defined that move beyond (plain) string similarity. This includes within-language similarity notions such as “is synonymous with” as well as between-language similarity notations such as “is translation of”.
User eXperience
Knowing the language of user-oriented literals such as
Semantic text search
Tools for semantic text search over Linked Data such as LOTUS [18] allow literals, and statements in which they appear, to be retrieved based on textual relevance criteria. To enable users to obtain relevant information for their use case, these tools use retrieval metrics that are calculated based on structured data and meta-information. High-quality language-tagged literals allow more reliable relevance metrics to be calculated. For instance, ‘die’ is a demonstrative pronoun in Dutch but a verb in English. Searching for the Dutch pronoun becomes significantly easier once occurrences of it in literals are annotated with the language tag for Dutch (i.e.,
The metadata on literal datatypes and language tags can be exploited by search systems to improve the effectiveness of their search and bring users closer to their desired results. However, as almost no previous work has focused on analysis and improvement of the quality of literals, contemporary semantic search systems will not make use of this potentially useful metadata. Certain text search tools allow queries to be enriched with meta-information about literals even though the reliability of this information is not high, which may lead to poor results. For instance, LOTUS attempts to improve the precision of literal search by looking up language tags, despite the fact that around 50% of the indexed literals in LOTUS have no language tag assigned to them, which could lead to a decrease in recall for literals with no language tag. Being able to assess whether a given dataset has sufficiently high literal quality would allow Semantic Search systems to improve their precision and recall.
Specifying quality criteria for literals
This section presents a theoretic framework for literal quality. It defines a taxonomy of quality categories in terms of the syntax and semantics of literals according to current standards. In addition to the taxonomy, different dimensions of measurement are described. The quality categories and dimensions of measurement can be used to formulate concrete quality metrics. Several concrete quality metrics that are used in later sections are specified at the end of this section.
Syntax of literals
We define the set of literal terms as
See
See
According to the RDF 1.1 standard [9], language-tagged strings are treated differently from other literals. Because the definition of a datatypes does not allow language tags to be encoded as part of the lexical space, language-tagged strings have a datatype IRI (
RDF serialization formats such as Turtle allow some literals to be written without a datatype IRI. These are abbreviated notations that allow very common datatype IRIs to be inferred based on their lexical form. The datatype IRI that is associated with such a lexical form is determined by the serialization format’s specification. For instance, the Turtle string
The meaning of an RDF name, whether IRI or literal, is the resource it denotes. Its meaning is determined by the interpretation function I that maps RDF names to resources
The set of syntactically well-formed lexical forms
The set of resources
A functional
A
Optionally, a functional
Suppose we want to define a datatype for colors. We may choose a lexical space
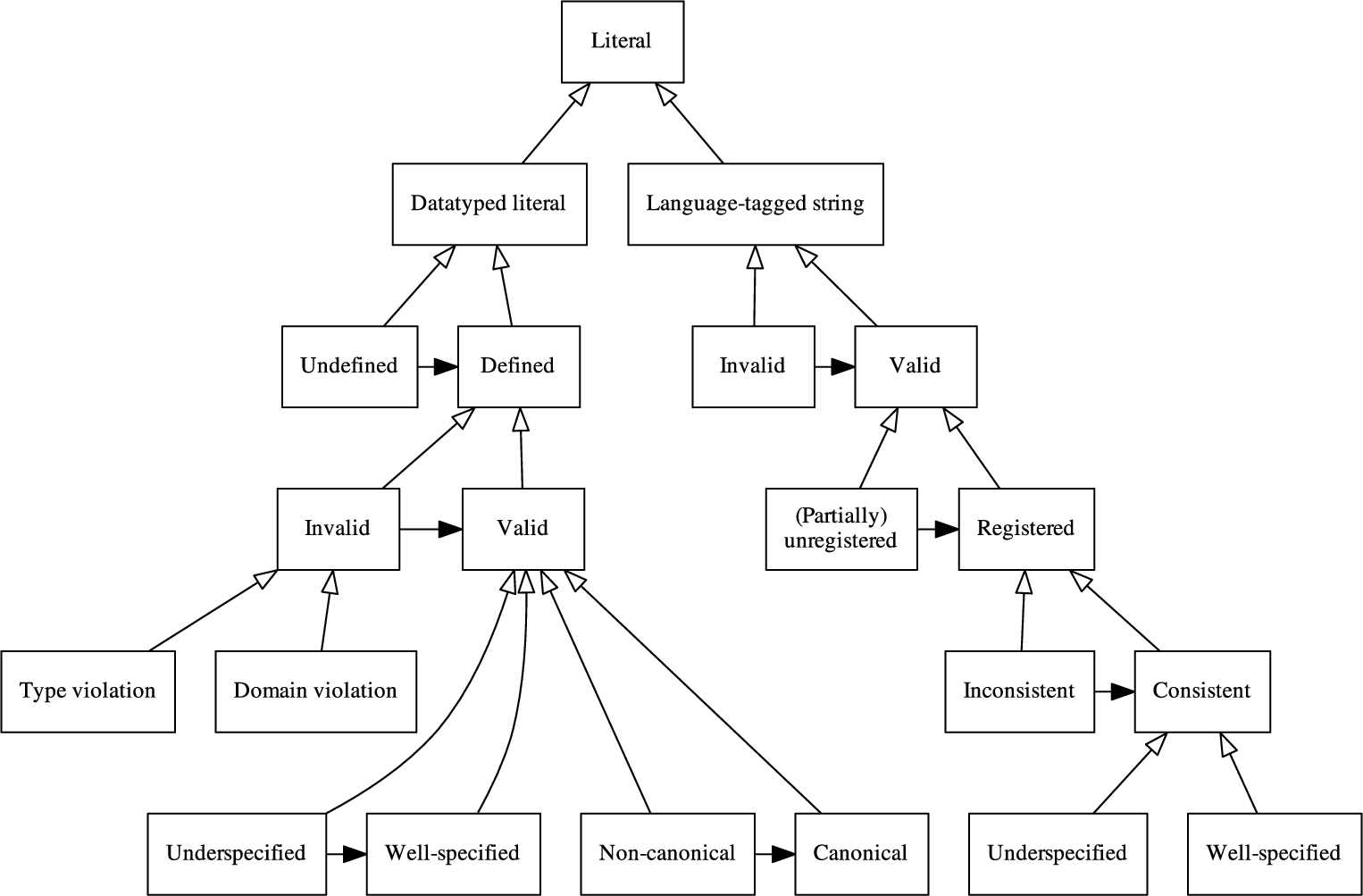
A taxonomy of RDF literal quality. The nodes show the categories a literal’s quality can be classified under. Vertical arrows denote specialization, from more specific to more generic. For instance, literals that are ‘Invalid’ are also ‘Supported’ and are also ‘Datatyped literals’. Horizontal arrows denote possibilities for quality improvement. For instance, ‘Non-canonical’ datatyped literals can be made ‘Canonical’.
The denotation of literal terms is determined by the partial interpretation function
where
RDF processors are not required to recognize datatype IRIs. Literals with unrecognized datatype IRIs are semantically treated as unknown names. An RDF processor that recognizes more datatypes is therefore not ‘more correct’ but it is able to distinguish and utilize more subtleties of meaning.
A taxonomy of literal quality
The categories of literal quality are shown in Fig. 1. Because of their fundamentally different syntactic and semantic properties, the quality categories of language-tagged strings are specified separately from those of datatyped literals. The following quality categories are defined for datatyped literals (the categories in Fig. 1 are described in the order of a depth-first traversal):
A datatyped literal is undefined if its datatype IRI does not denote a datatype. Formally:
A defined datatyped literal has a datatype IRI that denotes a defined datatype. Formally:
A defined datatyped literal is invalid if its lexical form cannot be mapped to a legal value. Formally:
A supported datatyped literal has a type violation if its lexical form cannot be parsed according to the grammar associated with its datatype. Formally:
A supported datatyped literal has a domain violation if its lexical form can be parsed according to the grammar associated with its datatype, but the parsed value violates some additional domain restriction. Formally:
Supported datatyped literals whose lexical form can be mapped to a value that satisfies all additional constraints for its datatype are valid. Formally:
A valid datatyped literal is underspecified if its datatype is too generic. Example: the number of people in a group can be correctly represented by a literal with datatype
A valid datatyped literal that is not underspecified.
A non-canonical datatyped literal is a valid datatyped literal for which there are multiple ways in which the same value can be represented, and whose lexical form is not the one that is conventionally identified as the canonical one. Formally:
A datatyped literal whose lexical form is canonical for the value denoted by that lexical form. Formally:
Language-tagged strings are sufficiently different from datatyped literals to receive their own quality categories. Specifically, language-tagged strings cannot be undefined (‘Undefined’ in Fig. 1) because datatype IRI
A language-tagged string is invalid if its language tag violates the grammar specified in RFC 5646 (BCP 47). Example:
A language-tagged string is valid if it is not malformed/invalid.
A well-formed language-tagged string is unregistered if the subtags of which its language tag is composed are not registered in the IANA Language Subtag Registry.9
See
A well-formed language-tagged string is registered if it is not partially unregistered.
Since the values of language-tagged strings are pairs of strings and language tags, it is possible for the string to contain content that is not (primarily) encoded in the natural language denoted by the language tag. If this occurs then the string and language tag are inconsistent. Example: in language-tagged string
A registered language-tagged string whose lexical form is a valid string in the language denoted by the language tag.
Underspecification occurs when the language tag of a language-tagged string is correct, but there exists a more specific language tag that is also correct. For example,
A consistent language-tagged string that is not underspecified.
There is a variant of the quality issue of underspecification that connects the sub-hierarchies of datatyped and language-tagged literal quality. Literals with datatype
There are issues with the ‘Underspecified’ language-tagged string category in Fig. 1. The current standards are insufficient for annotating natural language strings in several cases. For instance, proper nouns are often spelled the same way in different languages. Currently, the only option is to add distinct triples for each language in which the proper noun is used (e.g.,
Another limitation of the current standards surfaces when dealing with multi-lingual strings. The only solution for tagging these strings is to make assertions in which the string appears in the subject position and an RDF name that denotes a language appears in the object position. The predicate must denote a property that relates strings to one of the languages to which some of the string content belongs:

Since literals are normally not allowed to appear in the subject position, a blank node to literal mapping has to be maintained as well:

Because language tags cannot be used as RDF names, there is no way to link the object term identifier to its corresponding language tag.
The quality of literals can be assessed at different levels of granularity. We distinguish between at least the following three levels:
The quality of individual literals.
The quality of literals that have the same datatype.
The quality of literals that appear in the same document. The quality of literals in a document is an important ingredient for assessing the overall quality of that document.
The quality categories in Fig. 1 can be measured at each of the three granularity levels. Measurements on the literal level are straightforward: every literal belongs to some leaf node(s) in the taxonomy. In most cases a literal belongs to exactly one leaf node. The only exception is valid datatyped literals: they belong to either ‘Underspecified’ or ‘Well-specified’ and to either ‘Non-canonical’ or ‘Canonical’.
LOD Laundromat is a stream-based data cleaning infrastructure that is able to assess the quality of literals at the term and datatype levels. As such, it can give overviews of the state of literal quality on the LOD Cloud. Luzzu is a data quality framework that assesses literal quality at the document level.
More complex quality metrics can be defined in terms of the atomic quality categories in Fig. 1. Since Luzzu is an extendable framework, new composed metrics can be defined in it. For example, Luzzu measures the ratio of valid literals, or
The literal quality metrics introduced in this section are used in the analyses performed in Section 6. The first analysis is conducted in LOD Laundromat and covers the term and datatype levels. The second analysis is conducted in Luzzu and covers the document level.
Implementation
In this section we describe the data and software that are used for the analysis in Section 6 and the automatic quality improvements in Section 7.
Data
The analysis and the evaluation of the improvement modules are conducted over the LOD Laundromat [4] data collection, which currently consists of about 650 thousand RDF documents that contain 38 billion ground statements. The data is collected from data catalogs (e.g., Datahub10
See
See
Since the LOD Laundromat only includes syntactically processable statements, it is missing all literals that are part of syntactically malformed statements. The reason for this is that whenever a statement is syntactically malformed it is impossible to reliably determine whether a literal term is present and, if so, where it occurs. For example, the syntactically malformed line (A) inside a Turtle document may be fixed to a triple (B), a quadruple (C) or two triples (D). The ‘right’ fix cannot be determined by automated means.

The absence of literals that appear within syntactically malformed statements does not influence the meaning of an RDF graph or dataset. A statement must (at least) be syntactically well-formed in order to be interpretable. RDF semantics describes meaning in terms of truth-conditions at the granularity of statements:
Since we focus on the quality of literals, we do not cover quality issues that are not specific to literals. This mainly includes various encoding issues. For instance, a Turtle file that uses Latin-1 encoding, whereas the Turtle specification requires the use of UTF-8. When the encoding of a file is wrong or unknown, the file may contain characters that are probably not intended by the original data publishers. Such characters can then also appear in literals.12
An example of what is probably an encoding issue that appears in a literal: http://lotus.lodlaundromat.org/retrieve?string=%C3%85%E2%84%A2&match=terms&rank=psf&size=500&noblank=false.
The toolchain consists of the following components:
The RDF libraries used for parsing, interpreting and serializing RDF data, including the literals.
The data cleaning and republishing framework whose data is used in our evaluations. The LOD Washing Machine uses ClioPatria libraries.
A command-line tool that provides easy remote access to the LOD Laundromat data collection.
Existing libraries for detecting natural languages. These are run over data supplied by Frank.
A quality assessment framework for RDF documents. This is run over data supplied by Frank.
All components of the toolchain are (of course) published as Open Source software and/or as web services to the community. We now describe each component in more detail.
ClioPatria13
See
See
We have compared the results of our datatype implementation in ClioPatria with RDF4J15
See
LOD Washing Machine17
See
The LOD Washing Machine cleans the data in a stream, on a per-tuple basis. This means that memory consumption is almost negligible. The grammars of the implemented datatypes are all
Frank18
See
ALD libraries. For the assessment and improvement of language-tagged strings we use three existing state-of-the-art Automatic Language Detection (ALD) libraries:
We use a NodeJS wrapper19
See
See
The NodeJS CLD library21
See
See
This library,23
See
See
The chosen ALD libraries are widely used and are known to have high accuracy for the supported languages and text sizes. Although the chosen set still remains – to some extent – arbitrary, it is trivial to include more libraries into our framework, as one sees fit.
Luzzu25
See
The following literal-specific quality metrics are implemented in the Luzzu framework: (i) the validity of a datatype against its lexical value (category ‘Valid’ in Fig. 1); and (ii) the consistency between a language-tagged string’s lexical form and language tag (category ‘Consistent’ in Fig. 1).
For calculating the ratio of consistent language-tagged strings (Section 4.4) Luzzu uses natural language web services. For single word literals it uses the Lexvo [10] web service.26
See
For checking the correctness of multi-lingual language-tagged strings Luzzu uses the Xerox Language Identifier.27
This web service identifies the language of natural language phrases and sentences. While the service often returns correct results for languages that commonly occur in the LOD Cloud, this approach does not guarantee that the correct language will always be found [21]. The fact that this approach gives only approximately correct results is taken into account when encoding the metric into metadata.This section presents three analyses that are conducted to explore the framework presented in the previous section. The first analysis assesses multiple aspects of the quality of datatyped literals on a large scale. The second analysis assesses one quality aspect of language-tagged string, also on a large scale. The third analysis assesses quality aspects of datatyped literals and language-tagged string within documents. These three approaches are complementary, and together cover a large area of literal term use: datatyped as well as language-tagged, and LOD Cloud-wide as well as document-based.
Analysis 1: The quality of datatyped literals
We analyze 1,457,568,017 datatyped literals from the LOD Laundromat data collection. Table 1 gives an overview of the ten most occurring datatype IRIs. These are all from the RDF and XSD specifications.
For the datatyped literals we investigate the following quality categories defined in Section 4.3: undefined, invalid, and non-canonical. Overall we find that the vast majority of literals are valid and a modest majority of them are also canonical. However, 76% (or 1,112,534,996 occurrences) of literals are (language-tagged or XSD) strings (see Table 1). This is not surprising since strings enforce the least syntactic restrictions. Specifically, XSD string is often chosen as the default datatype in case no explicit datatype IRI is provided. It is relatively uncommon for an XSD string literal to be invalid, since in order to do so it must contain unescaped non-visual characters such as the ASCII control characters. For the more complex datatypes, e.g., those that denote dates, times and floating point numbers, the grammar is more strict. In these cases we see that there is still a lot of room for improvement (see the results below).
The ten most occurring datatype IRIs for the literals that were sampled from the LOD Laundromat data collection
The ten most occurring datatype IRIs for the literals that were sampled from the LOD Laundromat data collection
Undefined. Most datatype IRIs do not dereference to a proper definition of a datatype. Many datatypes that have some form of human-readable informal description do not provide enough information in order to properly implement them. An example of this is datatype IRI

Informal description of the Markdown datatype
We notice that there is currently not a strong practice of defining datatypes in terms of XML Schema. In fact, we did not find such a definition outside of the original XSD specification. Also, while there is no inherent reason why an informally specified datatype should be ambiguous or incomplete, in practice we have not found an informal description that is unambiguous and complete. Table 2 shows the most often occurring undefined datatypes. The vast majority of these are DBpedia datatype IRIs (namespace
Some datatypes are defined but do not include the optional canonical mapping. An example of such a datatype IRI is
The most often occurring undefined datatyped literals
Invalid. Table 3 shows the datatypes that have the highest number of invalid literals. Overall, only 0.11% of all literals are invalid. However, as was mentioned before, 79% of all literals are strings for which almost every lexical form is valid. As soon as the datatype becomes more complicated, the percentage of invalid occurrences goes up. For example, many integers with datatype IRI
The datatype IRIs with the highest number of invalid literals. The percentage is calculated relative to the total number of literals with a given datatype
Non-canonical. Table 4 shows the five datatypes with the highest number of non-canonical literals. Overall, 3.5% of all literals are non-canonical. Again, simple strings are canonical by definition, since they map onto themselves. On the other hand, the majority of the floating-point numbers (either
The datatype IRIs with the highest number of non-canonical literals. The percentages are calculated relative to the number of literals with a specific datatype IRI
We want to analyze literals with textual content, including textual content that has been explicitly tagged with a language tag (i.e., language-tagged strings) and textual content that is untagged (i.e., XSD strings). It is difficult to reliably determine when a literal contain textual content, which is an inherently vague notion. We want to at least exclude many XSD strings that are obviously non-textual. For this we require the lexical form of an XSD string to at least contain two consecutive Unicode letters. This coarse filter removes lexical forms that encode dates, lengths, telephone numbers, etc. Such non-textual strings are probably stored as XSD strings because the data publisher was unaware of an appropriate datatype, and/or did not have enough time to perform a proper transformation to an existing datatype.
When we use our coarse filter to distinguish literals with textual content, this results in 3,54 billion literals. 2.26 billion (or 63.83%) of these are language-tagged strings (have an explicit language tag). The remaining 1.28 billion (or 36.17%) are XSD strings (do not contain a language tag). These literals originate from 569,422 documents from the LOD Laundromat data collection.
The distribution of language tags over this collection of literals is given in Table 5. By far the most language-tagged literals are in English, followed by German, French, Italian and Spanish. This shows that Linked Data contains a strong representation bias towards languages of European origin, with the 10 most frequent language tags representing European languages. 73.26% of all language-tagged literals belong to one of the 10 most frequently occurring languages.
Unregistered. We analyze how many of the language-tagged literals are ‘Registered’ (see Fig. 1) by assessing whether their primary language tag belongs to the IANA language codes registry. Out of 313 two-digit country codes in the LOD Laundromat collection, 186 (59.4%) are also registered in IANA. The vast majority of language-tagged literals (98.6%) contains a registered language tag. Table 6 presents the five most frequently occurring unregistered language tags.
The distribution of language tags in the LOD Laundromat data collection
The distribution of language tags in the LOD Laundromat data collection
Unregistered primary language tags that appear in the highest number of language-tagged strings
In order to illustrate that the here presented toolchain integrates well with document-based quality frameworks, we run initial experiments of the Luzzu framework, receiving data and metadata through the Frank tool. Luzzu quantifies the quality of Linked Data documents, including the quality of literals. We used Luzzu in order to process 470 data document from the LOD Laundromat collection. For each of these documents Luzzu calculates the ratio of valid literals and the ratio of consistent language-tagged strings (Section 4.4). For these specific documents Luzzu determines that, on average, 70% of the language-tagged strings are consistent with respect to their language tag. On the other hand, only 39% of literals have a lexical form that belongs to the value space denoted by its datatype IRI (category ‘Valid’ in Fig. 1).
Manual inspection of the sample of documents whose quality value was less than 40% reveals the following four main issues for language-tagged strings:
A literal contains linguistic content but lacks a language tag (category ‘Underspecified’ in Fig. 1).
A literal contains both linguistic and non-alphabetic content (the multi-linguality problem discussed in Section 4). Example:
A literal contains linguistic content with syntax errors (category ‘Invalid’ in Fig. 1). Example:
A literal has a language tag that is not supported by the automated approaches used by Luzzu. Example:
The majority of problematic triples exhibit the first issue. The third issue, i.e., lexical forms containing syntax errors, actually result in incorrect identifications by the external services that are used to calculate the metrics. For example, in
See
Interestingly, many of the quality issues that were found upon manual inspection overlap with the ones that we considered problematic in Section 4. This leads us to believe that typo’s and multi-linguality may not be fringe cases after all, and that current standards may actually be too coarse to deal with the real-world quality issues of language-tagged string as they are used in the LOD Cloud today. Future work into these issues is needed.
In this section we show that the quality of literals can be significantly improved by using the processing and analysis framework presented in Section 5 and Section 6. The possible quality improvements are defined in the literal quality taxonomy in Section 4, as indicated by the horizontal arrows with filled arrows in Fig. 1. Based on the analysis in the previous section we are informed about some of areas where literal quality can be improved.
We note that not all aspects of literal quality can be improved by automated means. For instance, the quality improvement from ‘Underspecified’ to ‘Well-specified’ in Fig. 1 cannot be effectuated based on the available data alone but needs an interpretative decision from the original data publisher. Even though these quality issues cannot be fixed automatically, the current framework can still be used to automatically detect such problems. In general, suggestions for quality improvement can now be based on empirical observation rather than intuition.
In order to show that our toolchain indeed provides the required scale to fix quality issues in the LOD Cloud, we choose two quality aspects that can be automated. These two quality aspects also support two use cases in Section 3. The first one is the automatic conversion of non-canonical datatyped literals to canonical ones, supporting the efficient calculation of equivalence tests. The second one is the automatic assignment of language tags to textual literals that did not have a language tags before, supporting improved multi-lingual search indexing.
Improving datatyped literals
Undefined. The analysis in Section 6 gives an overview of the size of the quality issue of undefined datatypes. Based on this overview we can see that defining the DBpedia datatype IRIs would solve the vast majority undefined datatype IRIs, thereby significantly increasing the overall quality of literals in the LOD Cloud.
Underspecified → well-specified. An underspecified literal cannot be changed into a well-specified one based on the observed lexical form alone. For instance, the fact that the values
Invalid → valid. Invalid literals can only be improved upon by the original data publisher. We cannot automate this task since it requires us to choose between (1) changing the datatype IRI to match the lexical form, (2) changing the lexical form to match the datatype IRI, or (3) changing both. However, we can give an overview of mistakes that occur most often in the data. Based on our empirical observations these are the top 4 mistakes, along with suggestions of how to avoid them in the future:
RDF IRIs are case sensitive [9]. Specifically
Many datatype IRIs are not proper HTTP(S) IRIs. Since RDF serializations are very admissive when it comes to IRI syntax, many things that are parsed as literals contain datatype IRIs that do not parse according to the more strict IRI RFC specification [14]. Most of these improper datatype IRIs are due to undeclared prefixes (e.g.,
Non-canonical → canonical. Canonical literals provide a significant computational benefit over non-canonical valid literals for several use cases. For instance, checking whether two terms or statements are identical or not no longer requires parsing and generating of lexical forms, i.e., string similarity suffices where one would have to calculate
Improving language-tagged strings
Unregistered → registered. Standardizing the set of language tags in LOD Laundromat with respect to the central IANA registry would improve the quality of the literals. However, it is not trivial to adjust these language tags automatically. For instance, the unregistered tag
No language tag → language tag. We attempt to assign a language tag to textual literals that do not have one yet. For this purpose, we test the accuracy of automated language detection algorithms when applied to the textual lexical forms from the LOD Laundromat data collection. We define a textual lexical form as a lexical form of a literal with datatype IRI
We apply three language detection libraries (see Section 5.2) to the textual lexical forms in the LOD Laundromat data collection. We are interested in the following aspects: How often does the automatically detected language tag coincide with the user-assigned tag? How accurate are the language detection libraries? Does the accuracy of detection differ per primary language or for various string sizes? Are certain languages or string sizes easier for language detection? How often do the libraries refrain from assigning a language tag at all? Can we combine the libraries and thereby improve the overall accuracy of language detection?
We use the language-tagged strings that appear in LOD Laundromat and check whether the ALD libraries assign the same language tag to the lexical form as the one assigned by the original data publisher. We report the precision, recall and F1-value for each language detection library. We assume that the accuracy that we measure over language-tagged string extends to XSD string literals with a textual lexical form (i.e., ones that do not have a user-defined language tag).
The language tag assigned by the original data publishers can consist of multiple, concatenated subtags. Since our language detection tools only provide an ISO 639-2 two-character language code in most cases, we focus our comparison on the primary language subtag, i.e., the first two characters of each language-tagged string. Another motivation for enforcing this abstraction is that it is more difficult to distinguish fine-grained language differences from a semantic point of view. For instance, if the original data publisher supplied language tag
Table 7 gives an overview of the time that each ALD library needs for annotating the textual lexical forms. The (single-threaded) process of tagging takes 5 days. Most of this elapsed time (around 80%) is used by the ALD libraries themselves. The remaining time is used by the Frank tool to extract the required information from the LOD Laundromat web service. Considering that such an improvement procedure only needs to be executed once, and not necessarily in real time, we believe that the time needed to improve the coverage of language tags in the LOD Cloud is reasonable.
Running time for each of the three ALD libraries. The difference between the total duration and the library-specific runtime shows that the overhead of streaming through the LOD Laundromat data collection accounts for 20.5 hours
Running time for each of the three ALD libraries. The difference between the total duration and the library-specific runtime shows that the overhead of streaming through the LOD Laundromat data collection accounts for 20.5 hours
We also measure the accuracy of each ALD library and observe that the highest precision (75.42%) is achieved by the CLD library, which also covers the highest number of languages (160). It is notable that this library often gives no language suggestion, especially when it comes to short strings.
We further investigate to which extent the accuracy of the libraries is dependent on specific language tags or string sizes. The outcome of this analysis for the most frequently occurring 10 languages is shown in Table 8. Each of the cells represents an intersection of a primary language tag and a string size bucket. We measure the string size n in terms of number of words that constitute the string. A string size bucket b contains strings whose length fall within the same logarithmic value:
F1-value accuracy of the libraries per bucket size and language. Library results are given in the following order: Tika, CLD, LangDetect. The language tags are ordered by frequency, with the most frequent languages on the top of the Table
Figure 2 shows the aggregated accuracy per bucket for each of the three libraries. Note that there is hardly any intersection of the plotted lines: for any text size bucket (except for 0), CLD gives the highest F1-value, while Tika gives the lowest. However, the text size does correlate with the general success of language detection (by any library). Concretely, short strings which contain only one word (bucket 0) or two words (bucket 1) are much harder to detect correctly than longer strings. On the other hand, expressions from bucket 8 (between 129 and 256 words) can be detected with almost perfect accuracy.
This tendency is confirmed for the most frequent 10 languages (Fig. 3). Every data point represents the average F1-value, calculated over the three libraries for a given language and bucket. This shows that libraries are successful in detecting the language of sufficiently long literals (literals in bucket 3 already have an F-measure of around 75%, increasing to around 85–90% for bucket 4). Almost all common languages, except for Portuguese, follow this distribution. From Figs 2 and 3 it is clear that the accuracy of the ALD libraries for strings of moderate and long size is very high. In contrast, the language detection for short strings and less common languages has a much lower accuracy.
We also observe a significant decline in accuracy for the extremely large strings (belonging to bucket 10 and above), which is somewhat unexpected. We hypothesize that this decline could be due to the following factors: (1) The buckets 10 and above contain much fewer strings, between a few hundred and a few thousand strings per language, which leads to less stable and less reliable results; (2) the strings that belong to these categories are generally non-standard in terms of size, format and content. Specifically, some strings are so long that they result in errors for entering an unanticipated form of input. One example is the full text of the book “THE ENTIRE PROJECT GUTENBERG WORKS OF CHARLES D. WARNER”, which are stored in a single literal term.

Accuracy per language detection library.

Accuracy per language tag for the 10 most frequent languages.
In some instances a lexical form can be correctly annotated with multiple primary language tags. This is especially true for proper names – these often share the same surface form in a plurality of languages. For instance, what is the right language tag for “Amsterdam”: English, Dutch, or a set of languages? Ideally, the world languages would be grouped into a hierarchy of language tags, thus allowing the data publisher to specify a group or category of similar language tags (e.g. all Germanic languages). This representation is not standardized at the moment (see also Section 4).
It could also be argued that proper names and other short strings should be kept as non-language tagged strings, because their lack of context often allows multiple language tags to be considered correct. This is demonstrated in Fig. 2: strings that consist of only a few words are seldom tagged with a consistent language.
Finally, we enumerate the most frequently assigned languages by our libraries on the strings without a language tag in the published data (Tables 9, 10, 11). As on the language-tagged strings in Table 5, the major European languages, especially the English language, seem to prevail on the strings without a language tag. At the same time, we observe a set of small languages that are unexpectedly frequent, such as Tagalog (
Most notably, the Tika library shows a bias towards Eastern European and Nordic languages.
Languages among the untagged strings according to CLD
Languages among the untagged strings according to LD
Languages among the untagged strings according to Tika
We have focused on the quality of literals, an area of Linked Data quality conformance that has not been thoroughly investigated before. We have systematically specified a taxonomy of quality criteria that are specific to RDF literals. We have shown that quality metrics can be defined in terms of this taxonomy. We have shown that existing platforms and libraries can be reused in order to automatically check for literal quality conformance. Two concrete analyses were conducted on a very large scale and a third analysis has shown that our toolchain can also be used by existing quality assessment frameworks in order to assess the quality of RDF documents. Finally, we have presented initial attempts at automatically effectuating large-scale improvements to the quality of literals.
Implementation reuse. The implementations have not only be used for the here presented experiments, but have been consolidated into the ClioPatria Semantic Web library and triple store, which now supports a large number of datatypes as well as canonical forms. The literal quality categories for which conformance can be automatically checked have been integrated into the LOD Laundromat data cleaning process, which now records literal quality issues that are found in the data. Finally, the automatic detection of language tags is used by the Semantic Search engine LOTUS to improve its language-specific filters.
Literal quality & RDF processor conformance. Since every empirical measurement of literal quality must use a concrete RDF processor that interprets the input data documents, every empirical measurement of literal quality is inherently relative to the processor that was used. Differences between RDF processors include the set of datatypes that is implemented as well as bugs and/or purposeful deviations from Linked Data standards. While implementing the XSD datatypes in ClioPatria, we discovered that it helps to cross-validate against another library (in our case RDF4J). In a similar way, we hope that the availability of ClioPatria will make it easier for others to add support for more datatypes in their RDF processors as well.
Since this paper has focuses on the quality of literals, conducting a broad investigation into literal support by triple stores and RDF libraries was out of scope. Specifically, we have not conducted a broad investigation into which datatypes are implemented by which triple store or RDF library. Future research should focus on the tool support of literals, because the fact that very few non-XSD datatypes are currently in use may be because of the chicken-and-egg problem that RDF tools do not implement them because they do not occur that often, etc.
Datatype definitions. Even though we have shown that many quality issues can be automatically detected, and some can even be (semi-)automatically fixed, the issue of undefined (or badly defined) datatypes remains unresolved. By definition, a literal’s quality can only be determined once its datatype is properly specified. The existing of so many undefined datatypes, i.e., almost all datatypes that do not belong to the standard collection of XSD datatypes, may point to a lacuna in today’s RDF standards. In these standards, the issue of datatype definition is ‘outsourced’ to the XML Schema specifications. However, the current generation of Semantic Web practitioners may have less experience with XML Schema and related technologies. In order to improve the current situation, standardization organizations may consider introducing new ways of defining RDF datatypes and/or providing more assistance for using the existing ways.
Our approach. This paper presents a novel approach towards quality assessment; one that is large-scale, automated, and easily reusable in the context of other tools and libraries. Current standards and best practices are based on what experts consider to be the most important data quality issues. We show that, in addition to these existing approaches, future initiatives towards data quality improvement may also be based on empirical evidence of the state of the LOD Cloud. Our approach has many benefits, e.g., it allows the impact of quality improvement initiatives to be quantified beforehand. This makes it possible to identify the quality issues for which quality improvement would result in the biggest overall impact.
Our approach extends to the topic of automatically improving data quality. We show that millions of literals (and thereby statements) can be improved very quickly, by algorithmic means. While this does not apply to every quality criterion, e.g., ones that rely on the intention of the original data publisher, there are many quality criteria for which this can be done. Indeed, we have shown that by using state-of-the-art libraries – for instance libraries for natural language identification – we are able to improve the overall quality of the LOD Cloud. This means that many of the quality criteria that could previously only be improved on an ad-hoc basis can now be improved at a very large scale, thereby resulting in a Semantic Web that is more valuable for everyone.