
Abstract
Integrating fairness into machine learning models has been an important consideration for the last decade. Here, neurosymbolic models offer a valuable opportunity, as they allow the specification of symbolic, logical constraints that are often guaranteed to be satisfied. However, research on neurosymbolic applications to algorithmic fairness is still in an early stage. In this work, we bridge this gap by integrating counterfactual fairness into the neurosymbolic framework of logic tensor networks (LTN). We use LTN to express accuracy and counterfactual fairness constraints in first-order logic and employ them to achieve desirable levels of both performance and fairness at training time. Our approach is agnostic to the underlying causal model and data generation technique; for this reason, it may be easily integrated into existing pipelines that generate and extract counterfactual examples. We show, through concrete examples on three benchmark datasets, that logical reasoning about counterfactual fairness has some important advantages, among which its intrinsic interpretability, and its flexibility in handling subgroup fairness. Compared to three recent methodologies in counterfactual fairness, our experiments show that a neurosymbolic, LTN-based approach attains better levels of counterfactual fairness.
Introduction
In the last decade, there has been a considerable amount of research on the topic of fairness in deep learning, as neural networks are increasingly used in critical contexts such as credit scoring, risk assessment of recidivism, and job recruitment. Today, making these systems fairer remains a complex and multi-faceted challenge.
Considering fairness and bias in machine learning, there are two major aspects of interest: how to detect bias and how to mitigate it. A challenge regarding bias detection is that the many fairness criteria explored are sometimes incompatible (Castelnovo et al., 2021; Verma & Rubin, 2018). The fairness literature has largely divided itself into the two broad categories of group-based and individual-based notions, where the former see groups of individuals – rather than single individuals – as the ultimate objects of unfairness. A common objection to group-based fairness metrics is that they secure fairness for “the average individual” of a sensitive group, at the cost of ignoring existing unfairness within such groups, which contrasts with the main intuition that fairness has to do with treating similar individuals in a similar way (Dwork et al., 2012). To address these desiderata, some individual-based measures of fairness have been proposed. Among them, counterfactual fairness (CF) (Kusner et al., 2017) reframes the problem of algorithmic fairness through the lenses of causality, namely, as the counterfactual question: “Would I be treated in the same way, had my protected feature been different?”.
The question regarding bias mitigation concerns the level at which we want to mitigate bias, if before training (pre-processing), at training time (in-processing), or after (post-processing) (Caton & Haas, 2024; Hort et al., 2022). Pre-processing techniques comprise different transformations of the training data towards a more balanced dataset. The rationale behind it is, that a model that is trained on fair data will deliver fair predictions (Kusner et al., 2017). Post-processing handles bias of a trained model by correcting its input, the model itself, or its output (Hort et al., 2022). As they rather aim for (hard) correction than (soft) mitigation, these techniques are useful for constraints that must hold universally. In-processing comprises methods like regularisation, adversarial learning, model composition and adjusted learning methods (Caton & Haas, 2024; Hort et al., 2022). Instead of simulating a desired world or correcting biased predictions, it aims to induce intrinsically fair models that are able to handle unfair data (Wan et al., 2023). A practical benefit is that in-processing techniques can also be applied to pre-trained models for (fairness) constraint learning (Wan et al., 2023).
In this context, the idea of leveraging neurosymbolic approaches to tackle algorithmic unfairness has been largely underexplored so far. The potential for a good fit between these two research lines has been pointed out in recent surveys by Bhuyan et al. (2024) and Gibaut et al. (2023). Neurosymbolic AI allows one to reason symbolically about the neural network’s behaviour, by establishing a correspondence between its low-level information processing and high-level logical reasoning (Hitzler & Sarker, 2022; Sarker et al., 2021). As such, the approach shows many advantages for establishing trust in deep learning systems, by making models more interpretable and transparent (Gibaut et al., 2023). Furthermore, most in-processing bias mitigation frameworks adjust the loss function or the learning algorithm of machine learning models according to a distinct, hard-coded, notion of fairness. Instead, neurosymbolic models offer flexibility, as they provide an interface between arbitrary formalised constraints and their implementation into the machine learning process.
To bridge this gap, we propose an in-processing method to train a counterfactually fair neural network by means of the neurosymbolic method of logic tensor networks (LTN) proposed by Badreddine et al. (2022). Specifically, we integrate counterfactual fairness into the neural network learning process, in the form of logical constraints. Furthermore, we show how to exploit symbolic reasoning after network training to better secure fairness for specific sensitive subgroups. Lastly, we integrate a counterfactual knowledge extraction method into the LTN training process. We investigate how counterfactual explanations may be employed to reason about which features, had they been different, result in different outcomes, and show how to extract constraints to improve counterfactual fairness from this. We evaluate our method on three benchmark datasets with binary as well as score-based predictions. We find that our method is able to take accurate decisions with minimal infractions in terms of counterfactual fairness, especially when subgroup fairness is considered.
The main contributions of this work are the following. First, we push the state-of-the-art in neurosymbolic fairness approaches by showing how to integrate counterfactual fairness and subgroup counterfactual fairness into the LTN framework. Secondly, we introduce a novel methodology to automatically extract fairness constraints from counterfactual explanations. Finally, we show how LTN may be employed to provide individuals insights on their outcome. A short version of this paper was previously published at the NeSy conference 2025 (Heilmann et al., 2025).
Preliminaries
Our pipeline is based on two main algorithmic parts: LTN to specify counterfactual fairness constraints, and counterfactual knowledge extraction based on counterfactual explanations, in the dual role of injecting further fairness constraints and inspecting the impact thereof. In this section, we provide a preliminary discussion on counterfactual fairness, LTN, and counterfactual explanations.
Counterfactual Fairness
Kusner et al. (2017) introduced the notion of counterfactual fairness, according to which a classifier treats individuals fairly if they would have received the same outcome, had their sensitive attribute been different. Such a counterfactual outcome requires knowledge of the causal model
Let us assume that, in

As an example, take the Lawschool dataset (Wightman, 1998), which consists of lawschool applicants, their GPA and LSAT scores alongside admission status. Here, gender serves as the sensitive attribute
In real-world settings, it is infeasible to access the complete structural causal model
In the Lawschool admission example, this means that while the true causal model (e.g., how gender influences LSAT scores through societal factors) is unknown, domain knowledge suggests a plausible causal graph where gender and race both affect LSAT and GPA performance, and these features jointly determine the lawschool admission. We depict this partial causal graph in Figure 2. CNF leverage this graph structure to approximate counterfactual scenarios such as generating the LSAT score and GPA a female applicant would have achieved had she been male, while preserving her race.

Overview of our pipeline for binary predictions. Here,
The counterfactual explanation of a negatively predicted data point is generally defined as the set of minimal changes to that point sufficient to obtain a positive outcome. Since we are interested in the causality of such an outcome, we will focus only on the set of minimal changes that constitute interventions on the structural causal model
Counterfactual explanations can concern actionable features, that is, features that individuals are actually able and willing to change in order to achieve a favourable outcome (like job, education level, address, etc.) or immutable ones, that is, features that either cannot be actively changed (such as race, country of birth, age, gender) or because it would morally unacceptable to ask to do so (e.g., religion, marital status). Sensitive attributes are often immutable, and the definition of counterfactual fairness given in Section 2.1 precisely requires that counterfactual explanations of the model do not involve sensitive features. However, it has been observed that only a small and often insufficient set of characteristics is treated as sensitive (Simson et al., 2024). For this reason, in 4.3 we tackle the issue of counterfactual explanations involving immutable features.
Logic Tensor Networks
LTN are a neurosymbolic framework introduced by Badreddine et al. (2022(@), enabling generalisation and inference from data by defining, for example, a neural network’s loss function using logical formulas. More specifically, LTN integrate a fully differentiable first-order logic
Its signature includes a set of constants
LTN employ fuzzy semantics, where any value in
LTN learn by maximising the truth degree of logical formulas, called axioms, comprising a knowledge-base
Related Work
Fairness Through Neurosymbolic Methods
Wagner and d’Avila Garcez (2021) inaugurated a line of research that combines algorithmic fairness with neurosymbolic aspects. They propose a general method for instilling fairness constraints into deep network classifiers by applying the LTN framework and injecting fairness constraints as logically expressed axioms. Then, the learning process feeds back until these are satisfied. Their work is focussed on the group fairness metrics of demographic parity (i.e., the difference between the positive outcome rates of the disadvantaged and the advantaged group) for which the reported experiments reveal that fairness with respect to these metrics is achieved without sacrificing accuracy.
The reported experiments reveal comparable or even improved accuracy across three different sets (Adult, German and COMPAS) while achieving demographic parity, in comparison with a state-of-the-art neural network-based approach. Closely related to Wagner and d’Avila Garcez (2021), the work by Greco et al. (2023) experimentally shows that the effectiveness of LTN for securing fairness is highly dependent on the semantic interpretations chosen, and that the optimal combination of them yields results in line with previous non-neurosymbolic approaches to group fairness. Both works focus on group-based notions of fairness, whereas the integration of counterfactual fairness into neurosymbolic frameworks has not yet been researched to the best of our knowledge.
Approaches to Counterfactual Fairness
Among the existing approaches to counterfactual fairness (Kusner et al., 2017), the majority of the work proposes to enforce it by generating counterfactual data, and then use this data to enhance factual training data to input into a machine learning training pipeline (Javaloy et al., 2023; Kim et al., 2021; Kocaoglu et al., 2018; Lin et al., 2024; Louizos et al., 2017; Xu et al., 2019; Yang et al., 2021; Zuo et al., 2023). The main focus throughout these approaches lies on the counterfactual generation process leaving aside modifications on the final predictor itself. Differently, Grari et al. (2023) claim that additionally integrating counterfactual fairness objectives into the loss function of the machine learning pipeline contributes to more counterfactually fair predictions. Our proposal builds on the latter suggestion and develops the idea of a neurosymbolic approach in which the requirements of counterfactual fairness are expressed logically and injected at training time. We integrate counterfactual fairness by first estimating counterfactual examples with current methods (causal normalising flows Javaloy et al., 2023); we then develop a neurosymbolic approach that can achieve an overall counterfactual fair model. Broadly speaking, a neurosymbolic approach differs from other methods in that we can express the constraints symbolically and try to ensure that the prediction guarantees the satisfaction of these constraints. Some models might try to implicitly ensure correctness with respect to the fairness criteria, but this is hard to verify. This is why a neurosymbolic approach is particularly promising for ensuring fairness criteria in machine learning models and underscores the contribution of this paper.
Integrating Counterfactual Explanations
One active line of research explores the possibility of using XAI methods to detect and even mitigate violations of fairness (Deck et al., 2024). For instance, in the already mentioned pipeline by Wagner and d’Avila Garcez (2021), the SHAP explainability method (Lundberg & Lee, 2017) is used, but it plays no active role in it, as it is only employed to isolate problematic imbalances and subsequently check the efficacy of their fairness constraints in their mitigation. In contrast, our pipeline exploits explainability methods for the automatic generation and injection of ad hoc fairness constraints into the network.
An important explainability method is that of counterfactual explanations, that is, the set of minimal changes to a data instance sufficient to obtain a different classification outcome. Goethals et al. (2024) have introduced a method based on counterfactual explanations to detect significant patterns of discrimination. Namely, the method compares the distribution of counterfactual explanations between sensitive groups. As an example, they show that in the Adult dataset (Becker & Kohavi, 1996), women are more frequently returned marital-status=“husband” as a counterfactual explanation than men. Since it is problematic to suggest that an individual should change immutable features of this type to obtain a positive outcome, we consider undesirable all those counterfactual explanations that suggest to change an immutable feature, as we argue that it is unethical in itself to suggest individuals to change features such as marital status, or religion to obtain a favourable outcome.
For this reason, in Section 4.3, we develop a method to automatically smooth out possible imbalances in undesirable counterfactual explanations between sensitive groups. We integrate the method by Goethals et al. (2024) into our pipeline with minor adjustments: On the algorithmic level, for every negatively-predicted data point
Method
The goal of our pipeline is to enforce counterfactual fairness, while preserving the accuracy of predictions, and additionally disincentivising undesirable counterfactual explanations that suggest individuals to intervene on immutable features to achieve a favourable outcome. Specifically, we define certain data columns as immutable if they are either sensitive or particularly challenging for individuals to act upon. We achieve these three goals by integrating adequate axioms into the training process of the LTN framework. An overview of the pipeline for datasets with binary outcomes can be found in Figure 1.

Partial causal graphs for the COMPAS (a) and Lawschool (b) datasets. The arrows connecting nodes and rectangles indicate that the node is connected to every node inside the rectangle. White nodes denote immutable sensitive features, grey nodes immutable non-sensitive features, and blue nodes actionable features.
As a first pre-processing step, we approximate counterfactual examples for all data points
Finally, we optionally add axioms derived from our counterfactual knowledge extraction method, which disincentivise counterfactual explanations that recommend an intervention on an immutable feature. These axioms encode the knowledge that altering immutable attributes should not be proposed as a path to a more desirable outcome. We then train a model within the LTN framework, leveraging gradient descent to maximise the satisfaction of all axioms.
This trained model can be post-hoc queried for imbalances between sensitive subgroups or individual data points, allowing for a post-hoc analysis of potential biases. Importantly, the pipeline is iterative so that the results of this analysis can be fed back into the training pipeline by adding additional, targeted axioms, and retraining our model until a sufficient level of model satisfiability is reached. This approach allows for refinement of the fairness constraints and continuous improvement of the model’s behaviour. Our pipeline is capable to handle, with different sets of axioms, both binary predictions and score-based ones. Furthermore, the axiom-based approach allows for transparent and auditable fairness interventions, enabling practitioners to understand why the model behaves in a particular way and to tailor the fairness constraints to their ethical considerations.
The first axioms we add to the training pipeline ensure the accuracy of the model predictions. Here, for binary predictions, we adapt the axioms for predictive performance by Wagner and d’Avila Garcez (2021). Let

For a score-based prediction, where the output is a continuous value, our axioms have to take into account that predictions and ground truth are close. We therefore define a predicate for the equality

Counterfactual Fairness Axioms
By adding the axioms, we want that a data point and its counterfactual with respect to the sensitive attribute

It is worthwhile to discuss the implications of this setup with regard to the definition of counterfactual fairness. As already mentioned in Section 2.4, LTN measure the satisfaction of their axioms as a value in the interval
We now go one step further, showing how to integrate counterfactual fairness axioms for subgroups (or “subgroup counterfactual fairness”). The rationale here is that the general Axiom A4 doesn’t account for potential fairness disparities between different subgroups within the dataset. A model might enhance fairness more for one subgroup than for another, a behaviour that is not captured by a global fairness constraint. We therefore refine our axioms with respect to subgroups
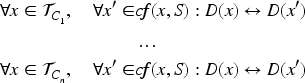
Counterfactual Knowledge Extraction Axioms
The overall idea for axioms from counterfactual knowledge extraction (CKE) is that we want to smooth out observed imbalances between sensitive groups in the frequency of certain undesirable counterfactual explanations. We consider all those counterfactual explanations
This points to a critical issue: the model may be learning to associate certain outcomes with immutable characteristics and then recommending changes to those characteristics as a pathway to a more favourable result. That not only reinforces the idea that certain identities or attributes are inherently less desirable, but also signals underlying problems within the model itself. The very presence of these imbalances should raise red flags and prompt a thorough analysis before deployment. Such recommendations can suggest that the model has amplified biases present in the training data, or that the features are interacting in unintended ways. Our approach seeks to address this by firstly discovering such issues and secondly discouraging the generation of such problematic counterfactual explanations. The goal is not simply to achieve statistical fairness, but to ensure that the model reasons fairly and doesn’t perpetuate harmful biases.
We hence want our pipeline to be able to detect an imbalance in the frequency of undesirable counterfactual explanations between sensitive groups and automatically generate ad hoc axioms to mitigate such an imbalance. To this end, we generate counterfactual explanations of negatively predicted data points. 2 We then compare the frequencies of counterfactual explanations across groups by aggregating the data points on the basis of the sensitive attribute, obtaining a score representing the difference of frequencies for undesirable explanations. This score provides an analyst with valuable information on which specific discrimination patterns should be addressed and for which sensitive class.
Let us denote these explanations with

While for counterfactual fairness axioms we add all axioms simultaneously in the training pipeline, these knowledge extraction-based axioms are added iteratively for better model surveillance and to oversee their individual influence to counterfactual fairness. Furthermore, a human-in-the-loop may be integrated in this part of the pipeline to assess which constraints are desirable to be integrated as axioms. It is also worth noting that explainability axioms can be applied in two ways: either in conjunction with counterfactual fairness axioms, or individually as minimal interventions to improve counterfactual fairness.
Post-Hoc Queries
Integrating counterfactual fairness into a neurosymbolic framework offers several advantages, primarily due to the framework’s inherent ability to reason about logical statements and their truth values. In particular, the satisfaction level to any logical query may be straightforwardly computed. This is of particular benefit in fairness-sensitive applications, offering a transparent way to assess and enforce fair behaviour. LTN allow us not only to ensure fairness but also to probe the model’s reasoning and understand why it makes certain decisions. Here, we elaborate on two post-hoc queries.
Firstly, after training our pipeline, an individual can run an existence query to investigate potential unfairness affecting them directly. For instance, they can ask is there a similar point in my subgroup which has a different outcome? Concretely, for an individual data point
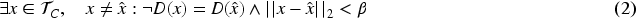
Secondly, the evaluation of CF can be flexibly queried for specific subgroups. This is especially interesting in applications where CF might not be relevant for all subgroups in the dataset as the application is specifically designed for one subgroup, for example, giving out loans to teachers. Here, one can run a universally-quantified query for this subgroup and evaluate if the model is counterfactual fair with respect to the sensitive attribute. This allows for a targeted assessment of fairness, focusing on the groups most relevant to the application. Formally, this query is similar to our subgroup counterfactual fairness axioms (A4

To assess our approach, we conducted experiments to showcase that integrating accuracy, CF and axioms from counterfactual knowledge extraction is beneficial for training counterfactually fairer models. The experiments address the following research questions: How does our method improve counterfactual fairness, overall and at the subgroup level? Here, we first aim to assess how well our approach reduces bias overall but also across different subgroups within the dataset. How does our method compare to other approaches in terms of fairness and accuracy? To tackle this question, we compare our pipeline against existing CF methods, evaluating its performance across both fairness metrics and predictive accuracy. Can counterfactual knowledge extraction be exploited to learn effective axioms? We explore whether automatically generated axioms based on observed imbalances in counterfactual explanations can contribute to improved fairness. What can we learn from post-hoc queries? Here, we explore the potential of the neurosymbolic framework to provide deeper insights into the model’s decision-making process.
In this section we introduce the datasets we tested our method on, the counterfactual generation method, the different baselines and our evaluation metrics. Our code can be found at https://github.com/xheilmann/CounterfactualFair_LTN.
Datasets
We conduct experiments across three benchmark datasets, as detailed below. Firstly, we ran experiments on the
Furthermore, we apply our method to the
As a third dataset, we employ the
Counterfactuals
Our function for approximating counterfactual examples
Yet, we stress that our method does not train to generate counterfactual examples but only requires them as input, and may be employed in conjunction with any counterfactual generation methodology. These generation methods can be applied in a pre-processing step and the generated counterfactuals can then serve as input into our pipeline.
LTN Setup
As predicate for prediction in the LTN, we train a multi-layer perceptron (MLP) with two layers of 100 and 50 neurons trained with the Adam optimiser with learning rate 0.1. We report averaged results over a 5-fold cross-validation. We use Reichenbach implication and
Baselines
In this section, we provide more information on each of the three baselines our pipeline is compared to: GAN-based method, DCEVAE and CNF. Also, we report hyperparameter settings and adaptions made for the comparison. All the following methodologies, differently from ours, generate counterfactual examples themselves. Our approach, however, is agnostic to the underlying counterfactual generation technique and may be easily integrated in existing pipelines that generate and extract counterfactual examples. This presents a challenge in terms of comparison, as these methods will tend to perform better on the set of counterfactuals that they themselves generated compared to other methodologies. Hence, we provide an evaluation of each baseline on a test set of the counterfactuals (approximated by CNF) we input into our pipeline (results in Section 7) as well as a study on how our method performs when we input the counterfactuals generated by the GAN method (Appendix A). Furthermore, for DCEVAE and CNF, we train an MLP with the same hyperparameters as the underlying MLP in our method on the complete set of counterfactual and original data points. This is not to be confused with other proposed settings in literature (Javaloy et al., 2023), where predictors are sometimes trained in an unaware setting, which means that sensitive attributes are left out during training or only trained on non-descendent variables of the sensitive attribute.
In terms of integration into our experimental analysis, we started from the public code release by Kim et al. (2021) 6 . However, we noticed that the main PyTorch backprop code consistently gave a tensor version mismatch error. Thus, we modified the backprop loop by slightly changing the parameter update logic. We note that other authors that sought to reproduce the results from Kim et al. (2021) relied on the same bugfix. 7
For hyperparameters we tested
Evaluation Metrics
To assess the performance of our method and baselines, we employ metrics to measure both the predictive accuracy and the counterfactual fairness of the models across the diverse subgroups within each dataset.
The primary metric for evaluating counterfactual fairness is the

We also report the
Experimental Results
(Q1) How Does Our Method Improve Counterfactual Fairness, Overall and At the Subgroup Level?

CF-MSE for the Adult dataset in three different axiom settings for each subgroup in (gender, race). Male corresponds to m, female to f, and asian-pac-islander, american-indian-eskimo are abbreviated with api and aie, respectively.
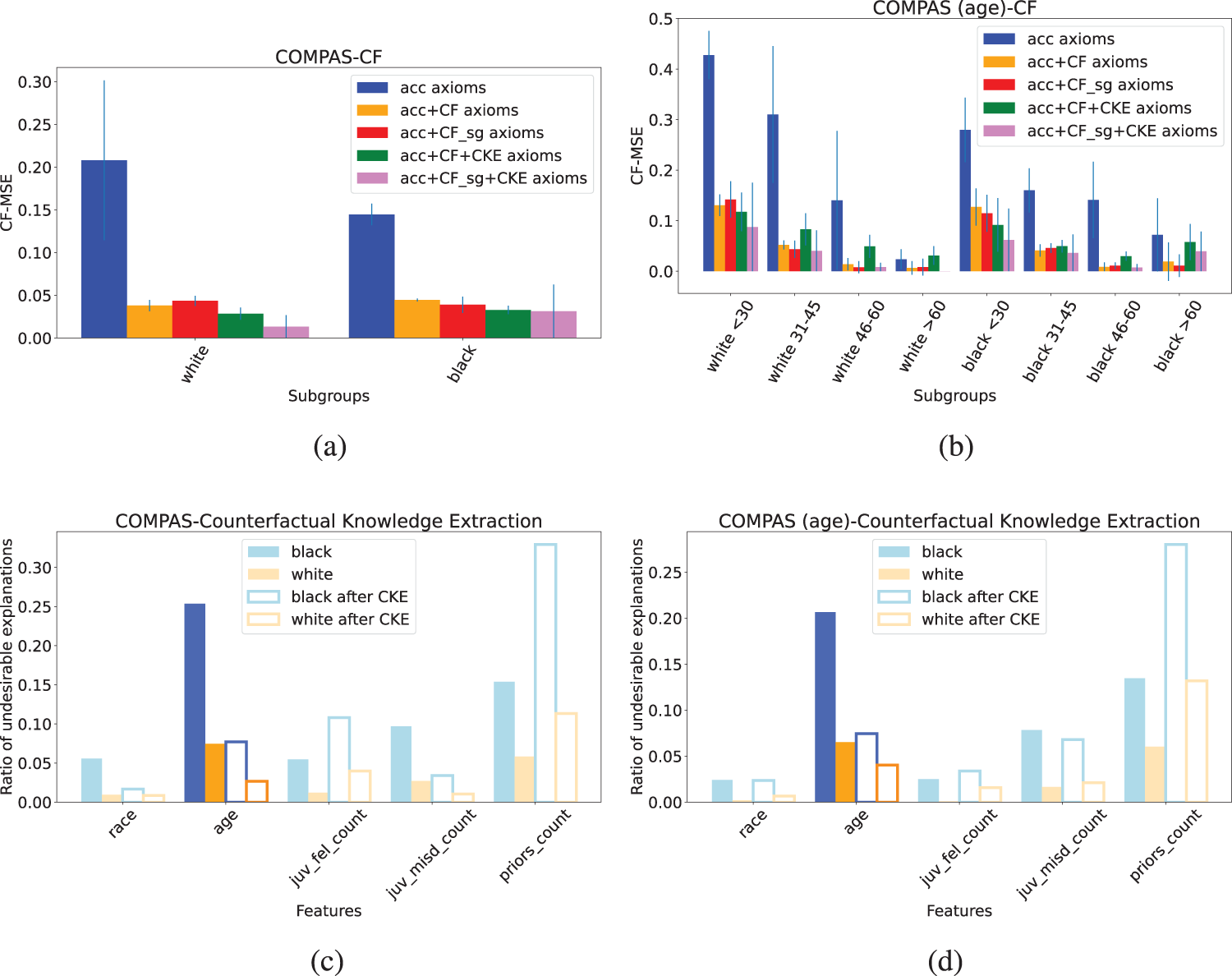
Top: Development of CF-MSE (lower is better) for our pipeline for 5 different axioms settings for both COMPAS datasets. Bottom: Ratio of undesirable explanations for each sensitive group before and after applying a CKE axiom for (black, age). (a) COMPAS - CF, (b) COMPAS (age) - CF, (c) COMPAS - Undesirable Expl. Ratio and (d) COMPAS (age) - Undesirable Expl. Ratio

CF-MSE for Lawschool in three different axiom settings for each subgroup in (gender, race).
Comparison of our pipeline (three different axiom settings) with current baselines evaluated on CNF approximated counterfactuals in terms of accuracy, CF-MSE and worst subgroup CF-MSE (sg) as average of 5 runs. Row-wise best results are in bold.

We conclude, in terms of
For
(Q3) Can Counterfactual Knowledge Extraction Be Exploited to Learn Effective Axioms?
For
For
Comparison of our proposed pipeline in five different axiom settings in terms of accuracy, CF-MSE and worst subgroup CF-MSE (sg) as average of 5 runs for both COMPAS datasets. CKE adds an axiom for (black, age).
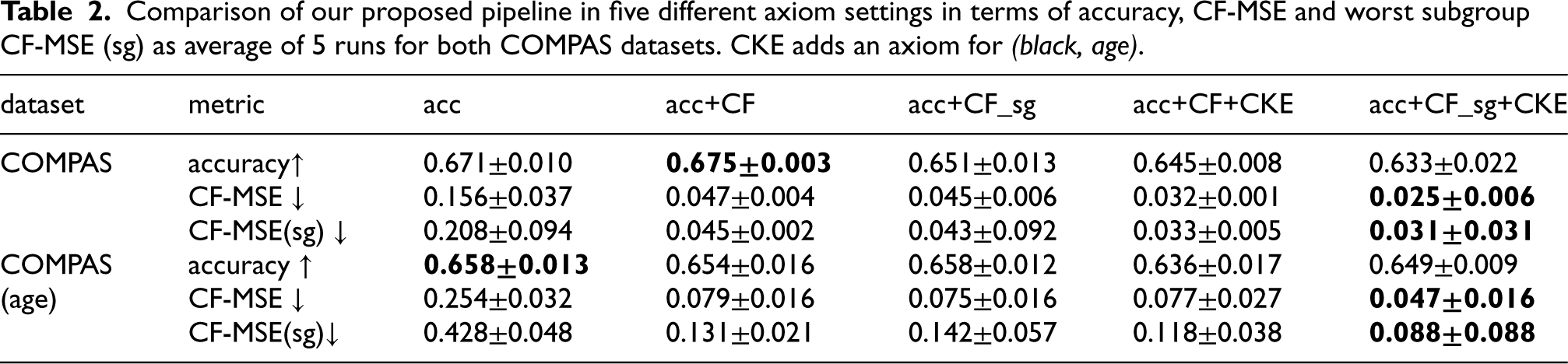
Comparison of our proposed pipeline in five different axiom settings in terms of accuracy, CF-MSE and worst subgroup CF-MSE (sg) as average of 5 runs for both COMPAS datasets. CKE adds an axiom for (black, age).
Impact for Adult of continuously adding CKE axioms on accuracy, CF-MSE and worst subgroup CF-MSE (sg). The CKE axioms are iteratively added in the order in which they appear in the table from left to right. Results are for one run, as the order of axioms varies across runs.

Our takeaway on the CKE technique,
Satisfaction value (sat) and exemplary data point to the query is there a similar point in my subgroup which has a different outcome? Here,
is equal to 3 for males and 5 for females.

Satisfaction value (sat) and exemplary data point to the query is there a similar point in my subgroup which has a different outcome? Here,
Overall, we conclude for
To conclude, we have shown how to integrate the individual-based notion of counterfactual fairness into an LTN training pipeline. We proposed axioms for this integration and refined these axioms to subgroups, achieving higher counterfactual fairness for these subgroups by this. Furthermore, we integrated counterfactual knowledge extraction into our pipeline with subsequent axiom extraction to discourage undesirable counterfactual explanations. After training our model can be post-hoc queried for further information. Our pipeline improves counterfactual fairness and decreases the discrepancy between subgroups w.r.t. the unfair baseline. It has clear benefits over existing approaches and through its additional knowledge extraction opportunities enhances the understanding of the underlying data and learning process. This paper and the previous work we relate to suggest that the neurosymbolic approach to fairness is promising. It allows for the explicit and transparent codification of fairness axioms, but also potentially balance different axioms depending on the trade-offs/constraints for the application at hand.
Our work lays a foundation for further exploration at the intersection of neurosymbolic methods and (counterfactual) fairness. Building upon the knowledge extraction capabilities demonstrated in Q4, one direction for future work involves extending our pipeline to provide individuals with actionable recommendations. Specifically, we aim to identify concrete feature changes an individual can make to alter a potentially unfavourable model outcome. Further research could also focus on dynamically adjusting axiom weights based on performance and fairness considerations. As another addition to our setup, future work should add experiments that focus on handling the issue of intersectionality, that is, multiple interacting sensitive attributes, with LTN and fairness axioms. To our knowledge, our proposal is the first to explore the integration of counterfactual fairness principles with neurosymbolic architectures. Hence, the integration with other architectures is another research blind spot. As of now, the flavours of demographic parity, disparate impact and counterfactual fairness have been formalised and implemented symbolically. Future research might target the formalisation and efficient application of other notions, for example, equalised odds (Hardt et al., 2016) or the Lipschitz condition as described by Dwork et al. (2012). Finally, we intend to evaluate our pipeline on more recent datasets, such as the ACS Income dataset (Ding et al., 2021), to provide additional tests of our method’s generalisability. This direction of further studies could be extended by a practical case study.
Footnotes
Acknowledgements
We thank the NeSy 2025 reviewers and participants for their helpful feedback.
Funding
XH and MC were supported by the ‘TOPML: Trading Off Non-Functional Properties of Machine Learning’ project funded by Carl Zeiss Foundation, grant number P2021-02-014. Author VB was supported by a Royal Society University Research Fellowship.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Notes
Comparing to Other Counterfactuals
As stressed before, unlike ours, all methodologies we compare to generate counterfactual examples themselves. Our method relies only on a set of counterfactuals given as input, so that it is agnostic to the underlying counterfactual generation technique. However, during comparison of the different methods we faced the challenge that just a comparison of methods without taking the generated counterfactuals into account is not appropriate for our method. We therefore firstly compared each baseline on a common test set of the counterfactuals (approximated by CNF) we input into our pipeline. Secondly, we took the counterfactuals generated by the GAN-based method as input into our method and compared it to the GAN pipeline. For this comparison, we had to modify the GAN-based method, as in the original version CF-MSE and accuracy is calculated on different data encodings which was not possible as input into our pipeline. In Table 5 the results show better values for CF-MSE when training with our method. For COMPAS and COMPAS(age) this results in a decreased accuracy, compared to the GAN-based method. However, for the Adult and Lawschool dataset accuracy and MSE is improved upon the GAN method. Altogether, these results show that our method is applicable to counterfactuals generated with different methods than with CNF. Also, for these counterfactuals our method shows improved results, specifically for CF-MSE, when compared to the original generation method.
Influence of Axiom Weights
Our pipeline supports different weights for each group of axioms (accuracy, CF, CKE). This has direct influence on CF and accuracy as can be seen in Table 6. As a trend, accuracy improves, if higher weights are chosen for the accuracy axioms while CF decreases. However, this is not the case for all datasets, and we suggest here to try out different weight settings when applying our pipeline.