Generating vector representations (embeddings) of OWL ontologies is a growing task due to its applications in predicting missing facts and knowledge-enhanced learning in fields such as bioinformatics. The underlying semantics of OWL ontologies are expressed using Description Logics (DLs). Initial approaches to generate embeddings relied on constructing a graph out of ontologies, neglecting the semantics of the logic therein. Recent semantic-preserving embedding methods often target lightweight DL languages such as , ignoring more expressive information in ontologies. Although some approaches aim to embed more descriptive DLs such as , those methods require the existence of individuals, while many real-world ontologies are devoid of them. We propose an ontology embedding method for the DL language that considers the lattice structure of concept descriptions. We use connections between DL and Category Theory to materialize the lattice structure and embed it using an order-preserving embedding method. We show that our method outperforms state-of-the-art methods in several knowledge base completion tasks. This is an extended version of our previous work, where we incorporate saturation procedures that increase the information within the constructed lattices. We make our code and data available at https://github.com/bio-ontology-research-group/catE.
Ontologies are usually developed and maintained by manual curation of experts and therefore the knowledge therein can be inconsistent or incomplete. Traditionally, symbolic reasoners are used to test for consistency of the knowledge within ontologies and to infer new statements. However, they are designed to infer statements that are logically entailed from the ontology or knowledge base; in some cases, it is useful to also suggest axioms that are probably true but not entailed, leading to the task of “ontology completion” or “knowledge base completion.”
From the viewpoint of knowledge graph completion (Chen et al., 2020), we can initially define knowledge base completion as the task of predicting “missing” or “novel” axioms in a knowledge base (or ontology). “Novel” may be understood temporally as axioms that are added at a later time to a knowledge base, or, more commonly, with respect to existing axioms in the knowledge base. However, unlike knowledge graphs, a knowledge base (ontology) has an infinitely large deductive closure with deductively entailed statements. Those statements can be considered “novel” because they do not exist in the knowledge base but can effectively be generated by a deductive reasoner. Therefore, knowledge base completion can have a two-fold presentation: (a) knowledge base completion as approximate entailment, where the completion system first generates the deductively entailed statements, and then, with potentially lower confidence, the system generates the non-entailed but probable statements, and (b) the completion system generates only non-entailed statements and, optionally, has access to information to the deductive closure.
Transversally, knowledge base completion methods can be evaluated based on the type of axioms to complete. We distinguish between two sub-tasks: “TBox completion,” when the axioms to generate are terminological and are of the form and “ABox completion,” when the axioms to generate are assertional and are of the form or . TBox completion systems have been proposed as supporting tools to assist or automate ontology curation procedures (Banerjee et al., 2023; Chen et al., 2023) or to match concepts between ontologies (Chen et al., 2023). ABox completion systems are evaluated alongside neuro-symbolic reasoners in challenges such as SemREC (Banerjee et al., 2023). Furthermore, ABox completion can be regarded as knowledge graph completion enhanced with ontological knowledge (Hao et al., 2019).
Several neuro-symbolic approaches have been developed to perform the knowledge base completion tasks (Chen et al., 2023, 2021; Jackermeier et al., 2023; Kulmanov et al., 2019), and most are based on generating embeddings that preserve some logical properties of a knowledge base. Methods that perform knowledge base completion follow different strategies. One type of method corresponds to transforming ontology axioms into graphs. Under this approach, axioms in a Description Logic (DL) knowledge base are transformed into a graph and then knowledge graph completion methods are applied (Chen et al., 2021). Although this strategy has proved to be useful, this set of methods does not capture all information in axioms and the embedding process is usually not invertible (Zhapa-Camacho & Hoehndorf, 2023); therefore, these methods do not allow exact inference of axioms and are often used for similarity-based tasks.
Another type of method for embedding DL knowledge bases constructs an approximate model of the knowledge base. ELEmbeddings (Kulmanov et al., 2019) represent concepts as -dimensional balls and roles are represented as geometric translations of concepts. By modifying the geometric structure from balls to boxes, methods such as BoxEL (Xiong et al., 2022) guarantee intersectional closure of concepts (i.e., the intersection of two boxes is a box). However, representing roles as translations can only encode one-to-one relations. Therefore, BoxEL Jackermeier et al. (2023) represents roles as two boxes, representing the domain and the codomain of the role, respectively. This representation enables encoding many-to-many relations. However, all these methods target the language, which is a lightweight language that does not support the construction of axioms involving full negation or universal restrictions, therefore they cannot leverage more expressive statements in DL knowledge bases. In this regard, methods such as FALCON (Tang et al., 2023), which is a method similar to Logic Tensor Networks (Badreddine et al., 2022), can construct an approximate model for knowledge bases. FALCON represents concepts as fuzzy sets and treats logical connectives as fuzzy operators (van Krieken et al., 2022). However, FALCON requires the existence of individuals to populate the fuzzy sets, which is a limiting factor in cases involving knowledge bases without individuals such as the gene ontology (GO). Another approach for modeling the language is found in Özcep et al. (2023) with a theoretical analysis on the use of axis-aligned cones to represent ontology concepts.
Proposed Approach: Lattice-Preserving Embeddings
To overcome the limitations of current ontology embedding approaches, we propose CatE, a lattice-preserving embedding method for the language. Our approach relies on the fact that the concept descriptions in a DL knowledge base can be arranged in a lattice structure. The lattice construction of DL concepts can be formulated in the context of Formal Concept Analysis (Baader & Sertkaya, 2004), using connections between DL and Modal Logic (Baader & Lutz, 2007; Schild, 1991; Venema, 2007) or using connections between DL and Category Theory (Brieulle et al., 2022; Duc, 2021). We use the category-theoretical formulation and construct a lattice out of all concept descriptions that are sub-concepts of any concept description in the knowledge base. After materializing the lattice, we represent its elements as vectors in an ordered-vector space. To enforce the ordered structure of the vector space, we use an order-embedding method. We apply CatE and show that it can outperform state-of-the-art methods in the different forms of the knowledge base completion task. We extend our previous work (Zhapa-Camacho & Hoehndorf, 2024) by incorporating saturation procedures that can introduce new information to the lattice in terms of new elements and morphisms. We apply partial saturation to the lattice and show that these procedures can improve the knowledge completion performance on some metrics such as mean reciprocal rank (MRR). Our contributions are the following:
We propose an embedding method for knowledge bases that preserves the lattice structure of the semantics of concept descriptions.
We show that our method can perform competitively in generating statements in the deductive closure and generating probable statements.
We show that our method can perform competitively in both TBox and ABox completion tasks.
We show that partial saturation procedures can enhance the embedding representation of ontology concept descriptions.
Preliminaries
Description Logics (DLs)
A DL signature consists of a set of concept names , a set of role names , and a set of individual names . In the DL , all concept names are concept descriptions; if and are concept descriptions, a role name, and are individual names, then , , , , and are concept descriptions; , and are axioms. A set of axioms is an theory (Baader et al., 2003).
An interpretation of an theory consists of an interpretation domain and an interpretation function such that for every concept name , ; for every individual name , ; and every role name , ; and, inductively:
An interpretation is a model for an axiom iff , for an axiom iff , and for an axiom if and only if (Baader et al., 2003). Given an theory , an axiom is entailed from if it is true in all models of .
Construction of the Lattice Structure
A preorder contains a set equipped with a reflexive and transitive binary relation . A partial order is a preorder that is also antisymmetric. A lattice is a partially ordered set where each two-element subset has a least upper bound and greatest lower bound. If a lattice has a greatest element, it is denoted , and if it has the least element it is denoted (Davey & Priestley, 2002).
In an theory , the set of concept names can be used to create arbitrarily complex and infinitely many concept descriptions. We consider only the concept descriptions in the knowledge base with their sub-expressions and call this set . We furthermore denote .
The pair can form a lattice where concept descriptions stand in a relationship if . Within models of theories, the relation is reflexive and transitive. For a pair of concepts descriptions , the least upper bound is denoted as and the greatest lower bound is denoted using . Additionally, for any concept description it holds .
To represent the lattice , we use the syntactic representation of the axioms (where the operator is and not ) and denote it as (Figure 1). The representation based on does not hold all the properties of lattices; however, it is used as an intermediate structure between the lattice and the embedding space which will be introduced later (Section 3.2).
Lattice representation. is the bottom element and is to top element. Arrows represent the operator.
The concepts in are materialized following a recursive process and, depending on the type of concept descriptions, can be extended with new elements. We rely on connections between DL and Category Theory described in Duc (2021).
Intersection of Concepts
Given a concept description in the theory, we add the following relationships to : and . Additionally, for any , if relationships are found in , we add the relationships and (Figure 2a). Concepts are processed recursively.
Lattice representations of complex concept descriptions.
Union of Concepts
Given a concept description in the theory, we add the following relationships to : and . Additionally, for any , if relationships are found in , we add the relationships and (Figure 2b). Concepts are processed recursively.
Negation of Concepts
Given a concept , elements and are added to . The relationships , are added to . Additionally, for any , if the relationship is found in , we add the relationship , and if the relationship is found in , we add the relationship (Figure 2c). The concept is processed recursively.
Existential Restriction of Concepts
First, an auxiliary preorder is constructed for DL roles, denoted as . In this preorder, elements stand in a relationship if or if is entailed. is extended from during the lattice construction process. For any role represented in , elements and are added to . Given a concept description , the relationship is added to . Relationships , and are added to . Additionally, if there are roles with relationships and , the relationship is added to . The concept is processed recursively.
Universal Restriction of Concepts
Given a concept description , the element is added to with relationships and . Furthermore, if there are roles with relationships and , the relationship is added to . Concepts , and are processed recursively.
Subsumption Axioms
Axioms are incorporated directly to the lattice. Additionally, relationships are added to . Concepts and are processed recursively.
Class Assertion Axioms
Given an axiom , we construct the element in with the following relationships: , and .
Role Assertion Axioms
Given an axiom , we construct elements in with the following relationships: , , , and .
Every operator () introduces a constant number of elements into and a constant number of relationships in . Therefore, for a formula in the knowledge base with operators the space and time complexity to process it is .
Saturation Procedures
The lattice construction process is not complete in the sense that we consider a subset from the infinite set of possible concept descriptions. Additional concept descriptions that can be generated by deduction rules will not have a representation in the lattice. While extra information might improve the quality of embeddings, the time and space requirements to construct and process the lattice will be bigger. We study the impact of adding new information to the lattice by introducing saturation procedures.
By saturation we refer to the process of adding new elements and morphisms to the lattice until a fixed point is reached. However, due to practical limitations, we apply saturation rules partially and the fixed point might not be actually obtained. Since the lattice is equipped with a transitive relation, an immediate saturation rule is to compute the transitive closure of the lattice. Additionally, as specified in Brieulle et al. (2022), certain deduction rules can be transformed into partial saturation procedures. We specify the rules below in the form of , where denotes the set of morphisms existing in the lattice and denotes the set of elements and morphisms to be added to the lattice. Therefore, for elements and for elements in :
Equations (1), (2), and (3) are applicable to a subset of the asserted morphisms in the lattice and all of them introduce one new element to the lattice. Equation (4) corresponds to the transitive closure of the lattice and only introduces new morphisms but not new elements. Equation (5) is applicable to all morphisms in the lattice and introduces elements per morphism in the lattice. Due to the large space complexity required when implementing equation (5), we do not consider it in our analysis.
Embedding Into an Ordered-Vector Space
With the structure in place, we proceed to embed it into an ordered-vector space. This step is crucial for preserving the hierarchical relationships within the lattice, ensuring that our embeddings reflect the inherent ordering of concept descriptions. We use an ordered-vector space over where, for elements in with and , if and only if . We show in Appendix 7 that is an ordered-vector space.
Consequently, we introduce a parameterized function which maps objects in to the ordered-vector space over . In this way, we intend to be a lattice-preserving function of . Since is unknown, our task is to find the set of parameters that accommodates the intended structure of the space . We optimize using gradient descent. We use the following order-preserving scoring function (Vendrov et al., 2016):
for elements with a relationship . If , then , and otherwise . We apply the following loss function to all relationships :
Relationships are called negative samples and are generated by replacing in an existing relationship by a corrupted entity obtained by random sampling in a uniform distribution. The parameter is a margin parameter enforcing a minimum score value of the negative samples.
We show that the space gets a partial-order structure whenever the loss function .
Lattice-preserving embeddings
Let be a theory with signature and the lattice of concepts descriptions generated from . Let be an ordered-vector space where for elements with and , if and only if . Let be a function mapping objects from to . If , then is a lattice-preserving function of into .
Let us assume that and there exists a relationship in the lattice such that , meaning that the order is not preserved in the vector space . Reordering the definition of in equation (7), we have that , where is a non-negative number. Therefore, since , it follows that . Consequently, we have that , which leads to a contradiction.
Now that we have shown that any relationship in the lattice is preserved as in , we now verify that preserves partial-order properties:
Reflexivity: Let be a relationship in . Since , it implies that .
Transitivity: Let and be relationships in . Since , it follows that and and, by the transitive property of , .
Antisymmetry: Let and be relationships in . Since , it follows that and and, by the antisymmetry property of , .
The embedding preserves a lattice structure. The lattice CatE preserves is generated from the objects and morphisms of the category that provides the semantics for a theory . This category is shown to be compatible with classical semantics in the sense that the theory is category-theoretically unsatisfiable if and only if is set-theoretically unsatisfiable (Duc, 2021). Therefore, by preserving the lattice structure, also preserves the categorical semantics, and therefore classical semantics.
Example in
Consider the theories and and their lattices shown in Figures 3a and 3b, respectively. Figure 3c shows an example of embeddings in . In theory , the concept is unsatisfiable (), which implies that is also unsatisfiable by the transitivity rule (equation (4)). This implies that, set-theoretically for all models, and category-theoretically the morphisms , and hold. By the antisymmetry property of , the only way to preserve the lattice structure is to make equivalent, which is reflected in Figure 3c, where, in the embedding space of theory , the embeddings for concepts get closer and, based on equation (7), will eventually converge.
(a, b) Present the lattices generated from theories and , respectively. (c) Shows the generated embeddings for objects in both theories. Notice that in the embeddings for theory , entities accommodate close to each other since they become semantically equivalent. (a) Lattice for theory ; (b) lattice for theory ; and (c) example of embeddings in of lattices generated by theories (left) and (right).
Evaluation
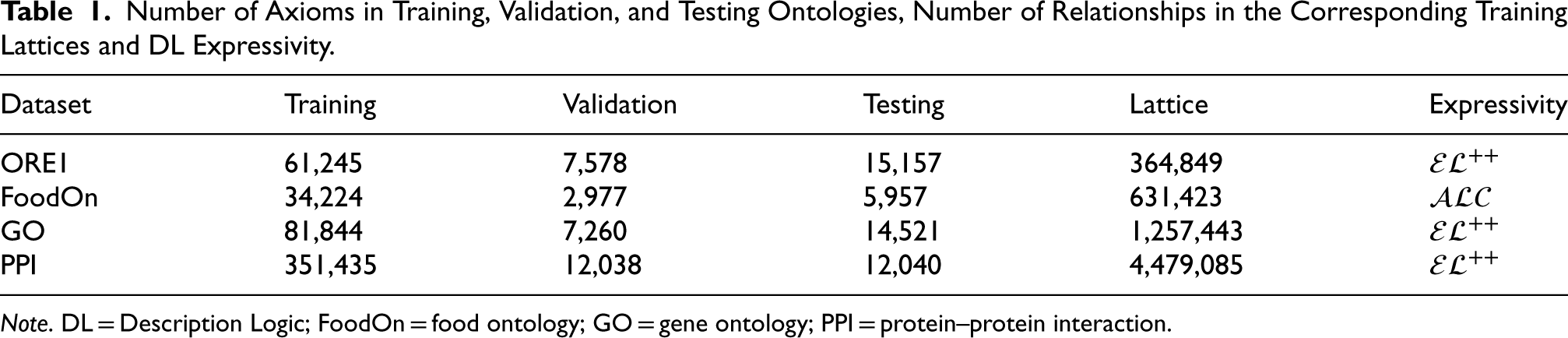
To show the effectiveness of our method, we evaluate the following tasks: (a) generation of entailed axioms and (b) generation of probable axioms. In the task of generating entailed axioms, we use the ORE1 dataset from SemREC (Banerjee et al., 2023) and generate axioms of the form , where is a concept name and is an individual. In the case of generating probable axioms, we constructed datasets using GO Ashburner et al. (2000) and FoodOn Dooley et al. (2018) to generate axioms of the form , where are concept names. For each case, we also show that partially saturating the constructed lattice impacts the performance of axiom generation. Additionally, we applied our method to the biomedical task of predicting protein–protein interactions (PPIs). This task is a form of generation of probable statements of the form , where is a role and are individuals. We show information about datasets in Table 1.
Number of Axioms in Training, Validation, and Testing Ontologies, Number of Relationships in the Corresponding Training Lattices and DL Expressivity.
Dataset
Training
Validation
Testing
Lattice
Expressivity
ORE1
61,245
7,578
15,157
364,849
FoodOn
34,224
2,977
5,957
631,423
GO
81,844
7,260
14,521
1,257,443
PPI
351,435
12,038
12,040
4,479,085
Note. DL = Description Logic; FoodOn = food ontology; GO = gene ontology; PPI = protein–protein interaction.
Experimental Setup
To find the optimal hyperparameters for our method, we performed a grid search over parameters: embedding dimension , margin () , number of negative samples , batch size , and learning rate . We used the Adam optimizer (Kingma & Ba, 2015) with a Cyclic Learning Rate scheduler (Smith, 2017).
As baseline methods, we selected those approaches that use only the ontology axioms, without any external knowledge such as text (Chen et al., 2023, 2021). Therefore, we selected ELEmbeddings (Kulmanov et al., 2019) and BoxEL (Jackermeier et al., 2023), and used the implementations provided in the mOWL library (Zhapa-Camacho et al., 2022). Since both methods can handle only axioms in , we normalized the ontologies to normal forms. In the case of FoodOn, we applied our method to both the normalized and versions. To obtain optimal parameters for baseline methods, we performed a grid search over embedding dimension , margin batch size and learning rate . Additionally, we compared with FALCON (Tang et al., 2023); however, due to high memory and time requirements, we were unable to test different hyperparameters for this method. All selected hyperparameters are provided in Table 6 of Appendix B.
We report a variety of rank-based metrics such as mean rank (MR), MRR, Hits@3, Hits@10, Hits@100, and receiver operating characteristic area under the curve (ROC AUC).
In all tasks, we report filtered metrics only and filter statements from the training set. In the task of generating axioms , we additionally filter statements from the deductive closure of the training set.
Generating Entailed Axioms
The SemREC challenge (Banerjee et al., 2023), which evaluates neuro-symbolic reasoners, provides a number of benchmark datasets. We selected a representative data set called ORE1. We used the ORE1 dataset to test our method on the task of predicting axioms , where is a concept description and is an individual. We perform a ranking-based evaluation, where we rank every testing statement against every , where is a named concept. We show results in Table 2, where we can see CatE performs better than baseline methods across all metrics.
Prediction of Axioms , Where is a Concept and is an Individual. We Selected the ORE1 Dataset Proposed in Banerjee et al. (2023).
Method
MR
MRR
Hits@3
Hits@10
Hits@100
AUC
ELEmbeddings
105
0.12
0.08
0.22
0.87
0.99
BoxEL
122
0.10
0.08
0.18
0.70
0.98
FALCON
603
0.02
0.00
0.02
0.34
0.92
CatE
37
0.18
0.10
0.51
0.96
0.99
Bold values indicate best performance, underlined values indicate second best performance.
Note. MR = mean rank; MRR = mean reciprocal rank; AUC = area under the curve.
Generating Probable Axioms
To evaluate the task of generating probable axioms, we generate two benchmark sets following procedures designed in previous methods (Chen et al., 2021; Mondal et al., 2021). We create two datasets using the GO (Ashburner et al., 2000) and the food ontology (FoodOn; Dooley et al., 2018). In each ontology, we remove 30% of the axioms uniformly at random and distribute 10% for validation and 20% for testing. The training set contains the 70% of the subsumption axioms together with the other axioms existing in the ontology.
We focus on the prediction of subsumption axioms and perform a rank-based evaluation ranking scores of axioms of interest over all axioms , where are named concepts. Table 3 shows the results. We can see that CatE consistently outperforms baselines in all metrics. In the case of FoodOn, we apply CatE to the (CatE-EL) and the (CatE) versions of the ontology. CatE-EL outperforms the baselines, demonstrating that our method generates better embeddings for this specific task. Adding extra information present in the version of FoodOn improves the Hits@k metrics.
TBox Completion Task Over Axioms in GO and FoodOn.
Dataset
Method
MR
H@10
H@100
AUC
GO
ELEmbeddings
3,562
0.19
0.37
0.92
BoxEL
6,621
0.01
0.07
0.85
FALCON (5 models)
8,982
0.02
0.08
0.79
CatE
2,968
0.22
0.58
0.93
FoodOn
ELEmbeddings
3,336
0.25
0.38
0.88
BoxEL
2,763
0.06
0.19
0.90
FALCON (5 models)
3,815
0.02
0.12
0.86
CatE-EL
2,633
0.29
0.43
0.91
CatE
2,764
0.30
0.47
0.90
Bold values indicate best performance, underlined values indicate second best performance.
Note. GO = gene ontology; FoodOn = food ontology; MR = mean rank; H@10 = Hits@10; H@100 = Hits@100; AUC = area under the curve.
PPI Prediction
PPIs are direct or indirect interactions between proteins, and information about PPIs is useful in systems biology and network-based bioinformatics methods. While PPIs can be investigated experimentally, several strategies have been developed to predict them using a variety of information, including the predicted or experimentally determined functions of proteins. The functions of proteins can be represented using the GO, and if is a class from the GO, the axiom asserts that the class of proteins has function . PPIs can be encoded in axioms , where are proteins. In order to apply our method, we need to ensure that elements exists in the lattice for any class of proteins . Therefore, we added the relationships and to the lattice structure for all classes of proteins . We used the PPI dataset provided in Zhapa-Camacho et al. (2022). We compare our method against state-of-the-art methods such as ELEmbeddings and BoxEL (Kulmanov et al., 2020; Xiong et al., 2022). We show the results in Table 4, where we can see that CatE is not able to outperform over baselines. The PPI benchmark relies on the assumption that the information GO acts as background knowledge to predict PPIs. To further investigate this task, we evaluate how well the methods capture the hierarchy of GO functions, which are axioms of the type . We compute the deductive closure of axioms using the ELK reasoner (Kazakov et al., 2013), and evaluate the capability of each method to generate the axioms in this new set. We find that ELEmbeddings and BoxEL do not capture the semantics of GO axioms at all, yet they can perform PPI predictions. Originally, ELEmbeddings and BoxEL are trained with negative samples just for PPI axioms, which can cause the other axiom types to converge to a trivial solution. Since CatE uses negative samples for all relationships in the lattice, it can predict PPIs while capturing other types of information in GO. Our analysis shows that predicting PPIs on its own is not sufficient to show that a particular embedding method is utilizing the background knowledge. Further analysis of embedding methods should be required, which is out of the scope of this work.
PPI Prediction on Yeast. Left-Side Shows the Results on PPI Axioms. Right Side Shows the Results on Axioms That are Learned During Training.
PPI axioms
Axioms
Method
MR
MRR
H@3
H@10
H@100
AUC
MR
H@100
AUC
ELEmbeddings
289
0.10
0.09
0.25
0.73
0.95
23812
0.00
0.53
BoxEL
188
0.17
0.19
0.43
0.81
0.97
23234
0.00
0.54
CatE
223
0.08
0.07
0.18
0.69
0.96
8936
0.28
0.82
Bold values indicate best performance, underlined values indicate second best performance.
Note. PPI = protein–protein interaction; MR = mean rank; MRR = mean reciprocal rank; H@3 = Hits@3; H@10 = Hits@10; H@100 = Hits@100; AUC = area under the curve.
Effect of Partial Saturation Procedures
To analyze the impact of the saturation procedures, we extend the lattices of the ORE1, GO, and FoodOn use cases. We first experiment with the ORE1 lattice as it is the smallest one and apply three types of saturation: (a) S1, which consists of applying equations (1), (2), and (3), (b) Tr, which consists on computing the transitive closure of the lattice, and (c) S1–Tr, which consists on performing S1 followed by Tr. For GO and FoodOn use cases, which produce larger lattices, we only apply S1 because the other settings introduce a large number of elements and morphisms which make the optimization costly and also hinder the hyperparameter search. We show performance results in Table 5 and notice that the S1 procedure contributes to improving the MRR and Hits@3 metrics in the three use cases. Additionally, for ORE1, the Tr procedure improves metrics such as MR and Hits@100; however, the combination of S1–Tr does not contribute to improving the performance.
Impact of the Application Saturation Procedures on the Performance of Generation of Axioms.
Dataset
Method
MRR
H@3
H@10
H@100
MR
ORE1
CatE
0.175
0.097
0.505
0.958
37
CatE-S1
0.176
0.115
0.426
0.884
46
CatE-Tr
0.164
0.104
0.381
0.991
23
CatE-S1–Tr
0.155
0.098
0.367
0.931
30
GO
CatE
0.062
0.008
0.216
0.578
2968
CatE-S1
0.066
0.011
0.226
0.595
3002
FoodOn
CatE
0.087
0.023
0.298
0.473
2764
CatE-S1
0.094
0.121
0.238
0.419
3310
Bold values indicate best performance, underlined values indicate second best performance.
Note. MRR = mean reciprocal rank; H@3 = Hits@3; H@10 = Hits@10; H@100 = Hits@100; MR = mean rank; GO = gene ontology; FoodOn = food ontology.
Effect of hyperparameters
The time and space complexity of CatE increases linearly with the number of operators. However, the number of operators can be arbitrarily large for axioms in . Furthermore, hyperparameters such as embedding size and number of negative samples can have an impact on training and/or inference time as well as on memory consumption. In Table 4, we analyze how these hyperparameters impact performance. We chose Hits100 and ROC AUC metrics and show that while the embedding dimension has a direct impact on performance (the higher the dimension the better the performance), the number of negative samples does not have a large effect (either positive or negative).
Impact of embedding size and number of negatives on the Hits@100 and receiver operating characteristic area under the curve (ROC AUC) over different datasets.
Discussion
We have developed a method named CatE that generates embeddings for the language. CatE consists of materializing the lattice structure of concept descriptions found in a knowledge base. Furthermore, we use an order-preserving loss function to optimize the embedding space, and we show that when our loss function is minimized, the embedding space preserves partial-order properties. We have applied our method to different forms of knowledge base completion tasks, and we showed that our method can outperform several state-of-the-art methods.
Additionally, we implemented saturation procedures to extend the lattices and the information therein. We showed that saturated versions of the lattices can improve on some metrics. However, not all the saturation rules can be applied if the knowledge bases are large because the size of the resulting lattice and the number of morphisms can hinder the application of the optimization process. A potential direction for future work can be to generate some concepts directly in the embedding space rather than explicitly materializing them within the lattice.
Current graph-based methods to embed DL knowledge bases (ontologies) construct graphs relying on syntactic information therein and the embedding process is not guaranteed to be invertible. On the other hand, methods such as ELEmbeddings, BoxEL, and FALCON are able to generate approximate models for DL knowledge bases. We state that CatE stands in a midpoint between both types of methods. CatE looks into the syntactical information in the knowledge base to construct a lattice and, consequently, an embedding space that is consistent with the semantics.
However, as in graph-based embeddings, CatE cannot make inferences over concepts that are not explicitly stated in the lattice. This is a limitation that was exposed in the PPI task, where we had to add concept descriptions a priori in order to be able to make inferences over them. To mitigate this issue, future work can focus on solutions based on inductive learning over knowledge graphs, which can be applicable in the context of lattices.
Conclusion
We developed an embedding method for the that preserves the lattice structure of concept descriptions. Our method materializes the lattice structure following connections between DLs and Category Theory. The lattice in place is embedded into an ordered-vector space. We provide empirical results that our method can perform effectively across different tasks involving knowledge base completion.
Footnotes
Acknowledgements
We acknowledge support from the King Abdullah University of Science and Technology (KAUST) Supercomputing Laboratory.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by funding from KAUST Office of Sponsored Research (OSR) under Award Nos. URF/1/4355-01-01, URF/1/4675-01-01, URF/1/4697-01-01, URF/1/5041-01-01, and REI/1/5334-01-01. This work was supported by the SDAIA–KAUST Center of Excellence in Data Science and Artificial Intelligence (SDAIA–KAUST AI), by funding from KAUST Center of Excellence for Smart Health (KCSH) under award number 5932, and by funding from KAUST Center of Excellence for Generative AI under award number 5940.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
ORCID iDs
Fernando Zhapa-Camacho
Robert Hoehndorf
The Ordered-Vector Space ( X,⪯ )
<inline-formula>
<math xmlns:mml="http://www.w3.org/1998/Math/MathML" display="inline" id="mml-inline383">
<mo stretchy="false">(</mo>
<mi>X</mi>
<mo>,</mo>
<mo>⪯</mo>
<mo stretchy="false">)</mo>
</math>
</inline-formula> is a partial order
The pair over , where for elements with and , if and only if , is a partial order.
We demonstrate for each property of a partial order:
Reflexivity : Let with . By definition, we have for any . : Let . Since for any , then .
Transitivity : Let . If and , we have that and ; therefore, for any . : Let with and for any . It follows that , which implies .
Antisymmetry : Let . If and , it follows that and . Therefore, and . : Let with for any . It implies that and , therefore, and .
Hyperparameter Selection
Selection of Hyperparameters for the Different Methods With Respect to the Dataset Used.
Dataset
Method
E.S.
L.R.
M
B.S.
N.N.
GO
ELEmbeddings
200
0.0001
0.1
20,000
1
BoxEL
200
0.00001
0.1
20,000
1
CatE
200
0.00001
1.0
32,768
4
FoodOn
ELEmbeddings
50
0.001
0.1
20,000
1
BoxEL
200
0.0001
0.1
40,000
1
CatE
200
0.0001
1
8,192
2
ORE1
ELEmbeddings
200
0.00001
0.01
4,096
1
BoxEL
200
0.0001
0
8,192
1
CatE
200
0.0001
1
32,768
4
PPI
CatE
256
0.0001
0.1
2,048
4
Note. E.S. = embedding size; L.R. = learning rate; M = margin; B.S. = batch size; N.N. = number of negative samples; GO = gene ontology; FoodOn = food ontology; PPI = protein–protein interaction.
References
1.
AshburnerM.BallC. A.BlakeJ. A.BotsteinD.ButlerH.CherryJ. M.DavisA. P.DolinskiK.DwightS. S.EppigJ. T.HarrisM. A.HillD. P.Issel-TarverL.KasarskisA.LewisS.MateseJ. C.RichardsonJ. E.RingwaldM.RubinG. M.SherlockG. (2000). Gene ontology: Tool for the unification of biology. Nature Genetics, 25(1), 25–29. https://doi.org/10.1038/75556
2.
BaaderF.CalvaneseD.McGuinnessD.NardiD.Patel-SchneiderP. F. (Eds.). (2003). The description logic handbook: Theory, implementation, and applications. Cambridge University Press. https://doi.org/10.1017/CBO9780511711787
BanerjeeD.UsbeckR.MihindukulasooriyaN.SinghG.MutharajuR.KapanipathiP. (Eds.). (2023). Joint proceedings of scholarly QALD 2023 and SemREC 2023 co-located with 22nd international semantic web conference ISWC 2023, Athens, Greece, November 6–10, 2023. In CEUR workshop proceedings (Vol. 3592). CEUR-WS.org. https://ceur-ws.org/Vol-3592
7.
BrieulleL.DucC. L.VaillantP. (2022). Reasoning in the description logic ALC under category semantics (extended abstract). In O. Arieli, M. Homola, J. C. Jung & M. Mugnier (Eds.), Proceedings of the 35th international workshop on description logics (DL 2022) co-located with federated logic conference (FLoC 2022), Haifa, Israel, August 7th to 10th, 2022CEUR Workshop Proceedings (Vol. 3263). CEUR-WS.org. https://ceur-ws.org/Vol-3263/abstract-7.pdf
8.
ChenJ.HeY.GengY.Jiménez-RuizE.DongH.HorrocksI. (2023). Contextual semantic embeddings for ontology subsumption prediction. World Wide Web, 26(5), 2569–2591. https://doi.org/10.1007/s11280-023-01169-9
DaveyB. A.PriestleyH. A. (2002). Ordered sets. In Introduction to Lattices and Order (2nd ed., pp. 1–32). Cambridge University Press. https://doi.org/10.1017/CBO9780511809088.003
12.
DooleyD. M.GriffithsE. J.GosalG. S.ButtigiegP. L.HoehndorfR.LangeM. C.SchrimlL. M.BrinkmanF. S. L.HsiaoW. W. L. (2018). FoodOn: A harmonized food ontology to increase global food traceability, quality control and data integration. npj Science of Food, 2(1), 23. https://doi.org/10.1038/s41538-018-0032-6
13.
DucC. L. (2021). Category-theoretical Semantics of the Description Logic ALC. In M. Homola, V. Ryzhikov & R. A. Schmidt (Eds.), Proceedings of the 34th International Workshop on Description Logics (DL 2021) part of Bratislava Knowledge September (BAKS 2021), Bratislava, Slovakia, September 19th to 22nd, 2021. CEUR Workshop Proceedings (Vol. 2954). CEUR-WS.org. https://ceur-ws.org/Vol-2954/paper-22.pdf
14.
HaoJ.ChenM.YuW.SunY.WangW. (2019). Universal representation learning of knowledge bases by jointly embedding instances and ontological concepts. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD’19 (pp. 1709–1719). ACM. https://doi.org/10.1145/3292500.3330838
15.
JackermeierM.ChenJ.HorrocksI. (2023). Dual box embeddings for the description logic EL++, In T. Chua, C. Ngo, R. Kumar, H. W. Lauw & R. K. Lee (Eds.), Proceedings of the ACM on web conference 2024, WWW 2024, Singapore, May 13–17, 2024 (pp. 2250–2258). ACM. https://doi.org/10.1145/3589334.3645648
KingmaD. P.BaJ. (2015). Adam: A Method for Stochastic Optimization. In Y. Bengio & Y. LeCun (Eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings. http://arxiv.org/abs/1412.6980
18.
KulmanovM.Liu-WeiW.YanY.HoehndorfR. (2019). EL embeddings: Geometric construction of models for the description logic EL++. In International joint conference on artificial intelligence (pp. 6103--6109). IJCAI.org. https://doi.org/10.24963/ijcai.2019/845
19.
KulmanovM.SmailiF. Z.GaoX.HoehndorfR. (2020). Semantic similarity and machine learning with ontologies. Briefings in Bioinformatics, 22(4), bbaa199. https://doi.org/10.1093/bib/bbaa199
20.
MondalS.BhatiaS.MutharajuR. (2021). EmEL++: Embeddings for EL++ description logic. In A. Martin, K. Hinkelmann, H. Fill, A. Gerber, D. Lenat, R. Stolle & F. van Harmelen, (Eds.), Proceedings of the AAAI 2021 Spring Symposium on Combining Machine Learning and Knowledge Engineering (AAAI-MAKE 2021), Stanford University, Palo Alto, California, USA, March 22–24, 2021, CEUR Workshop Proceedings (Vol. 2846). CEUR-WS.org. https://ceur-ws.org/Vol-2846/paper19.pdf
21.
ÖzcepÖ. L.LeemhuisM.WolterD. (2023). Embedding ontologies in the description logic ALC by axis-aligned cones. Journal of Artificial Intelligence Research, 78, 217–267. https://doi.org/10.1613/jair.1.13939
22.
SchildK. (1991). A correspondence theory for terminological logics: Preliminary report. In J. Mylopoulos & R. Reiter (Eds.), Proceedings of the 12th International Joint Conference on Artificial Intelligence. Sydney, Australia, August 24–30, 1991 (pp. 466–471). Morgan Kaufmann. http://ijcai.org/Proceedings/91-1/Papers/072.pdf
23.
SmithL. N. (2017). Cyclical learning rates for training neural networks. In 2017 IEEE winter conference on applications of computer vision, WACV 2017, Santa Rosa, CA, USA, March 2017 (pp. 464–472). IEEE Computer Society.
24.
TangZ.HinnerichsT.PengX.ZhangX.HoehndorfR. (2023). Falcon: Sound and complete neural semantic entailment over alc ontologies. arXiv:2208.07628. https://doi.org/10.48550/arXiv.2208.07628
VendrovI.KirosR.FidlerS.UrtasunR. (2016). Order-embeddings of images and language. In Y. Bengio & Y. LeCun (Eds.), 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2–4, 2016, Conference Track Proceedings. http://arxiv.org/abs/1511.06361
XiongB.PotykaN.TranT.-K.NayyeriM.StaabS. (2022). Faithful embeddings for EL++ knowledge bases. In Proceedings of the 21st International Semantic Web Conference (ISWC 2022) (pp. 1–18). Springer. https://doi.org/10.1007/978-3-031-19433-7\_2
29.
Zhapa-CamachoF.HoehndorfR. (2023). From axioms over graphs to vectors, and back again: Evaluating the properties of graph-based ontology embeddings. In Proceedings of the 17th international workshop on neural-symbolic learning and reasoning, La Certosa di Pontignano, Siena, Italy, July 3–5, 2023. https://ceur-ws.org/Vol-3432/paper7.pdf
30.
Zhapa-CamachoF.HoehndorfR. (2024). Lattice-preserving ontology embeddings. In T. R. Besold, A. d’Avila Garcez, E. Jimenez-Ruiz, R. Confalonieri, P. Madhyastha & B. Wagner (Eds.), Neural-symbolic learning and reasoning (pp. 355–369). Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-71167-1\_19
31.
Zhapa-CamachoF.KulmanovM.HoehndorfR. (2022). SmOWL: Python library for machine learning with biomedical ontologies. Bioinformatics (Oxford, England), 39(1), btac811. https://doi.org/10.1093/bioinformatics/btac811