
Abstract
In this position paper, we examine some of the assumptions held about logic and its relevance to the development of modern artificial intelligence (AI), which is primarily driven by deep learning. The paper aims to address fundamental misunderstandings about logic and ultimately argue for the benefits of symbolic formalisms in modeling uncertain worlds. While it is now recognized that statistical associations learned from data are limited in their ability to understand the world, there is still a great deal of criticism and hesitancy regarding the use of symbolic logic to achieve or support a broader vision for AI. By arguing that symbolic logic is more flexible than nonexperts believe, we make a case for neurosymbolic AI, which offers the best of both worlds.
Introduction
Artificial intelligence (AI) is widely acknowledged as a new kind of science that will bring about (and is already enabling) the next technological revolution. Virtually every week, exciting reports come our way about the use of AI for drug discovery, game playing, stock trading, and law enforcement. And virtually all of these are mostly concerned with a very narrow technological capability that of predicting future instances based on past instances.
Identifying statistical patterns, correlations, and associations is, without a doubt, extremely useful. In the first instance, it is needed in numerous applications to inspect features and properties of interest in observed data. It serves as the backbone of recommendation systems, for example, and is likely more than sufficient, even with flaws, when gathering context. While searching for “how to raise lambs” in an online bookstore, we might be a little disappointed if it suggests “Silence of the Lambs” by Thomas Harris, and somewhat annoyed if it suggests cookbooks on “how to cook lamb,” but such low-quality results are unlikely to have long-term effects. This type of AI might also be useful but somewhat problematic for, say, fast-tracking the review of job applications, provided these models are adjusted for bias, and a human intervenes and interprets the outcome and determines how to act further. This type of AI was largely believed to be sufficient for vision systems (Thrun et al., 2005), until it was observed that self-driving cars fail stupendously and that the state-of-the-art systems can be fooled in strange and unnatural ways (Goodfellow et al., 2014).
Be that as it may, this is a very narrow view of AI capabilities. AI, as understood by both scientists and science fiction writers, is clearly much broader. What distinguishes big-data analysis from AI is that the set of capabilities we wish to enable with the latter. We are interested in a general-purpose, autonomous computational entity that, in the very least, has agency. Many of these concerns were widely debated, discussed, and developed during the heyday of good old-fashioned AI (Dennett, 1989; Lakemeyer & Levesque, 2007; Levesque & Lakemeyer, 2001).
However, despite recognizing that data-driven statistical learning is limited in its ability to understand the world and model its knowledge (Marcus & Davis, 2019), there is still a lot of criticism and hesitancy about the use of symbolic logic to accomplish or assist in a broader vision for AI (Darwiche, 2018).
In this position paper, we examine some of the assumptions held about logic and its relevance to the development of modern AI, which is primarily driven by deep learning. The paper aims to address fundamental misunderstandings about logic and ultimately argue for the benefits of symbolic formalisms in modeling uncertain worlds. By arguing that symbolic logic is more flexible than nonexperts and critics believe, we make a case for neurosymbolic AI, which offers the best of both worlds.
Logic is Old-Fashioned
In the first part of this article, we will look at some of the criticisms against using logic. We then turn to a number of positive dimensions to examine the integration of logic and learning.
Neural Approaches and Nothing Else!
Modern AI has moved on, we are told. The idea of using symbolic logic is outdated, and the area of knowledge representation defined over symbolic logic is now affectionately (or perhaps pejoratively) called good old-fashioned AI or GOFAI for short. For example, Bengio et al. (2017) write: “… machine learning is the only viable approach to building AI systems that can operate in complicated real-world environments.”
In the early days of AI, John McCarthy put forward a profound idea to realize AI systems (McCarthy, 1959): he posited that what the system needs to know could be represented in a formal language, and a general-purpose algorithm would then conclude the necessary actions needed to solve the problem at hand. The main advantage is that the representation can be scrutinized and understood by external observers, and the system’s behavior could be improved by making statements to it.
Numerous such languages emerged in the years to follow, but first-order logic remained at the forefront as a general and powerful option (Morgenstern & McIlraith, 2011). Propositional and first-order logic continue to serve as the underlying language for several areas in AI, including constraint satisfaction (Bistarelli et al., 2001), automated planning (Rintanen, 2012), database theory (Libkin, 2004), ontology specification (Konev et al., 2018), verification (Barrett et al., 2009), and knowledge representation (Levesque & Lakemeyer, 2001).
And yet, “modern” AI has decided that these efforts are superfluous, or at least easily replaceable once a training dataset has been created. For example, Sejnowski (2020) writes:
The early goals of machine learning were more modest than those of AI. Rather than aiming directly at general intelligence, machine learning started by attacking practical problems in perception, language, motor control, prediction, and inference using learning from data as the primary tool. In contrast, early attempts in AI were characterized by low-dimensional algorithms that were handcrafted. However, this approach only worked for well-controlled environments. For example, in blocks world, all objects were rectangular solids, identically painted, and in an environment with fixed lighting. These algorithms did not scale up to vision in the real world, where objects have complex shapes, a wide range of reflectances, and lighting conditions are uncontrolled. The real world is high-dimensional and there may not be any low-dimensional model that can be fit to it. Similar problems were encountered with early models of natural languages based on symbols and syntax, which ignored the complexities of semantics. Practical natural language applications became possible once the complexity of deep learning language models approached the complexity of the real world. Models of natural language with millions of parameters and trained with millions of labeled examples are now used routinely.
He goes on to suggest that:
Is there a path from the current state of the art in deep learning to artificial general intelligence? From the perspective of evolution, most animals can solve problems needed to survive in their niches, but general abstract reasoning emerged more recently in the human lineage. However, we are not very good at it and need long training to achieve the ability to reason logically. This is because we are using brain systems to simulate logical steps that have not been optimized for logic. Students in grade school work for years to master simple arithmetic, effectively emulating a digital computer with a 1-s clock. Nonetheless, reasoning in humans is proof of principle that it should be possible to evolve large-scale systems of deep learning networks for rational planning and decision making.
The “theory of everything” approach in science, or perhaps its analog in AI, that of having a single algorithm/architecture/framework for all tasks (Domingos, 2015), is undoubtedly appealing. Some theoretical physicists have hopes pinned on string theory, for example, to come up with a single framework that unifies all observational data, across large and minuscule physical bodies (Dienes, 1997). Likewise, the appeal of a purely neural model is attractive. However, there is a lot to debate here.
Firstly, deep learning models are loosely inspired by the brains but not fully accurate representations (yet) (Mitra, 2014; Swanson, 2012).
Secondly, there is the notion of innateness (Tooby et al., 2005), and how much evolution might help the brain in understanding and processing the world in a structured manner. And thirdly, we must bear in mind that we still lack a complete understanding of how the neurons of a bird (let alone a human) are wired, and how that influences cognitive capabilities. Merely knowing that neural weights enable birds to solve puzzles and recognize faces does not necessarily imply that our implementation of their neurons should resemble or possess similar properties. These concerns had also been debated in the literature in the 1980s (Reeke & Edelman, 1988; Smolensky, 1987).
Lastly, Sejnowski (2020) also offers the social element of learning:
Although the focus today on deep learning was inspired by the cerebral cortex, a much wider range of architectures is needed to control movements and vital functions. Subcortical parts of mammalian brains essential for survival can be found in all vertebrates, including the basal ganglia that are responsible for reinforcement learning and the cerebellum, which provides the brain with forward models of motor commands. Humans are hypersocial, with extensive cortical and subcortical neural circuits to support complex social interactions.
Putting such issues aside, it is also worth noting that proponents of the symbolic approach to AI never explicitly claimed the existence of symbolic representations within our minds (Brachman & Levesque, 2004; Levesque & Lakemeyer, 2001). In essence, the symbolic approach offers a coherent strategy for: (a) executing symbolic expressions, which capture the knowledge of the system about the world and (b) comprehending the (idealized) implications of one’s knowledge, as specified by inference rules in logic.
As argued by Levesque (2012), this is not a novel concept—Leibniz articulated centuries ago that certain types of thinking adhere to symbolic processing. Hence, why not employ an algebraic treatment for cognition? As scientists, we may debate whether it is more useful to have an exact model of computation that approximates the reasoning in the brain (Jaynes, 1988; Smolensky, 1987) or whether we should forego these models altogether and simply be satisfied with informal descriptions of reasoning (Prado et al., 2011), as might emerge from a trained model (Creswell et al., 2022).
We reiterate that the allure of a purely neural approach is understandable, given its simplicity and the sense of a “unified theory” it evokes. However, the arguments regarding the effectiveness of the training process in capturing intricate reasoning (Hoernle et al., 2022) and the potential for incorrect (Valmeekam et al., 2022) and unreliable predictions (Azamfirei et al., 2023) suggest that a purely neural approach may not be sufficiently robust to exploit and capture structure. Indeed, despite Sejnowski (2020) offering that “it should be possible to evolve large-scale systems of deep learning networks for rational planning and decision making,” he admits also that “a hybrid solution might also be possible, similar to neural Turing machines developed by DeepMind for learning how to copy, sort, and navigate.”
More generally, by taking a step back, we realize that until the past few centuries, our understanding of the brain and neurons was limited. Yet, during this time, we were able to calculate, develop number theory, construct calculators, and ultimately build computers (Turing, 1950). Imagine if we had solely dedicated ourselves to constructing elaborate brain replicas in the hopes that they could handle (say) tax calculations for us. Most importantly, we cannot test for a capability without first defining that capability, such as (say) deduction (Prado et al., 2011).
All of this underscores the significance of the symbolic approach, which offers an idealized framework for well-defined (relative to the formal language) forms of reasoning. There is a popular analogy (Brachman & Levesque, 2004) suggesting that we need not build wings and feathers to build airplanes; comprehending the principles of aerodynamics is enough. So, why shouldn’t the development of a theory of artificial cognition be just as relevant for a type of AI that is behaviorally similar to humans in some instances, without necessarily resorting to a brain-like architecture? Or perhaps a combination of the symbolic and the neural, as offered by neurosymbolic AI (Hitzler, 2022)? The mistrust may stem from the misconception that logic and probabilistic learning are fundamentally incompatible or entirely separate domains—a notion we will now challenge.
There is a Dichotomy
A common view held by many in the broader community that there is an inherent dichotomy between symbolic logic and machine learning—the former for discrete domains, and the latter for continuous ones. The exact boundary between “discreteness” and symbolic logic might be obfuscated even in works that are strong proponents of using logic in machine learning. For example, in one of the most popular representations of probabilistic relational learning—so-called Markov logic networks (MLNs)—the following is said:
First-order logic (with assumptions above) is the special case of MLNs obtained when all weights are equal Every probability distribution over discrete or finite-precision numeric variables can be represented as a MLN.
The assumptions these statements refer to ensure that the set of constants in the domain of discourse is finite, leading to finitely many possible interpretations, all of which are of finite size. A reader not familiar with logic might incorrectly infer that we are only able to construct discrete probability distributions using first-order logic. Likewise, even in a nuanced survey such as Cartuyvels et al. (2021) on the importance of unifying logic and learning, they write:
The term “discrete representation,” used throughout this paper, denotes a discretely valued variable that represents some concept, which can take on either a limited or a countably infinite number of distinct values. Discrete processing consists of the application of any discrete function to input data. A discrete mathematical function has a domain, and hence a range, consisting only of discrete sets of values. Examples can be found in integer arithmetic, in computer programming languages, and in first-order logic. As deep models are currently trained using gradient descent, it is relevant to note that discrete functions are not differentiable (in any subset of their domain). Modern neural networks are representative of continuous processing. First-order logic or symbolic AI models are representative of discrete processing.
Although they go on to mention fuzzy logic and nonmonotonic logic later, readers might still come away with the impression that symbolic logic is primarily suited for discrete entities. To be clear, first-order logic, interpreted over a finite or a countably infinite domain and interpreted classically, does not lend itself to differentiability. We will return precisely to this point, but nonlogicians might conclude: (a) symbolic logic as used in AI is focused on discrete symbols and (b) symbolic processing in vector (real-valued) space is a separate topic of study that can be independently done from symbolic logic.
What we are seeing here is a narrowing of the use of “logic” simply as classical logic—say, as introduced in Enderton (1972)—defined over Boolean truth values. Moreover, the use of logic is also assumed to be limited to discrete propositional assertions, as seen in ontologies that capture relationships and hierarchies about commonsensical concepts (McCarthy, 1986), as well as in early attempts at logic programming (Kowalski & Sergot, 1986).
We will now discuss the use of non-Boolean truth values and continuous properties in logic, and how that is making an appearance in the area of neurosymbolic AI. The subtlety and clarification here is that indeed logical objects are discrete entities, or more precisely, discrete structures. To compute entailments, moreover, we algebraically manipulate symbols. However, these structures might capture continuous properties either by allowing nonbinary truth values, by using function symbols over the real space, or by distributions on the models of formulas. This leads to various paradigms of relational learning and neurosymbolic AI, many of which are differentiable.
Real-Valued Truth Values
To a large extent, it is true that the area of knowledge representation in AI focuses on discrete symbols and a Boolean interpretation (Brachman & Levesque, 2004). But, on the other hand, it has been close to 60 years since we have fuzzy logic (Zadeh, 1965), among other languages for nonbinary truth values (Katz, 1981). These allow us to assign a truth value between 0 and 1 to propositions, with the understanding that these values indicate the degree to which the proposition may be true. Fuzzy logic can also be utilized to represent ambiguous concepts, such as stating that a person is tall, without specifying tall as a categorical property.
The use of such values in propositions means that the interpretation of Boolean connectives also changes. For example, the formula

By construction, the outputs of neural networks can be mapped to real numbers between 0 and 1. Owing to the nature of truth values in such logics, these outputs can be directly modeled as atoms in logical formulas. This led to an early wave of neurosymbolic AI formalisms (Garcez et al., 2002) and the development of a field that integrates neural outputs in a logical language (Hitzler, 2022). Perhaps the most representative examples in this space are logic tensor networks (Badreddine et al., 2022) and other approaches based on fuzzy logic (van Krieken et al., 2022). The motivation for many of these languages is to logically capture concepts that have been learned from neural networks, in order to reason about these concepts as part of a commonsensical knowledge base. Thus, the agent would be reasoning about hierarchies and relationships, but many of the relations in this knowledge are learned directly using neural networks, presumably from observational data.
It is worth noting that reasoning about concepts and relations is an ongoing problem with neural networks—see efforts such as capsule networks (Sabour et al., 2017) and module networks (Andreas et al., 2016)—and there are very few general solutions. Neurosymbolic AI is stepping in here, especially if it were to allow a general framework for injecting knowledge expressed in a fragment of first-order logic, could be very welcome.
From Discrete to Continuous
Capturing the output of neural networks as truth values in a logical formula is one approach to reasoning about vector spaces. However, we can also use logic to reason about continuous properties as formulas.
Although it is common to discuss discrete properties in logical AI, it is not necessary that they must do so. Logical formulas are indeed discrete structures, but they can also express properties about countably infinite or even uncountably many objects (Belle, 2020; Belle & Levesque, 2013; Herrmann & Thielscher, 1996; Raman et al., 2013).
Reasoning about real numbers has long been an area of interest in mathematical logic (Jovanović & De Moura, 2013), going back to Tarksi, and are a major concern in satisfiability modulo theories (SMTs; Barrett et al., 2009). SMT can be seen as a generalization of satisifiability solving (SAT) for propositional logic and is being used for the verification of timed and hybrid systems that involve both discrete and continuous properties. For example, the following formula expresses that a logical function with one argument
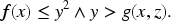
Therefore, we can use these formulas to represent constraints on geometric spaces. A recent body of work has examined the idea of regularizing neural networks by adding logical constraints to the loss functions. The idea is to train the network such that the loss is calculated against this logical constraint, which is backpropagated. The goal then is to train the network in such a way that predictions always satisfy these logical constraints. There is existing work on propositional constraints (Gajowniczek et al., 2020), real-valued constraints (Hoernle et al., 2022), as well as temporal formulas (Innes & Ramamoorthy, 2020), the latter of which trains the network to dynamically navigate an environment in only the valid geometric space.
One of the interesting observations in almost all of these papers on loss functions is that they demonstrate that it is much more effective to train the network using such loss functions than assuming the constraints are represented in the data. So it is much more sample efficient (Icarte et al., 2022). Moreover, some of these architectures also allow for the complete satisfaction of the constraints (Hoernle et al., 2022). This is necessary in safety-critical and high-stakes applications.
Logic is Not Good for Probabilistic Uncertainty
Classical quantifiers in logic, as well as the connectives, allow for disjunctive uncertainty, the existence of individuals, and properties applicable to all individuals in the domain. Because the data we collect are often noisy, or we sometimes have to approximate and average over populations, the use of probability theory is essential (Pearl, 1988). Since classical logic traditionally did not represent probabilistic assertions, much of the learning and uncertainty in the AI community moved away from logic. We will discuss here that the connection between logic and probability is deep, and there is a vibrant community focused precisely on this agenda (Raedt et al., 2016).
Probabilistic Logical Models
Since the work of Nilsson (1986), the use of logic to capture nontrivial probabilistic spaces and reason logically about events in those spaces has been a major concern in uncertainty quantification in AI (Russell, 2015) and statistical relational learning (Raedt et al., 2016). The key idea here is that it should be possible to assign probabilities to atoms, which would then provide a way to extend these probabilities to complex formulas. That is, if
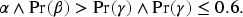
In recent years, there has been a steady progress in designing languages that can not only capture Bayesian networks and factor graphs (Kschischang et al., 2001), but also extend them with a relational and logical syntax. Popular languages for pragmatic specifications of logic and probability include MLNs (Richardson & Domingos, 2006), ProbLog (Raedt et al., 2007), and BLOG (Milch et al., 2005). Many of these not only investigate the representational restrictions that enable the capture of distributions succinctly, but also explore how to reason with the resulting distribution, and in some cases, learn the distributions or representations themselves. (They have to restrict the expressiveness of the language in order to ensure that their representations capture a single distribution; so the above formula may be difficult to express here too.) Consider the following program in ProbLog (Raedt et al., 2007):
This allows us to capture a mixture distribution composed of a biased coin toss and an unbiased coin toss, with the latter having a 0.6 probability of landing heads.
Interestingly, Bayesian networks can also be modeled as ProbLog programs (Raedt et al., 2016). And what is more interesting is that probabilistic inference in Bayesian networks (Chavira, 2008), ProbLog programs (Fierens et al., 2011), MLNs (Richardson & Domingos, 2006), and factor graphs (Kschischang et al., 2001) can all be shown to be reducible to the same computational task known as weighted model counting (Bacchus et al., 2009). Weighted model counting is an extension to SAT in the sense that each satisfying assignment is assigned a weight. By computing the sum of the weights of all satisfying assignments, we can relate that sum to the conditional probability and marginals in a Bayesian network. That is, for a propositional language

As argued in Van den Broeck (2013) and Belle (2017), it is not only the case that logical languages allow us to reason about probability distributions over combinatorial spaces, but it is also the case that the syntax of logic can help capture complex relationships that are difficult to model using standard probabilistic languages (Getoor & Taskar, 2007). Moreover, by way of weighted model counting, there is a single generic approach for probabilistic reasoning over discrete, combinatorial spaces that are competitive (Chavira, 2008). It is also amenable to both exact as well as approximate inference schemes (Chakraborty et al., 2014).
Recently, there have also been extensions from discrete combinatorial spaces to continuous ones (Belle et al., 2015; Chistikov et al., 2015), referred to as weighted model integration. Here, the formula
Generalizing the Specification of a Distribution
Going back to the history of the use of logic in AI (Morgenstern & McIlraith, 2011), there has been considerable interest in unifying logic and uncertainty. Note that, through the use of quantifiers, it is possible to express uncertainty that may not always align with a single distribution. For instance, McCarthy and Hayes (1969) were concerned about probabilities in the early years of using first-order logic for knowledge representation. However, they make a very salient point that we need to think carefully about how numbers and first-order sentences fit together. For example, they argue (McCarthy & Hayes, 1969):
It is not clear how to attach probabilities to statements containing quantifiers in a way that corresponds to the amount of conviction people have. The information necessary to assign numerical probabilities is not ordinarily available. Therefore, a formalism that required numerical probabilities would be epistemologically inadequate.
There point, simply, is that we should not be expected to put probabilities on every formula; sometimes it suffices to say that

More generally, probability measures (Gaifman, 1964) on first-order structures and other proposals on logic and uncertainty (Belle & Lakemeyer, 2017; Milch et al., 2005; Raedt et al., 2007; Richardson & Domingos, 2006) allow us to append probabilities and weights in a logical language in different ways, yielding formal frameworks that go beyond and generalize the standard definition for a probability space. There are also approaches (Dubois & Prade, 1988) that are based on possibility theory, which permits a different model for uncertainty that can be powerful when experts disagree or are uncertain about probabilistic assertions.
In the machine-learning literature, it is not uncommon to find syntactical objects, especially well-defined symbolic expressions, such as programs, that are learned without an explicit definition of the semantics (Lake et al., 2015). In such cases, one would need to define only the interpreter and the compiler (Ellis et al., 2022), with an implicit notion that the atomic objects refer to concrete objects in the real world, as obtained by the process of symbol grounding (Tellex et al., 2011).
However, with programs in the program induction literature (Gulwani, 2010), there is (or rather, should be) an implicit logical syntax and semantics that defines: (a) what sort of expressions can be constructed and (b) what they mean and capture. For example, sequential instructions could be understood as conjunctions, and while loops can be captured using second-order quantification (Gulwani, 2010; Levesque et al., 1997; Ternovska & Mitchell, 2009). If we further want to understand what properties are entailed by these programs, then we need to define the semantics comprehensively and analyze what follows from the logical theory corresponding to a program.
Indeed, without a clear specification of how compositions of expressions should be interpreted and evaluated, how are we to know what these programs are yielding (McCarthy, 1959)? There has been a surge of a new family of programming languages that capture intricate machine-learning models. Typically, these languages allow the use of random primitives as well as operators for conditioning and providing evidence. These are referred to as probabilistic programming—see, for example, Church (Goodman et al., 2008), ProbLog (De Raedt & Kimmig, 2015), and the generic construction in Staton et al. (2016). In some cases, they might support combinations of discrete and continuous distributions, and higher-order functions. A general approach to understanding how these programs can be constructed and what sort of distributions they model is through the use of a formal semantical setup, usually in a fragment of first- or second-order logic.
See also works such as Bartha et al. (2021) for discussions on attempting to construct the semantics for one programming language syntax from another. Such a move is especially desirable if we want to check for the internal consistency of an ad hoc programming language. For philosophical arguments on the importance of semantics, see, for example, Crane (1990).
Logic is About Categorical Propositional Assertions
As discussed above, often “logic” is synonymous with (the classical interpretation of) propositional logic.
There are many systems for writing down symbols and interpreting logical symbols and formulas built up these symbols. Classical approaches include propositional logic (Boolean symbols,
We might also be interested in entertaining multiple possible truth assignments to model uncertainty about the environment. For example, there is modal logic (Kripke, 1959), which can capture possibilities, beliefs, and intentions (Sardina & Lespérance, 2010). A variant of modal logic with numbers on worlds can lead to probabilistic logics (Halpern, 2003), that allow us to reason about probabilities on formulas (Fagin et al., 1990) as well as beliefs about these formulas (Belle & Lakemeyer, 2017; Fagin & Halpern, 1994).
Beyond these formalisms that map atoms (and by extension, formulas) to binary truth values, there are logics that relax that assumption. Fuzzy logics map Boolean symbols to real numbers, leading to real-valued semantics for nonatomic formulas constructed using connectives. For example, if
These are all part and parcel of symbolic logic. The choice of the language, the choice of the semantic rules that we use over the well-defined formulas, along with its computational properties such as decidability are aspects of a logical framework. Moreover, once a logical framework is considered, we could choose to prove logical entailments either by considering assignments to the variables and seeing if the consequent follows or by applying inference rules established in a proof theory (Halpern & Vardi, 1991). If we choose to add weights (Chavira, 2008), measures (Halpern, 2003), or belief functions (Dubois & Prade, 1988), this then leads to notions such as weighted model counting (Bacchus et al., 2009) and algebraic model counting (Kimmig et al., 2012), defined over the models of a formula (i.e., possible worlds). Ultimately, we could consider theorem proving (Halpern & Vardi, 1991), model checking (Baier & Katoen, 2008), SAT solving (Barrett et al., 2009), or model counting (Gomes et al., 2009), depending on the context and application.
Each of these dimensions is already impacting current inquiries into the properties of machine-learning models. For example, in tasks from knowledge-based completion to reasoning with ontology triples using neural techniques, there has been development on so-called neural theorem provers (Minervini et al., 2018). These are inspired by Prolog’s proof-theoretic backward chaining mechanism (De Raedt & Kimmig, 2015) and the aim of those works is to implement that scheme in an end-to-end learning paradigm. Both SAT solving (Wang et al., 2019) and model counting (Gajowniczek et al., 2020) are important ingredients in state-of-the-art approaches to regularizing neural networks using logical formulas. This is motivated by the need to ensure neural network predictions always satisfy certain domain constraints. Model-checking tools are mainstream for checking the robustness of neural networks (Gros et al., 2023). There is also some work (van Krieken et al., 2022) on studying whether using real-valued fuzzy logics to permit differentiability in neural networks is comparable to differentiability as a result of probabilistic extensions to model counting (Gajowniczek et al., 2020).
In summary, we can explore a variety of logical syntax and semantics, each of which may have interesting interactions with machine-learning properties and capabilities.
Monotoncity
Classical logic is monotonic. That is, if
John McCarthy was concerned about the problem of monotonicity and wondered how we might deal with exceptions and abnormality. The problem of monotonicity is so ubiquitous that it even comes up in the formulation of automated planning (Reiter, 2001). For example, imagine that you have an action to paint a box blue and another action that pushes the object. Let us say we paint the object and next, we push the object. When we execute the second action, it is implicit that the color of the object does not change. So we would have to somehow codify not only what the effects of the push action are, but also what the non-effects are. And if we start writing down all the non-effects, there could be exponentially many. Moreover, there are various preconditions that must hold for us to be able to push the object. For instance, we should be strong enough to push it, we must not be holding other objects, we are presumably operating under reasonable gravity assumptions, and so on. And if we start expressing all of them, it again looks like a hopeless task. Yet under some assumptions—so-called causal completeness (Reiter, 2001)—modeling domains is feasible. These assumptions state that the conditions provided are both necessary and sufficient for describing the action. (These concerns arise in causal modeling in machine learning as well (Pearl, 2009), as we need to accurately identify all the parent variables that influence the variable of interest and describe them at the appropriate level of detail.)
If we do not make that assumption, the alternative approach would be to consider a wide range of typical cases, while also accounting for unusual and exceptional cases by incorporating the concept of abnormality. All of this requires notions of nonmonotonicity.
It might be interesting to conceptually contrast this to the machine-learning approach to dealing with anomalies and exceptions. With learning models, when trained on existing data, they can identify typical patterns and detect abnormalities within that data (Kocijan et al., 2022; Marcus, 2017). An outlier is viewed as a data point with atypical features and an unusual label. For instance, while most men in their 40s might be categorized as low- or middle-income earners, a data point representing a 40-year-old male banker would likely be classified as a high-income earner. Conversely, we might expect a large proportion of high-income earners to be male bankers in their 40s, making them the group that deviates from the norm. In this case, they would be the outliers relative to the general population.
Be that as it may, there is no universal mechanism to address default concepts in a general way with such approaches. Moreover, nonmonotonic logic reasoning has given us notions such as stable model semantics (Gelfond & Lifschitz, 1988), which now powers recent approaches to neurosymbolic learning (Yang et al., 2020). Interestingly, nonmonotonic semantics can also allow us to capture cycles in graphs (Denecker et al., 2001), which ordinarily requires recursion using second-order logic (Enderton, 1972). This may be an important aspect as we utilize neural networks for reasoning about large graphs and the web more generally (Niu et al., 2012). Thus, attempting to disregard this area of research seems premature.
Differentiability
Recent approaches to machine learning can be summarized by emphasizing the importance of differentiability as a key concept. However, it is widely held that logic cannot play a role in this. For example, Turing Award winner Yann LeCunn quips (LeCun, 2022):
How can machine reason and plan in ways that are compatible with gradient-based learning? Our best approaches to learning rely on estimating and using the gradient of a loss, which can only be performed with differentiable architectures and is difficult to reconcile with logic-based symbolic reasoning.
But as indicated by the sections above, this view is simply uniform. Probabilities as well as real arithmetic can be mapped onto logical expressions and this means that both routes—a probabilistic one (Gajowniczek et al., 2020) and real-valued semantics (van Krieken et al., 2022) one—seem to naturally lead to differentiability. Let us elaborate further below.
There has been a historical understanding that logic and probability are compatible with each other (Belle, 2020; Raedt et al., 2016; Russell, 2015). These include topics such as 0–1 laws for studying the probability of satisfaction of first-order structures (Fagin, 1976), the use of probability to compare the fit of logical hypothesis against observations (Carnap, 1951), and perhaps most recently, the use of logic-based solvers by means of (weighted) model counting to compute conditional probabilities for Bayesian networks (Chavira, 2008).
At this point, there are plenty of approaches that explicitly use logic for the training of neural networks, especially in the context of regularization and differentiability. This started with the work of UCLA’s Semantic Loss (Gajowniczek et al., 2020) and KU Leuven’s DeepProbLog (Manhaeve et al., 2018), both of which adjust the loss function of the deep learning model based on a logical encoding of the constraints and program, respectively. This is an end-to-end approach in the sense that the predictions of the neural network are corrected using the logical solver and backpropagated to the network so that the trained network predicts outputs that are compatible with the constraints. There are also recent approaches that are based on real-valued variables, such as in Hoernle et al. (2022) and van Krieken et al. (2022). Providing arithmetic constraints to the training of deep learning networks and ensuring consistency with the provided domain knowledge is an important problem for areas such as physics (Stewart & Ermon, 2017) and robotics (Innes & Ramamoorthy, 2020).
However, it would be remiss not to point out that just because differentiability seems to be an important ingredient in the training of machine-learning models, it does not mean that we expect every scientist in the area of logic to play a game. There is still profound and rigorous work to be done on the integration of logical querying (e.g., computational effort needed to evaluate queries on a large knowledge basis Liu & Levesque, 2005) and probability (Beame et al., 2015), for example. On the representation side, there are important issues to grapple with, such as languages to reason about logic and probability that permit the domain of quantification to be countably infinite (e.g., natural numbers) and uncountable (e.g., reals) sets (Liu et al., 2023). Moreover, modal logics such as temporal logics and dynamic logics become useful for deep learning-based endeavors as we navigate to more open-ended problems in dynamic domains (Levesque et al., 1997). For example, in Icarte et al. (2022), temporal logic formulas are used to train deep reinforcement learning agents. In Sileo and Lernould (2023); Tang and Belle (2024), large language models (LLMs) are used to reason about dynamic epistemic properties (Belle et al., 2022), including the modeling of theory of mind (Fagin et al., 1995). And in Innes and Ramamoorthy (2020), a temporally extended semantic loss function is considered.
An orthogonal direction of work that has recently been considered is the capturing of neural architectures, such as graph neural networks, using fragments of first-order logic (Barceló et al., 2020). For the purposes of our discussion, it suffices to say that simply focusing on differentiability or differentiable logic does not quite capture the range of questions that one can investigate in the AI landscape. Issues such as expressiveness, computational properties, and the development of hybrid architectures that combine the advantages of logical and uncertain reasoning continue to be valuable areas of research.
It is worth noting that the meta-linguistic applications of logic can be both “external” and “internal.” In this subsection, we largely discussed the external view that the machine-learning system as a whole needs to be understood as a logical theory. This could involve providing a logical semantics with probabilistic programming or providing a logical language for multiple autonomous learning entities, even logically formalizing machine-learning properties such as fairness (Belle, 2023b). However, it is also possible to use logic as a mathematical function inside a machine-learning system—that is, applied internally—which is discussed in a few subsequent subsections. In these cases, for example, a logical formula may act as a constraint that could be incorporated into the loss function of learning paradigms or may serve as an oracle to reason correctly over machine-learning predictions. Thus, logic could be used as a mathematical language to understand the system as a whole or as a mathematical function inside a machine-learning system.
What About “Human-Like” Semantic Definitions?
The most well-studied semantics, or perhaps more accurately, the most widely used semantics in computer science, remains classical (Bradley & Manna, 2007). That is, atoms are accorded values of either 0 or 1, and so formulas become Boolean functions. If modalities are introduced, such as time and actions (Fagin et al., 1995), then we look at sequences of models: either a linear sequence or a tree-like sequence (Reiter, 2001), for example.
But as mentioned above, there are also approaches where a degree of truth is accorded to formulas, either by allowing the atoms themselves to have nonbinary values (Zadeh, 1965) or by according probabilities or other kinds of measures for complex formulas (Dubois & Prade, 1988).
All of these notions are explored by establishing some kind of well-definedness, and logicians explore the implications of those conditions. For example, intuitionistic logic looks to weaken material implication (Dummett, 1975). Nonclassical belief logics control the proof-depth of logical reasoners (Liu et al., 2004). Fuzzy logic (Zadeh, 1965) was initially introduced with the idea that a truth definition needs to be provided to vague notions (Fine, 1997) such as being tall or making water warm.
Be that as it may, there is an informal argument often made that a mathematically rigorous definition of truth is too precise. Perhaps by training neural networks with real-world observations, they might exhibit more human-like reasoning capabilities that eschew a well-defined notion altogether. The evidence for this has not yet been established. Moreover, is such a feature desirable? Let us, for the moment, consider correct reasoning and understand what can be said about deep learning models implicitly inferring logical steps.
Correct Reasoning
There are a number of recent papers looking at the reasoning abilities of LLMs, which are so-called transformer architectures trained on large troves of textual data (Birhane et al., 2023). Despite allowing for a number of different ways to backtrack and infer the correct premise for a query (e.g., so-called “chain-of-thought”), as shown in a number of papers, they seem to incorrectly reason in a number of different ways (Carlini et al., 2021; Creswell et al., 2022; Mirzadeh et al., 2024; Valmeekam et al., 2022; Zhang et al., 2022). For example, sometimes they struggle with symmetry (Pei et al., 2023; Yamamoto et al., 2024). Although newer models are able to recognize an increasing set of patterns and might get logical relationships and connectives, there is little evidence that they are consistently correct—as Kautz (2024) puts it: “So close, and yet so far!”
Thus, impressive as they are, these models are not reliable (Jang & Lukasiewicz, 2023). There is a also growing body of recent work on the limitations of formal reasoning with LLMs. For example, Tang and Belle (2024) consider how well LLMs perform with theory of mind reasoning, seen in card games and gossip protocols (Fagin et al., 1995). In Valmeekam et al. (2024), the performance of OpenAI’s latest model for reasoning (so-called “o1”) 1 for automated planning is considered, and generally poor performance is reported. A study from a team at Apple (Mirzadeh et al., 2024) reports that minor variations to the reasoning questions can lead to dramatic changes in performance, which is problematic. In Zhang et al. (2022), it is suggested that LLMs learn the statistical properties of logical tests, rather than emulate the correct reasoning function.
In light of these limitations, there is a compelling argument for a neurosymbolic approach. For instance, implementing a logical error checker as a post hoc mechanism could effectively verify the results, predictions, and completions generated by LLMs. For example, a systematic integration of ChatGPT and Wolfram Alpha was recently attempted. 2 More generally, recent approaches seek to incorporate logical solvers as oracles (Persia & Ozaki, 2022) that can validate or disprove the predictions of neural architectures, including LLMs (Miceli-Barone et al., 2023; Pan et al., 2023; Panas et al., 2024; Zhang et al., 2023).
Putting this together, the “native” reasoning capabilities of purely neural models seem clearly limited. It is, of course, plausible that a novel training architecture or new types of datasets might provide the right sort of environment for neural models to perform correct reasoning. But for the moment, validating results and/or improving the training of neural architectures using logical solvers—that is, a neurosymbolic learning pipeline—seems to be the most promising avenue. Kautz makes a stronger claim (Kautz, 2024):
The observation that tools greatly enhance the power of LLMs is not original. Indeed, commercial LLMs already make heavy use of tools—in particular, tools for internet search for the retrieval augmented generation (RAG) paradigm. Kambhampati et al. (2024) recently showed that an LLM can convert planning and verification problems presented in natural language into formal STRIPS notation and solve them using an external planning system. I go farther than most researchers pursuing the tool approach in that I mean the title of this paper, “Tools Are All You Need,” quite literally: a language model augmented with reasoning tools is sufficient to create true artificial intelligence.
He uses “tools” to mean SAT solvers, or other such logical oracles, very much in line with the thrust of this article, and goes on to argue how LLMs “are the only kind of machine learning system that, like humans, can reliably generalize from a single example,” and how that coupled with logical tools may support general-purpose AI.
The Intentional Stance
It is worth noting that, strictly speaking, we do not require that the semantics be given by humans, or that they be hand-written. Symbols can be obtained from low-level data (via symbol grounding), or from closely related languages (Bartha et al., 2021), or from abstract descriptions (De Raedt, 1997) of concepts (Lake et al., 2015). The use of symbols in AI also does not mean that symbolic logic experts assume humans manipulate symbols in their heads. See Levesque and Lakemeyer (2001), for philosophical discussions on this point, which can ultimately be tied to the “intentional stance” (Dennett, 1989). The intuition here is that any capability we attribute to an (artificial or human) agent could be understood in terms of intentions, beliefs, and other mental attitudes, which allow us to characterize what the agent is trying to do. It is a pragmatic perspective rather than a literal representation of the agent’s behavior model.
There is extensive work on trying to characterize natural language utterances (Moot & Retoré, 2019), including connectives (Heinamaki, 1974) and their formal counterparts (van Benthem, 1989). This also involves the use of terms and formulas, whose meaning may be built up from context and social environment (van Wijk, 2006). While the search for a logic that accurately characterizes these kinds of observations with humans is still ongoing, it is worth noting that we do not need a logical knowledge basis to be consistent either. For example, there is work on para-consistent logics (Blair & Subrahmanian, 1989).
Ultimately, we have a range of language choices to work with. We may disagree on the semantics, but having a few different systems that can be mathematically studied seems like a good start.
A follow-up question might be to the tune of: does it still make sense to bother with classical semantics? Just as it makes sense to study logic outside the context of differentiability, we would argue the study of classical semantics is also worthwhile in the AI context. Reasons include: (a) it is a well-defined mathematical model, (b) with the use of modalities and/or nonclassical semantics, we can relate different systems, (c) we do not really know which semantics best approximates human reasoning, (d) we may not want mathematical truths that play fast and loose with inevitable conclusions just because we think humans might have some cognitive biases and exhibit inconsistent reasoning, and (e) the science of robust AI is still evolving.
Logic and Learning can be Complementary
As already hinted above, symbolic logic can play an important role in training deep learning models but also in integrating reasoning as a post hoc process or as a metalinguistic paradigm. That is, we can ensure that the distribution of the trained network respects domain constraints (Hoernle et al., 2022). We can extract rules from trained models and reason about them outside the framework of the network (Persia & Ozaki, 2022). Or we can use the outputs of the network as inputs to a computational paradigm such as probabilistic programming (Manhaeve et al., 2018). There is very interesting work on the semantics of programs that inherently support some notion of differentiation (Abadi & Plotkin, 2019). This is an object of intense theoretical study that can have consequences on the types of distributions that are expressible in programming languages (Staton et al., 2016). So, this theory has far-reaching effects on what types of probabilistic models can be modeled effectively.
In the second half of the article, we make the following point: symbols and deep learning need not compete with each other, and can be complementary. Perhaps the most representative example of this is the burgeoning field of neurosymbolic AI (Garcez et al., 2002), which has come to encompass things such as neural program induction (Lake et al., 2015), neural theorem improvers, and differentiable logics (Zhang et al., 2023). We consider some other categories below, as usual, with overlap.
Symbolic Logic as Meta-Theory
An argument made previously (Belle, 2021) is that symbolic logic can be used to formalize notions currently out of the purview of standard machine learning. These include things such as the semantics of involved probabilistic programming languages (Staton et al., 2016) and understanding the limits of differentiable logics (van Krieken et al., 2022), but it can also pertain to a range of more exotic topics.
For example, it is very common in AI applications these days to require frameworks for multiagent reasoning (Albrecht & Stone, 2018). In explainable AI (Gunning, 2016), in particular, we might require that the robot holds beliefs about the human agent (Kambhampati, 2020). Modal logics study such phenomena. Thus, there has been a significant amount of recent work on incorporating agent modeling into learning frameworks, with multiagent reinforcement learning being a prominent example (Albrecht & Stone, 2018). Furthermore, incorporating agent modeling for explainable planning (Albrecht et al., 2021) and utilizing user-provided constraints as reward functions in reinforcement learning (Icarte et al., 2022) are topics of study.
Moreover, complex AI systems are not going to be purely based on providing predictions. They will involve search, constraint reasoning, and planning (Russell & Norvig, 2003). This has necessitated new approaches for compositionality (Staton et al., 2016) and modularity (Ternovska & Mitchell, 2009). On a related note, it was noted that weighted model counting (Gomes et al., 2009), which provides the foundation for mapping Bayesian inference to SAT solvers, can be upgraded to also reason about maximization and minimization of properties (Kimmig et al., 2012), leading to languages where a number of different AI subareas, such as search and optimization, can be unified (Belle & De Raedt, 2020).
An orthogonal but very interesting line of research in recent years looks at the expressiveness of mainstream neural architectures using logical languages. Primarily, they look at fragments of first-order logic to capture (a simplified version of) neural architectures such as transformers (Vaswani et al., 2017) and graph neural networks (Xu et al., 2018). These investigations have identified that graph neural networks capture fairly limited fragments of first-order logic (Barceló et al., 2020), while attention mechanisms have been shown to be Turing-complete (Pérez et al., 2021). In the case of graph neural networks, the community is still exploring the implications of these results but it is believed that these architectures may fail in tasks involving queries that require more expressiveness than the fragment they correspond to. So, in this sense, using logical tools to understand neural architectures can have serious implications in terms of how these architectures are being used and in which circumstances they could be considered reliable.
High-Level Knowledge
The interplay between reasoning and learning is often compared to Kahneman’s (2011) famous distinction of system 1 versus system 2 type cognition in humans (Rossi, 2024). This is owing to the fact that AI scientists, for a very long time, have been deliberating on the appropriate way to abstract away low-level perception data with high-level concept knowledge, perhaps going back to Shakey (Kuipers et al., 2017). Many “hybrid” formalisms for reasoning with perceptual data attempt to address the interplay between concepts and observations in a systematic way, for example, Kaelbling and Lozano-Pérez (2013) and Nitti et al. (2017).
Providing mechanisms as well as formal semantics for abstraction remains a topic of theoretical interest even today (Beckers & Halpern, 2019; Hofmann & Belle, 2023). Roughly, the idea is given a representation
In the specific case of deep learning systems, a key agenda point is how to define abstract concepts, whether extracted directly from data or defined externally, in order to coordinate and interoperate with these systems (Belle & Bueff, 2023; Bueff & Belle, 2024; Lake et al., 2015).
More generally, it is widely acknowledged that concepts such as time, abstraction, and causality will play a key role in designing a general-purpose AI (Marcus & Davis, 2019). We would expect such an AI to be capable of reasoning with a rich world model, one that can be interpreted by humans (Brachman & Levesque, 2022). Roughly, the idea is that given some system description,
Although there is some work on providing a causal semantics to deep learning systems (Luo et al., 2020), it is still in the early years and studied in a limited way. In contrast, we have very well-studied models of time (Prior, 1967) and causality with symbolic calculi (Halpern, 2016; Hitchcock, 2001; Reiter, 2001). It seems like a wasted opportunity to not utilize these frameworks simply because they are purely symbolic, and hence deemed “old-fashioned.”
As has been the case for many years now, symbols can be used as abstract identifiers for human-in-the-loop systems (Kambhampati, 2020), and/or interactive machine learning especially when you have nonexpert stakeholders engaging with predictors trained on high-dimensional data. In particular, there are very concrete examples from the neurosymbolic landscape that particularly highlight the benefits of using symbols. For example, the work on reward machines (Icarte et al., 2022) looks to train deep learning-based reinforcement learning agents by means of high-level, temporally extended specifications, such as formulas expressed in linear temporal logic (Chatterjee et al., 2015). The propositions of the language are abstract descriptions of properties that can be understood by humans. There is also work on reasoning about neural concepts in a logical language. Although there have been prior works on hybrid formalisms that allow for machine-learning constructs to be used in logic (Kaelbling & Lozano-Pérez, 2013), recent neurosymbolic approaches such as DeepProbLog (Manhaeve et al., 2018) allow us to not only include neural concepts as objects in the logical program, but also to reason about this program as signals that could be fed back into the neural network training. This leads to a trained model that provides predictions and learns distributions that are consistent with the logical specification (Hoernle et al., 2022).
Symbolic Logic can Instantiate New Methods of Inference
One observation we emphasized earlier is that precisely because of the close relationship between logic and probability (Belle, 2017; Carnap, 1951; van Benthem, 2017), it is possible to use logic-based solvers for doing probabilistic reasoning. This in turn, can mean that logic-based solvers are used in learning modules in probabilistic machine learning (Van den Broeck, 2013), or perhaps to reason about the output distributions of neural networks (Gajowniczek et al., 2020).
This is primarily instantiated via weighted model counting (Gomes et al., 2009), which—as discussed above—is an extension of SAT solving to identify all possible satisfying assignments (Bacchus et al., 2009). And as mentioned, there is also an extension of this strategy to deal with continuous properties via so-called weighted model integration (Belle et al., 2015). One broader observation here is that because weighted model counting is defined in terms of weights on the possible models of a logical formula, it is possible to use different types of weights. This means a whole range of different computational tasks defined over the models of a logical formula can be approached using the same abstract specification of weighted model counting. This leads to the notion of algebraic model counting (Kimmig et al., 2012), where instead of sums over the models and products over the weights of literals, we can consider different kinds of corresponding operations such as maximum and minimum (Bacchus et al., 2009).
A notable development in this space is knowledge compilation (Darwiche et al., 2018). This stems from the observation that given a probabilistic model, we may have to compute conditional queries repeatedly. Therefore, there have been efforts to represent a logical formula as a data structure that permits the computation of model counting (Darwiche et al., 2018), including in the presence of distinct conditional queries, effectively. This development can be coupled with the notion of algebraic model counting (Kimmig et al., 2012), but it has also served as a computational backbone for many emerging representations that unify logic and probability, such as relational Bayesian and Markov networks (Van den Broeck et al., 2013)—in addition to classical Bayesian networks Chavira (2008), of course—and probabilistic logic programming languages such as ProbLog (Fierens et al., 2011).
Circuits provide a new way of doing inference with probabilistic models with the following properties: you pay a one-time cost for compiling the representation, such as a Bayesian network, into such a circuit, and then every query afterward can be done in time polynomial in the size of the circuit. There is also a broader program of learning such circuits directly (Liang et al., 2017). The goal is to find an alternative to classical machine-learning models with attractive computational properties for inference (Vergari et al., 2021). This is a new and exciting way of doing probabilistic reasoning and has even led to new approaches to inference in probabilistic programming (Holtzen, Vanden Broeck, & Millstein, 2020).
Logical Oracles
There is considerable work on verifying neural networks (Shih et al., 2019) for safety properties (Casadio et al., 2022) as well as robustness (Gehr et al., 2018), where we want to ensure that the prediction of neural networks does not change arbitrarily for small perturbations to the input. Along these lines, there is a new direction of work where logical reasoners serve as oracles to machine-learning predictions to ensure that the predictions are consistent.
A representative example here is the contrasting reasoning capabilities of large-scale learned models, such as LLMs, against that of a symbolic oracle. Recent work on Wolfram Alpha (Wolfram, 2023) looks to integrate an arithmetic solver with the output of ChatGPT so that reasoning outputs are consistent and coherent with mathematical principles. Similarly, although there is some work on how the chain-of-thought prompting approach can lead to better reasoning outputs by LLMs, the use of a logical oracle leads to provably correct outputs. The capabilities of ChatGPT, for example, have been directly studied in Frieder et al. (2023) and Jang and Lukasiewicz (2023), and the use of a logical oracle to provide an externally sourced solution to reasoning problems with LLMs is considered in Pan et al. (2023). In Sileo and Lernould (2023) and Tang and Belle (2024), such an approach has been shown to be applicable to involved problems involving the mental states of multiple agents, commonly referred to as the theory of mind (Fagin et al., 1995; Shvo et al., 2020).
Intuitively, the idea here is related in spirit to the investigations on logic-based loss functions (Gajowniczek et al., 2020) because there too, predictions are expected to conform to logical constraints (Hoernle et al., 2022).
Logic Benefits From Learning
In the article written so far, we have made the case for machine learning benefiting from logical tools and languages. However, on the other hand, looking back to the early days of logical thought, Aristotle argued for the importance of the process of induction (Belle, 2021). We need mechanisms to learn the general from the particular, which involves generalizing from specific instances to create a generic statement that applies to all instances. That is, a quantified formula that entails all the atoms. In modern AI, this process is a key source of logical knowledge obtained from data (De Raedt et al., 2015; Sap et al., 2020), in addition to the information provided by experts (Davis, 2014).
However, if our logical knowledge is to consist of a combination of expert-provided knowledge and knowledge drawn from examples, there are a number of concerns we need to address. For example, how can we ensure that a hypothesis that is consistent with the background knowledge is extracted from the observations (Muggleton et al., 2012)? What kind of properties should the resulting knowledge base have (Michael, 2007)? How do we deal with observations that might be incorrect or noisy (Bacchus et al., 1999)? How do we ensure that the formula we generalize from the observations captures not only the observations made so far but also the observations we have not yet seen and might encounter in the future (Juba, 2013; Valiant, 1999)?
In recent years, a variety of approaches ranging from statistical relational learning (Raedt et al., 2016) to probably approximate correct semantics (Rader et al., 2021) to neural program induction (Lake et al., 2015) and neural rule induction (Evans & Grefenstette, 2018) have been explored. These approaches utilize state-of-the-art machine-learning tools and theory to learn logical expressions. In some cases, noise in the observations is treated by assuming that the observations are drawn from an unknown distribution. In other cases, the generalization capabilities of neural networks are exploited to learn representations that are empirically robust to this noise.
It is now believed that machine learning will likely impact almost all of computer science because it provides a mechanism to construct models from data (Shapiro et al., 2018). This means that we will continue considering combinations of model-based and data-driven domain knowledge in the future. All of this is even more reason to not entertain notions of a dichotomy between logic and learning.
Concluding Thoughts
In this article, we looked at a few of the misunderstandings that arise when considering the relevance and use of symbolic AI in modern AI systems. We hope the reader is convinced that not only does reasoning and learning have significant overlap—including ideas such as model counting appearing in and linking to multiple concerns—but it is also the case that recent advances are exploiting state-of-the-art learning for reasoning (and vice versa), and in the process, improving on the state-of-the-art.
Whether there might be a future architecture that is very close in spirit to current neural models and makes logical tools redundant is yet to be seen. However, as we have argued, it is hard to imagine that, from a theoretical standpoint, logical analysis itself will become redundant, because many of the desired properties sought out are logical in nature. Despite reported advances in the reasoning capabilities of LLMs, currently seen as the culmination of large-scale deep learning models, they still struggle with consistency and correctness in both logical and arithmetic problems.
Other Dimensions
We have not discussed a few key issues that are emerging in the AI landscape. With the growing use of AI systems in financial and industrial applications, issues of trustworthiness and responsibility keep coming up (Marcus & Davis, 2019).
For example, one area where symbolic logic is widely used in many stochastic systems (Chen et al., 2013) is the verification of safety properties (Shih et al., 2019), and/or testing for robustness (Casadio et al., 2022). The idea with safety properties is to ensure that certain regions in a geometric space are avoided because they might represent dangerous operational areas. In the case of robustness, we want to ensure that small perturbations to the input do not dramatically change the prediction from the neural network. It should not come as a surprise that ideas from logic-based computer science, including temporal logic (Chatterjee et al., 2015) as well as SMTs (Barrett et al., 2009), are the main tools to formalize and investigate these types of properties.
Another interesting avenue for examining trustworthy and responsible AI is understanding the ethical principles and norms under which AI systems should operate (Dignum, 2019). In this subarea, although mainstream models of concepts such as fairness do not necessarily use logic (Verma & Rubin, 2018), further analysis of how systems could conform to ethical principles is often pursued through symbolic logic (Dennis et al., 2016). For example, notions such as act-deontology (Krarup et al., 2022) or consequentialism can be formalized as properties that the system’s execution should obey (Pagnucco et al., 2021; Winfield et al., 2014). There has been work on using symbolic causal models to understand notions of blameworthiness, and the degree of responsibility (Chockler & Halpern, 2004). Finally, there is considerable recent work on explainable planning (Kambhampati, 2020), where a formal model is used to capture the user’s intent and contrast it with the system’s understanding of the world in which it operates (Shvo et al., 2020). For an overview of how knowledge representation can provide much-needed frameworks for ethical and trustworthy AI, see Belle (2023a).
Neurosymbolic AI
As we discussed, one area where concerns about the use of logic seem to disappear is neurosymbolic AI. Neurosymbolic AI holds a lot of promise because it can offer interesting ways to combine symbolic logic and deep learning and build on the success of both. And like the maxim: “the whole is greater than the sum of the parts,” such an integration may not simply be the communication of outputs in a divorced way, but could involve a deeper type of synthesis (Hitzler, 2022). Some approaches have dealt with loss functions, while others have focused on post-hoc logical reasoning or extracting rules from networks. All of these approaches are interesting in their own right.
There is also a tradeoff, at least as per our current understanding, between the complexity and level of detail of the logical knowledge and how effectively it can integrate with a learning system. For example, papers focusing on loss functions typically deal with smaller-sized formulas and constraints (Hoernle et al., 2022), while works exploring the integration of learning with knowledge graphs often consider ontologies with more than a hundred or even a thousand nodes (Niu et al., 2012). Some may argue at this point whether these examples clearly indicate instances of neurosymbolic paradigms exceeding the capabilities of state-of-the-art machine learning. However, this is somewhat of a nebulous measure because state-of-the-art machine learning does encompass various neurosymbolic notions, even if they do not explicitly acknowledge it. Examples range from concept learning (Lake et al., 2015) to Wolfram Alpha-type integrations with LLMs (Wolfram, 2023).
Of course, with such a diversity of solutions, it may be challenging to determine the correct approach. Perhaps there is no one-size-fits-all solution, and the combination of logic and deep learning can vary depending on the application. Regardless of the specific approach, it is clear that we need to understand the principles of logical languages and semantics to ensure that resulting mathematical objects are well-defined with desired properties. This appreciation is essential for both theoretical exploration and practical applications.
It should be noted that there is a case to be made for expressive representations. For example, some might come away feeling that the best way to approach the future of neurosymbolic AI is to focus on very limited languages. But such a view may not be fruitful in the long term. For example, it is widely understood that first-order is useful for generalized assertions (Levesque, 2012), and modal logics for time and multiagent beliefs (Fagin et al., 1995). In general, the language is critical for capturing the domain correctly. In a statement remarkably similar in spirit, Judea Pearl writes (Pearl & Mackenzie, 2018):
This is why you will find me emphasizing and reemphasizing notation, language, vocabulary and grammar. For example, I obsess over whether we can express a certain claim in a given language and whether one claim follows from others. My emphasis on language also comes from a deep conviction that language shapes our thoughts. You cannot answer a question that you cannot ask, and cannot ask a question that you have no words for.
Much to Learn
To sum up, there is a lot to be gained by relating the mathematical foundations of logic and deep learning. And the benefit is not purely for the logician, but also for the deep learning researcher who wants to think more broadly than prediction with big data.
We should, of course, celebrate successes—it is neither an accident nor misplaced opportunism that logic/programming language folks are interested in learning and are eager to understand the latest and best (Gulwani, 2010). Moreover, what combination of logic and/or learning would be needed for general-purpose AI is not well understood yet. We cannot point to the exact approach or balance of innateness versus tabula rasa we need for general AI, because we simply do not know. We can only loosely articulate requirements (e.g., correct, fair, and safe by design), capabilities (e.g., ability to reason about causality, time, and space models), and corresponding desiderata.
Indeed, although AlphaGo and LLMs represent a major triumph for AI, these achievements inevitably raise questions about generality and correctness. As mentioned earlier, Kautz (2024) argues that a reasoning oracle coupled with a language model might be providing the steps toward general-purpose automated intelligence. Conversely, we may want to be wary of “silver bulletism”—the notion of a single solution addressing all of AI’s concerns and capabilities. As Levesque puts it Levesque (2014):
As a field, I believe that we tend to suffer from what might be called serial silver bulletism, defined as follows: the tendency to believe in a silver bullet for AI, coupled with the belief that previous beliefs about silver bullets were hopelessly naïve.
Silver bulletism also contributes to the hubris and hype of AI. In view of creating general-purpose, safe, and reliable AI, we need to look at the best of all worlds. And in that regard, the unification of logic and learning continues to bear fruit, of which neurosymbolic AI is the latest installment.
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author was supported by the Royal Society University Research Fellowship.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.