
Abstract
With the widespread adoption of deep learning techniques, the need for explainability and trustworthiness is increasingly critical, especially in safety-sensitive applications and for improved debugging, given the black-box nature of these models. The explainable AI (XAI) literature offers various helpful techniques; however, many approaches use a secondary deep learning-based model to explain the primary model’s decisions or require domain expertise to interpret the explanations. A relatively new approach involves explaining models using high-level, human-understandable concepts. While these methods have proven effective, an intriguing area of exploration lies in using a white-box technique to explain the probing model. We present a novel, model-agnostic, post hoc XAI method that provides meaningful interpretations for hidden neuron activations. Our approach leverages a Wikipedia-derived concept hierarchy, encompassing approximately 2 million classes as background knowledge, and uses deductive reasoning-based concept induction to generate explanations. Our method demonstrates competitive performance across various evaluation metrics, including statistical evaluation, concept activation analysis, and benchmarking against contemporary methods. Additionally, a specialized study with large language models (LLMs) highlights how LLMs can serve as explainers in a manner similar to our method, showing comparable performance with some trade-offs. Furthermore, we have developed a tool called ConceptLens, enabling users to test custom images and obtain explanations for model decisions. Finally, we introduce an entirely reproducible, end-to-end system that simplifies the process of replicating our system and results.
Introduction
Deep learning solutions have been proven to be useful in a plethora of tasks in fields such as Computer Vision, Natural Language Processing, Signal Processing, etc. By tuning numerous neural network connection weights, decisions are driven toward their intended outcome repeatedly during the training process which in turn maximizes the likelihood of expected outcome during the inference phase. Such inferences incorporate a substantial amount of vector/matrix computations which are often untraceable in that, the sheer number of computations renders it impossible to be used as justifications of inference outcomes.
There are numerous techniques available to quantitatively and qualitatively measure such black-box models’ performance. However, attaining justification by cleverly peeking into the models’ internal mechanisms is a separate field, popularly termed as explainable AI (XAI). The need for XAI techniques designed for deep learning applications is manifold such as:
Bias Detection and Mitigation: Explanations can help unfold underlying potential biases in the data or model which allows adjustments to ensure fairness Improving Model Performance: Explanations can serve as additional debugging information providing insight into potential errors, underfitting, or overfitting. Thus, allowing targeted improvements and refinement of models. Additionally, explanation can also highlight what features are most influential in the model’s predictions. Ensuring Safety and Transparency: Explanations can serve AI Applications in Healthcare, Autonomous Vehicles, Finance by explaining their decisions which permits safe adoption of Deep Learning methods in such critical applications.
There are various families of XAI techniques—based on stages of explanation modeling: Ante hoc, Post hoc methods; based on scope of explainability: Global, Local methods; based on output formats: numerical, rule-based, textual, visual (A & R, 2023). Some of the popular methods belonging to these families are: CAM Zhou et al. (2016), Grad-CAM Selvaraju et al. (2017), LIME Ribeiro et al. (2016), SHAP Lundberg and Lee (2017a). A relatively recent effort aiming more user-understandable explanations has given to develop Concept-based Explainable AI (C-XAI) methods (Poeta et al., 2023). Some of the recent C-XAI methods are: T-CAV Kim et al. (2018), CAR Crabbé and van der Schaar (2022), CaCE Goyal et al. (2019), ACE Ghorbani et al. (2019), ICE Goldstein et al. (2015). An in-depth review of existing XAI methods is discussed in Section 2.
Many XAI techniques rely on intricate low-level data features projected into a higher-dimensional space in their explanations, limiting their accessibility to users with domain expertise (Lundberg & Lee, 2017b; Ribeiro et al., 2016; Selvaraju et al., 2017). Some of these methods have shown vulnerability to adversarial tampering; altering attributed features does not induce a change in the model’s decision (Alvarez-Melis & Jaakkola, 2018; Shrikumar et al., 2017; Slack et al., 2020). The C-XAI approaches employ manually selected concepts that are measured for their correlation with model outcomes (Crabbé & van der Schaar, 2022; Kim et al., 2018). However, a significant question remains unanswered: whether the limited set of chosen concepts can offer a comprehensive understanding of the model’s decision-making process. The absence of a systematic approach to consider a wide range of potential concepts that may influence the model appears to be the bottleneck. In some techniques (Oikarinen & Weng, 2023), a list of frequently occurring English words has been utilized to represent a broad concept pool, which may suffice for general applications but lacks granularity for specialized fields like gene studies or medical diagnoses, as the curation of the concept pool does not provide low-level control over defining natural relationships among concepts. An interesting aspect of XAI technique exploration is to have an explainer method that in itself does not utilize Deep Learning, but instead relies on symbolic, knowledge-based processing. Such an XAI method can be considered as a white-box method which is innately explainable.
Herein, we present a neurosymbolic XAI approach using symbolic reasoning in the form of Concept Induction. The approach is motivated by several key principles. Firstly, explanations should be understandable to end-users without requiring intimate familiarity with deep learning models. Secondly, there should be a systematic organization of human-understandable concepts with well-defined relationships among them. The extraction of relevant concepts for explaining a deep learning model’s decision-making process from this defined concept pool should be automatic, thus eliminating the bottleneck of manual curation prone to confirmation bias. Another significant goal is that the explanation generation technique itself should be inherently interpretable, avoiding the use of black-box methods. Our approach also incorporates a rigorous evaluation protocol encompassing various dimensions.
Concept Induction as core mechanism is based on formal logic reasoning (in the Web Ontology Language OWL Hitzler et al., 2010; Rudolph et al., 2012) and has originally been developed for Semantic Web Hitzler (2021) applications (Lehmann & Hitzler, 2010). The benefits of our approach are: (a) it can be used on unmodified and pre-trained deep learning architectures, (b) it assigns explanation categories (i.e., class labels expressed in OWL) to hidden neurons such that images related to these labels activate the corresponding neuron with high probability, (c) it is inherently self-explanatory as it is based on symbolic deductive reasoning, and (d) it can construct labels from a very large pool of interconnected categories.
We demonstrate that a background knowledge with the skeleton of an ontology coupled with the inherently explainable deductive reasoning (Concept Induction) should be capable of generating meaningful explanations for the deep learning model we wish to explain. To show that our approach can indeed provide meaningful explanations for hidden neuron activation, we instantiate it with a convolutional neural network (CNN) architecture for image scene classification (trained on the ADE20K dataset Zhou et al., 2019) and a class hierarchy (i.e., a simple ontology) of approx.
Our findings suggest that our method performs competitively, as assessed through Concept Activation analysis, which measures the relevance of concepts within the hidden layer activation space, and through statistical evaluation. When compared to other techniques such as CLIP-Dissect (Oikarinen & Weng, 2023), a pre-trained multimodal Explainable AI model, and GPT-4 (Open et al., 2024), an off-the-shelf Large Language Model, our approach demonstrates both strong quantitative and qualitative performance.
The existing literature emphasizes the importance of labeling neuron with concepts, the focus is mostly on identifying what concepts activate a neuron; corresponding to the notion of recall in information retrieval. We argue that in C-XAI, attempting to explain a Neural Network through concepts is a two-step process. If a neuron is consistently activated when the concept of Sky is present in an image (i.e., Recall with respect to neuron label Sky) and is assigned with the concept label of Sky; it is equally important to asses the neuron’s activation when only concepts other than Sky, for example, River, Skyscraper, etc., are present in the images (i.e., Precision with respect to neuron label Sky). If the neuron is activated for many concepts other than Sky, the usefulness of such a C-XAI method which attempts to explain a neural network with concepts diminishes. The gap between high recall and low precision, in other words—high false positive rate renders a C-XAI neuron labeling method unreliable. That this occurs is of course not at all unexpected: it is entirely reasonable to assume that any information conveyed by hidden neuron activations be distributed, that is, neurons naturally react to various stimuli, while specific information is indicated by simultaneous activation of neuron groups.
To that extent, we also present an analysis (based on Dalal et al., 2024b) which shows that our Neurosymbolic C-XAI method (based on Dalal et al., 2024a) achieves high recall as well as precision when labeling neuron with concepts. We do this by assigning error margins to neuron target labels. If a neuron is activated by a stimulus, then the error margin indicates the likelihood that the stimulus indeed falls under the neuron’s target label, and this likelihood can be conveyed to the user. The error margins are statistically validated by means of data obtained from a user experiment conducted on Amazon Mechanical Turk.
We also include a special study to test the capability of LLMs as a concept discovery method to be used as a substitute of Concept Induction (Barua et al., 2024). Our method discussed in Section 4 uses a heuristic implementation called ECII (Efficient Concept Induction from Individuals) (Sarker & Hitzler, 2019) for explanation generation. We were interested to assess LLM’s common-sense reasoning capability leveraging their vast domain knowledge for automated concept discovery in the same setting of Scene Classification using a CNN model. We have used GPT-4 to label neurons with high-level concepts through prompt engineering by essentially replacing ECII. Acknowledging the apparent trade-off of this method being a black-box XAI method as opposed to ECII being a white-box XAI method, human assessment conducted through Amazon Mechanical Turk to assess how meaningful the generated explanations are to humans, we find that while human-generated explanations remain superior, concepts derived from GPT-4 are more comprehensible to humans compared to those generated by ECII.
Core contributions of the paper are as follows. A novel zero-shot model-agnostic C-XAI method that explains existing pre-trained deep learning models through high-level human understandable concepts, utilizing symbolic reasoning over an ontology (or Knowledge Graph schema) as the source of explanation, which achieves state-of-the-art performance and is explainable by its nature. A method to automatically extract relevant concepts through Concept Induction for any concept-based Explainable AI method, eliminating the need for manual selection of Label Hypothesis concepts. An in-depth comparison of explanation sources using statistical analysis for the hidden neuron perspective and Concept Activation analysis for the hidden layer perspective of our approach, a pre-trained multimodal XAI method (CLIP-Dissect Oikarinen & Weng, 2023), and a large language model (GPT-4 Open et al., 2024). Introduction of error margins to neuron target labels to provide a quantitative measure of confidence for concept detection in Image Analysis tasks. A fully automated end-to-end system to use Concept Induction to interpret neurons’ in terms of concepts in a CNN (Akkamahadevi et al., 2024), discussed in Section 6. ConceptLens: A demonstrator designed to represent the concepts that trigger neuron activations in a CNN (Dalal & Hitzler, 2024), discussed in Section 7.
Our work shows that combining symbolic reasoning with LLMs offers a powerful approach for producing explainable, human-understandable insights from deep learning models. This combination promises to improve both the interpretability and the performance of XAI techniques, providing more trustworthy and reliable AI systems.
The structure of this paper is as follows: in Section 2, we discuss some of the important related research efforts. In Section 4, we present the main method Concept Induction and core findings. Following that, in Section 5 we discuss the use of LLMs as a substitute for Concept Induction, in Section 6 we present the end-to-end automated tool, and in Section 7 we discuss the tool ConceptLens. In Section 9 we conclude.
This paper is an extended merger of several conference contributions: Dalal et al. (2024a) is the central one for the overall narrative; Dalal et al. (2024b) is an extension with a finer-grained analysis; Barua et al. (2024) goes in detail on using LLMs as an alternative to concept induction; Akkamahadevi et al. (2024) reports on our automation of the analysis process (see Section 6); This paper extends these by providing a joint perspective, additional literature review, more discussion, and a demonstrator system (see Section 7) previously only reported as a pre-print (Dalal & Hitzler, 2024).
The need for explainable AI (XAI) has gained significant momentum since the 1970s with the growing complexity and opacity of deep learning models (LeCun et al., 2015). As AI is increasingly applied in diverse domains, explaining the rationale behind AI decisions is critical for trust and transparency (Adadi & Berrada, 2018; Gunning et al., 2019; Minh et al., 2022). Various methods have been proposed to achieve explainability, categorized primarily into approaches that focus on understanding features (e.g., feature summarizing Ribeiro et al., 2016; Selvaraju et al., 2016) and those that focus on the model’s internal units (e.g., node summarizing Bau et al., 2020; Zhou et al., 2018). Model-agnostic methods such as LIME Ribeiro et al. (2016) and SHAP Lundberg and Lee (2017a) aim to explain model predictions by assessing feature importance, while other techniques rely on counterfactual questions for human interpretability (Wachter et al., 2017). However, feature attribution methods like LIME and SHAP face challenges such as instability (Alvarez-Melis & Jaakkola, 2018) and bias susceptibility (Slack et al., 2020). Another such work, individual conditional expectation (ICE) (Goldstein et al., 2015) is a tool to visualize complex relationships between predictors and responses, allowing for a more granular view than traditional partial dependence plots. Though generating ICE plots can be computationally intensive, their model-agnostic nature allows them to interpret various “black box” models, enhancing flexibility across algorithms. Zhou et al. (2016) presents a pixel attribution method that uses global average pooling and class activation mapping (CAM) to enable CNNs to perform object localization, even when only trained on image-level labels. Another work Grad-CAM (Selvaraju et al., 2017) generalizes CAM by using the gradients of target classes flowing into the last convolutional layer to produce localization maps, thus making it compatible with a broader range of CNN models. Pixel attribution techniques, although useful for image-based models, encounter limitations with activation functions like ReLU and are prone to adversarial attacks (Kindermans et al., 2022; Shrikumar et al., 2017). Kalibhat et al. (2023) introduces a framework for interpreting image representation features by identifying human-understandable concepts through contrasting high- and low-activation images. But the framework depends on a pre-trained vision-language model (i.e., CLIP), which may lack sufficient representation when applied to models trained on niche or uncommon datasets.
Recent works have introduced concept-based approaches, which provide human-understandable explanations by linking model behavior to predefined concepts. For instance, methods like TCAV (Kim et al., 2018) use human-provided concepts, while ACE (Ghorbani et al., 2019) utilizes image segmentation and clustering to derive automated concepts. However, these approaches may lose information during segmentation or fail to capture low-level details. In another work, the limitations of TCAV approach are addressed for concept-based explanations in deep neural networks and concept activation region (CAR) (Crabbé & van der Schaar, 2022) is introduced. It allows for the nonlinear separability of concepts in the latent space, offering better accuracy and alignment with human-understandable concepts. In Goyal et al. (2019), the authors introduce the causal concept effect (CaCE) to measure the causal impact of high-level, human-interpretable concepts on a classifier’s predictions, aiming to reduce confounding errors common in correlation-based interpretability methods. Although CaCE estimation relies on the accuracy of generative models, such as VAEs (Kingma & Welling, 2014), which may not fully capture the true causal relationships in complex, real-world datasets. Other methods such as concept bottleneck models (CBMs) Koh et al. (2020) and post hoc CBM Yuksekgonul et al. (2023) attempt to map neural network models to human-interpretable concepts, but they often rely on hand-picked concepts, requiring significant human input and manual curation. Wang et al. (2023); Yang et al. (2023) make use of Concept Bottleneck techniques to achieve interpretability in Image Classification. Wang et al. (2023) represents an image solely by the presence/absence of concepts learned through training over the target task without explicit supervision over the concepts. Yang et al. (2023) uses GPT-3 to produce factual sentences about categories to form candidate concepts. Shin et al. (2023); Steinmann et al. (2024) study performing interventional interactions by updating concept values to rectify predictive outputs of the model. Chauhan et al. (2023) extends CBMs to interactive prediction settings by developing an interaction policy which, at prediction time, chooses which concepts to request a label for. Kim et al. (2023) introduces probabilistic concept-embeddings which models uncertainty in concept prediction and provides explanations based on the concept and its corresponding uncertainty.
The application of background knowledge, including the use of large ontologies, has been explored to generate more automated and systematic explanations. Semantic Web technologies (Confalonieri et al., 2020; Díaz-Rodríguez et al., 2022) and methods like Concept Induction (Procko et al., 2022; Sarker et al., 2017) have demonstrated the utility of formal logic and structured data to explain deep learning models, though these approaches often focus on input–output relationships rather than internal model activations. While methods such as Network Dissection (e.g., Zhou et al., 2018) provide valuable insights by mapping hidden units with semantic concepts by comparing neuron activations against a pre-defined set of labels (typically derived from human-annotated datasets), they do not capture the full hierarchical and dynamic nature of learned concepts, nor do they incorporate an explicit reasoning process. Notably, CLIP-Dissect (Oikarinen & Weng, 2023) employs zero-shot learning to associate images with labels using a pre-trained CLIP model, but this method is limited by its accuracy in predicting labels from hidden layers and its transferability across domains. Building upon this, Label-Free Concept Bottleneck Models (Oikarinen et al., 2023) leverage GPT-4 (Open et al., 2024) for concept generation, but similar to CLIP-Dissect, they face limitations in explainability and domain adaptability. Guan et al. (2024) propose a novel knowledge-aware neuron interpretation framework to explain model predictions for image scene classification, using core concepts of a scene based on a knowledge graph, ConceptNet. In Barbiero et al. (2023), neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. The Deep Concept Reasoner executes these rules on meaningful concept truth degrees to provide semantically-consistent and differentiable predictions. Sun et al. (2023) uses Segment Anything Model (SAM) in a lightweight per-input equivalent scheme to enable efficient explanation with a surrogate model. Norrenbrock et al. (2024) introduces quantization for sparse decision layers in an iterative fine-tuning loop which leads to a quantized self-explaining neural network.
Recent trends highlight the potential of large language models (LLMs) to bridge the gap between model complexity and human-understandable explanations. LLMs like GPT-3 and GPT-4 have been used in few-shot learning contexts to generate concepts with minimal human intervention (Oikarinen et al., 2023), providing a scalable solution to automated concept discovery. However, these approaches still require post-processing to filter and refine generated concepts for practical use (Confalonieri et al., 2021; Widmer et al., 2023). While LLMs show promise in automating concept generation, challenges remain in aligning explanations with human common sense and ensuring that they cater to diverse user needs, whether system developers or end-users. To provide an at-a-glance comparison across the main families of explainability methods discussed above, Table 1 summarizes key differentiating features (e.g., white-box reasoning, ontology-driven concept pools, model-agnosticism, and end-to-end automation) for representative approaches, including our Concept Induction (CI) framework.
Our approach distinguishes itself by leveraging symbolic deductive reasoning over a comprehensive background knowledge base derived from Wikipedia, comprising approximately 2 million interconnected classes to generate explanations. Unlike methods that depend on manual selection or post hoc filtering of candidate concepts, our framework systematically extracts human-understandable labels directly from this knowledge base, reducing potential biases and ensuring scalability. Moreover, by operating as a white-box system, Concept Induction provides inherent transparency: each explanation can be traced back to logical reasoning steps, which contrasts with black-box methods as discussed above that do not reveal the underlying rationale behind their output. In this way, our approach not only offers improved interpretability but also facilitates a more scalable and systematic framework for understanding and comparing neuron activations.
Methodology Overview
Before diving into the detailed methodology, we provide a concise “Preliminaries” overview of our system architecture, training protocol, and concept-analysis pipeline (see Figure 1). This roadmap highlights the key components—neural network training, Concept Induction, and Concept Activation Analysis—each of which is fully elaborated in the subsequent sections.

Overview: An input image dataset passes through a CNN (ResNet50V2) architecture with hidden layers to produce a scene classification output. The 64-unit dense layer (highlighted) feeds into two analysis modules: (1) Concept Induction (ECII), which generates human-readable concept labels from neuron activations, and (2) Concept Activation Analysis (CAV/CAR), which trains SVMs on the same activations to validate those concepts.
We train a CNN (ResNet50V2) on the ADE20K scene-classification task (10 classes, around 6200 images). All layers are fine-tuned for 30 epochs with early stopping (patience 3, lr=0.001) using categorical cross-entropy loss. This yields a stable 87% validation accuracy, ensuring the model is sufficiently reliable for downstream explanation without over- or under-fitting.
Next, we extract explanations at the network’s final dense layer (64 neurons). In the Concept Induction step, each neuron’s strongly activating images ( atleast 80% of its peak response) and weakly activating images (atmost 20%) are combined with a large background ontology (approximately 2 million Wikipedia classes) and fed into ECII (Efficient Concept Induction from Individuals). ECII returns a small set of candidate labels (e.g., “skyscraper,” “cross_walk”) whose class expressions best separate the positive and negative image sets. We also explore an alternative LLM-based labeling: prompting GPT-4 directly on the same activation sets to propose high-level concepts, enabling a comparison between symbolic- and language-model explainers.
Each proposed label yields a hypothesis (“Concept X drives Neuron N”). In hypothesis confirmation, we retrieve new images for Concept X via Google Images, measure neuron activations on those images, and apply a Mann–Whitney U test to ensure “target” images activate N significantly more than “non-target” images (
Finally, we introduce an error-margin analysis: for each neuron–concept pair, we compute the likelihood that an activation truly corresponds to the concept (precision margin) as well as the concept’s recall. This yields statistically validated confidence bounds on every explanation. All steps—from input image through CNN, Concept Induction or GPT-4 labeling, hypothesis testing, activation analysis, and error-margin computation—are integrated into our end-to-end tool, ConceptLens. The following sections unpack each component in detail.
We explore and evaluate three concrete methods to generate high-level concepts for explaining hidden neuron activations. Figure 2 is a high-level depiction of our workflow. Figure 2 and its components are further discussed below and throughout the paper. In Section 4.1 we present preparations regarding the scenario, the CNN training, and Concept Induction. In Section 4.2 we provide details on our three label hypothesis generation approaches. In Section 4.3 we describe our different evaluation protocols. In Section 4.4 we provide evaluation results, followed by additional discussion in Section 4.5.

An overview of the complete pipeline explored in this paper where Concept Extraction outlines the methods used to extract Target Concepts and Concept Evaluation outlines the evaluation methods.
In this section, we describe the experimental setup that underpins our evaluation of Concept Induction. We begin by outlining the scenario used to demonstrate our approach, including the selection of image data, training of a CNN, and the integration of background knowledge for concept extraction. These preparatory steps set the stage for a detailed explanation of our methodology, which is further elaborated in the following subsections.
Scenario and CNN Training
We use a scene classification from images scenario to demonstrate our approach, drawing from the ADE20K dataset (Zhou et al., 2019) which contains more than 27,000 images over 365 scenes, extensively annotated with pixel-level objects and object part labels. The annotations are not used for CNN training, but rather only for generating label hypotheses that we will describe in Section 4.2.1.
We train a classifier for the following scene categories: “bathroom,” “bedroom,” “building facade,” “conference room,” “dining room,” “highway,” “kitchen,” “living room,” “skyscraper,” and “street.” We selected scene categories with the highest number of images, and we deliberately include some scene categories that should have overlapping annotated objects—we believe this makes the hidden node activation analysis more interesting. We did not previously conduct any experiments on any other scene selections, that is, we did not change our scene selections based on any preliminary analyses.
We trained a number of CNN architectures in order to use the one with highest accuracy, namely Vgg16 Simonyan and Zisserman (2015), InceptionV3 Szegedy et al. (2016) and different versions of Resnet—Resnet50, Resnet50V2, Resnet101, Resnet152V2 (He et al., 2016a, 2016b). Each neural network was fine-tuned with a dataset of 6,187 images (training and validation set) of size
We select Resnet50V2 because it achieves the highest accuracy (see Table 2). Note that for our investigations, which focus on explainability of hidden neuron activations, achieving a very high accuracy for the scene classification task is not essential, but a reasonably high accuracy is necessary when considering models which would be useful in practice.
Comparison of Key Features Across Explainability Methods.

Comparison of Key Features Across Explainability Methods.
Performance (Accuracy) of Different Architectures on the ADE20K Dataset.

The System we used, Based on erformance, is
Concept Induction Lehmann and Hitzler (2010) is based on deductive reasoning over description logics, that is, over logics relevant to ontologies, knowledge graphs, and generally the Semantic Web field (Hitzler, 2021; Hitzler et al., 2010) including the W3C OWL standard (Rudolph et al., 2012). Concept Induction has been demonstrated in other scenarios to produce meaningful labels for human interpretation (Widmer et al., 2023). A Concept Induction system accepts three inputs, a set of positive examples
a set of negative examples
a knowledge base (or ontology)
all expressed as description logic theories, and all examples
For scalability reasons (Sarker et al., 2020), we use the heuristic Concept Induction system ECII (Sarker & Hitzler, 2019) together with a background knowledge base that consists only of a hierarchy of approximately 2 million classes, curated from the Wikipedia concept hierarchy and presented in Sarker et al. (2020). We use coverage as accuracy measure, defined as

For our setting, positive and negative example sets contain images from ADE20K, that is, we include the images in the background knowledge by linking them to the class hierarchy. For this, we use the object annotations available for the ADE20K images, but only part of the annotations for simplicity and scalability. More precisely, we only use the information that certain objects (such as Windows) occur in certain images, and we do not make use of any of the richer annotations such as those related to segmentation.
2
All objects from all images are then mapped to classes in the class hierarchy using the Levenshtein string similarity metric (Levenshtein, 1975a) with edit distance
In the following, we detail the components shown in Figure 2. We explain our use of Concept Induction for generating explanatory concepts, followed by our utilization of CLIP-Dissect and GPT-4 for the same. We describe our three evaluation approaches in Section 4.3.
Generating Label Hypotheses Using Concept Induction
The general idea for generating label hypotheses using Concept Induction is as follows: given a hidden neuron,
We first feed 1,370 ADE20K images to our trained Resnet50V2 and retrieve the activations of the dense layer. We chose to look at the dense layer because previous studies indicate (Olah et al., 2017) that earlier layers of a CNN respond to low level features such as lines, stripes, textures, colors, while layers near the final layer respond to higher-level features such as face, box, road, etc. The higher-level features align better with the nature of our background knowledge. The dense layer consists of 64 neurons, and we analyze each separately. Activation patterns involving more than one neuron are likely also informative in the sense that information may be distributed among several neurons, but this will be part of future investigations.
For each neuron, we calculate the maximum activation value across all images. We then take the positive example set
Concept Induction—The Omitted Neurons Were Not Activated by Any Image, That is, their maximum activation value was 0.

Concept Induction—The Omitted Neurons Were Not Activated by Any Image, That is, their maximum activation value was 0.
Images: Number of images used per label. Target %: Percentage of target images activating the neuron above 80% of its maximum activation. Non-target %: The same, but for all other images.
We give an example, depicted in Figure 3, for neuron 1. The green and red boxed images show positive and negative examples for neuron 1. Concept Induction yields “cross_walk” as target label. The example is continued below.

Example of images that were used for generating and confirming the label hypothesis for neuron 1.
CLIP-Dissect Oikarinen and Weng (2023) is a zero-shot Explainable AI method that associates high-level concepts with individual neurons in a designated layer. It utilizes the pre-trained multimodal model CLIP Radford et al. (2021) to project a set of concepts and a set of images into shared embedding space. Using Weighted Pointwise Mutual Information, it assesses the similarities between concepts and images in the hidden layer activation space to assign a concept to a neuron.
First, CLIP-Dissect uses a set of the most common 20,000 English vocabulary words as concepts. Then, we collect activations from our ResNet50v2 trained model for the ADE20K test images. This results in a matrix of dimensions (Number of Images
GPT-4
We employ a Large Language Model (LLM) for concept selection. Specifically, we use GPT-4, which represents the latest advancement in generative models and offers improved reliability, outperforming existing LLMs across various tasks (Open et al., 2024). These models appear capable of generating concepts essential for distinguishing between different image classes when prompted effectively (Oikarinen et al., 2023).
For this approach, we use the same positive (
Object tags from these images are passed into GPT-4 via the OpenAI API using prompts to generate explanations aimed at discerning the distinguishing features present in the positive set (
Positive example set: object tags of all positive images (
Negative example set: object tags of all negative images (
Prompt question: Generate the top three classes of objects or general scenario that better represent what images in the positive set (
We employ the most recent version of the GPT-4 model for this task, with the model’s temperature set to 0 and top_p to 1. These parameters significantly influence the output diversity of GPT-4: higher temperatures (e.g., 0.7) lead to more varied and imaginative text, whereas lower temperatures (e.g., 0.2) produce more focused and deterministic responses. Setting the temperature to 0 theoretically selects the most probable token at each step, with minor variations possible due to GPU computation nuances even under deterministic settings. In contrast to temperature sampling, which modulates randomness in token selection, top_p sampling restricts token selection to a subset (the nucleus) based on a cumulative probability mass threshold (top_p). OpenAI’s documentation advises adjusting either temperature or top_p but not both simultaneously to control model behavior effectively. For our study, setting the temperature to 0 ensured consistency and reproducibility across outputs. More detailed information regarding the experimental setup and complete prompt can be found in Section 5 below.
Although three concepts were generated for each neuron, we selected only one concept per neuron for analysis, resulting in 64 unique concepts, with several neurons having duplicate concepts.
We describe the two evaluations, Statistical and Concept Activation Analysis, that we have performed for each of the concept selection methods, as depicted in Figure 2. We also describe an additional Error Margin Analysis, in Section 4.3.3, that goes deeper on the Concept Induction scenario.
Statistical Evaluation
Confirming Label Hypotheses
The three approaches described above produce label hypotheses for all investigated neurons—hypotheses that we will confirm or reject by testing the labels with new images. We use each of the target labels to search Google Images with the labels as keywords (requiring responses to be returned for both keywords if the label is a conjunction of classes, for Concept Induction). We call each such image a target image for the corresponding label or neuron. We use Imageye
4
to automatically retrieve the images, collecting up to 200 images that appear first in the Google Images search results, filtering for images in JPEG format and with a minimum size of
For each retrieval label, we use 80% of the obtained images, reserving the remaining 20% for the statistical evaluation described later in the section. The number of images used in the hypothesis confirmation step, for each label, is given in the tables. These images are fed to the network to check (a) whether the target neuron (with the retrieval label as target label) activates, and (b) whether any other neurons activate. The Target % column of Tables 3, 4, and 5 show the percentage of the target images that activate each neuron.
CLIP-Dissect—The Omitted Neurons Were Not Activated by Any Image, That is, Their Maximum Activation Value was 0.

CLIP-Dissect—The Omitted Neurons Were Not Activated by Any Image, That is, Their Maximum Activation Value was 0.
Images: Number of images used per label. Target %: Percentage of target images activating the neuron above 80% of its maximum activation. Non-Target %: The same, but for all other images.
GPT-4—The Omitted Neurons Were Not Activated by any Image, That is, Their Maximum Activation Value was 0.

Images: Number of images used per label. Target %: Percentage of target images activating the neuron above 80% of its maximum activation. Non-Target %: The same, but for all other images.
Returning to our example neuron 1 in the Concept Induction case (Figure 3), 88.710% of the images retrieved with the label “cross_walk” activate it. However, this neuron activates only for 28.923% (indicated in the Non-Target % column) of images retrieved using all other labels excluding “cross_walk.”
We define a target label for a neuron to be confirmed if it activates for
For our example neuron 1, we retrieve 233 new images with the keyword “cross_walk,” 186 of which (80%) are used in this step. 165 of these images, that is, 88.710% activate neuron 1. Since
Evaluation Details for all Three Approaches as Discussed in Section 4.3.1.

Images: Number of images used for evaluation. # activations: (targ(et)): Percentage of target images activating the neuron;(non-t):same for all other images used in the evaluation. Mean/Median (targ(et)/non-t(arget)): Mean/median activation value for target and non-target images, respectively.
Label Validation
After generating the confirmed labels (as above), we evaluate the node labeling using the remaining images from those retrieved from Google Images as described earlier. Results are shown in Table 6, omitting neurons that were not activated by any image, that is, their maximum activation value was 0.
We consider each neuron-label pair (rows in Table 6) to be a hypothesis, for example, for neuron 1 in Table 6, the hypothesis is that it activates more strongly for images retrieved using the keyword “cross_walk” than for images retrieved using other keywords. The corresponding null hypothesis is that activation values are not different. Table 6 shows the 20 hypotheses from Concept Induction to test, corresponding to the 20 neurons with confirmed labels from method Concept Induction (recall that a double label such as neuron 16’s “mountain, bushes” is treated as one label consisting of the conjunction of the two keywords.)
Similarly, Table 6 also lists the 8 hypotheses to test, corresponding to the 8 neurons with confirmed labels from method CLIP-Dissect, and the 27 hypotheses to test, corresponding to the 27 neurons with confirmed labels from method GPT-4.
There is no reason to assume that activation values would follow a normal distribution, or that the preconditions of the central limit theorem would be satisfied. We therefore base our statistical assessment on the Mann–Whitney U test (McKnight & Najab, 2010) which is a non-parametric test that does not require a normal distribution. Essentially, by comparing the ranks of the observations in the two groups, the test allows us to determine if there is a statistically significant difference in the activation percentages between the target and non-target labels.
The resulting z-scores and p-values are shown in Table 6 and are further discussed in Section 4.4. For our running example (neuron 1), we analyze the remaining 47 target images (20% of the images retrieved during the label hypothesis confirmation step). Of these, 43 (91.49%) activate the neuron with a mean and median activation of 4.17 and 4.13, respectively. Of the remaining (non-target) images in the evaluation (the sum of the image column in Table 6 Concept Induction Section minus 47), only 28.94% activate neuron 1 for a mean of 0.67 and a median of 0.00. The Mann–Whitney U test yields a z-score of
It is instructive to have another look at our example neuron 1 for the Concept Induction case. The images depicted on the left in Figure 4—target images not activating the neuron—are mostly computer-generated as opposed to photographic images as in the ADE20K dataset. The lower right image does not actually show the ground at the crosswalk, but mostly sky and only indirect evidence for a crosswalk by means of signage, which may be part of the reason why the neuron does not activate. The right-hand images are non-target images that activate the neuron. We may conjecture that other road elements, prevalent in these pictures, may have triggered the neuron. We also note that several images show bushes or plants—particularly interesting because the ECII response with the third-highest coverage score is “bushes, bush” with a coverage score of 0.993 and 48.052% of images retrieved using this label actually activate the neuron (the second response for this neuron is also “cross_walk”). It appears that Concept Induction results should be further improvable by taking additional Concept Induction returns into consideration. While we will not entirely follow through on this idea in this paper, we look into it to some extent in Section 4.3.3.

Examples of some Google images used: target images (“cross_walk”) that did not activate the neuron; non-target images from labels like “central_reservation,” “road and car,” and “fire_hydrant” that activated the neuron.
Concept Induction is a separate process from the neural network based processes. Leveraging the strength of the background knowledge, it outputs a list of high-level concepts based on single neuron activation patterns. A question we can ask is: can we find existence or absence of such concepts in the full hidden layer activation space?
To that extent, we employ Concept Activation (Crabbé & van der Schaar, 2022; Kim et al., 2018), which is a concept-based explainable AI technique which works with a pre-defined set of concepts. It attempts at explaining a pre-trained model by measuring the presence of concepts in hidden-layer activations of a given image for a particular layer. For the purpose of comparative analysis, we evaluate all candidate concepts (label hypotheses), obtained from all three methods, through Concept Activation Analysis. Note that we do not restrict this analysis to only confirmed concepts, as the Concept Activation Analysis approach has not been developed with such a confirmation step as part of it.
For each candidate concept, a set of images are collected using Imageye (exactly as described above) and a concept classifier (i.e., a Support Vector Machine) is trained. The dataset given to the concept classifier requires some pre-processing:
The dataset for one concept classifier consists of images that exhibit the presence of the concept under description and with images where the said concept is absent. As the concept classifier will output the existence or absence of a concept, we assign the images to have labels 0 (when concept is absent) and 1 (when concept is present). Since we are interested in finding the concepts in the hidden layer activation space, not in the image pixel space, we need to transform the image pixel values to their activation values. To achieve that, the dataset is passed across the ResNet50V2 pre-trained model as it is the network we wish to explain. The activation values of each image in the dense layer is saved. If the dense layer consists of 64 neurons, then we end up with a matrix of dimensions (no. of images
The transformed dataset is split into train (80%) and test (20%) datasets. Thereafter, a support vector machine (SVM) is trained using the train split. We have used both linear (concept activation vector, CAV) and non-linear (concept activation region, CAR) kernel to see which decision boundary separates the presence/absence of a concept best. For the non-linear RBF kernel, we used the scikit-learn implementation and performed hyperparameter tuning over a range of kernel widths [0.1,50]. A kernel width (gamma) value of 5.7 provided the best validation performance and was selected for subsequent experiments.Once the concept classifier is trained, a test dataset is used to see to what extent the concept classifier can classify the presence/absence of concepts in the hidden layer activation space.
We use Concept Induction, CLIP-Dissect, and GPT-4 as Concept Extraction mechanisms. Thereafter we use Concept Activation analysis to measure to what extent such concepts are identifiable in the hidden layer activation space. We adopt two different kernels through CAV and CAR to train an SVM and then test the classifiers on unseen image data. Tables 15, 16, and 17 represent the test accuracies for the concepts extracted by Concept Induction, CLIP-Dissect, and GPT-4. Table 7 represents the results of the Mann–Whitney U test performed over the test accuracies obtained from all three approaches. Table 12 shows the Mean, Median, and Standard Deviation of the test accuracies for each of the three approaches.
Summary of Concept Activation Analysis Results of Concept Induction, CLIP-Dissect, and GPT-4 Using Mann–Whitney U test.

In this section, we outline our technical approach for assessing neuron-label associations through error-margin analysis (Non-target Label Activation Percentage, or Non-TLA). Non-TLA represents the percentage of images not falling under the target label that activate a neuron that carries the target label as per the prior analysis. Similarly, Target Label Activation Percentage, TLA, represents the percentage of images falling under the target label that activate the neuron that carries the target label.
To obtain error margins, we calculate activation percentages for both target labels and non-target labels per neuron based on Google Images retrieved from the labels as search terms, and we also take into account activation patterns of neuron groups for semantically related labels, analyzing TLA and Non-TLA across different cutoff values. We then use images from the ADE20K dataset (Zhou et al., 2019), with annotations improved through Amazon Mechanical Turk, to statistically validate the error-margins obtained earlier.
Computation of Non-TLA
Concept Induction generates a number of concept labels for each neuron unit, ranked by some accuracy measure. Herein, we consider the Top-3 labels (ranked by coverage score) for each of the 64 neurons in the dense layer. Using the Target-Label image dataset (each image falls under the target label), the TLA is calculated, and, using a Non-target Label image dataset (none of the images contain the target label), the Non-TLA is calculated. To obtain a nuanced understanding of how activation levels affect the reliability of the neuron–concept association, we calculate TLA and Non-TLA for each neuron at specified activation value thresholds, namely
Non-Target Label Activation Percentages (Non-TLA) for Google Dataset.
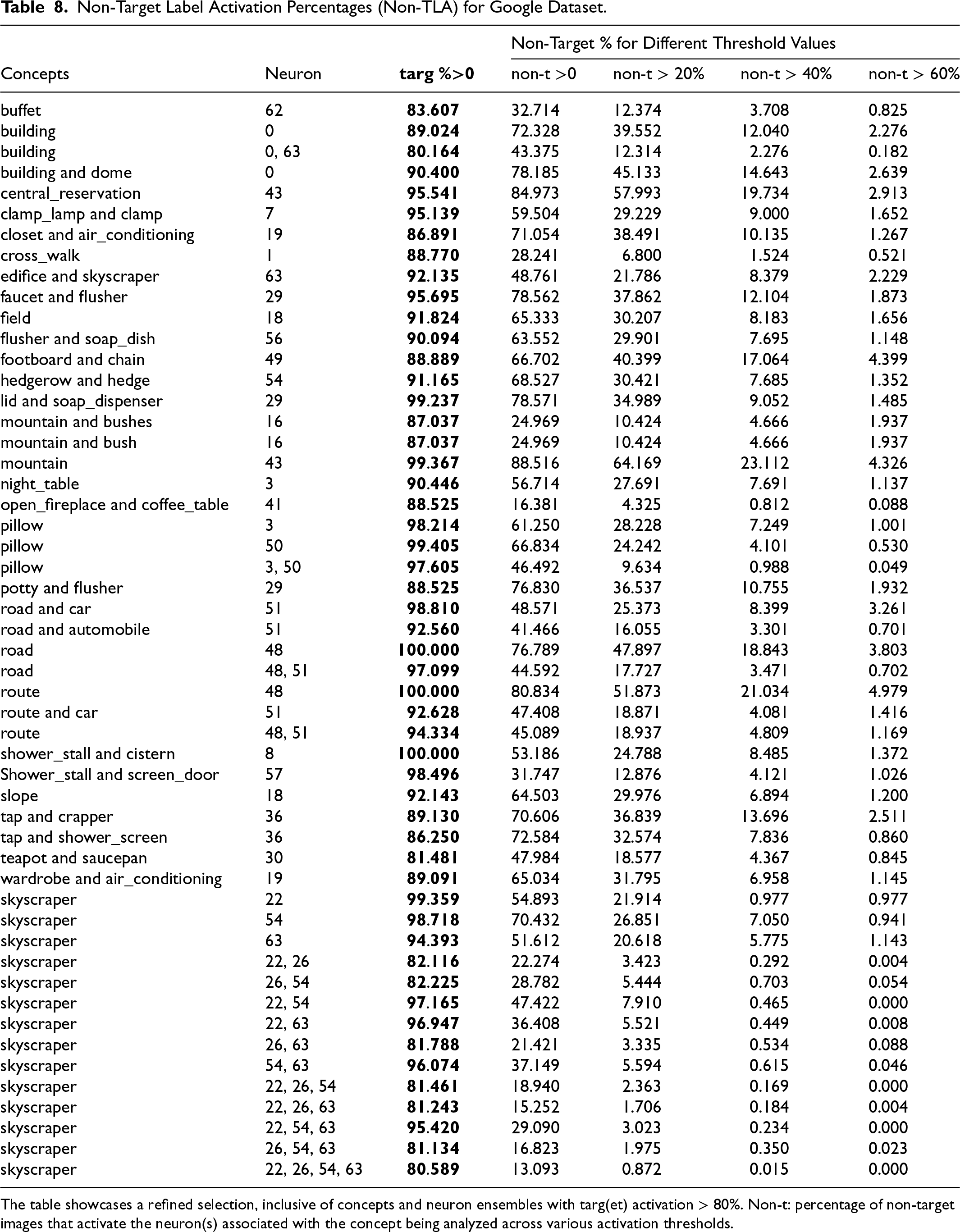
Non-Target Label Activation Percentages (Non-TLA) for Google Dataset.
The table showcases a refined selection, inclusive of concepts and neuron ensembles with targ(et) activation > 80%. Non-t: percentage of non-target images that activate the neuron(s) associated with the concept being analyzed across various activation thresholds.
Neuron Ensembles for Concept Associations
The distribution of input information across simultaneously activated neurons necessitates the investigation of neuron ensemble activations at different cut-off activation values. However, an exhaustive analysis of all neuron ensembles does not scale as even just 64 neurons give rise to
In scenarios where a concept activates more than two neurons, our analysis encompasses all possible combinations of pairs, triples, etc., of neurons (see skyscraper in Table 8). We then narrow our focus to a list of highly associated concepts corresponding to the neurons (see the Concepts column in Table 8), that demonstrate TLA exceeding
Annotations of ADE20K Dataset
The analysis just described yields error-margins associated with each concept, for each of the chosen activation thresholds listed in Table 8. For example, the concept buffet has an error-margin of 12.374 for the Non-TLA of
In order to substantiate our hypotheses, we analyse neuron activation values for new inputs, more precisely for images taken from the ADE20K dataset. We take advantage of the fact that ADE20K images already carry rich object annotations, however we have observed that they are still too incomplete for our purposes. Therefore we made use of Amazon Mechanical Turk via the Cloud Research platform, to add missing annotations from a list of concepts derived from Table 8 to 1,050 randomly chosen ADE20K images.
For this set of 1,050 ADE20K images, we conducted a user study through Amazon Mechanical Turk using the Cloud Research platform, to annotate images based on a list of concepts derived from Table8. The study protocol was reviewed and approved by the Institutional Review Board (IRB) at Kansas State University and was deemed exempt under the criteria outlined in the Federal Policy for the Protection of Human Subjects, 45 CFR §104(d), category: Exempt Category 2 Subsection ii. The study was conducted in 35 batches (each batch containing 30 images), with 5 participants per study compensated with $5 for completing the task. The task was estimated to take approximately 40 minutes, equivalent to $7.50 per hour.
For each image, users were presented with a list of concepts (a concise form of concepts from Table 8) to choose from, including buffet, building, building and dome, central_reservation, clamp_lamp and clamp, closet and air-conditioning, cross_walk, edifice and skyscraper, faucet and flusher, field, flusher and soap_dish, footboard and chain, hedgerow and hedge, lid and soap_dispenser, mountain, mountain and bushes, night_table, open_fireplace and coffee_table, pillow, potty and flusher, road, road and automobile, road and car, route, route and car, shower_stall and cistern, Shower_stall and screen_door, skyscraper, slope, tap and crapper, tap and shower_screen, teapot and saucepan, wardrobe and air-conditioning.
Users were allowed to select multiple concepts for each image, indicating all concepts that applied to the given image. These selected concepts were considered annotations for the respective image.
Validating Neuron-Concept Associations
To assess the validity of the error-margins retrieved from the Google Image dataset for all concepts in Table 8, we look at activations yielded by ADE20K images, and hypothesize that they are similar or lower (i.e., not higher), for non-target images. Non-TLA are computed across the predefined cut-off activation thresholds. Selected values can be found in Table 9. For example, the central reservation neuron 43 mentioned above activates above its 40% max activation threshold for about 14.9% of ADE20K non-target images (not showing central reservations), while it activates for about 19.7% of Google non-target images.
Non-Target Label Activation Percentages (Non-TLA) for ADE20K and Google Image Dataset.

Non-t: percentage of non-target label images that activate the neuron(s) associated with the concept being analyzed across various activation thresholds.
Both single-neuron and neuron ensemble activations are considered and shown in Table 9.
For the given test dataset split of ADE20K, we looked at Concept Induction, CLIP-Dissect, and GPT-4 for extracting relevant candidate concepts. Subsequently, we conducted two analyses from different perspectives. For each neuron of the dense layer, we identify the concepts that activate them the most (Statistical Evaluation). For each concept, we measure its degree of relevance across the entire dense layer activation space (Concept Activation Analysis).
We will now bring together the results. We will also present results from the additional error margin analysis.
The combination of the two evaluation perspectives—a detailed examination of how each neuron unit functions and a broader view of how the dense layer operates as a whole—enables us to gain a comprehensive insight into the inner workings of hidden layer computations.
Regarding statistical evaluation, we rigorously assess the significance of differences in activation percentages between target and non-target labels for each confirmed label hypothesis. We compute the z-score and p-value using the non-parametric Mann–Whitney U test. Additionally, we calculate the Mean and Median for both target and non-target labels to further characterize the results. In the Concept Activation Analysis, we evaluate the effectiveness of concepts across several dimensions. Initially, we assess each concept classifier considering both linear (CAV) and non-linear (CAR) decision boundary based on the presence and absence of each concept. To validate that the concept classifier’s test accuracy is not merely coincidental, we conduct K-fold cross-validation and calculate p-values. Additionally, we compute the Mean, Median, and Standard Deviation, and perform the Mann–Whitney U test to quantify the statistical significance of the test accuracies. This comprehensive approach ensures a robust evaluation of the concepts’ performance in activating the hidden layer.
Our findings suggest that Concept Induction consistently performs well in all evaluations conducted—Statistical Evaluation, Concept Activation Analysis, and also Error Margin Analysis. From the statistical evaluation, it is evident that Concept Induction achieves better performance than that of CLIP-Dissect and GPT-4. In the Concept Activation Analysis, quantitative measures reveal that Concept Induction achieves comparable performance to CLIP-Dissect, with GPT-4 exhibiting the lowest performance. Conversely, the Concept Induction approach demonstrates several notable qualitative advantages over both CLIP-Dissect and GPT-4: CLIP-Dissect and GPT-4 are black-box models used as a concept extraction method to explain a probing network, which in this case is a CNN model, that is, this approach to explainability is itself not readily explainable. In contrast, Concept Induction, serving as a concept extraction method, inherently offers explainability as it operates on deductive reasoning principles. CLIP-Dissect relies on a common English vocabulary (about 20K words) as the pool of concepts, whereas Concept Induction is supported by a meticulously constructed background knowledge (in this case with about 2M concepts), affording greater control over the definition of explanations through hierarchical relationships. While GPT-4/CLIP-Dissect emulate intuitive and rapid decision-making processes, Concept Induction follows a systematic and logic-based decision-making approach—thereby rendering our approach to be explainable by nature.
The results in Table 6 show that Concept Induction analysis with large-scale background knowledge yields meaningful labels that stably explain neuron activation. Of the 20 null hypotheses from Concept Induction, 19 are rejected at
The Non-Target % column of Table 3 provides some insight into the results for neurons 0, 18, 49 and neurons 14, 31 from Table 5: target and non-target values for these neurons are closer to each other. Likewise, differences between target and non-target values for mean activation values and median activation values in Table 6 are smaller for these neurons. This hints at ways to improve label hypothesis generation or confirmation, and we will discuss this and other ideas for further improvement below under possible future work.
Mann–Whitney U results show that, for most neurons listed in Table 6 (with
For the Concept Activation Analysis evaluation (see Table 12), Concept Induction yields
This analysis leads us to the following conclusion: among the three approaches we evaluate, Concept Induction demonstrates superior performance both in the quantity of high-quality concepts generated and in the relevance of these concepts within the hidden layer activation space. Furthermore, our approach possesses inherent explainability as it does not depend on any pre-trained black-box model to identify candidate concepts. However, there are undoubtedly trade-offs involved in selecting among the three approaches, which we elaborate on in Section 5.4.
Based on the results obtained from the Statistical Evaluation and Concept Activation analysis, our approach introduces a novel zero-shot, model-agnostic Explainable AI technique. This technique offers insights into the hidden layer activation space by utilizing high-level, human-understandable concepts. Leveraging deductive reasoning over background knowledge, our approach inherently provides explainability while also achieving competitive performance, thus confirming our initial hypothesis.
For a statistical evaluation of our error margin values, we treat each row, representing a concept-error pair at each threshold level, from Table 9, as an individual hypothesis. For example, the error-margin (Non-TLA) for the concept “central reservation” under the > 40 threshold constitutes one hypothesis. This way, we get
We conduct Mann–Whitney U tests (MWU) (McKnight & Najab, 2010) with the null hypothesis (H0) stating that there is no difference in Non-TLA across both datasets, while the alternative hypothesis (H1) posits that Non-TLA in Google Images is greater than in the ADE20K dataset. We choose the MWU test for its robustness with non-parametric data and its aptitude for comparing distributions of independent samples. As our Non-TLA data may not adhere to normality and we are comparing distinct datasets (Google Images and ADE20K), the MWU test provides a reliable means to analyze differences in Non-TLA.
Table 10 presents a comparison of Non-TLA between the Google Images and ADE20K datasets for all concepts. Each row represents a concept, with columns displaying the percentage of non-target label images activating associated neuron(s) in both datasets. The p-values from the MWU test indicate the significance of differences in Non-TLA between the datasets. The analysis reveals a consistent trend of decreased Non-TLA in the ADE20K dataset compared to Google Images across various threshold categories. Among the 33 hypotheses tested for the category of Non-TLA > 0, 13 were rejected at a significance level of p < 0.05. Similarly, for Non-TLA > 20%, 15 hypotheses were rejected at the same significance level. In the case of Non-TLA > 40%, 21 hypotheses were rejected, while for Non-TLA > 60%, 23 hypotheses were rejected, all at a p-value < 0.05. Concepts with p-value < 0.05 are deemed statistically significant and are identified as confirmed concepts, subject to further scrutiny for their reliability and potential implications.
Statistical Evaluation for Confirmed Concepts (Concepts Getting
-Value <0.05 for MWU).
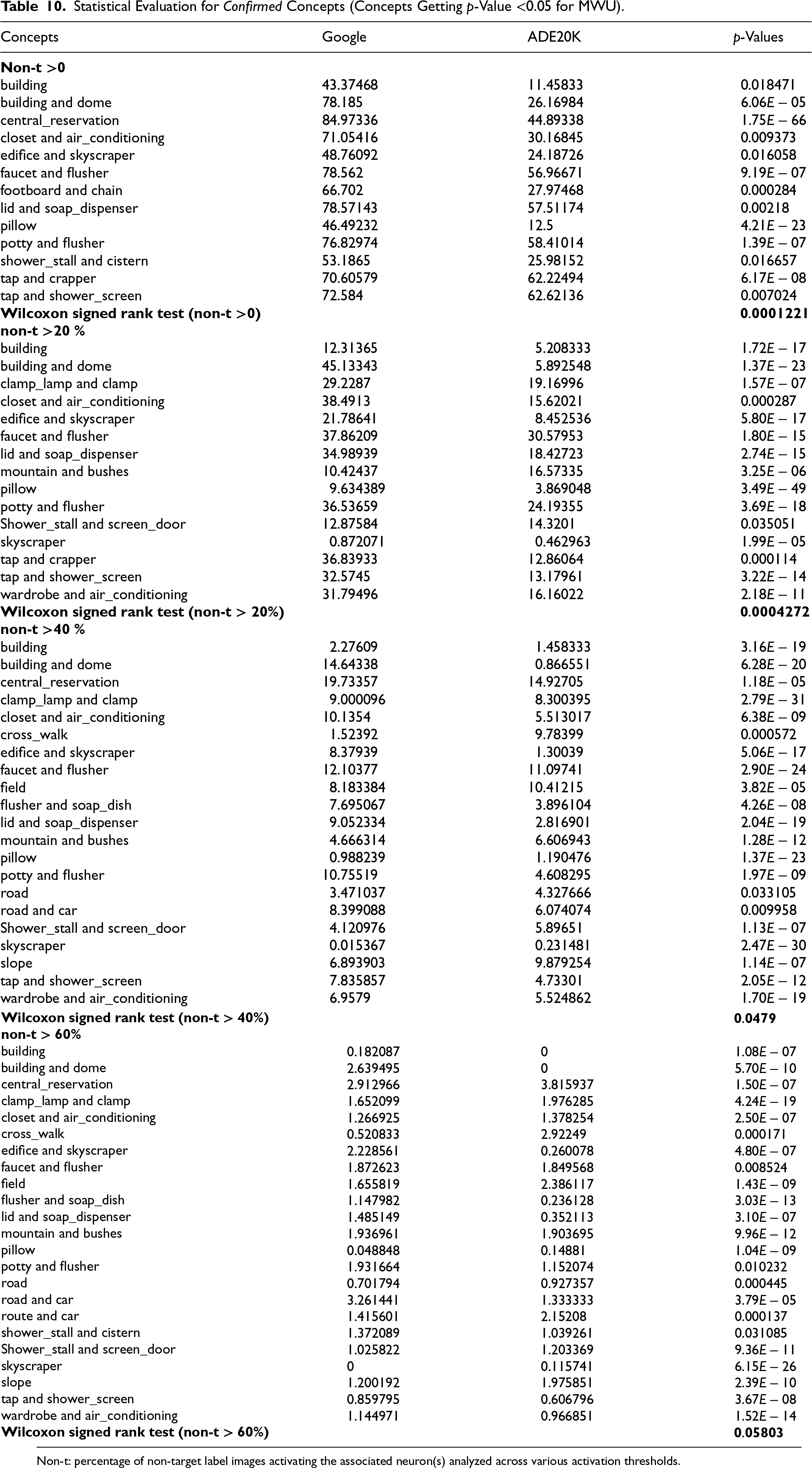
Statistical Evaluation for Confirmed Concepts (Concepts Getting
Non-t: percentage of non-target label images activating the associated neuron(s) analyzed across various activation thresholds.
After confirming concepts using the MWU, we proceed to validate them further using Wilcoxon signed-rank tests. To calculate the Wilcoxon test, we used an online website calculator called the Wilcoxon signed-rank test calculator by Statistics Kingdom 2017. 5 We employ the Wilcoxon test, with the hypothesis that the difference between Non-TLA of ADE20K and Google Image dataset would be less than or equal to zero (H0), while the alternative hypothesis (H1) suggested a decrease in Non-TLA in the ADE20K dataset compared to the Google image dataset. Each threshold serves as an individual hypothesis for the Wilcoxon test, with Non-TLA of the confirmed concepts for Google and ADE20K datasets grouped accordingly. For instance, all confirmed Non-TLA > 0 for both datasets constitute one hypothesis, while those > 20% form another. The p-values, denoting the significance of the test results, are displayed at the bottom of the table. Remarkably, the obtained p-values for each threshold suggest the rejection of the null hypothesis, indicating statistically significant differences in Non-TLA between the datasets when considered separately. A p-value < 0.05 from this test would indicate a statistically significant decrease in Non-TLA in the ADE20K dataset compared to the Google dataset, further strengthening our findings and highlighting that the error estimates from the Google image data hold, or are even bettered by, the ADE20K images.
We also examine all confirmed concepts from all thresholds together in the Wilcoxon test with the same alternative hypothesis ((H1) suggested a decrease in Non-TLA in the ADE20K dataset compared to the Google image dataset), which provides a comprehensive overview of the differences in Non-TLA between the Google and ADE20K datasets across various levels of activation thresholds. This approach aggregates the results from individual thresholds, offering a more consolidated perspective on the overall significance of the differences observed. In our analysis, obtaining a p-value of 5.633e-7, which is less than 0.05, implies the rejection of the null hypothesis. This indicates a statistically significant decrease in Non-TLA in the ADE20K dataset compared to the Google Image dataset when considering all thresholds collectively.
From the statistical evaluation, based on the percentage of target activation and from Concept Activation Analysis, based on the concepts’ test accuracies, we can categorize all confirmed concepts into three regions: high (90-100%), medium (80-89%), and low (
Count of Statistically Confirmed Concepts From Each Method (Table 11) Such That Their Percentage of Target Activation is Binned Into 3 regions Based on Their Degree of Relevance.

Count of Statistically Confirmed Concepts From Each Method (Table 11) Such That Their Percentage of Target Activation is Binned Into 3 regions Based on Their Degree of Relevance.
Mean, Median, and Standard Deviation (SD) of Concept Activation Analysis Test Accuracies, and Count of Concepts With Their Concept Classifier Test Accuracies Binned into 3 regions—High (90–100%), Medium (80–89%), and Low (<80%) Relevance.

Disregarding the duplicates, we have only 5 and 14 confirmed concepts from CLIP-Dissect or GPT-4, respectively, as opposed to 18 from Concept Induction.
This difference is likely due to Concept Induction’s reliance on rich background knowledge, necessitating additional preprocessing but offering additional value. While a candidate concept pool of 20K English vocabulary words for off-the-shelf GPT-4 may not be universally effective, Concept Induction’s ability to generate extensive, high-relevance concepts underscores the importance of well-engineered background knowledge.
If an application does not require comprehensive concept-based explanations, CLIP-Dissect/GPT-4 may serve as a useful solution, especially when time is limited. However, for detailed concept-based analysis, preparing background knowledge and leveraging Concept Induction is crucial. For CLIP-Dissect/GPT-4, it is unclear how to meticulously craft the pool of candidate concepts since it is difficult to manually curate a static set that is broad enough to capture all pertinent concepts while remaining specific enough to avoid noisy or ambiguous labels. By employing a background knowledge base, it is possible to define a large pool of potential explanations, tailored to the application scenario, with additional relationships among concepts. For example, in a medical diagnostic application, an ideal candidate pool would include specialized clinical terminology (e.g., “cardiomegaly” or “pleural effusion”) that is essential for accurate interpretation—an adjustment that is hard to achieve with a generic vocabulary. Concept Induction facilitates deductive reasoning utilizing this background knowledge, inherently offering transparency and flexibility in shaping the candidate concept pool.
While it is important to investigate methods that assess the relevance of concepts in hidden layer computations within a given candidate pool, it is equally, if not more, vital to thoughtfully design this pool. Neglecting this aspect could result in — (a) missing domain-critical concepts essential for gaining insights into hidden layer computations and (b) introducing noisy or ambiguous concepts that can lead to spurious activations and misleading explanations. Our ontology-driven approach mitigates both risks by integrating rich background knowledge and extract meaningful concepts from it.
Our focus on dense layer activations, while providing valuable insights, represents only a part of what the deep representation encodes. The dense layer likely relates to clear-cut concepts that separate output classes, aligning well with our goal of identifying high-level, interpretable concepts. However, these concepts are influenced by combinations of features from previous layers. This limitation underscores the complex nature of deep neural networks, where concepts identified at the dense layer result from hierarchical feature compositions throughout the network. While our method offers meaningful insights into these high-level concepts, it may not fully capture the nuanced feature interactions in earlier layers. Nonetheless, focusing on the dense layer allows us to extract concepts more directly relevant to the network’s final decision-making process, balancing interpretability with the complexity of internal representations. Future work could explore extending our method to analyze concept formation across multiple layers, potentially revealing a more comprehensive picture of the network’s decision-making process.
One drawback of utilizing Concept Induction (and GPT-4) is its dependency on object annotations, which serve as data points in the background knowledge. In contrast, CLIP-Dissect operates without the need for labels and can function with any provided set of images.
We view this as a trade-off that must be carefully considered based on the application scenario. If the application is broad and does not demand a meticulous design of candidate concepts, then employing approaches like CLIP-Dissect can be advantageous. Conversely, for applications that are focused or specialized, CLIP-Dissect may only provide broadly relevant concepts.
Our focus has been primarily on assessing the comparative effectiveness of Concept Induction within the confines of CNN architecture using ADE20K Image data. Nevertheless, it is imperative to investigate its suitability across different architectures and with diverse datasets. Given the model-agnostic nature of our approach, our results suggest its potential applicability across a range of neural network architectures, datasets, and modalities. While we utilized a Wikipedia Concept Hierarchy comprising 2 million concepts, it would be intriguing to observe the outcomes of our approach when powered by a domain-specific Knowledge Graph in specialized domains such as Medical Diagnosis.
The error margins derived from our analysis significantly enhance the interpretability and reliability of neural networks. These margins provide a quantitative measure of confidence for concept detection in image analysis tasks. For instance, when a neuron associated with a specific concept (e.g., “buffet”) activates above a certain threshold, the error margin allows us to estimate the likelihood that the image actually contains that concept.
Our study demonstrates the robustness of error margin methodology across diverse datasets without assuming identical neuron-concept associations between Google Images and ADE20K. Instead, our primary goal was to validate the generalizability of error margins across these distinct datasets. In our experiments, we observed varying neuron-concept associations across datasets. For instance, while neuron 62 prominently associated with ’buffet’ in Google Images, its activation pattern in ADE20K showed similarities but also notable differences. These variations stem from differences in dataset characteristics, training specificity, and concept granularity. Importantly, these differences strengthen our findings. The methodology’s ability to produce statistically significant results despite these variations underscores its robustness and broad applicability. This adaptability is crucial for real-world applications requiring reliable concept detection and interpretability across diverse data contexts.
Our statistical analysis, employing Mann–Whitney U and Wilcoxon signed-rank tests, reveals significant differences in non-target label activations (Non-TLA) between the ADE20K dataset and the Google Images dataset. Crucially, the lower Non-TLA values observed in the ADE20K dataset validate our error margins and underscore their reliability. This validation is important for several reasons:
These error margins significantly enhance the interpretability of neural network decisions by quantifying the reliability of neuron-concept associations. This offers a more nuanced understanding of how the network processes information, going beyond simple neuron labeling to provide insights into the degree of certainty with which we can interpret a neuron’s activation. Such information is crucial for building trust in AI systems, especially in critical decision-making scenarios.
Furthermore, our error margin analysis can guide the refinement of neural architectures. By identifying neurons or neuron ensembles with high precision for specific concepts, we can inform targeted improvements in network design. For example, architectures could be optimized to enhance the precision of key concept detections, potentially leading to more efficient and accurate models.
In summary, our analysis demonstrates that the concept associations and error margins derived from our method are both reliable and generalizable. These findings contribute significantly to the field of explainable AI by providing a validated approach to understanding and improving the interpretability of neural networks, paving the way for more advanced and trustworthy AI systems.
We explore the potential of a Large Language Model (LLM), specifically GPT-4, by leveraging its domain knowledge and common-sense capability, to generate high-level concepts that are meaningful as explanations for humans, for our specific setting of image classification. We use minimal textual object information available in the data via prompting to facilitate this process. To evaluate the output, we compare the concepts generated by the LLM with two other methods: concepts generated by humans and the ECII heuristic concept induction system. Since there is no established metric to determine the human understandability of concepts, we conducted a human study to assess the effectiveness of the LLM-generated concepts. Our findings indicate that while human-generated explanations remain superior, concepts derived from GPT-4 are more comprehensible to humans compared to those generated by ECII. The prompting approach we detail and evaluate below was also used for the GPT-4 based label hypothesis generation described in Section 4.2.3.
Expanding upon the framework introduced in Section 4, our goal is to explore the feasibility of replacing the ECII model with a Large Language Model (LLM) to produce explanations that remain meaningful and coherent. The objective is to identify “good” concepts that make sense to humans and can later be validated by mapping them with a Deep Neural Network (DNN) to accurately describe what neurons perceive. We utilized the GPT-4 (Open et al., 2024) model to generate meaningful explanations for a specific scene classification task, which was done using a logistic regression algorithm that classified images into scene categories based on semantic tags of objects present in each image. The explanations are generated using Prompt Engineering (Ekin, 2023) via the OpenAI API. Unlike logical-deduction-based systems such as ECII, which are limited by background knowledge, an LLM like GPT-4 can leverage its common-sense reasoning capability and vast domain knowledge to produce more comprehensive concepts. In Widmer et al. (2023), the quality of explanations generated by concept induction was assessed and found to be more meaningful than semi-random explanations but less accurate than human-generated (gold standard) ones. Our objective is to evaluate the extent to which explanations generated by LLMs align with human-generated explanations and potentially surpass the concept induction system in terms of accuracy and comprehensibility.
As discussed before, concept induction is a symbolic reasoning task that can be done using provably correct Lehmann and Hitzler (2010) or heuristic Sarker and Hitzler (2019) deduction algorithms over description logic knowledge bases. In this section, we attempt to make use of pre-trained LLMs to produce results that are comparable to or even better than those obtained from a concept induction system. In other words, we are making use of an LLM to do better than a symbolic-reasoning-based algorithm, at least in a specific setting.
Approach
Our approach and evaluation setting is essentially the same as in Widmer et al. (2023), however instead of their comparison of explanations generated by (a) humans, (b) concept induction, and (c) a semi-random process, we compare (a) human, (b) concept induction, and (c) GPT-4 prompting. We went into the study with the hypothesis that explanations produced by GPT-4 would outperform those produced by concept induction in terms of “meaningfulness to humans,” but that they would still not be as good as the human-generated gold standard.
Input Dataset
As in Widmer et al. (2023), we used the object tags associated with images from the ADE20K dataset (Zhou et al., 2017, 2019) as input, in this case for the GPT-4 model via the OpenAI API. As discussed previously, this dataset contains approximately 20,000 human-curated images annotated with scene categories and object tags present in the images. We used a selection of 45 image set pairs. Each image set pair consists of two groups of natural images representing distinct scene categories (A and B), with a total of 90 scene categories across all sets. Each set within a pair consisted of eight images selected at random from a particular category.
These image set pairs were curated in the previous study (Widmer et al., 2023), and we adopted the same set of pairs to maintain consistency. Although the object tags in the dataset indicate not only the presence of an object but also details such as the number of objects and occlusions, we focused solely on the object labels for our analysis, disregarding additional annotations.
To generate explanations from the GPT-4 model, we fed the object tags of the images into the model using prompts. Our objective was to describe what distinguished Category A from Category B in each image set pair, where each image set belongs to a specific scene category. These descriptions were defined as “concepts,” and for each image set, we produced a list of seven concepts. We tried to come up with concepts that encompass tangible objects depicted in the images (e.g., tree or bench) or general categories that align with the theme of the images (e.g., park or garden).
To prompt the GPT-4 model effectively, we experimented with different prompting techniques to obtain the most reasonable concepts. Our approach involved using a straightforward technique that leveraged only the object labels from each image set category. We instructed the GPT-4 model to differentiate between the two categories based on their object tags. Object tags, as the name suggests, could be anything physically present in the images. For example, the object tags coming from category A in Figure 5 include object labels such as stands, food, wall, tomatoes, bag, register, weighing machine, shopping carts, person, etc.

Prompting method: the GPT-4 model was prompted using the exact prompt mentioned in the image. Here, the positive and negative text indicates the object tags present in the images. The resulting set of seven concepts is mentioned in the GPT-4 response.
Similarly, the ECII system also used the same object tags to generate concepts. For the ECII model, all object tags from the images are automatically mapped to classes in the Wikipedia class hierarchy using the Levenshtein string similarity metric (Levenshtein, 1975b) with an edit distance of 0. The algorithm then assessed the images based on their object tags and returned a rating of how well concepts matched images in Category A but not Category B. ECII explanations were then created by taking the seven highest-rated unique concepts. This alignment allowed us to compare the concepts generated by our approach with those produced by the ECII system.
The process and the prompt used for interacting with the GPT-4 model are illustrated in Figure 5.
We used the latest version of the GPT-4 model for our prompt. We utilized zero-shot prompting with specific parameters, setting the temperature to 0.5 and top_p to 1. The temperature parameter in GPT-4 controls the level of creativity or randomness in the generated text. When predicting the next token from a vocabulary of size
Evaluation
To evaluate the concepts generated from GPT-4 we ran a study through Amazon Mechanical Turk using the Cloud Research platform. Our goal was to assess the quality of LLM explanations (i.e., GPT-4 explanations) compared to both human-generated (“gold standard”) explanations and ECII explanations.
We recruited 300 participants through Mechanical Turk, compensating each participant with $5 for completing the task, which was estimated to take approximately 40 minutes (equivalent to $7.50 per hour based on the minimum legal wage in the USA). Based on the previous study (Widmer et al., 2023), we aimed for a sample size of at least 89 unique participant judgments per trial to estimate the parameters (medium effect size of f2 = 0.15 and 95% power) of the Bradley-Terry model (Bradley & Terry, 1952), which is used to evaluate the survey results. This required collecting data from 300 participants, resulting in a total of 100 observations per trial after accounting for potential exclusions.
Across all questions, each participant encountered three types of explanations, although only two explanation types were compared in any given question. Each participant was asked to choose the more accurate explanation using a two-alternative forced choice design. For each pair of image sets, participants answered three questions comparing (a) Human versus ECII explanation; (b) Human versus LLM (GPT-4) explanation; and (c) LLM versus ECII explanation. For each pair of image sets (A and B), a given participant completed all three comparisons.
The 45 pairs of image sets in this study resulted in a total of 135 unique target questions. Participants were randomly assigned to 15 image sets (45 questions in total), ensuring that image sets were counterbalanced across participants to receive an equal number of responses.
For all image sets, ECII explanations and Human “gold standard” explanations were created in a previous study (Widmer et al., 2023). In this work, we generated LLM (GPT-4) explanations following the method described in Section 5.1. To form the ECII explanations, the object tags of the images were provided to the ECII algorithm, then the seven highest-rated unique concepts were selected based on the ranking of the F1 score. Human “gold standard” explanations were crafted by presenting image sets (without object or scene category tags) to three human raters, selecting concepts unanimously mentioned by all three, then by two raters, and finally filling in randomly selected concepts until seven unique concepts were reached.
In addition to the 45 image sets, five “catch trial” image sets were used to verify participant attention. These catch-trial image sets included two types of explanations: human explanations generated similarly to other human gold standard explanations, and explanations consisting of completely random concepts generated from a word generator to serve as obviously inaccurate explanations.
After providing consent, participants received brief training on the task, including instructions on how concepts and explanations were defined in the study. They then began answering questions, with the 50 questions (45 assigned targets and 5 catch trials) presented in random order. Figure 6 illustrates the stimuli presentation and response options shown to participants.

Survey interface, with human explanation presented on the left and LLM explanation on the right.
Prior to analysis, participant responses to catch trials were evaluated, and participants who failed more than one catch trial were excluded from further analysis. Among the 300 participants, 253 did not fail any catch trials, while 22 participants failed exactly one trial, and 35 participants failed more than one trial. The 35 participants who failed multiple trials were excluded from all subsequent analyses, resulting in a total of 265 participants included in the analyses.
Across all image sets, human explanations were overwhelmingly preferred over ECII explanations (chosen 3282 times versus 693 times; 83% preference) and over LLM (GPT-4) explanations (chosen 2762 times versus 1213 times; 69% preference). Additionally, LLM explanations were preferred over ECII explanations (chosen 2514 times compared to 1461 times; 63% preference). See Figure 7.

Number of times participants chose different explanation types.
Participants’ pairwise judgments were utilized in a Bradley-Terry analysis (Turner & Firth, 2012) to derive “ability scores” for each type of explanation, reflecting the extent to which each explanation type was preferred by participants. The Bradley-Terry model uses data where entities are compared pairwise, and the outcome (win/loss, preference ranking, etc.) is observed. From these comparisons, the model estimates the abilities
A post hoc analysis using Tukey’s honestly significant difference (HSD) test (Abdi & Williams, 2010) was conducted to determine which specific group means are significantly different from each other. When comparing multiple group means, the Tukey post hoc test is preferred over multiple t-tests (Kim, 2015) because it adjusts for multiple comparisons, controlling the overall Type I error rate (Nanda et al., 2021). Conducting multiple t-tests increases the risk of false positives, while the Tukey test maintains the integrity of statistical conclusions by adjusting the significance levels appropriately. This test confirmed significant differences in ability scores between human vs. ECII explanations and human vs. LLM explanations (both
p-Values of the Ability Scores Among Different Explanation Types From Tukey’s HSD Test.

The individual ability scores for human and LLM explanations for each image set pair are detailed in Table 14.
Ability Scores and Number of Wins for Human (H), ECII (E), and LLM (L) Explanations.

ECII explanations were set as the reference point in the Bradley–Terry analysis and so their ability scores were always equal to 0, and thus are not displayed here.
Concept Accuracy in Hidden Layer Activation Space of Concepts Extracted Using Concept Induction.

Concept Accuracy in Hidden Layer Activation Space of Concepts Extracted Using CLIP-Dissect.

Concept Accuracy in Hidden Layer Activation Space of Concepts Extracted Using GPT-4.

The source code, input data, and raw result files related to the evaluation tasks (i.e., survey questionnaires, and collected responses) are available online. 6
The analysis of the results presented in Table 14 provides evidence supporting our hypothesis that LLM (GPT-4) explanations are more meaningful for humans compared to ECII-generated ones. Human-generated explanations were consistently preferred as the most accurate in describing differences between image categories, followed by LLM explanations, with ECII explanations found as the least accurate. The preference for human-generated explanations over LLM explanations is expected given the messy nature of generalized Large Language Models. These models, trained on vast and diverse datasets, can produce responses that lack precision and clarity because of their broad generalization. This can lead to explanations that are sometimes inaccurate or unclear, making human-generated explanations generally more reliable and preferred. Also, there is potential for further refinement in prompting techniques using varied hyper-parameters (e.g., temperature and top-p). However, LLM explanations demonstrated notable explanatory power, suggesting their usability in concept generation.
It is important to note the variability in LLM performance across different image sets. In some cases, LLM explanations were chosen relatively more frequently than in others, with some instances showing LLM explanations being preferred more often than human explanations. Conversely, in other image sets, LLM explanations were chosen less often than ECII explanations. For instance, in Set 41 (see Figure 8), explanations generated by LLM are more comprehensive in identifying images of a bakery, while human-generated explanations also perform adequately. However, the concept “Women” included in the human-generated list is not as relevant for capturing the overall scene depicted in these images.

Example of different explanation types for Set 41: Bakery v Apartment Building
On the other hand, ECII concepts only identify the object names present in the images and fail to capture the broader category of the scenes (i.e., bakery). In most cases where LLM explanations fall short, they tend to introduce concepts that are unrelated to the images. For example, in Set 6 (see Figure 9), LLM produced a concept like “Public Transport,” which is contextually incorrect. One potential reason for this is the presence of object names (such as streetcar, tram, tramcar, swivel chair, trolley car, armchair) in the input images, which could be erroneously associated with public transport. Based on these examples, it is speculated that when GPT-4 was prompted to generate generic scenarios based on object tags, it attempted to produce seven distinct concepts. Limiting the number of concepts might lead to clearer explanations that are more pertinent. Additionally, running prompts to ask for simple object names rather than generic scenarios akin to ECII-generated explanations could yield different outputs that may prove useful. This suggests there is certainly still room for improvement in LLM explanations, but that on average there is promising evidence that LLMs can produce explanations that successfully describe the differences between two groups of data. Moreover, variability could be introduced by human participants. In our study, human explanations were preferred over ECII 83% of the time, whereas in the previous study (Widmer et al., 2023) with the same settings, the preference ratio was 87%.

Example of different explanation types for Set 6: Beauty Salon v Forest Path.
In this section, we report on an implementation that end-to-end automates the concept induction and statistical evaluation workflow. Our system uses automation in four stages (see Figure 10) to streamline processes and to enhance efficiency.

Automated four-stage pipeline for analyzing neuron activations, inducing concepts, and evaluating neuron significance using a ResNet50V2 model and ECII tool, created with BioRender.com.
Stage 1: Model Training and Data Configuration
Initially, our automation pipeline trains and configures a CNN model using the ADE20K dataset (Zhou et al., 2019). This process is executed on Beocat (Hutson et al., 2019), a high-performance computing environment optimized for managing extensive datasets. A Bash script automates job scheduling, resource allocation via SLURM, initializes the Python environment, securely clones the stage 1 repository from GitHub, and installs the necessary dependencies to establish the training environment. We employ a ResNet50V2 architecture implemented in TensorFlow, fine-tuned to enhance model performance using techniques such as data augmentation, early stopping, and batch normalization.
Stage 2: Parallelized Concept Induction and Label Hypothesis Generation
We used the concept induction process to generate label hypotheses for each of the 64 neuron activations in the CNN’s dense layer using the heuristic Concept Induction system ECII (Sarker & Hitzler, 2019). We automated the simultaneous execution of tasks for all 64 neurons by employing parallel processing with a SLURM-configured Bash script in Beocat. The script initializes the environment, installs necessary Java and Maven dependencies, and clones the latest stage 2 repository from GitHub. Each neuron-specific configuration file from Stage 1 was used to generate semantic concepts, producing output concept files with hypothesized labels and coverage scores using the background knowledge base from the Wikipedia concept hierarchy.
Stage 3: Parallelized Image Retrieval and Classification
Image retrieval and classification were automated for all neurons to validate the label hypotheses generated in Stage 2. A Bash script manages parallel task execution using SLURM, generating indices for neurons with configuration files. It clones the Stage 3 project repository, sets up the environment, installs dependencies. The script runs a Python program that utilizes the pygoogle_image library to extract labels from the top 3 solutions for each neuron, retrieves 100 images per label from Google, and classifies them using the trained CNN model. Retrieved images are divided into evaluation and verification sets for statistical analysis.
Stage 4: Statistical Analysis and Verification of Neuron Activations
Label hypotheses are validated through statistical analysis of neuron activations. A Bash script sets up the environment, clones the stage 4 repository, and installs dependencies. The script runs a Python program that combines activation data from evaluation and verification sets, generates summary statistics, and conducts a Mann–Whitney U test (McKnight & Najab, 2010) to compare activation values for target and non-target images. Evaluation sets, containing images that strongly activate neurons, provide initial activation metrics. Verification sets undergo further statistical testing to confirm the accuracy and robustness of the label hypotheses.
We provide a visualizing tool, ConceptLens, that quantifies the uncertainty and imprecision in neural concept labels through error margins. ConceptLens makes use of, and displays, identified concepts (using the Concept Induction approach) as well as confidence values based on the above discussed error-margin analysis. This approach allows users to see not only what stimuli activate specific neurons but also how confidently these neurons respond to different inputs. The demonstrator is currently restricted to the system trained as described in Section 4.1.
User Interface
ConceptLens features a user-friendly interface that allows users to upload images and receive real-time visualizations of neuron activations. The main components of the interface include:
Image Upload and Selection: Users can upload their images or choose from a curated gallery. The tool supports a wide range of images, although results may vary for images outside the 10 classes it was primarily trained on: bathroom, bedroom, building facade, conference room, dining room, highway, kitchen, living room, skyscraper, and street. Concept Detection and Visualization: ConceptLens processes the uploaded image through trained CNN and Concept Induction to detect relevant concepts. The detected concepts are then presented as bar chart visualization and their corresponding error-margin percentages, providing users with a clear understanding of the network’s predictions. Error-Margin Display: The interface highlights the error-margin percentages for each detected concept, allowing users to gauge the confidence of the network’s predictions. Lower percentages indicate higher confidence in the concept detection.
Demonstration
The ConceptLens demonstrator is available online, 7 together with a video for a preview of its features 8 and the source code is available on GitHub. 9 Figure 11 shows a screenshot of a ConceptLens output example. Note the (relatively) small error margins for the top mentioned detected concepts, most of which are clearly present in the image.

Example image and output, ConceptLens demonstrator.
Despite the strong performance and interpretability demonstrated by our neurosymbolic Concept Induction framework, several limitations remain:
Single-layer focus: We restrict our analysis to a single dense layer’s activations, yet deep networks encode hierarchical features across many layers. In future work, we will extend Concept Induction and Concept Activation Analysis to convolutional layers and to combinations of neurons, to reveal how concepts emerge and interact throughout the network. Dependence on labeled data: Our error-margin computations and positive/negative concept sets require image annotations, which may be costly to obtain. We plan to explore semi-supervised or weakly supervised approaches—for example, leveraging pseudo-labels or active learning—to reduce annotation requirements while maintaining explanation fidelity. Single-dataset evaluation: All experiments use the ADE20K dataset, which may limit generality. We intend to validate our approach on additional domains (such as medical or satellite imagery) and on other network architectures (e.g., Vision Transformers), to assess robustness across data modalities and model families. Fixed background-knowledge scale: We employ a 2 million-class Wikipedia-derived ontology, but domain-specific tasks may benefit from smaller, more focused knowledge graphs. Future work will investigate the trade-offs of ontology size and specificity, including experiments with specialized medical or scientific ontologies.
By acknowledging these limitations and outlining concrete next steps, we aim to guide future enhancements of neurosymbolic explainability methods.
Conclusion
In this study, we demonstrate and evaluate the use of Concept Induction as a post hoc XAI tool. Our findings indicate that indeed Concept Induction over a background knowledge provides detailed insights into the otherwise black-box nature of hidden layer computations. It is a neurosymbolic approach where the generation of explanations is not a black-box process, which has practical advantage across many applications, for example, where the explanation generation process necessitates provable correctness. Of course such an advantage is only achieved at a cost, in our case that is—requiring labeled data. We view this approach not as a replacement of existing non-white-box Explainable AI methods, rather we introduce a novel neurosymbolic approach to complement the existing techniques, especially for situations where provable correctness is of utmost importance regardless of the cost.
Additionally, we provide a systematic approach to evaluate neuron-labeling by means of high-level concepts obtained through Concept Induction. In our evaluation protocol, we not only measure the explanation performance by asking “What Concept(s) activate a neuron the most?,” but also “Given Concept X activates a neuron, how likely it is that the said neuron is activated by other concepts?,” we argue that the latter is necessary for a trustworthy Explainable AI technique.
The process of achieving explanations using Concept Induction involves many steps, as such we also provide an automated end-to-end system; thereby reducing any manual efforts. We hope that such an automated system gets rid of impediments toward replicating the results and would nurture future research opportunities.
In further work, we intend to extend our work to diverse datasets and various neural network architectures. Additionally, we aim to enhance model interpretability by exploring additional concept induction results, using different background knowledge, across various neuron layers.
Footnotes
Acknowledgments
The authors acknowledge partial funding under National Science Foundation grants 2119753 and 2333782.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article.