
Abstract
While remarkable recent developments in deep neural networks have significantly contributed to advancing the state-of-the-art in computer vision (CV), several studies have also shown their limitations and defects. In particular, CV models often make systematic errors on important subsets of data called slices, which are groups of data sharing a set of attributes. A slice discovery method (SDM) is meant to detect semantically meaningful slices on which the model performs poorly, called rare slices. We propose a modular neurosymbolic SDM whose distinctive advantage is the extraction via inductive logic programming of human-readable logical rules describing rare slices, and thus enhancing the explainability of CV models. To this end, a methodology for inducing the occurrence of rare slices in a model is presented. We validate the SDM approach on both the synthetic Super-CLEVR and real-world ImageNet datasets. Our experiments demonstrate the complete pipeline: first, we successfully induce targeted rare slices using our taxonomy-based heuristic; second, our neurosymbolic SDM correctly identifies these slices and produces precise, human-readable logical rules to describe them; and finally, these rules are used to guide a data augmentation process that successfully mends model behaviour and improves its predictive performance. 1
Introduction
Computer vision (CV) (Szeliski, 2022) is a field of artificial intelligence (AI) that enables computer systems to obtain semantic information from digital images and videos. Following the remarkable recent developments of deep neural networks, significant achievements have been made in advancing state-of-the-art performance in various CV tasks (Krizhevsky et al., 2017), among which it is crucial to mention safety-critical applications, such as autonomous driving (M. Zhang et al., 2018).
However, empirical studies, for example Recht et al. (2019), show that CV models struggle to generalise to new data slightly different from those on which they were initially trained and tested. A related problem is the presence of important subsets of data, called slices, for which deep learning models often make systematic errors (Eyuboglu et al., 2022). A slice is defined as a group of data sharing a set of attributes. For instance, one study found that some object recognition models systematically underperform in identifying common household items from non-Western countries and low-income communities (DeVries et al., 2019). This underperformance likely stems from variations in the objects themselves and the different contexts in which they appear.
Accurately detecting underperforming slices, called rare slices, allows one to carefully analyse such prediction errors and subsequently improve the model. Expectedly, identifying rare slices is a complex task, especially for high-dimensional and unstructured data, for example, images, where such slices often manifest as subtle, non-obvious patterns that are difficult to spot and extract. Furthermore, it is non-trivial to understand what makes slices rare. In view of this, the slice discovery problem (Eyuboglu et al., 2022) has been described as mining unstructured input data for semantically meaningful slices on which the model performs poorly.
In this work, we propose to tackle the slice discovery problem with a neurosymbolic AI approach (Hitzler & Sarker, 2021), given the capabilities of machine learning (ML), and in particular deep learning (DL), for unstructured data classification and knowledge representation and reasoning (KRR) methods for transparent logical inference and explainability. In particular, we provide a framework to experiment with different datasets the effectiveness of our inductive logic programming-based slice discovery method (SDM). This framework allows us to evaluate our SDM according to the semantic quality of the extracted rules in describing rare slices and the effect of such rules in reducing model misclassifications. To this end, we leverage Super-CLEVR (Z. Li et al., 2023), a well-known synthetic dataset with a data generator for images of vehicles organised in hierarchical classes, and ImageNet (Krizhevsky et al., 2017), a large-scale real-world image dataset organised according to the WordNet (Pedersen et al., 2004) hierarchy. The main contributions of our work are summarised as follows:
We present our modular neurosymbolic framework for slice discovery, which consists of a closed loop that involves data generation (or subsampling), object detection (or image classification), scene graph generation that describes the semantic contents of images, rule learning to detect rare slices, and neural network model mending. First, we provide image datasets with rare slices leveraging Super-CLEVR (via generation) and ImageNet (via controlled subsampling), on which we train YOLOv5 (Redmon et al., 2016) models. We then translate the images classified by YOLOv5 into scene graphs in the language of inductive logic programming (ILP) (Cropper & Dumancic, 2022). Depending on the ground truth, these scene graphs constitute the positive and negative ILP examples, that is, those in which the neural network incorrectly resp. correctly classified the image. Subsequently, we use three different ILP systems, Popper (Cropper & Morel, 2021), FOLD-R++ (Wang & Gupta, 2022), and FastLAS (Law et al., 2020), to obtain succinct logical rules that reveal which images are hard for the model to classify. Finally, the neural network model is trained on its checkpoint with further data generated using these rules. In order to test the proposed approach on various slice discovery settings, we focus on generating datasets with rare slices. Closest to our work, Eyuboglu et al. (2022) considered the generation of rare slices in the context of the hierarchical class structure, but did not consider further class taxonomies besides the default one; this makes their method not really suitable for the scenarios we are considering. In contrast, a taxonomy-based approach is pursued in this work, and a methodology for building datasets with rare slices is presented. We provide an implementation along with experimental results for both datasets to test the effectiveness of rare slice generation, rule extraction on the classification results of the neural network model, and model mending. The results show that our approach could reliably generate rare slices and that rule learning delivered meaningful rules describing rare slices. Furthermore, feeding the neural network with additional training data generated according to such rules resulted in a significant performance improvement, as misclassifications decreased considerably.
With our framework, we can generate controlled rare slices in datasets to then test the model behaviour on them. Furthermore, it allows the automatic mining via ILP of human-readable logical rules that pinpoint the deficiencies of a classification model and benefit the user’s intuition for model mending. The transparent nature of logical rules makes them highly interpretable and provides a basis for finding model explanations from possible background information.
This article extends our previous work (Collevati et al., 2024) with (i) a more detailed and extended related work section, (ii) the use of further ILP systems, (iii) a more rigorous experimental evaluation using an additional real-world dataset, and (iv) an improved implementation of the proposed SDM framework.
The remainder of the article is organised as follows. In Section 2, we provide a review of related work on SDMs. Section 3 presents an introduction to the Super-CLEVR and ImageNet datasets and the ILP systems. Section 4 describes the proposed neurosymbolic framework for slice discovery. Section 5 presents a taxonomy-based methodology for generating datasets containing rare slices. Section 6 describes the experimental setup and presents an overview of the obtained results. The experimental results are discussed in Section 7. Finally, conclusions and future work are provided in Section 8.
Related Work
Several studies (Buolamwini & Gebru, 2018; DeVries et al., 2019; Koenecke et al., 2020; Oakden-Rayner et al., 2020) have shown that neural network models often make systematic errors on data slices. The impact of such errors is especially pronounced for critical application areas, such as medical diagnostics (Olesen et al., 2024) and fraud detection (Kalid et al., 2024), where accurate identification of rare slices positively influences essential decision-making. Consequently, recent research has proposed automated SDMs aimed at identifying semantically meaningful slices in which the model exhibits prediction errors. An optimal SDM should automatically detect data slices containing coherent instances that closely correspond to a concept understandable by humans (Johnson et al., 2023) and on which the model underperforms.
Previous research has addressed the slice discovery problem by focussing on datasets with metadata or structured (e.g., tabular) data. In Chung et al. (2019) the Slice Finder system is proposed, which employs two different automated data slicing methods, viz. decision tree training and lattice searching. In Sagadeeva and Boehm (2021), the authors present SliceLine, an exact yet fast and practical enumeration algorithm to find problematic data slices leveraging monotonicity properties and upper bounds for effective pruning. On the other hand, the Premise algorithm (Hedderich et al., 2022) heuristically discovers those feature-value combinations (i.e., patterns) that provide clear insight into the systematic errors of NLP classifiers.
Dealing with the slice discovery problem becomes particularly challenging for unstructured data, such as images and audio. Recent studies have proposed methods for identifying slices in this context. Several of them embed the data in a representation space and then use clustering or dimensionality reduction techniques. The Domino SDM (Eyuboglu et al., 2022) exploits cross-modal embeddings and an error-aware Gaussian mixture model to discover and describe coherent slices, while the Spotlight method (d’Eon et al., 2022) for finding systematic errors is based on the idea that similar inputs tend to have similar representations in the final hidden layer of a neural network. Spotlight exploits this similarity by focussing on such representation space, aiming to identify contiguous regions where the model underperforms. In Sohoni et al. (2020), the authors describe a two-step method, called George, for identifying underperforming slices without requiring access to slice labels. In the first step, slice labels are estimated by training a model and splitting each class into estimated slices through unsupervised clustering in the model feature space. In the second step, these estimated slices are used to train a new model, optimizing for worst-case performance over all estimated slices via a robust optimisation technique (Sagawa et al., 2020).
The recent explosion of generative AI has seen various works considering the use of such models to address the slice discovery problem. The PromptAttack procedure (Metzen et al., 2023) identifies systematic errors by exploiting a text-to-image model to synthesise images, conditioned on a prompt that encodes information about subgroups and classes. In Gao et al. (2023), a human-in-the-loop tool is proposed, called AdaVision, which uses GPT-3 (Brown et al., 2020) to suggest coherent but potentially underperforming slices to explore, and CLIP (Radford et al., 2021) to retrieve relevant images to improve slice identification. In Boreiko et al. (2023), the authors present the SCROD pipeline for slice discovery in object detectors applied to synthetic street scenes. Such a pipeline consists of several generative models to synthesise images with fine-grained control in a fully automated and scalable way. The interactive VLSlice system (Slyman et al., 2023) is designed to test vision-and-language models by discovering their slices from unlabelled image datasets. In Luo et al. (2024), the SSD-LLM framework is proposed for automatic subpopulation structure discovery using a large language model (LLM) (Brown et al., 2020). Such a framework is based on the idea of generating informative image captions via a multimodal LLM (Wu et al., 2023), and then analysing and summarising the subpopulation structure of datasets through an LLM. SSD-LLM can be combined with subsequent operations to tackle various tasks better, including slice discovery.
Distinguishing between positive and negative examples is central to our method. Prior work has leveraged linear temporal logic over finite traces (LTLf) to separate temporal classes (Francescomarino et al., 2024), and used learning from interpretation transitions (LFIT) to explain black-box behaviour (Tello et al., 2023). Other approaches generate interpretable signal temporal logic (STL) formulas for time-series classification (Yan et al., 2022), integrate symbolic reasoning with neural models via abductive inference (Dai et al., 2019), or learn differentiable rule sets from continuous features (W. Zhang et al., 2023). Our method follows this line of research but focuses on ILP for discovering logical rules in the context of slice discovery for high-dimensional visual data.
While several prior works described above have tackled the problem of identifying data slices on which models underperform, they typically focus on black-box or subsymbolic techniques. A key challenge in this area concerns the lack of interpretability in the discovered slices. Our work directly addresses this gap by introducing a neurosymbolic approach that extracts human-readable rules to describe underperforming slices. Furthermore, we demonstrate that the rules can also be effectively applied to mend the CV model, thereby providing their direct practical application.
Preliminaries
In this section, we provide an overview of both the Super-CLEVR and ImageNet datasets, as well as a brief overview of ILP and the systems we use.
Super-CLEVR
Inspired by the seminal work on CLEVR (Johnson et al., 2017), the Super-CLEVR dataset was designed to test the visual reasoning capabilities of AI systems. It comprises images featuring classes of vehicles, such as motorcycles, cars, and aeroplanes. The classes are further divided into vehicle subclasses, which make the dataset hierarchical, a crucial characteristic for inducing the occurrence of rare slices within our SDM framework. For example, the “motorcycle” class contains “chopper”, “sportbike”, “dirtbike”, and “scooter” subclasses, also referred to as “shapes”. The hierarchical structure of vehicle classes and their corresponding subclasses (shapes) defined in the original Super-CLEVR dataset are shown in Table 1. Vehicles have four attributes, that is, colour, size, material, and texture. Each image is accompanied by a set of questions designed to test various aspects of visual reasoning, including types such as counting, existence, comparison, attribute identification, and spatial relationships as shown in Figure 1. Super-CLEVR contains about

The figure on the left shows images from Super-CLEVR (Z. Li et al., 2023) of vehicles made up of their parts characterised by four attributes, that is, colour, size, material, and texture. The middle and right figures show examples of Super-CLEVR renderings with generated questions.
Hierarchical Structure of Vehicle Classes and Their Corresponding Subclasses (Shapes) Defined in the Original Super-CLEVR Dataset.

The Super-CLEVR dataset generator employs an algorithm that uses Blender (Blender, 2018) to create a diverse set of images and corresponding questions. Each image is generated by randomly placing vehicles in a three-dimensional scene. The attributes of these objects are also randomly assigned within predefined categories. Spatial relationships are managed to ensure objects do not overlap unrealistically. Once an image is composed, the generator creates questions based on different types of reasoning tasks. The questions are formulated by randomly selecting objects and their attributes in the image and constructing queries that require an understanding of the objects and their relations. This procedural generation ensures a wide variety of questions and scenes, overcoming possible human biases when creating datasets.
Throughout the article, we use a running example to illustrate our methodology: a rare slice from the Super-CLEVR dataset involving the “utility bike” subclass. This slice is statistically rare, appearing with a very low occurrence frequency in the training data, and it is visually similar to the “mountain bike” subclass, making it a candidate for model misclassification and an ideal test case for the proposed SDM pipeline.
ImageNet
To validate our SDM framework on a real-world benchmark, we use the well-known ImageNet (Krizhevsky et al., 2017) dataset. Unlike the synthetic Super-CLEVR, ImageNet is a large-scale image dataset consisting of real-world images organised according to the WordNet (Pedersen et al., 2004) hierarchy. It contains over 14 million annotated images representing more than 20,000 categories, making it one of the most widely used benchmarks in CV. For our experiments, we did not use the entire, vast WordNet hierarchy. Instead, to create a realistic but controlled setting for evaluating the proposed SDM, we defined a custom taxonomy based on a curated subset of vehicles from WordNet. This allowed us to apply our taxonomy-based heuristic to induce the generation of specific rare slices in a focussed and challenging experimental environment to test our methodology.
ImageNet is primarily designed for image classification, where each image is associated with a single class label corresponding to the main object in the scene. It does not provide the detailed, object-level bounding box annotations found in object detection datasets. Furthermore, as a dataset of real-world images, ImageNet lacks a procedural image generator. Therefore, creating rare slices or augmenting the data for model mending are achieved through controlled subsampling of the existing dataset or using external data augmentation techniques.
Inductive Logic Programming
Inductive logic programming (Muggleton, 1991) is a subfield at the intersection of ML and KRR that aims to find patterns in data by learning logical descriptions, utilising background knowledge (
ILP has applications in various fields, among them robotics (Youssef & Müller, 2023), bioinformatics, for example, protein structure discovery (Turcotte et al., 1998), medicine, for example, drug design (Enot & King, 2003; Finn et al., 1998), and ECG waveform learning (Kókai et al., 1997), to mention a few; see Bratko and Muggleton (1995) and Lavrac and Dzeroski (1994) for more of them.
A number of ILP approaches and tools are available; for a comprehensive survey on ILP, we refer to Cropper et al. (2022). This work tests the following three ILP systems as symbolic reasoning components within the proposed neurosymbolic architecture for slice discovery:
Popper (Cropper & Morel, 2021) is a state-of-the-art first-order ILP system that implements the learning from failures approach by combining Answer Set Programming (ASP) (Lifschitz, 2019) and Prolog (Bratko, 2012). It supports infinite problem domains, reasoning about lists and numbers, learning textually minimal programs, and learning recursive programs. Furthermore, Popper can learn minimal description length logic programs as hypotheses from noisy data. FOLD-R++ (Wang & Gupta, 2022) is, in terms of efficiency and scalability, an improvement of the FOLD-R first-order inductive learning algorithm (Shakerin et al., 2017), which serves to learn answer set programs from mixed (numerical and categorical) data for classification tasks. The three main improvements of FOLD-R++ are the following: (i) it uses the prefix sum algorithm to speed up computation; (ii) it allows negated literals in the default portion of the learnt rules; (iii) it introduces the hyper-parameter exception ratio, which is the threshold of the ratio of false-positive examples (i.e., exceptions) to true-positive examples that a rule can imply. FastLAS (Law et al., 2020) is a recent first-order ILP system designed to perform learning tasks in the context of ASP, based on the context-dependent learning-from-answer-sets framework used by the ILASP (Law et al., 2015) system. FastLAS comes with several restrictions, that is, it is not as general as ILASP, but it is significantly more scalable. Furthermore, FastLAS has the advantage of taking as input a customised scoring function for hypotheses that allows the user to express domain-specific optimisation criteria. Such a scoring function defines the cost of a rule. Finally, a key feature of FastLAS is its capability to handle noisy data by introducing a penalty mechanism. This mechanism assigns a penalty to each example, representing the cost of not covering that example. The penalties are defined by a user-specified weight parameter
The ILP systems we use, with the exception of FOLD-R++, are guided by a mode bias specification, which is a set of declarations that constrains the structure of the hypotheses the system can learn. These declarations specify, for example, which predicates can appear in the head or body of a rule, their argument types, and whether negation is permitted. This syntactic specification is crucial for pruning the vast hypothesis space and focussing the search on meaningful rule templates.
The ability of these three ILP systems to learn from noisy data is fundamental to the functioning of our SDM. Indeed, a rare slice can be interpreted as a set of exceptions on which a classifier underperforms. In order to find the pattern that characterises such a set of exceptions, we use the same idea as in Shakerin et al. (2017), which is to consider misclassifications as positive examples and correct classifications as negative examples to obtain rules describing rare slices.
Continued
Continuing our example, suppose the trained model frequently confuses “utility bike” with “mountain bike” and misclassifies it as “sports bicycle” instead of “urban bicycle”. After feeding these misclassifications (positive examples) and correct classifications (negative examples) into an ILP system, it might produce the following logical rule:

This rule provides a precise, human-readable diagnosis. It has learned that “a scene
Neurosymbolic Framework for Slice Discovery
In order to construct a neurosymbolic SDM approach, we propose an architecture of a system as shown in Figure 2. The system comprises several modules, shown as boxes, which process inputs in a pipeline. From configuration files or available data sources, datasets containing rare slices are constructed (either through generation or subsampling) on which a neural network model is trained and evaluated. Then, a semantic description of the images is produced, from which rules for detecting rare slices are extracted. Finally, the rules are used to generate further training data to mend the neural network model, thus closing the loop of model learning. In the following, we describe the tasks in the processing pipeline in more detail.
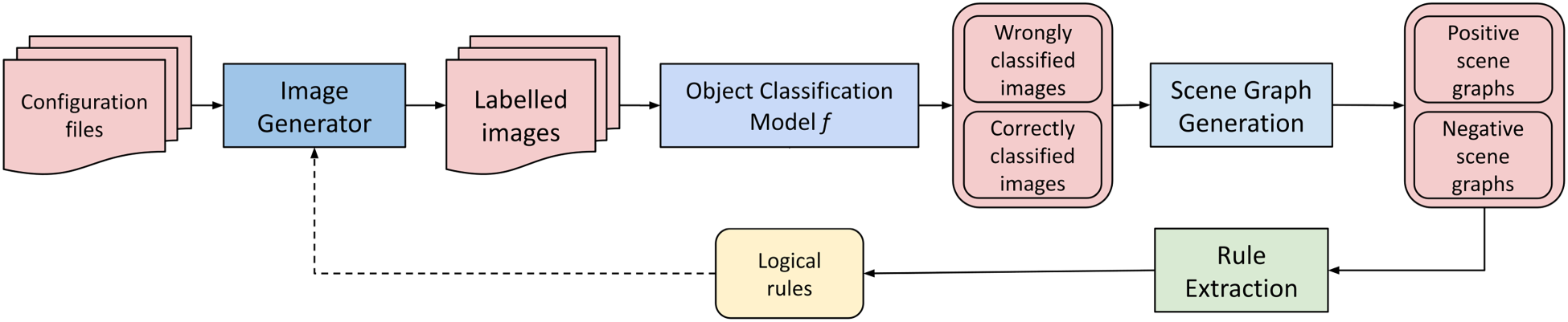
Overview of the proposed neurosymbolic SDM architecture. The solid arrows show the data flow, while the dashed arrow represents user input in selecting extracted logical rules to generate additional training data to improve classification performance.
According to Kautz’s taxonomy of neurosymbolic systems (Sarker et al., 2021), our SDM approach aligns with the [Neuro
The first step in the pipeline is concerned with data preparation, that is, producing datasets containing rare slices. We provide a methodology for them, which will be detailed in Section 5.
CV encompasses a wide range of tasks, among which image classification and object detection are two of the most prominent. Image classification assigns a single label to an entire image, identifying the most prominent object or scene within it. In contrast, object detection involves identifying and localising multiple objects within an image by predicting both their classes and bounding boxes. Our framework handles both tasks, but requires adjusting the processing pipeline accordingly.
At an abstract level, the task involves creating a labelled dataset
For illustration, in the Super-CLEVR setting
For datasets with a synthetic generator, such as Super-CLEVR, we directly modify the generator that renders images to control the distribution of objects. By adjusting the occurrence frequency of specific objects according to a given hierarchy
The Super-CLEVR generator produces further data for the images, such as questions about them (which we disregard, as not needed) and scene descriptions consisting of object attributes (e.g., colour and size). This enriched description serves as the ground truth for the images, which can be utilised for synthetic scene graph generation and fine-grained classification. For ImageNet, which lacks such built-in annotations, we obtain comparable semantic descriptions through automated scene graph generation methods applied to the subsampled images, as later described in Section 6.3.1.
Object Detection and Image Classification
Once a dataset is prepared, we train and evaluate a neural network model to produce classification results that will be analysed for the discovery of rare slices. This process involves a standard training and validation cycle, followed by a specific step to categorise the results for our SDM pipeline. First, a model (e.g., YOLOv5 ) is trained on the training split of the dataset
These sets of positive (failure) and negative (success) examples constitute the input for the subsequent scene graph generation and rule extraction steps.
Scene Graph Generation
Scene Graph Generation (SGG) involves creating a semantic graph representation from an input image. A scene graph is a (labelled) directed graph
In synthetic datasets like Super-CLEVR, ground-truth scene graphs can be directly obtained from the dataset generator, as rich annotations are available for all objects, attributes, and relations. These ground-truth graphs provide a perfect basis for constructing logical examples for rule extraction. In contrast, for real-world datasets like ImageNet, which lack such ground-truth annotations, scene graphs must be generated through external tools (e.g., automated SGG methods or additional annotation pipelines (H. Li et al., 2024)). These tools are able to derive the necessary object nodes, attribute nodes, and relation nodes, the latter also deducible from spatial configurations. In both settings, we convert validation examples in
Rule Extraction Via Inductive Logic Programming
We define an instance of the rule extraction problem in the ILP language to detect rare slices. To this end, we translate the scene graphs in
Context-Dependent Background Knowledge. We clarify that, while classical ILP systems often assume a single, global background knowledge

The left side of the figure shows excerpts of positive and negative examples with their context-dependent background knowledge, in the language of FastLAS. The right side of the figure shows an excerpt of the mode bias.
Then,
As an example of ILP encoding, Figure 3 shows excerpts of positive and negative examples and part of the mode bias used for Super-CLEVR. The representation is in the language of FastLAS, a state-of-the-art ILP system. Its expressive language allows the description of data and the specification of parameters and mode declarations to shape the search space. Specifically, FastLAS allows for a penalty to be set for each example by coding
Consider a scene where “a yellow, rubber utility bike facing south” is misclassified by the object detector. Its corresponding scene graph is translated into a positive example for the ILP system for rule extraction. In the FastLAS syntax, each
The mode bias then defines the structure for the rules the ILP system can learn. For example,
Given the complete input in Figure 3, FastLAS produces the following hypothesis

Informally, these rules express that a scene is considered difficult for the model to classify if it contains a “utility bike” with specific attributes. For example, the first rule says that whenever there is a scene with a “large rubber utility bike facing south”, the neural network model will likely make a misclassification error on such an object.
The Popper encoding is very similar in structure to the FastLAS encoding since it consists of a file for specifying the examples, one for the background knowledge, and one for the mode bias. In contrast, the FOLD-R++ encoding is more simplified as it only consists of a CSV file of tabular data, where the first row specifies the feature names for each column, and subsequent rows provide all the examples. The complete encodings for the Popper, FOLD-R++, and FastLAS systems used in the experiments are available in the online repository, with excerpts provided in Appendix B.
Model Mending
The final step in our SDM pipeline is model mending, where the extracted rules discovered in the previous stage are used to correct model deficiencies. In particular, we note that while ILP systems automatically extract logical rules from validation examples, our current SDM implementation requires user input for hypothesis formation and rule selection. The user analyses the extracted rules to identify common patterns and formulate generalised candidate rules for model mending. This human-in-the-loop approach enables the selection of the most appropriate rules to characterise rare slices. Model mending is then achieved by augmenting the original training data with new images that specifically target the identified rare slices. For a synthetic dataset like Super-CLEVR, we use the data generator to procedurally create new images that precisely match the conditions specified by the logical rules. For a real-world dataset like ImageNet, while generative models offer one possible path for data augmentation, our approach instead relies on curated subsampling. We identify and select images from the complete ImageNet dataset that match the rule conditions to effectively augment the training data without generating synthetic images. In both cases, the model is then retrained on this enriched dataset to improve its robustness and performance on rare slices.
Continued
Figure 4 shows the effectiveness of our model mending process: before the intervention, the model misclassifies the “utility bike” rare slice as “sports bicycle”, whereas after retraining it with data guided by the extracted rules, it correctly classifies the “utility bike” as “urban bicycle”.
The left figure shows a scene (based on the VT:
Motivated by the limitations of existing rare slice generation methods in our context and the need for a reliable testbed for our SDM, we present a taxonomy-based methodology to induce the occurrence of controlled rare slices in a model.
In our framework, following the characterisation introduced by Domino (Eyuboglu et al., 2022), we define a rare slice as an object subclass that appears infrequently in the dataset and on which the model underperforms. Therefore, a rare slice has two key properties: Statistical Rarity: The slice appears with a very low frequency in the dataset. Functional Rarity: The model systematically underperforms on the slice.
While statistical rarity can be directly controlled (e.g., by setting a low occurrence probability via the Super-CLEVR generator, or via controlled subsampling of the ImageNet dataset), functional rarity is a model-dependent property. To reliably induce functional rarity, we propose a heuristic that is based on the intuition that a CV model is more likely to fail when forced to distinguish between visually similar objects that belong to different target classes. Therefore, our heuristic is to intentionally design custom taxonomies that separate these similar object subclasses into distinct target classes (e.g., placing “dirtbike” in the “motorcycle” class and the visually similar “mountain bike” in the “bicycle” class). By then making one of these subclasses statistically rare, we induce the generation of a controlled rare slice in the classification model. This approach can be applied to any dataset, including Super-CLEVR (by defining custom class hierarchies for the generator) and ImageNet (by grouping and re-mapping classes from its native WordNet hierarchy).
To formally identify these underperforming slices, we use a main performance metric for each task as a proxy for difficulty. A target class is flagged as possibly containing a rare slice if its metric falls below a dataset-dependent target class threshold
Our methodology for generating rare slices begins with a given class hierarchy
Define Rare Slice Candidates: We first create a slice configuration file that specifies the set Set Occurrence Probability: We assign to each rare slice a low occurrence probability Configure Data Splits: A second configuration file defines the total number Rare and Non-Rare Slice Configuration: A third configuration file is generated containing the complete specification of all rare and non-rare slices as defined in step 1 according to the class hierarchy Generate or Subsample: The configuration files are used to either guide the modified Super-CLEVR image generator or the ImageNet subsampling script to produce the final data splits. In both cases, the goal is to create data splits with the desired object distributions. In Super-CLEVR, the generator computes the target number of rare objects for each subclass
Following the above steps, specific rare slices can be generated depending on the taxonomy under consideration. Furthermore, for each generated image, the Super-CLEVR generator produces a corresponding description that consists of the objects in the scene, their attributes, and the relationships between them. These descriptions allow scene graphs to be readily derived and then encoded into ILP examples, as shown in Figure 3. For ImageNet, which provides a single class label per image without detailed object annotations, the necessary scene graphs are generated using external tools, as detailed in Section 6.
Experiments
The proposed SDM approach was evaluated in a series of experiments aimed at assessing the effectiveness of rare slice generation, rule extraction, and model mending. To demonstrate the versatility of our approach, we performed the evaluation on two distinct benchmarks: the synthetic Super-CLEVR dataset for an object detection task, and the real-world ImageNet dataset for an image classification task. This section describes the evaluation platform, outlines the experimental setup for both benchmarks, and presents the results from our analysis. All data and details are available in the online repository.
Evaluation Platform
The evaluation platform is a server running Ubuntu 22.04.2 LTS (kernel version 6.8) with two Intel Xeon Silver 4314 CPUs (each having 16 cores at 2.40GHz, 2 threads per core, and 24MB of cache), 1,024GB of DRAM, four NVIDIA RTX A5000 GPUs (each having 24GB of VRAM), and the CUDA 12.2 API.
Super-CLEVR Experiments
This section details the experimental setup and presents the results from our evaluation of the proposed SDM architecture for the object detection task on the generated Super-CLEVR dataset. Specifically, we built a challenging and imbalanced training set and used it to train several YOLOv5 models for object detection, each based on a different set of target classes from our custom taxonomies. Afterwards, we iteratively evaluated, diagnosed, and improved these models on the validation set. We outline the data taxonomies, dataset composition, the neural network architecture, and the iterative process of slice discovery and model mending in our pipeline.
Experimental Setup
In the following, we describe the experimental setup for each module of our SDM architecture.
Taxonomies. In our experiment, we used two custom taxonomies based on vehicle subclasses available in Super-CLEVR : airliner, biplane, fighter jet, private jet, sedan, minivan, station wagon, pickup truck, SUV, school bus, articulated bus, double bus, transit bus, scooter, chopper, sportbike, dirtbike, tandem bike, utility bike, mountain bike, and road bike. First, we identified five pairs of vehicle subclasses as visually similar: (“dirtbike”, “mountain bike”), (“articulated bus”, “transit bus”), (“utility bike”, “mountain bike”), (“pickup truck”, “sedan”), and (“private jet”, “airliner”). Then, we defined two Super-CLEVR taxonomies according to the proposed heuristic presented in Section 5, separating the vehicle subclasses of the pairs into different target classes. Specifically, as we descend toward the bottom of a taxonomy, more pairs are separated into distinct classes. In this way, we induced the generation of five rare slices to test the SDM implementation. To investigate rare slice generation, we defined from these taxonomies a total of five sets of target classes, referred to as hierarchies, each serving as training data labels to train a separate YOLOv5 model. The two taxonomies are listed and described below: Vehicle Type (VT) classifies vehicles according to their type in a multilevel taxonomy, where target classes become more and more specific at each level. The name of a class suggests the vehicles it contains. For example, the “air vehicle” class contains air vehicles such as “airliner” and “biplane”. In contrast, the “scooter” and “mountain bike” vehicles are classified as “land vehicle”, but also fall into the class below, called “two-wheeler”, since they have only two wheels. However, “scooter” belongs to the more specific “motorcycle” class while “mountain bike” is in the “bicycle” class. The same applies to the other classes and vehicle subclasses, as shown in Figure 7 Appendix A, where vehicle subclasses are the leaves of the taxonomy. In the following, the four different hierarchies considered in the experiments to evaluate and compare the influence of rare slices on classification performance are reported. For each hierarchy of the VT taxonomy, the corresponding classes constitute the targets for training a neural network model. Hierarchy 1 (VT: Hierarchy 2 (VT: Hierarchy 3 (VT: Hierarchy 4 (VT: Note that we purposely designed VT: Primary Purpose (PP) classifies vehicles according to their primary use, as shown in Figure 8 Appendix A. For example, “scooter” is in the “urban vehicle” class, which contains vehicles intended for urban transportation, while “dirtbike” is in the “offroad vehicle” class. For the PP taxonomy, we considered only one hierarchy, referred to as PP:
Dataset. For the two taxonomies, we generated a single training set of 10,000 images using the Super-CLEVR generator. Each image contains between three and six vehicles from the vehicle subclasses listed in Table 1. Vehicle attributes taken into account in image generation include: “materials” (e.g., “metal”), “colours” (e.g., “gray”), “sizes” (e.g., “small”), and “directions” (e.g., “southwest”). To create rare slices, we introduced data imbalance in the training set by manipulating the occurrence probability
Neural Network. For each of the five hierarchies (VT:
Rule Extraction and Selection. For the rule extraction module, we employ Popper, FOLD-R++, and FastLAS to identify rare slices within underperforming target classes of each hierarchy. The ILP systems extract rules based on the scene graphs generated for each image; an example is shown in Figure 5. These rules consist of a combination of vehicle attributes, described earlier in Section 3.1. The process begins by identifying problematic target classes with recall at or below a predefined target class threshold For Popper, we used the noisy mode, which allows it to learn the minimal description length program from noisy data. Furthermore, we varied the sample size of the validation set, using For FOLD-R++, we tested nine configurations by combining the three sample sizes ( For FastLAS, we used the opl mode, which runs the original FastLAS1 algorithm. Furthermore, to utilise it in the mode that supports noisy data, we assigned a penalty to each example, representing the cost of violating it. As there are significantly fewer positive examples than negative ones and positive examples are more important to cover because they characterise rare slices, we set the penalty values for positive and negative examples to 4 and 2, respectively. To narrow down the hypothesis space, the maximum number of variables per rule was limited to 2. We also tested nine configurations for FastLAS, combining the three sample sizes with three rule head penalties (10, 20, 30) for the scoring function, which charges such penalty values for each extracted rule head, to observe how they affect the quality of the output result.
All hyperparameter values mentioned were empirically fine-tuned by exploratory experimentation. Specifically, we selected several reasonable values to test different configurations of ILP systems in extracting meaningful rules describing rare slices. All other system hyperparameters use default values. A set of rules was obtained for each experimental configuration based on the hierarchy, target class, ILP system, and hyperparameter values considered. This comprehensive evaluation allows us to assess the effectiveness, speed, and verbosity of each ILP system and to verify that the identified rare slices are consistent across different configurations.

Rules extracted by Popper for the “urban bicycle” class in VT:
Model Mending. We proceed with the model mending step after selecting candidate rules that describe rare slices. We augment the original training set with new images to address data imbalance and further train the model. These images, generated with the Super-CLEVR data generator, specifically contain the vehicle attributes based on the rare slices identified by the selected rules. As for the neural network hyperparameters, the initial learning rate is modified according to the specific needs of each model mending iteration, as we will discuss below. All other neural network hyperparameters remain as in the initial model training (see Section 6.2.1). The validation set remains unchanged for all iterations of our SDM pipeline to ensure a fair and consistent evaluation of performance improvements.
In the following, we present the experimental results for rare slice generation, rule extraction, and model mending from the iterative application of our SDM architecture.
Rare Slice Generation and Initial Model Training. Our method successfully generates rare slices on which YOLOv5 models underperform, as revealed by the experimental results described below. More precisely, confusion matrices from model validation confirm the effectiveness of our taxonomy-based approach in inducing the presence of rare slices within the neural network models trained on hierarchies satisfying the proposed heuristic. Furthermore, rare slices degraded model performance across all epoch values considered (i.e., 80, 160 and 320), highlighting the persistence of rare slices even as the number of training rounds increases. The YOLOv5 training process saves the model weights that achieve the highest performance on the validation set. Hence, 160-epoch models that performed best were designated as our baseline defective models. In our object detection task, model performance is measured by its recall metric, also known as true positive rate (TPR), on the target classes of the validation set. Recall represents the proportion of all true positives that were correctly classified as positive. To diagnose the models, we inspected the recall of each target class. To identify underperforming classes, we set the target class threshold For VT: VT: For PP:
First Rule Extraction and Selection Iteration. The poor performance of the nine target classes suggests investigating them in search of rare slices. To this end, we employed our rule extraction module, tasking ILP systems to find the rules that identify rare slices within each problematic class of the models. After extracting the rules, we analysed them to identify underlying patterns. As previously mentioned, these rules consist of a combination of vehicle attributes. Our analysis revealed that the vehicle subclass was the primary feature in the extracted rules, often appearing with specific secondary vehicle attributes that further defined the potential rare slice. Therefore, we simplified all these rules into more general candidate hypotheses, such as “an image is difficult for the object detection model if it contains a dirtbike facing north”. To formalise which of these candidate rules to consider as descriptions of potential rare slices, we set the rare slice hypothesis threshold
Rule Extraction Results of the First Iteration of the Popper System on the Models for Super-CLEVR.
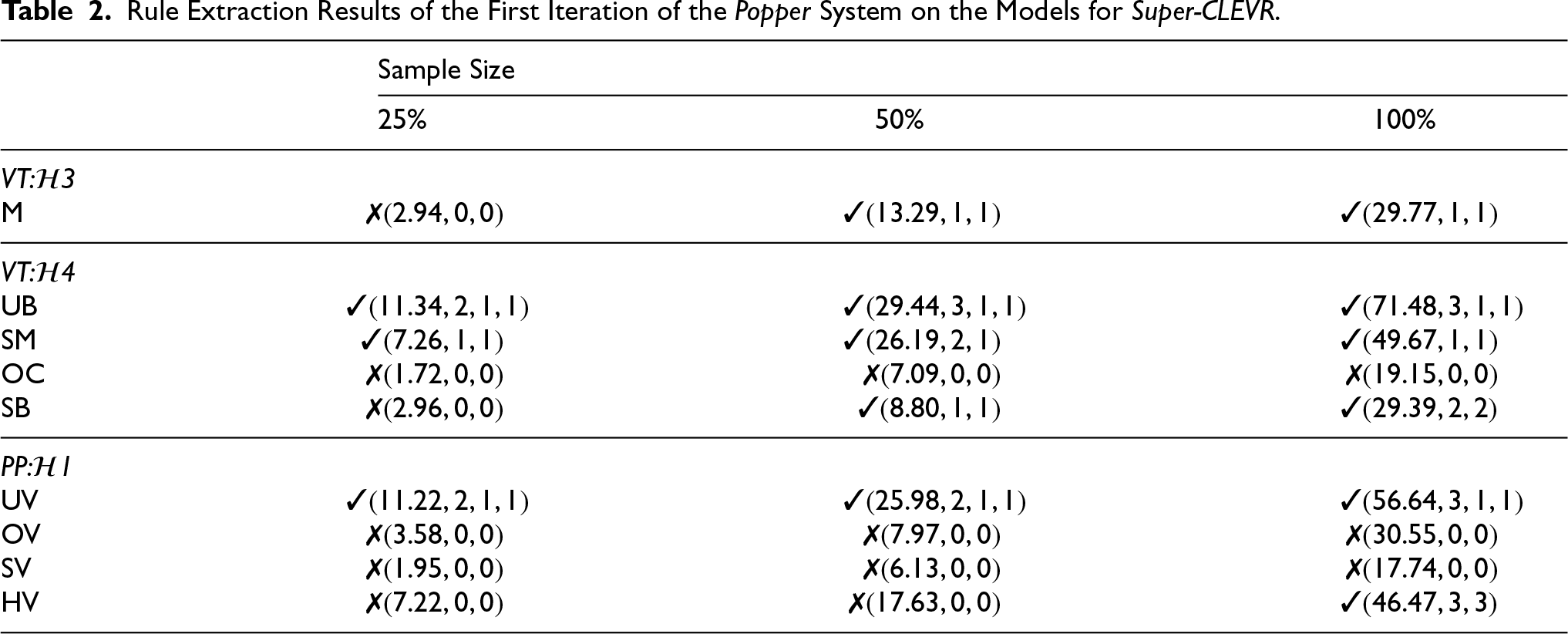
Rule Extraction Results of the First Iteration of the Popper System on the Models for Super-CLEVR.
Rule Extraction Results of the First Iteration of the FOLD-R++ System on the Models for Super-CLEVR.

Rule Extraction Results of the First Iteration of the FastLAS System on the Models for Super-CLEVR.

VT: Motorcycle first (and only)
3
candidate rule:
Rule Extraction Results of the “motorcycle” Class of the First Iteration on the VT:

where
VT: For “specialised bus”, For “offroad car”, For “sports motorcycle”, For “urban bicycle”, Rule Extraction Results of the “specialised bus” Class of the First Iteration on the VT: Specialised bus first candidate rule:
Offroad car first candidate rule:
Sports motorcycle first candidate rule:
Urban bicycle first candidate rule:
Urban bicycle second candidate rule:

where
PP: For “high-speed vehicle”, For “offroad vehicle”, For “specialised vehicle”, For “urban vehicle”, Rule Extraction Results of the “high-speed vehicle” Class of the First Iteration on the PP: High-speed vehicle first candidate rule:
Offroad vehicle first candidate rule:
Specialised vehicle first candidate rule:
Urban vehicle first candidate rule:
Urban vehicle second candidate rule:
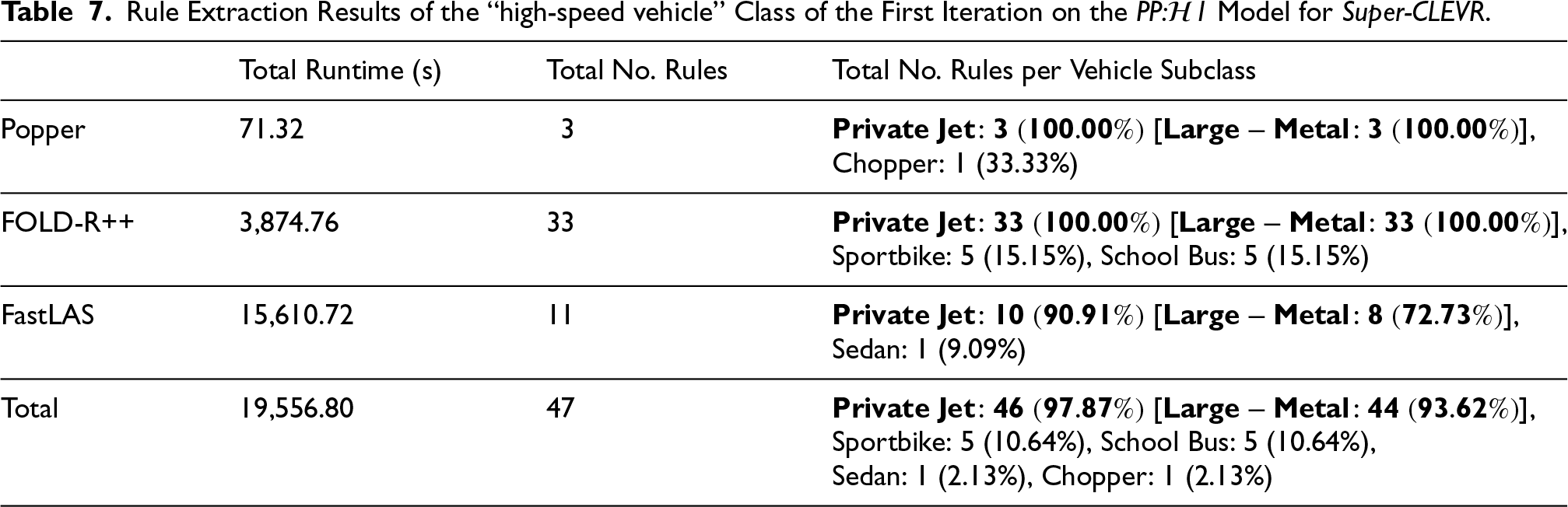
where
First Model Mending Iteration. To address the data imbalance without introducing catastrophic forgetting
4
, we augmented the original training set with new images generated by the Super-CLEVR generator according to the selected rules. This augmentation was done according to the rules selected in the previous step, which consist of both the rare vehicle subclass and its most common secondary attributes. For each hierarchy, the respective defective model (the best performing 160-epoch version) was then retrained on its newly balanced dataset for 20, 40, and 80 epochs, using the same hyperparameters as before. By comparing the outcomes of the three retraining epochs for each model, we determined the most effective model mending for each specific hierarchy. The results from the number of optimal retraining epochs are detailed below. For VT: For VT: For PP:
The mending process was successful across all hierarchies, substantially improving the recall of the target classes; notably, the overall performance of the model for VT:
Urban bicycle first candidate rule:
Rule Extraction Results of the Second Iteration of the Popper System on the VT:
Rule Extraction Results of the Second Iteration of the FOLD-R++ System on the VT:

Rule Extraction Results of the Second Iteration of the FastLAS System on the VT:

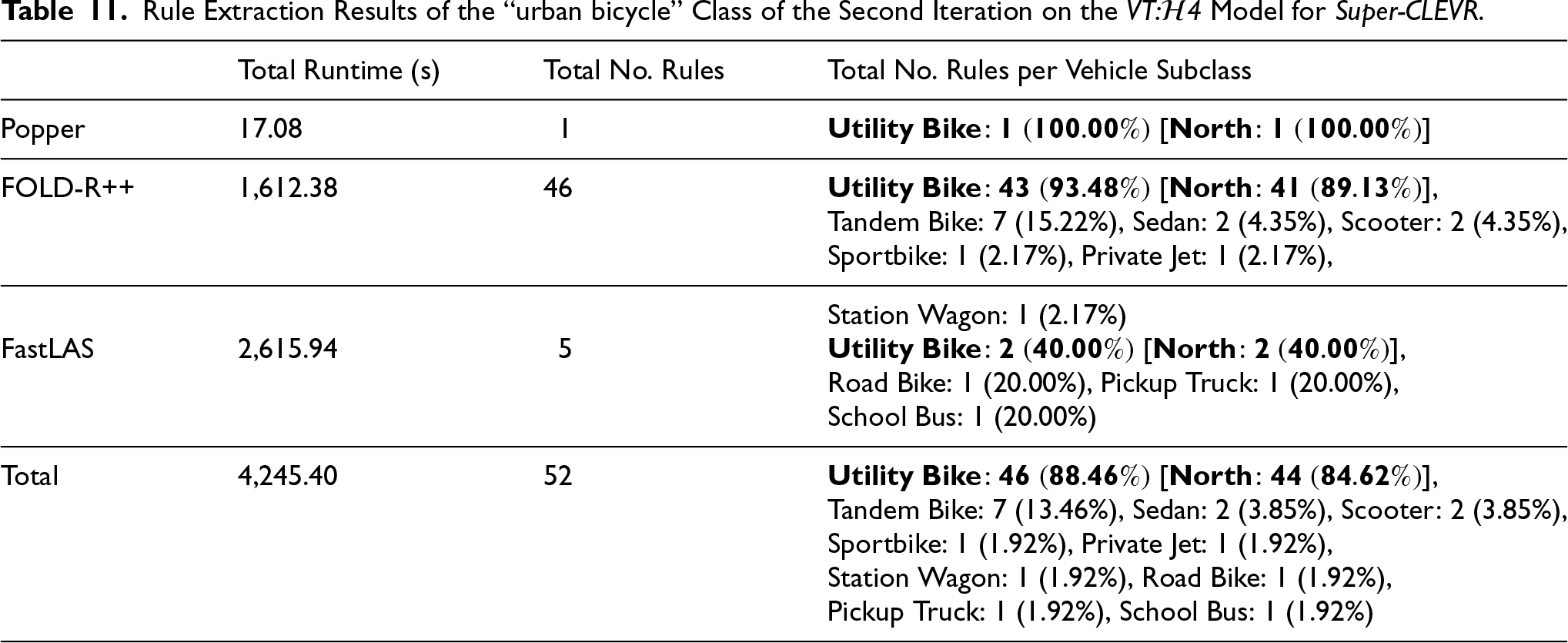
Rule Extraction Results of the “urban bicycle” Class of the Second Iteration on the VT:
Second Model Mending Iteration for VT:
The model retrained for an additional 20 epochs proved to be the most effective. This second intervention successfully resolved the persistent slice, as shown in Figure 24 Appendix C. The recall for the problematic “urban bicycle” class rose significantly from
This section details the experimental setup and presents the results from our evaluation of the proposed SDM architecture for the image classification task on a curated subset of the ImageNet dataset. Specifically, we built a challenging and imbalanced training set and used it to train a YOLOv5 model for image classification. Afterwards, we iteratively evaluated, diagnosed, and improved such a model on the respective validation set. As for Super-CLEVR, we outline the data taxonomy, dataset composition, the neural network architecture, and the iterative process of slice discovery and model mending in our pipeline.
Experimental Setup
In the following, we describe the experimental setup for each module of our SDM architecture.
Taxonomy. In our experiment, we used a reduced list of 11 vehicle subclasses from ImageNet : tandem bicycle, motorhome, moped, scooter, mountain bike, jeep, pickup truck, station wagon, convertible, minivan, and moving van. First, we identified the following four pairs of vehicle subclasses as visually similar: (“tandem bicycle”, “mountain bike”), (“moped”, “mountain bike”), (“jeep”, “minivan”), and (“station wagon”, “minivan”). Then, as for Super-CLEVR, we defined a taxonomy according to the proposed heuristic presented in Section 5, separating the vehicle subclasses of the pairs into different target classes. This taxonomy, which we refer to as the Vehicle (VE) taxonomy, classifies vehicles according to their type as illustrated in Figure 9 Appendix A. For example, the “scooter” subclass is in the “motorcycle” class, while the “pickup truck” subclass is in the “offroad vehicle” class. To investigate rare slice generation, we defined from the VE taxonomy a single set of target classes, referred to as Hierarchy 1 (VE:
Dataset. We built our training and validation sets using a subset of ImageNet. The training set consists of 3,634 images distributed across the five classes of our VE taxonomy. To create rare slices, we intentionally varied the number of images per vehicle subclass, introducing data imbalance. Specifically, we designated four vehicle subclasses – “tandem bicycle”, “moped”, “jeep”, and “station wagon” – as rare slices. These subclasses were chosen from each of the four visually similar pairs mentioned above. The occurrence probability
Neural Network. For the VE:
Rule Extraction and Selection. For the rule extraction module, we employ the same ILP systems (Popper, FOLD-R++, and FastLAS ) and a similar methodology as described in the Super-CLEVR experiments to identify rare slices within underperforming target classes. The process again begins by identifying problematic target classes, for which the ILP systems then extract rules based on the scene graphs generated for each image. These rules consist of a combination of vehicle and environment attributes, described in Section 6.3.1. The differences in this setup are as follows: Problematic target classes are those with a Top-1 accuracy at or below a predefined target class threshold While the hyperparameter settings for Popper and FOLD-R++ remain the same as in Super-CLEVR, for FastLAS we tested nine configurations combining the three sample sizes (
Then, the extracted rules are analysed to form candidate hypotheses, which are formally selected if they meet a predefined rare slice hypothesis threshold
Model Mending. We proceed with the model mending step using the same procedure as in the Super-CLEVR experiments. After selecting candidate rules that describe rare slices, we augment the original training set with new images to address the data imbalance and then further train the model to mend its behaviour. The primary difference in this setup is the source of the new data. Instead of using a generator, the new images are sourced from the ImageNet dataset, specifically chosen based on the rare slices identified by the selected rules. As before, the initial learning rate is modified according to the specific needs of each model mending iteration, while all other neural network hyperparameters remain the same as those used in the initial model training and described in Section 6.3.1.
Experimental Results
In the following, we present the experimental results for rare slice generation, rule extraction, and model mending from the iterative application of our SDM architecture.
Rare Slice Generation and Initial Model Training. In our image classification task, model performance is measured by its Top-1 accuracy, which represents the percentage of validation images where the main prediction of the model matches the correct label. The YOLOv5 training process saves the model weights that achieve the highest Top-1 accuracy on the validation set. We trained the model for 20, 40, and 80 epochs; the results are shown in Table 12. The model trained for 40 epochs yielded the best initial result, achieving an overall Top-1 accuracy of
Top-1 Accuracy of the VE:
1 Model on the ImageNet Validation Set after the Initial Model Training.

Top-1 Accuracy of the VE:
First Rule Extraction and Selection Iteration. The poor performance of the four target classes suggests investigating them in search of rare slices. To this end, we employed our rule extraction module, tasking ILP systems to find the rules that identify rare slices in each problematic class of the model. After extracting the rules, we analysed them to identify underlying patterns. As previously mentioned, these rules consist of a combination of vehicle and environment attributes. However, the vehicle subclass was the unifying feature in most rules for each potential rare slice. Therefore, we simplified these observations into more general candidate hypotheses, such as “an image is difficult for the model to classify if it represents a tandem bicycle”. To formalise which of these candidate rules to consider as descriptions of potential rare slices, we set the rare slice hypothesis threshold
Rule Extraction Results of the First Iteration of the Popper System on the VE:

Rule Extraction Results of the First Iteration of the FOLD-R++ System on the VE:

Rule Extraction Results of the First Iteration of the FastLAS System on the VE:

Leisure vehicle first candidate rule:
Rule Extraction Results of the “leisure vehicle” Class of the First Iteration on the VE:
Motorcycle first candidate rule:
Offroad vehicle first candidate rule:
Passenger car first candidate rule:
First Model Mending Iteration. To address the data imbalance without introducing catastrophic forgetting, we augmented the original training set with new images taken from ImageNet according to the selected rules. This augmentation aimed to precisely balance the distribution of all vehicle subclasses to a target of 500 images each. The number of new images added for each vehicle subclass was therefore the exact amount needed to reach this target from their initial count in the imbalanced set. Specifically, we added 473 new images for “tandem bicycle”, 473 for “moped”, 447 for “jeep”, and 473 for “station wagon”. The defective model (the 40-epoch version) was then retrained on this newly balanced dataset for 10 and 20 epochs, using the same hyperparameters as before. As shown in Table 17, the model retrained for just 10 epochs achieved the highest Top-1 accuracy of
Top-1 Accuracy of the VE:


The left figure shows a scene, based on VE:
Our experiments, conducted on both the synthetic Super-CLEVR and real-world ImageNet datasets, demonstrate that the proposed SDM is highly effective at identifying rare slices in CV models. By systematically training, diagnosing, and mending models for both object detection (for Super-CLEVR ) and image classification (for ImageNet ) tasks, we validated the general efficacy of our neurosymbolic approach. The taxonomy-based heuristic at the core of our approach consistently and successfully induced challenging, hard-to-detect rare slices in the trained models. This allowed for a rigorous evaluation of the SDM pipeline. The subsequent application of ILP systems not only identified underperforming slices, but also extracted interpretable logical rules that pinpointed the specific data attributes causing the model to underperform. These rules then guided a targeted data augmentation and model mending process, which led to significant and consistent performance improvements across all tested hierarchies. In the sequel, we compare the performance of the integrated ILP systems, discuss the impact of model mending, and briefly compare our work with some existing SDMs. Finally, we acknowledge current limitations.
Comparison of ILP Systems
Our comparative analysis among the three ILP systems – Popper, FOLD-R++, and FastLAS – reveals the differences in their performance: Popper was the fastest and least verbose system, but also the least effective. It failed to identify several key rare slices, and its success was highly dependent on having a large sample size of data. FOLD-R++ was a very reliable and robust system with respect to hyperparameters. It successfully identified the underlying rare slices in nearly all problematic classes across both Super-CLEVR and ImageNet experiments, even with smaller data samples. The exception ratio in FOLD-R++ had a minimal impact on its rule extraction, indicating limited sensitivity to this hyperparameter in our context. FastLAS was the most effective and expressive system, capable of identifying subtle rare slices, as demonstrated in the second iteration of the ImageNet experiments where other systems failed. However, this expressiveness comes at a cost. FastLAS was consistently the slowest system, and highly sensitive to its rule head penalty hyperparameter. Lower penalty values consistently produced meaningful rules, whereas higher values sometimes prevented the system from discovering any rules.
In addition to requiring less data for slice discovery, smaller samples have the advantage of significantly reducing the running time of ILP systems. In particular, using smaller samples was necessary for FastLAS in the Super-CLEVR experiments. One possible reason why FastLAS is slower may be its penalty mechanism and scoring function, which make the optimisation problem more challenging to solve. On the other hand, one probable explanation for the speed of Popper is the lack of negation in its extracted rules. Indeed, it is important to consider that both FOLD-R++ and FastLAS provide rules with negation, which greatly widens the hypothesis space. However, rules with negation allow for alternative and more concise descriptions of slices by specifying which vehicle attributes should not be present. The ability to express rules with negation may be one reason why FOLD-R++ and FastLAS have succeeded more than Popper in identifying rare slices. Despite their individual differences, the ILP systems showed a crucial consistency; when multiple systems succeeded, they invariably pointed to the same root cause (e.g., a specific vehicle subclass), reinforcing the validity of our findings. This convergence gives us high confidence in the identified slices and the subsequent mending strategies. Interestingly, while larger sample sizes generally improved the likelihood of success for all systems, both FOLD-R++ and FastLAS were often effective with as little as
Impact of Model Mending
The model mending phase, guided by the rules extracted via our SDM, proved highly effective across all hierarchies. By augmenting the training set with new images specifically targeting the identified rare slices, we achieved substantial improvements in model performance. For instance, in the challenging VT:
YOLOv5 models achieved high overall performance on the Super-CLEVR dataset, with mAP@0.5 values approaching 1.0 in all experiments. However, the goal of this work was not to maximise general object detection metrics, but rather to diagnose and correct highly specific, induced failures known as rare slices. For this purpose, per-class recall serves as a more precise diagnostic tool than a global metric like mAP. While a high mAP score confirms the good overall model performance, it can mask the poor performance on a specific, underrepresented slice of data, as the error is averaged out. By focussing on the recall of the problematic classes, we can directly measure the impact of the slice and, more importantly, verify the success of the mending process in a targeted manner. While the main analysis focuses on recall to clearly illustrate the diagnosis and repair of rare slices, a more comprehensive set of performance metrics is provided for completeness. We have included detailed results in Appendix C, which contains the confusion matrices, F1-Confidence curves, and other model training and validation performance metrics (e.g., mAP@0.5) for all Super-CLEVR hierarchies, both before and after model mending. This supplementary data confirms that the targeted improvements in recall discussed in the main text are accompanied by corresponding positive gains in the F1-score, reinforcing the overall efficacy of the proposed SDM pipeline.
Finally, the results across both the Super-CLEVR and ImageNet experiments indicate that model mending allows for significant improvements without extensive retraining. For the Super-CLEVR hierarchies, a relatively small number of additional training epochs – between 20 and 40 – was sufficient to integrate the new data and correct the identified rare slices. This efficiency was even more pronounced in the ImageNet experiments, where a brief retraining of just 10 epochs yielded effective results for both mending iterations.
Comparison With Existing Methods
As detailed in Section 2, the state-of-the-art can be broadly categorised, and our neurosymbolic architecture offers a distinct alternative that emphasises logical rule extraction. Several methods in slice discovery and rare data mining, such as Domino (Eyuboglu et al., 2022), Spotlight (d’Eon et al., 2022), George (Sohoni et al., 2020), and
Our neurosymbolic SDM contrasts with these methods by prioritising interpretability and targeted causality. The main technical difference is the use of ILP to move from systematic model errors to a set of compact, human-readable, and formal logical rules describing them. This provides several advantages: Transparency: Logical rules offer a clear semantic explanation of the failure condition of the model (e.g., Editability: Rules are not only descriptive, but also prescriptive. They provide a precise, actionable specification that can directly guide the model mending process. Debugging: Rules serve as a valuable tool for model debugging, allowing ML practitioners to understand the specific visual attributes that confuse the model.
In summary, our work addresses the fundamental challenge of making slice discovery interpretable and directly actionable for targeted model correction.
Limitations
For each CV task, our SDM approach builds on the availability of scene graph representations to extract interpretable logical rules describing “hidden” rare slices, that is, underperforming subsets of data not explicitly labelled and difficult to spot from unstructured data, such as images. These representations provide the rich semantic structure necessary for our method. However, scene graphs are generally not readily available for datasets, especially in real-world scenarios. Nevertheless, rapid advances in Vision Language Models (VLMs) are making it increasingly feasible to semi-automatically generate (curated generation) such semantic representations from image data. In our ongoing work, we are actively and systematically exploring the integration of VLMs to automate the scene graph generation step, as we have experimented here for real-world images from the ImageNet dataset. Consequently, our SDM is directly applicable whenever appropriate semantic representations can be obtained from image data, making automated semantic extraction a promising direction for our future work.
A second limitation is the current reliance on manual, exploratory tuning for the hyperparameters of the ILP systems. While our experiments show that robust rules can be found by testing a range of configurations, this process can be time-consuming and may require domain expertise.
Furthermore, the scalability of ILP systems can be computationally intensive, especially with large validation sets or with a complex hypothesis space defined by numerous attributes and predicates. As observed in our experiments, FastLAS was prone to timeouts when analysing the entire validation set in Super-CLEVR, indicating that the ILP system performance can be a bottleneck.
Finally, the current implementation of our SDM focuses on discovering rare slices defined by object attributes (e.g., “a yellow rubber utility bike facing south”). A limitation of this approach is that it does not yet consider slices defined by the relationships between objects (e.g., “a bicycle next to a car”). Extending the proposed SDM to incorporate object relations would allow for the discovery of more complex rare slices, providing deeper insights into model failures.
Conclusion and Future Work
In this work, we have presented a neurosymbolic approach to address the slice discovery problem. In particular, we have provided a modular architecture and an implementation that connects dataset generation (or subsampling), model classification, and rule extraction via ILP to identify misclassified rare slices. Our experiments, conducted on both the synthetic Super-CLEVR and real-world ImageNet datasets, demonstrate the effectiveness of our methodology. The proposed taxonomy-based heuristic reliably generated datasets with predictable rare slices, validating our approach for inducing specific model failures. The ILP systems proved effective at producing useful logical rules describing rare slices. Further training the models with new data guided by these rules resulted in significant performance improvements on the problematic classes for both object detection and image classification tasks. Our SDM approach can also be extended to the multi-label classification task, thus dealing with taxonomies structured as directed acyclic graphs in addition to tree-shaped ones. Furthermore, our results underscore the effectiveness of the iterative nature of the SDM pipeline. We showed that further iteration can successfully diagnose and resolve more subtle and persistent errors, demonstrating the ability of the SDM to progressively refine model performance and address increasingly difficult deficiencies.
The results obtained are encouraging and demonstrate the potential of simultaneously exploiting DL and KRR methods for slice discovery. In this way, compact and human-readable logical rules can be extracted that improve the interpretability and explainability of a CV model under examination, also paving the way to advanced concepts such as causal and contrastive explanations.
Ongoing and Future Work. Although our experiments confirm that rule-based augmentation helps improve classification performance, we acknowledge that the overall effectiveness of model mending may vary depending on the specific rules extracted. A systematic analysis of the sensitivity of model mending to rule quality, granularity, and specificity remains a promising issue for future work. In addition, while our current SDM implementation relies on user input to analyse and select candidate rules from the ILP system outputs, developing fully automated methods for hypothesis formation and rule selection represents an important direction for future research. Furthermore, to make the SDM pipeline more accessible and efficient, automated methods for setting the optimal hyperparameters for the various ILP systems could be explored, reducing the need for manual, exploratory tuning. Our ImageNet experiments relied on a VLM to generate the necessary scene graphs, as mentioned in Section 6.3.1. A key future direction is to systematically explore and integrate state-of-the-art VLMs to fully automate this step, rather than being provided with ground truth scene graphs, as is the case with Super-CLEVR. Creating a robust pipeline for generating high-quality semantic representations directly from input images will make our SDM framework scalable and applicable to any visual dataset. Using such tools for our SDM presents an interesting research challenge. Thus far, our work has focussed on object attributes. We plan to extend the framework to incorporate relationships between objects. This will allow for the discovery of more specific rare slices (e.g., “a bicycle next to a car”), providing deeper insights into model failures at the expense of higher computational cost. Moreover, exploring the integration of further ILP systems, such as recent neurosymbolic ones, for example,
Footnotes
Funding
The project leading to this research has received funding from the European Union's Horizon 2020 research and innovation programme under grant agreement No 101034440. Additionally, this research was funded in whole or in part by the Austrian Science Fund (FWF) 10.55776/COE12, and it was supported by Bosch Center for AI (BCAI) in Renningen, Germany.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.