
Abstract
Artificial intelligence (AI) has attracted great interest in the world of cardiology and cardiovascular surgery. For simplicity, AI has 3 distinct sectors: machine learning (ML), deep learning, and generative AI. In the case of ML, when calculating cardiovascular risk scores, ML algorithms analyze large, complex datasets (data mining) to predict the risk of morbidity and mortality.
Keywords
The perception of risk varies depending on background, preferences, and experience. Risk assessment is perhaps best described as a means of predicting adverse outcomes. It does so by analyzing hazards and then by predicting the probability of an adverse event occurring. Historically, the core aspect of risk scoring is an algorithm based on predictive modeling techniques commonly used in statistics and computer science. Such an approach is constructed out of large datasets that contain a key outcome to be predicted, a list of potential regressors, and an algorithm that uses predictive modeling to select regressors to obtain the best predictive model. Then each algorithm is said to be modified by its various parameters, outputs, identification, logging, and cache. The concept of prediction models has long been developed and validated among various clinical specialties. Against the cardiovascular backdrop, these models predict the probability of postoperative complications in cardiovascular surgery and guide management in preventative cardiology.
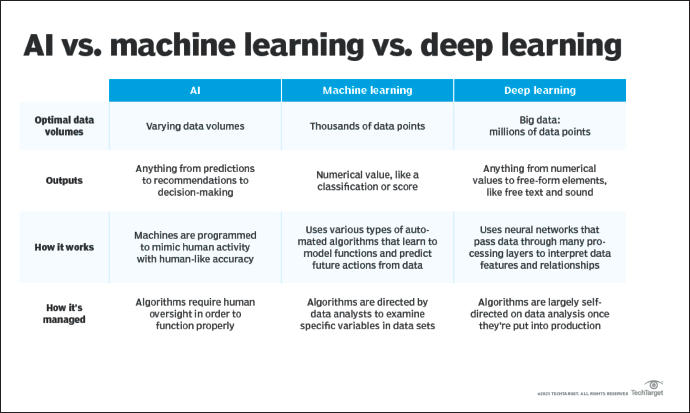
Lately, artificial intelligence (AI) has captured great interest in the world of cardiology and cardiovascular surgery. In some sense, AI can be described as a self-teaching machine without human intelligence, solving highly complex tasks and adapting to the environment. Key characteristics attributable to AI include cognitive pattern recognition, adaptive learning, and strategizing. For simplicity, AI has 3 distinct sectors: machine learning (ML), deep learning (DL) and generative AI (see Figure 1). In the case of ML, a problem is identified, the required data are inputted into a selected algorithm, and the algorithm identifies hidden patterns to provide a specific output. Furthermore, the algorithm is trained on the dataset and then reevaluated. 1 According to this approach, if the algorithm performs poorly, then the process is started again. If the algorithm performs well, however, the parameters are adjusted to optimize the performance. 1 The ML sector can be subdivided by 2 main features: supervised and unsupervised learning. On the lines of supervised learning, using retrospective data, a known outcome is labeled, and an unknown/unlabeled outcome is predicted. Such a supervised model trains the algorithm to make more accurate predictions than just logistic regression. When calculating cardiovascular risk scores, ML algorithms analyze large, complex datasets (data mining) to predict the risk of morbidity and mortality. To be clear, this is not the same as prescriptive analytics, using ML to suggest actions to be taken to achieve desired results.
Differences Between AI, Machine Learning and Deep Learning (Peterson). 15
Cardiovascular research continues to define technology largely through ML. For instance in one study, patients with chest pain were compared with external validation cohorts in order to develop and validate an ML algorithm for the ECG diagnosis of occlusive myocardial infarction. 2 In aggregate terms, the ML model outperformed practicing clinicians. 2 In another example, an ML model integrated cardiac troponin concentration with an individual’s probability of myocardial infarction. 3 The authors’ posited ML model was compared to pathways with fixed cardiac thresholds or risk scores and identified twice as many patients with low probability of myocardial infarction at presentation with a similar negative predictive value. 3 Fewer patients had a high probability, resulting in an improved positive predictive value. 3 As such, the authors rationalized that the ML model was able to incorporate the various features of symptoms, comorbidities, and risk factors into 1 model. 3 Traditionally, these parameters have been considered in isolation. 3 With respect to race and ML, traditional risk scores have been applied. For example, predominantly White adults were included in the Framingham Heart Study and analyzed with Cox proportional hazard regression. 4 An ML model, specifically the race-specific model, was then compared with a nonrace-specific model to predict 10-year risk of the incidence of heart failure. 4 The race-specific ML models performed superiorly to nonrace-specific ML models. 4
In cardiovascular surgery, the Society of Thoracic Surgery (STS) makes a risk calculator available whereupon the risk of operative mortality, major morbidity, and short-term outcomes after cardiovascular surgery is derived. The STS risk models are based on logistic regression modeling. For example, the STS taxonomy of operative mortality is all deaths, regardless of cause, that occur during hospitalization and all deaths that occur after discharge and within the 30th postoperative day. Kilic et al 5 developed an ML algorithm to explore mortality in 11,190 adults post cardiac surgery operations. The authors maintain that the ML model was modestly better than the STS risk score. 5 More recently, an ML model predicting the outcomes after surgical aortic valve replacement was only modestly better than existing STS models. 6
The characterization of an ML technique for cardiovascular risk score is by no means uniform, and there are both benefits and costs to be assessed. One positive finding is that large sets of data allow for calibration and fine-tuning of algorithms. The algorithms will be increasingly better in recognizing even more subtle patterns and making decisions based on this. Historically, risk scores are based on fixed algorithms. With ML, there are feedback loops such that as more data are available, the algorithms enhance and become better at their predictive capacity. The second benefit is the computing power available with modern technology. For example, cloud computing has enabled large datasets to link and thus be analyzed. Again, this will improve the algorithms and ultimately risk predictions. Contrary to the prior framework, some limitations point toward a negative effect of ML-risk score. First, each large dataset has its own population of patients and outcomes, which may not be translatable to another dataset with different patients and outcomes. A particular model might perform well in a defined patient population, but it may not be subsequently validated in a different, diverse population. For instance, an algorithm might predict ventricular arrhythmias in heart failure patients but not in healthy patients. A second limitation is that ML-prediction models require large datasets for training. This might require the sharing of confidential patient data, raising security concerns for sensitive information.
Despite the pace and interest in AI, the ethics of this technology has been a controversial subject in the medical community. One of the pillars of medicine is trust and accountability—trust both in terms of the source of and secure dissemination of information. Before data analysis can even begin, the questions of how data are to be collected and prepared are starting concerns of ML. Many uncertainties regarding how data are captured and cleaned, how sufficient data are obtained, and how to select relevant data to use exist.
Next, the question of whether the training data are relevant to the population of interest must be addressed. After selecting the dataset(s), next comes the question of whether the learning algorithm the data is trained on is appropriate for the particular dataset. Possible solutions to this include greater data transparency and open community vetting of the algorithms and data sources.
Another ethical problem with ML-cardiovascular risk scores is the privacy and protection of patients’ data. Issues arise over the right of patients to access their data, permission to use their data, and the data collection process. A third ethical concern is the lack of regulation and governance with AI. For example, regulatory agencies, like the United States Food and Durg Administration, are not currently regulating AI. Finally, data sources frequently include common societal biases. Algorithms based on these datasets will create predictions and that may harm marginalized and underrepresented patient populations. One proposed solution to this is developing computational techniques that better address and correct discrimination in the training dataset and algorithms: affirmative algorithmic action.
Unlike discriminative AI that determines a relationship between dependent and independent variables, generative AI models learn and mimic patterns from existing data to generate new, unique outputs. Generative AI involves an input or prompt with instruction, context and input data. Neural networks (CNN, convolutional neural network; RNN, recurrent neural network) then capture sequential relationships in linguistic data and generate a coherent output. The output can be any type of content, such as text, image, video, or audio. For example, the use of generative AI in the field of cardiac image-based diagnosis of heart disease. 7 Rojas-Albarracin et al 8 developed a myocardial infarction diagnosis model with CNN and color images of the heart for training, validation, and testing. The images were classified as normal or abnormal, yielding an accuracy of 92%. Alkhodari and Fraiwan 9 used CNN and RNN in phonocardiogram recordings to predict valvular heart disease with 99% accuracy.
It must be noted that spurious correlations in ML models lead to uncontrolled confounding biases. 10 These correlations can frequently be traced back to bias and poor robustness. 10 Ideally, a method to automatically distinguish between causal and spurious patterns without human intervention does not yet exist. 10 Recently, van Assen et al 11 reviewed implicit and explicit biases in cardiovascular disease datasets. In particular, the authors state that bias can be introduced by training a model on biased data, which only represents a specific demographic, and thereby excluding patients from other racial, ethnical, and/or geographical groups. 11 Consequently, when implemented in clinical practice, the model may incite bias in the end user and lead to disparities in care. 11 One type of bias is historical bias—biases inherited from past practices or systematic inequalities. 11 As an example, Lolic et al 12 evaluated over 100,000 US participants in a clinical drug trial, between 2015 and 2019, with the majority of participants being White (90%).
Clearly, selecting these data for training would lead to biased AI predictions. Another type of bias is labeling bias when assigning labels or categories to data is influenced by subjective opinions. 11 Thus, the labels are inaccurate and affect the AI algorithm. Breathett et al 13 investigated the role of bias in the allocation of heart failure therapies and discovered that implicit bias led to the belief that Black males were sicker than White males; While males received prioritization for therapy. Another type of bias is algorithmic bias. In this case, biases emerge from the design, implementation, or use of algorithms. 11 As an example, the AI algorithm pick up on features that are inadvertently correlated with sex or race, leading to discriminatory predictions. 11 Finally, there is feedback loop bias when the algorithmic systems reinforce and amplify biases over time through continuous feedback loops. 11
The Health Insurance Portability and Accountability Act Privacy Rule protects patient data by providing with access without consent only for a narrow set of socially beneficial uses (such as tracking epidemics, reporting child abuse, and advancing research). 14 AI performance in clinical settings may suffer from poor fit because of overfitting—lack of exposure to diverse, inclusive training data results in poor system performance for underrepresented populations. 14 This will result in a selection or conditional bias in the AI training dataset. The prescription is to use patients’ data that will truly represent the clinical scenario with minimal risk to privacy. 14 A new approach to consent may be needed.
Technological innovation refers to the incorporation of technology in the production process. It is useful to think of technology as something like a recipe entailing a design for a final product. The recipe specifies a set of data (eg, demographic, laboratory, imaging, and medical relationships) and a set of actions (algorithms) that need to be taken to achieve a desired outcome (eg, risk score). In fact, even importing these data into an algorithm is arduous. However, increasing effort has been stimulated by ML to accelerate finding clinical patterns and calculating risk. ML is now at the core of forecasting the risk of adverse outcomes in cardiovascular medicine and surgery with great accuracy. No matter how mechanized ML-risk scores are, the ability to employ it effectively will require clinical judgment. As clinical judgment is rooted in human learning, it involves a variety of aspects difficult to replicate by AI. Therefore, for ML-cardiovascular risk scores to be successful, synergy must exist. ML-derived risk scores and human judgment are intertwined owing to the complementarities between the two and the dynamics of clinical decision-making. Learning ML technology generally requires a knowledge base that is difficult to acquire. But for those cardiovascular specialists studying ML, modifications and refinements of the data and the algorithms are crucial areas of importance.
In conclusion, the majority of cardiovascular risk scores are conducted by computers today. ML will calculate risk scores with accuracy beyond what is available today. On the horizon is AI developing new and enhanced risk scores, the better prediction of which patients will have complications and to determine how to optimize patients prior to surgical procedures.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Ethical Disclosure
All the authors mentioned in the manuscript have agreed for authorship, read and approved the manuscript, and given consent for submission and subsequent publication of the manuscript.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.