
Abstract
Sumerian, an agglutinative language of unknown affiliation, surfaced in mankind’s earliest written sources around 3300
Keywords
Introduction
Writing surfaced in ancient Mesopotamia shortly after the middle of the 4th millennium
An important role in this development was played by the ‘token system’, a term that refers to small clay pieces of different shapes that are mostly abstract and therefore based on arbitrary semantics, but also include a considerable number resembling or representing objects from the natural environment (see Schmandt-Besserat, 1992, 1996; and especially Michalowski, 1993; also Wagensonner, 2009 and the collection of articles in Woods, 2010; and see now Selz, 2020a: 192–200 and Selz, 2022). Counting could be done by the manipulation of such objects in an abacus-like style; there is no need to pronounce such operations and linguistic aspects might be neglected. Such clay tokens were occasionally impressed on clay tablets, small cushion-like lumps of clay functioning as a kind of proto-signs.
Almost at the same time, the ancient accountants began using reed styluses in order to impress such ‘signs’ on tablets. The obvious motivation for these processes was an attempt to make the embedded information lasting and accessible for all sorts of control. One might therefore say that the combination of (durable) visual information and the rather ephemeral accounting processes stood at the birth of the Mesopotamian writing system(s). Of course, it was possible to pronounce such information, but a link to any specific language could be ignored (cf. Selz, 2021b).
The set of signs used in the early script was quite limited: some show their pictographic origin while others seem – at least to us – to be rather arbitrary ‘abstract’ signs. However, we observe in the earliest script rather sophisticated means for enlarging the body of such signs: the turning and mirroring of a sign, alteration by omitting or adding glyphs (‘strokes’) to a specific sign, and, above all, a synecdochic and metonymic use of some signs. Depictions of animal heads, for instance, are used to designate a member of animal species, and the depiction of several vessels is used to refer to offices with which they are typically linked, thus making reference to various social statuses (see D’Anna et al., 2016; Johnson, 2019; also Selz, 2020a: 214–216 and Selz, 2022). Also well attested is the combination of different signs, either by simply compounding signs or by sign-combinations, combined signs, in which often one or more ‘miniature’ signs are inscribed into a larger ‘framing’ sign.
It is important to note that the material (clay) and instrument (reed stylus) certainly contributed to the rapid loss of iconicity in the Mesopotamian script. The individual impression of a sign, the glyphs, soon took the shape of ‘wedges’ – hence the labelling of the typical Mesopotamian writing as cuneiform (‘wedge-shaped’).
The history of sign formation and the traceable use of these signs show, beyond reasonable doubt, that this script is best described as a kind of conceptual writing, despite the widespread labelling of these signs as ‘logograms’. They do not correspond to one word in a given language but rather to a set of ideas connected to these signs. Thus, the sign for HEAD 𒊕 – a simple depiction of a human’s head – may be expanded to the sign MOUTH 𒅗 by adding marking strokes on the mouth area of that picture, thus creating a new, derived sign. The sign MOUTH 𒅗 could then be used – and was used throughout the history of cuneiform writing – not only to denote MOUTH, but also WORD, TO SPEAK and other referents connected conceptually with MOUTH. Furthermore, in combining this MOUTH sign with the depiction of RATION VESSEL, the derived (new) sign could express the semantic concepts of EATING and CONSUMPTION. Conceptual or semasiographic (ideographic) writing is undoubtedly grounded in the polysemy of the written signs. It should also be noted that in the earliest stages of the script no unequivocal evidence for the existence of phonophores has yet been found. 1
To this day, the notion that writing has to be a fully fledged system to render speech prevails in scholarly literature (Boltz, 1994: 8; Falkenstein, 1936: 31; Gelb, 1963: 65; Handel, 2019: 41; the entire situation is reviewed in Selz, 2022). It has been repeatedly noted, however, that semasiographic writing dominates the transmission of Sumerian texts;
2
a relatively clear linguistic system representing the speech cannot be traced prior to the end of the 3rd millennium
Scholarly discussion was not limited to the ideographic and conceptual hypotheses; much effort was also made to identify and reconstruct the language behind the earliest Uruk texts. Throughout the history of cuneiform writing, the principle of homophony and homoiophony (similar phonetic shape) played a salient role, especially in Sumerian, a language with a large number of homonymous words. 3 Cuneiform script exhibits the rebus-principle, which means that a graph linked to a specific word is also used to write quite different words showing the same or similar phonetic shape. This phonetization of signs became necessary in order to render all sorts of names and titles.
By analysing these phonetic components, scholars made several attempts to identify the language that the script was being used to encode. While some of these lead to dead ends, most scholars – with the notable exception of Englund – are presently convinced that speakers of Sumerian made some contribution to the moulding of this early script. 4 Sumerian is an agglutinative language without inflection and rather narrow word boundaries. Therefore, it is extremely well-suited for the application of the rebus-principle. Be this as it may, the fact that the early Mesopotamian writing system is deeply grounded in two opposing principles – polysemy and homophony – can hardly be questioned.
The beginnings of semantic classification in the earliest texts from Uruk
Roughly 85% of the earliest Uruk texts originate in administrative contexts, most likely documenting the expenditures (specifically distributions), income and inventories (treasuring) of staple goods controlled by specific offices or persons. However, 15% of the texts are usually labelled ‘lexical lists’, and they have proven to be a salient means for understanding the semantics behind the administrative documents.
The most obvious purpose of the Uruk lexical lists was – as also in later tradition – to make the apprentice scribe familiar with the system. However, despite the fact that they show no particular concern with ‘metaphysical’ issues, the lists provide us with important insights into the Mesopotamian worldview. The world represented in these lists is organized in various themes, all reflecting the contemporary environment. Most importantly, these lists were transmitted to the later periods, although with notable changes. 5 Consequently, scholars of the ancient Near East call these texts ‘thematic lists’; their organizational scheme we have tabulated repeatedly points to their rather persistent scribal tradition. 6
These thematic lists can therefore also be taken as an expression of a Mesopotamian endeavour to organize and categorize their world: they are, in the strict sense, classificational. A more detailed analysis of the individual lists will further reveal classificational hierarchies and one might even say that they explicitly deal with the semantics of the signs and words. Most likely this attitude also affected sign formation; of special interest here are the so-called frame signs, a number of signs in which other specifying signs are inscribed.
7
In these frame signs, the frame might convey semantic information of the classifier type.
8
As an example, we choose here the sign EZEN/M (𒂡), which in the later tradition conveys the meaning FESTIVAL.
9
The word ‘festival’ entered Akkadian as a loan-word, isinnu. Pictographically, the sign represents a central place with four or two gateways 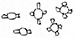 , and from the original meaning MEETING PLACE it acquired, by semantic extension, the meaning FESTIVAL.
10
In the earliest texts, however, in conjunction with the various inscribed signs, it functions sometimes as a kind of classifier for geographical names, in much the same ways as later the (37) [
, and from the original meaning MEETING PLACE it acquired, by semantic extension, the meaning FESTIVAL.
10
In the earliest texts, however, in conjunction with the various inscribed signs, it functions sometimes as a kind of classifier for geographical names, in much the same ways as later the (37) [ (ZATU 151)– that is, EZEM
(ZATU 151)– that is, EZEM
If this observation is correct, a closer look on such frame or matrix signs is wanted; besides classifiers based on their identification by various scholars in the ‘classical’ standard Sumerian script, we may reckon with further means of classification, at least in the earlier phases of cuneiform. There, frame or matrix signs play an important role. Some of them may have a graphic semantic function that so far 13 was rarely considered. 14 Such frame or matrix signs may have the function of a semantic indicator.
In addition to the just discussed EZEM, we would like to add a few remarks on the DUG. The sign is differentiated into DUGa and DUGb as follows: 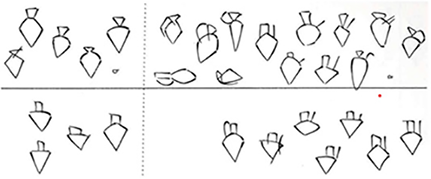 (ZATU 88). In fact DUGb has a shape quite similar to the sign UKKIN that, however, has to be kept apart:
(ZATU 88). In fact DUGb has a shape quite similar to the sign UKKIN that, however, has to be kept apart:
 (ZATU 580).
15
(ZATU 580).
15
DUGb is clearly the forerunner of the later 𒂁 ‘(clay) pot’; already Green and Nissen (1987: 189) observed that DUG ‘with inscribed sign functions as determinative’; in other words, they suggested a connection between a frame sign and the later classifier [ (cf. ZATU 97) is DUGbxGA ([POT]x[MILK]) and
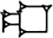
(cf. ZATU 97) is DUGbxGA ([POT]x[MILK]) and 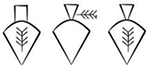 (cf. ZATU 118) is DUGbxŠE ([POT]x[BARLEY]); they might semantically refer to ‘milk pot’ or ‘barley pot’, or to ‘pot of milk/barley’. Therefore, we cannot (yet) establish a reading. Controversially, in the related sign
(cf. ZATU 118) is DUGbxŠE ([POT]x[BARLEY]); they might semantically refer to ‘milk pot’ or ‘barley pot’, or to ‘pot of milk/barley’. Therefore, we cannot (yet) establish a reading. Controversially, in the related sign  DUGbxKASKAL it was suggested that /kaskal/ 𒆜 ‘road’, as with the value /kas/, is here a phonetic indicator and that the combined sign may consequently stand for /kaš/ ‘beer’. As far as we can see, however, a semantic interpretation ‘travel vessel’ is by no means excluded.
DUGbxKASKAL it was suggested that /kaskal/ 𒆜 ‘road’, as with the value /kas/, is here a phonetic indicator and that the combined sign may consequently stand for /kaš/ ‘beer’. As far as we can see, however, a semantic interpretation ‘travel vessel’ is by no means excluded.
The signs GA2a  and GA2b
and GA2b  (ZATU 162) originally depict boxes of some sort. Both forms are attested in Uruk III-IV periods with a greater variety of inscribed miniature signs: thus, in GA2axEN or MEN
(ZATU 162) originally depict boxes of some sort. Both forms are attested in Uruk III-IV periods with a greater variety of inscribed miniature signs: thus, in GA2axEN or MEN 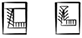 (ZATU 360), later read /menx/ 𒃉 and /men/ 𒃞 – the word designating a type of crown – the inscribed sign EN may be either a phonetic indicator /en/ or have a semantic function, for example, [BOX] (GA2)x[LORD](EN). Similarly in AMAa, analysed as GA2bxAN/AM6
(ZATU 360), later read /menx/ 𒃉 and /men/ 𒃞 – the word designating a type of crown – the inscribed sign EN may be either a phonetic indicator /en/ or have a semantic function, for example, [BOX] (GA2)x[LORD](EN). Similarly in AMAa, analysed as GA2bxAN/AM6 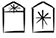 , and also written AMAb
, and also written AMAb  (ZATU 28), both are later 𒂼 and rarely 𒆾 = ama6(?). Later, the compounded sign has two readings /ama/ ‘mother’ and /daĝal/ ‘wide’. It is only for the first word that we may suggest that AN/AM6 is a phonetic indicator, but also a semantic interpretation [BOX]x[DIVINE] is not excluded
17
and may eventually explain why the sign represented the notion ‘wide’.
(ZATU 28), both are later 𒂼 and rarely 𒆾 = ama6(?). Later, the compounded sign has two readings /ama/ ‘mother’ and /daĝal/ ‘wide’. It is only for the first word that we may suggest that AN/AM6 is a phonetic indicator, but also a semantic interpretation [BOX]x[DIVINE] is not excluded
17
and may eventually explain why the sign represented the notion ‘wide’.
A little later, in the Early Dynastic periods, we find the sign GA2axNUN  , also written ĝa2-nun, for the word ĝanun ‘storehouse’. It is tempting to suggest that signs like GA2axGUD
, also written ĝa2-nun, for the word ĝanun ‘storehouse’. It is tempting to suggest that signs like GA2axGUD  , GA2axMAŠ
, GA2axMAŠ  (ZATU 176), GA2axKU6
(ZATU 176), GA2axKU6  (ZATU 173) and even
(ZATU 173) and even  GA2axKUG (ZATU 172) compounds designate containers or depositories for GUD ‘oxen’, MAŠ ‘goats’, KU6 ‘fish’ and even ‘shining metal’ KUG. Whether this was always mirrored linguistically – for example, by nominal compounds– remains uncertain. But this assumption can be corroborated by a word like /araḫ/, written GA2xŠE [BOX] x[BARLEY] (= araḫ3) and E2xŠE [HOUSE]x[BARLEY] (= araḫx),
18
writings that suggest that the word designates a ‘barley storage facility’ and has phonetically ‘house’ (ʾa3/e2) as its first element. Interestingly, the compound writing e2-us2-gid2-da, literally ‘house with long corridors’, is often understood as a DIRI writing
19
with the reading araḫ4.
20
GA2axKUG (ZATU 172) compounds designate containers or depositories for GUD ‘oxen’, MAŠ ‘goats’, KU6 ‘fish’ and even ‘shining metal’ KUG. Whether this was always mirrored linguistically – for example, by nominal compounds– remains uncertain. But this assumption can be corroborated by a word like /araḫ/, written GA2xŠE [BOX] x[BARLEY] (= araḫ3) and E2xŠE [HOUSE]x[BARLEY] (= araḫx),
18
writings that suggest that the word designates a ‘barley storage facility’ and has phonetically ‘house’ (ʾa3/e2) as its first element. Interestingly, the compound writing e2-us2-gid2-da, literally ‘house with long corridors’, is often understood as a DIRI writing
19
with the reading araḫ4.
20
Therefore, all types of semantic classifiers may originate as elements of nominal compounding, notwithstanding the observation that they increasingly became purely graphic elements in the standard form of cuneiform scripts.
Determinatives/classificators/classifiers: The situation in ‘classical’ Sumerian texts
Modern grammars of Sumerian mention several classes of cuneiform signs: besides (a) logograms (or semasiograms, as we prefer) these are (b) syllabograms (derived via the rebus-principle from (a)) and a special sub-class labelled phonetic indicators, referring to the pronunciation of a semasiogram in a given context, (c) number signs (including ‘combined notations of measure + number’) and, as a separate class, (d) ‘determinatives’. 21 In ancient Near Eastern studies, the term ‘determinative’ is used for allegedly unpronounced glyphs, ‘which precede or follow words or names in order to specify them as belonging to semantic groups’ (Edzard, 2003: 9). It is remarkable that this term was introduced into cuneiform studies in 1847 by Edward Hincks, 22 who was working in the decipherment of Egyptian and cuneiform scripts, and modelled apparently after the term Champollion coined in 1836 in his study of ancient Egyptian (see Goldwasser, 2006: 17–20). However, due to the chronological and typological diversities of cuneiform texts, the set of what scholars consider ‘determinatives’ is rather ill-defined. Considering the various accounts of renowned scholars (specifically Borger, 1978; Edzard, 2003; Ellermeier, 1979; Falkenstein, 1949, 1964; Foxvog, 2016; Huehnergard, 1996 [1998]; Labat, 1988 [1948]), we produced in 2017 a ‘consolidated list of cuneiform classifiers’, the shortcomings of which – most stem from a dearth of diverse sources – were explicitly acknowledged (see Selz et al., 2018: 287–305).
The Selz consolidated list of cuneiform classifiers
The list contains 50 items and is as follows (the position of the classified item is here marked by a hyphen (–))
23
(based on Selz et al., 2018): 1. –*didli (HAL) [
An evaluation of this list showed that 18 core items were identified by all or all but one of the authors, and can be considered as the constitutive set of Sumerian determinatives – that is, classifiers (Selz et al., 2018: 304). Based on the opinions of several prominent scholars, the thematic organization of the cuneiform classifier system reveals the picture shown in Table I, typographically differentiated in these ways:
Thematic organization of the Sumerian classifier system according to the consolidated list (Selz et al., 2018: 308).

With few exceptions – probably later inventions – we can observe that nearly all classifiers are sortal classifiers. In 2017 and 2021, we provided a structured table on the organization of the standard Sumerian classifiers.
25
When we ignore here
The relationship between the most common – and widely accepted – classifiers and the lexical tradition demonstrates the salient taxonomic and classificational reasoning of ancient Mesopotamia: ‘It is quite intriguing that of 13 “themes” of the so-called “thematic lists” a minimum of 10 relate to the later so-called “determinatives”’ (Selz, 2018: 415). The ‘determinatives’ do in fact classify (see already Farber, 1991: 83 and cf. Selz, 2018: 415), so henceforth, we should perhaps better use the term ‘(graphic) classifiers’. While the majority of scholars insist that these classifiers are purely graphical means to attribute a word to a semantic class (cf. above Edzard, 2003: 9; Civil, 2004: 3–4), the hypothesis that the Sumerian system of ‘classifiers’ or ‘semantic script determinatives’ is grounded in language was already suggested by Gadd (1924: 13): ‘It is by no means certain that their use (“determinatives”) is merely a device of writing. On the contrary, it is a strong probability that they were in most cases actually pronounced.’ 30 Bauer (2017: 67) summarizes the situation: ‘There is a remarkable lack of motivation of why script determinatives allegedly were not pronounced or – conversely – why that assumption is doubtful.’
As all Sumerian sortal classifiers are common nouns (nomina substantiva), it is necessary to study their linguistic function within the frame of noun-compounding. It is suggested here that the study of Sumerian noun-compounding and especially appositive compounding may illustrate what happened to the classifiers and elucidate their semantic functions. The vast majority of Sumerian nominal compounds (noun compounding) are left-headed. 31 This head is then semantically modified, specified or restricted by the addition of an attribute, either a nomen substantivum or adjectivum, 32 and might also be a deverbal (participle). We note that what is commonly termed classifier/determinative – the pre-positioned generic or common noun – corresponds to the hypernym in non-coordinate nominal apposition. 33 In deverbal modifiers, the modifier itself can be a compound, which, however, look like right-headed compounds according to the Sumerian verbal syntax. And further, there exist countless cases where the head of such a nominal compound is not written; these occur most commonly in profession names, but also appear in other items. 34 However, many cases are attested in which the head is expressed, and in post Old-Babylonian texts this manner of writing became dominant. In other words, we suggest that the pronunciation of the pre-positioned classifiers was a possibility, while in numerous cases they certainly remained unpronounced (and as the long tradition of cuneiform developed, increasingly so).
The situation of the post-positioned classifier is a bit different. There are only three major post-positioned classifiers: (6) [
If we accept this, we are left with only four post-positioned classifiers: [
Therefore, we suggest that the different position of the classifiers can be explained best within a hypernym-hyponym grid – that is, as a NOUN-APPOSITION chain. Whether or not they have become purely graphic indicators by the ‘classical’ Sumerian period, classifiers are linguistic phenomena, not mere morpho-graphemic aids. We hope that a comparison with other noun classifier languages as envisaged in the scope of the iClassifier project may yield additional insights (see Selz et al., 2018, especially 306–307; for the hieroglyphic classifiers, see also Goldwasser, 2006).
The iClassifier project and its application to Sumerian texts (preliminary report)
The starting point
So far, we have hopefully demonstrated the importance of Sumerian semantic nominal classifiers and the problems they precipitate in identifying the connected problems, especially the difficulties in identifying them and understanding their semantic functions. We turn now to a preliminary account of classifiers gleaned from the implementation of the Jerusalem-based iClassifier project. The greater benefit scholarly transcriptions of cuneiform texts offer is that they must account for every glyph or graph of the original document. We further possess the ePSD and ePSD2 (electronic Pennsylvania Sumerian Dictionary), a highly advanced electronic tool for lexical research, somewhat compensating for the lamentable fact that a stable Sumerian Dictionary is not yet in sight. 41 In the ePSD2, all classifiers are – according to good Assyriological practice – rendered in superscript, which opens a nice window for retrieving all presumed classifiers from this database. An additional advantage the ePSD2 offers is the ability to link to other databases incorporated into each entry, above all the CDLI (Cuneiform Digital Library Initiative), DCCLT (Digital Corpus of Cuneiform Lexical Texts), BDTNS (Database of Neo-Sumerian Texts) and ETCSL (Electronic Text Corpus of Sumerian Literature), thereby providing references to the individual original sources. Therefore, we hope that in the future we will be able to trace all collected information on a given lemma and its tokens to the original sources, to photos as well as to copies and transliterations of an individual text.
When Bo Zhang collected and entered the information from ePSD2 into the iClassifier database, we immediately became confronted with three major problems: Besides classifiers/determinatives, by academic tradition phonetic indicators (also termed phonetic classifiers or phonophores) are also given in superscript. For Sumerian, such phonetic indicators are simple reading aids in order to disambiguate linguistically the various semasiograms. However, in order to make our data set compatible with other projects with similar phenomena, we retained these phonetic indicators, but programmed the query system to allow for their exclusion. Semantic nominal classifiers are used not only for classifying simple common or proper nouns; they may also classify an entire nominal compound, or a single element of a compound which sometimes leads to multiple classification – for example, a divine name bearing the classifier [ An additional problem already addressed is that the existing databases, including ePSD2, sometimes make use of rather diverging transcriptions and what was perceived as a (mute) classifier or part of a pronounced nominal compound is often varying and inconsistent.
Thus, for a start we simply follow the transliteration modi of ePSD2. Therefore, all signs shown in superscript are considered as (possibly) relevant for our topic; only in a second step do we distinguish between phonophores and lexemes considered to represent classifiers. The result of this simplified use of the ePSD2 transcriptions is that they include a larger number of words, specifically material qualification, attested in adjectival position. Most of these alleged classifiers are in fact part of a NOUN + NOUN compound.
42
Data input – current state
So far, Bo Zhang has entered nearly 2800 lemmata, according to the normalized transcription of ePSD2. We consider only those lemmata that show at least one token with an identifiable classifier or phonetic indicator.
43
Tokens in our project are defined as script forms (transliterations as well as the basic original data sources can be reached via ePSD2). Statistics as of 12/04/2023 run as follows with almost double figures when compared with Selz (with Bo Zhang) (2021b) (nonetheless, the total number of qualified lemmata turned out to be even larger than we had estimated in 2021, and now we estimate that it may go beyond 6000 entries): Number of script variations (tokens): 9297 Number of lemmas: 2810
With one classifier: 4767 With two classifiers: 454 With three classifiers: 11 Without a classifier: 4065
This means that the database presently (12 April 2023) contains 4065 tokens (script variations) without a classifier, 44 4767 tokens with one classifier, 454 with two classifiers and 11 tokens with three classifiers.
All tokens (script forms) of a selected lemma, either with or without a classifier, are entered into the database (provided the lemma has at least one token with a classifier). A token presently refers to the transliterated form of a lemma, and does not necessarily reflect the transcribed (phonetically reconstructed) form of the word. In the add/edit tokens interface, we enter the following information: Choose the lemma to which a token belongs from the list of lemmas already put in. Choose ‘token type’. Presently, we register only simple tokens. Input the cuneiform writing form of a token in the field Token – for example, In the field Token with markup, for an un-classified token (i.e. a token without a classifier), we copy its for a classified token, tildes are used to mark its classifier(s): ∼ In the sub-field of Classifiers, choose Classifier level; we simply distinguish between lexical and phonetic. Under Phonetic reconstruction, we offer the normalized transcription– that is, the phonetic representation of a lemma as in ePSD2 – for example, bulug. Under Transliteration, we enter the transliteration of a given token– that is, its graphical representation according to Assyriological conventions. Braces are used to mark up its classifier(s) (or phonetic indicators) – for example, {urud} bulug. Under Classification status, we choose between ‘classified’ and ‘not classified’. Under Comments, we always enter the numbers assigned to the script forms (token) according to the sequential order of script forms of a lemma in ePSD2; in the future, we hope to connect this with the respective HYPERLINKS provided by ePSD2. Thus, eventually a chronological distribution will become accessible directly, adopting the grid used by ePSD2. Periods are: PC (Proto Cuneiform) – ED (Early Dynastic) IIIa – ED (Early Dynastic) IIIb – Ebla – OAkk (Old Akkadian) – Lag II (Lagaš II dynasty) – Ur III – OB (Old Babylonian) – Post-OB (Post-Old Babylonian) – (unknown).
Other relevant observations or discussions may be also included here – for example, the semantic range of a lemma, its function in nominal compounding or dialectic variations.
45
 (= bulug).
(= bulug).
 ∼
∼ (=urudbulug).
(=urudbulug).
Classifier list by iClassifier
Presently, we count 46 semantic 46 classifiers. 47 When they are arranged 48 in a graph (Figure 1), the list of classifiers exhibits a long-tailed distribution. 49 The meaning is given to the right of the classifier.
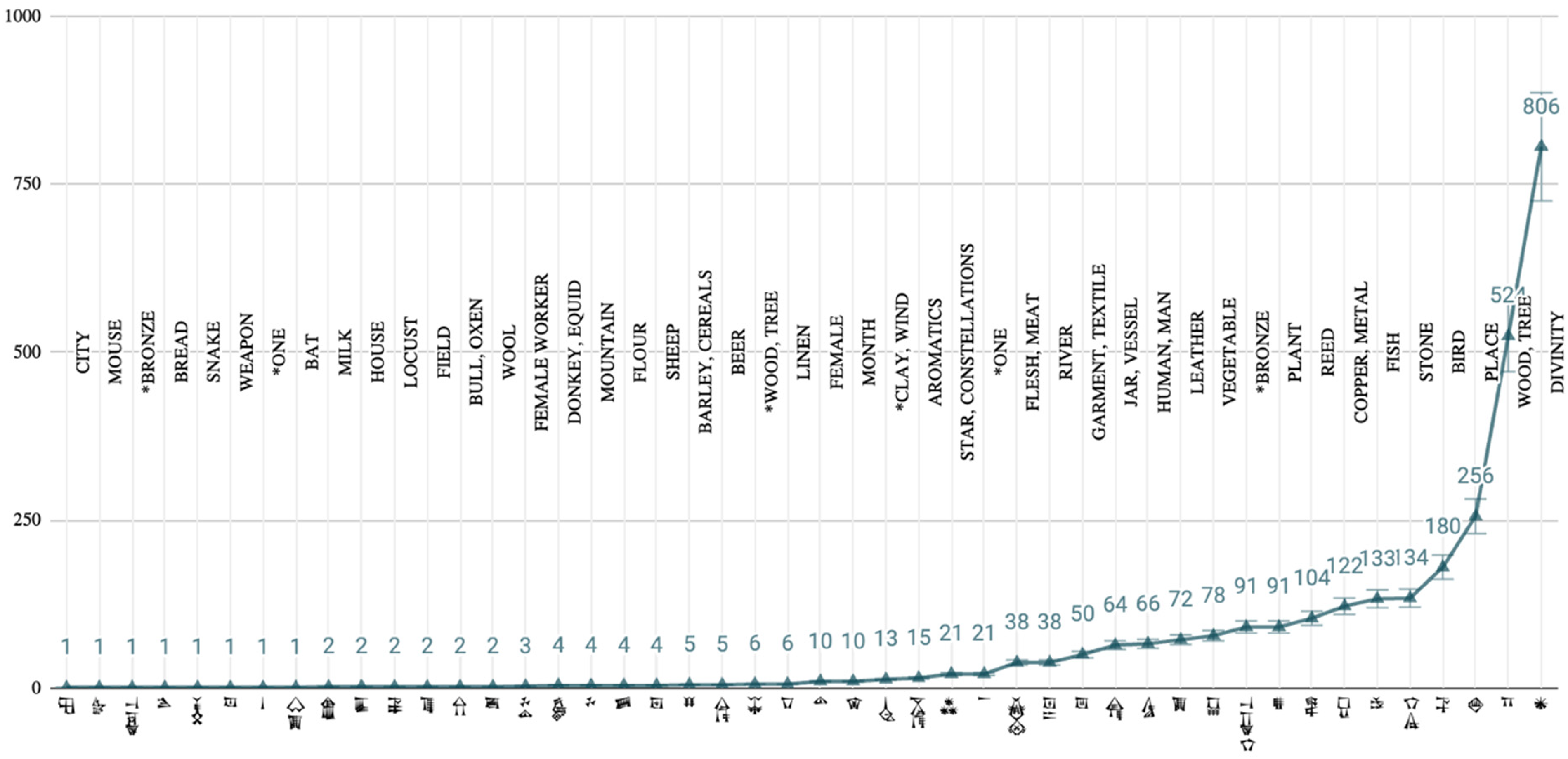
The classifier list according to iClassifier.
The most attested classifiers are [
Classifier axis: Classifier reports on a single classifier: The [hide ] classifier
By clicking on the classifier, we receive the following information, with kuš
Figure 2 shows all lemmata attested with this [hide] classifier. The hue of the node represents the percentage of occurrences of a certain lemma with this classifier. For example, the lemma ĝirikur ‘drum’ has a dark (red) hue, representing that it occurs with this classifier in all of its attested script variations (4 out of 4 forms). A light colour represents that the classifier occurs in fewer script forms with a lemma – for example, garig ‘comb’ (1 out of 12 script forms).
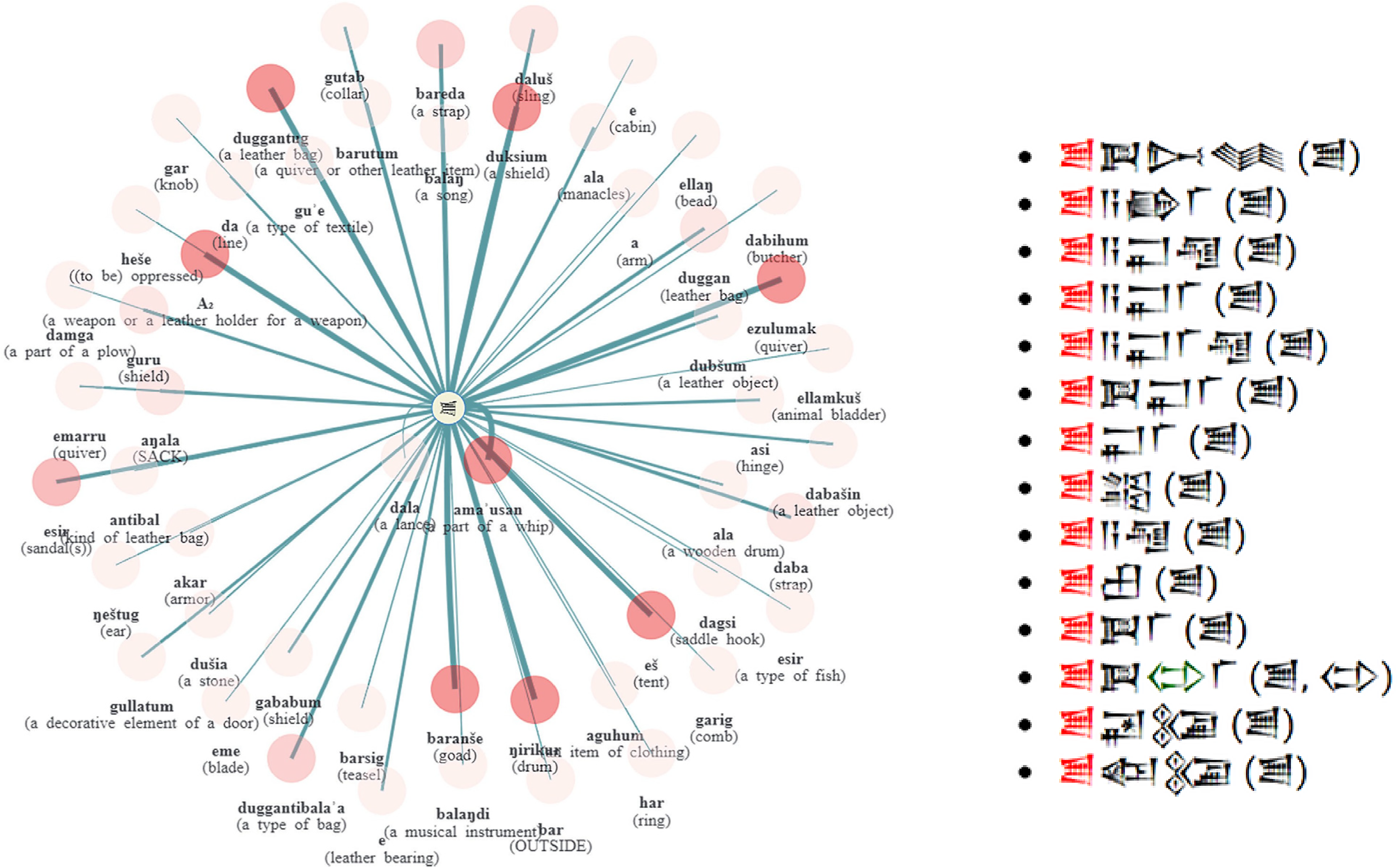
A map with all lemmata attested with the kuš [
The thickness of the (blue) lines between the classifier and each host lemma represents how many script variations a lemma has with a certain classifier.
We can see that the classifier kuš 𒋢 [
a [arm] (‘a strap’); A2 (‘a weapon or a leather holder for a weapon’); 50 aguhum [clothing]; aĝala [sack]; akar [armor]; ala [manacles]; ala [drum]; ama'usan [∼whip] (‘part of a whip’); antibal [sign] (‘kind of leather bag’); asi [strap]; balaĝ [instrument]; balaĝdi [instrument]; bar [outside] (‘skin’); baranse [goad]; bareda [strap]; barsig [garment]; barutum [object] (‘kind of quiver’); da [line] (‘shoe strap’); daba [strap]; dabasin [object] (‘tarpaulin?’); dabihum [slaughterer]; dagsi [hook]; dala [thorn]; daluš [sling]; damga [∼plow] (‘part of a plow’); dubšum [object]; duggan [bag]; duggantug [BAG]; duksium [shield]; duggantibala'a [bag] + [sign] (‘bag for wooden signs?’); 51 dusi'a [stone] (‘turquoise?’, > ‘greenish leather?’); e [leather strip]; 52 ellag [bead] (‘leather string for beads?)’; ellamkuš [bladder]; eme [tongue]; esir [shoe]; esir [fish]; emarru [quiver]; eme [tongue]; es [tent]; ezulumak [quiver]; gababum [shield].
We can also observe that the several script variations (tokens) for /esir/ ‘sandal’, /emarru/ ‘quiver’ and /aĝala/ ‘sack’ often receive the [
ln the case of /esir/ ‘a type of fish’ (certainly a flatfish of the order pleuronectidae) and lexically differentiated from /esir/ ‘shoe sandals’, the use of the [
The list of items attested with the [
ln a separate subfield exemplars of script variations – our tokens – attested with the [
The frequency of tokens (i.e. script forms) for a specific lemma is provided by the statistics given in Figure 4.

Percentages of occurrence of each lemma with the kuš [
Lemma axis: All classifiers attested with a specific lemma: esir ‘sandal’
Within the category, we present a sample lemma /esir/ ‘sandal’.
Figure 5 produced by iClassifier presents the first three tokens with zero classification, 10 tokens showing the [
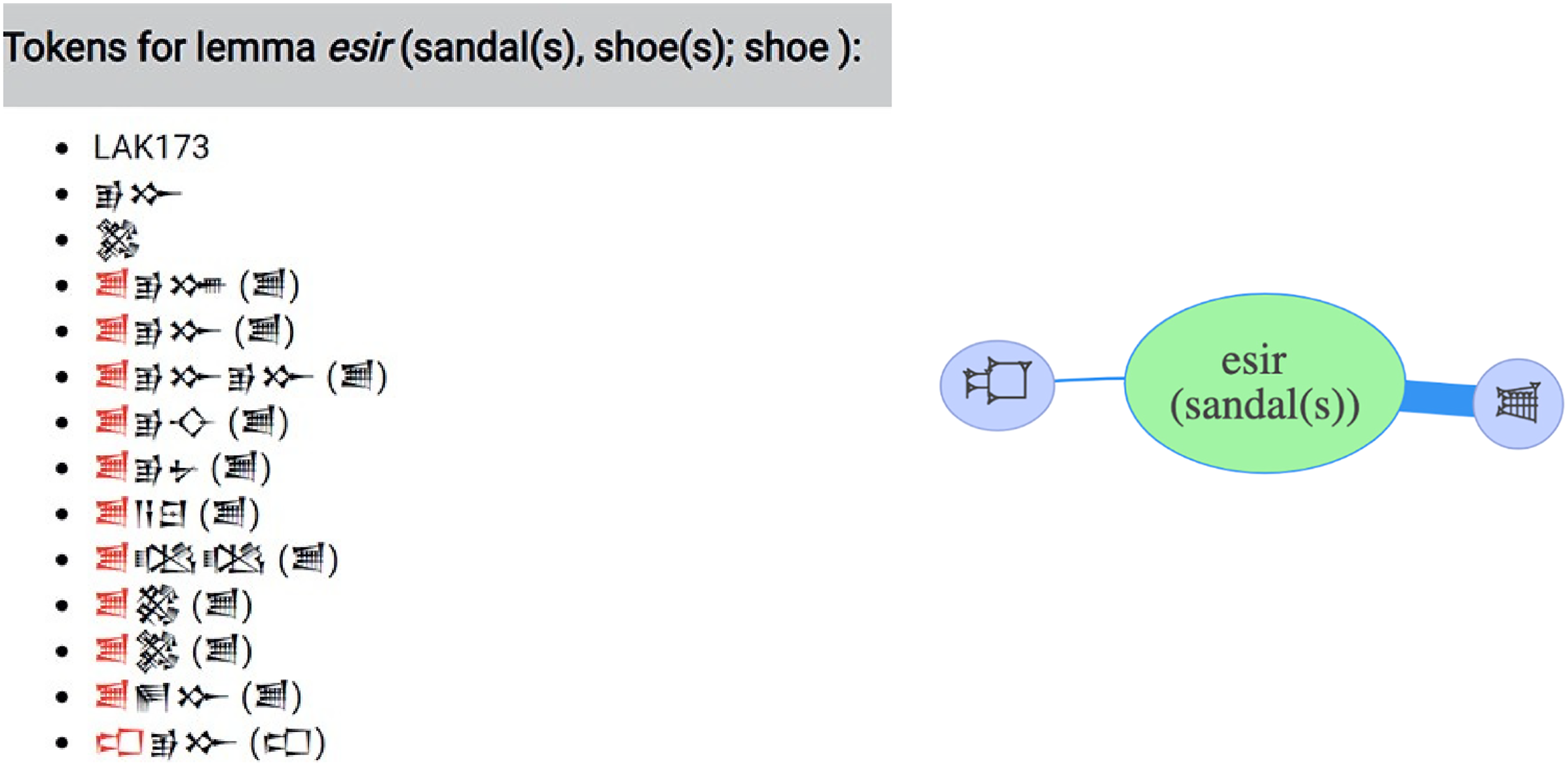
List of all script variations of the lemma /esir/ (with and without a classifier). Figure 6 (right). Classifiers attested with the specific lemma /esir/ ‘sandal’. Thickness of the blue line represents the number of examples.
The classified Cuneiform World NETWORK MAP
The iClassifier map. Concentrating on the phenomenon of unpronounced (mute) cuneiform classifiers, the iClassifier database produces a dynamic interactive map that provides important information on how the ancient peoples classified their world. To be sure, this map does not and will not cover all taxonomic or classificational phenomena, 56 which will continue to be uncovered by future research. However, even when restricting ourselves to the allegedly ‘mute’ classifier, we obtain an important basis for any comparison with similar phenomena in other writing systems – for example, Ancient Egyptian, Chinese or even Luwian and Maya scripts.
All the information entered into the iClassifier digital tool is summarized in a dynamic network classifier map (Figure 7). This map arranges all classified items (lemmata) with their classifiers. The frequency of tokens (script variations) is indicated by the thickness of the connecting lines. In the case of multiple or changing classifiers a lemma is, of course, connected to all classifiers attested with it. Although the frequency refers so far only to the script variations – our tokens – this representation offers a quick, intuitive understanding of which classifiers are ‘core’ and which are ‘fringe’.
A classifier-based network of Sumerian, according to the uppercase marking of classifiers (aka determinatives) in the ePSD2 lemma list, after Selz (2021b), updated (2023), includes 2810 lemmata, and 9297 written forms, digitized by Bo Zhang in iClassifier ©Goldwasser/Harel/Nikolaev. The Sumerian iClassifier, Conceptualization: Gebhard Selz. Data input: Bo Zhang, ArchaeoMind Lab (https://archaeomind.huji.ac.il). 59
At the fringes of the closer intertwined core sections, we see several rare and isolated classifiers. These are, for example, the gud [
After the [
Classifier map of ĝeš- [
Quite expectedly, the -ki [
Classifier map for -ki [
Conclusions and perspectives
Even at this preliminary stage, the relevance of our endeavours seems apparent: cuneiform classifiers usually attribute an item to a semantic class. The items – common nouns as well as proper nouns – stand in an appositive hyponymic relation to their classifiers. Our database offers unprecedented insights into the emic classification– that is, the ways in which these peoples conceived of their world and organized their mental representations.
Frequent uses of the various classifiers underline their emic mental salience. More specifically, this provides important insights into the taxonomic efforts of cuneiform scholars. In the future, when our database will account for the chronological and geographical distribution of these efforts, the perception of the evolution of cuneiform-linked Mesopotamian thinking will certainly become finer and more precise. Classification is, of course, a perpetual living process. As indicated above, a broader view of nominal classification should include linguistic features of nominal compounding, as well as additional graphic features attested in semasiographic compounding. 57 Subsequently, the evolution of the system of mute cuneiform classifiers can be described in more detail and better compared with related scripts. By now, it is already evident that the system of ‘determinatives’ evolved at the intersection between linguistic and mere graphic means of classification. Therefore, the origin of (the later unpronounced) cuneiform classifiers should be studied from the point of nominal and graphic compounding. In this vein, we hope to contribute to an improved understanding of cuneiform sources.
The data collected so far reflects the state of the art as presented in ePSD2. 58 It therefore overemphasizes the ancient lexical sources, and thus insufficiently reflects what might be termed ‘folk taxonomy’. Likewise, a genre-specific distribution of the classificational data is not yet in sight. However, as Mesopotamian lexical lists are the best and most important source for any sketch of the scientific reasoning of the ancient scholars, the value of our data collection is beyond doubt. It opens a window into the ways the Mesopotamians conceived of their worlds.
Footnotes
Acknowledgements
We are most grateful to Orly Goldwasser for including us into the iClassifier project and for numerous stimulating discussions. We are also obliged to Thedore Motzkin, who critically commented on this article and polished our English, and last but not least the operators behind the project, Dmitry Nikolaev and Haleli Harel (who also helped with the figures); see now Harel et al., 2023.
Authors’ contributions
Gebhard J. Selz: conceptualization, data curation, methodology, project administration, supervision, writing – original draft; Bo Zhang: data curation, investigation, writing – review and editing.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.