
Abstract
Ancient Chinese scripts are one of the most complex writing systems in the world. Many graphs contain components referred to as unpronounced semantic classifiers. These components bear a semantic relationship to the meaning of the word written by the graph. It is proposed that the set of semantic components, as well as the specific semantic concepts that they encode, reflect a cognitive map of knowledge organization of the community of script users at a particular place and time. By analyzing the semantic classifiers within a constrained manuscript corpus, it is possible to build a network that models aspects of the ancient Chinese knowledge organization as reflected in this corpus. With the help of the digital tool iClassifier, a corpus-based study is conducted based on the sample texts, Guodian bamboo manuscripts. Additionally, a list of semantic classifiers is presented, two prominent categories 心 [
Introduction
Within the field of linguistics, the terminology “classifier” was originally used in the domain of nominal classification concerned with linguistic categorization systems in the languages of the world, such as noun classifiers, numeral classifiers, genitive classifiers, and verbal classifiers (all pronounced, see Grinevald, 2015; Senft, 2000). The study of classifiers has been subsequently extended to other modalities, such as ancient complex writing systems (unpronounced classifiers) and sign languages (unpronounced classifiers, see Lincke and Kutscher, 2012). Within ancient complex writing systems, the analogous entity is referred to as a “graphemic classifier” (Egyptian: Goldwasser and Grinevald, 2012; Sumerian: Selz, 2021). These unpronounced graphemic classifiers provide additional (silent) semantic information for the host words. The study of graphemic semantic classifiers in ancient Chinese is in its fledgling stage (Goldwasser and Handel, 2024). Yet, it might offer a new window into how the ancients conceptualized the world they lived in.
This article is structured in four sections. The first section provides a concise overview of ancient Chinese scripts and the classification framework of Chinese scripts. Then the semantic classifier as the research object is discussed. The second section introduces the sample corpus and explains the reasons for its selection. The third section, which is the central part of the article, presents results and discussions based on research by the new digital tool iClassifier. 1 This section is divided into four subsets: a classifier list of the sample corpus, discussion of two main categories, presentation of the alternating and multiple classifications, and a network map of the sample corpus. The article ends with a short conclusion.
The ancient Chinese scripts
Dating back to the late Shang dynasty (14th century–1046
The former stage, collectively comprising the gǔwén 古文 (ancient Chinese scripts), has been defined differently in different eras. In the Han dynasty, ancient Chinese scripts referred broadly to pre-Qin scripts, namely scripts before the Qin dynasty. However, the small seal script and early clerical script both used in the Qin dynasty were excluded from the category of ancient scripts during the Han dynasty (Huang, 2015: 1).
Since the 1930s, Chinese scholars represented by Tang Lan tended to include small seal script of the Qin dynasty among the ancient Chinese scripts. However, the early clerical script in the Qin dynasty still was not included in the ancient scripts. Thus, Tang (1981: 33–34; 2005: 119–130) divided the ancient Chinese scripts into four categories by time and region: (1) Shang scripts, (2) Western Zhou and Spring and Autumn period scripts, (3) Six States scripts, and (4) Qin scripts.
Tang’s first category consists of scripts from the late Shang dynasty, mostly inscribed on oracle bones and bronzes. Bamboo strips are presumed to have been important and common written materials during this period because the graph, 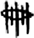 “bamboo strips bound up with strings,” had already appeared in the oracle bone inscriptions. Unfortunately, excavated evidence is absent as bamboo strips were perishable objects (Qiu, 2000: 63).
“bamboo strips bound up with strings,” had already appeared in the oracle bone inscriptions. Unfortunately, excavated evidence is absent as bamboo strips were perishable objects (Qiu, 2000: 63).
The second category includes the scripts from the Western Zhou dynasty (1046–771
The Warring States period (475–221
Consequently, the Six States scripts in the Warring States period include the scripts used in the eastern six states along with other small states. Moreover, the script of the six states shows more obvious regional characteristics in graph forms and component selection than the Spring and Autumn period. The known writing materials in this phase are diverse, such as bronze, stone and jade, bamboo strips and silk, to name but a few (He, 2017: 92–213). However, the distribution of excavated texts so far is uneven in different states and regions. Among them, the Chu region’s bamboo manuscripts are relatively more abundant.
The script of the Qin state, from the Spring and Autumn period to the Warring States period, evolved out of the Western Zhou script. The currently known materials are inscriptions on bronze, stone, weapons, seals, and so on. After the Qin state conquered other states and unified them as one great empire (subsequently called the Qin dynasty, 221–207
Since the 1970s, many bamboo manuscripts and a few silk manuscripts dating back to the Qin dynasty and the early Western Han dynasty (202–156
To summarize, the term ancient Chinese scripts once referred strictly to scripts in use before the Qin dynasty. In modern scholarship, however, the definition has broadened to also include the small seal script of the Qin dynasty and the early clerical script up until the early Western Han dynasty (Huang, 2015: 2).
The latter stage, the clerical and standard scripts, could be further subdivided into two phases: the modern scripts from the Han dynasty to the Qing dynasty (1644–1911
Classification framework of Chinese scripts: Liushu
The earliest known classification framework for Chinese characters was liùshū 六書 (six principles of writing). As recorded in SW, the six principles are xiàngxíng 象形 (pictographs), zhǐshì 指事 (iconographs), huìyì 會意 (Semantic-Semantic (SS) compounds, see Handel, 2016), xíngshēng 形聲 (Semantic-Phonetic (SP) compounds, see Goldwasser and Handel, 2024), 4 zhuǎnzhù 轉註 (meaning uncertain), 5 jiǎjiè 假借 (phonetic loan, rebus characters or loaned phonograms, see Goldwasser and Handel, 2024).
The six principles of writing were not Xu’s own invention. As far as we know, the term liùshū itself appeared for the first time in the ancient Chinese work called Zhōulǐ 周禮 (The Rites of Zhou, compiled no later than the Warring States period), without however stating what the six principles are. Subsequently, scholars in the Han dynasty also mentioned the six specific principles (even though some terms and their ordering are different) but without definitions and examples. Xu gave each one a short definition and examples to make them more understandable.
From then on, discussion and debate of the six principles of writing have never stopped. Some principles’ definitions have been widely discussed due to the ambiguities of Xu’s explanation. For example, the boundary between pictographs and SS compounds is blurred (Qiu, 2000: 156) and the very existence of SS compounds is in dispute (Wang, 1992: 344–345; Boltz, 1994; Handel, 2016). Among them, zhuǎnzhù is the most problematic class and there is still no consensus nowadays. 6
The applicability of the six principles of writing was experimented on Egyptian hieroglyphs and cuneiform in the last decades (Zhou, 1995; Gong et al., 2009: 238–249; Wang, 2015), but some parallel examples presented for the six principles in this literature are under discussion.
Semantic classifier as sign function: The research object
The type of character called xíngshēng 形聲 (SP compounds) contains semantic classifiers. Our main hypothesis is that each semantic classifier in the Chinese writing system reflects a conceptual category. The collection of words classified by a particular classifier presents us with a dynamic map of an emic category in the mind of the ancient Chinese culture. Classifiers allow us to trace central and marginal members of Chinese conceptual categories, spot interrelations between categories, observe diachronic developments within each category, and finally, view the system as a whole (Goldwasser, 2002, 2023; Handel, 2023). The semantic classifier is a sign function that exists both in Egyptian and Chinese scripts. These unpronounced parts of words are the primary focus of discussion in this article (for the definition and research history of semantic classifiers, see Goldwasser and Handel, 2024).
We use “the mind of the ancient Chinese culture” as a general concept. Considering the political situation in ancient China, especially during the Warring States period, there were distinct states and ethnic groups in different places. Taking the Guodian bamboo manuscripts in the Chu states as an example, the Taoist and Confucian texts were popular not only in the Chu states but also in other states during the Warring States period. However, the Chu script has obvious differences in structure and form compared to the scripts of other states during this time. Therefore, collecting classifiers in the Guodian bamboo manuscripts could probably reflect the “mind map” of elite groups of Chu people during the Warring States period, who constituted an integral part of the ancient Chinese culture.
The discussion on sign function focuses on the semiotic role a single graph may play in a word. Modern scholarship has suggested that in ancient Egyptian, hieroglyphic signs have six functions: pictograms, logograms, phonograms, classifiers (determinatives), morphograms (referring to ancient Egyptian roots, aka radicograms), and interpretants (phonetic complements) (Polis, 2018). 7 Taking the intriguing example mentioned in Goldwasser and Handel (2024), in the word 𓊠𓂝𓏲𓅬𓆟𓀜𓀀 wḥꜥ “fowler,” the first hieroglyph 𓊠 wḥꜥ functions as a phonogram and radicogram yet it also provides additional semantic information (boat). The second sign 𓂝 ꜥ functions as an interpretant (phonetic complement), not to be independently pronounced, repeating a sound that makes part of the radicogram. The third sign 𓏲 w functions as a phonogram signifying a sound that refers to a grammatical marker that indicates the word is a masculine deverbal. The remaining signs, 𓅬, 𓆟, 𓀜 and 𓀀, are hieroglyphs that function as semantic classifiers. The duck and the fish are the objects of fowling, and the standing man holding a stick and the seated man represent the agents of the action.
The six principles of writing were a mixture of character structures and sign functions. Among the six principles, huìyì 會意 (SS compounds) and xíngshēng 形聲 (SP compounds) refer to the structure of scripts, but each component in the compounds has its own function. However, jiǎjiè 假借 (loaned phonograms), as a sign function, can be either single or compound. An example of a single loaned phonogram is 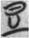 豆 (dòu, Old Chinese *dôh, “vessel”) in Guodian bamboo manuscripts. It was originally a pictograph but used as a single loaned phonogram to write the word 屬 (shŭ, Old Chinese *tok, “belong to”). Parallelly, one of the examples of a single loaned phonogram in Egyptian hieroglyphs is the duck sign in the combination of words
豆 (dòu, Old Chinese *dôh, “vessel”) in Guodian bamboo manuscripts. It was originally a pictograph but used as a single loaned phonogram to write the word 屬 (shŭ, Old Chinese *tok, “belong to”). Parallelly, one of the examples of a single loaned phonogram in Egyptian hieroglyphs is the duck sign in the combination of words  sꜣ-rꜥ “son of the sun,” the common title of the Egyptian king. The word
sꜣ-rꜥ “son of the sun,” the common title of the Egyptian king. The word  sꜣ “duck” was phonologically close to the word
sꜣ “duck” was phonologically close to the word  sꜣ “son.”
sꜣ “son.”
Compound loaned phonograms can be originally SS compounds or SP compounds in ancient Chinese scripts. For example, the word 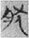 肰 (rán, Old Chinese *nan, “meat of dogs”) was originally an SS compound with two semantic components 肉 (ròu, Old Chinese *nuk, “meat”) and 犬 (quǎn, Old Chinese *khwînʔ, “dog”), but it was used as a compound loaned phonogram to write the word 然 (rán, Old Chinese *nan, “spontaneity”) in Guodian bamboo manuscripts. In this case, the semantic meanings of the composed character are neutralized on the top level and the character functions as a loaned phonogram.
肰 (rán, Old Chinese *nan, “meat of dogs”) was originally an SS compound with two semantic components 肉 (ròu, Old Chinese *nuk, “meat”) and 犬 (quǎn, Old Chinese *khwînʔ, “dog”), but it was used as a compound loaned phonogram to write the word 然 (rán, Old Chinese *nan, “spontaneity”) in Guodian bamboo manuscripts. In this case, the semantic meanings of the composed character are neutralized on the top level and the character functions as a loaned phonogram.
Another example is the character 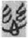 , an SP compound composed of the phonetic component 𢆶 (sī, Old Chinese *sə, “silk”) and the semantic component 心 (xīn, Old Chinese *səm, “heart”), which was originally used to write the word 慈 (cí, Old Chinese *dzə, “benevolence”
8
). However, it was used as a compound loaned phonogram to write the word 滋 (zī, Old Chinese *tsə, “more, abundant”) in Guodian bamboo manuscripts. In the last example, 心 “heart” has lost its semantic value as a classifier, and the whole SP compound
, an SP compound composed of the phonetic component 𢆶 (sī, Old Chinese *sə, “silk”) and the semantic component 心 (xīn, Old Chinese *səm, “heart”), which was originally used to write the word 慈 (cí, Old Chinese *dzə, “benevolence”
8
). However, it was used as a compound loaned phonogram to write the word 滋 (zī, Old Chinese *tsə, “more, abundant”) in Guodian bamboo manuscripts. In the last example, 心 “heart” has lost its semantic value as a classifier, and the whole SP compound 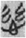 functions as a phonogram, without an additional classifier, to write the word
functions as a phonogram, without an additional classifier, to write the word 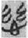 “more, abundant.” The semantic component 心 “heart” is not active anymore on the top level of the character meaning. This is not a rare example but exists extensively in ancient Chinses texts. For instance, 119 characters (557 occurrences) were originally SP compounds containing the semantic component 心 “heart” in the Guodian bamboo manuscripts, but 65 characters (148 occurrences) among them were used as compound loaned phonograms (see the 心 [
“more, abundant.” The semantic component 心 “heart” is not active anymore on the top level of the character meaning. This is not a rare example but exists extensively in ancient Chinses texts. For instance, 119 characters (557 occurrences) were originally SP compounds containing the semantic component 心 “heart” in the Guodian bamboo manuscripts, but 65 characters (148 occurrences) among them were used as compound loaned phonograms (see the 心 [
In Chinese, many phonograms that are SP compounds in origin are used as phonetic signifiers without the addition of a new semantic classifier related to the meaning of the second word to which the character has been applied. It causes a problem in discriminating compound loaned phonograms in Chinese from SP compounds containing semantic classifiers when there is no context. Studies were often conducted on semantic components in SP compounds either based on texts (e.g., oracle inscriptions, bronze inscriptions, and bamboo manuscripts) or dictionaries (e.g., SW), which mixed active semantic classifiers with the use of the same character in rebus function (e.g., Wang, 2007; Zhang, 2012). In the current study, SP compounds that are used as compound loaned phonograms in the Guodian corpus will not be accessed as characters that contain semantic classifiers.
It is necessary to differentiate the semantic classifiers from other related concepts. Firstly, semantic classifiers are not identical to bùshǒu 部首. Some scholars use bùshǒu as synonyms for the term “classifier” or “determinative.” However, bùshǒu refer to the lexicographic component used to look up characters in dictionaries. Bùshǒu can play different semiotic roles and have different functions. They often coincide with semantic classifiers but can play other semiotic roles, e.g., as semantic parts in SS compounds or logograms. Some bùshǒu are simply graphic subsets and play no functional role outside of dictionary organization and lookup.
Secondly, semantic classifiers are not identical to xíngpáng 形旁 (semantic components) or yìfú 義符 (semantic elements) 9 in SP compounds. As mentioned above, loaned phonograms (jiǎjiè 假借) can be compound characters such as SS compounds and SP compounds. When an SP compound was used as a compound loaned phonogram, the original semantic component in the SP compound is not active on the top level.
Modern Chinese scholarship uses the terminology lèifú 類符 (category markers) as a more accurate Chinese term meaning “semantic classifiers.” However, in Chinese-language grammatology, the term is not differentiated from bùshǒu, semantic components, or determinatives (Qiu, 2000: 8; Zhou, 1957), and is hardly ever used to refer to semantic classifiers. Instead, the Chinese term yìfú 義符 (semantic elements) was normally adopted when referring to semantic classifiers in Chinese scholarship (e.g., Xiang, 1987; Li, 1996; Chen, 2006). In my opinion, the term lèifú 類符 could be parallel in Chinese to the semantic classifiers that we discuss in this article, and I would advocate for its technical use with this meaning.
Corpus-based study
I chose to conduct this study in the framework of corpus linguistics. Corpus linguistics is the study of language as expressed in text corpora of a culture, i.e., as a body of “real world” texts. Corpus linguistics suggests that reliable language analysis is more feasible with corpora collected in their natural context and with minimal etic interference.
Two main strengths of the corpus-based approach are identified. Firstly, text corpora provide large databases. Secondly, they permit empirical analyses of the actual patterns of use in the texts. When coupled with (semi-)automatic computational tools, the corpus-based approach enables studies of a scope not otherwise feasible (Biber et al., 1998; Paquot and Gries, 2020).
On the choice of the Chu bamboo manuscripts
To study semantic classifiers in the ancient Chinese scripts using a corpus-based approach, I was looking for a corpus that maximally represents the targeted research question. Semantic classifiers are embedded in SP compounds in ancient Chinese scripts. Hence the proportion of SP compounds in sample texts is the major factor in corpus choice. 10
Liu (2009) counted the frequency of four script types (pictographs, iconographs, SS compounds, and SP compounds) of excavated texts in the major stages of ancient Chinese scripts.
11
The number of SP compounds/occurrences/tokens in the oracle bone inscriptions of the late Shang dynasty is 2,469 out of 43,897, constituting 5.62% of the corpus; in the bronze inscriptions of the Western Zhou dynasty is 14,018 out of 55,800, which is 25.12%; in the Chu bamboo manuscripts of the Warring States period is 24,733 out of 62,560, which is
Chu scripts are considered less standardized, however, they are an integral part of ancient Chinese scripts. They present more diversity because of the Chu region’s unique geographical location and cultural factors. As I have shown above, statistically, the Chu bamboo corpus has the best representative samples of SP compounds. In a later stage of my work, Qin scripts could be collected as a comparative corpus with Chu scripts.
The scope of the Chu bamboo manuscripts
The Chu scripts were inscribed or written on bronze objects, silk, bamboo strips, seals, currency, and so forth. The bamboo manuscripts are the most numerous among them, followed by the bronze inscriptions, and others are in minor quantities.
So far, the overall number of the published Chu bamboo manuscripts is around 130,000. The published Chu bamboo manuscripts with their approximate number of characters are as follows: 12 Chu bamboo manuscripts in Wulipai 13 (104), Yangtianhu (306), Yangjiawan (41), Xinyang/Changtaiguan (1,427), Wangshan (2,018), Zenghouyimu (6,700), Jiudian (2,425), Mashan (8), Xiyangpo (54), Baoshan (12,472), The Chinese University of Hong Kong (95), Angang (600), Caojiagang (33), Guodian (12,092), Shanghai Museum (all nine volumes, 35,000), Geling (8,000), Liye (43), Tsinghua University (volumes 1–12, 41,400), 14 Tazhong (88), Gaotai (23), Anhui University (volumes 1–2, 5,200), 15 Zaolinpu (975). Some of the texts were comparatively well preserved and published as high-definition pictures of original texts with interpretation and annotation such as Chu bamboo manuscripts in Guodian, Shanghai Museum, Tsinghua University and Anhui University. Yet, some of them were excavated in poor condition, for example, Chu bamboo manuscripts in Wulipai, Yangjiawan, Changtaiguan, Tazhong and Gaotai.
Some Chu bamboo manuscripts remain unpublished, such as Chu bamboo manuscripts in Tengdian, Tianxingguan, 16 Jiuli, Qinjiazui (M1, M13, and M99), Cili, Jigongshan, Zhuanwachang, Fanjiapo, Hongguang Zhuanwachang, Xinyang/Changtaiguan M7, Dingjiazui, Yancang, Wuhan University, Tuzishan, Wangshanqiao, Sanyanjing, Xiajiatai, Longhuihe, Zaolinpu/Zaozhichang, Wangjiazui, Qinjiazui M1093. They need more time to be studied and released.
The genre of bamboo manuscripts is generally divided into two categories: documents and literature (Li, 2008: 42–55; Zhao, 2004: 107; Zhang, 2004: 226). As for the genre of Chu bamboo manuscripts, Chen (2012: 3–5) separated them into four types: literary texts, divinatory records, inventory lists of burial goods, and administrative/legal documents. Table 1 presents the genre of published Chu bamboo manuscripts with the number of characters mentioned above.
Genre of published Chu bamboo manuscripts.
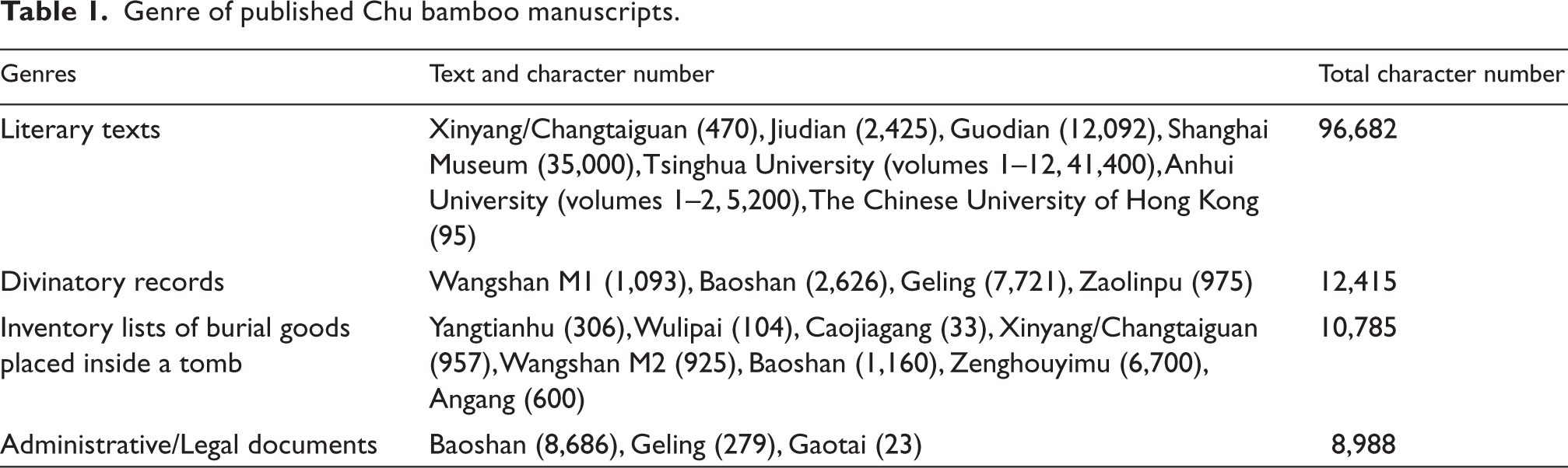
It is obvious that literary texts are the most numerous text types, which make up almost 75.02% (96,682/128,870) of the published Chu bamboo manuscripts. Literary texts include a variety of text types, such as philosophical texts, historical texts, poetry, and so forth, which are well-preserved compared to other genres. Therefore, literary texts could be good sample texts for a pilot corpus-based study while other genres could be used to enlarge and balance the corpus in the future.
The chosen sample corpus: Guodian bamboo manuscripts
The Guodian corpus, discovered in an excavation in a single tomb, contains over 703 bamboo strips with writing as well as several blank strips (Liu, 2017: 5). The texts include both Taoist and Confucian works, many previously unknown. The corpus has been well studied over the last two decades; most characters have been identified, and texts have been interpreted.
The data on Guodian bamboo manuscripts was provided by The Intelligent Retrieval Network Database of Chinese Characters (IRNDCC), which was built by the Center for the Study and Application of Chinese Characters (CSACC) in the East China Normal University (ECNU).
17
There are 12,092 tokens containing those tokens marked by chóngwénhào 重文號 (repetition marks)
18
in the original texts, for example, 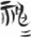 (Taiyishengshui 2, 5)
19
was marked by “two dots” below the character, namely the repetition mark, which indicates that the character 神 (shén, Old Chinese *m-lin, “gods”) should be repeated once again. Thus, it was counted as two identical tokens. In addition, a character written with héwénhào 合文號 (ligature marks)
20
is counted as a compound token. For example,
(Taiyishengshui 2, 5)
19
was marked by “two dots” below the character, namely the repetition mark, which indicates that the character 神 (shén, Old Chinese *m-lin, “gods”) should be repeated once again. Thus, it was counted as two identical tokens. In addition, a character written with héwénhào 合文號 (ligature marks)
20
is counted as a compound token. For example,  (Laozi B 16, 3) was also marked by “two dots” below the character. It is the ligature mark which has the identical form to the repetition mark but has a different function. The ligature mark indicates that two characters were written together, namely part of the strokes of the two characters overlapped. In the above example, two characters 子 (zǐ, Old Chinese *tsəʔ, “son, child”) and 孫 (sūn, Old Chinese *sûn, “grandson”) were written in the space of one character with the overlapped part 子. In such a compound token, two characters were given a token ID respectively.
(Laozi B 16, 3) was also marked by “two dots” below the character. It is the ligature mark which has the identical form to the repetition mark but has a different function. The ligature mark indicates that two characters were written together, namely part of the strokes of the two characters overlapped. In the above example, two characters 子 (zǐ, Old Chinese *tsəʔ, “son, child”) and 孫 (sūn, Old Chinese *sûn, “grandson”) were written in the space of one character with the overlapped part 子. In such a compound token, two characters were given a token ID respectively.
The original data from IRNDCC allows the special font of Chu scripts to be imported; otherwise, it would be hard to type some special Chu scripts with the existing fonts. The original data also contains other information about each token, for example, its screenshot of the original text and mark of loaned phonograms. The imported original data is of great help for the following manual work of the classifier tagging.
My data collection and tagging on the iClassifier platform was carried out as follows: The original texts 郭店楚墓竹簡 (Chu Bamboo Manuscripts Excavated in Guodian) published by Jingmen Museum in 1998 were uploaded to the witness page. Detailed information on a specific lemma such as its Chinese transcription and the English translation was taken from the Multi-function Chinese Character Database (MFCCD). The token pictures (token ID 2574-12092) were uploaded automatically from IRNDCC. Before that, token pictures from 1 to 2573 were tentatively cropped and uploaded manually from the original text Chu Bamboo Manuscripts Excavated in Guodian. All classifier pictures could only be added manually. Among various phonetic reconstruction systems of Old Chinese, I chose Minimal Old Chinese and Later Han Chinese: A Companion to Grammata Serica Recensa by Schuessler (2009).
21
However, some tokens were not included in the list. In these cases, I chose other reconstruction systems such as Baxter and Sagart (2014). By marking the “Liushu” category of all tokens in those texts, we can know which type of “Liushu” has the highest proportion. The proportion of SP compounds is directly related to the number of classifiers. Both “Token meaning” and “Context” have Chinese and English translations. The Chinese context and token meaning followed IRNDCC. The English translation of context and token meaning followed The Bamboo Texts of Guodian: A Study & Complete Translation by Cook (2012). However, some Chinese context and token meanings did not correspond with the English translations. The reason is that the meaning of some words in the texts is ambiguous, and scholars have different interpretations.
Studies by iClassifier
The great advantage of this research is the possibility of working with iClassifier (© Goldwasser, Harel, Nikolaev), a new digital platform developed in the Archaeomind Lab at the Hebrew University. This digital tool is a cutting-edge product created for the modern analysis of graphemic classifier systems (see Harel, Goldwasser and Nikolaev, 2024).
Classifier list of Guodian bamboo manuscripts
The Guodian bamboo texts have 12,092 tokens, of which 409 lemmas and 2,263 tokens contain 99 distinct semantic classifiers. Figure 1 presents classifiers with the number of lemmas in Guodian bamboo manuscripts. Among 99 classifiers, only 54 classifiers show more than a single member in the chosen corpus (45 classifiers have only a single member). Only 18 classifiers show more than four members (81 classifiers contain no more than four members). Only 10 classifiers show more than 10 classified lemmas. The most prominent feature of Figure 1 is that the first 10 categories of classifiers account for 50.12% (205/409) of the number of lemmas, which indicates a typical network pattern. However, there are 81.82% (81/99) of classifiers containing no more than four members. It shows that the category network of these specific categories is probably still not developed.
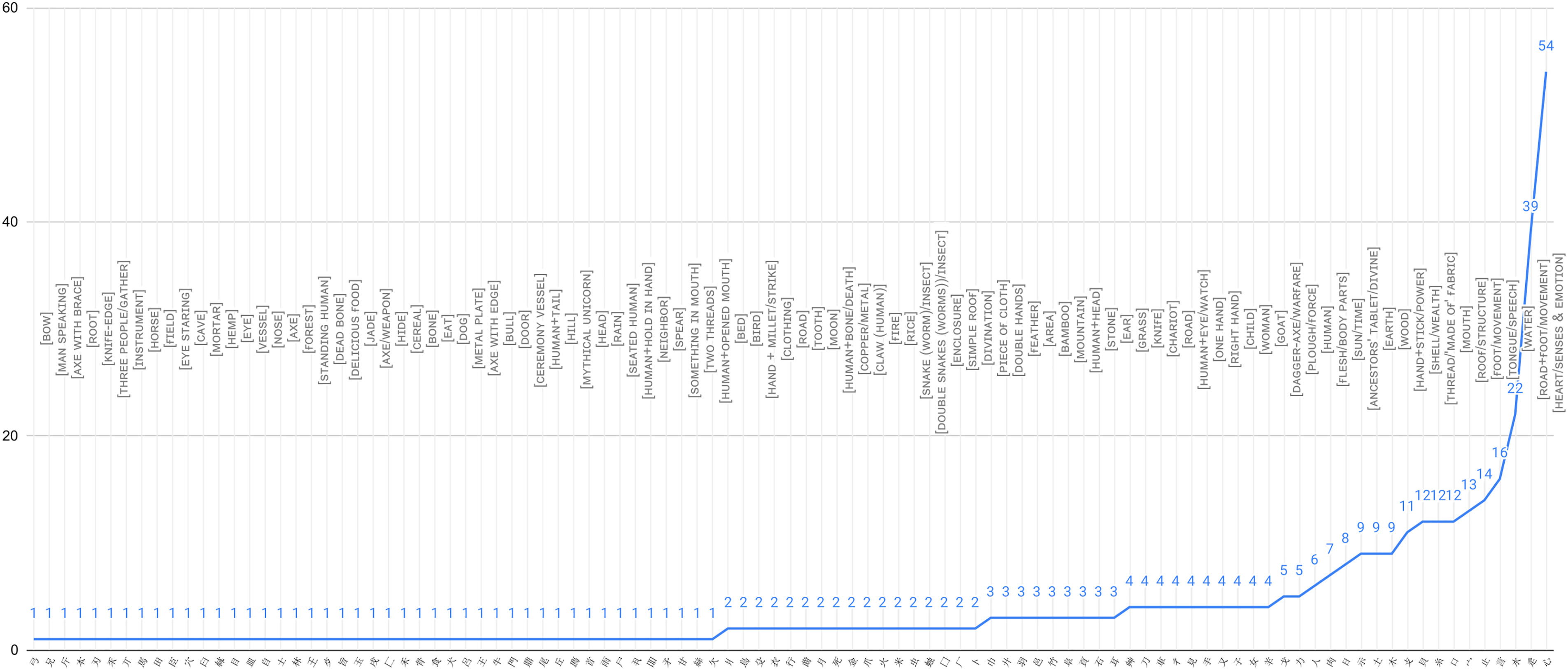
Classifiers by no. of lemmas classified, Yanru Xu (for long-tail distribution graphs in iClassifier, see Harel, 2023). Chinese character labels are in italics because of space limitation.
The first 10 categories are 心 [
The largest number of tokens in Table 2, related to the classifiers 心 [
The first 10 most common classifiers (by the number of lemmas) in Guodian bamboo manuscripts.
A complete list of classifiers in the Guodian bamboo manuscripts arranged by topics is as follows.
24
Asterisks mark one-member categories; the number of examples follows each category name. For increased clarity, the images of ancient signs are cropped from the Sign List of Chu Bamboo Manuscripts Excavated in Guodian (Zhang et al., 2000) rather than the original text reproductions of Chu Bamboo Manuscripts Excavated in Guodian. The names of the categories in English suggested by me are tentative and naturally a modern interpretation.
 人/亻[
人/亻[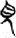 見[
見[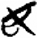 女[
女[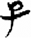 子[
子[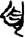 頁[
頁[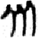 乑[
乑[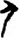 尸[
尸[ 𡈼[
𡈼[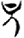 兄[
兄[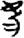 欠[
欠[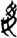 丮[
丮[ 尾[
尾[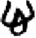 心/忄[
心/忄[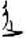 辵/辶[
辵/辶[ 言/讠[
言/讠[ 止[
止[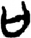 口[
口[ 攵/攴[
攵/攴[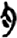 肉/月[
肉/月[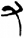 又[
又[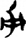 手/扌[
手/扌[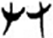 廾[
廾[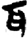 耳[
耳[ 𠚒/齒[
𠚒/齒[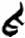 爪 [
爪 [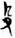 殳[
殳[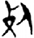 死[
死[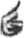 首[
首[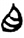 目[
目[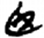 臣[
臣[ 自/鼻[
自/鼻[ 甘 [
甘 [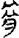 骨[
骨[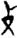 歺/歹[
歺/歹[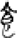 食[
食[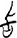 旨[
旨[ 羊[
羊[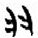 羽[
羽[ 鳥[
鳥[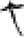 虫[
虫[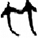 䖵 [
䖵 [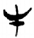 牛[
牛[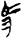 馬[
馬[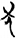 犬[
犬[ 廌[
廌[ 木[
木[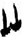 艸/艹[
艸/艹[ 竹[
竹[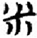 米[
米[ 林[
林[ 本[
本[ 禾[
禾[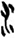 水/氵[
水/氵[ 土[
土[ 日[
日[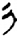 彳[
彳[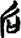 石/厂[
石/厂[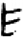 阜/𨸏[
阜/𨸏[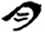 月[
月[ 火[
火[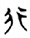 行[
行[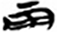 雨[
雨[ 丘[
丘[ 田[
田[ 宀[
宀[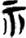 示/礻[
示/礻[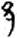 邑[
邑[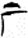 厂/广[
厂/广[ 囗[
囗[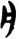 爿 [
爿 [ 穴[
穴[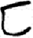 匚[
匚[ 門/门[
門/门[ 吅 [
吅 [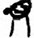 貝[
貝[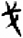 戈[
戈[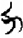 力[
力[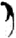 刀/刂[
刀/刂[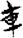 車[
車[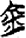 金/钅[
金/钅[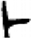 卜[
卜[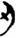 刃[
刃[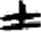 士[
士[ 戌[
戌[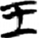 王[
王[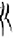 斤[
斤[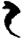 弓[
弓[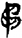 矛[
矛[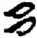 呂[
呂[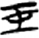 玉[
玉[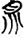 鼎[
鼎[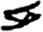 皿[
皿[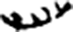 臼[
臼[ 丌/瑟[
丌/瑟[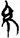 糸/糹 [
糸/糹 [ 巾 [
巾 [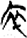 衣/衤[
衣/衤[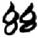 𢆶/絲 [
𢆶/絲 [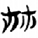 𣏟/麻[
𣏟/麻[
Classifier axis (classifier categories)—examples
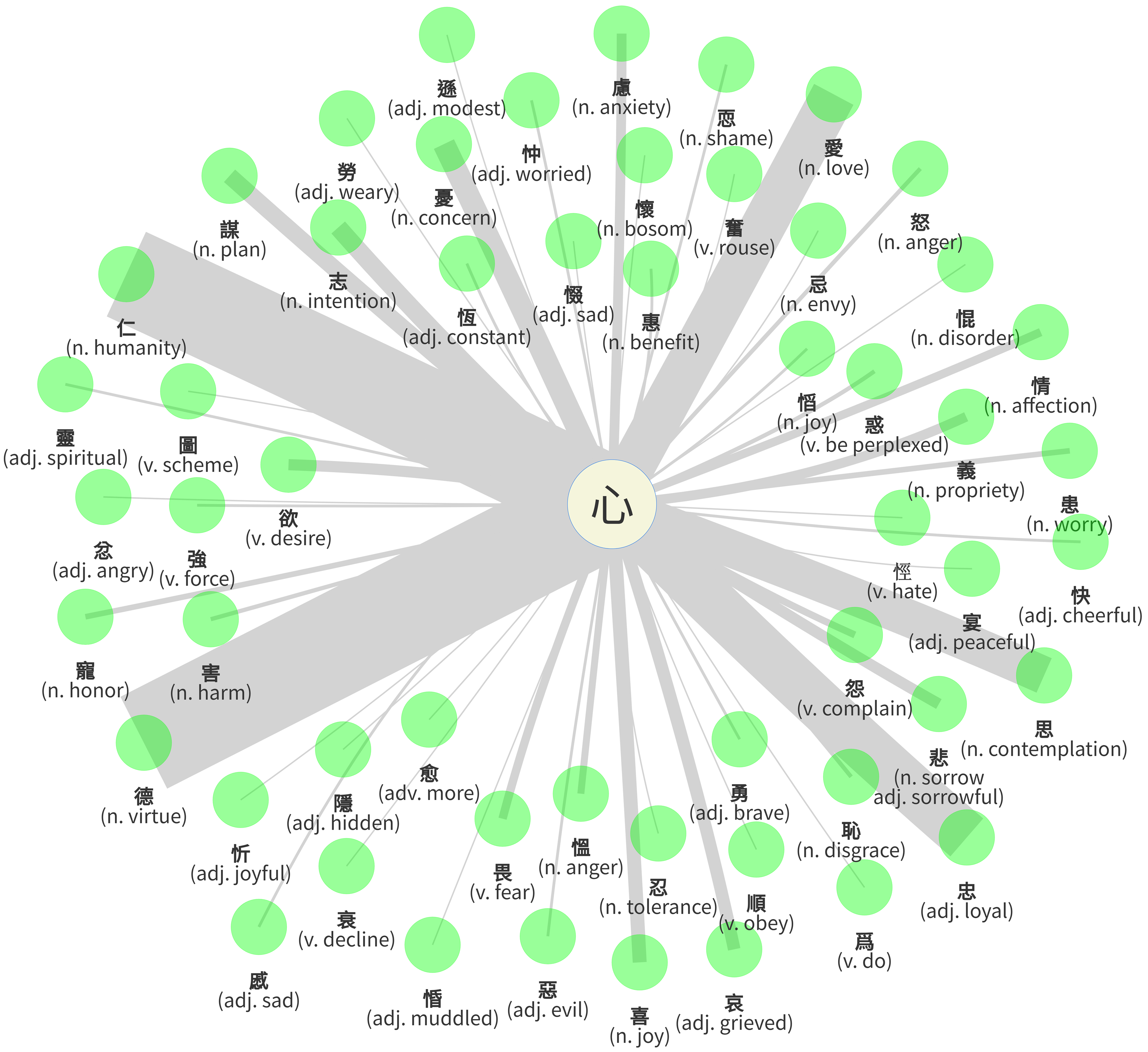
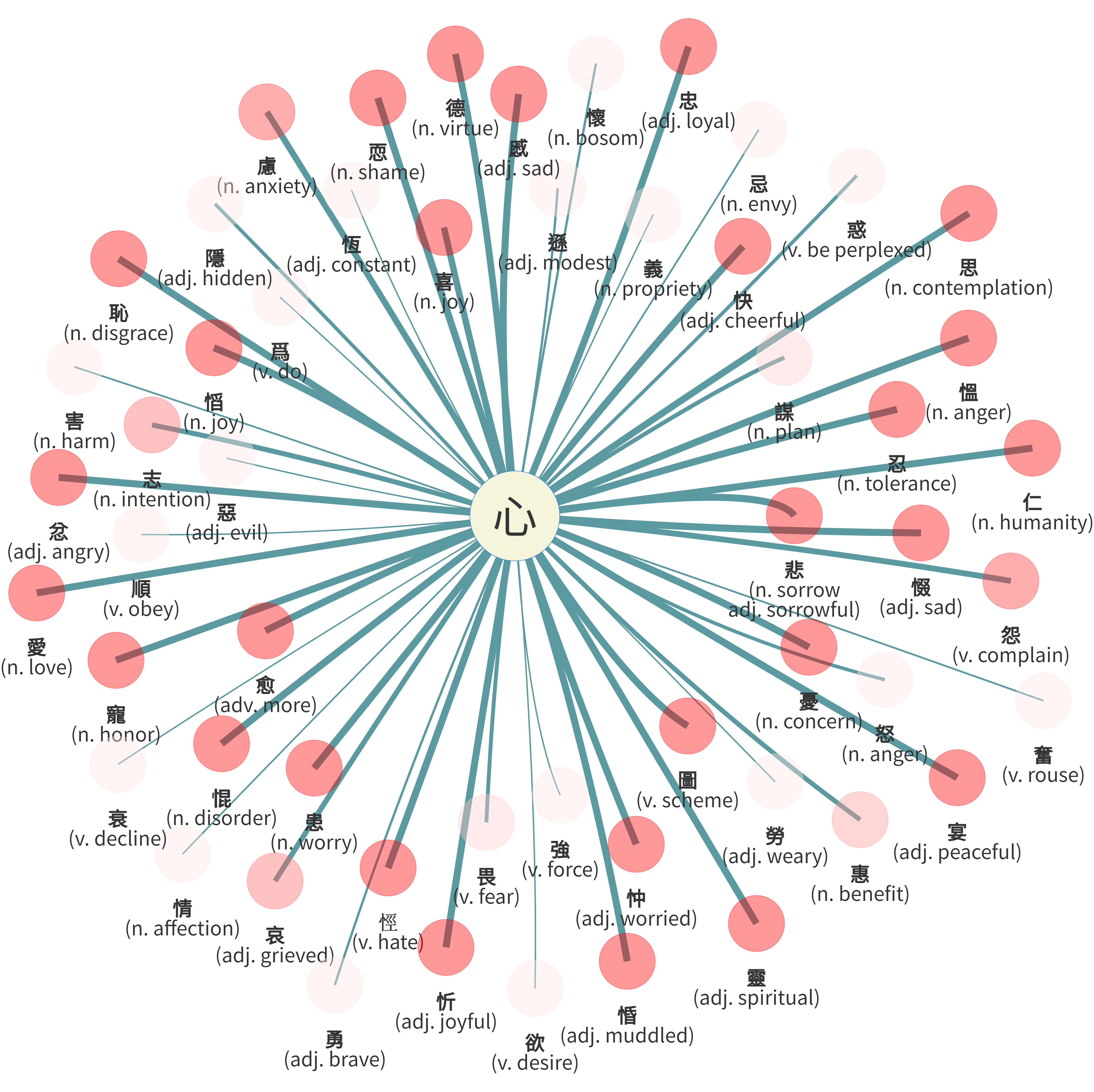
In the classifier network of Guodian bamboo manuscripts, classifiers related to humans and body parts are very prominent, and account for 36.36% (36/99) of classifiers in the corpus. Similarly, they appear as central classifiers in Egyptian hieroglyphs (Goldwasser and Soler, 2024). To present the framework of the classifier study, two prominent classifiers from the human sphere, 心 [
心 [heart /senses & emotion ]
26
The 心 [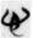 .
27
The Chinese conceptualize the 心 “heart” as the central faculty of cognition. The heart is understood as the “ruler of the body” (Yu, 2008). Several scholars discussed the classification of SP compounds containing the semantic component 心 “heart,” but most were based on SW (Luo, 2002; Lin, 2004; Wang, 2009; Bottéro and Harbsmeier, 2016; Yue, 2021, etc.). Lei (2017) conducted a corpus-based study of the semantic component 心 “heart” in Chu bamboo manuscripts without distinguishing semantic classifiers from compound loan phonograms.
.
27
The Chinese conceptualize the 心 “heart” as the central faculty of cognition. The heart is understood as the “ruler of the body” (Yu, 2008). Several scholars discussed the classification of SP compounds containing the semantic component 心 “heart,” but most were based on SW (Luo, 2002; Lin, 2004; Wang, 2009; Bottéro and Harbsmeier, 2016; Yue, 2021, etc.). Lei (2017) conducted a corpus-based study of the semantic component 心 “heart” in Chu bamboo manuscripts without distinguishing semantic classifiers from compound loan phonograms.
According to my data, there are 54 lemmas (409 tokens) in this category (Figures 2 and 3). Figure 2 presents the token number of each lemma in this category. Among them, the first two lemmas are 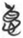 德 “virtue” (74)
28
and
德 “virtue” (74)
28
and 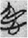 仁 “humanity” (67), followed by
仁 “humanity” (67), followed by 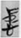 忠 “loyal” (36),
忠 “loyal” (36),  愛 “love” (32),
愛 “love” (32),  思 “contemplation” (27),
思 “contemplation” (27), 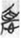 憂 “concern” (16),
憂 “concern” (16),  志 “intention” (13),
志 “intention” (13), 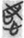 謀 “plan” (12), and
謀 “plan” (12), and  喜 “joy” (10). Then there are the lemmas
喜 “joy” (10). Then there are the lemmas 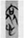 哀 “grief” (9),
哀 “grief” (9),  悲 “sorrow” (8),
悲 “sorrow” (8), 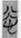 欲 “desire” (8),
欲 “desire” (8), 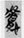 慮 “anxiety” (7),
慮 “anxiety” (7), 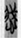 義 “propriety” (7),
義 “propriety” (7), 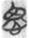 畏 “fear” (6),
畏 “fear” (6),  情 “affection” (6),
情 “affection” (6),  怨 “complain” (5),
怨 “complain” (5),  慍 “anger” (5). The remaining lemmas have less than five examples.
慍 “anger” (5). The remaining lemmas have less than five examples.
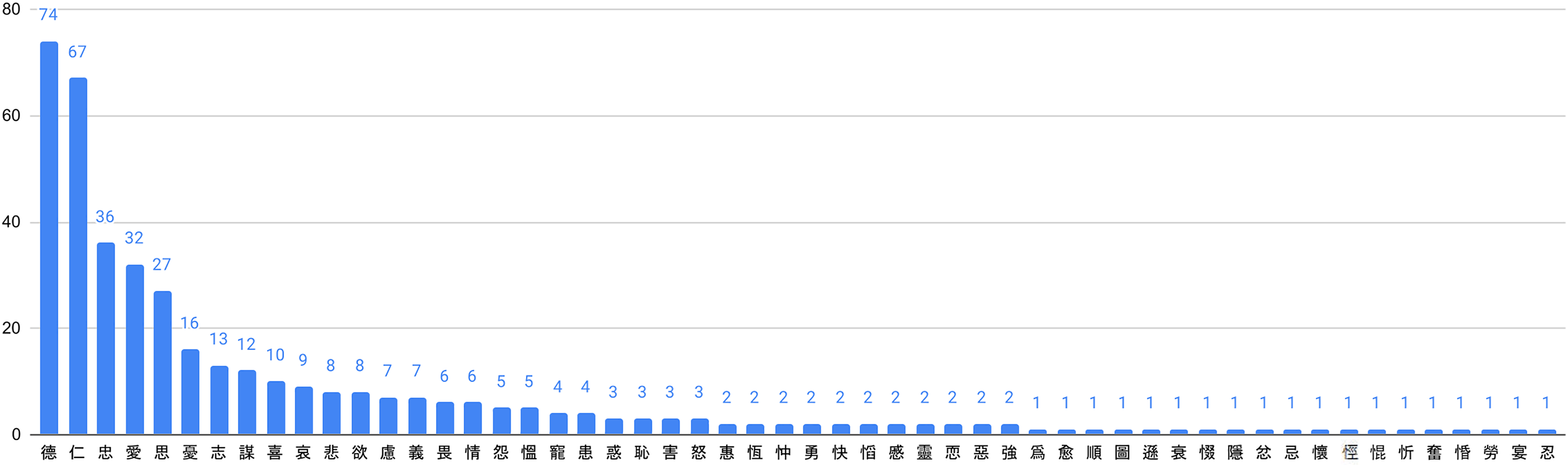
Lemma by no. of examples of classifier 心 [
Edge width by no. of examples of classifier 心 [
Figure 3 shows the 心 [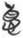 德 “virtue” in the network graph.
德 “virtue” in the network graph. 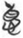 德 “virtue” is a crucial concept in both Taoist and Confucian philosophy. It may be interesting to note that the most common meanings of the lemmas in this category are positive, and
德 “virtue” is a crucial concept in both Taoist and Confucian philosophy. It may be interesting to note that the most common meanings of the lemmas in this category are positive, and 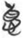 德 “virtue,” the socially “correct” behavior, is a center member in this category. More negative concepts, such as
德 “virtue,” the socially “correct” behavior, is a center member in this category. More negative concepts, such as 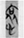 哀 “grief” and
哀 “grief” and  悲 “sorrow,” are less central.
悲 “sorrow,” are less central.
In Figure 4, the deeper red circles show the lemma is classified always or almost always by 心 [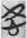 愛 “love” and
愛 “love” and 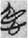 仁 “humanity” are 100% centrality rank, which indicates they are always classified by 心 [
仁 “humanity” are 100% centrality rank, which indicates they are always classified by 心 [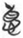 德 “virtue” has the greatest number of examples, showing 95% centrality rank, as it has a few unclassified tokens. Within 78 occurrences, there are also four tokens that were written in phonograms.
德 “virtue” has the greatest number of examples, showing 95% centrality rank, as it has a few unclassified tokens. Within 78 occurrences, there are also four tokens that were written in phonograms.
Edge width by lemma centrality rank of classifier 心 [
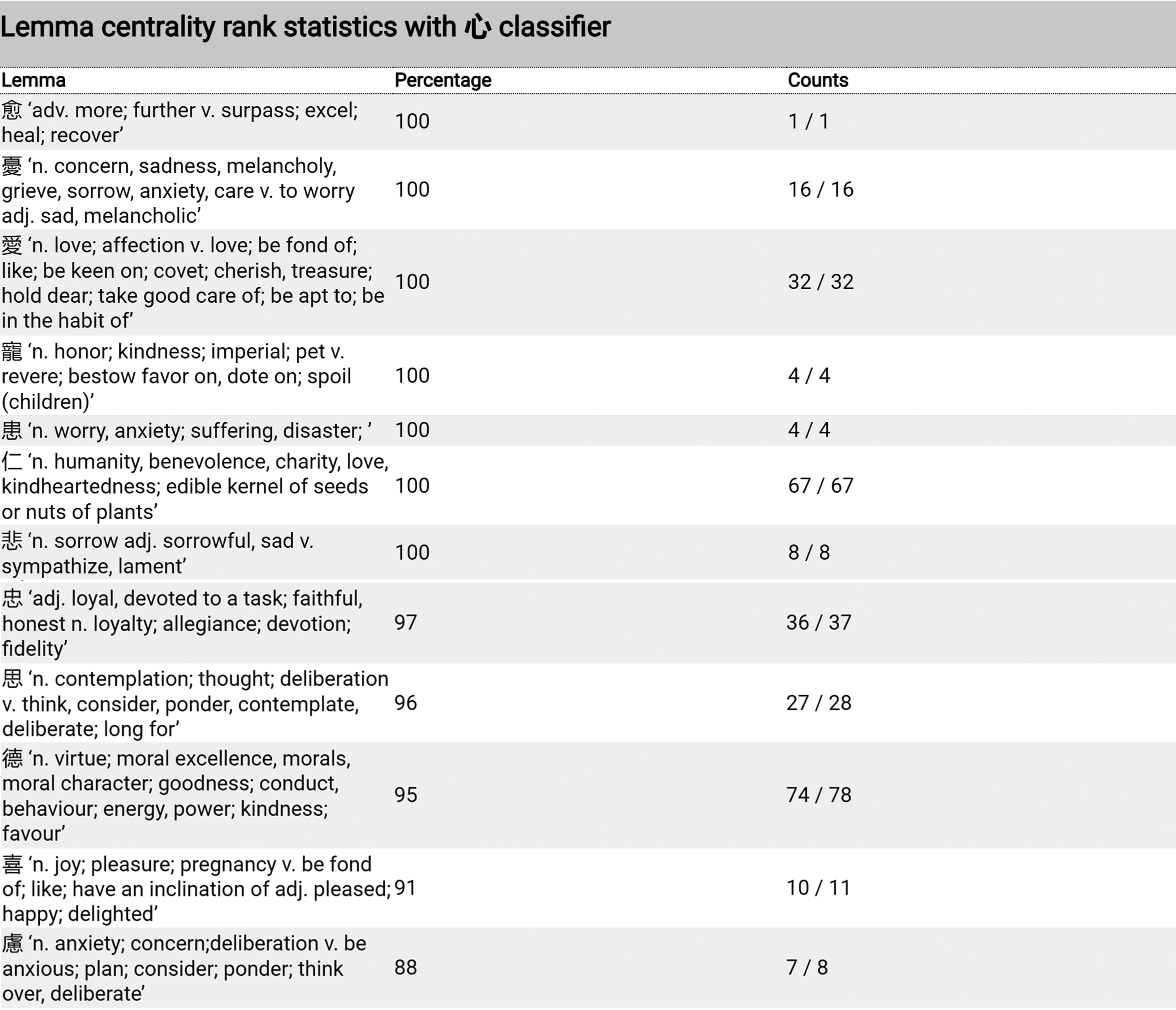
Lemma centrality rank statistics (partial list) of the classifier 心 [
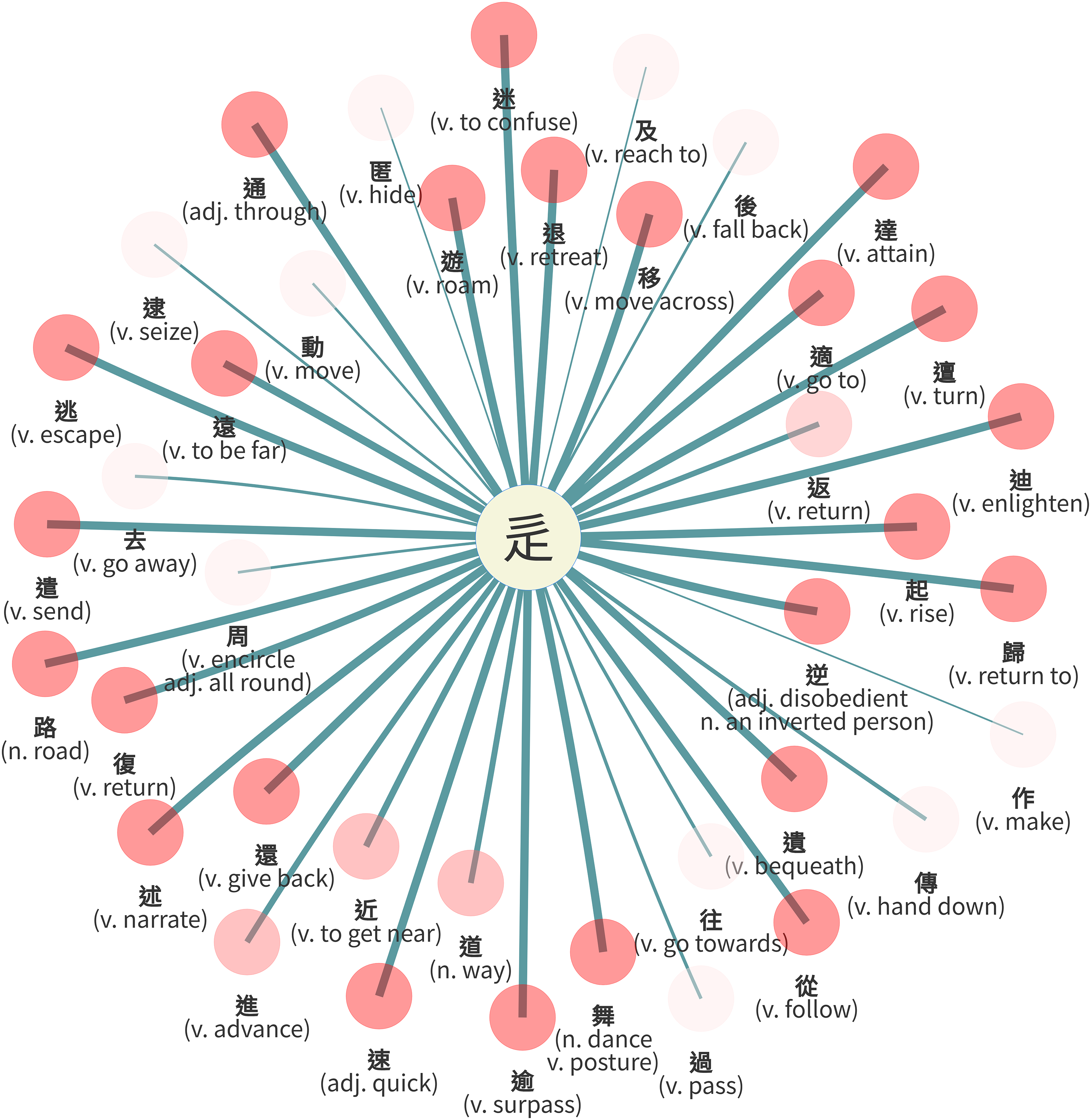
辵 [road + foot/movement ]
In the second biggest category 辵 [ “road with foot” is composed of
“road with foot” is composed of  “road” and
“road” and  “foot,” which is similar to the classifier
“foot,” which is similar to the classifier  道 “way, The Way” is the most significant member, which has 86 examples in the corpus. It is followed by
道 “way, The Way” is the most significant member, which has 86 examples in the corpus. It is followed by 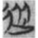 從 “follow” (30),
從 “follow” (30),  復 “return” (19),
復 “return” (19), 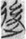 後 “fall back” (14),
後 “fall back” (14), 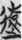 遠 “far” (12),
遠 “far” (12),  進 “advance” (11),
進 “advance” (11), 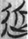 近 “near” (11),
近 “near” (11),  達 “attain” (8),
達 “attain” (8), 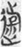 遊 “roam” (8),
遊 “roam” (8), 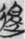 退 “retreat” (6),
退 “retreat” (6), 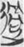 過 “pass” (6). The rest of the words have less than five examples.
過 “pass” (6). The rest of the words have less than five examples.
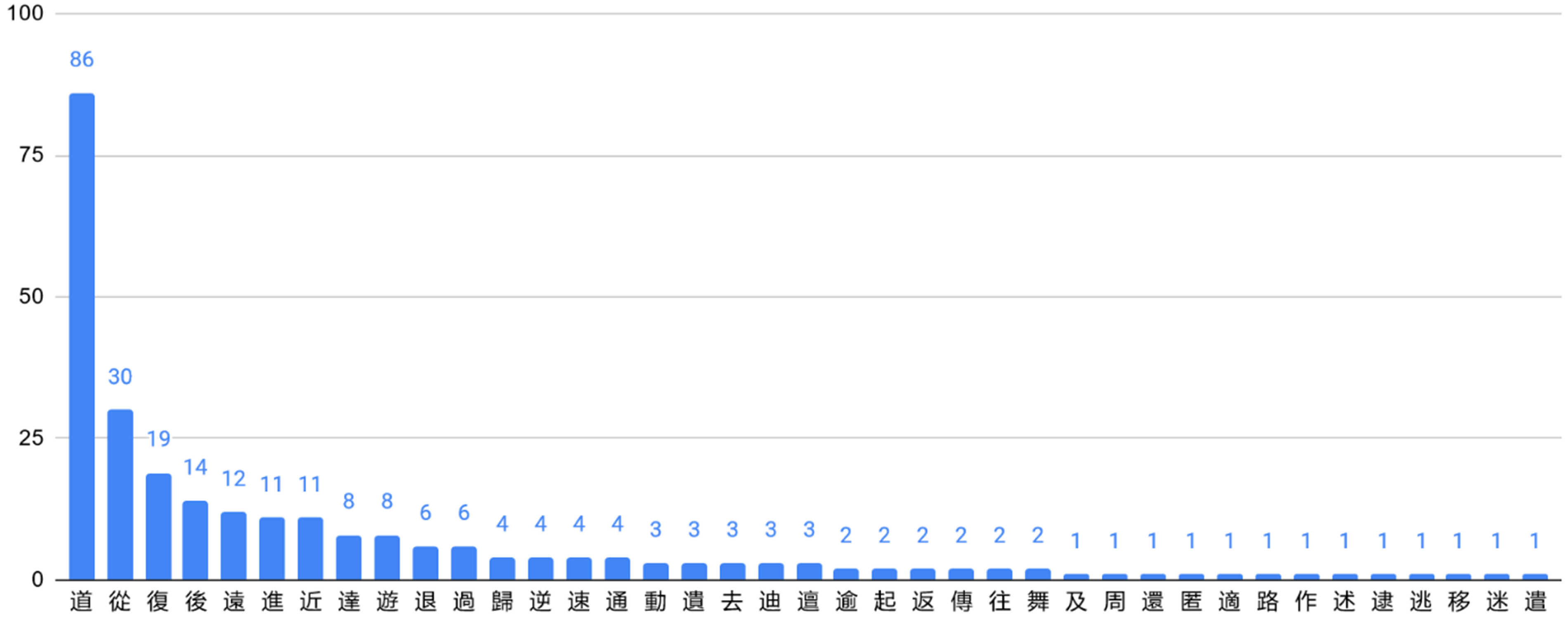
Lemma by no. of examples of classifier 辵 [
In the circle graph in Figure 7, edges link between the classifier in the middle and members presented as green circles. The widest edge is between the classifier and the member 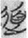 道 “way, The Way,” which indicates this lemma has the most examples of all the lemmas as mentioned above. The word
道 “way, The Way,” which indicates this lemma has the most examples of all the lemmas as mentioned above. The word 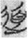 道 translated here as “way” (dào, Old Chinese *lûʔ), literally meaning “man walking on the road,” is an S(Sp) compound made of two semantic components, 首 “head” and 辵 “road and foot,” in which the component 首 (shǒu, Old Chinese *lhuʔ, “head”) functions as a phonetic component simultaneously.
道 translated here as “way” (dào, Old Chinese *lûʔ), literally meaning “man walking on the road,” is an S(Sp) compound made of two semantic components, 首 “head” and 辵 “road and foot,” in which the component 首 (shǒu, Old Chinese *lhuʔ, “head”) functions as a phonetic component simultaneously.
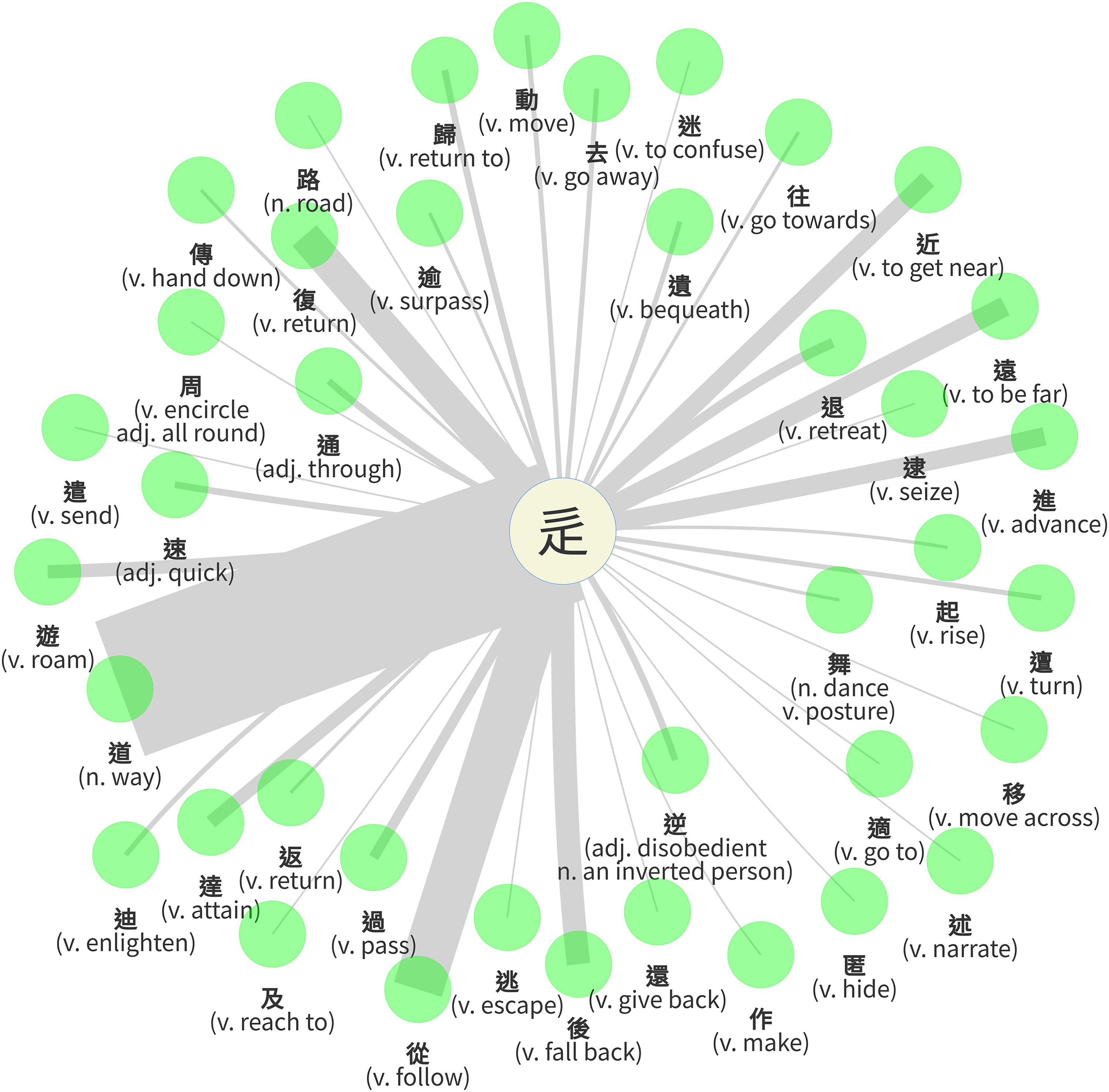
Edge width by no. of examples of classifier 辵 [
However, the word 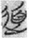 道 expands its semantic field to “the way of universe” as an abstract philosophic concept in most cases in the corpus. Thus, the concept 道 is the order and principle of the universe. There are two other variant forms of the word in the corpus,
道 expands its semantic field to “the way of universe” as an abstract philosophic concept in most cases in the corpus. Thus, the concept 道 is the order and principle of the universe. There are two other variant forms of the word in the corpus, 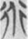 and
and  , which are both SS compounds: The former variation
, which are both SS compounds: The former variation 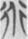 is comprised of two semantic components, 行 “road” and 人 “person”; the latter variation
is comprised of two semantic components, 行 “road” and 人 “person”; the latter variation  is comprised of two semantic components, 行 “road” and 頁 “human and head.” They do not enter our counting as SS compounds.
is comprised of two semantic components, 行 “road” and 頁 “human and head.” They do not enter our counting as SS compounds.
In Figures 8 and 9, the lemma centrality rank of classifier 辵 [ 起 “rise”) are marginal members in the sense that they show low numbers of occurrences. On the other hand, we see that the lemma
起 “rise”) are marginal members in the sense that they show low numbers of occurrences. On the other hand, we see that the lemma  道 “way, The Way,” which shows the largest number of tokens (121, see Figure 9), is classified by 辵 only in 71% of its occurrences. The other examples of “way, The Way” are SS compounds, as shown above.
道 “way, The Way,” which shows the largest number of tokens (121, see Figure 9), is classified by 辵 only in 71% of its occurrences. The other examples of “way, The Way” are SS compounds, as shown above.
Edge width by lemma centrality rank of classifier 辵 [
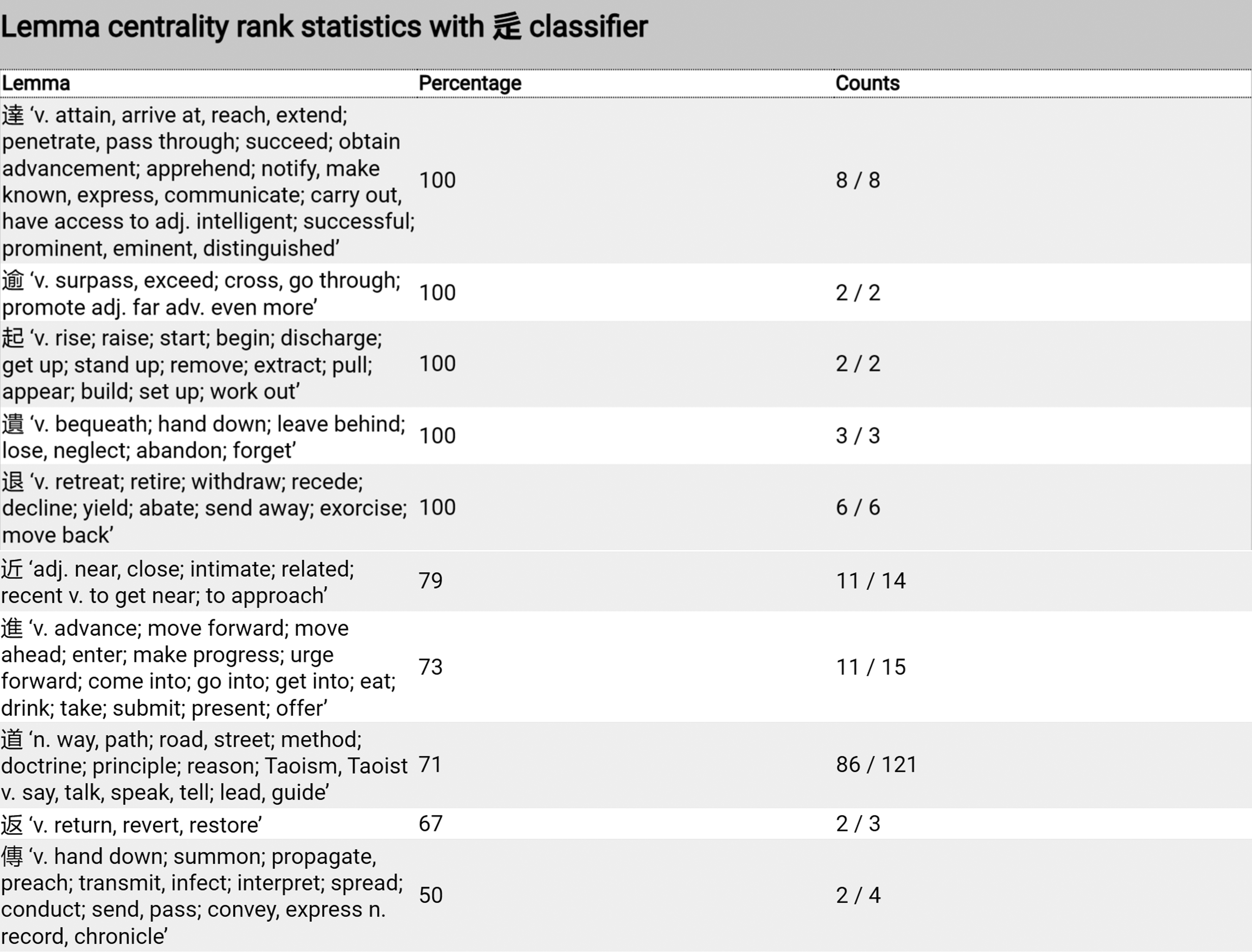
Lemma centrality rank statistics (partially) with the classifier 辵 [
Word axis
Alternating classification
Ancient Chinese script is a very dynamic system. Unlike the modern Chinese script, a word could be written in several ways, such as written by phonograms only, or with phonogram and semantic classifier. For example, all four characters 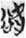 ,
, 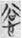 ,
, 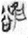 , and
, and 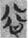 could be used to write the lemma 欲 (yù, Old Chinese *lok, “desire”), appearing 43 tokens in total in my corpus.
could be used to write the lemma 欲 (yù, Old Chinese *lok, “desire”), appearing 43 tokens in total in my corpus. 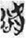 欲 (4 tokens) have the phonetic component
欲 (4 tokens) have the phonetic component 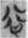 谷 (gŭ, Old Chinese *klok, “valley”) on the left and the semantic component
谷 (gŭ, Old Chinese *klok, “valley”) on the left and the semantic component 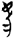 欠 [
欠 [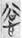 (8 tokens) is also an SP compound in which the phonetic component is the same, namely 谷 (gŭ, Old Chinese *klok, “valley”), but its semantic component is 心 [
(8 tokens) is also an SP compound in which the phonetic component is the same, namely 谷 (gŭ, Old Chinese *klok, “valley”), but its semantic component is 心 [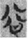 谷 (30 tokens) with a phonogram only (without a semantic classifier). An unusual example is
谷 (30 tokens) with a phonogram only (without a semantic classifier). An unusual example is 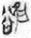 (1 token), a compound in which the phonetic component is the same, but the second component is 隹 “bird.” The 隹 is probably not a semantic component in this case but a component in rebus spelling. In Figure 10, two blue lines connect the word 欲 “desire” to its two classifiers. The wider blue line shows that the word 欲 “desire” has more examples with the classifier 心 [
(1 token), a compound in which the phonetic component is the same, but the second component is 隹 “bird.” The 隹 is probably not a semantic component in this case but a component in rebus spelling. In Figure 10, two blue lines connect the word 欲 “desire” to its two classifiers. The wider blue line shows that the word 欲 “desire” has more examples with the classifier 心 [

Classifiers 心 [
In Figure 11, the classifier is in red and in brackets. The token ID, witness and coordinates in the witness follow. Two examples (Token ID 136 and 161) are without semantic classifiers, but only phonograms.

Partial list of all tokens of lemma 欲 “desire,” by iClassifier, Yanru Xu.
Multiple classification
Compound characters in ancient Chinese scripts sometimes have more than two components, which indicates that a word may take more than a single semantic classifier. For instance, the word 哀 (āi, Old Chinese *ʔə̂j, “grief”) can be classified by either 心 [ “grief” (kind of emotion) while the classifier 口 [
“grief” (kind of emotion) while the classifier 口 [ “grief” (the mouth takes part in the grief process). When the word
“grief” (the mouth takes part in the grief process). When the word 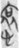 “grief” has a double classification, it shows that “crying out loud through the mouth” is the expression of grief.
“grief” has a double classification, it shows that “crying out loud through the mouth” is the expression of grief.

Table of double classification of the word 哀 “grief,” by iClassifier, Yanru Xu.
There are no examples of more than two classifiers in a single graph found in the Guodian bamboo manuscripts. However, Egyptian hieroglyphs could have more classifiers for a single lemma, for example, 𓊠𓂝𓏲𓅬𓆟𓀜𓀀 wḥꜥ “fowler” mentioned above, with four classifiers.
Network maps
While working on the corpus in iClassifier, all semantic classifiers were marked by two tilde signs (∼CL∼) so they could be identified by the digital tool. 29 A network of the classifier system has been gradually built up (Figure 13). In the network map, all members of each of the categories are connected by blue edges to their classifier category head. The edge width indicates the number of tokens of each member. Classifiers could be connected by red edges, which means that words could be classified by more than one classifier.

Classifier network map of Guodian bamboo manuscripts, by iClassifier, Yanru Xu.
In Figure 14, we see a detail from the full network map (Figure 13). There are four classifiers: 言 [ , or 子 [
, or 子 [ . The classifier 殳 [
. The classifier 殳 [
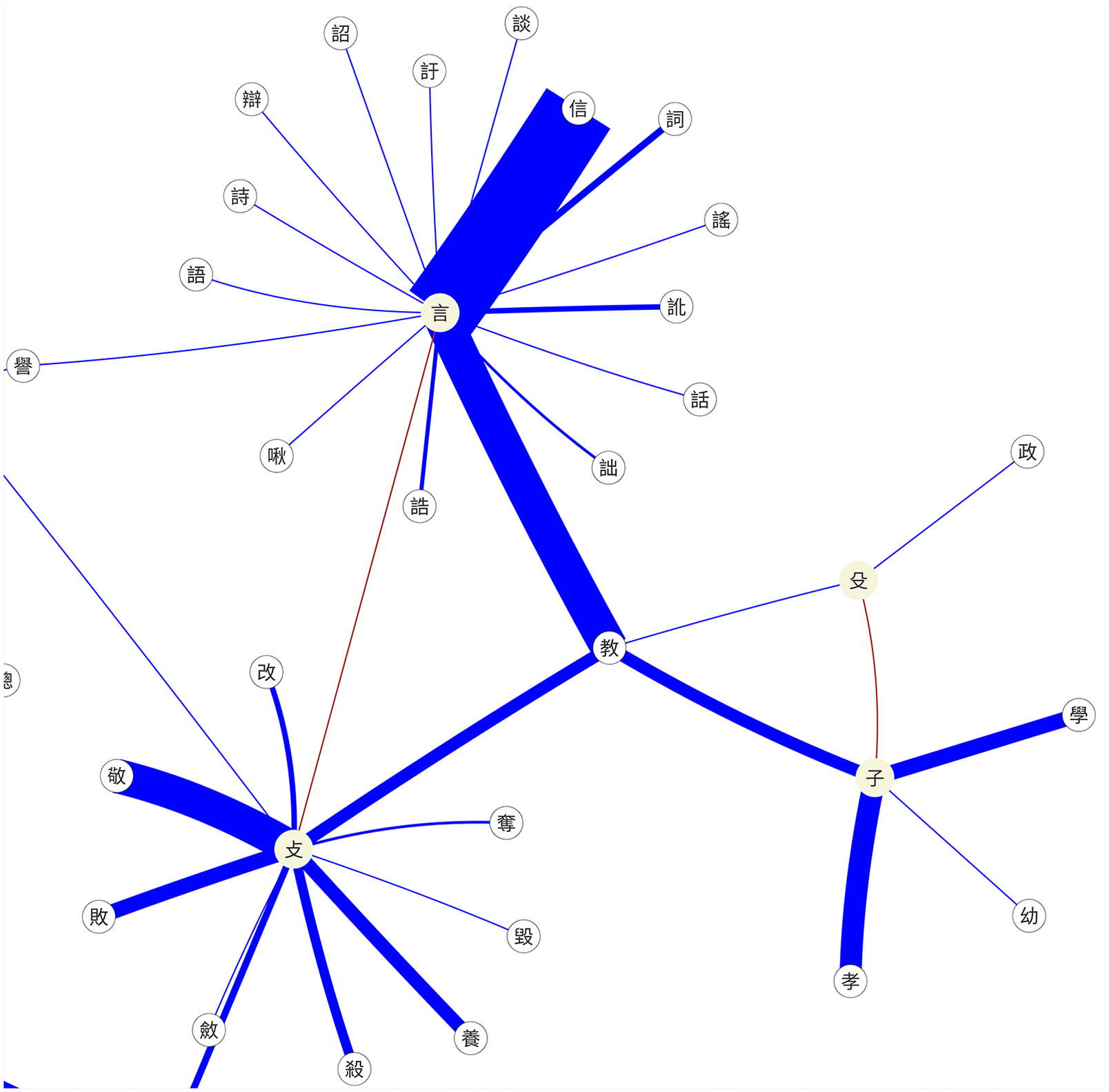
The word 教 “teach” double classified by 言 [
Conclusion
We are aware of the limitations of the study resulting from our relatively small corpus. Other corpora of texts from the same period or somewhat later texts will be studied in the near future. They will tell us if some small-scale categories of single or two members will grow into larger categories or would remain small or even disappear. For example, 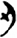 刃 [
刃 [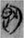 斷 (duàn, Old Chinese *tônʔ, “cut off”). Another direction is the study of other genres that may change the balance of statistical results of our corpus, which includes mainly literary and philosophical texts. Naturally, all kinds of genres could be studied and analyzed by the digital tool.
斷 (duàn, Old Chinese *tônʔ, “cut off”). Another direction is the study of other genres that may change the balance of statistical results of our corpus, which includes mainly literary and philosophical texts. Naturally, all kinds of genres could be studied and analyzed by the digital tool.
Taking the 示 [ 祖 “ancestor,”
祖 “ancestor,”  禱 “pray,” and
禱 “pray,” and  災 “disaster”.
災 “disaster”.
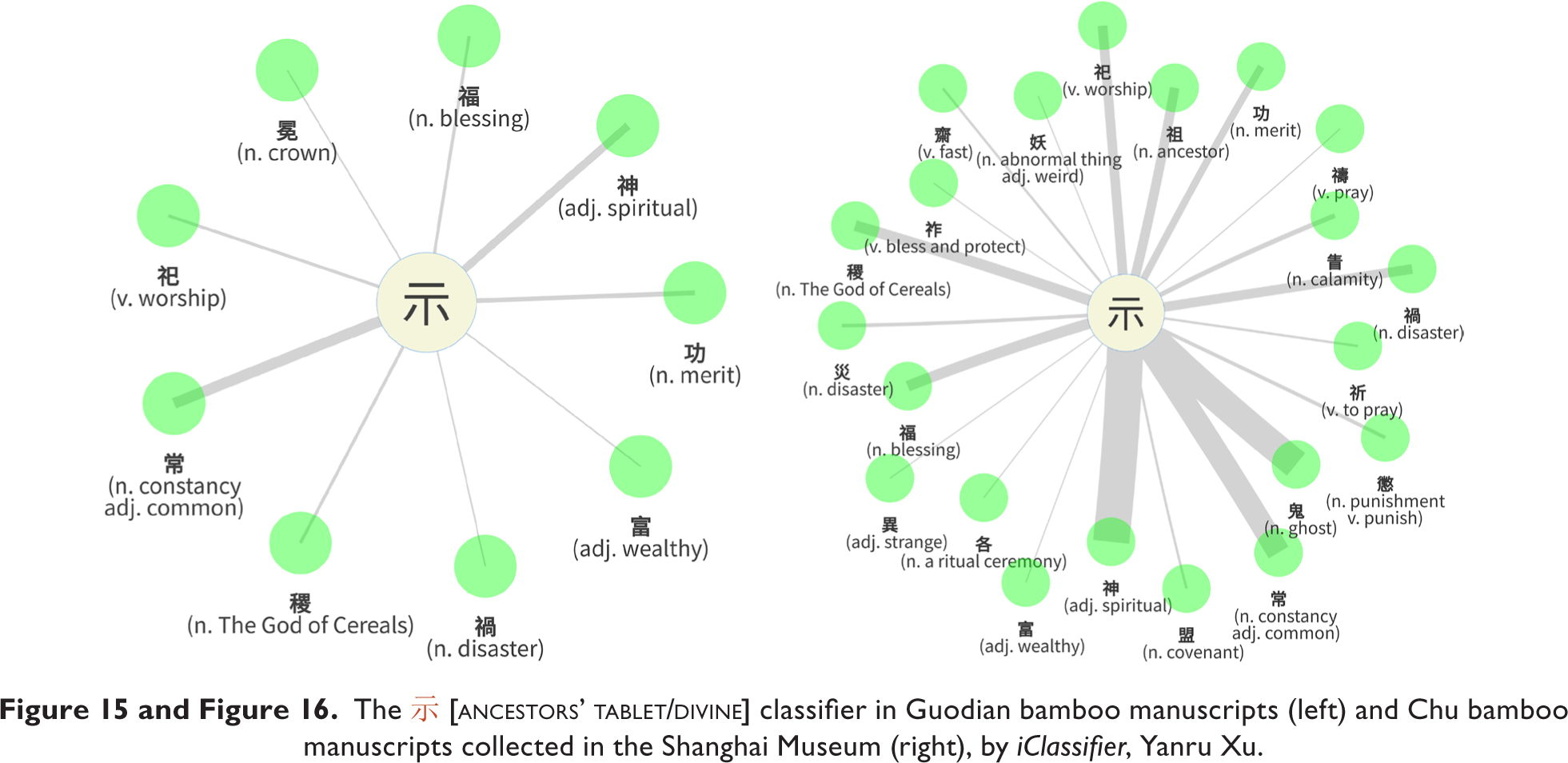
The 示 [
Due to space limitations, we could discuss the iClassfier results in this article only by some chosen examples. The mental maps that emerge from the analysis of the Guodian texts show universal affinities with Egyptian and Sumerian categorization of the world. Yet, clear culture-specific categorization typical of the Chinese conceptualization of the world during the Chu state as it is known to us from the rich contents of literary and philosophical texts can be identified in our results. Such is the attitude to the role of the heart as the seat of virtue, the prominent place of speech in texts that reflects a tradition of wisdom transmission, or even the 示 [
Footnotes
Acknowledgment
This article was translated into Chinese and discussed in the International Symposium on “Interdisciplinary Research on Chinese Characters and Knowledge Mining” at the 9th Annual Conference of the World Association of Chinese Characters Studies, held at KyungSung University in Busan, Korea from July 4–8, 2023. I would like to thank all the experts for their valuable comments to assist in the revision of this article. I am grateful to Dr. Haleli Harel for her technical support.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Israel Science Foundation (ISF) (grant number 1704/22, PIs Prof. Orly Goldwasser & Prof. Zev Handel), The ArchaeoMind Lab, The Institute of Archaeology, Jerusalem, the China Scholarship Council (2020-2024), and the Plaks Fellowship in Traditional China field (2022), Department of Asian Studies, Hebrew University of Jerusalem.