
Abstract
This article presents the method applied by the iClassifier (©Goldwasser/Harel/Nikolaev) digital research tool for the study of the linguistic phenomenon of classifiers. The tool was created in 2019 with the objective of curating corpus-based and data-driven documentation of classifier systems. The record of classifiers comprises millions of tokens worth of “big data” analysis. By tagging classifiers in various corpora, a topography of categories emerges, visualized as complex, multilayered networks. This article offers an overview of how classifier-based networks are created and how network analysis methods can be applied to analyze knowledge organization. We present the data structure and annotation scheme of the iClassifier research tool, demonstrating how one can plot classifier networks and generate reports of lemma and classifier repertoires in each corpus. The iClassifier tool provides quantitative reports, including classifier frequency, variation and co-occurrence statistics. Each data subset, such as a certain part of speech, timespan, geographical location or textual genre, can be queried and visualized. The tool is meant to allow browsing between a macro-overview of all categories in a corpus and zooming in into micro-analysis of the individual categories and lemmas that built up a corpus. Each classifier is seen as a category head, and the categories are drawn in their multilayered and multidimensional relationships. The potency of this tool is in documenting the phenomenon in large corpora of texts and expanding our knowledge about the rules and functions of classifier systems, leading us to a more refined mind-mapping of ancient cultures. Currently, very little systematic analysis has been done on this ancient record of emic information.
Introduction
Classifier lists and classifier categories
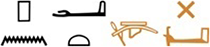
The repertoire of graphemic classifiers has been known mostly from lists of graphemes called “determinatives” in ancient scripts appearing in grammar books. An example is the case of the ancient Egyptian script and its “generic determinatives” list compiled by Gardiner (1957: 31–33), which is still used as a standard reference for Classifier Meanings (CMs). 1 Such lists assign each classifier a general overarching meaning label that does not always fully represent the semantic profile of the sign in its use as a classifier. Information on the range of lemmas it was attested with, in what combinations it appeared, or how its usage has evolved (diachrony) has remained unanswered.
Recent years have seen efforts to reevaluate the semantic scope of classifier categories in Egyptology. A digital sign list of hieroglyphs published as the Thot Sign List in a digital format arranges the Egyptian characters by their functions, including the function “classifier.” 2 Furthermore, attempts have been made to refine the list of categories and arrange the vocabulary by classifier categories and listing a variety of lemmas occurring with a classifier (e.g., Winand and Stella, 2013, for the MK and 18th Dynasty), or to map all classifiers occurring with a lemma (e.g., Werning, 2011: 323–325). Recently, Goldwasser and Soler (2024) have created a classifier list based on a study by iClassifier on the different versions of The Story of Sinuhe. The iClassifier 3 research tool enables quantitative research on classifiers and creates classifier lists that are data-driven and corpus-based. 4
The purpose of this article is to propose a dynamic and detailed record of classifier categories. Upon tagging all classifiers in a corpus, we can access their semantic range and analyze the classification patterns of host lemmas, such as tracking the stability of classification patterns, both synchronically and diachronically, and the combinational aspects of multiple classifications. With iClassifier, we also expose the incompatibility of categories in a single classifier combination, that is, incompatible categories that do not co-occur. In this study, we apply the method to three ancient complex scripts: ancient Egyptian, ancient Chinese and Sumerian. A classifier list was published recently for
From classifier lists to classifier networks
This article presents a
Classifier networks: Visualizing innate semantic topographies of categorization in ancient vocabularies
The classifier repertoire of each dataset can be visualized as a network, exposing a macro-outlook of the classified vocabulary. The semantic scope of each category is visible and connections between categories surface. A first attempt to analyze classifiers in an original corpus was recently performed by Goldwasser and Soler (2024) on the various manuscripts from different periods of an Egyptian canonical literary text, The Story of Sinuhe. Xu analyzed an original corpus of texts from the Warring States period (see Xu, 2024). Another analysis of an exemplary Egyptian text is presented in this article. 6
iClassifier, the new “network view” of classifier systems in ancient Egyptian
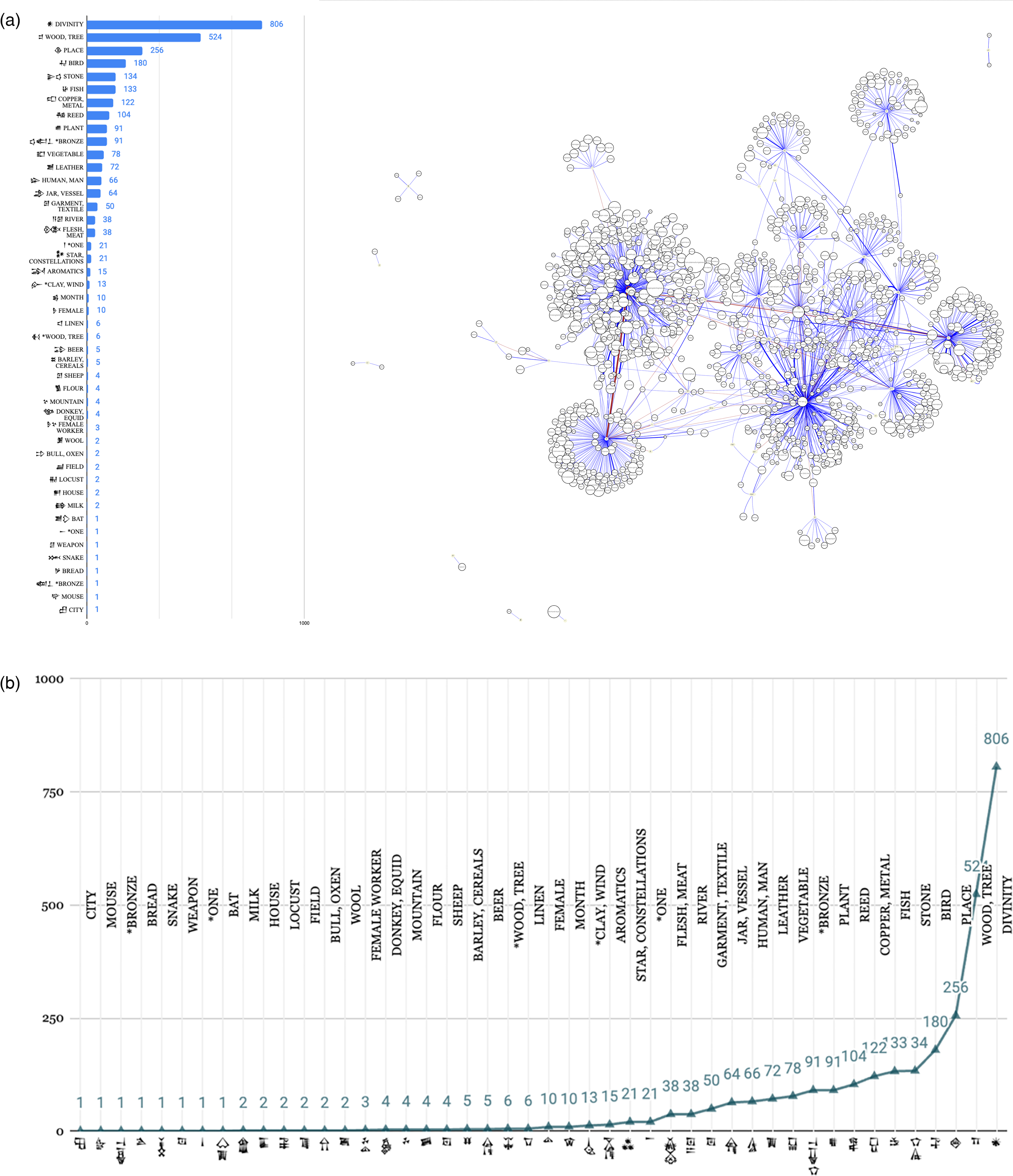
The network presented in Figure 1(a) reveals to us at one glance all classifier categories and their host lemmas as they are manifested in an actual text. The network depicts the classifier repertoire of an ancient Egyptian short tale written in cursive hieratic script on papyrus and named in modern scholarship The Tale of The Doomed Prince (Doomed Prince).
7
This text consists of 1640 words (=tokens) and dates to the New Kingdom, probably the first part of the 19th Dynasty (c. 1300–1200
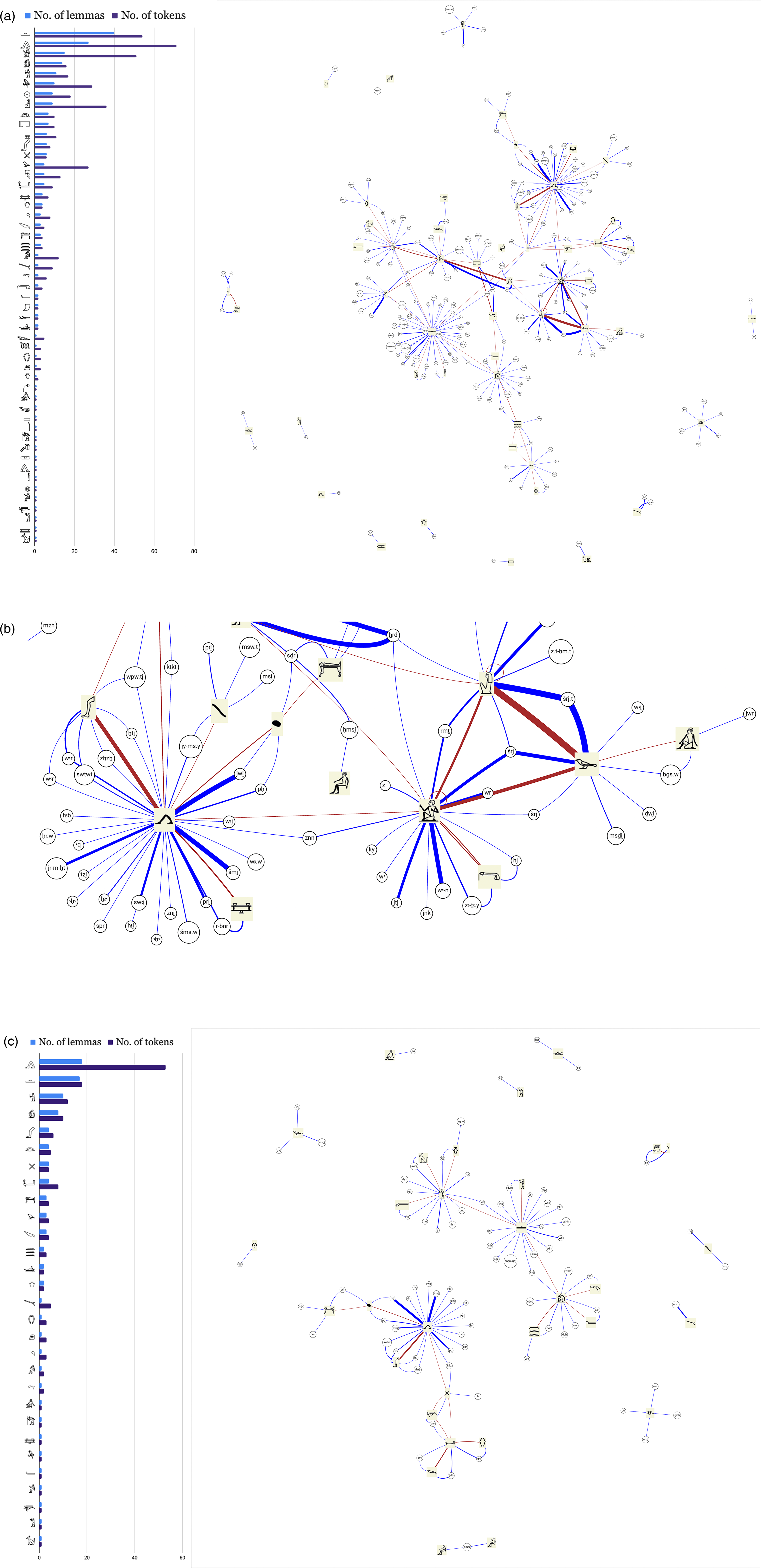
(a) A classifier-based network visualization (right) and a classifier frequency key (left) in The Tale of The Doomed Prince (p.Harris 500). Data imported from TLA. ©iClassifier, Haleli Harel. (b) A detailed view of the classifier-based network of The Tale of The Doomed Prince. ©iClassifier, Haleli Harel. (c) A classifier-based network of all verbal lexemes in The Tale of The Doomed Prince and a classifier frequency key. The text consists of 1640 tokens, of which 256 examples are of verbs and 144/256 are written with classifiers (56%). ©iClassifier, Haleli Harel.
Red edges are links between classifiers that co-occur with a particular lemma. In the selected text (Figure 1(a)), we can identify that the most connected and attested semantic categories are  [
[ [
[ [
[ [
[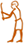 [
[ [
[ [
[ [
[
Zooming into the image (Figure 1(b)), we can examine closely such instances of multiple classifications. The hero of the story is an unnamed young prince identified as  šrj “lad.”
9
This lemma connects the generic
šrj “lad.”
9
This lemma connects the generic  [
[ [
[
One can identify the  [
[ šrj.t “young woman” in the text.
11
The high number of attestations of this lemma is indicated by the thick width of the blue edges linked to this noun. The noun portrays double classification and is linked in a red edge to two classifiers,
šrj.t “young woman” in the text.
11
The high number of attestations of this lemma is indicated by the thick width of the blue edges linked to this noun. The noun portrays double classification and is linked in a red edge to two classifiers,  [
[ [
[ glyph occurs with various verbs of motion and adverbs such as
glyph occurs with various verbs of motion and adverbs such as  r-bnr “outside,” portraying double classification with the
r-bnr “outside,” portraying double classification with the  [
[ [
[ [
[ .
13
Here, the classifier
.
13
Here, the classifier  [
[
Tagging all classifiers in the text, we learn that most nouns are classified (199/277, 72%), more than half of the verbs occur with classifiers (144/256, 56%), but adjectives are rarely classified (8/82, 10%). 15 Half of the adverbs appear with classifiers (13/24, 54%). The classification rate of grammatical elements is low, and rarely such elements are classified—for example, 2% of the prepositions (2/101) and 2% of the particles (4/185). 16
It is possible to query the network further using various variables that the scholar annotated in their text analysis—for example, by a selected part of speech (POS). One can draw a network of all POS types or query a specific POS, such as a network of verbs. In the network in Figure 1(c), all classified verb forms in the text are plotted and arranged around their classifiers. 17
Figure 1(c) shows the concentration of classified verbal lexemes
18
around five categories (or “mental hubs,” see Goldwasser, in press).
19
In the network’s key, the most common verb classifier,  [
[ [
[ [
[ [
[
With the guidelines described above for ancient Egyptian, a pilot project of the
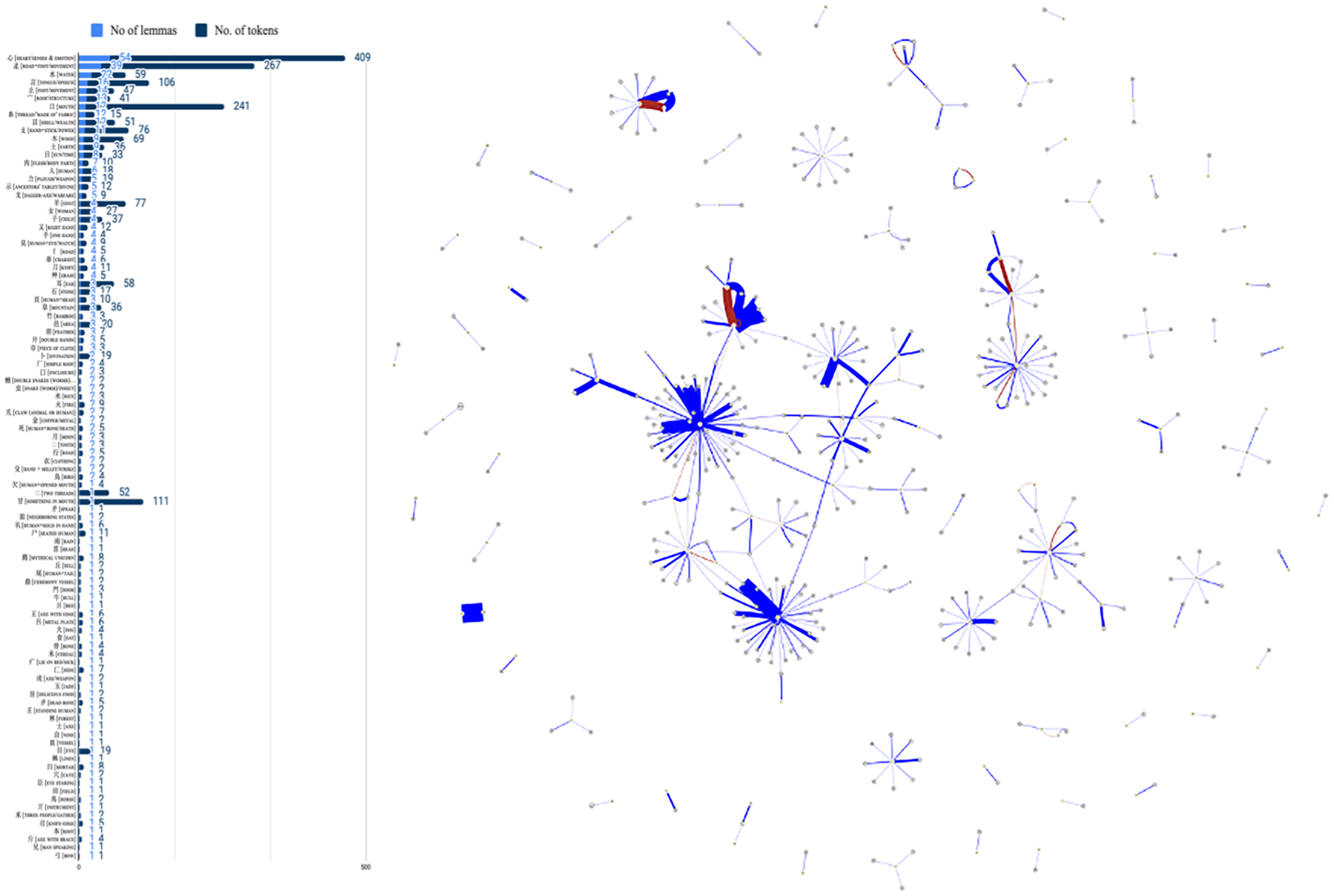
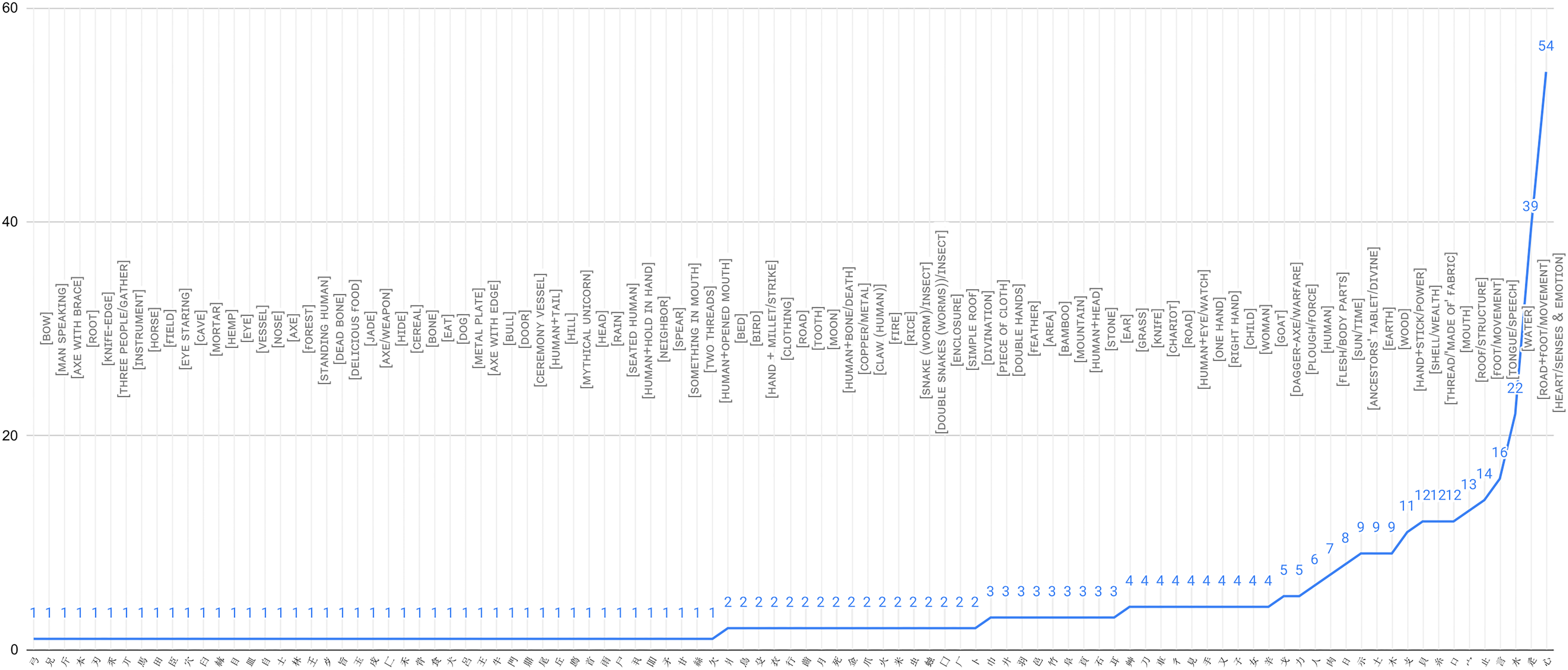
A classifier-based network of a corpus of Ancient Chinese philosophical texts (Guodian texts). Left: Key of the number of lemmas and tokens that occur with each classifier—for example, the classifier 心 [heart] occurs with 54 lemmas and 409 tokens. ©iClassifier, Yanru Xu. The frequency key illustrates the number of lemmas and tokens per classifier. Data courtesy of The Intelligent Retrieval Network Database of Chinese Characters (East China Normal University (ECNU), Shanghai).
The network in Figure 2 is based on a corpus of Guodian bamboo manuscripts containing 12,092 tokens, of 405 lemmas. A total of 2251 tokens are classified by 99 semantic classifiers (Xu, 2024). In the classifier-based network of this text corpus in ancient Chinese, the central categories are  [
[ [
[ [
[ [
[ , labeled as [
, labeled as [ [
[
A third classifier system digitized using the iClassifier tool is the cuneiform system used to transcribe the  [
[ [
[ [
[ [
[ [
[
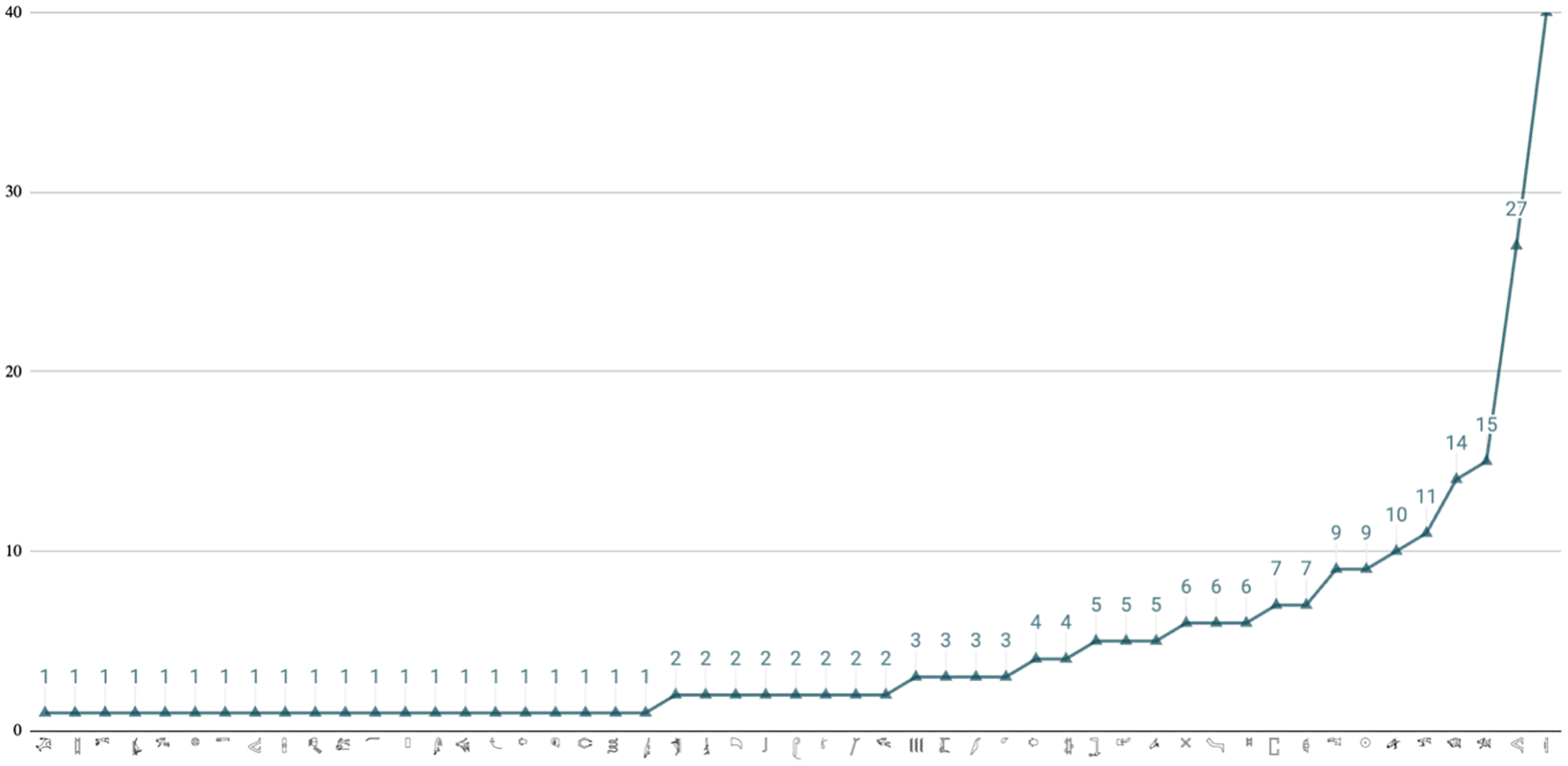
(a) A classifier-based network of Sumerian, according to the uppercase marking of classifiers in the ePSD2 dictionary after Selz, 2021; Selz and Zhang, 2024. The frequency key illustrates the number of lemmas per classifier. This network image includes 2859 lemmas and 9497 written forms, including proper names (June 2023). This list includes only one instance of each script variation (see n. 5). ©iClassifier, Bo Zhang and Gebhard Selz. (b) The classifiers of the Sumerian vocabulary, sorted by the number of lemmas per classifier. ©iClassifier (after Selz and Zhang, 2024, Figure 1).
The analysis of various classifier systems led to the identification of certain distribution patterns between the corpora (Harel, in press). For example, arranging all categories in Figure 3(a) according to the number of lemmas they occur have shown a “long-tailed” distribution (Figure 3(b)). 26
Figure 4 shows that the network of classifiers in the Guodian texts corpus compiled by Xu (2024) also distributes long-tail, including a large number of classifiers occurring with one single host.
The classifiers of an ancient Chinese corpus of philosophical texts, sorted by the number of lemmas per classifier. ©iClassifier (after Xu, 2024, Figure 1).
Similar results emerged in a pilot study of the Middle Kingdom and New Kingdom hieratic texts of The Tale of Sinuhe (Goldwasser and Soler, 2024). A more balanced distribution emerged in the Doomed Prince classifier repertoire discussed above (Figure 5 representing Figure 1(a)). Here, the classifier list includes 51 classifiers. As compared with other earlier Egyptian texts, the Doomed Prince contains fewer classifiers since it is a short tale and only survives in one manuscript. It also has repetitive vocabulary and thus a low lexical density.
27
One identifies more medium-sized classifier categories in this single text, and a lighter “tail,” as the number of categories in this specific text is smaller than in other Egyptian texts (e.g., 93 classifiers in The Story of Sinuhe corpus). Although the categories and their distribution are different, the core group of central categories reoccurs in the range of texts studied so far in Egyptian, led by the categories  [
[ [
[ [
[ [
[ [
[
The classifiers of The Tale of The Doomed Prince (p.Harris 500). Data imported from TLA. ©iClassifier, Haleli Harel.
Pioneering research on the diachrony of classification in Egyptian texts pointed to a reduced number of classifiers in New Kingdom hieratic. 28 On a general note, texts in the same language may differ to a certain extent in their semantic classifier-based networks due to various variables: for example, genre, script type, language phase, or type of support and materiality, among other variables. Still, the structure of the Sumerian (Figure 3(b)), Chinese (Figure 4) and Egyptian (Figure 5) corpus-based classifier networks testifies that various networks share a distribution of main “super” categories, some medium-sized, and many marginal and smaller categories. As we expand our data poll, we will be able to accurately describe these tendencies across data samples and draw the distribution of categories as well as the evolution of individual classifier categories more accurately.
Next, we inquire how the classifier repertoire in a dataset forms a complex semantic space. The data can be exploited by algorithmic methods such as community detection 29 to visualize its inner hierarchies. In Figures 6(a) and (b), the same network we previously presented in Figures 1(a)–(c) is visualized by sorting the data according to a community detection algorithm (using the software Gephi). The nodes are grouped into communities by their proximity of co-occurrence. 30 “A community is a densely connected subset of nodes that is only sparsely linked to the remaining network” (Gulbahce and Lehmann, 2008: 3). Applying community detection algorithmic methods, 51 semantic classifier categories are arranged into defined clusters. In many cases, these clusters are constructed of at least three classifiers. This clustering allows us to access which categories are interrelated based on classifier combination or variance. The network visualization in Figure 6(a) and (b) is merely an experimental investigation into the data. This method is being calibrated while we work on larger data from various corpora, aiming to use it to expose noteworthy connections and semantic structures emerging from the collected data. As shown in Figure 6(a), a community detection algorithm sorted the network presented in Figure 1 into clusters by color.
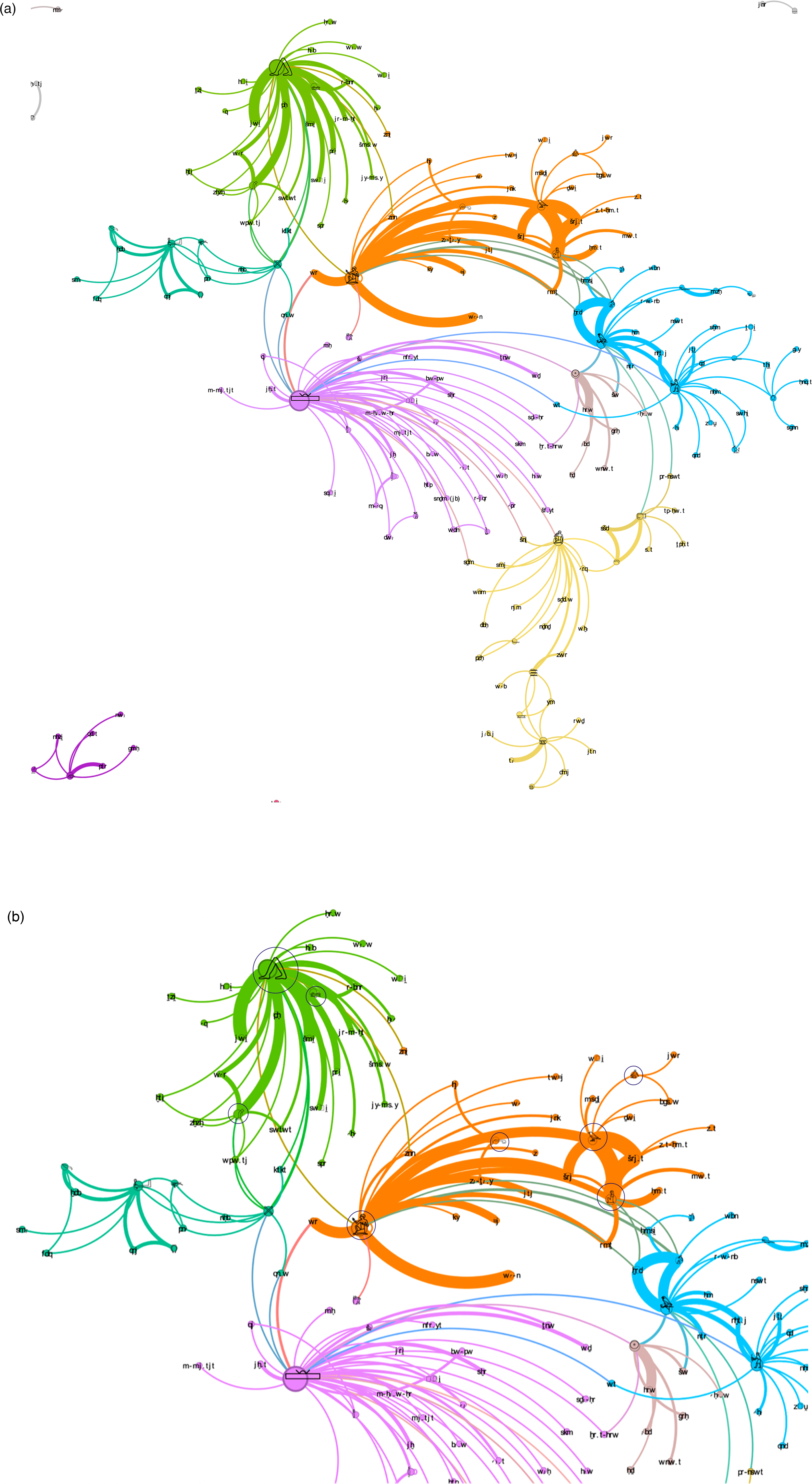
(a) A network of classifier categories of The Tale of The Doomed Prince. Arranged by a community detection algorithm, including “island categories.” ©iClassifier, Haleli Harel. (b) A detailed view of a network of classifier categories of The Tale of The Doomed Prince. Arranged by a community detection algorithm. ©iClassifier, Haleli Harel.
In the network represented in Figure 6(a), we see central and well-attested categories, and around them, some disconnected “islands” colored gray, visualizing smaller categories that do not have co-occurrence or interchangeability with other categories. Due to our limited space, we discuss here only a few examples. Some of the central and well-connected clusters can be seen in the magnified detail in Figure 6(b).
 A first central cluster groups actions of motion, most of which are instances of verbs of motion, regularly written with the classifiers
A first central cluster groups actions of motion, most of which are instances of verbs of motion, regularly written with the classifiers  [
[ [
[ [
[
 A smaller cluster colored in turquoise on the left (Figure 6(b)) is connected to the
A smaller cluster colored in turquoise on the left (Figure 6(b)) is connected to the  [
[ ktkt “to quiver,” classified with both × [
ktkt “to quiver,” classified with both × [ [
[ [
[ [
[ cluster. In the Doomed Prince, all lemmas classified with [
cluster. In the Doomed Prince, all lemmas classified with [ [
[ [
[
In order to document the classification combinations and patterns for each classifier, we generate detailed reports for each lemma and each classifier. An example is the report for this specific classifier, the taxonomic category  [
[

(a) The [ [
[
According to the results, in this text, the classifier  [
[ [
[ qnj “to embrace,” and with [
qnj “to embrace,” and with [ ẖdb “to kill”
ẖdb “to kill”  smꜣ “to slay” and
smꜣ “to slay” and  fdq “to slice.” The classifier of a turned-over boat
fdq “to slice.” The classifier of a turned-over boat  [
[ pnꜥ “turned upside down.” This combination occurs in a verb describing how the prince’s wife intoxicates a snake to protect the hero from its deadly bite. It features the use of a metaphor pnꜥ “to be like an overturned boat” in the language. The snake is upside down “as an overturned boat, i.e., out of function.”
32
pnꜥ “turned upside down.” This combination occurs in a verb describing how the prince’s wife intoxicates a snake to protect the hero from its deadly bite. It features the use of a metaphor pnꜥ “to be like an overturned boat” in the language. The snake is upside down “as an overturned boat, i.e., out of function.”
32
 Another central cluster is connecting the
Another central cluster is connecting the  [
[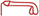 [
[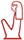 [
[ [
[ [
[

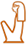 [
[ [
[
Apart from examining the macro image of an interconnected classifier network, iClassifier enables the user to examine closely each classifier (classifier axis) or each lemma (lemma axis). Via the classifier axis, we map the classifiers’ combination patterns. We will now demonstrate how to browse classifier reports, going through all parts of the online report form (Figure 7(b)). On the top left of the classifier report in Figure 7(b), several built-in queries are available, enabling to query all signs tagged as classifiers or to produce a report of a certain type of classifiers—for example, exclude the phonetic and grammatical classifiers and view only purely lexical/semantic categories, by choosing “subset by level” and “lexical.” The user can further select the texts, POS and script type presented in the classifier report. As shown in the image, only one text, “pHarris 500- Doomed Prince,” was selected and highlighted in black on the top left of Figure 7(b). Below it are additional queries based on annotations matched with the Thot metadata thesauri (presented in Section 3.4).
Two types of category graphs are displayed in the classifier report. The first, a circle with green nodes, appears on the left of Figure 7(b), titled  [
[ [
[
Another visualization of the classifier category  appears in the center column of Figure 7(b), titled
appears in the center column of Figure 7(b), titled  [
[ [
[ hieroglyph functions as a logogram. The color key for this graph appears below the table, and the exact percentages of classifier-lemma co-occurrence are written below in the “
hieroglyph functions as a logogram. The color key for this graph appears below the table, and the exact percentages of classifier-lemma co-occurrence are written below in the “
On the bottom part of the central column of Figure 7(b), a list titled “
The right column of Figure 7(b) begins with a network graph titled “ šw “sunlight,” the [
šw “sunlight,” the [ [
[
The table “
We visualize and produce classifier reports uniformly across all scripts. Therefore, one can produce a report on a comparable category  [[
[[
When we compare the category  [
[ [
[ [
[ [
[ /*taw/ “to enlight,” and its parallel in Egyptian
/*taw/ “to enlight,” and its parallel in Egyptian 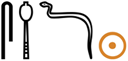 sḥḏ “to make bright; to illuminate,” among other instances of semantic overlap.
sḥḏ “to make bright; to illuminate,” among other instances of semantic overlap.
iClassifier, lemma axis
Another information axis in the iClassifier digital reports consists of detailed reports for each lemma in a dataset. The lemma report summarizes all information on the attestation of the lemma in the corpus, listing its examples and showcasing classification patterns, including attestations without classifiers. Figures 8(a) and (b) exemplify what reports of selected lemmas included in the category [

(a) The lemma
The lemma in Figure 8(a) is the ancient Chinese character 時 ( 寺) meaning “time; hour; season; period; era; age; opportunity,” regularly written with a semantic classifier
寺) meaning “time; hour; season; period; era; age; opportunity,” regularly written with a semantic classifier  (here in pre-position) labeled as [
(here in pre-position) labeled as [ hrw “day” occurs with the
hrw “day” occurs with the  [
[
We currently create additional research tools for iClassifier, such as analysis of the
Using the
Behind the screens: The iClassifier input system
Traditional transcriptions of ancient Egyptian have mostly omitted classifiers. They have been considered as “seen but not transcribed.” While phonological information is regularly transcribed, classifiers of all kinds remain mostly undocumented. 39 One of the tasks of the presented project is to create systematic transcription tag classifiers while encoding each word in the text. Users of iClassifier fill out or edit three primary input forms (see below). First is the token (=example) form, where classifiers are annotated (Section 3.1). Secondly, a token is linked to the text (Section 3.3) in which it is attested and to a specific lemma (=word; Section 3.2), the dictionary form of which it is an example.
iClassifier, token input form
The core of the input system of iClassifier is the
In Figure 9(a), the input form of the ancient Egyptian is presented with an example of a token classified by the sign  (N5) [
(N5) [ ), and next the classifier
), and next the classifier  [
[ , with a classifier in final position).
, with a classifier in final position).

(a) The iClassifier input system, TOKEN input form, ancient Egyptian. An example of a token page in ancient Egyptian of the lemma ꜣbd “month.” ©iClassifier, Haleli Harel. (b) The iClassifier input system, TOKEN input form, ancient Chinese. An example of a token page in ancient Chinese of the lemma
Similarly, in Figure 9(b), the Chinese example (=token) 時 ( 寺) “seasons” is fully analyzed. First, the character 時 is split into its elements, and the semantic classifier
寺) “seasons” is fully analyzed. First, the character 時 is split into its elements, and the semantic classifier  [
[
The iClassifier user may additionally perform a
Similarly, networks of grammatical classifiers or phonetic classifiers can be drawn.
39
Classifiers are tagged as grammatical in cases where the classifier marks mass or gender (Goldwasser and Grinevald, 2012: 28–29; Werning, 2011: 102–103). A typical case grammatical classifier is that of  [
[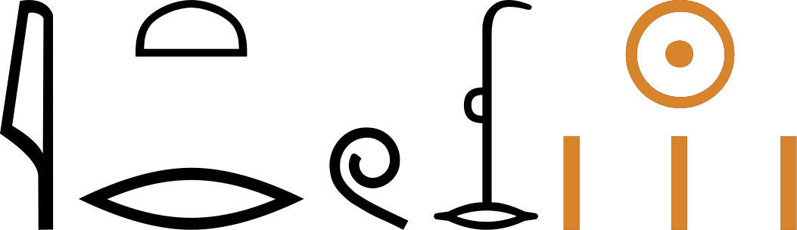 jtr.w “seasons.” The plural ending is spelled out in the final w of the word (
jtr.w “seasons.” The plural ending is spelled out in the final w of the word ( ) and is also repeated in the classification as [
) and is also repeated in the classification as [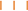 ). Another common instance of grammatical classification is the gender marker of the first person (
). Another common instance of grammatical classification is the gender marker of the first person ( [
[ [
[ [
[ [
[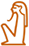 [
[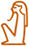 [
[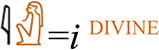 . Next, users of iClassifier can optionally annotate the
. Next, users of iClassifier can optionally annotate the
Semantic relations between classifiers and their hosts.

Semantic relations between classifiers and their hosts.
Attestations of classifiers are tagged in concrete examples (tokens). In the iClassifier input system, each token (a specific example of a lemma) is matched with the dictionary entry of a lemma. We upload a dictionary for each language to lemmatize the dataset within the common lexicographic tradition of each field. 45 If there is no digital dictionary or lemma list, the user can cite a published printed dictionary and link between the dictionary entry (i.e., lemma) and its examples (tokens). In cases where the user wants to highlight the semantic range of a lemma, meanings from several dictionaries can be added.
The Egyptian lemma form (Figure 10(a)) allows linking between stages of the Egyptian language (Demotic, Coptic) and linking lemmas to roots based on the TLA root list. 46 In addition, all lemmas can be assigned comparative concept-semantic field annotations based on a typological list published by the Concepticon project (see List et al., 2021).
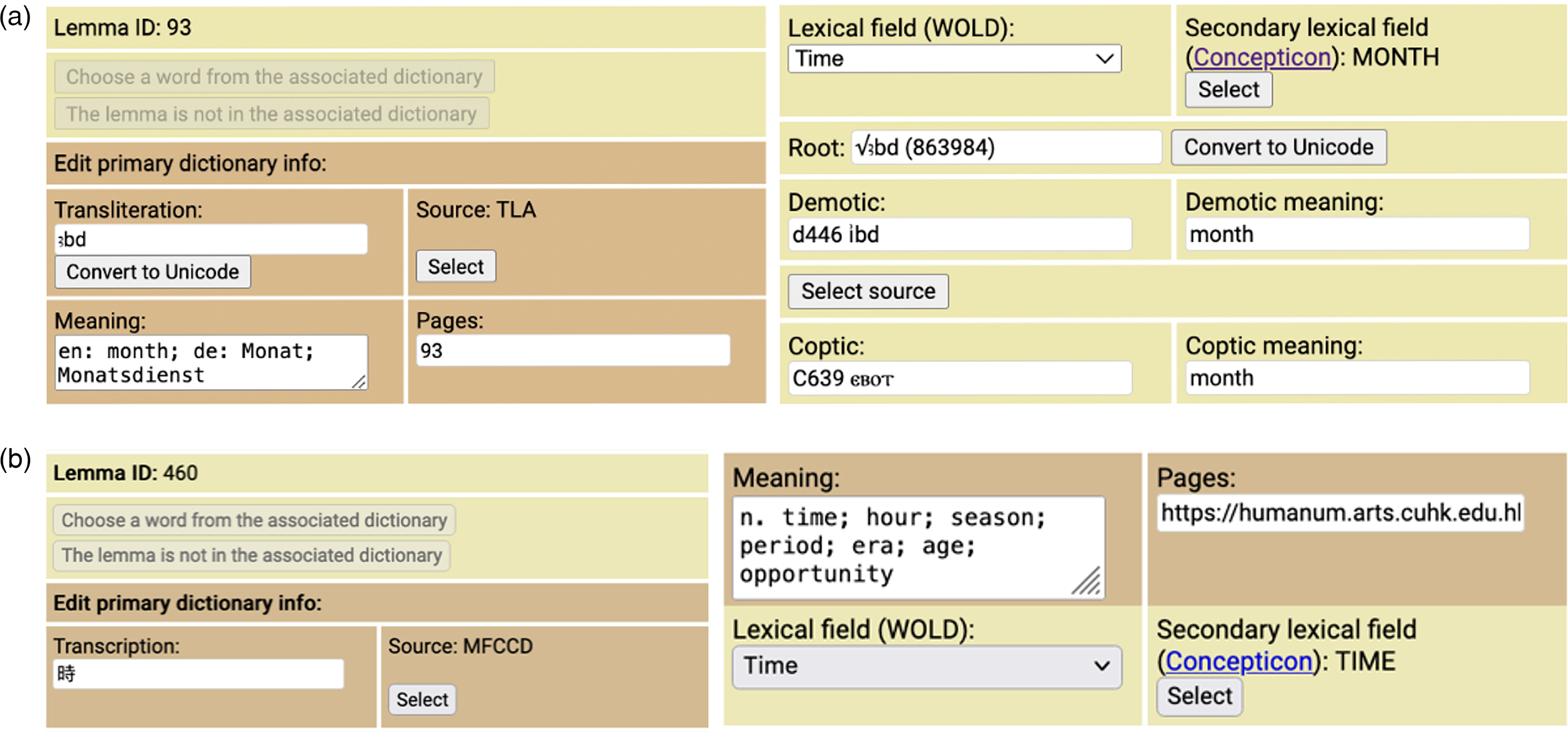
(a) The iClassifier input system, LEMMA input form, Egyptian. An example of the fully annotated lemma ꜣbd “month” in ancient Egyptian lemma list (TLA). The section of the input page on the right is optional. ©iClassifier, Haleli Harel. (b) The iClassifier input system, LEMMA input form, Chinese. An example of the lemma
In the Chinese portal, the lemma input form is identical (Figure 10(b)) and each lemma is a Chinese character. In specific tokens analyzed in ancient Chinese corpora, an English context-based meaning of the respective character is provided (see Xu, 2024).

(a) The iClassifier input system, TEXT input form. An example of metadata annotation for The Tale of The Doomed Prince in ancient Egyptian, imported from the TLA. ©iClassifier, Haleli Harel. (b) The iClassifier input system, TEXT input form. An example of metadata annotation for the text《郭店楚墓竹簡》《窮達以時》in ancient Chinese. ©iClassifier, Yanru Xu.
For ancient Chinese and Sumerian, metadata annotations were curated specifically and adjusted to common terminologies in each research field. For example, in Figure 11(b), we can see how a certain stage in the Chinese script is chosen for the text. In this example, the selected script is “Chu script,” and the text’s genre is “philosophical literary.” Object type is also noted (in this case, “Bamboo manuscript”). An original location and period or date are added, if available. Tracking such metadata variables allows the user to query later for results by place, time, script type or support.
The reports of projects created in iClassifier are published publicly with share-alike reuse and attribute license (CC BY-SA 4.0). The backend (data storage and web server) of the current version of the database, iClassifier BETA (released May 2020), is implemented as an array of SQLite databases with a separate database file for each project with Python (Flask + Gunicorn) and Golang web stack. Its user interface is based on Mithril.js.
The iClassifier network maps are drawn using the JavaScript library Vis.js. Textual data of each project can be easily exported as a .xlsx file with all database tables represented by a sheet according to the general database structure in Figure 12. The data of individual projects will be published with CC BY-SA 2.0 license together with the academic publication of each dataset.
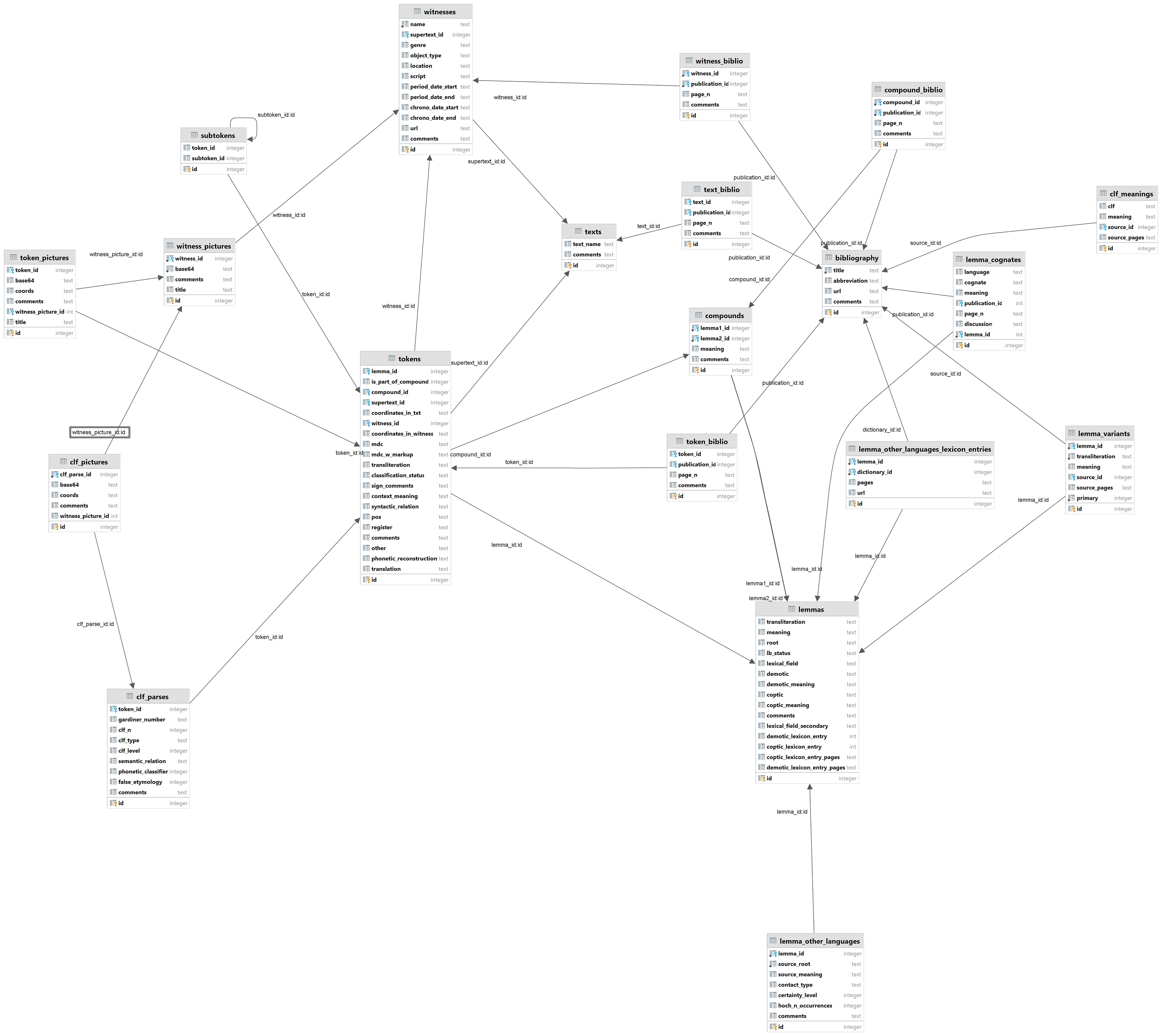
The iClassifier database structure. Drawn by Dmitry Nikolaev for iClassifier.
In this article, we presented a new method to visualize and study the complexity of innate categorization systems in ancient scripts. Guidelines of the report system of iClassifier were exemplified, and the annotation scheme of the input forms was surveyed. The presented research tool is a collaborative, digital environment created to apply quantitative measures to classifier systems. The tool enables philological and qualitative evaluation of each example by commenting on orthography, grammar or lexical semantics. Our project aims to record corpora containing classifiers, create data and test the universal versus culture-specific patterns in overt categorization systems such as classifiers. We are taking the first steps towards this goal by creating comparative measures to track the semantic contents of each system, calibrate our measuring tools, and compare semantic profiles. As corpora in each field will be curated, our next task is to apply similarity measures and show which meanings and categories are shared between various systems and what each system's general structure and hierarchy looks like. Preliminary results, such as the long-tailed distributions (Figures 3(b)–5), suggest that various systems of graphemic classifiers share a particular overarching structure. Still, such suggestions should be scrutinized based on accurate sample studies. By using the presented method, one can discover previously unseen topographies of inner hierarchies of the lexicon.
Corpus credits
The digitized text is accredited to Lutz Popko, with contributions by Altägyptisches Wörterbuch, “Joppe; Prinzenmärchen” (Object ID CVX3L24WLFAKNEOXEVC6QGPBJI) https://thesaurus-linguae-aegyptiae.de/object/CVX3L24WLFAKNEOXEVC6QGPBJI, in: Thesaurus Linguae Aegyptiae, Corpus issue 17, Web app version 2.01, 12/15/2022, T. S. Richter and D. A. Werning (eds), by order of the Berlin-Brandenburgische Akademie der Wissenschaften and H.-W. Fischer-Elfert and P. Dils by order of the Sächsische Akademie der Wissenschaften zu Leipzig (accessed: 19 June 2023). Classifier marking by Haleli Harel. Imported into iClassifier by Dmitry Nikolaev.
The Guodian inscriptions of Laozi, courtesy of The Intelligent Retrieval Network Database of Chinese Characters (East China Normal University (ECNU), Shanghai). Classifier marking by Yanru Xu. Imported into iClassifier by Dmitry Nikolaev.
All tokens and lemmas are referenced after the ePSD2 lemma list. Classifier marking by Bo Zhang. Imported into iClassifier by Dmitry Nikolaev. http://oracc.museum.upenn.edu/epsd2.
Authors’ contributions
Haleli Harel: writing, database design and realization, methodology, classifier analysis in The Tale of The Doomed Prince, classifier distribution and long-tail calculations. Orly Goldwasser: discussions in classifier theory, methodology, reviewing. Dmitry Nikolaev: IT for iClassifier, community detection algorithm, data transformation and upload. Other contributors (tables and graphs): Yanru Xu, Chinese; Bo Zhang, Sumerian.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by ISF (grant number 735/17) and ISF (grant number 2408/22).The ArchaeoMind Lab https://archaeomind.huji.ac.il/ (PI Orly Goldwasser), Institute of Archaeology, The Hebrew University of Jerusalem.
ORCID iDs
Haleli Harel https://orcid.org/0000-0002-4012-015X
Orly Goldwasser https://orcid.org/0000-0002-2152-6429
Dmitry Nikolaev https://orcid.org/0000-0002-3034-9794