
Abstract
Many behavioral science-based interventions, such as nudges and so-called psychologically wise interventions, seek to improve people’s lives by using words to shift them toward helpful perspectives and behaviors. Large language models (LLMs) such as OpenAI’s GPT models or Google’s Gemini have the potential to revolutionize these interventions by making them more personalized, scalable, and cost-effective. This article describes how three groups of people—designers of interventions, intermediaries who interact with the intended beneficiaries, and the intended beneficiaries themselves—might use LLMs and identifies potential benefits and risks of those uses for the intended beneficiaries of interventions. We hypothesize that the potential benefits and risks are lowest when designers interact with LLMs, higher when intermediaries interact, and highest when the intended beneficiaries interact directly. We provide suggestions for mitigating the risks so that policymakers can safely deliver on the promise of LLMs.
Behavioral science interventions that aim to improve people’s lives often rely on verbal communications that encourage a given course of action—such as certain nudges, which steer a decision gently without reducing someone’s options, 1 or psychologically wise interventions, which use brief, precisely targeted strategies to shift how people view themselves or their situations.2,3 Nudges might take the form of text message reminders to vote or complete other important tasks. 4 Wise interventions might involve reading and writing exercises that help a person be less stymied by uncertainties at a critical transition. In one experiment, for instance, minority college students who worried they would not fit in and do well at a college were told that concerns over belonging are normal for anyone at the start of college and usually go away over time. After considering this idea in a one-hour exercise, those students went on to have better grades at the end of three years than comparable students who did not do the exercise.5,6 (For further discussion of where and for whom nudges and wise interventions can be most effective, see References 7 through 9).
Artificial intelligence (AI) tools known as large language models (LLMs), such as OpenAI’s GPT models or Google’s Gemini, hold tremendous promise for tackling societal problems in ways that once seemed futuristic.10–14 LLMs, which can process vast volumes of information, can revolutionize the delivery of behavioral science interventions because they can generate text that is tailored to the needs of the recipients and do so at scale. For instance, LLMs can be designed to deliver motivational, supportive messages tailored to an individual student in response to concerns revealed by the student 15 —something that could be extraordinarily time-consuming and costly to provide manually for large numbers of recipients. In other words, LLMs can potentially deliver behavioral science-based interventions that are more adapted to the needs of individual recipients, more scalable, and less costly than is now the case.
Standing in the way of this vision, however, are the possible risks of having LLMs intentionally influence people’s thoughts and behaviors. When public officials and others use LLMs to interact with people, they relinquish some control over the information, advice, and ideas provided in the interactions. This loss of control can increase risk for the affected populations, especially if the algorithms that produce the outputs harbor unrecognized errors or biases. 16 It is paramount that researchers and policymakers understand and develop ways to mitigate these risks if they are to fully realize the potential benefits of using LLMs to power behavioral science-based interventions to improve societal well-being.17,18
In this article, we describe three ways LLMs could be used in behavioral science interventions: (a) LLMs could help intervention designers to construct interventions for intended beneficiaries (such as students or employees), (b) LLMs could intervene directly with intended beneficiaries by interacting with them in ways designed to support or influence them, or (c) LLMs could intervene with intermediaries (such as teachers or managers) by supporting or influencing how they engage with the intended downstream beneficiaries of that intervention (such as students or employees). We argue that both the promise and the risk of using LLMs increase as the LLMs come in closer contact with the intended beneficiaries, with use by designers entailing the lowest potential benefit and risk and direct interaction with intended beneficiaries entailing the most (see Figure 1). For each of the three uses, we draw on real examples as illustrations and highlight potential benefits and primary risks that stand in the way of reaping those benefits. We then provide suggestions for ways that policymakers and others in charge of LLM use can help to mitigate the risks.
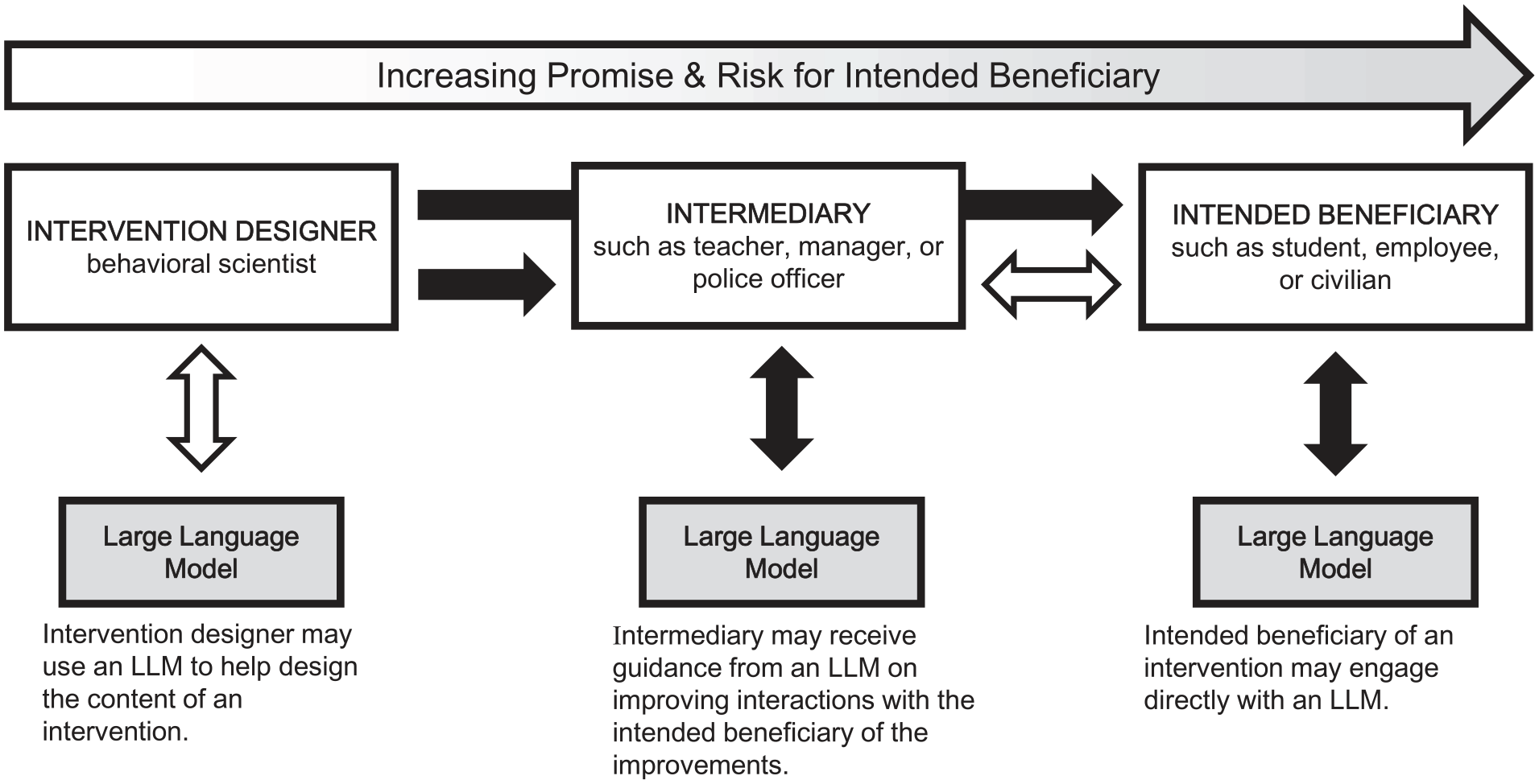
Conceptual model of how stakeholders in behavioral science interventions may interact with LLMs & the associated levels of benefit and risk to the intended beneficiaries of interventions
Benefits & Risks of Incorporating LLMs Into Interventions
When LLMs Interface With Intervention Designers
Behavioral scientists who design interventions might leverage LLMs in various ways. Here, we focus on two of the most likely.
First, designers might have LLMs generate initial drafts of intervention materials.Behavioral science interventions often include carefully crafted arguments aimed at shifting beliefs and behaviors.19,20 After having digested a huge amount of literature (including published behavioral science research and past examples of such arguments), LLMs could rapidly draft persuasive arguments or other intervention components—say, memorable metaphors that illustrate core concepts or writing exercises meant to reinforce desirable mindsets.21,22 One study found that LLM-generated messages encouraging individuals to be vaccinated during the COVID-19 pandemic were perceived to be stronger and more effective than messages developed by the U.S. Centers for Disease Control and Prevention. 23 The draft components produced by LLMs could then be piloted and refined in small iterative A/B tests (comparing two versions of a message) 24 before being tested at scale. Similarly, AI tools might be asked to generate messages or exercises that could be microtargeted to the populations most likely to be persuaded by those particular approaches. 16
Second, LLMs could be used to predict how human participants will respond to potential interventions.13,25–28 In a recent study, investigators had LLMs create virtual research participants that were intended to simulate the human participants in 476 experiments that used nationally representative samples; then the researchers compared the responses of the “silicon samples” to those of the humans in the original experiments. The researchers found a high correlation (0.85) between the simulated and the actual experimental effects. 26 An intervention designer might therefore use LLM-generated synthetic participants for fast and inexpensive initial A/B tests of proposed interventions and use the results to inform the design of a more refined pilot test involving humans. Indeed, if LLMs prove sensitive to various participant demographics (such as age, nationality, or gender) and can accurately reproduce heterogeneous responses to interventions, the use of these synthetic research participants 25 could be a viable way to anticipate and account for heterogeneity in the way different subgroups would respond to a given intervention message.7–9 This practice, if effective, could further accelerate the design process and help intervention designers make data-driven decisions about intervention materials at reduced cost.
As for risks posed to the intended beneficiaries of interventions designed with the help of LLMs, one is that LLMs have, at times, been found to generate information that could mislead or confuse recipients of an intervention, such as outputs not aligned with reality (colloquially known as hallucinations) 29 or that fail to apply common sense. 30
Another risk is that LLMs may generate content harmful to intended beneficiaries by perpetuating biases. Before LLMs are put into service, they are trained on a massive corpus of text generated by humans, often from the internet, discerning meaning via statistical learning. They are then trained further on materials relevant to outputs they are meant to produce and are given specific instructions, or prompts, on how to produce those outputs (such as, in simplified terms, “Draft a text message that will increase the rate at which mothers in community X set up vaccination appointments with pediatricians.”). Unfortunately, LLMs tend to perpetuate cultural biases embedded in the training data, such as favoring the values of the most-represented group31–33 rather than capturing human psychological diversity. 12
Similarly, messages microtargeted at subgroups less represented in the training data could also reflect inaccurate stereotypes about these minoritized subgroups. Cultural biases, of course, are not unique to LLMs. However, when bias is encoded in and replicated by AI tools that are widely used, especially foundational LLMs that form the basis of many AI tools, it spreads to many contexts—a condition known as algorithmic monoculture 34 —and its negative effects can become increasingly widespread. Without sufficient caution on the part of the designer, LLM-generated messages could thus disadvantage the very subpopulations they are designed to help.
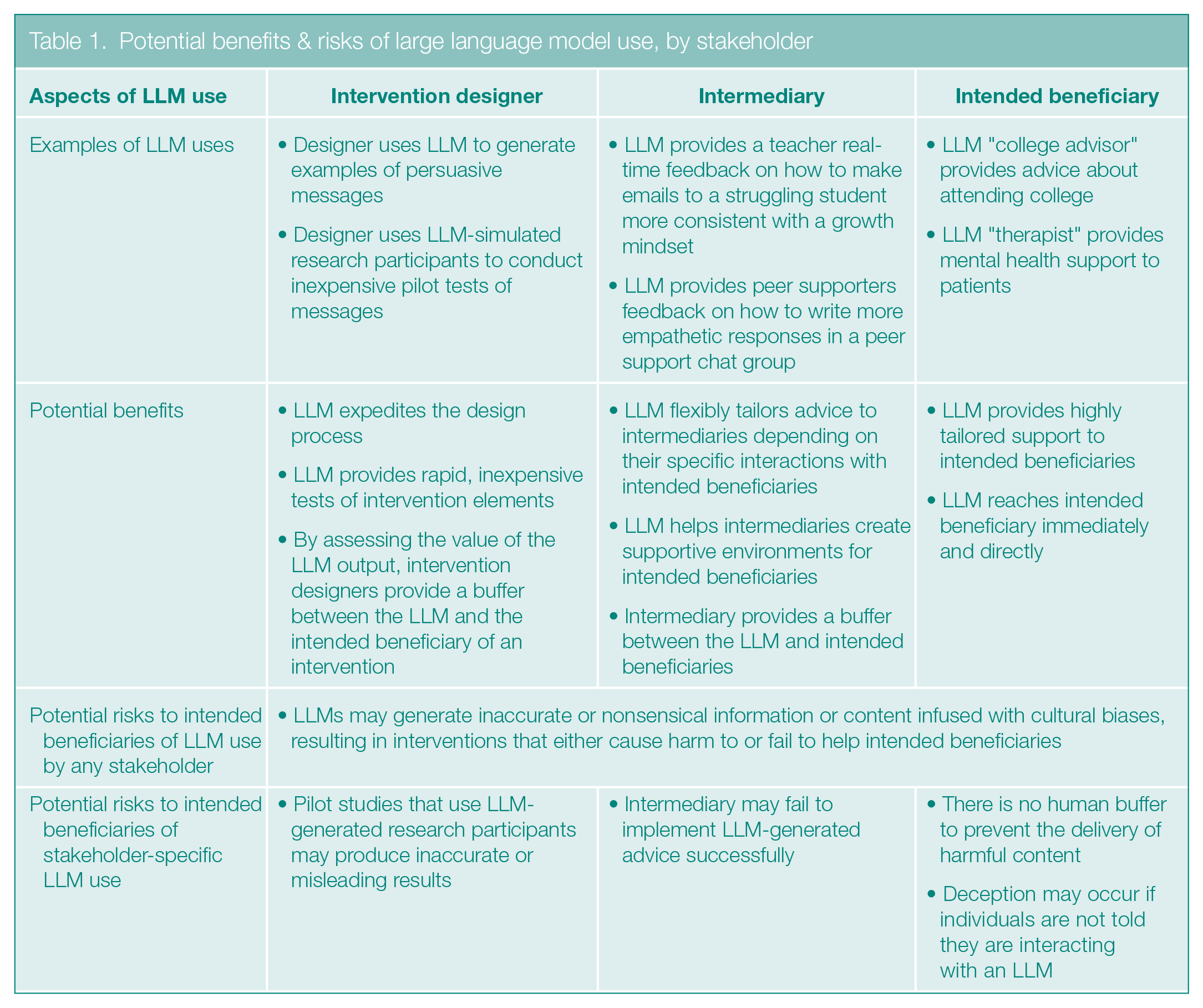
As Table 1 indicates, the possibility that LLMs will deliver flawed or biased information does not arise only when it is the intervention designer that uses LLMs; the same risks can occur when intermediaries or intended beneficiaries of interventions interact with LLMs. But a different problem is specific to the use of LLMs in intervention design: Using LLMs to test interventions on synthetic research participants can result in the delivery of useless or harmful interventions if the responses of the silicon samples do not, in fact, resemble the responses of the humans they were intended to mimic.
Potential benefits & risks of large language model use, by stakeholder
When LLMs Interface With an Intermediary
A major way that LLMs can intervene with intermediaries is by giving them feedback meant to improve the well-being of the people with whom the intermediaries interact. This feedback might relate to interactions that have already occurred with an intended beneficiary of an intervention 35 or, in digital environments such as chatrooms and emails, might be given in real time. 36
For instance, an LLM may provide teachers, workplace managers, or police officers with feedback on their language to facilitate their efforts to support more inclusive or empathic communication. Preliminary research has demonstrated success with this approach. One randomized controlled study used LLMs to provide real-time feedback to peer support providers who were interacting with support seekers on a text-based help platform 36 with the goal of promoting empathy, a feature of conversations that is linked to positive treatment outcomes in psychotherapy. 37 Compared to conversations that were not assisted by this AI tool, conversations assisted by LLM-based feedback were rated as more empathic by an independent group of support seekers. Related work has found similar effects in education, with AI feedback improving educators’ teaching practices as well as students’ academic performance.35,38 In one case, the software indicated how frequently an educator asked open-ended questions, built on a student’s contributions, and gave students time to talk in a one-on-one online discussion.
When providing feedback to intermediaries, rather than merely giving general advice, LLMs can flexibly tailor messages to individual intermediaries. Another potential benefit of having LLMs interact with intermediaries is that these people can buffer intended beneficiaries from aspects of LLM-generated suggestions they believe could be unhelpful or harmful.
It is worth emphasizing that, as the examples above show, it is not only the ultimate beneficiaries who can profit from LLM feedback to the intermediaries; the intermediaries, too, tend to benefit —for example, peer supporters became more confident in providing empathy, 36 and tutors used improved teaching strategies when given LLM assistance. 38 Although the prospect of LLMs potentially replacing certain intermediaries raises concerns, the findings we have described show that LLMs can augment the capabilities of, rather than replace, human intermediaries while at the same time enhancing the intermediaries’ relationships with the beneficiaries of the interventions (such as by helping teachers to be better educators and role models).
Beyond the risks posed to the intended beneficiaries of an intervention when any stakeholder interacts with an LLM, the primary risk of directing LLM feedback to intermediaries for behavioral science interventions is that the approach requires the individual intermediary to be able to (a) implement helpful LLM-generated advice effectively and (b) identify and dismiss harmful advice. To the extent that individuals fail to do so, they risk causing harm to the beneficiaries with whom they engage.
When LLMs Interface With the Intended Beneficiary
If successfully trained to interact directly with the intended beneficiaries of a behavioral science intervention, LLMs could provide the psychological support recipients need precisely when they need it.11,39–42 For instance, researchers examined whether an LLM could help address prospective college students’ concerns about attending college. After an LLM was trained on supportive language crafted by behavioral scientists, it was judged to be more supportive and understanding than were human-written messages on an existing college advising platform. 15 Thus, LLM-based tools may help to shift beneficiaries toward more adaptive ways of thinking by giving highly tailored advice as they confront distinct challenges. In the future, one could imagine equipping LLMs with a wide repertoire of scientifically proven intervention strategies that could be tailored to an intended beneficiary’s situation and delivered as and when the beneficiary required it.
Recent evidence suggests that LLMs could also help to address pressing social issues through argumentative dialogues. One study found that personalized, evidence-based conversations with an LLM reduced conspiracy theorists’ conspiracy beliefs by approximately 20% for at least two months, even among participants whose beliefs were deeply entrenched. 43 By responding precisely to the lines of thought and argumentation that undergird individuals’ beliefs, the personalized messages generated by LLMs have the potential to shift entrenched beliefs in ways that would be difficult for more static interventions (such as a standard e-learning module or a persuasive essay) to accomplish.
With this potential for great impact comes high levels of risk. Similar to LLM interactions with an intermediary, LLM-based tools could present harmful advice or ideas. In addition, in the absence of an intermediary, the messages would be delivered without being filtered by a human buffer who could mitigate potential damage caused by the promotion of behaviors and beliefs that would lead to negative consequences. What is more, unless intervention designers build in transparency, individuals may not know they are interacting with an LLM. Yet, there may be a tradeoff between effectiveness and transparency. For example, when recipients were told that the LLM-generated COVID-19 messages described earlier were produced by an LLM, they found the messages less persuasive than did people who were not given that information. 23 Likewise, empathic messages labeled as coming from an LLM were deemed to be less empathic than were messages labeled as written by a human.44,45
Mitigating the Risks of LLM-Powered Behavioral Science Interventions
Next, we address ways that LLM developers and intervention designers can mitigate risks that arise regardless of who is interacting with an LLM and then address ways they can mitigate risks related to interactions with specific stakeholders. After that, we offer specific recommendations for policymakers. For summaries, see the sidebars Risk-Mitigation Advice for Intervention Designers and Advice for Policymakers.
Mitigating Cross-Cutting Risks of Using LLMs in Designing or Delivering Interventions
Recall that one major cross-cutting risk of LLMs is the potential to generate inaccurate or nonsensical information or even content harmful to intended beneficiaries. Ensuring that LLM-powered behavioral science tools provide the intended type of information and advice will require intervention designers to rigorously fine-tune them, such as by specifically exposing the LLMs to the type of language that would be expected to help the intended beneficiaries and iteratively testing the tools’ efficacy across a wide variety of situations.46,47 LLMs could also be constructed in ways that help to address gaps in users’ understanding of AI’s limitations, such as by providing explanations of the processes that yielded the LLM’s output. 48
How might the other major cross-cutting risk—the potential for LLM-generated messages to be infused with cultural biases33,49—be mitigated? LLM developers and intervention designers can apply existing debiasing techniques,33,49 although these techniques have been unable to fully prevent bias. 50 Bias can also be limited by rigorously pilot testing intervention materials before they are implemented at scale. 24 For example, researchers might evaluate bias in their materials in an iterative process involving running focus groups with individuals from targeted subpopulations, refining the materials accordingly, testing them in small-scale pilot experiments, and then repeating the process as needed. Together, the use of debiasing techniques and pretesting may help to ensure that intervention materials avoid inadvertently privileging dominant social groups.
Mitigating Risks Related to Stakeholder-Specific Uses
Advice related to the use of LLMs by intervention designers. To avoid investing in ineffective or even harmful intervention materials, intervention designers who use LLM-generated recipients to assess their ideas will need a way to predict how well these silicon samples approximate the responses of human recipients. One solution could be to verify the silicon findings in small samples of human volunteers before testing an intervention at larger scale.
Advice related to the use of LLMs by intermediaries. To address the risk that intermediaries may fail to implement LLM-generated advice effectively, intervention designers should, of course, fine-tune the tools as much as possible. But they or others may also have to provide training on the capacities and limitations of these technologies, including teaching intermediaries how to identify potentially harmful language or, in cases where intermediaries have the opportunity for dialogue with the LLM, how to write prompts that will yield the best possible output. 51
Advice related to the use of LLMs by intended beneficiaries of interventions. When no intermediary will be present to buffer the harms that LLMs might cause, developers of LLM-powered tools that interact directly with intended beneficiaries should ideally take a “human-in-the-loop” approach, 52 which escalates challenging or uncertain circumstances to trained human agents. For instance, in the case of mental health or other specialized behavioral science chatbots, it will likely be necessary to flag conversations with people at high risk of harm and move these conversations, at least temporarily, to a human operator.
A human-in-the-loop approach may also help to resolve the apparent tension between transparency that individuals are interacting with an LLM and decreased effectiveness when they know they are doing so.23,44,45 For example, individuals conversing with an LLM may be transparently told that they are engaging with an AI-powered tool that is designed to help them with their specific situation but that if they want to talk to a human at any time, they can do so. A challenge for implementing this approach effectively is that the humans who step in may over-rely on an LLM’s judgments and fail to make better decisions. 53 Therefore, humans serving in this role will require rigorous training on the particular task the bot is intended to do (such as providing mental health services or psychologically supportive college advising) and how to correct LLM-generated output that is not consistent with the goals of the task.
Recommendations for Public Policy
Behavioral science’s influence on the interventions used in public policy is growing. 54 How can policymakers ensure that these interventions deliver the benefits of LLMs to society without exposing the recipients to significant risk? On the basis of our analysis of the uses of LLMs by different stakeholders, we offer five suggestions.
First, until an intervention is known to be safe for intended beneficiaries, favor the use of LLMs by people who are distal from those beneficiaries, such as intervention designers who use the LLMs to inform or test intervention ideas.
Second, to establish the safety of interventions that deploy LLMs directly to intended beneficiaries or intermediaries, insist on human trials of efficacy, preferably randomized controlled trials that can evaluate causality.
Third, given the ever-evolving nature of LLMs, demand ongoing evaluation of programs. Once an intervention is being applied in a population, trained researchers should sample human–LLM interactions for quality control.
Fourth, ensure that the intended beneficiaries of LLM-based interventions have ways of opting out and providing feedback if things go wrong.
Finally, develop policies that ascribe responsibility for LLM-generated errors; society will almost certainly require this action. These policies would clarify the circumstances under which a major error would be attributable to a tool’s developer, provider, or user. 18 To minimize risk to intended beneficiaries, policymakers must create unambiguous rules about which stakeholder is accountable for mistakes under various circumstances, and above all, must protect the interests of vulnerable individuals.
Conclusion
LLMs hold tremendous promise for accelerating the science of behavioral interventions, including making interventions more flexible to recipients’ individual needs, increasing scalability, and reducing cost, but they also pose risks. We have described three interaction paradigms in which LLMs might be incorporated into behavioral science interventions: interacting with intervention designers, with intermediaries who interact with intended beneficiaries, or with the intended beneficiaries of an intervention directly. And, for each paradigm, we have discussed the potential benefits and risks to the intended beneficiaries of interventions. Of course, behavioral science interventions may well incorporate LLMs in multiple ways. For instance, an intervention designer may use an LLM to not only suggest content for interventions but to also generate content used to train a new LLM that will interface with an intermediary or an intended beneficiary.
It may soon be possible to sufficiently mitigate the hazards associated with some of the least risky LLM uses described here, such as the creation of static text messages by intervention designers. Adequately tackling the greater risks that emerge when LLMs interact with intermediaries and intended beneficiaries will likely take more time. We are optimistic that the risks described in this article will ultimately be addressed, enabling researchers to deliver on the promise of LLMs to revolutionize behavioral science interventions.
Risk-Mitigation Advice for Intervention Designers
Select debiased LLMs or use existing tools to debias LLMs. Review outputs for bias.
Rigorously fine-tune LLMs for the task at hand.
Iteratively run pilot tests and then refine outputs and test proposed interventions across a wide variety of situations.
Before testing an intervention at scale, verify that any pretests done using synthetic research participants approximate the findings from humans.
Train intermediaries on the limitations of the LLM that give them advice and teach them how to identify harmful language.
For interventions that will be delivered directly to intended beneficiaries by an LLM, select an LLM that incorporates a human-in-the-loop strategy, enabling a human to step in when necessary.
Advice for Policymakers
Here, we suggest ways to protect the intended beneficiaries of interventions when LLMs are involved in the design or delivery of the interventions.
Favor the use of LLMs by intervention designers or intermediaries unless an LLM-based intervention has proven safe for the intended beneficiaries.
Insist on rigorous human trials of the efficacy of an intervention before an LMM is allowed to deliver an intervention directly to an intended beneficiary.
Require the ongoing postlaunch evaluation of programs that use LLMs to deliver interventions.
Provide the intended beneficiaries of direct LLM-based interventions with ways of opting out and providing feedback if things go wrong.
Develop unambiguous policies that, above all, protect the interests of vulnerable individuals and clarify who is responsible for errors attributable to LLMs.
Footnotes
Author Note
C. A. Hecht and D. C. Ong contributed equally to this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.