
Abstract
Purpose
To evaluate the performance of a custom ChatGPT-based chatbot in triaging ophthalmic emergencies compared to trained ophthalmologists.
Methods
One hundred hypothetical ophthalmic cases were created based on actual patient data from an ophthalmic emergency department, including details such as age, symptoms and medical history. Three experienced ophthalmologists independently graded these cases using a four-tier severity scale, ranging from Grade 1 (immediate care required) to Grade 4 (non-urgent care). A customized version of ChatGPT was developed to perform the same grading task. Inter-rater agreement was measured between the chatbot and the ophthalmologists, as well as among all human graders.
Results
The chatbot demonstrated substantial agreement with the ophthalmologists, achieving Cohen's kappa scores of 0.737, 0.749 and 0.751, respectively. The highest agreement was between ophthalmologist 3 and the chatbot (κ = 0.751). Fleiss’ kappa for overall agreement among all graders was 0.79, indicating substantial agreement. The Kruskal–Wallis test showed no statistically significant differences in the distribution of grades assigned by the chatbot and the ophthalmologists (p = 0.967). Bootstrap analysis revealed no significant difference in kappa values between the chatbot and human graders (p = 0.572, 95% CI −0.163 to 0.072).
Conclusions
The study demonstrates that a customized chatbot can perform ophthalmic triage with a level of accuracy comparable to that of trained ophthalmologists. This suggests that AI-assisted triage could be a valuable tool in emergency departments, potentially enhancing clinical workflows and reducing waiting times while maintaining high standards of patient care.
Background
The use of large language models (LLMs) such as ChatGPT (OpenAI, San Francisco, California, USA) or Claude (Anthropic, San Francisco, California, USA) in professional everyday practice has grown exponentially in the past years. Large language models are able to process and generate general-purpose language based on algorithms and can be used to execute specific tasks with surprising precision and within a record time. In the medical field, LLMs are starting to find their importance in various fields ranging from medical education to diagnostic and therapeutic assistance.1–10
A few studies have shown that LLMs are also helpful and suitable in the assistance for emergency triage.11,12 Currently, emergency triage is mostly managed by regularly trained nurses, with the support of trainees or senior physicians. Symptoms, findings, vital parameters and medical history are assessed, and the severity of each case is appreciated. Cases with higher severity are prioritized and taken care of first according to specific flowcharts. Emergency medicine fundamentally relies on algorithmic approaches and necessitates rapid decision-making processes to ensure optimal patient care. This also applies to the field of ophthalmology. Several factors have driven a re-evaluation of triage methods, including optimizing clinical workflow, reducing patient waiting times and tackling the growing shortage of specialized medical expertise. 13 In particular, novel triage formats have been implemented and evaluated, demonstrating comparable efficacy to traditional methods.14–17 These innovations address the above challenges while maintaining high standards of patient care. Studies have confirmed the effectiveness of these new approaches, as reported in the literature.1,14,17–20 In that context, LLMs have shown potential in diagnostic assistance and demonstrated particularly high triage accuracy.17,21 Currently most of the available LLMs can be fine-tuned and specialized for specific tasks and domains,22,23 and fine-tuning is expected to improve information retrieval accuracy. 24
We hypothesized that fine-tuned LLMs, specifically GPT, tailored specifically for the task of triage regardless of diagnosis, will perform similarly to ophthalmologists in non-scheduled ophthalmologic visits and could therefore be a considerable support in the clinical daily routine. In this study, we aimed to evaluate the performance of a custom GPT triage system specifically trained for ophthalmic emergencies compared to that of three ophthalmologists.
Methods
Methodology
This proof of concept study was conducted at the Department of Ophthalmology, Inselspital, University Hospital of Bern, Switzerland, over a period of 1 month. First, a customized version of ChatGPT specifically tailored for ophthalmology triage using OpenAI's customization capabilities on the GPT-4.0 architecture was developed. This Chatbot was trained using supervised learning fine-tuning with a set of 186 hypothetical ophthalmic cases designed to provide a diverse representation of ophthalmic conditions, ensuring broad coverage of common, urgent and emergent scenarios. The cases were based on typical ophthalmological presentations, incorporating essential triage-relevant information such as patient age, trauma mechanism (if applicable), laterality, symptoms and symptom duration. To fine-tune the model, the 186 cases were structured following an adapted version of the American Academy of Ophthalmology's Triage Algorithm, which categorizes patient conditions into four predefined severity grades: Grade1 = immediate care required, grade 2 = care within 1 week required, grade 3 = care within 4–6 weeks required and grade 4 = care in more than 6 weeks required.
In a second step, the Chatbot was used for the evaluation of another set of 100 hypothetical and thus fictive ophthalmic cases inspired by general clinical histories and pathologies of patients attending our emergency ophthalmic department over three consecutive days and remodelled as unique and standard ophthalmic emergency cases. These cases reflected typical unscheduled ophthalmological scenarios not only with high-level emergencies such as ocular trauma, acute angle-closure glaucoma or retinal detachments but also mid- to lower-level emergencies such as diabetic macular edema or dry eye disease. Since all cases were fictive, ethical approval was not applicable. Furthermore, no patient would have been directly visited but only an AI-derived LLM was used. An ophthalmologist not involved in the triage process prepared the case histories, which included relevant details such as patient age, trauma mechanism (if applicable), laterality, symptoms and symptom duration.
The evaluation set was used to assess the model's accuracy. Each case was independently graded by three ophthalmologists, all of whom regularly perform triage duties at a university hospital and they served as independent graders for these cases.
Statistical analysis
Statistical analysis was conducted with Python 3.12.3. Descriptive analysis (including frequency) and normality distribution test (Shapiro–Wilk) were performed. Intergrader agreement was assessed using Cohen's kappa (κ) coefficient to evaluate the level of agreement between pairs of graders. Additionally, Fleiss’ kappa was applied to assess agreement across all graders simultaneously. A p-value of less than 0.05 was considered statistically significant.
Results
A total of 100 cases were graded by three ophthalmologists and a chatbot. The frequency distribution of eye diseases is detailed in Table 1. The frequency distribution for each grader is illustrated in Figure 1. The chi-squared test for the frequency distribution across graders was not statistically significant in the distribution of grades assigned by the different graders (p = 0.998). Inter-rater agreement was assessed using Cohen's kappa scores. The results demonstrated substantial to almost perfect agreement among the ophthalmologists and the custom chatbot. The highest agreement was observed between ophthalmologist 1 and ophthalmologist 3, with a Cohen's kappa score of 0.922 (indicating almost perfect agreement). The lowest agreement was between ophthalmologist 2 and the custom chatbot, with a kappa score of 0.737 (indicating substantial agreement). Notably, the custom chatbot achieved substantial agreement with each of the ophthalmologists. Cohen's kappa scores are presented in Table 2 and illustrated in Figure 2. The overall agreement among the four graders was subsequently evaluated using the Fleiss kappa coefficient, with a value of approximately 0.79, indicating substantial agreement among all graders. To determine if there was any statistically significant difference in the distribution of grades assigned by the different graders, a Kruskal–Wallis test was performed, showing that there was no statistically significant difference (p = 0.967) in the grading patterns of the ophthalmologists and the custom chatbot.
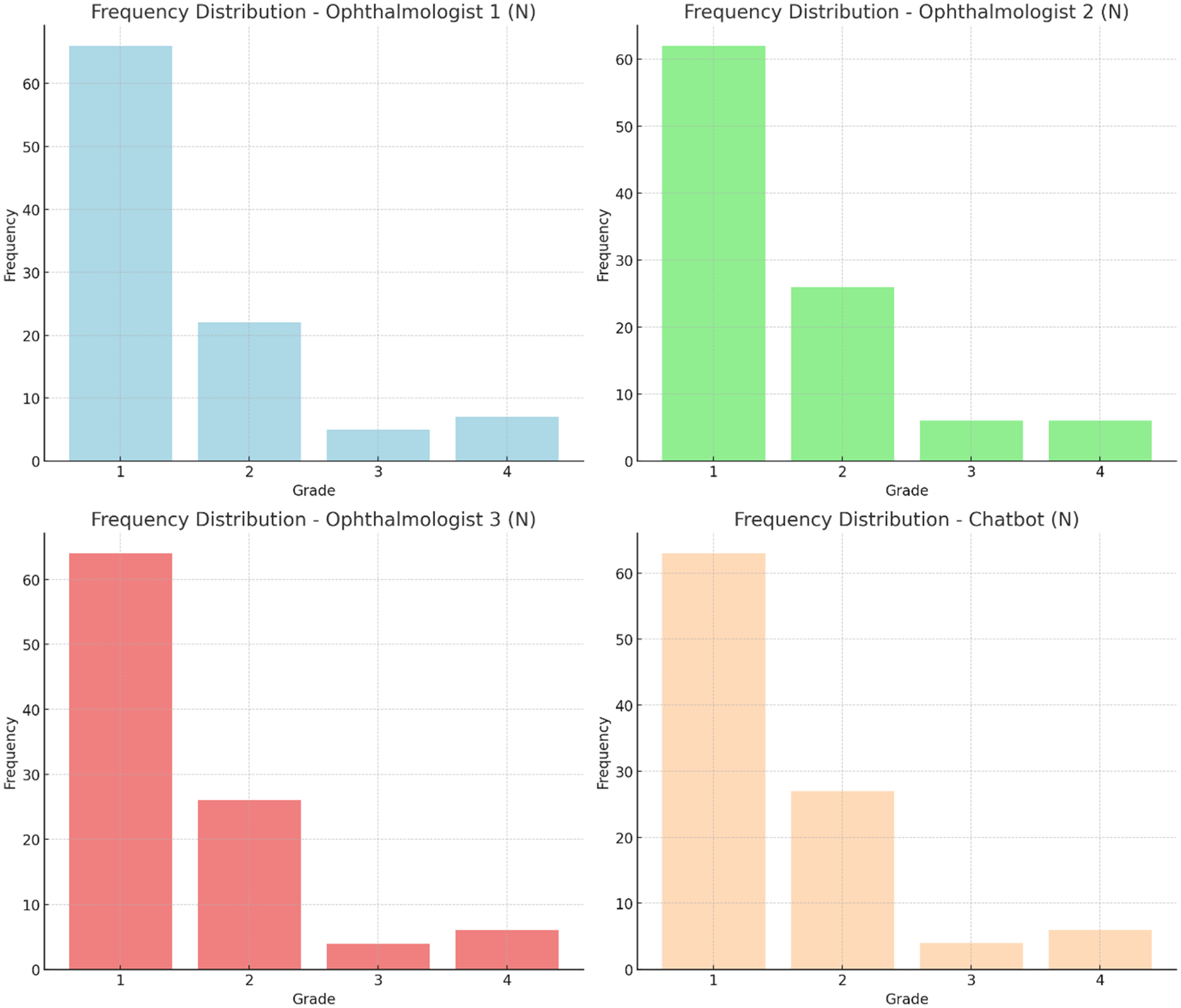
The severity of 100 emergency cases were graded by three trained ophtalmologists and the chatbot. Grade 1 meant that immediate care is required. Grade 2 that care within 1 week is required. Grade 3 that care within 4–6 weeks is required. Grade 4 that care is required not earlier than in 6 weeks. The frequency distribution for each grader is illustrated.
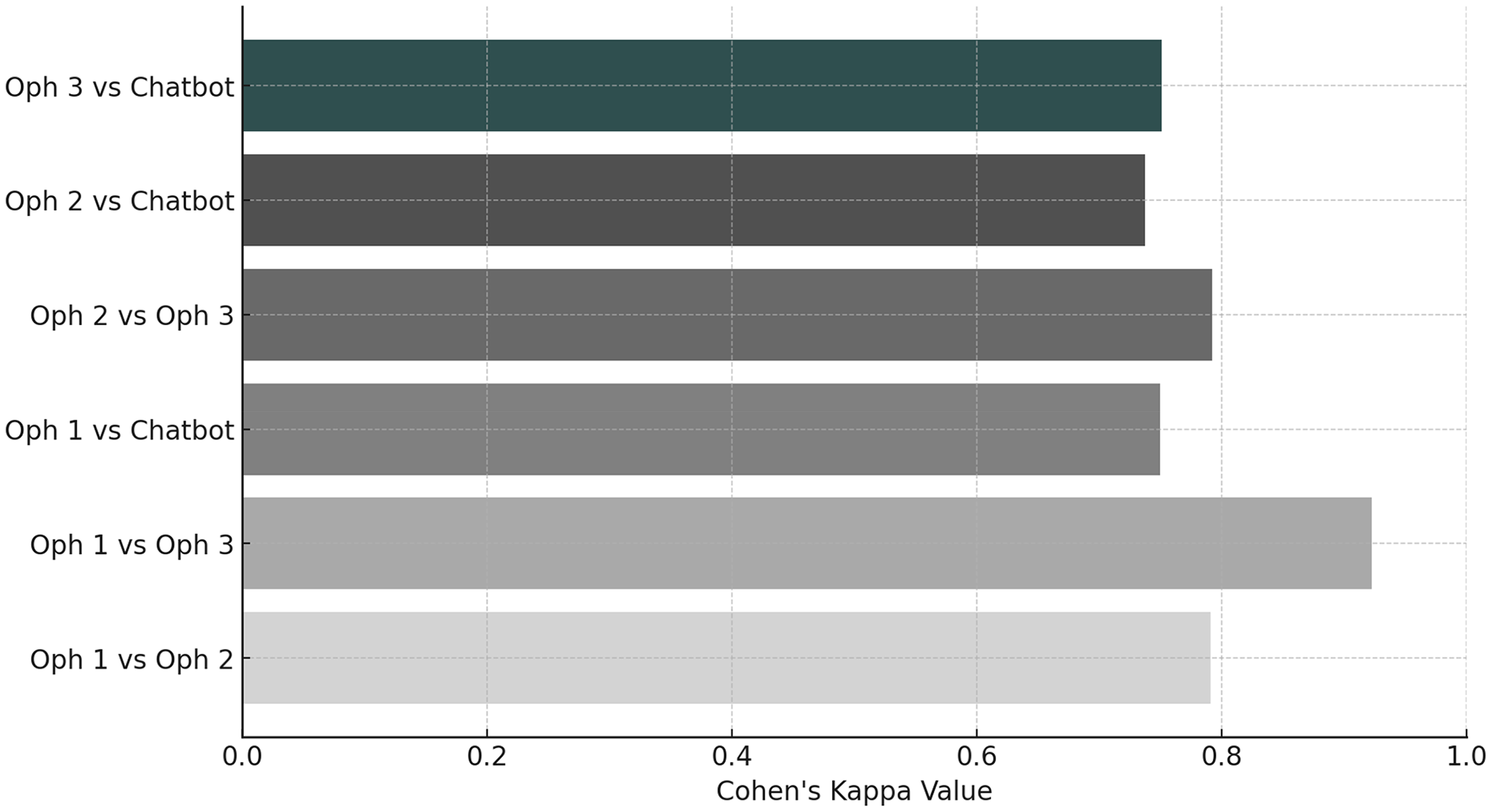
Intergrader agreement was assessed using Cohen's kappa (κ) coefficient. The level of agreement between pairs of graders are illustrated. The highest agreement was observed between ophthalmologist 1 and ophthalmologist 3 with κ = 0.922, and the lowest agreement was observed between ophthalmologist 2 and the custom chatbot, with κ = 0.737.
Frequency of cases divided into ophthalmological subspecialty graded by ophthalmologists and custom GPT.

Level of agreement between graders, as measured by Cohen's kappa (κ) scores.

To compare the agreement levels between the two groups – one including all graders (ophthalmologists and the custom chatbot) and the other consisting of only ophthalmologists – we calculated Fleiss’ Kappa for each group. As our data did not have a normal distribution, we used a bootstrap method to assess whether the difference in agreement between these groups was statistically significant. The bootstrap analysis revealed that the observed difference in Kappa values was −0.044, which was not statistically significant (p = 0.572, 95%CI −0.163 to 0.072).
Discussion
Our study aimed to assess the performance of a custom chatbot-based triage system specifically trained for ophthalmologic emergencies compared to that of ophthalmologists. The results suggest that the chatbot's grading is comparable to that of the ophthalmologists, with moderate to substantial agreement observed across all comparisons. Additionally, there is no evidence of bias towards consistently higher or lower grades by any grader, including the chatbot. These findings demonstrate a high level of consistency and reliability in the grading process across both human experts and the chatbot.
Our findings are consistent with recent studies exploring the potential of AI in medical triage. Paslı et al. implemented a trained GPT tool for triaging actual patients in an emergency department and it showed that the effectiveness was similar to that of an experienced triage team and to gold standard decisions with high sensitivity and specificity. 11 In the field of ophthalmology, Lyons et al. showed that ChatGPT offered a triage accuracy that was comparable with that of ophthalmology trainees. 17 The performance of ChatGPT was expected to improve even more, as it did with the release of GPT-4 or GPT-4.o. 16 These studies, along with our findings, suggest a promising future for AI-assisted triage in various medical specialties, including ophthalmology.
The potential impact of AI-assisted triage in ophthalmology is particularly significant given the current context of worldwide overcrowding in emergency departments and shortage of human expertise. The validated, targeted use of artificial intelligence has undeniable potential to save time- and improve cost-effectiveness in tasks such as emergency triage. In fact, correct triage not only enables fast medical care in all severe and sight-threatening cases but also allows fast-track models which will shorten waiting times, length of stay and lead to fewer patients leaving without being seen for less severe cases. 25
However, it is crucial to approach the integration of AI in healthcare with caution. While our study shows promising results, the ethical implications and potential biases of AI systems in healthcare decision-making must be carefully considered. Gianfrancesco et al. point out that there is a risk of perpetuating or even exacerbating existing health disparities if AI systems are not developed and implemented with careful consideration of diverse patient populations. 26
Our study has some limitations. Firstly, medical histories used in this study were written by a medical doctor, already formatted in a medical language, potentially facilitating the GPTs’ performance. Future studies should evaluate the performance of the GPT when confronted with input from non-medical staff or patients, which may present a more realistic challenge. This is particularly important when testing AI systems, which need to be evaluated in real-world clinical settings to ensure their robustness and generalizability. 11
Furthermore, the distribution of cases across severity grades was not equal, with a predominance of Grade 1 cases. While this reflects the reality of our emergency department admissions, it may have influenced the overall agreement metrics. Future studies should consider a more balanced distribution of case severities to provide a more comprehensive evaluation of the triage system's performance across all grades.
In the future, prospective studies involving real cases are necessary to validate the concept in a clinical setting. This would provide more robust evidence of custom GPTs’ performance under real-world conditions.
Conclusion
In conclusion, our study demonstrates the potential of AI-assisted triage in ophthalmology, showing performance comparable to human experts. However, careful consideration of ethical implications, real-world testing and constant evaluation is necessary when we integrate these technologies into clinical practice. The promise of AI in improving healthcare efficiency and accessibility is significant, but it must also ensure that patients receive care that is equitable, safe and high quality.
Footnotes
Contributorship
IS and RA conceived and designed the research. IS created the cases. IS and RA trained the customized chatbot. IS interrogated the LLM. LFD, VMMB and NS graded the cases. IS, JR and RA did the statistical analysis. All the authors analysed and interpreted the literature. All the authors drafted the manuscript. All authors made critical revision of the manuscript.
Data availability
The data that support the findings of this study are available on request from the corresponding author, RA.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
Ethical approval was not applicable because all cases were fictive. Furthermore, no patient would have been directly visited but only an AI-derived large language model was used.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Guarantor
RA.