
Abstract
Objectives
Large language models (LLMs) are increasingly used in healthcare, with the potential for various applications. However, the performance of different LLMs on nursing license exams and their tendencies to make errors remain unclear. This study aimed to evaluate the accuracy of LLMs on basic nursing knowledge and identify trends in incorrect answers.
Methods
The dataset consisted of 692 questions from the Japanese national nursing examinations over the past 3 years (2021–2023) that were structured with 240 multiple-choice questions per year and a total score of 300 points. The LLMs tested were ChatGPT-3.5, ChatGPT-4, and Microsoft Copilot. Questions were manually entered into each LLM, and their answers were collected. Accuracy rates were calculated to assess whether the LLMs could pass the exam, and deductive content analysis and Chi-squared tests were conducted to identify the tendency of incorrect answers.
Results
For over 3 years, the mean total score and standard deviation (SD) using ChatGPT-3.5, ChatGPT-4, and Microsoft Copilot was 180.3 ± 22.2, 251.0 ± 13.1, and 256.7 ± 14.0, respectively. ChatGPT-4 and Microsoft Copilot showed sufficient accuracy rates to pass the examinations for all the years. All LLMs made more mistakes in the health support and social security system domains (p < 0.01).
Conclusions
ChatGPT-4 and Microsoft Copilot may perform better than Chat GPT-3.5, and LLMs could incorrectly answer questions about laws and demographic data specific to a particular country.
Introduction
Large language models (LLMs) are increasingly integrated into various domains, including healthcare, demonstrating potential benefits and challenges.1–5 LLMs also demonstrate numerous possibilities for future clinical applications.6,7
Some LLMs, such as ChatGPT, developed by OpenAI, have been used to evaluate the performance of medical-setting knowledge in previous studies. In various countries’ medical license examinations, ChatGPT-3.5 often fails to reach passing criteria, whereas ChatGPT-4 has achieved a passing performance. 8 Differences in performance between several LLMs have been reported in previous studies that suggest that ChatGPT-4 and Microsoft Copilot showed good performance for medical knowledge, 9 but Google Bard may have a slightly lower performance than ChatGPT-4. 10 In addition, ChatGPT-4 shows good performance in license examinations of other healthcare providers.11,12 In nursing, ChatGPT-4 has demonstrated sufficient performance to pass the national nursing examination, whereas ChatGPT-3.5 has not, consistent with other healthcare license exam findings.13–15 In addition, the performance of LLMs in nursing has been evaluated for several outcomes, including critical settings and nursing education. 16 However, while these studies showed various possibilities for using LLMs in nursing, the differences in performance between ChatGPT and other LLMs were unclear regarding nursing license examinations.
LLMs may perform well with basic knowledge in medical settings. However, it is generally said that LLMs are incomplete and may sometimes answer incorrectly. 17 In a previous study, LLMs did not pass license examinations with complete answers, indicating that LLMs are incomplete; the error types of LLMs were examined in relation to medical knowledge. 18 However, it is unclear in which domains LLMs tend to incorrectly provide nursing knowledge. Understanding the domains to which LLMs tend to answer incorrectly is important for the effective use of LLMs by healthcare providers, particularly nurses.
Therefore, this study aimed to evaluate the performance of LLMs in terms of the accuracy rate for basic knowledge in nursing and gain insight into the tendency to answer incorrectly. The results of this study may guide nurses in the use of LLMs.
Materials and methods
Characteristics of examination
The Japanese national nursing examination is organized by the Ministry of Health, Labor, and Welfare (MHLW). The questionnaire used in this study was the Japanese National Nursing Examination for 3 years from 2021 to 2023. All the data, including the examination used in this study are publicly available. Details of the data are provided in the supplementary file (S-text 1). The examination consisted of 240 multiple-choice questions, in which examinees were asked to select one or two answers from a set of four or five options. Among these, 50 questions were designated as “compulsory questions” covering fundamental aspects of nursing knowledge. The remaining questions include 130 “general questions” and 60 “scenario-based questions.” In the examination, each correct answer to compulsory and general questions was worth one point, while correct answers to scenario-based questions were worth two points. Therefore, the total score for the examination was 300 points if all questions were answered correctly. The passing criteria were as follows: (i) achieving an accuracy rate of more than 80% (40 points) in the compulsory questions, and (ii) achieving a combined accuracy rate in general and scenario-based questions that exceeded the borderline score set by the MHLW. In the years considered in this study, the borderline scores were 159, 167, and 152 points for 2021, 2022, and 2023, respectively. The MHLW has determined and made public criteria for the examination, including 11 domains: structure and function of the human body, understanding disease and promoting recovery, health support and social security systems, basic nursing, adult nursing, geriatric nursing, pediatric nursing, maternal nursing, psychiatric nursing, home care nursing theory, as well as integrated and practical nursing. The domains where the questions belonged have not been opened to the public.
Analysis with LLMs
The LLM used in this study comprised three models: ChatGPT-3.5, ChatGPT-4 (OpenAI Incorporated, Mission District, San Francisco, USA), and Microsoft Copilot (Microsoft Corporation, WA, USA). We used the free versions of ChatGPT-3.5 and Microsoft Copilot and the subscribed version of ChatGPT-4. Responses by ChatGPT-4 were collected between January 25 and April 5, 2024; responses by Microsoft Copilot were collected between February 2 and March 5, 2024; and responses by ChatGPT-3.5 were collected between July 5 and July 29, 2024. All responses were collected in the laboratory of each researcher's institution. The questions were manually entered into each LLM via the website (not the Application Programming Interface [API]). Entering the question and collecting answers from the LLM were divided between two researchers (TK and KH). Before entering the first question, researchers provided the following prompt as input: “Please answer the questions to confirm your knowledge of nursing in Japan. This is a multiple-choice question, so please select the correct answer.” For subsequent questions, researchers preceded each question with the prompt: “This is the next question.” If the LLM did not provide the designated number of responses, the researchers added an additional prompt instructing it to comply with the specified answer format: “Please select one or two answers.” This process was standardized between the two researchers, and each entered prompt and retrieved answer was carefully checked by the two researchers separately to ensure their correctness. The 1-year examination was conducted by chat in each LLM. The collected answers were scored using the official corrected answers published by the MHLW. Image and table questions were excluded from this study because the LLMs could not be recognized. In addition, inappropriate questions from the MHLW that were open to the public were excluded.
Analysis of LLM results
A two-step approach was used to analyze the data. First, answers were collected, and the correct answer rate was calculated using compulsory questions. Then, the total points were calculated each time to evaluate whether each LLM passed the examination.
Next, deductive content analysis 19 was performed to identify error trends in the answers of the LLMs. This approach helps identify critical concepts based on existing theories and previous research. This study used a categorization matrix with 11 domains that were determined and opened by the MHLW, and coding and categorization were initiated. Incorrect answers were classified into groups of incorrectly answered LLMs before deductive content analysis. Deductive content analysis was performed as follows. (i) Incorrect answers to all examinations were prepared, and their content was used as the unit of analysis. (ii) Two researchers (TK and KH) read the question text and the choices of all incorrect answers and coded them accordingly. (iii) The codes were placed in a categorization matrix of 11 domains. Examples of incorrect answers outputted by LLMs were provided in the supplementary file, along with potential reasons that were discussed among researchers.
Statistical analysis
Descriptive analyses were performed in the first step of the LLM analysis to evaluate whether each LLM passed the examination. In addition, a one-way analysis of variance (ANOVA) for 3 years of examinations was performed with LLM models as a factor to analyze the differences in total scores among the LLMs. Furthermore, the analysis was followed by Turkey–Karmer's methods for exploratory multiple comparisons among groups.
In the second step to identify error trends in the answers of the LLMs, the number of codes analyzed in each category with deductive content analysis was counted, and a Chi-squared goodness-of-fit test and residual analysis were performed. The expected value was calculated by dividing the total number of incorrect answers by the number of domains, based on the hypothesis of uniform distribution across domains. A Chi-squared goodness-of-fit test was also conducted to examine whether errors were uniformly distributed across the domains. Residual analysis was performed using standardized residuals, not adjusted standardized residuals, because the analysis was conducted on a single column of frequency data.
All statistical analyses were performed using R version 4.2.2 (R Foundation for Statistical Computing, Vienna, Austria). Statistical significance was defined as p < 0.05.
Ethical considerations
This study did not involve human or animal participants, and all the data used in this study are publicly available on the Internet. Therefore, ethical approval and patient consent were not required.
Results
Input data statistics
The number of questions included in the analysis was 692 from the Japanese National Nursing License Examinations for 3 years. Of these, 234 questions were from 2021, excluding six questions on images or tables, 228 questions were from 2022, excluding 10 image or table questions and two inappropriate questions, and 230 questions were from 2023, excluding nine image or table questions and one inappropriate question.
Accuracy rate
The ChatGPT-3.5 could pass none of the years because the accuracy rate was lower than 80% for the compulsory questions. ChatGPT-4 and Microsoft Copilot passed the examinations in all years with an accuracy rate of more than 80% for compulsory questions, and the total score was above the borderline. The mean total score with ChatGPT-3.5 over 3 years was 180.3, and the standard deviation (SD) was 22.2, whereas for ChatGPT-4 and Microsoft Copilot, the mean and SD was 251.0 ± 13.1, and 256.7 ± 14.0, respectively. The differences in the total score among the LLMs were not statistically significant, as shown by the one-way ANOVA results (effect size = 0.398, 95% confidence interval [CI] [0, 1], F (2, 6) = 3.97, p = 0.08). The mean score of ChatGPT-3.5 was 53.7 points lower than that of Microsoft Copilot; however, exploratory multiple comparisons using Tukey–Kramer's methods showed there was no statistical difference between ChatGPT-3.5 vs. Microsoft Copilot (95%CI [-117.9, 10.6], p = 0.09). Similarly, 48.0 points difference between ChatGPT-4 and ChatGPT-3.5 (95% CI [-16.2, 112.2], p = 0.13), and ChatGPT-4 scored 5.7 points lower than Microsoft Copilot (95% CI [-69.9, 58.6], p = 0.96), these differences were not statistically significant. Details are shown in Table 1.
Test scores and accuracy rates.
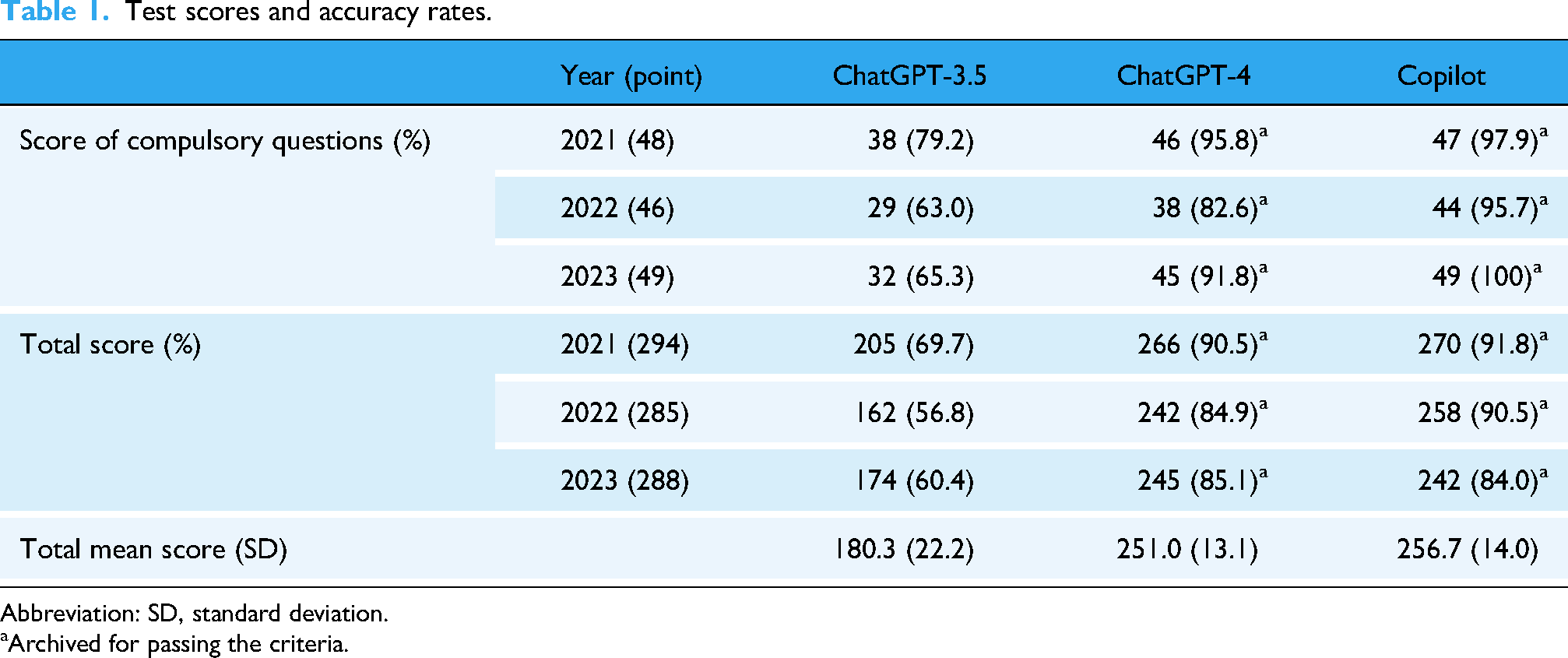
Abbreviation: SD, standard deviation.
Archived for passing the criteria.
Tendency to answer incorrectly
The number of incorrectly answered questions that were answered incorrectly by all LLMs was 35, and the group that were answered incorrectly by ChatGPT-3.5 and ChatGPT-4 included 35 questions. The results of deductive content analysis and a number of questions categorized in each domain for groups answered incorrectly by all LLMs and ChatGPT-3.5 and ChatGPT-4 are shown in Tables 2 and 3.
Domains of incorrect answers of all LLMs.
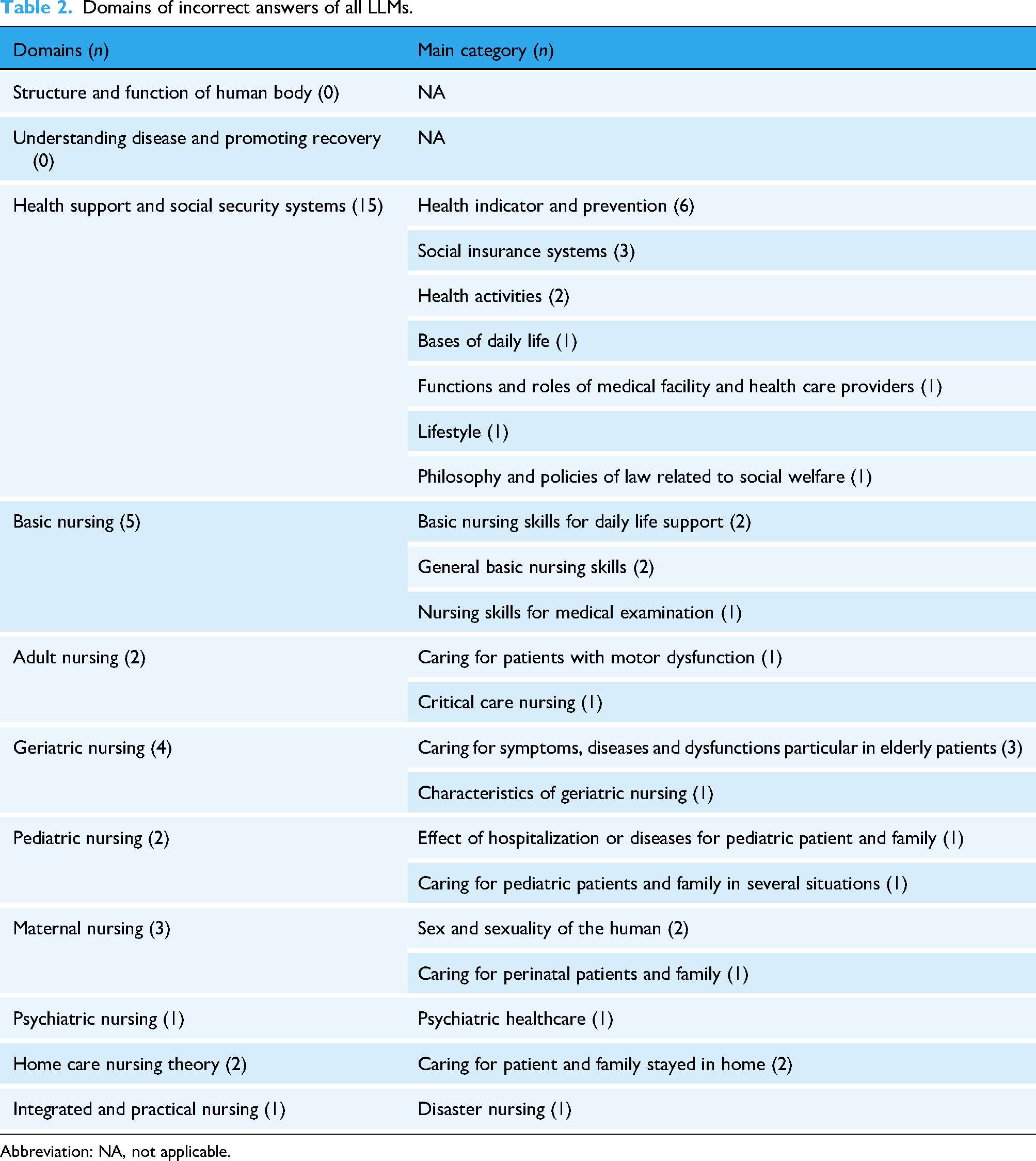
Abbreviation: NA, not applicable.
Domains of incorrect answers of ChatGPT-3.5 and ChatGPT-4.
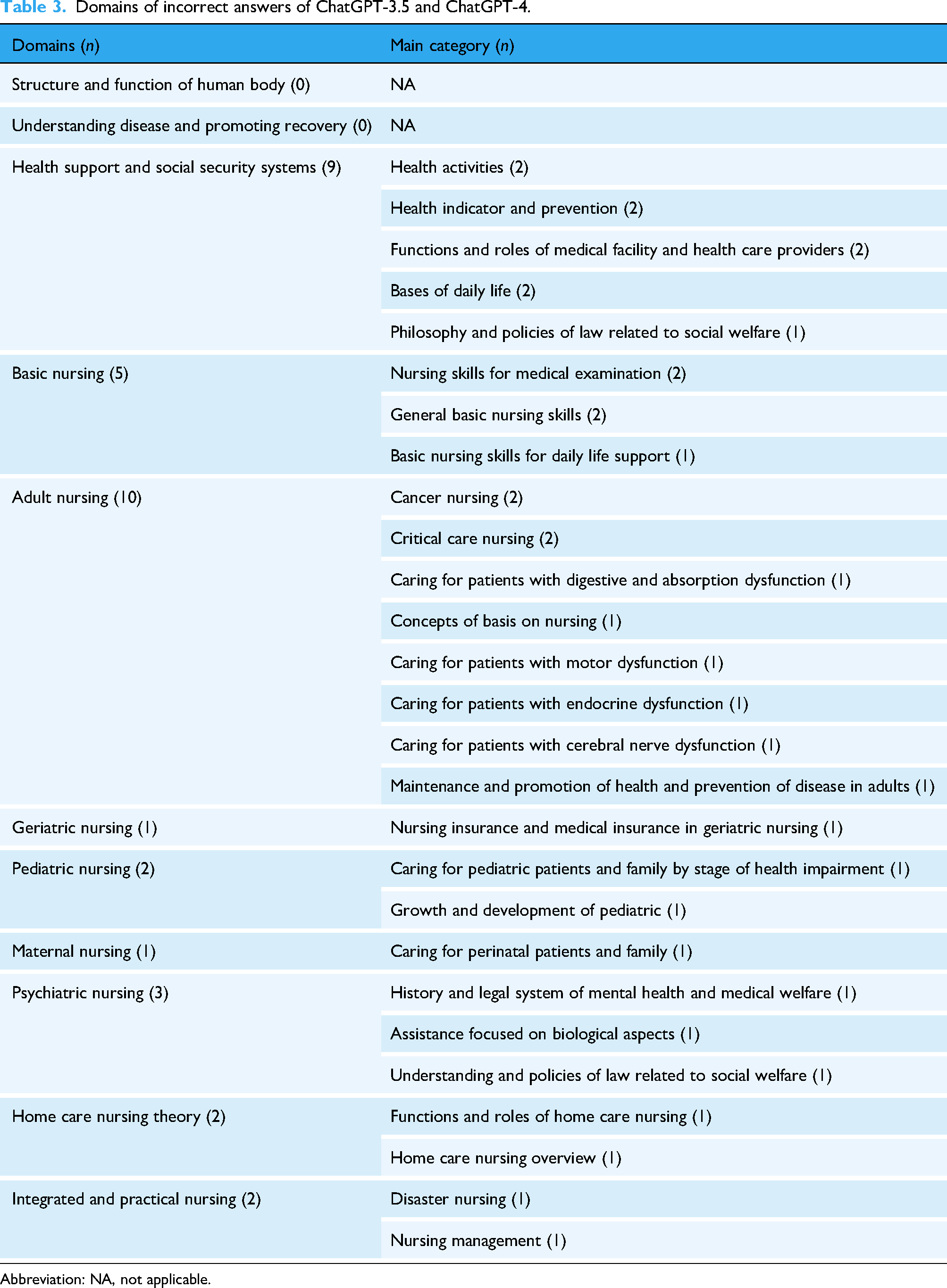
Abbreviation: NA, not applicable.
In the group of all LLMs that were incorrectly answered, the domains of health support and social security systems had the highest number of incorrect answers (15 questions). The next highest number was basic nursing with five questions and four questions were incorrect in the domains of geriatric nursing. In the group of ChatGPT-3.5 and ChatGPT-4 were incorrectly answered, the highest number of incorrect answers was the domains of adult nursing with ten. The next highest number of incorrect answers was the domains of health support and social security systems with nine, and basic nursing with five. The details of the other incorrectly answered groups and examples of incorrect answers are provided in the supplementary file (S-table 1 to 5). The results of the Chi-squared goodness-of-fit test of the group of incorrectly answered questions by all the LLMs showed a statistically significant difference (χ2 (10) = 55.8, expected frequencies = 3.18, p < 0.01), and the standardized residual in the residual analysis showed a statistically significant difference in the domains of health support and social security systems (p < 0.01). For the ChatGPT-3.5 and ChatGPT-4 group, the results of the Chi-squared goodness-of-fit test showed a statistically significant difference (χ2 (10) = 36.97, expected frequencies = 3.18, p < 0.01), and the standardized residual in the residual analysis showed statistically significant differences in the domains of health support and social security systems, and adult nursing (p < 0.01). Details of the results are listed in Table 4.
Tendency to answer incorrectly in each domain.
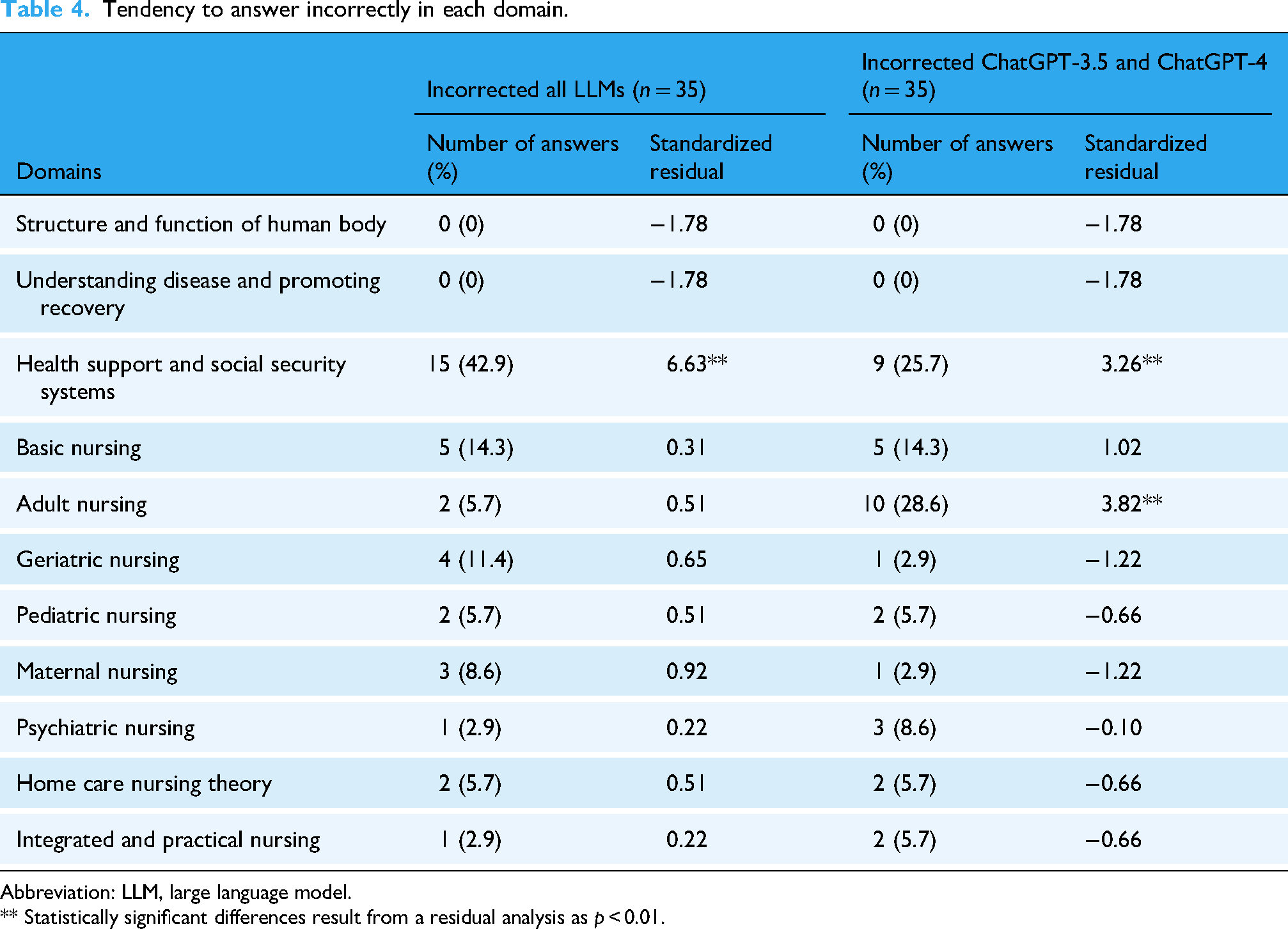
Abbreviation: LLM, large language model.
** Statistically significant differences result from a residual analysis as p < 0.01.
Discussion
The findings of this study highlight the performance of three LLMs on the Japanese National Nursing Examination and reveal their common patterns of answering incorrectly. ChatGPT-4 and Microsoft Copilot achieve passing accuracy rates, whereas ChatGPT-3.5 did not. All LLMs tested in this study made more mistakes in the health support and social security systems domains; in particular, ChatGPT-3.5 and ChatGPT-4 answered incorrectly for the health support, social security systems, and adult nursing domains.
The accuracy rate of ChatGPT-4 revealed in this study was sufficient to pass the national license examinations, similar to previous studies. The results of this study showed that ChatGPT-4 had sufficient performance to pass the Japanese nursing license examination for all years used in this study, but ChatGPT-3.5 did not perform well in passing the examinations, not even one of them. Our results are consistent with the previous study from China that ChatGPT-4 showed higher performance than ChatGPT-3.5 in national nursing examinations of the United States and China. 20 Several previous studies evaluating the performance of the license examination of other healthcare providers showed : ChatGPT-4 had sufficient performance to pass the examinations, but ChatGPT-3.5 did not have sufficient performance.11–13 Originally, GPT-4 technology was developed as a higher-performance model than ChatGPT-3.5 for various professional and academic benchmarks. 17 The results of this study demonstrate the actual performance of ChatGPT-4. It was not possible to compare the official accuracy rate and mean score for all participants of the Japanese nursing license examination because of their unavailability to the public by the MHLW.
In addition, the accuracy rate of Microsoft Copilot is similar to that of ChatGPT-4. This study revealed that ChatGPT-4 and Microsoft Copilot had sufficient performance to pass the Japanese nursing license examination, and the average total score over 3 years did not show statistical significance. A previous study showed that Microsoft Copilot had the same performance as ChatGPT-4, 9 which is similar to our results. The performances of ChatGPT-4 and Microsoft Copilot have a high probability of being the same because Microsoft Copilot was developed based on GPT-4 technology, similar to ChatGPT-4. 1 Thus, it is considered appropriate for the performances of ChatGPT-4 and Microsoft Copilot to be similar. The differences among the LLMs were not statistically significant (F (2, 6) = 3.97, p = 0.08), and the effect size was large (0.398). However, the wide 95% CI [0, 1] indicates substantial uncertainty in this estimate, likely due to the small sample size. Exploratory multiple comparisons using Tukey–Kramer's method also revealed no statistically significant differences between any pairs of LLMs, although ChatGPT-3 scored 53.7 points lower than Microsoft Copilot (p = 0.09), suggesting a potential difference that might have been detected if the sample size had been larger.
Finally, the LLMs may not be all-round and may have domains that tend to answer questions incorrectly, which could be due to the training data of the GPT-4 technology. The results of this study can be classified into groups of incorrectly answered LLMs, and the mistakes were similar among the LLMs. If LLMs had no performance bias, errors would be evenly distributed across the 11 domains. However, the deductive content analysis indicated that while the LLMs generally performed well on basic nursing knowledge applicable worldwide, they frequently incorrectly answered questions involving Japan-specific laws and demographic data. These differences were statistically significant based on the Chi-squared goodness-of-fit test and residual analysis. This situation may be related to the fact that ChatGPT and Microsoft Copilot were developed using the same or similar technology as GPT-3.5 and GPT-4. 1 The GPT-4 technology could respond to several languages, including Japanese. 17 However, the GPT technology is not complete and has some error types that have been clearly shown 21 ; the GPT technology can incorrectly understand tasks.18,21 Moreover, the LLMs may have more difficulties and complexities with the Japanese language compared with the English language, because the Japanese language networks differ significantly from English language networks owing to their different grammatical features. 22 This suggests that the LLMs may not have correctly understood the examination written in Japanese, as used in this study. In addition, LLMs may have inherent biases in answering questions about incorrect domains that were shown in this study. The health support and social security systems domains include knowledge of Japan-specific laws and demographic data. GPT-4 technology was trained using publicly available data such as Internet data and data licensed by third-party providers. 17 However, a previous study suggested that GPT-4 technology may have inherent biases that were reflected in the training data, and the details of the training set were not described.17,23 Consequently, the biased results in incorrectly answered domains may have reflected performance biases in LLMs stemming from the training data. Specifically, these inaccuracies may be ascribed to the lack of exposure of LLM to detailed, country-specific data. Thus, incorporating such localized data during the training phase could potentially enhance the accuracy and relevance of responses in region-specific contexts such as country-specific laws and demographic data. Moreover, LLMs, which are fine-tuned for the Japanese language, were developed in recent years, 24 and their respective companies may resolve the problems related to languages gradually in the future.
A key strength of this study is that the results had high validity because performance evaluations were performed using large sample sizes as multi-year examinations. However, this study has some limitations. First, the applicability of the results may be limited. The Japanese National Nursing Examination includes not only nursing knowledge worldwide but also Japan-specific laws and demographic data. Furthermore, ChatGPT-4 was the latest model at the time of data analysis, but new models have now been published, such as ChatGPT-4o. Thus, it is unclear and may depend on the training data of GPT technology whether LLMs show the same performance as in this study when examining examinations of other countries or new models of ChatGPT, especially the tendency to answer incorrectly. Second, this study could only evaluate selective performance. The Japanese National Nursing Examination is structured with only multiple-choice questions and uses only Japanese language, with the setting limited to only Japanese clinical settings; image or table questions were excluded from this study. The performance of the LLM in answers to open-ended question, regarding other languages or countries, and to image or table questions was unclear. Third, biases related to the manual entry of questions into each LLM may have occurred. The manual entry methodology could introduce unintentional errors or inconsistencies. However, all biases that could have significantly affected our findings are assumed to have been resolved because each entered prompt and retrieved answer were carefully checked by two researchers (TK and KH) separately. In future studies, using APIs may provide a more robust methodology. Finally, there were differences between the actual examinees. The accuracy rate could not be compared with that of the actual examinees because the accuracy rate of the actual examinees was not published publicly. The difference in the accuracy rate between the results of this study and those of actual examinees was unclear.
Nurses in clinical settings and nursing educators should recognize the potential problems of reliability when using LLMs, as incorrect answers due to biases in training data may be obtained, not only in Japan but also in other countries. LLMs are inherently imperfect, and their performance may be particularly limited in some domains, such as legal or demographic information specific to certain countries, with a high potential for errors, which could lead to incorrect conclusions. Additionally, personal information must not be entered, as LLMs may learn from input data, posing a risk of data leakage, when the LLMs are used via the website.
However, these uncertainties can be managed by ensuring accountability through cross-checking LLM responses with human experts and official guidelines and by anonymizing input data to include only generalized information. These practices can help ensure a safer and more reliable use of LLMs. This study did not evaluate LLM performance in handling advanced clinical nursing knowledge, open-ended questions, or questions involving images and tables. Recent studies have suggested that current LLMs such as ChatGPT-4 omni (ChatGPT-4o) have the potential for high performance to evaluate the images and tables 25 ; furthermore, the LLMs with fine-tuned with specific certain country's data have developping. 24 These recent LLMs may have higher performance potential than the LLMs used in this study. Thus, future research should address that combining multiple recent LLMs such as ChatGPT-4o, and fine-tuned LLMs to specific data may provide a better accuracy rate than in this result. The performance of LLMs to interpret such questions may not only improve daily nursing care and education but also may be essential for all healthcare providers in the future.
Conclusion
ChatGPT-4 and Microsoft Copilot may perform better than ChatGPT-3.5, and LLMs could incorrectly answer laws and demographic data specific to a particular country. Future studies should conduct more exploratory studies to provide more evidence.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251346571 - Supplemental material for Performance evaluation of large language models for the national nursing examination in Japan
Supplemental material, sj-docx-1-dhj-10.1177_20552076251346571 for Performance evaluation of large language models for the national nursing examination in Japan by Tomoki Kuribara, Kengo Hirayama and Kenji Hirata in DIGITAL HEALTH
Footnotes
Ethical considerations
This study did not involve human or animal participants, and all the data used in this study are publicly available on the Internet. Therefore, ethical approval and patient consent were not required.
Author contributions
Tomoki Kuribara and Kenji Hirata conceptualized this concept. Tomoki Kuribara developed the methodology and drafted the manuscript. Tomoki Kuribara and Kengo Hirayama performed the data analyses. Kenji Hirata made a supervision. All authors reviewed, edited, and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: the Japan Society for the Promotion of Science (grant number JP24K13831).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.