
Abstract
Objective
To investigate the performance (accuracy, comprehensiveness, consistency, and the necessary information ratio) of large language models (LLMs) in providing knowledge related to respiratory aspiration, and to explore the potential of using LLMs as training tools.
Methods
This study was a non-human-subject evaluative research. Two LLMs (GPT-3.5 and GPT-4) were asked 36 questions (32 objective questions and four subjective questions) about respiratory aspiration in English and Chinese. Responses were scored by two experts against gold standards derived from authoritative books. The accuracy of the two LLMs’ responses of objective questions were compared by chi-square test or Fisher exact probability method. For subjective questions, the t-test or Mann–Whitney U test was used to compare the differences between two LLMs.
Results
There was no significant difference in the ratings provided by the two experts. The accuracy scores of objective questions of two LLMs were high. LLMs also performed well on subjective questions, showing high levels of accuracy, comprehensiveness, consistency, and necessary information ratio. And no significant differences were found in the accuracy of the English and Chinese responses to subjective questions between the two LLMs (z = 0.331, p = 0.886; z = 1.703, p = 0.114). There was no significant difference in the comprehensiveness of the English and Chinese responses between the two LLMs (t = 0.787, p = 0.461; t = 1.175, p = 0.285).
Conclusions
LLMs demonstrated promising performance in delivering respiratory aspiration-related knowledge and showed promise as supportive tools in training, particularly when their limitations were well understood.
Introduction
Respiratory aspiration is a condition in which food, oral secretions, or stomach contents cannot be effectively swallowed or spit out, and enter the airway or lung. 1 The incidence of pulmonary aspiration is approximately 1 in 8,325, rising to 1 in 8,202 in emergency situations, 2 and the incidence of respiratory aspiration reaches as high as 88% among patients undergoing endotracheal intubation. 3 Respiratory aspiration is associated with impaired laryngeal function, esophageal diseases, alcohol consumption, reflux, tube feeding, dementia, and impaired consciousness. 4 Respiratory aspiration can lead to aspiration pneumonia which is life-threatening. 5 The incidence of aspiration pneumonia reaches 17.5% among hospitalized patients, 6 accounting for 5–66.8% of all pneumonia cases. 7 Furthermore, the incidence of aspiration pneumonia was increasing every year. 8 Aspiration pneumonia was estimated to incur annual healthcare costs exceeding 10 billion dollars. 6
The occurrence of respiratory aspiration is associated with nurses’, patients’, and caregivers’ knowledge of respiratory aspiration prevention and treatment. 9 Training nurses, patients, and caregivers can improve awareness of respiratory aspiration, reducing its incidence. Currently, the main forms of training were face-to-face teaching, written material, video and mobile phone application.10,11 However, current training lacks personalized guidance 12 and fails to meet clinical needs due to a shortage of respiratory aspiration specialists. 13 Therefore, exploring tech-driven approaches to respiratory aspiration training is essential.
Large language models (LLMs) have potential for the training of respiratory aspiration. LLMs are built based on deep learning to understand and generate human language. 14 LLMs can understand text and produce appropriate responses, allowing for multiple rounds of conversation in a row. LLMs were also used in healthcare and have great potential to improve patient health and enhance patient quality of life. 14 LLMs could provide a wealth of health knowledge and information to help people access health-related advice.15–17 Additionally, the ready availability of LLMs allows for efficient, real-time information retrieval in clinical settings. Therefore, it seemed feasible to apply LLMs to the training of respiratory aspiration.
Generative Pre-trained Transformers (GPT-3.5/4) are the most widely used LLMs in healthcare, offering disease-related information. 18 However, their performance in addressing respiratory aspiration remains unclear. This study aims to assess GPT-3.5/4's responses to respiratory aspiration-related questions in terms of accuracy, comprehensiveness, consistency, and the necessary information ratio, across English and Chinese contexts. We hypothesis that both LLMs will perform well, with no significant differences between versions or language settings. The results may support the integration of LLMs into respiratory aspiration training to help reduce respiratory aspiration and aspiration pneumonia incidence.
Methods
This study was non-human subject research, as no human subject was enrolled in this study. However, the testing questions used in this study were derived from clinical scenarios commonly encountered by patients with respiratory aspiration. To ensure ethical compliance, the study was reviewed and approved by the medical ethics committee of Capital Medical University (approval # Z2022SY027).
Design of test questions
Two researchers (SF and ZX) with a background in respiratory aspiration and artificial intelligence created 36 questions according to the clinical cases about respiratory aspiration from two widely recognized books on respiratory aspiration.19,20 At the same time, the gold standard of the answers to the questions was obtained from the books together with the questions. The questions were divided into two categories: basic knowledge (objective questions) and comprehensive analysis (subjective questions). The objective questions were structured into five thematic templates: (1) overview of respiratory aspiration (mechanism, definition, risk factors, and outcomes); (2) clinical symptoms of respiratory aspiration; (3) screening and diagnosis (screening scales and laboratory examinations); (4) management of adverse outcomes (emergency of choking and treatment of aspiration pneumonia); and (5) prevention strategies for different risk factors (dysphagia, weakened cough reflex, gastroesophageal reflux, oral problems, poor eating behaviors, and treatment-related factors). The subjective questions covered the identification of aspiration risks, corresponding countermeasures, and first aid treatment strategies. The objective questions were multiple-choice which were informal and easy to understand to simulate conditions in which caregivers or patients asked questions to LLMs. The subjective questions were specialized and challenging cases to simulate the professional inquiries of nurses. Then, the questions and gold standard were reviewed by the third expert (QX) who has extensive experience in the management of respiratory aspiration. Eventually, a list of questions and gold standard were formed after repeated modification (Supplementary Table S1).
Data collection
Two LLMs, GPT-3.5 (https://openai.com/blog/openai-api; accessed on 17 September 2023), and GPT-4 (https://openai.com/blog/openai-api; accessed on 20 September 2023) were asked the same questions in both English and Chinese. Before being asked objective questions, LLMs were told the follows, “You will be asked 32 multiple-choice questions next. Each question has four options, but there is only one correct answer. Please give the correct answer and analysis based on the latest knowledge.” Before being asked subjective questions, LLMs were told the follows, “Next, you will be asked questions about case analysis. Please give the best answer based on the latest knowledge.” All responses were accurately recorded by the researchers (SF and ZX), and no missing data were observed in this study, as all answers were automatically generated by the LLMs (Supplementary Table 2 and 3).
Outcomes
The main outcomes were the accuracy and comprehensiveness of responses. Accuracy refers to the correctness and reliability of the responses, as compared to the gold standard. Comprehensiveness refers to the extent of detail and coverage in the responses, as compared to the gold standard. For accuracy and comprehensiveness, there were the following comparisons: 1) the accuracy and comprehensiveness of the responses in English between the two LLMs; 2) the accuracy and comprehensiveness of the responses in Chinese between the two LLMs; and 3) the accuracy and comprehensiveness of the responses in various languages of the same model. The secondary outcomes were consistency and necessary information ratio. In this study, consistency refers to the degree of similarity in responses to the same question asked by different languages, regardless of their accuracy. And necessary information ratio is defined as the percentage of relevant content within the total output generated by the LLM in response to a given question.
Evaluation of the outcomes
After fully understanding the questions and the responses, two experienced experts in the field of respiratory aspiration scored the accuracy, comprehensiveness, consistency, and necessary information ratio of the responses. The responses of objective questions were assessed as correct /consistent or false /inconsistent. Subjective questions were scored out of five and the score of them was calculated by the following ways. The accuracy score was calculated by dividing the number of correct items in the LLM's response by the total number of items it provided, and then multiplying the result by five. The comprehensiveness score was determined by dividing the number of items in the LLM's response that matched the gold standard by the total number of items in the gold standard, also multiplied by five. And the score of consistency was calculated by multiplying the proportion of terms with the same answers in both English and Chinese by five. In addition, the necessary information ratio was calculated by dividing the number of items in the LLM's response that matched the gold standard by the total number of items provided by the LLM. The ultimate score of the subjective question would be the average of the two experts’ scores if there was a difference of less than one point between their scores. If the difference of the two experts’ scores was one point or more, a third expert would be asked to evaluate. The final score was obtained by calculating the average of the three experts’ scores.
Statistical analysis
The accuracy and consistency of responses to objective questions were described using frequencies and percentages, and differences between the two LLMs were compared using the chi-square test or Fisher's exact test. In addition, the scores for accuracy, comprehensiveness, and consistency of responses were described as means ± standard deviations or medians (first quartile–third quartile). Differences between the two LLMs were compared using the t-test or Mann–Whitney U test. In addition, to evaluate the consistency between the two experts’ assessments of model performance, based on the normality test results for the paired differences, the paired t-test was applied to dimensions with normally distributed differences, while the Wilcoxon signed-rank test was used for those violating the normality assumption. SPSS 28.0 statistical software was used for all statistical analyses. All statistical tests were two-sided, and a p-value of less than 0.05 was considered statistically significant.
Results
To evaluate the consistency between the two experts’ assessments of LLMs’ performance, paired analyses were conducted across five dimensions: accuracy in Chinese, accuracy in English, comprehensiveness in Chinese, comprehensiveness in English, and the consistency between Chinese and English responses. The results revealed no statistically significant differences between the two experts’ scores across all five dimensions (see Supplementary Table 4), indicating a high level of inter-rater consistency. The specific performance of LLMs was detailed as follows.
Accuracy
The accuracy of two large language models
As shown in Table 1, when English was used for conversation, GPT-3.5 and GPT-4 answered the objective questions with equal accuracy (90.63%, 29/32). When the LLMs were asked questions in Chinese, two LLMs also demonstrated high accuracy: GPT-3.5 with 84.38% (27/32) and GPT-4 with 81.25% (26/32). And there was no statistical difference in the accuracy of the Chinese responses to objective questions between the two LLMs (χ² = 0.110, p = 0.740).
The difference of the responses to objective questions of two LLMs.
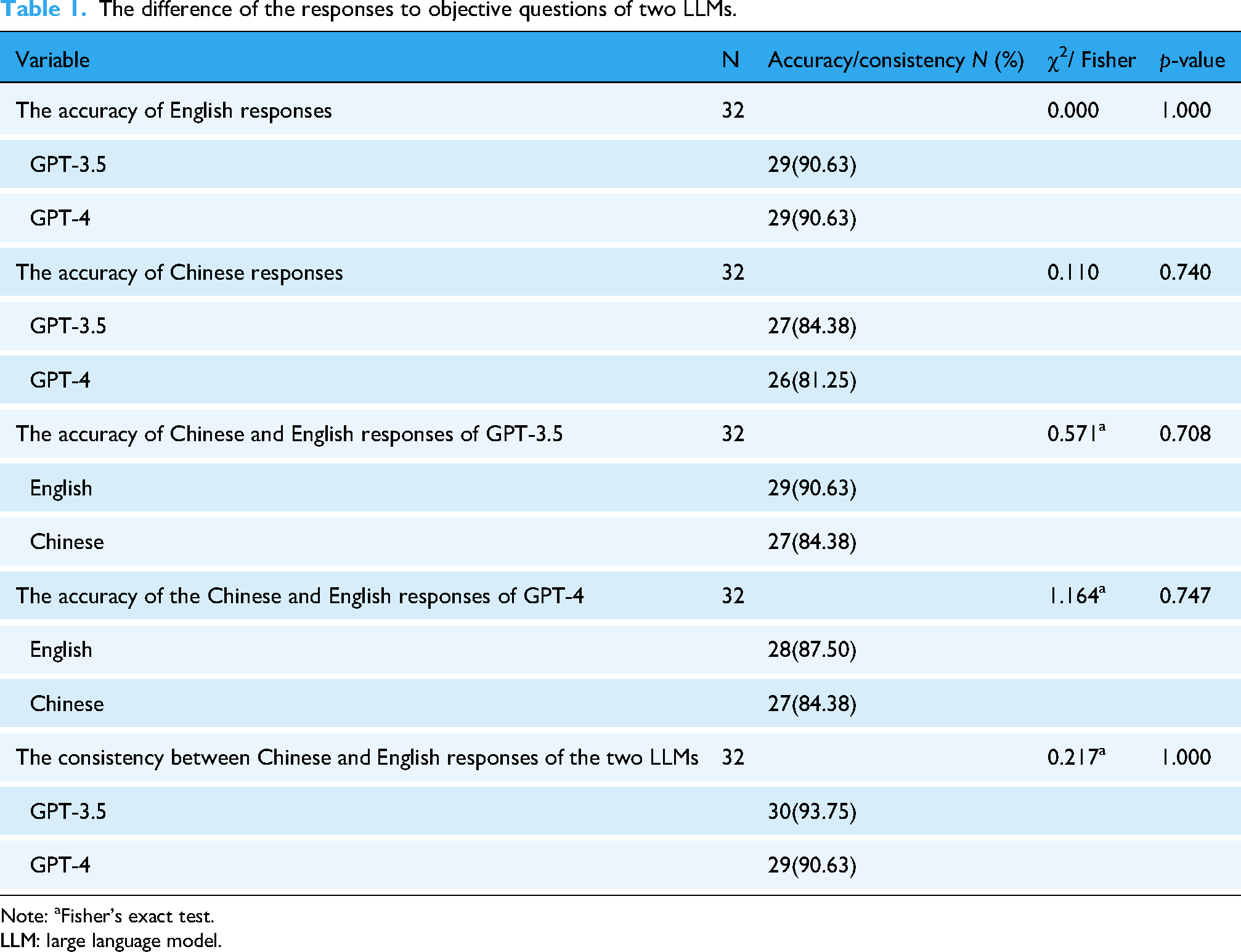
Note: aFisher's exact test.
LLM: large language model.
The scores of the LLMs’ responses to subjective questions are shown in Figure. 1. The accuracy scores of the two LLMs’ English responses to subjective questions were as follows: GPT-3.5: 5.00 (4.20, 5.00); GPT-4: 4.84 (4.17, 5.00). The accuracy of GPT-4's Chinese responses was the highest (GPT-3.5: 4.50 (4.41, 4.88); GPT-4: 5.00 (4.79, 5.00)). No significant differences were found in the accuracy of the English and Chinese responses to subjective questions between the two LLMs (z = 0.331, p = 0.886; z = 1.703, p = 0.114).

The accuracy scores of two LLMs’ responses to the subjective questions. LLM: large language model.
The accuracy of Chinese and English responses for the same model
There were no significant differences in the accuracy of Chinese and English responses to both objective and subjective questions for each model (Table 1, Figure 2).

The scores of two LLMs’ responses to the subjective questions in different language. LLM: large language model.
Comprehensiveness
The comprehensiveness of two large language models
The comprehensiveness scores of the LLMs’ responses are shown in Figure 3. The comprehensiveness scores of the two LLMs’ responses to subjective questions were as follows: for English responses, GPT-3.5 scored 3.77 ± 1.01, and GPT-4 scored 3.33 ± 0.48; for Chinese responses, GPT-3.5 scored 2.97 ± 1.06, and GPT-4 scored 3.66 ± 0.51. There was no significant difference in the comprehensiveness of the English and Chinese responses between the two LLMs (t = 0.787, p = 0.461; t = 1.175, p = 0.285).

The comprehensiveness and consistency scores of two LLMs’ responses to the subjective questions. LLM: large language model.
The comprehensiveness of Chinese and English responses for the same model
As shown in Figure 4, there were no significant differences in the comprehensiveness of Chinese and English responses to both objective and subjective questions for each model (GPT-3.5:t = 1.094, p = 0.316; GPT-4: t = 0.945, p = 0.381).

The comprehensiveness scores of two LLMs’ responses to the subjective questions in different language. LLM: large language model.
Consistency
The consistency scores of the LLMs’ responses to objective questions are shown in Table 1. The consistency ratios for objective questions were high for both models (GPT-4: 29/32, GPT-3.5: 30/32). No statistically significant differences were found in the consistency of responses to objective and subjective questions between the two LLMs (χ² = 0.217, p = 1.000; t = 0.608, p = 0.566). The consistency scores of the two LLMs’ responses to subjective questions were as follows: GPT-3.5 (3.11 ± 0.65), GPT-4 (3.57 ± 0.39) (Figure 3).
Necessary information ratio
The necessary information ratio of English responses was 84.50% ± 8.99% for GPT-3.5 and 78.75% ± 3.54% for GPT-4. For Chinese responses, the necessary information ratio was 95.00% (69.75%, 100%) for GPT-3.5 and 100% (75.25%, 100%) for GPT-4.
Discussion
This study aimed to investigate the performance of LLMs in providing knowledge related to respiratory aspiration, and to explore the potential of using LLMs as promising tools for the training of respiratory aspiration knowledge. The results showed the two LLMs scored high for the accuracy and comprehensiveness of responses regarding respiratory aspiration. There was no difference in the accuracy, comprehensiveness and consistency of the two LLMs’ responses. Moreover, there was no difference in the accuracy or comprehensiveness of the LLMs’ responses when the same model was asked in English or Chinese. And the necessary information ratio of two LLMs were high, suggesting that most of the information provided was indeed necessary. Based on the above results, LLMs could meet users’ needs for knowledge related to respiratory aspiration, and it was possible to apply LLMs in respiratory aspiration knowledge training. Consistent with the findings of this study, studies had also reported that LLMs performed well in answering questions related to the chronic respiratory diseases, 21 oncology, 22 and myopia, 23 further supporting their value in domain-specific clinical support.
LLMs had great potential to be applied to training nurses, patients, and caregivers on respiratory aspiration. The prerequisites for utilizing LLMs in respiratory aspiration training were the high accuracy and comprehensiveness of their responses to the respiratory aspiration questions. This study confirmed that LLMs could provide users with correct and comprehensive knowledge about respiratory aspiration. Previous studies have demonstrated the potential of LLMs to deliver medical knowledge in various domains, such as rheumatism, 24 rhinosinusitis, 25 and epilepsy. 26 These findings collectively support the feasibility of applying LLMs in the healthcare field. In addition, the LLMs enabled anthropomorphism, which was the basis for humans to interact with non-human entities. 27 When users talked to LLMs, it was like they were talking to medical professionals. Time, location, or money should not be taken into consideration when using LLMs to provide intensive or large-scale training of respiratory aspiration knowledge for nurses, patients, and caregivers. 28 Overall, using LLMs in the training of knowledge related to respiratory aspiration had certain benefits.
The application of LLMs was limited by some conditions, such as language, culture, and ethics. There was no difference in the accuracy and comprehensiveness of the responses when LLMs were asked in two different languages in this study, showing that users could communicate with LLMs in a language they were comfortable with. However, culture might have an impact on LLMs’ reactions. LLMs have shown human-like content biases. 29 Because of different programming and constraints imposed by different creators, LLMs carries kind of cultural perspective, both in the evaluative and value sense. 30 Users could use native LLMs to prevent cultural misunderstandings. Ethics also had a significant impact on the application of LLMs in the medical field.31,32 It was unclear who would be responsible for patient's injuries—the medical professionals, the LLMs, or their developers. 33 Additionally, LLMs would collect and store personal information of patients when LLMs interact with patients, which was a potential violation of patients’ privacy.34,35 Even more concerning was the possibility that patients would choose to believe LLMs rather than medical professionals even though LLMs provided wrong responses; this could have an impact on the rapport between patients and medical professionals. 31 The premise that LLMs follow fundamental human ethical standards was that their creators uphold intellectual virtue.
LLMs still had some shortcomings. Firstly, LLMs might provide users with incorrect or incomplete information, 30 which might lead to delays in disease treatment and progression. This limitation stems from the nature of their training data. LLMs were trained on large text datasets, which were usually crawled from the Internet. While such datasets contain a wealth of accurate medical knowledge, they also include misinformation, outdated content, and non-authoritative sources. 36 Consequently, LLMs may produce responses that are factually incorrect, overly general, or insufficiently comprehensive. In the healthcare, this issue was particularly critical, as over-reliance on LLMs might result in clinicians receiving outdated or incomplete knowledge. 37 Therefore, it was important to acknowledge that LLMs might not fully replace human-led instruction or training. Their value lay in serving as a powerful supplement—provided that clinicians remain fully aware of their limitation.
Secondly, it should also be noted that LLMs might provide some unnecessary information, which were difficult to avoid. 38 Although in this study, LLMs were able to deliver a high necessary information ratio, instances of off-topic or tangential details were still observed. Unnecessary information could distract users, increase cognitive load, and obscure key points. Therefore, caution should be exercised when using LLMs, particularly in healthcare. Thirdly, the accuracy of LLMs’ responses was related to the questioning strategies. 39 In this study, the main reason for the wrong responses of LLMs was the incorrect understanding of the question, especially when the questions involved anatomical terms, physiological mechanism, or numbers. Asking LLMs questions correctly was vital, which was the prerequisite for the use of LLMs. Nevertheless, users did not master the questioning strategy of the LLMs. Although there was study that suggested guidelines for asking questions of LLMs, that's not enough. 40 Lastly, LLMs lacked creativity. 41 The answers of LLMs came from the existing knowledge, and they would not create new information. If respiratory aspiration patients experienced an unreported dangerous situation, they would be unable to get suggestions from LLMs. Crucially, these shortcomings were pointed out without a preconceived pessimism toward LLMs, which aimed to ultimately make full use of LLMs.
The following ideas could be taken into consideration in order to better employ LLMs in the training of respiratory aspiration knowledge. Firstly, what role will the LLMs play in the training of respiratory aspiration knowledge? This is a question that requires ongoing investigation. Currently, LLMs can be used as a way to train online. Secondly, although LLMs might make wise decisions, 42 health professionals’ critical judgment should also be considered when making decisions. 43 At present, LLMs might be more suitable as supplementary tools. Thirdly, strategies should be developed to improve the LLMs’ understanding of the conversations, particularly when it comes to complex medical terms. Prompt engineering refers to the practice of designing, refining, and implementing prompts or instructions that guide the output of LLMs to help in various tasks, which is helpful for the communication of LLMs and users. 44 Taking respiratory aspiration as an example, directly point out the theme of “respiratory aspiration” at the beginning of the conversation to make the LLM clear about your focus. Then, progressively refine the inquiry through step-by-step questioning. If there are specific background details that need to be considered, you can add the background information in the prompt. Finally, you may specify the desired response style and format to further tailor the output to your needs. In the future, the application of prompt engineering in LLMs should be enhanced. Lastly, to improve the accuracy of LLMs’ responses, LLMs could be combined with knowledge graphs (KGs). 45 KGs are structured knowledge models that explicitly store rich factual knowledge. 46 Users will receive accurate and comprehensive responses when respiratory aspiration-focused KGs and LLMs are combined. Currently, recommendations for clinicians, technologists, and healthcare organizations on the use of LLMs in medicine have been released, which can be used as a reference. 40
Limitation
There were still some limitations in this study. Firstly, only the topic of respiratory aspiration was tested. Although this was an informed choice based on the characteristics of this particular health topic, it would be necessary to expand these findings to other domains. Further research is needed to explore the effects of using LLMs in other contexts of healthcare. Secondly, since LLMs were not yet widely available, we did not apply LLMs to train nurses, patients, and caregivers about respiratory aspiration. We will complete the follow-up study in the future. Thirdly, the number of questions used to test LLMs was limited. Further studies, which take these limitations into account, will need to be undertaken.
Conclusion
LLMs performed well in providing knowledge related to respiratory aspiration, highlighting their potential as valuable supplementary tools for training of respiratory aspiration knowledge. Users can select the most appropriate LLM based on their individual needs, language preferences, and cultural context. While LLMs have great potential as clinical training tools, they can't fully replace traditional training ways. When their limitations were clearly understood, LLMs could be powerful supplementary tools. In the future, it may be possible to investigate the effects of LLMs in other medical specialties to advance the reality of digital health. To enhance their utility, LLMs should continue to improve the accuracy and comprehensiveness of their outputs while adhering to ethical standards.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251349616 - Supplemental material for To take a different approach: Can large language models provide knowledge related to respiratory aspiration?
Supplemental material, sj-docx-1-dhj-10.1177_20552076251349616 for To take a different approach: Can large language models provide knowledge related to respiratory aspiration? by Yirou Niu, Shuojin Fu, Zehui Xuan, Ruifu Kang, Zhifang Ren, Shuai Jin, Yanling Wang and Qian Xiao in DIGITAL HEALTH
Footnotes
Ethical considerations
This study was reviewed and approved by the medical ethics committee of Capital Medical University (approval # Z2022SY027).
Author contributions
YN contributed to conceptualization, methodology, supervision, and writing—original draft. SF contributed to conceptualization, investigation, and writing—original draft. ZX contributed to investigation. RK contributed to conceptualization. ZR contributed to visualization. SJ contributed to methodology. YW contributed to writing—review and editing. QX contributed to conceptualization, methodology, supervision, and writing—review and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, (grant number 72174130).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The datasets during and/or analyzed during the current study available from the corresponding author on reasonable request.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.