
Abstract
Rapid advances in artificial intelligence (AI), including large language models (LLMs) with abilities that rival those of human experts on a wide array of tasks, are reshaping how people make important decisions. At the same time, critics worry that LLMs may inadvertently discriminate against some groups. To address these concerns, recent regulations call for auditing the LLMs used in important decisions such as hiring. But neither current regulations nor the scientific literature offers clear guidance on how to conduct these audits. In this article, we propose and investigate one approach for auditing algorithms: correspondence experiments, a widely applied tool for detecting bias in human judgments. We applied this method to a range of LLMs instructed to rate job candidates using a novel data set of job applications for K-12 teaching positions in a large American public school district. By altering the application materials to imply that candidates are members of specific demographic groups, we measured the extent to which race and gender influenced the LLMs’ ratings of the candidates’ suitability. We found moderate race and gender disparities, with the models slightly favoring women and non-White candidates. This pattern persisted across several variations in our experiment. It is unclear what might be driving these disparities, but we hypothesize that they stem from posttraining efforts, which are part of the LLM training process and intended to correct biases in these models. We conclude by discussing the limitations of correspondence experiments for auditing algorithms.
Keywords
Artificial intelligence (AI) tools increasingly assist employers with many aspects of decision-making. One prominent example is human resources (HR) management, an area in which AI tools have been used to facilitate benefits administration, coaching, development, and applicant screening. Prior to 2022, the global market for AI hiring technology was already growing rapidly. But the advent of large language models (LLMs)—AI models that are highly adept at understanding and generating text—has dramatically boosted interest in AI hiring tools.
LLMs are a potential boon for any setting where decisions must be made on the basis of a large volume of text. LLMs can be used to do work ranging from grading student essays to evaluating proposals from potential vendors. In the context of HR, LLMs can ingest entire application dossiers—including résumés, essays, and interview transcripts—to produce seemingly cogent assessments of candidates’ qualifications. But using LLMs in this way can be worrisome as well. Even as people put these LLMs to work in hiring, employers and policymakers are racing to establish guidelines for the algorithmic evaluation of candidates.
Bias is a particular concern. Traditional AI tools are “supervised,” meaning users train these programs by inputting labeled data—for instance, previous candidates’ application materials labeled with the ratings recruiters gave them. An AI model can learn statistical patterns from these labeled data and then use those patterns to generate predictions about new applicants. But LLMs go through a more complex and opaque training process that often does not involve any prelabeled data. In an unsupervised process called pretraining, LLMs examine and find patterns in a huge, unlabeled text corpus or data set. These training data sets may contain the equivalent of tens of billions of books 1 and are drawn largely from data publicly available on the internet. After being pretrained, LLMs are posttrained by being provided with a smaller, carefully curated set of data meant to enable them to learn patterns that will improve the accuracy, helpfulness, and safety of their outputs. Once an LLM is trained, users can deliver prompts (written questions and instructions or other text), such as a directive to the LLM to rank job candidates on the basis of their written application materials. Compared with traditional AI tools, the LLMs’ responses more closely resemble those of human evaluators, who might, when evaluating job candidates, produce candidate ratings that are based on an intuitive understanding of how professional experiences and responses to interview questions relate to a candidate’s competency and fit for a job. But for various reasons—including discriminatory content in the pretraining corpus and the complexity of the overall training processes—LLMs might also produce discriminatory or distorted responses that are hard to anticipate.
Employers and policymakers therefore fear that AI could run afoul of employment discrimination laws or otherwise produce unintended, undesirable effects, and they want to find ways to audit these tools to determine whether they are discriminatory. In this article, we demonstrate and examine one potential method for auditing LLMs—correspondence experiments—illustrating the approach by applying it to evaluate LLMs that could be used in making hiring decisions. We demonstrate the technique’s potential and discuss limitations.
Background
The ethical and legal implications of using AI tools in high-stakes settings, such as HR, have motivated much academic work.2,3 And policymakers have become as interested as firms and researchers, introducing a wave of legislation governing the use of algorithms in different contexts, especially hiring. These measures incorporate auditing requirements as an important element, in part because of the belief that informative audits help regulators protect the public from the potential harms of AI tools and that users and firms can use audit results to make informed decisions about which tools to deploy and how to deploy them.
For example, on October 30, 2023, President Joe Biden issued an executive order imposing mandates on federal agencies’ use of AI and calling for regulatory efforts by agencies with authority over private AI uses. 4 The order twice mentions audits as tools to advance fair public decision-making and to ensure AI safety. Meanwhile, the Digital Services Act (DSA) in Europe, which entered into force in February 2024, requires what it terms “very large online platforms” to conduct audits to promote transparency and accountability. 5 And in March 2024, the European Parliament adopted the more general AI Act, which imposes a variety of requirements that potentially involve audits. Most notably, it compels users of high-risk systems—for instance, systems used in critical infrastructure, biometric applications, law enforcement, and certain other high-stakes domains—to create quality management systems that may include a kind of audit. 6
The most developed audit mandate for AI HR tools was introduced in the United States under a New York City ordinance, Local Law (LL) 144, effective July 2023. 7 LL 144 requires a bias audit when employers use “any computational process, derived from machine learning, statistical modeling, data analytics, or artificial intelligence” to classify or recommend persons for employment. In these bias audits, independent third parties must calculate and publicly report an adverse impact ratio. This is defined by LL 144 as the rate at which individuals in a race or gender group are hired or move forward in the hiring process relative to people in the most frequently selected race or gender group. LL 144 imposes no legal obligations when a disparity is identified—in other words, no particular course of action is required. Employers also have broad discretion to determine whether they are covered by the measure. In the first 6 months after LL 144’s entry into force, only 19 audits linked to the law were published. 8
The adverse impact ratio is a relatively common auditing tool in both policymaking and scientific research—required not only by LL 144 but also by traditional hiring regulations such as the U.S. Equal Employment Opportunity Commission’s four-fifths rule (which holds that selecting candidates from a protected or minority group less than 80% as often as members of the group with the highest selection rate can be considered evidence of discrimination). But the adverse impact ratio is known to be imperfect: It cannot reveal whether disproportionate selection of one kind of candidate over another indicates a true psychological bias or if it simply reflects average differences in the qualifications of applicants from different groups.
Beyond the adverse impact ratio, relatively few tools exist for identifying potentially biased decision-making by LLMs. To date, no scientific consensus exists on how best to audit algorithms for bias, although researchers have proposed a wide variety of algorithmic fairness metrics.9–26 Here, we explore using correspondence experiments to audit LLMs for race and gender bias in high-stakes decision settings such as HR, in part because in behavioral science research, correspondence experiments have proven valuable for identifying discrimination in hiring decisions.
In correspondence experiments (also known as audit studies), researchers assume that two otherwise identical individuals from different demographic groups should receive similar treatment and that divergence is evidence of improper discrimination. 27 These studies are typically set in contexts where decision-makers learn about individuals exclusively through written documents (for example, an initial screening of job applicants). Researchers then experimentally manipulate elements of those materials that could suggest an individual’s race and gender. (For simplicity, throughout the balance of this article, we use the term race to refer to race or ethnicity.) In the study described here, we mainly assessed the effect of the name applicants use on their résumé, a practice in line with most research on this topic in the social sciences. 28 Names are the strongest signal of race typically perceived by recruiters in the United States. In other contexts or in countries with different hiring conventions, auditors might manipulate other application elements, such as the applicant photos included with résumés in Germany, Japan, China, and many other countries. (See note A for more information on the rationale for our decision.)
For at least 50 years, social scientists and government agencies have used correspondence experiments to study discrimination in hiring, 29 housing, 30 prosecutorial charging decisions, 31 and other domains.32–34 More recently, correspondence experiments have been proposed to similarly identify evidence of bias in the algorithms used in AI.35–45 For example, Latanya Sweeney found that Google searches of Black-sounding names were more likely to generate advertisements suggesting the named individual had an arrest record than were comparable searches of White-sounding names. 46
In our exploration of the potential value of using correspondence experiments to audit AI-based hiring decisions, we found overall that correspondence experiments are useful for identifying race and gender bias, and we provide a workable strategy for carrying out mandated algorithm audits. However, as we explain in the Discussion section, we also identified some key conceptual and technical limitations of this approach for auditing algorithms.
Empirical Analysis & Results
LLMs for Candidate Evaluation
To evaluate the use of correspondence experiments for auditing hiring algorithms, we first gathered a novel corpus from 1,373 applications to K-12 teaching positions in a large public school district in Texas by filing a public records request. (To our knowledge, this school district does not use algorithms to evaluate applicants.) Application materials included the applicants’ résumés as well as transcripts that we produced from self-recorded videos from the applicants. In these videos, applicants answered written questions about previous teaching experience, teaching style, hypothetical classroom situations, and other job-related subjects. Ultimately, we restricted our analysis to the 801 applicants who had provided both a résumé and video responses. These applicants represented a diverse pool, of which 67% were women, 2% were Asian, 45% were Black, 10% were Hispanic, and 38% were White. (We use “White” throughout to mean non-Hispanic White.)
For each applicant, we provided the LLM with (a) a description of the requirements for the teaching position based on a job posting from the school district; (b) the applicant’s résumé; (c) a written transcript of the applicant’s self-recorded responses to interview questions; (d) a request for the model to summarize the applicant’s qualifications in prose; and (e) a request for the model to provide numerical evaluations, on a scale from 1 to 5, on several measures, including the applicant’s experience, professionalism, and fit, as well as the model’s overall hiring recommendation, which was expressed as a score on a scale ranging from 1 (definitely do not hire) to 5 (definitely hire). (See the Supplemental Material for more information.) Although our primary statistical analysis focused on the models’ overall numerical hiring recommendation for the applicants, we requested additional information from the models—including written summaries and other scores—to improve the quality of the LLM results, a common strategy when using these models.
We audited 11 LLMs: OpenAI’s GPT-3.5, GPT-4, GPT-4o, and GPT-4o Mini models;47–50 Mistral’s Mistral 7B and Mixtral 8x7B models;51,52 and Anthropic’s Claude Instant, Claude 2, Claude 3 Haiku, Claude 3 Sonnet, and Claude 3.5 Sonnet models.53–55 Experts considered the OpenAI and Anthropic models to be the best of their kind available at the time of our evaluation. Mistral’s models are popular open-source competitors. We did not formally assess how well each LLM’s candidate ratings aligned with candidate qualifications, but an informal inspection suggested that the highest rated candidates generally had more experience and gave more polished responses to interview questions than did those receiving lower ratings. This rough assessment of the LLM ratings’ validity—and the LLMs’ relative ease of use—makes it likely that a pipeline like the one we implemented here will soon be used by employers to screen applicants, if one has not been launched already.
Assessing Adverse Impact Ratios
As we have previously noted, each LLM rated candidates’ overall suitability for the job on a scale of 1 to 5, where a higher number indicates a stronger positive recommendation. OpenAI’s GPT-3.5, one of the most popular and widely used LLMs at the time of our experiments, gave 20% of candidates an overall score of 5, 51% a 4, 24% a 3, 4% a 2, and 1% a 1.
We then turned to the issue of whether each LLM rated candidates similarly across demographic groups. We first looked at the adverse impact ratio, given its prominence in past research and the New York law. That is, we determined the rate at which individuals in one race or gender category were positively selected relative to those in another category. Per the Equal Employment Opportunity Commission’s four-fifths rule, a ratio of 80% or lower is particularly concerning and likely warrants some response, although federal law does not require a particular course of action. 56
The results of this adverse impact ratio analysis for OpenAI’s GPT-3.5 are shown in Figure 1; results across all models were similar. (See Figures S7–S10 in the Supplemental Material for results from other models.) When comparing the proportion of applicants across groups who received a 5, the highest threshold for recommendation, we found that female applicants received positive assessments more often than male applicants did and Black and Hispanic applicants received positive assessments more often than White applicants did. At a recommendation threshold of 4, the pattern flips for race—with White applicants receiving a positive assessment more often than Black and Hispanic applicants did—and we found near parity for gender. Finally, at a threshold of 3, we found near parity across both gender and race groups.
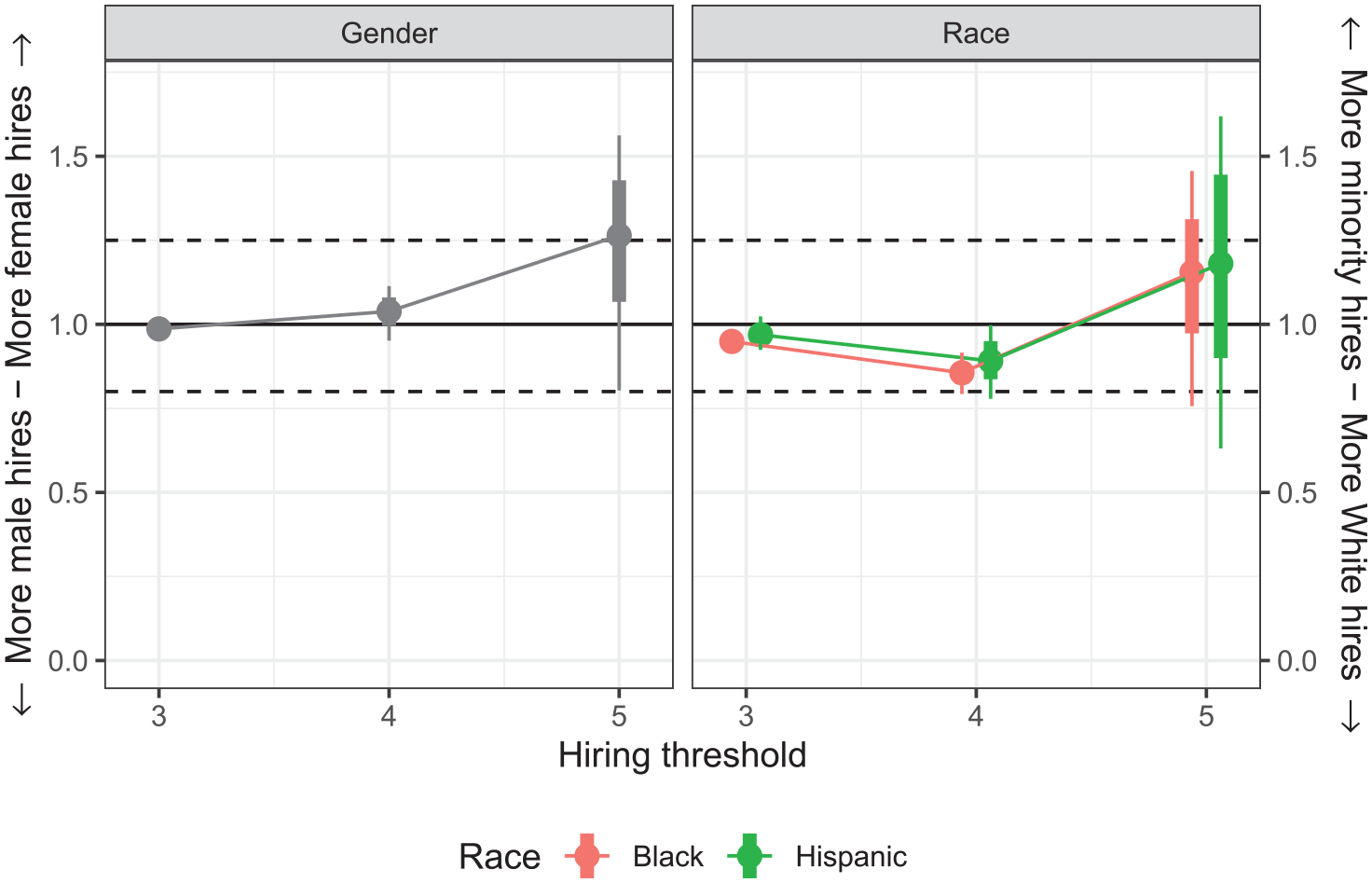
GPT-3.5’s adverse impact ratios highlighting disparities that may be the result of algorithmic bias while nevertheless being inconclusive on their own
This simple analysis suggests that GPT-3.5 and the other LLMs we studied might be favoring certain demographic groups. However, even with the comparatively large minority applicant pools in our corpus, we can estimate adverse impact ratios only imprecisely. In fact, of nine adverse impact ratios calculated at this stage, only three were statistically significant, suggesting this approach found only slight evidence of meaningful disparities.
Without further evidence, we cannot definitively say whether these disparities are due to algorithmic bias or group-specific differences in the applicant pool. Put another way, the women and racial minorities in our applicant pool might simply be more qualified than the other applicants for these positions, which would explain why the model ratings they received were higher than the ratings received by the other applicants. This makes it difficult to draw clear conclusions, which indicates that an adverse impact ratio analysis alone is too limited for auditing LLMs.
Assessing Correspondence Experiments
Correspondence experiments make it possible to differentiate between algorithmic bias and differences in candidate qualifications. We began by manipulating the real application materials to create synthetic application dossiers that differed only in details that strongly signaled an applicant’s race or gender. For each real applicant, we generated eight synthetic applications, corresponding to a particular race (Asian, Black, Hispanic, or White) and gender (female or male). We then replaced the applicant’s actual name throughout the materials with one that strongly signaled membership in that group. We similarly changed any mention of the applicant’s pronouns in the materials to match the assigned group, as well as other indicia of race or gender. (See the Supplemental Material for a detailed description of how we generated these synthetic applications.)
We presented the synthetic application materials to the LLMs, instructing the models to report the race and gender of the synthetic applicants. We found generally high agreement between the race and gender we intended to convey and the model’s perception of these attributes, which in most cases exceeded 90% but with the precise level of agreement varying from case to case (see Figures S1 and S2 in the Supplemental Material). This level of agreement is comparable to what has been found in studies that manipulate human perceptions of race by altering names in résumés. 29
Finally, we asked our LLMs to provide hiring recommendations for the synthetic candidates. The results of these correspondence experiments are shown in Figure 2. (Results for Mixtral 8x7B should be interpreted with caution, because the model often failed to follow the instructions, producing responses without ratings; see the Supplemental Material for details.) For each model, we created comparisons of groups of candidates relative to a historically favored reference group. To assess gender bias, we made men a reference group and looked at the estimated difference in average score for women versus men in each model. In the case of race, we made White people the reference group and looked for the difference in average scores for all other groups in comparison with the average score of these White candidates. (See the Supplemental Material for further methodological details.)
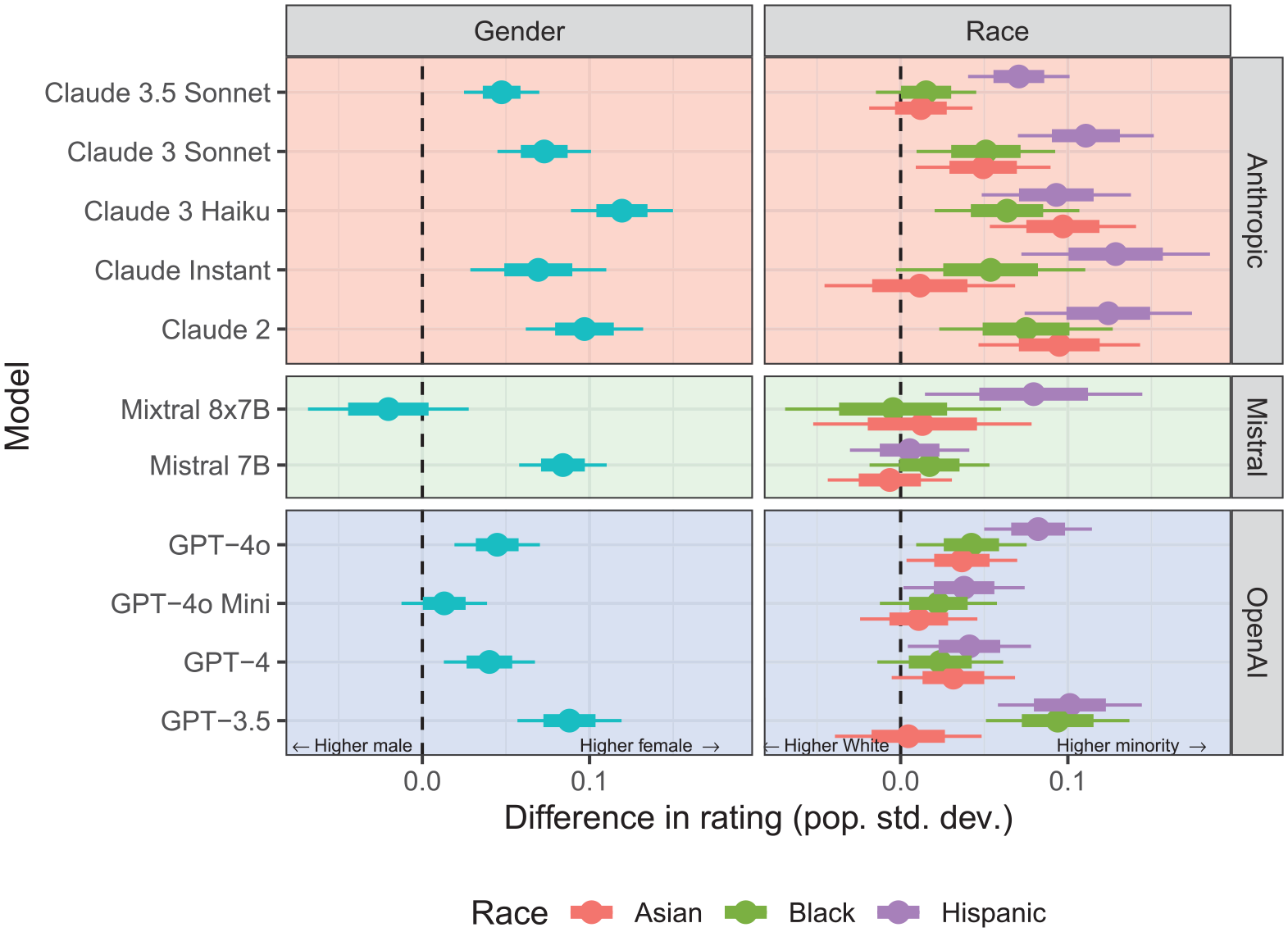
Correspondence experiments showing that the large language models tested modestly favor women & non-White candidates
Across models, we found that the LLMs rated synthetic female candidates moderately higher than they did the synthetic male candidates. Models also generally rated synthetic Black, Hispanic, and Asian candidates moderately higher than they did synthetic White candidates, although we found more variation between models, with Mistral’s models exhibiting smaller disparities.
Our correspondence experiments suggest that the models’ perceptions of race and gender influence algorithmic candidate assessments, at least to some degree. At each hiring threshold—the minimum rating (3, 4, or 5) at which we imagine hiring candidates—race and gender disparities were generally a few percentage points (see Figures S14 and S15 in the Supplemental Material). These disparities were modest but within the typical range identified in recent studies of human recruiters (for an example, see Reference 27). In other words, the LLMs showed a level of bias smaller than but still comparable to what people tasked with identifying the best job applicants in similar experiments often show.
Sensitivity to Prompt Variation & Context
An LLM’s approach to a given task—such as rating job applicants—can be modified and potentially improved by changing the directions the LLM is given. So we repeated our analysis with several variants of the initial prompt—that is, the set of directions we gave an LLM for evaluating our applicants and their suitability for the job. (See the Supplemental Material for more details on the prompt variants investigated.) For simplicity, we ran these robustness tests on only one model, OpenAI’s GPT-3.5, which exhibited approximately average disparities in our primary analysis. Regardless of the prompt used, we found the same general patterns persisted across all variants: a slight bias in favor of women over men and in favor of Hispanic, Black, and Asian applicants over White applicants. (See Figures S3 and S4 in the Supplemental Material.)
We then reran our primary analysis while inputting only an applicant’s résumé into the model, excluding interview transcripts. This variation on our experiment allowed us to gauge a scenario that frequently occurs in real-world settings, when employers must make decisions based on résumés alone. As with the robustness tests, we conducted this analysis on only GPT-3.5, and we again found that women and racial minority applicants received moderately higher scores than did men and White applicants, respectively.
Many LLMs can access virtually encyclopedic knowledge and incorporate this information into their evaluations. For example, in our analysis, the American school district to which our candidates applied is especially racially diverse—a fact known by the LLMs we examined. If a model took this information into account, the diversity might influence its ratings in some way. We therefore ran another analysis on GPT-3.5 in which we replaced all mentions of the district (and the city and state) with the name of a predominately White school district in West Virginia. Once again, we found disparities mirroring our primary results.
Discussion
Our results demonstrate that correspondence experiments can reveal race and gender disparities in LLM outputs. Unlike the commonly used adverse impact ratio analysis, correspondence experiments revealed not only differences in qualifications across groups in the candidate pool but also the effect of race and gender on LLM outputs. These experiments therefore offer policymakers a potentially useful tool for auditing algorithms. The patterns we observed were substantive and robust, persisting across several variations of our study, including changes to the instructions provided to the model and the specific application materials we inputted.
It bears emphasizing that the specific pattern we observed—with models favoring female applicants over male applicants and favoring Black, Hispanic, and Asian applicants over White applicants—may not generalize across contexts in which people use LLMs. Indeed, although some recent studies that focused on hiring decisions also found disparities similar to those we found in our work,36,43 others have reported disparities in the opposite direction.35,38–40,42,44 Such contrasting results are not surprising given the complex and often inscrutable ways in which LLMs are trained. In particular, recall that developers typically fine-tune models in a final alignment or posttraining phase in part to avoid mirroring overt discrimination in the training data. But this step may leave traces of bias in ways that are hard to predict. For example, efforts to mitigate discriminatory associations the model learned in pretraining might overshoot the mark, causing a distortion in the other direction.
Although correspondence experiments may be a useful tool for auditing algorithms, they also have notable limitations. First, all experiments—correspondence or otherwise—are inherently limited in their ability to manipulate race or gender while leaving other characteristics of people untouched. In the case of our study, names are imperfect signals of race and gender, and other aspects of the application dossier (such as history of employment in a male- or female-dominated field) can further attenuate that signal. Indeed, in our own pool of applicants, we find that LLM-like statistical models can nearly always infer an applicant’s race and gender from unaltered application materials as well as from masked application materials (that is, application materials with names and pronouns removed; see Figure S6 in the Supplemental Material). Nevertheless, as already noted, the models still identified the intended race and gender of our synthetic candidates more than 90% of the time, indicating that our name manipulation largely worked as designed.
Further, names may reveal information beyond applicants’ race and gender. Changing an individual’s name can also change an LLM’s perception of their age, their socioeconomic status, and other characteristics aside from race. This effect means we cannot be certain that we have accounted for all the ways in which LLMs rated our applicants or the precise degree to which race and gender alone could have influenced these decisions. These confounds limit our statistical conclusions.
Conceptually, it is challenging to rigorously define what it would even mean to manipulate an LLM’s perception of an individual applicant’s race in isolation from other factors. Considerable literature has explored the question of whether it is possible to discuss and perceive race in isolation, given the ways in which ideas around racial identity so often couple with perceptions of social status, wealth, religion, neighborhood of residence, and other variables (for examples, see references 57 and 61). For that reason, some scholars conceive of race as a “bundle of sticks,” lumping all of those elements together, along with skin color and ancestral origin, when determining an individual’s racial identity.57,62 Similar considerations apply to gender. 59 Which of these factors can or should be manipulated in an audit of race or gender bias is a difficult question.
Finally, even if models are not directly influenced by an individual’s race or gender in the way we test here, biases against other aspects of a candidate’s application could still produce undesirable outcomes. For instance, a model might, in theory, prioritize the applications of individuals who attended private school, regardless of their race or other qualifications. That pattern could unjustly disadvantage qualified minority applicants. 63
Ultimately, LLMs need to be audited for each specific use, and the conclusions drawn could vary on the basis of both the task and the pool of individuals evaluated. Context- and scenario-specific correspondence experiments can serve as tools for evaluating LLMs in many situations. For example, LLMs are already being used to determine credit risk, and policymakers keen to craft legislation and guidance for this use would benefit from the data generated by correspondence experiment audits of credit risk LLM outputs. The calls to audit algorithms are likely to increase as LLMs become even more capable and widespread and are used in ever more varied decision-making contexts. Correspondence experiments, despite their important limitations, represent one promising method of auditing algorithms for race and gender bias. We hope our work aids in the ongoing regulatory efforts to ensure that LLMs yield equitable outcomes.
Supplemental Material
sj-pdf-1-bsx-10.1177_23794607251320229 – Supplemental material for Auditing large language models for race & gender disparities: Implications for artificial intelligence-based hiring
Supplemental material, sj-pdf-1-bsx-10.1177_23794607251320229 for Auditing large language models for race & gender disparities: Implications for artificial intelligence-based hiring by Johann D. Gaebler, Sharad Goel, Aziz Huq and Prasanna Tambe in Behavioral Science & Policy
Footnotes
Author Note
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors received financial support from the Wharton AI & Analytics Initiative. Aziz Huq acknowledges support from the Frank J. Cicero Fund.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.