
Abstract
A translator’s style serves as a vital lens for examining the intricacies of the translation process. This is especially notable in translating technical classics, where a tension arises between the source text’s objective nature and the translator’s subjective stylistic choices. To address this tension, objective methods are required to complement subjective interpretation. A machine-learning approach is uniquely suited to this task, as it can impartially quantify stylistic features to reveal strategic decisions that might be obscured by subjective bias. Based on the self-constructed corpora and machine learning approach, this study investigates stylistic patterns in three complete English translations of the Chinese technical classic Tian Gong Kai Wu by applying the CVMI-RRMFT feature selection algorithm to identify the 15 most discriminative linguistic features across lexical, syntactic, and textual levels. These features delineate each translator’s unique style, revealing consistent preferences in linguistic expression. Specifically, Ren’s translation exhibits a scholarly “thick translation” style, marked by lexically rich and modified language, the longest average sentence length with nested syntactic patterns, and prolific use of square brackets for explanatory annotations. Li’s translation reflects a commitment to technical precision and cultural encoding, evident in numerically exact renderings and specialized terminology, a preference for complex phrasal construction, and the unique insertion of traditional Chinese characters within parentheses to assert cultural identity. By contrast, Wang’s translation pursues diplomatic clarity and reader-oriented accessibility through simplified vocabulary, shorter sentences, reduced syntactic complexity, and an overall streamlined use of punctuation to ensure fluent comprehension. Further analysis indicates that these stylistic features reflect not merely unconscious traces, but strategic choices influenced by the dynamic interplay between the translator’s individual agency and external factors. This study demonstrates the efficacy of computational methods in revealing stylistic variation, thereby advancing the empirical study of translation, and enriching the cross-cultural transmission of Chinese technical classics.
Plain Language Summary
This study uses machine learning and computational analysis to objectively measure how different translators develop distinct styles, even when translating the same technical work. The researchers examined three complete English translations of Tian Gong Kai Wu, a 17th-century Chinese classic on technology and craftsmanship. By applying a specialized algorithm, they systematically identified the 15 most distinguishing linguistic features across thousands of vocabulary, sentence structure, and textual patterns. The analysis revealed clear stylistic differences: one translation used complex sentences and extensive scholarly annotations, targeting academic readers; another emphasized technical precision and incorporated traditional Chinese characters, reflecting the translator's scientific expertise and cultural identity; the third employed simpler vocabulary and shorter sentences to make the ancient text accessible to a general audience. These patterns show that a translator’s style is not accidental but results from a combination of personal expertise, intended readership, and historical context. By transforming subjective impressions into quantifiable data, this machine-learning approach uncovers what can be called the “stylistic fingerprints” of each translator, offering a new, evidence-based way to understand how technical classics are adapted across languages and cultures.
Introduction
Translator style forms a major subfield within translation studies. Its foundational framework was established by Baker (2000), who pioneered the corpus-based analysis of translator style by characterizing it as a unique “fingerprint”—a concept that echoes Hermans’s (1996) notion of the “translator’s voice” embedded in translated texts. Baker defines translator’s style as the recurring linguistic choices a translator makes across their works, focusing on how a translator maintains stylistic consistency across different translations. In contrast, Malmkjær (2003) highlights the translator’s perception of stylistic features in the source text, as well as their preservation, modification, and re-constitution in translation, thereby underscoring the translator’s conscious engagement with the original. Based on this distinction, research on translator style is generally divided into two standards: target-text-oriented studies, which concentrate exclusively on the translated text, and source-text-oriented studies, which consider both source and target texts (Saldanha, 2011). Aligning with Malmkjær’s source-sensitive perspective, this study adopts a source-text-oriented approach. Such research typically employs parallel corpora to compare how different translators reproduce the stylistic features of the original, focusing on the reproduction of stylistic features across translations (D. F. Li et al., 2018). These comparisons reveal that translational distinctiveness manifests across multiple dimensions, including source text selection, translation strategies and etc. (Hu et al., 2017), collectively shaping a style that operates on linguistic, cultural, and strategic levels.
Corpus-based study of translator style investigates the nature, processes, and phenomena of translation by integrating statistical analysis with theoretical interpretation of authentic texts (Baker, 1993). Such a mixed-methods approach helps reduce the subjectivity inherent in traditional qualitative research, thereby enhancing the comparability of findings across studies (Zhu & Li, 2023). In recent years, scholarly interest has increasingly turned toward applying this methodology to literary translation. For example, Mastropierro (2018) and Wijitsopon (2022) have examined how style is transmitted from source to translated texts using various lenses, such as semantic prosody, lexical cohesion, and local textual functions. Nevertheless, conventional approaches to translator style remain limited in both scope and method. First, they tend to focus on formal linguistic features, offering little insight into the reconstruction of functional literary elements such as theme and narrative; methodologically, these studies rely on basic corpus statistics rather than advanced methods like natural language processing (Liu & Han, 2025). More fundamentally, Translation is an activity conducted within real social contexts, and as its primary agent, the translator is distinctly shaped by the social imprint. Therefore, it is necessary to systematically link linguistic patterns to the translator’s habitus, norms, agency or forms of capital (Bourdieu, 1986; Simeoni, 1998), thereby contextualizing professional translation within the wider discursive and social settings.
The integration of computer technology has established the study of translator style as a distinct and interdisciplinary area. A key driver of this development has been computational linguistics, which has introduced innovative methodological tools to the field. As an interdisciplinary domain connecting mathematics, linguistics, and computer science, computational linguistics builds mathematical models and employs computational programs to automatically analyze translated texts. This approach has thus laid a strong methodological foundation for quantitative research in translation, especially in the study of translator style. For instance, by integrating multiple classifiers, Lynch and Vogel (2018) showed that unigram and bigram features can reliably distinguish among different translators’ styles. Similarly, Zhan and Jiang (2016) successfully identified the translators of different Chinese versions of Pride and Prejudice with a support vector machine model.
Despite the great efforts made by researchers in the scope of literature, research on non-literary translation remains relatively scarce. Particularly, in the translation of technical texts, the translator must navigate a core tension between preserving the rigorous accuracy of the source text and ensuring accessibility for the target audience. An excessive focus on factual accuracy—often manifested through rigid adherence to the source text’s linguistic form—tends to overlooks readers’ comprehension habits, potentially resulting in translations that are awkward or obscure (Luo, 2011). This dilemma points to a central, yet underexplored question in translation studies: whether stylistic patterns are merely unconscious linguistic fingerprints or, sociologically speaking, tangible traces of the translator’s agency—a dynamic negotiation between individual habitus and multifaceted contextual constraints (Bourdieu, 1990). We further contend that such stylistic choices constitute strategic negotiations, shaped not only by the translator’s habitus, but also by institutional patronage. This is especially salient in the translation of a national technical classic, where style also functions as a tool for cultural diplomacy and nation branding, tailored to specific readerships. To examine this interplay, our study employs machine-learning approach to objectively analyze and compare stylistic features across three complete English translations of the Chinese technical classic Tian Gong Kai Wu. By integrating these data-driven findings with qualitative scrutiny, we aim to elucidate how individual translational choices interact with broader textual, cultural, and technological dimensions. The study is guided by the following research questions:
Question 1: Which linguistic features are the most discriminative among the three translations as identified by machine learning methods, and how are these features distributed?
Question 2: How are the distinctive styles of the three translators manifested, based on the quantitatively identified features, at both linguistic and extra-linguistic levels?
Question 3: What are the causes underlying the formation of these distinct translator styles?
This study contributes to the field in three main respects. Methodologically, it introduces the CVMI–RRMFT analytical framework to translator-style research, providing a robust approach to feature selection and comparison; and it shifts attention to non-literary texts, combining the examination of a Chinese technical classics with machine-learning techniques. Theoretically, the study bridges computational stylistics with sociological translation studies by using empirical data to hypothesize about the habitus and agency of translators working on technical classics. Practically, the findings are expected to yield concrete implications for the translation and global dissemination of Chinese technical classics, informing strategies that balance fidelity, clarity, and stylistic consistency.
Materials and Methods
Materials
The Chinese technical classic Tian Gong Kai Wu (《天工开物》), authored by Song Yingxing, was first published in 1637 during the Ming Dynasty. Comprising three volumes of 18 chapters and 123 illustrations, it serves as a comprehensive record of advanced techniques in agriculture, handicrafts, and manufacturing in China prior to the Ming Dynasty. Consequently, it holds a significant place in testament to China’s ancient scientific achievements. The term “Tian Gong” refers to natural forces, while “Kai Wu” signifies humanity ingenuity in developing and innovating in accordance with the laws of nature (Yang, 1991). Song Yingxing elucidated not only the intricacies of ancient Chinese technical skills but also integrated profound philosophical concepts regarding the harmony and coexistence between humanity and nature. Charles Darwin characterized Tian Gong Kai Wu as an “authoritative work,” while the British historian of science, Joseph Needham, lauded it as “an important work on engineering in the early 17th century” (Y. M. Wang et al., 2018). Such accolades have solidified its status as a pivotal scientific contribution on the international stage, making it a crucial resource for understanding the evolution of science and technology in ancient China.
The study of English translations of Chinese technical classics has garnered attention from scholars worldwide in the history of science and technology. To date, 12 English translations of Tian Gong Kai Wu have been identified, three of which are complete, while the remainder are excerpts, abridgments, interpretations, or retranslations (Lin & Wang, 2021). The first complete English translation appeared in 1966, nearly three centuries after the original’s publication, indicating a late start for related research. Additionally, a total of 11 international book reviews focusing on Ren’s translation have been published. Scholars (Bodde, 1967; Chan, 1968) have examined issues such as translation gains and losses, translation history (Zhao, 1997), terminology and sentence translation (Y. M. Wang & Xu, 2018), theory-based translation analysis (Lin & Wang, 2022), and multimodal translation approaches (Yu, 2023). These studies chiefly investigate the interplay among the translations, the translators’ role, and the historical contexts in which they were produced. However, existing methodologies often rely on subjective criteria and lack objective approaches, such as corpus-based studies that employ both quantitative and qualitative analyses.
As illustrated in Table 1, the three complete English versions span a period of 45 years. Influenced by factors such as historical context, publishing practices, identities and motivations of the translators, these versions collectively represent the landscape of Tian Gong Kai Wu English translations across time and space. They offer significant comparative value and research relevance.
The Three Translations of Tian Gong Kai Wu.

Being published works, they are utilized under fair use for stylistic analysis and limited quotation in this non-commercial, critical-comparative study.
Corpus Construction and Preprocessing
Text Digitization and Cleaning
The source materials were the scanned PDFs of the three published translations. Optical Character Recognition (OCR) was performed using ABBYY FineReader 15 to convert these scans into machine-readable text, followed by manual verification to correct errors.
To ensure the analysis focused on the translators’ core stylistic choices in rendering the main text, all paratextual elements were identified and removed. This included: translators’ prefaces, introductions, catalogue, footnotes, image captions, appendices, and chapter headings. The rationale for excluding paratexts is that they often serve distinct metadiscursive functions and follow different genre conventions. Including them would introduce extraneous variables and obscure the systematic linguistic patterns used in the translation of the technical narrative itself. Focusing solely on the body text ensures a controlled comparison of translational style across the three versions. Three cleaned texts were saved in UTF-8 encoded plain-text files.
To focus the analysis on stylistic choices within the core technical narrative, all paratexts (e.g., prefaces, catalogue, introductions, footnotes, image captions and appendices) were excluded. The cleaned body texts were saved as UTF-8 encoded plain-text files. This approach ensures a controlled and consistent basis required for subsequent feature selection. While paratexts offer valuable insights, they primarily reflect the translator’s or publisher’s external metacommentary and framing intentions, rather than a style linguistically embedded within the narrative itself. As such, a focus on the main text alone enables a deeper and more targeted analysis of the linguistic patterns that characterize each translator’s work.
Text Segmentation
Each cleaned text was segmented into 18 analyzable units based on their chapter structure. We used the natural chapter boundaries rather than shorter, arbitrary fixed-length windows for two primary reasons. First, chapters represent coherent thematic and narrative units within the technical text, preserving the integrity of the translator’s stylistic flow and rhetorical structure. Segmenting by fixed windows would artificially cut sentences and disrupt discourse cohesion, potentially obscuring stylistic patterns that operate over longer spans. Second, this approach aligns with the source text’s original organization, ensuring that comparisons across translations are meaningfully anchored in the same content segments. A total of 54 sampling units were saved in UTF-8 encoded plain-text files.
Final Corpus Composition and Validation
To validate the consistency and cleanliness of the processed corpora, a final check was conducted on all files, confirming the absence of residual OCR artifacts, misplaced paratext, or incorrect segmentation. The processed corpora are available upon request for research replication purposes. The final working corpus comprises 54 text files. Basic statistics are presented in Table 2.
Processed Corpus Statistics.
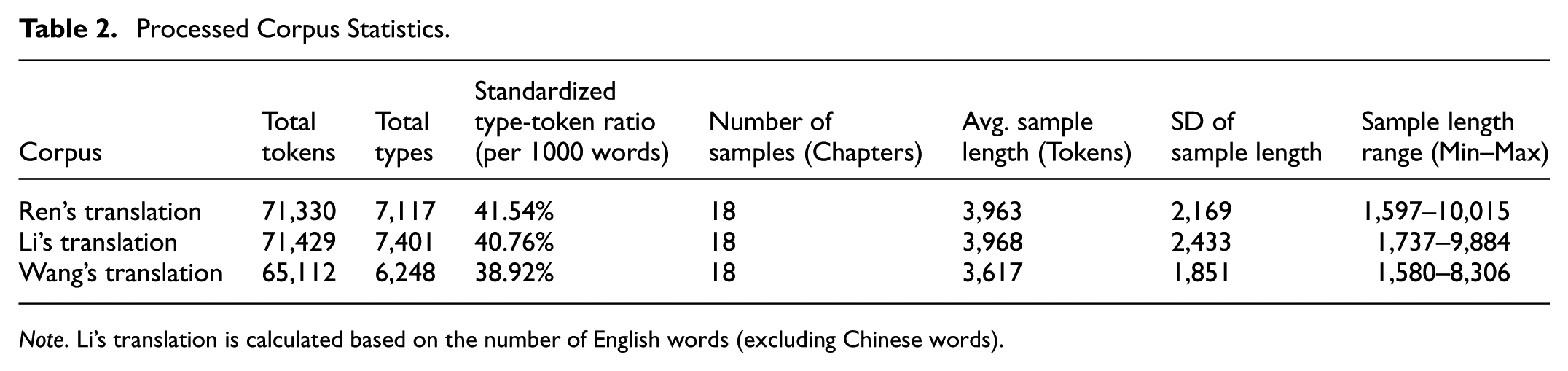
Note. Li’s translation is calculated based on the number of English words (excluding Chinese words).
Research Tools
The following corpus tools were used for information retrieval and statistical analysis: the CLAWS POS tagger (C7 tagset) for part-of-speech annotation; AntWordProfiler 2.2.1 and Vocab Level Checker for lexical profiling; and the L2 Syntactic Complexity Analyzer for syntactic measurement. Text exploration and analysis were carried out using AntConc 4.2.0 for qualitative, interactive examination and WordSmith 8.0 for systematic quantitative processing. Computational analysis was performed in Python (v3.8+) with pandas (v1.3+) for data handling, NumPy (v1.21+) for numerical computations, scikit-learn (v1.0+) for machine learning modeling and evaluation, and Matplotlib (v3.4+) for visualization. The custom CVMI-RRMFT feature selection algorithm was implemented within this Python environment.
Research Procedure
Feature Collection
Building upon the insight of translation stylistic studies by Leech and Short (1981) and Lynch and Vogel (2018), as well as features noted by scholars in studies of Tian Gong Kai Wu, this study compiles a set of 37 typical features across lexical, syntactic, and textual levels. The complete feature set is provided in Table 3.
Feature Set for Translation Styles.

Feature Selection
To objectively identify the most discriminative stylistic features among the three translations, this study employs the CVMI-RRMFT feature selection method (H. F. Xu et al., 2021). This method operates on two principles: first, an ideal discriminative feature should exhibit low variation within the same translator’s text (consistency) but high distinction across different translators’ texts (separability). Second, selected features should contain minimal redundant information. To clarify, CVMI quantifies two key aspects of a linguistic feature: its stability within a translator’s own writing (consistency), and its ability to distinguish one translator from another (separability).
Accordingly, the CVMI-RRMFT process consists of two main stages. In the first stage (CVMI scoring), each of the 37 candidate features is assigned a score. This score, termed the CVMI (Coefficient of Variation and Mutual Information) score, is calculated by a weighted combination of two metrics (see Formula 1 in Appendix A for the full equation):
Coefficient of Variation (CV):
Measures the internal consistency of a feature’s values within the samples of each translator. A lower CV indicates a more stable, habitual use of that linguistic feature.
Mutual Information (MI):
Measures the distinctiveness of a feature’s distribution between different translators. A lower MI indicates the feature’s values are more effective in telling the translators apart.
Features are then ranked by their CVMI scores, with lower scores indicating higher overall discriminative power.
In the second stage (RRMFT redundancy removal), the top-ranked features are further refined to eliminate redundancy. This is achieved by modeling the correlations between features as a “Maximum Feature Tree” and pruning it using a two-neighborhood strategy (detailed steps are provided in Algorithm 1, Appendix A). The final output is a compact, non-redundant set of the most style-indicative features.
Following this procedure, the CVMI-RRMFT algorithm selected the 15 most distinctive features from the initial set of 37. These features, listed in Table 4, form the basis for our subsequent quantitative and qualitative stylistic analysis (Figures 1 and 2).
The 15 Distinctive Features.
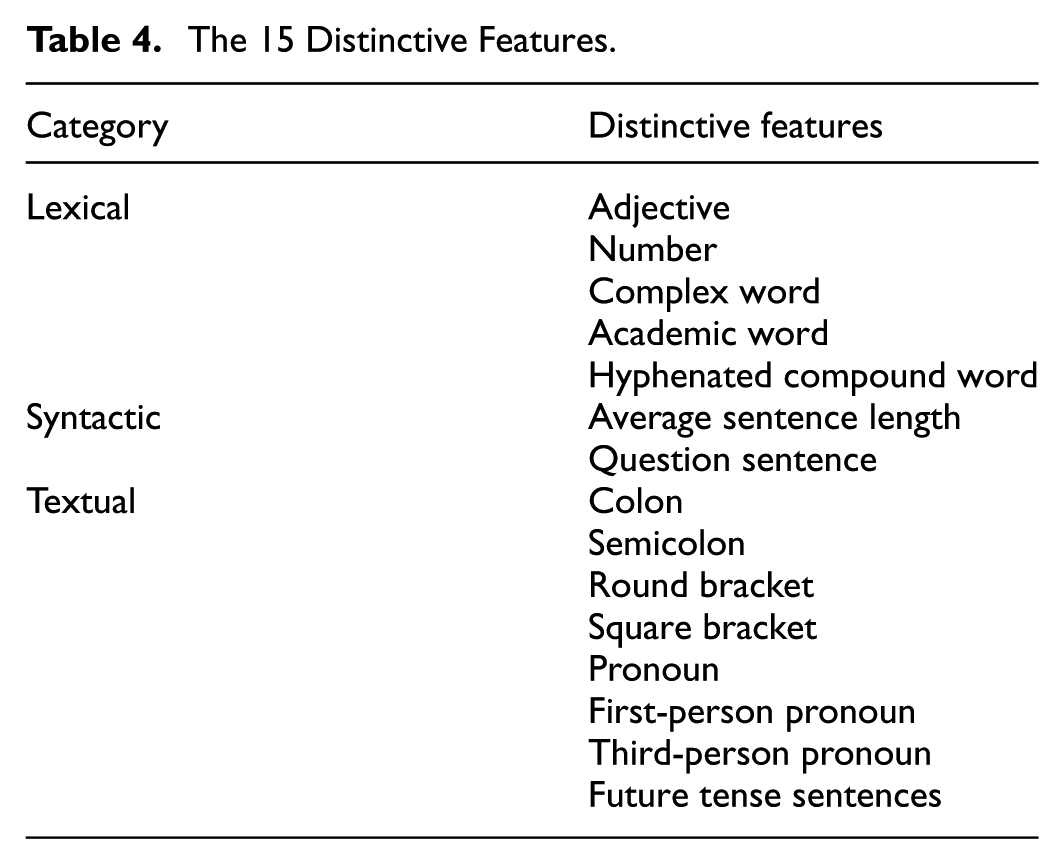
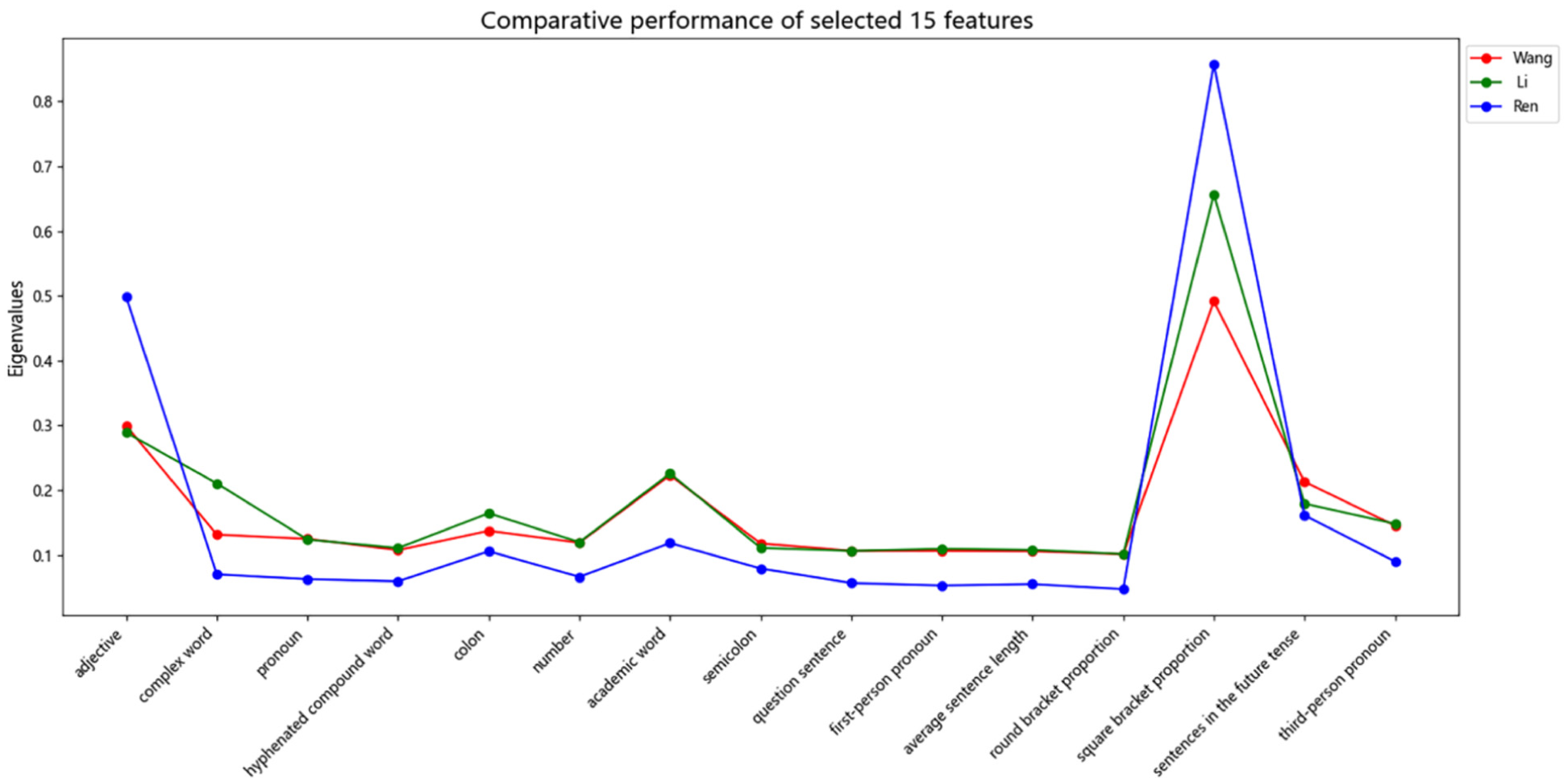
Comparative performance of selected 15 features.
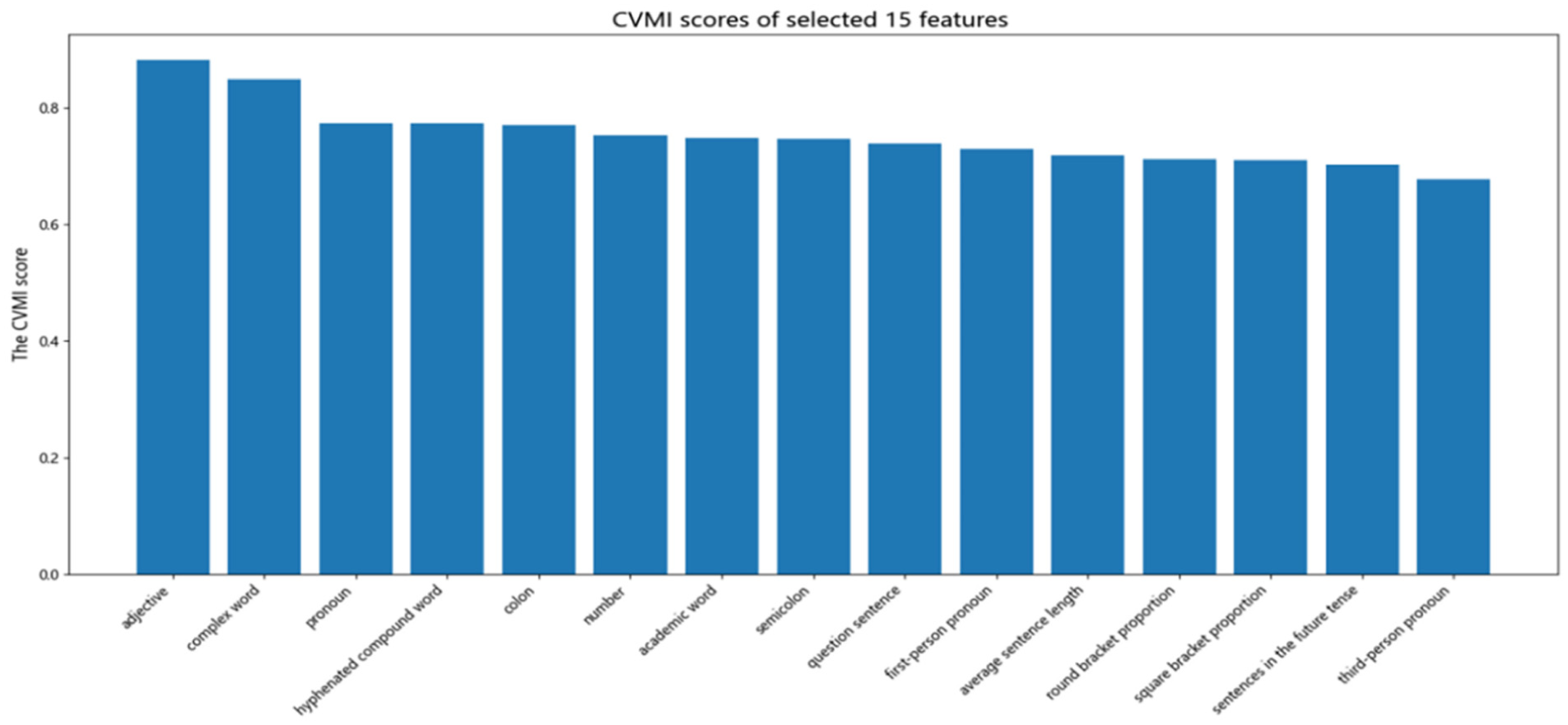
CVMI scores of 15 distinctive features.
Experimental Validation
The ten-fold cross-validation was used to evaluate the predictive performance of the classification models. The results are presented in Table 5, Figures 3 and 4.
Results of Experimental Validation.

Feature classification in random forest.

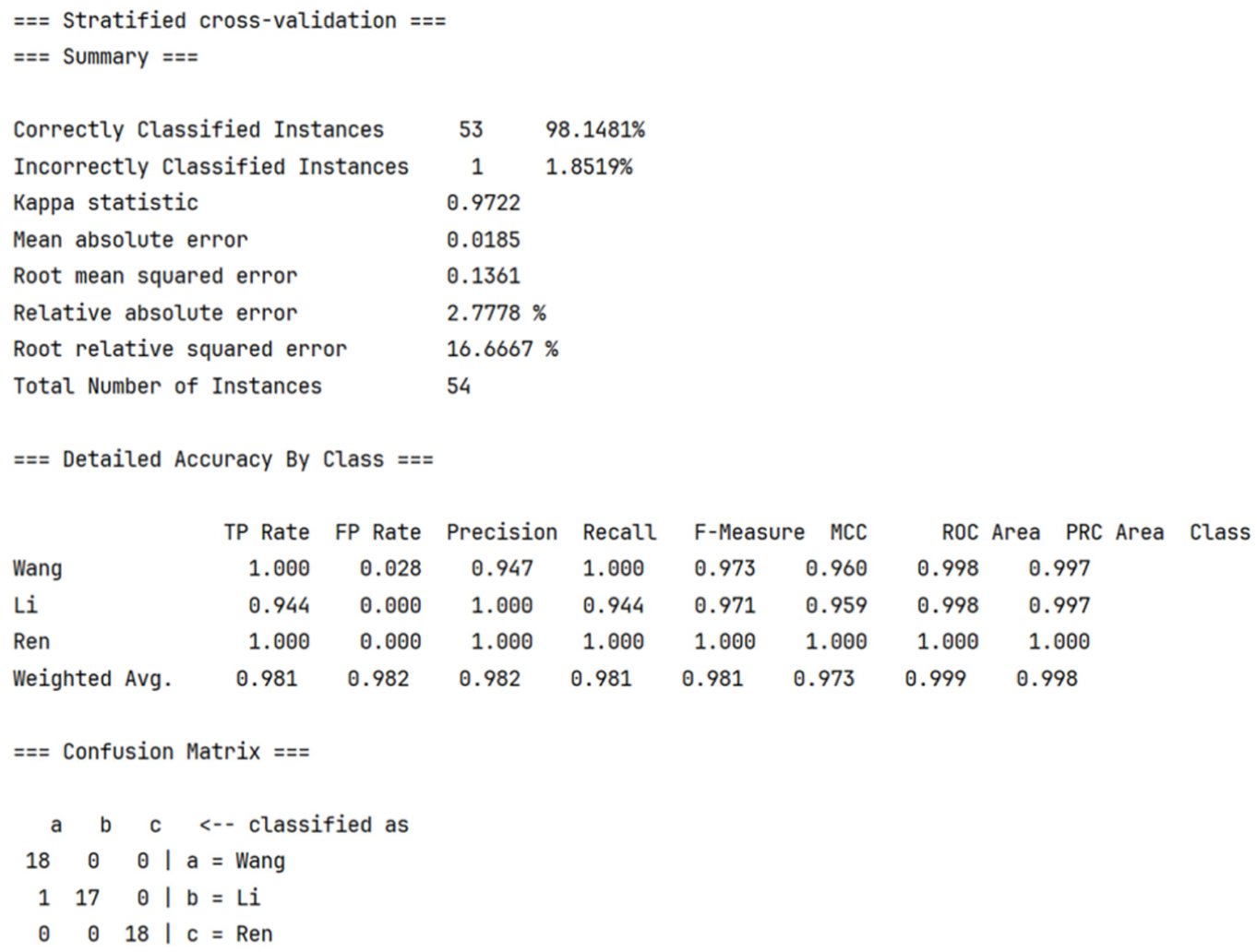
Confusion matrix—53/54 samples correctly classified.
Several classification algorithms were used, including Support Vector Machine (SVM), K-nearest Neighbors, Random Forest, and Naive Bayes. As shown in Table 5, all classifiers using the full set of 37 features achieved satisfactory results, with accuracies exceeding 94%, except for Naive Bayes. Using the 15 selected features significantly improved performance across the three classification metrics. This indicates that classification based on distinctive features leads to highly effective model performance.
Figures 3 and 4 shows the results of the Random Forest classifier based on the 15 selected features. Out of 54 samples, 53 were correctly classified. The confusion matrix below shows that one sample from Li’s translation was misclassified as belonging to Wang’s group. No other misclassifications occurred, underscoring the effectiveness of the selected features. These findings suggest that the 15 selected features are instrumental in distinguishing stylistic nuances among the three translated versions.
Results and Discussion
As a linguistic and social act, translation can be understood through recurrent patterns that reveal a translator’s cultural-ideological positioning and cognitive practice (Baker, 2000). This study employed an integrated qualitative-quantitative approach, which effectively illuminates the nuanced choices and underlying motivations across the three translations. Specifically, the analysis focuses on the 15 most discriminative features selected by the CVMI-RRMFT algorithm, corresponding to three stylistic dimensions—lexical, syntactic, and textual. By tracing the consistent patterns of each translator across these levels, the study demonstrates how style emerges from the interplay among linguistic habitus, strategy, and socio-historical context.
Lexical Features
Adjectives
Adjectives play a crucial yet often overlooked role in technical texts. S. F. Li et al. (1994) emphasized that adjectives serve key functions, such as defining conceptual attributes, delineating usage precisely, making subtle distinctions, and visualizing features. Quantitatively, the proportion of adjectives is comparable in Ren’s (8.09%) and Li’s (7.94%) translations. This similarity suggests that both versions employ adjectives to achieve a nuanced and detailed descriptive style. In contrast, the proportion of adjectives in Wang’s translation is slightly lower (7.59%), reflecting a more concise and direct depiction of facts and phenomena. A concrete example illustrates this stylistic inclination:
Ren: The industrious farmer fertilizes his fields and stimulates the [growth of] rice in many ways, for when the soil is lean and depleted the spears of rice become sparse and barren. Commonly used throughout the country as fertilizing agents are: …… Li: When the soil fertility of a paddy field becomes exhausted, the rice crop, if allowed to grow under such soil conditions, will set seeds sparingly on its panicles. Consequently, diligent farmers take every measure to manure their fields with excrements, in order to improve their soil productivity. Wang: If the paddy fields are barren, the rice spears and grains will not grow well. The industrious farmers fertilize their fields to stimulate the growth of rice in various ways.
In Ren’s translation, adjectives are employed with notable literary and rhetorical density. Descriptions such as “lean and depleted” and “sparse and barren” create vivid imagery that intensifies the desolate tone of the original. With free translation techiniques, this diction remains evocative, verging on the poetic in its descriptive effect.
Li utilizes adjectives with greater restraint and precision. Words like “exhausted” (for soil fertility) and “sparingly” (for seed setting) function as accurate technical descriptors. With literal translation strategy, the style is factual and expository, prioritizing clear information transfer over stylistic flourish and catering to technical readers.
Wang adopts less adjectival modification. Key concepts are rendered with broad, accessible terms such as “barren” and “not grow well,” effectively conveys the core message but reduces specificity and nuanced imagery found in the original. This reflects a functional translation strategy favoring readability and concision.
Numbers
In natural language, numerical expressions convey vagueness or serve as hyperbole to create an atmospheric effect in literary contexts (Jiang & Li, 1994). In technical translation, however, precision and rigor are paramount. Accurate descriptions supported by specific data are essential for conveying measurements of time, distance, quantity, and other critical parameters. The proportion of numerical expressions is 2.18% in Ren’s version, 2.55% in Li’s, and 1.99% in Wang’s. Notably, Li’s version, with the highest proportion, reflects a strong commitment to precision. Table 6 presents typical examples from the three versions.
Examples of Numerical Translation in Three Versions.

Based on the provided examples, the three translators employ distinct yet internally consistent strategies in rendering numerals and classifiers, reflecting varying degrees of cultural mediation and technical precision.
Ren’s translation adopts a domesticated approach that prioritizes cultural adaptation for the target reader. Numerals are frequently converted into Western units (“feet,”“ounce”) or rendered with English idiomatic approximations (“several feet,”“half a dozen or so”), which communicate complex data effectively. This strategy enhances accessibility for a Western audience but generalize values and replaces original units, thereby distancing the translation from the technical context of the original.
Li’s translation pursues documentary precision and fidelity to the source text. It meticulously preserves original numerical ranges through literal rendering (“2 to 3,”“3 to 4… 6 to 7”), and employs fractions like “3/100” where necessary to ensure exactness. Furthermore, it retains traditional Chinese measurement units through Wade–Giles transcription (“ch'ih,”“ts’un,”“taels”). This strategy maintains scholarly rigor and technical accuracy, making the translation especially suited for historical reference and reflecting a factual and historical authenticity. Such commitment to numerical precision not only preserves the textual integrity of the original but also facilitates the effective communication of technological details to the reader.
Wang’s translation maintains original numeral ranges (“two or three,”“3 and 6”), and renders Chinese units with modern Pinyin (“chi,”“cun,”“fen”). However, it occasionally introduces inaccuracies—for example, rendering the original “三四个或六七个” as “four or five.” The keeps the style of clarity and cultural retention of the technical information, but at the expanse of precision.
Academic words and complex words
The vocabulary used in a translation significantly influences its complexity. To assess lexical difficulty, this study employed AntWordProfiler 2.2.1, a tool designed to profile vocabulary levels. The reference word lists used in this analysis included the General Service List (West, 1953), the First and Second High-Frequency Word Lists, and the Academic Word List (Coxhead, 2000). Words not found in these lists are categorized as “off-list,” indicating that they constitute complex vocabulary requiring higher cognitive effort for comprehension.
In technical translation, precision and formality often take precedence, which encourages the use of less frequent but semantically unambiguous terms. This reflects the necessary balance between fidelity and accessibility in specialized texts. As shown in Figure 5, all three translations employ substantial technical terminology to maintain academic rigor—underscoring the role of specialized vocabulary in ensuring precision—yet their individual lexical choices differ markedly: Ren uses the most academic terms, Li the most complex vocabulary, and Wang the fewest of both. For instance, in rendering the original phrase “老足者,喉下两夹通明,” Ren translates “喉” as “throat,” Li as “pharynx,” and Wang as “cheek.” These divergent choices—from the general (“throat”) to the scientifically specific (“pharynx”) to the colloquial (“cheek”)—exemplify the fundamental tension in technical translation between terminological precision and interpretive flexibility, a balance each translator navigates differently based on their assessment of the text’s purpose and audience.

The proportion of academic words and complex words.
To further assess lexical difficulty and translators’ word preferences, this study employed the Level Vocab Checker, developed by Japanese Professor Dale Brown in 2019, which utilizes the JACET 8000 Word List to grade vocabulary on a scale from 1 (easiest) to 20 (most difficult).
Vocabulary at levels 1 to 10 accounts a similar proportion across all three translations (Ren: 40.8%; Li: 40.4%; Wang: 40.6%), indicating little variation in the use of basic words. As shown in Figure 6, Words from levels 11 to 17 represent the largest share in Wang’s translation, whereas levels 18 to 20 constitute a significantly larger proportion in both Ren’s and Li’s versions. Overall, Ren and Li use more complex vocabulary, suggesting a translation aimed at a professional readership and presenting a greater cognitive challenge. In contrast, Wang’s version is lexically more accessible.

The word difficulty levels in three translations.
Lexically, Ren’s version is notably complex, characterized by rich vocabulary and detailed descriptions. This approach align with a scholarly audience and is supported by the expertise of her spouse, a specialist in mining and metallurgy. The strategy manifests in her frequent use of adjectives and precise numerical descriptions, which articulate scientific concepts with accuracy—a tendency also reflected in her extensive use of annotations (not analyzed here). Li’s version exhibits comparable lexical complexity, marked by a high proportion of adjectives, exact numerical expressions, and academic terminology that clarifies scientific phenomena. His background as a chemist informs this preference for precision, ensuring conceptual clarity. In contrast, Wang’s translation employs more accessible vocabulary, consistent with its place in a state-sponsored publication series. This simplification functions as a deliberate instrument of cultural diplomacy to promote China’s heritage globally.
Syntactic Features
Sentence Length
Average sentence length, calculated as total words divided by total sentences often correlates with formality and structural complexity, reflecting proficiency in language use (Jiang, 2014). Following Butler’s (1985) classification—short (1–9 words), medium (10–25 words), and long sentences (over 25 words)—this study identified sentence boundaries using periods, exclamation points, and question marks, consistent with WordSmith 8.0 guidelines.
As shown in Table 7, all three translations contain more sentences than the source text, aligning with the tendency of translated texts to enhance clarity. Each version falls within the medium-length range (10–25 words). Notably, Ren’s translation has the fewest sentences but the longest average length, followed by Li’s version; Wang’s uses relatively shorter sentences. When including Li’s 1,538 traditional Chinese characters, his average sentence length increases further, underscoring his distinctive approach to textual expansion.
Sentence Statistics in Three Translations.

Sentence Structures
In addition to sentence length, the complexity of internal sentence structure is a key dimension for assessing a translator’s style. To further investigate the syntactic differences among the three translated versions—specifically, whether longer sentences correspond to more complex syntactic constructions—this study employed the L2 Syntactic Complexity Analyzer developed by Lu (2010) to extract 11 metrics across four dimensions, thereby systematically quantifying syntactic complexity. The results, presented in Table 8, reveal notable syntactic differences among the three translations, providing a quantitative basis for subsequent stylistic comparison.
Sentence Complexity Statistics in Three Translations.

Note. Asterisks indicate statistical significance levels as **p < 0.01 and ***p < 0.001.
A one-way analysis of variance (ANOVA) was conducted to identify significant differences in these syntactic complexity metrics. As shown in Table 8, significant differences were found in the dimension of “Overall Sentence Complexity,”“Amount of Subordination,” and “Degree of Phrasal Sophistication” (p < .01), confirming distinct syntactic profiles across the three versions. Specifically, mean values for “Overall Sentence Complexity” and “Degree of Phrasal Sophistication” decreased consistently across Ren’s, Li’s, and Wang’s translations. In Notably, “Amount of subordination,” Ren’s translation scored the highest, followed by Wang’s, while Li’s showed the lowest mean value. In contrast, differences in “Amount of Coordination” were not statistically significant, indicating similar use of coordinative structures across the versions.
These syntactic differences correlate with the perceived readability of the translations. Ortega (2003) observed that lower-level language learners tend to rely more on dependent clauses, whereas advanced learners employ more complex phrases. This suggests that texts rich in complex phrases generally pose greater reading challenges than those with frequent subordinate clauses. Accordingly, Li’s higher phrasal sophistication indicates a potentially higher reading difficulty compared to Wang’s version. It also illustrates that the proportion of subordinate clauses alone does not uniformly predict text difficulty. In the case of Tian Gong Kai Wu, syntactic complexity shows a positive relationship with average sentence length: complexity increases as sentences grow longer.
This correlation implies how translators’ syntactic choices shape stylistic effect and readability. Examining these features can therefore offer key insights into how translation strategies influence the effectiveness of technical communication and modulate readers’ cognitive load. The following excerpt illustrates how sentence structure is handled differently by each translator:
Ren’s translation reconstructs the source text into a single, densely layered sentence through nested clauses (“until… when… so that…”), which meticulously weave together temporal, conditional, and causal relationships. Characterized by intricate syntactic framework and a final explanatory “because” clause, Ren’s translation exhibits a high syntactic complexity, which effectively accommodates detailed academic information and explicit logic, making it tailored for readers seeking deeper contextual and technical understanding.
Li’s translation employs a measured use of coordination and a higher Degree of Phrasal Sophistication (CN/T). He breaks the whole sentence into short, declarative statements, adopting a paratactic flow rather than intricate subordination. The process is rendered as a clear sequence linked by “and.” Notably, he introduces a separate defining sentence (“It derives its name… from the fact that…”). This method avoids lengthy embedded clauses, conveying precise information through compact noun phrases and independent explanatory statements. Overall, it reflects a scientific orientation that prioritizes factual clarity, terminological precision, and documentary value.
Wang’s translation employs a balanced use of subordination to enhance accessibility. It follows a clear main-subordinate structure, opening with a “When” adverbial clause, extending through a “which” relative clause, and concluding with a “because” causal clause. This framework is more linear and predictable than Ren’s, with logical connectors used transparently to lower processing effort. Such syntactic streamlining with lower lexical and syntactic complexity facilitates comprehension for a broader readership, aligning with the translation’s aim of cultural dissemination and reader-friendly adaptation.
These findings reveal that Ren’s translation exhibits the highest syntactic complexity, a feature closely tied to her background as a Chinese-American scholar, which enables her to skillfully navigate cross-cultural nuances through sophisticated vocabulary and multi-layered sentences. In contrast, Li employs condensed phrasal structures to convey information, an approach rooted in his expertise in chemistry and prior experience translating The Chemical Arts of Old China, which afforded him a thorough understanding of Tian Gong Kai Wu (Y. M. Wang, 2022). His translation thus function as a key historical resource for studying China’s technological development. Wang’s version, produced under a state-sponsored project, prioritizes readability to facilitate broad international dissemination.
Textual Features
Referents For Textual Cohesion
English relies on pronouns to maintain referential clarity, which directly enhances text readability. In the translations, pronouns constitute 4.85% of Ren’s text, 5.32% of Li’s, and 5.20% of Wang’s. The higher proportions in Li’s and Wang’s versions suggest a greater focus on clarifying logical relations through pronominal reference.
As Halliday and Hasan (2014) note, third-person pronouns are particularly important for textual cohesion, serving anaphoric and cataphoric functions that aid continuity in technical discourse. As illustrated in Table 9, Ren’s frequent use of third-person pronouns reflects this cohesive emphasis, helping guide readers through complex technical descriptions. Furthermore, among personal pronouns, “it” occurs most frequently, representing 0.58% of Ren’s text, 0.63% of Li’s, and 0.81% of Wang’s. Generally, “it” signals a deliberate stylistic preference for objectivity (Biber, 1999). Thus, the high frequency of “it” particularly in Wang’s translation reflects a tone consistent with a more formal textual style. This pattern highlights how pronouns selection contributes to textual cohesion and clarity, and enhances the perceived credibility of the translator’s voice.
Statistics of Textual Features in Three Translations.

The continuous evolution of technology reshapes the language and expressive modes of science. While conventional translation practice often emphasizes objectivity through third-person or impersonal structures, such an approach can reduce textual vividness and hinder the cross-cultural reception of classical Chinese works (M. W. Xu & Li, 2021). Conversely, a growing trend among English-speaking professionals favors the first-person perspective to enliven technical writing (Fan & Liu, 2025). In translating Tian Gong Kai Wu, however, the use of first-person pronouns is constrained by the source text, which contains only a limited number of the author’s subjective expressions—notably, the characters “吾” (wu) and “我” (wo) appear just ten times. Among three translators, Li employs first-person pronouns most frequently, suggesting a deliberate strategy to enhance reader engagement and textual immediacy. This illustrates that first-person pronouns can serve as vital communicative resources, helping to bridge cultural distance and connect with target-language readers—a stylistic choice that may also align with contemporary preferences in reading technical texts.
Punctuation For Textual Expression
Semicolons and Colons
Lyu and Zhu (2013) assert that “each punctuation mark has its unique function, and it is not an exaggeration to state that they represent another form of functional units.” The proper application of punctuation marks is a strategic translation method that has received little attention in previous studies.
The selection of punctuation in translation directly shapes sentence structure and flow. For example, a semicolon connects clauses or sentences more tightly than a period (Q. Wang, 2023), sustaining continuity across ideas, whereas a colon introduces elaborations, lists or elaborations that clarify what precedes. In technical contexts, where precision and logical progression are essential, the deliberate use of semicolons and colons ensures organize complex information, guiding readers clearly through the message. Thus, these punctuation choices not only strengthen textual cohesion but also aid comprehension in translated technical texts.
As shown in Table 9, all three translations use semicolons and colons more frequently than the source text. In Ren’s translation colons are consistently employed to introduce explanations, enumerations, or procedural steps—such as “Jade has only two colors: white and green” and “The method of planting sesame is as follows: make farm plots….” This strategy enhances textual clarity, aids in restructuring complex technical descriptions, and improves overall readability.
Semicolons are commonly used in English to coordinate ideas, indicate pauses, and distinguish layers of content (Kong, 2023). Notably, Ren’s version uses semicolons approximately two to three times more frequently than the other two versions, as illustrated in the following example:
In the source text, two separate sentences are linked by two periods, whereas Ren’s version connects them with two semicolons, creating a more fluid and cohesive relationship. For instance, one semicolon joins “pearls” (珠) and “jade” (玉), illustrating how this punctuation can link not only full clauses but also parallel phrases based on semantic ties—functioning similarly to a comma in such contexts. Such flexible use of punctuation enhances the translations’ fluency, coherence, and rhythm. By contrast, Li’s version closely follows the original punctuation structure, while Wang’s reorganized sentence segments according to meaning, relying primarily on commas and periods to reflect the style of the source.
Square Brackets and Round Brackets
As shown in Table 9, Ren’s translation makes extensive use of square brackets. Examples such as “The mast is the arc of the bow [for shooting arrows],”“When a mussel [or an oyster] conceives a pearl,”and “the bamboo sections [gunwale?] are the tiles [atop the wall?],” illustrate how brackets perform multiple functions: clarifying technical details, signaling cultural or referential ambiguities. With over a thousand instances, these brackets primarily supply explanatory notes on vague or culturally specific references, thereby reducing sentence complexity and minimizing ambiguity. Furthermore, this innovative and frequent use of punctuation exemplifies a “thick translation” approach (Appiah, 1993), in which the translator embeds the source text within a framework of cultural and technical commentary. As a historian addressing a Western academic readership, Ren employs brackets to mediate between the classical Chinese technical discourse and the expectations of scholarly readers seeking deeper understanding. Consequently, her translation has become an authoritative reference for researchers studying China’s history of science and technology (Ho, 1967).
Li’s extensive use of round brackets with traditional characters is a politically nuanced form of thick translation, reinforcing cultural identity through visual and lexical means for a sinological audience. For instance, “稻灾” is translated as “RICE CROP DAMAGE (稻災).” This distinctive approach visually preserves the source text’s lexicon, a unique style rarely seen in conventional translations, offering readers direct access to the original terminology within the technical description. Fundamentally, this distinctive stylistic choice was ideological rather than merely technical. It stemmed from Li Ch’iao-ping’s patriotic sentiment from the Second Sino-Japanese War, and his mission to advance Chinese scientific civilization for Western sinologists and learners through translation. His strategic inclusion of more than 1,500 traditional Chinese characters within round brackets represents a deliberate act of cultural preservation, a strategy surpasses conventional translation to become a pronounced statement of cultural identity. Endorsed by Taiwan’s official publishing house within its specific historical context, he imbues his work with an archaic quality evocative of classical Chinese texts.
Faithfully mirroring the source text’s 245 round brackets, Wang’s translation exhibits a clear preference for simplification through easier vocabulary, shorter sentences, and lighter punctuation, collectively making it the most readable version. This stylistic choice, facilitated by a team proficient in both languages and subject matter, functions as a form of cultural diplomacy. It is fundamentally shaped by the macro-agenda of nation branding, which frames the translator as a diplomatic envoy. The ultimate aim is to enhance the global accessibility of the ancient classic, thereby supporting the twenty-first-century strategic goal of promoting Chinese culture abroad.
Limitations and Future Work
This study proposes a framework for analyzing translator style in technical classics, yet limitations should be noted. First, its focus on a single classic and three translations limits the generalizability of the findings. Second, the stability of the selected features should be tested on larger and more diverse corpora. Third, both the quantitative features and qualitative interpretations require further validation—the former on independent datasets to confirm broader applicability, and the latter through methods such as coder triangulation to minimize interpretive bias. Future work should therefore expand to multi-genre corpora, validate features across independent datasets, and incorporate systematic checks to strengthen the reliability of qualitative stylistic analysis.
Conclusion
By employing a corpus-based, machine-learning approach, this study has elucidated how translators communicate the Chinese technical classic Tian Gong Kai Wu, successfully addressing the three research questions and thereby revealing the intricate nature of translator style.
First, through the application of the CVMI-RRMFT feature selection algorithm, 15 highly discriminative linguistic features were identified across the three English translations (Question 1). These features, distributed across lexical (e.g., adjectives, numbers), syntactic (e.g., mean sentence length), and textual levels (e.g., punctuation, pronouns), provide an objective and quantifiable basis for distinguishing the translators’ stylistic fingerprints.
Second, analysis based on these distinctive features reveals significant differences in the translators’ styles, manifesting both within the texts and reflecting external influences (Question 2). The styles are systematic manifestations of socio-cultural positioning. Ren’s translation is characterized by a scholarly “thick translation” approach, evident in its complex sentence structures, sophisticated vocabulary, and prolific use of square brackets for annotations, underscoring her role as a historian translating for an academic readership. Li’s precision and cultural coding reflect his dual role as chemist and cultural guardian. This version emphasizes technical precision and cultural identity, marked by a high frequency of numerical expressions, specialized terminology, and the unique incorporation of traditional Chinese characters within round brackets, reflecting his background as a chemist and his cultural motivations. In contrast, Wang’s translation style is fundamentally a diplomatic mode, shaped by state patronage for global nation branding. It prioritizes accessibility and readability, featuring simplified vocabulary, shorter sentences, and a streamlined use of punctuation, aligning with its goal of promoting Chinese culture to a global general audience in the 21st century.
Third, the causes are strategic. Style emerges from the interplay of habitus and socio-historical constraints (Question 3). Internal factors, such as the translators’ expertise, professional identities, and personal translation philosophies, directly shaped their linguistic choices. Simultaneously, external factors—including target readership expectations, publishing sponsorship, historical context, and broader cultural-political agendas—significantly influenced their strategic adaptations. Linguistic choices strategically embody their perceived role—scholarly mediator, cultural guardian, or diplomatic envoy—within specific networks, a conscious negotiation between individuality and context. Therefore, this interplay confirms that translator style is not merely an unconscious imprint but a strategic negotiation, a dialectic between the translator’s individuality and the contextual milieu.
This study establishes a robust framework that integrates computational and qualitative analysis to uncover subtle stylistic patterns in translation, patterns often missed by purely subjective interpretation. By quantifying stylistic features and contextualizing them within professional and historical milieus, it provides a nuanced understanding of how technical classics are mediated cross-culturally. Future research should incorporate paratexts—images, annotations, explanatory notes—to explore how multimodal factors shape translation. Consequently, the work not only deepens our insight into the transmission of a Chinese classic but also demonstrates the significant potential of data-driven methods in the humanities.
Footnotes
Appendix
Acknowledgements
The Key Program of the National Social Science Fund of China is gratefully acknowledged.
Ethical Considerations
This study, being a textual analysis of published translations, required no ethical approval as it involved no interaction with human or animal subjects. The research complies with all applicable institutional policies.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Key Program of the National Social Science Fund of China (Grant No. 24AYY019).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be made avaiable upon request from the corresponding author.