
Abstract
This study systematically compares four prominent Chinese translations of Plato’s Republic against two authoritative English benchmark translations, addressing a critical gap in existing Platonic scholarship: the lack of objective comparative analysis of its diverse Chinese versions. Using a three-tiered computational stylistic framework comprising macro-stylistic positioning, micro-level syntactic and lexical features, and cognitive-linguistic profiling via LIWC categories, we analyzed a purpose-built parallel corpus of 935,861 tokens. The corpus comprises four influential Chinese translations (Gu Shouguan 2010, Guo Binhe 1986, He Xiangdi 2021, Xie Shanyuan 2016) and two English benchmarks (Allan Bloom 1968, C. D. C. Reeve 2004). Significant stylistic divergences emerged among the Chinese versions and in contrast to the English texts. Chinese translations consistently exhibit a pronounced tendency toward explicitation, marked by significantly higher frequencies of cognitive process words (13.7%–16.4% vs. 11.2%–12.7% in English versions, d = −1.75, p < .001) and elevated frequencies of logical connectives, particularly result and contrast markers. Notable variations in syntactic complexity were also found, ranging from Guo Binhe’s concise style (17.985 tokens per sentence) to Gu Shouguan’s elaborate style (27.419 tokens per sentence), with substantial variation among Chinese translations (η2 = 0.18–0.48). These findings underscore that the Chinese Republic translations are not mere linguistic variants but unique intellectual projects shaped by deliberate interpretive strategies and cultural contexts, highlighting translation’s active role in philosophical re-creation and re-localization.
Plain Language Summary
Plato’s Republic is a cornerstone of Western philosophy, but how does it read in another language? In China, students and scholars face a “paradox of choice” with over ten different translations available. This study uses computer-based analysis to compare four influential Chinese translations by Gu Shouguan 2010, Guo Binhe 1986, He Xiangdi 2021, and Xie Shanyuan 2016, against two English benchmark versions. We analyzed nearly 936,000 words, examining sentence length, word types, and how translators handle key philosophical terms. The results reveal notable variations. Gu Shouguan’s version tends to use extremely long, complex sentences averaging over 27 words, aiming for a formal style. In contrast, Guo Binhe’s translation tends to use shorter sentences averaging about 18 words, making Plato’s ideas more accessible. The Chinese translations tend to make Plato’s logical arguments more explicit than the English versions, often adding connecting words like “therefore” and “because” to guide readers. They also tend to use more words expressing contrast and result, while English versions rely more on words signaling reasons. These stylistic choices appear to reflect the translators’ unique backgrounds, the historical eras spanning from 1986 to 2021, and their different goals. This research suggests that a single classic can become multiple, distinct works in translation, each offering a different window into Plato’s thought for Chinese readers.
Introduction
Plato’s Republic is a foundational text of Western philosophy whose influence has permeated political theory, ethics, metaphysics, and epistemology for over two millennia. Translating such a work is not merely a linguistic exercise but a profound act of cross-cultural intellectual reconstruction, as a translator’s choices actively shape how new readers understand Plato’s complex philosophical system. In China, interest in the Republic (Lǐxiǎngguó [理想国] =Plato’s Republic) 1 is evidenced by at least 10 distinct translations. This abundance, however, has created a “paradox of choice” for students and scholars. However, a review of Chinese academic databases reveals a near-total absence of systematic, comparative scholarship on these versions, with evaluations largely confined to subjective online ratings. The prominence of certain editions, like Guo Binhe’s, may stem more from publisher prestige than from demonstrated stylistic merit. 2 Existing scholarship suffers from three limitations: analyses are predominantly qualitative and impressionistic; no objective framework exists for evaluating stylistic differences; and the relationship between translator choices and interpretive strategies remains underexplored. This gap is significant, as translation choices in philosophical texts profoundly impact how core concepts are understood across cultures. To address this gap, this study uses a computational stylistic framework to systematically compare four influential Chinese translations of the Republic (by Guo Binhe, Gu Shouguan, He Xiangdi, and Xie Shanyuan) against authoritative English benchmarks. 3 The study asks two primary research questions: (1) How do the four Chinese translations differ in quantifiable stylistic features (syntactic complexity, logical structure, cognitive-linguistic tone) when compared against each other and English benchmarks? (2) What strategies do the translators employ for core philosophical concepts (e.g., “justice,” “soul,” “form”), and what does this reveal about their role as active interpreters rather than passive conduits? To answer these questions, this paper employs a multi-layered computational framework moving from macro-stylistic positioning to micro-level features and cognitive-linguistic profiling (Biber, 1988, p. 55). The framework quantitatively profiles the translations by measuring key metrics—sentence length, syntactic tree depth, logical connective frequencies, and LIWC (Linguistic Inquiry and Word Count) word usage—analyzes choices for core terms, and synthesizes these findings to construct distinct “stylistic portraits” for each translation, providing an objective framework for their evaluation.
Literature Review
To situate this study, we synthesize three interconnected domains: computational stylistics as a methodological foundation, its application to Platonic studies as a historical precedent, and its integration with translation studies as a theoretical framework. This review demonstrates how concepts and tools from these domains converge to enable a rigorous, multi-layered analysis of translation style.
The Foundations of Computational Stylistics
Computational stylistics, or stylometry, has evolved from authorship attribution into a comprehensive framework for quantitative textual analysis. Its foundation is the principle that style—“the manner of writing” or “an ensemble of formal features” (Herrmann et al., 2021)—can be measured through statistical analysis of linguistic features. While early applications focused on identifying authors of disputed texts (Stamatatos, 2009), contemporary stylometry now addresses questions of genre, period, register, and translation.
The field’s most robust findings center on function words (prepositions, articles, conjunctions) as stylistic markers. Research consistently shows that the frequencies of the most common function words capture unconscious authorial habits without requiring complex linguistic parsers (Daelemans, 2013; Grieve, 2007). These features are powerful because they operate below the level of conscious choice, making them resistant to manipulation. Methodologically, the field employs various classification approaches, including machine learning and distance-based measures like Burrows’s Delta, a foundational technique for comparing texts based on word frequencies (Burrows, 2002; Eder et al., 2016).
The evolution from authorship attribution to broader stylistic analysis reflects a shift in understanding what stylometric features reveal. For instance, most-frequent-word-based stylometry can reveal patterns beyond authorial identity, such as theme, audience, and stylistic patterning (Hołobut & Rybicki, 2020). This expansion is crucial for translation studies, where patterns may reflect translator choices, genre, or cultural contexts more than an authorial signal. Thus, tools from authorship attribution provide a robust foundation for analyzing translation style, even as the theoretical focus shifts from identifying authors to understanding stylistic variation.
The Tradition of Stylometry in Platonic Studies
The application of quantitative methods to the Platonic corpus is not new; Plato’s dialogs have been a laboratory for stylometric inquiry for over a century. The term “stylometry” was introduced by W. Lutoslawski in his late 19th-century work on the chronological periodization of Plato’s works, marking the field’s origins in classical philology. The advent of computational methods, documented by Brandwood (1990), was a pivotal shift, enabling large-scale analysis of syntax, rhythm, and other complex features of style (Brandwood, 1990, pp. 235–248). This computational turn quickly confirmed the long-suspected division of Plato’s works into early, middle, and late groups.
More recently, the focus has expanded beyond chronology to more nuanced investigations, such as using stylometry to identify different literary registers and “voices” within single dialogs. For instance, M. Johnson and Tarrant (2014) used computational methods to analyze Plato’s Symposium, demonstrating that the Diotima material exhibits a distinct “female voice” similar to other passages where Socrates adopts a female voice, and is grouped with myth-like episodes (M. Johnson & Tarrant, 2014). This approach allows for a deeper understanding of Plato’s literary artistry by revealing stylistic patterns that inform literary interpretation.
Furthermore, the field provides quantitative evidence in debates over the authenticity of specific dialogs. Koentges (2020), for example, used a massive corpus of Greek literature to argue that the Menexenus is a stylistic outlier and likely not of Platonic authorship (Koentges, 2020). This tradition confirms that applying computational methods to Plato’s works is a well-established and increasingly sophisticated scholarly endeavor.
This tradition is relevant for translation studies because it shows that computational methods can reveal systematic patterns in texts reflecting underlying structures like chronology, register, or authorial identity. Applied to translations, these methods can reveal patterns reflecting translator choices, interpretive strategies, and cultural contexts. The tools developed for analyzing Plato’s Greek texts thus provide a proven foundation for analyzing translated texts, even as the research questions shift from authenticity and chronology to style and interpretation.
Bridging Stylistics and Translation Studies
While stylometry has a rich history in classical philology, its integration with translation studies is a more recent, synergistic development. For decades, stylistic analysis was largely excluded from translation theory, partly due to a narrow understanding of stylistics as early structuralist linguistics focused on source-text features. Recent scholarship has bridged this gap through three developments: corpus stylistics, the concept of “translator’s style,” and cognitive approaches to translation.
Corpus stylistics marked a pivotal shift, providing quantifiable evidence for stylistic patterns beyond mere intuition (J. H. Johnson, 2008). This approach was instrumental in developing the concept of “translator’s style,” which Baker (2001) defines as a “thumb-print” of recurring linguistic habits that distinguish one translator from another (Baker, 2001). Saldanha (2011) refines this, specifying that translator style must be recognizable, distinctive, coherent, and motivated (Saldanha, 2011). Corpus methods operationalize this concept, demonstrating how computational tools can reveal systematic patterns in translation choices. For instance, Baker’s analysis of type-token ratios and sentence length provides evidence of consistent stylistic habits (Baker, 2001), while Saldanha’s work on italics and foreign words shows how specific features can function as stylistic markers (Saldanha, 2011).
A complementary “cognitive turn” has shifted focus to the mental processes underlying text production and reception. This led to “translational stylistics,” defined by Malmkjær (2003) as studying “why, given the source text, the translation has been shaped in such a way that it comes to mean what it does” (Malmkjær, 2003). Boase-Beier (2014, 2023) develops this from a cognitive stylistics perspective, viewing style as an expression of mind states and worldviews (Boase-Beier, 2014, pp. 71–110, 2023). Ghazala (2018) frames translation as a cognitive process where style reflects mind (Ghazala, 2018). This perspective operationalizes style by analyzing features like transitivity patterns, which reveal how translators conceptualize meaning (Ghazala, 2018). The framework thus recognizes the translator as a distinct stylistic voice whose choices are motivated by cognitive processes of interpretation.
Recent developments in corpus-based translation studies, such as Meng and Oakes’s (2021) volume, show the field’s evolution from generating numeric attributes to developing sophisticated analytical paradigms integrating lexical, discourse, and stylistic analysis (Meng & Oakes, 2021). Corpus translation studies have expanded from a marginal tactic to a powerful framework permeating literary, cognitive, neural, and socially oriented translation studies (Meng & Oakes, 2021). This reflects a growing recognition that translation style requires analytical schemes connecting quantitative patterns to theoretical frameworks.
Similarly, Holobut and Rybicki’s (2020) work on film dialog shows how stylometric methods can reveal stylistic patterns in non-literary genres (Hołobut & Rybicki, 2020). Applying most-frequent-word-based stylometry to film dialog, his team showed that quantitative methods can reveal patterns of theme, audience, and style beyond authorial identity. This expansion validates applying computational stylistics to translation analysis, as the same tools used in authorship attribution can reveal systematic differences in how translators approach different genres, themes, and source texts.
Beyond translation studies, computational stylistics has been applied to other philosophical contexts. Botz-Bornstein and Mostafa (2017) used stylometric methods to distinguish between analytic and continental philosophy texts (Botz-Bornstein & Mostafa, 2017). More recently, Becker and Culotta (2025) used network analysis and NLP to analyze reference networks across 2,245 philosophical texts, revealing intellectual lineages (Becker & Culotta, 2025). These studies illustrate the broader applicability of computational methods to philosophical texts, validating their use in analyzing translation style.
By synthesizing these three domains—computational stylistics (methodology), Platonic studies (precedent), and translation studies (theoretical framework)—this study develops an analytical approach for the systematic analysis of translation style. Computational tools provide the means for analysis, the Platonic tradition demonstrates their applicability to philosophical texts, and translation studies provides the framework for understanding how stylistic patterns reflect translator agency and interpretive choices (e.g., translator style, cognitive processing). This synthesis enables a rigorous, multi-layered analysis that connects quantitative patterns to theoretical frameworks, illuminating the relationship between translator choices and their motivations.
Methodology
Corpus Selection and Construction
The analysis uses a purpose-built bilingual corpus pairing two benchmark English translations of Plato’s Republic with four Chinese editions. We include Allan Bloom’s (1968) and C. D. C. Reeve’s (2004) translations as a robust English reference axis (Plato, 1991, 2004). The Chinese set spans four decades, capturing translators with distinct affiliations and offering a diachronic view of the Republic’s reception in China (Lǐxiǎngguó, 理想国) (Weng, 2015a, 2015b). Table 1 summarizes the corpus composition.
Composition of the Republic Translation Corpus.
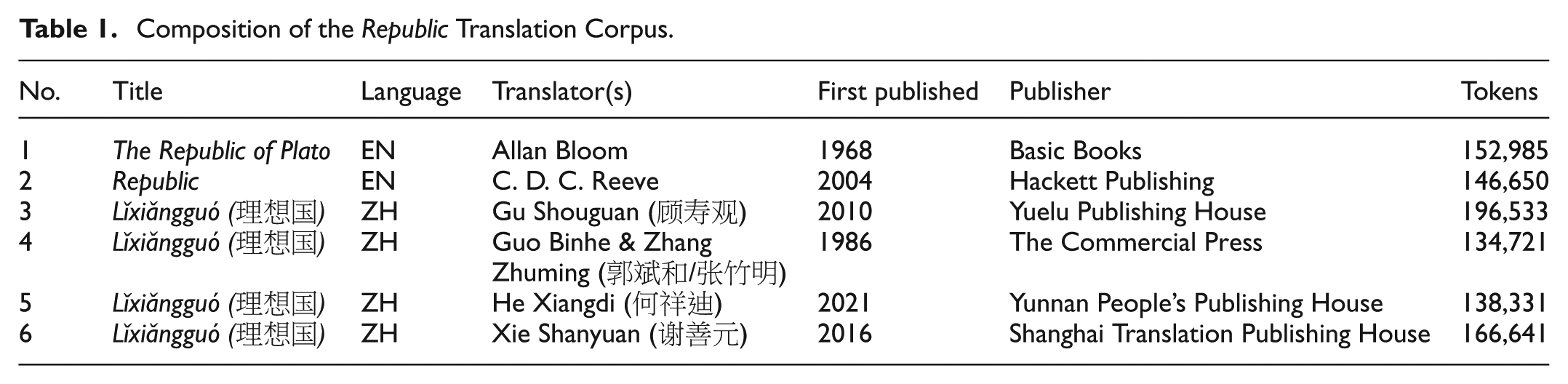
The six texts total 935,861 tokens. Including the widely cited 1986 Commercial Press edition and the recent He (2021) revision allows for a comparison between canonical phrasing and contemporary updates. The dual English benchmarks capture differences between a philosophically annotated rendering and a precise modern translation.
Source texts were digitized from print using ABBYY FineReader PDF 16. The raw OCR output underwent a double-pass manual audit: two annotators reviewed 1% to 2% samples, removed paratextual matter (e.g., prefaces, footnotes), and confirmed only the 10 main books remained, yielding 100% coverage. Pre-cleaning, the character error rate (CER) was 0.0758 and word error rate (WER) was 0.0508. Systematic artifacts were corrected using a regex rulebook. A post-cleaning spot-check found zero residual artifacts, and no narrative text was lost.
To harmonize the dataset, each file was saved in UTF-8, standardized with consistent headers, and segmented by book divisions (with supplementary 3,000-token windows where needed). Chinese texts were segmented and parts-of-speech (POS) tagged using Jieba (paddle mode), while English texts were tokenised and tagged with Natural Language Toolkit (NLTK). These decisions follow established digital humanities practices (Baker, 2001; Ball et al., 2024; Meng & Oakes, 2021). The resulting corpus provides the token-level comparability and provenance required to assess stylistic fingerprints across translations.
Analytic Framework and Steps
This study adopts an integrated, multi-layered analytical framework for a comprehensive stylistic comparison. As shown in Figure 1, this framework provides a holistic view of style by moving from broad generic positioning to fine-grained syntactic features and finally to the underlying cognitive-linguistic tone.

The three-tiered stylistic analysis framework.
Grounded in multi-dimensional analysis, which requires tracking co-occurring linguistic features (Biber, 1988), the three-tier framework moves from macro-style to micro-style and cognitive-style analysis. The first tier sketches the grammatical footprint, the second corroborates with sentence-level structure, and the third examines the cognitive-linguistic texture via psycholinguistic categories (Pennebaker et al., 2015).
Operationalizing the framework required a coordinated toolchain rather than a collection of isolated scripts. All processing ran inside a unified Python 3.7.12 environment so that segmentation, parsing, and statistical routines could share versions and seeds. Jieba 0.42.1 (paddle mode) handled Chinese segmentation and POS tagging, while NLTK 3.8.1 served the English pipeline. Stanza 1.6.1 provided constituency parses for both languages, and custom utilities replicated AntConc-style concordancing for the terminology and connective studies. Cognitive-linguistic profiles drew on the official English and Simplified Chinese LIWC-2015 dictionaries via the LIWC Python package (0.5.0), with NumPy 1.21.6, SciPy 1.7.3, and Scikit-learn 1.0.2 supporting statistical modeling.
Tool validation preceded large-scale processing. Published benchmarks show high accuracy for Stanza and Jieba on relevant corpora (PaddleNLP Contributors, 2021; Qi et al., 2020). Building on this, we created 100-sentence gold samples from our corpus. On this material, Jieba’s F1 score was 0.9956. Stanza achieved Chinese POS accuracy of 0.9314 (UAS/LAS 0.9007/0.8938), and the English pipeline recorded POS accuracy of 0.9978 (UAS/LAS 0.9504/0.9489). Sentence-boundary checks yielded an F1 of 1.0000 for both languages. Residual errors, clustering around philosophical terms and names, were mitigated by a user dictionary and manual review.
The analysis proceeded in three passes mirroring the framework. First, for macro-style analysis, POS-annotated files were summarized to generate grammatical footprints. Second, for micro-style analysis, we computed several metrics: the terminology study retrieved concordance lines for nine core Platonic concepts; we used sentence segmentation and Stanza trees to calculate syntactic complexity (e.g., average sentence length, tree depth); and the logical connective inventory was mapped to Penn Discourse Treebank (PDTB) 3.0 semantic classes. Third, for cognitive-style analysis, segmented corpora were processed with LIWC dictionaries to quantify the prevalence of relevant word categories. All outputs were then consolidated.
Measurement
With the workflow in place, this section clarifies the quantification of each tier. The selected metrics are widely used in stylistic and linguistic research, providing an interpretable basis for comparison.
Across all tiers, features are normalized for comparability. Frequencies are reported per 10,000 tokens, and long works are sliced into blocks. Rare items are additively smoothed or omitted. Family-wise error is controlled through Holm–Bonferroni correction, and significance tests are paired with effect sizes (Cohen’s d; η2). All stochastic components use fixed seeds to ensure reproducibility.
To situate each translation stylistically, this study compares their grammatical profiles against established genres in the Lancaster Corpus of Mandarin Chinese (LCMC) (A. McEnery & Xiao, 2004). As a balanced corpus of texts (e.g., news, fiction, academic), LCMC provides a representative baseline for contemporary Mandarin. The macro-genre position of each translation is determined by quantifying its stylistic similarity to the LCMC genres.
Using POS frequencies as a primary indicator of style is a foundational technique in quantitative stylistics. The principle, established by Biber (1988), is that different genres have distinct and stable distributions of grammatical features (Biber, 1988). For instance, a text heavy in verbs and pronouns may be more narrative, while one dense with nouns and adjectives may be more descriptive. The POS frequency vector thus serves as a “fingerprint” of a text’s fundamental grammatical style.
Long works are split into contiguous blocks of 3,000 tokens. For a POS inventory of size p, let

For genre g, let

Classification is by majority vote across blocks, with ties broken by the smaller mean distance. To report uncertainty, we compute robust z-scores and empirical p-values using the median and median absolute deviation (MAD) as robust estimators. This approach accounts for variance and correlation among POS features more effectively than the standard Euclidean distance (Eder et al., 2016).
A translator’s most critical decisions often concern core philosophical terms. This is not a neutral act but an interpretive choice with philosophical weight. This study analyzes nine foundational concepts from the Republic: justice, just, form, idea, soul, good, city/state, virtue/excellence, and necessity/necessary. These terms were selected for their centrality and the scholarly debate surrounding their translation. For instance, the Greek term δικαιοσύνη (“justice”) has a broader meaning than its modern equivalents, while εἶδος (“form”) and ἰδέα (“idea”) are difficult to render without misrepresenting Plato’s metaphysics (Plato, 2004; Sir Ross, 1976). Analyzing how translators navigate these controversies provides insight into their interpretive strategies.
To quantify these strategies, we measure the consistency and prominence of the Chinese renderings for each term. To assess consistency, we count the Number of Variants Used for each concept, which informs a qualitative Translation Strategy label (consistent or variable). To measure prominence, we calculate the Term Frequency, which is the combined frequency of all Chinese variants for a term, normalized per 10,000 words. The formula is:
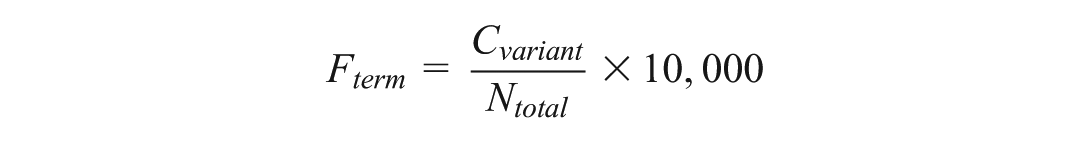
In this formula,
A text’s syntactic structure is a crucial dimension of authorial and translator style. Features like sentence length and grammatical complexity can reflect a translator’s approach—whether prioritizing readability with simpler sentences or replicating the source text’s elaborate structures. To investigate this, we measure syntactic complexity using two complementary metrics: Average Sentence Length (ASL) and Average Syntactic Tree Depth. These indicators, common in stylistics and computational linguistics, offer a quantitative view of the texts’ structural characteristics (Lu, 2010).
The first metric, ASL gives a surface-level overview of textual complexity. It is a robust indicator calculated by dividing the total number of words (

While useful, ASL cannot distinguish between long, simple sentences and shorter, complex ones. To capture this deeper complexity, we also calculate the Average Syntactic Tree Depth. This metric measures the hierarchical structure within a sentence, moving beyond simple length. Complex sentences are often built through embedding and subordination, creating nested structures (Yngve, 1960). Cognitively, greater syntactic depth increases processing load by requiring readers to hold more incomplete grammatical structures in working memory (Frazier, 1985).
This analysis was operationalized using the Stanza constituency parser, which models sentence grammar as a hierarchical tree of phrasal constituents. The tree’s depth, corresponding to the maximum level of grammatical nesting, is calculated recursively. The final metric, Average Syntactic Tree Depth (

The Republic’s philosophical weight rests on its intricate argumentative structure. The linguistic markers signaling relationships between propositions—logical or cohesive connectives—are crucial to its rhetorical force, guiding the reader’s reasoning (Halliday & Hasan, 2014). A translator’s use of these connectives is a significant stylistic choice. Explicitly rendering logical links can increase transparency, while a subtler approach may better preserve the original’s dialogic nature. To investigate these patterns, we analyzed the frequency of logical connectives, classified into 11 functional categories from PDTB 3.0: Reason, Result, Contrast, Condition, Purpose, Concession, Alternative, Synchrony, Subsequent, Until, and Free-choice. The high-frequency Addition category (e.g., “and”/“和”) was excluded to avoid distorting cross-linguistic comparisons.
To quantify usage patterns, we calculated the normalized frequency for each connective, ensuring fair comparison across texts. This involved counting the occurrences of each connective (

To probe the cognitive and psychological dimensions of the translations, this study uses a dictionary-based text analysis method grounded in the LIWC framework. This approach is built on the principle that the frequency of words in psychologically meaningful categories can provide an objective, quantifiable profile of a text’s character. The analysis measures the aggregate prevalence of different word types, revealing patterns in thinking style, emotional tone, and social focus (Tausczik & Pennebaker, 2010). This method is well-suited for stylistic analysis as it captures the subtle, aggregate effects of lexical choices.
This analysis was operationalized using a word-counting algorithm that matches text against the official English and Simplified Chinese LIWC2015 dictionaries. The process involves segmenting the text, converting tokens to lowercase, and matching them against LIWC categories, handling word stems to group related words. The raw count for each category (
This study focuses on seven LIWC dimensions relevant to philosophical dialog. Function Words are a powerful, topic-independent marker of style, as their usage is largely unconscious (Pennebaker, 2013). Cognitive Processes measures words related to thinking and reasoning, indicating how explicitly a translator signals the text’s logical nature. Prepositions capture structural and spatial-temporal relationships. Positive Emotion, Negative Emotion, and the combined Affective Processes measure emotional content. Social Processes tracks references to social interactions. These metrics allow us to test the assumption of purely rational discourse and determine if translators infuse the text with particular emotional or social valences.
For cross-language comparisons, we report both original and adjusted LIWC scores, excluding non-comparable categories. We identified 71 comparable categories through semantic equivalence assessment. Non-comparable categories, such as language-specific grammatical markers, are excluded from statistical tests to ensure that comparisons reflect genuine semantic differences, not structural ones.
Statistical comparisons between translations employ Welch’s t-tests for pairwise comparisons or Welch’s ANOVA for multi-group comparisons when variances are unequal, which is appropriate when the assumption of homogeneity of variance is violated. When variances are equal, standard t-tests or one-way ANOVA are used. Prior to statistical testing, assumption checks are performed: normality is assessed using Shapiro–Wilk tests, and homogeneity of variance is assessed using Levene’s test. When data violate normality assumptions, appropriate transformations (e.g., Box–Cox or logarithmic) are applied before testing, or non-parametric alternatives are considered. When testing multiple features within a family (e.g., multiple LIWC categories or multiple syntactic metrics), Holm–Bonferroni correction is applied to control the family-wise error rate. Effect sizes are reported using Cohen’s d for pairwise comparisons (with |d| ≥ 0.2, ≥0.5, and ≥0.8 indicating small, medium, and large effects, respectively) and η2 for ANOVA models (with η2 ≥ 0.01, ≥0.06, and ≥0.14 indicating small, medium, and large effects, respectively). All statistical tests use fixed random seeds (random.seed(42), numpy.random.seed(42), and random_state = 42 for Scikit-learn functions) to ensure reproducibility, and assumption checks are documented for each analysis.
Additional information regarding our methodology, datasets, and supplementary results is available in the Supplementary Material associated with this article.
Results
This chapter presents the empirical findings in the order of the analytical tiers: macro-stylistic positioning, micro-level features, and the cognitive-linguistic profile, directly following the methodology described.
Macro-Stylistic Positioning
To situate the four Chinese translations within modern Chinese writing, their stylistic profiles were compared against 15 LCMC genres using the shrinkage Mahalanobis distance metric from Section 3.3 (Eder et al., 2016; Ledoit & Wolf, 2004; Meng, 2013). Classification uses majority votes across 3,000-token blocks, with uncertainty quantified by robust z-scores and empirical p-values.
The distance matrix in Table 2 reveals divergent genre alignments. Guo Binhe’s translation (ZH Guo) shows the closest statistical match to Science Fiction (LCMC M), with a mean distance of 0.0482 (z = 1.53, p = .127), an alignment that cannot be rejected at conventional significance levels. In contrast, the other three translations (Gu Shouguan, He Xiangdi, and Xie Shanyuan) align most closely with Romantic Fiction (LCMC P). However, these alignments are not statistically significant (Gu: z = 5.86, p < .001; He: z = 7.02, p < .001; Xie: z = 4.74, p < .001). These results indicate that while these translations are nearest to Romantic Fiction, they remain stylistically distinct from all established LCMC genres.
Text-LCMC Genre Distance Matrix.

The principal component analysis (PCA) visualization in Figure 2 provides a complementary geometric perspective on these relationships, mapping the translations and reference genres into a two-dimensional space that captures the primary dimensions of stylistic variation.

PCA diagram of the Chinese translations.
The visualization shows the four Chinese translations clustering in a distinct region, confirming their unique stylistic space as philosophical translations. They are positioned closer to fictional genres than to informational or academic ones, aligning with the distance matrix. This positioning reflects the Republic’s dialogic and narrative nature, which blends argumentation with dialog, creating a grammatical profile closer to imaginative prose than expository writing.
Statistical comparisons confirm significant differences: Chinese translations are positioned closer to reference genres than English translations (t = −2.84, p = .006, d = −0.63), and significant variation exists among Chinese translations (F = 2.88, p = .044, η2 = 0.13).
These findings should be interpreted with caution. A translation’s “closest” genre does not mean it belongs to that genre. It only indicates that its grammatical structure most closely resembles that genre’s typical patterns. The proximity to Romantic and Science Fiction suggests that philosophical dialogs in Chinese translation share grammatical traits with imaginative narrative genres, likely due to their reliance on dialog and hypothetical scenarios. This distinguishes their style from the immediacy of press reportage or the formality of academic prose, confirming that the translators have captured the Republic’s unique nature as a speculative, argumentative dialog.
Terminology Strategy
This study analyzes translation strategies for nine core philosophical terms from the Republic: justice, just, form, idea, soul, good, city/state, virtue/excellence, and necessity/necessary (Plato, 2004; Sir Ross, 1976). These terms are challenging due to polysemy and the lack of direct equivalents between Greek and Chinese. To ensure reliable identification, disambiguation rules were applied to distinguish part-of-speech variants (e.g., “just” vs. “justice”).
The disambiguation protocol addressed several key ambiguities. For Chinese terms 正义/公正/正当 (just/justice), classification relied on syntactic context and POS tags. When followed by coordinating conjunctions (e.g., 和, 与), classification was based on POS tags. When followed by the particles 的 or 之, the classification depended on the head noun: if followed by abstract nouns (e.g., 定义, 意义, 概念) or location words (e.g., 上, 下, 中), the term was classified as a noun (this rule requires the presence of 的/之); if followed by entity nouns (e.g., 人, 事, 者), it was classified as an adjective regardless of whether 的/之 is present. When the following word was not in these filter lists, classification relied on the base word’s POS tag. The same rules applied to 善/好/好的/善的 (good): when followed by coordinating conjunctions, classification relied on POS tags; when followed by abstract nouns or location words after 的/之, they were classified as nouns (善/好); when followed by entity nouns (with or without 的/之), they were classified as adjectives (好的/善的); when not in filter lists, POS tags determined classification. Adverbial uses of 好 (tagged as adverbs, POS = d) were excluded unless in special token lists (e.g., 最好, 至好, 很好). The term 相 (idea) was distinguished from its adverbial uses (e.g., 相和谐, 相反) by excluding instances tagged as adverbs or adjectives. For English, “just” was identified as an adjective when preceded by determiners and followed by common nouns within two tokens, with adverb uses (RB) excluded; otherwise “justice” was counted as a noun. The term “good” required filtering to exclude plural nouns (goods) and economic usages (public goods), while retaining abstract noun usages (the good, the Good).
To validate this protocol’s reliability, a stratified 2% sample was double-annotated by two independent annotators. Inter-annotator agreement (Cohen’s κ) reached 0.8904 for Chinese and 0.8017 for English, both exceeding the 0.70 threshold for substantial agreement. Disagreements were resolved through third-round adjudication. This rigorous process ensures the reproducibility and consistency of term identification.
The analysis reveals that translators are active interpreters making significant and divergent lexical choices. The data shows a universal tendency toward variability, with no core concept translated with perfect one-to-one consistency. Table 3 provides a comprehensive overview of the translation variants for each core term across the four Chinese translations.
Statistics of Translation Variants of Core Terms.

The cross-translation summary reveals distinct patterns of variability. The concepts of good and necessity/necessary show the highest average number of variants (4.0 each), indicating translators use multiple terms for different nuances. Justice and its adjectival form just show moderate variability (averaging 2.25 and 3.0 variants), reflecting the complexity of the Greek term δικαιοσύνη. Conversely, virtue/excellence shows the lowest variability (averaging 1.75 variants), suggesting greater consensus, though still without perfect consistency.
The most striking divergence is in the translation of justice (δικαιοσύνη). Gu Shouguan and He Xiangdi consistently use 正义 (zhèngyì, “righteousness/justice”); Guo Binhe primarily uses 正义 but also 公正 (gōngzhèng, “fairness”) and 公道 (gōngdào, “impartiality”); Xie Shanyuan reverses this, using 公道 as the primary term. This divergence reflects different philosophical interpretations: 正义 emphasizes moral righteousness, 公正 foregrounds fairness, and 公道 carries connotations of public reason. For example, Gu’s “正义的人” (the just person) becomes Xie’s “公道的人” (the fair person), shifting the emphasis from moral righteousness to equitable balance.
Beyond consistency, the frequency with which these core terms appear reveals distinct differences in emphasis among the translators, as shown in the heatmap in Figure 3. Across all four Chinese versions, terms related to good and city/state are unsurprisingly the most prominent, confirming their centrality to the dialog.

Frequency of core terms in each translation.
However, there are significant differences in their usage frequencies. He Xiangdi’s translation, for instance, uses city/state (城邦) with the highest frequency (48.515 per 10,000 words), while Guo Binhe’s version shows a more balanced distribution between 国家 (guójiā, “nation/state,” 27.645) and 城邦 (chéngbāng, “city-state,” 20.000), reflecting different interpretive approaches to Plato’s political terminology. Similarly, the concept of good shows substantial variation: Guo Binhe’s translation uses 好的 (hǎo de, “good”) most frequently (19.645 per 10,000 words), while Gu Shouguan employs a more varied distribution across 好的, 好, 善的, and 善, suggesting a more nuanced approach to rendering the Greek agathon. These frequency differences demonstrate that translators not only vary their terminology for core concepts but also differ in the overall lexical emphasis they place on particular philosophical ideas, choices which inevitably shape the thematic texture and interpretive focus of the final translated work. Because each corpus provides a single aggregate observation per term, the terminology statistics are reported descriptively; assumption checks confirm that standard inferential models would be underpowered in this setting.
Syntactic Complexity
Syntactic complexity analysis reveals systematic differences in structural choices among the Chinese translations, reflecting distinct stylistic philosophies. The resulting metrics focus on comparative patterns rather than methodological detail, following the pipeline from Section 3.3. Table 4 presents five complementary metrics of syntactic complexity. These metrics capture different dimensions of structural complexity.
Syntactic Complexity Metrics of Each Translation.

Note. ASL = Average Sentence Length (tokens per sentence); Tree Depth = mean syntactic tree depth across sentences; MLC = Mean Length of Clause (tokens per clause); C/S = Clauses per Sentence; MATTR = Moving-Average Type-Token Ratio (window size 500).
A striking finding is the dramatic divergence in sentence length. Gu Shouguan’s translation (ZH Gu) has the highest ASL (27.419), exceeding both English benchmarks and favoring elaborate structures. In contrast, Guo Binhe’s (ZH Guo) has the lowest ASL (17.985), indicating a preference for concise prose. The other two translations, He Xiangdi (20.567) and Xie Shanyuan (22.179), occupy intermediate positions.
Average Syntactic Tree Depth, a more nuanced measure of grammatical complexity, corroborates the ASL findings. Gu Shouguan’s translation has the deepest syntactic structures (12.069), confirming its sentences are structurally complex. Guo Binhe’s has the shallowest tree depth among Chinese translations (10.369), aligning with its concise style. He Xiangdi (10.941) and Xie Shanyuan (11.195) show moderate depth. The English translations fall within a similar range (10.346–10.976), suggesting Chinese translations generally have greater syntactic complexity.
Clause-level metrics reveal additional patterns. The C/S ratio is highest in Gu Shouguan’s translation (5.301), indicating extensive subordination, while Guo Binhe’s is the lowest among Chinese versions (3.192), though still exceeding both English benchmarks. This suggests Chinese translations use more complex clause structures. Conversely, the MLC is higher in English translations than in Chinese ones. This suggests that while Chinese translations have more clauses per sentence, the individual clauses are shorter, reflecting different strategies for information density.
The MATTR metric, measuring lexical diversity, is highest in Guo Binhe’s translation (0.45), indicating greater lexical variety. Gu Shouguan’s version shows lower diversity (0.407). Both values exceed the English benchmarks (0.383 and 0.402), suggesting Chinese translations use a wider lexical range, perhaps reflecting the challenges of rendering Greek philosophical concepts.
Together, these metrics show a clear stylistic divergence. Gu Shouguan’s translation prioritizes structural complexity, creating a dense, formal style. Guo Binhe’s version favors accessibility with shorter sentences, simpler structures, and greater lexical variety. The other two translations occupy intermediate positions. Statistical tests confirm significant differences: Chinese translations show greater syntactic complexity than English (tree depth, C/S, MATTR) but shorter clause length (MLC), with substantial variation among Chinese translations across all metrics and among English translations in most.
Logical Connective Usage Patterns
Following the protocol from Section 3.3, the analysis groups tokens into 11 PDTB 3.0 functional categories, excluding Addition markers. Frequencies are reported per 10,000 tokens for comparability. Coverage of variants combines corpus-driven harvesting with lemma-anchored supplementation, while POS filters guard against non-connective homographs.
Semantically polyvalent markers were routed to their roles via the rule set from Section 3.3. For example, temporal versus causal readings of “since” were distinguished by temporal cues, and contrastive versus concessive uses of “but/however” depended on counter-expectation. Chinese causal-resultive pairs and temporal connectors were also separated based on contextual triggers. The results of this analysis are presented in Table 5.
Frequency of Logical Connectives Classified by Function (per 10k).

Note. Frequencies are reported per 10,000 tokens (simple proportional normalization); functional labels follow the 11 PDTB 3.0 categories retained for this study; coordination/addition markers are excluded from the inventory.
English translations have higher overall connective densities (323.30 and 340.95 per 10k), driven by a strong reliance on Reason and Alternative markers. Chinese translations redistribute this toward Contrast and Result. Gu Shouguan’s version foregrounds adversative framing (115.316 per 10k), while Guo Binhe and He Xiangdi compensate for sparser Reason markers by amplifying Result and Concession signals to guide readers.
The percentage profiles in Figure 4 clarify these strategic emphases. Gu Shouguan’s translation devotes almost two-fifths of its logical connectives to Contrast, reinforcing the agonistic dialog.

Percentage stacked area chart of logical connectives.
By contrast, Xie Shanyuan elevates Reason and Concession, a pattern consistent with his preference for explicit signaling. Guo Binhe’s translation is the most balanced, pairing low Contrast usage with the highest Result frequency, yielding a more linear argumentative rhythm.
Temporal coordination also differs. English versions use Synchrony markers (e.g., “when/whenever”) at nearly three times the rate of Gu Shouguan. In contrast, Chinese translators—especially Xie Shanyuan—use more Subsequent markers to choreograph narrative progression. These choices show how translators recalibrate the connective system to maintain cohesion and align with target-language expectations. English foregrounds logical scaffolding, while Chinese versions rely more on contrastive and resultative cues.
The observed density gap echoes documented typological differences and the tendency toward implicitation in Chinese renderings of hypotactic source texts (Baker, 2001; Huang, 2022; T. McEnery & Xiao, 2010). By modulating connective use, translators tailor argumentative flow to target-language conventions while preserving philosophical nuance.
Statistical tests confirm significant cross-linguistic differences with large effect sizes. English translations use more Reason, Alternative, and Synchrony markers, while Chinese versions favor Result, Contrast, Concession, and Subsequent markers. Substantial variation also exists among the Chinese translations (e.g., Contrast: η2 = 0.42; Concession: η2 = 0.39) and among the English translations (e.g., Result: d = 0.70).
Cognitive and Linguistic Profile
The cognitive-profile analysis follows the LIWC-based workflow from Section 3.3, using official English and Simplified Chinese LIWC2015 dictionaries. Category labels were harmonized to retain only semantically comparable dimensions, excluding language-specific categories. To avoid earlier anomalies, all reported values use adjusted scores with smoothing for sparse counts. Scores are reported as percentages of total tokens, following LIWC convention, which enables direct comparison while acknowledging the risk of culturally specific nuances. Table 6 compares the key cognitive style dimensions.
Comparison of Cognitive Style Dimensions Across Translations (% of tokens).

Note. Percentages reflect LIWC category coverage relative to total tokens; only categories deemed fully comparable across languages are reported.
Several cross-linguistic contrasts emerge. Function-word usage is broadly similar (45%–48%), indicating comparable reliance on grammatical scaffolding. However, Chinese versions show markedly higher Cognitive Processes coverage (13.7%–16.4% vs. 11.2%–12.7%), suggesting a stronger tendency to foreground reasoning and epistemic vocabulary, especially in He Xiangdi’s translation (16.434%). Conversely, English translations use substantially more prepositions (≈11.5% vs. 4%–4.6%), a predictable reflection of English hypotaxis.
Emotional tone also diverges. Chinese translations use more negative emotion words (2.15%–2.88% vs. 1.37%–1.49%) and fewer positive emotion words (≈2.2%–2.9% vs. ≈3.3%–3.4%) than the English versions. The consolidated affect category is therefore higher in Chinese (5.10%–6.76%) than in English (4.71–4.98%), implying a broader emotional palette. Social-process terms show a split: Bloom’s translation has the highest share among English versions (10.873%), but the Chinese translations by He and Xie peak higher (11.593% and 11.261%), reflecting their emphasis on interpersonal and civic vocabulary.
These tendencies underscore that cognitive and affective framing is not uniform. English versions focus more on structural cohesion (prepositions) and have a brighter affective tone. Chinese translations amplify cognitive and affective cues, potentially compensating for structural differences by signaling reasoning and emotional stakes more overtly. This aligns with the observation that Chinese renditions favor explicitation of argumentative roles, while English versions retain more of the implicit balance of the Greek. Statistical tests confirm significant cross-linguistic differences with large effect sizes in Cognitive Processes, Affect, Prepositions, Function words, and Positive emotion. Substantial variation also exists within both Chinese and English translations across several categories. Despite the inherent limits of dictionary-based proxies, the LIWC framework provides a consistent baseline for tracing how translators reshape the cognitive-emotional profile of the Republic.
Discussion
The quantitative profiles are entry points into a richer intellectual history: four translators re-situating Plato’s Republic within distinct Chinese contexts. The stylistic differences are not random but are legible fingerprints of specific translational projects. Following Weng’s notion of “re-locating” Plato (Weng, 2015a), each project pairs empirical habits with motivations from postscripts. Aligning these allows the discussion to move from description to interpretation, particularly along the axis of foreignization versus domestication (Schleiermacher, 2021). Ricoeur’s idea of translation as “equivalence without adequacy” (Ricoeur, 2006, p. 10) captures this balancing act between fidelity and reader expectations, which the styles in Chapter 4 materialize.
The translation by Gu Shouguan (2010) stands as a compelling embodiment of a foreignizing strategy, one that rigorously bends the target language to the contours of the source text (Venuti, 2018). As Venuti argues, foreignizing translation “Signifies the differences of the foreign text, yet only by disrupting the cultural codes that prevail in the translating language” (Venuti, 2018, p. 15). This strategy seeks to restrain the ethnocentric violence of translation and can serve as a form of resistance against cultural narcissism and imperialism (Venuti, 2018, p. 16). The quantitative data provides the initial outline of this strategy: with an Average Sentence Length of 27.419 tokens and an Average Syntactic Tree Depth of 12.069, Gu’s text is statistically the most complex among all translations analyzed. His translation also exhibits the highest Clauses per Sentence ratio (5.301), indicating extensive subordination and embedding that mirrors the layered structure of the original Greek. This abstract complexity becomes tangible in passages like his rendering of the tripartite soul at [441a]. Where others might simplify, Gu constructs a formidable periodic sentence that meticulously mirrors the layered, subordinate structure of the original Greek: “就像是在城邦里那样, 是有三个属类合起来构成为一个城邦的: 生聚财货的、协助守卫的、谋虑决断的…” (“Just as it is in the city-state, there are three classes that combine to form a city-state: that which accumulates wealth, that which assists in defense, that which deliberates and decides…”) (Plato, 2010, p. 198). This is not simply a long sentence; it is a deliberate architectural choice. Gu himself confirms this intent in the postscript to his work, where he notes that his editorial approach was to “Stay as close as possible to the original’s word order and tone, sometimes even at the expense of fluent Chinese expression.” 4 This explicit statement of purpose provides a direct link between his philosophical motivation and his stylistic execution.
Gu’s foreignizing impulse is not merely linguistic but may be understood within intellectual contexts like the rise of Straussian interpretation in Chinese academia, which provides a historical context for his method (Weng, 2015b). By preserving the original’s difficulty, the translator resists domestication, compelling the reader to journey “over to the author,” as Schleiermacher phrased it (Schleiermacher, 2021). This philosophy extends from syntax to lexicon. In his translation of Plato’s metaphysics at [477a], Gu’s choice of “一个完全地‘是’的东西是完全地可认识的” (“A thing that completely ‘is’ is completely knowable”) exemplifies lexical foreignization (Plato, 2010, p. 258). The slightly awkward, technical adverbial (“完全地”) and the bracketing of “is” (是) forces the reader to treat “being” not as a common verb, but as a specialized, alien philosophical concept. Gu’s approach can be understood through Gadamer’s “fusion of horizons,” where the translator’s horizon encounters the source text’s, creating a new one that preserves the text’s foreignness (Foran, 2018). His stylistic choices reflect this deliberate preservation of distance (Gadamer, 2011, p. 388), rendering Plato as a formidable figure accessible only through intense scholarly labor.
At the opposite end, the translations by Guo Binhe and Zhang Zhuming (1986) and He Xiangdi (2021) exemplify a domesticating strategy, prioritizing clarity for a contemporary Chinese audience. As Venuti observes, this can create an “illusion of transparency” by rewriting the text in discourse aligned with local cultural values (Venuti, 2018, p. 16). Guo Binhe’s version, with the shortest sentences (ASL: 17.985) and simplest syntax (tree depth: 10.369), is a clear example. Its domesticating function is immediately apparent when placed alongside Gu Shouguan’s rendering of the same passage at [477a]. Where Gu uses the technical and literal “是” (is), Guo opts for the far more common and concrete “有” (you, to have/to exist): “完全有的东西是完全可知的” (“A thing that completely exists is completely knowable”) (Plato, 1986, p. 220). This seemingly small substitution is a profound act of cultural translation, replacing an abstract metaphysical concept with a more intuitive notion of existence, thereby lowering the cognitive barrier for a non-specialist reader. This choice aligns with its context: published by the Commercial Press in 1986 during the “Reform and Opening Up” era, its purpose was likely pedagogical. 5 Guo’s high lexical diversityGuo’s high lexical diversity (MATTR: 0.45) also suggests a strategy of using varied vocabulary to enhance accessibility.
He Xiangdi’s 2021 translation represents a modern evolution of this domesticating impulse. His postscript is a remarkably transparent account of a translator’s process, explicitly stating his wish to re-translate the Republic for a “new era,” as previous versions had “room for improvement” in their accuracy and readability. He details a meticulous four-step methodology, moving from a literal “word-for-word” draft to a polished final version, a process designed to balance scholarly fidelity with modern Chinese fluency. His decision to reformat the text into a clear, turn-by-turn dialog is another powerful domesticating move that prioritizes the reader’s experience (Plato, 2021, pp. 474–476). He’s translation shows moderate syntactic complexity (ASL: 20.567, tree depth: 10.941), positioning it between Guo’s accessible style and Gu’s complex structures, while his cognitive processes score (16.434%) is the highest among all translations, reflecting his emphasis on explicit reasoning markers. This shared domesticating tendency among Guo and He can be understood through Ricoeur’s concept of translation as a “Work of mourning,” where the translator must give up the ideal of perfect translation and accept the task of creating “Equivalence without adequacy” (Ricoeur, 2006, pp. 8, 10). For Ricoeur, this work involves both mourning the loss of perfect equivalence and remembering that the mother tongue is not sacred but one language among many, allowing the translator to welcome the foreign text while making it accessible to the target audience (Ricoeur, 2006, p. 4). The domesticating strategies of Guo and He reflect this balance between faithfulness and accessibility. Their horizons of understanding, shaped by pedagogical goals and historical contexts, fuse with the source text to bring the reader closer to the author rather than maintaining distance.
The analysis of logical connectives reveals a more nuanced pattern that challenges simple assumptions about explicitation in translation. When Addition markers such as “and/和” are excluded, the overall density of logical connectives in Chinese translations (283.70 per 10,000 tokens) is actually lower than in English translations (332.12 per 10,000 tokens), representing approximately 85% of the English density. This finding suggests a pattern of implicitation rather than explicitation, where Chinese translators reduce the explicit marking of logical relationships compared to the English source texts. As Vinay and Darbelnet define it, explicitation is “A stylistic translation technique which consists of making explicit in the target language what remains implicit in the source language because it is apparent from either the context or the situation” (Vinay & Darbelnet, 1995, p. 342). However, the observed pattern in these translations demonstrates the opposite phenomenon: implicitation, where information that is explicit in the source language becomes implicit in the target language. This pattern aligns with fundamental typological differences between the two languages: English is a hypotactic language that favors explicit connectives, while Chinese is a paratactic language that often implies logical relationships through context, word order, and semantic coherence. In the process of English-to-Chinese translation, translators may adopt implicitation strategies, reducing the use of explicit connectives to align with Chinese expression habits and cultural background (Huang, 2022). While explicitation has often been regarded as a distinctive feature of translation, with target texts tending to be longer than source texts (Olohan & Baker, 2000), the observed implicitation pattern in these philosophical translations thus reflects not merely translator choice but the fundamental structural differences between the two language systems. However, this overall pattern of implicitation is nuanced by functional distribution: while Chinese translations use fewer connectives overall, they show particular emphasis on certain functional categories. Most notably, Chinese translations exhibit significantly higher relative frequencies in the Subsequent category (ranging from 0.881 to 5.262 per 10k) compared to English translations (0.392–0.818 per 10k), with the highest Chinese frequency (Xie Shanyuan: 5.262) being approximately 5.07 times higher than the average English frequency. This suggests that while Chinese translators may reduce overall connective density, they strategically increase the use of temporal sequence markers (如 “于是/以致”) to choreograph narrative progression and hypothetical scenarios, reflecting different discourse expectations in Chinese philosophical writing. This pattern can be understood through Blum-Kulka’s theory of shifts in cohesion and coherence, where translation necessarily entails changes in textual relationships, and the choice of which cohesive markers to retain, reduce, or amplify reflects both language-specific norms and translator strategies (Blum-Kulka, 1986). The finding of overall implicitation with selective emphasis on specific functional categories demonstrates that translation strategies are not monolithic but involve complex negotiations between source-text features, target-language conventions, and translator priorities.
Ultimately, the deepest interpretive divergences are in the translation of core philosophical concepts. The treatment of δικαιοσύνη is the most telling case. The term is fractured into distinct concepts in Chinese. Gu Shouguan and He Xiangdi consistently use “正义” (zhèngyì, righteousness), emphasizing moral correctness. Guo Binhe also primarily uses “正义” but occasionally employs “公正” (gōngzhèng, fairness) and “公道” (gōngdào, impartiality). Xie Shanyuan, in contrast, reverses this pattern, using “公道” as the primary term (243 occurrences) and “正义” only rarely (8 occurrences), shifting the emphasis from moral righteousness to public reason and equitable treatment, foregrounding the socio-political dimension of the concept. This choice is evident in passages like Socrates’ concluding words in Book I [354b]: “而如果我不知道‘公道是什么’ ,我就更不知道公道是不是美德,以及拥有公道的人究竟是不是幸福的了” (“And if I don’t know what justice is, I will hardly know whether it is a virtue or not, and whether the one who has it is happy or not”) (Plato, 2016, p. 59). These are not just different words; they are different philosophical starting points that create four different Republics (Yee, 2010). Each choice reflects a cultural negotiation—mapping Greek concepts onto the Chinese philosophical landscape. As Ricoeur argues, translation creates “equivalence without adequacy,” balancing faithfulness and betrayal (Ricoeur, 2006, p. 10). The divergent choices for δικαιοσύνη exemplify this negotiation. The “critical void” is, in fact, a vibrant space where translators continually reinvent a classic text. Through their divergent choices, informed by their personal histories and eras, these translators have gifted the Chinese-speaking world with four unique philosophical arguments.
Conclusion
This study demonstrated that computational stylistics can reveal how four Chinese translators of Plato’s Republic created distinct interpretive projects. Our multi-layered framework uncovered systematic differences beyond surface-level variation: Gu Shouguan’s translation shows the highest syntactic complexity, reflecting a foreignizing strategy, while Guo Binhe’s is the most accessible, embodying a domesticating approach. The analysis of core philosophical terms reveals that translators are active interpreters; for instance, the Greek term δικαιοσύνη is fractured into four distinct Chinese concepts, each reflecting a different philosophical emphasis. The examination of logical connectives shows that Chinese translations have lower connective densities than English benchmarks, suggesting implicitation, yet with strategic emphasis on categories like Subsequent markers. Cognitive-linguistic profiling confirms these differences, with Chinese translations showing higher cognitive process coverage, indicating a tendency to foreground reasoning vocabulary.
While these findings provide robust evidence, several methodological challenges warrant reflection. Although the NLP tools were validated with high accuracy, their performance on philosophical texts may still introduce subtle biases. The corpus provides valuable diachronic coverage, but its limited size constrains generalizability. Finally, the cross-language LIWC comparison, despite careful mapping, remains subject to the challenge that even aligned categories may encode culturally specific nuances.
Despite these limitations, this framework establishes a reproducible methodology for comparative translation analysis. Future work should expand the corpus to include more translations, apply the framework to other philosophical genres, develop domain-specific NLP tools to reduce bias, and extend the analysis to other languages to explore cross-cultural patterns. Through such extensions, computational stylistics can continue to illuminate how translators, as cultural mediators, shape the reception of canonical philosophical texts.
Supplemental Material
sj-rar-1-sgo-10.1177_21582440261416755 – Supplemental material for Stylistic Fingerprints: A Multi-Layered Computational Analysis of Chinese Translations of Plato’s Republic
Supplemental material, sj-rar-1-sgo-10.1177_21582440261416755 for Stylistic Fingerprints: A Multi-Layered Computational Analysis of Chinese Translations of Plato’s Republic by Lexin Huang and Liangkun Chen in SAGE Open
Footnotes
Ethical Considerations
The data that were used in the study are open-access texts of journal articles. The author has no ethical issues to report.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported by the MOE (Ministry of Education in China) Liberal Arts and Social Sciences Foundation (22YJC710045).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.