
Abstract
Scoring constructed responses in large-scale language tests is crucial, as it affects the reliability, validity, and fairness of test results. While previous research has examined rater-related factors in explaining scoring variations, most studies focused on raters’ background variables, with limited attention to their cognitive decision-making. Although a few studies have examined raters’ decision-making styles in writing assessments, revealing the importance of raters’ cognitive differences in scoring, little is known about how such styles operate in translation assessments. This study employs a two-phase design to investigate the decision-making characteristics of translation raters. First, to assess the applicability of the General Decision-Making Style Inventory (GDMSI) in the College English Test (CET) translation rating context, responses from 469 CET raters were analyzed using exploratory factor analysis, confirmatory factor analysis, and reliability analysis. Second, a convergent parallel mixed-methods approach was used to construct decision-making profiles for ten experienced raters by integrating their GDMSI responses with qualitative think-aloud data. The results showed that, with minor adjustments, the GDMSI is a valid tool for assessing decision-making styles among CET translation raters, and the ten experienced raters exhibited three primary styles: rational, intuitive, and a hybrid of both rational and intuitive. These findings have practical implications for improving rater training and quality control in translation assessment contexts.
Plain language summary
Past studies on how raters vary in large language tests have mostly looked at their backgrounds. They haven't paid much attention to how raters think when making decisions. Most of these studies have only looked at writing, not translation. To learn more, we checked if the General Decision-Making Style Inventory (GDMSI) works well with 469 experienced raters from the CET translation test. Then, we had ten raters talk out loud while they rated. We looked at what they said and filled out a questionnaire to see their decision-making styles. We found three main ways they made decisions: by thinking it through, by feeling, and by using both. This helps us train raters better and make sure translations are rated well.
Keywords
Introduction
Constructed-response tasks are increasingly used in large-scale standardized language tests to assess test-takers’ language abilities (Knoch et al., 2021). Unlike selected-response items, such as multiple-choice questions, the assessment of constructed responses, which often relies on one or more human raters, has long been recognized as a significant challenge for large-scale language tests worldwide (Huang & Whipple, 2023), as seen in the TOEFL (Test of English as a Foreign Language) and the IELTS (International English Language Testing System). This is because when raters are involved in assigning scores, scoring variability across raters introduces measurement error, which affects the reliability or precision of test-takers’ proficiency estimates and, in turn, impacts test validity and fairness (American Educational Research Association, American Psychological Association, and National Council on Measurement in Education, 2014). Given the myriad possible interpretations that raters can have of test-takers’ responses, the assessment variability and reliability of constructed responses constitute a major concern across international language communities (Huang & Whipple, 2023).
To address these concerns, empirical studies have examined various rater-related factors contributing to scoring variability, including severity differences (e.g., Palermo et al., 2019; E. Wolfe et al., 2015), linguistic backgrounds (e.g., Marefat & Heydari, 2016), rating experience (e.g., Attali, 2016; Neittaanmäki & Lamprianou, 2024), and rating strategies (e.g., J. Zhang, 2016). These studies consistently suggest that raters’ characteristics are the primary source of scoring variation (McNamara, 1996). However, most existing research focused on raters’ background variables, with limited attention to their inherent behavioral tendencies and cognitive decision-making styles. To date, only two studies, respectively conducted by Baker (2012) and Xu (2016), have explored raters’ general decision-making styles in writing assessment. Both emphasized the importance of cognitive differences in explaining scoring variation, yet neither study directly linked decision-making styles to raters’ actual scoring outcomes. Moreover, little is known about how such styles may vary in other constructed-response domains, such as translation, especially in the context of large-scale standardized local assessments.
Translation tasks, a type of constructed-response task, require test-takers to reproduce the content of a source text in the target language. These tasks, although less prevalent in international language tests, are frequently employed in locally developed, large-scale language tests. For instance, the College English Test (CET) in China includes a Chinese-to-English translation task to assess test-takers’ abilities to use appropriate language and strategies to convert textual information into English (C. Yang et al., 2022). Similarly, the Test for English Majors (TEM) in China also employs translation tasks to measure language proficiency (Jin & Fan, 2011). Despite their growing use, evaluating the quality of translation tasks is complex. Although several prominent theoretical models for assessing translation quality have been introduced, such as those discussed in House (2014), they are not readily adaptable to real-world applications to evaluate translated texts on a large scale, which often rely on personal human assessments (Han, 2020). Furthermore, there is a scarcity of empirical investigations concerning the reliability, validity, and practicality of translation assessments (Campbell & Hale, 2003). Thus, the cognitive differences among raters in their assessment of translation quality could seriously threaten the validity of these tasks, with the extent of this impact being unclear. Therefore, this study aims to illuminate translation raters’ cognitive decision-making styles to account for the complex rater variability in scoring within large-scale language assessments.
Literature Review
Translation Quality Assessment (TQA)
Translation quality assessment has long been a central concern in translation studies, evolving in step with broader methodological and theoretical advancements. Han’s (2020) critical review highlights seven primary TQA methods—intuitive assessment, error analysis, corpus-based evaluation, rubric scoring, mixed-methods scoring, item-based assessment, and comparative judgment—each addressing reliability, validity, or practicality gaps in prior approaches. Error analysis, for instance, emerged to counter the subjectivity of intuitive assessment but faced criticism for its reductionist focus on micro-textual errors (Colina, 2008). Rubric scoring, conversely, emphasizes holistic textual and functional dimensions, though its descriptors often lack empirical validation (Martínez Mateo et al., 2017). Recent innovations like corpus-based evaluation leverage empirical data to refine error typologies (Jiménez-Crespo, 2011), while comparative judgment (Han et al., 2019) circumvents explicit criteria by relying on raters’ relative judgments. Despite these developments, TQA remains fraught with challenges, including inconsistent rater agreement, arbitrary acceptability thresholds, and limited exploration of consequential validity (Han, 2020).
Despite the development of structured rubrics and psychometrically grounded scoring models, these methods frequently overlook the cognitive and behavioral realities of rater decision-making. Han and Shang (2023) propose an item-based, Rasch-calibrated approach that enhances psychometric rigor, yet such models do not directly engage with the psychological mechanisms that underlie rater variability. Earlier work by Han (2015) in interpreter testing similarly reveals that well-trained raters may still exhibit severity differences and bias, challenging the assumption that methodological refinement alone ensures consistent scoring. These findings highlight the need to move beyond surface-level scoring mechanisms and toward a deeper understanding of the decision-making styles that raters bring to translation assessment. House (2014) also asserts that translation quality assessment must go beyond surface-level scoring to engage with deeper textual and contextual understanding. Her insistence that evaluative judgment is futile without prior analytical and interpretive engagement supports the present study’s argument that rater cognition, including decision-making styles, is integral to understanding how judgments are actually formed in practice. These issues underscore the need for cross-disciplinary collaboration with psychometrics and language testing to strengthen methodological rigor, particularly in high-stakes contexts like the CET translation task, where rater variability threatens score interpretation (Campbell & Hale, 2003). By integrating insights from TQA research, this study bridges a critical gap by examining how raters’ decision-making styles influence translation assessment, thereby advancing both theoretical and practical understanding of rater-mediated evaluation.
Decision-Making Style
Scoring is a critical part of language testing and has been widely regarded as a form of decision-making behavior (e.g., Baker, 2012; Lyu, 2024; Şahan & Razı, 2020; Xu, 2016). To assign scores, raters must process various inputs (e.g., writing or speaking samples), apply scoring criteria, retrieve relevant knowledge, and draw on prior experience to make evaluative judgments. As such, scoring involves cognitive operations that evaluate options and make choices, requiring the integration of perceptual data and stored information. This process is closely linked to cognitive style, which refers to an individual’s preferred way of perceiving, organizing, and processing information (Witkin et al., 1977). Research suggests that cognitive style influences decision-making style, as individuals with an analytical cognitive style (e.g., field-independent) may lean toward rational decision-making, whereas those with a holistic cognitive style (e.g., field-dependent) may exhibit more intuitive or dependent decision-making tendencies (Kozhevnikov, 2007).
Decision-making styles are defined as the learned, habitual response patterns that individuals use in decision-making situations (Scott & Bruce, 1995). They are related to various aspects of decision behavior, including outcomes, processes, and strategies (Zhou et al., 2014). Integrating all decision-making styles in earlier works, Scott and Bruce (1995) developed a General Decision-Making Style Inventory (GDMSI). This inventory identifies distinct decision-making styles: rational (preferring to make decisions systematically and logically after gathering information), intuitive (preferring to make decisions based on subjective feelings or intuition), dependent (preferring to rely on the help or guidance of others to make decisions), avoidant (preferring to delay decisions to avoid making them), and spontaneous (preferring to make decisions as quickly as possible).
Although the GDMSI provides “a conceptually consistent and psychometrically sound measure of decision-making style” (Scott & Bruce, 1995, p. 818), its underlying construct lacks an established theoretical basis (Zhou et al., 2014). Empirical evidence has shown that the dimensions of the GDMSI were interrelated across multiple samples. For example, intuitive and spontaneous styles are positively correlated, while the rational style is negatively correlated with the intuitive, avoidant, and spontaneous styles (Scott & Bruce, 1995). Drawing on both dual-process theory and appraisal tendency theory, Dewberry et al. (2013) proposed a two-component model to explain individual differences in decision-making styles. This model distinguishes between two types of styles: those addressing how information is processed (core processes, including the rational, intuitive, and spontaneous styles) and others with the regulation of decision-making (regulatory process, such as when and if choices are made, including the avoidant and dependent styles). This distinction aligns with cognitive style theories, where information processing styles (e.g., analytical vs. intuitive) shape how individuals approach decisions, while regulatory aspects (e.g., avoidance or dependence) reflect contextual or affective influences (Kahneman, 2011). The two-component model proposed by Dewberry et al. (2013) can help clarify variability in decision styles but requires further validation across different samples (Geisler & Allwood, 2018).
Another explanation for the intercorrelations among GDMSI dimensions is that individuals often employ a combination of styles, rather than adhering to a single, consistent approach when making important decisions (Scott & Bruce, 1995). Therefore, when depicting an individual’s decision-making style, it is advisable not to focus on a single style, but on a profile of styles (Geisler & Allwood, 2018).
Importantly, Strough et al. (2015) proposed that decision-making is a contextually embedded process. It is not only influenced by the immediate context (e.g., the decision domain and presence of others) but also by the sociocultural context (e.g., the state of the economy and cultural attitudes). Thus, the context for decision-making also affects behavioral patterns, underscoring the need for further research to verify its construct across different cultural settings. Although decision-making style refers to specific context, research has yet to validate the application of the GDMSI in real-world decision-making scenarios, except for a few on wellbeing and health choices (e.g., Fischer et al., 2015). More research is needed to investigate the relationship between the GDMSI-identified styles and behaviors observed in actual decision-making contexts (Thunholm, 2004), such as those in language assessment scoring practices (e.g., Baker, 2012; Xu, 2016).
Previous Research on Raters’ Decision-Making Styles
Within the domain of language testing, empirical research on raters’ decision-making styles has predominantly concentrated on assessing written compositions. For instance, E. W. Wolfe et al. (1998) explored the cognitive variations among essay raters of varying qualities, discovering that superior raters tend to focus more on the essays’ global attributes and exhibit a more precise understanding of the scoring rubrics. Baker (2012) developed decision-making style profiles for six Canadian pre-service teacher raters by analyzing four types of data: raters’ general decision-making styles as determined by the GDMSI, the incidence of raters’ deferring scores, the underutilization of failing score levels, and raters’ comments on their decision-making processes captured through write-aloud protocols. Her findings indicated that two raters exhibited a singular dominant decision-making style (avoidant and rational, respectively), whereas the others demonstrated a combination of two or three primary styles. This research sheds light on the diversity of decision-making styles among raters and represents a pioneering effort in studying rater decision-making styles within language testing.
In the context of English as a Foreign Language (EFL), Xu (2016) examined the decision-making traits of raters assessing CET Band 4 (CET-4) essays. By utilizing think-aloud protocols during the scoring process, this study mitigated potential biases in raters’ cognitive processes that could arise from the write-aloud method (Baker, 2012), thereby enhancing research validity. It also compiled a comprehensive dataset, encompassing raters’ scores, confidence levels in scoring, GDMSI outcomes, and think-aloud durations, to construct decision-making style profiles for 13 essay raters. The study revealed that high-quality raters did not exhibit a singular dominant decision-making style. Although both Baker (2012) and Xu (2016) applied the GDMSI to actual scoring scenarios, neither study conducted a validation of its construct validity within the specific context. Whether this instrument can be used for the group of raters in large-scale tests still needs further empirical evidence, because decision-making is vulnerable to personal and contextual factors as Strough et al. (2015) suggested.
The Present Study
The translation task is critical for evaluating students’ practical translation proficiencies (Lv, 2016) and is extensively utilized in foreign language education and large-scale assessments in China. Nonetheless, compared to other language skills—listening, speaking, reading, and writing—the translation task has garnered limited attention in language testing. Empirical research in this area primarily focuses on its washback effects (e.g., Z. Yang et al., 2014), reliability (e.g., Lei & Gu, 2015), and assessment quality (e.g., Y. Li & Xiao, 2020). The decision-making styles and cognitive processes of translation raters remain primarily uncharted territories. Despite this, a solitary study by Xu and Ye (2020) has delved into the scoring cognitive strategies of translation raters. They found that five main strategies, including revising, diagnosing, self-evaluating, inferring, and comparing, could explain 58.25% of the variance in translation rating behaviors. Notably, two diagnosing sub-strategies—diagnosing language features that distinguish test-takers’ proficiency and diagnosing whether the translation is faithful to the source text—are unique to translation tasks and differ from those used in writing assessments. However, to the best of our knowledge, no research has explicitly examined translation raters’ cognitive decision-making styles when scoring. In light of this gap, the present study first employs quantitative methods to validate the applicability of the GDMSI to the scoring decisions of CET translation raters. This leads to Research Question 1 (RQ1): “What are the reliability and validity of the GDMSI within the CET translation rater population?” Based on the results of RQ1, a convergent parallel mixed-methods design (Creswell, 2010) is conducted to explore the cognitive patterns and decision-making characteristics of experienced translation raters by integrating their think-aloud data and validated GDMSI responses. Therefore, Research Question 2 (RQ2) is proposed: “What are the predominant decision-making styles of experienced CET translation raters?”
Method
This study was conducted in two phases. The first phase involved validating the application of the GDMSI within the context of translation scoring. The second focused on constructing the decision-making profiles of translation raters. To achieve this, we employed a convergent parallel mixed-methods approach (Creswell, 2010), integrating quantitative data from translation raters’ responses to the GDMSI with their qualitative data from a think-aloud session. Both data types were analyzed concurrently to develop comprehensive profiles of these raters’ decision-making styles.
Context of the Study
This study examines the scoring of translation tasks within the CET, a large-scale, high-stakes English language assessment in China (Jin, 2017). The CET, administered by the Ministry of Education, is designed to assess undergraduate students’ English proficiency against national College English curriculum standards (H. Li et al., 2012). Traditionally, it consisted of five sections: listening, reading, vocabulary and structure, cloze (error correction and/or question answering), and writing (H. Li et al., 2012). Since 2013, a task of paragraph translation from Chinese to English has been added (Jin, 2017). Specifically, it requires translating 140 to 160 Chinese characters for Band 4 and 180 to 200 for Band 6. It measures the accuracy of information transfer from Chinese to English at both the sentential and textual levels, the appropriate use of vocabulary and sentence structures, coherence in the translated text, and the application of fundamental translation strategies (National College English Testing Committee, 2016). The task is worth 15 points, with scoring criteria divided into five bands: 2-point (0–3 points), 5-point (4–6 points), 8-point (7–9 points), 11-point (10–12 points), and 14-point (13–15 points). Each band provides detailed descriptions for content expression, vocabulary appropriateness, coherence, and text accuracy.
Initially, the translation task was scored by human raters, typically university teachers, using an online scoring platform. Since 2018, several CET scoring centers have implemented a hybrid scoring system, integrating both human and automated scoring methods (Knoch et al., 2021). Raters are trained to use a holistic scoring approach to evaluate the content and language aspects of test-takers’ translation texts. During training, raters receive the CET translation rating scale (Appendix 1) and benchmark essays (referred to as range-finders) with pre-assigned scores by expert raters. The training aims to help raters internalize the rating scale by using range-finders and supervisors’ explanations. The goal is for raters to associate each score band with the mental image of the corresponding range-finder. In the online marking system, real-time statistics for each rater are provided to the supervisor, including the mean score, the standard deviation, the graphical score distribution, and the correlation coefficient between the essay scores awarded by the rater and the total scores of the objectively rated items for the same test-taker group (J. Zhang, 2009). If supervisors identify any outlier raters—those with unusually low/high means or standard deviations, or a particularly low correlation coefficient—they may decide on interventions. These interventions can range from clarifying rating rationales, reviewing the rating scale and benchmark essays, re-evaluating the last 10 test-takers’ translation texts, to retraining.
Participants
In the first phase, a total of 469 raters were recruited through snowball sampling from three marking centers in Guangzhou, Changchun, and Xi’an in October 2022 during the CET rating period. They were all certified CET raters who completed a series of training sessions and demonstrated satisfactory performance on rating exercises before participating in operational scoring, which is a standard procedure in most large-scale language assessments (Yan & Chuang, 2023). In addition, they were all teachers of the College English program (Chen & Cui, 2022) and native speakers of Chinese. Their English language teaching experience ranged from 1 to 36 years, with a mean of 10.21 years (SD = 5.64). They had participated in CET scoring between 1 and 20 times, averaging 5.44 times (SD = 4.23). Regarding their academic ranks, 10.02% were teaching assistants, 82.52% were lecturers, and 7.46% were professors or associate professors.
To mitigate the risks associated with participation, the study was designed with strict ethical standards to ensure confidentiality and voluntary participation. Activities were structured to minimize any psychological stress, providing participants with adequate breaks and support while completing the questionnaire. The potential benefits of this research include significant improvements in rating consistency and fairness, enriching the CET translation rating. Written consent was obtained from all participants.
For the second phase, ten raters from the first phase were selected. Initially, a follow-up questionnaire was sent to the 469 raters who had completed the GDMSI survey, asking if they were interested in participating in a think-aloud session. Those experienced raters who expressed interest were invited to an online meeting for a brief think-aloud training. During this training, participants were instructed to verbalize their thought processes while solving an arithmetic problem, such as calculating “How much is 127 plus 35?” as Wulfert et al. (1991) suggested. This training can be used to assess voluntary raters’ ability to clearly express cognitive processes, which is crucial in think-aloud studies, as the effectiveness of the protocol relies heavily on participants’ ability to verbalize their cognitive processes (Ericsson & Simon, 1993). Based on the principle of theoretical saturation (Glaser & Strauss, 1967), ten raters were finally selected, as no new decision-making subcategories emerged after including two additional raters beyond the initial eight. This is a common practice in qualitative research methods (Guest et al., 2006), such as think-aloud protocols, to confirm the adequacy of the sample size and data richness and depth. The selected ten raters hailed from various universities and possessed diverse levels of rating and teaching experience. They all granted written consent. As an incentive for their participation, each received a monetary reward. Table 1 provides a detailed profile of these raters. To ensure their privacy, they have been anonymized as R1, R2,…, R10.
The 10 Experienced Raters’ Background Information.

Instruments
The Translation Task
The translation task in the September 2022 CET-4 administration, along with its official English translation and five translation range-finders, served as the materials for this study. These materials are presented in Appendices 2, 3, and 4, respectively. The range-finders were also chosen for the think-aloud protocols and had been previously scored by experts with 2, 5, 8, 11, and 14 points, respectively. The topic of the translation task is Taijiquan, a traditional Chinese martial art renowned for its health benefits, self-defense applications, and contributions to spiritual growth.
For the think-aloud session, ten translations samples were examined. Following J. Zhang’s (2016) procedure of screening raters who might be affected by the think-aloud method when rating in the investigation of CET-4 essay raters’ cognitive and meta-cognitive strategies, eight scripts were chosen for their representativeness of each scoring category, including typical features manifested by the range finders, whereas the other two translations (the 5-point and the 8-point scripts) were selected from the five range-finders to examine whether raters’ judgments were affected by the think-aloud method.
The GDMSI
The GDMSI was employed to gather data on raters’ general decision-making styles. It is widely used, being both reliable and valid, for assessing individual decision-making styles (e.g., Alacreu-Crespo et al., 2024), and has been adapted and validated to many languages, including Swedish (Thunholm, 2004), Italian (Gambetti et al., 2008), Slovak (Bavoľár & Orosová, 2015), German (Fischer et al., 2015), French (Girard et al., 2016), and Spanish (Alacreu-Crespo et al., 2019). In this study, the GDMSI was administered in its original English version, as all participants were College English teachers. This questionnaire utilizes a 5-point Likert scale, ranging from “1” for “strongly disagree” to “5” for “strongly agree.” It comprises five subscales: avoidant, rational, intuitive, spontaneous, and dependent, each containing five items. The scale’s overall reliability, as measured by Cronbach’s alpha, ranges from .68 to .94, with subscale reliabilities varying between .62 and .84 (Zhou et al., 2014). Appendix 5 presents the GDMSI.
Data Collection
GDMSI Questionnaire
In the first phase, participants were invited to complete the GDMSI in a printed format in October 2022 during the CET rating period, resulting in 469 collected responses. After data cleaning, 43 incomplete or patterned responses were excluded, yielding 426 valid responses, representing 91% of the collected total.
Think-Aloud Protocols
In the second phase, the ten experienced translation raters were engaged in the think-aloud session to capture their decision-making processes during scoring. The think-aloud technique is widely recognized in language testing for its role in examining rating behavior and developing raters’ process models (e.g., Huot, 1993; J. Zhang, 2016). It is grounded in Green’s (1998) principles that task-relevant information temporarily stored in short-term memory can be verbalized when prompted.
To ensure valid protocol data, the ten raters first received a concise briefing on the research purpose and procedures and underwent intensive training based on Ericsson and Simon’s (1993) approach. During training, they practiced verbalizing their thoughts while solving sample arithmetic problems to develop fluency in articulating cognitive processes without interpreting their reasoning. For the formal think-aloud of rating, each rater scored ten translation samples while continuously verbalizing their thoughts. Each rater’s think-aloud session lasted up to 30 minutes, and raters were encouraged to speak in the language and style most natural to them. No sample verbal report of rating processes was provided to avoid influencing their natural rating behavior. All sessions were audio-recorded for subsequent analysis.
Data Analysis
To ascertain the construct validity of the GDMSI within the specific context of CET translation raters, both exploratory factor analysis (EFA) and confirmatory factor analysis (CFA) were employed. EFA was first conducted to explore the underlying factor structure of CET translation raters’ decision-making styles, given that the GDMSI had not been validated in this population and that decision-making, as discussed in the literature review, is a contextually embedded process influenced by both immediate and sociocultural factors (Strough et al., 2015). Although the GDMSI has been used in prior scoring studies (e.g., Baker, 2012; Xu, 2016), neither study examined its construct validity in this rater group, necessitating an investigation of whether its factor structure holds in this context. Therefore, CFA was subsequently carried out to verify the stability and adequacy of the identified factor structure through EFA, thereby providing stronger evidence of construct validity by evaluating how well the data fit the hypothesized measurement model. This two-step approach aligns with established psychometric validation practices when adapting instruments for new populations (Brown, 2015).
Exploratory Factor Analysis (EFA)
The remaining data of participants’ responses to the GDMSI (n′ = 426) were randomly split into two equal groups: Group 1 (n1 = 213) and Group 2 (n2 = 213). EFA was performed on the GDMSI responses from Group 1 with SPSS 26 to investigate the factor structure that underlies the decision-making styles of CET translation raters. Prior to executing the EFAI, the Kaiser-Meyer-Olkin (KMO) measure and Bartlett’s test of sphericity were employed to ascertain the suitability of the data for factor analysis.
Confirmatory Factor Analysis (CFA)
CFA was performed on Group 2 (n2 = 213) using Amos 17. The analysis aimed to test the factorial validity of the structure uncovered by EFA and to evaluate how well the data conformed to the hypothesized GDMSI measurement model (Brown, 2015). Adhering to Hoyle and Panter’s (1995) guidelines, model fit was assessed with the following indices: the ratio of the Satorra-Bentler Chi-square to model degrees of freedom (χ2/df; ideally ≤ 2.5, as per Kline, 2015), the Goodness of Fit Index (GFI; ≥0.90), the Tucker-Lewis Index (TLI; ≥0.90), and the Comparative Fit Index (CFI; ≥0.90). In addition to these indices, a Root Mean Square Error of Approximation (RMSEA) value of 0.08 or lower is also indicative of an adequate fit (Browne & Cudeck, 1993).
Reliability Analysis
The reliability of the entire scale and each subscale of the validated GDMSI was calculated using Cronbach’s alpha. Based on these assessments, the final version of the questionnaire was established.
Think-Aloud Protocol Analysis
Following the think-aloud procedure, none of the raters reported discomfort or difficulty. To ensure the reliability of the method, the average score discrepancy among the ten experienced raters on two overlapping range-finder scripts (rated five and eight points, respectively) remained within three points during both training and the actual session, indicating that the verbalization process did not substantially interfere with scoring performance.
All audio recordings were transcribed verbatim by a research assistant (an MA student in Applied Linguistics) in accordance with Noushad et al.’s (2024) transcription guidelines and reviewed by the third author for transcribing accuracy. Guided by grounded theory, the reviewed transcripts were segmented into 349 individual meaning units by the second author using Green’s (1998) methodology. The third author verified the segmentations. The second and third authors then independently conducted three stages of coding in NVivo 12: (1) open coding for initial categorization and conceptualization, (2) axial coding to establish hierarchical relationships among categories, and (3) selective coding to integrate these relationships and identify core categories. Inter-coder reliability reached 0.92, and all divergences were resolved through in-depth discussions until a consensus was achieved. The final coded protocols were integrated with GDMSI results to construct comprehensive decision-making style profiles for the ten experienced raters. Figure 1 presents the procedure for developing the ten translation raters’ decision-making style profiles.
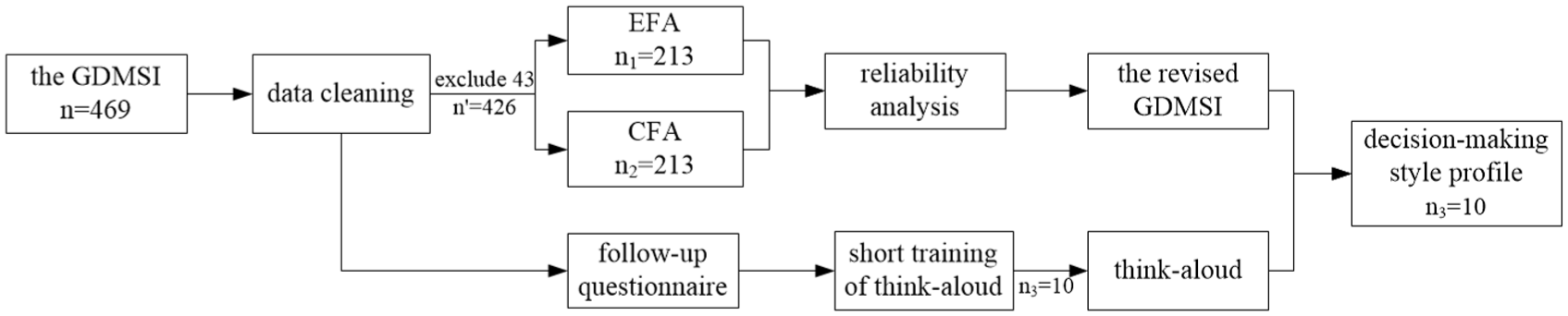
Procedure for constructing experienced translation raters’ decision-making style profiles.
Results
First, we reported on the applicability of the GDMSI among translation raters, addressing RQ1. Subsequently, we outlined the overall decision-making styles of the translation raters based on their responses to the revised GDMSI, and reported on the think-aloud results from ten selected experienced raters. Finally, by integrating the GDMSI outcomes with the qualitative data from these ten raters, we constructed decision-making style profiles for them. This comprehensive approach allows for a deeper understanding of the decision-making styles of translation raters and offers insights that could enhance the monitoring of scoring in translation tests.
The Reliability and Validity of the GDMSI
Results of EFA
The initial EFA yielded a KMO value of 0.76 and a highly significant Bartlett’s test sphericity (p < .001), confirming the appropriateness of the data for EFA. Utilizing principal component analysis (PCA) with orthogonal rotation, six factors were extracted, each with eigenvalues exceeding 1. These factors accounted for 54.29% of the total variance. However, several changes were made in the factor structure. Items 3 and 17 were excluded due to factor loadings below the 0.45 threshold (Bastug, 2015), while item 25 was removed as it failed to load on its initially assigned dimension (dependent style). Furthermore, the sixth factor was dropped because it consisted of only two items (items 16 and 18), which is considered insufficient for a stable factor structure—factors with fewer than three items are typically regarded as unreliable (Carpenter, 2018).
These five excluded items were deemed either ambiguously worded or contextually inappropriate for translation rating. For instance, Items 3 and 18 refer to seeking external assistance, which conflicts with the independent nature of CET translation scoring. Item 16 refers to a goal irrelevant to the rating context. Item 17 confounds intuitive and rational tendencies, lacking conceptual clarity. Item 25 also exhibited ambiguity in its construct direction.
These findings align with Fischer et al.’s (2015) argument that the GDMSI should be revalidated in specific contexts and support Strough et al.’s (2015) view that decision-making is highly context-dependent. Based on this evidence, a revised version of the GDMSI was proposed for use with translation raters, consisting of 20 items across five factors. A second EFA was conducted to validate this revised structure.
Before initiating the second round of EFA, the KMO measure and Bartlett’s test were reassessed. The results reaffirmed the data’s suitability for EFA, with a KMO value of 0.80 and a significance level well below .001 (p < .001), indicating the sample’s adequacy and the fulfillment of EFA assumptions. Through PCA and factors with eigenvalues over 1, five distinct factors were identified, which explained a combined variance of 55.23%. The outcomes of the second EFA round, detailed in Table 2, designated the five factors as avoidant, rational, intuitive, spontaneous, and dependent decision-making styles, aligning with the dimensions of Scott and Bruce’s (1995) original scale.
The EFA Result of GDMSI Among CET Translation Raters.

Note. A = avoidant; R = rational; I = intuitive; S = spontaneous; D = dependent.
Results of CFA
Drawing from the findings of the EFA, a factor model with five dimensions and 20 observable items was formulated for CET translation raters. To substantiate the construct validity of this model, CFA was conducted using the GDMSI data from Group 2 (n2 = 213). The outcomes are graphically represented in Figure 2. The CFA model fit indices suggested a strong alignment between the proposed model and the collected data (χ2/df = 1.28, GFI = 0.91, TLI = 0.94, CFI = 0.95, RMSEA = 0.04). Consequently, the revised scale was affirmed, retaining the 20 items as detailed in Table 2.

The CFA result of GDMSI among CET translation raters.
Reliability of the Revised GDMSI
The reliability analysis examined the internal consistency of the revised GDMSI using responses from 426 participants who completed the revised 20-item questionnaire. The overall reliability coefficient for the questionnaire was 0.71. The individual reliability coefficients for the five factors, in descending order, were as follows: avoidant (0.78), rational (0.72), intuitive (0.69), spontaneous (0.69), and dependent (0.64). These coefficients were considered acceptable as they exceeded the threshold of 0.60, which is commonly used as a benchmark for internal consistency reliability (Hair et al., 2019).
Given that the five-factor structure derived from the CFA validly reflected the decision-making styles of CET translation raters and the instrument’s reliability was acceptable, the revised GDMSI can be effectively employed to evaluate the general decision-making styles among CET translation raters.
Descriptive Statistics of Participants’ GDMSI Scores
The mean scores across the five decision-making dimensions varied between 2 and 4. The rational style exhibited the highest mean score and the lowest standard deviation (Mean = 3.91, SD = 0.40), indicating its prevalence among CET translation raters. This suggests that most raters engaged in a meticulous and systematic review of the translation content before awarding scores, thereby enhancing the reliability and validity of the translation scoring process. The dependent and intuitive styles had mean scores of 3.49 (SD = 0.59) and 3.30 (SD = 0.59), respectively, which reflects a propensity among raters to seek guidance from others or to rely on their intuition. The avoidant style demonstrated a lower mean score (Mean = 2.58, SD = 0.58), potentially indicating that some raters experienced discomfort and procrastinated in their decision-making. The spontaneous style had the lowest mean score (Mean = 2.44, SD = 0.51), implying that a small subset of raters may make decisions hastily, with limited deliberation.
Decision-Making Styles of Experienced CET Translation Raters
The GDMSI Results of the Ten Experienced Raters
Adhering to the methodology established by Xu (2016), we scored the GDMSI results for each identified decision-making style. A translation rater’s dominant decision-making style was ascertained based on two criteria: (1) the style must have the highest score among the five, and (2) the rater’s score for that style must surpass the category’s average. Applying this approach, we could pinpoint their primary scoring decision styles of the ten experienced raters, as outlined in Table 3. It showed that four raters exhibited a predominantly intuitive decision-making style, four demonstrated a rational style, and the remaining two displayed a blend of rational and intuitive styles. These findings indicate that experienced CET translation raters generally manifest intuitive, rational, or hybrid decision-making tendencies in their scoring processes.
Decision-making Styles of CET Translation Raters Based on GDMSI Results.

Note. A = avoidant; D = dependent; I = intuitive; R = rational; S = spontaneous; DMS = decision-making style.
Results of Verbal Protocol Analysis
Drawing inspiration from the framework developed for CET-4 writing rater decision-making by Xu (2016), a similar coding framework to identify decision-making styles of CET-4 translation raters was constructed. To account for the distinctions in task types and characteristics, we replaced “essay” with “translation” in the original framework and introduced new subcategories, denoted by an asterisk (*). The coding outcomes, as presented in Table 4, encompass five main categories aligned with Scott and Bruce’s (1995) classification, along with 22 subcategories. The number of subcategories increases sequentially from spontaneous (1), dependent (3), avoidant (4), intuitive (6), to rational (8). The five newly incorporated subcategories specifically pertain to awarding a middle score (avoidant), expressing uncertainty regarding the accuracy of an expression (dependent), hypothesizing about test-takers’ English proficiency levels (rational), employing personalized scoring techniques (rational), and providing feedback or suggestions (rational).
Codes for CET Translation Raters’ Decision-making Styles.

Note. An asterisk (*) indicates new subcategories.
According to Baker’s (2012) methodology for identifying decision-making styles, a particular style was considered dominant if it accounted for more than 5% of the total think-aloud units. Based on this criterion, the think-aloud data (Table 5) revealed that all ten experienced raters demonstrated more than one style when scoring the ten translation texts. No rater exhibited a single style exclusively. As shown in Table 5, they exhibited a variety of decision-making styles in scoring different translation responses, with the following unit counts: 155 for rational, 141 for intuitive, 25 for avoidant, 17 for dependent, and 11 for spontaneous. The rational and intuitive styles were the most frequently observed, representing 44.41% and 40.40% of the total units, respectively. In addition, diverse patterns of decision-making styles emerged across individuals. Specifically, three raters followed a pattern of dependent, intuitive, and rational styles (D–I–R); three exhibited an intuitive–rational (I–R) pattern; two displayed an avoidant, intuitive, and rational pattern (A–I–R); one demonstrated an intuitive, rational, and spontaneous pattern (I–R–S); and one adopted an avoidant–rational (A–R) pattern. These patterns reflect considerable variability across raters, with no fixed or uniform combinations observed.
Decision-making Styles of CET Translation Raters Based on Think-aloud Protocol Results.

Note. A = avoidant; D = dependent; I = intuitive; R = rational; S = spontaneous; DMS = decision-making style.
Rational Decision-Making Style
The rational decision-making style is the leading category among the five, comprising 44.41% of the total codes. This category includes eight subcategories, three of which were newly identified compared to Xu’s (2016) study on CET-4 essay raters’ decision-making styles.
Based on these codes, we infer that rational raters tended to specify a score range first and then refine it to a specific score. For instance:
I’ll initially place it in the 5-point range, and then I’ll examine each sentence closely to assign the exact score. (R9)
In the process, they systematically compiled evidence of translation quality. As one rater stated:
The translation is complete and coherent, with concise language, which definitely places it in the highest score range. (R1)
When making judgments on test-takers’ translation quality, they often undergo a comparison process, either by comparing different translation texts or by referring to the rating scale. For example:
This student correctly translated the challenging part, but there are numerous minor errors, not as good as the last translation I reviewed. (R5) According to the rating scale, most expressions in this translation are incorrect, failing to convey the meaning of the original text. (R2)
Sometimes, they even referred to their own translation to evaluate test-takers’ translation quality, which resulted in offering suggestions during rating. As one rater stated:
I believe the translation should read ‘doing Taijiquan’ instead of ‘Taijiquan practicing’. (R7)
In addition, they may also develop personalized scoring methods, such as back-translating the text, as illustrated in the following case:
If I back-translate their version to Chinese, it doesn’t make sense and deviates entirely from the original text. (R3)
Moreover, rational raters may infer the test-takers’ English proficiency level while rating. A rater remarked:
Given the use of ‘be traced back’, I assume this test-taker has a high level of English proficiency. (R8)
For rational raters, if they felt uncertain about assigning a score, they may re-evaluate the translation, which leads them back to the evidence-gathering process in scoring. An example of this is:
But at the moment, I can’t differentiate this from the previous translation, so I need to read it again. (R6)
In summary, rational raters tended to establish a score range initially and then to gather sustainable evidence of test-takers’ translation proficiency before assigning a score. If they felt uncertain about their judgment, they turned back to reading the translation text again to gain enough evidence until they had sufficient confidence to make the final decision. During the process, a variety of rational strategies (such as comparing different translations, back-translating test-takers’ versions to Chinese, and inferring test-takers’ English proficiency levels) were used, which could be attributed to the rater training, as discussed later.
Intuitive Decision-Making Style
The intuitive decision-making style is the second most prevalent, representing 40.40% of the total codes. This category comprises six subcategories, none of which were identified as new when compared to Xu’s (2016) study.
These subcategories show that raters were inclined to make an initial decision and assign scores based on their intuition, as two raters commented:
After a quick look, I believe it merits a 14-point score. (R1) I believe it’s unnecessary to closely examine high-scoring and low-scoring translations, as their differences are apparent. I can intuitively determine their score range at first glance. (R10)
In addition to intuition, they may also rely on their initial or overall impression to guide their scoring decisions. For instance:
The test-taker made numerous errors from the outset, and the entire translation is disorganized. I would certainly not award a high score. (R2) The fifth translation text appears quite natural and fluid overall. (R6)
Furthermore, the subcategories also display that raters may form their impression from key information in the translation text during the reading process. As raters noted:
This translation has an omission, so it can only be scored below 8, indicating that the candidate failed to accurately translate even half of the original text. (R3) The last two sentences are poorly translated, leaving me with a negative impression. (R7)
To sum up, most raters exhibited several instances of intuitive decision-making. A possible explanation is that they, possessing considerable rating experience, have internalized and automated their information-processing behaviors. Consequently, they exerted less cognitive effort in making scoring decisions and often assigned scores intuitively.
Avoidant Decision-Making Style
The avoidant decision-making style was associated with 25 codings, and nine of the raters utilized it, with R1 employing it on ten occasions. This style can be divided into four subcategories.
First, raters may exhibit hesitation in making scoring decisions, as illustrated by the following example:
I’m struggling giving this translation a 5 or a 6—my decision is not clear. (R8)
Second, raters might contemplate assigning a lower score but ultimately decided against it, as demonstrated in this instance:
I’m inclined to give this translation a score of 11, even though it merits a 10. Translating text of this quality is challenging in an actual testing scenario, so I’ll add an extra point. (R5)
Third, raters tended to provide a score range rather than a precise score. One rater’s perspective is as follows:
This translation likely falls within the 11-point range, somewhere between 10 and 12. (R6)
Last, raters may opt for a middle score within a range to avoid committing to either a lower or higher score. An example of this approach is:
This translation is somewhere between a 10 and an 8, and without certainty about the exact score, I choose to give it a 9, the median score. (R1)
This final subcategory represented a novel addition compared to Xu’s (2016) study, suggesting that experienced raters in this study were prone to assign a middle score when uncertain about a precise score within a range.
Overall, the prevalence of the avoidant style is relatively low, indicating that the raters generally exhibited high confidence in their scoring decisions.
Dependent Decision-Making Style
The dependent decision-making style is the second least frequently employed by the ten raters, yet each rater demonstrated it at least once. This style encompasses three subcategories.
First, raters might employ rhetorical questions to express their uncertainty regarding rating-related decisions, as evidenced by the following example:
Is it unusual to use ‘test’ in place of ‘research’? (R3)
Second, raters may invoke conditional clauses to contemplate the actual rating scenario, recognizing that the current context is experimental. For instance, one rater stated:
Under official rating conditions, I might assign it a score of 3. (R7)
Last, raters sometimes expressed doubt about the accuracy of certain expressions, a nuance not observed in Xu’s (2016) study. An example of this uncertainty is:
But I’m uncertain whether ‘at the beginning’ is correct and ‘in the beginning’ is incorrect. Perhaps ‘in the beginning’ could also be right. (R4)
The infrequent use of the dependent decision-making style is advantageous as it appears to confirm that the ten raters were generally self-reliant in making scoring decisions. A likely explanation for this is their collective experience and successful completion of the training session conducted as part of this study.
Spontaneous Decision-Making Style
The spontaneous decision-making style was the least utilized by the ten raters, with only six individuals observed to employ it. This category comprises a single subcategory characterized by making immediate scoring decisions. An illustrative example is as follows:
From the first sentence alone, I can almost conclude that it falls within the 2-point range, given the numerous errors present; there’s no need to read further. (R4)
Profiles of the Ten Experienced Raters’ Decision-Making Style
By integrating the qualitative insights from the think-aloud results with the quantitative data from the GDMSI, comprehensive profiles of individual decision-making styles for the ten experienced raters were constructed, which are presented in Table 6. This table demonstrates that all decision-making styles identified through the GDMSI were also reflected in the think-aloud protocols, indicating mutual validation between the quantitative (GDMSI) and real-time observational (think-aloud) data sources. Additionally, among them, four primarily adopted an intuitive style, four favored a rational style, and the remaining two exhibited a combination of both. These findings suggest that experienced translation raters tend to rely on intuitive, rational, or a blend of intuitive and rational decision-making styles when making scoring decisions. Notably, their dominant styles were consistent with their responses to the revised GDMSI, providing further support for the instrument’s effectiveness in capturing general decision-making tendencies among translation raters.
Decision-making Style Profiles of CET Translation Raters.

Note. A = avoidant; D = dependent; I = intuitive; R = rational; S = spontaneous; DMS = decision-making style.
Discussion
Reliability and Validity of the GDMSI Within CET Translation Raters
In addressing RQ1, we initially utilized EFA and CFA to assess the suitability of the GDMSI for CET translation raters. EFA identified five factors aligning with the dimensions of the original scale, leading to the exclusion of five items (3, 16, 17, 18, and 25) from further analysis. These items were also deemed ambiguous in terms of their descriptions and inappropriate for the translation rating context. This supports the perspective by Fischer et al. (2015) that the GDMSI needs to be revalidated in specific contexts, further reinforcing the view of Strough et al. (2015) that decision-making is contextually integrated process. First, the descriptions of Items 3 and 18 involve external assistance, contradicting the independent scoring process of CET translation tasks. Second, Item 16 mentions a goal unrelated to scoring and thus not applicable to the translation rater group. Third, Item 17 contains unclear constructs, involving part of the intuitive dimension and part of the rational dimension. Last, Item 25 also has ambiguous construct direction. Consequently, we proposed a revised GDMSI for translation raters’ decision-making styles, which includes 20 items with a five-factor model. Subsequent CFA confirmed a good fit between the data and the model, with each factor’s reliability reaching an acceptable level. Thus, we validated Scott and Bruce’s (1995) decision-making style theoretical model for CET translation raters, offering an effective tool for measuring their decision-making styles.
Decision-Making Style of Experienced CET Translation Raters
Regarding RQ2, we first gained qualitative insights from think-aloud protocols to explore CET translation raters’ decision-making styles. The analysis revealed that most raters primarily employed a rational style, while others exhibited at least two distinct decision-making styles. These findings align with those of Baker (2012) and Xu (2016), highlighting the prevalence of rational decision-making and the occurrence of multiple styles. Despite individual differences, such as scoring experience and educational background, the ten participating raters, who were experienced and well-versed in the rating scale, consistently demonstrated a rational decision-making style. During the scoring process, they employed metacognitive strategies, such as self-regulation and cognitive strategies, including modification, diagnosis, inference, and comparison, consistently reflecting a rational decision-making style. Furthermore, their scoring quality was closely monitored by supervisors in real practice, encouraging raters to engage in thorough and rational deliberation before making decisions.
In addition to qualitative data, we concurrently integrated the ten experienced CET translation raters’ qualitative data with their quantitative responses to the revised GDMSI to construct their decision-making style profiles. The results indicated that four raters primarily used an intuitive style, four favored a rational style, and the remaining two exhibited a combination of both. This suggests that experienced CET translation raters typically adopt intuitive, rational, or a combination of these decision-making styles when making scoring decisions. There are two possible reasons for this. First, CET translation scoring training helps raters develop their scoring methods and make decisions after gathering and comparing various information against scoring criteria, thus reflecting a rational decision-making style. Second, engaging in a large volume of practice scoring tasks before formal grading enables raters to automate the evaluation process, leading to intuitive judgments. Regarding methodology, the think-aloud protocols from the ten experienced translation raters revealed that all except R6 exhibited intuitive decision-making styles, with each rater demonstrating a combination of two or more decision-making styles. In contrast, the revised GDMSI responses indicated that raters generally preferred either an intuitive or rational decision-making style, with only a few showing a combination of both. This discrepancy between the two data sources further underscores the value of using both methods for triangulation, thereby enhancing the credibility of both quantitative and qualitative findings.
The decision-making style profiles for the ten translation raters also highlight individual differences, which is consistent with the findings of Baker’s (2012) and Xu’s (2016) studies regarding the individual differences in the decision-making styles of writing raters. However, the translation raters in the present study predominantly exhibit rational and/or intuitive decision-making styles, whereas writing raters in previous research displayed a wider range of decision-making styles without a clear trend. This difference may stem from the distinct task requirements and constructs between translation and writing assessments. Specifically, the scoring criteria for translation tasks emphasize the faithfulness to the original text and fluency of language (Wang & Wen, 2009), whereas writing scoring conventionally probes into content, structure, and language (Wu et al., 2018), which requires higher cognitive engagement from raters. In addition, methodological differences also played a role. Previous studies by Baker (2012) and Xu (2016) collected four different data types. Baker collected raters’ responses to the GDMSI, frequency of rating deferring, underuse of failing score levels, and comments through write-aloud protocols, while Xu used Many-facet Rasch Measurement (MFRM) analysis of raters’ scores, the degree of certainty for each score, raters’ GDMSI outcomes, and think-aloud protocols. These studies revealed the complexity of raters’ decision-making styles from various perspectives. Consequently, no dominant decision-making style was identified. In contrast, the present study involved relatively fewer data types—only two (think-aloud protocols and responses to GDMSI)—which may explain the more pronounced identification of specific decision-making styles. Future research could benefit from incorporating a broader range of data collection methods to better capture the complexity of translation raters’ decision-making processes.
Conclusion
This study employed a convergent parallel mixed-methods approach to investigate the decision-making styles of CET translation raters. The research yielded two major findings that advance our understanding of rater cognition in translation assessment contexts.
First, through comprehensive psychometric analysis, we established the validity and reliability of the GDMSI for translation raters. After excluding several ambiguous items, exploratory and confirmatory factor analyses confirmed the instrument’s robust five-factor structure (rational, intuitive, avoidant, dependent, and spontaneous), consistent with Scott and Bruce’s (1995) theoretical framework. The refined 20-item version demonstrated strong internal consistency, confirming its suitability for assessing decision-making styles in translation rating contexts. This adaptation underscores the GDMSI’s potential as a diagnostic tool in rater recruitment and pre-training to identify innate decision-making tendencies (e.g., rational vs. intuitive) and enable targeted interventions.
Second, by integrating quantitative GDMSI data with qualitative think-aloud protocols, we identified distinct patterns in raters’ decision-making approaches. Three notable findings emerged: (1) rational and intuitive styles predominated, often appearing in combination; (2) detailed analysis revealed that raters systematically gathered evidence (rational) while also relying on initial impressions (intuitive) during scoring; and (3) while avoidant, dependent, and spontaneous styles occurred less frequently, their presence—particularly avoidant raters’ tendency to assign middle scores—raises fairness concerns for high-stakes testing. The coexistence of rational and intuitive styles aligns with translation tasks’ dual demands: systematic evaluation of accuracy (rational) and fluency judgments honed through experience (intuitive). This duality implies that effective rater training should combine rubric internalization (for rational raters) and exemplar-based calibration (for intuitive raters), using think-aloud protocols to surface and address implicit biases. Notably, discrepancies between GDMSI results (which identified distinct styles) and think-aloud data (revealing hybrid approaches) emphasize the value of mixed-methods designs to capture rater cognition complexity. Future training systems could leverage this by pairing GDMSI screening with real-time scoring analytics to triangulate data and provide dynamic feedback.
While these patterns echo findings from writing assessment research (Baker, 2012; Xu, 2016), our study uniquely highlights how translation-specific requirements (particularly source-text fidelity) and specialized rater training may reinforce rational-intuitive decision-making. However, the focus on experienced CET raters limits generalizability; future studies should include novice raters and diverse language pairs to validate the GDMSI’s broader utility. Besides, longitudinal research is also needed to assess whether style-tailored training reduces scoring variability over time. Finally, while self-reports and think-aloud protocols provide valuable insights, they may not fully reveal raters’ unconscious processes. Future research should supplement these with response time analysis and Many-Facet Rasch Modeling (Han, 2015; Han & Shang, 2023) for a more complete understanding of rating decisions.
Supplemental Material
sj-doc-1-sgo-10.1177_21582440251379569 – Supplemental material for Investigating the Decision-making Style of Translation Raters in Large-scale Language Tests
Supplemental material, sj-doc-1-sgo-10.1177_21582440251379569 for Investigating the Decision-making Style of Translation Raters in Large-scale Language Tests by Xiaodong Li, Jie Yuan and Ying Xu in SAGE Open
Footnotes
Acknowledgements
The authors want to thank all rater participants in the study.
Ethical Considerations
The study involving human participants was reviewed and approved by the Ethics Committee at School of Foreign Languages, South China University of Technology (approval no. 2022/23) on May 6, 2022.
Consent to Participate
The participants gave their written consent for review and signature before participating in this study.
Author Contributions
(1) Xiaodong Li: Writing – review & editing, Writing – original draft, Visualization, Validation, Software, Methodology, Investigation, Formal analysis, Data curation. (2) Jie Yuan: Writing – review & editing, Investigation, Formal analysis. (3) Ying Xu: Writing – review & editing, Writing – original draft, Visualization, Validation, Supervision, Software, Resources, Methodology, Investigation, Formal analysis, Funding acquisition, Data curation, Conceptualization.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Social Science Foundation of China (grant number 22BYY089).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available on request from the corresponding author, Ying Xu, upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
Studies Involving Animal Subjects
Generated Statement: No animal studies are presented in this manuscript.
Studies Involving Human Subjects
Generated Statement: The studies involving human participants were reviewed and approved by the ethics committee at School of Foreign Languages, South China University of Technology (approval no. 2022/23) on May 6, 2022. The participants gave their written consent for review and signature before participating in this study.
Inclusion of Identifiable Human Data
Generated Statement: No potentially identifiable human images or data are presented in this study.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.