
Abstract
The present study is likely the first to investigate translation style through the lens of dependency distance. While translator style has been explored using various indicators—such as STTR, LR, MSL, and typical language patterns like reporting verbs and loan words—prior research has rarely accounted for syntactic structures, particularly syntactic complexity, which has been widely discussed in fields like second language acquisition. Dependency distance is considered a valid measure of syntactic complexity, and studies have demonstrated that its ability to differentiate between translational and original English. Given this, it can be hypothesized that translation style could also be distinguished by dependency distance. Accordingly, this study examines the translator styles of four English versions of the Chinese classic novel Hongloumeng. The results support the hypothesis, showing that dependency distance can effectively distinguish translator styles. Moreover, the findings suggest that dependency direction should also be considered when analyzing translator style.
Keywords
Introduction
Style, as defined by Leech and Short, refers to “the way in which language is used in a given context, by a given person, for a given purpose” (1981, p. 10), suggesting that style arises from a series of deliberate linguistic choices. Mona Baker expands on this, describing style as “a kind of thumb-print that is expressed in a range of linguistic—as well as non-linguistic—features” (2000, p. 245). In the context of translation, style is often analyzed from two perspectives: translation style and translator style. Regarding translator style, Baker argues that the study “must focus on the manner of expression that is typical of a translator…[and] must attempt to capture the translator’s characteristic use of language, his or her individual profile of linguistic habits, compared to other translators” (2000, p. 245). From Baker’s perspective, analyzing translator style can reveal a translator’s unique linguistic habits, or idiolect, distinguishing them from others and defining their identity as an individual translator. Furthermore, translator style sheds light on how different translators interpret and represent the same author in various translations. As Munday (2007, 2008) has demonstrated, translator style can also reflect the ideology of the translator, a particular community, or even a nation.
Traditionally, translator style has been assessed through intuitive analysis of examples. For example, Zhao and Sun (2004) explored how idiolect translation influences translator style in literary translation, while Yao (2009) examined translator style by analyzing wordplay in two versions of Hongloumeng. While this kind of non-quantitative analysis can help distinguish translators, especially when significant linguistic differences exist, it becomes less effective when the differences are subtle. In such cases, corpus-based stylometric analysis offers distinct advantages.
In corpus-based translation studies (CTS), translator style has been examined using methodologies that rely on corpus statistics such as STTR (standard type-token ratio) ASL (average sentence length) or MSL (mean sentence length), as seen in Baker (2000). With the development of corpus linguistics, additional statistical indicators have emerged for exploring various topics in the humanities and social sciences, such as MATTR (moving average type-token ratio) by Covington and McFall (2010) and idea density by Covington (2007) and Brown et al. (2008). These indicators, like STTR, ALS, or MATTR, generally focused on surface-level linguistic features. Few studies, however, have investigated translator style through statistical analysis of deeper linguistic features, such as syntactic complexity. Surface-level features like ASL can indeed differentiate styles, but sentences of similar length may exhibit fundamentally different grammatical structures or relations. These differences can affect readers’ interpretations and reveal a translator’s characteristic linguistic choices in subtler ways, forming an implicit “thumb-print” of translator style.
Therefore, this study aims to identify translator style through implicit linguistic indicators by analyzing dependency relations in different translations.
Literature Review
Corpus-based Studies of Translator Style
Since the early 2000s, corpus analysis has emerged as an effective method for examining translator style, largely due to advancement in computer technology and natural language processing. Various analytical approaches have been adopted to investigate translator style using indicators that reveal distinct linguistic features.
One approach has focused on lexical features, utilizing indicators such as AWL (average word length), TTR (type-token ratio), STTR, LD (lexical density), LR (lexical richness), and LI (lexical idiosyncrasy). For instance, Baker (2000), one of the earliest corpus-based studies on translator style, proposed a methodology that incorporated TTR and STTR as statistical indices. Numerous subsequent studies followed Baker’s lead, including TTR and STTR in Li et al. (2011); STTR and LD in Wang and Liu (2012); STTR and MSL in Huang and Chu (2014); and TTR and STTR in Liu et al. (2011). These studies reflect early effort to explore translator style using the then-emerging corpus-based approach. By calculating values for basic lexical-level indicators, scholars were able to uncover linguistic features that are difficult to detect through traditional, intuitive methods.
Another line of analysis explored typical language patterns to uncover a translator’s linguistic habits. For example, Baker (2000) examined the use of reporting structures, specifically the use of the verb “say” in its various forms by different translators. Following Baker’s example, Liu and Yan (2010) analyzed the translation of reporting verbs headed by the Chinese character dao (道). Olohan (2003) investigated the use of contractions such as can’t, don’t, and it’s. Winters (2004a, 2004b, 2007, 2009) included modal particles, load words, and report verbs as indicators of translator style. Mastropierro (2018) suggested that “key clusters” might serve as potential indicators of translator style (p. 256), while Saldanha (2011) examined the use of emphatic italics, foreign words, the connective that, and reporting verbs.
While these studies also examined translator style through lexical-level linguistic features, they focused more on identifying typical or unique language patterns characteristic of a translator rather than relying sorely on statistical indices like STTR and LD. This approach expanded the scope of corpus-based analysis, opening up new possibilities for investigating translator style. As more indicators were employed and new ones were developed, this line of inquiry contributed significantly to the evolving understanding of translator style through corpus analysis.
Some studies have included syntactic features as indicators of translator style, such as ASL and SS (syntactical sequence). In pioneering research, Baker (2000) examined ASL alongside other indicators, while Wang and Liu (2012) also incorporated ASL in their exploration of translator style. Ge (2020) extended this line of inquiry by examining syntactic features such as sentence length, paragraph length, sentence type, and the degree of hypotactic conformity as indicators of translator style. These studies expanded the scope of corpus-based analysis beyond the lexical level to the syntactic level, providing a more comprehensive understanding of translator style. However, the syntactic-level analyses have generally been limited to basic corpus indicators, such as average sentence length and paragraph length.
In the studies on translations of Hongloumeng, researchers have also used corpus-based analysis to investigate translator style. For instance, Sun and Liu (2025) investigated the stylistic nuances of narration and dialogue in the Hawkes and Yang translations of Hongloumeng using indexes of syntactic complexity. Their analysis revealed that the Hawkes translation employed longer linguistic units in narration and exhibited a higher frequency of subordinations in dialogue. Similarly, Kwok et al. (2024) examined the translation styles of the Hawkes and Yang versions using the activity index from quantitative linguistics. They found that the Hawkes translation exhibited a higher level of activity compared to the Yang version, displaying greater activity in fictional dialogues and greater descriptivity in fictional narration. Chou and Liu (2024) also explored the stylistic features of speech and narration in the two translations, but adopted a multidimensional approach to capture more nuanced patterns. In a related study, Tan (2024) conducted a multi-perspective stylometric analysis of the joint translation of Hongloumeng, identifying notable stylistic differences between the sections translated by David Hawkes and those by John Minford. Distinct from these stylistic investigations, Hu et al. (2025) applied entropy-based features and machine learning algorithms for translator attribution of the Hawkes and Yang translations.
Further extending this line of inquiry, Liu et al. (2022) analyzed the translation styles of two Hongloumeng translations, focusing on the use of hedges and boosters in fictional dialogues. Their study revealed that the Hawkes version employed more hedges and boosters than the Yang version, suggesting a more nuanced and interpersonally engaged style. Similarly, Liu and Afzaal (2021) conducted a corpus-driven analysis of translator style in the two English versions of Hongloumeng, using three-word and four-word lexical bundles as indicators of stylistic preference. Zhang and Liu (2014) examined Joly’s English translation of Hongloumeng to assess its stylistic consistency, employing both lexical and syntactic indicators such as average sentence length, reporting verbs, and endearing terms. In a related study, Hou (2013) explored the translator styles of Joly and the Yangs by focusing on nominalization, illustrating how each translator developed a distinctive style through this particular syntactic feature.
These studies have significantly enriched our understanding of translator style in Hongloumeng through both lexical and syntactical analyses. However, while lexical features have been widely examined, in-depth exploration of deep syntactic-semantic features—particularly those based on dependency syntax—remains limited.
As mentioned earlier, scholars have employed various types of indicators to reveal translator style, and most studies tend to incorporate both lexical and syntactical indicators rather than focusing on just one. For example Altamimi (2016), Wang and Liu (2012), and Baker (2000) used a combination of indicators in their analyses.
Among studies on translator style, some have investigated sentence-level linguistic features, such as ASL. While a few have explored syntactic complexity, there remains a notable gap in examining deeper syntactic-semantic relationships as indicators of translator style. Specifically, current research seldom utilizes syntactic perspectives that capture nuanced syntactic-semantic distinctions, which could enrich the analysis of syntactic complexity in translated texts. Dependency grammar, as a robust framework for analyzing such features, offers valuable tools to uncover these underlying patterns. In particular, it holds significant potential for advancing the study of translator style and translation universals (Han et al., 2019, p. 92), especially in nuanced cases such as stylistic variations in translations of Hongloumeng.
Studies of Stylometry
Stylometry, also known as computational stylistics, was first developed in the 19th century (Liu & Xiao 2020, p. 32). As a quantitative methodology, it has been widely employed in corpus linguistic research. Stylometric analysis, which relies on “the quantifiable features and structures of a text to study the style and author’s writing habits” (Liu & Xiao, 2020, p. 32), differs from traditional stylistic research that often depends on “the reader’s feelings and understanding of the words, sentences, and paragraphs of the text” (Liu & Xiao, 2020, p. 33). By leveraging quantifiable data, stylometric analysis provides a more scientific approach, as long as the linguistic features analyzed are valid and appropriate to the research questions at hand. Due to its robustness, this methodology is used in various fields, including authorial attribution (see Collin et al., 2004; Dooley & Ramirez, 2009; Holmes, 1995; Schöberlein, 2017; Zhu, Lei & Craig, 2020) and style analysis (see Kestemont et al., 2015; Klaussner et al., 2015).
Compared to studies that apply stylometric analysis to investigate original works by examining linguistic features at different levels, from character and word to sentence, paragraphs, grammar, and semantics, there are far fewer studies aiming to reveal the stylistic features of translations, address issues of “translator-ship,” distinguish translator styles, or detect textual similarity in translated texts. Nevertheless, scholars are increasingly applying stylometric methodologies in translation studies to examine stylistic features of translated texts. For example, Olohan and Baker (2000) investigated the use of the reporting structure “say/tell + that” in literary texts using data from the Translational English Corpus (TEC), revealing that “that is used more with simpler syntactic constructions in TEC than in the BNC” (p. 157). Winters (2004a, 2007, 2009) explored the translator’s style in German translations of F. Scott Fitzgerald’s novels, while Huang and Chu (2014) analyzed Howard Goldblatt’s translation of Chinese novels, proposing a multiple-complex model for comparing translator styles by considering both source-text and target-text styles. Covington et al. (2015) distinguished 10 English versions of the Bsible through stylometric measurements of ASL, vocabulary diversity, idea density, and clustering, concluding that “quantitative stylometry and clustering can produce classifications that reflect or reveal literary history, even when the only literary creativity involved is translation” (p. 325). Brashi (2021) examined style shift in the Arabic translation of Susan Glaspell’s play Trifles, finding that the style shift was demonstrated through “a number of linguistic phenomena, namely contraction, elision, subject-verb agreement, and figurative multi-word expressions” (p. 79).
The use of stylometric methodologies has advanced the study of literary works’ styles, enabling researchers to uncover features and aspects of both original and translated texts that are not easily identifiable through traditional close reading. These studies also provide a framework for the present research on examining the translator style of Hongloumeng through stylometric analysis.
Studies of Dependency Relation
Analyses of dependency relations have been conducted in various contexts. One area of research involves the typological analysis of languages, where dependency distance and/or dependency direction are used as variables (see Bi & Tan, 2024; Jing & Liu, 2017; Liu, 2010; Liu & Xu, 2012; Lei & Jockers, 2018). These studies have shown that dependency distance and direction can serve effectively as quantitative indices for language categorization.
Another line of research explores the cognitive mechanisms involved in language processing, specifically how dependency distance affects cognitive effort in code-switching and interpreting (see Liang et al., 2017; Wang & Liu, 2013, 2016).
A further line of inquiry examines the tendency for changes in dependency distance. Research in this area has found that dependency distance in human languages tends to decrease, a phenomenon labeled as dependency distance minimization or dependency length minimization (see Futrell et al., 2015; Lei & Wen, 2019; Temperley, 2007, 2008).
Other studies have explored how dependency distance and/or direction vary across genres and text types. These investigations reveal that dependency distance displays different distributions depending on genre and text type, suggesting that these factors may influence dependency distance and direction (see Fan & Jiang, 2019; Wang & Liu, 2017).
Despite the application of dependency distance and direction as quantitative indices in various research fields, such as language categorization and cognitive mechanisms, dependency relations have not garnered significant attention in translation studies. However, a few studies have employed dependency distance and/or direction as quantitative variables to examine specific issues in translation and interpreting. For example, Liang et al. (2017) examined how dependency distance varies in different types of interpreting. Fan and Jiang (2019) used dependency relations to differentiate translational English from native English, revealing that “the MDD of the translated texts and native texts is significantly different from each other and the MDD of the translated texts is longer than that of the native texts” (p. 58). Their findings also show that dependency direction can distinguish between translational and native English texts. Nevertheless, in the study of translator style, dependency distance and/or dependency direction have rarely been utilized as variables for quantitative analysis.
From the above literature review, it is evident that corpus-based stylometric analysis offers significant advantages over traditional close reading in examining translator style. Inspired by previous studies on translator style that focus on lexical and syntactical indicators, which predominantly target formal rather than semantic features, we aim to take this research further by examining syntactic indicators—specifically, the semantic relations between sentence constituents, known as dependency relations. As previous studies (e.g., Han et al., 2019) have suggested, dependency relations offer valuable insights into translator style at the syntactic level. We propose that dependency relations, which expose the underlying semantic connections between sentence components, can serve as crucial complementary indicators to the syntactic-level features already explored, such as ASL. This is because sentences of similar length may exhibit entirely different semantic relations among their constituents, resulting in distinct stylistic characteristics at the syntactic level. In light of this, we conducted a preliminary study on the translator style of four English translations of Hongloumeng through corpus-based stylometric analysis, using dependency relations as key indicators. This research seeks to both corroborate the findings of earlier studies and test our hypothesis regarding the role of dependency relations in translator style.
Methodology
Theoretical Basis
In this study, we aimed to explore translator style through a quantitative analysis based on dependency grammar (DG). DG is a theoretical framework that describes language structures through the relationship between their elements, known as dependencies—an asymmetrical relationship between two sentence constituents, typically words, where one functions as the governor or head, and the other as its dependent or modifier (Fraser, 1994). In dependency grammar, two key measures of analysis are dependency distance and dependency direction, which have rarely been used as variables in the quantitative study of translator style.
Dependency distance (Liu 2007, 2008; Liu et al., 2017), also referred to as dependency length (Futrell et al., 2015; Gildea & Temperley, 2010; Temperley, 2007, 2008; Temperley & Gildea, 2018), is defined as the linear positional difference between two words within a sentence—namely, the governor and its dependent (Hudson, 1995, 2010; Liu et al., 2009). The value of dependency distance is measured by counting the number of intervening words between the dependents and its governor (Hudson, 1995). According to Liu et al., (2009), for any dependency relation between two words, Wx and Wy, where x is the governor and y is the dependent, the dependency distance between them is measured as the difference x-y. By this measure, the dependency distance between adjacent words is 1. When x is greater than y, the dependency distance is positive, meaning the governor follows the dependent; when x is smaller than y, the dependency distance is negative, indicating the governor precedes the dependent. However, mean dependency distance (MDD) is calculated using the absolute values of these distances. The MDD of a sentence is computed using the following formula:
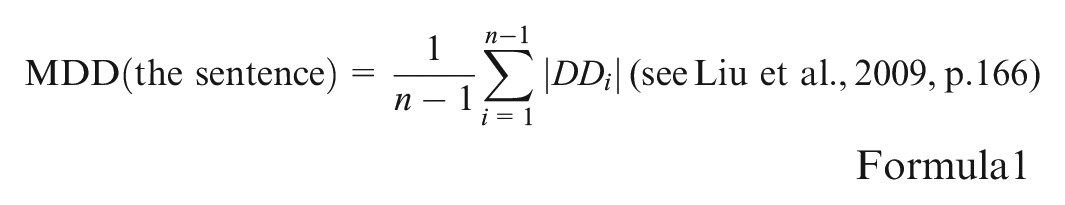
In this formula, n represents the number of words in the sentence, and DDi refers to the dependency distance of the i-th syntactic relation within the sentence. Typically, each sentence contains one word without a governor, known as the root verb, whose dependency distance is considered to be zero.

In this formula, n represents the total number of words in the sample, and s denotes the number of sentences in the sample. DDi is the dependency distance of the i-th syntactic relation within the sample.
The following example demonstrates a dependency analysis. Figure 1 illustrates the dependency structure for Example 1, and Table 1 lists the corresponding dependency relations and the dependency distances between word pairs.
Example 1 Original: 不知有何祸事,且听下回分解。 Translation: But if you wish to know who it was, you will have to read the next chapter. (Last sentence of Chapter 1 in David Hawkes’s translation of Hongloumeng)
Figure 1 illustrates the dependency relations between governors and their dependents in the example sentence. Each syntactically related word pair is connected by a labeled line with an arrow pointing from the governor to the dependent. Labels, such as nsubj, det, obj, amod, and punct represent the specific dependency relations between the words.

Dependency structure of Example 1.
Dependency Relations of Example 1.

According to formula 1, the MDD of the example can be calculated as follows:

As mentioned earlier, the value of dependency distance can be either positive or negative, depending on whether the governor precedes or follows its dependent. If the governor precedes the dependent, the dependency distance is negative, indicating a governor-initial (or head-initial) dependency relation. Conversely, if the governor follows the dependent, the dependency distance is positive, indicating a governor-final (or head-final) dependency relation. This variable is referred to as dependency direction (Fan & Jiang, 2019; Jiang & Liu, 2015; Liu et al., 2009; Liu, 2010; Wang & Liu, 2017). The dependency direction of a sample can be quantified by calculating the percentage of head-initial and head-final relations, using the following formulas:


(see Liu, 2010, p. 1570)
The dependency direction of Example 1 can be calculated as follows:
Percentage of head-final dependencies in Example 1=
Percentage of head-initial dependencies in Example 1=
As indicated by these percentages, the example sentence has significantly more head-final dependencies than head-initial ones, meaning that in most cases, the dependents precede their governors.
Corpus Data
The corpus used in this study consists of a large dataset featuring four English translations of Hongloumeng—one of the four greatest classic novels in Chinese literary history—translated and published under different titles: The Dream of the Red Chamber by H. Bencraft Joly (1891), The Story of the Stone by David Hawkes & John Minford (1973–1986), and A Dream of Red Mansions by Yang Hsien-yi (Xianyi) & Gladys Yang (1978–1980).
The dataset was divided into four sub-datasets based on authorship, or more accurately in this context, “translator-ship”: Sub-dataset 1 (The Dream of the Red Chamber, hereafter DRC) consists of the first 56 chapters of Hongloumeng. Sub-dataset 2 (The Story of the Stone, volumes 1–3, hereafter SOS 1) contains the first 80 chapters, translated by David Hawkes. Sub-dataset 3 (The Story of the Stone, volumes 4-5, hereafter SOS 2) covers the last 40 chapters, translated by John Minford. Sub-dataset 4 (A Dream of Red Mansions, hereafter DRM) includes all 120 chapters of Hongloumeng, translated by Yang Hsien-yi (Xianyi) and Gladys Yang. Although the four sub-datasets are imbalanced in size due to the varying number of chapters each translator worked on, this imbalance does not negatively affect our analysis. This division is determined by the translators’ respective contributions: Joly translated only the first 56 chapters, while Hawkes translated the first 80 chapters, with the remaining 40 chapters translated by Minford. Instead of relying on traditional corpus analysis methods—such as calculating metrics like the TTR, which are sensitive to dataset size—we focused on the MDD of each chapter within the four sub-datasets, as well as the overall MDD for the entire corpus. This approach is less affected by the size of the corpus and allows for a more balanced comparison of translator styles.
The four sub-datasets are categorized into two groups: L1 translation (translated into one’s mother tongue or first language) and L2 translation (translated into one’s second language). DRC, SOS 1 and SOS 2 belong to the L1 translation category, while DRM falls into the L2 translation category. This division allows us to examine whether there are notable difference in dependency distance and dependency direction between L1 and L2 translations, as well as among the translations of different translators. For this reason, The Story of the Stone was split into two sub-datasets: SOS 1 and SOS 2. Despite being the complete translation of Hongloumeng, SOS 1 was translated by David Hawkes, while SOS 2 was translated by his son-in-law, John Minford, who claimed to have maintained stylistic consistency with Hawkes in the latter part of the translation (Zhu & Minford, 2017, pp. 51–52). The descriptive statistics of the dataset are provided in Table 2, giving insight into the structural characteristics of the different translations and laying the groundwork for analyzing the role of dependency relations in the translators’ styles.
Descriptive Statistics of the Dataset.

Research Questions
This study is guided by the following three questions.
(1) Is there a significant difference in dependency distance among the four English translations of Hongloumeng?
(2) Is there a significant difference in dependency direction among the four English translations of Hongloumeng?
(3) Can dependency distance and dependency direction serve as reliable indicators for distinguishing the translator style of the English versions of Hongloumeng?
Data Processing
The procedure for data processing is outlined as follows:
Data Extracting and Cleaning
The raw data was extracted from a self-built corpus of the English translations of Hongloumeng. The corpus was compiled by scanning printed copies of the works by Cao (1973, 1977, 1980, 1982, 1986, 1994, 2010) and saved as PDF files. These files were processed using OCR (Optical Character Recognition), and the OCR results were saved in Word files for manual error-checking. Following this, data cleaning was performed to ensure accuracy in the subsequent analysis. This step primarily involved removing meta-information to achieve more precise statistical results. All data was stored in UTF-8 encoded files to prevent any compatibility issues with corpus analysis tools.
MDD Computing
The leoDDcalculator (Lei & Jockers, 2018), an R package designed to calculate MDD values, was used to compute the syntactic dependencies of the texts.
Results
In this section, we present the findings related to the translator style of the four English translations of Hongloumeng by examining syntactical complexity through two indicators of dependency grammar: dependency distance and dependency direction.
Dependency Distance (DD) of Chapters in the Sub-datasets
This subsection reports the MDD of the chapters in each of the four sub-datasets. Figure 2 illustrates the evolution of MDD across the chapters of the sub-datasets, shown as individual datapoints (Raw MDD data for each sub-dataset is available upon request). The vertical axis represents the MDD values, while the horizontal axis denotes the chapters of the sub-datasets respectively. The density of datapoints corresponds to the number of chapters for each sub-dataset, meaning that more datapoints indicate more chapters. For instance, the graph in the top left corner contains significantly fewer datapoints than the one in the bottom right corner, as DRC consists of only 56 chapters, while DRM comprises 120 chapters.

MDD of Chapters in the Sub-datasets.
As shown in Figure 2, the four sub-datasets exhibit distinct patterns of MDD evolution. The scatterplots indicate that, overall, DRM—the sub-dataset at the bottom right corner—has a lower MDD value compared to the other three sub-datasets. This variation in MDD evolution across the sub-datasets suggests that the sample texts can be differentiated by their MDD values. In other words, MDD can serve as a syntactic-level indicator of the translators’ styles in the case of the four English versions of Hongloumeng analyzed here. The lower MDD value in DRM suggests that, in terms of syntactic features, this translation is of less formal, characterized by simpler syntax and greater succinctness compared to others.
Table 3 presents the descriptive statistics of MDD for the four English translations of Hongloumeng. The data reveals notable differences among the four English texts, with DRM showing the lowest dependency distance. Although the values of dependency distance differ significantly between the translations, the overall patterns of dependency distance evolution across chapters are not as divergent, particularly for SOS 1, SOS2, and DRM. These three translations exhibit similar patterns, as reflected by the standard deviations (SD) of their MDD values—0.09, 0.08, and 0.09, respectively. The low SD of MDD for these texts indicates internal consistency in translator style, meaning that these translators maintained a consistent approach to syntactic features throughout their translations. In contrast, DRC stands out from the other three translations in terms of dependency distance evolution, with an SD of MDD at 0.21, significantly higher than the rest. This larger SD suggests a lack of internal consistency in the translator’s style, implying that the translator did not maintain a consistent approach to syntactic features. This finding aligns with Zhang and Liu’s (2014) observation that the first 24 chapters differ markedly in style from the subsequent 32 chapters. As illustrated in Figure 2, the datapoints for DRC are divided into two distinct groups: 24 points in the upper left corner and 32 points in the bottom right corner, corroborating the results of Zhang and Liu’s (2014) study.
Descriptive Statistics of MDD of the Sub-datasets.

Table 4 provides the overall MDD values for the four sub-datasets. As shown in the table, sub-dataset 4 (DRM) has an MDD of 2.3158, which is lower than the values for the other three sub-datasets. Compared to the MDD of 2.543 for original English texts (Liu, 2008), sub-dataset 4 (DRM), along with sub-dataset 2 (SOS1) and sub-dataset 3 (SOS2), demonstrates significantly lower MDD values. However, sub-dataset 1 (DRC) presents a higher MDD value than that of the original English texts. At present, there is no substantial research available on the MDD of translated texts using large datasets, leaving it unclear whether the MDD values of sub-dataset 2 (SOS1), sub-dataset 3 (SOS2), and sub-dataset 4 (DRM) are representative of translated English texts. This remains a subject for future investigation. Nevertheless, the results shown in Table 4 suggest that MDD can serve as an indicator of translator style at the syntactic level, at least in this specific case.
MDD of the Sub-datasets.

To explore whether the differences in MDD between the four texts are statistically significant, we conducted an independent sample t-test on the MDD values.
Table 5 presents the t-test results for the MDD of the sub-datasets. The results indicate that the four datasets differ significantly from one another, as the p-values for each pair of texts are all below the significance level of 0.05, with each p-value being less than .001. Therefore, it can be confidently stated that MDD is effective in distinguishing between the translated texts of different translators and can serve as an indicator of the translator style for the four English versions of Hongloumeng.
MDD t-test Results.

Dependency Direction (DDI) of Chapters of the Sub-datasets
Dependency direction refers to whether the governor in a dependency relation precedes or follows its dependent, determining if a dependency structure is governor-initial or governor-final. Previous studies, such as Liu (2010) and Fan and Jiang (2019), have demonstrated that dependency direction is an effective indicator of linguistic typology, useful for distinguishing translational language from native language and classifying natural languages.
In this study, dependency direction is employed as a factor to assess whether it can differentiate the translator styles of the four English translations of Hongloumeng. Using Formula 3 as defined earlier, the DDI for each sub-dataset has been calculated, with the results presented in Table 6.
DDI of Sub-datasets.

As shown in Table 6, sub-dataset 4 (DRM) exhibits a higher percentage of HI (head-initial) dependency relations compared to the other three sub-datasets. Sub-dataset 2 and sub-dataset 3, which represent the two parts of The Story of the Stone, show a similar percentage of HI dependency relations, albeit slightly lower than sub-dataset 4.
To determine whether the differences in DDI evolution are statistically significant, we performed independent t-tests between sub-dataset 4 (DRM) and the other sub-datasets. For the t-test, we used the raw DD (Dependency Direction) data. First, the DD values of each sub-dataset were categorized into two groups: negative values, representing head-initial dependency relations, and positive values, representing head-final dependency relations. Next, we input the negative DD values of DRC and DRM, SOS 1 and DRM, SOS 2 and DRM into R to conduct the t-test. The same procedure was repeated for the positive DD value of these three pairs of sub-datasets. The t-test results are presented in Table 7.
DDI t-test Results.

As shown in Table 7, among the six pairs of sub-datasets, five pairs—excluding the pair of SOS 1 and SOS 2—exhibit significant differences in their dependency direction evolution, with p-values below the significance level of .05, each less than .001. For SOS 1 and SOS 2, however, the p-value of the t-test is .147, which is above the significance level, indicating that the two texts are not significantly different in their dependency direction evolution. When SOS 1 and SOS 2 are combined as a whole, representing the complete English translation of Hongloumeng, the combined dataset shows significant differences from the other two texts, DRC and DRM, with p-values below 0.001 in the t-tests of dependency direction. However, for the individual sub-datasets, dependency direction cannot be conclusively considered a reliable indicator to distinguish the translated texts of different translators or as a definitive indicator of translator style for the four English translations of Hongloumeng.
Examples of MDD Difference
In the Theoretical Basis section, an example from the sub-dataset SOS 1 was provided, specifically the last sentence of Chapter 1 translated by David Hawkes, which had an MDD of 1.9375. To further illustrate the stylistic differences among the four translated texts, three additional examples from the other sub-datasets are presented. These examples highlight how differences in MDD reflect distinct translator styles. The relevant figures (Figures 3–6) and tables (Tables 8–10) accompanying each example show the corresponding dependency structures and relations.

Dependency structure of Example 2.

Dependency structure of Example 3.

Dependency Structure of Example 4.

Style in a continuum of the degree of succinctness.
Dependency Relations of Example 2.

Dependency Relations of Example 3.

Dependency Relations of Example 4.

Since SOS 1 and SOS 2 were translated by two different translators but together form the complete English translation of Hongloumeng, it is impossible to find the exact same sentence to compare MDD across all four texts. As a compromise, we chose the last sentence of Chapter 1 from DRC, DRM and SOS 1, and the last sentence of Chapter 81 of SOS 2. This approach works because the author of Hongloumeng frequently ended many chapters with the same sentence pattern, “…且听下回分解,” which roughly means “read the next chapter to find out what is going on.”
Example 2 Original: 欲知明日听解何如,且听下回分解。 Translation: But to learn how he fared the following day, you must read the next chapter. (This is the last sentence of Chapter 81 in the English translation of Hongloumeng by John Minford.)
Example 3 Original: 不知有何祸事,且听下回分解。 Translation: What calamity was impending is not as yet ascertained, but, reader, listen to the explanation contained in the next chapter. (This is the last sentence of Chapter 1 in H. Bencraft Joly’s version of Hongloumeng).
Example 4 Original: 不知有何祸事,且听下回分解。 Translation: To find out, read the next chapter. (This is the last sentence of Chapter 1 in Yang Hsien-yi (Xianyi) and Gladys Yang’s version of Hongloumeng.)
Based on formula 1, the MDD of the above three examples can be calculated as follows:
MDD (Example 2_SOS 2) =
MDD (Example 3_DRC) =
MDD (Example 4_DRM) =
Drawing on the results from these calculations, along with the MDD of Example 1, we can create a comparative table of the MDD values from the four sub-datasets.
As Table 11 shows, Example 3 from sub-dataset 1 has the longest MDD, and Example 4 from sub-dataset 4 has the shortest MDD, with the other two examples falling between them. The results demonstrate a significant variation in dependency distance across the four texts, with MDD values of 1.8333, 2.5263, 1.9375, and 2.2143 respectively.
MDD of the examples.

The DDI of the three examples can be calculated as follows, using the previously discussed Formulas 3 and 4:
percentage of head-final dependency of Example 2 =
percentage of head-initial dependency Example 2=
percentage of head-final dependency of Example 3 =
percentage of head-initial dependency Example 3=
percentage of head-final dependency of Example 4 =
percentage of head-initial dependency Example 4=
As Table 12 shows, the four examples also differ in their dependency direction, further emphasizing that dependency direction effectively distinguishes the four English texts of Hongloumeng.
Dependency Direction of the Examples.

To determine whether the four examples differ significantly in dependency relations, we conducted a t-test. The results show that the four sentences are significantly different in both MDD (t = 13.706, p < .001) and DDI (t = 27.474, p < .001). This suggests that dependency relations can indeed distinguish the four sentences in terms of syntactic structure, highlighting distinct translator styles at the syntactic level.
As demonstrated by the dependency analysis of the four examples:
But if you wish to know who it was, you will have to read the next chapter. (SOS 1)
But to learn how he fared the following day, you must read the next chapter. (SOS 2)
What calamity was impending is not as yet ascertained, but, reader, listen to the explanation contained in the next chapter. (DRC)
To find out, read the next chapter. (DRM)
They are distinguishable in dependency relations at the syntactic level. Example 4 from DRM has the shortest MDD (1.8333), indicating less syntactic complexity, making it easier for readers to comprehend due to simpler dependency relations. Sentences with shorter MDD tend to be more succinct in style, while longer MDD suggests more complexity and verbosity. Therefore, in terms of stylistic succinctness, Example 4 from DRM demonstrates the highest degree of succinctness. Example 3 from DRC, by contrast, presents a style of lower succinctness, with example 1 from SOS 1 and example 2 from SOS 2 falling somewhere in between. Based on the degree of succinctness, Example 3 from DRC is the most verbose, while Example 4 from DRM is the most succinct, with the other two examples occupying the middle ground. If we were to place the style of these four examples on a continuum from succinctness to verbosity, the relationship can be presented in the following figure.
In summary, the four examples exhibit distinct styles when evaluated by syntactic complexity. Example 4 from DRM demonstrates the highest degree of succinctness, while Example 3 from DRC reflects the lowest degree of succinctness. SOS 1 and SOS fall between DRM and DRC, with SOS 1 displaying greater succinctness than SOS 2. Additionally, the length of the sentences correlates with their stylistic succinctness: Example 4 from DRM is the shortest, and Example 3 from DRC is the longest, with SOS 1 and SOS 2 situated in between. Therefore, Example 4 from DRM exemplifies a more concise style, whereas Example 3 from DRC presents a more verbose style. Thus, it can be concluded that dependency relations serve as a useful metric for identifying translator styles, particularly when assessing the degree of succinctness.
Discussion
Previous studies have demonstrated that dependency grammar is an effective tool for typological analysis in translation studies (Fan & Jiang, 2019; Liang et al., 2017). Based on this, we hypothesized that dependency distance could reveal translator style. In the present study, we extended the application of dependency grammar to stylometric analysis, utilizing two key indicators—dependency distance and dependency direction—to differentiate translator styles. The results are discussed below in relation to the three research questions.
First, the findings reveal a statistically significant difference in dependency distance among the English translations of Hongloumeng under examination. As shown by the statistics in the previous section, the MDD values for DRC, SOS 1, SOS 2, and DRM are 2.5582, 2.4742, 2.3775, and 2.3158, respectively, all of which differ significantly from the MDD of native English texts (2.543, according to Liu, 2008). This result answers the first research question and part of the third research question, indicating that there is a significant variation in dependency distance among the four English translations of Hongloumeng. Furthermore, dependency distance can serve as a marker for distinguishing translator styles at the syntactic level, particularly with regard to the degree of succinctness.
Second, we found that, with the exception of the SOS 1 and SOS 2 pair, the other five pairs of English texts of Hongloumeng showed significant differences in dependency direction. This finding does not fully confirm the second research question, as it cannot be conclusively stated that there is always a significant difference in dependency direction across all four English translations of Hongloumeng. However, it is worth noting that SOS 1 and SOS 2 were expected to have similar styles, given that John Minford, the translator of SOS 2, had studied SOS 1 to ensure stylistic consistency (Zhu & Minford, 2017, pp. 51–52). Despite this effort, the analysis of dependency distance revealed a significant difference between SOS 2 and SOS 1, suggesting that translators inevitably imprint their unique style on their work, even when attempt to remain invisible.
Among the four English translations of Hongloumeng, three—DRC, SOS 1, and SOS 2—are by native English speakers: H. Bencraft Joly, a British vice-consul in Macao; David Hawkes, a British sinologist and translator, and John Minford, also a British sinologist and translator. The fourth, DRM, was translated by Yang Hsien-yi (Xianyi), a Chinese literary translator. In terms of the translators’ native languages, DRC, SOS 1, and SOS 2 are translations from L2 into L1 (from a second language into the translator’s first), while DRM is a translation from L1 into L2 (from the translator’s first language into a second). The findings of this reveal show that DRM, translated from L1 to L2, shows significant differences from the other three, particularly in terms of dependency distance (DD), with a much shorter mean dependency distance (MDD) than the others. A possible explanation for this sharp difference is the translation direction: DRM was translated into L2, while the others were translated into L1. Translation direction may thus have influenced this variation in dependency distance. Although some scholars, such as Fan and Jiang (2019), have demonstrated that dependency distance can distinguish translated texts from non-translated ones, no research to date has focused on whether dependency distance can distinguish L1 translations (those translated into the translator’s first language) from L2 translations (those translated into a second language). If we argue that translation direction can be distinguished through MDD, more evidence is needed, which will be the goal of our future research.
In addition to translation direction, time may also have influenced the differences in dependency distance. This study finds that DRC, translated in 1891, has a significantly longer MDD than the other three texts, which were translated much later: SOS 1 in 1973 (82 years later), SOS 2 in 1982 (91 years later), and DRM in 1978 (87 years later). A general tendency of decreasing MDD can be observed, from 2.5582 in DRC to 2.3158 in DRM. Previous studies have noted a minimization process in DD over time (Lei & Wen, 2019; Temperley, 2007, 2008). In this context, the decrease in MDD from DRC (2.5582) to SOS 1 (2.4742) could partially be explained by this minimization, as it reflects humans’ tendency to seek the least effort in communication. Thus, it can be hypothesized that time is a factor influencing translator style, as measured by dependency distance. To further explore this, a diachronic corpus would be necessary to investigate the effect of time on translator style.
Additionally, the factor of source text accessibility may have played a role. Although we eliminated the influence of the source texts themselves—all four translated texts were based on the same Chinese text, Hongloumeng—we did not consider the accessibility of source text. Our study did not explore whether a translator would produce translations with similar dependency relations when working from source texts of varying accessibility. To draw a more definitive conclusion about whether dependency relations can serve as indicators of translator style, further research is needed, particularly using a translational corpus that includes different source texts translated by the same translator.
Regardless of whether the differences in MDD among the four English translations of Hongloumeng are due to translation direction, the principle of least effort in human communication, source text accessibility, or other factors such as ideologies or communities of practice, it is clear that the four translations exhibit significant differences in MDD. This suggests that dependency distance can indeed serve as an indicator of translator style—at least for the four English translations of Hongloumeng.
Based on the above analysis and discussion, we propose that in the stylometric analysis of translator style, dependency relations—particularly dependency distance—can be considered an effective indicator, which we refer to as an implicit measure of translator style. In our view, measures of translator style in the stylometric approach fall into two categories: explicit measures and implicit measures. Explicit measures examine observable indicators that can be easily calculated manually or by computer, such as word length, sentence length, paragraph length, and typical language patterns. These require only one step of calculation. Implicit measures, on the other hand, examine indicators that are not directly observable and are difficult to be calculated manually. They require at least two steps of calculation, such as TTR (Type-Token Ratio), STTR (Standardized Type-Token Ratio), lexical density (LD), and MDD. For example, calculating MDD requires an initial a step of POS tagging, followed by syntactic parsing before the final MDD calculation. In most cases, implicit measures rely on natural language processing (NLP). Compared to explicit measures, implicit measures reveal hidden features of translator style that are beyond what can be detected by the naked eye.
Conclusion
Dependency distance is an effective indicator for measuring syntactic complexity (Oya, 2011; Lei & Wen, 2019). This study examined translator style from the perspective of syntactic complexity, using dependency distance and dependency direction as measurement indicators. Based on the analysis and discussion in the preceding sections, it can be confidently concluded that MDD (Mean Dependency Distance) is an effective indicator of translator style. In addition to MDD, DDI (Dependency Direction) can be considered a supplementary indicator for measuring translator style.
However, several limitations should be addressed in future research. First, the data used in this study consists of only four English translations of the Chinese novel Hongloumeng, which may be limited in both quantity and genre. Therefore, caution is required when considering the representativeness of the data and the generalizability of the findings. Future research should include a larger dataset spanning different genres and languages. Second, the dependency relations in this study were automatically annotated using the leoDDcalculator. Due to the large volume of data, only a portion of the parsed data was manually verified. Although some annotation errors were found during manual checks, they likely do not significantly impact the overall findings, given the relatively high accuracy of the calculator (Lei & Jockers, 2018).
Footnotes
Acknowledgements
The author would like to express sincere thanks to the anonymous reviewers and the editor for their thoughtful and detailed comments, which significantly enhanced the clarity and rigor of the paper.
Ethical Considerations
This article does not contain any studies with human or animal participants.
Author Contributions
The author is solely responsible for the conception, design, data collection, analysis, interpretation, and writing of this manuscript.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the China Postdoctoral Science Foundation [grant number 2023M730702]; the Center for Translation Studies of Guangdong University of Foreign Studies [grant number CTS202010]; the Humanities and Social Sciences Funds of Department of Education of Hubei Province [grant number 20G012].
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated and/or analyzed during the current study are not publicly available but are available from the author on reasonable request.