
Abstract
Data elements are profoundly transforming the innovation paradigm. However, ambiguities in data rights have significantly constrained firms’ ability to fully harness this potential. Taking China’s data rights confirmation policy as a quasi-natural experiment, this study employs the Random Forest method to examine the impact of data rights confirmation on the innovation performance of digital firms, using panel data from Chinese A-share listed companies from 2010 to 2022. The findings indicate that data rights confirmation enhances substantive innovation while inhibiting strategic innovation among digital firms. These effects are particularly pronounced in state-owned enterprises, firms located in economically developed regions, and areas with advanced digital inclusive finance, as clarified data rights help mitigate inefficiencies in state-owned enterprises and enable firms in advantaged regions to leverage data and resources more effectively for innovation. Mechanism analysis reveals three primary channels through which data rights confirmation promotes innovation: facilitating inter-firm data sharing, improving information processing capability, and stimulating digital consumption. Furthermore, data rights confirmation strengthens firm’s long-term innovative capability and generates spillover effects to non-digital firms via data circulation and knowledge diffusion. These findings highlight the critical need for establishing robust data rights policies and offer actionable insights for digital firms seeking to foster innovation effectively.
Plain Language Summary
Data is now a key driver of innovation, but unclear ownership rules often stop companies from using it effectively. When it is uncertain who can own, process, or share data, firms may be unwilling to cooperate or invest in new ideas. This study examines a Chinese policy that formally confirms data ownership and related rights. Using information from listed companies between 2010 and 2022, we compare innovation outcomes before and after the policy. We find that clear data rights encourage companies to create genuine, substantial innovations but reduce “strategic” innovations aimed mainly at short-term gains, such as collecting patents for appearance rather than real use. The positive impact is strongest for state-owned companies, firms in richer regions, and areas with advanced digital financial services. The policy works in three main ways: promoting data sharing among firms, improving their ability to process and use information, and increasing digital consumption. Clear data rights also help firms sustain innovation in the long term and produce benefits that spill over to non-digital companies. These findings suggest that strong, well-designed data ownership policies can make data more valuable, encourage collaboration, and support higher-quality innovation across the economy.
Introduction
Data has emerged as a fiercely contested strategic resource among countries, propelled by advances in machine learning algorithms and substantial gains in computational power (Jones & Tonetti, 2020; Y. Zheng and Dai, 2025). This explosion in data generation has fundamentally reshaped production processes and significantly impacted enterprise innovation (Y. Zhang et al., 2026). Distinct from traditional production factors, data is characterized by non-rivalry, a feature that challenges the applicability of the Coase theorem (Arpetti & Delmastro, 2021). While an extensive body literature has addressed data rights (Acemoglu et al., 2022; Zhong & Feng, 2025), a consensus on the optimal design of data rights frameworks remains elusive. This theoretical gap has resulted in fragmented data rights regimes across nations, thereby constraining the potential for data-driven innovation. Therefore, establishing a robust system for data rights confirmation is an urgent imperative.
According to forecasts by the International Data Corporation (IDC), China is projected to possess 48.6 zettabytes of data by 2025, accounting for 27.8% of the global total and positioning the country at the forefront of the world’s data economy. Given its massive data resources and the slowing momentum of economic growth, China issued the “Opinions on Building a Data Basic Institution to Better Utilize the Role of Data Elements” in 2022, emphasizing the promotion of data rights to unleash data value. Even prior to this national policy, several Chinese provinces and cities had already begun piloting data rights confirmation schemes to foster innovation among digital firms. Despite China’s leading role in data rights institutionalization and the potential global relevance of its experience, there remains limited literature examining the effectiveness of these policies. This research gap highlights the need for academic assessment of China’s approach, especially as major economies worldwide are actively exploring data governance frameworks. Such an evaluation would help clarify how data rights confirmation shapes innovation and provide insights for governing data-driven economies globally.
While existing literature acknowledges the role of data in shaping technological innovation (Y. Zhang et al., 2026) and its importance as a key driver for firms (M. Xiao et al., 2025), little is known about how formally establishing data rights affects innovation in digital firms. Yet, given the critical role of data rights in facilitating innovation, it is essential to understand the specific prerequisites required for innovation to thrive (Yang et al., 2024), including clear and legally defined data rights. Ambiguities in data rights can stifle innovation, risking a “tragedy of the commons,” whereas, overly strict private rights may cause a “tragedy of the anti-commons” (Ho, 2025; Zygmuntowski, 2023). China’s approach to data rights confirmation addresses this balance by delineating ownership, usage and revenue rights, thereby promoting data sharing and circulation. However, the impact of this approach on innovation remains underexplored. This paper examines the effects of data rights confirmation on digital firms in China, providing essential empirical evidence to elucidate this issue.
Most existing studies on the economic implications of data rights are theoretical, with some empirical literature drawing on “the General Data Protection Regulation (GDPR)” to evaluate the impact of personal data protection policies (Dorfleitner et al., 2023; Wu, 2024). While the EU’s GDPR emphasizes privacy protection—an approach that may constrain data circulation and inadvertently suppress innovation, China’s strategy focuses on facilitating enterprise data utilization through data rights confirmation to foster innovation. Although data rights confirmation aims to encourage data sharing, it may also create friction, as firms might hoard data to preserve market advantage (Bergemann & Bonatti, 2024). Furthermore, the non-rivalrous nature of data raises concerns about misuse (Miklós-Thal et al., 2023), leading consumers to protect their privacy and thus limiting data availability (Mazzarello et al., 2025). The unequal allocation of data rights may also create welfare disparities, depending on whether ownership is assigned to consumers or firms (Ali et al., 2023), and the optimal ownership structure remains debated (Markovich & Yehezkel, 2021). Given the absence of data rights confirmation in most countries (Dosis & Sand-Zantman, 2023), empirical evidence to validate these theoretical findings is scarce, leaving best practices unclear. This paper aims to address this gap by investigating the practical effects of China’s data rights confirmation policy.
Employing a quasi-natural experiment based on 14 provincial policies and annual data of Chinese digital firms from 2010 to 2022, this paper examines the impact of data rights confirmation on innovation. To mitigate potential endogeneity concerns, we use the synthetic control method and propensity score matching. Our findings indicate that data rights confirmation facilitated substantive innovation without increasing strategic innovation among digital firms. The positive effects operate primarily through three channels: fostering inter-firm data sharing, enhancing information processing capability, and stimulating digital consumption. The impact of data rights confirmation varies depending on enterprise ownership, regional economic development, and the level of digital inclusive finance. Further analysis also demonstrates that data rights confirmation can boost the long-term innovation potential of digital firms and generate positive spillover effects on non-digital firms.
This paper makes several important contributions. First, while prior studies on data rights have predominantly remained theoretical (Acemoglu et al., 2025; Dosis & Sand-Zantman, 2023), this paper provides novel empirical evidence by exploiting quasi-natural experiments from provincial-level policy pilots in China. This enables us to move beyond abstract theoretical debates and deliver concrete evidence on the innovation effects of data rights confirmation.
Second, unlike most empirical research that relies on privacy-oriented regulations such as the GDPR (Dorfleitner et al., 2023; Goldberg et al., 2024), our analysis focuses on China’s data rights confirmation, which emphasizes data utilization and circulation rather than strict data protection. This institutional contrast provides new insights into the global discourse on data governance and its connection with innovation.
Third, our causal inference utilizes the Random Forest algorithm, a nonparametric machine learning adept at capturing complex, nonlinear relationships with data. This flexibility is particularly suitable for analyzing data rights confirmation, a policy with multifaceted effects on digital firms’ innovation (Johnson, 2022; M. Xiao et al., 2024b). Compared with traditional Difference-in-Differences approaches, Random Forest relaxes restrictive functional form assumptions and more effectively controls for potential confounders, thereby enhancing the reliability of policy effect estimation.
Finally, this study highlights three key mechanisms: enhanced data sharing, improved information processing capability, and stimulated digital consumption—through which data rights confirmation fosters innovation in digital firms. This finding advances the theoretical understanding of data rights and provides practical insights for innovation decision-making. Furthermore, we show that data rights confirmation not only drives immediate innovation but also strengthens the long-term dynamic innovation potential of digital firms, thereby expanding the research perspective beyond the static focus prevalent in prior studies.
Institutional Background and Research Hypotheses
Institutional Background
Since the eighteenth CPC National Congress, China has actively pursued the strategy of network power and big data, elevating data to the status of the fifth major factor of production, alongside land, labor, capital, and technology. However, the ambiguity in data rights has led to market inefficiencies, hindering the full realization of data’s potential. Clear data rights confirmation is essential for fostering a functional data market; in its absence, both the creation of such a market and the effective utilization of data remain constrained. In response, several Chinese provinces have introduced data rights confirmation policies aimed at unlocking data’s potential and advancing the digital economy.
As a leader in China’s big data industry, Guizhou Province took an early initiative by issuing the “Promotion Regulations of Guizhou Province on the Development and Application of Big Data” in 2016. This regulation pioneered the registration of data rights and explored open bidding for data usage and operation rights. Following Guizhou’s lead, other provinces such as Tianjin, Hainan, and Guangzhou have enacted regulations focused on data openness, sharing, and rights protection. Meanwhile, regions such as Shanghai, Jiangsu, and Zhejiang issued policies concerning the management and opening of public data, offering valuable policy references for resolving data rights issues. By 2022, 14 provinces had enacted and implemented data rights policies. Appendix Table A1 provides a detailed description of the data rights confirmation policies and corresponding measures implemented by various provinces in China. Building on these regional efforts, the central government issued the “Opinions on Building a Data Basic Institution to Better Utilize the Role of Data Elements” on December 9, 2022. This document laid the foundation framework for national data governance, representing China’s first comprehensive, nationwide policy on data rights.
In general, China’s data rights confirmation exhibits three key characteristics. First, it demonstrates policy and legal innovation. The introduction of the “three-rights separation” framework—distinguishing data ownership, data processing and usage rights, and data product management rights—demonstrates a nuanced understanding of the unique attributes of data as a factor of production and represents a significant institutional innovation. Second, China places strong emphasis on data marketization. By establishing data trading platforms, developing pricing and transaction mechanisms, and promoting compliant and efficient data circulation, China is rigorously exploring ways to unlock the economic value of data. Third, China seeks to balance data security and development. While advancing data rights confirmation, the government underscores the importance of safeguarding data security and personal privacy, ensuring that data utilization aligns with risk mitigation. Consequently, China’s policy initiatives in data rights confirmation offer a unique quasi-natural experimental setting for empirical research.
Research Hypotheses Development
As the digital economy thrives and data becomes the new factor of production, firms are undergoing revolutionary transformations in their innovation approaches through big data applications (Ferrigno et al., 2025). Previous studies consistently show the significant impact of big data applications on innovation (Farboodi et al., 2022; Sivarajah et al., 2024), noting that its value in promoting innovation highly depends on the volume and quality of the data (Peukert et al., 2024). However, the Coase theorem fails in the realm of data (Arpetti & Delmastro, 2021), leading to the complexity of data rights confirmation in practice. Accordingly, no country has yet established a unified legal framework for data rights. This regulatory ambiguity exposes firms to considerable policy risks when collecting, processing, and trading data, which in turn limits the improvement of data scale and quality. Ultimately, these limitations restrict the role of big data applications to fully promote the innovation in digital firms (C. Zheng et al., 2024).
China’s data rights confirmation system represents an innovative institutional approach to defining data rights. By shifting the focus from ownership to usage rights, the framework prioritizes data circulation and sharing. This emphasis is critical, as facilitating data flow supports value transfer and co-creation, which in turn enhances enterprise innovation (Yu et al., 2023). Although data rights confirmation, such as regulations that enhance privacy protection, may restrict enterprises’ collection of consumer information (Johnson, 2022), it also reduces the legal risks for businesses by establishing clear rules on which data can or should be utilized for innovation. Moreover, by granting enterprises rights to process, analyze, and trade data, data rights confirmation reduces transaction costs in data utilization, such as those involved in negotiations, contracting, and enforcement (Zhao et al., 2025). Equally important, the assurance of stable rights incentivizes firms to undertake long-term, innovation-oriented investments, since they can internalize the returns from data-driven R&D rather than facing the risk of expropriation or free-riding (Jones & Tonetti, 2020).
It is important to note that many policies in China, often shaped by government intervention, have been criticized for potentially leading to “government failure” (Wei et al., 2026). For example, a number of innovation-oriented policies have failed to yield high-quality results (Branstetter & Li, 2022) and have instead incentivized firms to adopt strategic innovation, resulting in low-quality innovation (Z. Zhang et al., 2024). The primary purpose of enterprises implementing strategic innovation is to pursue tax incentives or government subsidies (Song & Wen, 2023). In contrast, data rights confirmation does not provide direct or indirect subsidies, thereby eliminating the incentive for low-quality innovation. Additionally, it facilitates the circulation and sharing of data, helping to break down “data silos” and increase the market competition. In line with the “Escape competition effect” (Aghion et al., 2018), increased competitive pressure can motivate firms to enhance their competitiveness through technological and product innovation. This mechanism further contributes to substantive innovation growth within enterprises. Therefore, we propose the following research hypothesis:
This study examines the mechanisms through which data rights confirmation influences innovation in digital firms from three distinct perspectives, as illustrated in Figure 1.
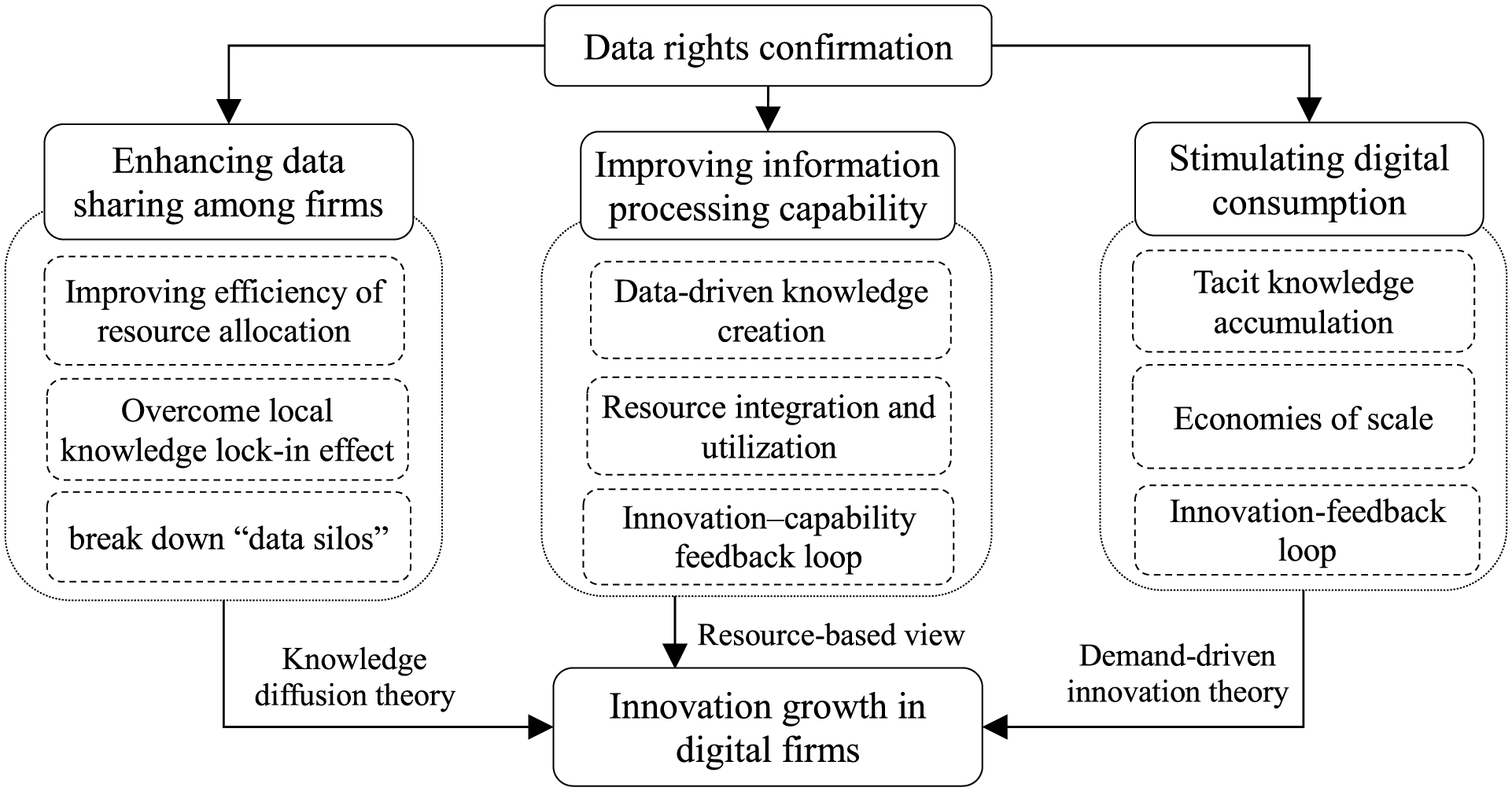
Theoretical analysis framework.
Data possesses non-rivalrous characteristics, making it easily open-sourced, shared, copied, and recombined (Jones & Tonetti, 2020). However, data sharing may infringe upon third party interests, creating significant obstacles (Ali et al., 2023). Data rights confirmation helps overcome these obstacles by clarifying rights and obligations, thereby protecting the interests of all parties and encouraging sharing. On the one hand, it alleviates firms’ concerns by establishing “exemption clauses” (Mylly, 2024). For instance, Shanghai’s data rights policy includes such clauses that limit liability under certain conditions, weaking firms’ reluctance to share. On the other hand, data rights confirmation requires enterprises to strengthen data protection measures—such as anonymizing personal information—to prevent data leaks or misuse (Z. Wang, 2026), which in turn lowers resistance to sharing. Furthermore, by enabling data to be managed and traded as an asset, data rights confirmation legitimizes enterprises’ claims to data-derived benefits (Acemoglu et al., 2022). The prospect of generating revenue through data sharing provides a strong economic incentive for firms to engage actively in data circulation.
Based on knowledge diffusion theory, data sharing can enhance the accessibility and circulation of knowledge, creating broader opportunities for innovation in digital firms (Yu et al., 2023). First, data sharing enables data to be produced once and reused multiple times across different entities (Qin et al., 2025), improving resource allocation efficiency and unlocking the full innovative potential of data. Second, it not only enables firms to leverage complementary data resources but also facilitates deeper technological exchanges, sharing, and collaboration (Di Dio & Correani, 2019). Such interactions help overcome local knowledge lock-in and strengthen firms’ innovation capability (Foerderer, 2020). Additionally, by breaking down “data silos” and intensifying market competition, data sharing motivates digital firms to enhance their innovation efforts—consistent with “Escape competition effect.” For example, Jones and Tonetti (2020) found that data sharing can increase the likelihood of disruptive innovation, thereby greatly improving the quality of innovation. Based on this, the following hypothesis is proposed:
According to real options theory (J. Li & Wang, 2026), ambiguity in data rights leads to significant policy uncertainty in data processing, and the subsequent fluctuations in cost and risk can suppress digital firms’ willingness to use digital resources. Data rights confirmation enables enterprises to better understand the legal requirements for data use, reducing the legal risks associated with non-compliant data usage (Martin et al., 2019), and encouraging innovation in data collection, processing, and analysis.
As enterprises leverage an increasing volume of data, they gain experience that enhance their information processing capability (W. Jiang and Li, 2024). Improved capability, in turn, supports the generation of reusable knowledge through in-depth mining and forecasting based on massive datasets (Cong et al., 2021), thereby enhancing the innovation capability and efficiency of digital firms. For example, by analyzing consumption big data, digital enterprises can predict demand trends and more accurately determining the orientation of innovation. Moreover, according to the resource-based view and strategic perspectives, competitive advantage stems not only from possessing superior resources but also from utilizing existing resources more effectively (Nie et al., 2024). Strengthened information processing capability allows firms to better integrate existing resources, thereby providing enhanced support for data-driven innovation (J. Xiao et al., 2024a). More importantly, a positive feedback loop exists between information processing capability and innovation: enhanced information processing promotes innovation, which yields higher quality-data, and this improved data further elevates the firm’s innovation capability (Farboodi et al., 2022). Based on the above, this study proposes the following hypothesis:
Based on demand-driven innovation theory, demand embodies tacit knowledge in local culture, institutions, and social contexts (Bağci et al., 2026). Firms can absorb and integrate such knowledge from consumer demand to generate creative ideas and guide innovation. Consumer activities generate substantial data (Jones & Tonetti, 2020), and through in-depth analysis of such data, firms can more accurately identify consumer preferences and market trends, thereby increasing the likelihood of successful innovation (Ferrigno et al., 2025). However, as an information carrier, data is subject to inherent information asymmetry. Data providers often cannot anticipate how their data will be used or whether it will be misused (Z. Wang, 2026), which limits the potential of consumer data to fully support innovation.
Data rights confirmation emphasizes protection of personal data privacy, thereby strengthening consumer trust in digital products and services (Quach et al., 2022). An expanded market size not only generates economies of scale—enabling digital enterprises to allocate more resources to innovation—but also allows them to diversify product lines and spread innovation-related risks (Aghion et al., 2018). Additionally, robust data protection increases consumers’ willingness to share personal information, supplying firms with richer data for innovation (Niebel, 2021). By analyzing these data, companies can deliver personalized products and services (Micus et al., 2023), which in turn enhances consumer purchase intention and reinforces the innovation-feedback loop.
Based on the above, data rights confirmation enhances consumer trust and digital consumption, while the resulting economies of scale and richer consumer data jointly foster innovation in digital firms. Accordingly, the following hypothesis is proposed:
Research Design
Data
We define digital firms according to the “Statistical Classification of Digital Economy and Its Core Industries (2021)” issued by the National Bureau of Statistics of China. The financial data for these firms is sourced from the China Stock Market & Accounting Research (CSMAR) database, while innovation data is obtained from the China Patent Database. We process the raw data as follows: (i) remove samples with abnormal or missing values in key variables; (ii) retain only firms classified as digital. After all processing steps, the final panel consists of 9,709 firm-year observations for the period 2010 to 2022.
Random Forest Approach
Traditional matching methods can yield biased outcomes due to the choice of matching variables. In contrast, the Random Forest method offers several advantages for our analysis. By leveraging an ensemble of decision trees, it effectively addresses multicollinearity and panel data imbalances through an intelligent weighting of neighboring observations, thereby reducing dependence on subjective variable selection. This approach enhances predictive accuracy and mitigates bias from manual specification. Additionally, the inherent randomness in construction of the forest allows it to handle noisy and missing data. This method is also less prone to overfitting and demonstrates strong robustness, rendering it a superior choice for complex datasets. Compared to this, traditional Difference-in-Differences methods are less suitable, as they typically assume linear and homogeneous treatment effects, potentially failing to capture the complex, non-linear heterogeneity in firms’ innovation responses to data rights confirmation.
The specific estimation of the Random Forest approach is as follows: Xi represents the feature space, Yi∈R represents the response value, and Wi is the treatment variable, forming a set of n independent and identically distributed observations (Xi,Yi,Wi ), i = 1,2,3 ~ n. There are two potential outcomes in the model: Y(0) i denotes the outcome value when individual i does not receive the treatment, and conversely, Y(1) i denotes the outcome when individual i receives the treatment. The average treatment effect (ATE) is then defined as:

Since only one potential outcome can be observed for each individual, τ(x) cannot be directly estimated by Random Forest. Considering this, it is standard practice to impose the non-confounding assumption on the data, stating that in the feature space Xi, the potential outcomes Yi are independent of the treatment variable Wi. Thus, based on the non-confounding assumption, it can be derived that:

Where e(x) denotes the probability of receiving the treatment at x. Wager and Athey (2018) indicate that under the regularity condition, without explicitly estimating the propensity e(x), consistent estimates can be obtained by using non-confounding assumptions. The specific approaches are as follows: (i) build a CART regression tree and continuously, recursively partition the feature space until it is divided into a causal tree containing L leaf nodes; (ii) given test points x, identify the leaf nodes L(x) which are used to predict
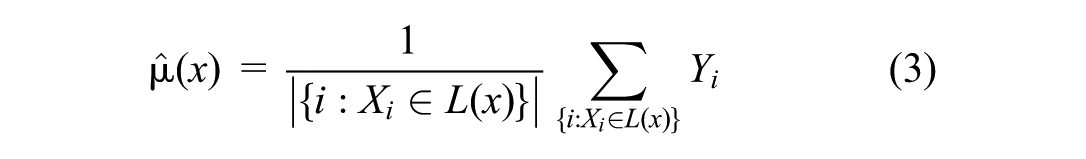
Observations are considered to have passed the randomized test when the leaf nodes are small enough. Next, we estimate the mean on each leaf node, and then calculate the difference between the two types of means. Finally, an estimate of ATE can be obtained based on Equation 4.

In this paper, Wi denotes the indicator for data rights confirmation, which is equal to 1 in year t and subsequent years if the province where the firm is located implements data rights confirmation policies in year t, and 0 otherwise. Details of the model parameter settings are provided in Appendix Table A2.
Variables
Innovation of Digital Firms
China’s Patent Law delineates three distinct categories of patents: invention patents, utility model patents, and design patents. Among these, invention patents are typically regarded to be of higher quality, as they require a higher degree of innovation and practicality, and undergo more thorough examination processes. Following previous studies, we measure innovation in digital firms using the number of patent applications, categorized into three types: invention patents (Innovation), utility model patents (Innovation1), and design patents (Innovation2). Following the distinction made by Z. Zhang et al. (2024), we categorize innovation into substantive and strategic types. Substantive innovation aims at technological advancement and competitive advantage, while strategic innovation focuses on upgrading patent system to meet policy or regulatory requirements. Accordingly, based on China’s patent law and relevant literature (H. Jiang et al., 2025), we employ the number of invention patent applications as a proxy for substantive innovation and the number of applications for utility model patents and design patents to measure strategic innovation. To mitigate the impact of zero patent applications in our empirical models, we apply the natural logarithm of one plus the patent application count in all empirical models.
Treated Variable
In our Random Forest analysis, we incorporate an interaction term, treat × post, to capture the effect of the treatment. The binary variable treat equals 1 for firms located in provinces that have enacted data rights confirmation policies (treated group), and 0 for those in provinces without such policies (control group). The variable post indicates the time period relative to policy implementation, taking the value of 1 for the implementation years and subsequent years, and 0 otherwise. Since Guangdong Province implemented the policy in July, whereas all other provinces introduced their policies in the first half of the year, we uniformly classify the implementation year as the post period.
Control Variables
In line with existing studies (Shi et al., 2023; M. Xiao et al., 2025; Yang et al., 2024), we control for several key variables to account for potential confounding factors. These variables include firm size (Size), measured as the natural logarithm of total assets, and firm value (TobinQ), represented by Tobin’s Q. We also control for capital structure (Leverage), defined as the gearing ratio, and cash flow (Cash), measured as the ratio of cash and cash equivalents to current liabilities. Additionally, we include the current ratio (Flow), measured as the ratio of current assets to liabilities, and profitability (Roa), calculated as the ratio of net profit to total assets. Finally, we control for firm age (Age), defined as the number of years since the firm’s establishment. To mitigate the influence of outliers, all continuous variables are winsorized at upper and lower 1%.
Descriptive Statistics
Table 1 presents the descriptive statistics for the main variables. The mean value of firms’ substantive innovation (Innovation) is 1.788, with a maximum of 6.852, a minimum of 0, and a standard deviation of 2.032. These statistics reveal significant variability in innovation performance among digital firms, suggesting that some firms are highly innovative while others demonstrate limited innovation output. This variation underscores the importance of exploring the determinants of innovation disparities, particularly the role of data rights confirmation.
Descriptive Statistics of Key Variables.

Furthermore, this paper categorizes samples based on the presence of data rights confirmation policies and performs a t-test to compare the mean innovation values between treated and control groups. As shown in Table 2, the mean values of both substantive and strategic innovations for digital firms in regions with such policies are significantly higher than those in non-policy regions, at the 1% significance level. These findings provide preliminary statistical evidence supporting the potential innovation-enhancing effect of data rights confirmation for digital firms. However, establishing rigorous causality requires further analysis.
The Results of t-Test.

Significance at the 1% level.
Results and Discussion
Baseline Results
The baseline results are presented in Table 3. As shown in Column (1), data rights confirmation leads to a significant increase in the number of invention patent applications, indicating a positive influences on substantive innovation at the 1% significance level. In contrast, columns (2) and (3) reveal that data rights confirmation has negative effect on utility model patents and design patents, although the effect on utility model patents is not statistically significant. These findings suggest that data rights confirmation fosters substantive innovation while curbing strategic innovation.
Results of Benchmark Regression.

Note. Standard errors in parentheses, ** and *** denote 5% and 1% significance levels, respectively.
Our findings support the Porter Hypothesis, which posits that well-designed regulations can stimulate higher-quality innovation (Warthon, 2025), a similar effect appears to arise from the implementation of data rights regulation. This contrasts with the findings of Blind et al. (2024), who argue that the EU’s data regulation has encouraged low-quality innovation at the expense of high-quality innovation. A key explanation for this divergence may lie in how data rights are allocated (Jones & Tonetti, 2020). EU data regulation emphasizes the protection of individual data privacy rights, while China’s approach prioritizes enabling data utilizing and sharing by firms This confirms the insight by Zhao and Wu (2025) that “data access” may be more important than “data ownership.” Additionally, variable importance analysis shows that firm age has the greater impact on innovation, the current ratio has the least impact, and the other control variables fall in between.
Figure 2 illustrates the impact of data rights confirmation on the innovation of digital firms in the form of a spectrum chart. Compared with strategic innovation (utility model patents and design patents), the treatment effect of data rights confirmation on substantive innovation (invention patents) is more significantly distributed to the right of the 0 value, further indicating that data rights confirmation can promote the growth of substantive innovation and suppress strategic innovation.

Heterogeneous treatment effect: (a) invention patents. (b) utility model patents. (c) design patents.
Robustness Tests
Replace the Dependent Variables
Firstly, we measure substantive innovation by the number of granted invention patent, and assess strategic innovation by the granted number of utility model and design patent. Table 4 shows that data rights confirmation significantly enhances substantive innovation and negatively affects strategic innovation. These results are consistent with our baseline findings, further reinforcing that data rights confirmation promotes substantive innovation while potentially inhibiting strategic innovation.
Robustness Test: Replacing the Dependent Variables.
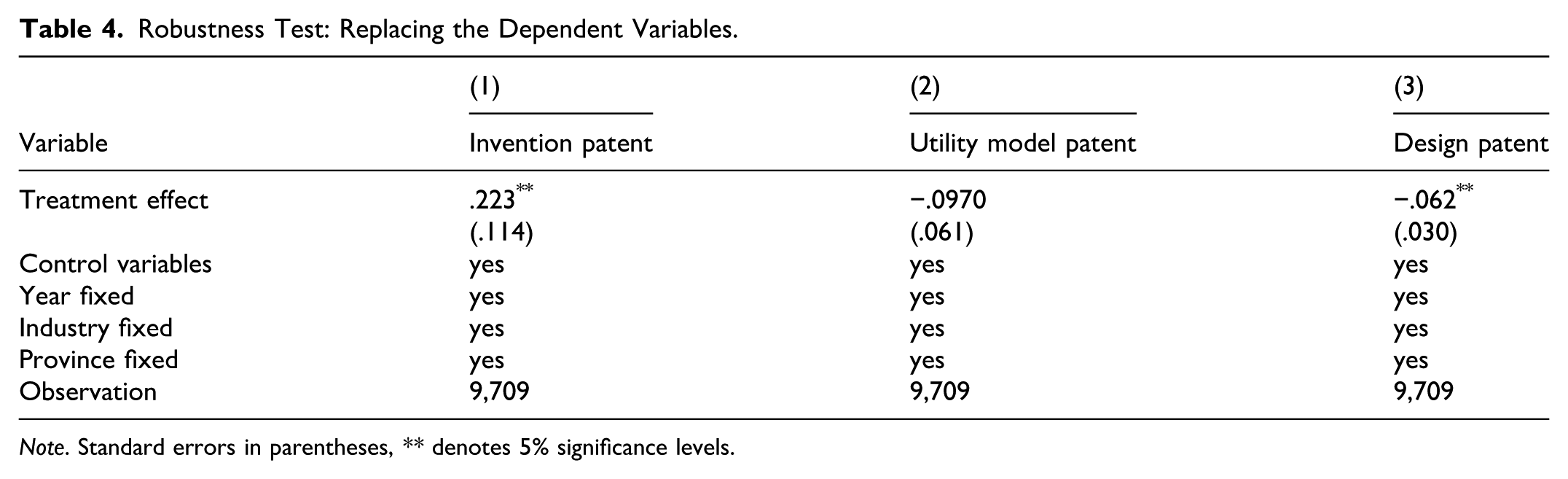
Note. Standard errors in parentheses, ** denotes 5% significance levels.
Synthetic Control Method
We employ the Synthetic Control Method (SCM) to conduct a robustness test. This approach accounts for unobserved time-varying confounders by constructing a weighted counterfactual unit, thus addressing potential biases related to the time span (Papyrakis et al., 2025). Guizhou, recognized as China’s “data center,” was the first province to implement data rights confirmation and serves as an ideal case for this analysis. We treat digital firms in Guizhou as the treatment group, and firms in regions without such data rights policies as the control group. Figure 3 illustrates the comparative innovation trends of digital firms in Guizhou alongside the synthetic control group from 2010 to 2021, visually representing their evolution over time.

Changes in innovation of digital firms in Guizhou and synthetic Guizhou: (a) substantive innovation and (b) strategic innovation.
Data rights confirmation was implemented in Guizhou in March 2016. To illustrate protentional lagged effects, we designate 2017 as the policy implementation year in our analysis. The policy’s impact on the innovation of digital firms is evident in the post-2017 divergence of innovation trends between Guizhou and the synthetic control. Before the policy, substantive and strategic innovations in both regions were comparable. However, post-implementation, Guizhou’s digital firms experienced a significant increase in substantive innovations compared to the synthetic control, while strategic innovations in the synthetic Guizhou surpassed those in the actual region. These results indicate that data rights confirmation in Guizhou has promoted substantive innovation and potentially reduced strategic innovation, aligning with our baseline findings.
Event Study Method
For provinces other than Guizhou that have implemented data rights confirmation policies, we employed the event study method to analyze the policy’s dynamic effects, thereby enhancing the robustness and broader applicability of our findings. Figure 4 illustrates that data rights confirmation exerted a significant influence in the immediate period following its implementation and continued to show a substantial, positive effect over the long term.

Substantive innovation dynamic effects.
Propensity Score Matching
We use Propensity Score Matching (PSM) to select digital enterprises that satisfy the ex-ante parallelism assumption, thereby mitigating selection bias. We use TobinQ, Leverage, Cash, Flow, Roa, Size, and Age as matching variables. Using a caliper width of .01, we apply PSM to estimate the probability p of each digital enterprise receiving treatment. By using a 1:2 nearest-neighbor matching, we ensure the propensity scores p are as close as possible. Finally, through a Random Forest analysis, we find that data rights confirmation significantly promotes the growth of substantive innovation, consistent with our earlier findings, as shown in Table 5.
Robustness Test: PSM.

Note. Standard errors in parentheses, * denotes 10% significance levels.
Replace the Explanatory Variable
This section exploits the pilot policy on Data Intellectual Property Rights (DIPR) to further test the innovative effects of data rights confirmation. In 2021, the State Council launched the development of DIPR protection rules and initiated a nationwide DIPR protection project. Subsequently, the DIPR pilot policy was officially implemented in 2022, designating Beijing, Shanghai, Jiangsu, Zhejiang, Fujian, Shandong, Guangdong, and Shenzhen as pilot regions. The policy refines the framework of data rights confirmation by establishing a DIPR registration system that emphasizes compliance and clear ownership. By employing this pilot policy as a quasi-natural experiment, we re-examine the role of data rights confirmation in fostering innovation
The event study method was first employed to observe the dynamic changes in innovative effects before and after the implementation of the DIPR policy. Figure 5 shows that the innovative effects of the DIPR policy became significant one period before the policy implementation. Thus, the pilot regions were designated as the treatment group with treat1 set to 1, while the remaining regions were assigned as the control group with treat1 set to 0. The year 2021 was selected as the policy node, and for the years 2021 and thereafter, post1 was set to 1, otherwise it was set to 0. The interaction term treat1 × post1 measures the treatment effect of data rights confirmation.

The dynamic innovative effects of the DIPR.
The estimation results from the random forest model are presented in Table 6. The results in columns (1) to (3) indicate that, compared with non-pilot cities, the number of invention patent applications by digital economy enterprises in DIPR pilot cities significantly increased, while the number of utility model and design patent applications decreased. This suggests that data rights confirmation can promote substantive innovation and avoid strategic innovation.
Robustness Test: Replace the Explanatory Variable.

Note. Standard errors in parentheses, * denotes 10% significance levels.
Possible Channels
Enhancing Data Sharing Among Firms
Data sharing involves making data resources accessible to multiple applications, users, or organizations. Due to the lack of direct indicators for inter-firm data sharing, this study uses the “digital cohort effect” as an indirect proxy. This effect captures the phenomenon whereby firms within the same industry or region enhance their digitalization and innovation capability through shared data, experiences, and resources.
Following Grennan (2019), we quantify the “digital cohort effect” by assessing the digital transformation of peer enterprises, with a stronger effect indicating a higher level of data sharing. This assessment is conducted in two steps: First, we measure the extent of digital transformation for each firm by counting keywords across four dimensions—digital technology application, internet business models, intelligent manufacturing, and modern information systems—in the annual reports of listed companies. The total keyword count is then log-transformed after adding one to adjust for zero values. Second, we compute the industry-level “digital cohort effect” (Share A), as the average digital transformation score of other enterprises within the same industry. Similarly, the regional-level “digital cohort effect” (Share B) is calculated as the average digital transformation of other enterprises located in the same province.
Columns (1) and (2) of Table 7 indicate that data rights confirmation significantly enhances both Share A and Share B. Given the established notion that data sharing can promote innovation (Yu et al., 2023), these findings suggest that data rights confirmation may foster innovation by enhancing data sharing among firms. It is worth noting that the regional homogeneity effect is much stronger than the industry homogeneity effect. This likely reflects the active role of local governments in China in promoting regional data platforms, which facilitate data sharing more effectively at the regional level than at the industry level.
Mechanism Test: Enhancing Data Sharing.

Note. Standard errors in parentheses, *** denotes 1% significance levels.
If the above conclusion holds, it logically follows that the impact of data rights confirmation on digital firms’ innovation should be more pronounced in regions with higher levels of data sharing. Based on the “China Government Data Governance Development Report (2021),” which classifies cities according to the frequency of data sharing demands, we divide our sample into digital firms located in cities with high-frequency sharing demands and those in cities with low-frequency sharing demands. Columns (3) and (4) of Table 6 show that data rights confirmation significantly promotes the innovation of digital firms in highly data-sharing cities, while the impact is not significant in cities with less data sharing.
Existing literature confirms that communication between firms can stimulate innovation (Foerderer, 2020). Yu et al. (2023) reinforces this notion by demonstrating how data sharing among firms can enhance innovation. Collectively, these studies validate the proposition that data rights confirmation improves data sharing, which in turn promotes the innovation of digital firms, thereby supporting Hypothesis 2.
Improving Information Processing Capability
Information processing capability refers to an organization’s ability to collect, interpret, synthesize, and disseminate information effectively, thereby addressing uncertainties (Huang et al., 2014). In other words, it reflects a firm’s ability to process the right amount of required information in a timely and accurate manner. Following X. Zhang et al. (2023), we measure this capability using the net value of hardware and software capital investment.
Hardware capital is calculated as the net value of a firm’s electronic, communication, and computer equipment, while software capital is similarly defined based on the net value of software assets. As shown in columns (1) and (2) of Table 8, data rights confirmation significantly bolsters the information processing capability of digital firms. Given that textual analysis is widely used in economic research, especially for measuring digitalization-related indicators using the annual reports of listed companies (Yang et al., 2024), we employ a comprehensive approach to measure firms’ information processing capability, which includes analyzing the frequency of specific keywords related to artificial intelligence, big data, digital technology applications, and modern information systems in the annual reports of listed companies. These dimensions encompass the breadth of technological capability that contribute to a firm’s ability to process information. The capability is quantified using the natural logarithm of the total keyword frequency, incremented by one to adjust for zero values. The results presented in columns (3) and (4) of Table 8 confirm that the positive effect of data rights confirmation on information processing capability is statistically significant.
Mechanism Test: Improving Information Processing Capability.
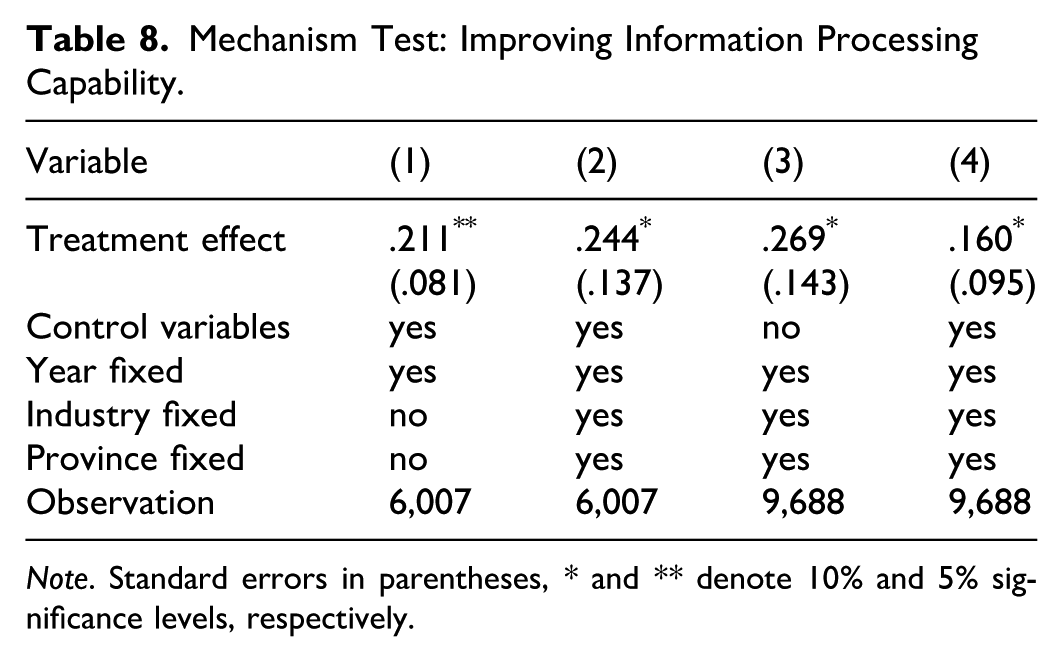
Note. Standard errors in parentheses, * and ** denote 10% and 5% significance levels, respectively.
The above conclusion supports the view that property rights policies can influence firms’ investment in productivity-enhancing activities (Alquist et al., 2022). Data rights confirmation can motivate enterprises to increase investments related to data processing, thereby enhancing their information processing capability. W. Jiang and Li (2024) demonstrate that enhanced information processing capability leads to improved decision-making and resource allocation, thereby enabling data-driven innovation (L. Li et al., 2024). Consequently, Hypothesis 3 is confirmed: data rights confirmation fosters the innovation of digital enterprises by enhancing their information processing capability.
Stimulating Digital Consumption
Following Hu and Hou (2024), digital consumption is measured using the digital payment indicator from “Digital Inclusive Finance Index,” published by Peking University. Column (1) of Table 9 demonstrates a significantly positive treatment effect, indicating that data rights confirmation promotes digital consumption, which in turn enhances the innovation of digital firms. If this mechanism holds, the innovation-enhancing effect of data rights confirmation should be stronger in regions with more developed digital consumption.
Mechanism Test: Stimulating Digital Consumption.

Note. Standard errors in parentheses, * and *** denote 10% and 1% significance levels, respectively.
Using the average value of digital payment indicators, we classify regions into high and low digital consumption groups. Regions with values above the mean are designated as high-level areas, while those below are considered low-level areas. As shown in columns (2) and (3) of Table 9, data rights confirmation significantly boosts the innovation of digital firms within regions of high digital consumption. In contrast, the effect is not significant in regions with lower levels of digital consumption.
The above findings indicate that data rights confirmation fosters innovation by stimulating digital consumption. This aligns with the insights of Blind et al. (2024), who found that data rights confirmation can cultivate consumer trust in the digital economy, increasing demand for digital consumption, and Martin et al. (2019), who revealed that the increased demand can lead to market expansion, ultimately enhancing the returns on innovation.
Heterogeneity Test
Ownership
State-owned enterprises (SOEs) and non-state-owned enterprises (non-SOEs) differ markedly in terms of resource and governance structures, which may lead to variation in their innovation response. This study classifies digital firms into SOEs and non-SOEs and regress the number of invention patent applications on the dependent variable. Columns (1) and (2) of Table 10 show that data rights confirmation significantly enhances innovation among SOEs. This can be attributed to the typical definition of general property rights in SOEs, which makes the clarification of data rights particularly impactful in mitigating inefficiencies, strengthening governance of digital assets, and promoting more targeted R&D investment to drive innovation.
Results of Heterogeneity Tests.
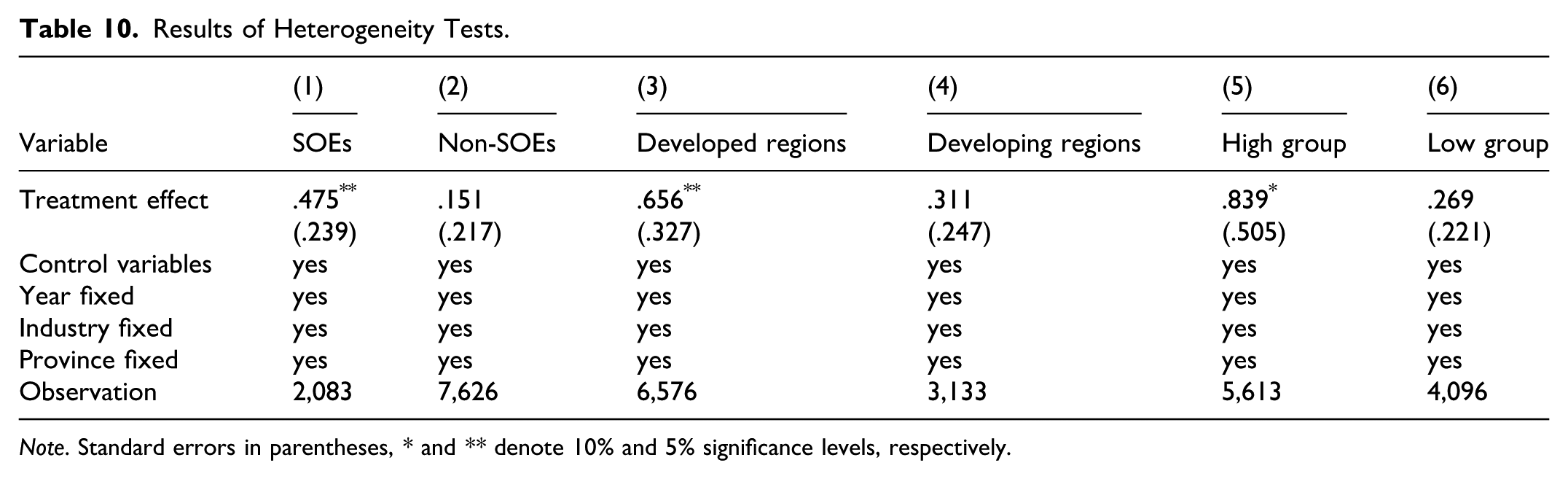
Note. Standard errors in parentheses, * and ** denote 10% and 5% significance levels, respectively.
Economic Development
Innovation is intrinsically linked to economic development. Accordingly, this study categorizes firms into those located in developed regions (with GDP per capita above the average) and those in developing regions (with GDP per capita below the average). As shown in columns (3) and (4) of Table 10, the positive treatment effect of data rights confirmation on innovation is significant only in developed regions, where firms benefit from superior infrastructure, a more skilled workforce, and stronger collaborative networks, enabling them to leverage clarified data rights more effectively to drive innovation.
Digital Financial Inclusion
Digital finance can support innovation by broadening firms’ access to financial resources (Liu & Si, 2025). We assess digital financial inclusion at the city level using the “Digital Inclusive Finance Index.” Firms in cities with a digital financial inclusion level above the median are classified as the high group, while other firms are classified as the low group. Columns (5) and (6) of Table 10 indicate that the treatment effect of data rights confirmation on the innovation of digital firms is significant in regions with high levels of digital financial inclusion but not in regions with lower levels. This discrepancy may arise because access to digital financial services not only alleviates financing constraints but also facilitates data acquisition and utilization, thereby enhancing firms’ capacity to innovate.
Further Analyses
Spillover Effects of Data Rights Confirmation
The existing literature widely acknowledge that the digital economy generates substantial spillover effects (L. Li et al., 2024). This consensus prompts an important inquiry: whether data rights confirmation can similarly produce spillover effects on innovation in non-digital firms. To explore this, we adopt the methodology of Kim et al. (2020), applying the Random Forest method to a sample of non-digital firms.
Column (1) of Table 11 reveals a significant increase in invention patent applications for non-digital firms subsequent to data rights confirmation. Furthermore, as shown in columns (2) and (3), strategic innovations within these firms also exhibit a positive impact. These findings indicate that the benefits of data rights confirmation spill over to non-digital firms, likely through improved data circulation and knowledge diffusion in digital firms, which non-digital firms can leverage. These findings underscore the additional benefits of data rights confirmation. As Geng et al. (2023) have emphasized, the government should consider these additional benefits when formulating policies.
Further Analysis: Spillover Effects.

Note. Standard errors in parentheses, * denotes 10% significance levels.
Long-term Innovative Capability
In this section, we further explore how data rights confirmation influences the long-term innovative capability of digital firms. Long-term innovative capability, as a critical intangible asset, is a defining element of a firm’s dynamic capability. It signifies the firm’s ability to reconfigure resources over time, thereby achieving sustained innovation and development. Drawing on C. L. Wang and Ahmed (2007), we assess long-term innovative capability through three key indicators. Creative capability captures a firm’s ability to generate new ideas and products, measured by the annual R&D intensity and the proportion of technical personnel. Both indicators are standardized and then summed to form a composite score. Absorptive capability reflects a firm’s capacity to acquire and integrate external knowledge and technologies, proxied by R&D expenditure intensity, defined as the ratio of annual R&D spending to operating revenue. Adaptive capability represents a firm’s responsiveness to market shifts, measured by the coefficient of variation of three major annual expenditures—R&D, capital investment, and advertising—capturing the flexibility in resource allocation.
Table 12 demonstrates that data rights confirmation positively affects multiple innovation-related indicators, exerting a notably strong influence on creative and adaptive capability. These results indicate that data rights confirmation is instrumental not only in catalyzing immediate innovation but also in reinforcing the underlying capability essential for sustaining and amplifying a firm’s innovative potential over time. This underscores the pivotal role of data rights confirmation in enabling firms to develop and implement sustainable innovation strategies. These conclusions are consistent with the study by Blind et al. (2024), which emphasizes the need for continued investigation to understand the full extent of the effects of data rights policies on innovation dynamics.
Further Analysis: Longer-Term Potential Innovation Capability.

Note. Standard errors in parentheses, * and *** denote 10% and 1% significance levels, respectively.
Conclusion
This paper examines the relationship between data rights confirmation and the innovation of digital firms using Random Forest model on data from Chinese A-share firms from 2010 to 2022. The research findings highlight the pivotal role of data rights confirmation in enhancing substantive innovation while simultaneously curbing strategic innovation in digital firms. This impact is particularly pronounced in state-owned enterprises, firms located in economically developed regions, and areas with high levels of digital inclusive finance. These results provide novel empirical evidence for institutional innovation theory, suggesting that effective data governance frameworks are essential for unlocking the full potential of data as a strategic resource.
Mechanism analysis suggests that data rights confirmation enhances the innovation of digital enterprises by enhancing inter-firm data sharing, improving information processing capability, and stimulating digital consumption. These mechanisms highlight that the primary purpose of data rights confirmation is to activate the data market, rather than focusing solely on data ownership.
Further investigation indicates that data rights confirmation not only bolsters the long-term innovation capability of digital firms but also generates positive spillover effects for non-digital firms. These findings align with externality theory, highlighting the broader effects of policy interventions, and underscore the complexity of data governance policy evaluation, particularly in assessing cross-sector spillover effects, as well as both immediate and prospective consequences.
In light of the findings from this research, we propose the following recommendations. First, it is urgent to establish a comprehensive data rights framework that clarifies ownership while facilitating effective data utilization. Policymakers could design specific mechanisms, such as data sharing exemption clauses. These clauses would legally permit the exchange of non-sensitive data among firms. Additionally, they could implement data pricing mechanisms that provide clear incentives for data trading and licensing. Such measures would foster data circulation while safeguarding legal compliance. Second, policies should help firms leverage data and promote structured data sharing, with clear legal guidelines to manage risks and protect proprietary rights. The integration of privacy-enhancing technologies such as secure multi-party computation and differential privacy can help balance data utilization with privacy protection, strengthen consumer trust, and stimulate digital innovation. Finally, while our empirical analysis focuses on Chinese firms, the underlying mechanisms, which include enhancing data sharing, improving information processing capability, and stimulating digital consumption, may be relevant across contexts. Other countries exploring data governance reforms can draw lessons from China’s experience and adapt these policy tools to their institutional and market contexts.
There may be some possible limitations in this study. First, while the Causal Forest results are robust for the dataset of Chinese A-share listed companies, they may exhibit heightened sensitivity to the dataset’s specific characteristics, potentially affecting their generalizability across different datasets. Future research should integrate machine learning techniques with traditional econometric methods and extend the analysis to include diverse types of firms and national contexts. Second, while we identify key mechanisms such as data sharing and information processing capability, our measurement remains indirect and may not capture all aspects. Future research could adopt more direct measures, such as transaction platform or survey data, and employ qualitative case studies to further examine the underlying processes. Lastly, the interplay between emerging technologies like artificial intelligence and blockchain, and their impact on data rights confirmation, warrants investigation. Future studies might examine how these technologies shape the mechanisms identified in our findings, potentially offering new avenues for innovation in digital firms.
Footnotes
Appendix
Random Forest Model Parameters.

| Parameter | Trees | Seed | Training set ratio | Test set ratio |
|---|---|---|---|---|
| Value | 2,000 | 1,839 | 70% | 30% |
Ethical Considerations
This article does not contain any studies with human or animal participants.
Author Contributions
Jun Yang and Mingyue Xiao was involved in writing—review and editing, methodology, funding acquisition, conceptualization. Hongyu Wu was involved in writing—original draft, software, investigation. Fei Meng and Mingyue Xiao was involved in Writing—original draft. Jun Yang and Mingyue Xiao was involved in supervision, project administration.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Social Science Fund of China (23BJY124), Zhejiang Social Science Fund Special Project: Study of the Spirit of the Third Plenary Session of the 20th CPC Central Committee and the Fifth Plenary Session of the 15th Provincial Party Committee (98), Major Humanities and Social Sciences Research Projects in Zhejiang Higher Education Institutions (2024QN120), Soft Science Research Program of Zhejiang Province (2025C25018), and Research Project of Zhejiang Federation of Humanities and Social Sciences (2026N015).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data required to support the result and conclusion of study are available on request.