
Abstract
This study aimed to develop and validate an analytical rating scale specifically designed to assess the lexical proficiency of Chinese college students in Academic English speaking tasks. A multi-layer construct of lexical proficiency was first developed and operationalized into an eight-dimension rating scale, including word diversity, word sophistication, word accuracy, and word fluency, phraseological diversity, phraseological sophistication, phraseological accuracy, and phraseological fluency. The reliability and validity of the scale were then examined by using the many-facet Rasch model and confirmatory factor analysis with 600 academic speech samples. The results showed that the rating scale could successfully and reliably differentiate levels of lexical proficiency among participants. High construct validity was confirmed with excellent model fit and support for the proposed dimensions. The proposed analytical rating scale provides a practical approach to comprehensively assessing lexical proficiency in academic speaking contexts. The study has implications for L2 vocabulary instruction, assessment, and speaking assessment in L2 academic contexts.
Plain Language Summary
A large body of research on lexical vocabulary has been conducted by using a quantitative approach, with few attempts to evaluate it through human rating. Even involved as an essential component in grading the speaking or writing proficiency in testing practice by human raters, lexical proficiency fails to be assessed independently and comprehensively in this approach. Besides, automated scoring needs a human rating as a reference. Taking these issues into consideration, we attempted to explore the potential of the human assessment of lexical proficiency in academic English speech. In this study, we developed and validated an analytical rating scale for lexical proficiency among Chinese learners of English with varying levels of English proficiency and from diversified university backgrounds. The study process included three steps. First, we established a multi-dimensional construct of lexical proficiency targeted to this research based on the existing literature and testing practice. Second, we operationalized the construct into an analytical rating scale. The preliminary scale was tested through a pilot study in which 200 samples of academic English speeches were rated by trained raters and analyzed statistically. The scale was further revised based on the rater interview, reflection and statistical data. Finally, the raters received a new round of training to use the revised scale to evaluate another 400 samples. The reliability and construct validity of the rating scale were tested. The research findings indicate that the constructed analytical rating scale is capable of effectively evaluating the lexical proficiency of Chinese college students in their academic English speeches.
Introduction
Developing proficiency in academic English oral communication is a crucial objective for college students learning English as a second language. A persistent obstacle to achieving this goal is students’ inadequate L2 lexical proficiency, which hinders their development of academic speaking abilities (Dang et al., 2017). As an indispensable part of communicative competence (Bachman & Palmer, 2010), lexical proficiency plays a vital role in academic oral contexts, where a sophisticated and precise command of vocabulary is essential for effective communication (Crossley et al., 2013). The critical significance of lexical competence in L2 speaking performance has been well supported by empirical evidence. For example, vocabulary measures can explain substantial variance in speaking performance, ranging from 63% for vocabulary size alone to over 71% when combined with vocabulary depth measures (Enayat & Derakhshan, 2021; Koizumi & In’nami, 2013). Moreover, various vocabulary types make differential contributions to speaking performance. High-frequency productive vocabulary (the 3,000 most frequent word families) demonstrates predictive power of speaking competence (Alharthi, 2020). High-frequency receptive vocabulary predicts overall oral proficiency while mid-frequency receptive vocabulary serves as a key predictor of lexical resources (Derakhshan & Enayat, 2020). Given this well-established relationship between lexical knowledge and speaking performance, effective vocabulary instruction must be built on accurate diagnosis of learners’ particular vocabulary strengths and weaknesses. Such a diagnosis requires comprehensive and reliable assessment tools that can provide insights into students’ lexical competence in academic speaking contexts.
However, current assessments of lexical proficiency in academic English speech remain problematic due to limitations in existing approaches. Traditional vocabulary assessments mainly focus on discrete-point, decontextualized testing formats such as form-meaning matching, multiple-choice questions, or word association tasks (Read, 2021). While this type of assessment proves valuable, it is unable to fully reflect the multi-dimensional nature of lexical proficiency in real language contexts.
Recent performance-based lexical assessment studies have adopted computational approaches to addressing dimensions such as lexical diversity and lexical sophistication (e.g., Kyle & Crossley, 2015; Read, 2000). Among the body of quantitative research on productive lexical competence assessment, focus is either on traditional word-level analysis (Lu, 2012) or on formulaic sequence analysis (Xu, 2018). Comprehensive approaches that examine both single-word and multi-word dimensions have emerged only recently (Kim et al., 2018; Kyle & Crossley, 2015; Leńko-Szymańska, 2020). In addition, although academic vocabulary represents a distinct feature of Academic English oral discourse (Smith et al., 2020), research on assessing academic lexical competence in learners’ academic oral English is pretty limited (Kyle & Crossley, 2015).
Apart from limitations in quantitative research, significant gaps exist in the qualitative evaluation of lexical competence as a construct. So far, few studies have attempted qualitative, human-rated lexical assessments that serve as a baseline for automated scoring of vocabulary use in an academic context (Crossley et al., 2011, 2015). Even in testing practice where human rating is required, lexical assessments in high-stakes academic English tests remain inadequate. The lexical proficiency in TOEFL and IELTS speaking tests is often scored as a component of rubrics of speaking proficiency rather than as an independent and comprehensive measure of a construct (TOEFL iBT® Independent Speaking Rubric; ielts-speaking-band-descriptors.pdf). Such blending fails to provide diagnostic feedback for students on their lexical strengths and weaknesses.
Additionally, existing lexical rating scales require further investigation. One significant limitation of the analytical rating scale developed by Crossley et al. (2015) is that it lacks validation analysis. The latest research methodology in applied linguistics emphasizes that the development of a reliable and valid rating scale for lexical proficiency as a complex multi-dimensional construct needs to be undertaken based on theoretical foundations and empirical validation measures, such as Rasch modeling, exploratory factor analysis (EFA), confirmatory factor analysis (CFA) or exploratory structural equation modeling (ESEM; Cong-Lem, 2025). To bridge these gaps, this study aims to develop an independent multi-dimensional analytical rating scale based on validation analysis to evaluate L2 learners’ lexical proficiency in academic English oral discourse.
Theoretical Background
Models of Lexical Proficiency
In the field of L2 acquisition research, lexical proficiency typically refers to the knowledge and ability to use vocabulary in a language (Council of Europe, 2018). Research on lexical proficiency can be primarily explored from cognitive and communicative perspectives. Lexical proficiency in cognition is closely related to lexical knowledge, including declarative and procedural knowledge of vocabulary (Bulté et al., 2008). Descriptions of lexical proficiency from a communicative perspective, on the other hand, integrate vocabulary knowledge and processing with the context and strategic use (Chapelle, 1994; Council of Europe, 2018). These theories have laid a solid theoretical foundation for lexical ability assessment (Z. Wu & Luo, 2020). However, the lexical knowledge they described represent inherent and unobservable implicit knowledge (Chapelle, 1998).
When lexical proficiency is defined as a behavioral construct, which can be observable and measurable, to reflect the ability of L2 learners to use vocabulary for communication (Leńko-Szymańska, 2020), this line of research primarily focuses on constructs such as lexical diversity, lexical sophistication, lexical accuracy, and lexical fluency (Bulté & Housen, 2012; Bulté et al., 2008; Wolfe-Quintero et al., 1998). It is these behavioral constructs that provide the theoretical background for this research.
Wolfe-Quintero et al. (1998) classified lexical proficiency into lexical complexity, lexical accuracy, and lexical fluency, and classified lexical complexity into lexical density, lexical diversity, and lexical sophistication. Bulté et al. (2008) proposed a hierarchical three-level (cognitive, behavioral, and statistical) construct model of lexical proficiency. The behavioral level consists of five dimensions: lexical diversity, lexical sophistication, lexical complexity, lexical productivity, and lexical fluency. Both models focused on the single-word level. Following the three dimensions (complexity, accuracy, fluency, CAF) of language proficiency framework (Housen & Kuiken, 2009; Skehan, 1998), Bulté and Housen (2012) focused on complexity alone and developed a lexical complexity model, which included density, diversity, compositionality, and sophistication. Notably, this model paralleled single words and collocations with the same weight, which marked the researchers’ theoretical concern about collocations as an integral part of lexical proficiency.
Lexical proficiency at the phraseological level has also been under scrutiny. Xu (2018) proposed a spoken collocational competence model to measure collocations by complexity, accuracy, and fluency. Paquot (2019) and Paquot et al. (2022) measured phraseological complexity through dimensions of phraseological diversity and phraseological sophistication in both learners’ written as well as spoken discourses. This phraseological line of research reflects the growing recognition of collocations in the field of vocabulary assessment (Eguchi & Kyle, 2023; Kyle & Crossley, 2015; Read, 2000). Leńko-Szymańska (2020) proposed a model of lexical proficiency with both single words and collocations after the author had comprehensively measured lexical complexity, accuracy, and fluency in the written texts of L2 university students.
Crossley et al. (2013, 2015) categorized lexical knowledge as collocation accuracy, lexical diversity, and several psycholinguistic dimensions, based on which they developed an analytical rating scale to validate computational lexical measures and explore the relationships between holistic and analytical assessments of L2 lexical proficiency.
Limitations of Existing Lexical Models
These lexical proficiency constructs all emphasize the central role of lexical knowledge and provide valuable theoretical framework. However, these constructs show limitations for assessing L2 lexical proficiency in academic contexts. For example, the use of academic vocabulary in L2 academic contexts is insufficiently explored in existing models. The use of academic vocabulary is not only a distinctive feature of academic English but also a key factor that can manifest L2 students’ the academic English communicative competence of L2 students (Gardner & Davies, 2014). However, most existing lexical proficiency models do not address this issue. Although Chapelle (1994) addressed contextual factors, her framework lacks an adequate description of specific vocabulary use in academic English.
Second, the significant value of formulaic sequences has been underestimated. Formulaic sequences play a pivotal role in L2 lexical proficiency assessment (Read, 2000; Wood, 2010), and fluent use of formulaic sequences indicates high language proficiency (Kim et al., 2018; Kyle & Crossley, 2015. However, many models fail to take phraseological dimensions into theoretical frameworks. For example, Wolfe-Quintero et al.’s (1998) lexical proficiency model is comprehensive in its breadth plus accuracy, but it lacks its depth without probing into the use of formulaic sequences. While Bulté and Housen (2012) absorbed formulaic sequences in the theoretical construct, they didn’t provide feasible observational dimensions for formulaic expressions. Moreover, some research categorizes formulaic sequences as a subdivision of sophistication (Kim et al., 2018; Kyle & Crossley, 2015). Such treatment overlooks the multi-dimensional characteristics of formulaic sequences, which, like single words, can be examined in terms of diversity, sophistication, accuracy, and fluency (Paquot, 2019; Xu, 2018), leading to conceptual and practical confusion.
Additionally, current L2 lexical proficiency research is primarily carried out through computational approaches, while human-judgment-based exploration is quite insufficient. Although Leńko-Szymańska (2020) proposed a lexical proficiency framework concerning lexical complexity, lexical accuracy, and lexical fluency at both single-word and phraseological levels, the model was grounded in a quantitative approach.
Research Questions
Based on a systematic analysis of theoretical and methodological limitations, this research aims to develop an analytical rating scale to evaluate lexical proficiency in L2 academic English speaking, by integrating both single-word and formulaic sequences, and the academic context with a human-judgment-based assessment approach. It attempts to answer the following questions:
(1) What dimensions constitute the construct of lexical proficiency in the context of Academic English speaking, and how are they operationalized into an analytical rating scale?
(2) To what extent does the analytical rating scale show adequate reliability and construct validity when evaluating Chinese college students’ lexical proficiency in their Academic English oral performances?
In the sections that follow, we will develop a theoretical analytical framework for the construct of lexical proficiency, operationalize its components, and then establish an analytical rating scale based on the construct operationalization and testing practice. The reliability and construct validity of the rating scale proposed in the second question will be confirmed by empirical evidence.
Construct Definition and Operationalization
This section will answer the first research question of the constituents of the lexical proficiency construct and its operationalization.
Construct Definition
The present study focuses on assessing the lexical proficiency of Chinese college students in general academic English oral performances. To define an appropriate construct applicable to this study, we carefully examined the behavioral models of vocabulary ability at both the single and phraseological levels, then chose Wolfe-Quintero et al.’s (1998) triad model as a primary single-word framework for several reasons: (1) The model was most comprehensive in its inclusion of complexity, accuracy and fluency despite its lack of phraseological concern.
(2) We integrated the dimensions presented in Bulté et al.’s (2008) and Bulté and Housen’s (2012) models into Wolfe-Quintero et al.’s (1998) model. For example, among Bulté et al.’s (2008) five dimensions at the behavioral level: lexical diversity, lexical sophistication, lexical complexity, lexical productivity, and lexical fluency, lexical complexity was used to evaluate a learner’s ability to understand or use the deep knowledge of a specific word through forms of cloze or gap-filling tests rather than learners’ oral productions targeted in this study. Therefore, this dimension was left out. On the other hand, the dimensions of lexical diversity and lexical productivity in Bulté et al.’s (2008) were merged into lexical diversity in Bulté and Housen’s (2012), suggesting that lexical productivity (the number of words a speaker uses to complete a given task, Bulté et al., 2008) be an indicator of lexical diversity assessment, as has been involved in many studies (Jarvis, 2017; Lu, 2012). Besides, lexical compositionality proposed by Bulté and Housen (2012) referred to the number of lexical forms or semantic elements, which may be applicable to L2 learners with low language abilities or at young age (Zareva, 2019), while less relevant for the college students with relatively high English abilities in this study.
To fill the gap in Wolfe-Quintero et al.’s (1998) model, we add Xu’s (2018) and Paquot’s (2019) phraseological construct to align with the single-word construct, both constituting the construct of lexical proficiency in this study. It is defined as Chinese college students’ knowledge of and ability to use English vocabulary in the context of general academic oral performance. It consists of three primary dimensions: lexical complexity, lexical accuracy, and lexical fluency. In this case, lexical complexity is classified into word complexity and phraseological complexity. Word complexity is categorized into word diversity and word sophistication, and phraseological complexity into phraseological diversity and phraseological sophistication. Lexical accuracy is classified into word accuracy and phraseological accuracy. Lexical fluency consists of word fluency and phraseological fluency (Figure 1).

Construct of lexical proficiency in academic English oral performance.
Construct Operationalization
The instrument for this study was a rating scale of lexical proficiency. Scale development concerns the operationalization of rubric dimensions, the establishment of the rating scale, and its optimization. Based on the construct definition, there are eight lexical variables as indicators of EFL leaners’ lexical proficiency in academic English oral productions: word diversity, word sophistication, word accuracy, word fluency, phraseological diversity, phraseological sophistication, phraseological accuracy and phraseological fluency. These variables were operationally defined as follows:
Word diversity refers to the richness and variation of word use, achieved through synonyms, hyponyms, paraphrases, and so on, to avoid repetition (Jarvis & Daller, 2013; Read, 2000). If a participant’s spoken output is rich and diverse with low repetition, the sample will receive a high score in the word diversity dimension.
Word sophistication characterizes the size or proportion of high-frequency academic words, uncommon words, and advanced words (Kim et al., 2018; Kyle & Crossley, 2015). If academic words, uncommon words, or other advanced words that appear in formal contexts are used more frequently, it indicates a stronger level of word sophistication used by a learner.
Word accuracy is the extent to which learners present error-free word usage, considering errors in word form, word formation, semantics, and morphology within the discourse context (Leńko-Szymańska, 2020; Saito et al., 2016). Fewer such errors in the learner’s sample indicate a higher level of word accuracy.
Word fluency is defined as the speed with which the learner produces or encodes words (Bulté et al., 2008), considering pauses, speed, and repairs (Bosker et al., 2013; Skehan, 2003). Shorter duration and lower frequency of pauses, lower frequency of self-repairs and repetitions perceived in a sample reflect a higher level of word fluency of the participant.
Phraseological diversity refers to the size and variety of formulaic sequences used (e.g., lexical and grammatical collocations, phrasal verbs, idioms; Stengers et al., 2011; Wood, 2010; Wray, 2002). A greater number of different formulaic expressions indicates a higher level of phraseological diversity.
Phraseological sophistication refers to the size of high-frequency academic or other uncommon, advanced formulaic sequences (Paquot, 2019). More academic, uncommon, or formal collocations, phrases, and idioms used suggest a greater proficiency in the use of sophisticated phrases by the learner.
Phraseological accuracy refers to the extent to which L2 learners present error-free phraseological usage in their academic speaking performance, including precise meaning, appropriate form, and morphological use (Huang, 2015; Xu, 2018). Fewer errors in form, usage, and meaning represent a higher level of phraseological accuracy.
Phraseological fluency is the degree of automation in phrase production, measured by the proportion of non-fluent formulaic sequences (Xu, 2018). Fewer noticeable pauses, repetitions, or self-repairs within phrases indicate a stronger level of phraseological fluency (Bosker et al., 2013).
Methodology
Participants
The study involved 600 participants whose academic English speech data were randomly selected from the MCAESCL (A Multimodal Corpus of Academic English Speech by Chinese Learners) database, which was designed to investigate the differences in students’ critical thinking abilities and their use of multimodality in academic speaking discourse (Chen, 2022). The corpus comprises over a thousand prepared speeches (still expanding) by sophomore students (about 19 years old, with nearly even gender distribution) from various levels of universities in China, from top national universities to general provincial universities. A total of 78 majors from humanities, social sciences, and STEM fields were involved. The participants had just completed 1 year of college English instruction. Most of them have passed the College English Test Band 4 (CET-4), reaching intermediate to upper-intermediate proficiency level.
According to the literature, when construct validity analysis includes confirmatory factor analysis (CFA), a minimum sample size of 200 is generally recommended, and an average sample size is approximately 375 (Kline, 2023). Many-facet Rasch Model (MFRM) analysis requires a minimum of 30 observations per facet (Linacre, 2023). With eight dimensions and three raters, this study chose a minimum sample size of 200 (100 males and 100 females) in the pilot study and 400 (219 males and 181 females, nearly evenly distributed) in the main study.
Tasks
Since the MCAESCL corpus serves as a data set for multimodal automated scoring, participants had to face the camera so that their complete features of verbal and nonverbal language could be captured. Accordingly, the project designers chose academic speech as a task type rather than group discussion. Neither the question-and-answer format was considered due to its limitations in terms of discourse length and completeness (Chen, 2022).
The participants were required to prepare and deliver approximately 2-minute speeches on one of the two prompts: “How to prepare for an oral presentation?” (an informative speech) and “To read selectively or extensively? That is a question. What’s your understanding? Support your opinion with some details” (a persuasive speech). These tasks were selected to align with the participants’ academic and educational backgrounds, eliciting language relevant to academic oral discourse.
The participants had 1 week to prepare and were told in advance that they would deliver the speech in front of a camera. Before the speaking task, they were informed about the purpose and procedures of the research, including the video recording requirement, data usage for research purposes only, and their right to withdraw at any time without consequence. Verbal consent was obtained and their personal information was documented before proceeding with data collection. All participants voluntarily agreed to participate after receiving the detailed explanation. In this research, audio recordings and transcribed texts were used to assess L2 lexical proficiency.
Raters
Three Chinese PhD students specializing in foreign language linguistics and applied linguistics participated as raters in the scoring process. They have been engaged in teaching college English for years and possess rich theoretical knowledge and practical experience in the field of vocabulary acquisition research. Two of them have engaged themselves in compiling English dictionaries. In addition, all have participated in scoring oral and written sections of College English Tests (China’s national standard English tests for college students) multiple times, thus having rich experience in human rating.
Scale Development
Establishment of the Preliminary Rating Scale
The lexical proficiency rating scale included eight 5-level dimensions, with descriptors developed based on lexical proficiency descriptions in large-scale speaking tests (e.g., IELTS, TOEFL, CET-4, CET-6) and the CEFR. The preliminary scale was used to assess 200 samples in the pilot study to examine its appropriateness and rater consistency.
The raters received at least four training sessions, each lasting over 2 hr. The first training session helped them understand the construct definition of lexical proficiency, the operationalization of each dimension into measurable criteria, and the application of the analytical rating scale in the samples of different levels. They were trained to score one dimension at a time using benchmark samples of various levels to avoid interference among dimensions. After the training, the raters assessed each lexical dimension for a few samples and discussed those scored over two levels of discrepancy until an agreement was finally reached. This rating session continued for every 30 to 50 samples till the end.
SPSS and many facet Rasch analyses demonstrated the following problems: (1) reliability wasn’t satisfactory enough. While overall rater reliability (Cronbach’s α) for eight dimensions ranged from .868 to .917, the rater reliability between two raters of some dimensions, such as word diversity and lexical accuracy, was between 0.6 and 0.7. (2) The percentages of high and low scores among the samples were very low. It was partly due to the raters’ central tendency and severity effects (Knoch, 2009), resulting in difficulty distinguishing between proficiency levels, particularly between advanced and intermediate learners and between intermediate and low-level learners.
The interview conducted after the rating process focused on rater reliability, the clarity and discriminative power of the descriptors, and other issues encountered during the rating process. It reflected that (1) definitions and rating scale for dimensions were not operationally clear and appropriate enough. Take word diversity as an example, the raters complained about the tricky treatment of those samples with short lengths. “While the words expressed seemed quite varied, there were only four sentences in this discourse. What score should I give it?” (2) Those descriptors, with general modifiers such as “very” and “limited,” were not instructional enough to discriminate between levels, confusing the raters. (3) Raters need more adequate training. For example, another reason for the central tendency of student scores was disagreement in rater severity. The raters tended to be more severe when assessing a sample of higher lexical proficiency. A rater commented, “Be conservative when giving a high score, as students always make mistakes.” However, they tended to be more lenient over a weak sample. “As long as he/she says something, I’ll give him/her some points.”
Optimization of the Rating Scale
Based on rater interviews, inter-rater consistency checks, and many-facet Rasch analysis of the preliminary rating results, the researchers revised the rating scale, including the improvement of the descriptors and the addition of quantitative assistance. Building on the experience from the pilot study and the practices of Knoch (2009) and Zhao (2013), we established quantitative thresholds for each level of each dimension for raters. For example, an oral discourse shorter than 80 words was assigned to the lowest level of word diversity. Those with 6 to 8 academic, formal, or less frequently-used words belonged to the mid-level of word sophistication (see Table A1 in Appendix A). Besides, frequency density (the occurrences of target feature per line or every two or three lines) was an effective means that could helped raters better perceive lexical features distributed in a long discourse with a lower extent of subjectivity. Based on the optimized rating scale, the raters received a new round of training and then used the scale to assess another 400 samples. The final inter-rater reliability across all dimensions increased to 0.9.
Data Analysis
Many-Facet Rasch Model (MFRM)
The MFRM offers a framework for assessing and analyzing multiple facets of data. In this study, a four-facet Rash model was adopted including participant ability, rater severity, task difficulty, and item type. It provided insights into the discrimination of lexical proficiency levels among participants, the consistency and potential biases of raters, the relative difficulty of tasks and scoring criteria, and the overall fit of the rating scale to the Rasch model, shown as follows:
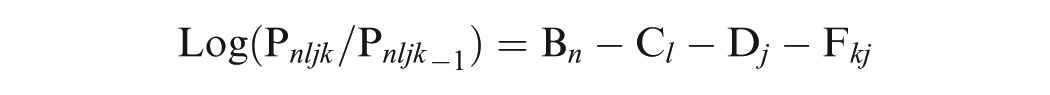
Pnljk = probability of participant n receiving a score of k on task l when assessed by rater j;
Pnljk−1 = probability of participant n receiving a score of k−1 on task l when assessed by rater j;
Bn = ability of participant n;
Cl = severity of rater j;
Dj = difficulty of task j;
Fkj = difficulty of achieving a score of k on item j relative to the adjacent score of k−1.
Key statistics examined in the MFRM analysis included: (1) Infit and Outfit mean square (MnSq) values, indicators of data-model fit, with values between 0.5 and 1.5 considered acceptable (Linacre, 2021). (2) Separation indices and reliability indices, measures of the ability to reliably distinguish different levels of proficiency, tasks, and criteria, with values greater than 2 and 0.8, respectively, considered adequate (Bond & Fox, 2015). (3) Fixed chi-square tests, assessments of the statistical significance of differences among facet elements.
Confirmatory Factor Analysis (CFA)
CFA was employed to evaluate the construct validity of the proposed lexical proficiency model and its underlying dimensions. The analysis examined the extent to which the observed data fit the hypothesized model, as well as the convergent and discriminant validity of the proposed dimensions using the data of the main study.
Indicators used to assess model fit included: the chi-square test to degree-of-freedom ratio (CMIN/DF), root mean square error of approximation (RMSEA), goodness-of-fit index (GFI), adjusted goodness-of-fit index (AGFI), comparative fit index (CFI), normed fit index (NFI), and parsimonious normed fit index (PNFI). If CMIN/DF < 3, RMSEA < 0.05, while GFI, AGFI, CFI, and NIFI > 0.9, the model shows an ideal fit. If 3 < CMIN/DF < 5, 0.05 < RMSEA < 0.08, the model fits well (M. Wu, 2020).
Convergent and Discriminant Validity
Convergent validity implies that the measurement indicators for the same trait concept should fall under the same factor, emphasizing the correlation between various scoring items within the factor structure (Sawaki, 2007). The key indicators for testing convergent validity are the average variance extracted (AVE) and composite reliability (CR). If the AVE for each factor is >0.5, CR > 0.7, and the factor loadings for each measurement item are greater than 0.5, high convergent validity is proved (Cheung et al., 2023).
Discriminant validity examines whether each factor can reflect different aspects of the target ability concept (Sawaki, 2007). It is assessed by comparing the square root of the AVE for each factor with the correlations between that factor and other factors. If the square root of AVE exceeds the inter-factor correlations, discriminant validity is established (Cheung et al., 2023).
Results
This section aims to answer the second research question concerning the reliability and construct validity of the established rating scale for the lexical proficiency assessment of Chinese college students in their academic English oral performances.
Reliability of the Analytical Ratings
The reliability of the analytical scales was assessed through the MFRM analysis, examining the facets of participant ability, rater severity, task difficulty, and criterion difficulty.
Participant Ability
The primary purpose of the analytical rating scale is to differentiate the lexical proficiency of Chinese college students in academic English speeches. Figure 2. presents a Wright map illustrating the distribution of participant lexical ability, rater severity, task difficulty, and criterion difficulty measures on a shared logit scale. This visual representation provides a comprehensive overview of how these facets interact within the assessment framework.
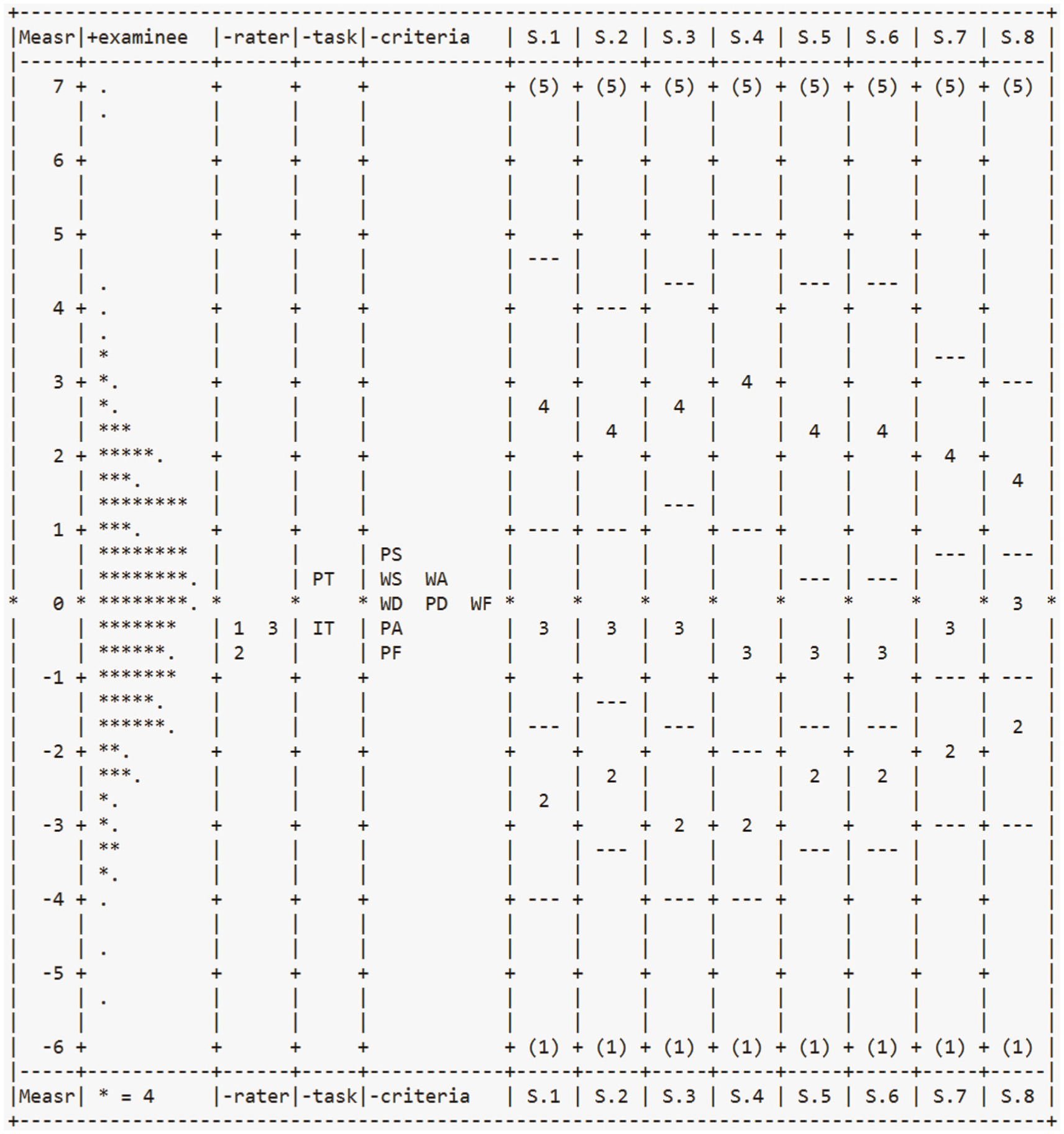
The Wright map.
The second column of the Wright map displayed a wide distribution of points representing the varying lexical proficiency levels of the student participants. The participants’ lexical abilities followed an approximately normal distribution, with measures ranging from approximately −5.4 to +6.9 logits. The value of strata for participant ability was 6.76, indicating that participants could at least be divided into six levels.
As shown in Table 1, for the participant facet, the Infit Mean Square (MnSq) of 1.00 indicated an excellent fit to the Rasch model expectations. The high separation index (4.82) and reliability (0.96), combined with the significant fixed chi-square (χ2 = 9,751.5, df = 399, p < .001), demonstrated that the rating scale effectively differentiated students’ lexical proficiency.
General Model Fit of Four Layers.

p < .001.
Rater Severity
The data of rater severity in Table 1 showed statistically significant differences among raters (χ2 = 27, df = 2, p < .001). The overall Infit MnSq of 1.01 represented a good model fit. The separation index was 2.83, and the reliability index was 0.89, both higher than expected values, confirming the severity difference. From Table 2, which presented more detailed information about facets, rater severity measures ranged from −0.10 to 0.11 logits, with Rater 3 being the strictest and Rater 2 the most lenient. Despite the statistical significance, the range of rater severity (−0.10 to 0.11 logits) is considerably smaller than that of participant ability. This suggests that differences in rater severity are unlikely to have a substantial impact on overall student scores.
Model Fit Statistics of Individual Raters, Tasks, and Rating Items.

Note. PS = phraseological sophistication; WA = word accuracy; WS = word sophistication; WF = word fluency; PD = phraseological diversity; WD = word diversity; PA = phraseological accuracy; PF = phraseological fluency.
Task Difficulty
Two task types were included in the analysis: the informative task (IT) and the persuasive task (PT). The separation index for tasks was 4.89, with a reliability of 0.96. A significant difference in difficulty was found between the two task types (χ2 = 49.8, df = 1, p < .001; Table 1). The PT (0.12 logits) was more difficult than the IT (−0.12 logits; Table 2), indicating that it is more challenging for students to achieve as high scores in persuasive speech tasks as in informative speech tasks.
Criterion Difficulty
The eight criteria demonstrated significant differences in difficulty levels (χ2 = 543.6, df = 7,p < .001), with a high separation index of 7.89 and reliability of 0.98 (Table 1), indicating that the criteria effectively distinguish different aspects of lexical proficiency. Criterion difficulty ranged from 0.53 logits for phraseological sophistication (PS) to −0.82 logits for phraseological fluency (PF; Table 2). This hierarchy demonstrated the relative challenges students face in different aspects of lexical proficiency, among which phraseological sophistication seemed to be the most challenging one for them.
The Infit MnSq values for all criteria (ranging from 0.89 to 1.18; Table 2) fell within the acceptable range, indicating good model fit. This suggests that all criteria contribute meaningfully to the assessment of lexical proficiency without redundancy or inconsistency.
Category probability curves (Figure 3) were examined to assess criterion category discrimination. Six criteria (WD, WS, WF, PD, PS, PF; criteria 1–4, 7–8) displayed distinct peaks for all categories, with monotonically advancing thresholds and appropriate spacing (1.4–5 logits) between curve intersections (Eckes, 2015), indicating that for these criteria, the 5-point rating scale functioned well, with each category representing a distinct level of performance.

Category probability curves.
However, word accuracy and phraseological accuracy (WA, PA; criteria 5–6) exhibited less distinction between lower score (1–3) categories, with spacing less than 1.4 between the curve intersections on the horizontal axis. The result showed that the raters may have found it difficult to distinguish between the lower performance levels for these two criteria.
Bias Analysis
While the overall rater consistency was high, bias analysis revealed some specific interactions between raters and criteria. As shown in Table 3, no significant bias was found between raters and participants’ ability or between raters and tasks, indicating that raters applied the scale consistently across different ability levels and task types. However, 5 out of 24 (20.8%) rater-criterion interactions showed significant bias (χ2 = 57.4, df = 24, p < .001).
Bias Effect Between Rater and Criterion.

Rater 1 showed a tendency to be lenient in scoring word sophistication (bias = −0.18, t = −2.05) but strict in scoring phraseological fluency (bias = 0.16, t = 2.10). Rater 2 was lenient in scoring phraseological sophistication (bias = −0.20, t = −2.23) but strict in scoring word fluency (bias = 0.25, t = 3.28). Rater 3 showed leniency in scoring word fluency (bias = −0.27, t = −3.81). These biases, while not severely impacting the overall assessment, indicated the need for potential rater training or scale refinement.
Construct Validity of the Rating Scale
Data Fit
The statistical analysis showed that the skewness of vocabulary proficiency scores for the 400 samples ranged from −0.19 to −0.89, and the kurtosis ranged from −0.14 to 1.11, falling within the range of −2 to 2, indicating a normal distribution and allowing entry into the structural equation model. The CFA results demonstrated an excellent fit between the proposed lexical proficiency model and the observed data. The CMIN/DF ratio (2.617), the RMSEA (0.064), GFI (0.976), AGFI (0.942), CFI (0.99) and NIFI (0.985) values all met the recommended criteria for a well-fitting model (M. Wu, 2020) (Table 4).
Model Fit.

Convergent Validity
The factor loadings for the measurement indicators ranged from 0.83 to 0.95 (Table 5), exceeding the recommended threshold of 0.5 and providing evidence of convergent validity. Furthermore, the average variance extracted (AVE) values for each factor (0.749 to 0.901) and the composite reliability (CR) values (0.857 to 0.948) were all above the respective cut-offs of 0.5 and 0.7, further supporting the convergent validity of the proposed model.
Convergent Validity.

Discriminant Validity
As shown in Table 6, the square root of the AVE for each factor (values on the diagonal) exceeded the inter-factor correlations, indicating that the proposed dimensions of lexical proficiency exhibited discriminant validity. This finding suggests that the dimensions correspond to the distinct aspects of the lexical proficiency construct (Sawaki, 2007).
Pearson Correlation and the Square Root of the AVE.

Note. The numbers on the diagonal represent the square root of the AVE for each factor.
p = .00.
Discussion
This study aimed to develop and validate an analytic rating scale for assessing lexical proficiency in L2 Academic English speech. The results provide strong evidence for the reliability and validity of the proposed scale, offering several important insights into the nature of the construct itself and the assessment of lexical proficiency.
Construct Dimensionality and Scale Development
The proposed construct showed good model fit and high convergent validity and discriminant validity, indicating that the dimensions within the construct are well-defined and empirically supported. Unlike Wolfe-Quintero et al.’s (1998) focus on single words, Xu’s (2018) focus on collocations, and Leńko-Szymańska’s (2020) focus on quantitative study, the construct developed takes into account of both single words and formulaic sequences from the perspective of human rating, broadening the scope of traditional assessment models of lexical proficiency. More importantly, the dimensionality was validated by empirical evidence from the assessment of Chinese college students’ academic English speech, confirming that these aspects are interrelated and collectively form the construct of lexical proficiency.
Within the construct, diversity, sophistication, accuracy, and fluency of words and formulaic sequences showed strong explanatory power for the lexical construct, indicating that the more varied and sophisticated the words and formulaic sequences used by learners in academic speech, and the more accurate and fluent their use, the stronger the learners’ lexical proficiency. This result is consistent with previous research findings (Kim et al., 2018; Kyle & Crossley, 2015; Saito et al., 2016; Xu, 2018).
Besides, the relationships between the internal dimensions of the construct model are clarified. Lexical complexity is categorized into word complexity and phraseological complexity, with word complexity distinguishing between word diversity and word sophistication, and phraseological complexity distinguishing between phraseological diversity and phraseological sophistication. The classification is consistent with Wolfe-Quintero et al.’s (1998) word complexity classification and Paquot’s (2019) phraseological complexity classification. This categorization reveals a closer relationship between diversity and sophistication at the word or phraseological level than the relationship between words and phrases at the diversity or sophistication level. Empirical evidence reveals that learners with higher lexical diversity proficiency tend to use more academic or low-frequency words and formulaic sequences. However, learners with lower lexical proficiency tend to repetitively use familiar high-frequency words, resulting in lower diversity and sophistication (Ansarin et al., 2021; Bayazidi et al., 2019; Siskova, 2012).
Reliability and Rater Performance
The MFRM analysis revealed that participants could be differentiated into at least six levels, indicating high reliability in discriminating participants’ lexical proficiency levels. This finding aligns with previous research, suggesting that lexical proficiency is a multifaceted construct that can be reliably evaluated (Crossley et al., 2015; Kyle & Crossley, 2015).
Raters achieved satisfactory performance despite statistically significant differences observed in rater severity and rater-criteria bias. Especially in the assessment of word accuracy and phonological accuracy, raters showed less satisfactory perceptions in both low-level performances, probably due to their difficulty distinguishing between the lower performance levels. As Yan (2014) stated, raters tend to agree more on higher score levels than on lower score levels. While the impact of rater effects on student overall scores is minor, improvement in rater training or more detailed descriptor elaboration for a certain criterion is still required.
Task and Criterion Difficulty
Divergence in difficulty between informative and persuasive tasks leads to differential outcome of L2 lexical performance, proving supportive evidence to the body of research that have revealed the influence of task types on language performance in L2 speech (De Jong et al., 2012; Skehan, 2009). Compared to an informative task, a persuasive task is more challenging for students, which requires more logical reasoning, persuasive abilities, and better lexical resources (Lucas & Stob, 2020). Observed task effects highlight the necessity for varied assessment tasks when evaluating academic lexical proficiency.
The hierarchy of criterion difficulty provides valuable insights into the challenges L2 students face in vocabulary learning. First, phraseological sophistication turned out to be the most challenging criterion. The finding aligns with previous studies (Paquot, 2019; Siyanova-Chanturia & Omidian, 2019) that sophisticated phrases or formulaic sequences are not easy for L2 students as they require innate native intuition (Siyanova-Chanturia & Omidian, 2019). Moreover, formulaic structures (e.g., Verb + direct objects collocations) can be used to discriminate the most advanced level of proficiency (Paquot, 2019). This result emphasizes the importance of explicit instruction and the assessment of phraseological competence in academic L2 programs.
The relative difficulty of word accuracy and sophistication over diversity observed in this study could was similar to that reported in Polat and Kim’s (2014) longitudinal case study, where a learner of English exhibited progress in lexical diversity while accuracy remained unchanged, suggesting slow development and acquisition of language accuracy.
Conversely, the relative ease of phraseological fluency suggests that learners may have acquired some common, familiar phrases before achieving sophisticated ones. Characterized by being stored and retrieved holistically, L2 students’ use of common formulaic expressions experiences faster processing speed and higher accuracy than that of non-formulaic expressions (Carrol & Conklin, 2020; Jiang & Nekrasova, 2007).
Implications
The validated rating scale offers several implications for L2 pedagogy and assessment in academic contexts. First, the multi-dimensional construct of lexical proficiency provides a framework for more targeted instruction and feedback to students. Teachers can use the scale to identify specific lexical strengths and weaknesses in L2 academic speeches and thereafter provide personalized pedagogical interventions. Secondly, lexical proficiency assessment should extend beyond single-word vocabulary knowledge to emphasize the appropriate use of formulaic expressions, particularly when distinguishing between intermediate and advanced learners in academic contexts. The development of phraseological competence for L2 learners should play a crucial part in L2 academic language instruction.
Limitations
Despite the robust evidence offered for the reliability and validity of the proposed rating scale, several limitations should be acknowledged. First, sample size and sample background are limited and should be expanded to ensure greater generalizability of the rating scale. In this research, the rating scale was developed to assess the lexical proficiency of Chinese college learners of English only. Chinese language and Chinese academic cultural communication style (e.g., indirectness in Chinese rhetoric) may have a distinctive influence on their lexical proficiency. Therefore, further study is necessary to verify whether the scale should be adjusted to better function in a different language or a different academic cultural setting.
Another limitation is that this study only examines two task types. A broader range of academic speaking tasks, such as debate and question-and-answer tasks, should be explored to assess the robustness of the scale. Additionally, the slight inconsistencies observed in the lower categories of the word accuracy and phraseological accuracy criteria need further investigation through larger sample sizes, refined criteria, or more comprehensive rater training for these specific aspects of lexical proficiency.
Conclusion
This study has developed and validated an analytic rating scale for assessing lexical proficiency in L2 academic English speech. The findings presented strong psychometric properties of the scale, supporting its structural multidimensionality, sensitivity to task effects and ability to differentiate multiple proficiency levels in academic English contexts. The multidimensional approach provides several theoretical contributions to our understanding of lexical proficiency. First, it confirms the integrated contributions of single words, formulaic sequences, and lexical academic specificity to the assessment of lexical proficiency in academic speaking contexts. Second, varied difficulty patterns across dimensions suggest different trajectories of lexical development for L2 academic English learners. Furthermore, differentiated assessment outcomes between tasks highlight the significance of context-specific assessment in L2 academic English speaking.
This 8-dimensional scale is a nuanced tool for pedagogical applications in lexical proficiency assessment in L2 academic speaking. Teachers can use it as a diagnostic assessment tool to identify learners’ lexical strengths and weaknesses and provide targeted feedback. Through this feedback, L2 learners can be aware of the specific areas that need to improve, such as phraseological variety, academic vocabulary, or advanced word usage.
Further research should establish a simplified scale for routine classroom use by identifying the dimensions most predictive of overall lexical proficiency. Additionally, the scale’s generalizability beyond Chinese linguistic and academic cultural contexts, its performance across broader tasks such as discussion and debate, and the potential of automatic speech analysis tools to address rater subjectivity need further investigation.
Footnotes
Appendix A
The Analytical Rating Scale of Lexical Proficiency in Academic English Speech.

| Score | Word diversity | Phraseological diversity | Word sophistication | Phraseological sophistication |
|---|---|---|---|---|
| 5 | Uses a wide range of words, adept at expressing similar meanings through paraphrasing or synonyms | Uses rich and various formulaic expressions such as collocations, phrasal verbs and idioms (20+) | Regularly uses less-common, formal, or academic words. (12+) | Uses quite a few less-common, formal, or academic collocations, phrases and idioms (8+) |
| 4 | Uses a fairly wide range of words and paraphrase effectively with some repetition | Uses adequate, non-repetitive collocations, phrasal verbs, and idioms (16–20) | Uses quite a few uncommon, formal or academic words (9–11) | Uses adequate less-common, formal, or academic collocations, phrases and idioms (5–7) |
| 3 | Lacks an adequate range of words with noticeable repetition in expression | Uses a moderate number of non-repetitive collocations, phrasal verbs and idioms (11–15) | Mainly uses common words, with limited less-common, formal or academic words (6–8) | Uses a small number of less-common, formal, or academic collocations, phrases and idioms (3–4) |
| 2 | Uses limited words, short in length with frequent repetition (<80) | Uses limited non-repetitive collocations, phrasal verbs and idioms (6–10) | Mostly uses common, basic words, with quite limited less-common or academic words (3–5) | Mostly uses common, basic collocations, with occasional uncommon or academic collocations (1–2) |
| 1 | Uses a very limited range of words, severely short in length (<60) | Uses very limited non-repetitive collocations, phrasal verbs and idioms(0–5) | Uses very common, basic words, barely with academic words (0–2) | Uses very common basic collocations, with no use of less-common or academic collocations (0) |
| Score | Word accuracy | Phraseological accuracy | Word fluency | Phraseological fluency |
| 5 | Uses words appropriately and accurately, with occasional minor errors(0–1) | Has accurate and appropriate usage of phrases with occasional minor errors (0–1) | Speaks fluently with few repetitions or self-repairs(0–1) | Speaks holistically and fluently with rare unnatural pauses, repetitions or self-repairs (0–1) |
| 4 | Uses words appropriately with several errors barely affecting communication.(2–4) | Has fairly accurate and appropriate usage of phrases with a few errors insignificantly affecting communication (2) | Speaks fairly fluently with several unnatural pauses, brief repetitions or self-repairs (1–2) | Speaks fairly completely and fluently with a couple of unnatural pauses, repetitions, or self-repairs within phrases (1–2) |
| 3 | Uses words with noticeable errors somewhat affecting communication. (5–6) | Has some noticeable serious errors in phrasal usage affecting communication (3) | Speaks with longer pauses, noticeable repetitions, or self-repairs (3–5) | Speaks with several longer pauses, repetitions, or self-repairs within phrases (3) |
| 2 | Has frequent serious errors significantly affecting communication (7–8) | Has frequent serious errors in phrasal usage significantly affecting communication (4) | Has many longer pauses, repetitions, or repairs, resulting in incompleteness of sentence perception (6–9) | Has a few noticeably longer pauses, repetitions, or self-repairs within phrases (4–5) |
| 1 | Has numerous serious errors leading to almost impossible communication (9+) | Has too many serious errors severely affecting communication (5+) | Has frequent long pauses, repetitions, or repairs, or frequent repetitions in the same places, resulting in fragmented sentences (10+) | Has frequent serious breakdowns, repetitions, or self-repairs within phrases (6+) or fails to score successfully |
Acknowledgements
We express our sincere gratitude to all the young participants who contributed to the sample data, the responsible university staff who collected the data and the dedicated PhD student raters who participated in the whole rating process.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: this study was supported by the Key Project of National Social Science Fund of China (20AYY013).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be made available on request.