
Abstract
The present study aimed to investigate the patterns and predictors of FL lexical attrition among Chinese college students. Participants were 17 non-English major undergraduates from a comprehensive university in Shandong, China, all native speakers of Mandarin Chinese. A longitudinal follow-up was conducted at four time points: immediately after the end of formal English instruction, and 3, 7, and 10 months thereafter. Data on participants’ free vocabulary output were collected via vocabulary fluency tests and two types of oral production tasks (topic speaking and film retelling tasks). Background questionnaires and vocabulary size tests were used to extract individual difference variables. A total of 340 transcribed texts were analyzed using lexical complexity software. Multivariate analysis of variance and linear regression revealed that: (1) lexical fluency declined at the second test point but partially recovered in the third and fourth tests; lexical density in oral production tasks did not differ significantly across time; certain lexical complexity indicators showed individual variation; lexical diversity significantly differed in topic speaking task but not in film retelling task; (2) initial vocabulary scores significantly predicted lexical fluency but did not directly predict lexical richness in either oral production task, and FL use showed no significant predictive effect on any lexical measures.
Plain Language Summary
This study explores how university students lose or maintain their English vocabulary over time after completing their college English courses. The research followed 17 non-English majors for nine months, collecting data at four points: right after their course ended, and then three, seven, and ten months later. To measure vocabulary loss, students took vocabulary fluency tests and completed speaking tasks. Researchers also gathered background information and vocabulary test results to identify factors that might influence vocabulary retention. A total of 340 spoken responses were analyzed using specialized software. The findings showed that students experienced a decline in vocabulary fluency three months after finishing their course. However, their performance improved and stabilized in later tests. While there was no clear change in the density of words used in free-speaking tasks, certain aspects of vocabulary complexity varied. Additionally, vocabulary diversity in oral tasks showed significant differences, but there were no major differences in film retelling tasks. Regression analysis revealed that students with higher initial vocabulary scores were more likely to maintain fluency over time. However, these scores did not predict their ability to retain vocabulary richness in speaking and film retelling tasks. Surprisingly, the amount of second language use did not significantly impact vocabulary retention in any of the measured areas. These findings suggest that while vocabulary fluency can decline soon after language learning stops, it may stabilize over time. Initial vocabulary knowledge plays a role in fluency retention, but other factors, like language use, may not be as influential as expected.
Keywords
Introduction
Vocabulary constitutes a fundamental pillar of second language (L2) acquisition, particularly in foreign language education (Li & Wu, 2023). In the Chinese educational context, English is predominantly taught as a foreign language (EFL) through structured classroom instruction that typically includes vocabulary lists, reading comprehension exercises, grammar explanations, and oral practice activities (Yang et al., 2023). While such instruction can promote short-term vocabulary gains, the limited opportunities for naturalistic use outside the classroom often result in post-instructional attrition (Ni, 2015).
Despite decades of research on vocabulary learning, comparatively less is known about how different dimensions of vocabulary knowledge—particularly lexical fluency (the speed and ease of lexical retrieval) and lexical richness (the diversity and sophistication of vocabulary use)—develop or decline after formal instruction ends. These dimensions are crucial because fluency supports real-time communication efficiency (Bergmann et al., 2015; Lehtinen et al., 2024), while richness reflects the depth and breadth of vocabulary available for complex expression (Jessner et al., 2021; Schmid & Yilmaz, 2021). Both are essential for sustaining overall L2 communicative competence, yet their respective susceptibility to attrition remains underexplored, especially in contexts where input is sharply reduced. Furthermore, most existing studies on L2 lexical attrition either rely on general vocabulary size tests or treat vocabulary knowledge as a single, undifferentiated construct (e.g., N. Schmitt & D. Schmitt, 2020). This overlooks the possibility—documented in recent longitudinal research—that attrition is dimension-specific, with fluency and richness showing different trajectories depending on learners’ initial proficiency, type and amount of post-instruction exposure, and the nature of the learned lexical items (Tracy-Ventura et al., 2025).
Addressing this gap, the present study examines patterns of lexical retention and attrition among Chinese non-English major college students after completing two years of college English instruction under the national College English Curriculum, which includes weekly vocabulary instruction, reading and listening practice, speaking tasks, and written assignments. By quantitatively analyzing changes in lexical fluency and lexical richness over time, this research seeks to capture the dynamic, nonlinear processes underlying L2 vocabulary development in low-input contexts and to identify the extent to which initial proficiency and foreign language use predict retention outcomes.
Literature Review
Language attrition plays a fundamental role in illustrating the dynamic and nonlinear characteristics of vocabulary development. Schmid and Köpke (2019) emphasized that verbal impairment permeates an individual’s linguistic knowledge and application, with word-level impairments emerging earliest and most prominently. Consequently, examining verbal impairment provides valuable insights into the dynamic nature of language attrition. Notably, words that are lost can often be recovered through relearning, a phenomenon known as the storage effect in vocabulary acquisition (Tomiyama, 2008). This suggests that second language (L2) words experiencing loss are not permanently erased but are temporarily inaccessible or unretrievable. Recent research has increasingly focused on detailed representations of lexical attrition within the lexical subsystem and its developmental dynamics (Jarvis, 2019).
Lexical Fluency as an Important Indicator of Language Attrition
One of the earliest and most widely observed manifestations of language attrition is difficulty in lexical fluency such as retrieval and activation during real-time language production. Such retrieval problems may present as slowed speech rate, hesitations, filler use, self-corrections, or increased lexical borrowing. Early studies often employed verbal fluency tasks (VFTs)—originally developed in psychology to assess word retrieval speed and lexical access—as a principal diagnostic tool for detecting attrition effects (Waas, 1996; Yagmur, 1997). In language attrition research, VFTs typically involve timed, naturalistic spoken production tasks that allow researchers to analyze corpus-based measures of fluency and infer learners’ vocabulary access proficiency (Schmid, 2011).
The theoretical framing of retrieval difficulty has been strongly influenced by Ecke’s (2004) retrieval-failure model, which argues that forgetting in attrition contexts does not necessarily result from the permanent loss of lexical items, but from temporary access problems. Retrieval failures, as described by Ecke and later supported by Yang and Tan (2016), involve increased cognitive effort and processing load, particularly under time pressure. This view predicts that the earliest and most pronounced symptom of vocabulary loss is difficulty in retrieval rather than a complete erasure of lexical knowledge.
Empirical studies have provided mixed evidence regarding the sensitivity of VFTs to attrition. Research focusing primarily on first-language attrition has shown that semantic fluency tasks can detect significant differences between attriters and native controls (Badstübner, 2011; Schmid & Jarvis, 2014), although results for formal fluency tasks are less consistent. Some studies (Dostert, 2009; Kasparian, 2015) have reported no significant differences, while Schoofs (2013) found that attriters even outperformed controls in certain conditions, underscoring the complexity of lexical attrition processes.
More recent longitudinal studies (Pan et al., 2024; Jessner et al., 2021) have shifted attention from global vocabulary loss to the dimension-specific nature of attrition. These studies suggest that spoken fluency measures—such as speech rate and pausing patterns—tend to decline earlier than lexical richness measures (e.g., diversity or sophistication) when exposure is reduced. For example, in an exploratory longitudinal study of advanced instructed L2 learners, retrieval speed deteriorated with limited post-instruction exposure, while measures of lexical variety remained stable, suggesting that initial attrition often reflects slowed access rather than wholesale lexical attrition.
Theoretical debates continue regarding the precise mechanisms driving retrieval difficulty. While Ecke’s (2004) retrieval-failure position remains influential, recent research highlights the role of frequency effects, cross-linguistic competition, and semantic network connectivity in shaping retrieval outcomes (Jessner et al., 2021; Schmid & Jarvis, 2014; Tracy-Ventura et al., 2025). The dominance of each mechanism appears to depend on factors such as exposure patterns, task demands, and individual learner differences.
Finally, the choice of task substantially affects whether attrition effects are detected. Timed semantic fluency and picture-naming tasks are highly sensitive to speed-of-access issues, while untimed narrative tasks may mask retrieval problems by allowing compensatory strategies. This underscores the importance of using complementary measures to distinguish between temporary retrieval failures and more permanent lexical loss. Despite these methodological insights, research employing VFTs in the context of second language lexical attrition—especially in instructed EFL settings—remains scarce, representing a key gap in the literature.
Lexical Richness to Assess Language Attrition
Early research on language attrition often relied on relatively rudimentary corpus analyses derived from VFTs. Schmid (2007) argued that examining lexical richness in parallel with lexical attrition yields a more comprehensive evaluation of lexical diversity in spontaneous language production, as this dual perspective allows for a deeper understanding of the cognitive processing demands involved in managing two linguistic systems. Lexical richness is generally conceptualized as comprising three primary dimensions: lexical density, lexical sophistication, and lexical variation (Kyle, 2020). The notion of lexical complexity proposed by Bulté and Housen (2012) is closely aligned with lexical richness, as it incorporates both structural and semantic dimensions of lexical knowledge.
Despite its theoretical and empirical importance, lexical density has been relatively underexplored in attrition studies (Jarvis, 2019). Typically defined as the ratio of content words to total words, lexical density serves as an indicator of vocabulary richness and cognitive effort in speech production. While some studies (e.g., Taura & Nakanan, 2013) have incorporated lexical density, their operational definitions have often deviated from conventional standards. Lexical sophistication, by contrast, concerns the use of low-frequency words appropriate to the topic and style of a text (Read, 2000). Similarly, Jarvis (2019) introduced the concept of lexical rarity in attrition research, which applies word-frequency analyses to assess lexical features. Schmid and Jarvis (2014) further demonstrated that speakers experiencing lexical attrition tend to rely more heavily on high-frequency words from their L1.
Among the most widely used tools for evaluating lexical sophistication is the Lexical Frequency Profile, often implemented via software such as Range. These tools provide detailed analyses of word families, frequency bands, and coverage percentages (Kyle, 2020). In addition, the Type–Token Ratio (TTR) remains a standard measure of lexical variation, though it is highly sensitive to text length. To address this limitation, this study adopts the Corrected Type–Token Ratio (CTTR) (Lu, 2012), which normalizes for text length and yields more reliable estimates. Verb richness measures can also supplement these indices to capture lexical variation across texts.
Lexical richness—the breadth and depth of vocabulary a speaker uses—is thus multidimensional and measurable through a variety of indices. Traditional metrics (TTR, CTTR, MATTR, LFP) remain indispensable but are increasingly combined with network science and longitudinal corpus analyses to capture both structural and developmental aspects of lexical knowledge. Evidence from spoken and written learner corpora indicates that the dimensions of richness can develop or decline asynchronously: for example, lexical sophistication may increase while density and variation change more slowly, depending on task type and language exposure (Kyle, 2020).
A major methodological advance is the application of semantic and lexical network analysis to attrition research. The recently proposed Lexical Attrition Foundation (LeAF) framework (Chaouch-Orozco & Martín-Villena, 2024) applies network metrics—such as connectivity, clustering coefficient, and centrality—to semantic fluency and free-association data. This approach enables the detection of early structural weakening in the lexical network (loss of connectivity) even before overt word loss is observed in production. In other words, network-based metrics offer a mechanistic link between micro-level retrieval difficulties and macro-level declines in richness. Combining network metrics with CTTR or MATTR provides a more sensitive and interpretable account of lexical attrition.
The Influence of the Initial Proficiency and Language Exposure on Lexical Attrition
Research on lexical attrition has long investigated how initial proficiency levels and language exposure shape long-term retention outcomes. Yet, the precise nature and relative weight of these factors remain contested.
Early studies (Weltens, 1989) suggest that higher initial vocabulary proficiency tends to support better long-term retention. The critical threshold hypothesis posits that once learners surpass a certain proficiency threshold, vocabulary retention stabilizes over time. However, empirical support for this claim is inconsistent. Few studies have employed robust correlational or predictive models linking initial vocabulary knowledge with later measures of lexical fluency and richness, leaving the strength of this relationship unclear.
Research on the effect of language exposure on lexical attrition has produced mixed findings. Ni (2010) reported a significant negative correlation between exposure and attrition (r = –0.49), coining the normalization hypothesis, which suggests that vocabulary loss decreases proportionally with increased exposure. Hansen (1999) further found that exposure was a stronger predictor of retention than initial proficiency level. Similarly, Alharthi and Al Fraidan (2016) identified a positive association between internet use and productive vocabulary, while Murtagh (2003) observed that increased reading exposure was strongly linked to higher foreign language proficiency.
Conversely, other studies (Bahrick, 1984a, 1984b; Mehotcheva, 2010; Murtagh, 2003) reported no significant relationship between L2 exposure and vocabulary loss. Such discrepancies likely stem from methodological variation in operationalizing “exposure”—for example, differences in whether exposure is measured in hours, interaction type, communicative domain, or quality of input—highlighting the multifaceted nature of its influence.
The relationship between initial proficiency and retention is not straightforward. While some classical accounts support a critical threshold effect, others suggest that initial level alone has limited predictive value once patterns of exposure and use are taken into account. Recent longitudinal research indicates that sustained, meaningful L2 use—whether through work, study, or digital engagement—significantly reduces declines in both lexical fluency and richness. This evidence points to exposure quality and quantity as stronger determinants of retention than peak proficiency attained during instruction.
In addition, language exposure is multidimensional, encompassing both quantity and modality. Digital learning tools such as spaced-repetition flashcards and platforms that support retrieval practice have been shown to produce small-to-moderate positive effects on vocabulary retention in meta-analyses, particularly when they promote spaced, repeated retrieval in meaningful contexts. Pedagogical interventions that combine social-constructivist tasks with frequent opportunities for productive language use—speaking, writing, and peer teaching—also enhance retention outcomes. Therefore, attrition research should systematically measure not only how much exposure learners receive but also the type (oral, written, multimodal), distribution (spaced vs. massed), and cognitive demands of exposure when modeling retention trajectories.
Research Design
Research Questions
This study adopted a longitudinal within-subject design to investigate English vocabulary attrition among Chinese university students over a ten-month period following the completion of formal English instruction. Four testing sessions (T1–T4) were conducted at fixed intervals: (1) T1: Immediately after the completion of The New Standard Comprehensive Course of College English (Book 4) (Greenall & Wen, 2016), the final module of the university’s compulsory English program. (2) T2: Three months after T1. (3) T3: Seven months after T1. (4) T4: Ten months after T1.
This study seeks to answer the following research questions:
(1) What are the changes in lexical fluency indices over time during L2 lexical attrition and retention?
(2) What are the changes in lexical richness indices over time among L2 learners undergoing attrition?
(3) To what extent do initial vocabulary proficiency scores and FL exposure statistically predict lexical attrition and retention outcomes?
Participants
Consistent with Ni’s (2013) definition, the onset of attrition in this study was operationalized as the conclusion of the university’s compulsory English curriculum. Participants were sophomore students majoring in non-English disciplines at a comprehensive university in Shandong Province in China.
An initial pool of 143 students was identified through departmental class lists. All prospective participants completed a bilingual Vocabulary Size Test (Fu & Liu, 2018; Nation & Beglar, 2007) and a background questionnaire. Eligibility criteria were as follows: (1) Voluntary agreement to participate in a longitudinal follow-up study. (2) A minimum vocabulary size of 5,000 words, ensuring baseline homogeneity in English proficiency for oral production analyses.
This screening yielded 31 qualified and willing participants for T1. Due to natural attrition over the study period, 17 students (9 males, 8 females; M age = 19.20, SD = 0.17) completed all four rounds. On average, they had studied English for 12.34 years (SD = 4.33).
Research Tools
Verbal Fluency Task
The verbal fluency task (VFT) required participants to produce as many English words as possible within one minute for two semantic categories: fruits and vegetables and animals. These categories were selected because: They are widely used in attrition research (Dostert, 2009; Schmid, 2011), facilitating cross-study comparability. And they are culturally familiar to Chinese learners, minimizing the potential confound of topic unfamiliarity. And more, they have well-defined semantic boundaries, enabling objective scoring. Semantic fluency tasks have been shown to be more sensitive than formal fluency tasks in detecting lexical attrition.
Oral Production Tasks for Lexical Richness
Oral Topic-Speaking Task
At each time point, participants delivered a short monologue on two of eight predetermined topics, drawn from IELTS speaking materials with a difficulty coefficient of 2. Topics were pre-screened for familiarity and comparable cognitive demands. This task elicited spontaneous, unstructured speech, reflecting everyday communicative conditions.
Charlie Chaplin Film Retelling Task
Participants viewed a 10-minute excerpt from Modern Times, a silent film by Charlie Chaplin, and retold the storyline in their own words. This task was included because: It is a standard elicitation method in international attrition research (Schmid, 2011). And it requires narrative reconstruction, engaging memory, sequencing skills, and precise lexical retrieval. It complements the free-speaking task by providing structured narrative output, thereby enabling a broader assessment of lexical richness across discourse types.
Vocabulary Size Test, Background Questionnaire, Extracurricular Contact Self-Report
The vocabulary size test was based on the Chinese-English bilingual versions of Nation & Beglar (2007) and Fu & Liu (2018). The bilingual format was chosen due to its superior validity and reliability in assessing Chinese English learners (Cronbach’s α = .855 vs. α = .816) while also minimizing test anxiety.
The background questionnaire gathered demographic information and details regarding participants’ English learning experiences. Additionally, an extracurricular contact self-report scale was developed to assess participants’ frequency of exposure to and use of English outside the classroom. This scale, constructed based on established methodologies in language attrition research and the English learning habits of Chinese college students, comprised ten items. Responses were recorded on a seven-point Likert scale ranging from 1 (never) to 7 (several times a day). The scale exhibited high internal consistency reliability (Cronbach’s α = .844).
Research Process and Data Analysis
Research Process
Initially, 143 participants completed a vocabulary size test and a social background questionnaire. Based on the principle of voluntary participation, individuals with a vocabulary size exceeding 5,000 words were selected as suitable candidates for longitudinal tracking. This study adopted a long-term follow-up design, comprising four testing sessions. The first test (T1) was administered at the end of the College English course, followed by the second test (T2) 3 months later, the third test (T3) 7 months later, and the fourth test (T4) ten months later. Across all four sessions, three tasks were employed to elicit spoken language output: the VFT, a topic-speaking task, and a film retelling task. The vocabulary test and background questionnaire were administered in a classroom setting, requiring approximately 30 min to complete. The VFT, oral topic task, and film retelling task were conducted individually via Tencent Meeting, with each session lasting about 30 min per participant. An overview of the research procedure is presented in Figure 1.
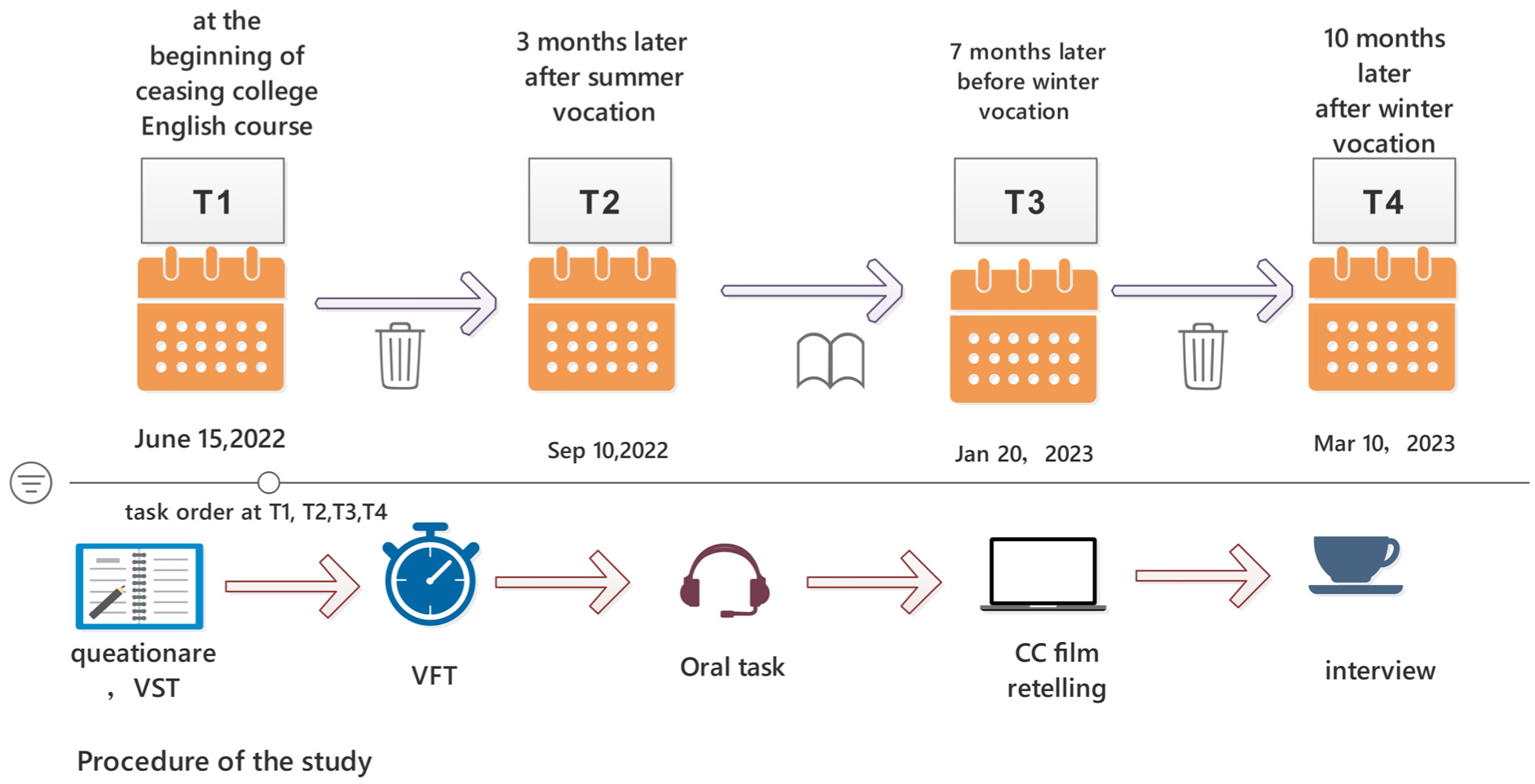
Main procedure of the study.
Data Processing
The entire data collection process was recorded using voice software. In total, 136 VFT tasks were transcribed, yielding 3,170 words; 136 oral topic tasks were transcribed, yielding 20,792 words; and 68 film retelling tasks were transcribed, yielding 16,533 words, resulting in a corpus of 340 texts. The VFT corpus was processed by calculating the number of total words and distinct words produced within 1 min. For the oral topic and film retelling corpora, Sound Forge was used for initial audio processing, while ifeC software was employed for text transcription and subsequent verification by two independent teachers. The processed texts were then analyzed for lexical richness using the Online Vocabulary Complexity Analyzer (Lu, 2012) and Range software. Seven indicators across three dimensions of lexical richness were examined in detail. The resulting VFT corpus and lexical richness data were subjected to multivariate analysis of variance (MANOVA). For Research Question 3, correlation and regression analyses were conducted to examine the relationships between the relevant dependent variables, vocabulary test scores, and self-reported vocabulary use (see Table 1).
Vocabulary Output Measurement Index System.

Research Results
Lexical Fluency in Lexical Attrition
Two semantic VFTs were used in this study. In each task, participants were asked to generate as many entries as possible from a given semantic category within 60 s. The two categories used are (a) fruits and vegetables and (b) animals. The total output of the two tasks is the average value per participant (VFT). In the four tests, 17 subjects produced 68 VFT1 texts and 68 VFT2 texts, a total of 3170 tokens and 358 types. We conducted text transcription and statistical analysis for each speech and analyzed the VFT attrition/retention of the subjects according to the number of outputs and the proportion of high and low-frequency words (Table 2).
VFT Lexical Attrition/Retention in VFT.

p < .05.
To assess the degree of vocabulary attrition/retention after the College English course ends, we compared the mean number for VFT production across the four time points. The total mean number was found to be 38.76, 35.59, 43.12, and 45.29 at T1, T2, T3, and T4, respectively. Repeated measures ANOVAs indicated significant differences among these times [F(3,48) = 5.517, p = .032 < .05]. Tukey’s HSD post hoc tests showed a significant reduction in the number of total VFT words from T1 to T2 and then showed an increase from T2 to T3, and T4 to T3. These results suggest that after all the vocabulary items they produced, the total VFT decreased at the first interval and then developed in the continued stage. The results of the repeated comparison showed that the number of VFT produced in the second test was lower than that in the first test (MD = −3.17), and significantly higher in the third test than that in the second test (MD = 7.53). Although the fourth test was higher than that in the third test (M = 2.17), there was no significant difference. The number of VFT1 and VFT2 outputs is also consistent as a whole (see Figure 2).

The mean of VFT from T1 to T4.
Figure 3 combines the scaled scores for the participants for all four tests and presents them in number order. Participants S1, S2, S5, S9, S11, S12, S15, and S16 are the 8 individuals whose lowest score in the T2 test, and the rate of VFT development followed the route with the results discussed above. The total output of the four VFT tasks of the 17 participants was presented individually, and there were strong individual differences.

The individual differences of VFT from T1 to T4.
Lexical Richness in Lexical Attrition
The topic-speaking task collected 136 texts with 20,792 tokens and the film retelling task collected a total of 64 texts with 16,533 tokens. We transcribe the spoken data and use the lexical richness index to measure vocabulary loss and retention. According to Lu (2012), the relationship of lexical richness to the quality of ESL Learners’ oral narratives, we analyzed all data in lexical diversity, lexical sophistication, and lexical variation by Lu Xiaofei’s lexical complexity Analyzer and Range in 7 indices related to text quality.
According to the research (Schmid & Jarvis, 2014), for the differences in lexical richness in oral topic and film retelling tasks, we evaluated the ratio of low-frequency morphological symbols in lexical complexity, low-frequency morphological symbols in lexical complexity, verb complexity, and lexical diversity. A multivariate analysis of variance was performed on 7 indicators including Uber index and corrected verb diversity to detect the performance of vocabulary richness in these four tasks (Table 3).
Lexical Richness in L2 Vocabulary Attrition and Retention.
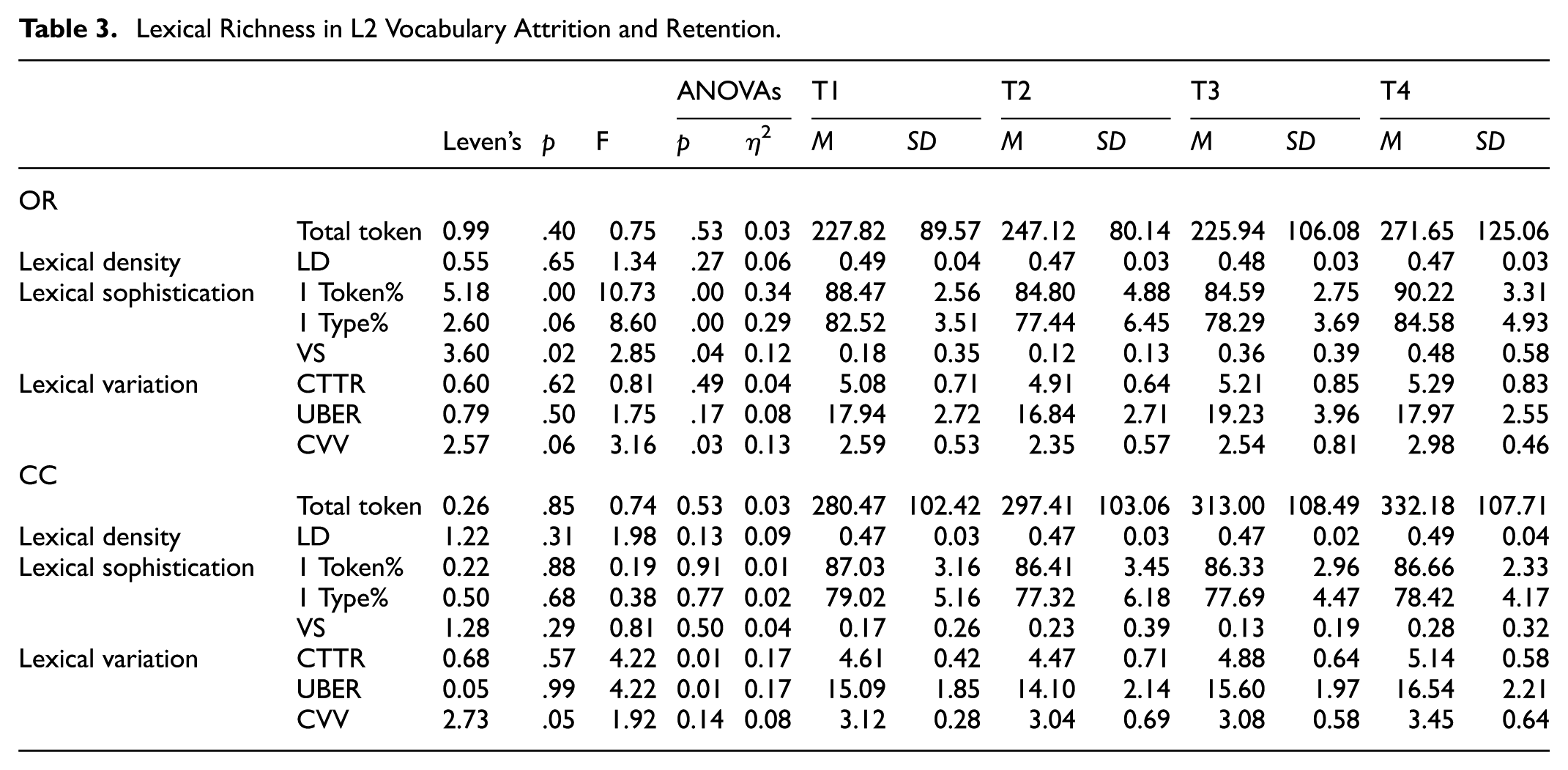
According to the obtained data, we further carried out a statistical description of the mean development of each indicator.
The Development Trend of Lexical Density
The development trend of lexical density: the results of multivariate analysis of variance (see Table 2) showed that there was no significant difference in word density between the two output tasks in the four tests (F(3,64) = 1.335, p = 0.271, η2 = 0.059; Word density F(3,64) = 1.981, p = .126, η2 = 0.085) in CC task. Tukey’s HSD post hoc tests showed no significant differences in changes in T1, T2, T3, and T4 levels. The results showed that the vocabulary density of the two tasks in four tests showed diverse development. As shown in Figure 4, compared with T1, the lexical density in the oral topic task test T2 showed an obvious downward trend, and then increased slowly in the T3 stage, and also decreased slightly in the T4 stage. The CC film retelling task shows an upward trend as a whole.

Lexical density development trend.
The Development Trend of Lexical Sophistication
The development trend of lexical sophistication (Figure 5): the results of multivariate analysis of variance show that there are significant differences in lexical complexity among the four test oral topic tasks (the proportion of high-frequency morphology in the oral task F(3,64) = 10.725, p = .000, η2 = 0.335; The proportion of high frequency characters (F(3,64) = 8.60, p = .000, η2 = 0.287); Verb complexity (F(3,64) = 2.853, p = .044, η2 = 0.118)). Tukey’s HSD postmortem tests showed significant differences in changes in T1, T2, T3, and T4 levels. As shown in Figure 5, the proportion of high-frequency lexical symbols in 5-A is consistent with the trend of class symbols. T1 to T2 decreases significantly, T2 to T3 is relatively flat, and T3 to T4 increases significantly. There was no significant difference in lexical complexity in the film retelling task. Figure 5b illustrates that learners’ 1Type% decreased relative levels between T2 and T1, slightly increased from T3 to T2, and then increased in larger increments from T4 to T3. A Tukey post hoc test revealed significant differences between T1 and T2 (p = .015) and T3 and T4 (p = .002) but no significant differences between T2 and T3 (p = .954). Figure 5c illustrates that learners’ VS decreased relatively between T2 and T1, then increased in larger increments from T2 to T3, and increased slightly from T4 to T3. A Tukey post hoc test revealed no significant differences between T1 and T2 (p = .972), T2 and T3 (p = .304), and T3 and T4 (p = .835).
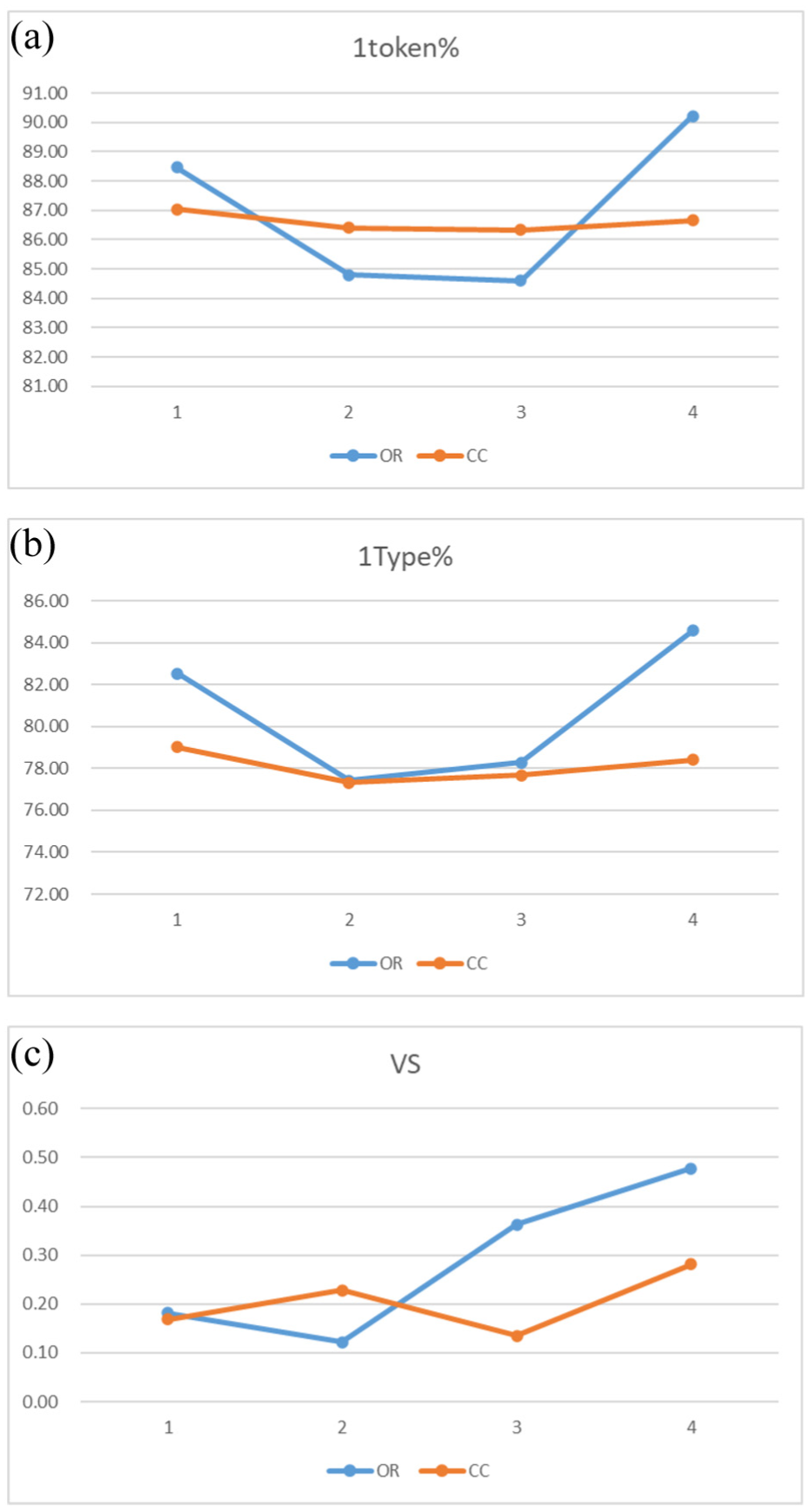
The development trend of lexical sophistication: (a): 1token%; (b): 1Type%. (c) VS.
The Development Trend of Lexical Diversity
The development trend of lexical variation (Figure 6): the results of multivariate analysis of variance showed that the modified verb diversity in oral topic tasks had significant differences among the four tests (F(3,64)=3.159, p = .031, η2 = 0.129). In the film retelling task, the modified shape class ratio (F(3,64) = 4.224, p = .0009, η2 = 0.165) and Uber value ((F(3,64) = 4.217, p = .009, η2 = 0.165) were significantly different across the four tests. There was no significant difference in other indicators. Tukey’s HSD post hoc tests also showed significant differences in the changes in the above indicators at T1, T2, T3, and T4 levels. As shown in Figure 6, the development trend of the modified symbol class ratio of the two tasks in Figure 6a is consistent, with a significant decline from T1 to T2, and a significant increase from T2 to T3 and T3 to T4. In Figure 6b, the development trend of the two tasks with Uber value is relatively smooth. Figure 6c shows that the revised verb diversity index is also relatively flat, with a decline from T1 to T2 and then a gradual increase.
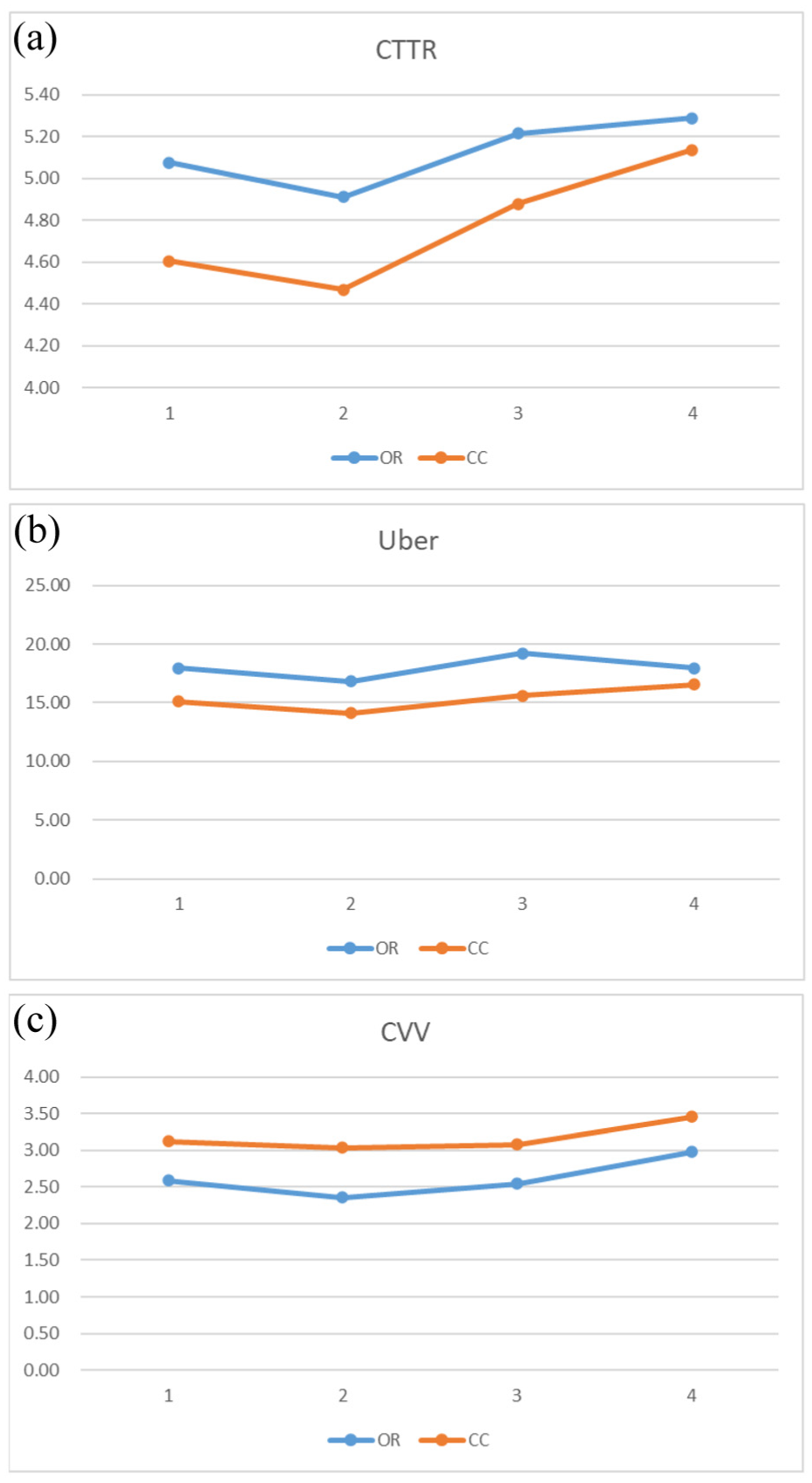
The development trend of lexical variation: (a) CTTR. (b) Uber. (c) CVV.
Factors in Lexical Attrition
According to the different results of lexical fluency and richness in the four stages, we found that the following indicators were statistically significant: (1) the total number of VFT in four lexical fluency tests; (2) The proportion of high-frequency lexical symbols (token1 (OR)), the proportion of high-frequency lexical symbols (type1 (OR)), the complexity of verbs (VS (OR)), and the diversity of modified verbs (CVV (OR)) in oral topic tasks; (3) The modified symbol class character ratio (CTTR (CC)) and Uber value (Uber (CC)) in the Film retelling task. We take it as the dependent variable of vocabulary attrition or retention, and explore the correlation and predictability of the subjects’ initial vocabulary scores and individual FL use (Table 4).
Descriptives and Correlation Coefficients of Variables (n = 17).

p < .05,**p < .01.
Table 5 shows the description and correlation analysis of 8 dependent variables and 2 independent variables, in which the initial vocabulary scores of the subjects have a significant correlation with the total number of VFT in the second and fourth times (r = 0.474, r = 0.615). There was a significant correlation between self-reported FL use and total VFT at the first and third tests (r = 0.414, r = 0.413). There was no significant correlation between initial vocabulary scores and FL use on the six indicators of vocabulary richness. Table 5 types 8 dependent variables and 2 independent variables into a multiple linear regression model. Multiple regression satisfies the normal distribution of errors and the errors are not correlated with the predictors. The results of forced regression showed that among the predictive variables, the initial vocabulary score and FL use of the subjects had the best predictive power for VFT4 and VFT2, and their explanatory amounts were 38.1% and 13.6%, respectively. In other words, the predictive variables could explain 38.1% and 13.6% of the variation in VFT4 and VFT2. Among the predictive variables, the initial vocabulary score and FL use of the subjects had the second predictive power for VFT1 and VFT3, and their explanatory quantities were 10.9% and 9.9%, respectively. In other words, the predictive variables could explain 10.9% and 9.9% of the variation in VFT1 and VFT3. However, there was no significant correlation between the six indicators of lexical richness as predictors and the partial indicators of dependent variables (Tables 4 and 5). The results of forced regression showed that initial vocabulary score and FL use had no predictive effect on the indicators of vocabulary richness.
Multiple Linear Regression: Important Statistics (n = 17).
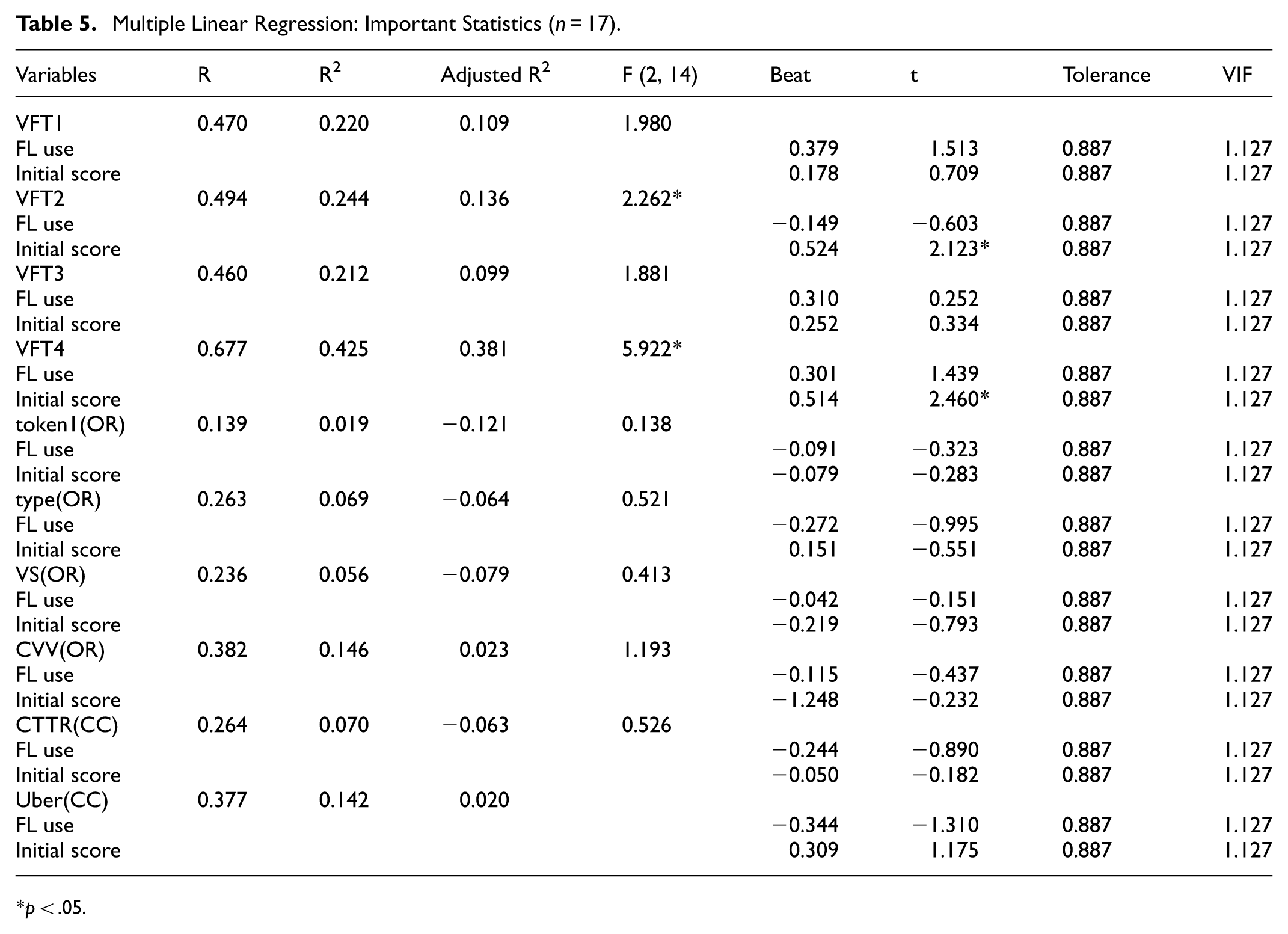
p < .05.
Discussion
FL Lexical Fluency in Attrition
Our findings show that the mean total lexical output in the VFTs at T1, T2, T3, and T4 was 38.76, 35.59, 43.12, and 45.29, respectively. The significant drop at T2 suggests an immediate post-instruction decline in lexical fluency, aligning with the “rapid initial loss” pattern frequently reported in attrition studies (Bahrick, 1984a, 1984b; Weltens, 1989). This decline is often attributed to weakened retrieval pathways when formal L2 use ceases (Mehotcheva, 2010). However, our data also reveal a rebound in lexical output at T3 and T4, with some participants reaching their highest scores in later assessments. Although the overall effect size (η2 = 0.151) indicates that these increases were not statistically significant, the upward trend resonates with the partial recovery trajectories documented in long-term attrition research, which highlight the role of renewed exposure and self-directed engagement in reactivating dormant lexical items.
The VFT, while widely used in attrition research due to its efficiency (e.g., Schmid and Köpke, 2019), provides only a snapshot of lexical accessibility and does not fully capture qualitative shifts in vocabulary knowledge. Traditionally applied in studies of aphasia and neurocognitive decline, the VFT has been increasingly adapted to second language attrition research as an indicator of lexical fluency. The pattern observed here—initial decline followed by gradual recovery—supports usage-based perspectives, which argue that frequency and recency of use are critical in maintaining lexical representations. The rebound suggests that participants’ lexical networks remained intact but temporarily less accessible, becoming reactivated through incidental contact with English in the months following instruction.
Qualitative analysis of participants’ responses revealed three notable features that echo prior findings. First, associative activation (e.g., potato–tomato, dog–cat) reflects the semantic clustering often reported in fluency tasks, suggesting that word retrieval follows network connectivity patterns. Second, cross-linguistic influences from both L1 and L3 were evident, supporting the dynamic systems view that multiple languages interact within a shared mental lexicon. Third, possible practice effects due to repeated testing every three months underscore the methodological caution raised by Schmid (2011) regarding longitudinal attrition designs.
Overall, our results contribute to the growing body of evidence that FL lexical attrition is not necessarily a permanent process but can exhibit non-linear trajectories shaped by post-instructional exposure, cognitive accessibility, and cross-linguistic interaction. While VFTs offer practical value, they should be complemented by more comprehensive, multi-dimensional measures to fully capture the complex interplay between lexical retention, attrition, and reactivation.
FL Lexical Richness in Attrition
The analysis revealed no significant differences in lexical density across the four testing points for either task, a finding consistent with earlier research suggesting that lexical density is not a reliable predictor of overall text quality in either spoken or written production (Kyle, 2020). Previous studies have further shown that non-interactive tasks such as writing tend to yield higher lexical density than interactive communicative tasks like interviews (O’Loughlin, 1995; Shohamy, 1994). In contrast to these established patterns, our results did not reveal a systematic link between lexical density and task interactivity. In our dataset, the spoken topic task involved greater communicative demands, while the film retelling task emphasized content reproduction. Interestingly, lexical density in the film retelling task was lower than in the spoken topic task only at T1; in subsequent testing points, it was equal to or higher, suggesting that density patterns may shift over time in ways not strictly tied to task type.
A more nuanced pattern emerged in the distribution of high-frequency words within the lexical complexity construct. In the spoken topic task, the proportion of high-frequency words declined significantly at T2 and T3. In lexical studies, such a decline is often interpreted as a sign of development, as learners expand their repertoire beyond the most common words (Read, 2000). However, in the film retelling task, no significant variation was observed across the four testing points. This discrepancy likely reflects differences in cognitive and linguistic demands: high-frequency words are typically acquired early due to frequent exposure, whereas low-frequency words—often domain-specific—require more sustained engagement and are considered a more sensitive indicator of advanced FL proficiency. The ability to select low-frequency vocabulary relevant to a given communicative or thematic context enables greater precision and sophistication, reducing reliance on generic, high-frequency items.
Verb complexity displayed a non-linear trajectory, fluctuating across time points. This supports the view that lexical complexity measures can serve as useful indicators of vocabulary retention and attrition, but that their developmental paths are strongly mediated by task type and communicative context. Lexical diversity measures showed a parallel pattern of decline followed by recovery, aligning with the “dynamic fluctuation” model of lexical attrition (Schmid, 2011). The three diversity indices revealed clear differences between tasks: CTTR and Uber scores were consistently higher in oral tasks than in film retelling tasks, whereas verb diversity was significantly lower in oral production. Following a three-month interruption, all diversity measures showed marked declines, followed by a rebound—suggesting processes of lexical retrieval, reorganization, and partial recovery. Similar non-linear patterns of depletion and reactivation have been documented in controlled studies of lexical richness, reinforcing the notion that FL lexical systems are dynamic and highly responsive to changes in usage conditions.
The Influence Between the Initial Proficiency, the Language Exposure on Lexical Attrition
Correlation analysis revealed a strong association between initial proficiency and VFT scores at T2 and T4, suggesting that learners with higher starting proficiency were better able to retrieve lexical items both shortly after instruction ceased and at later stages. In contrast, no direct relationship emerged between initial proficiency and lexical complexity indices. Similarly, foreign language exposure was significantly correlated with VFT scores at T1 and T4, but showed no measurable effect on lexical complexity measures. Motivation, due to its inherent variability and measurement challenges, was excluded from this analysis.
These findings indicate that while initial proficiency and foreign language exposure influence lexical accessibility, their impact on vocabulary richness is less direct. This aligns with Schmid and Jarvis (2014), who argue that such individual-difference variables contribute to attrition and retention at a micro level, whereas macro-level contextual and experiential factors also shape outcomes. Language attrition and development are thus best understood as complex, multi-layered processes, in which micro- and macro-level variables interact over time. This study’s treatment of initial proficiency and exposure is necessarily preliminary, underscoring the need for future research that situates these factors within an integrated framework. Such research should examine how individual differences interact hierarchically and dynamically with external influences, an approach well suited to a dynamic systems perspective.
From a dynamic systems viewpoint, several insights emerge. First, the L2 vocabulary subsystem demonstrates non-linear developmental patterns, with distinct trajectories across dimensions. Analysis of two dimensions and eight indicators revealed two dominant patterns. The first—evident in VFT scores and lexical diversity—follows a decline–recovery–growth trajectory: an initial drop at T2, recovery at T3, and continued growth at T4. This mirrors the rapid-onset attrition often observed immediately after formal instruction ends (Bahrick, 1984a), followed by partial reactivation as learners re-engage with the language through incidental or self-directed means. The second trajectory, marked by competitive interactions among subsystems, appears in measures such as lexical density and complexity. Here, changes in one component may occur at the expense of another, reflecting the self-organizing and adaptive properties of dynamic systems (Larsen-Freeman, 2012).
Second, the role of individual differences is pronounced. Learners’ developmental pathways vary considerably, shaped by a complex interplay of proficiency, exposure, cognitive resources, and learning context. Capturing these variations requires an analytical lens that accommodates complexity, variability, and interdependence over time. Integrating dynamic systems theory into lexical attrition research allows for a more holistic understanding of how individual and contextual factors jointly influence the retention, loss, and reorganization of L2 vocabulary.
Conclusion
This study investigated the retention and attrition of FL lexical fluency and richness over time, emphasizing the dynamic and non-linear nature of vocabulary development. Results showed that lexical fluency declined temporarily after the end of formal instruction but later rebounded, suggesting that continued exposure and self-directed learning can partially restore lost vocabulary. In contrast, lexical richness—measured in terms of complexity, density, and diversity—followed fluctuating trajectories, which were shaped by both task type and individual learner differences. Correlation analyses indicated that while initial proficiency and foreign language exposure influenced lexical retrieval, they did not have a direct impact on lexical complexity measures. These findings highlight the importance of adopting a broader analytical framework when examining vocabulary attrition. The integration of dynamic systems theory further revealed that foreign lexical retention and loss are self-organizing processes, jointly shaped by individual cognitive resources and contextual conditions.
Overall, the study underscores that FL lexical attrition is not a uniform, one-way process, but rather the outcome of complex interactions among cognitive, linguistic, and environmental factors. Future research should investigate additional learner-specific and macro-level variables to gain a more comprehensive understanding of foreign lexical vocabulary development and to inform more targeted interventions for mitigating lexical attrition.
Footnotes
Acknowledgements
The author would like to thank Lianrui Yang and Xiaofei Lu for their assistance with specific contributions. Special thanks are also due to Qingdao Binhai University and Ocean University of China for their institutional support.
Ethical Considerations
The study design ensured minimal risk to participants by maintaining anonymity and confidentiality. No personally identifiable information was collected or reported. Participation did not involve any foreseeable psychological or physical harm. Formal ethical approval was not obtained from an institutional review board, as no such ethics review process was in place at the author’s institution at the time of the study. Nevertheless, the study adhered to the ethical principles outlined in Section 8.05 of the APA Ethical Principles of Psychologists and Code of Conduct, and all efforts were made to protect participants’ rights and well-being.
Consent to Participate
This study involved human participants (university students) who participated in English film retelling and vocabulary-related tasks over a period of time. All participants were fully informed about the purpose, procedures, and voluntary nature of the study, and written informed consent was obtained from each participant prior to data collection.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by Qingdao Binhai University Doctoral research start-up project [grant number BS2024B020].
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.