
Abstract
Digital adoption has increasingly been seen as a key driver for accelerating human development. However, contextual factors affect digital adoption in a particular geographical setting. These factors have gendered differences due to systemic patriarchy and social stereotypes. There is limited scholarship on identifying such factors and gender differences in semi-urban settings. The study uses factor analysis to show that the experience of digital training, a basic ability to operate computers, and ease of online presence are the key factors affecting digital adoption in a semi-urban area of India. The study thereby adds a layer of socio-economic context to the categorisation of technology users within the Diffusion of Innovations Theory and considers societal barriers such as gender gaps as key differentiators for digital adoption. The study also finds that teenage girls are at a disadvantageous position in semi-urban areas of India with respect to feeling supported during digital training, having computer skills, having ease of social media usage, etc.
Introduction
The rapid advancement of digital tools has transformed many communities and regions worldwide. Many rapidly growing economies, such as India, the Philippines, Vietnam, etc., owe their growth to extensive technology infrastructure. However, the extent to which nations, regions and communities adopt these tools depends on various factors. Digital adoption, or the ability to use digital technologies to their fullest capacities, has been shown to have multiple determinants such as gender, age, income levels, education, etc. (Audrin & Audrin, 2022; Dong et al., 2021). The factors affecting digital adoption may vary in different socioeconomic contexts at a community, district and micro-regional level (Castilla et al., 2018; Peng & Yu, 2022; Satpati & Sharma, 2022). At the same time, the adoption of digital tools by the mass population has a significant impact on the socioeconomic indicators of a particular region (Park & Choi, 2019). In emerging economies, digital adoption can accelerate growth and development by making the flow of information seamless.
Many studies that explore the determinants of digital adoption focus on the rural-urban disparity, for example, the presence of digital access in an urban area or the absence of digital access in a rural area etc. (Chang & Tsou, 2006; Furuholt & Kristiansen, 2007; Nogueira et al., 2021). However, since semi-urban contexts are socio-economically neither completely under-developed nor completely developed, the determinants of digital adoption in these areas may be unique and can have wide applicability in emerging economies where semi-urban areas are growing fast. Identifying these factors is key to accelerating digital adoption by diverse socio-economic groups in order to positively impact education, healthcare, jobs, etc.
The digital access and experiences of the population in developing economies such as India highlight glaring gender gaps. The factors affecting digital adoption are gendered and manifest themselves in deep digital divides that are due to entrenched patriarchy and traditional social preferences in favour of boys and against girls (Bala & Singhal, 2018; Nayak, 2024). A lack of freedom in decision-making, low self-efficacy and low educational opportunities are some of the key factors behind the gender digital divide (Potnis, 2015). According to the Mobile Gender Gap Report 2023, women are 19% less likely than men to use mobile internet, and of those who don’t use it, almost two-thirds live in South Asia and Sub-Saharan Africa (GSM Association, 2023). In India, women were found to be 9% less likely to own a mobile phone and 21% less likely to use mobile internet than men (GSM Association, 2023). The gender digital divide may manifest in various ways due to inter-sectional issues like poverty, differences in education levels, etc. (GSM Association, 2023).
The present study explores the following research questions:
What are the factors that affect digital adoption in teenagers living in semi-urban areas of India?
What is the measurable gender gap within the factors affecting digital adoption in teenagers living in semi-urban areas of India?
The study attempts to answer these questions through focus group discussions that explore themes related to the determinants of digital adoption and gender gaps within these determinants. The study then uses exploratory and confirmatory factor analyses to identify such determinants and uses statistical tests such as t-tests, χ2 tests, etc., to measure the gender gaps within those determinants. The study was conducted with participants comprising teenagers (13–19 years old). Selected teenagers come under the adolescent age group. Most adolescents, when they reach this age group, attain the ability to make decisions based on an understanding of choices and consequences, face high peer influence, and build skills to be self-sufficient (Huberman, 2016). They start responding to media information and start seeking independence (Huberman, 2016). Such a group is in a phase of transitioning from dependence to independence in decision-making and is relatively more acquainted with digital tools than people in other life stages (Oni, 2020). Thus, teenagers were chosen for this study so that the digital adoption patterns are captured at the early stages of development without those patterns being diluted by other age-related factors that may be relevant to older age groups, for example, working adults who adopt digital literacy as a job-related requirement.
The study adds an additional layer to the understanding of the Diffusion of Innovations Theory, which proposes that some individuals will adopt technology earlier than others depending on the relative advantage, observability, triability, complexity and compatibility of that technology (Rogers, 1962). The theory does not factor in an individual’s socio-economic context, such as gender, income, social support they have, etc., in its technical categorisation. The present study explores how contextual factors such as the level of urbanisation and gender blend with digital adoption behaviour. This study also serves as a starting point for governments and independent organisations to account for contextual determinants in policymaking related to digital adoption. Such a consideration can help in designing government interventions to close the gender gap in digital adoption.
The study chooses Sangareddy, a semi-urban district in Telangana state, as the study site. Sangareddy has existing disparities between men and women on various socio-economic indicators. As per the 2011 Census of India, the district has a population of 1,527,628. The literacy rate is 64.08%, which is much lower than that of India, 74.08%, and slightly lower than that of Telangana state, 66.54%. In Sangareddy, the male literacy rate is 73.02%, and the female literacy rate is 54.84% (Government of Telangana, n.d.). Hence, there is a wide gap of 18% in literacy rate between males and females. The sex ratio is 955 females to 1,000 males, 65.31% of the population lives in rural areas (Government of Telangana, n.d.).
The study begins with a literature review of the existing literature on factors affecting digital adoption and associated gender gaps. Then, it discusses the research methodology, which explains the different stages of the study and the context of the study location. Further, the article analyses the results from the selected methods and explores the interpretations of those results, followed by a discussion. Finally, the study concludes the findings, makes recommendations, and discusses its limitations.
Literature Review
Theoretical Review
Multiple theories, such as the Technology Acceptance Model (TAM), Social Cognitive Theory (SCT), Diffusion of Innovations Theory (DOI), etc., explain how users adopt an innovation. TAM states that the decision to adopt a technology is based on two factors—its perceived usefulness and its perceived ease of use (Davis, 1989). However, it does not emphasise much how the skill required to adopt, as in the case of digital adoption, will be attained to make the adoption successful. SCT focuses more on the peer learning behaviour of users (Bandura and National Inst of Mental Health, 1986). It states that individuals learn by observing others. While this theory may explain some degree of digital adoption, the wide gender digital divide in society in different forms and levels highlights the insufficiency of this theory.
Digital adoption can be understood using DOI, which suggests how technological advancements propagate in a society and are adopted by a specific population within the society (Rogers, 1962). It states that the adoption of technology is dependent on its relative advantage, compatibility with values, complexity of use, triability before use, and observability for producing tangible results (Rogers, 1962). The theory categorises the technology users as innovators (people who are first to try new ideas or products), early adopters (people who are interested in trying new technologies and are opinion leaders), early majority (people who need evidence that innovation works before they adopt), late majority (people who are skeptical of change and await a majority to adopt the innovation before they adopt) and laggards (people who resist change and are conservative) (Rogers, 1962).
However, one’s situated context goes far beyond individual values and entails various dimensions such as socioeconomic status, age, gender, etc., which DOI does not account for. Hence, the present study addresses this gap by highlighting how contextual factors such as gender and level of urbanisation blend with digital adoption in Indian semi-urban teenagers.
Conceptual Review
Digital adoption is a process in which individuals learn and use digital technologies to meet their personal, professional, social, and economic goals (Granić, 2023; Liu, 2010; Smidt & Jokonya, 2021). It has been linked positively to economic growth and development (Beck et al., 2014; Jensen, 2007). Further, developing countries benefit more from digital adoption than developed countries (Kim et al., 2021; Qiang et al., 2009). However, there are determinants of digital adoption, such as age, gender, income, education, infrastructure development, etc., that determine the economic trajectory of a country (Asrani, 2021; Rao, 2005; Várallyai et al., 2015). The factors affecting digital adoption may be related to digital access, basic familiarity with digital tools, internet availability, internet speed, feeling supported during digital adoption, skill training, digital safety, etc. (Bondar et al., 2021; Fallows, 2005; Karlin, 2019; Llorens & Alarcon, 2020; OECD, 2018; Purushothaman, 2011).
Since different geographical contexts may have different social systems, it is likely that the factors affecting digital adoption in a specific region may be unique to its context, as learning is both contextual and social (Lave & Wenger, 1991). Hence, adopting digital tools as a learning construct is likely dependent on social and contextual factors.
Globally, digital adoption has seen wide gender gaps. Women are more disadvantaged, get lower access and experience lower benefits from digital adoption (OECD, 2018, pp. 19, 22, 50). Such gaps are often a result of masculine identity perception of technology (Marini et al., 2020, p. 139). These gender gaps in digital adoption can be classified into four broad categories: affordability, availability, ability, and appetite (Tyers-Chowdhury, 2021, p. 6). Affordability denotes lower income levels in women, which leads to lower access. Availability denotes having only basic handsets, lack of handsets, lower network coverage and network quality available to women. Ability covers lower levels of digital literacy skills in women. Appetite covers safety and security issues that women face, which deter them from using digital technology.
Age is an important determinant of digital adoption (Anane, 2022; Jaradat, 2014). The adolescent group of 13 to 19 is a critical development period when individuals experience fast social, cognitive and emotional changes that shape their identity (Landis, 2020). This period shows increased digital engagement, which is shaped by income background, education and gender (Banaji et al., 2018; Micheli, 2016; Wong et al., 2020). Further, the policy focus on this age group will likely bring long-term benefits in terms of economic productivity and social development indicators.
Socially equitable digital adoption links to Sustainable Development Goals (SDGs) 4 (Quality education), 5 (Gender equality), 9 (Industry, innovation and infrastructure) and 10 (Reduced inequalities). Quality education is an important component of digital skilling. Gender inequality manifests in the digital gender divide as well. Equity in digital adoption is a part of building inclusive, sustainable and resilient infrastructure. Ultimately, achieving equitable digital adoption is crucial for bridging socio-economic inequalities within and between countries.
Empirical Review
Existing gender disparities go beyond unequal digital access between men and women. For example, merely increasing subscriptions does not ensure an increase in the usage of phones (Samudra, 2022, pp. 23–24). National Family Health Survey (NFHS-5, 2019–2021) in India reveals that 33% of women (in the age group 15–49) use the internet, while the figure is 51% for men in the same age group (Ministry of Health and Family Welfare, Government of India, 2021). Many women in India still use basic handsets with voice and SMS service only and use them less frequently and for limited purposes (Tyers-Chowdhury & Binders, 2021, p. 6). Furthermore, these handsets are often not user-friendly and use only English, widening the gap in digital usage (Tyers-Chowdhury & Binders, 2021, p. 11). Women also struggle with the skills and confidence to engage with digital technologies (Kuroda, 2019, p. 5).
Online safety is a critical issue for women in order to use digital technology effectively. Fifty-two percent of young women in the world have experienced digital harm, and 87% of them feel the situation is getting worse (Tyers-Chowdhury & Binders, 2021, p. 13). Ninety percent of child sexual abuse images are of girls (Tyers-Chowdhury & Binders, 2021, p. 13). Hence, the digital space is quite unsafe for girls and women.
The gender gap in digital adoption is more pronounced in rural areas (Krishnan, 2020). Rural women are ‘less likely than men to exclusively own smartphones’ (Islam & Manchanda, 2023, p. 2). In rural areas, socio-cultural views like patriarchy impede women’s ownership/possession and use of mobile phones (Patil & Muthmainnah, 2022, pp. 15, 262). Infrastructure is concentrated in urban areas, and many women still live-in rural areas (Bala, 2017, p. 43). Since infrastructure in rural areas is mainly shared amongst households, women’s digital access is inhibited due to a lack of accounting of women’s time use, settings that women are less likely to visit and social customs (Bala, 2017, p. 50).
Semi-urban areas may have slightly better digital infrastructure compared to rural areas. For example, in Tanzania, semi-urban areas have more frequent internet cafe users than rural areas (Furuholt & Kristiansen, 2007). Oyedemi and Mogano (2018) find that students in rural areas make their first contact with the Internet at a later age than students in semi-urban and urban areas. They further find that students from semi-urban regions find it less challenging than students from rural areas but more challenging than students from urban areas to use a computer the first time they arrive at their university. Hence, it is likely that the level of digital disparities in semi-urban areas sits between the levels in rural and urban areas.
Hence, the existing scholarship on digital adoption highlights the following problem.
Problem Statement
Despite significant strides in technology implementation, significant disparities exist with respect to digital adoption. Factors such as gender, socioeconomic status, etc., impede equitable adoption. Semi-urban areas experience unique digital gaps compared to rural and urban regions, determinants for which are not well explored. Further, adolescents are highly exposed to such vulnerabilities, considering the criticality of socio-cognitive development during this age group.
Hence, the study explores the factors affecting digital adoption among teenagers in semi-urban areas of India and the extent of the gender digital divide within those factors. Exploration of such contextual factors is critical for emerging economies where semi-urban areas are expanding rapidly due to growth, development, migration, economic investment, structural reforms, etc.
Research Methodology
The study is rooted in pragmatist philosophy, focusing on real-world outcomes and applications, and uses a combination of methods such as focus group discussions, surveys, statistical analyses, etc. It considers both objective facts and subjective experiences while designing the research tools. The study uses cross-sectional primary data from a survey conducted from February 2023 to April 2023 in the Sangareddy district of the state of Telangana in India.
The study employs a mixed-methods approach that involves a scale development using focus group discussions, literature study, a pilot study, factor identification using exploratory factor analysis and confirmatory factor analysis, and analysis of the gender digital divide within the identified factors and items. The study began with focus group discussions because of the need to develop survey statements based on common themes around digital adoption and supplement them with emerging themes from the literature. The literature provides themes linked to the common discourse around rural-urban-based, gender-based, income-based and education-based dimensions of digital adoption. However, the focus group discussions grounded those themes in the semi-urban context of the study. The study employed a stratified purposive sampling method based on geographical location (semi-urban area of Sangareddy), gender (boys and girls) and age (13–19). The questionnaire was primarily a Likert-scale survey, preceded by basic demographical questions in order to disaggregate the data at the analysis stage. The questionnaire was administered in person in district schools, and both local and English language formats were used, depending on the student’s proficiency.
Sample size and the nature of the sample across different stages of the research are discussed below:
Stage 1 (Focus Group Discussions): Six focus group discussions were conducted with 10 to 14 participants each (two with mixed-gender participants, two with only girls and two with only boys) in the age group 13 to 19 to arrive at the statements for the pilot questionnaire. The topic of the discussion was digital literacy and its manifestation in the gender gaps. The focus group discussions aimed to get a preliminary insight into the factors affecting digital gaps in Indian semi-urban teenagers and to arrive at questions for the subsequent survey.
Stage 2 (Hypothesis Formulation): The focus group discussion and literature study complemented each other to highlight the possible influence of access, digital training experience, basic familiarity with computers, basic computer skills, basic communication skills and online safety on digital adoption among Indian semi-urban teenagers. To identify determinants of digital adoption using a survey, the following hypothesis was formulated with respect to factor analysis: ○ Exploratory factor analysis:
● H1 (Model Fit): The survey items group into distinct underlying factors corresponding to dimensions of digital adoption in teenagers in semi-urban areas of India. ● H2 (Factor Loadings): Specific items load significantly and positively into distinct latent factors based on underlying themes. ○ Confirmatory factor analysis:
● H3 (Model Fit): The hypothesised factor-item model fits the data well, suggesting that it precisely represents the underlying dimensions of digital adoption in teenagers in semi-urban areas of India. ● H4 (Discriminant Validity): The factors are distinct, with acceptable inter-item correlations, supporting the conceptual distinction between the factors in the hypothesised factor-item model.
Stage 3 (Pilot Study): A Likert-scale-based pilot survey (designed based on insights from the focus group discussions and literature review) was conducted for a sample size of 50 teenagers (25 boys and 25 girls) within the age group 13 to 19 from Sangareddy to identify the suitability of the factor analysis. The suitability of the methods was assessed by establishing univariate normality (testing range of skewness and kurtosis and using the Jarque–Bera Test) and conducting factor analysis.
Stage 4 (Exploratory Factor Analysis): A mixed-gender sample of 240 teenagers (age group 13–19) spread across the three administrative divisions of Sangareddy was used for exploratory factor analysis. The Likert scale responses from the survey with these 240 participants were used to identify the factors and items affecting digital literacy using Exploratory Factor Analysis. In factor analysis, variables were grouped together based on their common variance, which is explained by the underlying factors (DeVellis, 2017, p. 155). Factors are the underlying latent constructs that explain the variation amongst a set of observed variables (DeVellis, 2017, p. 155), for example, a variation in eight observed variables may reflect a variation in two underlying constructs. The observed variables are called items, and the underlying constructs are called factors (DeVellis, 2017, p. 155). Within this analysis, Eigenvalues, factor loadings, inter-item correlation and Cronbach Alpha were measured. Kaiser–Meyer–Olkin (KMO) values were measured, and the Bartlett test of sphericity was also conducted.
Stage 5 (Confirmatory Factor Analysis): The model of the identified set of factors and the selected items for each factor from the previous stage were tested for goodness of fit using responses from another set of 240 teenagers (age group 13–19) through Confirmatory Factor Analysis. The values of Comparative Fit Index (CFI), Root mean square error of approximation (RMSEA), Standardised Root Mean Residual (SRMR) and Tucker–Lewis Index (TLI) were checked against acceptable ranges, and the Composite Reliability was assessed.
Stage 6 (Gender-wise Comparisons): Based on the factors identified and confirmed through EFA and CFA, respectively, gender-wise comparisons were made using mean scores on each item under the finalised factors and performing t-tests with respect to responses by boys and girls. The sample used for this comparison was the combined sample for EFA and CFA, with 480 responses.
Stage 7 (Chi-squared (χ2) test to assess gender disparity in categorical responses): Both the surveys that were used for Exploratory Factor Analysis (EFA) and Confirmatory Factor Analysis (CFA) also had questions of categorical responses on themes identified in the focus group discussions. Statistically significant disparities on those questions were assessed between boys and girls using the Chi-squared (χ2) test. The sample used for this test was the combined sample used for EFA and CFA, with 480 responses.
Results
Demographic Information
Table 1 shows the demographic information of the chosen sample (50 teenagers for the pilot survey, 240 teenagers for the exploratory factor analysis and 240 teenagers for the confirmatory factor analysis). Table 1 shows the gender distribution (boys and girls) and annual family income distribution of the sample (USD 0-1145, USD 1146-4515, USD 4516-14005, USD 14006 and above). Income distribution in our analysis is based on the World Bank’s country classification by income group, which states that countries with per capita Gross National Income less than USD 1,145 per year in the year 2023 are low-income, per capita GNI between USD 1,146 and USD 4,515 are lower-middle income; per capita, GNI between USD 4,516 and USD 14,005 are upper-middle income, per capita GNI above USD 14,005 are high income (The World Bank, n.d.). It also presents the distribution of educational courses students are enrolled in (8th grade, 9th grade, 10th grade, 11th grade, 12th grade, BCom, BSc, BA).
Profile of the Survey Participants.

Interpretation of Themes Emerging from the Focus Group Discussions
The focus groups highlighted bright spots and challenges related to digital access, training experience, basic familiarity with computers, data and information processing, communication and safety. While some participants shared that they had access to mobile phones, others reported limited computer experience and poor internet connection. Some of the concerns raised were not learning how to use computers or learning only typing, a lack of sufficient support, a lack of utility of learning, etc., and the lack of opportunity to learn computer skills. Some shared that they have basic proficiency with MS Word or MS Excel, while others had no prior experience with these applications. Safety was another theme that emerged. Common safety issues shared were getting spammed, losing privacy, online theft, hacking, etc.
While some common issues emerged for both genders, there were differences between the responses of boys and girls to some of the issues. A common concern was girls not having their phones and having to borrow them. Focus groups highlighted that boys were preferred to girls by parents when giving them access to the phone, and boys enjoy more freedom to use social media. They emphasised that girls must limit their social media usage, especially when it comes to uploading photos, interacting with others, etc.
The focus groups also highlighted that girls face safety issues like bullying, harassment, etc., online and offline. Sometimes, girls face negative comments from family or neighbours if they use social media freely.
Thus, based on the above insights, the notes from the focus group discussions were coded into six themes: access, experience, basic familiarity with computers, data and information processing, communication and safety.
The quotations from the groups were mapped to their respective codes in Table 2.
Coded Themes and Corresponding Quotations.

Based on the themes emerging from focus group discussions and literature study, the following possible factors and dimensions were proposed (Table 3). Each of these items was framed as a statement. The rating options for some questions were Strongly Disagree, Disagree, Neutral, Agree, and Strongly Agree. For some other questions, the rating options were Never, Rarely, Sometimes, Often, and Always. The source of each of the dimensions, be it the literature study or focus group discussions, is mentioned in Table 3.
Possible Factors and Dimensions for Factor Analysis.

Note. The term ‘FGD’ in the table means Focus Group Discussion. The acronym is followed by the sequence number of the group discussions that were conducted.
Understanding Significant Factors to Assess Gender Gaps
Pilot Study to Establish the Suitability of Factor Analysis
The pilot study was conducted to assess whether factor analysis is suitable for identifying the relevant factors affecting digital literacy in Indian semi-urban teenagers. A mixed-gender sample of 50 teenagers was selected. The mean score and standard deviation for the responses to each item were noted. To establish the suitability of factor analysis, the univariate normality was established in the pilot survey, which means checking whether the responses to each item in the sample chosen for the pilot follow a normal distribution or not (Child, 2006). If the responses follow a normal distribution, then factor analysis is used to explore the different factors. Univariate normality was assessed using skewness, kurtosis and the Jarque–Bera Test. Skewness is a measure of the asymmetry of the normal distribution. It refers to the extent to which a normal distribution is not symmetrical (Chen, 2023). Kurtosis is a measure of the tailedness of distribution, and tailedness is how often outliers occur (Turney, 2022). ‘Data is considered to be normal if skewness is between −2 and +2 and kurtosis is between −7 and +7’ (Byrne, 2016; Hair et al., 2016). In the pilot data, each of the items was coded, as shown in Table 4. Skewness for each item was within the range of −2 and +2, and the kurtosis of the ratings for each item was within the range of −7 to +7. Further, the Jarque–Bera test was performed to test the normality of the pilot data. The null hypothesis in the Jarque–Bera test is that the data is normally distributed. The alternate hypothesis is that the data is not normally distributed. After conducting this test, except for item codes B1, B8, D1, D2, C4 and S2, as shown in Table 4, the p-value for the rest of the items is greater than .05. Thus, the study fails to reject the null hypothesis for 28 out of 34 items. Hence, univariate normality was established for most of the items. The mean, standard deviation, skewness, kurtosis and p-value from the Jarque–Bera Test are tabulated in Table 4.
Assessing Univariate Normality in the Pilot Survey.

The Kaiser–Meyer–Olkin test determines the suitability of data for factor analysis by examining the correlation between variables and determining the extent to which they share a common variance. The test produces a statistic between 0 and 1, with values above .5 indicating an appropriate dataset for factor analysis (Bernard et al., 2020, p. 45). The KMO value for the pilot data was above .5 (KMO MSA = .71), which establishes the adequacy of the sample. Bartlett’s Test of Sphericity shows whether the correlations in the data are strong enough to use a dimension-reduction technique such as factor analysis (Wicklin, 2022). The Bartlett test of sphericity in the pilot data was less than .05 and .01 (p-value = 0), which establishes the suitability of the data reduction technique. This score further means that there are some relations between items to compress these items into factors once factor analysis is used.
Cronbach’s alpha measures the internal consistency, or reliability, of items in a scale to check whether a group of items consistently measures the same characteristic (Frost, 2022). The value of Cronbach’s alpha was more than .7 in the pilot data set, establishing the internal consistency of the scale, as shown in Table 5.
Cronbach Alpha for the Proposed Six Factors in the Pilot Data.

Finally, the inter-item correlation was tested for each dimension under each factor. Inter-item correlations are a required measure to conduct item analysis (Piedmont, 2014, p. 3304). Inter-item correlations examine ‘the extent to which scores on one item are related to scores on all other items in a scale’ (Piedmont, 2014, p. 3304). It provides ‘an assessment of item redundancy: the extent to which items on a scale are assessing the same content’ (Piedmont, 2014, p. 3304). The acceptable range for inter-item correlation is .3 to .8 (Huang et al., 2009, p. 283). Barring a few exceptions, most of the inter-item correlation values are within the acceptable range in pilot data. None of the items had an inter-item correlation higher than .75.
Based on all these results, all items were taken into consideration for exploratory factor analysis. No items were dropped at the pilot stage. The responses considered in the pilot study were not included in the final analysis.
Identification of Factors Using Exploratory Factor Analysis
A mixed-gender sample of 240 teenagers spread across the 3 administrative divisions of Sangareddy district in India and in the age group 13 to 19 was used for exploratory factor analysis (EFA). The responses on each item finalised in the pilot study were assessed for EFA.
The screeplot of eigenvalues suggested three factors. Eigenvalues show the amount of variance in the original data that is accounted for by each factor. According to the Kaiser rule, factors with eigenvalues greater than one must be retained, as each of these factors explains more variance than any of the observed variables in the factor (Goodwyn, 2012). Eigenvalue scores inform how many factors need to be extracted. Hence, in this case, three factors needed to be extracted. Thus,
H1 is accepted: The three distinct factors in EFA results show unique dimensions of digital adoption in semi-urban teenagers.
The items were then tested for communality, which shows the proportion of variance in the given variable that can be explained by retained factors. All the items with a communality value of more than .3 should be retained (Guadagnoli & Velicer, 1988). The factor loadings of items of each of the three factors were checked, as shown in Table 6. Factor loadings with scores higher than .4 are considered stable (Guadagnoli & Velicer, 1988). Items must not cross-load too highly between factors (measured by the ratio of loadings being greater than 75%; Samuels, 2017, p. 1). There must be as many factors as possible, with at least three non-cross-loading items with an acceptable loading score (Samuels, 2017, p. 1). Items shall be removed one by one until the final set of factors and items satisfies all the requirements of communality and factor loadings (Samuels, 2017, p. 1). The retained factor numbers and corresponding items are tabulated in Table 7.
Factor Loadings.

Summary of Identified Factors and Items.

KMO was more than .8, which established excellent sample adequacy (KMO = .82). The Bartlett test of sphericity showed p-values less than .05 and .01 (p = 0), which established the suitability of the data reduction technique. The three factors explained more than 50% of the variance (Variance explained = 65.79%). This result meant that the three factors captured a significant amount of variation in the factors being measured.
Cronbach alpha for each of the hypothesised factors was greater than .7, establishing a strong internal consistency of the scale, as shown in Table 8.
Cronbach Alpha for Exploratory Factor Analysis.

Thus,
H2 is accepted: Specific items in Table 6 demonstrated significant loadings on their respective factors with standardised loading values above .5, which suggests that those items are associated with distinct underlying themes of digital adoption among teenagers in semi-urban areas of India.
Interpretation of Results from Exploratory Factor Analysis (EFA)
The first factor was loading strongly on all the digital training experience-related questions (E1, E2, E3 and E4). Hence, the experience of digital training can be a factor affecting digital literacy. The second factor was loading strongly on B5, B6, D2 and D3. All these items pointed to the basic ability to operate computers. Hence, a basic ability to operate computers may be a factor affecting digital literacy. The third factor was loading strongly on C2, C3, C4 and C5. All these items pointed to ease of online presence. Hence, ease of online presence may also be a factor affecting digital literacy. Overall, these 3 factors and 12 items affect digital literacy in the context studied.
Confirmation of the Factors Using Confirmatory Factor Analysis (CFA)
The Exploratory Factor Analysis suggested the following factor-item combinations, as shown in Table 7 previously.
Using this factor-item set, the confirmatory factor analysis was conducted with a mixed-gender sample of 240 teenagers spread across the 3 administrative divisions of Sangareddy. The model was first checked for discriminant validity. Discriminant validity establishes how a factor is distinct from other factors in the same model. This validity was assessed using hetero-trait mono-trait (HTMT) test. HTMT evaluates the extent to which a given factor shares more variance with its own indicators (monotrait) than with the indicators of other factors in the model (heterotrait). The inter-trait HTMT values should be less than .9. The HTMT values were interpreted as estimates of inter-factor correlations. All the inter-trait HTMT values for the CFA sample were less than .9, suggesting that the factors are sufficiently distinct from other factors. Thus,
H4 is accepted: The three factors in the hypothesised factor model are distinct, with acceptable inter-item correlations, supporting the conceptual distinction between the factors in the hypothesised factor-item model.
The goodness of fit of the model was checked using the Comparative Fit Index (CFI), Root Mean Square Error of Approximation (RMSEA), Standardised Root Mean Square Residual (SRMR) and Tucker-Lewis Index (TLI). The CFI and TLI are ‘incremental fit indexes that assess the improvement in the fit of a model over that of a baseline model with no relationship among the model variables; larger values indicate better model fit’ (Kline, 2015, pp. 276–277). The SRMR is a ‘measure of the mean absolute correlation residual, with smaller values suggesting a good model fit’ (Kline, 2015, p. 277). The RMSEA ‘provides information about ‘badness of fit’, with lower RMSEA values indicating good model fit’ (Kline, 2015, p. 273). The acceptable ranges and actual values of these indices are summarised in Table 9. All indices were within the acceptable range suggesting an acceptable fit of the model.
Fit Values for Confirmatory Factor Analysis.

Composite reliability was also tested for confirmatory factor analysis. This test measures ‘the internal consistency of the factors’ and whether the factor measures the items under it reliably (Veiga et al., 2019, p. 339). Its range is from 0 to 1, with higher values denoting greater internal consistency and reliability of the factor (Haji-Othman & Yusuff, 2022, p. 381). Composite Reliability was achieved when all composite reliability values for each of the factors exceeded .60 (Veiga et al., 2019, p. 339). The composite reliability of each factor in the CFA sample exceeded .60 (crf1 = .820; crf2 = .803; crf3 = .803).
Considering the fit indices and composite reliability:
H3 is accepted: The hypothesised factor-item model fits the data well, suggesting that it precisely represents the underlying dimensions of digital adoption in teenagers in semi-urban areas of India.
Interpretation of Results from Confirmatory Factor Analysis
Since all the fit indices were within an acceptable range, the three factors (training experience, basic ability to operate computers and ease of online presence) and the 12 items within these 3 factors could reliably be considered factors affecting digital literacy in Indian semi-urban teenagers. Further, all three factors showed strong internal consistency, which meant that these factor measures explained the variation in items within them reliably. The final scale was confirmed, as shown in Table 10.
Final Digital Literacy Scale With Factors and Dimensions.

Gender-Wise Comparison of Identified Items
Based on the factors identified and confirmed through EFA and CFA, the gender-wise comparisons were made by performing a t-test on the mean Likert scale scores of boys and girls in the combined sample used for EFA and CFA on the respective items. The items with significant mean score differences between boys and girls were determined by looking at the p-value < .05. The tabulated data is shown in Table 11. The selected items thus were E1, E4, B6, D2, D3, C3, C4 and C5 with p-value less than .05.
T-test to Find a Difference in Mean Scores Between Boys and Girls.

The selected items for gender-wise comparisons thus were E1, E4, B6, D2, D3, C3, C4 and C5 based on the significance of the p-value of the difference in the two means.
Interpretation of Findings from Gender-Wise Comparisons
Girls felt significantly less supported during digital training than boys.
Girls felt significantly less utility of digital training than boys.
Girls felt significantly less ability to create a folder, compare information online or create word documents than boys.
Girls felt significantly less ability to perform audio/video calls online or find using social networking websites easy than boys.
These findings can result in lower digital skill levels and lower engagement levels in girls in digital training. Further, the inability to network online can impact their exposure to the digital network. These gaps can affect their opportunities for education and jobs. As a result, these gaps can impact the personal, social and economic development of girls.
Assessing Gender Disparities in Categorical Responses on Digital Access and Basic Familiarity With Computers
Chi-squared (χ2) tests were conducted to assess the difference between boys and girls in the responses to the following questions, where the response options were yes or no. p-values and χ2 values for each of the responses are mentioned in Table 12.
χ2 Results for Categorical Responses.
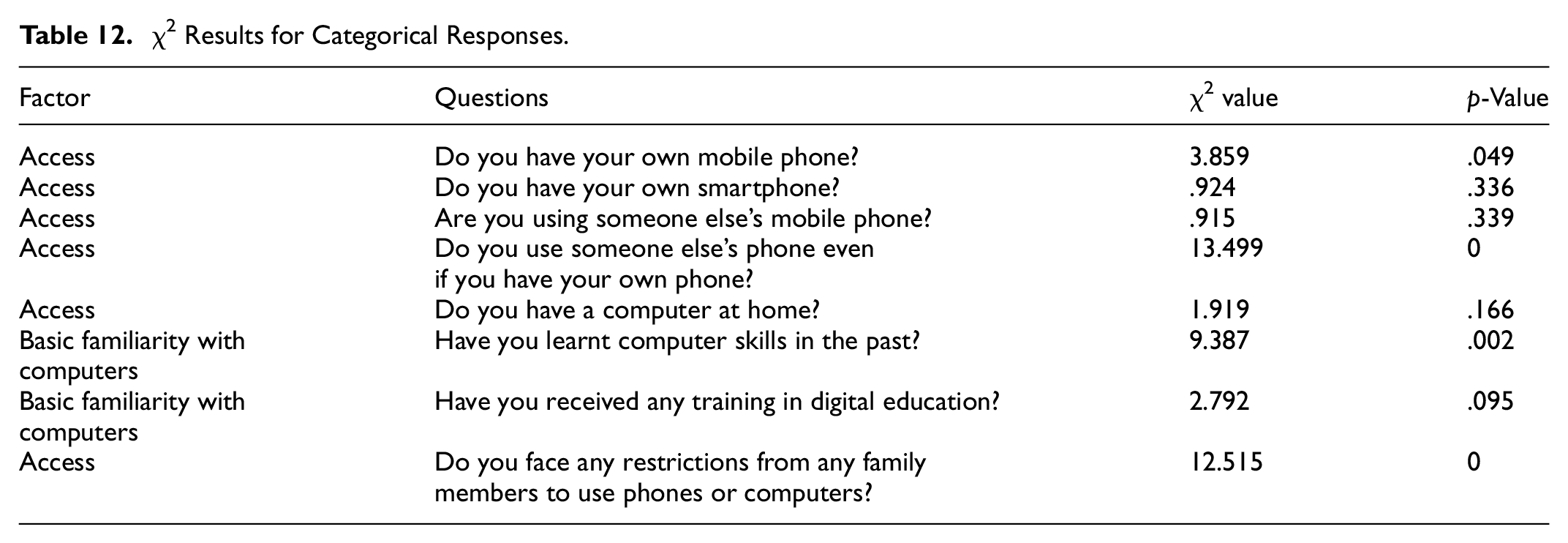
The responses to the following questions showed a statistically significant difference between boys and girls (p-value < .05):
Do you have your own mobile phone?
Do you use someone else’s phone even if you have your own phone?
Have you learned computer skills in the past?
Do you face any restrictions from family members to use phones or computers?
Then the percentage of yes responses to the questions, which showed statistically significant p-value, is listed as shown in Table 13.
% of ‘Yes’ Responses on Retained Yes/No Questions Categorised by Gender.

Interpretation of Findings on Gender Disparities in Categorical Responses on Digital Access and Basic Familiarity With Computers
These findings meant that:
Girls had significantly lower ownership of mobile phones than boys.
A significantly higher percentage of girls used someone else’s phone even if they have their own phones, than boys.
A significantly lower percentage of girls had learned computer skills in the past than boys.
A significantly higher percentage of girls faced any restriction from any family member to use the mobile phone and computer than boys.
A significantly lower ownership of mobile phones in girls will impact their exposure to the digital world, be it social media, education, or employment opportunities. Having to borrow a phone also means that its use may be possible only for a limited time. Further, the restrictions at home on using digital devices and the limitations in learning computer skills can further restrict their education and employment opportunities in the long run.
Discussion
Teenagers in semi-urban areas of India still face a lack of opportunities towards digital adoption, and such a lack is gendered. Digital adoption amongst teenagers in semi-urban areas of India is influenced by digital training experience, having computer skills, and ease of online presence. While online safety may be a concern in some pockets of teenagers in semi-urban areas, it is not a key determinant of digital adoption. Even though most of the existing discourse focuses on the need to advance digital access, while it may be required, it doesn’t necessarily guarantee digital adoption in semi-urban contexts. Situated factors in semi-urban areas determine the translation of access to adoption. Digital adoption will not be achieved or be effective unless access is followed by effective training, skilling, and making the online presence comfortable.
Further, teenage girls in semi-urban contexts feel significantly less supported in digital training and struggle more with the ease of online presence as compared to boys. The digital learning they get is also less useful to them than to boys. Thus, while access continues to be gendered, the struggle goes beyond access and includes other situated factors such as support for digital training and ease of online presence. Girls cannot use phones whenever they want, rather only when the parents allow them to use phones or the girls get to borrow phones. A semi-urban teenage girl could, at best, serve specific immediate needs with permission from parents instead of performing a freewheeling chase of aspirations. These limitations can likely impact the education levels of girls and their career opportunities, pushing them to face income, growth and development barriers in society.
The study thus adds a layer of understanding to the Diffusion of Innovations Theory by bringing the socioeconomic context of users (gender, urbanisation, etc.) as key to determining digital adoption. Its identification of determinants of digital adoption in semi-urban contexts of India and gendered differences within those determinants offers a unique explanation to argue that diffusion is not just based on the features of technology but also on the user’s situated context.
While variables like training support, learning of a new skill, etc., have been previously determined to affect digital adoption, variables such as relevance of digital learning, ease of sending and receiving messages, etc., have not been considered previously. There is a need to look beyond access as a determinant of digital adoption, especially in semi-urban contexts. Further, the study asserts that the fact that this context is gendered presents an unequal playing field for girls with respect to digital adoption.
These findings have major policy implications. Mere digital interventions that focus on giving laptops and phones to the young population may not be enough to bridge the digital divide. Even if access is a concern, what matters is what the young people do with the access once it is provided. Access alone may not translate into adoption.
Conclusion
The study extends the understanding of the technical categorisation of technology users based on the Diffusion of Innovations Theory by showing how a particular social context (gender, level of urbanisation, etc.) blends with digital adoption. The experience of digital training, a basic ability to operate computers, and ease of online presence are key determinants of digital adoption in Indian semi-urban teenagers. However, access may not be a determinant in such a context, while it may still be gendered.
Teenage girls in the Indian semi-urban context are disadvantaged with respect to feeling supported during digital training, feeling the utility of training, having proficiency in computer skills, having basic familiarity with information processing, and having ease of social media usage. This section of the population also struggles with ownership of digital devices and having the freedom to use digital devices without family restrictions.
The findings on the unequal playing field need to be considered during the design of gender interventions by policymakers. The digital interventions by the government, such as an app for accessing government services, should be made simpler to use. The training programs should identify learning barriers for girls, including gender-specific struggles, in attaining job-oriented skills through diagnostic assessments and then tailor the training to their needs.
The study is limited in its context as it only studies teenagers in a semi-urban district of India. The study can be replicated in other age groups and districts to enhance its generalisability. Further, the research studies two genders while diverse and multiple genders exist in society. The reasons for these limitations are constraints of the time and scope of the research. Future studies should widen the context by including diverse genders. Further, urbanisation is a continually progressive metric. As India is also an emerging economy, rural-urban lines are highly blurred. Hence, instead of studying segmented contexts, looking at the relationship between progressive degrees of urbanisation and digital adoption may give even better feedback to the digital interventions made by policymakers.
Footnotes
Acknowledgements
We thank Dr. Vasudha Katju for her guidance and insights on gender inequalities in society and intersectionalities associated with the same. We thank Mr. Shyam Rathod for connecting us with relevant sample groups at different stages of the study.
Correction (November 2025):
This article has been updated to correct typos in Table 1.
Consent to Participate
Verbal consent was taken from each of the participants of the study who participated in the field survey and attended the focus group discussions.
Author Contributions
Pritish Anand reviewed the theoretical and empirical literature, conducted the field survey and data analysis, performed the relevant interpretation of the results, and co-wrote the article. Amrendra Pandey reviewed the theoretical and empirical literature, conducted the data analysis, performed the relevant interpretation of the results, and co-wrote the article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The participants of this study did not give consent for their data to be shared publicly. Anonymised data can be made available on reasonable request.