
Abstract
Predicting operational performance enables organizations to develop operational effectiveness goals considering different combinations of resources. Measuring performance is consolidated with advances in relative efficiency analysis techniques, including data envelopment analysis (DEA) and stochastic frontier analysis (SFA), albeit these methods lack predictive capability. This paper proposes an approach for performance prediction by integrating relative efficiency measurement models with machine learning algorithms. Data analyses were conducted using data provided by the energy assessment project offered to small and medium-sized manufacturing companies in the United States (n 7,548) using sales as the output, with the inputs being the number of employees, hours of operation, electricity, natural gas, cost of electricity, and cost of natural gas. Performance was estimated differently, employing parametric (SFA) and non-parametric (DEA) methods. The prediction benchmarking process occurred by adopting machine learning algorithms: regression (LM), support vector machine (SVM), K-nearest neighbor (KNN), linear discriminant analysis (LDA), random forest (RF), and decision tree (DT). The findings showed that it is possible to identify the best prediction algorithm associated with a performance model. However, the performance prediction may differ if different strategies for measuring performance or machine learning model configurations are used. In addition, SFA-LOG and SVM had the best performance for regression, and DEA-VRS/IRS excelled with random forest; the RF algorithm was the best fit across all performance approaches. The error rate depends on the algorithm and the performance model, and the number of classes must be reduced to obtain a higher success rate.
Plain language summary
Predicting operational performance enables organizations to develop operational effectiveness goals by considering different combinations of resources. Companies that incorporate more accurate forecast models into their strategies can have a competitive advantage in the market, mainly by delivering the product to the right place, in the exact quantity, and at the right price. Given this context, there is a need to test new models and their combinations to achieve better results. This paper proposes an approach for performance prediction by integrating relative efficiency measurement models with machine learning algorithms. To test the prediction models, data analyses were conducted using data from the energy assessment project offered to small and medium-sized manufacturing companies in the United States (n 7,548). The findings showed that it is possible to identify the best prediction algorithm associated with a performance model. However, the performance prediction may differ if different strategies for measuring performance or machine learning model configurations are used. The error rate depends on the algorithm and the performance model, and the number of classes must be reduced to obtain a higher success rate. One of the main contributions of this article is that it demonstrates that the prediction performance can differ if distinct strategies to measure performance or configuration of the model are used. The results showed that it is possible to identify the best prediction algorithm associated with a given model performance.
Keywords
Introduction
Given the exponential growth and complexity of the managerial hierarchy (Cameli, 2023), new forms of management, such as continuous improvement processes and competitiveness (K. S. Wang, 2013), have emerged in the literature, especially after the advance of globalization to leverage resources (Czinkota & Ronkainen, 2005; Kwok & Arpan, 2002). This wave has generated the need for organizations to increasingly monitor performance at all stages of producing goods and services (Chandler, 1977; Neely, 1999; Shin et al., 2022). In this context, performance measurement systems have become vital for organizations to maintain a competitive advantage in the market (Gerhardt et al., 2021).
Numerous performance measurement systems have become important at strategic and operational levels (Bach et al., 2019; Danese & Kalchschmidt, 2011; A. D. Neely, 1999; Vegter et al., 2023). Performance measurement can be defined as “the process of quantifying the efficiency and effectiveness of action” (A. Neely et al., 1995, p. 4), with efficiency being an ex-post measure that shows how managers have solved different optimization issues, and effectiveness being an ex-ant measure that provides a goal for solving problems (Mariano, 2007; O’Donnell, 2018). According to Mariano (2007, p. 3), “an efficient system does not necessarily need to be effective and vice versa, meaning that the goal set can diverge from the maximum value on the optimization curve.”
The problem with effectiveness is that it relies on a utility function U(.) unknown beforehand. This problem was overcome by applying Farrell’s (1957) efficiency concept, shifting the focus from effectiveness to relative efficiency. Among the techniques for measuring relative efficiency, two stand out: stochastic frontier analysis (SFA) and data envelopment analysis (DEA); the first technique originates in econometrics and the second in mathematical programming (Bogetof & Otto, 2010a,b). The agents involved in this process are generally called decision-making units (DMU). Traditional relative efficiency analysis techniques such as DEA and SFA have limitations in terms of predictive capability. One of the problems of these techniques, which has been recognized throughout the literature, is that they have no predictive ability, meaning that a new model must be developed to encompass a new case (Dalvand et al., 2014; Hong et al., 1999; Kwon, 2017; Zhu et al., 2021).
Predicting operational performance for organizations to develop operational effectiveness goals is important. One of the primary importance of implementing a predicting operational performance is that it enables the organization to develop strategies and effectiveness targets considering different combinations of resources (inputs) (X. Wang et al., 2022). Accurate predicting also enables sensitivity analyses, allowing one to know the impact on the performance of marginal input changes (Yen et al., 2021). Establishing the importance of each input and output to performance is another competitive advantage (Puchalsky et al., 2018).
Research has demonstrated that the best-performing prediction models meet the needs of organizations, improving accuracy and service level (fill rate) for superior alignment of production capacity in meeting demands. In fact, evidence has shown that operational decisions can be based on prediction (da Veiga et al., 2016). Hence, manufacturing companies should consider prediction a necessary process to direct production activities (Danese & Kalchschmidt, 2011). To this end, prediction models are expected to be parsimonious, with few parameters, lower implementation costs, and adjust an organization’s prediction performance to achieve better results (Agostino et al., 2020; da Veiga et al., 2016).
Given this context and the need and importance of performance prediction (Kourentzes et al., 2019), this paper proposes an approach for performance prediction using machine learning (ML). Machine learning methods have been well explored in recent decades and have shown promising results, especially in helping solve prediction problems. Despite providing relevant results, there is still a need to further investigate new approaches and non-linear applications to improve performance prediction (Mariani et al., 2019). In the proposed method, different performance models are predicted by various ML algorithms to find the prediction with the lowest error rate associated with each performance model. Thus, in order to validate and test the model in an empirical study and provide practical evidence, the proposed experiment was performed with information from the North American energy assessment project for the industrial sector and involved small and medium-sized companies (SMEs).
This study’s results indicate that a systematized approach that integrates performance models SFA and DEA with machine learning algorithms has yet to be developed. The findings shed light on the literature through insights into the realized experiments. Energy performance prediction can create a higher learning environment for decision-making.
Materials and Methods
Systematic Literature Review
To justify the need for this study and this paper’s originality, it was necessary to first conduct a systematic literature review to identify the research gap that addresses the approach for performance prediction that considers different models, such as SFA, DEA, and a benchmarking process of predictive models. Therefore, the review was conducted to identify papers that specifically address performance prediction using relative efficiency analysis techniques. To this end, this review proposed to uncover which performance models were used, which prediction algorithms were adopted, how the features and targets were set up in the prediction, and what were types of problems modeled (Table 1 and Figure 1).
Papers on Performance Prediction.

Note. *AED

Approach for performance prediction.
The papers were selected using the search string (TITLE-ABS-KEY (“machine learning” OR “artificial intelligence” OR “deep learning”)) AND (TITLE-ABS-KEY (“data envelopment analysis” OR “stochastic frontier analysis”)) and searched on the Web of Science (WoS) and Scopus databases with no time limit. The selection criteria for the papers were based on the abstract (ABS), keywords (KEY), and title (TITLE), with no other filter added. The database search was performed in March/2020 and updated on 06/May/2021, and 196 papers were found in Scopus and 118 in WoS. After analyzing the titles and abstracts, 20 articles were selected for full-text analysis, and eight met the initial search protocol (Table 1).
Table 1 lists previous papers that analyzed research corroborating this article. For instance, Hong et al. (1999) was the first one identified and cited 41 times in the Scopus database. Recent interest in the topic stands out, with five papers published between 2017 and 2021. The second study was cited 21 times (Kwon, 2017), followed by the more recent studies of Nandy and Singh (2020) and Tsolas et al. (2020), with five and six citations, respectively. Despite the number of papers in WoS and Scopus, many cover the joint use of performance/efficiency and ML techniques. Still, the main goal is not prediction, thereby reinforcing the novelty and originality of this paper.
Approach to Performance Prediction
The literature showed that DEA and SFA propose to identify the efficient frontier (performance) so that on the frontier will be the equally efficient cases relative to the others. The SFA is a parametric (econometric) technique that estimates the stochastic frontier, assuming random residuals. The SFA was developed simultaneously by Aigner et al. (1977) and Meeusen and van Den Broeck (1977) and can be represented mathematically in Cobb-Douglas and translog forms by Equations 1 and 2, respectively, where q is the output, z is possible environment variables, x is the inputs, v is the error, and u is the inefficiency. The SFA is estimated by the maximum likelihood principle (O’Donnell, 2018).

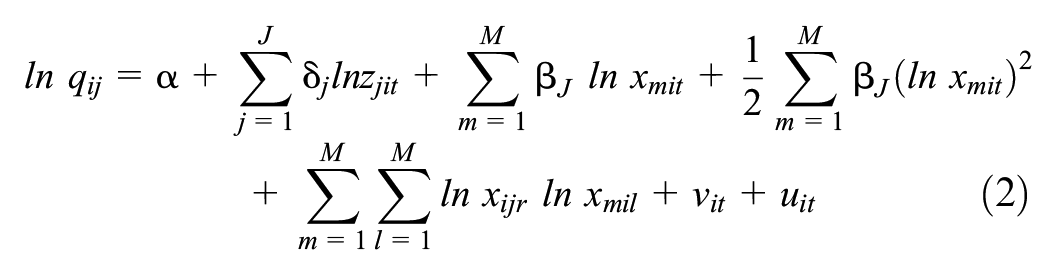
The DEA is used to determine the efficiency frontier via mathematical programming (i.e., non-parametric). It was developed by Charnes et al. (1978) as a minimization (input-oriented) problem (Equation 3), where:

The differences in performance estimation come from the multiple alternatives for the modeling. One of the first challenges in prediction is that there is a range of possible models. For instance, SFA can be estimated in Cobb-Douglas, quadratic, cubic, and other forms, whereas DEA can be input or output oriented as well as assume different assumptions for the return to scale, as shown in Equation 3: constant (CRS), variable (VRS), increasing (IRS), and decreasing (DRS). Some models even combine both approaches, such as stochastic non-smooth envelopment of data (StoNED; M. Andor & Hess, 2014; M. A. Andor et al., 2019; Bogetof & Otto, 2010a,b; O’Donnell, 2018).
The second challenge refers to a significant amount of learning algorithms. As a limitation of this study, the interest in the proposed application lies in the supervised algorithms, as the goal is to predict a continuous or categorical target. The systemic literature review performed herein presents some of these algorithms in Table 1. It is important to note that machine learning libraries, including “mlr3”and “scikit-learn,” implement dozens of learners that are ready to be configured and used (Becker et al., 2022; Grus, 2016; James et al., 2013; Müller & Guido, 2017).
This paper aims to develop an approach integrating models with predictive algorithms; to this end, was adopted the definition of a predictive model of Provost and Fawcett (2016, p. 45): “A predictive model is a formula for estimating the unknown value of interest: the target. The formula can be mathematical or it can be a logical statement, such as a rule.” In summary, learning a predictive model is done in a training process in which the data is randomly divided into training and test samples. This can be just two samples, training and testing (holdout) or cross validation with multiple samples for training and testing (cross validation; Becker et al., 2022).
The Model
Based on the results found in the systematic literature review, the characteristics of the performance models (DEA and SFA) and the training process of the predictive algorithms, this paper proposes an approach for performance prediction (Figure 1). The following steps were developed for this: (a) performance (efficiency) estimation is done through parametric and non-parametric models. After the estimation, (b) the inputs and outputs enter as attributes, and the performance (efficiency) enters as the variable to be predicted (target) in the predictive modeling. The target variable should be put on the same scale (normalized between 0 and 1) for comparison purposes. Different discretization strategies can be implemented for ranking, such as simple split, probabilistic, cluster, or sliced/tiered DEA. Notably, Hong et al. (1999) introduced the notion of DEA tiers as a strategy to identify similar DMUs. In practice, this method identifies all production functions in a data set, forming clusters.
In addition to outputs and inputs, environmental variables can enter as explanatory attributes in the prediction model depending on the outcome. Various environmental turbulences in the market can impact the production of goods and services in an organization (Chatterjee et al., 2023). This phenomenon has been thoroughly investigated over the decades (Ansoff, 1979, Duncan, 1972; Feng et al., 2021; Marzall et al., 2022). These authors corroborated the literature by demonstrating how unexpected environmental changes cause some organizations to thrive and others not. Managers cannot control environmental variables in the market environment, including technological, natural, political, economic, demographic, and cultural variables (Kotler & Keller, 2012; O’Donnell, 2018). Hence, it is imperative to highlight that some predictive models achieve superior results when data are placed on the same scale considering environmental issues (i.e., normalized or standardized) (Müller & Guido, 2017), with a better configuration of variables and attributes.
After setting up attributes and the target variable, the data is divided into training and testing (different strategies exist) and submitted to different prediction and classification algorithms in a benchmarking process. It is a complex task to determine a priori which algorithm will best fit the data; therefore, training should be conducted with several supervised algorithms, and it is mathematically complex to treat each algorithm. Nonetheless, algorithms can be classified into three types: those that (a) fit a mathematical model to the data (regression [LM], support vector machine [SVM]), those (b) based on similarity (K-nearest neighbor [KNN], linear discriminant analysis [LDA]), and lastly, those (c) that can present information gain (random forest [RF] and decision tree [DT]), among others (Provost & Fawcett, 2016).
Linear regression is one of the best-known algorithms and primarily aims to estimate a vector of parameters
Notably, the proposed prediction approach has two necessary feedback processes in case the prediction result is not satisfactory. The first indicates that environmental variables can be used as additional attributes (Figure 1, left side). The extreme case of Nandy and Singh (2020) used only environment variables (Table 1). The feedback on the right side of Figure 1 is related to three considerations in performance modeling: (a) the need for redesign, (b) the use of a new model, and (c) the combination of models. The combination of performance models is not new in the literature; for instance, Azadh et al. (2009) combined parametric and non-parametric modeling through geometric mean, while M. A. Andor et al. (2019) employed both mean and maximum value between DEA and SFA.
The packages “scikit-learn” (https://scikit-learn.org/) and “mlr3” (https://mlr3.mlr-org.com/) have tools (pipelines) that facilitate benchmarking these algorithms (Lang et al., 2019). These tools also provide a series of metrics for evaluation, and in the regression problem, the most commonly used ones are: (a) mean absolute error (MAE), (b) root mean square error (RMSE), and (c) bias. The classification includes (a) accuracy, (b) classification error, and (c) accuracy and recall. The final process is the choice of the algorithm(s) with the best result.
The result of the algorithm(s) can still be improved by hyperparameter tuning before the final approach is chosen. Optimization is a process that automatically tests many parameters of the algorithms. For example, the number of neighbors and trees are the main hyperparameters of the KNN and random tree algorithms, respectively.
Data Collection and Processing
In order to develop the application, the sample comprised the energy assessment project offered to small and medium-sized manufacturing companies in the United States. This sample was selected given its relevance and scope. The project is one of the largest in the world in this modality and involves over 30 American universities and almost 20,000 assessments. The sample and the data evaluated are available on the website (https://iac.university/). For the final version of the proposed model, this study employed the data downloaded on 04/29/2021, totaling 19,491 assessments from 1981 to 2020. The main limitation of the selected data is related to its processing, and other authors have also reported this issue (Abadie et al., 2012; Anderson & Newell, 2004).
Since DEA is sensitive to extreme values, the data were treated using the “tidyverse” package of the R environment. The analyses included (a) manufacturing firms with ≥50 employees, (b) firms with >2,000 hr of annual operations, (c) >1,000 (kWh) annual energy use, and (d) >$10,000 in sales, since obscure sales data were identified. Some missing data were also excluded, so the sample consisted of 11,883 assessments, which is still a considerable number. Not all DEA models ran properly even after the data treatments, and an outlier detection process was adopted. Based on the literature, it was necessary to apply the box-plot method; with this, the final sample consisted of 7,548 assessments. This is considered a large sample for DEA modeling and not feasible for spreadsheet processing. The solution was to use the R environment, which is the most viable option for the proposed case.
Results: Application Development
After various tests, the variables (a) sales (SALES) as the output and employees (EMPLOYEES), use of (b) electricity in kWh (USAGE_ELEC), use of (c) natural gas in MMBtu (USAGE_NAT), (d) cost of electricity (COST_ELEC), (e) cost of natural gas (COST_NAT), and (f) operational hours (PRODHOURS) were selected for the inputs (inputs). Table 2 lists the descriptive statistics of the data. It is worth noting that the restrictions regarding using natural gas were not added. Therefore, it is indicated that the minimum value of $ 38.00 refers to a manufacturing company that uses little of this resource, despite its considerable size for a small company, with up to 50 employees.
Summary of the Annual Data of the 7,548 Assessed Manufacturing Companies.
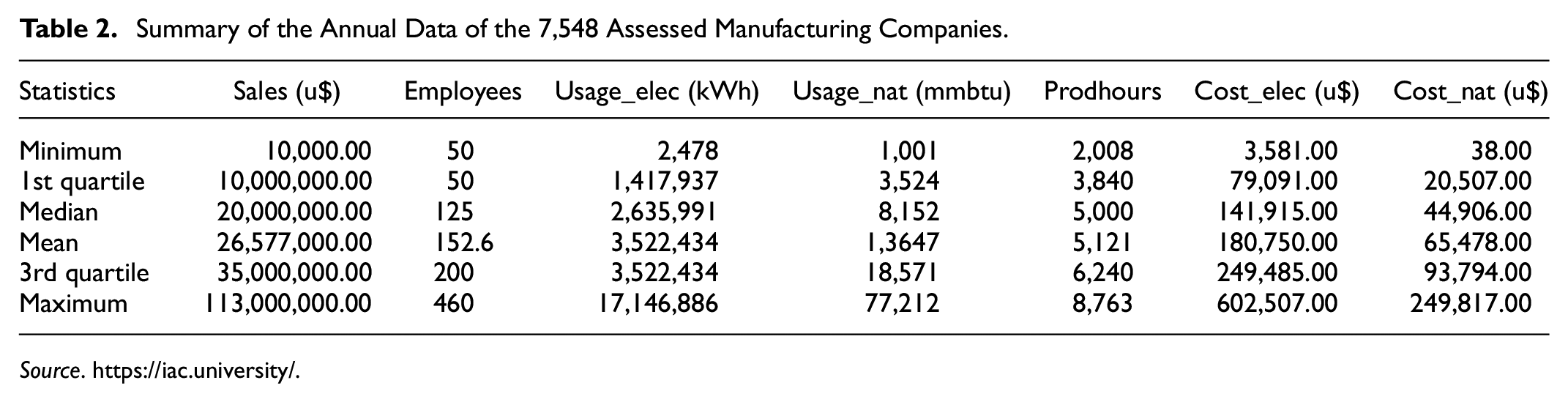
Source. https://iac.university/.
Estimating the energy performance models was done in the “Benchmarking” and “Frontier” packages of R, developed by researchers at the Copenhagen Business School (CBS) and the University of Queensland in Australia (Bogetoft & Otto, 2020; Coelli & Henningsen, 2020). The performance of the 7,548 manufacturing firms was calculated in six different ways, where one assumes four returns in the DEA to scale: (a) constant (CRS), (b) variable (VRS), (c) increasing (IRS), (d) decreasing (DRS), and two functional forms are used in SFA: (a) log-linear (SFA-LOG) and (b) quadratic in logarithms (SFA-TRANSLOG). Figure 2 shows the coding developed in R on Google Colab, which is a cloud environment for code execution created in Google Suite (Figure 3).

Coding for the performance/efficiency models.

Colab environment.
The result is presented in Figure 4 through the frequency distribution. One can observe the similarity in the distribution of the SFA models and between the returns to scale: VRS and IRS and CRS and DRS. The first point is whether the performance can be predicted using the inputs and outputs for the attributes. The second point is to know how the machine learning algorithms fit the different performance models. It is worth noting that this is an important contribution to the proposed model.

Frequency distribution of energy performance models.
As illustrated in Figure 1, both regression and classification models can be used by adopting either a continuous or discrete scale. In Figure 5, the continuous scale TGH is the target variable for the regression problem, and the discrete scale TGH_cat is the prediction objective in classification.

Coding for continuous and discrete scaling.
For the proposed prediction model, six learning algorithms were selected. The algorithms were selected based on their popularity, applicability, and agreement with the literature in Table 1 and Figure 1. The algorithms were KNN, LM, LDA, RF, DT, and SVM.
For the benchmarking process, the k-fold cross-validation strategy was implemented, and after various tests, k = 5 were selected, where the data is partitioned into five parts called folds. Sequences of models are trained so that each part is used in training and testing, ensuring greater stability to the process (Müller & Guido, 2017). For regression, the main comparison metric was a mean square error (MSE), and for classification, the accuracy. For this, modeling was performed in “mlr3” (R environment) and “scikit-learn” (Python) using Google Colab; “mlr3” was selected for its convenience in the benchmarking process. The regression coding and classification are detailed in Figures 6 and 7.
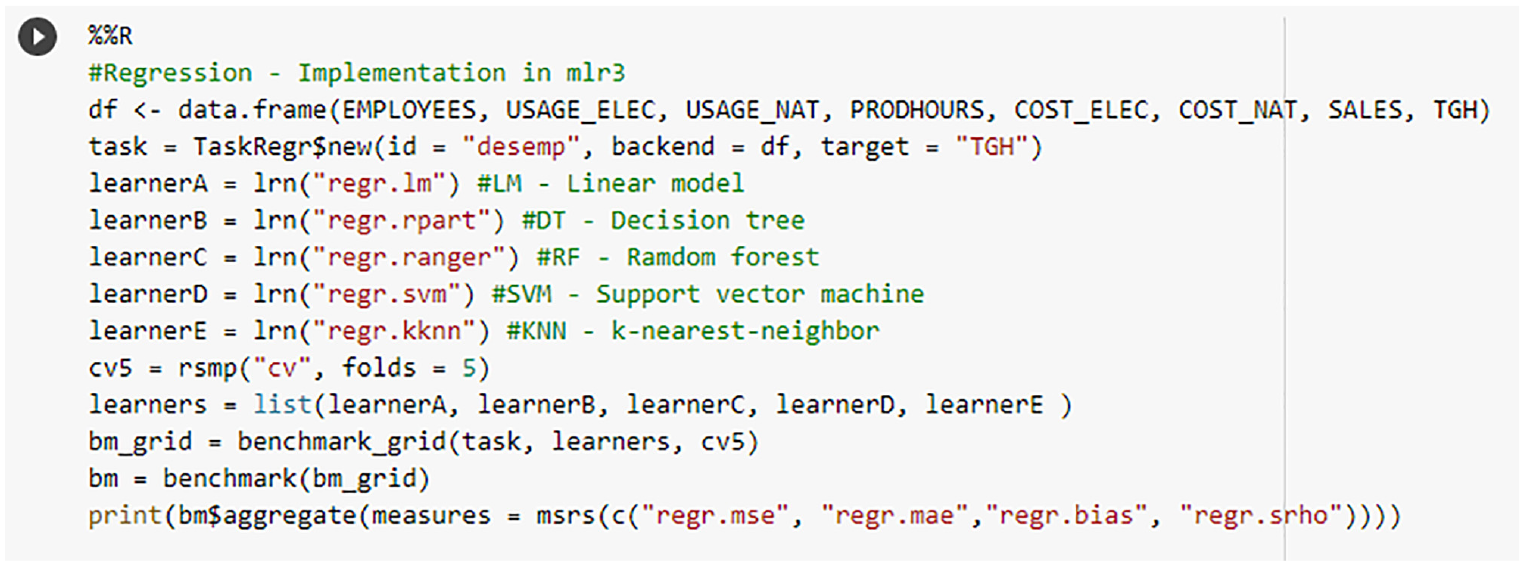
Coding for benchmarking algorithms for regression.

Coding for benchmarking algorithms for classification.
Table 3 lists the RMSE of the algorithms for the six regression approach performance models. The darkest blue represents the best result (lowest error), and the red color represents the worst result (highest error). The best fit occurs with the SVM on the SFA-LOG model. However, the algorithm that adapted best to all models was RF, and the worst was LM. The algorithms were configured with the same parameters to compare model performance (Table 3).
Regression Approach for Energy Performance Prediction.


Note. Hyperparameters: KNN (K = 7); RF (num.trees = 500; alpha = 0.5); DT (minsplit = 20; cp = 0.01; maxdepth = 30); SVM (kernel = radial). The values given in bold likely indicate the best performance for each model across the different regression methods (KNN, LM, RF, DT, SVM). These bold values represent the lowest error rates or best predictive accuracy achieved by the corresponding model-method combination. For example: For the DEA-CRS model, the bold value under the RF method (0.001105) suggests that this combination achieved the best performance among all methods tested for DEA-CRS. Similarly, for the SFA-LOG model, the bold value under the SVM method (0.000919) indicates the best performance for this model. This boldface highlighting helps quickly identify the most effective regression method for each model in terms of minimizing prediction error or maximizing prediction accuracy.
Learning by classification is not as simple as regression since the performance generated in Figure 4 is continuous and not categorical. For discretization, it was necessary to use an unsupervised method available in the “arules” package, implementing the strategy of intervals of the same size (Hahsler et al., 2011; Figure 5). Another method used was stratification using sliced DEA (DEA-TIER), which was first presented by Hong et al. (1999). The latter is a supervised method for identifying performance clusters. Since no package was identified in R to train this process, a custom function had to be built in R (Figure 8). Since this is a supervised technique, choosing the number of clusters is impossible. For the 7,548 manufacturing firms, the function identified 15 to 20 clusters, depending on the return to scale, which were regrouped by performance level to match the number of classes in the analysis.

Function for training the DEA-TIER.
Table 4 lists the accuracy of the five algorithms for the six performance models using the two discretization strategies for DEA (tier and non-tier) and organized with classes of four sizes (2, 3, 5, and 10), generating 200 comparisons. In this case, in the overall context, the best algorithms are also RF and SVM, with the best result being in the RF with the DEA-IRS and DEA-VRS models. This study found that the prediction model’s performance worsens considerably as more classes are aggregated. Nonetheless, the interval strategy showed superior results when compared to the tier method, although the construction of the latter is much more complex.
Classification Approach for Predicting Energy Performance.


Source. Research data.
Note. Hyperparameters: KNN (K = 7); RF (num.trees = 500; alpha = 0.5); DT (minsplit = 20; cp = 0.01; maxdepth = 30); SVM (kernel = radial).The bold values indicate the best model.
An important issue regarding classification is the limitation of the accuracy metric for unbalanced data, as is the case for DEA-CRS (Figure 4). Two other metrics that capture the behavior in each class are accuracy and recall, and that in the first, it is possible to identify the proportion of false negatives (FN = 1-recall), and in the second, the proportion of false positives (FP = 1-accuracy), present in each class, a result corroborated by Müller and Guido (2017). Another issue that is not limited to classification is the optimization of the hyperparameters. Given this, the following examples were highlighted to work with the optimization approach for RF since this algorithm presented the best result for classification. The coding of the hyperparameter identification is illustrated in Figure 9, and the training is shown in Figure 10. To generate the confusion matrix (with the test data), the holdout strategy was used.

Identification of the best hyperparameters for the random forest.
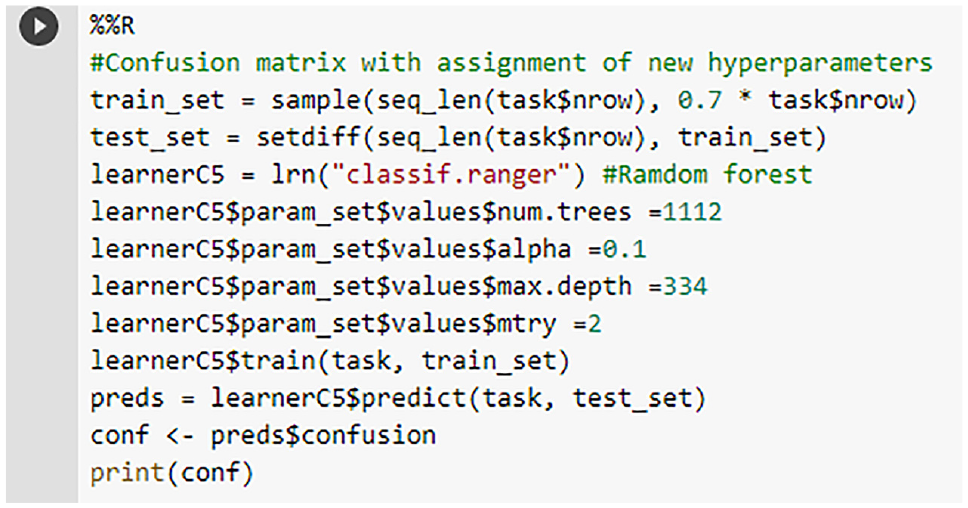
Training the model and generating the confusion matrix.
Table 5 lists the confusion matrix of the DEA-VRS model using the RF algorithm to predict five classes, where “A” represents the best energy performance and “E” is the worst. In this case, there is no disproportionality between false positives and negatives, as the classes are relatively balanced. The accuracy was 97% using the holdout method (slightly higher than the result in Table 4). In Table 6, the same procedure was performed for 10 classes. Although class D has a higher proportion of false negatives, it does not represent an outlier. Therefore, accuracy was 93%, with no significant improvement over Table 4.
Confusion Matrix for RF-DEA-VRS Prediction (Five Classes).

Source. Prepared by the authors using the R package “mlr3.”
Note. Optimized hyperparameters: (num.trees = 1,112; alpha = 0,1; max.depth = 334; mtry = 2)—Accuracy: 97%.The boldface values highlight the correct predictions for each class.
Confusion Matrix for RF-DEA-VRS Prediction (10 Classes).

Source. Prepared by the authors using the R package “mlr3.”
Note. Optimized hyperparameters: (num.trees = 1,667; alpha = 0,1; max.depth = 500; mtry = 3)—Accuracy: 93%.The boldface values highlight the correct predictions for each class.
The confusion matrix in Table 7 uses the DEA-CRS to predict ten classes, and the result differs from the previous ones. This occurred because the classes were unbalanced, and the error reached 100% for class B; the accuracy was 87% (i.e., a little better than the result using the cross-validation strategy).
Confusion Matrix for RF-DEA-CRS Prediction (10 Classes).

Source. Prepared by the authors using the R package “mlr3.”
Note. Optimized hyperparameters: (num.trees = 556; alpha = 0,60; max.depth = 500; mtry = 4)—Accuracy: 87%.The boldface values highlight the correct predictions for each class.
Final Considerations
This paper shows that a systematized approach that integrates performance models (SFA and DEA) with machine learning algorithms has not yet been developed, although the results shed light on the literature in various ways and key findings. The first finding of this paper is related to (a) the need for a broader approach involving various performance models and ML algorithms; (b) it shows that the literature has not yet considered SFA in performance prediction; (c) it is in line with the introduction of efficiency scaling that enables the comparison of different models (e.g., DEA, SFA, input, and output-oriented models). The fourth finding lies in (d) different discretization forms that can be used, such as interval, frequency, probability, and clustering, and lastly, (e) the fifth insight highlights benchmarking in two stages within the model and between models.
The proposition of a new prediction model in the literature is a complex topic, and this study did not seek to exhaust the possibilities suggested in the proposed approach for industrial energy performance prediction modeling presented herein. Nevertheless, one of the main contributions of this article lies in the fact that it demonstrates that the prediction performance can differ if distinct strategies to measure performance or configuration of the ML model are used. The results showed that it is possible to identify the best prediction algorithm associated with a given model performance, as suggested in Figure 1. Moreover, SFA-LOG and SVM performed best for regression, and DEA-VRS/IRS stood out with random forest. In fact, the RF algorithm was the best fit across all performance approaches.
In terms of classifying the best-performing prediction model, the results in Table 4 demonstrate that as the number of classes increases, the error grows considerably, as the error rate was found to rely on both the algorithm and the model performance. One must decrease the number of classes to obtain a higher success rate. The results in Table 7 also confirm such a need if the number of classes is unbalanced. In the latter case, a change of strategy for performance measurement (efficiency) may be necessary. The key point is that the highest proportion of false positives and negatives occur in adjacent classes.
In the context of Industry 4.0, the performance prediction approach (classification or regression) can be useful for companies, since it can be incorporated into business intelligence systems and into the equipment itself from an Internet of Things perspective. The possibility of energy performance prediction can create a higher learning environment for decision-making. Since the approach implements learning algorithms that typically perform better as more data is trained, it is emphasized that implementing this approach requires organizations to have a data-driven culture. In light of this, it is believed that failure to develop such a culture may be an obstacle to making this modeling work in organizations.
Even in the face of several contributions, this article has limitations that need to be observed. The first limitation is the single database. In this context, exploring databases of other types of companies is necessary to generalize the results. Another limitation is in the forecasting process, which is uncertain by nature. Testing new techniques and parameter adjustments is crucial for better accuracy. Given this, future studies are suggested to test new performance models and the constructs that combine parametric and non-parametric modeling. Another possibility for future research is to adopt the simulation procedure for model selection proposed by M. A. Andor et al. (2019) to verify if the models with the best-predicting results have the best success indicators of actual inefficiency since these methods share the same metrics for outcome evaluation. Predicting is complex, and this study did not intend to exhaust the subject. Therefore, new studies are needed, especially for empirical work based on evidence, and to test new models to assist managers and decision-makers in various organizations, whether for-profit or not-for-profit, public or private.
Footnotes
Acknowledgements
The authors wish to express their gratitude to the Editor and Anonymous reviewers for their constructive input and kind feedback. Also, thanks to Fundação Dom Cabral (FDC) for financial support for the publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors Veiga and Silva thank the National Council for Scientific and Technological Development—CNPq (Grants number: 312023/2022-7-PQ and 302407/2022-7 PQ) for its financial support of this work.
Fundação Dom Cabral—The APC was funded by FDC.
Ethical Approval
No applied.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Support data may be requested from the corresponding author.