
Abstract
This paper provides a diachronic and bibliometric overview of register studies in the past decade. A total of 545 articles were selected from the field of linguistics of the database of Web of Science Core Collection for the analysis. For bibliometric analysis, CiteSpace and VOSViewer were used in order to reveal the co-citation analysis, the high-frequency keywords, keyword clusters, and the timeline of the keyword network in register studies. The results are summarized as follows. First, register studies have been gaining considerable academic attention in the examined years. Second, the major theoretical origins of register studies were text linguistics, systemic functional linguistics, and sociolinguistics. Third, corpus analysis and discourse analysis are the main research methods, followed by genre analysis, and conversation analysis. Fourth, important research themes were extracted and classified based on the following dimensions of register studies, namely, linguistic features, register types, register variations and pragmatic function. Furthermore, Teaching and education was an important dimension in register studies. Fifth, the recent research tended to focus on the register variations caused by the audiences, and corpus analysis and discourse analysis were widely used for broad analyses in different register studies. This bibliometric analysis also shows that online registers have become the research hotspot.
Plain Language Summary
Research purpose: This paper provides a diachronic and bibliometric overview of register studies in the past decade. Methods: bibliometric analysis. Conclusion: First, register studies have been gaining considerable academic attention in the examined years. Second, the major theoretical origins of register studies were text linguistics, systemic functional linguistics, and sociolinguistics. Third, corpus analysis and discourse analysis are the main research methods, followed by genre analysis, and conversation analysis. Fourth, important research themes were extracted and classified based on the following dimensions of register studies, namely, linguistic features, register types, register variations and pragmatic function. Furthermore, Teaching and education was an important dimension in register studies. Fifth, the recent research tended to focus on the register variations caused by the audiences, and corpus analysis and discourse analysis were widely used for broad analyses in different register studies. Implication: The research may be a useful resource for novice researchers and established scholars in the field, and perhaps also critical in assisting journal editors to continue to promote theoretical or methodological advances in the field.
Keywords
Introduction
Register refers to “a variety of language, corresponding to a variety of situation,” with situation interpreted “by means of a conceptual framework using the terms field, tenor and mode” (Halliday, 1989, pp. 29, 38). Register can be distinguished for “their audiences, mediums (e.g., spoken or written mode), interactivity, production circumstances, communicative purposes” (Seoane & Biber, 2021, p. 2).
Register analysis focuses on “the functional relationships between linguistic patterns of use and the situational characteristics of registers” (Biber & Conrad, 2019, p. 7), including three major components, “the situational characteristics, the pervasive linguistic features, and the communicative functions that explain why these linguistic features occur in this situational context” (Biber & Conrad, 2019, p. 31).
Early studies on register analysis provided linguistic accounts of a single register. Later, more attention has been paid to investigate register variation, which “typically compare two or more registers to identify meaningful patterns of variation that are mediated by register, such as differences across speech and writing (e.g., Biber, 1988; Biber et al., 2011)” (Goulart et al., 2020, p. 7.3). Research on register variation thus emphasizes comparing the linguistic characteristics in different texts and exploring the linguistic co-occurrence patterns, usually interpreting the variations relative to the situational characteristics of those registers.
Some previous reviews of register studies have been conducted to provide insights into the field, such as the main research methods of register studies over the past 25 years (Sardinha & Pinto, 2014) and register studies from the perspective of linguistics (Goulart et al., 2020). The previous reviews of the subject field are mostly introspective experience and lack empirical analysis based on authoritative data, and it seems that an integrated review of register studies from the bibliometric perspective is in need. With the use of visual analytic tools CiteSpace and VOSviewer, this study aims to conduct a diachronic and bibliometric overview of articles published in the Web of Science Core Collection database to present a quantitative analysis of the current status and emerging trends in register studies. More specifically, the study seeks to answer the following research questions:
RQ1. What are the general characteristics (publication trend, productive authors, productive institutions, and countries) in the field of register studies?
RQ2. What are the major theoretical frameworks in register studies?
RQ3. What are the important research methods in register studies?
RQ4. What are the main research themes in register studies?
RQ5. What are the emerging trends in register studies?
Data and Methodology
The data analysis procedure consists of CiteSpace and VOSviewer-based bibliometric analysis. As one of the widely-used bibliometric tools, CiteSpace used in the study is “a Java application for analyzing and visualizing co-citation networks” (Chen, 2004, p. 363). It provides different bibliometric analyses, including the overall structure of the keyword network, the author network, and the network clusters, those help researchers identify the current situation and emerging research trends in a specific field (Mou et al., 2019). For instance, Liu and Hu (2021) used CiteSpace to explore the major research themes and historical trends in English-for-specific-purposes (ESP) research with the support of the co-citation analysis.
VOSviewer is a new mapping technique, “which stands for visualization of similarities” (van Eck et al., 2010, p. 2405), with the function of Citation of sources, Co-authorship of authors, Co-occurrence of keywords, and Co-citation of cited authors to identify main publication venues, productive authors, influential scholars and dominant research themes in the area of register studies. In addition, VOSviewer-based bibliometric analysis helps pinpoint the strands of linguistics. For example, Yilmaz et al. (2022) adopted VOSviewer to discuss the studies of foreign language teaching in early childhood education.
As the visual analytic approach of the network, the advantage of CiteSpace and VOSviewer-based bibliometric analysis can be utilized to comprehensively insight into the research structure and grasp the current research focus based on statistical quantitative profiling and reliable databases (Xiao & Li, 2021, p. 485). For instance, Xiao and Li (2021) employed CiteSpace and VOSviewer-based methods to explore critical discourse analysis’s research status and implications. Figure 1 is the research steps of bibliometric analysis of register studies.

Steps of bibliometric analysis of register studies.
Data Collection
The bibliometric information of the research articles was retrieved in the Web of Science Core Collection on February 08, 2022. Table 1 presented the information of queries presented. To be more specific, the aim of the information retrieval was to search the articles related to register studies in the research area of linguistics that was published in English between 2012 and 2021. The queries identified a total of 785 articles and their bibliometric records, including such information as article titles, journal titles, publishing years, keywords, abstracts, citations, etc., were downloaded for further analyses.
Retrieval Queries.

Inclusion and Exclusion Criteria
To diminish the influences caused by researcher bias on the study, the main elements of each article, including the titles, keywords, and abstracts, were manually coded by two researchers to eliminate studies that are not relevant to register studies. First, articles were excluded if they are book reviews, literature reviews, and book chapters. Next, articles concerning topics that are not relevant to register studies, such as pitch register, and “register” used as a verb were excluded. Both authors repeatedly reviewed all the options to ensure that all decisions were reached in agreement. Overall, a total of 545 research articles were retained for the following analysis after excluding those irrelevant ones.
Data Analysis
The following data analysis procedures were adopted. First, to present the general characteristics in the field of register studies, the bibliometric information was detected based on the publication trend, main publication venues, productive authors, productive institutions, and countries. Moreover, the software SPSS was used for linear regression analysis to explore the relationship between publication year and number of articles.
Second, to identify the major theoretical frameworks in the area of register studies, the co-citation analysis (the journal co-citation analysis, author co-citation analysis, document co-citation analysis) generated by both CiteSpace and VOSviewer was utilized and systematically analyzed.
Third, the keyword list of 292 keywords (freq. ≥ 2) was produced using CiteSpace and 93 keywords (freq. ≥ 5) using VOSviewer (Table 2 listing those being at least 0.02 centralities in CiteSpace and at least 30 link strength in VOSviewer) to pinpoint the important research methods of register studies. At first, the same or semantically relevant keywords were combined, for instance, “multi-dimensional analysis” and “multidimensional analysis.” Then, the keyword list was checked based on classifications of research methods in linguistics indexed in Phakiti et al. (2018) and McKinley and Rose (2020), such as corpus analysis, to ascertain the repeatedly used research methods in register studies.
Keyword List (Centrality ≥ 0.02, Link-strength ≥ 30).

Note. The keywords generated by CiteSpace were ranked according to the centrality, while VOSviewer’s keywords were ranked by link strength.
Fourth, the high-frequency keyword was further surveyed to confirm the main research themes. Keywords with a frequency of five or more in VOSviewer were retained (93 keywords). Then, the same or semantically relevant keywords that occurred in CiteSpace were searched and retained (69 of 292 keywords). The sharing keywords that occurred in both two tools may best represent important research themes. Next, the following types of keywords were excluded: (1) keywords that were too general to be considered as research themes, such as “language”; (2) keywords that were related to the research targets of this study, such as “register analysis”; (3) keywords that were related to other research questions, such as “corpus analysis.” Finally, 87 keywords (48 keywords from CiteSpace and 39 keywords from VOSviewer) were left for further analyses based on Biber and Conrad’s (2019) analytical framework on register analysis (See Section 3.4).
Fifth and lastly, the keyword clusters generated by CiteSpace were explored to reveal the emerging trends of register studies. To offer a diachronic perspective on the developments of register studies, the timeline visualization of the keyword network generated by CiteSpace was also displayed and analyzed.
Results and Discussion
General Characteristics
In this section, the publication trend, productive authors, productive institutions, and countries in register studies are discussed.
Publication Trend
Table 3 presents the number of academic journal publications by year between 2012 and 2021. A linear regression model was used to “examine the trend of a group of values on a time series” (Lin & Lei, 2020, p. 4) and was fit to show the publication trend. The results of a linear regression model show a steady increase in the number of articles published in the examined years (F = 47.541, p = .000, R-squared = .856, Adjusted R-squared = .838). As shown in Figure 2, the publication trend shows that register studies have been gaining considerable academic attention in the examined years.
Number of Publications Published Per Year.

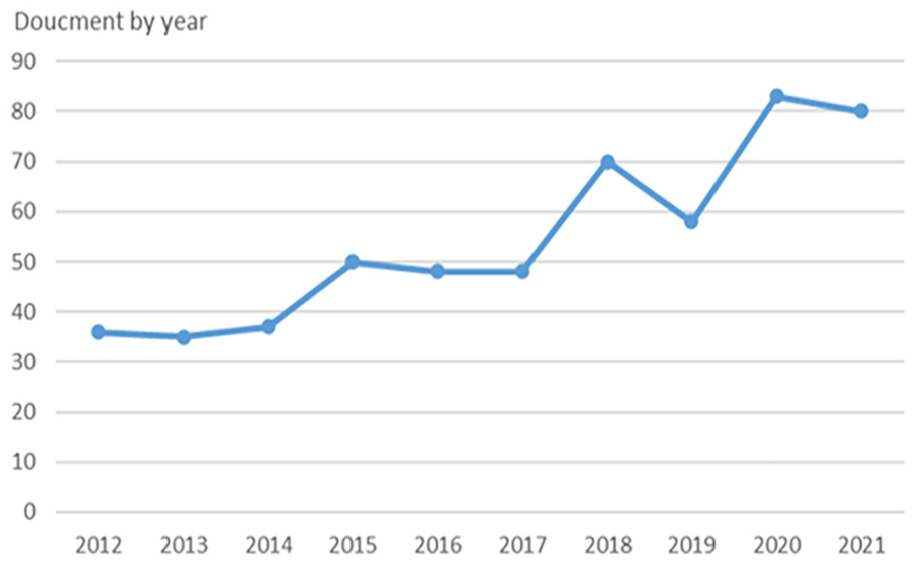
Publication trend (2012–2021).
Table 4 and Figure 3 present the journals which publications are at least 10 relevant articles. Most journals are dominant ones in the field of linguistics, such as Journal of English for Academic Purposes and Journal of Pragmatics. The most popular journals can be broadly categorized into three research areas as journal titles suggest. Register studies are conducted based on language teaching and education (i.e., Journal of English for Academic Purposes, English for Specific Purposes, Linguistics and Education and Iberica), corpus linguistics (i.e., International Journal of Corpus Linguistics, Corpus Linguistics and Linguistic Theory) and pragmatics (i.e., Journal of Pragmatics). Moreover, some conduct interdisciplinary research in linguistics, anthropology and communication, such as Journal of Linguistic Anthropology, Language and Communication. Along with the general-linguistics journals such as Lingua, some journals reflect the target language in register studies, such as English language studies (i.e., Journal of English Linguistics, English Language and Linguistics), and Spanish language studies (i.e., Revista signos, Iberica).
Publication Venues (Number of publications ≥ 10).

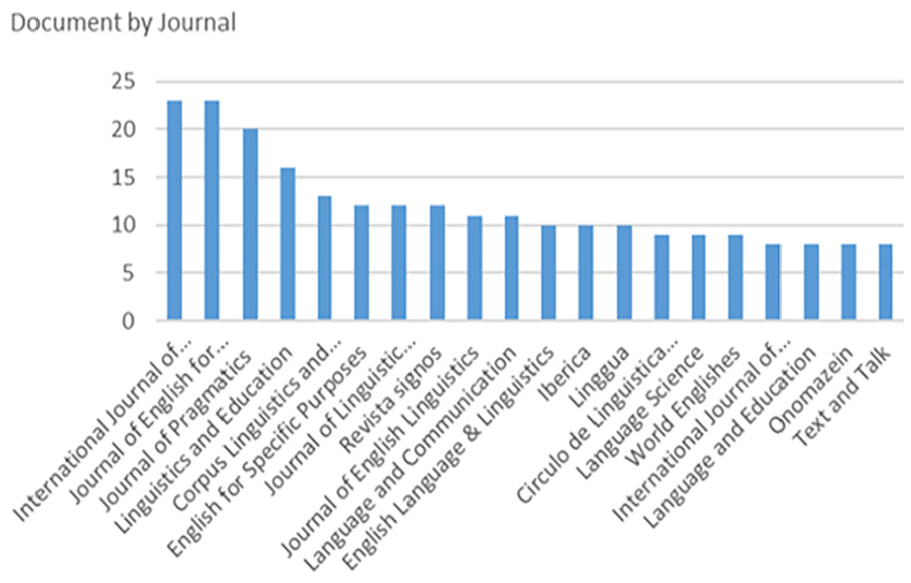
Publication venues trend (2012–2021).
Productive Authors, Institutions, and Countries
Table 5 presents the most productive authors in register studies. The most productive authors are Douglas Biber (12 articles), Haidee Kruger (nine articles), and Jesse Egbert (eight articles). And the following authors are Bertus Van Roody (seven articles), Shelly Staples (six articles), and Yao Xinyue (six articles).
Productive Authors (number of publications > 5).

As shown in Figure 4, significant contributions have been made by several universities, such as Macquarie University (17 articles), Northern Arizona University (13 articles), the Hongkong Polytechnic University (11 articles), and North-West University (10 articles). Figure 5 illustrates the most productive countries in register studies in the examined years. The United States yielded 120 articles, followed by Spain (55 articles), and China (51 articles). The top five productive countries contributed more than 50% of publications in register studies.

Major research institution.

Major countries.
Major Theoretical Frameworks
Co-citation analysis is grounded on a hypothesis that “the more frequently the pair are co-cited, the more likely they address the same subject matter and/or use similar methodology” (Liu & Hu, 2021, p. 100), which has been widely used to demonstrate the relationships and structure of a scholarly field in terms of authors, articles, journals, or keywords (Hu et al., 2011, p. 658).
Thus, the main theoretical frameworks of register studies are presented based on co-citation analysis, including journal co-citation (hereinafter abbreviated as JCA), author co-citation (ACA), and document co-citation (DCA) to explore the major theories and key concepts in register studies.
JCA can help define the structure of a research field in which academic journals are an important means of communication (Hu et al., 2011, p. 658). The journal co-citation frequency list and journal co-citation network were generated by CiteSpace and VOSviewer as shown in Table 6 and Figure 6.
Journal Co-citation Frequency List (Freq. ≥ 50).

Journals co-citation network.
As can be seen from Figure 6, except for the journal Thesis which cannot involve the field of linguistic studies, the other highly co-cited journals (see Table 6) can generally be divided into four strands, namely pragmatics, sociolinguistics, corpus linguistics, and language teaching and education. This classification can be confirmed not only by the titles of the journals, such pragmatics-oriented journal as Journal of Pragmatics and sociolinguistics-oriented journals as Language in Society, Journal of Sociolinguistics, but also by the keyword list shown in Table 2, such as “identity” and “stance,” which are repeatedly discussed topics in pragmatics and sociolinguistics.
ACA is a common approach to mapping knowledge domains and describing scientific knowledge structures (Bu et al., 2020). Table 7 and Figure 7 present the list of the highly cited authors (freq. ≥ 50) and author co-citation network. Douglas Biber is the most co-cited author in the field, followed by Michel Halliday, Asif Agha, Ken Hyland, Susan Conrad, and William Labov, indicating that their papers played an important role in register studies. A more in-depth analysis of the highly cited authors’ publications reveals the main theoretical foundations of register studies, such as text linguistics (i.e., Biber, Conrad), systemic functional linguistics (SFL, i.e., Halliday), anthrolinguistics (i.e., Agha), and sociolinguistics (i.e., Labov).
Author Co-citation Frequency List (Freq. ≥ 50).

Author co-citation network.
DCA is believed that constantly and frequently cited research sets the knowledge foundation of a given field (Huan & Guan, 2020, p. 10). Table 8 and Figure 8 display the most highly cited references in register studies, Moreover, the centrality score indicates that they were the most influential ones among the landmark publications in register studies. Similar to the findings of author co-citation analysis, Biber was the most influential author in register studies, who contributed six of the most-cited references (Biber, 2014; Biber et al., 2011, 2016; Biber & Conrad, 2019; Biber & Egbert, 2016; Biber & Gray, 2013).
Co-citation Frequency List of References (Rank 10).


Document co-citation network.
Among them, the most-cited reference in register studies is the one by Biber and Egbert (2016). Biber and Egbert’s (2016) research used multi-dimensional analysis (hence after abbreviated MDA) to explore grammatical complexity in academic English. MDA was also adopted in Biber’s (2014) research.
Moreover, Biber and Gray (2013) analyzed two case studies from the perspectives of historical linguistic change of register differences, which provided a methodology to compare registers in corpus-based historical research. Biber’s studies adopted the register perspective of systemic functional linguistics (Biber & Conrad, 2019, p. 22) and proposed an analytical framework, intending to explore “functional relationships between linguistic patterns of use and the situational characteristics of registers” (Goulart et al., 2020, p. 7.2).
A more in-depth analysis based on the journal, document, and author co-citation analysis revealed that the main theoretical frameworks in register studies are text linguistics, systemic functional linguistics, and sociolinguistics.
Text linguistics refers to a significant approach in terms of theory and methodology in register variation studies which conduct quantitative methods to describe the linguistic features of texts, as “the basis for comparing the patterns of register variation across texts” (Biber, 2019, p. 43). For instance, Smith et al. (2014) quantified linguistic features of specific and general clinical text through a comparative register analysis.
Systemic functional linguistics studies have mainly investigated registers as “different semiotic dimensions together with other types of linguistic variation” in register analysis (Matthiessen, 2019, p. 31). Lukin (2013), for instance, analyzed a TV news report within the framework of SFL and presented functional varieties in the register of news reports on the context-construing work.
Sociolinguistics has also played a critical role in register studies. For instance, Gal (2019) examined the role of register-making in constructing and evoking authority for political discourses and suggested that registers display connections between organizations in different social arenas.
Important Research Methods
Table 9 presents a grouping of keywords of the important research methods used in register studies and their classification grounded on Phakiti et al. (2018) and McKinley and Rose (2020). Among them, the quantitative method mainly includes corpus analysis. Corpus analysis, for instance, was employed by Biber et al. (2021) to investigate the conversation register in the British National Corpus, and findings showed that most conversational talks consisted of sequences of coherent discourse units that can help identify the communicative goals.
Research Methods and Keywords.

As a methodological approach based on corpora, MDA is one “specifically frequently used approach to explore register variation” (Seoane & Biber, 2021, p. 236). MDA was developed to identify “the salient linguistic co-occurrence patterns” in a language from the perspectives of empirical and quantitative and explore register variations defined by the co-occurrence linguistic patterns (Biber & Conrad, 2001, p. 5). The approach can be traced back to Biber (1985, 1986) and then developed further in Biber’s (1988) study, and has been applied for interpreting register features and analyzing register variation based on corpora of Web (Biber & Egbert, 2018).
MDA identifies 67 linguistic features in each observed text (e.g., pronouns, nominal forms, tense and aspect markers, and negation), and reduces the features to six dimensions including “involved versus informational production, narrative versus non-narrative discourse, situation-dependent versus elaborated reference, overt expression of argumentation, abstract versus non-abstract style and online information elaboration” (Biber, 1988, pp. 831, 835) to confirm the register patterns (e.g., science and technology exposition, general narration, interactive persuasion). MDA has been widely used to analyze a range of register studies, such as corporate annual reports (Ren & Lu, 2021), academic writing between Anglophone and non-Anglophone experts (Omidian et al., 2021), contemporary American television (Sardinha & Pinto, 2021) and the extra- and intratextual characteristics of Czech texts (Cvrček et al., 2021).
Register studies are combined with qualitative methods, such as discourse analysis, genre analysis, and conversation analysis. Discourse analysis, for example, was adopted by Baker and Vessey (2022) to compare Islamist extremist texts to reveal similar and distinct discursive themes and linguistic strategies in the same register of different languages. In another example, Corella (2020) adopted discourse analysis to investigate academic spoken register in peer interactions in an elementary classroom.
Genre analysis was used by Gholaminejad (2021) to compare lexical bundles in academic written registers, such as textbooks and research articles, and found different discourse functions between the two registers. Moreover, Sindoni (2021) applied conversation analysis to explore spoken register and findings showed that mode-switching played important role in the management of conversation flow as a self-repair strategy in multi-party interactions.
Main Research Themes
Table 10 presents the grouping results of keywords based on Biber and Conrad’s (2019) analytical framework on register analysis, which reflects important research themes in register studies. To identify the important research themes in register studies, the following dimensions are discussed: linguistic features, register types, register variations, and communicative functions. Furthermore, teaching and education is one important strand in register studies, as discussed in Section 3.2 and thus it is discussed as one of the dimensions of research themes.
Keywords of Research Themes.

Linguistic Features
In the dimension of linguistic features, the frequently explored items are lexical bundles, discourse markers, construction, stance, and formulaic sequences.
Lexical bundles, referred to as multi-word expressions, are the key distinguishing features of particular registers (Hyland & Jiang, 2018). For example, Grabowski (2015) analyzed lexical bundles used in the English pharmaceutical written register and found that there are salient links between different features across different pharmaceutical registers, such as linguistic features and functional features. In another example, Gholaminejad (2021) compared lexical bundles in academic written registers and found that attitudinal/modality lexical bundles are used more in textbooks than research articles.
Another important topic of linguistic features, discourse markers, used as the “linguistic indicators of register” (Brizuela et al., 1999, p. 128), serve an important function in the articulation of the text, such as connecting sentences, clauses, and phrases (Altikriti, 2019). For example, Garcia (2016) identified the usual discourse markers in oral conversations and written speech in Spanish and found the preference of written speech for discourse organizers or the conversation markers tendency to oral interactions.
Constructions involve observations of conventionalized pairings of meaning and form of language features (Goldberg, 2003), which were adopted in the specific constructions in different registers. Schönefeld (2013), for example, examined the English specific construction in four registers (academic prose, newspaper texts, fiction, and conversation) and findings suggested that register leaves a mark on the patterns used in authentic communication. In another example, Bao et al. (2017) examined perfect construction in different registers, including spoken, fiction, magazine, newspaper, and academic registers, to explore the synchronic changes of perfect construction in different registers of American English.
Stance is a cover term for expressing “attitudes, feelings, judgments, or commitment concerning the propositional content of a message” (Biber & Finegan, 1989, p. 93). For example, Poole (2021) compared the variation of stance adverbs between legal writing register and other registers and suggested that there are conflicts between the practical use of stance adverbs and the legal writing style guides.
Formulaic sequences, linking to “a single meaning/pragmatic function” (Conklin & Schmitt, 2008, p. 72), often serve a vital function in discourse. Wang (2018) identified formulaic sequences in academic writing registers and revealed that novice writers used more formulaic sequences with interpersonal functions in academic writing in comparison to expert writers.
Register Types
In the dimension of register types, the repeatedly examined types are spoken, written, academic and online register.
Spoken registers include broadcasts (Zhang et al., 2017), public and non-public conversation (Verhoeven & Lehmann, 2018), and television programs (Sardinha & Pinto, 2021). For example, Sardinha and Pinto (2021) analyzed American television programs and found that all the programs can be categorized into different specific registers, such as “presentation of information, opinion, and discussion,” and so on.
Written registers include business emails (Gimenez-Moreno & Skorczynska, 2013), legal documents (Ingham, 2016; Poole, 2021), novels of Charles Dickens (Egbert & Mahlberg, 2020), news articles (Clarke et al., 2021), and corporate annual reports (Bu et al., 2020; Ren & Lu, 2021). For example, Poole (2021) examined stance adverbs in law written registers and compared the use and function of stance adverbs in different judicial texts.
Next, academic registers include research articles of different disciplines (Hyland & Jiang, 2018), classroom oral interaction (Hong & Basturkmen, 2020), and students’ academic writing (Nasseri, 2021). For example, Hyland and Jiang (2018) examined the diachronic change of the lexical bundles in academic written register, including applied linguistics, sociology, biology, and electronic engineering.
Last, another type emerging in register analysis is online register (indicated by the keyword “computer-mediated communication,” freq. = 6 in VOSviewer, and other relevant keywords, e.g., “blog” and “web”), including both the public-oriented communication registers such as blogs, web pages, and the personal-oriented communication registers such as Emails, Twitter, and Facebook (Sardinha & Pinto, 2014, p. 81).
Most researches tended to describe and identify linguistic features of online language in a broad sense (Goulart et al., 2020, pp. 7.12), for example, by comparing a variety of online registers including websites, Twitter, blogs, and Facebook (e.g., Biber & Egbert, 2018; Sardinha, 2018; Titak & Roberson, 2013).
Furthermore, Twitter and Facebook as the new topics of the personal-oriented communication registers, have been widely taken into consideration, such as the styles of specific individuals’ tweets (Biber & Conrad, 2019), the functional linguistic variation in Twitter trolling (Clarke, 2019), stylistic variation in the celebrity’s tweets (Clarke & Grieve, 2019), companies’ responses to customer complaints on Twitter (Fuoli et al., 2021). For example, Clarke and Grieve (2019) examined Trump’s tweets posted in the past decade and identified four dimensions of stylistic variation, including “conversational, campaigning, engaged, and advisory discourse” (Clarke & Grieve, 2019).
Register Variations
Register variation is meant that two or more registers are compared to identify linguistic patterns of variation which can be interpreted by “the communicative purpose, the context of production, and topic, among other situational factors” (Goulart et al., 2020, p. 7.3), and resonate with the field, tenor and mode of discourse across different registers.
First, the “field” of discourse (what is going on in a given context, indicated by keywords, such as “classroom”) leads to variation in representing motion across different registers (tourist guidebooks, physics textbooks, weather forecasts, among others) (Kashyap & Matthiessen, 2019). For example, Farrugia (2013) examined conversations in a mathematics classroom and illustrated various routes of language choice from informal to formal language in the classroom register.
Second, the “tenor” of discourse (who are taking part in the activity, indicated by keywords, such as “children,”“speaker,” and “gender”) causes variation in employing different patterns of language use across speakers. For example, Bernicot et al. (2012) explored the short message service (SMS) register among French-speaking adolescents and found that the commonly reported distinctions between genders were mitigated in the online register.
Third, the “mode” of discourse (the function of the text in the event, including both the channel taken by the language, indicated by keywords, such as “spoken” and “written”) accounts for variation in using metadiscourse across non-discussion and discussion broadcasts, scripted and unscripted speeches, public and casual conversations (Zhang et al., 2017).
In addition, register variations are accounted for by English varieties, indicated by the keywords “Australian English,”“Spanish English,” and “American English.” For example, Shakir and Deuber (2018) compared the online registers-comments of Pakistani English to U.S. English and identified four dimensions of variation.
Furthermore, other register variations resonated with the diachronic linguistic changes, indicated by the keywords “late modern English.” For example, Hiltunen et al. (2020) explored the patterns of intensification in medical writing by using Late Modern English Medical Texts.
Functional Dimension
In the functional dimension, the commonly examined communicative functions are those of constructing identity and communicative ideology. Identity is commonly produced and reproduced through speakers’ particular language use (Bucholtz & Hall, 2004). For example, Ohashi (2018) analyzed the emails of Japanese men and illuminated that the use of honorifics could index a specific social identity. Revis (2021) explored the naturally-occurring family discourse in a diasporic community and revealed that the participants partially shared socialization trajectories that reflected their immigration identity.
Another communicative function of register is to communicate ideologies. For example, Friedman (2023) analyzed Ukrainian-Russian adolescent bilinguals’ spoken register and showed these young people conducted different language strategies to communicate prevailing purist ideologies.
Teaching and Education
In the dimension of teaching and education, the repeated explored topics are academic register variations in terms of field (indicated by the keyword “classroom”) and tenor (indicated by the keywords “student” and “learners”). As discussed earlier, academic register is an important theme in register studies, and register is fundamentally important for any student’s language learning and one of the main goals of education is “to learn the specialized register of a particular profession” (Biber & Egbert, 2018, pp. 3–4).
Register studies concentrated on linguistic features’ application in language teaching and education, such as discourse markers, and lexical bundles in different language teaching. For example, Garcia (2016) identified of the usual discourse markers in oral conversations and written speech of Spanish and extend those already taught for the acquisition of discourse competence in Spanish as a Foreign Language. Galloway et al. (2019) argued that student-generated metalanguage in academic registers can be used as a primary instructional resource to help learners build knowledge of academic language.
Moreover, some studies involved the implication and application of registers in teaching and education. Schleppegrell (2020) emphasized the importance and implication of register in English teaching and education, namely, understanding variation in the registers in different classroom tasks and identifying language features used in the different disciplinary discourses. With the advent of online teaching, the application of register in online classrooms has received attention. For example, Ho and Tai (2021) explored how online teachers draw on different registers to teach English vocabulary, which offered some pedagogical implications for developing teaching and learning materials on digital platforms.
Emerging Trends in the Area of Register Studies
The keywords in the articles can indicate the fundamental aspects of the study field (Xiao & Li, 2021). Thus, emerging trends in research can be identified by analyzing the co-occurrence of keywords, and “the profile of a specific field can be examined via keyword cluster analysis” (Xiao & Li, 2021, p. 493). The keywords cluster analysis was adopted to highlight emerging trends in register studies.
Table 11 provides the keywords clusters by employing the log-likelihood ratio (LLR) agglomeration calculation and Figure 9 displayed the timeline view of keywords clusters year by year. As shown, all clusters share and overlap similar characteristics between Table 11 and Figure 9. In the 14 labels of clusters, these were most frequently discussed in the second 5 years (2016–2021), namely, #0 systemic functional linguistics, #1 multi-dimensional analysis, #3 discourse, #8 audience, #10 function, and #12 corpus analysis.
Key Labels as Topics in Register Studies.

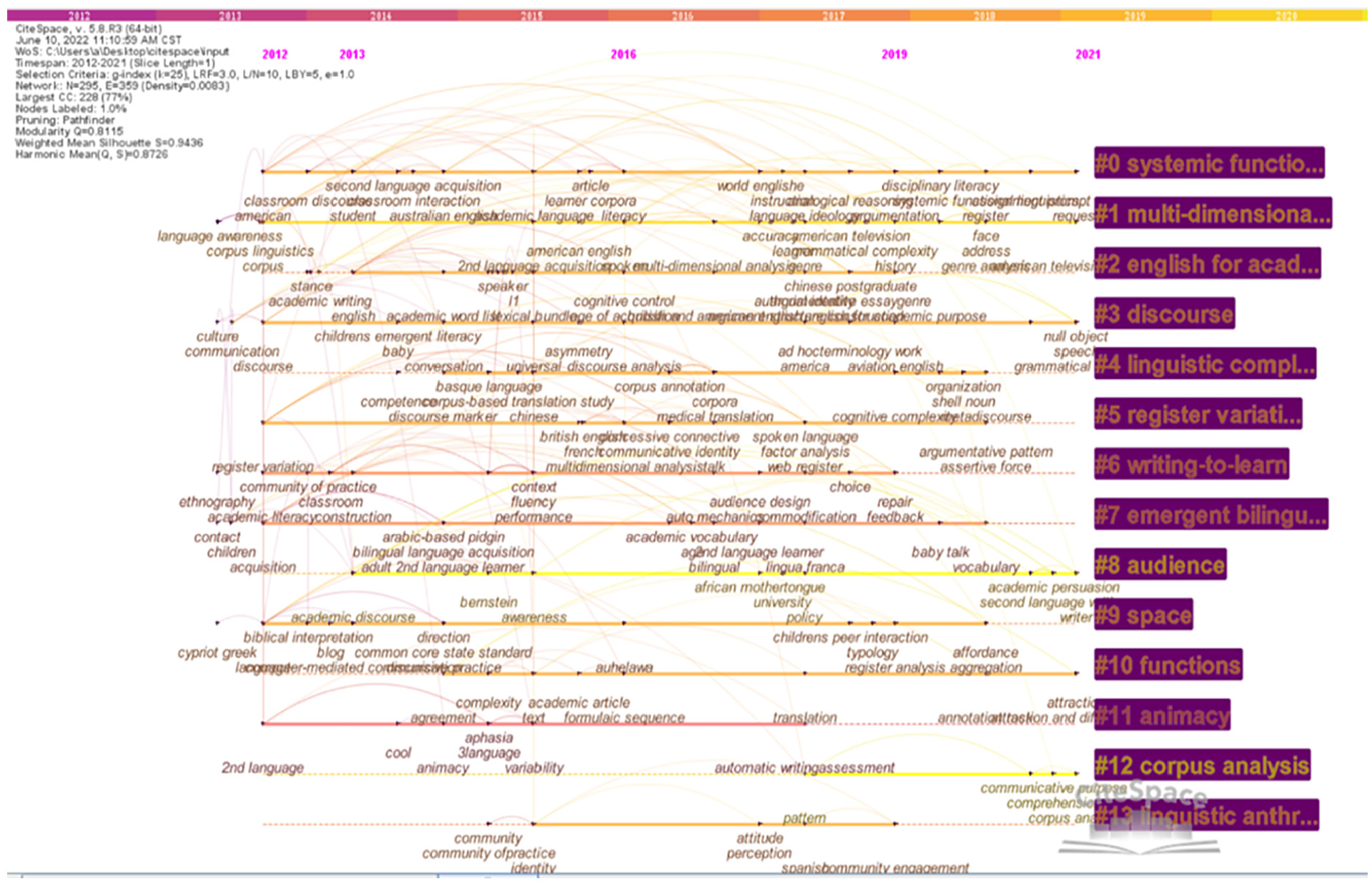
Timeline view of keywords clusters year by year.
First, the label of Cluster #0 relates to “systemic functional linguistics (SFL),” which indicated the important theoretical basis in register studies, as discussed in Section 3.2 To be more specific, SFL involved the keywords, such as “Australian English, academic language, classroom interaction, and metalanguage.” For example, Forey (2020) analyzed the use of a metalanguage taken from SFL in students’ classroom interactions and writings. SFL was adopted to investigate the system of causation in different languages from a contrastive register-based perspective (Sellami-Baklouti, 2021).
Second, the label of Cluster #1 and #12 are associated with MDA and corpus analysis, which demonstrated the trend of the quantitative research methods in register studies. In the two clusters, the important keywords “pragmatic development” and “applied linguistics discourse” might indicate register studies have gained increasing attention in pragmatics and applied linguistics.
As discussed, represented by MDA, corpus analysis was widely used in register analysis. Corpus was adopted to perform an empirical bottom-up analysis of linguistic features based on the collection of texts, and the development of empirical register research coexists with that of empirical corpus-based research (Seoane & Biber, 2021). MDA, as the corpus-based method, was widely used in different register studies, such as Czech texts (Cvrček et al., 2021) and television programs (Sardinha & Pinto, 2021). Moreover, MDA was also used in some new-burgeoning online registers, such as internet texts (Sardinha, 2018), blogs (Shakir & Deuber, 2018), and Twitter (Bohmann, 2020).
The label of Cluster #3 is related to discourse, which includes the discourse produced by different speakers and audiences, such as different genders, ages, and nationalities. Qin and Uccelli (2020), for instance, studied linguistic complexity and register flexibility across academic writing and spoken registers produced by learners of different ages and language backgrounds. Findings revealed that participants’ language proficiency can lead to textual linguistic complexity, but is not consistent with register flexibility.
The label of Cluster #8 is related to “audience,” which is of considerable importance in all models of registers. Barkaoui (2021) examined the potential relationship between audiences and L2 learners in writing and indicated that the participants tended to adopt different writing strategies and styles when writing to different audiences. With the affordance of technology, academic blogs and other platforms provide opportunities for writers to reach wider audiences.
The label of Cluster # 10 is related to “function,” which indicated that the function of the language receives increasing attention in register studies. Register studies focus on “the functional relationships between linguistic patterns of use and the situational characteristics of registers” (Goulart et al., 2020, p. 7.2), and thus tend to functional variations from the description of linguistic features.
Conclusion
This study attempted to present the current situation of register studies using bibliometric analysis. Several findings illustrated in the study may provide new insights and understanding in register studies.
The first finding presented the key journals, most productive authors, institutions, and countries in the field. A group of productive and core authors in the field are identified by the publications and co-citation analysis which may be useful for future researchers to retrieve influential research literature.
The second finding revealed text linguistics, SFL, and sociolinguistics were the major theoretical origins of register studies. Moreover, mixed methods are not uncommon in register studies with the development of corpus linguistics and computational linguistics. In register studies, quantitative methods were used to describe the general linguistic characteristics of each register, and qualitative approaches can focus on specific communicative purposes.
The third finding is that research themes and trends identified by high-frequency keywords and the timeline of the keyword network show that register studies have emerged as increasingly distinctively pragmatic and sociological. Moreover, some emerging trends for register studies display the tendency of register variations from register descriptions. Register has been conceptualized even more specifically, and online registers, such as Twitter and blogs, have become the research hotspot (Biber & Egbert, 2018). The major research themes and emerging trends are a useful resource for novice researchers and established scholars in the field, and perhaps also critical in assisting journal editors to continue to promote theoretical or methodological advances in the field.
There are also limitations in the study in some aspects. On the one hand, the analyzed data are narrowly limited to those articles published in journals and did not take account of the other types of literature, such as book chapters. On the other hand, the coding schemes and classifications are pre-determined on the previous related studies and subjective evaluations should be involved in the analysis. To this end, the reviewed aspects of research methods, research themes, and emerging trends are worth exploring more comprehensively in future research.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Humanities and Social Sciences Project of the Ministry of Education, the People’s Republic of China (Grant Number: 21YJA740035).