
Abstract
With the rapid development of social media, new opportunities have been provided for the generation and dissemination of online rumors, making systematic study of rumor detection of great significance for the control and governance of internet rumors. Addressing the limitations of past review studies on rumor detection which were characterized by a single perspective, reliance on subjective judgment, and lack of technological evolution theory, this paper reviews 983 rumor detection articles in the SCI-EXPANDED, SSCI, CPCI-S, CPCI-SSH, CCR-EXPANDED, and IC databases of the Web of Science. Utilizing Citespace and VOSviewer for visual analysis of the articles, and adopting bibliometric theories like network analysis and topic evolution analysis, this study identifies core research groups in the field of rumor detection based on author collaboration network and institution collaboration network. Through high-frequency keyword clustering graph and keyword co-occurrence graph, the study unveils topic associations and cluster structures among keywords, explicates research hotspots in the field of rumor detection, and conducts a fine-grained critical comparative analysis. According to keyword time graph, keyword bursts table, and trends in the number of publications in hot technology fields, combined with the S-curve technology evolution theory, the study discerns the life cycle and research trends of technologies in the rumor detection field. Compared to existing literature reviews, this paper is the first to propose integrating bibliometrics and S-curve technology evolution theory to reveal the state of relevant technologies and research frontiers.
Plain Language Summary
There are many rumors on social media, which can mislead the public and disrupt the social order. How to detect rumors is an important research problem. Rumor detection can help control the spread and diffusion of rumors, and reduce their negative impact on the public and society. This article reviews and analyzes the research on rumor detection, using a combination of bibliometrics and S-curve technology evolution theory, and summarizes the research status, hotspots and trends of rumor detection. It finds that the research on rumor detection mainly has five aspects: rumor detection based on machine learning, deep learning, natural language processing, multimodal fusion and trust network. These aspects have their own advantages, challenges and improvements. The technologies used are in different stages of maturity and have different development potentials. The most promising ones are multimodal fusion and trust network, which can extract more rich and effective rumor features, and enhance the effect and credibility of rumor detection. This article provides a new perspective and method for the research on rumor detection, and helps researchers better understand and predict the technical status and research frontier of rumor detection.
Keywords
Introduction
With the rapid development of computer and internet technology, human society has entered an era of information interconnection and high integration. In particular, since the proposition of Web 3.0, the rapid development of various social platforms (including Facebook, YouTube, Twitter, TikTok, WeChat, Weibo, etc.) has provided an excellent medium for current information dissemination (Hangloo & Arora, 2022; H.-Y. Lu et al., 2022). Owing to the characteristics of networked, fragmented, and rapid information dissemination, users can freely post, spread, and acquire various information on the internet (S. Xu et al., 2023). However, the complexity of network structures leads to the rampant spread of many unfettered rumors (H. Zhou et al., 2022). As we see it now, rumors have the characteristics of a high number of disseminators, fast spread speed, significant difficulty in identification, and profound impact (M.-Z. Huang & Yin, 2022). The emergence and spread of rumors disrupt normal communication on the internet, cause significant negative emotions among the public, and affect social stability (Yu et al., 2017). Therefore, it is essential to control rumors, and the most significant challenge lies in the precise identification of rumors. Rumor identification is to analyze the multidimensional semantic features of information and capture the feature differences between rumor and real information from different modalities. Accurately identifying rumor information helps control its further spread and diffusion and reduces its negative impact on the public.
The technology for rumor identification mainly focuses on machine learning, deep learning, natural language processing, and multimodal fusion. As research continually advances, some scholars have systematically analyzed past studies in this field from various perspectives. Specifically, Cardoso Durier da Silva et al. reviewed different types and evaluation indicators of rumor identification from the perspective of technology classification, establishing a relatively comprehensive technical classification system (Cardoso Durier da Silva et al., 2019). X. Zhou and Zafarani (2020) reviewed the basic concepts, models, and methods of rumor identification from theoretical and practical perspectives, striving to establish a theoretically complete and practically effective framework. Oshikawa et al. (2018) reviewed the language features, semantic analysis, and context understanding methods in rumor identification detection from the perspective of natural language processing, summarizing the methods of extracting semantic features using natural language processing technology. Shahzad et al. (2022) discussed the tools and frameworks for rumor identification from the perspective of artificial intelligence and big data analysis, comparing the effects of different tools on improving the accuracy and credibility of rumor identification. Ali et al. (2022) explored the datasets and methods for rumor identification in European and Asian languages from a multilingual perspective, summarizing the differences and difficulties in using different methods for rumor identification in various languages. Rani et al. (2022) explored the methods to improve users’ trust in the identification results through psychological intervention and social network analysis from the perspective of psychology and sociology. Capuano et al. (2023) sorted out the content- and context-based rumor identification methods from the perspective of computer science and data science, comparing the accuracy of rumor identification under different types of methods. Athira et al. (2023) discussed the goals, methods, and challenges of explainable rumor detection, and the methods to improve users’ understanding of identification results from the perspective of interpretability.
The aforementioned scholars have written review articles of a summary nature, but they often conduct literature reviews of specific fields from a single perspective, each focusing on different research subjects, research scopes, and research methods. Most of the articles rely on subjective judgments, without visualized bibliometric analysis, and lack the support of technology evolution theory. In response to the above research issues, this paper uses bibliometric theories such as network analysis and topic evolution analysis to perform fine-grained analysis of literature data. Combining the visualized analysis results generated by Cite Space and VOSviewer with the analysis based on the S-curve technology evolution theory (Baldwin & Clark, 2000), and carrying out a critical comparison analysis of existing rumor identification technologies, we explore the knowledge structure, current status, and future trends of the rumor identification field. This helps authors in this field to understand more comprehensively and objectively the current status of rumor identification research and accurately grasp research hotspots and trends, which is of high theoretical value.
The structure of this paper is as follows: the first part introduces the research background and issues of rumor identification; the second part introduces the theories of network analysis, topic evolution, and S-curve technology evolution theory, and presents the research methods; the third part displays the quantitative analysis results of Cite Space and VOSviewer, analyzes research hotspots, and conducts fine-grained critical comparison analysis, discerning the lifecycle and research trends of hotspot technologies; the fourth part discusses in depth the content of data measurement, research hotspots, lifecycle of hotspot technologies, and research trends; finally, the paper concludes with the main findings.
Theoretical Framework and Research Methods
Theoretical Framework
Bibliometrics uncovers information regarding the output, citation, and influence of articles by quantitatively analyzing and measuring the numerical characteristics and citation relationships of articles, thereby gaining a quantitative understanding of academic research. This paper employs bibliometric theory and the S-curve technology evolution theory to perform a fine-grained critical comparison analysis based on the visualization of articles data and deep investigation, unraveling the research hotspots, technology life cycle, and research trends in the field.
Theories Related to Network Analysis
(1) Co-occurrence Theory: According to the Co-occurrence Theory, if two authors appear together in multiple pieces of articles, it is likely that they have a collaborative relationship. Analyzing the author’s cooperation network can identify the core research groups in the field. By performing a co-occurrence theory-based cluster analysis on high-frequency keywords, keywords can be divided into categories with similar characteristics, thus identifying the research hotspots in the field.
(2) Graph Theory and Network Science: Theories of graph theory and network science provide the theoretical and methodological foundations to analyze and describe citation networks in this paper. These theories, including Degree Centrality, Clustering Coefficient, and Network Centrality, are used to measure the importance of articles in the citation network and analyze the position of the articles in the citation network.
Theories Related to Topic Evolution Analysis
(1) Burst Detection: Burst Detection uses statistical methods and machine learning algorithms to identify burst behaviors, where the frequency of keyword appearance significantly increases within a certain period, thereby recognizing emerging words in the topic evolution process, as well as the intensity and burst time period of these words.
(2) Evolutionary Clustering: Evolutionary Clustering clusters articles according to its keyword characteristics and time features, revealing the evolution pattern of articles topics from a temporal dimension. articles with similar keyword features and temporal characteristics can be clustered into one category, forming a clustered structure of topic evolution, thereby displaying the changes in articles topics over time, that is, the research trends in the field.
S-Curve Technology Evolution Theory
S-curve technology evolution theory is a theoretical framework for economic evolution and technological change proposed by Carliss Y. Baldwin and Kim B. Clark, using the computer industry as an example, and is widely used to predict and identify the emergence and maturation of technologies. This framework is widely used to predict and identify the emergence and maturation of technologies. According to this theory, the development process of technology can be depicted by an S-shaped curve, divided into four stages: initiation, transition, modularization, and decline. This paper uses the S-curve technology evolution theory to interpret and predict the visualization results of bibliometric analysis, judging the technology life cycle stage of the articles based on the citation network and high-frequency keyword list.
Based on the above theories, this paper uses Citespace and VOSviewer to conduct a fine-grained visualization analysis of the articles in the field of rumor identification research. The visualization outcomes include author collaboration network, institutional collaboration network, keyword co-occurrence graph, high-frequency keyword clustering graph, keyword time graph, and keyword bursts table, among others.
Research Methods
This paper conducts a search in the Web of Science database under the topic of “Rumor Identification,” selecting the SCI-EXPANDED, SSCI, CPCI-S, CPCI-SSH, CCR-EXPANDED, and IC datasets. It is typical to search for relevant articles within a given time interval. However, given that the field of rumor identification is relatively nascent, this study does not set a search time range (Z. Liu et al., 2015).
The search syntax used in this study is: ((((((((((((((TS=(“rumo$r identif*” OR TS=(“rumo$r recogni*” OR TS=(“rumo$r discern*” OR TS=(“rumo$r detect*” OR TS=(“rumo$r find*” OR TS=(“rumo$r discover*” OR TS=(“rumo$r distinguish*” OR TS=(“fake news identif*” OR TS=(“fake news recogni*” OR TS=(“fake news discern*” OR TS=(“fake news detect*” OR TS=(“fake news find*” OR TS=(“fake news discover*”)))))))))))))))))))))))))) OR TS=(“fake news distinguish*”). To ensure the completeness of the articles retrieved, it is necessary to consider multiple English expressions for “rumor identification,” for instance, the vocabulary for rumor includes: rumor, rumor, and fake news; the vocabulary for identification includes: identify, recognize, discern, detect, find, discover, and distinguish, etc. At the same time, it is necessary to use certain wildcards to ensure the completeness of the articles, such as “$” and “*”, where “$” stands for zero or one character, and “*” represents any character group, including empty characters (C. Chen et al., 2012; Song et al., 2016). After excluding one piece of articles from 2004 that does not belong to the topic of “rumor identification” from the final retrieved articles data set, a total of 983 pieces of articles between 2017 and 2023 are retained as the articles samples for this study (Tian & Li, 2019; Xie, 2015).
Data Analysis Results
Descriptive Statistical Analysis
Analysis of Publication Volume
In the field of rumor identification, the number of publications can reflect the level of development in this field (Qiu et al., 2017). As indicated by the bar chart of annual publication volume (Figure 1), it can be observed that from 2017 onward, the annual publication volume on rumor identification exhibits a linear growth trend, reflecting the annual increase in academic research on rumor identification (the number of publications in 2023 is lower than in 2022, due to the cut-off for articles statistics in May 2023).

Annual publication volume in the field of rumor identification, 2017 to 2023.
Research on rumors originated in the 1940s as World War II sparked interest among social psychologists (Allport & Postman, 1947; Knapp, 1944). With social development, academic focus gradually shifted to the genesis and development of rumors, with relatively few studies on rumor identification (Buckner, 1965; Daley & Kendall, 1964) The advent of the 21st century, and the prevalence of social networks, whose characteristics make them a breeding ground for rumors (Zanette, 2002) marked the beginning of research on rumor identification in 2017. Therefore, how to identify and control the spread of rumors in social networks has become a hot topic in academia (Moreno et al., 2004).
Analysis of Highly Cited Articles
The frequency of a document’s citation refers to the number of times it is cited by other documents within a certain period after its publication. This is an important indicator for measuring the quality and academic level of journal articles (Guo, 2013). Highly cited articles reflects the high level of attention and acceptance that the thoughts and views of the articles have garnered from other scholars (Ma, 2012). This paper has compiled the top five highly cited documents from 2017 to 2023 (Table 1).
Top Five Highly Cited Articles in the Field of Rumor Identification, 2017 to 2023.

From Table 1, it can be seen that the top five cited studies all adopted qualitative subjective judgment methods. The first four papers were reviews of rumor identification methods, with the article by Zubiaga et al. (2019) being the most cited. This paper was the first to review the identification and resolution methods of rumors in social media, including definitions of rumors, life cycle, datasets, evaluation metrics, identification tasks, and technologies. The fifth paper introduced an explainable rumor identification framework, reflecting the research hotspot of interpretability.
Regional Distribution Map of Publications
Figure 2 depicts a global geographical distribution of published articles by country or region, comprehensively showing the geographical distribution of publications from 2017 to 2023. According to the number of publications, there are four levels: China has more than 200 publications, the USA and India have between 150 and 200 publications, Saudi Arabia has between 50 and 150, and all other countries and regions have fewer than 50 publications. The distribution of publications by region is uneven, with China, the USA, and India having more publications than other regions, indicating that these countries have more investment in scientific research, policy support, academic exchanges, and social demand in the field of rumor identification.
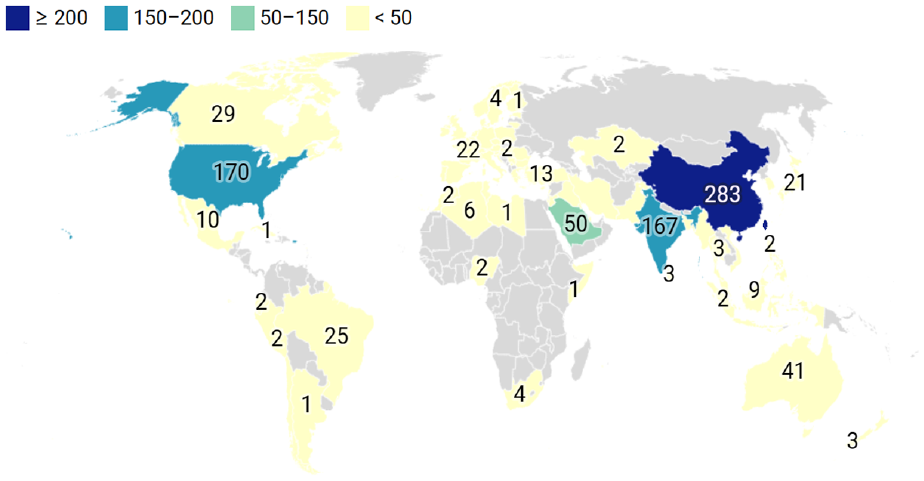
Regional distribution map of the number of articles issued in the field of rumor identification, 2017 to 2023.
Analysis of Author Collaboration Network
The VOSviewer software was used to draw an author collaboration visualization graph of 983 data, resulting in an author collaboration network graph (Figure 3). Authors with ≥4 publications were selected for display. In the network, the larger the author’s name, the higher the frequency of their appearance in the articles data. The lines between nodes represent the connection between authors, and the thicker the line, the closer their collaboration. From Figure 2, it can be seen that Shu, Kai; Liu, Huan; Choras, Michal; Vishwakarma, Dinesh Kumar; and Kaliyar, Rohit Kumar, etc., have relatively larger names, indicating that they are the top five most productive authors in this field.
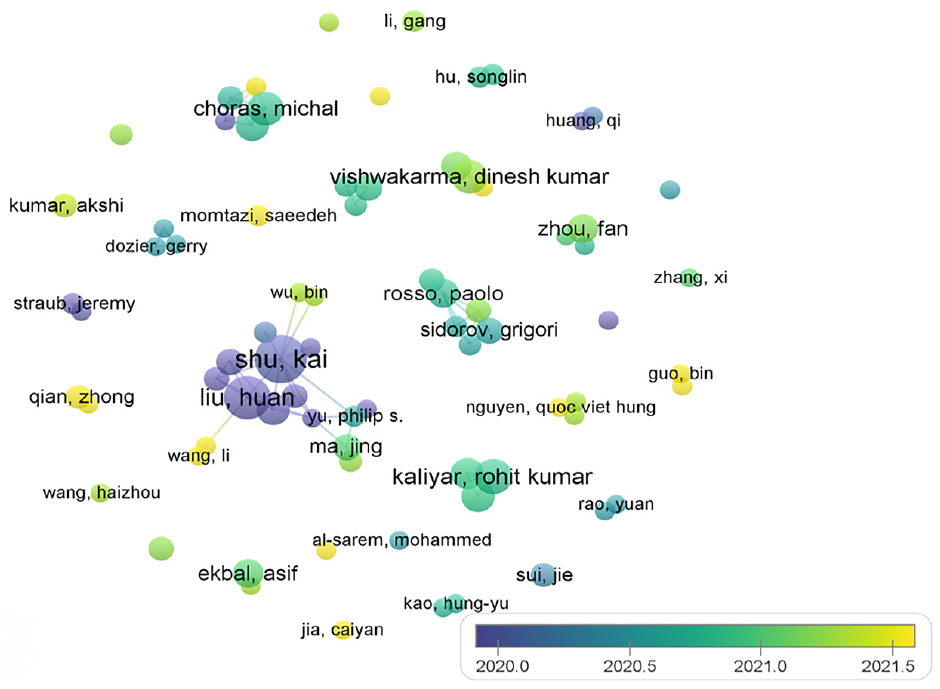
Principal cooperation network of authors in the field of rumor identification.
The overall connections in the author collaboration network are relatively sparse, indicating that the connections between authors are few and not close, with only a few authors having collaborative relationships. From Figure 3, it can be seen that the main author collaboration periods were from 2020 to 2021. Coupling this with high publication authors’ Citations and Total link strength, it can be inferred that the most closely cooperating team in the field of rumor identification is represented by Shu, Kai, and Liu, Huan. This team’s research topic is the impact of rumor transmission on social media and how to identify rumors, mainly elaborating on methods such as machine learning, natural language processing, multimodal methods, and mentioning that a large number of rumors were generated during the COVID-19 pandemic. Overall, collaboration between authors needs to be further improved to accelerate research in the field of rumor identification.
Analysis of Institutional Collaboration Network
The VOSviewer software was used to select the node type as Organizations for visualization analysis of organization collaboration, resulting in an organization collaboration network (Figure 4). Generally speaking, the larger the name of the organization, the more publications the organization has. The lines between nodes represent cooperation between organizations, and the thicker the line, the higher the frequency of cooperation between organizations. From Figure 4, it can be seen that Chinese Acad Sci, Univ Chinese Acad Sci, Arizona State Univ, Penn State Univ And Univ Elect Sci & Technol China have more publications, making them the top five most productive organizations.

Principal cooperation network of institutions in the field of rumor identification.
The main collaboration between institutions is from 2020 to 2022, mainly represented by the Chinese Acad Sci. The connections between other institutions are fewer and thinner, indicating that there is very little cooperation between various institutions in the current field of rumor identification. Therefore, there is a need to increase cooperation between publishing institutions. Establishing a friendly cooperation network between institutions is an important method to promote the development of research in the field of rumor identification.
Analysis of Research Hotspots
Co-Occurrence Analysis of Keywords
Keywords can reflect the main ideas of a paper, and they serve as a high-level summary of the content, hence, research in a specific field is generally analyzed using related keywords (H. Liu et al., 2019; J. Wang et al., 2018). We chose the node type as “keyword” in the VOSviewer interface for visualization analysis, generating a keyword co-occurrence graph (Figure 5), which resulted in 1,968 nodes (keywords) and 1,228 links (co-occurrence relationships), demonstrating a relatively close connection between the keywords.
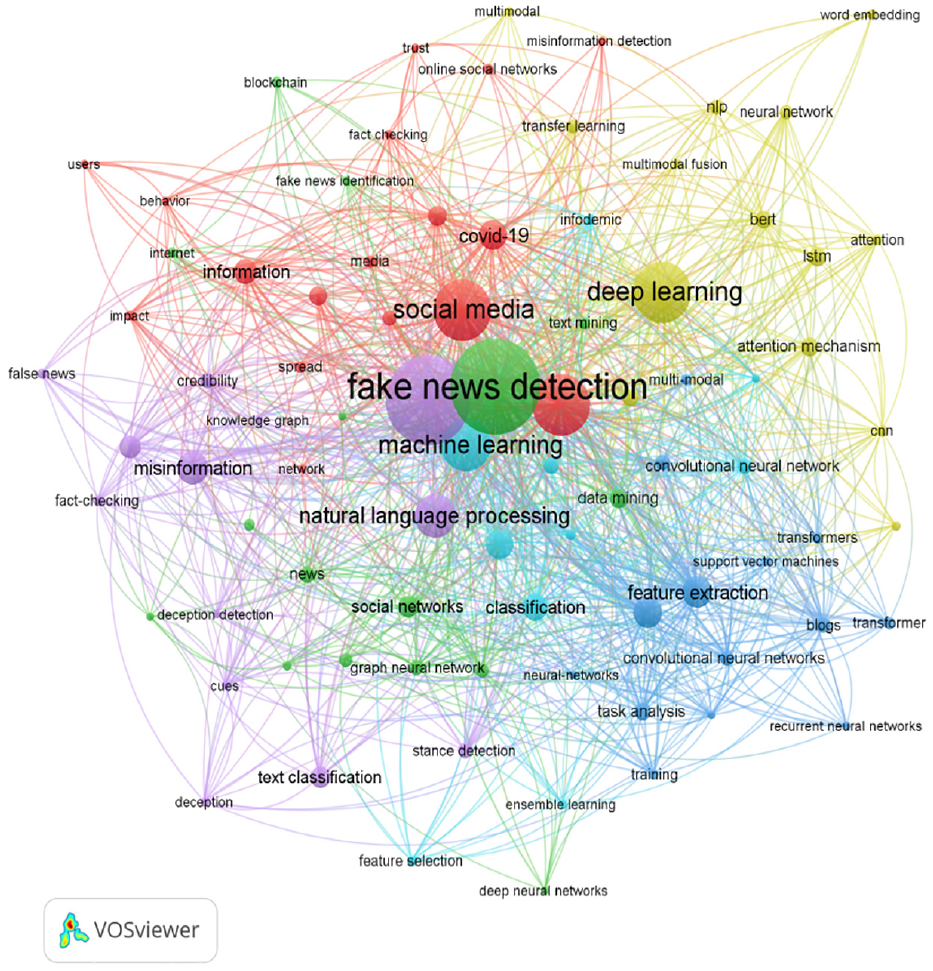
Co-occurrence graph of keywords in the field of rumor identification.
In Figure 5, the color of the lines in the graph represents the co-occurrence relationship; the same color indicates the same category. The size of the text in the nodes represents the frequency of the keywords: the larger the text, the higher the frequency. The links represent the degree of connection between the keywords: the more the links, the tighter the connection. From Figure 5, it can be seen that the nodes for “fake news detection,”“social media,”“deep learning,”“machine learning,”“natural language processing,” and “covid-19” have larger text. The node for the keyword “fake news detection” is the largest, with a frequency of 308, as this is the focus of our research. The second most frequent keyword is “social media,” with a frequency of 155, indicating that the generation and spread of rumors rely heavily on this medium. Other frequently occurring keywords include “deep learning” (153 times), “machine learning” (122 times), and “natural language processing” (88 times), which implies that most scholars in the field of rumor identification use technologies such as deep learning, machine learning, and natural language processing for rumor detection. “Covid-19” appears 48 times, indicating a close relationship between rumor identification and the recent pandemic. During the pandemic, the spread of a large number of rumors led to panic, misled the public, and hindered prevention and control efforts.
Keyword Clustering Analysis
Since the keyword co-occurrence graph contains many keywords, to increase the precision of summarizing the research hotspots, this paper uses the keyword clustering function of CiteSpace. After comparing three different calculation methods, LSI, LLR, and MI, the LLR algorithm was selected as the clustering algorithm for this paper (C. Chen, 2004). The keywords with close connections in the keyword co-occurrence graph were then aggregated to form clusters, resulting in a keyword clustering graph (Figure 6). Together with Figure 5, these graphs allow for a relatively accurate analysis of the research hotspots related to rumor identification.

Keyword clustering graph in the field of rumor identification.
CiteSpace, based on network structure and cluster clarity, provides two metrics: the Modularity (Q value) and the Weighted Mean Silhouette (S value). When Q > 0.3, the cluster structure is significant; when S reaches 0.7, the clustering is considered convincing. The data in the keyword clustering graph shows a Q value of 0.8394 and an S value of 0.9548, indicating that these clusters have obvious theme effects and the content of the articles within the clusters is also similar, hence, the cluster structure of this clustering graph is significant and convincing (C. Chen et al., 2012; Y. Chen et al., 2015).
Based on the keyword clustering diagram (Figure 6), this paper identifies 17 clusters of keywords. Among them, cluster#7 rumor detection and cluster#13 rumor detection are synonymous and recurrent, meaning rumor identification, which along with cluster#11 rumor verification and cluster#2 fake news detection, represent research directions in false information detection and verification. However, these clusters cover too broad a scope and do not align with the objective of hot technology analysis; thus, they are excluded. Similarly, cluster#5 social networks and cluster#14 social network are synonymous and recurrent, referring to social networks. Along with cluster#3 information, they represent the main research objects in the field of rumor detection, that is, various information within social networks. These clusters are not sufficiently representative and are therefore also excluded. After cleaning the clustering results, this paper identified 10 keyword clusters reflecting research hotspots in the field of rumor detection. However, these 10 clusters still have overlapping and covering content. To clarify the boundaries of each cluster, combined with the keyword co-occurrence graph (Figure 5), the authors, based on in-depth research into rumor detection-related techniques, conducted a further clustering with human-computer collaboration, ultimately dividing the 10 clusters into three primary research hotspots: cluster#15 Deep Learning (including cluster#1 novelty prediction, cluster#8 Attention Mechanism, cluster#17 transfer learning), cluster#10 Machine Learning (including cluster#0 Feature Extraction, cluster#12 representation learning), and cluster#9 Natural Language Processing (including cluster#4 Text Mining, cluster#6 Text Classification, cluster#16 partial observation).
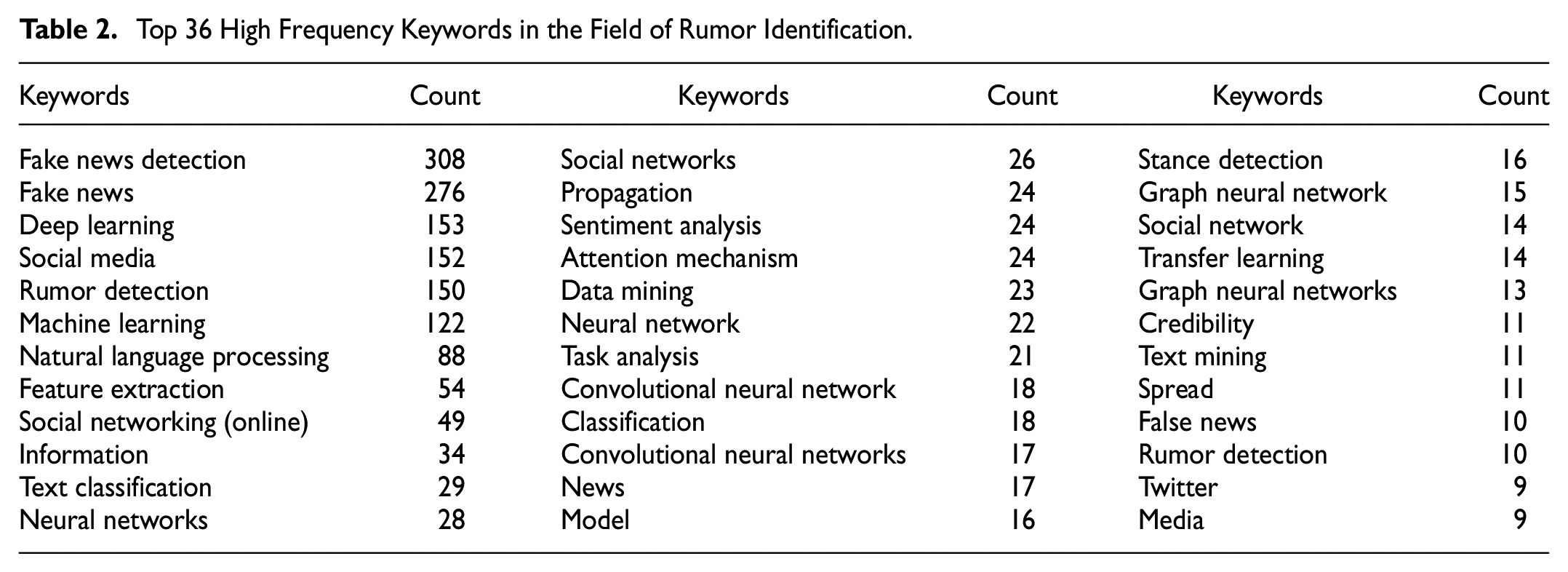
Since the keyword clustering diagram (Figure 6) only displays the clustering results of some high-frequency keywords, many emerging research hotspots have a low total number of publications and are not displayed in the clustering diagram, reducing the representativeness of the hot research analysis. To address this issue, this paper sequentially analyzes the membership of each keyword in the high-frequency keyword list (Table 2), combined with the emergent diagram (Figure 9) and articles research results. This process added two major categories of research hotspots, namely Multimodal Fusion (including Multimodal Fake News Detection, Feature Fusion) and Trust Network (including Explainable Machine Learning, Trust Networks, Knowledge Graph). Furthermore, this paper divided the remaining high-frequency keywords into five major categories of research hotspots based on articles research, which, while enriching the content and structure of the research hotspots, also provides data support for the analysis of hot technology lifecycles based on the S-curve theory of technology evolution. The final clustering results for research hotspots in the field of rumor detection are:
Top 36 High Frequency Keywords in the Field of Rumor Identification.
cluster#1 Machine Learning
Rumor detection methods based on machine learning perceive the problem of rumor detection as a binary classification issue within supervised learning, serving as an automated improvement over manual rumor detection methods. Such methods utilize a variety of machine learning algorithms to automatically learn the representation of rumor data, achieving intelligent classification. Feature extraction and classifier construction are two key steps in the machine learning method. The current machine learning-based rumor detection primarily embodies the following characteristics:
(1) In terms of rumor feature extraction, it can be divided into text feature extraction and semantic feature extraction methods.
① Text feature extraction methods include Bag-of-Words (BoW) model, Term Frequency-Inverse Document Frequency (TF-IDF), Statistical Language Model (N-gram), etc. Kaur et al. (2020) employed three types of feature extraction techniques: Term Frequency-Inverse Document Frequency (TF-IDF), Count Vectorizer (CV), and Hash Vectorizer (HV). A. Kumar and Sangwan (2019), I. Ahmad et al. (2020), Hakak et al. (2021), Thaher et al. (2021), Mishra et al. (2022), and Ansar and Goswami (2021) used TF-IDF and the Bag-of-Words model for rumor text feature extraction.
② Semantic feature extraction methods include word embedding, Named Entity Recognition (NER), sentiment analysis, topic models, and so on. I. Ahmad et al. (2020) used a sentiment dictionary to aid in capturing emotional features of rumors. Choraś et al. (2021) and Braşoveanu and Andonie (2021) used word embedding, Named Entity Recognition, sentiment analysis, among other techniques, to extract the semantic information from rumor texts.
Furthermore, to improve the accuracy of feature selection, Choudhary and Arora (2021) and Thaher et al. (2021) utilized genetic algorithms and Harris hawk optimization algorithms to select the optimal feature subset. Hakak et al. (2021) and Vasist and Sebastian (2022) employed Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) to reduce feature dimensionality, thus reducing feature redundancy and noise.
(2) The construction of classifiers has gradually shifted from singular machine learning algorithms to ensemble algorithms. Machine learning algorithms frequently utilized in the early days of rumor detection include K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Random Forest (RF), Logistic Regression (LR), etc. However, with the constant expansion of the rumor domain, rumors from different fields have unique text structures, and it is challenging for a single machine learning algorithm to build a general classifier that suits all specific domains. Ensemble algorithm classifiers can achieve higher accuracy. Thus, ensemble algorithm classifiers have become the mainstream method in rumor detection methods based on machine learning. At present, it mainly includes the following two types:
① Ensemble classifiers based on deep learning and machine learning algorithms. Reis et al. (2019), Posadas-Durán et al. (2019), and Chauhan and Palivela (2021) used an ensemble classifier based on neural networks and support vector machines to handle rumor classification tasks. Jiang et al. (2021) proposed a stacked classifier for rumor detection based on transformers and support vector machines.
② Ensemble classifiers that integrate multiple machine learning algorithms. I. Ahmad et al. (2020) proposed a rumor detection framework based on ensemble machine learning methods, using multiple machine learning algorithms such as logistic regression and support vector machines to construct different classifiers, and combined these classifiers using voting, stacking, and cascading methods for rumor detection. Kaur et al. (2020) constructed a multilayer voting model for fake news detection based on 12 machine algorithms, including logistic regression and decision trees.
(3) Some scholars attempt to use explainable tools to enhance the credibility of rumor detection based on machine learning technology. Reis et al. (2019) proposed a visualization technique based on Gradient-weighted Class Activation Mapping (Grad-CAM) to interpret rumor classification models. Shu et al. (2019) proposed a visualization technique based on attention weights and activation mapping to demonstrate the principle of rumor classification.
This field of study still poses several challenges. First, existing research focuses predominantly on supervised learning algorithms, requiring a substantial amount of labeled data for model training, yet currently, there is not much publicly available data in the rumor domain, making it difficult to obtain datasets for specific fields. Second, most existing studies focus on text features and semantic features, disregarding other features of rumors on social media, such as social network structures, user information, and multimodal information. Finally, most of the existing research focuses on rumor detection in a particular language, rarely considering cross-linguistic and cross-platform issues, lacking multilingual generalization ability. This field of study has room for further in-depth research in data acquisition, feature extraction, and cross-language detection.
cluster#2 Deep Learning
Compared to machine learning, deep learning has stronger feature learning capabilities and more accurate classification results. An increasing number of studies explore rumor detection based on deep learning methods. Such research mainly focuses on using different deep learning models to handle features and classification to realize rumor detection, improving the effectiveness and robustness of rumor detection by utilizing the powerful feature extraction and representation capabilities of deep learning technology. The main characteristics of this type of research include:
(1) Feature extraction based on deep learning models primarily targets content features, propagation features, and user interaction features, comprehensively covering available information to enhance the comprehensiveness of rumor detection. Khoo et al. (2020) used CNN and BiLSTM to extract content features of rumors; Z. Chen et al. (2023) proposed a Topic and Structure Sensitive Neural Network (TSNN) model that uses GNN to extract the propagation structure features of rumors; Ke et al. (2020) extracted content features of rumors through a multimodal approach; T. Ahmad et al. (2022) proposed an augmented deep learning model that uses CNN and LSTM to extract content and social features of rumors.
(2) The datasets cover different themes and contexts, and experiments are carried out based on real-world datasets, validating the effectiveness of deep learning models in dealing with different types of rumor detection. This includes publicly labeled news and comment datasets, such as BuzzFeedNews (Alghamdi et al., 2023), PolitiFact (Alghamdi et al., 2023), CPSS (Q. Zhang et al., 2019), FakeNewsNet (Tao et al., 2023), LIAR (Tao et al., 2023), as well as datasets for specific scenarios, like COVID-19 related rumors (Al-Sarem et al., 2021; S. Kumar et al., 2020; Q. Zhang et al., 2019), specific domain language rumors (Ke et al., 2020; Kishwar & Zafar, 2023), etc.
(3) The model structures mainly consist of neural network models such as Convolutional Neural Networks (Al-Sarem et al., 2021; Kaliyar et al., 2021; Michail et al., 2022), Recurrent Neural Networks (Krešňáková et al., 2019), Graph Neural Networks (Kong et al., 2020; Sahoo & Gupta, 2021; Tesfagergish et al., 2021), Attention Mechanisms (Alghamdi et al., 2023; Q. Zhang et al., 2019), and Bidirectional Long Short-Term Memory Networks (Alghamdi et al., 2023; Q. Zhang et al., 2019). Integrating various neural network models and improving detection performance through parameter optimization has also been a recent research hotspot. Al-Sarem et al. (2021), Alsaeedi and Al-Sarem (2020), and S. Kumar et al. (2020) used a hybrid deep learning model of CNN and LSTM to quickly detect text-based rumors; Ke et al. (2020) and Khoo et al. (2020) combined CNN and BiLSTM to extract rumor features. Some scholars are also exploring special deep learning models and algorithms for rumor detection, such as Capsule Neural Networks (Mohawesh et al., 2023; Palani et al., 2022), Dynamic Routing Algorithms (Mohawesh et al., 2023), etc.
This type of research still presents several challenges. Firstly, deep learning models require a large amount of data as a foundation. In the case of small datasets or lack of labels, it is easy to cause data sparsity and overfitting problems. Some models may rely too much on specific feature representations or training data, and their generalization capabilities may be inadequate when facing different contexts or new types of rumor data. Secondly, deep learning models are often considered “black boxes” and it is challenging to reveal the inherent logic and reasons for rumor detection. Existing research lacks studies on the interpretability of models, which could affect the credibility of rumor detection. Therefore, deep learning models in the field of rumor detection still need further improvements and optimizations to enhance their efficiency, comprehensiveness, robustness, and interpretability.
cluster#3 Natural Language Processing
Natural Language Processing (NLP) constitutes the most vital technical methodology in rumor detection research, playing a pivotal role at every stage of text-based rumor detection. NLP technologies primarily apply to two core steps of text-based rumor detection: feature representation and feature type selection, exhibiting the following characteristics:
(1) In feature representation, current research primarily utilizes NLP technologies to convert text from rumors into numerical vectors for similarity computation. Common feature representation methods can be roughly divided into sparse representation methods and dense representation methods.
① Sparse representation methods are represented by Bag of Words (BOW), Term Frequency-Inverse Document Frequency (TF-IDF), etc. These methods convert text into a high-dimensional sparse vector, reflecting the frequency information of words. Research from Ksieniewicz et al. (2019), I. Ahmad et al. (2020), Hakak et al. (2021), Choudhury and Acharjee (2023), Kishwar and Zafar (2023), and Ahmed and Ahmed (2023) utilized TF-IDF and BOW for text feature representation. Similarly, Reis et al. (2019), Silva et al. (2020), and Y.-F. Huang and Chen (2020) employed BOW as their text feature representation method.
② Dense representation methods, represented by word embedding models and pre-training language models, convert each word or the entire text into a low-dimensional dense vector, reflecting semantic and context information of words. Umer et al. (2020), Alonso et al. (2021), and Ayoub et al. (2021) utilized pre-trained word embedding models, GloVe, as their text feature representation method. Research from T. Zhang et al. (2020), Kaliyar et al. (2020), Alghamdi et al. (2023), and Palani et al. (2022) made use of the pre-trained model BERT for text semantic feature representation.
(2) In feature type selection, current research primarily employs NLP technologies to extract categories of features for rumor detection from rumor text. Commonly seen feature types mainly involve text content, supplemented by text structure, emotion, and theme. Different features can reflect various aspects of rumors, including the semantic information, logical information, emotional information, and topic information of text, thereby enhancing the representation and discriminability of text. Y.-F. Huang and Chen (2020), Cheng et al. (2020), Umer et al. (2020), and Ayoub et al. (2021) considered text content as the primary feature for rumor detection. Elhadad et al. (2020), Silva et al. (2020), Al-Ahmad et al. (2021), and Kar and Aswani (2021) used features such as text content, text structure, emotion, and theme for rumor detection. Alonso et al. (2021) used text content features and emotional features as auxiliary features for rumor detection.
There are still some challenges in this type of research. Firstly, current studies give insufficient consideration to the structure, hierarchy, and hidden features of rumor text, making it difficult to capture deep semantic features. Secondly, in terms of feature type, most researchers commonly use features based on rumor text when identifying rumors, and these text features may be subject to forgery or tampering, causing bias in authenticity. Lastly, most existing studies only focus on the detection of rumors in a single text or topic, but in reality, rumors may involve multiple texts or topics and can change with time and social environment. Therefore, future research needs to consider factors such as multimodality, multi-topic, multi-perspective, and dynamic changes to improve the complexity and practicality of rumor detection.
cluster#4 Multimodal Fusion
In the early stages, rumors were predominantly in text modalities. However, with the rapid development of the Internet, online rumors have gradually shifted from a single text modality to a combined form of multiple modalities such as text, audio, images, and videos. Multimodal rumor detection methodologies utilize information from multiple modalities such as text, audio, visual, user characteristics, and social network information to extract more comprehensive and detailed rumor features, thereby enhancing the accuracy and reliability of rumor detection. Currently, research on multimodal rumor detection mainly focuses on two key issues: the extraction of multimodal rumor features and the fusion of these features, which manifest the following characteristics:
(1) In the extraction of multimodal rumor features, scholars primarily focus on extracting features from text and images.
② For text features, the principal extraction techniques comprise Knowledge Graphs (KG), Graph Convolutional Networks (GCN), Bidirectional Long Short-Term Memory networks (BiLSTM), Transformer models, and pre-trained models (BERT). H. Zhang et al. (2019), Li et al. (2022), and Qian, Hu et al. (2021) employed KG and GCN to extract knowledge information from the text. Yang et al. (2021), J. Wang et al. (2022), Peng and Xintong (2022), and P. Liu et al. (2023) used BiLSTM to extract semantic features from the text. Qian, Wang et al. (2021) applied BERT and self-attention mechanisms to extract semantic information from the text. Ying et al. (2021b), B. Wang et al. (2023), and H. Zhang et al. (2022) employed Transformer models to extract features from the text.
③ Image features are commonly extracted using ResNet to obtain high-level features from images. Q. Zhang et al. (2019), X. Zhou et al. (2020), H. Zhou et al. (2022), and Peng and Xintong (2022) utilized ResNet to extract visual information from images.
(2) In the fusion of multimodal rumor features, current research generally leverages the correlation and complementarity between text and images to improve the accuracy of detection. The fusion techniques adopted can be broadly categorized as follows:
① Feature fusion based on similarity or consistency, achieved by adjusting the weights of different modalities or designing alignment modules to integrate text and image information. For example, Cui et al. (2019) implemented text and image feature fusion through an adaptive multimodal embedding method; Li et al. (2022) utilized a multimodal alignment and fusion network to achieve multimodal fusion.
② Feature fusion based on inconsistency or authenticity, where the inconsistency or authenticity between modalities is treated as an additional feature for cross-modal fusion. P. Liu et al. (2023) integrated text feature vectors, image feature vectors, and inconsistency feature vectors into a comprehensive multimodal feature vector. P. Wei et al. (2022) utilized event extraction technology and adversarial learning technology to enhance the event representation capacity of text and eliminate inconsistency between text and images. Xiong et al. (2023) enhanced contrast capacity via two rounds of inconsistency judgment.
③ Techniques like attention mechanisms, knowledge distillation, knowledge perception, loss functions, etc., are used to enhance the interaction and integration between text and image features. For instance, Lv et al. (2023) and B. Wang et al. (2023) used the Multi-Head Attention Mechanism for multimodal fusion between text and images. Qian, Wang et al. (2021) employed a hierarchical multimodal context attention mechanism to achieve context-related fusion of text and images. Z. Wei et al. (2022) used a Cross-media Knowledge Distillation Loss Function (CMKDL) to optimize multimedia feature fusion. H. Zhang et al. (2019) utilized an Event Memory Mechanism (EMM) for event-related fusion between text and images. Madhusudhan et al. (2020) and Ying et al. (2021a) guided the connection between text and image features using attribute information, topic information, and other knowledge information. Ying et al. (2021b) and J. Wang et al. (2022) optimized feature fusion using loss functions.
Such research is still in its nascent stage and faces several challenges. Firstly, existing studies’ multimodal feature representation relies heavily on specific rumor features in datasets. Although some researchers have attempted to enhance the generalization capability of features using techniques like Knowledge Graphs (Cui et al., 2019), adversarial learning (H. Y. Lu et al., 2021), and transfer learning (Lv et al., 2023), they still struggle to adaptively handle new categories of rumors, necessitating further in-depth research. Secondly, most current studies fix the multimodal features of rumors to the extraction and fusion of knowledge information features from texts and images, rarely leveraging other information in social networks to assist in rumor detection, such as text style, sentiment orientation, and social context features. This omission may affect the accuracy of detection, and future studies should consider combining external features to improve the effectiveness of rumor detection.
cluster#5 Trust Networks
The task of rumor detection is complex and dynamic, encompassing a multitude of techniques and information sources. In the current era rampant with black-box neural network algorithms, an increasing number of scholars are turning their attention toward making rumor detection more reliable, interpretable, and transparent. They aim for both the process and the results of rumor detection to be understandable and trustworthy. The characteristics of rumor detection research based on trust networks are as follows:
(1) The study of users’ trust levels in the authenticity of information. This involves analyzing the factors that cause cognitive biases in users’ perception of the authenticity of internet information, such as news and comments. These factors, including cultural background, political leanings, media sources, and information literacy, can lead users to varying levels of trust or cognitive preferences concerning the authenticity of information. Studies by Babaei et al. (2022), Aswani et al. (2019), and Altay et al. (2023) found that political orientation, media source, and social influence are factors affecting users’ perception of information authenticity. Aoun Barakat et al. (2021) found through surveys that education level and media literacy affect users’ ability to identify rumors. Chan (2022) discovered through comparative experiments that exposure to false information does not significantly affect users’ ability to recognize such information. Dabbous et al. (2022) found through surveys that cultural background is an important factor affecting users’ fake news detection and trust. Snijders et al. (2023) found through comparative experiments that confidence levels significantly affect users’ trust in the authenticity of information.
(2) Research on the credibility and interpretability of detection results, which mainly includes three categories:
① Using facts and logic in the knowledge base for rumor judgment, or using trust information, social information, emotional information, and other metadata in social networks not directly included in text knowledge as features for detection. Pathak and Srihari (2019) constructed a news corpus, containing true and false news articles from different topics and sources, as well as related facts that support or refute the news, for guiding the training and evaluation of various detection methods. Voloch et al. (2021) proposed a safety model based on context trust, using users’ trust relationships and their evaluations of information content to calculate the credibility of information, and filtering rumors based on a credibility threshold. Voloch et al. (2022) employed trust relationships among users to enhance the performance of rumor classifiers. Works by Paschalides et al. (2019), Bagade et al. (2020), Bukhari et al. (2021), and Fischer et al. (2022) used sentiment analysis, social media user behavior, author information, source websites, publication time, and other data as features to train rumor detection models.
② Providing evidence of the explainability of rumor detection results through auxiliary functions, including visualization interfaces, summary generation, user feedback, and information sources. Paschalides et al. (2019), Bagade et al. (2020), and Voloch et al. (2022) built rumor detection systems that provide a visualization interface showing the truthfulness scores of network news and related evidence. Khan et al. (2021) and Miró-Llinares and Aguerri (2023) suggested establishing fact-checking agencies and enacting laws and regulations to prevent the spread of rumors. Mukherjee et al. (2022) built a neural network model using text content, metadata, and user feedback features, which can not only detect and classify rumor information, but also generate credible summaries from the information. Paschalides et al. (2019) developed the Check-it rumor identification system plugin, which provides functionalities such as news source ratings and user feedback assistance.
③ Improving the explainability and transparency of rumor detection using explainability technologies, including blockchain, knowledge graphs, and graph neural networks. Xiao et al. (2020) used blockchain technology, transparency, traceability, and anti-tampering features to propose a fast fake news detection method based on edge computing and blockchain technology to verify the authenticity of news. Zhao et al. (2021) built a dynamic knowledge graph model that objectively displays entities and their relationships, combined with a graph neural network classifier to implement anomaly information detection. J. Xu et al. (2022) used knowledge graph technology to obtain related information from multiple data sources and evaluated the consistency of the information using an energy flow algorithm.
Currently, research has shifted from focusing on the fundamental theory of the trustworthiness and explainability of rumor detection to focusing on the application of rumor detection explainability technology, providing a practical basis for rumor detection. However, there are still challenges. Explainability and accuracy are two important goals in rumor detection, but there is a certain contradiction and conflict between them. Improving the accuracy of rumor detection often requires complex models and multiple information sources, which, in turn, may reduce the explainability of the detection. In existing studies, scholars often overlook the issue of how to balance the explainability and accuracy of rumor detection, which is a challenging problem for future research.
Analysis of Research Trends
Analysis of Keyword Time Graph
The keyword time graph is developed on the basis of a keyword clustering graph with time as an added parameter. On the time graph, keywords are displayed within their corresponding clusters according to the year they first appeared. This visualization provides insights into the core status and development of keywords within clusters. By utilizing keyword time graph, we can better understand how primary keywords within research clusters evolve over time. This includes keyword timezone graph and keyword timeline graph. CiteSpace is used to create keyword time zone graph (Figure 7) and keyword timeline graph (Figure 8), providing a visual analysis of the evolution and development of keywords related to rumor detection from 2017 to 2023.
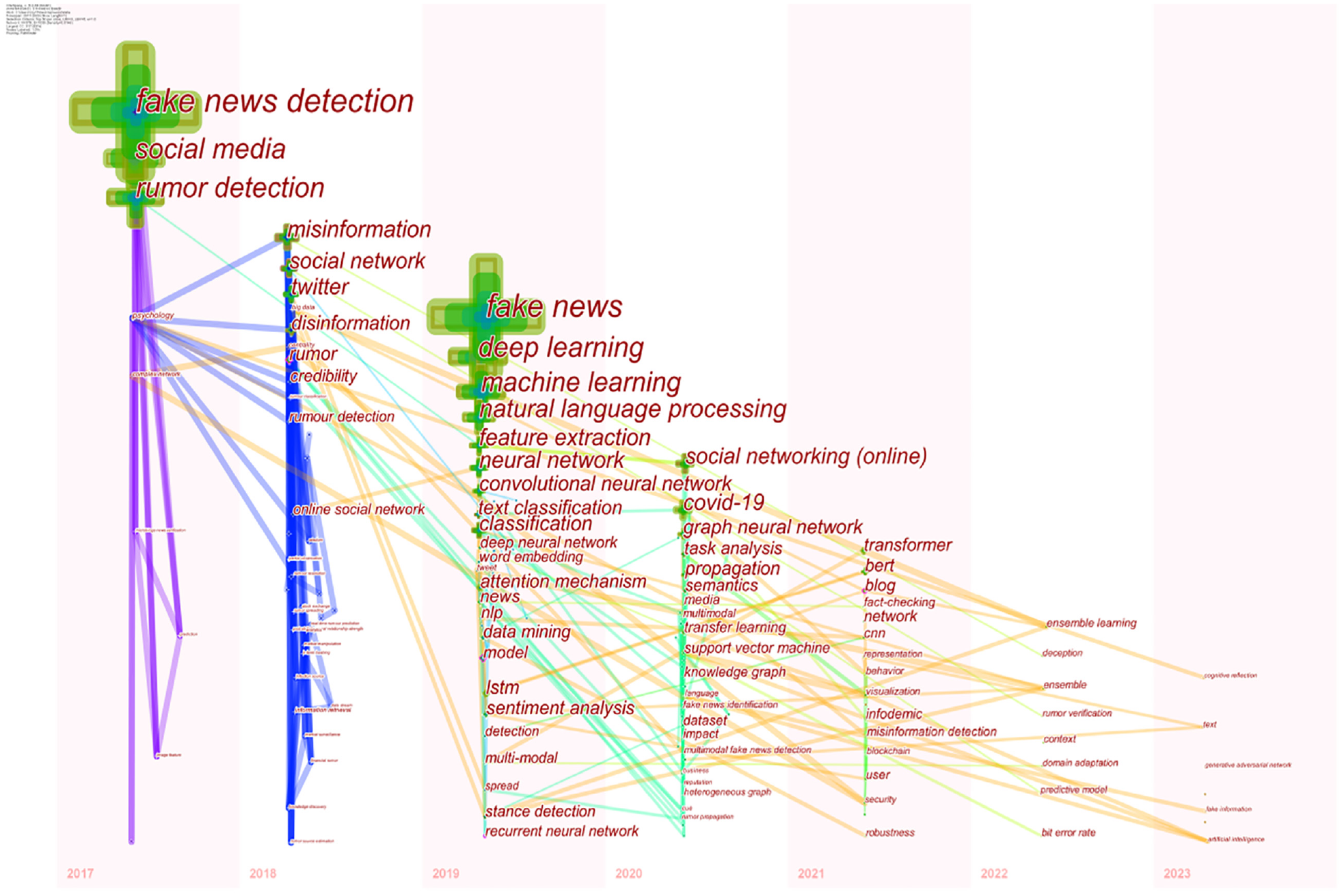
Keyword timezone graph in the field of rumor identification.

Keyword timeline graph in the field of rumor identification.
Most keywords in Figures 7 and 8 are distributed between 2017 and 2021, with critical nodes being social media, fake news detection, rumor detection, feature extraction, machine learning, natural language processing, deep learning, and neural networks. The dense distribution of keywords indicates that most of the themes under study are centered around exploring rumor detection in social media. In the timeline graph for 2022 to 2023, fewer keywords appeared for the first time. High-frequency keywords for this period include multi-task learning, ensemble learning, explainable artificial intelligence, rumor verification, multimodal learning, evaluation metrics, etc., showing a research trend toward multimodal learning and explainable artificial intelligence.
Analysis of Keyword Bursts
Burst terms refer to keywords that have a sudden and substantial increase in co-occurrence frequency within different time periods. They represent keywords in the selected articles data that have significant short-term frequency changes. The stronger the burst, the more academic attention it received within a certain period. These can be used to identify the frontier research directions, hotspots, and predict future research trends in the field. The CiteSpace software is used, on the basis of a keyword co-occurrence graph, to select Burstness from the control panel, set the parameters, and refresh to generate a keyword bursts table (Table 3).
Top 18 Keywords With the Strongest Citation Bursts.

According to Table 3, the articles in the field of rumor detection research from 2017 to 2023, after detecting keyword bursts, generated 18 burst terms, representing the frontier research at different times in the field of rumor detection. In the future research field, keywords with high burst strength such as rumor detection, deep neural networks, users, logistic regression, trust, graph convolutional network, multimodal fusion, fake news classification, etc., can predict that rumor detection will carry out frontier research in technologies such as multimodal fusion and trust networks.
This paper counts the number of publications in five major research hotspot technology fields, predicts the number of publications in 2023 based on historical data and the number of publications before May 2023, and draws a line chart of the number of publications over time (Figure 9). By observing the slope change of the line chart, the line chart is accurately mapped to certain stages of the S-curve, and the technical characteristics of the current stage of the hotspot technology are compared with the characteristics of each stage of the life cycle, and the life cycle of the hotspot technology is comprehensively judged. In addition, based on the “S-curve technology evolution theory,” this paper reviews the evolution path of rumor detection technology by combining the keyword timeline graph (Figure 8) and the keyword bursts table (Table 3), and predicts the future development trend of hotspot technology.

Trend of publication volume in five major hot technology fields.
cluster#1 Machine Learning
After searching for the seven keywords in the cluster#1 Machine Learning cluster, a total of 73 documents related to this hotspot technology were found in the articles set. Among them, papers using machine learning technology for rumor detection research began to appear in 2019, the number of papers began to increase rapidly in 2021, and it is expected that the number of papers will reach 27 in 2023, which is consistent with the 27 papers in 2022, the slope of the number of papers has dropped to 0, and the line chart is fitted and mapped to the initial stage, transition stage, modularization stage, and decline stage of the S-curve. This field is relatively mature and saturated, and technical research is mainly focused on improving classification models such as support vector machines, logistic regression, random forests, etc., and there is a lack of disruptive technical innovation research, which is in line with the technical characteristics of the decline stage of the S-curve. Considering the growth trend of the number of papers in this field and the technical characteristics, this paper believes that rumor detection technology based on machine learning has entered the old age and belongs to the decline stage of the technology life cycle.
cluster#2 Deep Learning
After searching for the 13 keywords in the cluster#2 Deep Learning cluster, a total of 252 papers related to this hotspot technology were found in the articles set. Among them, papers using deep learning technology for rumor detection research began to appear in 2019, the number of papers began to increase rapidly in 2021, and it is expected that the number of papers will reach 75 in 2023, which is a decrease compared to the 90 papers in 2022, and the slope of the number of papers is gradually leveling off, and the line chart is fitted and mapped to the initial stage, transition stage, and modularization stage of the S-curve. This field has appeared technical subdivisions based on models such as convolutional neural networks, deep neural networks, recursive neural networks, etc., and the research of various models is basically mature, showing fully modularized characteristics, which are in line with the technical characteristics of the modularization stage of the S-curve. Considering the growth trend of the number of papers in this field and the technical characteristics, this paper believes that rumor detection technology based on deep learning is relatively mature and belongs to the modularization stage of the technology life cycle.
cluster#3 Natural Language Processing
After searching for the nine keywords in the cluster#3 Natural Language Processing cluster, we found a total of 214 papers related to this hotspot technology in the articles set. Among them, papers utilizing Natural Language Processing (NLP) technology for rumor detection research began to appear in 2018, with the number of papers beginning to grow rapidly in 2021. It is expected that the number of papers will reach 56 in 2023, a decrease compared to the 66 papers in 2022. The slope of the number of papers is gradually leveling off, mapping to the initial stage, transition stage, and modularization stage of the S-curve. After conducting in-depth research into the specific applications of NLP technology in the field of rumor detection, we found this field already has subdivisions such as text classification, sentiment analysis, data mining, etc. The research of various models is basically mature, presenting fully modular characteristics, which correspond with the technical characteristics of the modularization stage of the S-curve. Considering the growth trend of the number of papers in this field and the technical characteristics, we believe that rumor detection technology based on NLP is relatively mature, belonging to the modularization stage of the technology life cycle.
cluster#4 Multimodal Fusion
After searching for the four keywords in the cluster#4 Multimodal Fusion cluster, we found a total of 40 papers related to this hotspot technology in the articles set. Among them, papers using multimodal fusion methods for rumor detection research began to appear in 2019. The number of papers began to grow rapidly in 2021, and it is expected that the number of papers will reach 20 in 2023, an increase compared to the 13 papers in 2022. The slope of the number of papers is gradually rising, mapping to the initial and transition stages of the S-curve. After conducting in-depth research into the specific applications of multimodal fusion technology in the field of rumor detection, we found this field already has subdivisions such as feature fusion, model fusion, reinforcement learning fusion, etc., but all types of model technologies are still improving and developing, which aligns with the technical characteristics of the transition stage of the S-curve. Considering the growth trend of the number of papers in this field and the technical characteristics, we believe that rumor detection technology based on multimodal fusion is still in high-speed development, belonging to the transition stage of the life cycle.
cluster#5 Trust Network
After searching for the three keywords in the cluster#5 Trust Network cluster, we found a total of 26 papers related to this hotspot technology in the articles set. Among them, papers using trust network methods for rumor detection research began to appear in 2019. The number of papers surged in 2021 but has since remained relatively low. It is expected that the number of papers will reach 5 in 2023, consistent with the five papers in 2022. The slope of the number of papers has remained flat, mapping to the initial stage of the S-curve. We found that research papers in this field exhibit characteristics of low quantity, low level of innovation, and a trend toward homogeneity. The technology design is highly integrated, lacking modular features, which aligns with the technical characteristics of the initial stage of the S-curve. Considering the growth trend of the number of papers in this field and the technical characteristics, we believe that rumor detection technology based on trust networks is just budding, belonging to the initial stage of the life cycle.
This paper applied the “S-curve technology evolution theory” to judge the life cycle of rumor detection hotspot technologies, determining the life cycle stages of the five major research hotspot technologies. Among them, cluster#1 Machine Learning is at the decline stage, cluster#2 Deep Learning and cluster#3 Natural Language Processing are at the modularization stage, cluster#4 Multimodal Fusion is at the transition stage, and cluster#5 Trust Network is at the initial stage. The keyword timeline graph (Figure 8) displays the distribution of hotspot keywords from 2017 to 2023. The keyword bursts table (Table 3) shows the keywords whose frequency significantly increased during 2017 to 2023, illustrating the research hotspots in the deep learning field in recent years are focused on Deep Neural Networks and Graph Convolutional Network; The emerging direction of research hotspots in the field of trust network has gradually shifted from Knowledge Graphs to trust and explainability-centric Trusted Network research.
This paper has determined the life cycles of five major research hotspots by applying the “S-curve technology evolution theory” to the life cycle determination of rumor detection hot technologies. Specifically, cluster#1 Machine Learning is in the decline phase, cluster#2 Deep Learning and cluster#3 Natural Language Processing are in the modularization phase, cluster#4 Multimodal Fusion is in the transition phase, and cluster#5 Trust Network is in the initial phase. The timeline of keywords (Figure 8) shows the distribution of hot keywords from 2017 to 2023. Among them, cluster#1 Machine Learning (Feature Extraction, Representation Learning) as a relatively traditional technique, has been widely applied in the field of rumor detection since 2018. Representation Learning is an early research direction in this field, and Feature Extraction is a significant hotspot in the field of machine learning feature engineering. cluster#2 Deep Learning (Novelty Prediction, Attention Mechanism, Transfer Learning) started early and developed rapidly. The keywords of Deep Learning and Transfer Learning appeared before 2017, and the Attention Mechanism became a research hotspot in this field in 2019. Novelty Prediction is an emerging technology in recent 2 years. cluster#3 Natural Language Processing (Text Mining, Text Classification, Partial Observation), as the fundamental technological basis for rumor detection, has always maintained a high research heat. Partial Observation appeared before 2017, while Text Mining and Text Classification are the research hotspots in this field in recent 3 years. The table of emerging keywords (Table 3) shows the keyword themes with significantly increased frequencies during 2017 to 2023. Deep Neural Networks and Graph Convolutional Network emerged in 2021 and maintain high emergent heat in recent years, indicating that the research hotspots in the field of deep learning in recent years are concentrated on deep neural networks and graph convolutional networks. Logistic Regression, as an important model of machine learning, showed a high level of emergence from 2021 to 2023, indicating that the research hotspot in this field in recent years mainly focuses on the improvement and innovation of logistic regression model. The emergence of Multimodal Fusion was concentrated from 2021 to 2023, indicating that multimodal fusion is an emerging research hotspot in recent 2 years. The emergence of Knowledge Graph was concentrated from 2020 to 2021, and that of Trust was from 2021 to 2023, indicating that the research hotspot in the field of Trust Network has gradually shifted from knowledge graph to trust and explainable network research centered on trust and explainability.
Discussion
This article searched the Web of Science database using “rumor detection” as the primary theme and retrieved a total of 983 papers published from 2017 to 2023 relevant to the field of rumor detection. We adopted bibliometric analysis and the S-curve technology evolution theory to utilize this data as research samples for descriptive statistical analysis, hotspot analysis, and evaluation of hotspot technology life cycles and research trends.
The paper primarily unfolds in the following three areas: Descriptive statistical analysis: Statistical analysis of the quantity of papers, publication regions, co-authors, cooperative institutions, etc., to reflect the research activity and degree of collaboration in the rumor detection field. Research hotspot analysis: Utilizing co-occurrence of keywords and cluster analysis to reveal the research themes, hotspot issues, and knowledge structure in the rumor detection field. Hotspot technology life cycle and research trend analysis: Applying the S-curve technology evolution model combined with keyword timeline graph and burst table, we evaluated the technical maturity and potential of various technological methods in the field of rumor detection, predicting possible future research directions.
From the results of the descriptive statistical analysis, it can be seen that research in the field of rumor detection is on the rise, with more and more scholars beginning to pay attention to this field. Specifically, in terms of the number of papers: China, the United States, and India are the three countries with the most papers published, with China publishing 283 papers, accounting for 28.8% of the total. In terms of cooperation: Both author collaboration and institutional collaboration mainly concentrated after 2020. In China, authors and institutions have a certain degree of cooperation and high output of results. However, as a whole, neither author cooperation nor institutional cooperation has formed a tightly knit cooperation network.
From the analysis of research hotspots, it can be seen that the research themes and hot issues in the field of rumor detection have been continuously changing and developing over time. Specifically, in terms of research themes, this study has categorized 983 papers into five theme categories based on keyword clustering analysis. These categories are rumor detection based on machine learning, rumor detection based on deep learning, rumor detection based on natural language processing, rumor detection based on multimodal approaches, and rumor detection based on trust networks. These theme categories reflect the core technical methods in the field of rumor detection. As for hotspot issues and research challenges, this study has identified some hotspot issues in each theme category based on keyword frequency and burst strength, and analyzed their existing challenges. Specifically: (1) In rumor detection based on machine learning, current research mainly extracts text features and semantic features of rumors, and uses ensemble algorithm classifiers to classify rumors. Challenges lie ahead in data acquisition, feature extraction, and cross-language recognition. (2) In rumor detection based on deep learning, current research is based on real Internet data, using multiple features such as rumor content, rumor dissemination, and user interaction, and utilizes single deep learning models or multiple deep learning models to implement rumor detection. Some challenges still exist in the acquisition of datasets and the interpretability of models. (3) In rumor detection based on natural language processing, existing research mainly utilizes natural language processing techniques to achieve sparse and dense representations of rumor texts and extracts features such as text content, text structure, sentiment, and topics for rumor detection. There are challenges in capturing deep semantic features and extracting dynamic features. (4) In rumor detection based on multimodal approaches, current research primarily focuses on extracting and integrating rumor text features and image features. There are challenges in improving feature generalization capabilities and incorporating external features. (5) In rumor detection based on trust networks, current research mainly focuses on user trustworthiness of information authenticity and on the trustworthiness and interpretability of rumor detection results. There are challenges in balancing the interpretability and accuracy of rumor detection.
From the results of the hotspot technology life cycle and research trend analysis, it can be seen that various technological methods in the field of rumor detection are at different stages of technical maturity and have different development potentials. Specifically, in terms of development stages: this paper divided the technical methods mentioned in the articles into four maturity stages according to the S-curve model: the initial stage, the transition stage, the modularization stage, and the decline stage. Among them, in the field of rumor detection, machine learning technology has reached saturation and belongs to the decline stage of the life cycle; deep learning technology and natural language processing technology are relatively mature and belong to the modularization stage of the life cycle; multimodal fusion technology is still in rapid development, belonging to the transition stage of the life cycle; trust network technology is just emerging, belonging to the initial stage of the life cycle. In terms of development potential: this paper evaluated the possible influence and prospects of the technical methods mentioned in the articles in the future based on the emerging intensity index. Among them, the technical methods that may have high development potential in the future include multimodal fusion and trust networks. These technical methods can extract richer and more effective rumor feature information, enhance the effect and credibility of rumor detection; deep learning technology will enter a slow development stage and needs to be optimized in terms of interpretability and credibility; while machine learning technology has a lower development potential and needs to be combined or innovated with other technical methods.
Conclusion
Research Findings
The annual number of publications on rumor detection is showing a linear increase, with China leading the charge with 283 articles, but no tight global collaboration network has formed among authors and institutions. The research field sprouted in 2017, and has undergone a transition from single machine learning algorithms to ensemble algorithm classifiers based on machine learning technology. In deep learning technology, Graph Convolutional Networks have become a new research hotspot. By 2019, research based on natural language processing technology held a high research heat in text classification and text mining. Post 2021, research based on machine learning technology has saturated, and the growth rate of research based on deep learning and natural language processing technologies has gradually slowed down. Multimodal fusion has become an emerging technology in this field, transitioning from a single text modality to a combination of text, audio, image, video, and other multimodal forms. The research heat of this technology is increasing year by year and it has great future potential. Trust networks, also emerging technologies, focus on the credibility, explainability, and transparency of rumor detection. Although their current research heat is not high, they have great potential for future development.
Theoretical Contributions
This paper is the first to propose the integration of bibliometrics and S-curve technology evolution theory to reveal the state of related technologies and research frontiers. Specifically, the paper uses the author cooperation network and institutional cooperation network to analyze the cooperation relationships of authors and institutions, identifying core research groups in the field of rumor detection; reveals theme associations and cluster structures between keywords based on high-frequency keyword clustering graph and keyword co-occurrence graph, parsing out research hotspots in the field of rumor detection; and combines keyword timeline graph, keyword bursts table, and trend graphs of articles volumes in hotspot technology fields with the S-curve technology evolution theory to analyze the life cycle and research trends of technologies in the field of rumor detection.
Limitations and Outlook
The paper aims to help researchers predict the future direction and development space of the rumor detection research field, as well as the development potential of possible emerging themes and hotspot technologies, providing reference and guidance for subsequent researchers.
(1) There are still limitations and deficiencies in the research:
Firstly, in terms of analysis methods, this paper mainly uses bibliometrics and the S-curve technology evolution theory to analyze and predict the research hotspots and challenges, technology life cycles, and research trends in the field of rumor detection from a macro and quantitative perspective, without providing detailed solutions to specific technical problems in this research field.
Secondly, in terms of data selection, this paper only selects 983 articles data from the Web of Science database, ignoring other databases that may contain relevant research data.
(2) Future improvements could include:
Firstly, in terms of analysis methods, future research can consider using empirical analysis and experimental analysis methods from a micro perspective to provide solutions to major granular technical problems, and evaluate and verify their feasibility and effectiveness on standard datasets, improving the practicality and specificity of the analysis results.
Secondly, in terms of data selection, attempts can be made to add more sources and types of research data, such as journal articles, conference papers, invention patents, research reports in databases like CNKI, ACM, Scopus, Google Scholar, etc., broadening and diversifying data selection, and improving the comprehensiveness and accuracy of the analysis results.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was financially supported by the Major S&T project (Innovation 2030) of China (2021ZD0113702),Xi’an Major Scientific and Technological Achievements Transformation and Industrialization Project (20KYPT0003-10).
An Ethics Statement
The study did not address ethical issues.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.