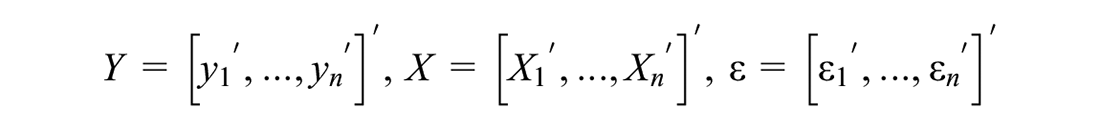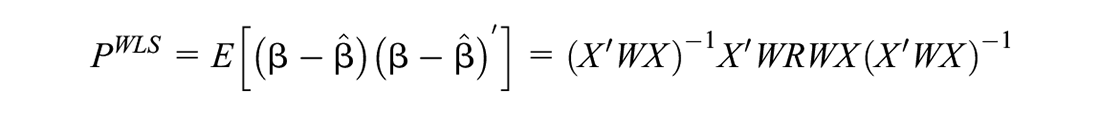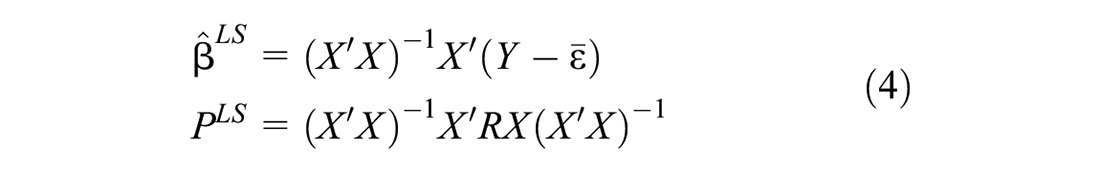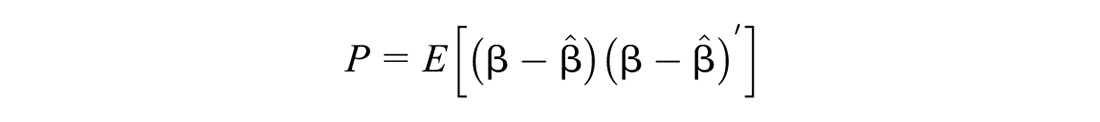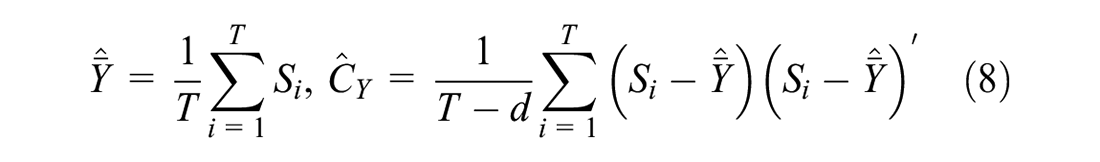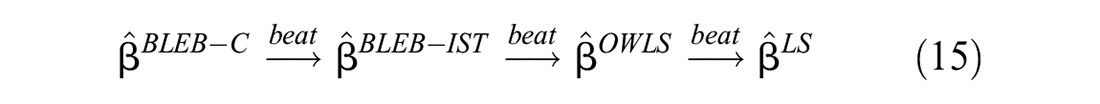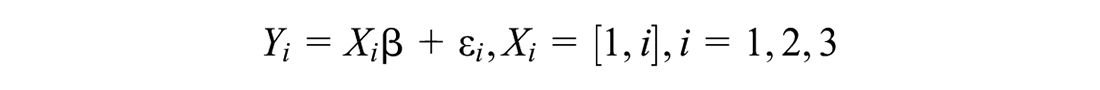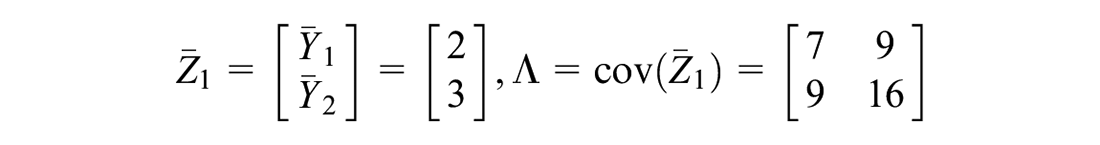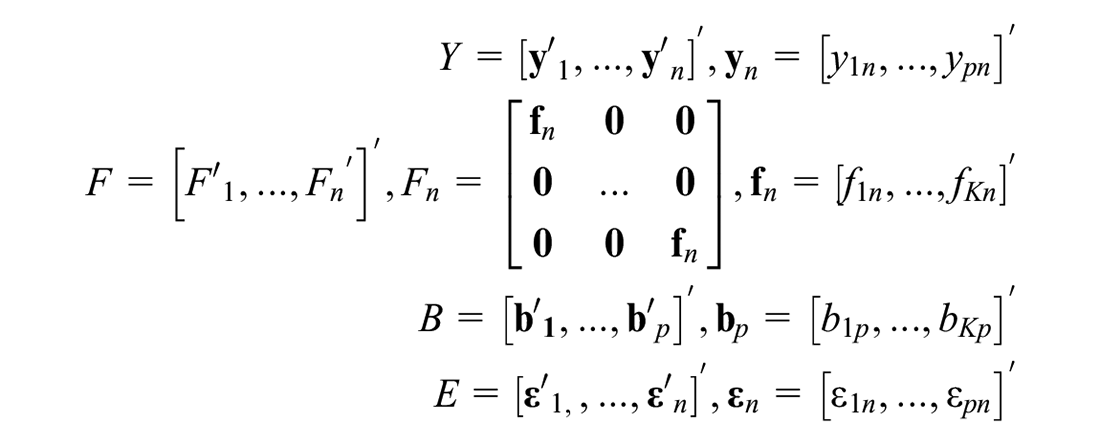Covariance matrix estimation plays a significant role in both in the theory and practice of portfolio analysis and risk management. This paper deals with the available data prior to developing a factor model to enhance covariance matrix estimation. Our work has two main outcomes. First, for a general linear model with unknown prior parameters, a class of best linear empirical Bayes estimators is established through two kinds of architectures to improve the estimation accuracy by utilizing additional data prior. The theoretical results indicate two key points: the proposed estimators are equivalent to the linear minimum mean-square error estimator when complete or sufficient partial data prior are provided; and the proposed estimators perform better than the optimal weighted least squares method, which ignores the data prior in each situation. Second, the proposed estimators are used for calculating a high-dimensional covariance matrix through factor models. The numerical example and the simulation results verify the effectiveness of our methods.
Estimation is a problem concerning how to make the best of the information contained in data for the purpose of inferring an unknown quantity. This information includes the prior information and the observable sample data. The two most popular philosophies for estimation are:
Classical: the parameter is viewed as an unknown constant (not random) and thus it does not have a (prior, posterior, or marginal) distribution.
Bayesian: the parameter is regarded as a random variable with a known prior distribution.
The debate between the two schools has been on-going for many decades. Some of the major criticisms leveled are (Robbins, 1983):
The classical philosophy ignores the existence of any prior information, which makes the inference rely entirely on the sample observation data. This could represent a significant waste of information.
The Bayesian philosophy forces people to select a prior distribution subjectively and/or arbitrarily and thus the correctness/appropriateness of the inference results is questionable.
The empirical Bayes methodology is a compromise between these two approaches. It assumes that the parameter is a random variable but with an unknown distribution which can be estimated from sample data. In economics, management, and many other disciplines, it is usually difficult for us to obtain any prior knowledge about the parameter, so we usually adopt a classical estimation theory to estimate the parameter, such as the least squares (LS) method. Although it is difficult to obtain prior knowledge of a parameter, we can generally estimate relatively reliable prior knowledge about the data from the sample observation data. Therefore, the empirical Bayes method can be used to deal with this kind of problem. Table 1 contrasts the classical, Bayesian, and empirical Bayes philosophies.
Comparison of Different Estimation Philosophies.
Classical
Bayesian
Empirical Bayes
Parameter
Unknown constant
Random variable
Parameter prior distribution
Does not exist
Known
Exist but unknown
Sample data prior distribution
Known
Known
Known (could be estimated from sample data)
Likelihood (model)
Known
Known
Posterior distribution
Does not exist
Known
This paper is motivated by the work of X. R. Li et al. (2003) which established and improved the weighted least squares (WLS) estimation, the best linear unbiased estimation (BLUE), and their generalized versions with complete, partial, or no prior knowledge of the parameter. In this work, we consider the widely used linear data model with unknown prior knowledge of the parameter and develop a class of best linear empirical Bayesian (BLEB) estimation methods when the data prior is assumed to be complete or incomplete, identified by two kinds of estimation architectures in explicit forms. The proposed method is essentially a type of Bayesian method that can improve the estimation performance since prior information regarding the data is considered, while this information is ignored in the classical estimation theory.
Covariance matrix estimation plays a significant role both in the theory and practice of portfolio analysis and risk management (De Jong, 2018; Ismail & Pham, 2019; Ledoit & Wolf, 2022; Menchero & Ji, 2021; Wang et al., 2021; Xin & Zhao, 2022). The famous mean-variance portfolio optimization theory of Markowitz (1952) indicates that we can create an optimal portfolio if the expected returns, the variance and the covariance of every asset can be estimated accurately. Therefore, we need an effective and accurate covariance matrix estimation method (Clifford & Feng, 2018; Lan et al., 2018; Wang & Xia, 2021). The importance of covariance matrix estimation has led to the emergence of a large number of estimation methods for covariance matrices in the existing literature (Agrawal et al., 2022; Dong & Tse, 2020; Fan & Mincheva, 2011; Harris & Yilmaz, 2010; Jiang et al., 2023; Ledoit & Wolf, 2003; Stein, 1977; Sun & Xu, 2022; Vassallo et al., 2021). However, high-dimensional covariance matrix estimation is challenging in nature and has been widely studied in recent years (Moura et al., 2020; So et al., 2022; Zhu et al., 2021). Moreover, dimensionality disaster is the main problem in high-dimensional covariance matrix estimation. For instance, in optimal portfolio allocation and portfolio risk assessment, the number of stocks, , is usually of the same order as the sample size, , which is in the order of hundreds or thousands. In particular, when , there are more than 10,000 unknown parameters in the covariance matrix to be inferred. However, we may only have roughly by using weekly data for the past five years. Therefore, in this case, it is almost impossible to forecast the covariance matrix accurately without using any structure (Fan, 2005).
Multi-factor models have been commonly used theoretically and empirically in economics, finance and management. The well-known arbitrage pricing theory (APT) proposed by Ross (1976, 1977) shows that the excessive return of assets has a certain relationship with specific factors through a special linear model. In this context, multi-factor models have been widely used and studied, (Aguilar & West, 2000; Alfelt et al., 2022; Bai, 2003; Chamberlain, 1983; Engle & Watson, 1981; Fan et al., 2008). Thanks to these multi-factor models, if several factors can capture the cross-sectional risks completely, the number of parameters to be estimated in the covariance matrix can be reduced significantly (De Nard et al., 2021; X. L. Li et al., 2022). For instance, taking a three-factor model as an example, there are only instead of unknown parameters (Fan et al., 2008).
Moreover, when estimating a high-dimensional covariance matrix with a multi-factor model, the most critical aspect is the estimation of factor loadings or factor returns. When all or part of the prior information for the parameter is known, we can use the linear minimum mean-square error (LMMSE) estimation proposed by X. R. Li et al. (2003) to obtain the optimal linear unbiased estimator for the parameter, while prior information for factor loadings or factor returns is rarely impossible to obtain, and thus the classical LS estimator is commonly used for estimation. However, although it is difficult for us to obtain prior information for the parameter, prior information for asset returns can usually be summarized roughly from historical data or experience, so an estimation method that does not consider any prior information wastes a lot of prior information contained in sample data.
Generally speaking, the more abundant the prior information is, the higher the estimation accuracy will be. Therefore, in order to make full use of the available information, we first use the BLEB estimator proposed in this paper to estimate the factor loadings or factor returns, and then calculate the high-dimensional covariance matrix through the factor models.
Linear Estimation With a Linear Data Model
Linear estimation is extremely popular mainly due to its simplicity. There have been many theoretical achievements in linear estimation. Invented by Gauss in 1795, the LS approach is the oldest and one of the simplest methods for classical estimation philosophies. The WLS method treats the parameter as an unknown constant and makes inferences relying only on the sample observation data. Another famous linear estimation method, developed and perfected by X. R. Li et al. (2003), is the LMMSE estimator. LMMSE is a Bayesian method that views the parameter as a random variable and performs the estimation by combining the prior information for the parameter and the current sample observation data. These two well-known estimators are simple but powerful. Next, we will briefly introduce the linear data model, the WLS estimator, and the LMMSE estimator, which will be used and compared in the next Section.
Linear Data Model
Consider the linear data model:
where vector is the sample data, is a matrix that is not a function of parameters vector and is the error, or more compactly
with
The error has a mean and its covariance matrix is given as . In general, is given as a nonsingular diagonal matrix and is a full column rank matrix.
The linear WLS estimator of an unknown but nonrandom vector using sample data is the estimator that minimizes the quadratic fitting error:
where the weighting matrix is symmetric.
Minimizing gives the linear WLS estimator:
with the estimation error covariance matrix:
is minimized by choosing the optimal weighting matrix , and:
where the optimal WLS estimator (OWLS) is:
It can be seen that the linear WLS estimator is always unbiased and the OWLS estimator in fact minimizes the error covariance matrix of all linear unbiased estimators using linear data model (2) for a non-random parameter. In particular, when we choose the weighted matrix , we can obtain the classical LS estimator
Linear Minimum Mean-Square Error Estimator (LMMSE; Bayesian Philosophy)
The LMMSE estimator is a linear Bayesian estimator of a random vector with additional prior information:
Under the linear data model (2), we have:
It can be seen that the error and the parameter are usually uncorrelated (i.e.,) in many practical problem; thus:
The LMMSE estimator is the one that is linear (actually affine) in the data and minimizes the following mean-square error (MSE) matrix:
Minimizing gives the LMMSE estimator:
The above results are valid if is replaced with the Moore–Penrose inverse when the inverse of is singular.
The above LMMSE estimator is unbiased and is the best linear estimator for with known prior information (and thus a BLUE).
It can be seen that the OWLS estimator in Section 2.2 is also called a BLUE, with the assumption that is a non-random constant vector without the concept of prior information. When we view the parameter as a random vector with known prior information, the BLUE of the linear data model (2) is the LMMSE estimator .
As previously stated, in many research fields, such as the multi-factor model, we are seriously short of direct prior knowledge of the parameter, so LMMSE estimation with complete prior information cannot be directly used. Considering that the prior of the sample data is important for the final estimation accuracy, we will study the specific form of the linear empirical Bayes estimator under the general linear data model (2) in Section 3.
Best Linear Empirical Bayes Estimators (BLEB) With a Linear Data Model
Assumptions
For linear estimation, prior knowledge, in general, refers only to the knowledge of the first two moments of random vectors as mentioned in Section 2. In the Bayesian framework, all of these eight moments are existing and known. In the classical non-Bayesian philosophy, however, the parameter is an unknown constant vector, thus the prior does not exist. Since the error is also viewed as a random vector in the classical school, exists under the linear data model (2) with .
As stated before, the empirical Bayes method holds that exists but is unknown, which can be estimated from the known true data prior or the approximate data prior that can be inferred from the sample observation data.
Now considering the linear data model (2), we define the best linear empirical Bayes (BLEB) estimators as linear (actually affine) in the data and minimize the MSE matrix with two different kinds of assumptions:
A. Complete data prior means all elements in , and are known;
B. Partial data prior means some but not all elements in , and are known.
BLEB Estimators With Complete Data Prior
We develop two architectures to deal with this problem from different perspectives.
Express the Prior for the Parameter Explicitly
For convenience, we say that a BLEB estimator is has complete data prior if both the prior mean and the covariance of the sample data (as well as its correlation with the error ) are known, because the only prior knowledge of the sample data used by a BLEB estimator is its first two moments. Using the data model (2), the BLEB estimator with complete data prior can always be inferred by the first two moments of and . In other words, we can express the unknown in terms of the known complete data prior . The following theorem presents the BLEB estimator in the case of complete data prior for data model (2).
Theorem 1 (BLEB estimator with complete data prior). Using data model (2), the BLEB estimator with complete data prior , , and is:
where the superscript + stands for the Moore–Penrose inverse, and for a full column rank matrix , we have . Usually, and are uncorrelated and in this case we have:
Without using the prior for parameter , the BLEB estimator with complete data prior is equivalent to the LMMSE estimator in (5) and thus a BLUE. It outperforms the OWLS estimator in formula (3) which does not use any prior information. This will be described in detail later in Theorem 5.
In practice, and are usually assumed to be uncorrelated. However, the exact data prior are usually unknown but can be estimated by the past sampling data, as in the general empirical Bayes methodology. For instance, given a set of (past) data and (current) sample data , where and have the same dimension , the practical BLEB estimator is obtained by replacing in formula (7) with their sample mean:
and this converges to the theoretical result in formula (7) under very general conditions due to the famous law of large numbers.
Treat the Prior Mean of the Sample Data as Data
For the linear data model (2), the problem of obtaining the BLEB estimator with complete data prior can always be converted to a problem of obtaining a BLUE estimator without any prior, as given by the Lemma 1 as follows.
Lemma 1: Given complete data prior , the problem of obtaining a BLEB estimator with complete data prior for the linear data model (2) can always be converted to obtain a BLUE estimator without any known prior. This can be achieved by treating the prior mean of sample data as an extra data using the following augmented linear data model (assume that and are uncorrelated):
The following theorem presents a BLUB estimator without any known prior using the data model (9).
Theorem 2 (BLEB estimator with complete data prior by treating the prior mean of the sample data as data). Using data model (9), the BLEB estimator by treating the prior mean of sample data as data is:
where , is any matrix satisfying , and is any square-root matrix of . This estimator is unique almost surely and it is equal to .
It can be seen that the error covariance matrix in the data model (9) is always singular since is full column rank.
This theorem shows that for optimal linear estimation, data prior can always be completely embedded into the linear data model (9) by viewing the prior mean as observation data. The BLEB estimator (10) is algebraically equivalent to the BLEB estimator (7) since they both use the same information just in different ways. The equivalence will be discussed and proved in Theorem 5.
The above equivalence reveals that the prior information can also be viewed as a kind of observation data, and thus the BLEB estimator (10) can be thought of as a unification of Bayesian and classical linear estimators.
It is noticed that, the form of the BLEB estimator (10) is similar to the OWLS estimator (3). However, the parameter is random here which is different from the OWLS estimator, and the optimization objective here is the MSE matrix, not the fitting error in WLS, despite the OWLS also optimizing the MSE with non-random . Details can be found in the poof of Theorem 2.
In practice, the estimated may be nonsingular and then the BLEB estimator (10) will degenerate into
BLEB Estimators With Partial Data Prior
Similar to Section 3.2, we consider using two architectures to deal with this problem from different perspectives.
Express the Prior for the Parameter Explicitly
In reality, sometimes the corresponding moments do not fully exist. This would be the case where some but not all components of data prior , and are available. For instance, there can be some newly listed assets when we estimate the mean and covariance of the return of assets from historical sample observation data. In this case, it is almost impossible to estimate relatively accurate prior for these newly listed assets from a few sample data. Therefore, we generally think that there is no data prior for these newly listed assets.
Let , where is an orthogonal matrix , and is the subvector of that corresponds to a nonsingular in the sense that . Then the partial data prior can be denoted as .
Using data model (2), the BLEB estimator with partial data prior can sometimes be inferred by the first two moments of and . In other words, we can express the unknown in terms of the known sufficient partial data prior of . Theorem 3 gives the BLEB estimator with sufficient partial data prior. It can be seen that, in this paper, sufficient partial data prior means that is full column rank and insufficient partial data prior means that is not full column rank.
Theorem 3 (BLEB estimator with sufficient partial data prior). Given of full column rank, and uncorrelated and , by using data model (2), the BLEB estimator with sufficient partial data prior is:
where the superscript + stands for MP inverse, and:
Without using the prior for parameter explicitly, the BLEB estimator with sufficient partial data prior (i.e., is full column rank) is equivalent to the LMMSE estimator in (5) and thus a BLUE. It outperforms the OWLS estimator in (3) which does not use any prior information. This will be described in detail later in Theorem 5.
is full column rank, which is a necessary condition in this theorem for expressing the prior for the parameter explicitly and uniquely.
Treat the Prior Mean of the Sample Data as Data
Similar to Theorem 2, for the linear model (2), the problem of obtaining a BLEB estimator with partial data prior can also be converted to a problem of obtaining a BLUE estimator without any prior, as presented in Lemma 2 as follows.
Lemma 2: Given partial data prior , the problem of obtaining a BLEB estimator with partial data prior for the linear data model (2) can always be converted to obtain a BLUE estimator without known prior by treating the partial prior mean of the sample data as extra data using the following augmented linear data model (assume that and are uncorrelated):
Similarly, once is treated as sample observation data, there is no data information about at all. Further, obviously, the form of the data model (12) is the same as that of the data model (9). The BLEB estimator with partial data prior is then given in the following Theorem 4.
Theorem 4 (BLEB estimator with partial data prior by treating the prior mean of the sample data as data). Given partial data prior and using data model (12), the BLEB estimator with partial data prior has the same form as that of the BLEB estimator (10) in Theorem 2:
except with
and the other matrices are defined in the same way as in the BLEB estimator (10).
Note that the error covariance here is singular, and it depends on whether in the data model (12) is full column rank or not.
The BLEB estimator proposed in Theorem 3 is also a BLUE with the corresponding assumption.
The BLEB estimator in Theorem 3 is essentially equivalent to the BLEB estimator with complete data prior in Theorem 1 and 2 when sufficient partial data prior is given. This makes sense as the prior knowledge of data or is actually redundant in this situation. Then the complete prior for parameter can be totally expressed by the complete data prior in or . In other words, the sufficient partial data prior is the same as the complete data prior with respect to the complete prior for , since is full column rank. This will be stated and proved in detail in Theorem 4.
What is more serious is that when insufficient partial data prior is given (i.e., is not full column rank). In this case, the loss of partial data prior information will lead to a worse BLEB estimator which will have a larger MSE matrix than the BLEB estimator using sufficient partial or complete data prior. However, the BLEB estimator with insufficient partial data prior still has a smaller MSE matrix than the OWLS estimator since more information has been used. This will also be stated and proved in detail in Theorem 5.
In practice, the estimated data prior is not equal to its theoretical value, and thus the final estimated results with partial data prior are different from the one which uses complete data prior even if sufficient partial data prior is given. Generally speaking, no matter whether is full column rank or not, the practical BLEB estimator using complete estimated data prior will perform better than that using partial estimated data prior , since usually contains more data information than in most practical situations.
Equivalence and Relationships
The remarks of the previous theorem have mentioned the equivalence of the BLEB estimators (7), (10), (11), and (13) with a full column rank matrix . The remarks have also stated some important relationships among these different linear estimators under different assumptions. The following Theorem 5 will present the concrete quantitative relationships among several classical, Bayesian, and empirical Bayes linear estimators that have been mentioned or proposed in this article.
Theorem 5 (relationships). Assume that are all existing while different BLUE estimators can only use corresponding known prior information since they have their own prior assumptions, as previously stated. Then the LS estimator, the OWLS estimator, the LMMSE estimator, and the BLEB estimators proposed in Theorems 1, 2, 3, and 4 exist and must have the following relationships:
and their MSE matrices have the relationships:
Where stands for the BLEB estimator with complete data prior in formula (7), stands for the BLEB estimator with complete data prior by treating the prior mean of the sample data as data in formula (10), stands for the BLEB estimator with sufficient partial data prior in formula (11), stands for the BLEB estimator with sufficient partial data prior by treating the prior mean of sample data as a data in formula (13), stands for the BLEB estimator with insufficient partial data prior by treating the prior mean of the sample data as a data in formula (13), stands for the LMMSE estimator in (5), stands for the OWLS estimator in formula (3), and stands for the LS estimator in formula (4).
, , , , , , and represent the MSE matrix of the corresponding estimator with the same superscript, respectively. In addition, “” indicates that the estimation accuracy of the former is the same as that of the latter, while “” indicates that the estimation accuracy of the former is higher than that of the latter.
The LS estimator and the OWLS estimator mentioned above are both classical linear estimation methods that consider the parameter as an unknown constant vector for which prior information no longer exists. The LMMSE estimator is a Bayesian method that views the parameter as a random vector with known complete prior about . The other five different BLEB estimators are all empirical Bayes estimation methods that also treat the parameter as a random vector but with unknown prior information.
As stated before, all these estimators presented in Theorem 5 are BLUEs with their corresponding special assumptions, except for the LS estimator . The LS estimator will become a BLUE when the error covariance matrix is given.
Theorem 5 shows that the more prior information is used, the more accurate the estimation result will be. This makes good sense: we should try to make the most of the prior information even if it can only be estimated from sample observation data.
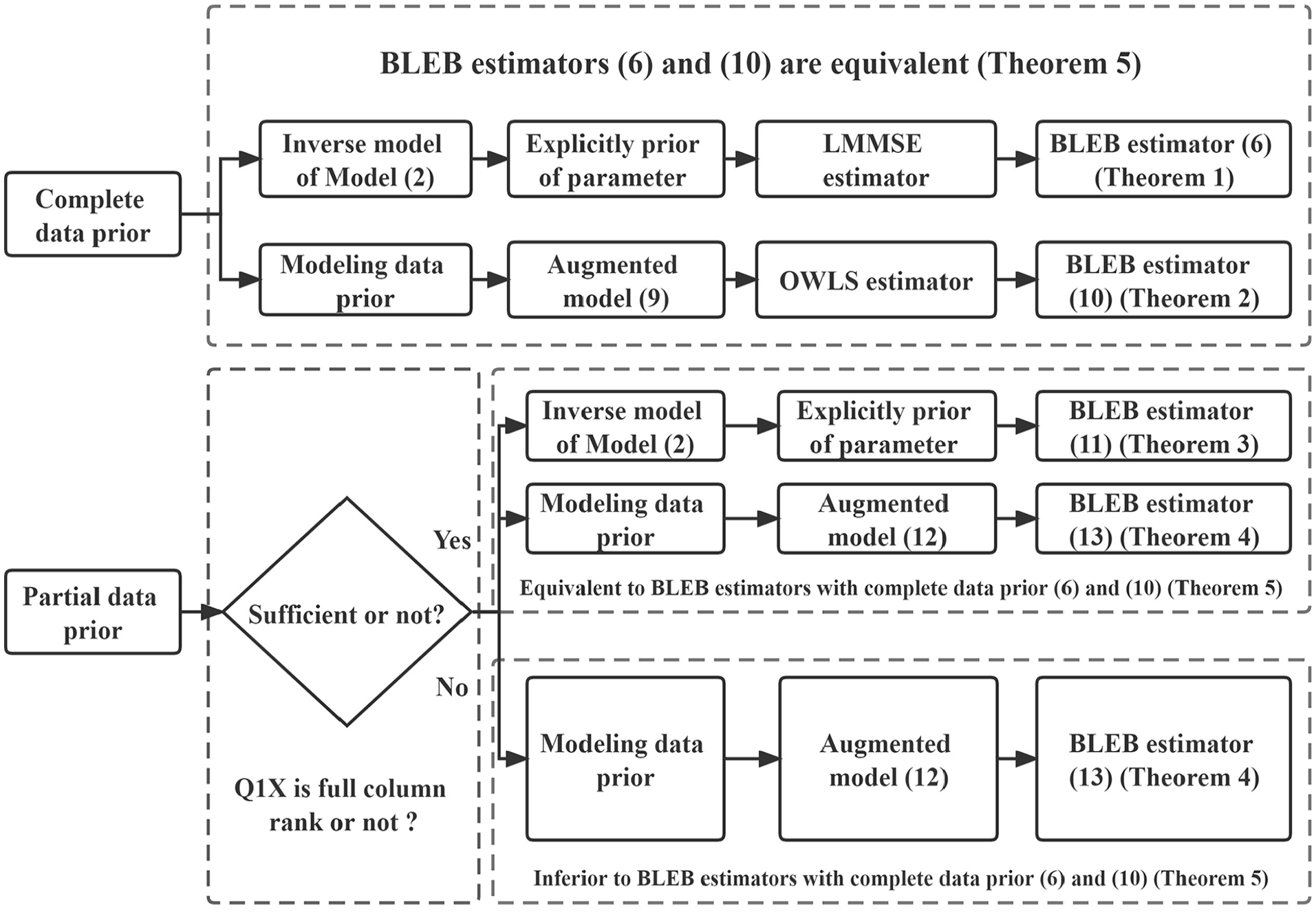
In order to make the use of Theorems 1 to 5 clearer, the flow chart of the BLEB methods with different assumptions of data prior is shown in Figure 1. In addition, Table 2 summarizes the BLEB estimators and the other BLUE estimators for ease of employment.
Flow chart of the BLEB methods with different assumptions of data prior.
The BLEB Estimators With Complete, Sufficient, and Insufficient Data Prior.
Architecture A: Express the prior of parameter explicitly
Architecture B: Treat the prior mean of sample data as a data
Complete data prior
with , ,
Sufficient data prior ( is of full column rank)
with , ,
Insufficient data prior ( is not of full column rank)
Can not express the prior of parameter explicitly
with , ,
All prior
None prior
Relationships
A Numerical Example
Consider the following linear data model
where parameter is a two-dimensional unknown vector to be estimated, is a random sample, and is a current sample observation data. and are mutually uncorrelated, , , and the prior of parameter and sample data are assumed as:
respectively, and they satisfy the relationship , where, we denote , , and .
A. The LS estimator assumes that the parameter is an unknown constant vector, which refuses to accept the existence of the prior information for the parameter presented above. Thus, by using formula (4), we have:
B. The OWLS estimator has the same assumption as the LS estimator, and by using formula (3), we have:
C. The LMMSE estimator assumes that the complete prior information about exist and is known as given above; thus by using the formula (5), we have:
D. The BLEB estimator with complete data prior assumes the prior of parameter is unknown but data prior is completely known as given above, then by using the formula (7), we have:
E. The BLEB estimator with complete data prior by treating the prior mean of the sample data as data has the same assumption as the BLEB estimator with complete data prior, and by using the formula (10), we have:
F. The BLEB estimator with sufficient partial prior ( is full column rank) assumes that the partial data prior is known as:
Then, by using the formula (11), we have:
G. The BLEB estimator with sufficient partial data prior by treating the prior mean of sample data as a data ( is of full column rank) assumes that the sufficient partial data prior is known as:
Then by using the formula (13), we have:
H. The BLEB estimator with insufficient partial data prior by treating the prior mean of sample data as a data ( is not of full column rank) assumes that the insufficient partial data prior is known as:
Then, by using the formula (13), we have:
It is easy to check that the estimates and MSEs of in A-H totally satisfy Theorem 5: the estimates and corresponding MSEs in cases D-G are the same as those in case C, which shows that the BLEB estimators , , , and are equivalent to the LMMSE estimator . The MSE in case H is smaller than that in case B, which shows that the BLEB estimator performs better than the classical OWLS estimator . The MSE in case H is large than those in case E to G, which shows that the BLEB estimator with insufficient data prior performs worse than the BLEB estimators with complete or sufficient data prior.
Covariance Matrix Estimation Using the BLEB Estimators
In the case of a large number of assets, it is extremely difficult to forecast the covariance matrix directly and accurately, and the rough estimation of the high-dimensional covariance matrix will be seriously disadvantageous to the optimal allocation of subsequent portfolios. Fan et al. (2008) proposed using multi-factor models to transform the estimation of the high-dimensional asset return covariance matrix into the estimation of the low-dimensional factor covariance matrix (the number of factors is generally much smaller than the number of assets). The following is a detailed description of how to use the BLEB estimators proposed in this paper to forecast the high-dimensional asset return covariance matrix on the basis of the multi-factor model.
The multi-factor model shows that the excessive returns of assets over the risk-free interest rate satisfies:
where and represent the number of assets and the number of sample return data available for each asset. denotes the factor returns of factors in the th sample of asset . denotes the factor loadings of factors in the th sample of asset , and is an error term that is unrelated both to factor loadings and factor returns.
Multi-factor models assume a certain relationship among specific factors. These factors can be macroeconomic (unexpected inflation, interest rate changes), fundamental (profit growth, return on net assets, market share), or market-related (beta, industry ownership). There are two common structured models, depending on the type of factors used in the model.
Structured Model 1: Estimating Factor Loadings Given Factor Returns
When using a factor model to forecast the covariance matrix of high-dimensional returns on assets, we first need to estimate factor loadings or factor returns. When the selected factors are macro factors, time series data should be used, that is, multiple sample data (). The Fama-French three-factor model is a typical example of these structured models. In this case, factor returns are observable (i.e., known) and are the same for different assets , while factor loadings are unknown estimated quantities and are the same for different samples . Then by using the multi-factor model (16), we can obtain get the following specific linear data model:
where
In addition, under the assumption of independent and identically distributed samples, the first two moments of the augmented sample data and the augmented noise are as follows:
where is the mean of the -dimensional asset return vector; is the covariance matrix of the -dimensional asset return vector; and are the mean and covariance matrix of the independent and identically distributed error term , respectively.
In linear data model (17) using multiple independent samples, the estimated quantity is a vector consisting of factor loadings, and is a matrix consisting of observable factor returns. Generally, it is difficult to know the prior information for factor loadings, so the OWLS method (3) without considering the prior data is simply used to estimate in most of the existing literature. In this paper, from the perspective of making full use of information, the estimators of the mean and covariance matrices using historical sample data or existing experience structures are substituted for the first two moments of the return vector of assets and we have
In addition, the mean and covariance matrices of errors are unknown in practice and need to be estimated by residual error. We note that the estimate of is . Now, treating the estimated prior above as the known prior for the sample data in the model (17), and then using the proposed BLEB estimators, we can then obtain a more accurate estimate of the factor loadings vector , which is better than the LS estimator commonly used in the existing literature.
After obtaining the estimator of the factor loadings vector , we can use the following formula to obtain the updated estimator of the covariance matrix for the return on high-dimensional assets:
where is the matrix representation of the estimated factor loadings , and is the estimator of the observable factor return covariance matrix.
It can be seen that when some elements of prior are not available, such as the assets that have just been listed in the asset vector, we should extract the sub-vector part with known prior for the original asset vector, and use the BLEB estimators with partial data prior proposed in this paper.
Structured Model 2 : Estimating Factor Returns Given Factor Loadings
When the selected factor is the fundamental factor, cross-sectional data analysis should be used. For each cross-section in the sample, there is only one sample for each asset. On the th cross-section, factor loadings are directly observable (known), while factor returns are the quantities to be estimated and are the same for different assets . The Barra risk model is a typical example of these structured models (Briner et al., 2009). In this case, by using multi-factor model (16), we can obtain the following specific linear data model:
where
and
In addition, under the assumption of independent and identically distributed samples, the first two moments of the sample data are as follows.
where, is the mean of the -dimensional asset return vector, and is the covariance matrix of the -dimensional asset return vector.
In the linear data model (19), the quantity to be estimated is a vector consisting of factor returns on the cross-section , and is a matrix consisting of observable factor loadings on the cross-section . Generally, it is difficult to know the prior information for factor returns, so the OWLS method (3) without considering the prior is simply used to estimate in most of the existing literature. In this paper, from the perspective of making full use of information, the estimators of the mean and covariance matrices using historical sample data or existing experience structures are substituted for the first two moments of the return vector of assets and we have
In addition, the mean and covariance matrices of errors are unknown in practice and need to be estimated by residual error. We note that the estimate of is . Now, treating the estimated prior above as the known prior for the sample data in the model (19), and then using the proposed BLEB estimators, we can then obtain a more accurate estimate of factor loading vector , which is better than the LS estimator commonly used in the existing literature.
By using the above estimation method on cross-sections, we can obtain an estimator sequence of the factor returns vector. Using this estimation sequence, we can obtain the sample estimator of the factor returns covariance matrix. Then, the updated estimator of the covariance matrix of high dimensional asset returns can be obtained by using the following formula:
Where is a matrix consisting of observable loadings on a cross-section of interest out of the sample.
Similarly, when some elements of prior are not available, such as assets that have just been listed in the asset vector, we should extract the sub-vector part with known prior for the original asset vector, and use the BLEB estimators with partial data prior proposed in this paper.
In order to make our method clearer, Figure 2 shows the flow chart of the BLEB estimators based high-dimensional covariance matrix estimation method.
Flow chart of the BLEB estimators based high-dimensional covariance matrix estimation method.
Simulation Results
In this section, we use a simulation study to illustrate our theoretical results and to verify the finite-sample performance of our proposed BLEB estimators. Since our primary concern is to verify the practical improvement of estimation accuracy by using our BLEB estimators through factor models, we compare the performance of the proposed BLEB-based covariance matrix estimators only with that of the LS-based covariance matrix estimator using factor models. To contrast different covariance matrix estimators to the truth , we examine the estimation error of and using the root mean-square error (RMSE) criteria: , where stands for the Frobenius norm.
For simplicity, we fix in our simulation and consider the three-factor model
The Fama-French three-factor model (Fama & French, 1992, 1993) is a practical example of the model (21) and is a kind of Structured Model 1 in Section 4.1. In the Fama-French three-factor model, is the excess return of the th stock or portfolio. The first factor is the excess return of the proxy of the market portfolio and the other two factors and are created using six value-weighted portfolios based on book-to-market ratio and size.
We take the parameters used in the study of Fan et al. (2008) as our simulation parameters to make our simulation more realistic. The sample means and sample covariance matrices of , are obtained from a fit of the Fama-French three-factor model using the three-year daily data for 30 industry portfolios from 1 May, 2002 to 29 Aug, 2005 and given as follows (Fan et al., 2008).
In our simulation, we consider comparing five covariance matrix estimators , and the definition of these five estimators is described in Table 3.
The Covariance Matrix Estimators Compared in Simulations.
Estimator
Explanation
The BLEB based covariance matrix estimator with true complete data prior
The BLEB based covariance matrix estimator with estimated complete data prior
The BLEB based covariance matrix estimator with estimated half data prior (only half assets prior are assumed known)
The BLEB based covariance matrix estimator with estimated one third data prior (only one third assets prior are assumed known)
The LS based covariance matrix estimator without using any data prior
Then we take the following steps for each simulation:
Generate random samples of from the trivariate normal distribution as the sample data to be used for estimation.
Generate factor loadings vectors as random samples from the trivariate normal distribution .
Generate standard deviations from a gamma distribution with (Fan et al., 2008).
Generate random samples from the -variate normal distribution .
From model (21), we obtain random samples with .
Calculate the true mean and covariance matrix of returns on assets by and with .
Generate “historical” assets return data from -variate normal distribution and denote the data set as .
Calculate the sample estimator of assets return data prior using the data set . Calculate the sample estimator of error from the fit of classical factor model.
Compute the five covariance matrix estimators , and .
Calculate the estimation error of the above estimators and the true covariance matrix using the RMSE criteria.
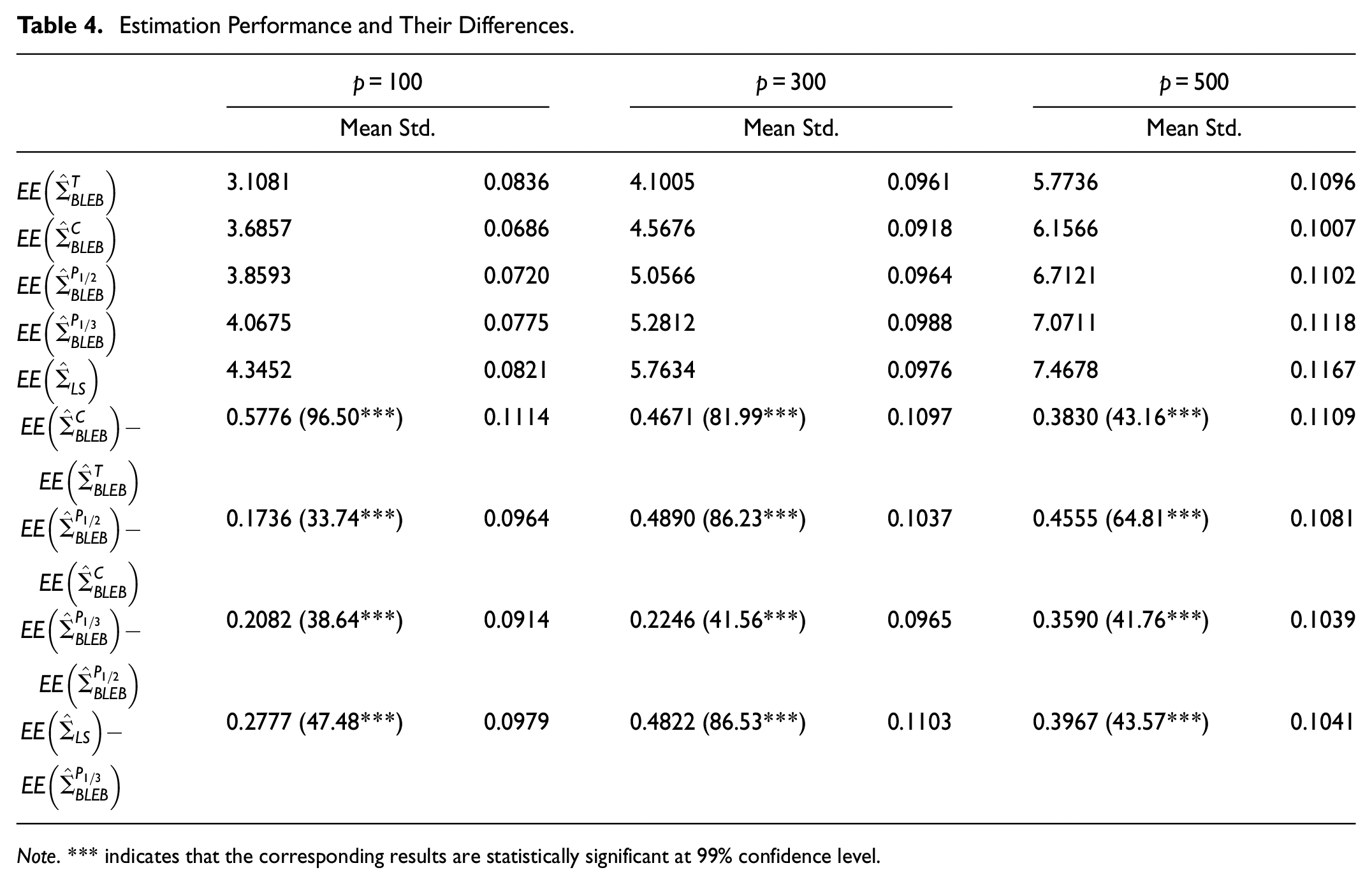
Table 4 reports the estimation performance of the five covariance matrix estimators when , , and the number of assets is set to 100, 300, and 500. The reported average estimation error and associated standard errors are based on 1,000 simulations. The pair-wise differences of the estimation performance of the five estimators are also reported, along with the corresponding t-statistics.
Note. *** indicates that the corresponding results are statistically significant at 99% confidence level.
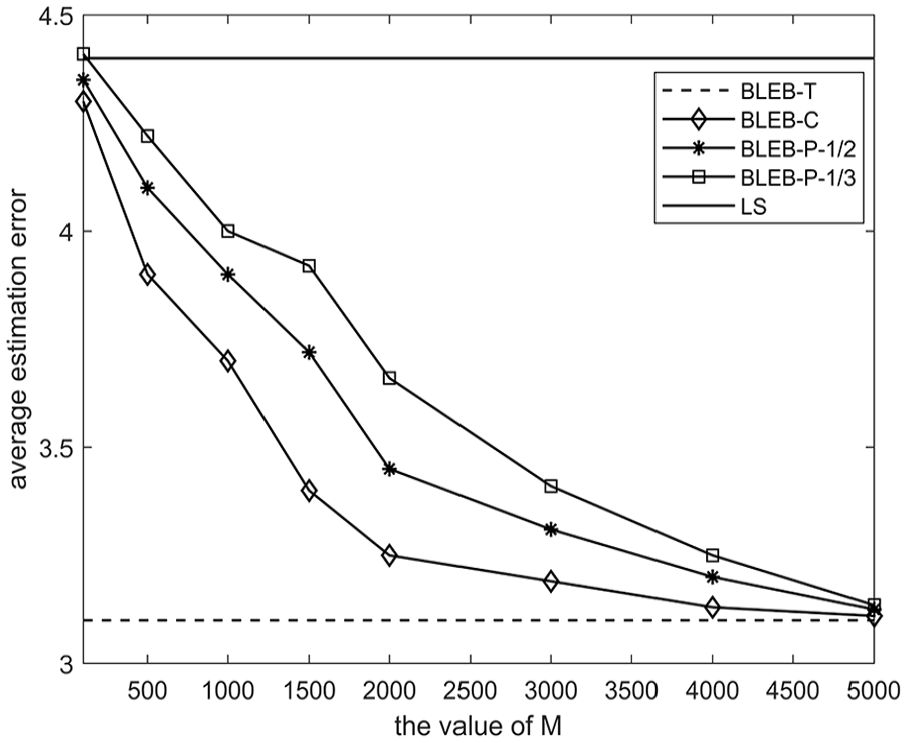
Figures 3 to 5 present the average estimation error of the five covariance matrix estimators when the number of assets is set to 100, 300, and 500, respectively. In each figure, we let grow from low to high to represent different accuracies of prior.
Average estimation error with different M at p = 100.
Average estimation error with different M at p = 300.
Average estimation error with different M at p = 500.
The average estimation performance of the five estimators has the relationship
when , at each of 100, 300, and 500. This result shows that the more information is used, the more accurate the estimator will be.
The estimator performs the best since true prior of returns data has been used for estimation, although this is not achievable in practice. The estimator performs the worst because none of the prior information is considered. These results are consistent with Theorem 5.
The estimator performs worse than since the estimated complete prior of returns data is inadequate. The estimator performs better than the estimator and since the former one has used more prior information for returns data, while this is not consistent with the conclusion that the BLEB estimator with complete data prior is equivalent to the BLEB estimator with partial data prior (full column rank case) in Theorem 5. This is because that the estimated data prior used in the simulation is different from the theoretical value of the data prior. However, the differences among , , and decrease with the increase of and they all converge on when is large enough. This is because that the estimated data prior gradually approaches to the theoretical value with the increase of . Clearly, the simulation results tell us that we should use estimated prior information as much as possible in practice.
Figures 3 to 5 show that the average estimation errors of estimators , , and decrease with the increase of the value of . This makes good sense because the more accurate the estimated data prior is, the higher the estimation accuracy will be. This encourages us to discover more accurate data prior in practice as far as possible.
The estimators , , and may perform worse than the estimator when (see Figures 4 and 5). This result indicates that the BLEB based covariance matrix estimators may lose efficacy when a extremely poor data prior is used for estimation.
Conclusions
In this paper, a class of BLEB estimation methods under the linear data model have been developed to improve the estimation accuracy in the case of unknown prior for the parameter. The proposed BLEB estimators perform better than the OWLS estimator since more data information is used to infer the parameter and they are equivalent to the LMMSE estimator when the complete or sufficient partial data prior is provided. Only when insufficient partial data prior is known is the MSE of the corresponding BLEB estimator larger than that of the LMMSE estimator, and it is still smaller than that of the OWLS method. A simple numerical example has been presented to verify the correctness of our method.
In addition, the estimation accuracy of high-dimensional covariance matrix using a factor model depends on the estimation accuracy of factor exposure or factor return. Therefore, we used the proposed BLEB estimator that fully considers the prior information of the data in this paper to estimate the high-dimensional covariance matrix, that is, we proposed the BLEB-based covariance matrix estimation method. Moreover, according to the different observable variables in the factor model, we given the specific implementation form of the BLEB method in two different cases of observable factor return and observable factor exposure. Finally, the simulation results also showed that the proposed BLEB-based method has a significant improvement in estimation accuracy compared with the traditional factor model method.
The works in this paper still have some limitations and need to be further studied in the future work. First, the BLEB-based high-dimensional covariance matrix estimation method is proposed in view of the shortcomings of the traditional factor model method. Therefore, this paper compares and analyzes the differences in the estimation accuracy of the two factor model based methods in detail, but we have not yet compared the performance differences between the BLEB method and other types of high-dimensional covariance matrix estimators. We will study this problem in future research. Second, in practical application, the BLEB method needs to first determine the prior mean and covariance of the return on assets. This paper has not yet discussed the possible impact of different prior estimators on the estimation results of the high-dimensional covariance matrix. In the future study, we will consider designing different prior of asset return, and analyze the impact of different prior on the actual estimation results.
Footnotes
Appendix: Proofs
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Jin Yuan
Xianghui Yuan
References
1.
AgrawalR.RoyU.UhlerC. (2022). Covariance matrix estimation under total positivity for portfolio selection. Journal of Financial Economics, 20, 367–389.
2.
AguilarO.WestM. (2000). Bayesian dynamic factor models and portfolio allocation. Journal of Business and Economic Statistics, 18, 338–357.
3.
AlfeltG.BodnarT.JavedF.TyrchaJ. (2022). Singular conditional autoregressive Wishart model for realized covariance matrices. Journal of Business & Economic Statistics. Advance online publication. https://doi.org/10.1080/07350015.2022.2075370
4.
BaiJ. (2003). Inferential theory for factor models of large dimensions. Econometrica, 71, 135–171.
5.
BrinerB. G.SmithR. C.WardP. (2009). The Barra European equity model (EUE3) (Research notes). MSCI Barra.
6.
ChamberlainG. (1983). Funds, factors and diversification in arbitrage pricing theory. Econometrica, 51, 1305–1323.
7.
CliffordL.FengP. (2018). A nonparametric eigenvalue-regularized integrated covariance matrix estimator for asset return data. Journal of Econometrics, 206, 226–257.
8.
De JongM. (2018). The covariance matrix between real assets. The Journal of Portfolio Management, 45, 85–95.
9.
De NardG.LedoitO.WolfM. (2021). Factor models for portfolio selection in large dimensions: The good, the better and the ugly. Journal of Financial Econometrics, 19, 236–257.
10.
DongY.TseY. K. (2020). Forecasting large covariance matrix with high-frequency data using factor approach for the correlation matrix. Economics Letters, 195, 109465. https://doi.org/10.1016/j.econlet.2020.109465
11.
EngleR. F.WatsonM. W. (1981). A one-factor multivariate time series model of metropolitan wage rates. Journal of the American Statistical Association, 76, 774–781.
12.
FamaE. F.FrenchK. R. (1992). The cross-section of expected stock returns. Journal of Finance, 47, 427–465.
13.
FamaE. F.FrenchK. R. (1993). Common risk factors in the returns on stocks and bonds. Journal of Financial Economics, 33, 3–56.
14.
FanJ. (2005). A selective overview of nonparametric methods in financial econometrics with discussion. Statistical Science, 20, 317–357.
15.
FanJ.FanY.LvJ. (2008). High dimensional covariance matrix estimation using a factor model. Journal of Econometrics, 147, 186–197.
16.
FanJ.MinchevaL. M. (2011). High dimensional covariance matrix estimation in approximate factor models. Annals of Statistics, 39, 3320–3356.
17.
HarrisR. D. F.YilmazF. (2010). Estimation of the conditional variance-covariance matrix of returns using the intraday range. International Journal of Forecasting, 26, 180–194.
JiangB. Y.LiuC.TangC. Y. (2023). Dynamic covariance matrix estimation and portfolio analysis with high-frequency data. Journal of Financial Economics. Advance online publication. https://doi.org/10.1093/jjfinec/nbad003
20.
KhatriC. G. (1990). Some properties of BLUE in a linear model and canonical correlations associated with linear transformations. Journal Multivariate Analysis, 34, 211–226.
21.
LanW.FangZ.WangH. (2018). Covariance matrix estimation via network structure. Journal of Business & Economic Statistics, 36, 359–369.
22.
LedoitO.WolfM. (2003). Improved estimation of the covariance matrix of stock returns with an application to portfolio. Journal of Empirical Finance, 10, 603–621.
23.
LedoitO.WolfM. (2022). The power of (non-) linear shrinking: A review and guide to covariance matrix estimation. Journal of Financial Economics, 20, 187–218.
24.
LiX. L.ZhangX. F.LiY. (2022). High-dimensional conditional covariance matrices estimation using a factor-GARCH model. Symmetry, 14(1), 158. https://doi.org/10.3390/sym14010158
25.
LiX. R.ZhuY.WangJ.HanC. (2003). Optimal linear estimation fusion, Part I: Unified fusion rules. IEEE Transactions on Information Theory, 49, 2192–2208.
26.
MarkowitzH. M. (1952). Portfolio selection. Journal of Finance, 7, 77–91.
27.
MencheroJ.JiL. (2021). Advances in estimation covariance matrices. Journal of Investment Management, 19, 60–80.
28.
MouraG. V.SantosA. A. P.RuizE. (2020). Comparing high-dimensional conditional covariance matrices: Implications for portfolio selection. Journal of Banking & Finance, 118, 105882. https://doi.org/10.1016/j.jbankfin.2020.105882
29.
RobbinsH. (1983). Some thoughts on empirical Bayes estimation. Annals of Statistics, 11, 713–723.
30.
RossS. A. (1976). The arbitrage theory of capital asset pricing. Journal of Economic Theory, 13, 341–360.
31.
RossS. A. (1977). The Capital Asset Pricing Model CAPM, short-sale restrictions and related issues. Journal of Finance, 32, 177–183.
32.
SoM. K. P.ChanT. W. C.ChuA. M. Y. (2022). Efficient estimation of high-dimensional dynamic covariance by risk factor mapping: Applications for financial risk management. Journal of Econometrics, 227(1), 151–167. https://doi.org/10.1016/j.jeconom.2020.04.040
33.
SteinC. (1977). Lectures on multivariate estimation theory. Journal of Soviet Mathematics, 34, 4–65.
34.
SunY.XuW. (2022). A factor-based estimation of integrated covariance matrix with noisy high-frequency data. Journal of Business and Economic Statistics, 40(2), 770–784. https://doi.org/10.1080/07350015.2020.1868301
35.
VassalloD.BuccheriG.CorsiF. (2021). A DCC-type approach for realized covariance modeling with score-driven dynamics. International Journal of Forecasting, 37, 569–586.
36.
WangH. C.PengB.LiD. G.LengC. L. (2021). Nonparametric estimation of large covariance matrices with conditional sparsity. Journal of Econometrics, 223, 53–72.
37.
WangM.XiaN. (2021). Estimation of high-dimensional integrated covariance matrix based on noisy high-frequency data with multiple observations. Statistics & Probability Letters, 170, 108996. https://doi.org/10.1016/j.spl.2020.108996
38.
XinH. Q.ZhaoS. D. (2022). A compound decision approach to covariance matrix estimation. Biometrics. Advance online publication. https://doi.org/10.1111/biom.13686
39.
ZhuR.ZhangX. Y.MaY. Y.ZouG. H. (2021). Model averaging estimation for high-dimensional covariance matrices with a network structure. Econometrics Journal, 24, 177–197.