
Abstract
This study mainly explores the cross-generational differences of basic vowels in Zhongyuan Mandarin. By adopting speech materials of two generations from seven cities in Henan Province, namely, Kaifeng, Shangqiu, Xuchang, Luohe, Zhoukou, Nanyang, and Zhumadian, we attempt to identify the positional features of each vowel in two generations with the acoustic vowel charts and the V-value charts, to observe the cross-generational differences of each vowel through the main distribution vowel charts, and to predict the future tendencies of the vowels with the help of the skewness chart.
Introduction
In China, for most speakers in Henan Province and the neighboring provinces, Zhongyuan Mandarin is always thought of as the Henan dialect. However, they are actually two partially-overlapping terms.
Zhongyuan Mandarin, in a broad sense, is one of the eight sub-groups of the Mandarin dialect (also known as the Northern dialect). It has the largest distribution in central China with a total coverage of 387 cities and counties in 11 provinces (He, 2005). The reason why Zhongyuan Mandarin is viewed as the Henan Dialect is that among the 11 provinces, Henan Province has the most areas dominated by Zhongyuan Mandarin. That is to say, in a narrow sense, Zhongyuan Mandarin refers to the dialect mostly spoken in Henan Province.
The Language Atlas of China (1987) and the Local Gazetteer of Henan (1995) show that dialects spoken in Henan Province (i.e., the Henan dialect) are generally divided into two groups: the Jin dialect and the Zhongyuan Mandarin. The former one resides in the northern part of Henan Province, covering only 19 cities and counties whereas the latter one takes up more than half of Henan Province, covering 111 cities and counties. In this study, Zhongyuan Mandarin is used in the narrow sense, namely, Zhongyuan Mandarin in Henan Province.
Based on the Vowel Pattern Theory, this study utilizes speech materials out of the Project for the Protection of Language Resources of China (henceforth PPLRC) to examine vowel change in two male generations in Zhongyuan Mandarin. In other words, the current paper aims to answer the following three questions: (1) What are the positional features of the basic vowels in two generations? (2) What are the characteristics of the cross-generational differences? How to explain the differences? and (3) What are the future tendencies of the basic vowels in Zhongyuan Mandarin?
This paper is organized as follows. In Section 2 previous sound studies of Henan dialects are reviewed. Section 3 demonstrates the methodology used in this study, Section 4 describes the results, and Section 5 is a general discussion. Section 6 is Conclusion.
Literature Review
The sound studies of the Henan dialect have been made for almost 60 years. Before the millennium, these studies are mainly at the service of the promotion of Putonghua. At the beginning of the 21st century, field works, traditional transcriptions, and synchronic/diachronic comparisons are three most-frequently-adopted research methods. However, plenty of works and theses tend to be superficially descriptive but lacking in theoretical depth, leading to a situation where the sound studies of the Henan dialect are rich in phonological descriptions but deficient in theoretical explanations (cf. Y. Duan, 2008).
Since the process of industrialization and urbanization has been accelerating, sociolinguistic studies have been applied to the Henan dialect since 2007. Linguistic variations in this dialect are believed to have a strong correlation with social factors such as the promotion of Putonghua since 1955 (Yu, 2009, p. 48), the improvement of educational level as well as the wide broadcasting of mass media (cf., e.g., Y. Chen, 2015; N. Duan, 2007; Li, 2013; Liu, 2018; Zhao, 2017).
As compared with impressionistic transcriptions, instrumental (or experimental) studies are more objective and scientific. On this account, scholars gradually apply acoustic analyses to the study of the Henan dialect. They have explored the acoustic features of tones in the Changge dialect (Hu, 2008), the Jiaozuo dialect (Y. Chen, 2012, 2014), and the Yuzhou dialect (Zhang & Kong, 2014), and that of vowels and consonants in the Huaiyang dialect (Q. Zhu, 2017) and the Luoyang dialect (Chang, 2018). However, these are mainly dialect-specific experimental studies, no general acoustic features have been investigated from the perspective of comparative studies.
To sum up, although there are many reports in the literature on the sound studies of the Henan dialect, most are constrained by research patterns of traditional dialectology, that is, field works, traditional transcriptions and synchronic/diachronic comparisons. It can be seen that social linguistic studies and experimental studies in the Henan dialect are still in their infancy. Researchers with insightful views and skilled experimental operations are bound to make further intensive investigations. Up to now, very little acoustic research has been carried out on comparative experimental studies, not to mention cross-generational studies.
Drawing on an extensive range of sources, Jacewicz et al. (2011a, p. 1) report that vowel change has been “a central topic in the emerging field of sociophonetics” for decades. Age and gender are two frequently-adopted social factors in studies on vowel change or vowel variation (cf., e.g., Berns, 2019; Hillenbrand, et al., 1995; Jacewicz et al., 2011a, 2011b; Labov, 1963, 1994).
The present study makes a cross-generational study of basic vowels in Zhongyuan Mandarin. It combines experimental methods with the recording samples taken from the PPLRC in Henan Province. It is regarded to be significant in two aspects:
For one thing, the present study is deemed to enrich the experimental study of the Henan dialect. It compares the presentation of basic vowels in two genarations. Even though experimental approach has been employed to the study of the Henan dialect for at least 14 years, it still needs deeper and wider investigation. In other words, the quantity as well as the quality is badly in need of experimental studies in the Henan dialect.
For another, the method proposed in this article is instructive to the post-project study. According to Cao (2015, pp. 10–17), the primary missions of PPLRC include “investigation pooling, banking and preservation, protection and research, development and application.” Through the combination of recording materials from the PPLRC with experimental studies, this article is believed to provide a new perspective to further study the speech materials in PPLRC.
Methodology
This study select speech materials from the PPLRC and it adopts Vowel Pattern Theory as theoretical framework. This section firstly describes how to choose tokens in speech materials of PPLRC (3.1). It then introduces the Vowel Pattern Theory (3.2).
Sampling in the PPLRC
As reported in Tian (2015, p. 7), the Project for the Protection of Language Resources of China (abbreviated as PPLRC) is launched in 2015 by the Ministry of Education of China and State Language Commission. The plan of this project is to conduct a 5-year-nation-wide field survey of 1,500 locations (where people speak Chinese dialects or the minority languages) from 2015 to 2019. L. Wang (2015, p. 19) considers the project as “a continuation, extension and upgrading of the establishment of the Audio Database of Language Resources of China” (quoted in Wang & Zhuang 2020, p. 141). It is in essence a kind of coping strategy to the decreasing diversity of language resources (Tian, 2015).
By the end of 2019, the PPLRC has exceeded the target with a total collection of language materials in 1,712 locations. In each location, materials are collected under the guidance of Questionnaires on the Chinese Language Resources (2015; henceforth, Questionnaires), in which there is a rigid set of criteria for the recruitment of participants and strict restrictions on the recording of speech materials.
PPLRC in Henan Province
As reported in Wang and Zhuang (2020, p. 142): In Henan Province, six universities undertook this Project. They are “Henan University, Henan Institute of Science and Technology, Henan Normal University, Luoyang Institute of Science and Technology, Xinyang Vocational and Technical College, and Beijing University of Technology.” From 2016 to 2020, scholars of these universities have successfully completed the collection of speech materials in 34 dialect locations by means of paper recording as well as audio-visual recording.
Among these locations, nine of them (Xinxiang, Hebi, etc.) belong to the range of the Jin dialect and the rest of them belong to the coverage of Zhongyuan Mandarin. It is noteworthy that the materials in 17 locations are collected by scholars in Henan University. The speech matrials utilized in this study are also provided by Henan University.
Subjects and materials
Being an important issue in experimental study, sampling is determined by the number of speakers and the size of samples (Shi & Shi, 2007, p. 24). As observed by S. Sun (2004, pp. 1, 2), typical sampling “does not rely on the number of samples” as much as probability sampling does. It can guarantee the accuracy of a dialect survey (Chang, 2018, p. 35). The PPLRC adopts this kind of sampling as well.
In each location, the PPLRC recruits four typical participants mutually different in age and gender. Requirements of the recruitment listed in the Questionnaires (2015, p. 4) are as follows (quoted in Wang & Zhuang, 2020, p. 144):
The age range of old speakers is 55 to 65 and that of young speakers is 25 to 35.
They were born, raised, and have spent most of their lives in a given speech community. They have a “pure” domestic language environment where their parents and spouses are all native speakers.
Old participants are preferred to select those with primary or elementary education while there is no limit in selecting young participants.
They have the abilities of thinking, reaction, and expression and speak in a loud and clear way.
With such strict criteria, several speakers are finally chosen as typical participants. They all get paid after investigation.
According to the Questionnaires (2015, p. 5), the four participants in each location are investigated with different linguistic items, as shown in Table 1:
Investigation Items for Different Participants.

Labov (2001, p. 366) claims that “The leaders of linguistic change have been located as women who are members of the upper working class or skilled work force, with a dense network of local ties and a broad range of connections outside the local neighborhood.” That is to say, adult females does not have a stable linguistic status as compared with adult males. Since the present study concentrates on the basic, fundamental vowel systems of the speakers, speech samples are taken from the first item only, that is, all the tokens are selected from the 1,000 words.
You (2016, p. 200) has argued that urban areas “are deemed to have more age-related differences in sound” than rural ones because of “the fast pace of life and the strong inclination to new fashions”. In order to find a relative overt cross-generational difference, this study selects speech materials in PPLRC from seven urban dialect locations. The seven locations are Kaifeng, Shangqiu, Xuchang, Luohe, Zhoukou, Nanyang, and Zhumadian.
With regard to the basic vowel systems of the seven cities, the number of basic vowels are slightly different. By basic vowel we mean a vowel in a rime has neither a preceding medial nor a following coda (Shi, 2002a). Finally we choose five basic vowels, namely, /i/, /u/, /y/, /a/ and /ə/.
In a Chinese syllable, a vowel interacts with its preceding consonant as well as the concomitant tone. In order to reduce unnecessary errors brought by the two components to the largest extent, some principles in choosing tokens are listed below (quoted in Wang & Zhuang, 2020, p. 144):
Try to select characters with zero consonants and level tones (X. Wang, 2011, p. 13).
If not available above, unaspirated plosive consonants are also acceptable (Xian & Tang, 2015, p. 37).
Avoid using falling-rising tones and nasal consonants.
Do not use heteronyms (Gu et al., 2015, p. 41).
By so doing, 27 tokens of /i/, 27 tokens of /u/, 22 tokens of /y/, 20 tokens of /a/, and 14 tokens of /ə/ are finally chosen in each generation of the seven cities. The sequence numbers of the tokens taken from the Questionnaires (2015) are listed as follows (Table 2):
Examples Adopted from the Questionnaires (2015).
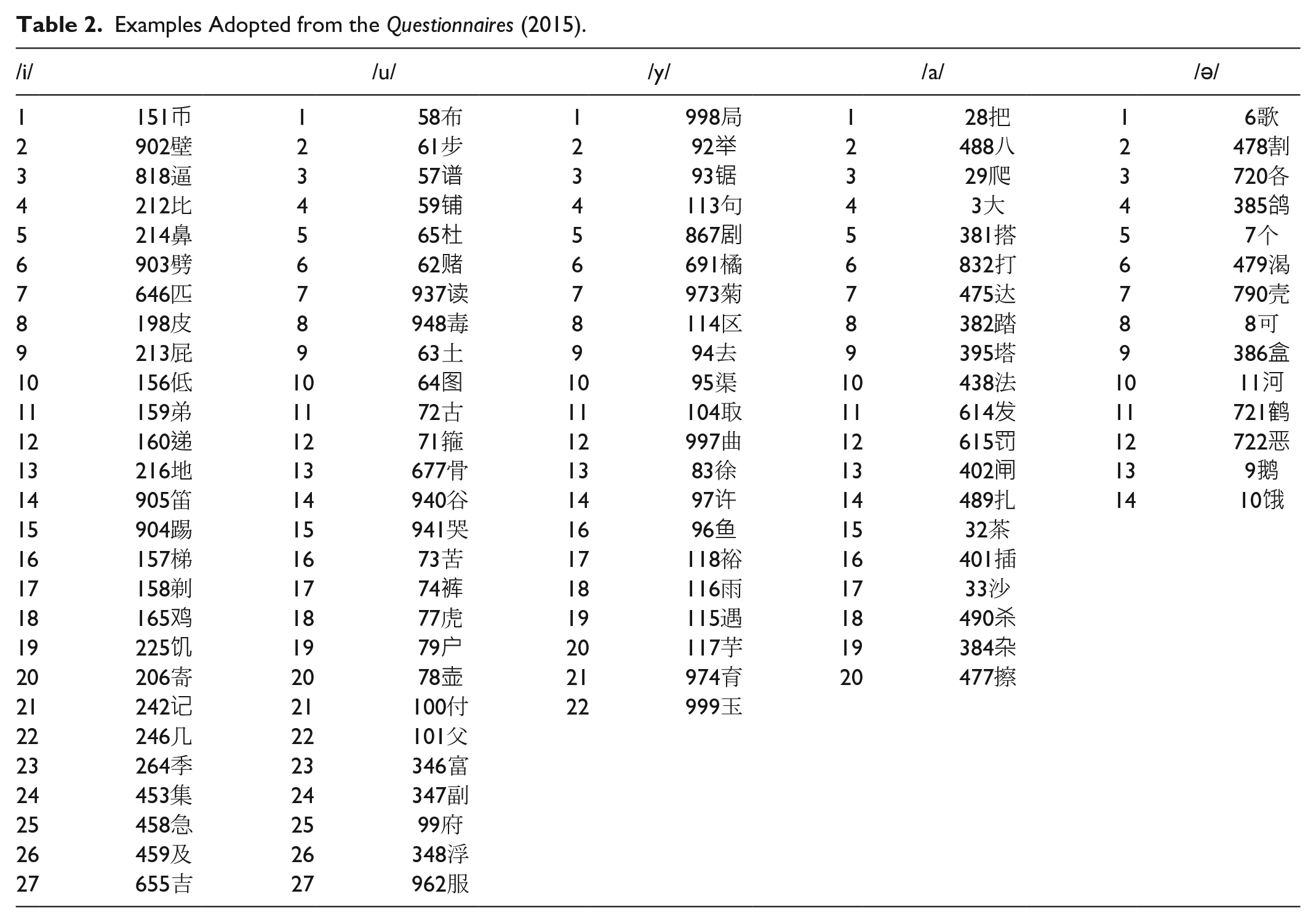
Therefore, speech materials selected in the present study include five basic vowels of two males in seven cities. The total tokens selected from the Project are 1,540 ([(27 + 27 + 22 + 20 + 14) × 2 × 7]).
Procedures
The Project requires that all the collected speech materials should obtain a uniform set of data and a homogenous speech sample. According to the Questionnaires (2015, p. 10), all the speech materials must be recorded under the following sampling parameters:
The sampling channel should be mono.
The sampling rate should be 44,100 Hz.
The sampling precision should be 16 bit.
All the recording files should be saved in *.wav format.
In addition, ambient noise should be no more than 36 dB (Questionnaires, 2015, p. 12). All the microphones used in seven cities are in the same model (Samson C03U). In doing so, a rigorous vowel comparison has achieved the first critical step.
Before an acoustic analysis begins, speech materials need to be converted to numeric values. We use Mini-Speech-Lab to achieve this goal. Mini-Speech-Lab is a software for speech analysis developed by Nankai University. Firstly, the 1,540 tokens should be down-sampled to 11,025 Hz. In the original speech materials, each token is recorded in a separate file. In order to suit this software, the separate tokens need to be integrated into longer *.wav files according to different vowels, for example, tokens of the same /i/ vowel can be integrated into a longer /i/ file. It is notable that each of the files should be saved within 12 seconds so that the software can work properly. After inputting the files, there would appear spectrograms of the tokens.
Then it is time to start the conversion. As reported in Wang and Zhuang (2020, p. 145), in Figure 1, there are “three horizontal lines in each shaded area”. From the bottom up, each of them represents “the first formant (F1), the second formant (F2) and the third formant (F3)”. Between F1 and F2, there is a comparatively parallel part. It is regarded as the steady portion of the vowel spectrum which contains all the information that is needed to specify the vowel quality. It is also presumed to be the section of a vowel on which phonetic context effects have the least influence (Lehiste & Peterson, 1961; Lindblom, 1963). Through clicking on this steady part, there would appear a spot in the blank F1 by F2 plane. This spot then symbolizes the particular vowel in the acoustic space (in this Figure 1, the spot represents /a/). Simultaneously, the F1 and F2 values of this spot are automatically extracted. With the repetition of this procedure, the F1 and F2 values of the five basic vowels are finally obtained.

Taking spots in the steady state of /a/.
Some Basic Considerations on Theory and Technology
This study adopts the Vowel Pattern Theory as the basic theoretical framework. The Vowel Pattern is a sub-study of the Sound Pattern characterized by quantification extraction and statistical graphs derived from the corresponding relations (Shi et al., 2010). Concerning the analysis of Vowel Pattern, investigations are made from two aspects, that is, the levels of vowels and the vowel charts based on the data extracted from the vowels.
The levels of vowels
In accordance with Shi (2002a, 2002b), the Vowel Pattern reflects the vowel system and focuses on the positional features, the behavior of internal variation and the general distribution of vowels. In particular, the Basic Vowel Pattern is the fundamental pattern. Chinese syllables are traditionally made up of three parts (Cheng, 1973, p. 10): initials (the beginning consonants), finals (the remainder of the segmental sequence), and tones (distinct pitches superimposed over the whole syllables). A final may further consist of a medial (or a head vowel), a nucleus (or a main vowel), and a coda (or an ending).
In Chinese syllables, the levels of vowels are represented in different combinations of the main vowels with medials and codas.
In short, a Chinese syllable can simply be formulated as follows:

Where S = Syllable, C = Consonant/Initial, M = Medial, Vn = Main Vowel/Basic Vowel/Nucleus, and Co = Coda. The components in parenthesis mean that they can occur or not in the combination of a Chinese syllable.
Therefore, the levels of vowels are identified with the different combinations between the main vowel and other components.
As illustrated in Table 3, a vowel in the same language or dialect can simultaneously be V1, V2, V3, and V4. It performs different representations in distributions, indicating the different structural levels of vowels. Among the four levels of vowels, the V1s (or the basic vowels) make up the Basic Vowel Pattern, which is of typical representation of a language or a dialect.
The Levels of Vowels.

Quantitative analysis of vowels
A visual Sound Pattern is represented by quantification extraction and statistical graphs derived from the corresponding relations among vowels (Shi et al., 2010). The basic steps of the quantification analysis in Sound Pattern research should contain normalization, relativization, categorization, stratification, and systematization.
Four types of charts are employed in present study when it comes to the quantification analysis of the Vowel Pattern, that is, the acoustic vowel chart, the V-value chart, the main distribution vowel chart and the skewness chart.
Acoustic vowel chart
The acoustic vowel chart is a two-dimensional F1 by F2 plane. Sometimes, it is hard for formant frequencies measured in Hz to detach individuality from universality, leading to the conversion of Hz values into Bark values with the adoption of the following formula (Schroeder [1979], recited from Wu & Lin, 1989, p. 90):

where f is the formant frequency extracted from the steady state of vowels. By utilizing this formula, it is possible to remove individuality and retain universality to some extent.
V-value Chart
The normalization and relativization of vowels can be achieved via adopting the V-value formula. The V-value chart (a relativized Vowel Pattern chart) is obtained through the calculation of Bark values (Shi & Shi, 2007):

where V1 is the relativized value of F1 of a vowel and V2 the relativized value of F2 of the same vowel. B1max means the maximum of the Bark value in F1 among the vowels in the same vowel pattern while B1min the minimum of the Bark value in F1 among the vowels. The same to B2, B2max, and B2min.
According to Shi (2006), Shi and Shi (2007), the high vowels, low vowels, front vowels, back vowels, and mid-central vowels roughly take up four parts:
The high front vowel ranges from 0 to 30 in V1 and from 80 to 100 in V2; the high back vowel ranges from 0 to 30 in V1 and from 0 to 20 in V2; the low central vowel ranges from 70 to 100 in V1 and from 40 to 60 in V2 and lastly, the central vowel ranges from 30 to 70 both in V1 and V2. Such descriptions can be drawn as the following Chart 1:

The division of vowels in height and backness.
The purpose of adopting the V-value formula is to continually filter the individual differences to the largest extent caused by physiological differences among speakers (for instance, the effect of vocal tract length) and to preserve the relative relations among vowels.
Main distribution vowel chart
The main distribution vowel chart is obtained through a modified formula in calculating the V-values (X. Sun, 2009; X. Sun & Shi, 2009, p. 23):

where B1max and B1min respectively refer to the maximum and the minimum of the Bark values of F1 from all the vowels in question, and StB1max and StB1min are the corresponding standard deviations of B1max and B1min. The same to B2max, B2min, StB2max, and StB2min.
Skewness chart
Synchronically, linguistic variants changing in progress always represent an asymmetrical distribution, reflecting the tendencies and directions of sound change (Liu & Shi, 2016). Labov (2001) believes that skewness is the most important parameter in tracing the path and mechanism of sound change. P. Wang (2009, p. 84) proposes a set of fairly simple algorithms in calculating the skewness of vowels:

Where
If (
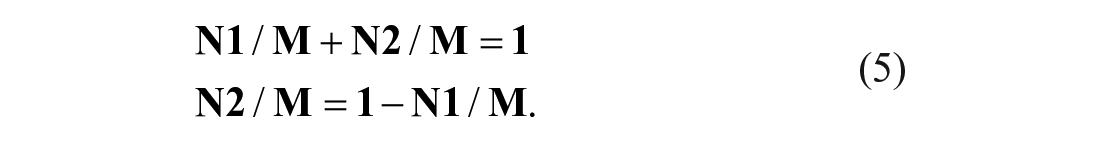
Providing that S is the standard deviation, then
On the basis of V-value chart and the algorithms of skewness, it is conspicuous to predict the tendencies of the vowels.
By utilizing the four types of charts step by step, this study is able to (1) establish the acoustic vowel space in acoustic vowel charts and observe the relative relations among vowels in V-value charts, (2) find out the cross-generational differences in main distribution vowel charts, and (3) predict possible tendencies and directions of vowel change in a skewness chart.
Results
The acoustic vowel space is represented in the acoustic vowel chart with a two-dimensional F1 by F2 (or V1 by V2) plane. The vertical axe (F1/V1) roughly corresponds to the high/low dimension of the tongue position while the horizontal axe (F2/V2) roughly corresponds to the front/back dimension of the tongue position. Besides, the F2/V2 is also considered to be affected by the rounding of lips.
To put it more precisely, if the F1 value is high, the tongue will be in a low position; if the F2 value is high, the tongue will be in a front position. The lip rounding makes the F2 value decrease.
The Positional Features of Basic Vowels
In the study of Vowel Pattern, the formant frequencies of vowels are required to be extracted at the static target. It is a section of a vowel that is presumed to be least influenced by phonetic context effects (Lehiste & Peterson, 1961; Lindblom, 1963). The acoustic vowel chart and the V-value chart of each speaker in the seven cities are automatically obtained after inputting the speech files into Mini-Speech-Lab.
The acoustic vowel charts and the V-value charts are illustrated in Charts 2 to 8. Each chart stands for the realization of vowels in one city. According to the geographical positions of the seven cities, the sequence of the charts are arranged from north to south and from east to west. Therefore, the seven charts represent Kaifeng, Shangqiu, Xuchang, Luohe, Zhoukou, Nanyang, and Zhumadian in order.

Kaifeng.
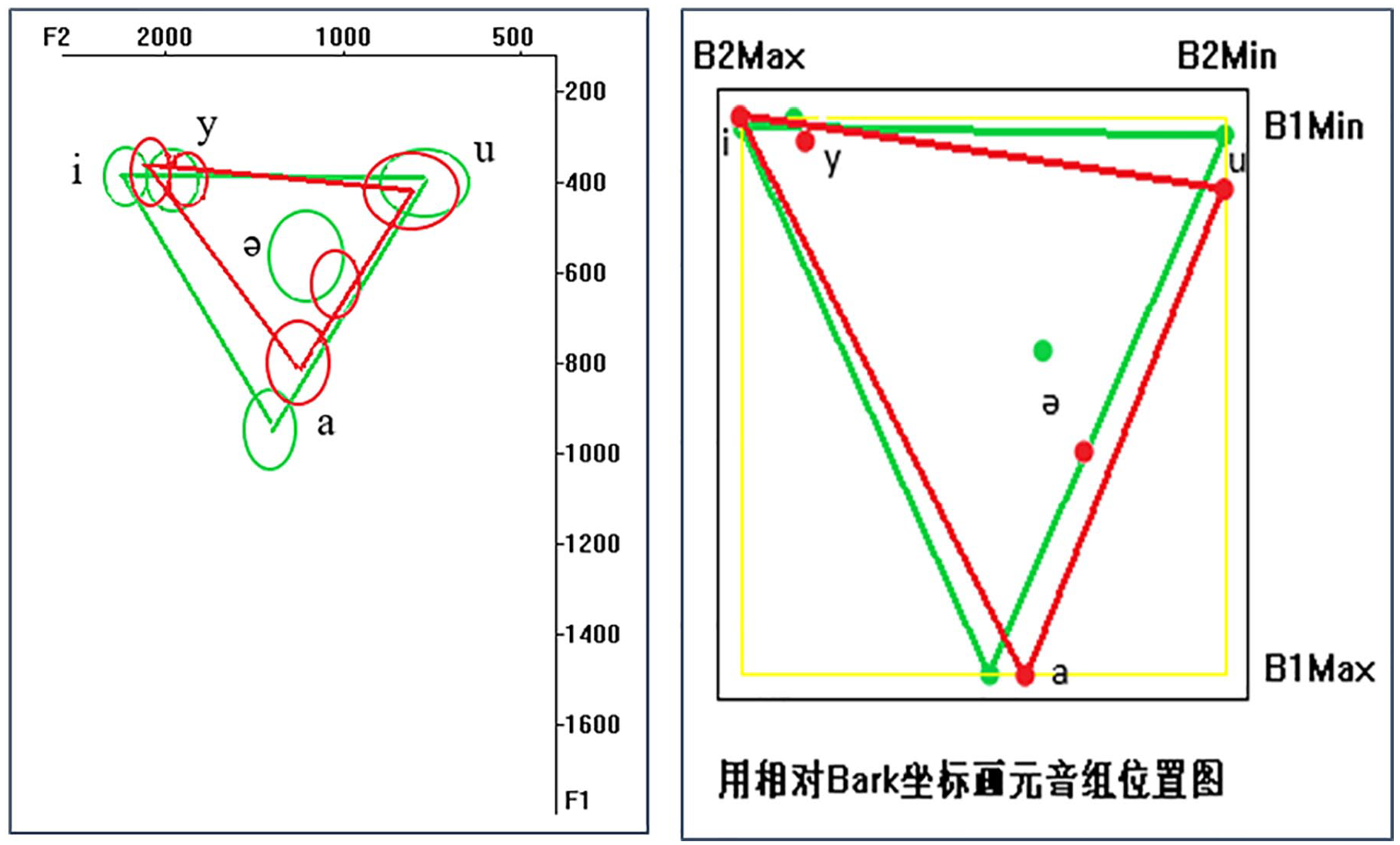
Shangqiu.

Xuchang.

Luohe.

Zhoukou.

Nanyang.

Zhumadian.
In the vowel charts of the seven cities, the left ones are cross-generational comparisons in the acoustic vowel charts and the right ones are cross-generational comparisons in the V-value charts. Red dots represent vowels of the old generation (OG, for short) and green dots represent that of the young generation (YG, for short).
With the observation of the left acoustic vowel charts of the seven cities, it is evident that individual characteristics of the speakers cause difficulty in detaching the universalities of Zhongyuan Mandarin: vowels in each generation display variously both in the high/low dimension and in the front/back dimension. However, when the basic vowels are gathered into one acoustic space according to the speaker, there occurs a relative stable relationship among the vowels. Such phenomena corroborate Joos’ (1948) opinion: although the formant frequencies of the same vowel vary when it is pronounced by different speakers, the relative positions of each vowel keep stable under the same acoustic vowel space (quoted in Shi, 2002a).
In each of the acoustic vowel chart, there are three levels in both of the high/low dimension and the front/back dimension. That is, in the high/low dimension, /i/, /y/, and /u/ are in the high level and /a/ is in the low level, /ə/ is regarded to be in the mid level but is a little closer to the low vowel /a/. There seems to be an overlapping area between the range of /y/ and that of /i/, this is because F2 is related not only to the backness of tongue position but also to the rounding of lips (Shi et al., 2010). In the front/back dimension, /i/, /y/ are in the front level, and /u/ is in the back level. /a/ and /ə/ are in the central level. Comparatively, /ə/ is a little backward to /a/ when they are observed in the same horizontal dimension.
In short, in the acoustic vowel space, /i/ and /y/ take the high front position and they are differentiated by the rounding of lips; /u/ takes the high back position and /a/ takes the low central position. /ə/ roughly takes the central mid position.
The V-value charts are obtained via the calculation of relativization through which the individual variations caused by physiological differences are filtered to the largest extent (Shi & Shi, 2007). Since the Bark value is an auditory equivalent, the wide gap illustrated in the V-value charts between the two high front vowels suggests that people can differentiate them easily in perception. Besides, high vowels /i/ and /u/ and the low central vowel /a/ form a triangle configuration. /i/, /u/, and /a/ are therefore regarded as peripheral vowels taking the extreme positions of the acoustic space (Wang & Shi, 2014).
In addition, as demonstrated in the V-value charts, in the high levels, the V1 values of /u/ are always higher than that of /i/ and /y/, indicating that, in the articulation of /u/, the tongue position is not as high as that in articulating /i/ and /y/, which means, in the articulation of high vowels, the tongue position of the front vowel is higher than that of the back vowel. Similar phenomenon is proven in foreign languages such as English, French, and Czech (Cao, 1990). Lin and Wang (1992) explain this from the constriction of human’s physiological organs: In articulating the back vowel /u/, the rounding of the lips renders the tongue to get retracted, leading to the lowering of the tongue position (P. Wang, 2009).
To sum up, the basic Vowel Pattern in Zhongyuan Mandarin has three levels in both the high/low dimension and the front/back dimension in the vowel space. With regard to the three peripheral vowels, the vowel /i/ is in the high front position, /u/ is in the high back position, and /a/ is in the low position. In addition, the vowels /i/, /u/, and /a/ constitute a triangle configuration. The phenomenon that the position of /u/ is lower than that of /i/ in the high/low dimension is consistent with the limitation of human’s physiological articulatory organs. The vowel /ə/ with a large range in the acoustic vowel charts of the seven cities in the two generations indicates that there is less phoneme competing space with it in the central level.
The cross-generational acoustic vowel charts of the seven cities represent variously because automatic extraction of vowel values cannot remove speakers’ individualities.
Salient Features of Basic Vowels in Two Generations
In the last section, the acoustic vowel charts and the V-value charts are presented in order to describe the positional features of the basic vowels. As seen from the V-value charts, the high front vowel /i/ in two generations generally coincides with each other. The back vowel /u/ in the high/low dimension and the low vowel /a/ in the front/back dimension form into lines. However, this is inconsistent with the fact that the vowels are presented in categories in the vowel space (Sun & Shi, 2009).
In this section, the main distribution of basic vowel charts are presented so as to observe the features of vowels in each generation by means of formula (3) in Section 3.2.2. Charts 9 and 10 represent the main distribution of vowels in the OG and the YG, respectively.

Main distribution of vowels in the OG.

Main distribution of vowels in the YG.
Wang and Shi (2014, p. 19) set a criterion for judging the degree of dispersion by taking account of the standard deviation values (Standard values) calculated in each vowel. To put it precisely, if the standard value of a vowel does not exceed 6, either in the high/low dimension or in the front/back dimension, the vowel is considered to be distributed in a centralized way in this dimension, which means, the vowel has a salient feature in this dimension. Otherwise, the vowel is regarded to be distributed in a discrete way in the dimension, which means, the vowel has a less distinctive feature in this dimension. The standard values of vowels in each generation of the seven cities are listed in Table 4.
The Standard Values of Basic Vowels in Two Generations.

Through the observations of Chart 9, Chart 10, and Table 4, the salient features of the five basic vowels represented in two generations can be summarized as follows:
With the comparison of salient features of basic vowels in two generations, it is shown in Table 5 that:
(1) In the high level of the YG, all of the three vowels are characterized with [+HIGH]. However, this [+HIGH] feature of different vowels becomes salient under different circumstances as compared with the features of three high vowels in the OG:
(a) The vowel /i/ remains its [+HIGH] feature. It loses its salient [+FRONT] feature;
(b) The vowel /y/ obtains the new [+HIGH] feature. It is no longer distinctive in the [+FRONT, +ROUND] feature;
(c) In addition to the salient [+BACK] feature, the vowel /u/ gets a new [+HIGH] feature.
(2) In the central and low level of the two generations, both /ə/ and /a/ are featured with [+CENTRAL]. It seems that there is no difference in the features of the two vowels between the two generations.
In order to further discover the hidden cross-generational differences, the comparison chart of the two generations are obtained in Chart 11 by means of relativization. As demonstrated in this chart, the whole vowel space of the YG raises as compared with that of the OG. In the central level, the distribution range of /ə/ in the YG is larger than that in the OG, implying that there is less phoneme competing with /ə/ in the central space of the YG. In the low level, the main distribution space of /a/ gets higher in the YG.
The Salient Features of Vowels in Two Generations.


Main distribution of vowels in two generations.
Representations of Basic Vowels in Skewness Chart
In 4.2, the main distributions of vowels in two generations are obtained on the assumption that the data extracted from speech samples are in Normal Distribution where the median equals to the mean. However, language is not a homogeneous system but an orderly heterogeneous structure, which means, the distribution of data skews to some extent.
Based on the set of algorithms in P. Wang (2009, p. 84; as shown in 3.2.2), the skewness chart is finally obtained in Chart 12.

Skewness vowel chart in Zhongyuan Mandarin.
In this chart, there are five quadrilaterals respectively representing the main distributions of the five basic vowels. The central point in each quadrilateral stands for the mean value. Each of the quadrilateral is made up of MEAN ± SD. The shaded areas in the quadrilaterals symbolize the centralized domains of the vowels which are considered to be the main carriers of vowel qualities. The dispersion areas beyond the shaded ones are believed to change easily as compared with the stable centralized domains.
P. Wang (2009, p. 95) argues that the quantitative representations of skewness can “provide a bond for connecting synchronic representations with diachronic changes”.
With regard to the high vowels, /i/ is centralized in the front and low part, /y/ is centralized in the front part and /u/ is centralized in the high part. As for the central vowel /ə/, it is centralized in the low part and the low vowel /a/ is centralized in the high and back part. Such representations suggest that the high front vowels /i/ and /y/ have a tendency of fronting, that the high back vowel /u/ has a tendency of fronting and raising, that /ə/ has a tendency of centralizing and that the low vowel /a/ has a tendency of raising and backing. Among the tendencies of the vowels, the tendencies of /i/, /u/, and /a/ in Zhongyuan Mandarin conform to the existed historical changes as well as synchronic changes.
Discussion
This section mainly discusses cross-generational differences and possible tendencies of the five basic vowels.
Cross-Generational Differences
Articulatory characteristics of basic vowels
Wang and Shi (2014, p. 20) consider that “acoustic representations can reflect the articulatory characteristics”. Specifically, if the data of a vowel are centralized in either acoustic dimension (the high/low dimension or the front/back dimension) in the main distribution chart, it means that the vowel will have a salient feature in that dimension. At the same time, it suggests that the tongue position is highly restricted in the corresponding physiological dimension. In other words, salient acoustic features of a vowel can reflect the physiological articulatory characteristics.
In accordance with Tables 4 and 5 and Chart 11, the articulatory characteristics of the basic vowels in the OG are:
In articulating /i/, the tongue takes the highest and the frontmost position and in articulating /y/, the tongue reaches the frontmost position. In the meanwhile, the lips are rounded as much as possible to make a sharp contrast between /i/ and /y/. The tongue moves backward in the articulation of /u/. As shown in Chart 11, the vowel /ə/ in the OG takes up a smaller size than that of the vowel in the YG. This implies that in the articulation of /ə/, speakers in the OG tend to keep their tongues fixed in the middle of the oral cavity. They would open their mouths as wide as possible to make the tongue reach the lowest position in the articulation of /a/.
Similarly, the articulatory characteristics of the five vowels in the YG are:
In the articulation of /i/, the tongue takes the highest position but it does not reach the frontmost position. With regard to the main distribution of /y/, there is a relatively larger range in the acoustic front/back dimension and a smaller gap between /i/ and /y/. This phenomenon indicates that the lips put less effort in the movement of rounding. The vowel /u/ is featured with [+HIGH] and [+BACK]. This demonstrates that the tongue needs to retract as much as possible in the articulation of /u/. In so doing, the vowel can be easily discriminated from other vowels. As stated previously in the interpretation of Chart 11: the whole vowel space of the YG raises as compared with that of the OG. In the central level, the distribution range of /ə/ in the YG is larger than that in the OG. In the low level, the main distribution space of /a/ gets higher in the YG. Such statements denote that, (i) the central vowel /ə/ requires the tongue to stay relaxed in the oral cavity; and (ii) in articulating /a/, the mouth is wide-open so that the tongue can get stable in the low central position.
In summary, the articulations of the two high front vowels /i/ and /y/ in the YG need smaller effort in the movement of the lips and the tongue. However, it seems that the YG has to put more effort in the articulation of the high back vowel /u/ than the OG does. In the articulation of /a/, the aperture in the YG is smaller than that in the OG.
Analysis of the differences
In brief, the differences of basic vowels in terms of articulatory characteristics represented in the two generations can be summarized into one sentence: The OG devotes full effort to the articulation of all the basic vowels while the YG puts less effort in articulating the same vowels (with an exclusion of /u/). This phenomenon conforms to the Principle of Least Effort (or the Economy Principle).
Zipf (1949, p. 1) proposes that human behavior is universally subject to the Principle of Least Effort:
“The Principle means, for example, that a person strives to solve his problems by minimizing the total work that he must expend. And in so doing he will be minimizing his effort. The term Least effort, therefore, is a variant of least work.”
This proposal is warmly supported by scholars since its birth. Based on this principle, Martinet (1952, 1955) puts forward the Economy Principle in demonstrating the effect it takes in sound change. Under such principle, people tend to select the simplest, the most economic, and the most effective way to meet the requirements of communication. In other words, people are required to put least effort in articulation to distinguish meanings. Language economy principle is a fundamental one to guide language use.
In order to understand how and why a language changes, Martinet (1962, p. 139) further argues two “ever-present and antinomic factors” from the perspective of speakers. The first factor is the “requirements of communication (the need for the speaker to convey his message),” and second, “the principle of least effort, which makes him restrict his output of energy, both mental and physical, to the minimum compatible with achieving his ends” (Jiang, 2005).
Possible Tendencies of Basic Vowels in Zhongyuan Mandarin
In the above section 4.3, vowels in Zhongyuan Mandarin represents a tendency of a chain-like shift: The high front vowels /i/ and /y/ have a tendency of fronting, the high back vowel /u/ has a tendency of fronting and raising, the central vowel /ə/ has a tendency of centralizing and the low vowel /a/ has a tendency of raising and backing.
Chain shift in vowel change
Language is an orderly heterogeneous structure. P. Wang (2009, pp. 12, 13) argues that in the investigation of systematic changes of a language, studies of paradigmatic structures should be taken as the most important and the studies of syntagmatic structures are taken as necessary references and complementation.
The vowel system is an important sub-system of the sound system. The “Cardinal Vowels” put forward by Jones (1955) has established three dimensions of the vowel system which are strongly correlated with the physiological descriptions of the tongue position, that is, the front/back dimension, the high/low dimension and the roundness of the lips. The three dimensions are the crucial clues and penetration points for investigating the systematic changes of vowels.
The change of a vowel system is the chain shift (Labov, 1994). There are two patterns of chain shift, that is, the push chain and the drag (or the pull) chain, which are two opposite ways for the vowel change or vowel shift. They differ in the force of change. In general, push chains are not as common as drag chains in vowel shifts. Both of the two patterns of chain shifts are initiated by balancing the distinctions of phonemes to meet the commands of communications (F. Wang, 1999).
Analysis of the possible tendencies
The raising of vowels in chain shift is a common phenomenon among world languages (cf. Labov [1994, pp. 123–125] in Indo-European languages; L. Wang [2010] in the history of Chinese). Pan (2010) discusses the two important rules of vowel change in Chinese historical phonology: the raising of long vowels and the lowering of short vowels. He concludes that the former one is regarded as the rule the most frequently occurred. As reviewed by Jin (2017), there are two types of concepts for the raising of vowels concerning the research objects: In the narrow sense, it means the frictionization and apicalization of high vowels with a wide distribution and an apparent degree of raising. In the broad sense, it means the raising tendency of vowels, including the centralization of low vowels (/a/), the raising of central vowels (/o/, /ɔ/), the frictionization and apicalization of high vowels (/i/, /y/, /u/), the monophthongization of diphthongs (the monophthongized vowel occupies the high position), etc.
In the English history, the Great Vowel Shift is “a series of changes in the pronunciation of the English language that took place primarily between 1350 and the 1600s and 1700s”. In this shift, the high vowels /i/ and /u/ firstly become diphthongs (in Middle English), then the other long vowels are raised to a higher place; hence forming a drag chain. The changes of pronunciations that happened between late Middle English and today’s English are simply shown in Table 6 (Lass, 2000, p. 72):
The Process of the Great Vowel Shift.

In this table, the long low vowel /aː/ in the Great Vowel Shift raises with front vowels and the long high vowels /iː/ and /uː/ are diphthongized through vowel breaking.
X. Zhu (2005) argues that there has happened twice of the vowel shift in the period from Ancient Chinese to Middle Chinese and both of two chain shifts involve the raising and backing of /a/. As observed by Xu (1991), the vowel /a/ has a covert opposition in Chinese. When the vowel /a/ occurs as a monophthong, the raising and backing movement always takes place. While when the vowel /a/ occurs as the nucleus of compound vowels, the raising and fronting movement often arises because the basic vowel is easily influenced by the assimilation of the medial and the coda.
Since the vowel /a/ in the present study comes from simple finals (/a/ occurs as the monophthong), it is therefore in accordance with the raising and backing movement.
The fronting of /u/ is also proven not only through diachronic/synchronic comparisons (L. Chen, 2005) but also through experimental studies (Labov, 2001; Liu et al., 2013). The fronting of /i/ is a common phenomenon in Chinese dialects. Six processes of the fronting of high vowels in Chinese dialects are discussed in X. Zhu (2004), including frictionization, apicalization, diphthongization, lateralization, nasalization, and centralization. Among the six processes, the former three processes frequently happen in dialects while the latter ones occur sporadically. He hypothesizes that the frictionization is caused by an attempt to increase auditory distance from /y/.
Zhang (2006, pp. 61–65) believes that the apicalization of /i/ results from the fronting of the place of articulation and the raising of the manner of articulation. The change of /i/ in chain shift is a mutual influence caused by raising and fronting. In accordance with the physiological features of articulation, the fronting should be regarded as the major force.
Besides, the tendencies of the three peripheral vowels represented in Zhongyuan Mandarin corroborate the three General Principles of vowel shifting proposed by Labov (1994, p. 116):
Principle I: In chain shifts, long vowels rise.
Principle II: In chain shifts, short vowels fall.
Principle II a: In chain shifts, the nuclei of upgliding diphthongs fall.
Principle III: In chain shifts, back vowels move to the front.
The single vowel series behaves like the long vowels, and follows Principle I (Labov, 1994, p. 121).
Summary
Let us take stock. With the combination of experimental study and dialectology, this study makes a comparative study of basic vowels in Zhongyuan Mandarin in two male genarations, attempting (1) to discover the general positional features of the two generations, (2) to explore the representations of the cross-generational differences, and (3) to predict the possible tendencies of synchronic changes.
Four types of vowel charts are adopted in this research with the theory of Vowel Pattern, namely, the acoustic vowel chart, the V-value chart, the main distribution chart and the skewness chart. Major findings are listed as follows:
Firstly, with the observation of the acoustic vowel charts and the V-value charts of two generations in seven cities, it is found that the basic vowels keep a relative sh relationship under the same acoustic vowel space. The basic Vowel Pattern in Zhongyuan Mandarin is made up of three levels both in the high/low dimension and in the front/back dimension. The vowels /i/, /u/, and /a/ in Zhongyuan Mandarin respectively take the highest and frontmost, the highest and most back, and the low central positions in the triangle configuration of the vowel space.
Secondly, by means of normalization and relativization, the main distribution vowel charts are established to identify the characteristics of vowels in the two generations. The standard values in the two dimensions are deemed to be available in revealing the different features of vowels. Since the acoustic representations can reflect the articulatory characteristics, the acoustic features of vowels represented in the two generations can be converted into the articulatory characteristics.
The OG devotes full effort to the articulation of the basic vowels while the YG puts less effort in articulating the same vowels (with an exclusion of /u/). This conforms to the Principle of Least Effort (the Economy Principle). It means that the YG tends to decrease the movement of the tongue and lips to convey the same messages.
It seems that the YG had put more effort in the articulation of /u/ for it is featured with not only [+BACK] but also [+HIGH]. Actually, this is the combined effect of the Economy Principle (the Principle of Least Effort) and the Principle of Discrimination.
Finally, by calculating the data of vowels from two generations in the seven cities with a set of algorithms, it is possible to observe the tendencies and directions of the vowels with the observation of skewness chart:
/i/ has the tendency of fronting and lowering; /y/ has the tendency of fronting; /u/ has the tendency of fronting and raising; /a/ has the tendency of raising and backing and /ə/ has the tendency of centralizing. Among the tendencies, the fronting of /i/ and the backing and raising of /a/ are proven diachronically and synchronically in Chinese dialects and other languages.
Conclusion
The current study makes a comparative study of basic vowels in two generations. By combining experimental methods with the recording samples taken from PPLRC in Henan Province, it attempts to explore the characteristics of the cross-generational differences and to predict the direction of synchronic changes. It might to be innovated as well as significant in two aspects.
For one thing, this study is deemed to enrich the experimental study of the Henan dialect. Even though experimental ideas have been introduced to the study of the Henan dialect in recent years, it still needs deeper and wider investigation. The quantity as well as the quality is badly in need of experimental studies in the Henan dialect.
For another, through the combination of recording materials of PPLRC with experimental studies, it can check the correctness of phoneme identified by traditional auditory discrimination. The method proposed in this article is instructive to the further research of materials of PPLRC. It is hoped to make a modest contribution to the post-project study.
However, due to the fact that the study is lacking in a larger size of samples, the present study leaves a big research gap for future study. Larger samples of investigation should be conducted, especially in comparing the speech samples from the urban areas with those from the rural areas. This is believed to get more clues for sound change.
In addition to the Vowel Pattern, there are also Tone Pattern, Consonant Pattern, and even Intonation Pattern worthy of discussion. We will solve these issues for further research.
Footnotes
Acknowledgements
We would like to express our sincere gratitude to the four anonymous SAGE Open reviewers for their valuable suggestions and constructive comments. We also wish to thank Prof. Xiangling Li and Prof. Feng Shi for their guidance and support in writing this paper, Zixia Fan, Huijuan Hu, Jingwen Huang, Wei Wu, and Feng Xu, for their aids on technique in data processing, and Yaguang Duan, Bing Lu, Yingjie Lyu, Joe Salmons, Shaoshuai Shen, Xin Wang, and Yongfen Xin for their comments on earlier drafts of the current paper. We alone are responsible for all errors in this paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study is supported by the National Social Science Foundation of China (21&ZD286).