
Abstract
Credit default has always been one of the critical factors in the development of personal credit business. By establishing a default identification model, default can be avoided effectively. There are some existing methods to identify credit default. However, these methods have some problems: Problem (1): It is different to deal the non-linear data, Problem (2): The local stagnation results in the high error rate, and Problem (3): The premature convergence leads to the low classification rate. In this paper, the sinhTSA-MLP default risk identification model is proposed to solve these problems. In this model, the proposed sinhTSA method can effectively avoid the problems of falling into local optimum and premature convergence. And the benchmark test results demonstrate sinhTSA is superior to other methods. According to the two experiments, the classification rate reaches 77.35% and 96.48%. Therefore, the sinhTSA-MLP default identification model has some particular advantages in identifying credit problems The feasibility of the sinhTSA-MLP default identification model has been proved through helping to manage credit default more consciously.
Introduction
Credit risk, also known as default risk, refers to the risk of economic loss caused by the failure of the counterpart to fulfill the obligations in the agreed contract (Oreski & Oreski, 2014). Trustees ignore the obligation of repayment of principal, interest, causing that the expected return of the grantee may deviate from the actual return, which is the primary type of financial risk (Ramos-Tallada, 2015). In recent years, due to the non-rich research in credit default, the international economic growth is weak. Among the banks, the management and control mechanisms of credit default is not advanced yet and the insufficient information making the research on credit default confronted with many challenges (Butaru et al., 2016). Therefore, there is a need to create a systematic prevention and control mechanism. That is to say, the involvement of research on credit default, the establishment of a forward-looking default supervision system, and the reinforcement of the supervision default prediction and default identification are necessary.
With the increasingly diversified assets of financial institutions and the rise of internet finance, the management of credit assets becomes more complex, making bank credit face more accordingly defaults (Ozbayoglu et al., 2020). The loss of bank capital caused by the credit default not only affects the survival and development of the bank itself, but also causes the chain reflection of the correlation (Bhattacharya et al., 2020). To achieve risk control, traditional financial institutions often build credit scoring models based on a rule or statistical analysis of historical data. The traditional customer credit default identification system has been challenging to meet the actual needs. Therefore, the proposal of an appropriate and effective method to identify credit default has become the dominating intersection point of many scholars and practical applications (Wang, Ma, et al., 2014).
Many methods have been proposed to address credit default identification problems (Chou et al., 2017; Liu et al., 2019), which can be divided into three categories: specialized judgments (Huang et al., 2005), statistical methods and Computational Intelligence (CI) approach (Chou et al., 2017). The most common method of CI credit default identification, the supervised learning method is better than that of the traditional methods (Carcillo et al., 2021; Zhang et al., 2021). At present, the traditional methods contain Random Forest (RF; Rao et al., 2020), Decision Tree (DT) (Abri Aghdam et al., 2021), Logistic Regression (LR; Fan et al., 2020), Support Vector Machines (SVM; Danenas & Garsva, 2015) and so on.
Credit default identification, belonging to supervised learning in machine learning, has an explicit target variable—the type of customer (Jordan & Mitchell, 2015; Ping & Yongheng, 2011). With the evolution of artificial intelligence, artificial neural networks (ANN) is employed to forecast credit default (Lopez-Garcia et al., 2020; Thomas, 2000). The construction process of supervised learning is the same as that of the traditional method, which follows the basic business norms (Rtayli & Enneya, 2020). The independent and dependent variables, including many typical indicators and good or bad samples, are determined by the business needs. In essence, machine learning does not have an impact on the existing credit business from the practical application and there is some room for promotion and application. Owing to the complex and non-linear characteristics of the financial market, these methods generally have limitations in timeliness and data integrity so that the comprehensive and reliable risk control can not be achieved. What’s more, the phenomena of local stagnation and premature convergence constantly emerge (Malhotra & Malhotra, 2003; Pławiak et al., 2019). Consequently, the traditional statistical methods are not suitable for the analysis of complex, high dimensional and noisy data.
To summarize, in the big data environment, according to the features of massive transaction data, the improved artificial neural networks are emerging, which can solve the problem of high-level, complex data (Falavigna, 2012; Meng et al., 2021), and it has been applied in the field of intelligent finance and big data risk control. Under the financial background, the model can be trained to quickly identify credit default identification. The Multi-Layer Perceptron (MLP) method has high accuracy in the classification problems and real-world problems (Feng et al., 2020; Mohammadi et al., 2021). The MLP with a hidden layer is a typical architecture of the ANN. It needs to be optimized since it always falls into local optimum when dealing with massive data (Meng et al., 2021). In solving specific problems, traditional swarm intelligence methods are relatively perfect and mature (Ertenlice & Kalayci, 2018). This triggered us to utilize the swarm intelligence methods to optimize the weights and biases term of MLP to achieve the optimal performance (Meng et al., 2021; Mirjalili et al., 2012). Because of the merits, MLP can effectively prevent credit risks and reduce the non-performing loan ratio. MLP complies with the development trend, giving full play to new advantages such as the internet and big data, which compensates for the shortcomings of traditional default identification methods, and provides more space for improving the ability of credit default identification In this paper, the swarm intelligence optimization method optimizes the weights and biases of the MLP mainly used in the field of credit default identification, which makes up for the limitations of traditional technology.
Tree-Seed Algorithm (TSA) is a swarm intelligence optimization method to imitate the way of propagation between trees and seeds (Kiran, 2015). At present, TSA method has been applied in many fields: engineering optimization (Jiang et al., 2020a), symmetric traveling salesman problem (Cinar et al., 2020), optimal power flow problem (El-Fergany & Hasanien, 2018). Compared with traditional and some meta-heuristic method, it has space for research and development due to the characteristics, such as fewer parameters (Kiran & Hakli, 2021) and easy to implement (Jiang et al., 2020b). Meanwhile, many scholars have been concerned, and many variants have been proposed to improve the performance and solve the real- world problems showing in Table 1. These variants also have produced very significant results in their areas. It is worth mentioning that TSA is not enough to optimize the MLP processing massive data, so it is necessary to propose a TSA variant to enhance the performance of TSA and further optimize MLP.
The Exiting Variants of the Basic TSA.

Here, we can get the motivation of this paper:
The MLP credit default risk identification model can effectively identify credit default problems.
The TSA variant improves the MLP performance to obtain the precious classification rate.
From two aspects of MLP and swarm intelligence optimization method, this paper aims to build a credit default identification model based on an intelligent optimization method. To achieve the above research objectives, the following research contents are drawn up:
Firstly, based on the TSA, candidate and adjustment mechanisms are introduced to propose the TSA variant called sinhTSA.
Secondly, the sinhTSA-MLP credit default identification model is proposed to obtain the default results and improve the final classification rate and accuracy.
Thirdly, the feasibility and effectiveness of the proposed sinhTSA-MLP default identification model are verified by financial credit identification data.
Literature Review
Theory
With the rapid development of personal consumer loans, it is common to occur default events. In fact, there are many factors influencing credit default. Due to asymmetric information, banks and other lenders are in a relatively weak position, while borrowers are the opposite. Banks often do not have knowledge of the borrower’s repayment motivation, repayment ability and “project risk” (Ma, 2020). Currently, in the risk control process, the first and second lines of defense of banks are usually due to the emergence of obvious risk indicators. It is a typical stop loss risk control method, such as too many overdue days of loans, loss of contact with borrowers, etc. There is a certain lag in risk identification and remedial measures. According to the possibility of repayment, the classification of loan risk is divided into default and non default, so as to reveal the real value of the loan. Personal credit default is related to the characteristics of individual loans (Zhang, 2013), including age, education level, length of service, residence, family income, loan income ratio, credit card debts, other debts, sex, the value of fixed assets, loan term, whether mortgage, the family structure and so on. For example, Women prefer stable and are less likely to choose default than men.
Data Mining Techniques
Logistic regression (LR) can predict the credit risk of the small and medium-sized enterprises for financial institutions (Zhu et al., 2016) and consumer default risk (Costa e Silva et al., 2020). Naive Bayes (NB) is a classification method based on Bayes theorem and independent assumption of feature conditions (Chen et al., 2020). The two most widely used classification models are the decision tree model (Zhou et al., 2021) and naive Bayesian model (NBM; Yager, 2006). The first payment default (FPD) loans prediction is solved by the NB (Koç & Sevgi̇li̇, 2020) K-Nearest Neighbor (KNN) not only applies to the consumer credit risk (Kruppa et al., 2013) but also it can apply in bank loan default prediction (Arora & Kaur 2020; Kou et al., 2014). Consequently, it can be concluded that KNN has a great prospect in predicting credit default.
This paper uses hybrid model to identify credit risk. Hybrid model refers to using relevant data to generate several learners based on certain rules, and then integrating the above learners into a model through some algorithm model integration strategy. In the model output stage, the results of each learner are fused by using the pre-determined judgment criteria, and the final output is the output of the hybrid model. Through the proposed model, this paper selects two data sets and judge whether the customer is defaulted by taking the influencing factors as the input.
Method
Tree-seed Algorithm
Tree-seed Algorithm (TSA) is a heuristic method that simulates the propagation behavior between trees and seeds. And there are the following several essential parts.
Firstly, trees are generated through the initialization phase.
Secondly, seeds are generated through parent tree controlling by the search tendency (ST).
Thirdly, when the fitness value of seed is less than that of the tree, the tree is updated by seed.
Finally, when reaching the maximum iterations, the optimal global value is obtained.
Multi-Layer Perceptron
Multi-Layer Perceptron (MLP) has been widely applied to the finical problems (Chen et al., 2016). For example, it obtains superior outcome for the bankruptcy prediction of Iranian companies (Mokhatab Rafiei et al., 2011).
MLP is one of the Artificial Neural Network (ANN; Turkoglu & Kaya, 2020). In addition to the input and output layer, it can have multiple hidden layers between the input layer and the output layer. Equations (1)–(4) complete the whole MLP optimization process.
Firstly, calculate the weighted sum of the inputs by equation (1):

Secondly, calculate the output for the hidden nodes by equation (2):

Thirdly, calculate the result of the hidden node to get the final output by equations (3) and (4):

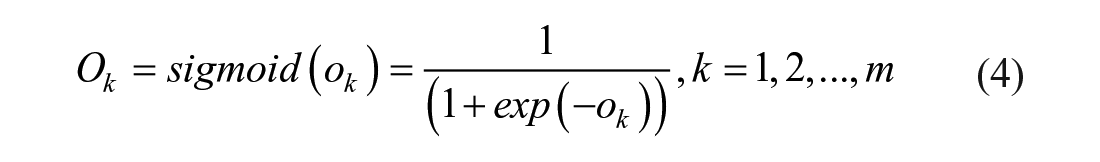
where n is the number of the input nodes, Wij indicates the weight linking the ith input layer node and the jth hidden layer node. Xi presents the ith input. wjk is the weight connecting between the jth hidden node and the kth output node. θj and θ
Proposed sinhTSA
The candidate mechanism
The candidate mechanism is considered to enhance the global diversity and the ability of exploration. And it can adjust the convergence speed based on the original TSA, guiding the optimal global solution.


where, the
An adjustment mechanism k with iteration
The main contribution is the definition of suitable hyperbolic coefficients, the dynamic regulation of the expansion factor coefficient with the iteration, inspiring by the hyperbolic function as shown in equation (7).

The hyperbolic coefficients (k1, k2) changes with the number of iterations, where coefficients k1 and k2 are updated by equations (8) and (9).


In the basic TSA, the seed generation mechanism results in premature convergence. Meanwhile, tree update mechanism leads to local stagnation. The hyperbolic coefficients that can reduce the local stagnation and increase the global diversity to a certain extent. The adjustment coefficients k1 and k2 are variables that decrease to negative numbers with the number of iterations. At the end of iteration, it can help the fine-regulation of the current search area to find the global optimum.
Through the above analysis, the new seed production mechanism is the effective combination of the two mechanisms. The equation (10) utilizes the candidate and adjustment mechanisms to generate the seed based on the current and random trees when the ST is less than the random constant. This generation method increases the global search diversity and decrease the possibility of local stagnation. On the contrary, equation (11) computes the seed generation position. This mechanism is based on the current, best and random trees to generate seeds. This mechanism can efficaciously increase the accuracy of finding the optimal global solution, avoid premature convergence, and accelerate the convergence speed.


IEEE CEC 2014 benchmark test functions are used to verify the superior performance of the sinhTSA, which includes unimodal, multimodal, hybrid, and composition test benchmark functions. To fully test the searching precision and convergence rate of the proposed sinhTSA, eight representative methods are employed to compare the performance including GA (Holland & Reitman, 1977), ABC (Karaboga & Ozturk, 2011), BA (Yang & He, 2013), DE (Wang, Li et al., 2014), SCA (Mirjalili, 2016), BOA (Arora & Singh, 2019), EST-TSA (Jiang et al., 2019), and STSA (Jiang, et al., 2020b). The parameter settings of the eight methods are shown in Table 2. Table 3 shows the experimental results on the standard test set, and the best results are reflected in bold. The smaller the value, the better performance of the sinhTSA. Table 4 shows the Wilcoxon rank sum test, and it is also a nonparametric method to test whether there is a significant difference in the distribution of the population from which the two paired samples come. When the p-value is less than α, it presents the sinhTSA is superior to other algorithms. It can be seen from Tables 3 and 4, the sinhTSA has advantages on dealing with complex problems. Hence, the sinhTSA can train the MLP and form a model to identify credit default.
The Initial Parameters Settings for Corresponding Methods.

The Results of the sinhTSA and Other Methods.

The Results of the Wilcoxon Rank Sum Test for the sinhTSA and Other Methods.

The Proposed sinhTSA-MLP Credit Default Identification Model
The sinhTSA-MLP Credit Default Identification Model
We use sinhTSA to construct the credit default identification model. Through the continuous optimization of weights and biases, the performance of MLP has been improved, which has achieved the effect of enhancing classification rate and reducing the error rate.
Parameter Setting and Criteria
The sinhTSA-MLP is compared with other methods to verify the ability of the proposed method for credit default identification. Table 4 shows the comparison method parameter settings. Meanwhile, reasonable evaluation criteria are of great importance, and in the paper, equation (12) computes the mean squared error (MSE).

where m is the number of outputs, d

where s is the number of training samples. There are some uncertainties in training MLP, where MSE for the sinhTSA method is consistent to the equation (14).

The error rate is one of the criteria of the evaluation model (Jain & Duin, 2000; Lessmann et al., 2015) and it is not sensitive to the classification accuracy of the model. Therefore, the error rate is a criterion in the paper.
Description of the Data
This Taiwan Data Set was selected because it is widely used and compares the predictive accuracy of default probability among six data mining methods. In order to further verify the effectiveness of the proposed method, the South German Credit (UPDATE) Data Set is chosen.
Taiwan data set
The data from an important bank (a cash and credit card issuer) in Taiwan from April to October, 2005 is adopted to train and verify the proposed default identification model. The data from the UCI, which includes a total of 25,000 observations, and 5,529 observations (22.12%), are the cardholders with default payment. In the paper, the binary variables are used (Yes = 1 and No = 0). As shown in the Table 5, the 23 variables are selected as inputs and the default is selected as output (Steenackers & Goovaerts, 1989; Yeh & Lien, 2009).
The 23 Variables for Taiwan Data Set.

South German credit (UPDATE) data set
The data donated by the German professor Hans Hofmann via the European Statlog project is obtained from the UCI dataset. The 20 variables (status, duration, credit history, purpose, amount, savings, employment duration, installment rate, personal status sex, other debtors, present residence, property, age, other installment plans, housing, number credits, job, people liable, telephone, and foreign worker) are selected as inputs and the default is selected as output (Fahrmeir & Hamerle, 1981).
For Taiwan Data set, one-half of the data is used to train the model, and the remaining dataset is used to validate the model (32.43%). For South German Credit (UPDATE) Data Set, 50% of the data was used for training and 50% for verification. To reduce the impact of variable inconsistency, this paper preprocesses the data referring (Yu et al., 2012) to compute.
Empirical Analysis and Suggestion
According to the deal data, we can see the distribution of gender, marriage, education, and age among the defaulting customers.
For Taiwan Data Set. Figure 1 shows the proportion of customers in different situations. Through the analysis of the experimental results, it can be seen that the features of defaulting users are uneven, and women are more likely to default than men. Graduate school tends to default. Subscribers of different ages have different degrees of default risk.
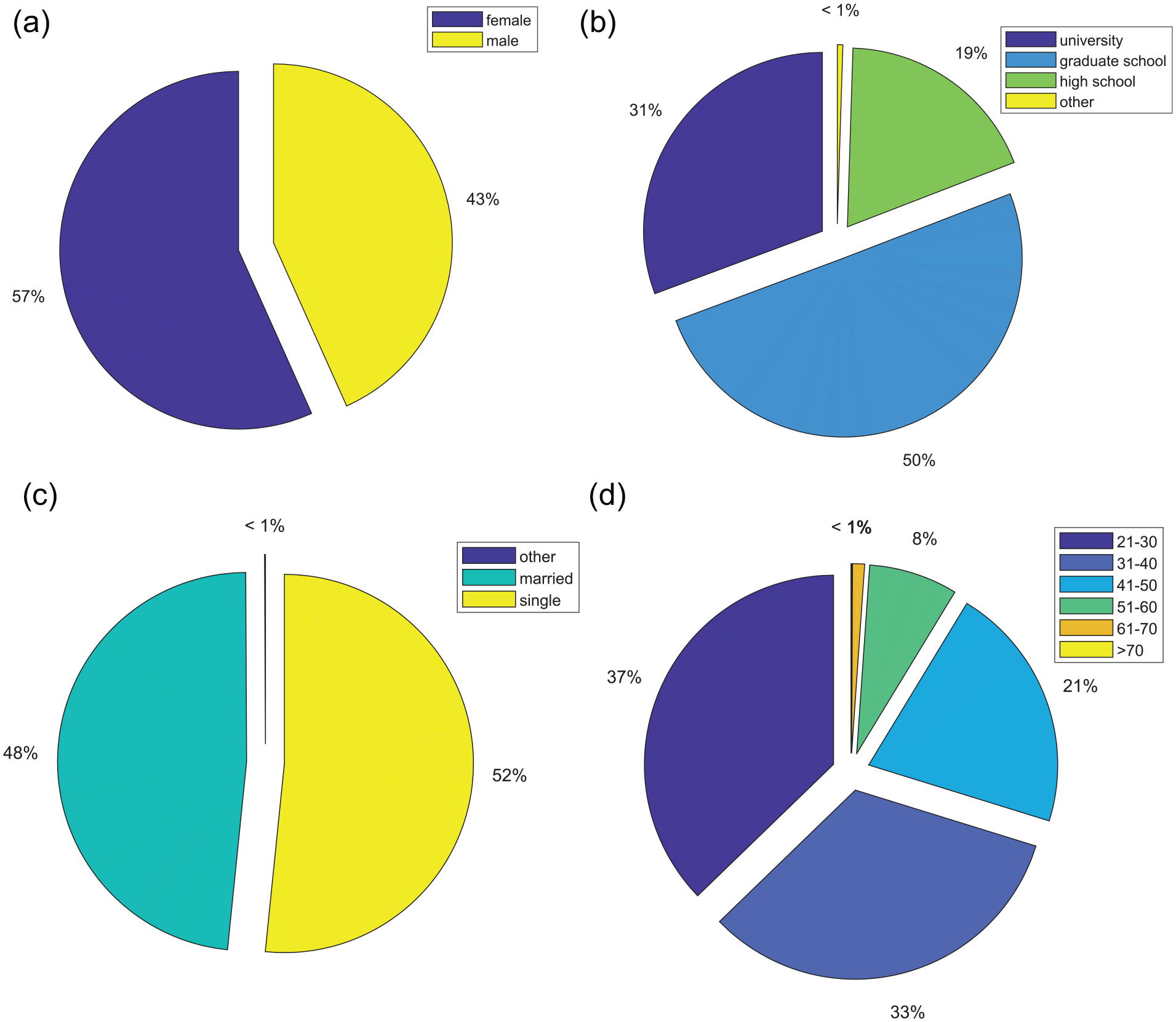
Different characteristics of defaulting customers: (a) Proportion of male and female customers in default, (b) Proportion of default customers with different education level, (c) Proportion of default customers with different marriage status, and (d) Proportion of default customers with different age.
For South German Credit (UPDATE) Data Set, Figure 2 shows the debtors’ some characters. Through the experimental results, it can be seen that the features of defaulting users are uneven, and married men are more likely to default than divorced men. Both renting housing and no counting saving debtors tend to default.

Different characteristics of defaulting customers: (a) Proportion of male and female customers in default, (b) Proportion of quality of debtor’s job, (c) Proportion of housing the debtor lives in, and (d) Proportion of debtors savings.
Analysis and Discussion of the Credit Default Identification Through the sinhTSA-MLP
In order to verify the performance of the proposed model in identifying credit default, some models are compared together, such as PSO-MLP (Mirjalili et al., 2012), DE-MLP (Wang, Li, et al., 2014), TSA-MLP (Kiran, 2015), GWO-MLP (Mirjalili, 2015), SCA-MLP (Mirjalili, 2016), GA-MLP (Singh & De, 2017) and AGWO-MLP (Meng et al., 2021). In this section, sinhTSA combines with MLP to identify the credit default. For the results, the final classification rate and error rate are the criteria to evaluate the performance of the sinhTSA- MLP.
Taiwan data set
From Table 6, the sinhTSA has the highest final classification rate and the lowest error rate. That is because sinhTSA has strong exploration ability and the ability to avoid local optimum. In short, in this data set, the credit default identification model’s classification accuracy and performance using the sinhTSA method are improved.
The Results of the Taiwan Data Set.

South German credit (UPDATE) data set
From Table 7, the sinhTSA-MLP has the highest final classification rate and the lowest error rate. The GWO-MLP, DE-MLP, PSO-MLP, SCA-MLP, and AGWO-MLP have the same classification rate, but the error rate is different. It can be seen that the performances of convergence, exploration and exploitation for algorithms are different to update the MLP. From the results, it can be concluded that sinhTSA has a strong exploration ability to avoid local stagnation and it can effectively update the weights and biases of MLP to improve the classification rate.
The Results of the Credit Default Identification.

It can be seen from Tables 6 and 7 that sinhTSA-MLP has certain advantages in credit default identification. Compared with the basic TSA-MLP, GWO-MLP, AGWO-MLP, DE-MLP, PSO-MLP, SCA-MLP, and GA-MLP, sinhTSA-MLP can obtain a higher classification rate and lower error rate. The error rate proves that sinhTSA has strong global search ability, effectively balances the exploration and exploitation, and avoids the local stagnation to improve the convergence speed. These abilities can enhance the performance of the sinhTSA-MLP credit default identification model. Through the error rate, it can be seen that over fitting will occur in the classification process. However, the precious classification rate can be obtained, which can be proved that sinhTSA-MLP is an effective credit default identification model.
Countermeasures and Suggestions
Through the above experimental results and discussion, countermeasures and suggestions are put forward as follows:
Bank managers should establish a predictive risk supervision and management system to strengthen the control of credit default. We should make a systematic and comprehensive risk response mechanism to strengthen the industry’s handling and response-ability to uncertainty. We can effectively resolve the default risk of non-performing loans in commercial banks by increasing the risk reserve for the imperfect system.
Different approval fluency and mechanisms, such as different repayment periods, loan lines, and different types of customers are set for customers with different economic strengths.
In order to handle the banking business, the customer’s credit database is built to record the monthly repayment situation.
From the perspective of the policy-making level, a knowledge system should be formed according to the accumulation of practical application data. Besides, policy terms should be timely updated to prevent new credit risks. Taking the macro-economy as the premise, it is advisable to measure the current and long-term risk of credit loans and predict the possibility of future losses of bank credit business, so as to effectively resolve the default risk of bank non-performing loans. What’s more, it is essential to clarify management regulations, implement the application of information technology, and utilize digital thinking and computational thinking, making more optimized and rational decisions.
Conclusion and Future Prospects
Conclusion
Credit default identification is complex and highly nonlinear. Default identification and evaluation models, such as support vector machine models, expert systems, etc., are constantly emerging. However, credit default identification is still a challenging problem. Different models need to be combined with varying application objects to accurately predict the actual credit process risk. This paper integrates swarm intelligence optimization method and MLP effectively to identify credit default. According to the No Free Lunch theorem, the swarm intelligence optimization method, TSA has some shortcomings. Therefore, a variant of TSA called sinhTSA is first proposed, innovated by the candidate and adjustment mechanisms. The sinhTSA is tested by the IEEE CEC 2014 benchmark test functions and compares with the EST-TSA, STSA, DE, BA, GA, SCA, ABC, and BOA. It is superior to these methods in terms of exploration ability and local optimum avoidance. It can demonstrate the sinhTSA can deal with complex and real-world problems.
With the rapid growth of personal credit assets, the risk of personal credit assets is gradually showing, which has aroused social attention, regulatory authorities, and banks themselves. Accurately grasping the risk situation of personal credit business and promoting the sustainable and healthy development of personal credit business are essential for the manager. Therefore, it is necessary to conduct in-depth research on the current risk situation and management means of personal credit to exactly understand the problems existing in the development of private credit.
The sinhTSA-MLP credit default identification model is proposed to identify credit default. Based on results, sinhTSA-MLP credit default identification model obtains the highest classification rate and lowest error rate among comparative methods-MLP credit default identification models. The classification rate of the sinhTSA is highest at 77.3565% and 96.8% with the lowest error rate.
By analyzing the experimental results and applying the method, the corresponding countermeasures are given to reduce the possibility of customer default and minimize the default risk.
Future Prospects
Though the accuracy of default identified by this model is high, other users’ behaviors, such as whether they have car loans and housing loans, can be considered in future research to achieve a better prediction.
The artificial neural networks method has high accuracy in credit default identification, which can effectively prevent credit default from happening. It can be further improved to build credit risk identification, for example, finding an appropriate structure and coordinating the parameters based on gradient learning algorithm. At the same time, more complex artificial neural networks should be chosen to identify credit defaults.
Footnotes
Acknowledgements
The authors are grateful to the financial support by the Foundation of the Education Department of Jilin Province, China (nos. JJKH20200141KJ, JJKH20210133KJ).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The Foundation of the Education Department of Jilin Province, China (no. JJKH20200141KJ, JJKH20210133KJ);