
Abstract
This study aims to reveal the predictors of individuals’ financial behavior associated with credit default for accurate and reliable credit risk assessment. Within the scope of credit use research, a systematic review of 108 studies was performed. Among the reviewed studies, a fair number have analyzed the determinants of default and delinquency. A remarkable number has examined the factors affecting outstanding and problematic debt levels, and some have investigated the financial behavior in terms of responsibility, debt repayment, and credit misuse. A wide range of socioeconomic, demographic, psychological, situational, and behavioral factors was explored, and their role in predicting the investigated outcome domain at various time-points was analyzed. The main analysis techniques and mix of predictors in papers also differed based on different time periods. While the synthesis of findings revealed some strong and consistent predictors for each outcome variable, mixed results were obtained for some factors. Additionally, a cluster of new practices that includes a wide range of alternative factors to improve prediction accuracies were uncovered. Study findings revealed a paradigm shift regarding the use of non-traditional data sources, especially big data, and novel techniques.
Introduction
In recent years, socioeconomic developments and the spending patterns of individuals and populations have expanded the use of credit. Since individuals use credit to fulfill various needs, lending has started to produce more revenue for banks and other financial institutions. Credit can boost the economy and solve cash-related issues in the markets when used properly. Nevertheless, they inflict damages and disruption to the economy when used carelessly (Alma Çallı, 2019). The root causes of the credit crisis in 2008 are still unresolved. On the other side, the unpaid amount of credit worldwide has doubled in accordance with the lending rate of 2008, and more credit decisions are being made on an ongoing basis (van Thiel & van Raaij, 2019). Financial organizations should analyze credit applications based on scientific methods to prevent economic and social damages (Alma Çallı, 2019) and reduce credit risks.
Credit risk-related research is vital for guiding new researchers and practitioners who want to improve their credit risk management practices. For this reason, algorithms integrating various criteria and models have been developed to predict risk-based credit scores (Alma Çallı, 2019). The study of Durand (1941) is the most significant first phase in developing credit scoring techniques. Risk factors were determined, and their weights were calculated empirically for the first time. Nonetheless, past payment behavior and behavioral variables that are closely related to default risk were not considered. Capon (1982) reported that the characteristics of applicants, which are directly and closely related to credibility, were ignored in credit scoring models at that time. However, after the 1980s, the focus was on searching for new predictor variables, as computers and statistical programs became accessible and powerful (Bumacov et al., 2017).
After the 1990s, the subject of default risk gained renewed interest as a consequence of the introduction of the Basel Capital Accords, which had a profound effect on credit risk management processes. With the introduction of Basel II in 2004, banks had to calculate their risks on the basis of the ratings given to their borrowers by their internal rating mechanisms. Accordingly, similar to banks and non-bank lenders, academics had to concentrate their interest on examining default predictions (Ciampi et al., 2021). In addition to the momentum of Basel II, during the period of the financial crisis in 2008, policymakers, banks, and other lenders were firmly committed to controlling the consequences of the gradual rise in defaulted loans. Therefore, the need for better default prediction models has substantially enhanced and become the focal point of the academic and managerial arguments (Oliveira et al., 2017). Consequently, new environmental developments typically increase scholarly and professional interest in a specific research field. The most significant environmental effects in credit scoring are the gradual growth in information storage and computing power, along with the introduction of the Basel accords, which suggest a shift in how to manage credit risk (Louzada et al., 2016).
According to the findings of Onay and Öztürk (2018), the most studied topics in credit risk-related research are “statistical methods and accuracy” and “new determinants of creditworthiness.” Moreover, Louzada et al. (2016) discovered that the most common objective of the papers related to credit scoring was the suggestion of new techniques. After the release of the Fair and Accurate Credit Transactions Act in 2003, the topic of “regulations” became common among the studies during this period. After 2010, there has been an increase in the number of studies examining new variables related to creditworthiness. Further, the regulations renewed to overcome the risk management difficulties in the digital era have increased the relevant research output in the field (Onay & Öztürk, 2018).
When the review studies on the subject are examined, although the general trend of these studies is to explore the default prediction models, it is seen that their subgoals and scopes are quite different. Some of them focus on more specific topics and areas, including data mining applications (Sadatrasoul et al., 2013), evolutionary computing techniques (Marqués et al., 2013), binary classification techniques (Louzada et al., 2016), default prediction for SMEs (Kovacova et al., 2019), performance evaluation (Abdou & Pointon, 2011; Lessmann et al., 2015), and evolution of credit scoring topics (Onay & Öztürk, 2018). Some studies are in the form of literature review (Abdou & Pointon, 2011; Kamleitner et al., 2012; Lessmann et al., 2015; Marqués et al., 2013).
Previous literature has not systematically reviewed the predictors of creditworthiness-related outcomes comprehensively to the best of our knowledge. To date, the only available study consolidating dominant themes based on stages of credit use is the study of Kamleitner et al. (2012). However, this is not a systematic review study and concentrated on the main psychological aspects of credit use. Manz (2019) performed a systematic review and investigated the determinants of non-performing loans. The authors reviewed 44 articles, and they synthesized the literature according to three broad themes: macroeconomic events, bank, and loan-specific factors. However, there are many different groups of factors used in default prediction. Manz (2019) called for additional research for the deep understanding of these factors as scholars place a high value on the investigation of credit risk determinants. Furthermore, some other studies pointed out that a thorough understanding of the determinants is needed (Ghosh, 2015; Zhang, Cai et al., 2016). Hence, this was the one source of motivation for this present analysis.
The findings of previous studies have shown that there has been an ongoing effort of researchers to develop risk models with high predictive performance. Therefore, studies have used new techniques and new variables to develop default risk models. Recently, there has been a growing trend toward replacing statistical and traditional machine learning techniques with deep learning techniques (Dastile et al., 2020). In this rising information age, new techniques in credit risk scoring can be the foundation of a financial institution’s continuity (van Thiel & van Raaij, 2019). In this context, this study aims to examine whether there is a real paradigm shift in the field and how default risk models and techniques have changed over time. Digitalization has brought the need for practitioners to transform their processes. In this regard, it is of great importance to determine the state of existing theoretical studies in terms of contributing to this process. Accordingly, this systematic review aims to address the following research questions:
RQ1: What were the predictors of the outcome domain within the scope of this study?
RQ2: How has the mix of predictors evolved over time?
RQ3: How have sample size selections evolved over time?
RQ4: What were the main sample types?
RQ5: Which countries were the subject of the reviewed studies?
RQ6: What were the main analysis techniques in the reviewed papers?
RQ7: How have the main analysis techniques evolved over time?
This study provides several contributions to the related literature. First, to the best of our knowledge, this study is the first to comprehensively analyze credit default predictors and predictors of other creditworthiness-related outcomes. By doing so, this study responds to the calls of other researchers. Second, the present study is different from the review studies in the field in terms of methodology and objectives. As a result of the implementation of the detailed selection criteria and the quality assessment framework, the methodological limitations of the existing studies in the field were revealed.
Further, in contrast to other studies, the investigation of the relationships between variables such as sample type, study design, source of data, and country of the study in the current research provided to identify research gaps in the field. Study findings confirmed a paradigm shift regarding the use of alternative data and novel techniques. Hence, more research in developed countries can get benefit from alternative data sources from digital platforms and advanced techniques. Predictors that are commonly found to have a strong effect on dependent variables are important findings for practical applications. In this context, it can be estimated what kind of personality, attitudinal, behavioral, and situational characteristics will be searched in alternative data sources for digital lending. Big data and the security and privacy issues that related advanced analysis technologies will bring are also significant issues that future studies should address. The remainder of the paper is organized as follows: In section two, a literature review associated with credit default risk and credit risk assessment is presented, displaying the evolution in the field. The methodology part is presented in section three. Section four tackles with analyses and research findings. In section five, research findings are discussed, and contributions of the study are highlighted. The study concludes with the limitations of the research, and future directions are also displayed in this section.
Literature Review
Since default risk refers to the risk of loss that stems from credit users’ incapability to meet the responsibilities of the previously granted credit (Louzada et al., 2016), estimating default probability is critical for effective credit risk management (Ntwiga, 2016). Automation and technological advancements have remarkably changed the decision-making in credit risk management (Anderson, 2007). By the same token, automating processes and quantifying risk calculations have offered fast and reliable decision-making by reducing redundant bureaucratic stages (Abdou & Pointon, 2011). Before credit scoring systems and automation, decisions were based on judgmental approaches. The judgmental approach (5C’s approach) evaluates applicants in terms of factors, including character, capital, collateral, capacity, and condition. The inadequate capacity to process large numbers of applications, vulnerability to misclassification errors, and inaccuracies are among important limitations of this approach (Crook, 1996; Dastile et al., 2020; Sinkey, 1992). Modern principles and thoughts in credit score research emerged with Durand (1941) (as cited in Louzada et al., 2016). For the first time, Durand (1941) attempted to develop an objective credit scoring mechanism by assigning weights to identified risk factors (as cited in Bumacov et al., 2017).
Starting in the 1990s, default risk prediction has gained growing interest thanks to the introduction of the “Basel Capital Accords,” which had a substantial effect on credit risk management practices (Ciampi et al., 2021). After the Basel Accords releases, particularly after Basel II in 2004, the utilization of credit scoring has increased remarkably, not only for decision-making but also for credit risk management (Lessmann et al., 2015; Louzada et al., 2016). The requirement for effective credit risk management has led financial institutions to continuously improve their credit analysis approaches, which caused the implementation of several quantitative techniques (Louzada et al., 2016).
Quantifying the risk assessment reduces the information asymmetry, which occurs when borrowers have more information regarding their ability to repay than lenders. Digital risk management reduces the data dependency coming from borrowers by collecting data from various sources (Leyshon & Thrift, 1999). Technological developments, their pace of diffusion, and advanced approaches such as artificial intelligence have led to increasingly sophisticated decision support systems (Kabari & Nwachukwu, 2013). To establish robust decision support mechanisms for credit risk assessment, the identification of the predictor variables assisting in classifying potential “good” and “bad” credits and the design of the classifiers for prediction are critically important (Abedin et al., 2018; Louzada et al., 2016).
Financial and demographic data has been used as the most common approach in credit risk assessment. However, the lack of some applicants’ financial background has contributed to developing new methods for predicting default risk. A significant number of studies have examined the socioeconomic and behavioral factors behind the probability of default (San Pedro et al., 2015). Besides, personality variables have been analyzed in terms of their effects on default and repayment behavior. Many variables strongly associated with the probability of default have contributed to searching for new data sources representing personality and behavior (San Pedro et al., 2015). Improving risk management is also closely related to gathering more information for profiling clients, and recently big data has great potential for overcoming credit scoring obstacles (Tounsi et al., 2017).
In 2020, the COVID pandemic transformed e-commerce, perhaps more than any period in history. Several brick-and-mortar retailers digitalized their business processes to endure the pandemic (Wertz, 2020). The worldwide growth rate of e-commerce sales was 16.5% in 2020, and it is expected to rise (Samet, 2020). About a decade ago, Wang et al. (2013) stated that the payment method of e-commerce shifted from money transfer to credit transfer, which meant a significant dependence on credit risk management. Besides, both banks and technology giants such as Amazon and Alibaba have rapidly penetrated into the market for lending in the present situation. The quality of credit portfolios has again damaged with the significant expansion of online retail lending and peer-to-peer lending (van Thiel & van Raaij, 2019). Due to transactions performed online, considerable changes occur even within seconds. Therefore, it is not possible to update the indicators used in traditional credit management in real-time. For instance, financial indicators cannot represent an applicant’s real-time credit status which necessitates new approaches. Besides, data scarcity and lack of credit bureaus, especially in developing countries, have driven to seek alternative ways for credit risk assessment recently (Bjorkegren & Grissen, 2018). Hence, non-financial predictors are vital for reflecting a comprehensive picture related to creditworthiness (Wang et al., 2013).
Big data is now changing how financial services, especially credit scoring, are performed (Onay & Öztürk, 2018). Although big data can implement more efficient credit scoring algorithms and offer tailored products/services, it also poses data privacy and security challenges. One criticism is that how scores derived from big data are not adequately protected by the existing laws, and misclassification of applicants needs to be prevented to avoid stigmatization. Regulations are necessary for these novel credit scoring systems to perform objective and accurate credit risk assessments (Citron & Pasquale, 2014). King and Forder (2016) also attracted attention to “lack of transparency” as an important privacy concern. Organizations do not make it clear how they process data on account of commercial confidentiality, which causes information asymmetry between organizations and applicants. Implementation of data analytics facilitates extraction of hidden private information, which can also be utilized for profiling. Consumers become vulnerable to identity theft and fraudulent behavior because of the data that personally identifies them (King & Forder, 2016).
Overview of Factors
A considerable number of the reviewed papers included demographic factors and life events to examine different aspects of the credit use process (Abdou et al., 2008, 2016; Akben-Selcuk, 2015; Chakravarty & Rhee, 1999; Costa, 2012; Dew, 2007; Gardner & Mills, 1989; Gathergood, 2012; Godwin, 1999; Guo et al., 2016; Ismail, 2011; Kim & DeVaney, 2001; Nelson et al., 2008; Nurcan & Bicakova, 2010; Perry, 2008; Rogers et al., 2015; Rutherford & DeVaney, 2009; Stone & Maury, 2006; Šušteršič et al., 2009; Tokunaga, 1993; Wang et al., 2014; Yilmazer & Devaney, 2005; Zhang, Jia et al., 2016). On the other side, a stream of research focused on the investigation of personality factors and attitude of individuals associated with credit risk (Davey & George, 2011; Harrison & Chudry, 2011; Kamleitner et al., 2012; Limerick & Peltier, 2014; Livingstone & Lunt, 1992; Nyhus & Webley, 2001; Rogers et al., 2015; Yang & Lester, 2014; Zainol et al., 2016).
According to Kamleitner et al. (2012), the social practice view of point associated with the credit use process emphasized the economic socialization by examining peer and parental effects on credit use behavior. In this context, social norms, parental instructions and guidance, peer pressure, and parental norms were pronounced within the relevant literature (Griffin & Husted, 2015; Harrison & Chudry, 2011; Lea et al., 1995; Norvilitis & Bat, 2016; Webley & Nyhus, 1998; Xiao et al., 2011; Zainol et al., 2016).
The stream of the research focusing on the processes at the time of credit application mainly considered financial and institutional factors such as terms and conditions of the loan, other loan characteristics, and financial ratios. Different groups of research concentrating on the repayment period of credit use put emphasis on financial literacy, attitudes toward money and credit, social dynamics, spending behavior, consumption patterns, age, income and wealth, socioeconomic status, money management skills, mental health, wellbeing and financial knowledge as correlates of repayment behavior (Baek & Hong, 2004; Brougham et al., 2011; Chakravarty & Rhee, 1999; Costa, 2012; Dahiya et al., 2015; Ganzach & Amar, 2017; Hojman et al., 2016; Jiang et al., 2018; Kamleitner et al., 2012; Limbu, 2017; Masyutin, 2015; Norvilitis, 2014; Norvilitis et al., 2003; Norvilitis & MacLean, 2010; Norvilitis et al., 2006; Ottaviani & Vandone, 2011; Rogers et al., 2015; Sidoti & Devasagayam, 2010; Strömbäck et al., 2017; Vieira et al., 2016; Wang & Xiao, 2009; Wang et al., 2011; Webley & Nyhus, 1998; Zhang & Devaney, 1999).
Overview of Techniques
Estimating the probability of default or determining problematic financial behavior has been routinely performed by employing classification algorithms (Lessmann et al., 2015). Classification techniques can be either conventional techniques including linear regression, discriminant analysis, logistic regression, probit models, or other types of regression analysis, or novel techniques such as neural networks, fuzzy approaches, genetic algorithms, support vector machines, and expert systems (Hand & Henley, 1997). Other proposed techniques for credit risk assessment purposes encompass decision trees, random forests, k-nearest neighborhood, Bayesian networks, and cox proportional hazard model (Abdou & Pointon, 2011; Bjorkegren & Grissen, 2018; Tounsi et al., 2017). In addition to being used individually, these techniques are sometimes combined for establishing hybrid risk assessment models (Dahiya et al., 2015). Currently, ensemble classifiers that can handle different sample characteristics with independently trained multiple classifiers and hybrid models incorporating different techniques are used to improve performance (Dahiya et al., 2015; Hsieh & Hung, 2010; Louzada et al., 2016).
Among the reviewed papers, linear regression was employed by (Joireman et al., 2010; Sidoti & Devasagayam, 2010; Wang et al., 2014), and several studies implemented probit regression for model construction (Bryan et al., 2010; Fay et al., 2002; Gathergood, 2012; Oni et al., 2005; Ottaviani & Vandone, 2011; Wang et al., 2014; Yilmazer & Devaney, 2005). Tobit analysis was used by (Brown et al., 2013; Greene, 1989), and cointegrated vector autoregression (CVAR) was implemented by (Meng et al., 2013).
On the other hand, Chen and Wiederspan (2014) applied a zero-one inflated beta regression model. It was also explored that ordinary least squares regression (Brougham et al., 2011; Grable & Joo, 1999; Hojman et al., 2016; Kim & DeVaney, 2001; Santiago et al., 2011; Strömbäck et al., 2017) and cox regression (Nurcan & Bicakova, 2010) were among other types of regression analyses utilized in the reviewed papers. Additionally, a wide range of papers applied logistic regression (Akben-Selcuk, 2015; Costa, 2012; Ganzach & Amar, 2017; Ge et al., 2017; Masyutin, 2015; Mewse et al., 2010; Rogers et al., 2015; Wang & Xiao, 2009). It was also discovered that some research implemented novel methods, likewise decision trees, neural networks, ensemble and hybrid approaches for estimating the probability of default (Bjorkegren & Grissen, 2018; Guo et al., 2016; Huo et al., 2017; Jiang et al., 2018; Netzer et al., 2019).
Overview of Trends
Because credit risk assessment has been dependent on heavy documentation and financial history over a long period, thin-file individuals referring to those with insufficient credit history have limited access to financial services and credit, especially in developing countries. However, today, social networks and online trading websites provide large amounts of data in a non-structured format and enable access to a wide range of user-profiles (Ntwiga & Weke, 2016). Recent studies emphasized user-developed contents, mobile data, social network profiles, blogs, and forums as data resources to be utilized instead of traditional indicators of financial risk assessment (Ntwiga & Weke, 2016; Pedro et al., 2015). Provost and Fawcett (2013) keynoted the importance of novel data processing technologies and data mining for employing data-driven decision-making. These up-to-date technologies are capable of handling large amounts of data in contrast to traditional data processing systems. Therefore, big data analytics and advanced technologies facilitate extracting valuable information from non-traditional data sources for financial risk assessment (Masyutin, 2015; Tounsi et al., 2017). Accordingly, mobile data and social networks revealing the behavioral profile of individuals and advanced data processing technologies have contributed to shifting to digital credit, which is granted online (Bjorkegren & Grissen, 2018).
Depending on the fact that microfinance offers small loans to unbanked and low-income individuals without bureaucratic processes and heavy documentation, primarily through online platforms (Kagan, 2020), the microfinance sector, especially in developing countries, has recently become larger (Blanco et al., 2013). Hence, digital credit lending with automated systems capable of extracting data from a wide range of resources and faster decision-making mechanisms enable microfinance business and peer-to-peer lending (Blanco et al., 2013). The popularity of these platforms and their increasing number of applications have caused a recent research stream that focuses on alternative data for capturing indicators of behavior and personality for sociodemographic profiling (Bjorkegren & Grissen, 2018; Guo et al., 2016; Huo et al., 2017; Jiang et al., 2018).
Methodology
The method of the present review is in line with the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) (Moher et al., 2009; Petticrew & Roberts, 2006) and the systematic reviews (Al-Emran et al., 2018; Louzada et al., 2016; Merkouris et al., 2016). Besides, 12 review studies related to credit use or default prediction were examined for the development of the study. The list of these studies is demonstrated in Supplemental Materials.
Data Sources and Search Strategies
We conducted a systematic search to explore all appropriate peer-reviewed and grey literature that examine predictors of credit default and related outcomes. According to Godin et al. (2015), sole dependency on peer-reviewed literature can result in the absence of potentially important work. Search methods should aim to find all records that meet the pre-defined inclusion and exclusion criteria. PRISMA reporting guidelines also suggest using grey literature, provided that it complies with the selection criteria (Moher et al., 2009). Although some forms of publication can be found in some databases, such as Google Scholar, for other forms of grey literature on the Internet, Google search can also be performed (Godin et al., 2015). Thus, both database search and Google search were conducted for this study. Regarding the database search, this systematic review utilized the following databases: ScienceDirect, Taylor & Francis Online, Elsevier, Springer, ERIC, Google Scholar, ACM Digital Library, and SAGE.
Halevi et al. (2017) compared Google Scholar to the databases such as Scopus and Web of Science and discovered that Google Scholar’s coverage has dramatically increased over time, making it a valuable source of academic literature. According to Harzing (2010), Google Scholar’s scope is broader than ISI and Scopus in terms of sources and longer than Scopus in terms of time. Google Scholar includes a considerably higher number of studies than both Web of Science and Scopus (Harzing & Alakangas, 2016).
Scopus is mostly an indexing/citation database that includes a wide variety of journals but does not include full-text articles from those journals. The ScienceDirect archive contains full-text articles in those indexed journals in the Scopus (Elsevier, 2018). Consequently, Google Scholar and ScienceDirect were used for retrieving papers. As Elsevier, Taylor & Francis, Springer, and SAGE are considered among the largest publishers of journals (Laakso & Björk, 2016), they were also taken into account for database search. ACM Digital Library was included since it is considered the top database for the computer science discipline, which has contributed to credit use and risk management research by mainly focusing on classification techniques and more novel methods. The search terms included the keywords “creditworthiness,” “credit use,” “credit scoring,” “repayment behavior,” “probability of default,” “probability of delinquency,” “indebtedness,” “level of debt,” and “problematic debt.” The search resulted in 705 studies, and their distribution based on databases is demonstrated in Table 1.
Distribution of Studies.

Besides, based on Godin et al. (2015) and Merkouris et al. (2016), the top 10 pages on Google were analyzed for each search term. However, most of the potentially relevant records provided insufficient information for making a judgment based on the inclusion and exclusion criteria. Other reasons for exclusion are presented in the Supplemental Materials. Consequently, none of the potentially relevant records obtained by Google search could be included. Table 2 represents inclusion and exclusion criteria. These criteria were chosen in a way that allows us to make the analyses we targeted and are related to the objectives of the study.
Inclusion and Exclusion Criteria.

Although default, bankruptcy, delinquency, and insolvency have different meanings in credit utilization research, they are closely related and widely used to investigate risky credit behavior (Ntwiga, 2016). The use of credit is a multifaceted and complex phenomenon that should be approached from an interdisciplinary perspective. The concepts of over-indebtedness, problematic/outstanding debt, probability of default, irresponsible financial behavior, and credit misuse are interrelated. Chronic borrowers may exhibit common attitudes and behavior regarding excessive borrowing on credit and debt, irresponsible financial behavior, and credit misuse. As a result, the likelihood of default due to over-indebtedness may increase. In this context, the factors associated with over-indebtedness, problematic/outstanding debt, probability of default, irresponsible financial behavior, and credit misuse are all critical for having a profile of high-risk borrowers (Microfinance Center, 2014).
This study aims to reveal which variables can be effective while evaluating the credit default risk of individuals. For this purpose, this systematic review included the studies that considered outcome variables defined as “probability of default/delinquency/bankruptcy,” “probability of debt repayment difficulty,” “outstanding level of debt,” “problematic debt,” “repayment of debt,” “credit misuse,” “debt repayment behavior,” “level of indebtedness,” and “financial behavior.” Therefore, the first selection criterion was determined to include the studies dealing with these output variables. Another purpose of the study is to determine what percentage of the studies in which the relevant analysis was performed reached statistically significant findings for each dependent-independent variable relationship. Accordingly, the percentage of statistically significant coefficients was estimated. Hence, for the findings to be accurately synthesized, the definition of the criterion five, six, seven, and eight was critically important. Quantitative studies demonstrating the significance of the predictor variables were taken into account, and the studies with lower than 30 sample sizes were excluded (Barnicot et al., 2012; Merkouris et al., 2016). Criterion nine was adapted from the study of Merkouris et al. (2016), who reviewed predictors and conducted a similar analysis within a different research field.
Student loans are considered one of the most significant categories of consumer loans (Hill, 2018). For this reason, student loans related studies were included. Taking into account the study of Ciampi et al. (2021), who discovered a meaningful research cluster for the studies published after the mid-80s by employing a bibliometric analysis, and the substantial increase in consumer loans after the mid-80s (Zhu & Meeks, 1994), we focused on the studies published after 1985. Among 705 studies identified through database searching, the number of studies after removing duplicates was 549. After applying the inclusion and exclusion criteria, 108 of the 549 studies remained for further analysis (Figure 1). Table 3 represents the distribution of the studies based on the form of publication.
Number of the Studies Based on the Form of Publication.


The procedure of the systematic review.
Quality Assessment Framework
The quality assessment criteria and the procedure were adopted from frameworks proposed by (Al-Emran et al., 2018; Kitchenham & Charters, 2007; Merkouris et al., 2016). These criteria, which were determined with reference to other studies, were shaped according to the aims of our study. In order to obtain the predictor-outcome relationship and the variables that show significant results, the studies had to specify the variables explicitly. Besides, it was necessary for the studies to explain these variables without causing any confusion and to report the results of the analysis appropriately. The studies were required to indicate the objectives clearly for determining the outcome variables. Based on the analysis performed, the sample size should be sufficient. Barnicot et al. (2012) suggest a minimum of 30 participants, and the sample size should also be acceptable based on the analysis performed for the reliability of results. The studies went through a stage of quality evaluation from the viewpoint of two authors. The inter-rater agreement was 94%, which was indicated as sufficient agreement rate according to (Miles & Huberman, 1994). The conflicts were undertaken by means of discussions and consensus was established (Table 4).
Quality Assessment Criteria.

Each question was rated on a three-point scale with “Yes” as 1 point, “No” as 0 points, and “Partially” as 0.5 points. For each study that can score between 0 and 9, the higher the score obtained by the study, the higher the probability that the research questions will find answers in the study. All the studies passed the quality check by scoring at least seven over 10, indicating that they are all eligible for further analysis.
Data Coding and Analysis
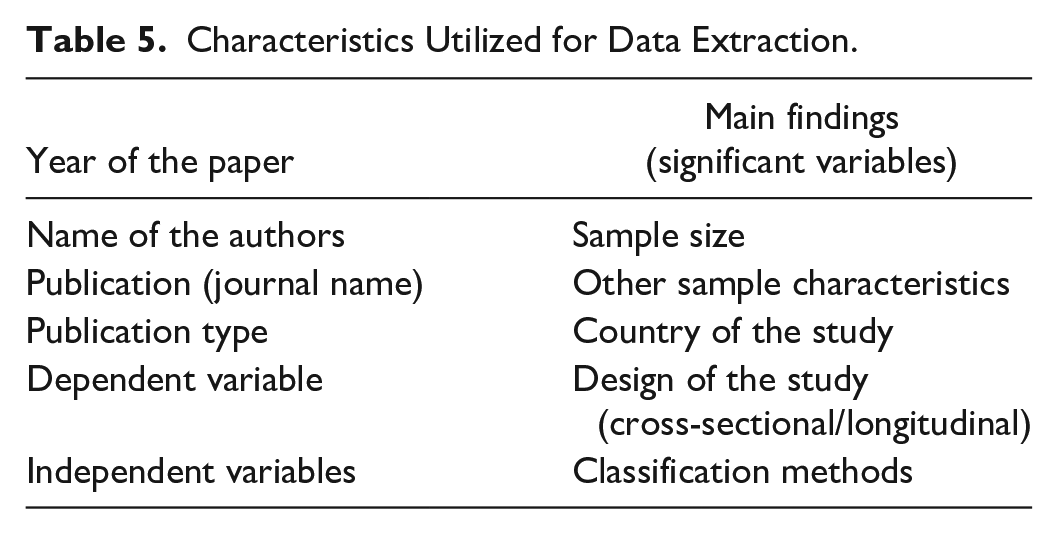
The data were extracted utilizing a uniform form, including the characteristics of the studies. These characteristics are represented in Table 5.
Characteristics Utilized for Data Extraction.
Because of the variability in outcome variables, performing a meta-analytic review was not attainable. Hence, an alternative approach focusing on the influence of different predictors on the predetermined outcome variables and the percentage of statistically significant coefficients were utilized. Multiple coefficients reported within the studies were recorded to examine aggregated effects. The findings were tabulated according to the number of the studies that assessed a particular independent variable and the number and percentage of statistically significant results. Synthesized findings are represented in the Supplemental Materials. Independent variables mentioned in three or more studies were represented and analyzed in a more detailed manner, which was accepted appropriate for synthesizing other research findings (Merkouris et al., 2016). In order to examine the historical occurrence of each group of variables study period was divided into six time periods (Period 1: Year ≤ 1990; Period 2: 1991 ≤ Year ≤ 1996; Period 3: 1997 ≤ Year ≤ 2002; Period 4: 2003 ≤ Year ≤ 2008; Period 5: 2009 ≤ Year ≤ 2014; Period 6: Year > 2014) (Table 6).
Classification of Outcome Variables.

The number of studies may exceed 108, as some studies assessed more than one outcome variable.
The list of independent variables examined in reviewed studies was categorized into ten groups. In order to provide accuracy in data coding, a focus group study was performed with multiple coders, including experts from finance, behavioral finance, banking, psychologists, and academicians from behavioral sciences (11 participants). To prevent ambiguity, a codebook including the definition of the variable groups mentioned above was prepared by researchers as recommended by Creswell (2013). Independent coding of participants produced 92% inter-rater agreement (Table 7).
Classification of Predictor Variables.

Research Findings
Characteristics of the Studies
Table 8 demonstrates the distribution of the reviewed papers based on different sample types. The findings explicitly reveal that sample sizes differed significantly (p < .05).
Main Sample Types Utilized in Reviewed Studies.
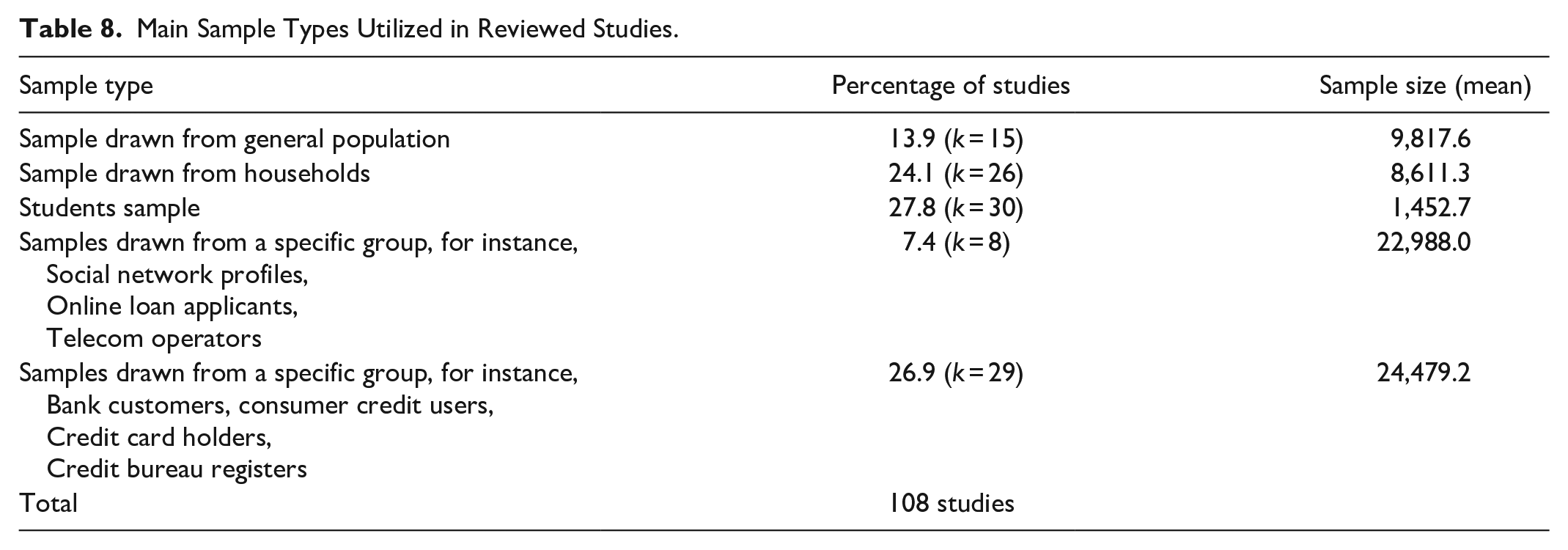
Table 9 represents that credit use and risk assessment research was frequently conducted in the U.S., followed by developing economies, the U.K., and other developed economies. Among longitudinal studies, merely 10.2% were employed in developing countries, and they were primarily dependent on secondary data (81%, k = 34). Across the studies utilizing secondary data, 74.5% of them were conducted in developed nations. Other studies were primarily based on self-reported survey data obtained in a cross-sectional manner. The nature of the study design (cross-sectional or longitudinal) significantly differed (p < .01) based on the data type and source. The high percentage in the usage of secondary data in developed countries is not surprising due to large-scale household surveys collected periodically by national statistics offices, data dissemination efforts, and the existence of credit bureaus. However, the relationship between the type of data source and the country that the sample was drawn was not statistically significant as a substantial number of the research in developing countries also used secondary data resources.
Other Characteristics of the Studies.

Examining the relationship between sample type and country of the study revealed that sample type was significantly related to the context in which the study was performed (developed or developing nations) (χ2(4) = 32.725a, p = .000). Among the studies conducted in the U.S., U.K., or other developed countries, the most significant number (35.4%, k = 28) was based on student samples. The second greatest number was based on samples from households (30.4%, k = 24). Focusing on developing countries specifically, the analysis revealed that drawing samples from specific groups was more popular; 75.9% of studies were interested in examining groups of specific bank customers, owners of delinquent loans and consumer credits, and alternative data sources. The findings revealed that samples drawn from alternative data sources were more likely to interest studies in developing countries (75%). Also, it was detected that there was a statistically significant difference among the countries regarding alternative data usage (p < .01).
Distribution of Sample Types Used Over Time
The use of alternative data sources for credit scoring is a relatively recent phenomenon. Time-based analysis indicated that the trend of alternative data utilization in reviewed papers was observed after 2014. Further analysis displayed that sample types utilized over different periods altered significantly (χ2(8) = 38.191a, p = .000). Data sets in papers published after 2014 (Period 6) mainly included the samples of specific groups, which comprised social network profiles, mobile phone operators, online lending, and trade platforms (34.8%). Figure 2 represents how sample types utilized have evolved.

Distribution of sample types used over different time periods.
The choice of data type and methodologies for credit risk assessment is often related to the researcher’s subjectivity or state-of-the-art requirements. Limited access of thin-file customers for credit, an increasing number of young adults without a prior credit history, a growing number of peer-to-peer lending platforms, developments in microfinance credit, and opportunities offered by recent data technologies have boosted the professional and theoretical research activity in the relevant field. Data from social networks, mobile phone usage, and e-commerce platforms, which offer behavioral signals for managing credit risks, have altered how risks are evaluated and managed. Hence, the opportunity of addressing state-of-the-art requirements by managing risks more accurately might have caused a growing academic interest in the use of alternative data sources.
Distribution of the Studies Based on Main Analysis Techniques
A wide range of statistical techniques has been used so far for predictive purposes associated with credit risk assessment. The most prevalent analysis technique used in the reviewed studies was regression analysis, including various regression types (except logistic regression) (40.7%, k = 44). The logistic regression was the second common analysis technique in the reviewed papers (25.9%, k = 28). Generally, the main analysis techniques in the papers involved traditional approaches. Novel techniques comprising decision trees, neural networks, ensemble (combined) techniques, and hybrid techniques accounted only for 9.3% of all studies. Utilization of traditional techniques such as logistic regression, other regression types, and discriminant analysis has become less common recently, while the use of novel methods such as ensemble and hybrid approaches has increased rapidly. The logistic regression was mostly utilized in Period 3, while other regression analysis techniques were frequently used in Period 4 and Period 5, with 53.8% and 54.3%, respectively (Figure 3).

Distribution of main analysis techniques used over different time periods.
The investigation of analysis techniques based on different sample characteristics demonstrated that significant differences exist in the use of novel and traditional analysis techniques based on sample characteristics (χ2(4) = 49,105a, p = .000). Studies including samples drawn from alternative data sources were mainly conducted with novel techniques (75%, k = 6). Besides, among the studies that utilized novel classification techniques, many of them (80%) were conducted in developing countries, reflecting the up-to-date requirements for credit risk assessment, especially in developing nations.
Analysis for different time periods
Significant differences in the use of traditional and novel techniques were observed based on different periods (χ2(5) = 23.273a, p = .000). The last time scenario, referring to the period after 2014, depicted a fast increment of novel techniques. Ensemble, hybrid classification techniques, decision trees, and neural networks are the techniques that have been used predominantly recently. Although there were significant differences in the use of the methods based on the periods, logistic regression and other types of regression analysis were used in all periods. It was determined that psychometric variables were frequently used in every period. The data collection method for these characteristics, which has generally been a questionnaire survey, and the number of samples included accordingly might have caused the use of traditional analysis techniques.
Distribution of Predictors Based on Dependent Variables Examined
Predictors of default/delinquency/bankruptcy
Regarding the predictors of this outcome domain, the most common factors that displayed a statistically significant effect were adverse life events, age, ethnicity, marital status, income/family income, education, and loan amount.
Predictors of problematic debt/outstanding debt/indebtedness/level of debt
Characteristics related to the problematic level of debt/outstanding debt/indebtedness were quite different from default indicators. The most prevalent factors that demonstrated significant findings were the locus of control, financial knowledge/literacy, time horizon/orientation, attitudes toward credit, risky credit behavior, attitudes toward money, attitudes toward debt, and compulsive buying. Age, marital status, gender, employment status, homeownership, education, and the number of credit cards also revealed a significant effect in a remarkable number of studies.
Predictors of financial behavior/debt repayment behavior
This stream of research has focused on examining the financial behavior associated with debt repayment and financial responsibility. Age, income, and education were consistently reported as significant determinants. The most common factor revealing statistically significant results was attitudes toward money. Compared to other outcome domains, more personality variables exhibited a significant effect on financial behavior. For instance, agreeableness, conscientiousness, and neuroticism frequently demonstrated a significant impact on financial behavior.
Predictors of credit misuse
Among indicators of credit misuse, attitudes toward money, risk-taking/risk attitudes, self-efficacy, sensation-seeking, emotional stability, self-esteem, impulsiveness, social motivation, financial knowledge, time horizon, risk tolerance, delay of gratification, income, age, and education displayed significant results in a considerable number of studies.
Distribution of the Studies Based on Independent Variables
Independent variables, which were widely examined in 108 reviewed studies, were related to socioeconomic characteristics (66.7%, k = 72), demographic characteristics (66.7%, k = 72), values/attitudes/behavioral characteristics (56.5%, k = 61), institutional/financial characteristics (45.4%, k = 49), and personality characteristics (35.2%, k = 38). Fewer than 20% of the studies concentrated on situational, educational, macroeconomic, health-related, and alternative factors. Further analysis revealed the distribution of each group of factors across time periods (Table 10).
Distribution of Group of Factors Across Different Time Periods.
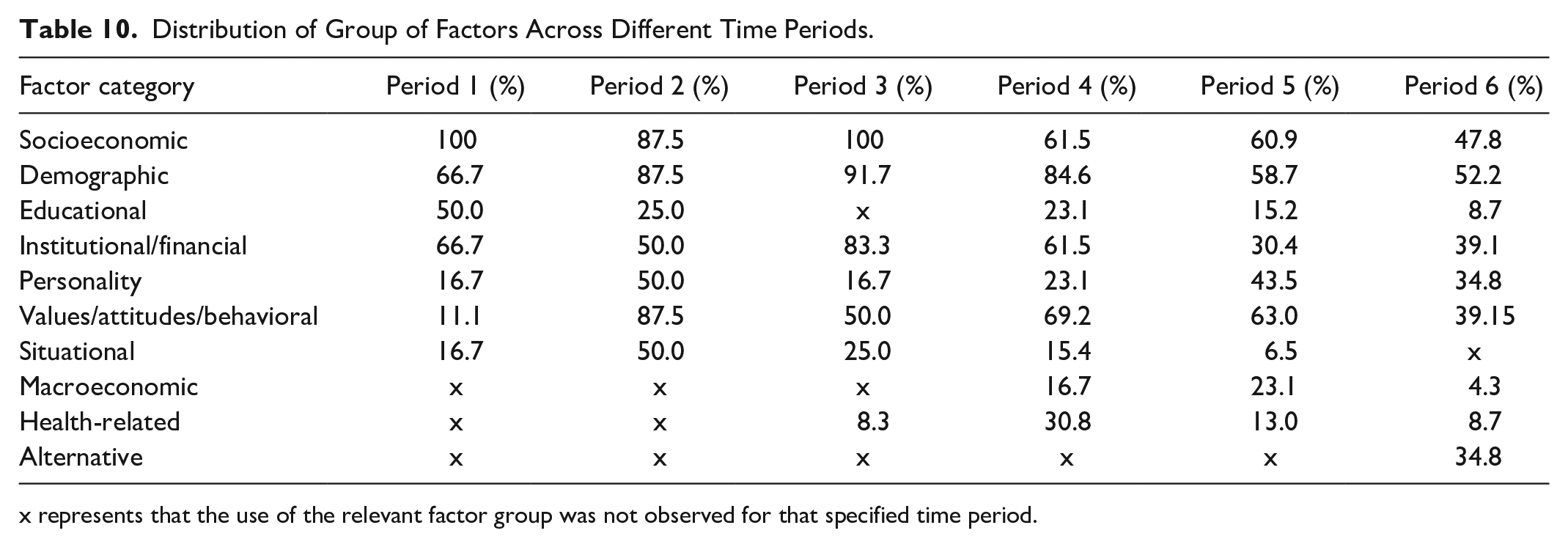
x represents that the use of the relevant factor group was not observed for that specified time period.
It was explored that the use of financial factors has decreased in recent years, and different types of variables have been examined. Regular investigation of psychometric variables starting from Period 2 indicates their significance. The use of alternative variables in Period 6 signals a paradigm shift in the field, reflecting the efforts to enhance prediction performance using non-traditional data sources, especially big data.
Socioeconomic factors
Socioeconomic factors, which produced significant findings, included home ownership, number of children/dependents, household size, length of employment, employment status, occupation, family income, income, wealth, parents’ income, social class, and education. Homeownership, the number of dependents, and wealth displayed significant findings in all examined studies. Social class, family income, employment status, and parents’ income demonstrated significant effects in 83.3%. 80%. 73.7% and 75% of the studies, respectively.
Demographic factors
Among demographic factors, age, gender, ethnicity, marital status, and family life cycle were widely investigated by the relevant literature. Regarding the family life cycle, entire studies examining this variable reported significant findings. Age (59. 7%, k = 34), ethnicity (72.2%, k = 13), marital status (48.3%, k = 14), and gender (35.3%, k = 18) also represented significant impact. Among these factors, age, gender, ethnicity, and marital status were consistently found significant predictors of the probability of default, problematic debt, and debt repayment behavior. At the same time, the family life cycle only revealed significant effects on the probability of default and problematic debt.
Institutional/financial factors
Across the studies that examined Institutional/financial factors, variables including the number of debts, length of relationship with the bank, the number of bank accounts, debt to income ratio, total financial assets, payment pattern, credit limit, and existing credit commitments, all of them reported significant effects. Other significant variables were as follows; credit score (80%, k = 4), number of credit cards (90%, k = 9), credit history in the past (87.5%, k = 7), loan amount (63.6%, k = 7), taking debt advice (75%, k = 3), loan duration (66.7%, k = 4), account balance (66.7%, k = 4), and purpose of loan (66.7%, k = 3).
Personality factors
Regarding personality factors, self-control, emotional stability/neuroticism, and intelligence (IQ score) revealed significant findings in all the examined studies. Additionally, locus of control (64.3%, k = 9), self-efficacy (66.7%, k = 4), agreeableness (60%, k = 6), optimism (75%, k = 3), self-esteem (66.7%, k = 4), extraversion (63.6, k = 8), conscientiousness (69.2%, k = 9), openness to experience (83.3%, k = 5), emotional stability/neuroticism (61.5%, k = 8), and impulsiveness (71.4%, k = 5) produced significant findings for more than half of the studies. Locus of control, self-efficacy, agreeableness, conscientiousness, and openness to experience reported significant results for the probability of default, problematic debt, and financial behavior. Emotional stability/neuroticism and optimism were found to be the indicators of problematic debt and financial behavior.
Values/attitudes and behavioral factors
Among values/attitudes and behavioral factors; socio-motivation/others’ attitudes toward debt, parent facilitation, time horizon, perceived financial wellbeing, attitudes toward positive financial behavior, religious practices, consumer behavior, and level of expenditure (spending pattern) consistently and significantly produced significant findings in all the investigated studies. The attitudes toward money/money beliefs and behaviors (85%, k = 17), the attitudes toward risk-taking (75%, k = 3), attitudes toward credit (75%, k = 9), compulsive buying (80%, k = 8), delay of gratification (80%, k = 4), and financial knowledge (68.8%, k = 11) were also significant variables which exhibited significant results in a considerable number of studies.
Situational factors
Situational factors have also been considered the components of a multi-disciplinary behavioral model and described as unexpected situations that cause financial constraints. Hence, adverse life events or life-altering events have been widely investigated. Across the studies examining situational factors, (90%, k = 9) of them reported that situational predictors had a significant impact on the outcome domain, and most of them reported (60%, k = 6) that situational factors were the indicators of the probability of default
Educational, macroeconomic, and health-related factors
Regarding the educational factors, the field of study, GPA, and year at school were investigated in an adequate number of studies to make accurate conclusions. All these variables represented a significant impact on the problematic debt level of students. However, a wide range of predictors was detected, which needs further investigation as they were examined in less than three studies. This also applies to macroeconomic and health-related factors. These predictors are represented in the Supplemental Materials. Considering other predictor categories, there are several behavioral, personality, socioeconomic, and financial variables used in a small number of studies but found to be related to the outcome domain. It is essential to consider these predictors in future studies and to analyze them in different contexts.
Alternative factors
Alternative factors are captured from diverse sources and derived from social networks, online platforms, e-commerce activities, and telecom data. Such digital data are used for complementary purposes and capturing individuals’ personality characteristics, behavior, and socioeconomic profile. It is, therefore, not surprising that an extensive list of alternative predictors was identified in this review, including social network visiting patterns, posting patterns, usage of photo for posts, major things in people’s lives, qualifications of people within individuals’ network, social network prestige, membership score, retweet behavior, emoticon utilization, posting time, number of followers, friends, the slope of daily calls sent (for mobile data), SMS sending pattern, number of messages, disclosure of social media profile and geographical locations. According to Figure 4, credit risk assessment research was extended by different types of factors over time, adding variables from alternative sources.

Distribution of main analysis techniques used over different time periods
It is observed that, in most of the studies performed in the earlier periods, the use of socioeconomic and demographic factors was dominant, with entire articles published in Period 1 (Before 1990) focused on socioeconomic factors. The numbers remained relatively consistent and high till the end of Period 3 (1997–2002). On the other hand, the percentage of studies utilizing personality, values/attitudinal/behavioral, and situational variables peaked in Period 2 (1991–1996) (50%, 87.5%, and 50%, respectively). This significant increase might be attributed to approaching the debt phenomenon from a multi-disciplinary aspect, especially after the beginning of the 1990s. The higher number of studies concentrating on personality, behavioral and situational factors in this period reflected the interest of economic psychologists in investigating the psychological perspectives.
The thin-file or no-file applicant problems, an increasing number of young credit applicants without financial history, dynamics of developing markets, such as the non-existence of credit bureau gathering information, and enhancement in credit demand shifted the risk assessment process. After the beginning of Period 5 (2009–2014), the remarkable fall in the utilization of financial factors might be attributed to searching for alternative resources of data for credit risk assessment. In Period 5, the number of studies focusing on personality and behavioral factors was still worthwhile, and the incorporation of macroeconomic variables gained interest over this period (23.1%).
Online peer-to-peer lending (P2P) and the requirements for more agile financial processes, the potential of online platforms, telecom data, and social networks that provide the signals of personality and behavior have contributed to enlarge the set of factors. The sudden emergence of alternative factors in Period 6 (after 2014), together with a sharp decrease in the utilization of behavioral predictors from 63% to 39.15%, might indicate that behavioral characteristics can be derived from digital data (Figure 5).

Distribution of mix of factors over different time periods.
Discussion and Conclusion
This study explored that review studies in the field of credit use have generally focused on the models developed for the default prediction (Abdou & Pointon, 2011; Alaka et al., 2018; Ciampi et al., 2021; Dastile et al., 2020; Kovacova et al., 2019; Lessmann et al., 2015; Louzada et al., 2016; Marqués et al., 2013; Onay & Öztürk, 2018; Sadatrasoul et al., 2013). Some of these studies are in the form of a literature review. Some have expanded their scope to include performance comparison, feature selection, data balancing, and evolution of themes in the field. The study of Louzada et al. (2016), which is known as a comprehensive review study in the field, only mentioned a limited number of variables used for default prediction. Although the administrated techniques were evaluated in terms of historical development, the study did not consider the more advanced techniques like ensemble methods. Kamleitner et al. (2012) assessed the variables that come to the fore at different levels of credit use from a psychological point of view, while Manz (2019) consolidated predictors under three categories. None of the mentioned reviews performed a predictor analysis. To the best of our knowledge, relevant literature has not specifically focused on reviewing the predictors of creditworthiness-related outcomes that several studies have suggested. On the contrary, this study performed a comprehensive consolidation of predictors by considering all outcome variables that may be associated with credit default risk. Hence, this review is the first to systematically synthesize the evidence relating to predictors of creditworthiness-related outcomes to provide useful guidance for practical applications and researchers interested in credit default risk. This study has made a significant contribution by responding to researchers’ calls in the field regarding the need for detailed analysis of predictors (Ghosh, 2015; Manz, 2019; Zhang, Cai et al., 2016).
A wide range of synonymous terminology associated with predictors and outcome variables is used in literature and practice, often without a clear definition. Hence, we also performed a focus group study with practitioners and scholars to prevent ambiguity and to refine the literature findings. The findings of this review were structured into a concept-centric framework, and ten aggregate dimensions representing categories of predictor variables were obtained.
From the methodological aspect, unlike the review studies in the field, the selection criteria in this study were determined in a very detailed and meticulous manner, and the studies were also subjected to a quality evaluation process. As a result of not meeting the eligibility criteria, a remarkable number of studies was excluded. This is one of the critical findings that reveals methodological constraints of the existing studies in the field. A significant number of the current studies is limited due to the lack of clear explanation of dependent-independent variables, not specifying the sampling technique, size, and characteristics, providing inadequate information on the analyzes performed, and inaccurate reporting. Future studies need to be designed to take these issues into consideration. Besides, it is vital to do research that focuses on the terminology and concepts used in defining variables to enable the conduction of meta-analysis studies.
The systematic reviews we have conducted generally presented descriptive results. Those studies did not check the relationships between variables. We found that contrary to what it should be, these studies did not analyze the relationships between important variables statistically. The statistical significance of the results for the variables whose distributions were given according to specific time intervals was not tested (Dastile et al., 2020; Louzada et al., 2016; Onay & Öztürk, 2018; Sadatrasoul et al., 2013). Alaka et al. (2018) gave summary statistics and descriptives. Marqués et al. (2013), Lessmann et al. (2015), Kovacova et al. (2019), and Kamleitner et al. (2012) performed literature reviews and summarized literature findings. The paper of Manz (2019) is more like a conceptual discussion.
Testing the relationships between variables statistically is important in basing the interpretations on a more solid basis. In this context, we identified some research gaps and several interesting topics for future research. For instance, longitudinal studies are primarily employed in developed countries, alternative data use is prevalent in developing countries, secondary data use is more common in developed countries, and the studies that use alternative data apply novel methods. From our point of view, future longitudinal studies are required to determine causality. The biggest issue with the existing research is that most of the research designs are cross-sectional, making it impossible to determine causality.
A fair number of studies in developed countries depend on secondary data obtained from financial institutions, credit bureaus, or large-scale nationally representative surveys. Although alternative data use is prevalent in developing countries, it is also noteworthy to establish public data repositories that academicians can access to perform cross-cultural studies and experiment with different data sets and samples.
As a result of analyzing the change in the use of predictor groups over time, it was concluded that there was an important scientific paradigm shift in the field. Technology and the digital environment allow instant and rapid assessment of the creditworthiness of individuals, and big data is a significant resource for granting credit. This argument was welcomed in this study as the emerging trend of alternative data use was observed. It was detected that the trending research topics have concentrated on big data and digitalization in credit risk management, the development of credit scoring systems that depend on novel techniques, and the use of alternative data sources. Hence, one avenue for future research in developed countries is to benefit from alternative data sources and novel approaches, including deep learning and artificial intelligence techniques.
It is not clear which behavioral, and personality characteristics are considered by the real-life applications, which seek some behavioral traces by integrating data from different data points. The topic of psychometric assessment and the use of unconventional data sources is relatively new in academic publications. Thus, addressing the gap between practitioners and academics is of great importance, and the findings are believed to contribute to the field in this regard. For example, adverse life events were found to be the most important and consistent predictors of default. If it is detected which variables are worthy of citing, the data sources which can provide the data about the variables can be focused. In this way, real-time online analyses can be conducted effectively. This kind of information about individuals can only produce meaningful results with real-time data and analysis. In this context, data points from which this kind of specific information about users can be inferred are identified more effectively.
The output of this study makes an original contribution to the literature, as this is the first systematic review performing a comprehensive predictors’ analysis. It was determined how often the relationship between a particular dependent and independent variable was found statistically significant in the examined studies by focusing on the percentage of statistically significant coefficients. Regarding the predictors of default, the most common factor that displayed a statistically significant effect was adverse life events. Consistent and robust predictors of problematic level of debt/outstanding debt/indebtedness were the locus of control, financial knowledge/literacy, time horizon/orientation, attitudes toward credit, risky credit behavior, attitudes toward money, attitudes toward debt, and compulsive buying. Concerning financial behavior, it was uncovered that personality and behavioral variables stand out and effectively predict financial behavior.
Similarly, in the studies examining the misuse of credit, the factor groups related to personality, behavior, and attitude are at the forefront. As a result, we improve the knowledge of which personality-related and behavioral characteristics are important in evaluating creditworthiness. Besides, some factors which demonstrated significant impact were analyzed by a limited number of studies, which require some additional research. Some of those characteristics were as follows: forms of other debts, utilization of forms of credit, autonomy, being meticulous, controllability, awareness of loan repayment, general ethical judgment, general coping, social comparisons, job performance, and perceived importance of terms of credit.
From a developing country perspective, this review contributes to practical applications by giving insight into the characteristics that can be used for digital lending or psychometric assessment. More tailored models can be proposed and tested for different contexts by a different set of variables. Existing models can be enhanced by incorporating different predictors. The paradigm change that comes with big data and digitalization brings along problems with data security and privacy. The practitioners gather the personal data, how they use and store them should be controlled by the relevant mechanisms. In this context, it is crucial to establish new regulations and amend consumer privacy laws. Considering that alternative data is on the rise, especially in developing countries, it poses new research topics on whether the legal infrastructure and practitioners in these countries are prepared in terms of data security and privacy and what improvements need to be made.
Although this systematic review offers important insights into credit use and risk assessment literature, it also has some limitations. First, the results were based on the studies obtained from particular databases and publishers. As a result, selected databases cannot provide a complete representation of all studies conducted on credit use and risk assessment. Additional research could broaden the present research by incorporating studies from other databases, such as Wiley, Emerald, Inderscience, or De Gruyter. Last but not least, the review of 108 documents is insufficient to cover the complexities of the results discussed in each paper; on the other hand, it should be viewed as a reference and a starting point for potential studies on the topic.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440211061333 – Supplemental material for A Longitudinal Systematic Review of Credit Risk Assessment and Credit Default Predictors
Supplemental material, sj-docx-1-sgo-10.1177_21582440211061333 for A Longitudinal Systematic Review of Credit Risk Assessment and Credit Default Predictors by Büşra Alma Çallı and Erman Coşkun in SAGE Open
Footnotes
Author Note
This article is a part of a PhD thesis approved in Sakarya University, Sakarya, Turkey.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.