
Abstract
Behavioral scientists are increasingly able to conduct randomized experiments in settings that enable rapidly updating probabilities of assignment to treatments (i.e., arms). Thus, many behavioral science experiments can be usefully formulated as sequential decision problems. This article reviews versions of the multiarmed bandit problem with an emphasis on behavioral science applications. One popular method for such problems is Thompson sampling, which is appealing for randomizing assignment and being asymptoticly consistent in selecting the best arm. Here, we show the utility of bootstrap Thompson sampling (BTS), which replaces the posterior distribution with the bootstrap distribution. This often has computational and practical advantages. We illustrate its robustness to model misspecification, which is a common concern in behavioral science applications. We show how BTS can be readily adapted to be robust to dependent data, such as repeated observations of the same units, which is common in behavioral science applications. We use simulations to illustrate parametric Thompson sampling and BTS for Bernoulli bandits, factorial Gaussian bandits, and bandits with repeated observations of the same units.
Keywords
Introduction
Many investigations in and applications of behavioral science involve assigning units (e.g., people, organisms, groups) to treatments. For example, experiments frequently randomly assign people to different treatments with the aim of learning about the effects of those treatments and thereby testing theory. The resulting scientific knowledge is often subsequently applied by changing policies (i.e., treatment assignment rules, guidelines) employed by practitioners, firms, and governments. These are often quite distinct steps, whereby behavioral scientists conduct multiple experiments, publish papers reporting on these, and thereby influence policies. However, behavioral scientists are increasing able to more rapidly iterate on experiments—including field experiments—such that what has been learned from an experiment so far may be used to modify that experiment moving forward to, for example, focus on increasing precision where it is most needed or to allocate units according to a policy that appears better. Such experiments in the behavioral sciences can be seen as instances of a sequential decision problem in which units are allocated to treatments over time, with the possibility of information from earlier units outcomes being used for later allocations.
In this article, we review a particular class of sequential decision problems, multiarmed bandit problems, and contextual multiarmed bandit problems, in which units are each assigned to one of a number of distinct treatments (i.e., arms), perhaps according to covariates (i.e., context) that is observed about those units, with the aim of maximizing a random outcome affected by treatment (i.e., the reward). We present a pair of methods for solving these problems, Thompson sampling and bootstrap Thompson sampling (BTS), which have appealing properties for behavioral science applications. This article is structured as follows. We first formalize these problems and give some examples from applied behavioral sciences. We then introduce the algorithms for solving these problems and illustrate them applied to simulated data having characteristics common in behavioral science applications (e.g., model misspecification, dependent data).
Multiarmed Bandit Problems
In multiarmed bandit problems, a set of actions have potentially heterogeneous stochastic payoffs and an experimenter aims to maximize the payoff over a sequence of selected actions (Macready & Wolpert, 1998; Whittle, 1980). Multiarmed bandit problems can be formalized as follows. At each time
Contextual Bandit Problems
In many social science applications, the outcome distribution likely depends on observable characteristics of the units being allocated. In the contextual bandit problem (Beygelzimer, Langford, Li, Reyzin, & Schapire, 2011; Bubeck, 2012; Dudík, Erhan, Langford, & Li, 2014; Langford & Zhang, 2008), the set of past observations
Examples
Bandit problems appear throughout the behavioral sciences. Here, we briefly highlight examples in political science, medicine, and educational psychology.
Donation requests to political campaign email list
A political campaign has a list of email addresses of likely supporters and is trying to raise money for the campaign. Staffers have written several versions of emails to send to supporters and there are many different photos of the candidate to use in those emails. The campaign can randomize which variant on the email is sent to a supporter and observe how much they donate.
Chemotherapy following surgery
Following surgery for colon cancer, some guidelines recommend adjuvant chemotherapy, but there is substantial uncertainty about which patients should be given chemotherapy (Gray et al., 2007; Verhoeff, van Erning, Lemmens, de Wilt, & Pruijt, 2016). For example, should older patients still be given chemotherapy? Continuing to randomize treatment of some types of patients even as the best treatment for other types is known could help discover improved treatment guidelines that reduce, for example, 5-year mortality.
Psychological interventions in online courses
Interventions designed to increase motivation and planning for overcoming obstacles are sometimes used in educational settings, including online courses where students begin and complete the course at their own pace. There are many variations on these interventions and students may respond differently to these variations. For example, motivational interventions might work differently for students from collectivist versus individualist cultures (Kizilcec & Cohen, 2017). The learning software can randomize students to these interventions while learning which interventions work for (e.g., result in successful course completion) different types of students.
How should we solve these bandit problems? Many possible solutions to bandit problems have been suggested (Auer & Ortner, 2010; Garivier & Cappé, 2011; Gittins, 1979; Whittle, 1980) and, while in some cases there are exactly optimal methods available, these are often not readily extensible to realistic versions of these problems. Thus, popular solutions are fundamentally heuristic methods, though many are approximately (e.g., asymptotically) optimal. We now turn to the two methods we focus on in this review: Thompson sampling and a recent variant, BTS.
Thompson Sampling
Recently, there has been substantial interest in Thompson sampling (Agrawal & Goyal, 2012; Gopalan, Mannor, & Mansour, 2014; Thompson, 1933). The basic idea of Thompson sampling is straightforward: randomly select an action

where
Thompson sampling asymptotically achieves the optimal performance limit for Bernoulli payoffs (Kaufmann, Korda, & Munos, 2012; Lai & Robbins, 1985). Empirical analyses of Thompson sampling, also in problems more complex than the Bernoulli bandit, show performance that is competitive to other solutions (Chapelle & Li, 2011; Scott, 2010).
When it is easy to sample from
Thompson Sampling for Contextual Bandit Problems
In the contextual bandit case, Equation 1 becomes

In this specification, and with rewards
Consider, for example, the problem of adaptively selecting persuasive messages where the outcome of interest is a click or a conversion, such as donation to a political campaign (Gibney, 2018) or purchase of a product (Hauser & Urban, 2011; Hauser, Urban, Liberali, & Braun, 2009; Kaptein & Eckles, 2012; Kaptein, Markopoulos, de Ruyter, & Aarts, 2015; Kaptein, McFarland, & Parvinen, 2018). Such efforts often generate data that have a complex, cross-random effects structure (Ansari & Mela, 2005). In these cases, Thompson sampling is computationally challenging, and effectively implementing Thompson sampling often requires a problem- or model-specific approach and considerable engineering work.
We now turn to a variation on Thompson sampling that is computationally feasible with such models and with dependent data.
Bootstrap Thompson Sampling
BTS replaces samples from the Bayesian posterior
Bootstraps and Bayesian Posteriors
Bootstrap methods are widely used to quantify uncertainty in statistics. The standard bootstrap distribution (Efron, 1979) is the distribution of estimates of
Statisticians have long noted relationships between bootstrap distributions and Bayesian posteriors. With a particular weight distribution and nonparametric model of the distribution of observations, the bootstrap distribution and the posterior coincide (Rubin, 1981). In other cases, the bootstrap distribution can be used to approximate a posterior, for example, as a proposal distribution in importance sampling (Efron, 2012; Newton & Raftery, 1994). Moreover, sometimes the difference between the bootstrap distribution and the Bayesian posterior is that the bootstrap distribution is more robust to model misspecification, such that if they differ substantially, the bootstrap distribution may even be preferred (Eckles & Kaptein, 2014; Liu & Rubin, 1994; Szpiro, Rice, & Lumley, 2010).
The computational benefits of reweighting bootstrap methods, their robustness, and their direct link to Bayesian posteriors, suggest the use of reweighting bootstrap methods in sequential decision problems. In sequential decision problems, uncertainty quantification is a key element that drives the exploration behavior of decision policies.
BTS replaces the posterior
BTS Algorithm
In contrast to Thompson sampling, as specified in Equation 1, BTS replaces the posterior
Algorithm 1 details BTS for the contextual bandit problem. At each step

Note that in large-scale applications, requests for which arm to use can be randomly routed to different servers with different replicates. Then the algorithm updates a random subset of the replicate models using the observed data (
For BTS, as long as
Properties and Performance of BTS
What can we say about the performance of BTS analytically? Osband and Van Roy (2015) have shown an equivalence of BTS to Thompson sampling when using Exp(1) weights with a Bernoulli bandit; such a version of BTS would thus inherit established results for Thompson sampling described above. Lu and Van Roy (2017) prove that in a linear bandit problem the expected regret BTS is larger than that of Thompson sampling by a term that can be made arbitrarily small by increasing
There are empirical evaluations of BTS that show its promise in comparison with Thompson sampling and other methods. Eckles and Kaptein (2014) compared BTS with Thompson sampling, illustrating its robustness to model misspecification. Bietti et al. (2018) included BTS and greedier variants in an empirical evaluation using conversion of classification problems to contextual bandit problems, where it performed competitively. We further illustrate the performance of BTS below. In particular, a novel contribution of the present article is to illustrate the straightforward use of versions of BTS for dependent data, which frequently arises in the behavioral science, as suggested by Eckles and Kaptein (2014).
Alternatives
Here, we briefly discuss some alternative solutions to bandit problems besides “vanilla” Thompson sampling and BTS. Other papers (Dudík et al., 2014) and textbooks (Sutton & Barto, 2018) provide a broader overview.
Thompson Sampling With Intractable Likelihoods
When Thompson sampling is computationally impractical, such as when sampling from the posterior would require using MCMC, there are sometimes other alternatives available. In some specific cases, sequential Monte Carlo and other online methods (Carvalho, Johannes, Lopes, & Polson, 2010) may be available (Chapelle & Li, 2011; Scott, 2010) when complex models are considered. However, substantial engineering work may still be required to develop custom Monte Carlo algorithms to efficiently sample from the posterior distribution—above that for just computing a point estimate of the expected reward. Particular problems may involve one-off engineering to, for example, combine MCMC with other approximations for parts of the likelihood, as when Laber et al. (2018) consider a sequential decision problem in the presence of spatial contagion.
Greedier Methods
Solutions to sequential decision problems often try to balance exploration and exploitation. Thompson sampling may sometimes overexplore; that is, it is dominated in some settings by other “greedier” methods that exploit existing information more readily. Bastani and Bayati (2015) argue that many contextual bandit problems provide enough implicit exploration through randomness in the context that explicit exploration is often suboptimal. Closer to this review, Bietti et al. (2018) evaluate contextual bandit algorithms, noting the benefits of being greedy compared with typically used algorithms. In particular, they evaluate versions of BTS that include among the bootstrap replicates estimates using the full data set; this makes BTS greedier.
2
Bietti et al. (2018) find that such versions of BTS perform well, notably with very few bootstrap replicates (e.g.,
Illustration via Simulations
To empirically examine the performance of BTS, we run a number of simulations studies. First, for didactic purposes, we demonstrate how BTS is implemented for the simple
Bernoulli Bandit
A commonly used example of a bandit problem is the
Note that in this simple
BTS for the k-armed Bernoulli bandit is given in Algorithm 2; we write this version out explicitly to demonstrate its implementation. We start with an initial belief about the parameter
After observing reward

The choice of J limits the number of samples we have from the bootstrap distribution
To examine the performance of BTS, we present an empirical comparison of Thompson sampling to BTS in the
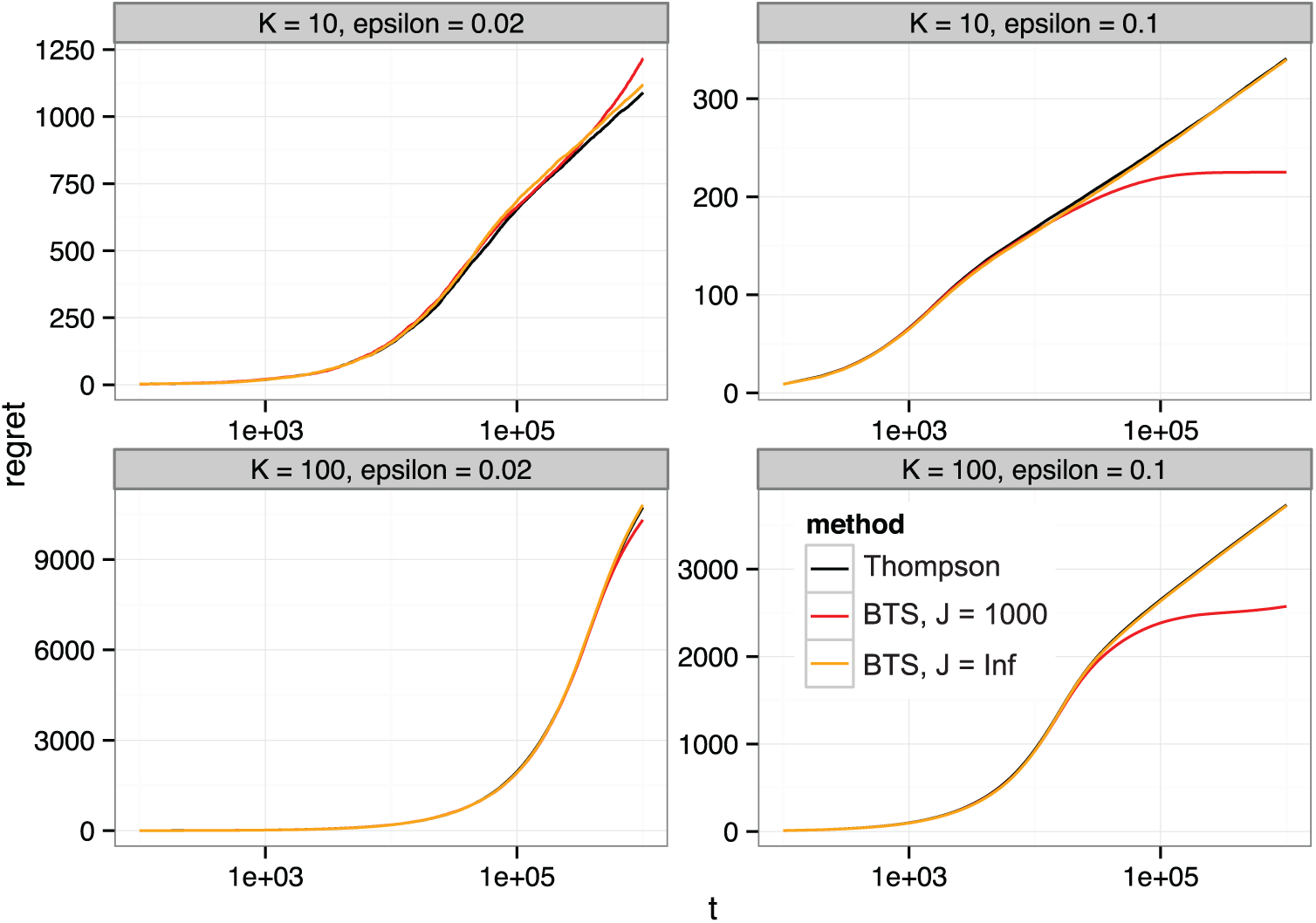
Empirical regret for Thompson sampling and BTS in a K-armed binomial bandit problem with varied differences between the optimal arm and all others
Clearly, the mean regret of BTS is similar to that of standard Thompson sampling. In some sets of simulations, BTS appears to have a lower empirical regret than Thompson sampling (and even lower than the optimal performance limit); however, this is because the use of a finite J makes BTS greedy, and this particular set of the number of simulations(1000) is insufficient to properly illustrate the expected performance of the method in this greedy case: in each of the
To further examine the importance of the number of bootstrap replicates J, Figure 2 presents the cumulative regret for the

Comparison of empirical regret for BTS with varied number of bootstrap replicates J.
Robustness to Model Misspecification
We expected BTS to be more robust to some kinds of model misspecification, given the robustness of the bootstrap for statistical inference. 6 Bootstrap methods are often used in statistical inference for regression coefficients and predictions when errors may be heteroscedastic because the model fit for the conditional mean may be incorrect (Freedman, 1981). To examine this benefit of BTS, we compare the performance of BTS and Thompson sampling in simulations of a factorial Gaussian bandit with heteroscedastic errors.
The data-generating process we consider here has three factors,

and
We then compare the performance of Thompson sampling and BTS. For both Thompson sampling and BTS, we fit a full factorial linear model. For Thompson sampling, we fit a Bayesian linear model with Gaussian errors and a Gaussian prior with variance 1. We fit the linear model at each step to the full data set
Figure 3 presents the difference in cumulative reward between BTS and Thompson sampling for
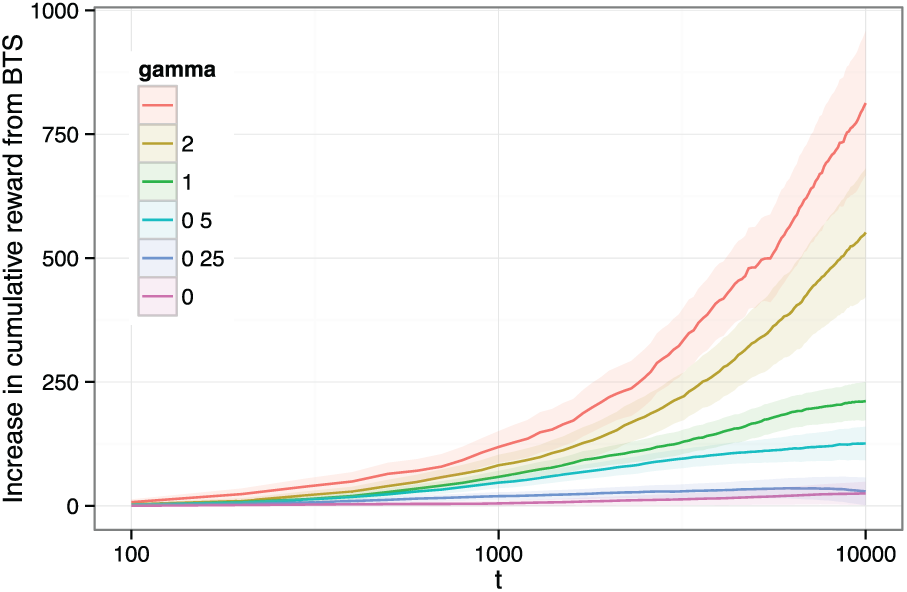
Comparison of Thompson sampling and BTS (with J = 1000) with a factorial design and continuous rewards with a heteroscedastic error distribution.
Dependent Data
Bootstrap methods are easily adapted to use with dependent observations (e.g., repeated measures, time series, spatial dependence), and so are widely used for statistical inference in these settings, especially when this dependence is otherwise difficult to account for in inference (Cameron & Miller, 2015). Similarly, when observed rewards are dependent, BTS can easily be adapted to use an appropriate bootstrap method for dependent data. For example, if there are multiple observations of the same person, BTS can use a cluster-robust bootstrap (Davison & Hinkley, 1997) that reweights entire units. On the contrary, a typical Bayesian approach to such dependent data is a hierarchical (or random effects) model (Gelman et al., 2013). Not only can this present computational challenges, but these models only guarantee valid statistical inference when the specific model for dependence posited is correct, unlike the very general forms of dependence for which cluster-robust bootstraps are valid (Cameron & Miller, 2015; Owen & Eckles, 2012). In the case of multiple sources of dependence (i.e., crossed random effects), fitting crossed random effects models remains especially difficult to parallelize (Gao & Owen, 2016), but bootstrap methods remain mildly conservative (McCullagh, 2000; Owen, 2007; Owen & Eckles, 2012).
For an initial examination of value of BTS in cases in which the observations are dependent, we replicate the simulations above, but with the following changes: (a) we set
Varying
Here, we implement BTS using a clustered DoNB. In particular, all observations of the same unit update the same subset of the bootstrap replicates; this can be accomplished by using a hashed unit identifier as the seed to a random number generator as demonstrated in Owen and Eckles (2012). In Algorithm 1, this corresponds to seeding the Bernoulli draw with hash(
Figure 4 presents the results of our simulations. Thompson sampling is implemented as above, and thus does inference assuming the observations are independent, while BTS uses a bootstrap clustered by unit, requiring only that observations of different units are independent. As expected, for moderate and large values of
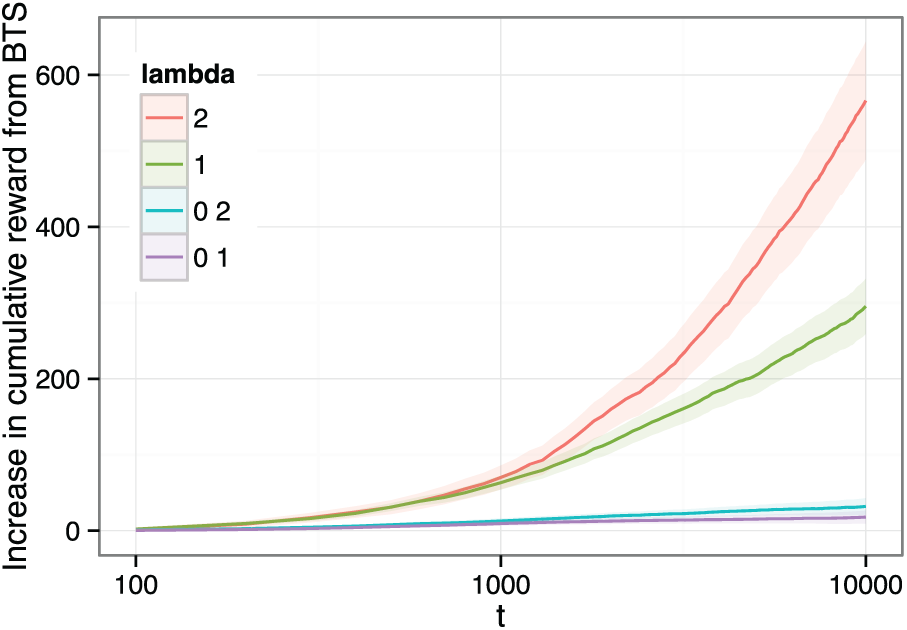
Comparison of Thompson sampling and BTS with dependent data, with BTS using a clustered bootstrap.
This result is unsurprising in that the model for Thompson sampling does not account for the dependence in the true data-generating process. Although a hierarchical model with varying coefficients could account for this particular case, implementing this with Thompson sampling would in practice require substantial engineering work. The adaptation of BTS for this dependent data, however, is very simple, and provides a very general approach to dealing with dependent observations in bandit problems.
The addition of unit-specific coefficients effectively makes the underlying problem a contextual bandit problem where each unit
Discussion
BTS relies on the same idea as Thompson sampling: heuristically optimize the exploration–exploitation trade-off by playing each action
The practical appeal of BTS is in part motivated by computational considerations. The computational demands of MCMC sampling from
We presented a number of empirical simulations of the performance of BTS in the canonical Bernoulli bandit and in Gaussian bandit problems with heteroscedasticity or dependent data. The Bernoulli bandit simulations allowed us to illustrate BTS and highlight the importance of selecting the number of bootstrap replicates J. The Gaussian bandit illustrated how BTS is robust to some forms of model misspecification. Finally, simulations with dependent data, some versions of which (e.g., repeated observations of the same units) are common in applied problems, demonstrate how BTS can easily be made cluster-robust. Our proposed clustered DoNB scheme here provides a very general alternative when observations are dependent (or nested); a situation that is common in many applied bandit problems. We conclude that BTS is competitive in performance, more amenable to some large-scale problems, and, at least in some cases, more robust than Thompson sampling. The observation that BTS can overexploit when the number of online bootstrap replicates is too small needs further attention. The number of bootstrap replicates J can be regarded a tuning parameter in applied problems—just as the posterior in Thompson sampling can be artificially concentrated (Chapelle & Li, 2011)—or could be adapted dynamically as the estimates of the arms evolve; for example, replicates could be added or removed. Future work could also consider even more computationally appealing variations on the bootstrap, such as streaming subsampling methods (Chamandy et al., 2012) or the bag of little bootstraps (Kleiner, Talwalkar, Sarkar, & Jordan, 2014).
General Discussion
Widespread adoption of information and communication technologies has made it possible to adaptively assign, for example, people to different messages, experiences, interventions, and so on. This makes it felicitous to think of many empirical efforts in the applied behavioral sciences as sequential decision problems and often, more specifically, contextual multiarmed bandit problems. Thompson sampling is a particularly appealing solution for many of these problems and for behavioral scientists in particular; this is largely because, conceptually at least, it is readily extensible to many variations on the standard multiarmed bandit problem. Here, we accompanied our discussion of Thompson sampling with a variant, BTS, largely for this same reason: It allows applying the central idea of Thompson sampling to a wider range of models and settings without some of the computational, practical, and robustness issues that arise for Thompson sampling.
Behavioral and social scientists may find BTS particularly useful, especially as multiple software packages that implement BTS currently exist (Kruijswijk, van Emden, Parvinen, & Kaptein, in press; van Emden & Kaptein, 2018). Bandit problems in the behavioral and social sciences will frequently feature repeated observations of the same units (e.g., people) and possible model misspecification. For example, in economics and political science, there is a norm of using inferential methods, especially cluster-robust sandwich and bootstrap estimators of variance–covariance matrix that are robust to model misspecification and dependence among observations (Cameron & Miller, 2015). Other areas address this same problem in other ways (e.g., use of random effects models in psychology and linguistics [Baayen, Davidson, & Bates, 2008]). BTS makes achieving such robustness in sequential decision problems straightforward.
Footnotes
Acknowledgements
This work benefited from comments from Eytan Bakshy, Thomas Barrios, Daniel Merl, John Langford, Joris Mulder, John Myles White members of the Facebook Core Data Science team, and anonymous reviewers. Dean Eckles contributed to earlier versions of this article, while being an employee of Facebook, Inc.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Dean Eckles had significant financial interests in Amazon, Netflix, Facebook, and GoFundMe while conducting this work. He was an employed by Facebook and Microsoft during the time he contributed to this article. He has received funding from Amazon, though this was not used for this work.