
Abstract
Latent basis growth modeling is a flexible version of the growth curve modeling, in which it allows the basis coefficients of the model to be freely estimated, and thus the optimal growth trajectories can be determined from the observed data. In this article, Bayesian estimation methods are applied for latent basis growth modeling. Because the latent basis coefficients are important parameters that determine the growth pattern in latent basis growth models, we evaluate the impact of different priors for the basis coefficients on parameter recovery and model estimation. Noninformative priors, informative priors with varying levels of accuracy and precision, and data-dependent priors are considered. In addition, the issue of model specification is treated as a prior selection procedure. The impact of model misspecification and priors for model parameters are investigated simultaneously. A Monte Carlo simulation study is conducted and suggests that misspecified models adversely affect the parameter estimation much more than inaccurate priors. Recommendations on prior selection in latent basis growth models are given based on the simulation results. A real data example on the development of schoolchildren’s reading ability is also provided to illustrate the comparison among different sets of priors.
Keywords
Longitudinal data are commonly used in social and behavioral sciences to study change over time. Latent growth curve models are powerful tools to analyze longitudinal data and can directly investigate intraindividual change over time and interindividual difference in intraindividual change (McArdle & Nesselroade, 2014). Latent basis growth models (LBGMs) are a type of latent growth curve models. This type of growth curve models typically fixes the basis coefficients/loadings for the first and last waves of data for identification purposes, while allowing other basis coefficients/loadings to be freely estimated. In this way, the optimal growth trajectory, either linear or nonlinear, can be determined by observed data (e.g., McArdle & Nesselroade, 2014; Meredith & Tisak, 1990). Because of such a flexibility, there is an increasing number of research implementing LBGMs to analyze longitudinal data (e.g., Phan, 2013).
In estimating LBGMs, Bayesian approach has many advantages. First, in longitudinal data, developmental complexities such as unequally spaced occasions, nonlinear or compound trajectories, or nonnormally distributed repeated measures arise commonly (e.g., Curran, Obeidat, & Losardo, 2010; Grimm & Ram, 2009). Even after a complicated transformation of the data, Bayesian inferences can still be easily drawn based on posterior distributions of model parameters (Gelman, Carlin, Stern, & Rubin, 2015). Second, Bayesian methods can be applied to estimate complex models. With a complicated data structure, Bayesian posteriors of model parameters can be approximated using a simulation-based Markov Chain Monte Carlo (MCMC) algorithm (e.g., Dunson, 2000; Lu & Zhang, 2014). Third, previous literature suggested that Bayesian methods are more plausible than the maximum likelihood (ML) estimation when sample size is small, because Bayesian inference is not based on asymptotic theory, and limiting approximations are not needed for Bayesian inferences of posterior distributions (e.g., Casella & Berger, 2001; Hoogland & Boomsma, 1998; Schafer, 1997; Scheines, Hoijtink, & Boomsma, 1999). More specifically, Scheines et al. (1999) showed that Bayesian estimation outperforms ML estimation when sample size is small. Lee and Chang (2000) demonstrated that the MCMC algorithm provides a smaller prediction error such as the mean squared deviation and is slightly more efficient with small sample growth data.
Furthermore, the improvement in computing powers and accessibility to Bayesian software have popularized the Bayesian approach in estimating growth curve models. Consequently, more and more researchers conduct growth curve analysis from a Bayesian perspective (e.g., Elliott et al., 2005; Li, Chang, & Chen, 2010; Tong & Zhang, 2012; Zhang, Lai, Lu, & Tong, 2013)
Bayesian methods take advantage of prior information along with the observed data to make inferences. Because the sample is already the fixed data evidence once it is drawn from the population, how to make the best use of prior knowledge is important to obtain the Bayesian posterior distributions of the parameters. Prior typically refers to researchers’ previous knowledge or belief of a hypothesized parameter distribution. When little explanatory information about the unknown parameter is provided by intention, the prior is noninformative; when existing information at hand is inserted deliberately, the prior is informative (Gill, 2014). The noninformative prior is a product of mitigating criticism of being “subjective” about Bayesian methods. Although it appears convenient to use noninformative priors, previous research casts doubt on the performance of noninformative priors in Bayesian research. It was found that noninformative priors had poor performance in parameter recovery and led to large bias in posterior distributions in univariate mixture models, and researchers suggested against using noninformative priors in the mixture modeling context (Richardson & Green, 1997; Roeder & Wasserman, 1997). In addition, using noninformative priors is a waste of resources if there is sufficient prior information available (Bolstad, 2007). Studies have favored informative priors in several aspects. The empirical results reported in Zhang, Hamagami, Wang, Grimm, and Nesselroade (2007) demonstrated that informative priors increase statistical efficiency and power, especially when sample size is small. Moreover, using informative priors is analogous to having additional data in the form of priors.
Zhang et al. (2007) argued that informative priors provide us additional information, similar to the “data pooling” technique (p. 381). Some researchers even viewed using informative priors as an alternative to meta-analysis (Wolf, 1986) or mega-analysis (McArdle & Horn, 2004).
Depaoli (2014) found that using informative priors has a positive impact in parameter recovery on growth mixture modeling. Empirically, Muthen and Asparouhov (2012) proposed a Bayesian structural equation modeling approach, and through simulation studies, they argued that informative priors with small variances better reflect substantive theory. In longitudinal data analysis, researchers may have previous knowledge of the growth trajectory, and would like to further study the growth pattern or related factors that may cause the pattern of growth. The previous knowledge helps researchers create new ideas and have a reasonable prediction about the growth. Moreover, incorporating prior information can mitigate the effect of a small sample size and other selection effects so that researchers may acquire more balanced results.
Although informative priors can bring useful information to the study, they may also cause problems under some circumstances. For example, given misleading prior knowledge, the parameter estimates may be inefficient, or even biased (Bolstad, 2007; Depaoli, 2013). In fact, for informative priors, the degrees of accuracy and precision of the information may vary. In cases where prior information is verified and strengthened with additional knowledge and benefits future research, the prior is an accurate informative prior. On the contrary, with the acquisition of more data or research evidence, it is also possible that the prior knowledge is proved to be inconsistent or incorrect (Bolstad, 2007). Because the posteriors of model parameters are affected by both observed data and the priors, we may risk having inconsistent information when the prior knowledge is inaccurate, which eventually leads to a biased conclusion. Depaoli (2013) found that in the growth mixture modeling, the recovery of growth parameters could be affected by the accuracy of priors, given class proportions and growth trajectories across latent classes.
Despite the three facts that LBGMs are useful, Bayesian methods are flexible to estimate LBGMs, and prior selection is important in Bayesian analysis, no study has systematically investigated the impact of priors on the Bayesian latent basis growth modeling. In latent basis growth modeling, researchers are usually interested in the latent basis coefficients because these parameters determine the shape of the growth trajectories. Therefore, assigning appropriate priors to the basis coefficients is important in determining the optimal growth trajectories for the longitudinal data, which will eventually affect the model estimation in latent basis growth modeling. If the estimates of the basis coefficients are incorrect, the entire growth pattern may be misinterpreted. Furthermore, by assigning different basis coefficients, the growth curve models can even be different. For example, if the basis coefficients are equally spaced, the LBGM is simplified to a linear growth curve model. In fact, practical researchers usually use a linear growth curve model to fit their data because they “believe” that their participants’ scores increase/decrease linearly and the linear growth curve model is easier to estimate. What they believe can also be viewed as prior information. As a result, we can also treat model specification as a prior selection procedure, especially for latent growth models. For example, when researchers believe that the change pattern is linear, quadratic, or cubic, they fit a linear, quadratic, or cubic growth curve model to their data, respectively. In these cases, prior information is applied when specifying a model, and thus model specification can be viewed as an informative prior. In some other cases when researchers have no knowledge about the change pattern and fit a more general growth model to their data such as a LBGM, model specification is viewed as a noninformative prior. Note that fitting a LBGM is not always noninformative. If researchers believe the change pattern is nonlinear and specify a LBGM, model specification is informative. In sum, model specification can be considered as a prior selection procedure, and thus, we can also evaluate the impact of model misspecification for latent growth modeling by evaluating the impact of different priors. To summarize, the major contributions of the study are to (a) systematically investigate the impact of different types of Bayesian priors on latent basis coefficients estimation and examine the overall latent basis model estimation, (b) propose the idea of treating model specification as a prior selection procedure, and (c) evaluate the adverse effect that model misspecification may have on statistical inferences and provide prior selection guidelines.
In this article, we investigate the impact of priors with different levels of accuracy and precision for the basis coefficients of LBGMs on parameter recovery and model estimation. We propose two layers of prior selection procedure—the model layer and the parameter layer. In the next section, we introduce Bayesian estimation methods for LBGMs. Then we briefly discuss Bayesian priors for LBGMs. To investigate the influence of different priors on model estimation, we conduct a Monte Carlo simulation study by varying three factors including sample size, correlation between the two latent variables, and variance of intraindividual measurement errors. A real data example is also provided to illustrate the effects of accuracy and precision of the prior information on parameter estimation. In the end, conclusions and recommendations are provided regarding the prior selection in latent basis growth modeling.
Bayesian Estimation for Latent Basis Growth Modeling
Latent growth curve models are commonly used to analyze longitudinal data. Growth curve models capture both the overall growth pattern and interindividual differences of the participants.
A typical form of growth curve models can be written as


where
LBGMs are a special case of the general latent growth curve models. By selecting the parameters in latent growth curve models as
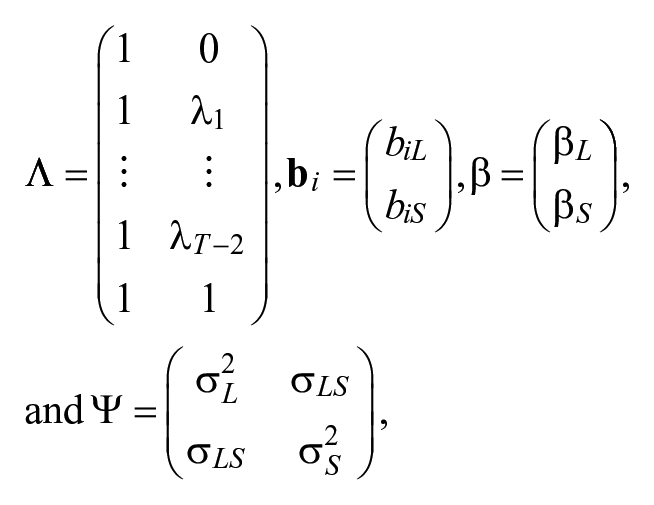
the general latent growth curve models become LBGMs. In LBGMs, there are two latent factors,

Latent basis growth curve model with four measurement occasions.
We use Bayesian methods to estimate LBGMs. In the Bayesian framework, we rely on one single tool, the Bayes’s Theorem to obtain the joint posterior distributions of parameters based on the prior distributions and the data information. In the LBGMs, the joint probability distribution of
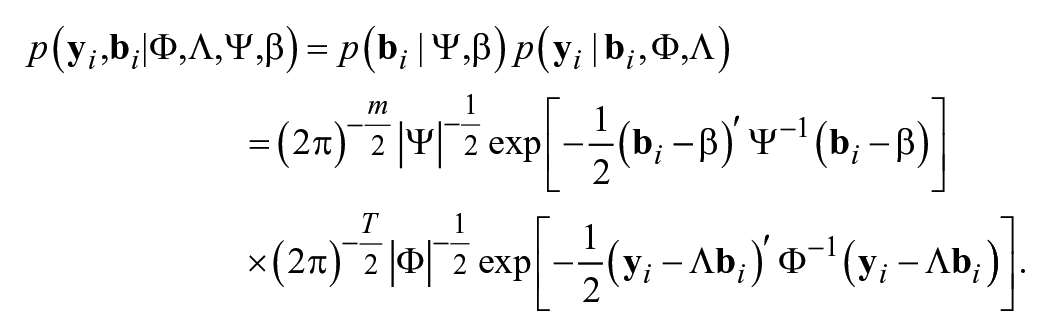
Thus, the likelihood function for the LBGM is


where the unknown parameters in the LBGM include

Statistical inferences are usually difficult to be made directly from the joint posterior distributions. In Bayesian analysis with complex models, the conditional posterior distributions are relatively easy to obtain and can be used as a transition kernel to the joint distribution. Gibbs sampling, a MCMC algorithm, is often used to generate a sequence of samples from the joint probability distribution of two or more random variables (Casella & George, 1992). To be specific, Gibbs sampling alternately samples one parameter each time from its conditional posterior distribution conditional on the current values of the other parameters by treating the other parameters as known. After a sufficient number of iterations, the sequence of samples constitutes a Markov chain that converges to a stationary distribution. Geman and Geman (1984) showed that the stationary distribution of the Markov chain is actually the sought-after joint posterior distribution. Therefore, the Markov chain for model parameters or even augmented latent variables can be used to construct parameter estimates (Zhang et al., 2013). Gibbs sampling is especially useful when the joint probability distribution is too complex or unknown at all, but the conditional distribution for each parameter can be easily made available.
The Gibbs sampling algorithm is used to get parameter estimates for LBGMs. The detailed steps of the Gibbs sampling algorithm are given below.
Start with initial values
Assume at the
At the 3.1. Sample 3.2. Sample 3.3. Sample 3.4. Sample 3.5. Sample
Repeat Step 3.
Bayesian Priors
In Bayesian statistical inference, prior of an uncertain quantity refers to one’s beliefs about this quantity before some evidence is taken into account. It can be knowledge gained previously such as background information or established theories, or even one’s intuitions. Often, the unknown quantity concerns parameters in a model. In this article, we believe model specification can also be viewed as an uncertain quantity. Although parameters in a model quantify characteristics of the population, the model specification reflects our beliefs of the structure of the data and it is at least as subjective as selecting a prior distribution for a model parameter. The rationale of incorporating model specification into the prior selection is that as both models and model parameters provide venues to understand the observed data and both model selection and parameter distribution selection are subjective, the source of information for Bayesian priors can be either from the model parameters or the models themselves.
There are two types of priors for the model parameters in the Bayesian framework: the noninformative priors and the informative priors. When previous knowledge is limited and priors are thus difficult to construct (Gill, 2014), noninformative priors are desirable to use. The rationale for using the noninformative priors is to “let the data speak for themselves” (Gelman et al., 2015, p. 51), such that the posterior distributions are dominated by the likelihood function, and the influence of prior information is minimized. In contrast, when researchers have a belief of the parameter distributions and use such information in model estimation, such prior knowledge is called informative prior, regardless of the sources of the information (e.g., a hypothesis being revised from theory, a pilot study or researchers’ intuitions; Gill, 2014; Muthen & Asparouhov, 2012). In latent growth curve modeling, it is likely that researchers are interested in the growth pattern of a psychological development or a cognitive ability, but they have no access to prior knowledge about it (e.g., no related study has been done previously). In this case, they may consider using noninformative priors. In practice, however, it is more likely that researchers have already had some prior knowledge about the parameters of interest in hand, and are doing further analysis of the data. For example, psychologists interested in learning participants’ change in attitude toward science may have had some expectations of the development in mind based on professional knowledge or empirical observations; educational researchers interested in studying children’s mathematical achievement may have learned previous academic growth from other published work (NICHD Early Child Care Research Network, 2007). These pieces of information are valuable to later research on understanding participants’ psychological development or academic growth, and they could serve as informative prior knowledge. With a strong belief and comprehensive prior knowledge, the informative prior of the development or growth could be accurate and precise. The informative prior distribution could also be “informative but weak,” as it is enough to keep posterior distribution within roughly reasonable bounds, but unable to capture the parameter knowledge (Gelman et al., 2015; Lambert, Sutton, Burton, Abrams, & Jones, 2005, p. 51). In such an instance, rather than a complete ignorance of knowledge, sometimes including even a small amount of information might be useful.
In LBGMs, prior selection for the basis coefficients adds an uncertainty in the parameter estimation. Specifically, different latent basis coefficients determine the shape of the growth trajectory and even the growth curve model. When priors of the latent basis coefficients are specified either incorrectly (i.e., the data are very different from what is expected from the prior) or with a lack of precision (i.e., prior distribution with a large variation), the posterior may be strongly influenced and the entire growth pattern may be distorted. Furthermore, selecting different priors for latent basis coefficients may lead to different models because the model specification can be viewed as being based on prior information. If the true growth pattern is nonlinear whereas latent basis coefficients are restricted to equally spaced values based on prior information, the LBGM becomes a linear growth curve model. Under this circumstance, model misspecification is a result of inaccurate prior selection and may greatly influence the parameter recovery and statistical inferences. In some sense, prior information can be divided into two layers. On the first layer, a model is specified based on researchers’ substantive theories or previous experiences. If there is no prior knowledge, a most general model is usually specified at the first step and this can be treated as a noninformative prior in model specification. On the second layer, given a specified model, priors are selected for model parameters. In the context of latent basis growth modeling, the two layers can be considered simultaneously. Consequently, the purpose of this study is to consider the two layers of prior selection procedure simultaneously in latent basis growth modeling, or in other words, to examine the impact of priors for model parameters as well as the impact of model misspecification on model estimation.
In this article, we evaluate the impact of priors for latent basis coefficients in LBGMs. For all the other model parameters, noninformative priors are applied. We consider four different types of priors for the latent basis coefficients to reflect commonly encountered situations in the real world. First, noninformative priors are used. In particular, we use diffuse priors as they are widely used noninformative priors that contain vague information with a large variance component to reflect “uncertainty in beliefs” (Kruschke, 2011, p. 39) or lack of knowledge in the prior information. Second, several sets of informative priors with different levels of accuracy and precision are investigated. It is rare but possible that researchers have a strong belief of very accurate knowledge about the parameters of interest before collecting data and conducting data analysis. Such prior information is very accurate and precise. In practice, it is more likely that researchers’ previous knowledge may be outdated or slightly biased, meaning that the prior knowledge is less accurate. If researchers have strong beliefs about such biased information, the prior is inaccurate yet with high precision. In some circumstances, researchers may get the prior knowledge based on the observed data and thus use data-dependent priors (DDPs). As its name suggests, DDPs are formulated based on the information obtained from the same data, such as having the parameters being approximated by a sample statistics (Serang, Zhang, Helm, Steele, & Grimm, 2015). Third, when researchers strongly believe that the latent bases are equally spaced, they may simply fit a linear growth curve model by constraining the latent basis coefficients to be some exact numbers. These priors actually lead to a model misspecification issue. Naturally, because specifying models can be treated as applying informative prior knowledge, we further study another type of nonlinear growth curve model—the quadratic growth curve model and evaluate how these types of prior information affect the latent growth modeling. A quadratic growth curve model is another special case of the general growth curve models. The matrix form of the parameters in quadratic growth curve models can be presented as
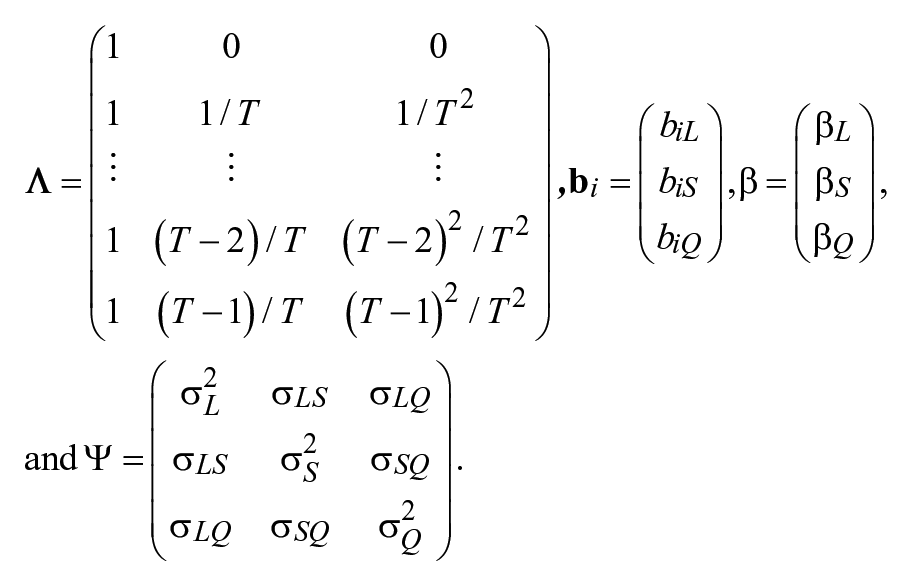
Evaluating the Impact of Priors Using a Monte Carlo Simulation Study
Study Design
In this section, we evaluate the impact of eight different sets of priors for the latent basis coefficients in latent basis growth modeling through a Monte Carlo simulation study. Because a pilot study showed that the number of measurement occasions does not affect the model estimation, we focus on a LBGM with four measurement occasions as shown in Figure 1. The population parameters of the LBGMs are given by

We manipulate three factors to generate data, including sample size, covariance between the two latent variables
For each set of the simulated data, the impact of eight sets of priors (see Table 1) for the latent basis coefficients, which fall into the four types as discussed in the previous section, is studied and compared.
Prior Specification of Latent Basis Coefficients for Simulation.
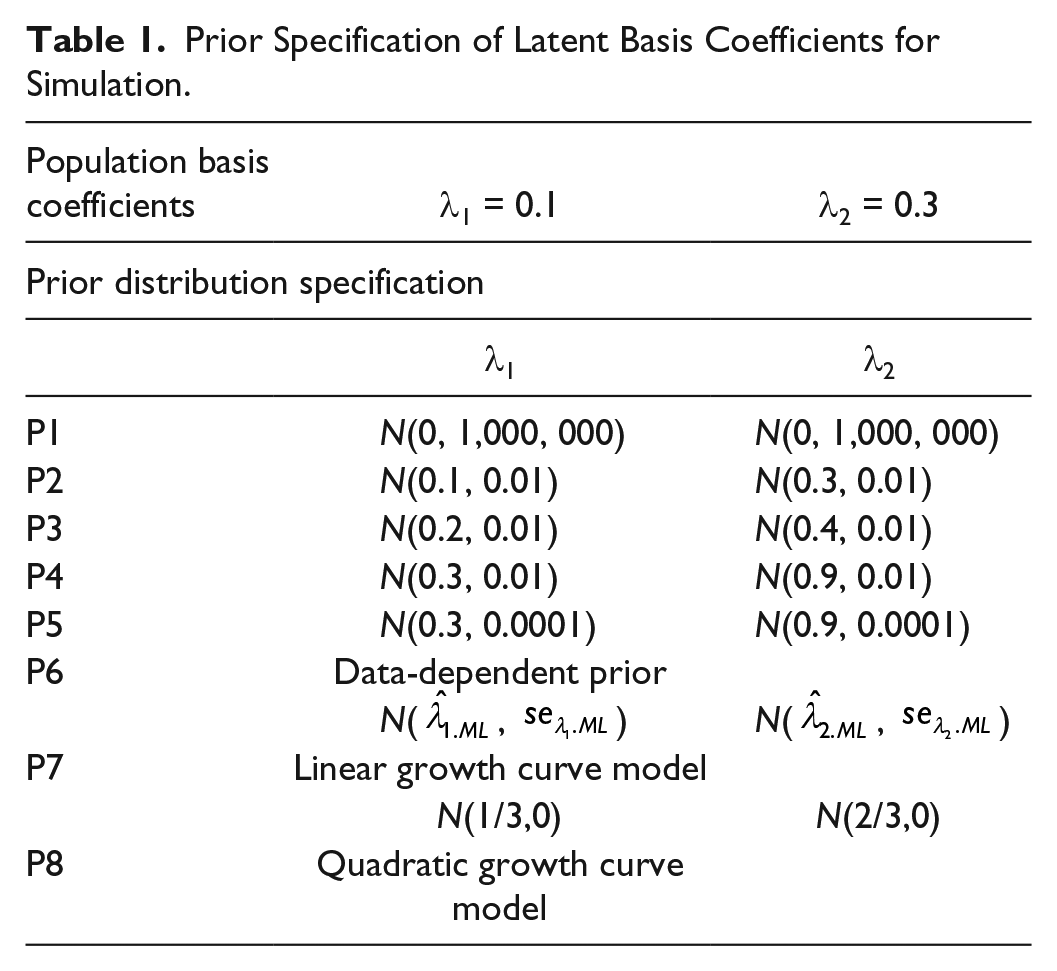
Priors P1 are noninformative priors. Priors P2 to P6 are informative priors. Particularly, priors P2 are the accurate informative prior as the priors reflect the actual parameter information. Priors P3 to P5 can be seen as the “weakly informative priors,” as information contained in these priors is not accurate but with a reasonable range of actual knowledge (Gelman, 2006). Priors P6 are also informative priors as they are data-dependent and gain information from the data. From priors P2 to P4, the accuracy of the priors reduces as the means of the priors deviate more from the true parameter values. Priors P5 have the same level of accuracy as priors P4 (both are inaccurate), but the distributions in P5 have smaller variances, meaning that we are more certain about the prior information in P5 than in P4 although the information is incorrect. Because DDPs are found to reduce bias in small samples in growth curve models (McNeish, 2016) and provide a possible alternative strategy to incorporate prior information when the information is limited, we also use DDPs as priors P6. For these priors, ML parameter estimates and the associated standard errors (SEs) are first obtained through the ML estimation of the model to the data, and the estimates and the associated SEs are then used as the hyperparameters in Bayesian prior specifications. When we have even stronger belief about the latent basis coefficients, the model specification may be influenced more. Priors P7 and P8 are used to illustrate this situation and are the remaining two types of priors for model specification. In P7, the latent basis coefficients are fixed at equally spaced values (λ1 = 1/3 and λ2 = 2/3), and thus the model becomes a linear growth curve model. We further study the effect of model misspecification and consider priors P8—specifying a quadratic growth curve model. In P8, the latent basis coefficients for
All the models are estimated using Bayesian methods. The simulation is conducted using R (R Development Core Team, 2011) and OpenBUGS (Thomas, O’Hara, Ligges, & Sturtz, 2006). An example of OpenBUGS script is provided in the appendix to facilitate the application of the Bayesian methods for latent basis growth modeling.
Evaluation criterion
The impact of the priors on model estimation is evaluated. First, for the LBGMs, we assess bias, SEs, and mean squared errors (MSEs) of the parameter estimates for the latent basis coefficients λ1 and λ2, as well as other model parameters. Let θ denote the population parameter value, and let
Bias captures the distance between the replication estimate and its population parameter value,
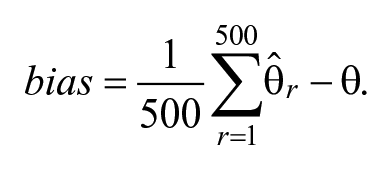
SE is the standard deviation of the replication estimate, and MSE of the estimate is the expectation of its squared deviation from the true value.

Second, to compare the prior condition P7 where the model becomes a linear growth curve model with conditions P1 to P6, we study the estimates of the average latent intercept βL and the average total change over time βS, and compare them across conditions.
Third, the deviance information criterion (DIC; Spiegelhalter, Best, Carlin, & Linde, 2002) is used as a useful tool for Bayesian model assessment and model comparison. Similar to the model fit index BIC (Bayesian information criterion) from frequentist approach, DIC measures a combination of model complexity and model fit (e.g., Gill, 2014; Zhang et al., 2013). DIC is particularly useful in Bayesian model comparisons as the posterior distributions of the parameters have been obtained by MCMC simulations. Given the fact that the parameter estimates from the quadratic growth curve models cannot be directly compared with those from the other models, we use DIC to compare the quadratic growth curve models with the others and determine the best fitting models.
Results
Bias, SE, and MSE of the estimated basis coefficients
VBias, SE, and MSE for the Latent Basis Coefficient λ1.
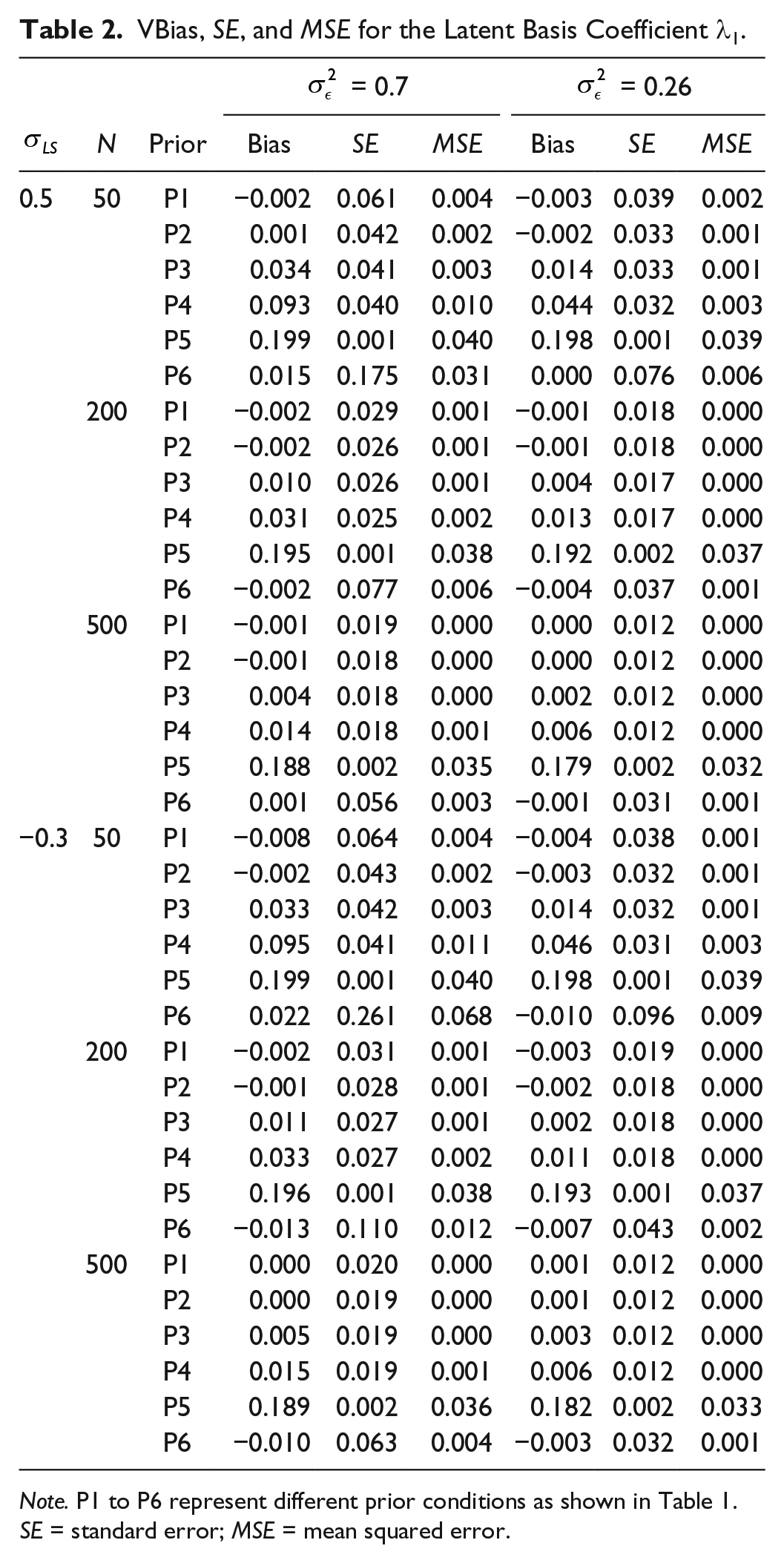
Note. P1 to P6 represent different prior conditions as shown in Table 1. SE = standard error; MSE = mean squared error.
Bias, SE, and MSE for the Latent Basis Coefficient λ2.

Note. P1 to P6 represent different prior conditions as shown in Table 1. SE = standard error; MSE = mean squared error.
Bias, SE, and MSE for the Parameter βS.

Note. P1 to P7 represent different prior conditions as shown in Table 1. SE = standard error; MSE = mean squared error.
The estimates for other model parameters are available upon request, but not given in this section to save space. To evaluate the impact of priors which resulted in model specification, DICs for the misspecified models are compared with those for latent basis models with noninformative priors and accurate informative priors.
Overall, as sample size increases, parameter estimates have decreased bias and SEs, and the impact of prior specifications on the parameter estimation decreases. The covariance between the two latent variables,
We take a close look at the impact of different priors on model estimation. Prior specifications on the latent basis coefficients affect the parameter estimates for LBGMs. Among all the prior specifications, priors P2 lead to the smallest MSE, showing that accurate informative priors P2 lead to the most accurate and efficient combination of parameter estimates across all conditions.
Comparing the performance of all the informative priors in the basis coefficients estimation, the benefit of using priors P2 over other informative priors is especially obvious when sample size is small. For example, when sample size is 50,
For DDP priors P6, nonconvergence occurs in ML estimation for the basis coefficients especially when sample size is small, and only converged results are reported. Comparing the performance of priors P6 to the performance of other informative priors, although DDP priors P6 performs slightly worse than the accurate informative priors P2, they produce relatively smaller bias than other inaccurate informative priors P3 to P5. For example, when N = 200,
Comparing the performance of the informative priors with that of the noninformative priors P1, using priors P1 and priors P2, lead to very similar results in terms of bias. For example, when sample size is 50,
As shown in Table 4, when priors P7 are applied, in other words, when we believe that the growth pattern is linear and fit a linear growth curve model to the data whereas the true model is nonlinear, the model parameter estimates are biased. The bias under P7 conditions is much larger than those under prior conditions P1 to P6, although priors P4 are inaccurate priors with small precisions. Therefore, we conclude that prior information which results in model misspecification can largely influence the model estimation and interpretations.
As discussed previously, model specification can be treated as a prior selection process, and we use DIC to evaluate the impact of such prior information. Table 5 presents average DICs across all replications under prior conditions P1, P2, P7, and P8. Corresponding DICs under prior conditions P3 to P6 are relatively larger than those under prior conditions P1 and P2, and thus are omitted here. The result shows that DICs for the LBGM with noninformative priors P1 and accurate informative priors P2 are comparable. Although DICs are smaller when priors P2 are used, the difference is almost negligible, especially when sample size is large and the intraindividual measurement error is small. For example, in conditions where no correlation between the latent intercept and slope is present, when
DIC for Models With Priors P1, P2, P7, and P8.

Note. DIC = deviance information criterion.
Example
A subset of the National Longitudinal Survey of Youth data from the 1979 cohort is used to illustrate that different prior specifications on the latent basis coefficients affect the model estimation and the interpretation of the growth pattern in latent basis growth modeling. Fifty schoolchildren’s Peabody Individual Achievement Test (PIAT) reading recognition was measured biyearly in 1986, 1988, 1990, and 1992. Figure 2 shows a trajectory plot of the data, with the red line representing the average score at each measurement occasion. The overall trajectory seems nonlinear. Given the prior knowledge that Zhang et al. (2007) fitted a LBGM to PIAT reading scores collected from the same cohort and the model fitted their data well, we use a LBGM (Figure 1) to analyze our data. In the latent basis growth modeling, we specify different priors for the latent basis coefficients and use noninformative priors for the remaining parameters. For illustration purposes, we compare four prior conditions. First, noninformative priors are applied, where both λ1 and λ2 follow a normal distribution N (0, 106).
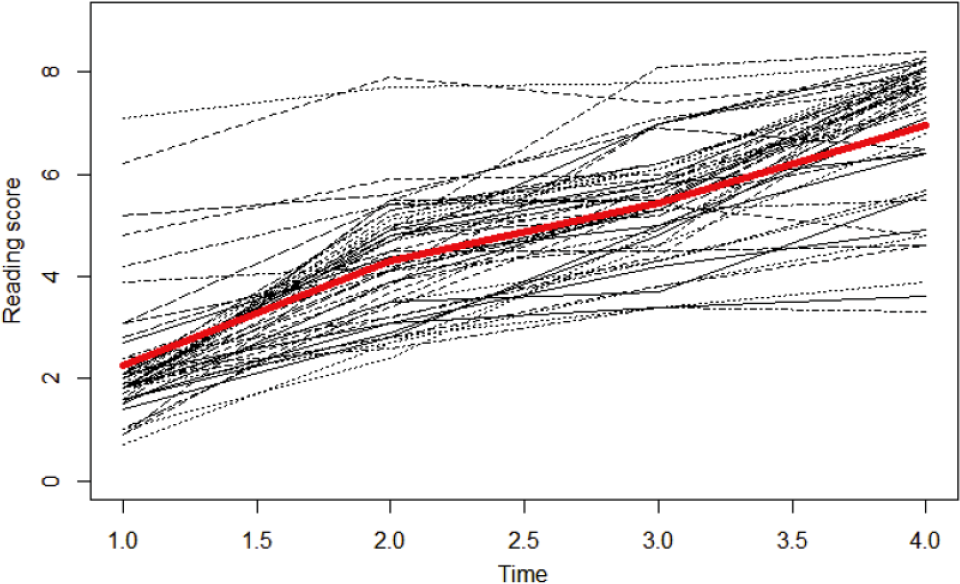
Longitudinal trajectory plot of PIAT reading data.
Second, based on the results from Zhang et al. (2007), informative priors λ1 ∼ N (0.5, 0.01) and λ2 ∼ N (0.8, 0.01) are used. Because Zhang et al. analyzed data from the same cohort, we assume their results can be trusted and treat this set of priors as accurate informative priors. Third, by fixing λ1 at 1/3 and λ2 at 2/3, the LBGM becomes a linear growth curve model, which is widely used in practice as it is easier to estimate and interpret. Because the trajectory plot suggests a nonlinear growth pattern, we treat this set of priors as inaccurate informative priors. In addition, we also fit a quadratic growth curve model to the data for comparison. As discussed previously, model specification can be also viewed as a way of prior selection. Thus, we compare four prior conditions in total.
The DICs for the linear growth model and quadratic growth model are 458.5 and 438.7, respectively. Both are much larger than the DICs for the LBGMs (DIC = 414.8 when the noninformative priors are used, DIC = 422.8 when the accurate informative priors are used, and DIC = 411.4 when the DDP are used), meaning that the LBGMs fit data better than the linear growth model and the quadratic growth model. Thus, we only compare the parameter estimates for the LBGMs with noninformative priors, accurate informative priors, and DDP. The results are provided in Table 6. The first two sets of priors lead to slightly different parameter estimates. The SEs of the estimates from the latent basis model with accurate informative priors are uniformly smaller than those from the latent basis model with noninformative priors, indicating that the accurate informative priors result in more precise parameter estimates. The DDP produces similar results to those from noninformative priors, and thus is an alternative strategy to be considered as a type of informative prior.
Parameter Estimates for PIAT Reading Data.
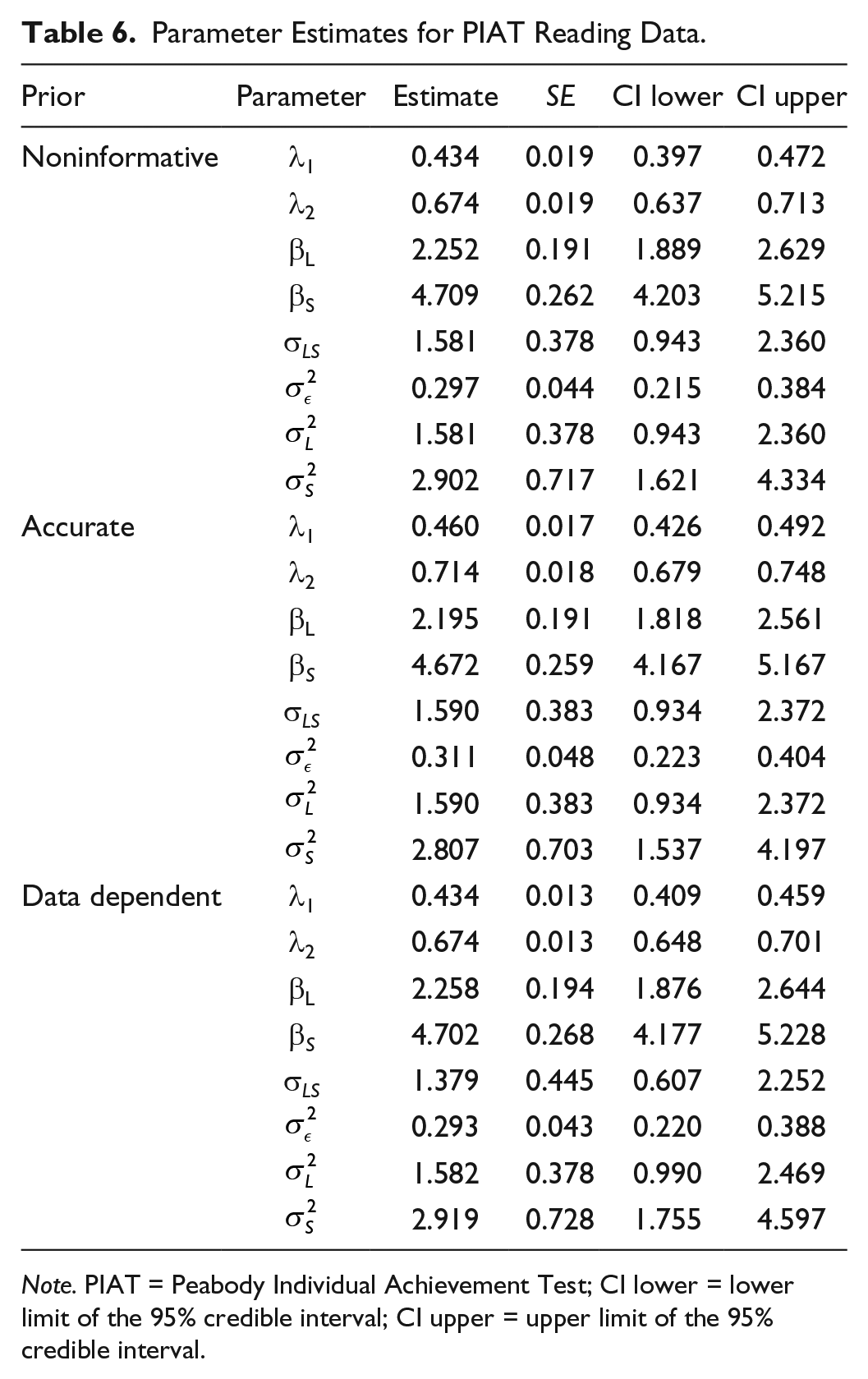
Note. PIAT = Peabody Individual Achievement Test; CI lower = lower limit of the 95% credible interval; CI upper = upper limit of the 95% credible interval.
Based on the simulation results discussed previously, we rely on the results from the LBGM with accurate informative priors because the sample size is relatively small in this example. The estimated basis coefficients show that the growth pattern of the reading scores is curvature rather than linear. The increase of schoolchildren’s reading scores was relatively faster at the beginning and slowed down at the later period of time. The average initial reading score is 2.195, and the average total change from 1986 to 1992 is 4.672. There are interindividual differences at both the initial values and the total changes over time, and the initial reading scores are positively correlated with the total change scores over time.
Discussion
In this study, the impact of two layers of prior information on the Bayesian estimation of LBGMs was investigated through a simulation study. In particular, eight sets of prior information with different levels of accuracy and precision were considered. Among the eight sets of priors, two are misspecified models: linear and quadratic growth curve models. We treated model misspecification as a special case of applying inaccurate informative priors and studied the impact of the model misspecification on the LBGM estimation. Three potentially influential factors were considered, including covariance between the two latent variables, variance of intraindividual measurement errors, and sample size. Based on the simulation results, following conclusions are drawn.
Overall, sample size affects the Bayesian estimation of latent basis coefficients. As sample size increases, the impact of prior information decreases and the posterior parameter estimation is more affected by the observed data. When sample size is extremely large, the prior is said to be “swamped by the data” (see, for example, Bolstad, 2007; Muthen & Asparouhov, 2012; Scheines et al., 1999). Then, under different prior specifications, intraindividual measurement errors have an influence on the parameter estimates. Small measurement errors yield relatively more accurate and efficient basis coefficient estimates, even when the priors are inaccurate. This is probably because with small measurement errors, the observed sample data have explained the majority of the variance of accuracy in basis coefficients, which in turn reduces the influence of the prior information. In addition, the covariance between the two latent variables has no apparent influence on the parameter estimates.
Specifying priors on the latent basis coefficients does not only affect basis coefficients estimates but also has an impact on the performance of the other model parameter estimates, including the average latent intercept and the average total change over time. Therefore, even the growth pattern may be misinterpreted when inaccurate priors are applied, let alone the interpretations for interindividual differences and the relationship between the initial values and the total change scores. When previous information leads to misspecified models, DIC can be used to detect the inaccurate prior information. For example, DIC shows strong model misfit in the simulation study as the true growth pattern is nonlinear whereas we fit a linear growth model to the data. Therefore, as we never know whether previous information is accurate or not, a linear relationship should be specified with caution as potential problems of model misfit might arise and result in misleading interpretations. A LBGM is more general and thus recommended to use.
In Bayesian methods, prior selection is important for latent basis growth modeling, as prior information affects the model parameter estimates and thus the shape of the latent growth trajectories. Theoretically, when one is certain about previous knowledge and the previous knowledge is correct, such informative priors produce the most accurate and efficient parameter estimates. Limited and inaccurate previous knowledge is very likely to lead to inefficient or even incorrect parameter estimates. Although the performance of the noninformative priors and the accurate informative priors seems similar in terms of bias and SEs, accurate informative priors P2 bring in a substantive increase in statistical power compared with noninformative priors P1 under some circumstances. Note that the positive impact of noninformative priors in the context of LBGMs runs differently from that in the growth mixture modeling context, where research on the latter concluded that the noninformative priors on the specification of mixture proportions in the growth mixture model had a harmful impact and recommended against using noninformative priors under any conditions (e.g., Roeder & Wasserman, 1997).
In practice, it is impossible to know whether previous knowledge is accurate or not. Thus, we recommend doing more empirical research and obtain a comprehensive understanding of the substantive interest before making prior selection decisions. It is always a sound scientific practice to do more research in the substantive model to seek for accurate information. However, if prior knowledge is not easily accessible, or even no information is available at all, or previous studies had contradictory conclusions, several remedial strategies may be considered. First, if sample size is reasonably large, one may use noninformative priors in Bayesian estimation to “let the data speak for themselves” (Gelman et al., 2015). However, using noninformative priors should only be seen as a “provisional” strategy and the posterior distribution should always be examined after the model is fitted (Gelman, 2006). If the posterior distribution contradicts previous knowledge or the assumptions of prior distributions, one should always look for additional prior information and fine-tune prior distributions accordingly. Second, when sample size is small and researchers are not confident about the previous knowledge they obtained, we suggest comparing the estimation results based on some informative priors as well as those based on noninformative priors. If the results differ dramatically, further research is needed to obtain more information or additional data need to be collected. Empirically, the DDPs may be adopted as they combine the information from the data using frequentist method and take advantage of the Bayesian method for the estimation. Last, as the model misspecifications adversely affect the model estimations, when limited information about the data structure is available and the choice of the model specification is unclear, a more flexible version of the growth curve model, the LBGM is recommended to be used.
In Bayesian analysis, priors are usually selected for model parameters, but in this article, we treated the model specification as a prior selection procedure as well. Model misspecification is treated as if we had applied inaccurate prior information to the data analysis. This type of inaccurate priors affects the model estimation the most. For example, when a linear growth trajectory is incorrectly specified given the true growth pattern is nonlinear, the estimated growth pattern could be distorted. In addition to LBGMs, the idea of viewing model specification as a prior selection procedure can be extended to other models. For example, in confirmatory factor models with cross loadings, misspecifying models by omitting cross loadings can be viewed as a procedure of selecting wrong priors (Shi & Tong, 2016). This type of prior information should be carefully applied as it may substantially affect model estimation, and may result in misleading interpretation. For confirmatory factor analysis, Bayesian ridge regression priors (Muthen & Asparouhov, 2012) and spike-and-slab priors (Lu, Chow, & Loken, 2016) have been used as variable selection tools. The same ideas can be applied to latent basis growth modeling as well.
We would like to note that although Bayesian statistics has been criticized for its “subjectivity” in assigning prior distributions to model parameters, the model specification itself is subjective regardless of the choice of Bayesian or frequentist approach. For example, in a longitudinal study of child development where the underlying growth trajectory is nonlinear, the first step of selecting a linear growth curve model to fit the data is subjective and may be misleading. This study shows that the model misspecification adversely affects the parameter estimation much more than selecting inaccurate prior distributions. Therefore, the subjectivity of specifying a prior for model parameters in Bayesian method is no more serious than specifying a model. Bayesian approach is more flexible in considering the uncertainty in the model specification.
Footnotes
Appendix
An OpenBUGS script for the latent basis growth model with accurate informative priors in the simulation study.
Model {
for ( i i n 1 :N) {
LS [ i, 1 : 2 ] ~ dmnorm ( muLS [ i, 1 : 2 ], inv_cov [ 1 : 2, 1:2]) muLS [ i,1] < −bL [ 1 ]
muLS [ i,2] < − bS [ 1 ]
for ( t i n 1 : 4 ) {
y [ i, t ]~ dnorm (muY[ i, t ], inv_sig_e2 ) muY[ i, t ]<−LS [ i,1]+ LS [ i, 2 ] * A[ t ]
}
}
## Priors for the latent intercept and the total change over time for ( i i n 1 : 1 ) {
bL [ i ]~ dnorm ( 0, 1 . 0 E−6) # diffuse bS [ i ]~ dnorm ( 0, 1 . 0 E−6) # diffuse
}
## Priors for the latent basis coefficients
A[1] < −0
A[ 2 ] ~ dnorm ( . 1, 1 . 0 E+ 2 ) ## accurate informative A[ 3 ] ~ dnorm ( . 3, 1 . 0 E+ 2 ) ## accurate informative
A[4] < −1
## Priors for the covariance between the intercept and the total change over time inv_cov [ 1 : 2, 1 : 2 ] ~ dwish (R [ 1 : 2, 1 : 2 ], 2 ) # d i f fuse
R[1,1] < −1
R[2,2] < −1
R[2,1] < −R[ 1,2] R[1,2] < −0
## Priors for the residual variance
i n v _ s i g _ e 2 ~dgamma ( . 0 0 1, . 001) # d i ffuse sig_e2 <−1/ inv_sig_e2
cov [1:2, 1:2] < − inverse ( inv_cov [ 1 : 2, 1:2])
## Priors for the variance of the latent intercept and the variance of the total change over time sig_L2 <−cov [ 1, 1 ]
sig_S2 <−cov [ 2, 2 ] cov_LS<−cov [ 1, 2 ]
rho_LS<−cov [1,2]/ sqrt ( cov [ 1, 1 ] * cov [2,2])
## Summarize the parameters into a vector
parm [1]< −A[ 2 ] # basis coefficients
parm [2]< −A[ 3 ] # basis coefficients
parm [3]< −bL [ 1 ] # mean of latent intercept
parm [4]< − bS [ 1 ] # mean of total change over time
parm [5]< − cov [ 1 : 2, 1 : 2 ] # covariance between latent intercept and the total change over time
parm [6]< − sig_e2 # residual variance
parm [7]< − s ig_ L 2 # variance of the latent intercept
parm [8]< − s i g _ S 2 # variance of the total change over time
}
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.