
Abstract
Studies on the going-on COVID-19 pandemic face small sample issues. In this context, Bayesian estimation is considered a viable alternative to frequentist estimation. Demonstrating the Bayesian approach’s advantage in dealing with this problem, our research conducted a case study concerning ASEAN economic growth during the COVID-19 pandemic. By using Monte Carlo standard errors and interval hypothesis testing to check parameter bias within a Bayesian MCMC simulation study, the author obtained significant conclusions as follows: first, in insufficient sample sizes, in contrast to frequentist estimation, the Bayesian framework can offer meaningful results, that is, expansionary monetary and contractionary fiscal policies are positively associated with economic growth; second, in the face of a small sample, by incorporating more information into prior distributions for the model parameters, Bayesian Monte Carlo simulations perform so far better than naïve Bayesian and frequentist estimation; third, in case of a correctly specified prior, the inferences are robust to different prior specifications. The author strongly recommends applying specific informative priors to Bayesian analyses, particularly in small sample investigations.
Introduction
The COVID-19 outbreak, which took place in Wuhan (China) at the end of 2019, has been spreading worldwide at an extraordinary speed and scale. The COVID-19 shock severely damaged the ASEAN community (ADB, 2022). This unprecedented epidemic has become an enormous academic interest, with an increasing number of investigations conducted on its multidimensional impacts on the economies around the world. Recently, Padhan and Prabheesh (2021) provided a review of literature on the economics of the COVID-19 pandemic. Nevertheless, due to small sample sizes, most of the studies on the effects of the COVID-19 crisis derived conclusions relying mainly on conceptual arguments or descriptive data analyses (e.g., Alberola et al., 2021; Allen, 2021; Anand, 2020; Atkeson, 2020; Chetty et al., 2020; Curdia, 2020; Eichenbaum et al., 2020; Fornaro & Wolf, 2020), or frequentist econometric inferences with large data sets (e.g., Baqaee & Farhi, 2020; Chadha et al., 2020; Costa Junior et al., 2021; Faria E Castro, 2021; Iyke, 2020a; Jones et al., 2020; Jorda et al., 2020; Li et al., 2021). Data sample sizes needed for statistical inferences are insufficient to obtain unbiased, robust estimation results, especially in the case of one country or one small group of countries. The Bayesian approach is considered an alternative to more traditional frequentist estimation in small sample contexts.
Hence, the main goal of the current research is to conduct a case study in which the impacts of specific factors on GDP growth are estimated utilizing a small cross-section of 8 ASEAN nations to illustrate the advantages of Bayesian Markov chain Monte Carlo (MCMC) simulations over frequentist and even naïve Bayesian estimation. The results of the analyses suggest recommendations for using Bayesian methods in small sample investigations.
The remainder of the research is organized as follows: A review of literature on the COVID-19 effects and methodological and applied studies on the Bayesian paradigm is performed in Section 2. The methodology in the third section describes Bayesian MCMC simulation methods in which prior specifications are presented for a case study on ASEAN GDP growth. Section 4 demonstrates the Bayesian outcomes of the case study and interprets the results acquired. The fifth section concludes the research.
Literature Review
The COVID-19 outbreak has raised academic interest in business cycle theory. A growing literature on the impacts of the COVID-19 disease has highlighted several aspects. The influence of the COVID-19 pandemic on financial markets was accessed by Al-Awadhi et al. (2020), Baker et al. (2020), Cao et al. (2021), Gil-Alana and Claudio-Quiroga (2020), Gormsen and Koijen (2020), Harjoto et al. (2021), D. Liu et al. (2020), Phan and Narayan (2020). Negative sentiments in connection with the COVID-19 pandemic have caused high volatility in the exchange rate of economies (Iyke, 2020b). Barro et al. (2020), Iyke (2020c), Choi (2020), Jorda et al. (2020), and L. Liu et al. (2020) concentrated attention on production and credit reduction during the COVID-19 period. There are plenty of studies on negative supply and demand shocks in the oil market (Apergis & Apergis, 2020; Devpura, 2020; Devpura & Narayan, 2020; Fu & Shen, 2020; Gil-Alana & Monge, 2020; Huang & Zheng, 2020; Kartal, 2021; Narayan, 2020; Polemis & Soursou, 2020; Qin et al., 2020). Also, there are a large number of analyses of monetary and fiscal policy instruments for fighting the COVID-19-driven recession (Alberola et al., 2021; Allen, 2021; Anand, 2020; Atkeson, 2020; Baqaee & Farhi, 2020; Chadha et al., 2020; Chetty et al., 2020; Costa Junior et al., 2021; Curdia, 2020; Eichenbaum et al., 2020; Faria E Castro, 2021; Fornaro & Wolf, 2020; Iyke, 2020b; Jones et al., 2020; Jorda et al., 2020; Li et al., 2021; Padhan & Prabheesh, 2021). The health impacts of the disease were analyzed by Najabat et al. (2021) The macroeconomic consequences of COVID-19 were assessed by McKibbin and Fernando (2020). Compared to the relatively rich body of literature on the COVID-19 impacts, studies on the influence of the COVID-19 pandemic on ASEAN economies are relatively scarce (e.g., Aziz et al., 2022; Gil-Alana & Monge, 2020; Hooi Hooi, 2022; JETRO, 2020; Kliem, 2021; Makun & Jayaraman, 2021; Morgan & Trinh, 2021; Purnomo et al., 2022; Rizvi et al., 2021; Sharma, 2020; Topcu & Gulal, 2020). Notably, most of the mentioned studies implemented descriptive analyses of data or frequentist modeling relying on sufficiently large data samples. In contrast, studies on COVID-19 impacts like ours face small sample issues due to a limited population.
Small data sets are often encountered in social science research for several reasons, such as the limitation of the research population (Roe-Sepowitz, 2009; van der Lee et al., 2008) or are hard to recruit and prone to drop-out (Mäkelä & Huhtanen, 2010; McCabe et al., 2016; Peeters et al., 2014), high costs of data acquisition (Price, 2012); ethical and moral constraints (van der Lee et al., 2008; van de Schoot et al., 2015), that all “make efforts to obtain a larger sample quite difficult (or impossible)” (Zondervan-Zwijnenburg et al., 2017). In small sample sizes, because of power issues, it is often impossible to acquire meaningful outcomes (Button et al., 2013; Lee & Song, 2004; Price, 2012). Many authors (Button et al., 2013; Kenward & Roger, 2009; Lee & Song, 2004; Natesan, 2015; Price, 2012; Smid et al., 2020; van de Schoot et al., 2015; Zondervan-Zwijnenburg et al., 2017, 2018) have stressed the power failure within the frequentist framework. Frequentist inference in small sample studies regularly leads to “non-convergence, inadmissible parameter solutions, and inaccurate estimates” (Smid et al., 2020), “low statistical power and level of relative bias” (B. O. Muthén & Curran, 1997; van de Schoot et al., 2015; Zondervan-Zwijnenburg et al., 2017). Non-significant p-values from underpowered estimations cannot offer a meaningful interpretation in the null hypothesis significance testing. As shown in comparative analyses, according to coverage levels for structural and variance parameters in small sample studies, least square (LS), maximum likelihood (ML), or restricted maximum likelihood (REML) perform worse than three Bayesian estimation methods with naïve, thoughtful (specific), and data-driven priors, respectively (Bradley, 1978); compared to ML, REML, and LS, the choice of thoughtful prior settings increases power for structural parameters in Bayesian estimation (Miočević et al., 2017; Price, 2012; van de Schoot et al., 2015; Zondervan-Zwijnenburg et al., 2018); Bayesian analysis with thoughtful and data-driven prior settings performs well for both parameter types, but bias level for variances is higher than structural parameters (Hoogland & Boomsma, 1998). Remarkably, the results from Bayesian inference using naïve prior settings are more biased than even data-driven frequentist inferences (Browne & Draper, 2000; Chen et al., 2014; Depaoli & Clifton, 2015; Holtmann et al., 2016; D. M. McNeish, 2016). One main reason behind a high bias level in naïve Bayesian estimation is the priors’ relatively more significant effect on posteriors in the case of small sample sizes and complex models (Lee & Song, 2004; D. M. McNeish, 2016; Natesan, 2015). Diffuse or vague prior distributions give a vast range of plausible parameter values that can be sampled in the MCMC iterations. The probability mass, as a consequence, often lies on outliers. More importantly, Bayesian inference with thoughtful prior settings performs better than frequentist and naïve Bayesian inference in most simulation studies (Depaoli & Clifton, 2015; D. M. McNeish, 2016; Miočević et al., 2017; Natesan, 2015; Price, 2012; Serang et al., 2015; van de Schoot et al., 2015; Yuan & MacKinnon, 2009; Zondervan-Zwijnenburg et al., 2018) whereas only some authors gave a preference for one of the two approaches depending on the quantity or precision of information captured in priors (Depaoli, 2012, 2013; Holtmann et al., 2016; D. M. McNeish, 2016), or prior choice (Baldwin & Fellingham, 2013).
Frequentists often ask, “how large must a data set be?” and can find a solution to this problem in ratios of the number of parameters to the sample size in a research model. Lee and Song (2004) suggested that for structural equation models, to generate reliable results from ML estimation, this ratio should be 1:5, while a ratio of 1:3 might yield some parameter bias. The Bayesian analysis does not require large data sets, as with frequentist methods. A Bayesian simulation study assumes a much smaller ratio of parameters to observations. A 1:3 ratio can be used instead of 1:5. The use of Bayesian modeling allows us to circumvent all the problems mentioned above as recommended by Bayesians (e.g., B. Muthén & Asparouhov, 2012; Smid et al., 2020; Wagenmakers et al., 2008). In Bayesian inference, a posterior distribution resulting from a combination of a prior distribution with the data distribution is demonstrated as a distribution representative of the probability of parameter values.
Throughout the current research, a cross-section concerning ASEAN economic growth is analyzed as a case study to display the advantages the Bayesian approach has to handling inadequate sample issues. In the case study, with the inclusion of featured variables in a multivariate regression model based on a dataset of 8 ASEAN nations (excluding Laos, Cambodia, and Timor-Leste for lack of data), the adoption of frequentist estimators can lead to biased, variable, and unreliable outcomes. Hence, a Bayesian approach via Monte Carlo simulations needs to be employed instead to obtain meaningful outcomes. The study is expected to achieve the following conclusions: first, in small sample sizes, compared to frequentist and naïve Bayesian estimation, a thoughtful Bayesian approach can generate meaningful results; second, in small sample studies, the more information is available in the priors for the parameters in the model, the more precise and robust the posterior results become.
Methodology
Monte Carlo Simulations in Bayesian Perspective
Since the 1990s, we have witnessed a rapid increase in the application of Bayesian statistical methods in a variety of scientific areas (e.g., Hung et al., 2019; König & van de Schoot, 2018; Rietbergen et al., 2017; Thach et al., 2021, 2022, 2022). A sharp rise in both methodological and applied elaboration of the Bayesian approach has been observed in economics. That is thanks to recent advancements in software programs and significant advantages the Bayesian approach has over the frequentist framework, such as the capability of solving too complex models or models too demanding for frequentist methods; straightforward probability interpretations of estimation results; application of simple probability rule, Bayes’ law to all models; the flexibility to involve model uncertainty (Kaplan, 2014; van de Schoot et al., 2017; Wagenmakers et al., 2008). One of the superior features of Bayesian inference over frequentist inference is that the former is not based on asymptotic theory. A combination of prior information with available data results in a posterior distribution that presents a probabilistic distribution of parameter values irrespective of sample size. Prior distributions contain knowledge about model parameters before observing the data. If no information is available, default or non-informative priors are often chosen that specify a wide range of parameter values. In such a way, however, the Bayesian approach will get rid of its main advantages. As a rule, researchers tend to limit the admissible parameter space by specifying informative priors. With such a prior specification, the accuracy of the posterior distribution can increase. When more information is incorporated into a prior distribution, it becomes narrower, so the posterior distribution is influenced more by the prior information. In that case, an increase in statistical power might cause less parameter bias. To summarize, Bayesian inference with informative priors, no matter the sample size, can produce meaningful results, and the precision of the conclusion increases if more information is included. In particular, a thoughtful Bayesian approach allows for mitigating statistical issues related to frequentist inference, such as multicollinearity (Block et al., 2011).
Smid et al. (2020) categorized priors into three types for Bayesian inference: naïve, thoughtful (specific), and data-driven, and there are various levels of informativeness and various combinations of naïve, thoughtful, and data-driven priors within each of these Bayesian categories. The prior setting is viewed as thoughtful in case at least one prior distribution contains information, often used in conjunction with default priors (Smid et al., 2020). Naïve priors rest on software defaults, or generalized suggestions, while data-driven priors are derived from the output of LS, ML, REML, or naïve Bayesian estimation. Smid et al. (2020) emphasized that studies applying naïve or data-driven priors are justifiable under some circumstances; they can be used as thoughtful priors.
The superiority of thoughtful priors over naïve priors is documented in most of the simulation studies (Chen et al., 2014; Depaoli & Clifton, 2015; Holtmann et al., 2016; D. M. McNeish, 2016; Miočević et al., 2017; Natesan, 2015; Price, 2012; Serang et al., 2015; van de Schoot et al., 2015; Yuan & MacKinnon, 2009; Zondervan-Zwijnenburg et al., 2018). Posterior distributions become less biased and more accurate than frequentist and naïve Bayesian methods when more prior information is added, mainly when the hyperparameters of a prior distribution are similar to the population values. In the thoughtful Bayesian category, the level of informativeness is varied by adjusting the variance hyperparameter of the prior distribution (Depaoli, 2012, 2013; Depaoli & Clifton, 2015; Holtmann et al., 2016; van de Schoot et al., 2015; Zondervan-Zwijnenburg et al., 2018) or by adjusting both the hyperparameters (D. M. McNeish, 2016; Natesan, 2015). Based on weakly informative priors, Bayesian performance might still be poor for large variance hyperparameters are specified. But, adding strongly informative priors improves the results in terms of power and relative bias (Depaoli, 2012; Holtmann et al., 2016; D. M. McNeish, 2016).
In the case of lacking knowledge about model parameters, Darnieder (2011) recommended selecting data-driven priors for small sample analyses. Lee and Song (2004), D. M. McNeish (2016), and van Erp et al. (2018) reported that Bayesian results based on data-driven priors are better than those from frequentist and naïve Bayesian estimations.
Variance parameters often have more bias than structural parameters (D. M. McNeish, 2016). B. Muthén and Asparouhov (2012) stated that the prior for variance terms is substantial for small sample sizes. Furthermore, in Bayesian modeling, with the use of half-Cauchy or Inverse Gamma priors, variance parameters give better results than other priors (Gelman, 2006; D. McNeish & Stapleton, 2016). van de Schoot et al. (2015) advised using non-informative Inverse Gamma (0.001, 0.001) or very informative Inverse Gamma (0.5, 0.5) for variance components.
All the analyses presented above assist us in designing a simulation strategy for this research. First, to identify our model’s distributions of structural parameters, we plot the density of all the variables. They are all normally distributed. Figure 1a and b display the normal distribution of the parameters of interest, ΔR and ΔG. These regression parameters are normally distributed with mean and variance hyperparameters. In the second step, emphasizing policy responses to the economic growth of the ASEAN countries, we assign informative priors to the two parameters. At the same time, default prior settings are specified for the remaining variables. The mean values are extracted from LS estimates as well-specified priors in our context (van de Schoot et al., 2015). Although the Bayesian framework is preferable to tackle the inadequate sample issues, simply switching to the Bayesian approach can generate a worse result than the frequentist framework when a small sample model is fit without due diligence to ensure that outcomes are as trustworthy as possible. So, a sensitivity analysis needs to be performed to check how varying values for prior variance influence the posterior distribution. For our case study, the prior variance can be varied in descending order (10,000,1,000, 100, 50, 20, 10, 5, 3, 1). A variance of10,000 is the default prior setting. A variance of 100 is still considered non-informative, whereas a variance of 1 is strongly informative. However, different from the previous studies (Smid et al., 2020; van de Schoot et al., 2015), along with standard deviations, Monte Carlo standard errors are used as a measure of bias, and interval hypothesis testing serves to determine parameter significance in this research. The third step suggests varying both the prior mean and the prior variance. For illustrative purposes, a misspecified prior mean of −5, vastly distinguished from the well-specified one, can be chosen while the prior variance is varied as in the above. Another sensitivity analysis is carried out to check how the misspecified prior distribution influences the posterior distribution when the prior variance ranges from10,000 to 1. According to Bayesians (Gelman, 2006; D. M. McNeish, 2016; D. McNeish & Stapleton, 2016; van de Schoot et al., 2015), variance terms are often problematic, so we set Inverse Gamma distributions of (0.01, 0.01) (non-informative) and (0.5, 0.5) (strongly informative) for the overall variance and perform a sensitivity analysis through a convergence test. Last, we choose the most suitable model to run MCMC simulations and draw inferences.

The density of the parameters of interest. (a) For ΔR and (b) For ΔG.
Model and Data
For this simulation design, we fit a Bayesian regression model:

In the case study, the data utilized to estimate the specific effects on GDP growth in times of the COVID-19 pandemic are a cross-country sample of 8 ASEAN nations (Brunei, Indonesia, Myanmar, Malaysia, the Philippines, Singapore, Thailand, and Vietnam). The point of time is 2021, except for variable Int with its updated data available only to the year 2020. Notice that because observations and parameters reach the same amount of 8, a 1:1 ratio is accessed; as defined by Lee and Song (2004), we obtain a too-small data set. The specific factors of GDP growth that are selected for the case study are variables lagged GDP, trade openness, internet penetration rate, coronavirus infection rate, and monetary and fiscal policy instruments as used in Thach, Linh et al. (2022). Still, the key difference is that this research selects decreases in the interest rate and government expenditure as proxies for policy decisions (Table 1).
Explaining Model Variables.

The simulation study uses a target MCMC sample size of 10,000, with the first 2,500 burn-in iterations discarded from the MCMC sample. To check chain convergence, the author set a thinning of 10 and simultaneously increased the MCMC sample size to 50,000. The total amount of iterations for the Metropolis-Hastings sampling is 102,491. Note that checks for sequence convergence have to be conducted using a Monte Carlo technique before the inferential stage. Once the MCMC chain has converged to a stationary distribution, resulting inferences become reliable.
Bayesian Simulation Outcomes
By default, the structural parameters are normally distributed with hyperparameters of (0,10,000), a non-informative prior setting. An inverse gamma distribution with hyperparameters of (0.01, 0.01) was specified by default for the variance parameter. Concerning the parameters of interest, ΔR and ΔG, to examine the influence of the prior specification on the posterior distribution, we implemented the first sensitivity analysis with the decreasing values for the prior variance (10000–1). Default prior settings were specified for the rest of the parameters in the model. The effects of different specifications of the prior variance on the posterior standard deviation (SD) and the Monte Carlo standard error (SE) for ΔR and ΔG with the fixed prior means of 492 and 35, respectively, are demonstrated in Figures 2 and 3. It is clearly shown that the narrower the specified prior variance, the lower both posterior SD and Monte Carlo SE.

Influence of OLS versus Bayesian methods and various values for prior variance, but with a fixed mean for ΔR.

Influence of OLS versus Bayesian methods and various values for prior variance, but with a fixed mean for ΔG.
It is concluded that in case a well-specified prior mean is included in a small sample simulation study, the more information is captured in the prior variance, the more accurate the posterior estimates become (i.e., estimates of SD and Monte Carlo SE become lower), and, more importantly, thoughtful Bayesian estimation outperforms both naïve Bayesian and frequentist estimation in terms of bias. Besides, the author makes one more immediate conclusion that with the well-specified prior setting, the results remain robust across the different specifications for the prior variance; that is, the various values for the prior variance do not change the posterior estimates.
To analyze the effects of potential misspecification of the prior mean, both the hyperparameters of the normal distribution for ΔR and ΔG were varied. Instead of the well-specified prior mean, a prior mean of −5 and, at the same time, a wide range of values for the prior variance (1000–1) were set on the parameters ΔR and ΔG. The results of the second sensitivity analysis are exhibited in Figure 4. The various values for the prior variance are displayed on the x-axis and probability of the posterior distribution on the y-axis. As is visible, the narrower the value for the prior variance, the lower the probability of the posterior estimates. From the sensitivity analysis results, we can conclude that in the case of misspecification of the prior mean, the more information captured in the prior variance, the more biased the posterior estimates become. In some cases, there may even be changes in the results.
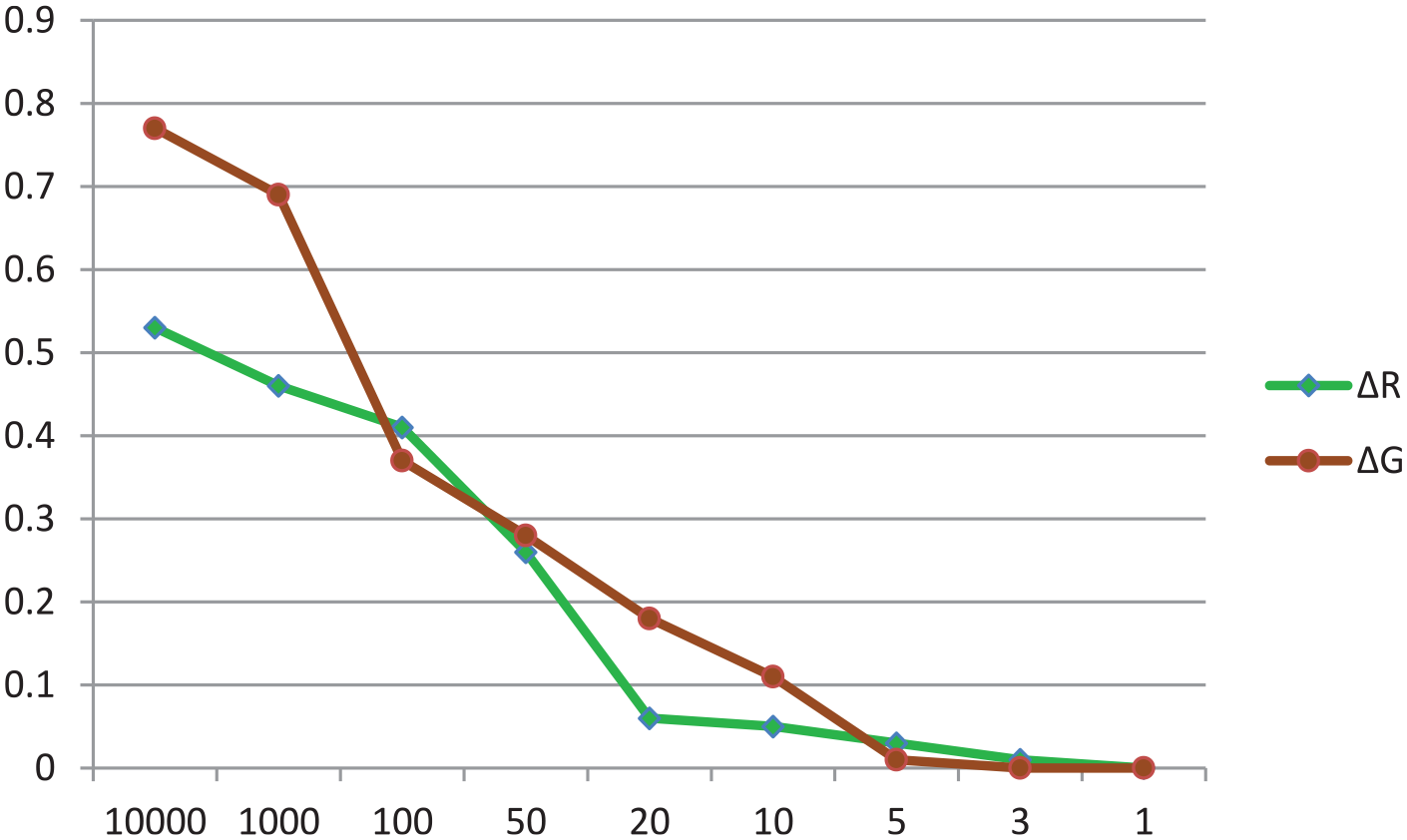
Probability of posterior estimates being significant in the case of a misspecified prior mean (=−5) for ΔR and ΔG.
The biased results for the overall variance can be clarified by testing trace plots. As is demonstrated in Figure 5a and b, trace plots for the overall variance parameter with an inverse gamma distribution, IG (0.5, 0.5), look better than those with an inverse gamma distribution, IG(0.01, 0.01). IG(0.5, 0.5) is a too-informative prior distribution, while IG(0.01, 0.01) is the default setting. According to the trace plots, since the Markov chain has converged for IG(0.5, 0.5), we chose this probability distribution for the prior variance of the model. As a result, the appropriate empirical model for our analysis has the normal distributions with the hyperparameters N(492, 1) and N(35, 1) for ΔR and ΔG, respectively, and an inverse gamma distribution, IG(0.5, 0.5) for the overall variance parameter. An immediate conclusion is that the prior specifications of the overall variance influence the estimation of the posterior variance.

Trace plot for the overall variance of the gamma distribution, IG(0.5, 0.5) (a) and inverse gamma distribution, IG(0.01, 0.01) (b).
According to the estimation results, an acceptance rate of 6% and average efficiency of 4% are admissible for a Monte Carlo simulation algorithm (Roberts & Rosenthal, 2001). The trace plots for all the model parameters are verified for anomalies, and none are revealed. As the trace plots for ΔR and ΔG are exhibited in Figure 6a and b.

Trace plots of ΔR (a) and ΔG (b).
In sum, a conclusion derived from all the analyses above is that the Bayesian Monte Carlo simulation method relying on the informative prior settings could yield meaningful posterior estimates in small samples. Our results are consistent with Yuan and MacKinnon (2009), Price (2012), Depaoli and Clifton (2015), Natesan (2015), Chen et al. (2014), van de Schoot et al. (2015), Serang et al. (2015), Holtmann et al. (2016), D. M. McNeish (2016), Miočević et al. (2017), and Zondervan-Zwijnenburg et al. (2018).
The estimation summary recorded in Table 2 indicates that the posterior estimates are acceptably accurate and robust. Regarding probability, PPIs for ΔR and ΔG do not contain zero, implying that changes in the central bank interest rate and government expenditure strongly impact GDP growth (proxied by Grow). A reasonable explanation for the contractionary fiscal policy is that most government expenditure is non-productive and used almost inefficiently during COVID-19. Similarly, the internet penetration rate (proxied by Int) is strongly positively correlated to GDP growth, while the COVID-19 infection rate (proxied by Cov) is strongly negatively correlated to GDP growth. However, on the contrary, the effects of trade openness (proxied by OT) and the lagged GDP (proxied by Grow-1) are ambiguous.
Posterior Estimates With Specific Priors.

Source. The author’s calculation.
Note. SD = standard deviation; SE = standard error; PPI (Posterior probability interval) = the 95% probability that a parameter lies between two values in the population.
Concluding Remarks
By implementing a case study on ASEAN economic growth, the current research showed that in a small sample investigation, with the assignment of specific prior settings, Bayesian performance is better than both naïve Bayesian and frequentist performance, and more importantly, the Bayesian results are meaningful. Furthermore, the more information incorporated in the prior distributions, the less biased and the more precise the posterior estimates become. By using Monte Carlo standard errors to measure the level of bias and interval hypothesis testing to check parameter significance, the outcomes show that a model with highly informative priors is the best fit for statistical inferences in a small sample context. Based on the outcomes, the author derives some generalized conclusions as follows. In modeling small sample data, thoughtful (specific) Bayesian estimation outperforms naïve Bayesian and frequentist estimation. Besides, in small sample sizes, Bayesian inferences are highly sensitive to prior specifications of the model parameters: with specifying default prior or diffuse settings, naïve Bayesian estimation can produce even more biased inferences than frequentist estimation; but, with the correctly specified prior hyperparameters, the posterior distributions become more accurate (less biased) and more robust (less variable) when more information is added to the prior distributions. From the outcomes acquired in this study, the author strongly recommends users of Bayesian methods adopt thoughtful priors in research, regardless of data sample size. Additionally, some policy implications are provided: first, an expansionary monetary policy is needed in a crisis, as Keynesians suggest. However, fiscal policy needs to focus on productive government spending, while non-productive expenses should be adequate; second, in the current information technology era, the Internet is also one of the essential factors for economic, cultural, and social development and so increases in internet penetration are necessary; third, infection and death cases caused by the COVID-19, reducing labor force, adversely affect economic growth, so healthcare measures should be implemented efficiently.
Limitation and future research direction: This study used data-driven priors for the variables of interest. Although Bayesian estimation with priors derived from performs better than frequentist and naïve Bayesian estimation, a future Bayesian simulation study will have a more exciting result if the researchers specify informative priors rather than data-driven priors.
Footnotes
Acknowledgements
Thank editors and reviewers a lot for valuable suggestions and comments.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.