
Abstract
Quantile treatment effects are estimated to study the impacts of household credit access on health spending by poor households in one District of Ho Chi Minh City, Vietnam. There are significant positive effects of credit on the health budget shares of households with low health care spending. In contrast, when an average treatment effect is estimated, there is no discernible impact of credit access on health spending. Hence, typical approaches to studying heterogeneous credit impacts that only consider between-group differences and not differences over the distribution of outcomes may miss some heterogeneity of interest to policymakers.
Introduction
The impacts of access to credit on poor household’s consumption and health have been widely studied (e.g., Coleman, 1999; Nguyen, 2008; Pitt & Khandker, 1998; Pitt, Khandker, Chowdhury, & Millimet, 2003). However, the literature concentrates on finding average treatment effects (ATE), which assumes that all of the treated households get the same impact from program participation. Studies in other settings show that treatment effects can vary widely, not only across sub-groups but also along the distribution of outcomes (Bitler, Gelbach, & Hoynes, 2006, 2008; Djebbari & Smith, 2008).
This evidence of varying treatment effects is not just an econometric curiosity; it also accords well with what may interest policymakers. For example, finding that a credit program had much larger impacts for male borrowers would likely prove influential if policymakers were interested in closing gender gaps. Hence, a theme in the literature evaluating impacts of credit is to compare average treatment effects for sub-groups defined by observable characteristics (e.g., age, education, and gender). However, the similarly interesting comparison of whether the impact is the same along the outcome distribution, such as for households with already high consumption versus those with low consumption, or already high health care spending versus the low health care service spenders, is rarely done. This sort of heterogeneity in treatment effects can be studied using a quantile treatment effects (QTE) estimator.
In this article, we report QTE estimates of the impact that access to credit has on the health care spending of poor households in peri-urban Vietnam. We used a survey designed by the authors and applied to a sample of poor households that are all under the urban poverty line. 1 Hence, in typical approaches to studying heterogeneity in treatment effects, this sample would be one identifiable sub-group, who would have an average treatment effect estimated and assumed to apply to all members of the group. Our estimated results show that such an approach hides considerable within-group heterogeneity in the treatment effects.
The remainder of this note is organized as follows. The next section describes the data collection and estimation framework. The empirical results are reported in Section 3, and the final section concludes.
Data and Analytical Framework
A sample of 411 borrowing and non-borrowing households was interviewed in early 2008 in the peri-urban District 9, Ho Chi Minh City, Vietnam. Because our focus is on microcredit impacts on poor households, the sample was selected from a list of poor households whose initial income per capita was below the HCMC general poverty line of Vietnam Dong (VND) 6 million (approximately US$1 per day). The target sample size was set at 500 households, including 100 reserves, to achieve a realized sample of 400. In fact, 411 households were successfully interviewed, accounting for 26% of the total number of poor households in each of the selected wards in the district. The interviewed sample provides 304 borrowing households and 107 non-borrowing households, with 2,062 members, 955 (46.3%) males and 1,102 (53.7%) females. The sample is likely to be representative for the poor group whose initial income per capita is below the poverty line at the survey time in the district but will not be representative for Ho Chi Minh City nor for Vietnam.
The survey was designed to collect data on household and individual demographic–economic variables, commune characteristics, household durable and fixed assets, child schooling and education expenditure, health care, food, non-food, housing expenditure, and borrowing activities. I also utilized global positioning system (GPS) receivers to collect data on locations of households and facilities to measure distances from each household to facilities.
The surveyed areas are located in the most dynamic region, Ho Chi Minh City, in Vietnam. The city is the biggest economic–financial center of the country; it accounted for only 6.6% of the country’s population in 2005 but one third of its gross domestic product (GDP). The city economy has recently been growing at above 10% per annum.
The surveyed district is the 5th lowest population density district and one of the peri-urban districts of HCMC. When it was established in 1997, the district relied heavily on agricultural production, but its economic structure has changed drastically due to current fast industrialization and urbanization. The average growth rate of industrial production and services has been very high for the period 1997-2008, namely, 24.7% and 28.1% per year, respectively. The total number of enterprises, approximately 400 in 1997, increased to 1,658 in 2006. In addition, the district population growth rate is very high; it increased 59% over the period 1997-2008. Population density within the surveyed district in 2008 is heterogeneous. Some wards are very highly populated, for example, Phuoc Binh (PB; 18,981 people/km2), Tang Nhon Phu A (TNPA; 6,546 people/km2), while others are relatively low, for example, Long Phuoc (LP; 300 people/km2) and Long Truong (577 people/km2). The main economic activities of the district are non-farm economic activities such as industrial production, construction, and services. For our sample, 72% of household heads are small traders, housewives, casual workers, factory workers, and the jobless.
We use a quantile regression (QR) estimator, which examines the effects of the regressors on the dependent variable at various points on the conditional distribution of responses (e.g., at the 25th and 75th percentiles). The model specifies the θth − quantile (0 < θ < 1) of conditional distribution of the dependent variable; given a set of covariates xi, and assume that residual distributions of each quantile are normally distributed, we have,
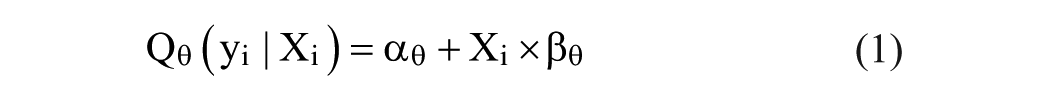
where yi is the outcome of interest (the budget share for health care in this case) for household i, and xi is a set of explanatory variables including an indicator for credit participation and variables measuring the household head’s sex, age, marital status, and education, along with household size, household expenditure, initial income and assets, and location of the dwelling. The treatment variable of interest is credit participation, which equals one if a household had received any loans in the 24 months prior to the survey and zero otherwise. A total of 304 households were borrowers, and 107 households were non-borrowers under this definition. The estimator (Equation 1) is the solution to the following minimization problem (see Cameron & Trivedi, 2009):

In other words, this is the solution to a problem where the sum of the weighted absolute value of the residuals is minimized. As θ is increased, the entire distribution of outcome y is traced, conditional on xi. We estimate βθ for a particular θth quantile of distribution rather than β. If we estimate β for θ, then much more weight is placed on prediction for observations with y ≥ xi.β than for observations with y < xi.β (i.e., 1 − θ).
When QR is adapted to investigate heterogeneity in program impacts, the QTE of Heckman, Smith, and Clements (1997) results. Let Y1 and Y0 be the outcome of interest for the treated (1) and comparison groups (0). F1(y|xi) = Pr[Y1 ≤ y|xi] and F0(y|xi) = Pr[Y0 ≤ y|xi] are the corresponding cumulative distribution functions of Y1 and Y0 conditional on xi. If θ denotes the quantile of each distribution, then yθ(T) = inf{y: FT(y|x) ≥ θ}, T = 0, 1 (treatment status) where “inf” is the smallest value of yθ that meets the condition in the braces. For example, y0.25 = inf{y: FT(y) ≥ 0.25}, T = 0, 1. The quantile treatment effect at quantile θth is defined as Δθ = yθ(T = 1) − yθ(T = 0), and the Δθ is the difference between the outcome of interest for the treatment and comparison groups at a particular θth quantile. In other words, the QTE shows how the treatment effect changes across specified percentiles of the outcome distribution.
The QTE relies on the rank-invariance assumption, that the relative value (rank) of the potential outcome for a given household would be the same under assignment to either treatment or comparison group (Firpo, 2007). However, because outcomes for the same household may differ from one distribution to another based on observable and unobservable characteristics, bounds have to be computed for the QTE (Heckman et al., 1997). Even without rank invariance, the QTE may still be meaningful as policymakers may be interested in the marginal distributions of the potential outcomes. In such cases, QTE is simply the difference between the same quantile of the marginal distributions of outcomes for the treated households and for comparison group households.
Heterogeneity in the outcome variable may correspond either to variation across particular sub-groups (or cohorts) in the population that would generate a local average treatment effect (LATE) or to impacts of unobservable characteristics (Angrist, 2004). In this article, we assume that we have a homogeneous population, so there are no sub-groups that would have the LATE (and for whom a particular instrumental variable might bind while it does not bind for others), and that the heterogeneity in the outcomes comes from the random errors. Because we assume it is unobservables rather than local treatment effects causing the heterogeneity, we do not necessarily need an instrumental variable estimator (which can be combined with the QTE to address bias from selection on unobservable characteristics (Abadie, Angrist, & Imbens, 2002)). If good instruments are available, the QTE with instrumental variables (IQTE) may be more precise than the conventional IV estimator at the median (Abadie et al., 2002) in addition to addressing the potential selection bias. However, in previous results with the same data used here, no good instruments are identified (Doan, Gibson, & Holmes, 2014), so we rely on the assumption that the selection into the treatment is based on observables.
Empirical results
Table 1 presents unconditional differences in monthly average health care expenditure (in 1,000 Vietnam Dong) and in the health care budget share. At all points in the distribution of health care spending considered here, households who were borrowers spent more on health than their non-borrowing counterparts. The households that borrowed had similar initial income and assets to the non-borrowers, but higher current total monthly consumption (appendix). So, one possible reason for higher health care spending might be that the same budget share generates more spending for richer households. However, in fact, that is not the case; the borrowing households also are devoting larger shares of their budgets to health at all points in the distribution.
Monthly Average Health Care Expenditure of B and NB.

Note. The budget share for health care in the parentheses. B = borrowers; NB = non-borrowers.
To see whether the higher health care spending of borrowers across the distribution persists when we condition on explanatory variables, we estimate QTE at the 25th, 50th, and 75th percentiles (Table 2). The table also presents ordinary least squares (OLS) estimates in the final column of each panel. The explanatory variables used are listed in the appendix. Our basic specification includes location, household size, and expenditure per capita in addition to the credit participation treatment variable, while an extended specification adds the gender, age, marital status, and education of the household head, and pre-treatment values of income per capita and assets. 2
Quantile Regressions of Credit Impact on Budget Shares of Health Care Expenditure.

Note. Bootstrap standard errors in parentheses with 1000 replications; OLS standard errors are robust. Dependent variable is the budget share for health spending; Log size is the log of household size; Log PCX is monthly expenditure per capita (in log). The number of observations is 411 households. Both the basic and extended models control for location dummies. The extended model specification further controls for head’s sex, age, marital status, education, and initial income per capita and assets. OLS = ordinary least square.
Significant at 10%. *Significant at 5%. **Significant at 1%.
In both the basic and extended specifications, there is considerable heterogeneity in the treatment effects of credit on the health care budget share (Table 2). For households with health budget shares below the median, access to credit is associated with significantly higher health care spending. However, for households above the median, health care spending goes down (insignificantly) when a household is a borrower. The same pattern is observed when using the extended model specification. In neither case would these effects be apparent when using OLS.
Thus, it appears that access to credit increases the health care budget share of households who had lower health care budget shares prior to their credit participation. This positive effect of credit is hidden when estimating an average treatment effect, although the sample is for a homogeneous group of urban households from one district who are all below the poverty line.
There also appears to be some heterogeneity in the effect of per capita household expenditure (used as a proxy for permanent income) on the health care budget share. The OLS estimates suggest that the health care budget share rises by about three percentage points for every one log point increase (approximately two standard deviations) in per capita expenditure. However, this hides an effect (which is statistically significant in the extended specification) of the budget shares falling with higher expenditure at the 25th percentile.
Conclusion and Limitations
Treatment effects can vary widely, not only across sub-groups but also along the distribution of outcomes. In this note, we provide an example where our sample is all under the urban poverty line and would typically be considered one identifiable sub-group, for which an average treatment effect would be estimated. Yet we find considerable heterogeneity in treatment effects within this seemingly homogeneous sample, which would be hidden if we only reported an average treatment effect.
Specifically, although OLS estimates of ATE show no significant effect of credit participation on health care budget shares, the QTE estimates show that credit has positive impacts on health care budget shares for households with low levels of health care spending. From a policy point of view, this suggests that facilitating access to credit sources may be a significant factor in improving health status of the urban poor, and the policy may work better if it is better designed targeting the right families who need the help most.
Land loss (due to urbanization) may be an issue in fast growing/urbanizing areas in HCMC as well as in other big cities in Vietnam and where the capital market is less developed then informal sector has a role to play in which interpersonal relationship or social capital may affect the access to credit. It may be appropriate to instrument the credit access by these factors in an IV model. This limitation opens up a venue for future study. Furthermore, our study focuses on peri-urban areas of HCMC, the biggest city. However, the households in big cities may be different from those in smaller cities as well as in other regions of the country where socioeconomic conditions are fairly diversified. As a result, our results may not be representative of the whole country.
Footnotes
Appendix
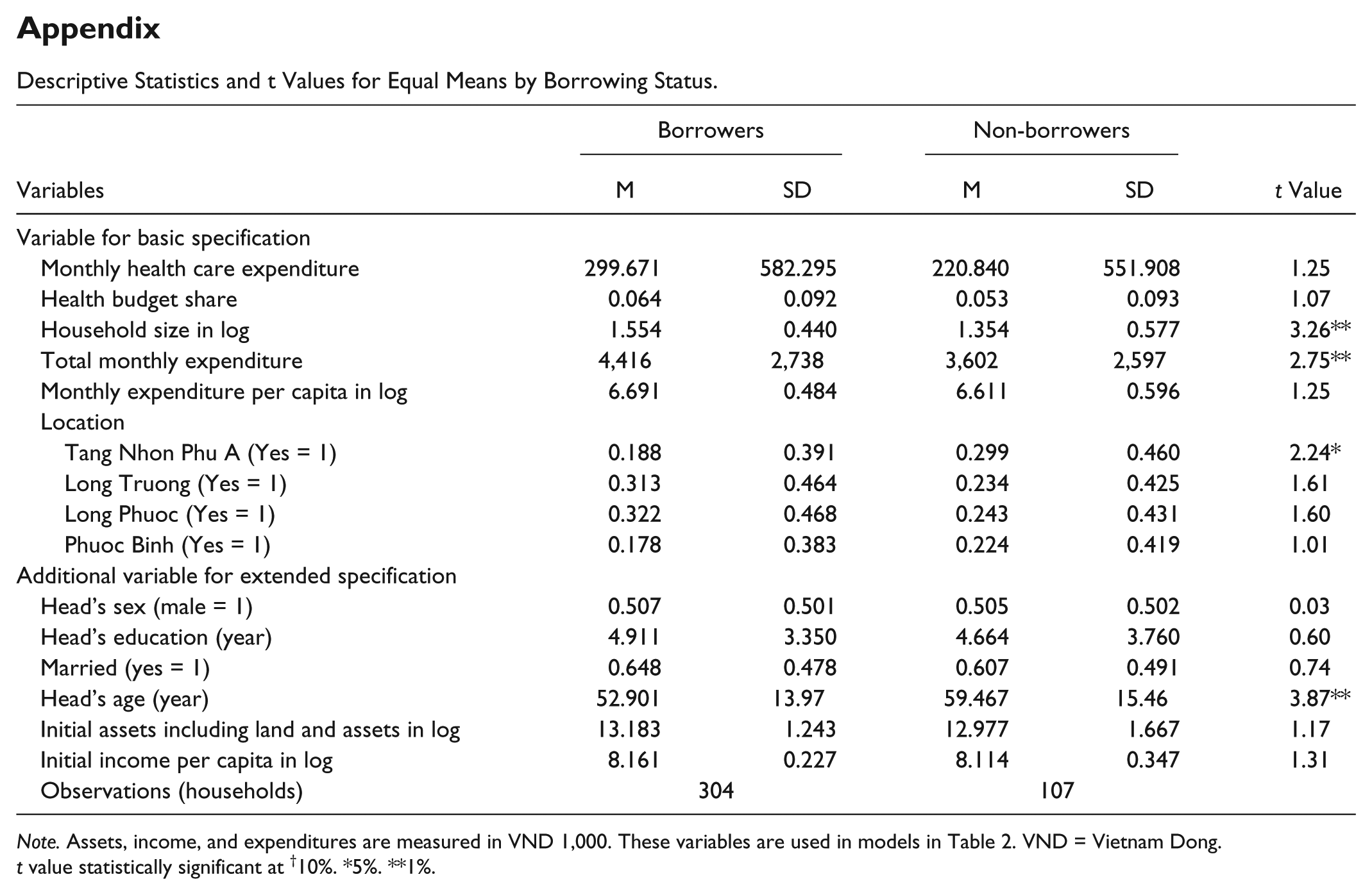
Descriptive Statistics and t Values for Equal Means by Borrowing Status.
| Variables | Borrowers |
Non-borrowers |
t Value | ||
|---|---|---|---|---|---|
| M | SD | M | SD | ||
| Variable for basic specification | |||||
| Monthly health care expenditure | 299.671 | 582.295 | 220.840 | 551.908 | 1.25 |
| Health budget share | 0.064 | 0.092 | 0.053 | 0.093 | 1.07 |
| Household size in log | 1.554 | 0.440 | 1.354 | 0.577 | 3.26** |
| Total monthly expenditure | 4,416 | 2,738 | 3,602 | 2,597 | 2.75** |
| Monthly expenditure per capita in log | 6.691 | 0.484 | 6.611 | 0.596 | 1.25 |
| Location | |||||
| Tang Nhon Phu A (Yes = 1) | 0.188 | 0.391 | 0.299 | 0.460 | 2.24* |
| Long Truong (Yes = 1) | 0.313 | 0.464 | 0.234 | 0.425 | 1.61 |
| Long Phuoc (Yes = 1) | 0.322 | 0.468 | 0.243 | 0.431 | 1.60 |
| Phuoc Binh (Yes = 1) | 0.178 | 0.383 | 0.224 | 0.419 | 1.01 |
| Additional variable for extended specification | |||||
| Head’s sex (male = 1) | 0.507 | 0.501 | 0.505 | 0.502 | 0.03 |
| Head’s education (year) | 4.911 | 3.350 | 4.664 | 3.760 | 0.60 |
| Married (yes = 1) | 0.648 | 0.478 | 0.607 | 0.491 | 0.74 |
| Head’s age (year) | 52.901 | 13.97 | 59.467 | 15.46 | 3.87** |
| Initial assets including land and assets in log | 13.183 | 1.243 | 12.977 | 1.667 | 1.17 |
| Initial income per capita in log | 8.161 | 0.227 | 8.114 | 0.347 | 1.31 |
| Observations (households) | 304 | 107 | |||
Note. Assets, income, and expenditures are measured in VND 1,000. These variables are used in models in Table 2. VND = Vietnam Dong.
t value statistically significant at †10%. *5%. **1%.
Acknowledgements
We thank two anonymous referees and the editor for their helpful comments, which significantly improved the quality of our article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research and/or authorship of this article.