
Abstract
This study implements the multivariable logistic regression to develop a credit scoring model based on tenants’ characteristics. The credit history of tenant is not considered. Rental information of tenants was collected from a landlord company in Malaysia. Parameters of the multivariable logistic regression were estimated by using the penalized maximum likelihood estimation with ridge regression since separation in training data was detected. The initial factors considered that affect tenants’ credit score were their gender, age, marital status, monthly income, household income, expense-to-income ratio, number of dependents, previous monthly rent, and number of months late payment. However, the marital status factor was then excluded from the logistic regression model due to its low significance to the model. Meanwhile, a tenant’s credit scoring model was generated by calculating the tenant’s probability of defaulting. The main factors of the tenant’s credit score are the number of months late payment, the expense-to-income ratio, gender, previous monthly rent, and age. There is no underfitting or overfitting in the proposed credit scoring model which means the model’s bias and variance are low.
Introduction
According to World Bank Group (2022), Malaysia ranks 55th out of 157 countries. Malaysia will need to advance further in education, health and nutrition, and social protection outcomes to achieve a high-income and developed country status. The key priority areas include improving the quality of schooling, rethinking nutritional interventions to reduce childhood stunting, and providing adequate social welfare protection for household investments in human capital formation.
The issue of affordable housing has always been a hot topic in many countries around the world, including Malaysia. The household income classification in Malaysia is divided into three categories: B40, M40, and T20. The B40 represents the bottom 40% of the Malaysian household group whose household income is below RM4,850 per month. Meanwhile, M40 is the middle 40% of the household group with the household income is between RM4,850 and RM10,959 per month. Finally, the T20 represents the top 20% class with a household income of at least RM10,960 per month (Department of Statistics Malaysia, 2020). The housing issue has become more serious as 20% or about 600,000 households in the M40 group have slipped into the B40 group as a result of the Covid-19 crisis (The Star, 2021).
According to the Central Bank of Malaysia (2018), the key reasons for housing loan rejection include insufficient income to support debt repayment, adverse credit history, and inadequate income or financial documentation. In Malaysia, some housing schemes are introduced by the government to assist the M40 and B40 groups to own a house such as Perumahan Rakyat 1 Malaysia (PR1MA), Program Perumahan Rakyat (PPR), and the Rent-to-Own scheme (Liu & Ong, 2021). However, due to the limited units, not all low household income groups will be benefited from the housing schemes. In addition, 60% of affordable home loan applications are rejected by banks and financial institutions due to the applicants’ age or poor credit scores (The Sun Daily, 2021). A credit score is a creditworthiness indicator used by banks and financial institutions to determine their potential borrowers’ likelihood of defaulting on a loan. The higher the loan applicant’s credit score, the higher the chance of the loan application being approved.
In Malaysia, the Central Credit Reference Information System (CCRIS) is a system created by the Central Bank of Malaysia to synthesize the credit information of borrowers and is available to every financial institution. The CCRIS report shows the outstanding loans, special attention accounts, and the number of approved or rejected loan or credit facility applications made in the past 12 months, but without providing a credit score (Ebekozien et al., 2019). Besides, Malaysians can obtain their credit reports with credit scores through the private credit reporting agencies in Malaysia, such as Credit Tip-Off Service (CTOS) and RAM Credit Information Sdn. Bhd. (RAMCI). In the United States, the FICO score created by Fair Isaac Corporation (FICO) and VantageScore introduced by United States national consumer reporting agencies (“NCRAs”), that is, Experian, Equifax, and TransUnion, are the common credit scores used (Albanese, 2021). The FICO, VantageScore, and CTOS credit scores utilize similar factors, that is, payment history, credit amounts owed, length of credit history, credit mix, and new credit but with different proportions.
In the past, the credit bureaus such as FICO and Experian only set credit history as the factor of credit score. The credit scoring model that depends only on credit history cannot be used to gain credit scores for those individuals with little or no credit history. As a result, some credit bureaus have generated credit scoring models using additional non-financial data, that is, the use of rental payment records by Experian and the use of utility data, evictions, and other variables by FICO (Djeundje et al., 2021). The research papers that use non-financial data such as rental payment records, utility data, criminal history, and delinquency are reviewed (Njuguna & Sowon, 2021).
Besides, some papers utilized other non-financial data such as individual characteristics, loan characteristics, and behavioral variables to compute the probability of default or credit score. Lin et al. (2017) stated gender, age, marital status, educational level, working years, company size, monthly payment, loan amount, debt to income ratio, and delinquency history play a significant role for loan defaults in China. Chamboko and Bravo (2019) found gender, age, income earned, debt-to-income ratio, loan terms, and the number of past missed payments in Zimbabwe. On the other hand, Adzis et al. (2020) and Saha et al. (2021) concluded house equity, age, gender, ethnicity, location, the types of occupation, guarantor availability, and loan characteristics like payment-to-income (PTI) ratio, loan original balance, loan tenure, loan interest rate, and loan-to-value (LTV) ratio are the significant factors that influence loans default in Malaysia. The chance of individuals who lack credit histories getting a loan will be increased if financial institutions use non-financial data to develop the credit scoring model.
A wide range of papers applied machine learning such as neural networks, support vector machine, logistic regression, and genetic programming to develop credit scoring models (Louzada et al., 2016). Besides, some papers applied hybrid credit scoring models, such as Munkhdalai et al. (2020) used a hybrid credit scoring model with neural networks and logistic regression whereas Kumar et al. (2021) used a hybrid credit scoring model with neural networks and k-means algorithm.
Problem Statement
Individuals with very little credit history or thin files are referred to as “credit unscored” and those without any credit history are referred to as “credit invisible” (Njuguna & Sowon, 2021). In Malaysia, the B40 category in rural areas is usually classified as “credit unscored” or “credit invisible” where they have no credit records or poor credit scores due to insufficient credit history to support their housing loan application. Hence, they normally rent a property since they cannot afford to own it. However, their rental payment records are not accounted for the housing loan applications. In addition, no agency in Malaysia introduces a credit scoring for the tenant.
Nowadays, the use of credit scores has extended from banks to other areas such as rental property, car and home insurance (Njuguna & Sowon, 2021). For example, TransUnion introduced “ResidentScore” which utilizes rental data to predict the likelihood of eviction. Furthermore, Turner and Walker (2019) showed that the addition of rental payment data as a factor in FICO or VantageScore credit scoring models tends to dramatically reduce credit unscorable.
In addition, some studies generated credit scoring models without using credit history. Berg et al. (2020) proposed a credit scoring model using only digital footprint variables such as device type, operating system, and email host. In order to create a different model for comparison, the credit bureau scores and digital footprint variables were considered. It was concluded that digital footprint variables complement rather than a substitute for credit bureau information. Additionally, the email usage variables such as the fraction of emails sent in certain periods, the fraction of emails sent or received from non-top financial product providers, and the number of contacts sent were used to build a credit scoring model (Djeundje et al., 2021). The study also found that a model that incorporates email usage and psychometric variables performs better than a model that incorporates only individual characteristics. Shema (2019) generated a credit scoring model only based on mobile airtime recharge or top-up history. However, no study generates a credit scoring model without depending on credit history in Malaysia.
In this research, we focus on computing tenant’s credit score, especially the credit score of the B40 group who rent a house. The credit scoring model proposed in this study does not depend on the credit history of tenants but is based on the tenant’s individual characteristics, monthly rent, and rent payment behavior. This credit scoring will increase the confidence of future property owners and developers to select the “credit unscored” or “credit invisible” B40 group as their potential customers. Furthermore, this credit scoring will also increase the credit scorable of low income group with limited credit history and hence might increase the approval rate of their loan application. The multivariable logistic regression is implemented to develop a credit scoring model for the tenants in this study. The parameters of the multivariable logistic regression model are estimated using the maximum likelihood method and the performance of the proposed model is also evaluated. In Section “Methodology,” the methodology implemented in this study is explained in detail. Next, the obtained results are presented and discussed in Section “Results and discussion.”
Methodology
Data
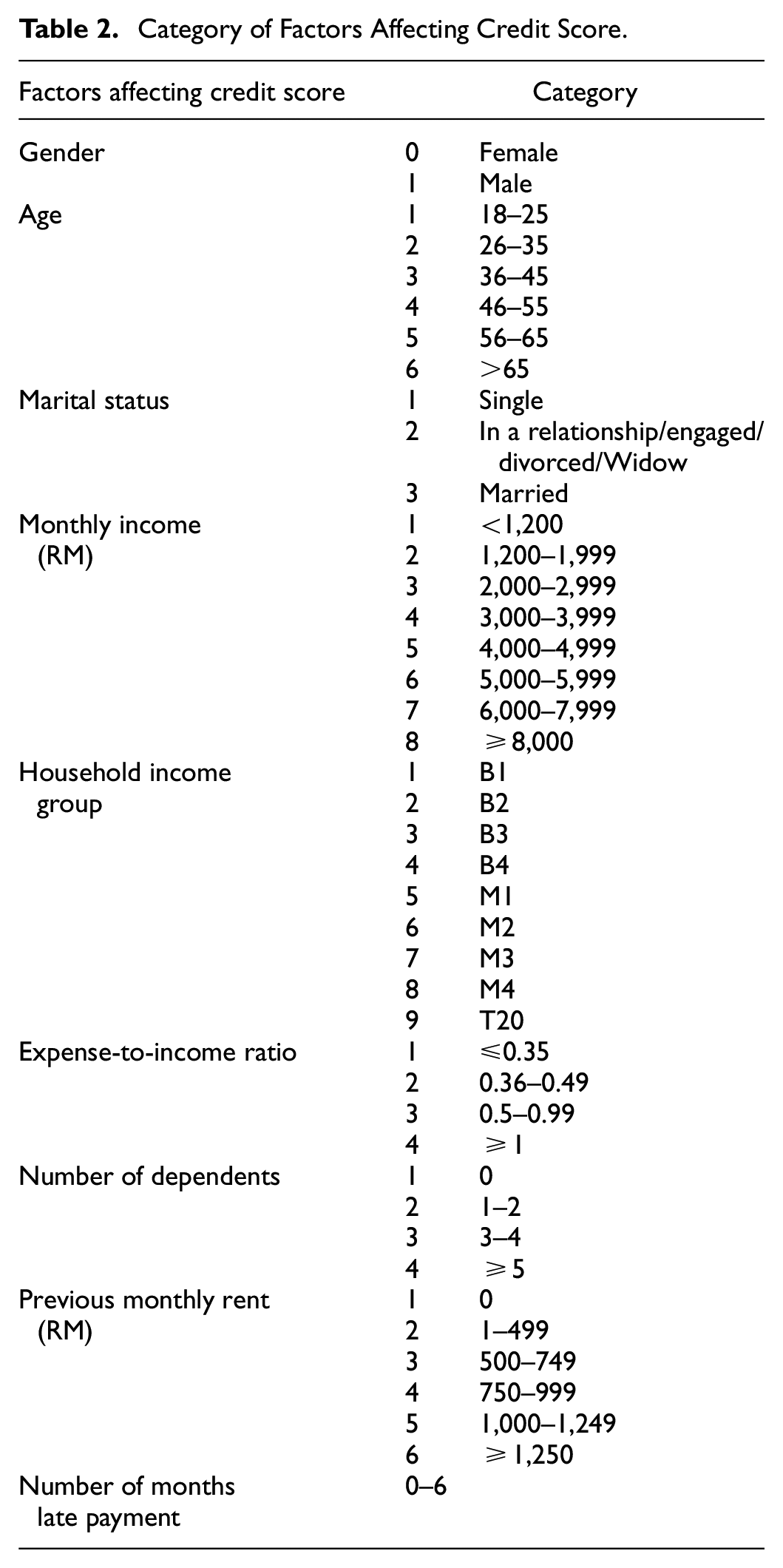
In this study, the initial factors considered that affect tenants’ credit scores are their gender, age, marital status, monthly income, household income, expense-to-income ratio, number of dependents, previous monthly rent, and number of months late payment. Hence, these informations were collected from a landlord company in Malaysia. In this study, the rent paid after 1 week is considered a late payment. Moreover, the tenant who makes late payments for more than 2 months will be assumed to default on rent, otherwise, assumed as not default. There are 33 data collected and among them, 7 (21.21%) are considered default. The statistical description of the collected data is shown in Table 1. As shown in Table 1, 93.94% of the respondents are B40 group and 81.82% of them are single. The collected data were next transformed into numerical data based on Tables 2 and 3 and were then split into training data (70%) and testing data (30%).
Statistical Description of Data.

Category of Factors Affecting Credit Score.
Income level for household income decile group. Adapted from Household Income and Basic Amenities Survey Report (p. 75), by (Department of Statistics Malaysia, 2020). (https://bit.ly/HISReportMalaysia). Copyright 2020 by Department of Statistics Malaysia. Adapted with permission.

Multivariable Logistic Regression
Logistic regression is the log odds of a binary outcome event success expressed linearly as the combination of all independent variable or factors considered (Botes, 2013). The factors considered in logistic regression can be either qualitative or quantitative. The logistic regression transforms the linear regression to the probability of an event success with the range values from zero to one. Therefore, the logistic regression also can be a classifier to classify the event as success or failure based on the probability computed. The multivariable logistic regression is a logistic regression with more than one factor. The logit of the multivariable logistic regression is (Grant et al., 2019)
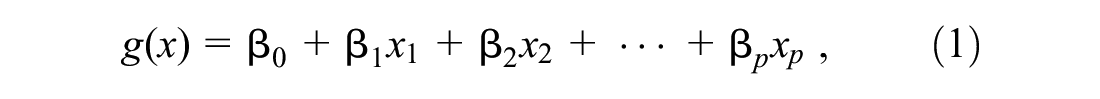
where
Let binary outcome dependent variable,
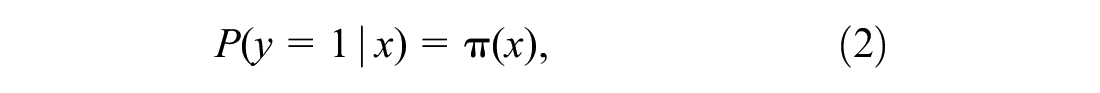

On the other hand, the logit transformation of

Since the logit transformation of

which is also a sigmoid function (Zou et al., 2019).
Sometimes, there is multicollinearity among independent variables where a lot of independent variables are highly correlated with each other. This problem can lead to the logistic regression model overfitting the data (Bolton, 2010). In this study, the multicollinearity among the factors in the training data set was ensured not to exist by showing the absolute Spearman’s correlation coefficient of any two factors in the training data set was less than .8 (Marime et al., 2020).
Maximum Likelihood Estimation
Maximum likelihood estimation can be utilized to estimate the parameters of logistic regression,
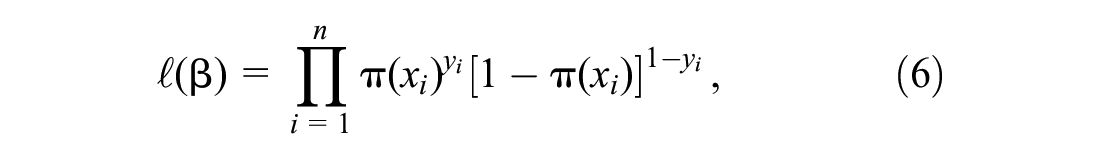
where
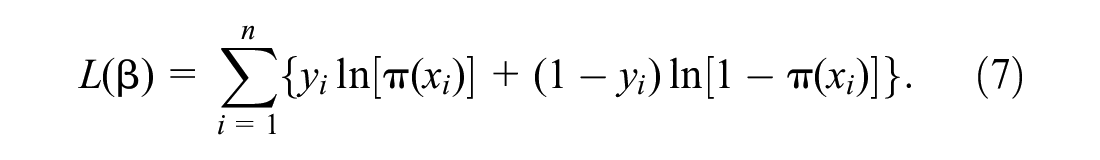
In theory, maximum likelihood estimates will not exist if the data is separated (Albert and Anderson, 1984). The data of logistic regression can be classified into three different mutually exclusive and exhaustive classes, that is, complete separation, quasi-complete separation, and overlap (Botes, 2013). Separation is either complete or quasi-complete separation in the data most frequent under the same conditions that lead to small-sample and sparse-data bias, such as the presence of a rare outcome and multicollinearity among independent variables (Mansournia et al., 2018). In 2007, Konis (2007) discussed the existing methods for separation detection and proposed a new method for separation detection using linear programming. The proposed linear program to be solved is



where
In this research, the parameters of logistic regression were estimated using maximum likelihood estimation with Limited-memory Broyden–Fletcher–Goldfarb–Shanno (BFGS) through the Scikit-learn library in Python. Meanwhile, the objective function of maximum likelihood estimation will be the natural log of likelihood function,

where
Factor Reduction
The closer a logistic coefficient,
According to Agresti (2018), the Wald Test is the least reliable of the three tests when the sample size is small to moderate. Therefore, the Likelihood Ratio Test was applied rather than the Wald Test in this study for testing the significance of the logistic coefficient since the size of collected training data is small. The null hypothesis will be accepted if the Likelihood Ratio Test statistic follows a chi-square distribution with a degree of freedom equal to the number of factors removed (Botes, 2013). The Likelihood Ratio Test statistic can be defined as

where
Tenant’s Credit Scoring Model
In this research, we proposed a credit scoring model with a minimum credit score of zero and a maximum score of 100. For the proposed model, the tenant with lower probability of default will have higher credit score. Since

Predictive Performance of Model
In this research, the testing data was considered as default if the computed probability of default,

where



There are two fundamental causes of the machine learning classifier’s prediction error, that is, the model’s bias and its variance (Hackeling, 2017). A model with high variance overfits the training data, while a model with high bias underfits the training data. Overfitting occurs if the accuracy of training data is significantly higher than testing data, while underfitting occurs if the accuracy of both training and testing data is low (Gu et al., 2016).
Besides, the area under the receiver operating characteristic (ROC) curve (AUC) was computed to determine the ability of the model to distinguish the default and not default classes. ROC curve plots the classifier’s true positive rate



where
The higher the AUC, the better the model is at distinguishing between the default and not default classes. However, the risk of overfitting occurs is higher if the AUC of training data is higher than the AUC of testing data (Nusinovici et al., 2020). Hence, the accuracy and AUC of both training and testing data also were compared to check whether the model is overfitting or underfitting.
The flow chart of the research methodology can be summarized in Figure 1.
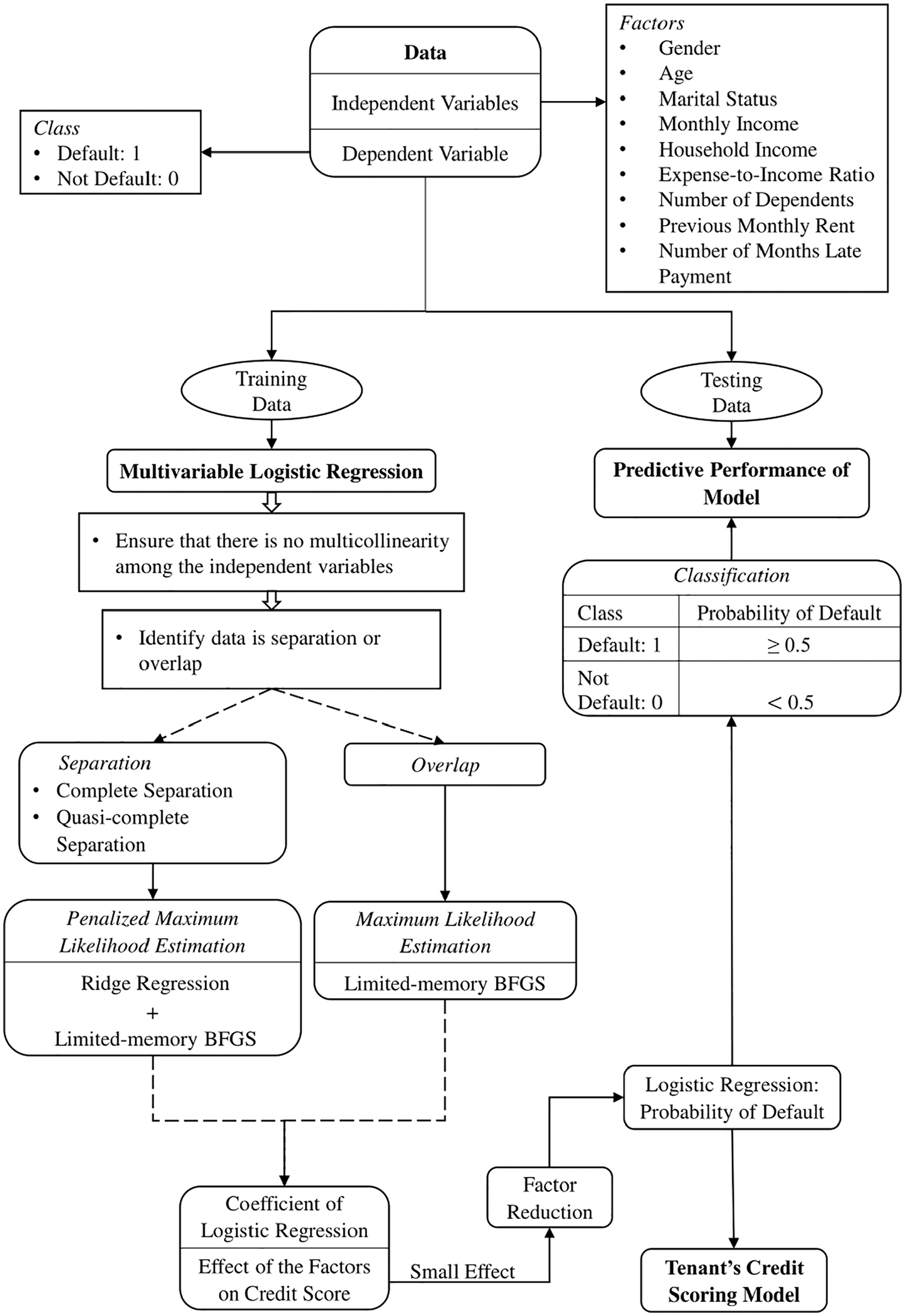
Flow chart of tenant’s credit scoring model.
Results and Discussion
Logistic Regression Results
The Spearman’s correlation matrix of training data is presented in Table 4. From Table 4, we can conclude that there is no multicollinearity among the factors in the training data set as the correlation coefficient of any two factors is less than .8. In addition, separation was detected in the training data set by solving the linear program (Equation 10). Thus, the parameters of the logistic regression model were estimated using the penalized maximum likelihood estimation with ridge regression. In this study, the regularization strength of the penalty was set as one.
Spearman’s Correlation Matrix of Training Data.

It is noticed that only the logistic coefficient of marital status is close to zero among the 9 factors. The result of the Likelihood Ratio Test of marital status is visualized in Figure 2. As shown in Figure 2, the marital status factor can be removed as it is insignificant to the model. The comparison of the logistic coefficients with all factors and without marital status is presented in Table 5. From Table 5, there is not much difference between logistic coefficients of the factors before and after the marital status factor was removed from the model. This result is consistent with the result of the Likelihood Ratio Test.

Result of likelihood ratio test.
Comparison of Logistic Coefficient with All Factors Versus Without Marital Status.

Let

Let
Analysis of Logistic Coefficient.

Notice that the positive sign of the logistic coefficient indicates that the higher the
The default probability increases with age because the tendency for tenant to forget or miss to pay rental is high as the tenant gets older. On the other hand, the more the number of dependents, the greater the tenant’s sense of responsibility to pay rent, which can be the reason of default rate decreases with the number of dependents. The inference that the probability of default decreases with rent can be the tenant’s preference for the amount of rent according to their ability to pay.
Predictive Performance of Logistic Regression
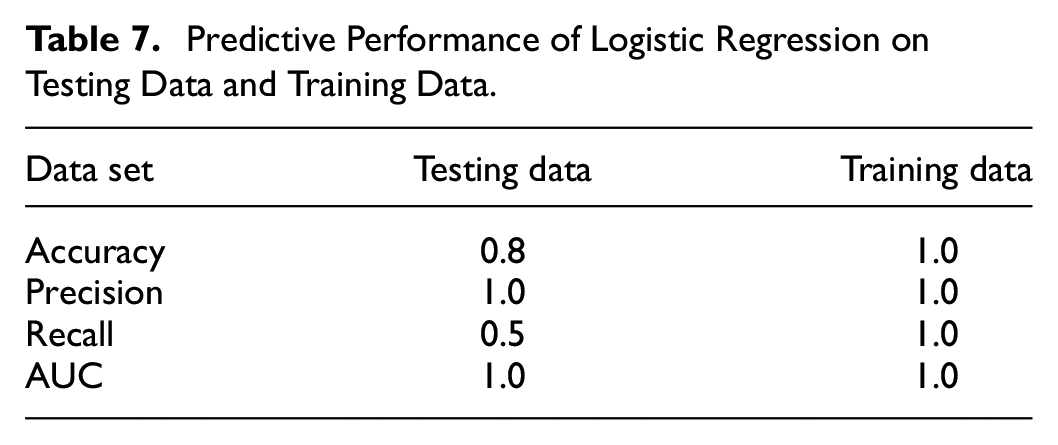
The confusion matrix of testing data and confusion matrix of training data are shown in Figure 3(a) and (b), respectively. The predictive performances of logistic regression on the testing and training data are also summarized in Table 7. From Table 7, we can say that neither underfitting nor overfitting occurs in this research since the accuracy of testing data is slightly lower than the accuracy of training data and the AUC of both training data and testing data are the same.

Confusion matrix: (a) confusion matrix of testing data and (b) confusion matrix of training data.
Predictive Performance of Logistic Regression on Testing Data and Training Data.
Conclusion
This study proposes credit scoring for the tenant in Malaysia. This study found that the number of months late payment, monthly rent, and the tenant’s individual characteristics, that is, the expense-to-income ratio, gender, and age, were the main factors affecting the credit score. The proposed credit scoring will increase the confidence of future property owners and developers to select the low income group, especially the B40 group, as their potential consumers. Besides, this credit scoring will reduce the credit unscorable of the low income group with limited credit history and might increase the probability of the low income group for getting a loan. Lastly, this paper can be a reference for future research to develop a credit scoring system without depending on credit history.
Footnotes
Acknowledgements
Communication of this research is made possible through monetary assistance by Ministry of Higher Education (MOHE) via Fundamental Research Grant Scheme (FRGS) (FRGS/1/2021/STG06/UTHM/02/1).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received financial support for the research, authorship, and/or publication of this article: Communication of this research is made possible through monetary assistance by Ministry of Higher Education (MOHE) via Fundamental Research Grant Scheme (FRGS) (FRGS/1/2021/STG06/UTHM/02/1).