
Abstract
Chinese jingju (Peking opera) typically distinguishes several stock character types differentiated by narrative function, appearance, and vocal timbre. Though aspects of jingju music and dramaturgy have been thoroughly mapped by scholars, the contribution of timbre to the differentiation and characterization of dramatic roles has not been theorized. Here we sampled 20,000 excerpts of a cappella recordings of dan (woman) and laosheng (old man) singers from a large corpus. We analyzed the acoustic characteristics of the two roles both qualitatively and computationally, extracting and comparing relevant acoustic descriptors including spectral centroid, roughness, inharmonicity, and spectral fluctuation. We found statistically significant differences between the roles in spectral centroid (controlling for differences in fundamental frequency), roughness, and spectral flux (1600–3200 Hz). Lower normalized spectral centroid and reduced roughness in dan timbre is semiotically congruent with this virtuous and gentle female role; higher normalized spectral centroid, roughness, and spectral flux in laosheng timbre are congruent with an elderly, powerful, and educated man, indicating the contribution of vocal timbre in communicating identification and narrative information to audiences. These timbral attributes also reflect traditional Confucian ideals for music, gender, and age. These patriarchal and filial hierarchies are reiterated through Peking opera vocal timbre, displaying the effectiveness of music, and timbre specifically, in reflecting and reinforcing cultural and societal scripts.
Peking opera, or jingju, originated in the late 18th century during the Qing dynasty (1644–1912), and is considered China's national style of musical drama. Often accompanied by traditional instruments such as erhu, drums, and cymbals, operas narrate famous stories of ancient Chinese history. Operas have minimal set design, eschewing props and instead relying on complex costuming, makeup, and movement to provide visual and narrative information. Performers utilize song, speech, dance, combat, and stock movements to evoke actions like laughing, crying, and fighting (Mackerras, 1994). Jingju gained popularity in the 19th century, spreading to other regions of China including Shanghai, and reached its zenith of popularity in the early 20th century as it made its global debut. Since 1950, jingju has been supported by the People's Republic of China as an element of traditional culture.
Historically, jingju performances often took place in courtyards, where audience members could drink tea: it was only in the early 1900s when performances moved to Western-style theaters with stages. Rather than refer to attending jingju shows as “watching” (kan), audiences in Beijing traditionally went to performances to “listen” (ting), often closing their eyes and beating time during performances (Xu, 2012), thus indicating the importance of orienting aurally to the form. Correspondingly, practitioners developed musical strategies alongside visual skills to convey important narrative and affective cues independent of visual mediation. In the past century, jingju performances adapted to formats such as film, TV, and radio, and though its overall popularity has diminished, its preservation and promotion as an element of traditional Chinese culture has not waned.
Jingju includes several stock personae or character types that are differentiated by vocal style, costuming, movements, makeup, and rules within the drama. These personae include male roles (sheng), female roles (dan), the painted face character (jing), and the clown or villain (chou), and each type has subtypes based on age and personality (Wu, 1981). Beginning in the late 19th and early 20th century, jingju actors attend opera training schools before joining professional theater companies, where they first receive generalized jingju training and then specialize in one of the four roles based on their natural appearance and vocal aptitude (though switching roles later in their training is possible). Training schools are usually role-specific, and at the height of jingju's popularity, multiple training schools for each role existed and competed to produce the best performers (Xu, 2012). Ethnomusicologist Frederick Lau refers to these stock characters as identified aurally by differences in tessitura and timbre. Generally, for example, the “refined gentleman” (sheng) role sounds “nasal,” the rough man with a painted face (jing) sounds “strong,” and the villain (chou) sounds “shrill” (Lau, 2008, p. 73). However, little research has quantified how sonic impressions such as these translate (if at all) into systematic timbral differences between roles.
Research analyzing the jingju voice has primarily focused on singer physiology, pitch content, and vibrato, particularly in comparison to Western operatic singing. In traditional Chinese culture, the timbre of the human voice is prioritized over that of musical instruments and tends toward a more penetrating and transparent sound with a brighter or narrower singing timbre, possibly due to the prevalence of high vowels in Mandarin Chinese (Zhou, 2019). Accordingly, as shown in Zhou (2019), Chinese singers tend to utilize a higher tongue position and shorter vocal channel compared to Western singers. Wang (1986) compared the physiology of Chinese and Western opera singers, finding that the larynxes of Chinese singers stayed above their resting position and moved higher as they sang increasingly higher pitches, while Western singers’ larynxes remained below resting position and moved lower when singing increasingly higher pitches.
Work by Sundberg et al. (2012) studied the laosheng and jing roles and found that jingju singers sang in higher ranges than Western tenors and, on average, spoke at higher fundamental frequencies (F0) than Western adult males. Using long-term-average spectrum analyses, they noted a missing formant cluster in jingju vocals that would typically be found in Western singing, a potential contributor to differences between jingju and Western opera vocal timbres. Additionally, jingju singing spectra typically contained continuous, uninterrupted series of harmonic partials up to 17 kHz in LTAS[.9] curves, whereas Western operatic singing spectra contained only a few groups of harmonic partials above 4 kHz (Sundberg et al., 2012).
Recent research from Han and Zhang (2017) analyzed vibrato in all four jingju roles, finding that vibrato rates are 2–3 Hz slower than in Western opera. Vibrato rates tend to decrease with increasing age of the character, but the extent of the vibrato increases with increased character age. Yang et al. (2015) specifically compared the pitch range and vibrato of the laosheng and zhengdan (younger to middle-aged woman) roles, discovering that laosheng sang in a wider pitch range than zhengdan, but the laosheng range is lower and utilizes a one-semitone vibrato extent compared to the zhengdan's half-semitone extent. Their findings suggest that jingju singers utilize slower vibrato than Western opera singers and vibrato rates and extent depend on the age of the role they play.
Research analyzing the acoustics of jingju vocals has examined elements of singing technique and style specific to jingju and its roles. However, the contribution of vocal timbre to characterization, narrative function, and affect in jingju stock characters has not yet been explored, though authors often reference timbre in their descriptions of the roles. Furthermore, considering that jingju audiences at courtyard performances often listened to opera performances without receiving constant visual information, timbre would be among the most salient auditory input they could perceive when a character began to sing. Since timbre contributes significantly to auditory grouping and sound source identification (Bregman, 1990), the specific vocal timbre of each character would then signal their identity and function in the plot. What are the timbral profiles, then, for the major jingju character types?
Recent work on the singing voice has located timbre as a key element for interpretation and identification. Nobile (2022) examines the timbral profile of singer Alanis Morissette and how she deploys six distinctive timbral registers to signal different personae within her Jagged Little Pill album–for example, “sweet voice” and “squeal.” In this case, vocal timbre serves as a structuring element through both its acoustic features and their implied physiology, contributing to both the identification of album personae and to the expressive potency of Morissette's singing. Similarly, Eidsheim (2019) shows that timbral elements of sui generis jazz singer Jimmy Scott were crucial to the gendered and racialized reception of his singing. In other words, vocal timbre reinforces contextually specific social values (see, e.g., Lomax, 1968). Vocal timbre can be conceptualized phenomenologically, whether consciously or unconsciously: embodiment or simulation of vocal timbre allows listeners to imaginatively coexperience the affective states implied by vocal expression and the human agency that stands behind such expression (Heidemann, 2016; Wallmark et al., 2018). Thus, it is crucial to consider the role of vocal timbre in the articulation of a singer's identity within specific historical and social contexts. In the context of jingju, it has long been acknowledged that the specific stock character of the singer can be inferred from timbral attributes relating to age, gender, and power based on social context. Less well understood, however, are the specific acoustical attributes that index different roles, and how these timbral signatures reinforce characterization.
This paper examines the timbral attributes of the two most prominent jingju character types, dan (woman) and laosheng (mature, wise older man), using an existing corpus of a cappella jingju recordings created by Gong et al. (2017). The dan role, historically performed by males, sings elegantly and sweetly in falsetto, ranging in character subtypes such as the qingyi (virtuous young or middle-aged woman wearing blue gowns) or wudan (female warrior) (Han & Zhang, 2017; Li, 2010). The most famous example of a dan role is the character Yu Ji from The King's Parting with his Favorite, also known as Farewell My Concubine (Bawang bieji; 1918). In the story, Yu Ji, wife of the King of Chu, discovers on the eve of battle that the king's soldiers plan to forsake him. Full of grief, she tries to boost his spirits as the enemy begins to attack; rather than seek safety from the enemy by surrendering, she insists on maintaining her virtue and commits suicide. Though dan roles vary greatly based on their subtype, they are typically the wife or daughter of an important figure and tend to embody ideals of virtue, beauty, femininity, gentleness, and heroism (Figure 1: “Beijing Opera Famous Performers, n.d.”).

Dan actor Mei Lanfang (left) and laosheng actor Yan Jupeng (right).
Traditionally, the laosheng role is an older, bearded, dignified man who sings seriously and slowly with chest resonance and careful enunciation; he is often a rich, educated figure such as an emperor or a scholar (Figure 1: Colville, 2021). Early jingju served as education as well as entertainment, so the laosheng role reinforced mainstream feudal values of Chinese society (Xu, 2012). An example of the laosheng role is the character Zhuge Liang in The Empty City Ruse (Kong cheng ji), a story of war between rival kingdoms from The Romance of the Three Kingdoms (Sanguo yanyi). Liang, a brilliant military strategist alone in the city, conceives a clever plot to fool the enemy forces into thinking they were outnumbered by casually sitting on the city walls, playing his lute. He manages to stall the advancing army until his reinforcements arrive. Laosheng roles, due to their advanced age, typically act as a voice of reason and distinction, either holding or having retired from a position of authority (Wu, 1981). It should be noted that the actors who play laosheng roles are of the same age as actors playing roles that are meant to be young or middle-aged, since actors differentiate their typical role during their early training (Xu, 2012).
The relationship between vocal timbre and jingju stock characters, which is referenced often in the literature and in audience reception, merits attention. Though dan roles, which are now typically sung by women, differ from laosheng in register, timbral differences irrespective of pitch also exist between the two roles. Dan performers, regardless of gender, must alter their vocal timbre to be aurally recognizable. In our investigation, we sought to examine the acoustic characteristics of dan and laosheng vocal timbre while considering the roles’ typical functions and characterizations within jingju. Our project was motivated by two primary questions: (1) What acoustic distinctions exist between dan and laosheng? and (2) How might dan and laosheng vocal timbres reinforce each role's typical narrative function and relate semiotically to their stock type?
Methods
Our analysis was based on an audio corpus created by Gong et al. (2017) containing a cappella recordings of four female dan singers (65 recordings total) and four laosheng singers (74 recordings total), including both professionals and amateurs. To create this corpus (hereafter, the Gong corpus), the researchers asked five professional singers from the National Academy of Chinese Theatre Arts and four amateur singers from jingju associations at non-art schools to participate in recording sessions. On of the singers performed the jing role; therefore their recordings are not included in this analysis. The researchers included recordings of 120 arias, categorizing them by jingju role, mode or modal system (shengqiang), and metrical patterns (banshi), also providing Praat metadata, lyrics, and annotations for each aria and melodic line (for details, see Caro Repetto & Serra, 2014). The Gong corpus was created with the intent of facilitating music information retrieval research on musical features, having noted a lack of computational research on jingju. It is the largest and most representative public dataset of a cappella jingju singing currently available.
The Gong corpus provides sufficient high-quality musical and acoustic data to reveal characteristic features of each jingju role. Recording corpora have been used widely for acoustic and perceptual analyses, including computational analysis of melodic and rhythmic patterns in improvised jazz solos (Norgaard, 2014), acoustic cues in string quartet synchrony (Duane, 2013), and differences in key and pulse clarity in atonal compared to tonal classical music (Mencke et al., 2019). Prior to approaching the corpus globally with computational tools, we isolated several representative audio excerpts as case studies of dan and laosheng timbre to ascertain acoustic differences in vocal timbre. Then, using these initial findings as a qualitative guide, we performed our computational analysis on the entire corpus, extracting acoustic features relevant to our initial observations.
Analysis
First, to get a qualitative sense for the timbral attributes that characterize each role, we aurally identified moments of timbral interest that were characteristic of each role and generated spectrograms for visual identification using Sonic Visualizer (Cannam et al., 2010). Figures 2 and 3 compare four spectrograms of representative excerpts. Spectrographic evidence revealed differences in envelope: Dan harmonics are typically all present at the attack and taper gradually at the end of a typical phrase, while laosheng harmonics tend to bloom or rise gradually at the attack. On average, laosheng singers exhibit a wider spectral distribution of energy and greater harmonic distortion than dan. In sum, the qualitative observations suggest that the roles differ in attack envelope, spectral peak, spectral fluctuation, and distribution of spectral energy throughout the frequency range, though this general observation cannot of course be quantified through spectrographic evidence alone (Audio 1–4: see supplemental material).
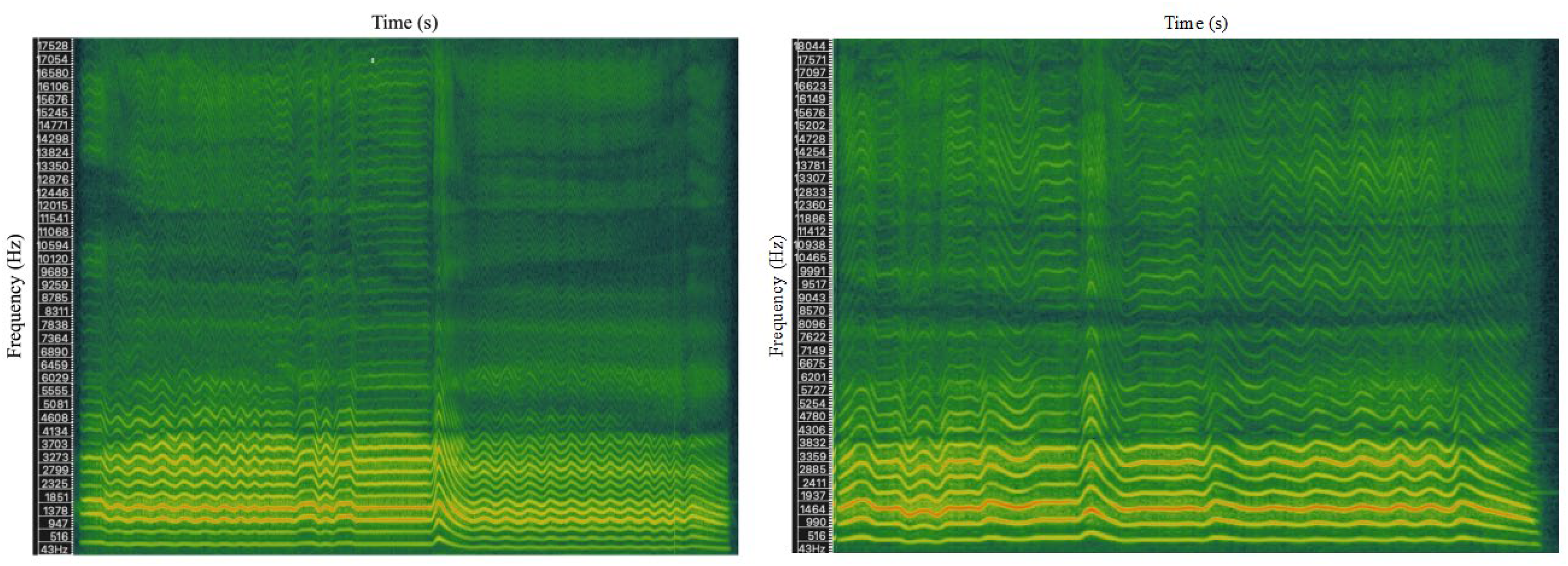
Spectrograms of timbral case studies for dan.

Spectrograms of timbral case studies for laosheng.
We next sought to determine whether the timbral patterns observed in the qualitative analyses were more broadly replicable across the corpus. To do so, we performed a statistical analysis on acoustic data extracted from the corpus. After truncating silences from the recordings, we had approximately 117 continuous minutes of dan recordings and 80 min of laosheng recordings, represented by four singers of each role. We randomly sampled 2,500 brief excerpts (500 ms each) per singer, resulting in a total dataset of n = 20,000 samples (Audio 5–12).
We used MIRToolbox1.8.1 (Lartillot & Toiviainen, 2007) in the
Inharmonicity refers to the amount of energy in the sound that lies outside of the ideal harmonic series. Auditory roughness, a measure of sensory dissonance, is found by measuring all the peaks in the spectrum and averaging the dissonance between every possible pair of peaks. Roughness is typically heard as amplitude fluctuation, or “beating.” Spectral centroid (SC) refers to the geometric center of a sound's spectral distribution and is often referred to as “brightness,” “sharpness,” or “nasality” (see respectively Kendall & Carterette, 1993; Schubert & Wolfe, 2006; von Bismarck, 1974). To compare SC data across signals while statistically controlling for differences in F0, we normalized SC by dividing SC by F0 (Kendall & Carterette, 1996). Spectral flux is computed as the distance between the spectra of successive frames, and here we divided spectral flux into 10 half-overlapping sub-bands of 25 ms each, a model introduced in Alluri and Toiviainen (2010).
Results
Table 1 presents a description of our results for inharmonicity, roughness, and normalized spectral centroid. To determine whether there was an association between these three acoustic variables, we first calculated a correlation matrix across all samples, finding weak though statistically significant positive correlations between inharmonicity and roughness, r(19998) = .26, and normalized SC and roughness, r(19998) = .30; p’s < .0001. Normalized SC and inharmonicity were weakly negatively correlated, r(19998) = –.05, p < .0001. Due to the non-independence of these variables, we calculated three separate binomial logistic regression models predicting role (dan or laosheng) from acoustic descriptor (SC, roughness, inharmonicity) using the lme4 package in R (Bates et al., 2015), and significance levels of the fixed main effects were calculated using Type II Wald chi-square tests in the car package (Fox & Weisberg, 2010). Singers were modeled as a random effect. Roughness data were log transformed due to non-normal distribution, and outliers (± 3 SDs) were excluded. P-values for models were adjusted for multiple tests using the Bonferroni correction (α = .017).
Descriptive statistics for spectral acoustic descriptors by role.
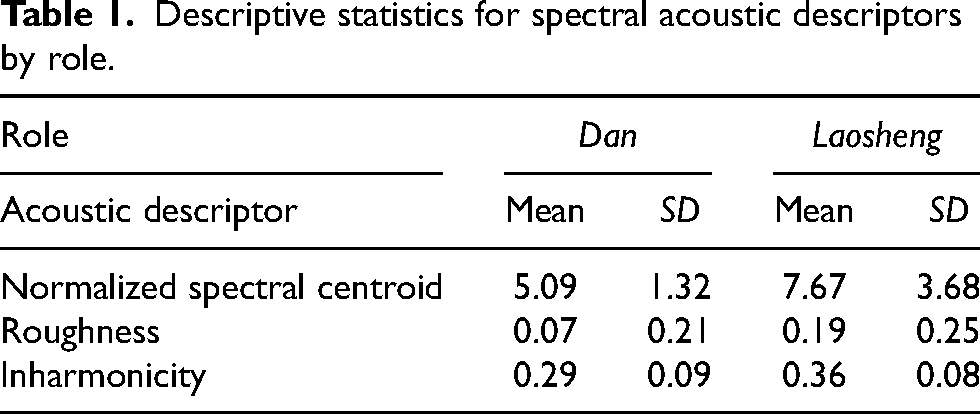
Table 2 displays the model results. We found that laosheng had a significantly higher normalized SC (M = 7.67, SD = 3.68) compared to dan (M = 5.09, SD = 1.32). 1 Similarly, laosheng timbre was rougher (M = 0.19, SD = 0.25) than dan (M = 0.07, SD = 0.21). Inharmonicity did not vary systematically by role. These results roughly align with previous qualitative observations and are congruent with the broader cultural associations of these two character types, as discussed below.
Wald χ2 results for binomial logistic regression models.

Bonferroni corrected, p < .017.
Figures 4 and 5 visualize the differences in normalized SC and roughness as a function of role. The figures reveal a wide range of spectral centroid in laosheng singers compared to a relatively consistent dan spectral centroid. Roughness does not vary as much between singers within roles, but laosheng singers still vary in roughness more than dan singers.
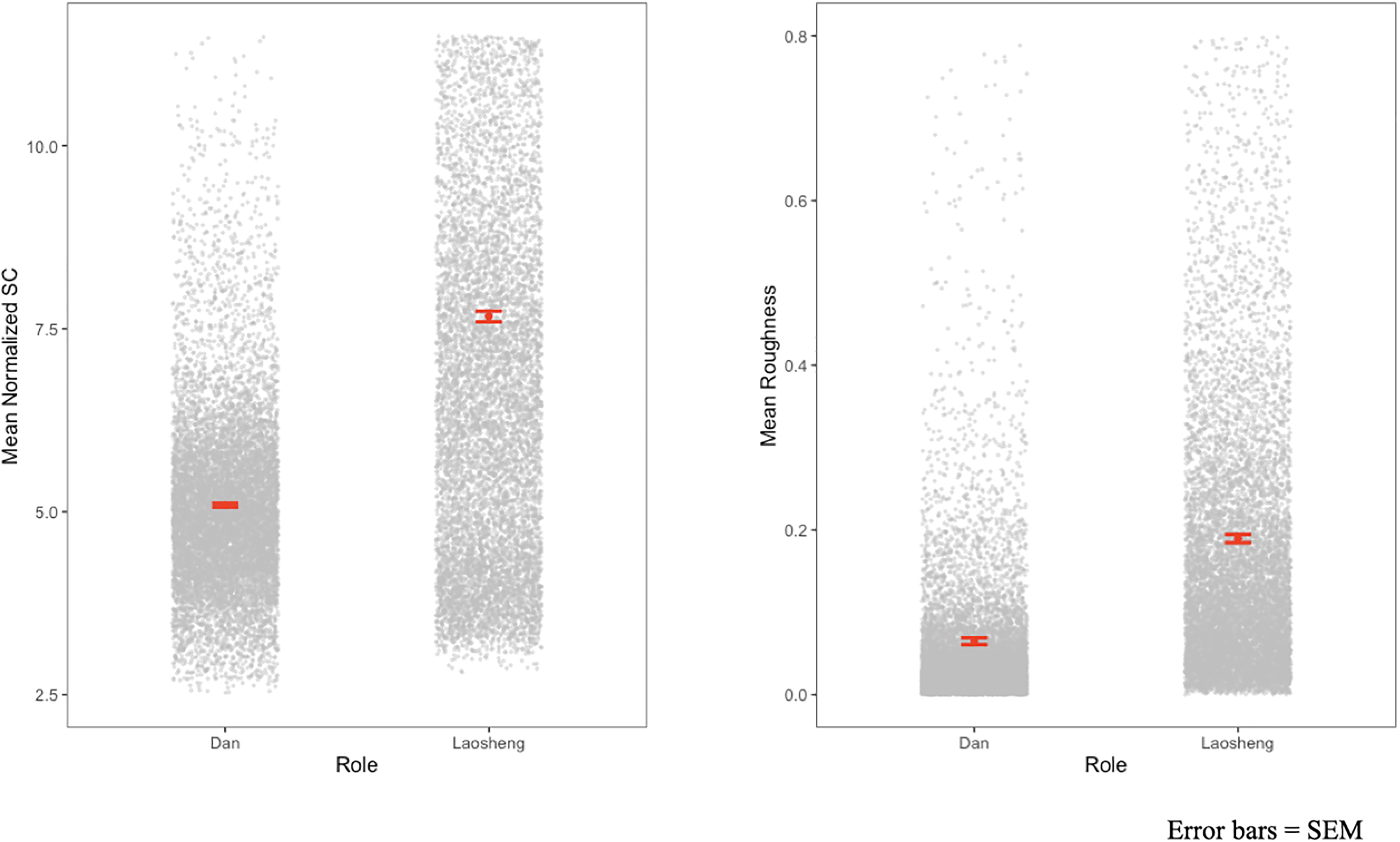
Mean normalized spectral centroid and roughness for dan and laosheng roles.

Normalized spectral centroid and roughness for individual dan and laosheng actors.
Regarding spectral flux, after applying the same binomial logistic regression models, we found that dan and laosheng roles varied significantly in certain sub-bands. Across frequency sub-bands 3 (100–200 Hz) and 7 (1600–3200 Hz), laosheng spectral flux was significantly higher than dan. This aligns with Sundberg et al. (2012), who found key laosheng formants at 800 Hz, with an additional, lower decibel peak between 1600 and 3200 Hz. Table 3 displays the descriptive statistics and Type II Wald chi-square test results for the middle 8 sub-bands (2–9), where the majority of singing voice energy is located.
Spectral flux sub-band descriptive statistics and Wald χ2 results for binomial logistic regression models by role.

Bonferroni corrected, p < .0045.
Discussion
Based on analysis of select acoustic descriptors extracted from a corpus of representative jingju recordings of a cappella singers (Gong et al., 2017), dan and laosheng voices are found to exhibit their own distinctive timbral profiles. Qualitative analyses of recordings from this corpus suggested differences in attack envelope, spectral peak, spectral flux, and distribution of spectral energy in laosheng timbre relative to dan. Statistically controlling for differences in F0 and individual singers, logistic regression models largely confirmed these initial observations, indicating that laosheng singers tend to employ higher normalized spectral centroid (SC) and roughness compared to dan. Laosheng singers also displayed significantly higher spectral flux in bands 3 (which can primarily be attributed to vibrato differences in F0) and 7 (1600–3200 Hz). Inharmonicity did not differ by role. Together, these results indicate an association between role and certain timbral attributes.
We theorize that timbral differences contribute perceptually to the stock characters’ functions within an opera performance. Dan, typically conceptualized as a sweet and elegant female character, produces a smoother vocal timbre than the laosheng, a seasoned and powerful male figure (Li, 2010). The rougher timbre of the laosheng could allow audiences to infer his advanced age and wisdom, a crucial part of the role's narrative function. Moreover, the higher spectral flux of the laosheng in sub-band 7 has been shown to correlate with perceived “activity,” a measure combining “power” and “vibrancy” (Alluri & Toiviainen, 2010), as well as a characteristic laosheng formant peak (Sundberg et al., 2012). In the jingju context, wobbliness in spectral distribution within this crucial frequency range, along with roughness, may signal advanced age and authority. Perceptually, advanced age is typically associated with an increase in hoarseness and a decrease in vocal stability compared to younger voices (Gregory et al., 2012; Lortie et al., 2015). Therefore, conventionalization of these timbral attributes to portray an older male indicates a naturalistic technique of communicating age through the performer's voice. Researchers in other contexts of global music analysis (e.g., the Middle Eastern mijwiz) have shown that roughness can be an important component in modulating musical expression (Vassilakis, 2005). Moreover, the brighter, more nasal sound due to higher normalized SC could indicate authority or wisdom; such a singing style tends to be preferred in traditional Chinese music and displays consistency with the laosheng's archetypal traits in jingju stories (Zhou, 2019). Considering the historical practice of men playing dan roles by singing in falsetto, performing a strategic timbral difference (i.e., exaggerating timbral brightness, roughness, and spectral deviation within a peak formant) might have effectively conveyed the character and its core dramatic attributes, especially since early performance contexts were often casual and prioritized listening over viewing the performers. In conjunction with costuming, makeup, and movement, moreover, these timbral attributes were likely to reinforce the association of this role with age, authority, and wisdom, both naturalistically and culture-specifically.
These findings also reflect traditional Confucian gender roles where women, relegated to the “inside” sphere, are considered inferior, still, and gentle compared to men, who in the “outside” sphere are superior and associated with motion and firmness (Shen & D’Ambrosio, 2014). SC and roughness are often associated, in vocal and acoustic instrumental contexts, with greater energy input and arousal (Wallmark et al., 2018). It is intuitive, then, that the sweet, gentle dan would sing in a voice that is timbrally smoother and darker than the rough, brilliant laosheng, who deploys timbral markers that index high-arousal physical and emotional states. Additionally, the wider range of normalized spectral centroid, increased roughness, and spectral flux in regions signaling vocal “activity” found in the laosheng role implies these singers command a greater level of timbral freedom than the timbrally constrained and somewhat more homogeneous dan singers. This, too, aligns with the gender roles articulated and enforced by dan and laosheng roles in jingju.
Discussing the relation of music to social structure, Confucius famously advocates for “proper music,” that is, music that allows for suitable governance and self-cultivation of people (Lam, 2003). In the section “Record of Music” in his work Liji, Confucius writes: “Music can be used to represent human affairs and activities, revealing principles behind intimate and remote relationships, high and low status, old and young ages, and males and females. Thus there is a saying that music shows what is deep inside societies” (Lam, 2003, p. 99). These Confucian hierarchies of age, gender, and status are illustrated in traditional Chinese music like Peking opera, not only in the plot or lyrics, but in the vocal timbre itself.
These findings in traditional Chinese music point to a similar relationship between singing vocal timbre and identity as discussed by Nobile (2022) and Wallmark (2022). Their work, which focuses on rock and hip-hop performers, respectively, points to vocal timbre as a source of both formal function and semiotic meaning, and as a signifier of persona or identity. Listening to the voice inherently begs the question, as posed in Eidsheim's (2019) “acousmatic question”: “Who is this?” Elements of the voice and its timbre, then, allow the listener to identify or glean information about the source using markers dependent on social and cultural context. Likewise, jingju actors utilize vocal timbre as a potent semiotic ground on which to stage identity, signaling who they are with aspects of vocal timbre belonging to their specific role. These timbral markers are based both in naturalistic associations—for example, the characteristic activity and roughness of an aged vocal tract—and in cultural specificities—for example, a preference for brighter singing timbre or vocal practices reinforcing a strict gender dichotomy. These role-based timbral differences, in turn, aid singers in communicating narrative function and affect.
There are several limitations to the current study. We drew on a corpus of audio recordings that included both amateur and professional jingju singers; conceivably, differences in training could have skewed our results. In our case, normalizing spectral centroid was necessary since the roles represent different genders employing differing vocal ranges; thus, statistical control over F0 was required to empirically compare vocal timbres. However, normalizing F0 may inflate SC for natural sounds with lower F0 while attenuating SC for sounds with higher F0 (Siedenburg et al., 2021). Additionally, as shown in Santos et al. (2023), male singers’ voices typically exhibit higher overall roughness than those of female singers due to physiological differences. Therefore, the higher degree of roughness found in laosheng voices may be partially attributed to the male performers’ physiology. The prevalence of errors in F0 measurements may have also affected inharmonicity measurements. Finally, this study examined only dan and laosheng vocal timbres; though laosheng is a popular role, it is only a subtype of sheng roles. The decision to focus on laosheng reflects the broader organization of the Gong corpus, which features substantially more laosheng samples than other sheng subtypes. Further work could parse the sheng and dan roles’ subtypes for increased specificity of vocal timbral differences, as well as including the other two roles not addressed in this study, jing (painted face) and chou (clown).
Conclusion
Our computational findings reveal differences in vocal timbre between two principal Peking opera roles, dan (female) and laosheng (old man). We found that laosheng is characterized by statistically significantly higher normalized spectral centroid, spectral flux in an important formant, and auditory roughness compared to dan. The vocal timbre of dan and laosheng stock characters communicate cultural values, aesthetic ideals, character identification, and narrative information to audiences. Limitations to this study include exclusion of other jingju roles beyond dan and laosheng, physiological differences between male and female voice relating to roughness, and sampling from a corpus with both amateur and professional jingju singers. In future research, we aim to include all jingju stock characters by applying this analysis to the jing and chou roles and further probe the relationship between F0, vocal range, and timbre for each role and subtype. Additionally, the current sampling procedure does not discriminate note onsets. In future studies, we plan to examine the attack profiles of the different roles. By applying perception and timbre analysis tools to non-Western music, where work of this nature is lacking, this study constitutes a small step toward a greater understanding of cross-cultural music perception (Jacoby et al., 2020). This work also fits within a broader conversation across cultures, music genres, and disciplines about the timbre of the singing voice and its link to the articulation of identity.
Supplemental Material
sj-wav-1-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-1-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-2-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-2-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-3-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-3-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-4-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-4-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-5-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-5-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-6-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-6-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-7-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-7-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-8-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-8-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-9-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-9-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-10-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-10-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-11-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-11-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Supplemental Material
sj-wav-12-mns-10.1177_20592043241278450 - Supplemental material for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng
Supplemental material, sj-wav-12-mns-10.1177_20592043241278450 for Identifying Peking Opera Roles Through Vocal Timbre: An Acoustical and Conceptual Comparison Between Dan and Laosheng in Music & Science
Footnotes
Action Editor
Kai Siedenburg, Signal Processing and Speech Communication Laboratory, Graz University of Technology.
Peer Review
Jonathan Stock, Department of Music, University College Cork; one anonymous reviewer.
Author Contributions
AYL conceived of the research questions, performed the analysis, visualized results, and wrote this paper. ZW advised and assisted with analysis and visualization.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
This research did not require ethics committee or IRB approval. This research did not involve the use of personal data, fieldwork, experiments involving human or animal participants, or work with children, vulnerable individuals, or clinical populations.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.