
Abstract
In the investigation of musical features that influence musical affect, timbre has received relatively little attention. Investigating affective timbres as they vary between instrument families can lead to inconsistent results, because one instrument family can produce a wide variety of timbres. Here, we consider timbre descriptors, as fine-grained acoustic representations of a sound. Using identical methods, we re-analyzed and synthesized results from three previously published studies: Eerola et al. (2012, Mus. Percept.), McAdams et al. (2017, Front. Psychol.), and Korsmit et al. (2023, Front. Psychol.). In doing so, we aimed to reveal robust timbre descriptors that consistently predict the affective response and to explain any discrepancies in results arising from differences in experimental methodology. We computed spectral, temporal, and spectro-temporal descriptors from all stimuli and used these to predict the affect ratings using linear and nonlinear methods. Our most consistent finding was that the fundamental frequency or higher-frequency energy of a sound predicted pleasant affect (i.e., positive valence, happiness, sadness) in one direction and unpleasant affect (i.e., tension, anger, fear) in the opposite direction. Clear discrepancies in previous findings may be attributable to differences in experimental design. When pitch variation was present in a stimulus set, energy arousal was predicted by pitch and inharmonicity, whereas when attack variation was present in the stimulus set, energy arousal was predicted by a faster attack and shorter sustain.
Introduction
Background
When listening to music, listeners are generally able to perceive the affective qualities that music expresses, and potentially feel changes in their internal affective state as well. The finding that listeners can make reliable affective judgments on sounds as short as 250 ms, during which structural features of mode or tempo cannot be established, indicates that temporally local features such as timbre can influence musical affect (Bigand et al., 2005; Filipic et al., 2010). Furthermore, in orchestration practices, timbre is considered a fundamental tool in expressing musical affect (McAdams, 2019; Schutz et al., 2008). Several studies that consider timbre as it varies between instruments and instrument families have shown how it is related to perceived affect (Chau et al., 2015; Grimaud & Eerola, 2022; Hailstone et al., 2009; McAdams et al., 2017). However, there are some discrepancies in their findings where, for example, strings are either associated with emotions of anger and fear (Grimaud & Eerola, 2022) or more positively valenced affects (McAdams et al., 2017). Discrepancies in these findings may be explained by the fact that a single instrument or family is not characterized by a single timbre but rather a “constrained universe of timbres” (McAdams & Goodchild, 2017a, p. 129). Indeed, the perception of timbre can change when an instrument plays at different pitches or dynamics (Marozeau et al., 2003; Risset & Wessel, 1999). To more fully consider how timbre influences musical affect, this paper investigates timbre at a more fine-grained level than the group level of instrument or family—more specifically, as it manifests in individual instruments in particular pitch registers.
Such a detailed investigation of affective timbres can be conducted by considering the characteristics of the temporal, spectral, and spectro-temporal properties of a sound, that is, timbre descriptors. This meta-analytic study consists of the (re-)analysis of results from three previously published papers, which are described in more detail below: Eerola et al. (2012), McAdams et al. (2017), and Korsmit et al. (2023). The three studies diverge in a few key methodological characteristics, which resulted in seemingly inconsistent findings for the first two studies and inhibits a closer comparison of results. By analyzing the three studies using consistent methodologies, we synthesized results to investigate the influence of timbre descriptors on the obtained affect evaluations of musical sounds.
Eerola et al. (2012) and McAdams et al. (2017), henceforth referred to as Eerola12 and McAdams17, respectively, both studied the role of timbre descriptors in the perception of the affect dimensions of valence (negative/positive or unpleasant/pleasant), tension arousal (tense/relaxed), and energy arousal (tired/awake; Schimmack & Grob, 2000). In Eerola12's experiment, participants were asked to rate perceived affect on these three dimensions in response to single-tone stimuli, all played at a single pitch height by a wide variety of common (e.g., piano, guitar, clarinet) and less common (e.g., shawm and crumhorn) instruments, from different eras and music genres. Due to strong correlations between valence and tension arousal, the authors only considered the two dimensions of valence and energy arousal in a subsequent acoustic analysis. They found that positively valenced sounds showed a high (or late) envelope centroid in the temporal domain (which indicates a more sustained sound) and contained more energy in the lower frequencies. Energetic sounds showed faster attacks and were less sustained, with more energy in the higher frequencies.
McAdams17 extended the experiments from Eerola12 by analyzing the perceived affective response to stimuli at varying pitch registers, instead of tones at a single pitch height. Here, in contrast to Eerola12, the two arousal dimensions did not correlate strongly, and, consequently, all three affect dimensions were considered. Their results revealed that more positively valenced sounds showed more high-frequency energy, a clear emergence of partials, a sharper attack, and an earlier decay. This is nearly opposite to the findings of Eerola12, who found that positively valenced sounds had more low-frequency energy and a sustained temporal development. McAdams17's results on tension arousal revealed that highly tensed sounds contained more high-frequency energy and showed more spectral variation and gentler attacks. Highly energized (awake) sounds were mostly predicted by pitch-related spectral descriptors. The discrepant findings between Eerola12 and McAdams17 on the temporal component of valence and the pitch component in energy arousal may be explained by significant differences in study design (stimulus selection), methods to extract the timbre descriptors (MIRToolbox vs. Timbre Toolbox; Lartillot & Toiviainen, 2007; Peeters et al., 2011), and regression techniques to predict the affect ratings (linear and nonlinear). This motivates the approach of the current paper to re-analyze the data of Eerola12 and McAdams17 using identical methods to enable a clearer synthesis of the results.
With a different goal, Korsmit et al. (2023) leveraged the acoustic characterization of affective timbre to investigate the structure of musical affect. Their experimental design allows for the dataset to be included in the current re-analysis and synthesis. Here, too, participants gave affect ratings in response to short musical sounds played at different pitch registers. They compared the dimensional affect model (valence, tension arousal, energy arousal, as in Eerola12 and McAdams17) to the discrete affect model (anger, fear, sadness, happiness, and tenderness) in how effectively they represent musical affect (see also Eerola & Vuoskoski, 2011). In both cases, ratings were given on three (dimensional) or five (categorical) separate scales. Furthermore, Korsmit et al. compared the perceived and induced affect structure, by either asking participants what emotional quality they perceived in the sound or what emotional quality they felt in response to the sound. Perceived affect (e.g., a song is perceived as sad) may not be the same as induced/felt affect (e.g., the sad song may induce more positive feelings; Gabrielsson, 2001), and consequently, the timbre descriptors that predict perceived and induced affect may diverge. Finally, whereas in Korsmit et al.'s (2023) first experiment (hereafter Korsmit1) the stimuli consisted of single tones, as in Eerola12 and McAdams17, in their second experiment (Korsmit2), they used chromatic scales, thus increasing the stimulus duration, introducing pitch variation, and more closely approximating ecologically valid examples of music. Here, we will extract the timbre descriptors from Korsmit et al.'s stimuli and use these to predict the affect ratings, thus enabling the synthesis of the results of four experiments: Eerola12, McAdams17, Korsmit1, and Korsmit2.
Affect Structure
Comparing the structure of the different studies’ affect ratings can inform our hypotheses and interpretation of results on the timbre descriptors that predict the affective response. The differences or similarities between studies, and between affect ratings, should translate into differences and similarities in timbre descriptors that predict affect. For Korsmit1, Korsmit2, and Eerola12, valence and tension arousal were strongly correlated, whereas this correlation was more moderate for McAdams17. For Eerola12, tension and energy arousal were also strongly correlated, whereas this correlation was weak for McAdams17 and moderately significant only for induced affect in Korsmit1 (and otherwise nonsignificant).
Further analyses of Korsmit1 and 2 showed that perceived and induced affect were also strongly correlated and only showed some minor differences in correlation strength. Based on principal component analyses, Korsmit et al. (2023) found that most of the variance in the ratings was explained by two principal components. Most scales showed high loadings on the first component differentiating more unpleasant affects (tension arousal, anger, fear) from more pleasant affects (positive valence, happiness, tenderness), whereas energy arousal behaved more independently, loading on a second component, with sadness loading on both components. Although the authors do not draw conclusions on the cognitive mechanisms that may underlie this affect structure, they do highlight that it is likely context-dependent and that there is not a “one-size-fits-all” structure to represent all musical affect. In the context of short musical sounds varying in timbre, we bear the abovementioned findings on affect structure in mind to inform our hypotheses and interpret the final results.
Hypotheses
Because pleasant affects could be clearly distinguished from unpleasant affects, we hypothesize that:
Because energy arousal (especially for McAdams 17 and Korsmit 1 and 2) behaved more independently from this pleasant/unpleasant distinction, we hypothesize that:
Because Korsmit 1 and 2 showed strong correlations between perceived and induced affect, as well as single notes and chromatic scales, we hypothesize that:
Methods
Experimental Design
The detailed experimental designs of Eerola12, McAdams17, Korsmit1, and Korsmit2 can be found in their respective publications (Eerola et al., 2012; McAdams et al., 2017; Korsmit et al., 2023). During the listening tasks of all experiments, participants listened to each stimulus and gave their subjective rating on the different affect scales. For comparison, we provide an overview of all experiments in Table 1. Whereas participants in Eerola12 and McAdams17 only rated perceived affect using dimensional affect scales, in Korsmit1 and Korsmit2 participants also rated induced affect and used discrete affect scales. Korsmit1 and Korsmit2 tested the largest number of participants but also used fewer stimuli and lacked variation in playing techniques or attack types. For example, the attack types in the brass stimuli of McAdams17 varied, having a weak, normal, or strong attack (as labeled by VSL), whereas for Korsmit1 all selected stimuli had a “normal” attack. Eerola12 did not include pitch variation in their stimulus set, which the other experiments did. Conversely, Eerola12 did include a wider variety of instruments. All experiments used slightly different stimulus durations. Korsmit1 and Korsmit2 were conducted online, whereas Eerola12 and McAdams17 were done in a laboratory setting. Finally, for participants’ tension arousal ratings, relaxed/relaxation was presented on the right-hand side for all experiments, but for analysis purposes, we inverted those scores so that higher ratings reflect higher tension.
Comparison of methodological approaches of Eerola12, McAdams17, Korsmit1, and Korsmit2.

Note. MUMS (McGill University Master Samples; Opolko & Wapnick, 2006); VSL (Vienna Symphonic Library; Vienna Symphonic Library GmbH, 2022); OrchSim (McAdams & Goodchild, 2017b; OrchPlayMusic, 2022).
Computational and Analytical Approach
As described earlier, Eerola12 and McAdams17 employed different methods for extracting the timbre descriptors (i.e., computational approach; MIRToolbox vs. Timbre Toolbox) and different methods for the prediction of affect ratings (i.e., analytical approach). This inhibits a more direct comparison of results and thus here we employ an identical computational and analytical approach in the re-analysis of the four experiments.
For the computational approach, timbre descriptors were extracted from all stimuli using the latest version of the Timbre Toolbox (Kazazis et al., 2021). We computed descriptors from the short-term fast-Fourier transform (STFT; spectral domain), the partials (harmonic domain), and the temporal energy envelope (temporal domain). For time-varying spectral and harmonic descriptors, we used the median and interquartile range (IQR) over the duration of the stimuli as summary statistics. For the chromatic scales of the second experiment, we also included the range (maximum – minimum) of the harmonic and spectral descriptors, as they provide additional information relevant to longer stimuli. Because the accuracy of the harmonic descriptors depends on the accuracy of the estimated fundamental frequency, we excluded the harmonic descriptors for 12 stimuli (11 percussion, 1 organ) whose pitch estimation was inaccurate. The resulting 54 descriptors, as described in Table 2, were used to predict the affect ratings.
List of timbre descriptors used from the timbre toolbox.

Note. Median and IQR were extracted from the harmonic and spectral domains; only median from the temporal domain.
We followed two approaches for predicting affect—linear and nonlinear regression methods—as the original publication by McAdams17 revealed that the relation between timbre and affect may be better explained by nonlinear relationships, particularly for stimuli varying in pitch. For the linear method (henceforth LM), we conducted variable selection using lasso regression (Tibshirani, 2011), followed by standard linear regression with the predictor variables selected by the lasso procedure. Lasso regression is well-suited to predictor sets that contain high collinearity (as is the case for timbre descriptors) and allows variable selection without a priori assumptions or multiple comparisons. Linear regression with the selected predictors was performed to obtain nonregularized regression coefficients for each selected timbre descriptor and to measure model performance. For the nonlinear method (henceforth NM), we conducted random-forest regression (Biau & Scornet, 2016; Breiman, 2001) and obtained relative variable importance (RVI) for each timbre descriptor (Liaw & Wiener, 2002). Model performance measures were computed with fivefold cross-validation repeated three times for the LM and NM models. The goodness of fit as variance explained (R2) is calculated for the models run on the full dataset, which were trained using the cross-validation method. The predictive relevance (test-R2) averages the R2 of each of the five iterations where the four folds predicted the fifth fold. Although the NM is expected to show higher predictive accuracy than the LM, the relatively simpler LM is generally preferred over the NM in terms of comprehensibility (Freitas, 2014). The full model performance statistics are reported in the Appendix.
The Timbre Toolbox in MATLAB version 2020b (The MathWorks Inc., Natick, MA) was used. All further analyses were conducted in R version 4.2.1 (www.r-project.org). We used: the glmnet package to perform lasso regression analysis (Friedman et al., 2022); the standardize_parameters function of the effectsize package to calculate standardized regression coefficients (Ben-Shachar et al., 2022); the lm function for the linear regression; the train function for the RF regression; and the varImp function for the RVI values from the caret package (Kuhn et al., 2022).
Results
Perceived and Induced Dimensional Affect in Response to Single Tones
First, we compare the timbre descriptors that predicted dimensional affect ratings in Eerola12, McAdams17, and Korsmit1, because these three experiments were the most similar to each other. Specifically, we discuss the main consistencies and discrepancies between the experiments. Figure 1 summarizes the modelling results. In particular, predictors are of interest in terms of consistency if they appear in multiple columns in Figure 1 (i.e., predict affect in multiple experiments) and if they show up as filled ellipses (i.e., both significant in LM and NM).
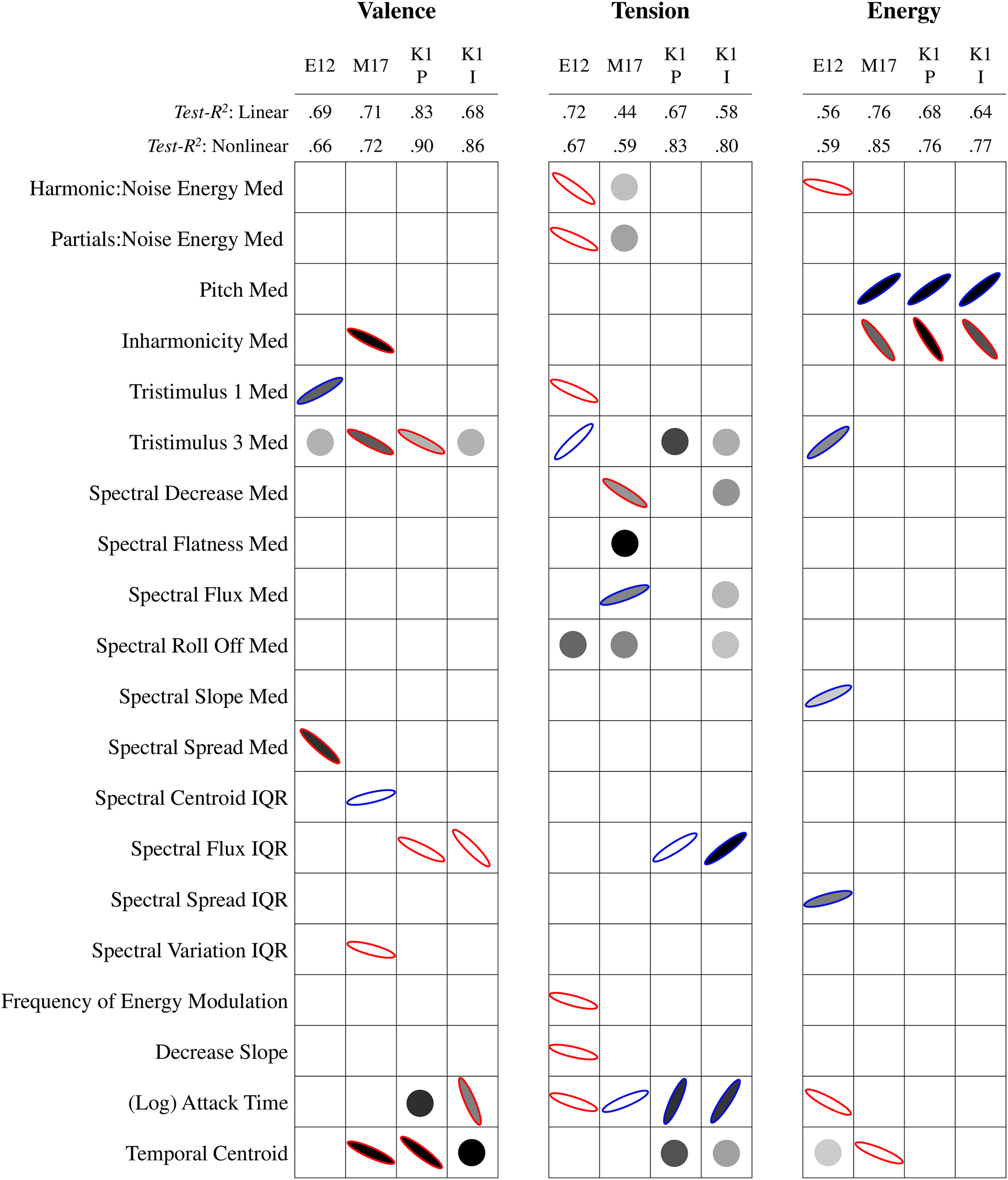
Linear and nonlinear modelling performance (test-R2) and results for timbre descriptors predicting dimensional affect in Eerola12 (E12), Mcadams17 (M17), and the perceived and induced ratings of Korsmit1 (K1P & K1I). Note. Ellipses represent standardized coefficients of the LM. Ellipse orientation and outline color signify coefficient direction (+blue/− red), and steepness represents coefficient magnitude. The darkness of the fill represents the RVI of the NM, with no fill for RVI < 20. Descriptors with RVI > 20 but no significant contribution in the LM are represented by circles.
When we consider the scale of valence across the experiments, the NM showed slightly better model performance than the LM in terms of variance explained (mean ΔR2 = .07, SD ΔR2 = .05), which is mirrored by the increase in predictive relevance and normalized error (mean Δtest-R2 = .06, SD Δtest-R2 = .09; mean ΔNRMSE = –.02, SD ΔNRMSE = .02). For all experiments, valence is predicted by median tristimulus 3, with a related median tristimulus 1 predictor for Eerola12. Taken together, the increase in tristimulus 1 (more relative energy in the first harmonic) and decrease in tristimulus 3 (less relative energy in upper harmonics) indicate that more positively valenced sounds have a more strongly emerging fundamental frequency. For both McAdams17 and Korsmit1, but not Eerola12, positive valence is also predicted by a decrease in variability in spectral flux or variation. In addition, McAdams17 and Korsmit 1 find that valence is predicted by temporal timbre descriptors of log attack time and temporal centroid; that is, more positively valenced sounds have a sharper attack (decrease in log attack time) and are less sustained (decrease in temporal centroid). It should be noted that in Eerola12's original analysis, temporal centroid was also a significant predictor of valence, but in an opposite direction so that positive sounds were more sustained. However, this result was not found with either of our LM or NM.
For tension arousal, Eerola12 does not show much improvement with the NM compared to the LM, but McAdams17 and Korsmit1 do (mean ΔR2 = .17, SD ΔR2 = .06; mean Δtest-R2 = .18, SD Δtest-R2 = .04; mean ΔNRMSE = –.04, SD ΔNRMSE = .01). Thus, the NM results of those latter datasets will be considered, even if they were nonsignificant in the LM. For Eerola12 and McAdams17, contrary to valence, tension ratings are predicted by a decrease in median tristimulus 1 and an increase in median tristimulus 3 (though only in the NM for Korsmit1). Tense sounds thus have a less strongly emerging fundamental frequency. Notably, the McAdams17 data are predicted by a decrease in spectral decrease, which indicates that tense sounds have more high frequency energy and may be related to the tristimulus results. When we investigate the temporal timbre descriptors, McAdams17 and Korsmit1 tension ratings are predicted by an increase in (log) attack time and temporal centroid. Thus, opposite to valence, more tense sounds have a slower attack. Interestingly, Eerola12 finds that tension is predicted by a decrease in attack time, so for this dataset tense sounds have a faster attack. Finally, predictors related to relative noisiness of sounds (harmonic:noise energy and partials:noise energy) for Eerola12 and McAdams17 indicate that more tense sounds also have more noise energy.
Finally, for energy arousal, Eerola12 again shows little improvement of the NM over LM, whereas there is a slight improvement for McAdams17 and Korsmit1 (mean ΔR2 = .04, SD ΔR2 = .05; mean Δtest-R2 = .10, SD Δtest-R2 = .03; mean ΔNRMSE = –.02, SD ΔNRMSE = .02). Figure 1 shows that McAdams17 and Korsmit1 are consistently predicted by median pitch and inharmonicity; more awake/energetic sounds are higher in pitch and lower in inharmonicity. This is not the case for Eerola12, who did not include pitch variation in their stimulus set. Eerola12 does show some overlap with McAdams17 in the temporal component, where awake sounds have a faster attack or an earlier temporal centroid. Korsmit1, who did not include attack variation in their stimulus set, does not find any temporal timbre predictors for energy arousal.
Perceived and Induced Discrete Affect in Response to Single Tones
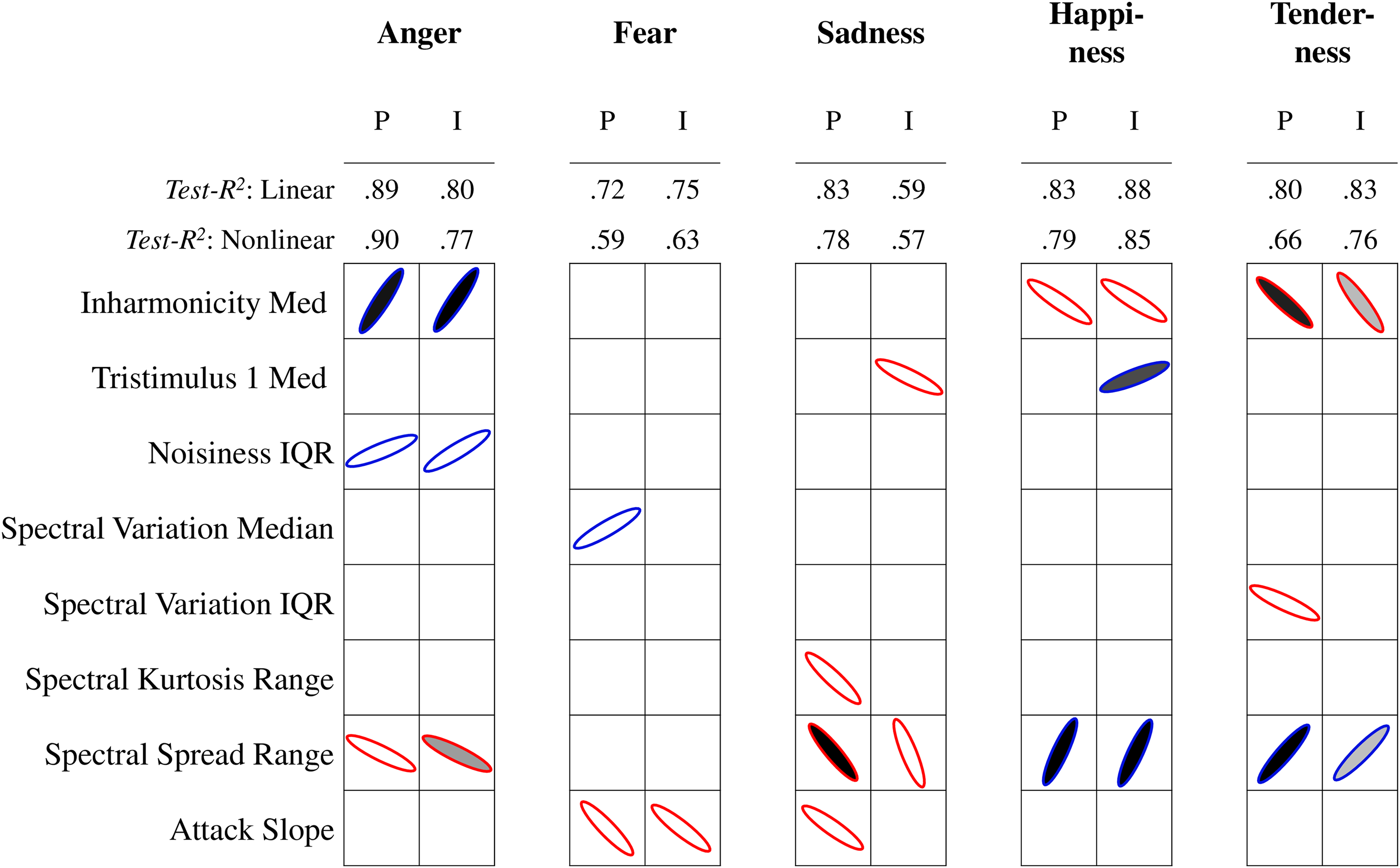
Now we consider the modelling results of the timbre descriptors predicting the discrete affect ratings, which were only obtained by Korsmit1. Figure 2 summarizes the modelling results, and here again, we will focus on the main consistencies and discrepancies that we see across the affect scales. Concerning model performance of all discrete affect scales in Korsmit1, there is a slight improvement of the NM over the LM overall (mean ΔR2 = .07, SD ΔR2 = .07; mean Δtest-R2 = .06, SD Δtest-R2 = .07; mean ΔNRMSE = –.02, SD ΔNRMSE = .03), in particular for anger (mean ΔR2 = .17, SD ΔR2 = .03; mean Δtest-R2 = .15, SD Δtest-R2 = .08; mean ΔNRMSE = –.07, SD ΔNRMSE = .04). There are no major differences in performance between the models predicting perceived or induced affect. Both anger and fear are predicted by increases in median tristimulus 3, in the IQR of spectral flux, and in log attack time, which is mostly in line with our findings on valence and tension arousal. Thus, angry and fearful sounds have a less strongly emerging fundamental frequency, more variability of spectral flux, and a slower attack. Happiness and tenderness, on the contrary, are predicted by a decrease in median tristimulus 3 and the IQR of spectral flux. In addition, they are predicted by effective duration, meaning that happier and more tender sounds are perceptually shorter. Sadness behaves slightly differently from the other four discrete affects. Both perceived and induced sadness are predicted by an increase in temporal centroid (i.e., more sustain) and a nonlinear contribution of effective duration. There are also some differences between perceived and induced sadness if one examines the predictors of median inharmonicity, median spectral crest (tonalness), median spectral decrease (high-frequency energy), and attack slope (increase of signal energy). This indicates clear differences between the timbre descriptors related to sadness that is perceived in music and sadness that is induced when listening to music.

Linear and nonlinear modelling performance (test-R2) and results for timbre descriptors predicting perceived (P) and induced (I) discrete affect in Korsmit1. Note. See Figure 1.
Perceived and Induced Dimensional Affect in Response to Chromatic Scales
In this section, we analyze the results of the dimensional affect ratings of Korsmit2, which used chromatic scales. These results are summarized in Figure 3. Contrary to what we saw in Korsmit1 with single tones, Korsmit2 does not show much improvement in model performance for the NM compared to the LM. In fact, in some cases nonlinear model performance is worse. Only induced tension arousal is better predicted by the NM (ΔR2 = .23; Δtest-R2 = .21, ΔNRMSE = .01). Consequently, this is the only scale for which we have highlighted timbre descriptors that were only significant in the NM in Figure 3. Valence is predicted by an increase in the range of spectral spread values over the stimulus duration, whereas tension arousal is predicted by a narrower range of spectral spread values. The range of spreads around the mean is correlated with the median and range of spectral rolloff values, rmedian(30) = .77, p < .0001; rrange(30) = .94, p < .0001, and the median and range of spectral centroid values, rmedian(30) = .73, p < .0001; rrange(30) = .86, p < .0001. Thus, taken over an entire chromatic scale stimulus, positively valenced and low tension (i.e., relaxed) sounds have a larger range of higher-frequency energy values. Valence and energy arousal are also predicted by a decrease in median inharmonicity. In addition, energy arousal is predicted by an increase in pitch, which, along with inharmonicity, is very similar to the energy arousal findings in Korsmit1 and McAdams17. Median spectral crest (tonalness) also influences both valence and tension arousal, which may be related to the emergence of the fundamental frequency found in Korsmit1.

Linear and nonlinear modelling performance (test-R2) and results for timbre descriptors predicting perceived (P) and induced (I) dimensional affect in Korsmit2. Note. See Figure 1.
Perceived and Induced Discrete Affect in Response to Chromatic Scales
Finally, we investigate the discrete affect ratings obtained in Korsmit2, using the chromatic scales. These results are summarized in Figure 4. Again, unlike Korsmit1, the NM does not show much improvement in model performance when predicting the discrete affect ratings in Korsmit2. In fact, the NM performs slightly more poorly than the LM overall (mean ΔR2 = –.07, SD ΔR2 = .09; mean Δtest-R2 = –.06, SD Δtest-R2 = .05; mean ΔNRMSE = .03, SD ΔNRMSE = .02). Consequently, we again focus on the LM results. As we found with valence and tension, all discrete affect scales, except for fear, are predicted by the range of spectral spread values. Sounds that are rated as angrier and sadder, as well as less happy and tender, have a narrower range of high-frequency energy taken over the entire chromatic scale. Median inharmonicity is also increased for sounds that are considered angrier, less happy, and less tender. Temporal descriptors are much less prominently featured as predictors in Korsmit2, but attack slope (the rate of energy increase during the attack) is less steep for ratings of induced and perceived fear and perceived sadness. Given that temporal descriptors are obtained from the entire stimulus, this slope only refers to the first tones in the chromatic scales, particularly as the scale was played legato.
Linear and nonlinear modelling performance (test-R2) and results for timbre descriptors predicting perceived (P) and induced (I) discrete affect in Korsmit2. Note. See Figure 1.
Discussion
The goal of this paper was to analyze how fine-grained differences in musical timbre influence affective responses to music. To do so, we re-analyzed results from four (previously published) experiments using identical computational and analytical methods to enable a close comparison of results. Through the synthesis of these results, we can find clear consistencies and discrepancies between experiments that considered perceived and induced affect on dimensional and discrete representations in response to single tones and chromatic scales.
Figure 5 shows a diagram highlighting the relevant timbre descriptors that predict the affect ratings from each experiment. It overlays the principal component analysis loading plot from Korsmit et al. (2023) based on the ratings of Experiments 1 and 2. This affect structure helps with the interpretation of how certain timbre descriptors are (dis)similar for the different affect scales. The results for the perceived and induced affect ratings are combined here, as they did not show many large differences.
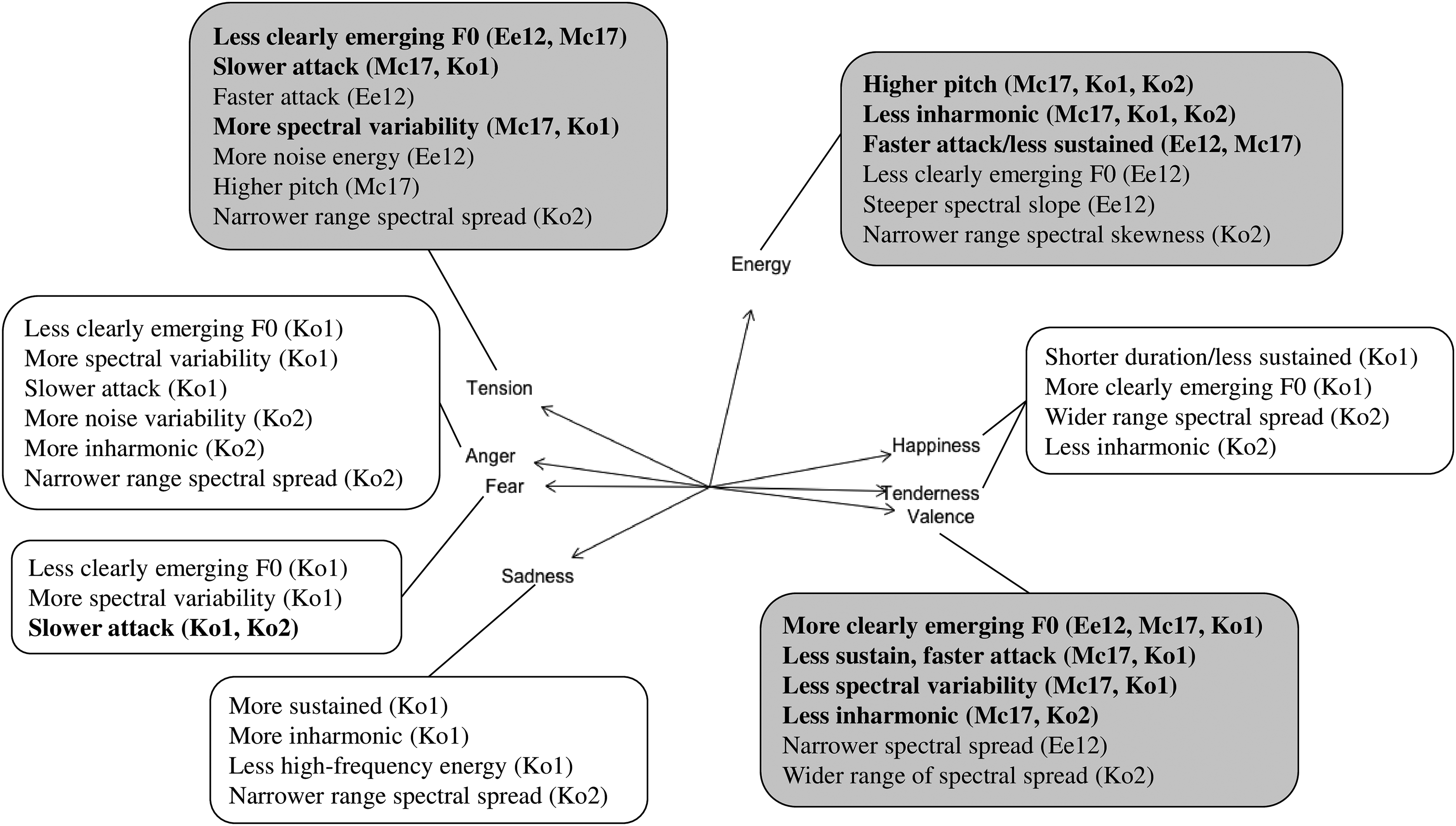
Diagram summarizing the relevant audio descriptors in predicting the dimensional (gray) and discrete affect ratings of Eerola12 (Ee12), McAdams17 (Mc17), Korsmit1, and Korsmit2. Note. The diagram is overlayed on the principal component analysis loading plot obtained from the ratings of Korsmit1 & Korsmit2 as described in Korsmit et al. (2023), with descriptors that are relevant to two or more experiments highlighted in bold.
Consistencies
First, we will highlight the most consistent finding in our result: the emergence of the fundamental frequency or perceptual brightness. This consistency illustrates robustness because, even with differences in experimental design (e.g., stimulus selection), the timbre descriptors were found to influence affect across the board. Following the affect structure shown in Figure 5 for single tones, positively valenced, happy, and tender sounds have a more clearly emerging fundamental frequency, whereas tense, angry, and fearful sounds have a less clearly emerging fundamental frequency. These findings are mostly in line with the original published results from Eerola12 and McAdams17. For chromatic scales, spectral descriptors that can be associated with perceptual brightness were a more consistent predictor. This also followed the affect structure in that sounds with more high-frequency energy were considered more positively valenced, happy, tender, and less angry, tense, and sad. Thus, in line with H1, timbre descriptors influence pleasant and unpleasant affects in opposite directions. In addition, in line with H3, although there were some minor differences between perceived and induced affect, this distinction between pleasant and unpleasant affect was found in both cases.
Discrepancies
Two main differences in experimental design between experiments have led to clear discrepancies in results—namely, whether pitch variation and/or attack variation were included in the stimulus set. First, the experiments that included pitch variation (i.e., McAdams17, Korsmit1, and Korsmit2) found that energy arousal was predicted by an increase in pitch and a decrease in inharmonicity—that is, more awake or energetic sounds (both single tones and chromatic scales) were higher in pitch and less inharmonic. This is also in line with H2, which stated that energy arousal would be predicted by different predictors than the pleasant/unpleasant affects mentioned in H1. Interestingly, although different instruments playing the same pitch height can produce varying levels of inharmonicity, pitch and inharmonicity are both perceptually and computationally related. In terms of computation, due to the Nyquist limit and the mechanics of instruments that cannot produce very-high-frequency modes of vibration, there are more audible harmonics in lower-pitched sounds than in higher-pitched sounds. Consequently, on average, the ability to detect and produce inharmonicity decreases as pitch increases. On a perceptual level, it has also been found that listeners are better at detecting inharmonicity at lower fundamental frequencies (Järveläinen et al., 2001). The high similarity between results for McAdams17 and Korsmit1 is in line with the previous findings that the use of affective auditory stimuli leads to comparable results in-lab and online (Seow & Hauser, 2022). The role of pitch and inharmonicity, however, was not found for the dataset of Eerola12, whose stimuli were all played at the same pitch height.
Second, the experiments that included attack variation (i.e., Eerola12 and McAdams17) found that energy arousal was also predicted by a temporal component of a faster attack or shorter sustain. The datasets that did not include attack variation (i.e., Korsmit1 and Korsmit2), did not find a role for temporal timbre descriptors in predicting energy arousal. Consequently, a lack of variation in stimulus selection can cause major differences in results. On the one hand, this finding ought to motivate researchers to include maximal variation in their stimuli, and on the other hand, this raises awareness that any lack of variation (which is often inevitable) can play a big part in the eventual findings.
Limitations
Some discrepancies in our results cannot be as easily explained by differences in experimental design and thus may be a topic for further investigation in future studies. For example, for McAdams17 and Korsmit1, tenser sounds had a slower attack, whereas for Eerola 12, tenser sounds had a faster attack. Future research may investigate whether the variations in pitch height or instrument selection caused variations in attack that may explain these divergent results. In addition, apart from energy arousal, there was little overlap between the findings on single tones and chromatic scales. This is not in line with H3 and the affect structure described in the introduction, based on which one would expect consistent results between single tones and chromatic scales. Continuous measurements could potentially further translate the role of local to more global timbral features in perceiving and inducing affect. Finally, one finding that we did not expect based on the affect structure was that happiness and tenderness were predicted by the perceived duration of a sound, whereas none of the other affect evaluations were. Although playing techniques and stimulus durations were kept constant across stimuli, the effect of perceptual duration may be related to differences between staccato and legato, as previous research has associated staccato playing techniques with more perceived happiness (Carr et al., 2023).
A potential limitation of our analytical approach was that it was not able to reveal any quadratic patterns that the timbre descriptors may have shown in relation to the affective responses. McAdams17, however, found in their original publication that pitch showed a quadratic effect on valence and tension arousal (not energy arousal). Thus, any pitch-related timbre descriptors may also show a quadratic relationship to valence and tension arousal, which was not revealed in the current analyses. The linear relationship between pitch and energy arousal, however, was clear.
Conclusions
In the re-analysis and synthesis of multiple experiments, we have been able to pinpoint affective timbres that are consistent across stimulus sets, experimental designs, participant populations, affect loci, and analytical approaches. The relative emergence of the fundamental frequency and higher-frequency energy play a prominent role in perceiving and inducing musical affect. This effect mainly follows the affect structure that distinguishes unpleasant from pleasant affect. Changes in variation of sound characteristics like attack techniques or pitch height led to clear divergence in results, arguing for future studies to include maximal variation in their stimulus selection.
Footnotes
Acknowledgements
The authors would like to thank Eerola et al. (2012), McAdams et al. (2017), and ![]() for making their data available for this study.
for making their data available for this study.
Action Editor
Charalampos Saitis, Queen Mary University London, School of Electronic Engineering and Computer Science.
Peer Review
Victor Rosi, University College London, Speech Hearing and Phonetic Science. Bruno Giordano, Centre National de la Recherche Scientifique, Institute of Neuroscience and Psychology.
Author Contributions
IRK was responsible for the background research, data analysis, and interpretation, and wrote the paper. MM advised and helped develop the analytical approach. AYTWM assisted in the development, execution, and analysis as part of their undergraduate thesis project. SMc supervised the project and provided feedback throughout all stages of the research.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
The McGill University Research Ethics Board II approved this study for ethical compliance.
Funding
The authors disclose receipt of the following financial support for the research, authorship, and/or publication of this article: IRK was supported by funding from the Cultuurfonds (the Netherlands). This project was also funded by a Canadian Social Sciences and Humanities Research Council Insight Grant (435-2021-0224), a Social Sciences and Humanities Research Council Partnership Grant (895-2018-1023), and a Canada Research Chair (950-231872) to SM.
Data Availability Statement
All stimuli, data, and R scripts are available online at https://doi.org/10.5683/SP3/2BZJRF (Korsmit, 2023).
Appendix
Model performance for the lasso and random forest regressions in predicting the discrete affect ratings on discrete scales in Korsmit2.

| Perceived | Induced | ||||
|---|---|---|---|---|---|
| Lasso | RF | Lasso | RF | ||
| Anger | R2 | .90 | .91 | .82 | .80 |
| Test-R2 | .89 | .90 | .80 | .77 | |
| Avg NRMSE | .18 | .17 | .17 | .18 | |
| Fear | R2 | .69 | .75 | .75 | .75 |
| Test-R2 | .72 | .59 | .75 | .63 | |
| Avg NRMSE | .12 | .15 | .13 | .14 | |
| Sadness | R2 | .86 | .65 | .60 | .57 |
| Test-R2 | .83 | .78 | .59 | .57 | |
| Avg NRMSE | .07 | .12 | .09 | .12 | |
| Happiness | R2 | .81 | .74 | .85 | .69 |
| Test-R2 | .83 | .79 | .88 | .85 | |
| Avg NRMSE | .15 | .20 | .10 | .17 | |
| Tenderness | R2 | .76 | .61 | .81 | .70 |
| Test-R2 | .80 | .66 | .83 | .76 | |
| Avg NRMSE | .11 | .14 | .10 | .11 | |