
Abstract
Background
Artificial intelligence (AI) is emerging as a transformative force in digital health, offering novel solutions to overcome traditional barriers in patient education, such as the low readability of materials and the high cost of personalization. The rapid integration of Large Language Models (LLMs) necessitates a clear understanding of the current research landscape to guide effective and ethical implementation.
Objective
This study aims to systematically map the global research landscape of AI in patient education. This bibliometric analysis identifies the knowledge structure, research hotspots, key contributors, and evolutionary trends to guide future research and practice in this rapidly emerging domain.
Methods
We retrieved 837 relevant documents published between 2016 and 2025 from the Web of Science Core Collection. Bibliometric data were analyzed using CiteSpace and RStudio to conduct visual analyses of publication trends, international collaborations, co-citation networks, and keyword evolution.
Results
The analysis revealed an exponential increase in publications since 2021, a trend that strongly coincides with the advent of LLMs. The USA and China are the primary research contributors, with Harvard University leading institutional output. Research hotspots have evolved from foundational concepts like machine learning to application-focused themes such as health literacy, readability, and adherence. The intellectual base is highly interdisciplinary, drawing from medicine, computer science, and education.
Conclusion
AI is rapidly transforming patient education, with a clear trajectory from technology-focused validation to patient-centered outcomes. While LLMs show immense potential, significant challenges persist regarding accuracy, ethical implementation, and systematic integration into clinical workflows. Future efforts must prioritize developing robust validation frameworks and strengthening international collaboration to enhance digital health equity.
Introduction
Patient education is a cornerstone of the modern healthcare system, crucial for enhancing patient health literacy and improving treatment outcomes. 1 However, traditional patient education faces a dual dilemma: first, professional education materials (PEMs) often suffer from inefficient information transfer due to complex terminology and high reading difficulty; 2 second, the creation of high-quality, personalized educational resources is time-consuming and labor-intensive, making widespread adoption difficult.
The digital transformation of healthcare, particularly the advent of artificial intelligence (AI), has brought new opportunities to overcome the bottlenecks of traditional patient education. 3 Large Language Models (LLMs) possess powerful natural language processing (NLP) capabilities, allowing them to simulate human communication and rapidly generate simplified medical content. These models show immense potential for practical applications, such as automating educational material, interpreting complex reports, and providing instant Q&A support.4–6 The academic community has initiated preliminary explorations into the application of AI in patient education, with existing reviews affirming its potential in generating educational materials, interpreting medical information, and improving physician-patient communication. 7 However, as an emerging interdisciplinary field, the application of AI has also raised widespread concerns. 8 Research has revealed its limitations in accuracy and reliability, especially when dealing with complex medical issues, where problems such as misinformation, errors, and content fabrication (“hallucinations”) can occur.9–11 Furthermore, challenges such as algorithmic bias, data security, privacy protection, and ethical deployment urgently need to be addressed.12–14 Addressing this gap, pioneering research has begun to systematically evaluate the potential ethical risks and biases of AI in specific clinical domains, such as nephrology, 15 and to explore how AI-driven translation can promote health equity, especially for populations with language barriers. 16 This cutting-edge work highlights the pressing need to establish robust ethical frameworks during technological integration. 17
Faced with the explosive growth of literature in this field, it is particularly important to systematically map its developmental trajectory and research frontiers. Traditional systematic reviews and meta-analyses are advantageous for evidence synthesis. However, bibliometric analysis offers a different strength: it uses quantitative indicators, such as citation networks and keyword co-occurrence, to systematically map the knowledge base, collaboration patterns, and evolutionary trajectory of an entire field. 18 This large-scale scientific knowledge mapping technology not only provides researchers with a panoramic view of the field but also helps identify knowledge gaps and formulate strategic plans for innovation. 19 Therefore, this study employs bibliometric methods to systematically analyze the global literature on “AI in patient education.” Our objective is to present its knowledge base, hotspot evolution, and future trends. We achieve this by analyzing indicators like keyword co-occurrence and document co-citation, providing a macro-level guide for future research and clinical decisions.
Materials and methods
Search strategy
To ensure the authority, reliability, and comprehensiveness of the data, this study selected the Web of Science Core Collection (WOSCC) as the sole data source. WOSCC is widely used in bibliometric research for its high-quality peer-reviewed literature and complete citation indexing system. The scope of this study's search covered core subsets such as the Science Citation Index Expanded (SCIE) and the Social Sciences Citation Index (SSCI). The literature search was completed on July 27, 2025, with the search period set from January 1, 2016, to July 27, 2025. To achieve maximum recall, the search strategy employed a Topic Search (TS), combining multiple sets of keywords related to “artificial intelligence” and “patient education” using the Boolean operators “OR” and “AND.” The specific search query was constructed as follows: TS = (“artificial intelligence” OR “machine learning” OR “deep learning” OR “natural language processing” OR NLP OR chatbot* OR “expert system*” OR “conversational agent*” OR “virtual assistant*” OR “AI-based” OR “AI-powered”) AND TS = (“patient education” OR “patient teaching” OR “patient instruction*” OR “patient counseling” OR “health education” OR “health literacy” OR “patient information”).
Inclusion and exclusion criteria
This study established clear inclusion and exclusion criteria. The inclusion criteria were: (1) peer-reviewed research articles or review articles published in English; (2) studies that explicitly explored the application of AI in patient education; (3) a publication date range from January 1, 2016, to July 27, 2025. The exclusion criteria included: (1) non-peer-reviewed materials (e.g., preprints, conference abstracts, letters, book chapters, data papers); (2) retracted publications; (3) studies whose topics were not directly related to AI or patient education; (4) to ensure consistency in data processing, non-English literature was excluded.
The literature screening process was conducted independently by two researchers. They first performed an initial screening by reading titles and abstracts, followed by a second screening through full-text reading. Any discrepancies encountered during the screening process were resolved through discussion and consultation with a third researcher to ensure the consistency and accuracy of the screening results. This structured approach allowed us to progressively narrow down the initial dataset, resulting in 837 publications that met all established inclusion criteria.
Data extraction and cleaning
All literature records meeting the inclusion criteria were exported from the WOSCC database in “plain text” format, containing complete records and cited reference information. The exported data fields included title, author, institution, country/region, keywords, abstract, publication year, journal, citation frequency, and reference list, among others. Before analysis, the raw data underwent standardization, including merging different spellings of authors’ names, unifying institutional names, and combining synonyms for keywords to ensure the accuracy of the subsequent bibliometric analysis.
Bibliometric analysis
The extracted data were imported into CiteSpace (version 6.3.R1 Advanced), Microsoft Excel, RStudio (version 4.4.2), and an online bibliometric analysis platform (http://bibliometric.com/) for data processing and network visualization. CiteSpace served as the core analytical tool, employing visualized bibliometric methods to reveal the underlying knowledge within scientific literature. It generates scientific knowledge maps that intuitively display the structure and distribution of scientific knowledge. 20 These maps cover various types, including institutional/national collaboration networks, reference co-citation clusters, burst detection graphs, keyword co-occurrence networks, cluster analyses, and timeline views, providing researchers with diverse analytical perspectives. RStudio was used in conjunction with the “Bibliometrix” package to generate thematic maps and thematic evolution analyses.
In the visualized knowledge networks generated by CiteSpace, various elements are depicted through a topological structure to delineate the evolutionary characteristics of the research field. Nodes, as the fundamental units of the network, represent multiple academic entities (such as keywords, countries, institutions, journals), with their size being proportional to research activity or citation frequency. The lines connecting the nodes represent co-occurrence relationships; for instance, a topological link is formed between two countries or institutions when they co-author a paper. A color-mapping mechanism integrates the time dimension into the visualization: cool colors (like blue) represent data from earlier years, while warm colors (like red) indicate recent research output, thus forming a visual gradient of temporal evolution. Notably, a purple ring around a node highlights the strength of its Betweenness Centrality, an indicator that measures the pivotal role of a node in knowledge dissemination pathways. Nodes with high centrality often correspond to groundbreaking publications that connect different disciplines or to “knowledge gatekeepers” in social networks, exerting significant regulatory influence on the flow of knowledge within the field. 21 For further details, please refer to the relevant in-depth literature. 22
The main operational steps in CiteSpace are as follows: First, a new CiteSpace project was created, and the full records obtained from the aforementioned search process were imported. Next, relevant parameters were configured within the project, including setting the Time Slicing to one-year intervals, analyzing the results year by year before merging them, and selecting authors, keywords, journals, categories, and references as node types for analysis. Detailed parameter configurations are provided in Supplementary Table 1. The specific parameters used in each analysis are indicated in the top-left corner of the corresponding figure.
In the cluster analysis of references and keywords, the Log-Likelihood Ratio (LLR) algorithm was used for term extraction to ensure the accuracy and reliability of the clustering. The top-left corner of the generated maps displays the Modularity Q value and the mean Silhouette S value, which are key indicators for evaluating the quality of the clustering. The range of the Q value is [0,1]; a Q > 0.3 indicates a significant cluster structure, Q > 0.5 suggests a reasonable clustering, and Q > 0.7 reflects a highly credible clustering result. For the burst detection of keywords and references, the γ value was set to 1.0 with a minimum duration of 1 year. Based on the co-occurrence relationships in citations, keyword co-occurrence maps, cluster maps, timeline views, and burst detection graphs were generated to comprehensively reveal the frequency, centrality, cluster structure, time span, and thematic evolution of keywords. The timeline view transforms the co-occurrence network into a chronological format with annual legend labels, allowing researchers to intuitively observe the evolution of research trends over time. 23
Results
Annual publication trends
After rigorous screening, this study ultimately included 837 documents for bibliometric analysis. The entire screening process, including the reasons for exclusion at each stage, is detailed in Figure 1. An analysis of annual publication volume trends (Figure 2(a) and (b)) shows that research output in this field remained relatively stable between 2016 and 2020 (with an average annual publication count below 30), followed by exponential growth starting from 2021. A notable feature is that the cumulative publication volume in the last five years (2021–2025) reached 795, accounting for 95.0% of the total literature, and the output in the first half of 2025 alone (January to July) has already surpassed 300. This trend clearly indicates that the application of AI in patient education has rapidly become a research hotspot. A three-dimensional coupling analysis of country-theme-institution (Figure 2(c)) further reveals that the USA and China are the core contributors to research in this field, with their main research institutions highly focused on utilizing AI technologies, represented by Chat generative pre-trained transformer (GPT), to explore effective pathways for improving information delivery to enhance patient “health literacy.”

Flowchart of study identification and selection based on web of science core collection. SCIE: Science Citation Index Expanded; SSCI: Social Sciences Citation Index; WOSCC: web of science core collection.
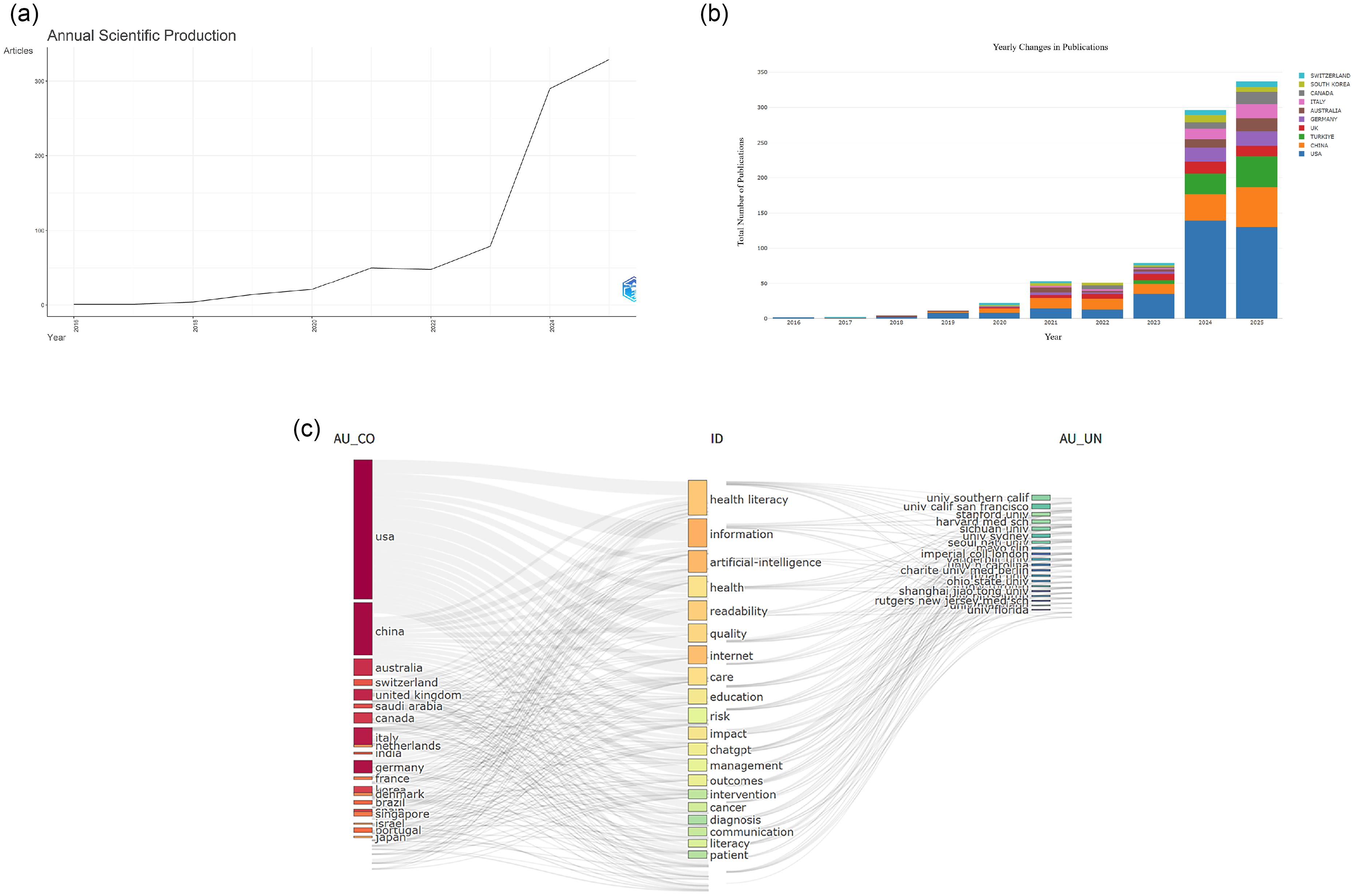
(a) Annual scientific production. (b) The annual number of publications in major countries. (c) RStudio–Three-fields plot left-countries, middle-keywords plus from the data records, right-authors affiliations.
Core authors and academic networks
The author collaboration network analysis shows that 396 authors formed 784 collaborative relationships (Supplemental Figure 1A). Prolific authors are listed in Table 1, with Xie, Wenxiu leading with 5 publications, followed by Margetis, Konstantinos, and Balyan, Renu, among others. Co-cited author analysis aims to uncover the knowledge base and core scholars of the field. The results show that Ayers, John W. from the USA is the most cited scholar (84 citations), with Sallam, Mohammed (71 citations) and Kung, Tiffany H. (63 citations) also demonstrating prominent academic influence (Table 2). In the co-cited author map (Supplemental Figure 1b), the size of the nodes intuitively reflects the foundational status of these scholars in the field.
The top 5 authors with the most publications.

The top 5 authors with the most citation accounts.

Country and institutional distribution
The country collaboration network analysis included researchers from 100 countries, forming 100 nodes and 519 links (Supplemental Figure 1c). The top five countries in terms of publication volume and centrality are detailed in Table 3. The USA (349 publications, 41.7%) and China (131 publications, 15.7%) hold an absolute advantage in total publication volume. It is noteworthy that despite their high output, neither country ranked in the top five for centrality, indicating that there is still room for improvement in the international collaboration and bridging role of their research outcomes. In contrast, Qatar, despite a modest number of publications, ranked first in centrality (0.22), showing that its research plays a key bridging role in the international collaboration network. The connection strength between nodes indicates that Italy, the UK, and Canada play important roles in promoting transnational academic exchange, while the research of some countries remains relatively independent, suggesting a need to strengthen international cooperation (Supplemental Figure 1d).
The top 5 countries with the most publications and centrality.

At the institutional level, 261 institutions formed a collaboration network with 261 nodes and 497 links (Supplemental Figure 1e), where the purple ring around the nodes represents their centrality. The top five institutions in terms of output and centrality are shown in Table 4. Harvard University Medical Affiliates and the University of California System tied for first place in output with 34 publications each. In terms of centrality, Harvard University Medical Affiliates (0.15) and Ain Shams University (0.15) tied for the top spot, followed closely by the State University System of Florida (0.14), indicating that these institutions are not only core research producers but also key hubs in the international collaboration network.
The top 5 institutions with the most publications and centrality.

Journal and citation analysis
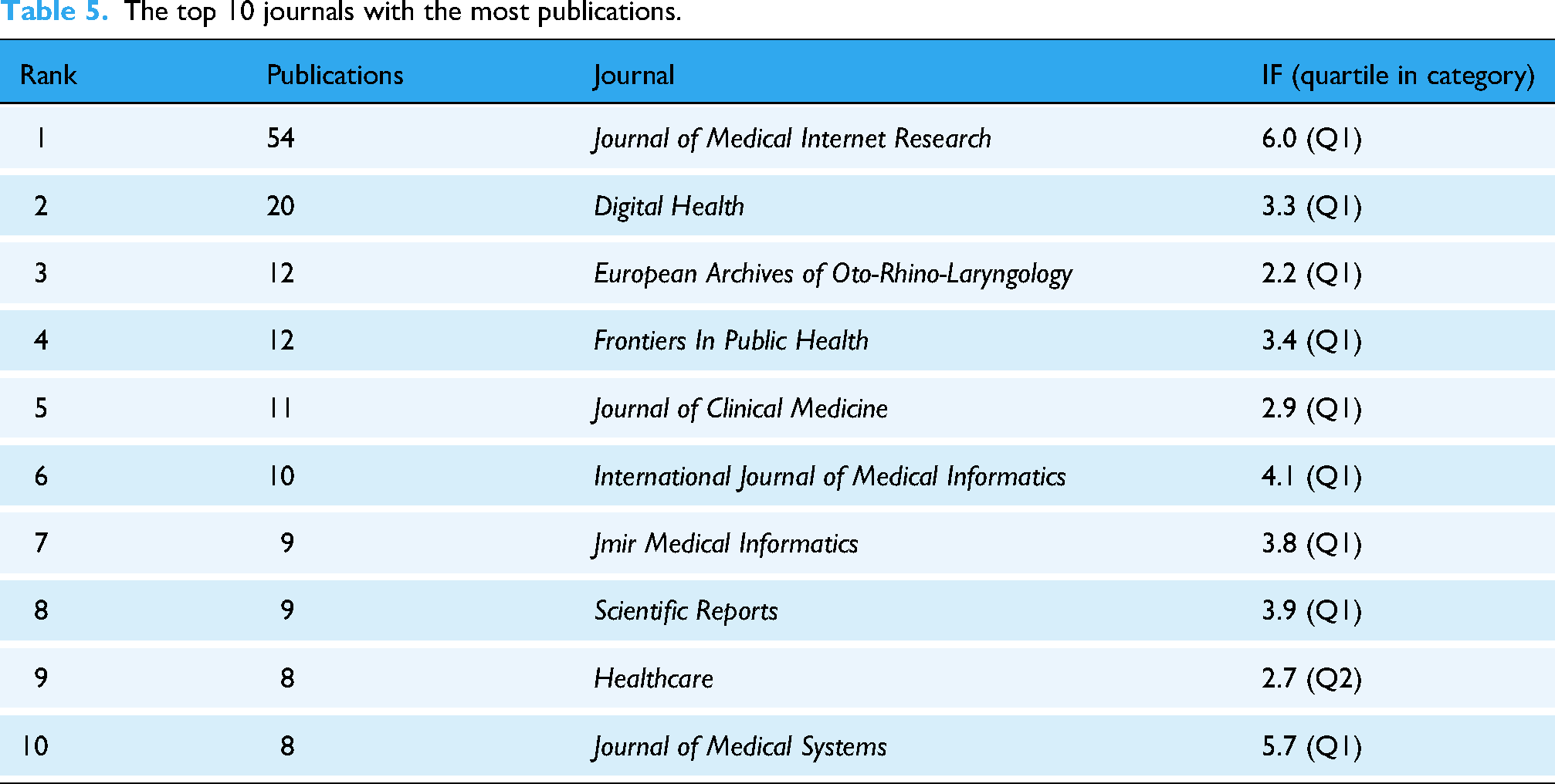
Core journal analysis (Table 5) shows that the Journal of Medical Internet Research ranked first with 54 publications, followed by Digital Health (20 publications) and European Archives of Oto-Rhino-Laryngology (12 publications), among others. The top 10 journals by publication volume collectively published 153 papers (accounting for 18.3% of the total), with an average impact factor of 3.8, and 90% of these journals are in the Q1 quartile. The journal co-citation network (Supplemental Figure 1f) consists of 602 nodes and 1517 links, where J Med Internet Res (cited 393 times) is the most influential knowledge source in the field (Table 6). The dual-map overlay of journals (Supplemental Figure 1g) further reveals the interdisciplinary knowledge flow characteristics of the field. The two main citation paths in the map clearly indicate that current research published in “MEDICINE, MEDICAL, CLINICAL” journals heavily relies on theoretical foundations and knowledge sources from multiple related disciplines such as “HEALTH, NURSING, MEDICINE” and “PSYCHOLOGY, EDUCATION, HEALTH.” This knowledge integration model provides an important reference for new researchers in selecting journals and tracing literature.
The top 10 journals with the most publications.
The top 10 cited journals with the most citation counts and centrality.

Reference and knowledge base evolution
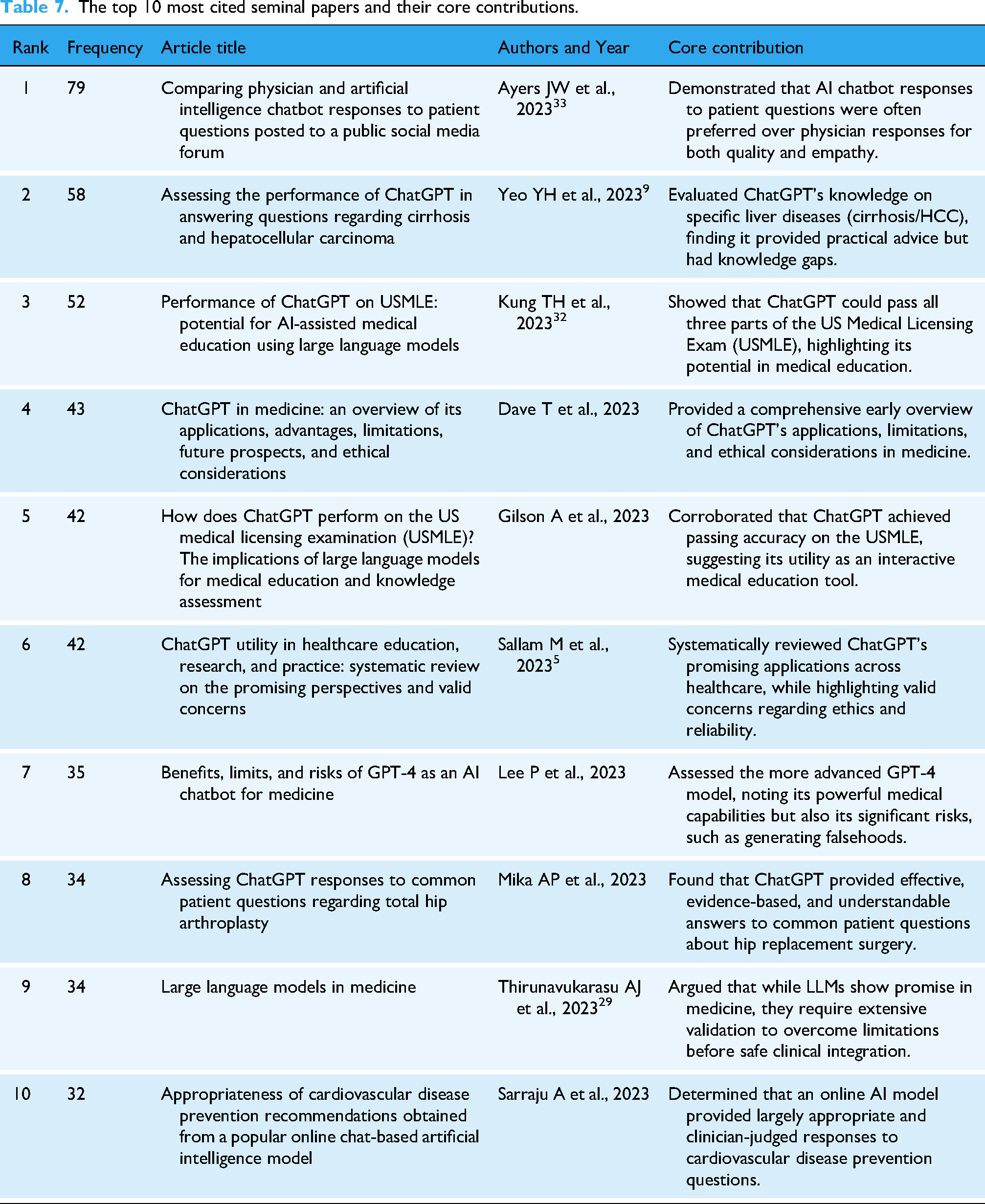
By analyzing the reference co-citation network (Supplemental Figure 2a), the knowledge base of the field can be revealed. This network consists of 562 nodes and 1157 links. The 10 most frequently cited documents, which represent the seminal papers of this field, are detailed in Table 7, with the top three being “Comparing physician and AI chatbot responses…” by Ayers et al. (2023), “Assessing the performance of ChatGPT…” by Yeo et al. (2023), and “Performance of ChatGPT on United States Medical Licensing Examination (USMLE)…” by Kung et al. (2023). Citation burst analysis further identified landmark key literature (Supplemental Figure 2b). The results show that the evolution of the research frontier in this field exhibits a significant acceleration trend. The earliest citation burst began in 2017 (Rusk N., 2016), 24 but the vast majority (7/10) of key literature bursts are concentrated in 2022–2023. Particularly in 2023, as many as five burst documents emerged, 11 25–28 and their influence is ongoing (burst period extends to 2025), marking a period of unprecedented activity and rapid development for this research area. The timeline map of reference clusters (Supplemental Figure 2c) reveals the evolutionary trajectory of research themes. The early foundation of research (cool-toned areas) was mainly built on fields like “public health informatics (#10),” whereas in recent years, the research frontier (characterized by red citation bursts) has significantly shifted towards next-generation AI technologies represented by “generative pre-trained transformer (#5)” and “Gemini (#0),” and their application in specific clinical scenarios such as “informed consent (#2).”
The top 10 most cited seminal papers and their core contributions.
Keyword and research hotspot evolution
High-frequency keyword and burst keyword analysis reveal the research hotspots and emerging trends in the field. The keyword co-occurrence network consists of 394 nodes and 1080 links (Supplemental Figure 2d). In addition to “AI” and “patient education materials,” “large language models,” “health literacy,” and “machine learning” are important research hotspots (Table 8). Keyword cluster analysis identified 13 major research clusters (Supplemental Figure 2e), with the largest including #0 patient information, #1 digital health, #2 machine learning, #3 readability, and #4 health literacy, which together form the core knowledge structure of the field. The keyword timezone view (Supplemental Figure 2f) dynamically illustrates a clear shift in research focus: in the early phase of research (approx. 2016–2020), discussions primarily revolved around foundational topics such as “health literacy” and “deep learning”; whereas recently (2021 to present), research hotspots have rapidly shifted to applied themes like the effective delivery of “health information,” the design of “intervention” measures, and addressing “challenges” in practice. Keyword citation burst analysis (Supplemental Figure 2g) further confirms a significant shift in research hotspots since 2021, with the emergence of several new burst words including “prediction,” “adherence,” “quality of life,” and “digital health,” indicating that the research focus has moved from early basic technology discussions to a greater concern for patient outcomes and clinical applications.
The top 10 keywords with the most citation count and centrality.

Thematic structure and evolutionary path
To systematically reveal the thematic structure of the discipline, this study constructed a strategic diagram (Figure 3(a)), which divides core themes into four quadrants based on the two dimensions of centrality and density. Centrality represents the pivotal status of a theme in the disciplinary network, while density reflects its developmental maturity. The first quadrant (high centrality-high maturity) represents “core-driving themes” that reflect mainstream research directions; the second quadrant (low centrality-high maturity) refers to “specialized-niche themes” with independent, mature research systems; the third quadrant (low centrality-low maturity) corresponds to “emerging/declining themes,” and the fourth quadrant (high centrality-low maturity) highlights “foundational themes” that require in-depth exploration. Building on this, the thematic evolution analysis (Figure 3(b)) divides the research progress into three distinct stages: the Foundational and Exploratory Period (2016–2021), the Developmental and Differentiating Period (2022–2023), and the Emerging Development Period (2024–2025). The research trajectory shows that themes evolved from early macro-level concept exploration (such as “AI,” “communication”) and specific disease applications (such as “surgery”), to a mid-term focus on evaluating the “performance” of technology and the “quality” of services. Finally, in the emerging stage, the focus has shifted to more specific and challenging issues, such as patient “adherence” management, “system” construction, and addressing practical “challenges.”

(a) The strategy map of identified topics clustered by keywords plus. (b) Thematic Evolution of artificial intelligence in patient education research from 2016 to 2025.
Discussion
Through bibliometric methods, this study has, for the first time, comprehensively and systematically mapped the global research landscape, knowledge structure, and evolutionary trajectory of AI in the field of patient education over the past decade. Our analysis reveals an emerging field characterized by explosive growth, rapid iteration of research focus, and significant interdisciplinary features.
General trends and thematic evolution
One of the most significant findings of this study is the exponential growth in the literature output of this field, especially after 2021. The annual number of publications surged from an average of fewer than 30 before 2020 to several hundred per year recently, clearly indicating that the intersection of AI and patient education has rapidly evolved from a marginal exploratory direction to a prominent mainstream research hotspot. This timing highly coincides with the public release and widespread application of LLMs, particularly ChatGPT. 29 Before the advent of ChatGPT, research in this area was more sporadic and technology-driven, mainly focusing on specific application scenarios of traditional machine learning, NLP, and virtual reality. 30 The emergence of ChatGPT, especially GPT-4 with its unprecedented natural language interaction capabilities and content generation efficiency, significantly lowered the technical barrier, enabling clinicians and education researchers without a computer science background to easily explore the potential of AI in patient education, thus contributing to an explosion in research activities.31,32 As shown by the co-citation analysis of references, papers on ChatGPT performance evaluation published by Ayers et al., Yeo et al., and Kung et al. in 2023 quickly became the most cited foundational literature.9,32,33 While this strongly suggests that generative AI, represented by ChatGPT, was a significant contributing factor that helped ignite research enthusiasm in this field, we acknowledge that this exponential trend is likely multifactorial. Other contributing factors, such as increased government and private-sector funding for AI in healthcare, 34 new digital health policies aimed at technology integration, 35 and significant global media hype surrounding generative AI, 36 have likely synergized to accelerate research in this domain. A full quantitative analysis of these economic and policy drivers is beyond the scope of this bibliometric study, but it represents a critical and necessary avenue for future research to fully disentangle the dynamics of this field.
Our thematic evolution analysis clearly divides this development into three stages: the Foundational and Exploratory Period (2016–2021), the Developmental and Differentiating Period (2022–2023), and the Emerging Development Period (2024–2025). This division accurately captures the dynamic evolution of the research focus. In the foundational and exploratory period, the core of the research was to verify the feasibility of applying AI technology in the medical field, with keywords such as “AI,” “communication,” and “surgery” reflecting the initial attempts by researchers to introduce AI as a new communication or diagnostic support tool in clinical practice. Entering the developmental and differentiating period, as technology matured, the focus of research shifted to evaluating the “performance” and “quality” of AI systems. Research in this stage, as described in the review by Aydin et al., was dedicated to answering fundamental questions about whether AI-generated content is accurate, reliable, and readable. 7 The current emerging development period marks the maturation of the field. The emergence of keywords “adherence,” “system,” and “challenges” indicates that research has moved beyond simple technical evaluation to deeply explore how to systematically integrate AI into healthcare service workflows, how to use AI to improve patients’ long-term health behaviors (such as treatment adherence), and the complex ethical, bias, and safety challenges faced in real-world applications. This evolutionary path is consistent with the macro-analysis of AI development in the entire medical field by Dalky et al., which follows a maturation path from technical feasibility verification, to performance optimization, and then to systematic integration and ethical reflection. 37
Global research landscape and collaboration networks
This study reveals the absolute leadership of the USA and China in this field, with the two countries contributing over half of the literature output. This reflects their strong technological prowess and substantial research investment in the field of AI. Top academic institutions, represented by Harvard University and the University of California System, form the core research force. However, a phenomenon worthy of deep consideration is that although the USA and China dominate in output, they did not rank in the top five on the centrality metric, which measures international collaboration and influence. This may indicate that the research in these two countries has largely formed relatively independent “self-contained” research ecosystems dominated by domestic collaboration. In contrast, some European countries (like Italy and the UK) and Middle Eastern countries (like Qatar), despite having lower output than the US and China, play more critical “bridging” roles in the international collaboration network. Qatar, in particular, with its extremely high centrality score, suggests it may be a significant international academic exchange hub, connecting research forces from different regions. This asymmetry between “output” and “influence” suggests that future research needs to strengthen global collaboration, especially promoting the deep integration of the two major research engines, the US and China, with the research networks of other countries to avoid forming academic silos and to jointly address the global challenges AI faces in the medical field.
Core authors and academic networks
The group of high-output authors identified in this study has not only led the field's development in terms of quantity but has also made key contributions to its research directions. Their work has deepened our understanding of the application of AI in patient education from various dimensions. For example, high-output author Xie, Wenxiu and her team focus on developing explainable machine learning algorithms, using natural language features to predict and evaluate the communication effectiveness and readability of online health information (such as child health and mental health resources), providing new tools for the automated assessment of the quality of health education materials38–40 The research of Balyan, Renu et al. focuses on using NLP techniques to analyze safety information between physicians and patients, developing “literacy profiles” that can automatically assess patient health literacy. This non-invasive method opens up new avenues for identifying and assisting large groups of patients with low health literacy on a large scale41–43 Meanwhile, other core authors are dedicated to evaluating and applying the latest generative AI technologies. Cacciamani, Giovanni E. and Ganjavi, Conner, and other scholars have done pioneering work in urologic oncology, systematically evaluating the capability of generative AI, represented by GPT-4, in producing patient education materials that are compliant with the latest clinical guidelines and possess both accuracy and readability. They have validated its application value from the perspectives of both clinicians and the public.44,45 The research team of Erdemir, Ismail conducted a horizontal comparison of the Q&A performance of several mainstream AI chatbots (such as ChatGPT, Bard, Gemini) on key medical topics like cardiopulmonary resuscitation and palliative care, with a focus on evaluating the quality, reliability, and readability of the generated content, providing empirical evidence for the clinical selection and use of these tools.46,47 Karabacak, Mert et al. developed machine learning models to predict postoperative outcomes and wrote a scoping review that systematically summarized six major application themes of large language models in patient education, including generating educational materials, interpreting medical information, and optimizing physician-patient interactions, providing a macro perspective on the application landscape of the field.7,48 The research of these core authors has collectively propelled the field's in-depth development from theoretical exploration to clinical application, and from single-technology evaluation to multi-dimensional system integration.
Knowledge base and interdisciplinary flow
The dual-map overlay of journals clearly demonstrates the significant interdisciplinary knowledge flow characteristic of this field. The main flow of knowledge is from journals in the “Medicine, Medical, Clinical” and “Psychology, Education, Health” domains, converging into journals in the “Health, Nursing, Medicine” domain. This finding has profound implications. It indicates that the application of AI in patient education is by no means a purely technical issue, but a complex systems engineering that deeply integrates knowledge from multiple disciplines, including medicine, computer science, education, psychology, and communication science. Clinical medicine provides the application scenarios and professional knowledge; psychology and education provide the theoretical basis and methodologies for how to effectively deliver information and change patient behavior; and computer science provides the technological tools to achieve all this. As emphasized in the research by Lyu et al., achieving “trustworthy patient education” requires a multi-faceted ecosystem engineering. 49 Our analysis provides strong bibliometric evidence for this viewpoint. The Journal of Medical Internet Research becoming the journal with the highest publication volume and citation frequency also confirms the field's identity as a core component of Digital Health. This interdisciplinary nature places higher demands on future researchers and practitioners: they not only need to understand AI technology but also need to possess the ability to integrate knowledge across fields, enabling them to design and evaluate AI educational tools from the perspective of the patient's cognitive, psychological, and behavioral levels.
Research hotspots and frontier trends
Keyword analysis is a powerful tool for gaining insight into research hotspots and frontier trends. Our analysis reveals a clear shift in research focus from being technology-centric to patient-centric. The 13 major research clusters identified by keyword cluster analysis further detail this macro trend. The five largest clusters—#0 patient information, #1 digital health, #2 machine learning, #3 readability, and #4 health literacy—collectively delineate the core issues of the field: using digital health technologies, represented by machine learning, to process patient information, with the core objective of enhancing the readability of information to ultimately empower patients and improve their health literacy.
To provide deeper contextual interpretation, these clusters link directly to patient outcomes and education practice. For example, Cluster #3 “readability” and Cluster #4 “health literacy” are foundational, as low health literacy is a well-established barrier to patient engagement and positive health outcomes. The field's focus here reflects a practical need to solve the long-standing problem of overly complex patient materials. Furthermore, the emergence of “adherence” and “quality of life” as top burst keywords signals a critical and recent shift away from validating the technology itself (e.g., “machine learning “) and toward measuring patient-centric outcomes. This suggests the field is maturing, moving from the question “Can AI write patient education?” to the more important question, “Can AI-driven patient education, by improving comprehension and personalization, actually improve a patient's treatment adherence and overall quality of life?”
This transition from technology-centric validation to patient-centric outcomes is the most significant thematic shift identified in our analysis, and this focus on readability is highly consistent with the conclusions of a systematic review by Nasra et al., who pointed out that improving the readability of patient education materials is one of the core goals of current AI application research, but it also faces challenges of accuracy and reliability. 2 This critical trade-off is powerfully demonstrated by recent empirical research. For instance, a study by Abdelgadir et al. found that while ChatGPT could significantly enhance the readability of patient education materials regarding glomerular disease treatment options, this improvement came at the expense of content comprehensiveness and accuracy. 50 This finding highlights the complex tension between simplifying information and maintaining medical rigor, underscoring the necessity of a careful balance. Looking forward, the timeline map of reference clusters more forward-lookingly points to future research directions. The new generation of AI technologies, represented by GPT and Gemini, has become the undisputed research frontier. At the same time, the emergence of “informed consent” as a new cluster predicts that as AI plays an increasingly important role in physician-patient communication, how to use AI to assist patients in understanding complex medical information, making informed medical decisions, and the related ethical and legal issues will become important topics for future research. The study by Malerbi et al. also emphasized the importance of digital health education for healthcare professionals and patients to ensure that AI technology can be deployed safely and ethically. 3
Contextualizing the field: distinctions from related domains
Our bibliometric findings gain sharper focus when contextualized against the related, yet distinct, domains of AI in clinical education and the foundational concept of digital literacy.
First, AI in clinical education targets medical professionals and trainees (e.g., medical students, residents), whereas our field of study targets laypersons (patients and the public). This fundamental difference in audience dictates entirely different objectives. As our co-citation analysis revealed, the goal of clinical education AI is often to enhance diagnostic acumen, procedural skill, or mastery of complex knowledge (e.g., performance on the USMLE). 32 In stark contrast, our core keyword clusters—such as “#3 readability” and “#4 health literacy"—demonstrate that the primary goal of AI in patient education is the simplification of complex medical information, enhancement of understanding, and the promotion of behavior change (e.g., “adherence,” a top burst keyword) to support shared decision-making.
Second, digital literacy is not a parallel field but a foundational prerequisite for the effective deployment of all digital health interventions, including AI in patient education. 51 An AI chatbot, no matter how accurate or empathetic, is rendered ineffective if the target patient lacks the basic digital literacy to access or interact with it. This fundamental dependency is reflected in our thematic evolution map, where “challenges” and concerns for equity have emerged as key research frontiers. These “challenges” are inextricably linked to the “digital divide” and the baseline digital literacy of the target population, which will determine whether these advanced AI tools narrow or widen health disparities.
Connecting trends to theoretical frameworks
In order to move beyond a purely descriptive analysis of the bibliometric data, we contextualized our findings within established conceptual frameworks. This methodology imbues the analysis with deeper explanatory power, revealing that the identified trends are not isolated phenomena but are instead reflective of wider macro-dynamic patterns, such as technology adoption and health communication.
First, the prominence of the “#4 health literacy” and “#3 readability” clusters aligns directly with established Health Literacy Frameworks (e.g., Nutbeam 52 ; Sørensen et al. 53 ). These frameworks posit that health literacy is a multi-dimensional construct involving not just access to information, but also the cognitive skills to understand, appraise, and apply it. Our findings show the research field is leveraging AI to move beyond simple information access. The focus on “readability” and “plain language” (as seen in the “patient information” #0 cluster) is a direct attempt to use AI to solve the “understanding” barrier, which is a core component of functional health literacy.
Second, the thematic evolution from foundational concepts (“machine learning”) to applied outcomes (“adherence,” “quality of life”) mirrors the components of the Technology Acceptance Model (TAM). 54 TAM suggests that user acceptance is driven by Perceived Usefulness (PU) and Perceived Ease of Use (PEU). The early research (pre-2021) focused on proving the technology's ‘PEU’ (e.g., Can AI even write accurate medical text?). However, the recent explosion of burst keywords like “adherence” and “quality of life” signals a critical shift to proving ‘PU’ (e.g., Does this tool actually improve patient outcomes?). This TAM perspective highlights that the field's survival depends on demonstrating clinical value, not just technical feasibility.
Finally, the exponential growth pattern itself can be interpreted through Rogers’ Diffusion of Innovations theory. 55 The pre-2021 period represents the “Innovators” and “Early Adopters” (e.g., computer scientists, informatics specialists). The release of accessible LLMs (like ChatGPT) acted as a critical tipping point, lowering the barrier to entry and triggering the “Early Majority” phase, which is exactly what our post-2021 growth data reflects. This theory helps explain the speed of the trend and predicts that the field will now face the challenges of mainstream adoption, such as system integration (“system” and “challenges” are emerging keywords) and managing “late majority” adoption.
By situating our findings within these frameworks, we can interpret the bibliometric map not just as a static snapshot, but as a dynamic reflection of the field's maturation along established pathways of health innovation and technology acceptance.
Strengths and limitations
As the first bibliometric analysis in this field, the main strength of this study lies in its objective and comprehensive revelation of the global research landscape, knowledge structure, and evolutionary patterns. By using various visualization tools like CiteSpace and RStudio, we were able to systematically map the complex academic network from multiple dimensions (authors, countries, journals, keywords, references), providing a clear knowledge map and directional guidance for future research.
However, this study also has inherent limitations. First, bibliometric analysis is essentially a quantitative study; it can reveal “what” (the trends) but struggles to deeply explain “why” (the causal drivers). For example, while we observe an exponential publication growth strongly coinciding with the release of LLMs, we cannot, from this data alone, disambiguate its causal role from other powerful, concurrent factors such as shifts in research funding, new governmental policy initiatives, or intense media hype. Our study identifies the trend, but a dedicated health policy or economic analysis would be required to rigorously validate these causal relationships. The underlying social, technological, funding, media, and policy drivers therefore require dedicated future research. Second, this study is limited by its data source strategy. Our selection of the WOSCC as the sole data source inevitably leads to the omission of potentially relevant literature from other databases, particularly journal articles that may be indexed in PubMed or Embase but not in WOSCC. Consequently, the knowledge map constructed in this study primarily reflects the academic landscape within WOSCC-indexed literature, and its comprehensiveness is constrained by this retrieval strategy. Future research should explore methodological innovations to attempt data fusion from multiple databases, including PubMed and Embase, to construct a more comprehensive and unbiased knowledge map of the field. Third, analytical metrics (such as citation counts, centrality) have a certain time lag. High-quality literature published recently may not have received sufficient citations due to its short publication time, and its academic influence may be underestimated. Finally, this analysis focuses on the external characteristics of the literature and cannot conduct an in-depth evaluation of the research quality, methodological rigor, and reliability of the conclusions of individual papers. Therefore, the conclusions of this study should be regarded as a depiction of the macro trends in the field, rather than a quality judgment on specific research content.
Conclusion
In summary, this study, through bibliometric analysis, has systematically depicted the knowledge landscape of the emerging interdisciplinary field of AI in patient education. Our findings indicate that, driven by LLMs, the field is experiencing unprecedented high-speed development. The research focus has deepened from early technological feasibility validation to a concern for clinical application effects, patient-centered outcomes, and the challenges of systematic integration. The global research landscape is dominated by the USA and China, but the breadth and depth of international collaboration still need to be strengthened. The interdisciplinary nature of knowledge flow highlights the importance of integrating knowledge from medicine, computer science, and social sciences.
Looking ahead, and based on our bibliometric findings, the future roadmap (2025–2030) for AI in patient education must move beyond simple accuracy checks to establish standardized, robust validation frameworks. Future research should prioritize real-world clinical trials to evaluate not just content reliability, but the long-term impact on patient behaviors and health outcomes. This includes developing regulatory policies for the seamless and safe integration of these tools into clinical workflows. In parallel, as our analysis of emerging ‘challenges’ suggests, active health equity strategies are critical. The next research phase must pivot from observation to action to mitigate bias and ensure AI tools do not widen the digital divide, ensuring accessibility for populations with low digital literacy or disabilities. Furthermore, while current research is dominated by text-based LLMs, the future lies in multimodal AI. We anticipate a research boom in systems that combine text, voice, and images to create more engaging, accessible, and personalized educational experiences, such as interactive avatars that can verbally explain complex procedures. Ultimately, the future of AI in patient education will depend on our ability to find the optimal balance between technological innovation and humanistic care, ensuring that technology truly serves the ultimate goal of enhancing physician-patient trust and improving health literacy for all.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251406653 - Supplemental material for The evolving landscape of artificial intelligence in patient education: A bibliometric knowledge mapping study
Supplemental material, sj-docx-1-dhj-10.1177_20552076251406653 for The evolving landscape of artificial intelligence in patient education: A bibliometric knowledge mapping study by Jingyu Zhou, Wei Zhang and Shichao Liu in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251406653 - Supplemental material for The evolving landscape of artificial intelligence in patient education: A bibliometric knowledge mapping study
Supplemental material, sj-docx-2-dhj-10.1177_20552076251406653 for The evolving landscape of artificial intelligence in patient education: A bibliometric knowledge mapping study by Jingyu Zhou, Wei Zhang and Shichao Liu in DIGITAL HEALTH
Footnotes
Abbreviations
Ethical considerations
Ethics committee approval was not required because this study was a retrospective bibliometric analysis of existing published studies.
Author contributions
Wei Zhang is the co-first author. Jingyu Zhou and Wei Zhang have contributed equally to this study. All authors contributed to the study conception and design. Material preparation, data collection, and analysis were performed by Wei Zhang and Jingyu Zhou. The first draft of the manuscript was written by Jingyu Zhou and all authors commented on previous versions of the manuscript. Shichao Liu critically revised the work. All authors read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
The cleaned dataset, comprehensive search strategy, and high-resolution network visualizations generated during this study have been deposited in a public repository (Zenodo) and are available at the following DOI: 10.5281/zenodo.17548444. This ensures full reproducibility of our findings.
Guarantor
Shichao Liu, the corresponding author, accepts full responsibility for the work and/or the conduct of the study, had access to the data, and controlled the decision to publish.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.