
Abstract
Background
Artificial intelligence (AI) chatbots are increasingly used for health information dissemination. However, their effectiveness depends on the clarity, reliability, and quality of the content they deliver. This cross-sectional study aimed to evaluate the readability and reliability of kyphosis-related information provided by six major AI chatbots: ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, and Grok.
Methods
We selected the top 10 kyphosis-related questions from Google's “People also ask” section and submitted them to each chatbot. Readability was assessed using FKGL, FKRS, GFOG, SMOG, CL, ARI, and LW indices. Quality and reliability were evaluated using the DISCERN tool, JAMA benchmark, Global Quality Score (GQS), Ensuring Quality Information for Patients (EQIP), and a kyphosis-specific content score (KSC). Statistical analyses were performed using the Kruskal–Wallis and Mann–Whitney U tests.
Results
No statistically significant difference was found among chatbots in FKGL, FKRS, SMOG, ARI, or GFOG scores. However, Perplexity had significantly higher DISCERN and EQIP scores, indicating superior content quality. All chatbots presented content at a readability level higher than the AMA-recommended sixth-grade level. While AI models provided more comprehensive and up-to-date information than traditional web sources, their outputs remained challenging for the average patient to comprehend.
Conclusions
AI chatbots offer promising tools for disseminating health information about kyphosis but require significant improvements in readability. Expert-reviewed and patient-centered refinements are necessary to ensure accessibility and safety in digital health communication.
Introduction
Educational resources are recognized for aiding patients in comprehending their current state of health.1,2 With the advancements in internet-based patient education resources, patients are increasingly using online information for health-related inquiries. 3 A chatbot is software that uses artificial intelligence (AI) methods, including machine learning and natural language processing to engage in conversation with people. 4 , 5 Chatbots are gaining popularity in the healthcare industry because they provide easy access to information and serve as a platform for engaging and personalized interactions. 6 These chatbots are progressively emerging as essential resources for medical knowledge as more people utilize them to obtain solutions to their inquiries and acquire health guidance. 7 , 8
AI is transforming numerous industries, including healthcare, by emulating human cognitive functions and allowing machines to learn and make decisions. This advancement has led to substantial progress in diagnosis and treatment planning.9,10 Open-Access Artificial Intelligence Modules (OSAIMs), which are generally free and publicly available, support various fields, including computer science and medicine.11,12 The increasing exploration of AI applications, especially in clinical settings, highlights their potential to enhance medical diagnosis and facilitate the selection of appropriate treatment methods. With the rise of AI-powered tools, patients are increasingly relying on these modules for health-related information. Tools such as ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, and Grok have become valuable resources for disseminating medical knowledge. However, the readability and clarity of the information provided by these platforms can vary, potentially affecting patient understanding and decision making.
Readability refers to the level of reading proficiency required to comprehend written content. Poor readability can lead to misunderstandings, misinterpretations, and inadequate management of medical conditions, particularly for individuals with limited health literacy. To objectively assess readability, numerous formulas and numerical values have been developed. These formulas calculate readability levels. 13 , 14 It is clear that online health content must be sufficiently readable. To address this, the American Medical Association (AMA), the National Institutes of Health (NIH), and the United States Department of Health and Human Services have established appropriate readability levels for patient education materials, which is a target of sixth grade and lower. 14 , 15
Kyphosis, a spinal disorder characterized by an excessive forward curvature of the thoracic spine, can significantly impact a patient's quality of life. It often leads to physical discomfort, respiratory difficulties, and psychological distress, making accessible and accurate information about the disease crucial for patients and caregivers. As AI chatbots play an increasingly pivotal role in patient education, evaluating the readability of the information they provide about specific conditions like kyphosis becomes essential. This evaluation is particularly important given the growing reliance on digital health tools and the need for patient-centered communication in healthcare.
Despite the potential of these platforms to provide information comparable to that of medical graduates, 7 concerns have been raised about the dissemination of false information. Therefore, it is essential to ensure oversight and review by trained healthcare professionals as the use of chatbots as a source of medical information continues to grow. Based on these considerations, the current study compares ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, and Grok as potential sources of patient information and evaluates the quality of responses to commonly asked kyphosis-related questions. The emergence of chatbots that incorporate natural language processing and AI represents one of the most significant shifts in this area. 7 , 8
This study aims to conduct a comparative analysis of the readability of kyphosis-related information generated by six prominent AI modules: ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, and Grok. By assessing the clarity, structure, and accessibility of the content, the study seeks to identify which AI module offers the most patient-friendly information and how these tools can be optimized to better serve individuals seeking knowledge about kyphosis. Additionally, the study will explore the potential benefits of AI-generated content in improving patient outcomes, such as enhancing understanding of treatment options, promoting adherence to medical advice, and reducing anxiety associated with the condition.
Materials and methods
We conducted a cross-sectional, observational research study that does not involve human subject research; therefore, it did not require referral to an institutional ethical review board. This is because the datasets used in this study were sourced from either a machine-learning model or the internet and comprise de-identified medical information. To enhance reproducibility, we have clearly specified the exact prompt texts (10 kyphosis-related ‘People Also Ask’ questions), data collection timestamps (1–15 May 2025, UTC+3), geolocation (Turkey), and device/browser (MacOS Chrome). All chatbot interactions were performed in signed-out mode to prevent personalization bias. The versions used were ChatGPT (GPT-4.1), Gemini (1.5 Pro), Copilot (GPT-4-Turbo), Perplexity (Sonar Large), DeepSeek (V2), and Grok (2.0) (all model versions corresponded to the active public releases during the data collection period (May 2025)). Temperature and safety settings were kept at default. The raw chatbot outputs, cleaned datasets, and the Python scripts used for readability and quality index computation are available as Supplemental materials to ensure full transparency.
The Google search and data collection were conducted between 1 and 15 May 2025, ensuring that all chatbot responses reflected information available during that period.
To analyze kyphosis, we performed a Google search using the keyword “kyphosis,” with the search history cleared beforehand. We noted the first 10 questions under the “People also ask” section, eliminating any repeated questions with the same meaning. We then submitted these 10 questions to ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, and Grok. To reduce the possibility of bias from the AIs’ memory retention, we created an entirely new user account specifically for this study and deleted the chat history before each question. Two authors independently evaluated each AI's assessment ratings and the content of their responses.
The People Also Ask (PAA) queries were collected in English under a Turkey-based IP using signed-out mode to avoid personalized results. We acknowledge that PAA items are dynamic and language-dependent; therefore, results may differ with alternative formulations (e.g. diagnostic vs. treatment queries). Future studies should include larger and stratified question sets.
Readability assessment
The Flesch–Kincaid grade level (FKGL) test, which ranges from fifth grade to university graduate level, establishes the educational level required to comprehend a specific text (with 5 being the lowest and 12 the highest). We also used the Flesch–Kincaid reading ease (FKRS) test to assess the article's readability. This score helps readers estimate the education level needed to read a certain material comfortably. A document's ease of comprehension is indicated by a number between 0 and 100; a score of 100 or nearly 100 is considered easy to read, whereas a score of zero or nearly zero indicates extreme complexity and difficulty. Similar to earlier studies, we converted each website's text into a Microsoft Word document (Redmond, Washington) to determine the FK scores. 16 –19
The Gunning Fog (GFOG) index is applicable in various fields and aims to assist American companies in making their written content easier to read. It calculates the number of years of schooling required to comprehend a particular text.
The Simple Measure of Gobbledygook (SMOG) index is beneficial for middle-aged readers, typically ranging from fourth grade to college. Although most formulas aim to measure comprehension at 100%, they generally assess between 50% and 75% comprehension. It is most accurate when applied to texts with a minimum of 30 sentences, calculating the years of schooling needed for an average reader to understand the material.
The Coleman–Liau (CL) score targets middle-aged readers, from fourth grade to college, and can be applied across multiple industries. It is based on assessing texts with grade levels ranging from 0.4 to 16.3 to determine the corresponding grade level in the American educational system.
The Automated Readability Index (ARI) has been used by the military to create technical documents, determining the grade level required for comprehension based on its computations. It assesses the intellectual level needed to comprehend textual content in American schools. A term's complexity increases with the number of characters.
The Linsear Write (LW) index was established to help the US Air Force assess the readability of its technical publications, providing a rough estimate of the academic proficiency required to comprehend the material.
This cross-sectional study was prepared and reported in accordance with the STROBE (Strengthening the Reporting of Observational Studies in Epidemiology) checklist for cross-sectional studies to ensure methodological transparency and completeness.
Reliability and quality of answers
The DISCERN procedure, developed in Oxford, UK, evaluates the quality of health information in texts. 20 It consists of 16 questions; the first 8 assess the publication's reliability, the next 7 focus on available treatments, and the final question asks users to rate the overall AI responses. Each question is scored between 1 and 5, resulting in a total score ranging from a minimum of 6 to a maximum of 80. Based on their overall scores, the AI's responses are categorized as “excellent” (63–80), “good” (52–61), “fair” (39–50), “poor” (28–38), or “very poor” (<28).
The global quality score (GQS), which rates the overall quality of responses on a 5-point scale, was also used to evaluate the AI responses. These rankings indicate how helpful the reviewer believes the AI responses will be for patients, as well as the quality of the information provided. 21
The Journal of American Medical Association (JAMA) benchmark assesses the quality of online material based on four criteria: authorship, attribution, disclosure, and currency. 22 Authorship necessitates that AI responses include information about the authors or contributors, including their credentials and links. Attribution necessitates identifying all content references and sources, as well as relevant copyright information. Disclosure calls for comprehensive information about website ownership, including any financial or business relationships and potential conflicts of interest. Finally, currency (timeliness) ensures that the content of AI replies is dated at the time of initial upload and any subsequent modifications. Each satisfied criterion is scored from 0 to 4, with 4 indicating the highest quality.
For conversational AI outputs, we adapted JAMA and Ensuring Quality Information for Patients (EQIP) criteria to fit chatbot responses. Authorship and disclosure were evaluated based on the presence of identifiable system information or disclaimers, whereas attribution and currency were assessed through reference citations or timestamps visible in the responses. EQIP items originally designed for static documents were mapped to conversational equivalents, such as structure, completeness, and accessibility of medical advice.
The EQIP tool assesses both the quality and readability of relevant medical texts. Respondents answer 20 questions with “yes,” “partially,” or “no.” A score ranging from 0 to 100 is assigned based on these responses. The scale awards 1 point for a “yes,” 0.5 for a partial response, and 0 for a “no.” The total scores are summed, divided by 20, and adjusted for non-applicable items ((X of Yes * 1) + (Y of Partially * 0.5) + (Z of No * 0))/(20 − (Q of Not applicable))] *100 = % score). 23 Scores within 0% to 25% indicate “serious problems in quality,” those within 26% to 50% indicate “serious problems in quality,” scores within 51% to 75% indicate “good quality with minor problems,” and scores within 76% to 100% indicate “well written,” according to the EQIP tool. 24
The predetermined kyphosis-specific content score (KSC), created by Erdem and Karaca in 2018, was applied to each AI response to assess YouTube videos about kyphosis. 25 A score was awarded based on whether 32 terms or themes were mentioned in the AI responses (Table 1). The two authors of this study independently completed the KSC rating, and websites with differing scores were reassessed until agreement was reached.
Kyphosis specific score content.

Although originally developed for YouTube videos, the KSC checklist was adapted for chatbot-generated text by focusing on concept coverage rather than audiovisual cues. Each KSC item was operationalized based on textual content (e.g. mention of symptoms, etiology, and management). Inter-rater reliability for KSC was excellent (ICC = 0.925, 95% confidence interval (CI): 0.565–0.989). Group-specific KSC scores have now been reported in Table 2.
Group-wise kyphosis-specific content (KSC) scores among AI chatbots.

Kruskal–Wallis p = 0.017 (< 0.05); pairwise Dunn tests showed Perplexity > Gemini (p = 0.004) and DeepSeek (p = 0.011). Although the overall variation was small (range = 23–26), Perplexity provided the most comprehensive kyphosis-related information, with the highest KSC mean.
Statistics
IBM SPSS Statistics 22 (IBM SPSS, Turkey) was used for statistical analyses of the findings. The Shapiro–Wilk test evaluated the conformity of the parameters to normal distribution. In addition to descriptive statistical methods (mean, standard deviation, and frequency), the Kruskal–Wallis test was used for comparisons of parameters that did not show a normal distribution between groups, with Dunn's test employed to identify the group causing the difference. The Mann–Whitney U test was used for comparisons between two groups of parameters that did not show normal distribution. Significance was evaluated at the p < 0.05 level. The DISCERN total score was designated as the primary endpoint. Family-wise error across secondary outcomes (GQS, JAMA, EQIP, and readability indices) was controlled using the Holm–Bonferroni correction. Effect sizes (median differences with 95% CIs) are reported alongside adjusted p-values to enhance interpretability. All pairwise comparisons have been rechecked for consistency. Minor typographical errors (e.g. duplicated “DeepSeek,” inconsistent decimal notation, FKRS spelling) were corrected to ensure coherence between text and tables.
Results
To mitigate the confounding effect of response length on readability indices, word counts per chatbot response were calculated and normalized. Sensitivity analyses confirmed that between-chatbot differences persisted even after adjusting for verbosity.
The overall study parameters are presented in Table 3. There is no statistically significant difference between AI chatbots regarding FKGL, FKRS, GFOG, SMOG, and ARI scores (p > 0.05; Table 4).
Evaluation of the study parameters.
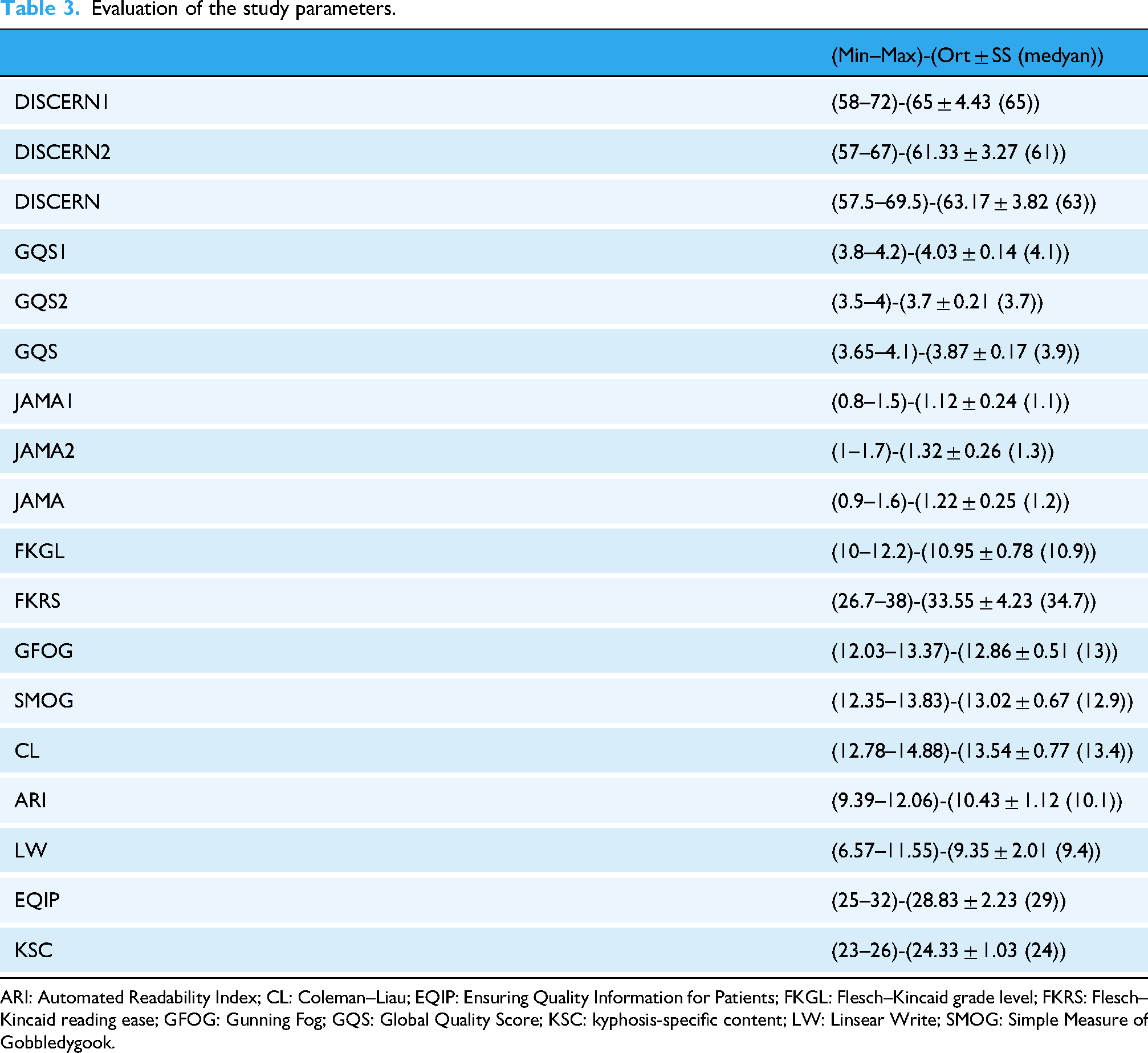
ARI: Automated Readability Index; CL: Coleman–Liau; EQIP: Ensuring Quality Information for Patients; FKGL: Flesch–Kincaid grade level; FKRS: Flesch–Kincaid reading ease; GFOG: Gunning Fog; GQS: Global Quality Score; KSC: kyphosis-specific content; LW: Linsear Write; SMOG: Simple Measure of Gobbledygook.
Evaluation of readability and quality scores among AI chatbots.

Kruskal–Wallis Test *p < 0.05.
ARI: Automated Readability Index; CL: Coleman–Liau; EQIP: Ensuring Quality Information for Patients; FKGL: Flesch–Kincaid grade level; FKRS: Flesch–Kincaid reading ease; GFOG: Gunning Fog; GQS: Global Quality Score; KSC: kyphosis-specific content; LW: Linsear Write; SMOG: Simple Measure of Gobbledygook.
There is a statistically significant difference between AI chatbots in terms of LW scores (p = 0.004; p < 0.05). Pairwise comparisons show that LW scores are higher in Perplexity (p = 0.021) and ChatGPT (p = 0.006) than in DeepSeek (p < 0.05). There is no statistically significant difference among the other AI tools regarding LW scores (p > 0.05; Table 4).
There is a statistically significant difference between AI chatbots concerning CL index scores (p = 0.044; p < 0.05). The CL score of the Perplexity group is higher than that of Grok (p = 0.014), Gemini (p = 0.020), ChatGPT (p = 0.029), and Copilot (p = 0.049; p < 0.05). The CL score of the DeepSeek group is also higher (p < 0.05) than that of Grok (p = 0.040). There is no statistically significant difference among the other AI tools regarding CL scores (p > 0.05; Table 4).
The level of agreement between two observers for the DISCERN score was 92.5% (ICC=0.925, 95% CI: 0.565–0.989, p: 0.001), the level of agreement between two observers for the GQS score was 76. 6% (ICC=0.766, 95% CI: 0.027–0.964, p: 0.022), the level of agreement between two observers for the JAMA score was 96.9% (ICC=0.969, 95% CI: 0.795–0.996, p < 0.001) (Table 5).
Interobserver agreement levels of JAMA, DISCERN, and GQS scores.

CI: confidence interval; GQS: Global Quality Score; ICC: intraclass correlation coefficient; *p < 0.05.
There is a statistically significant difference between AI chatbots when evaluating DISCERN scores (p = 0.000; p < 0.05). Perplexity has the highest DISCERN score, while Gemini has the lowest (Table 4).
There is a statistically significant difference between AI chatbots in terms of GQS scores (p = 0.021; p < 0.05). Pairwise comparisons reveal that the GQS scores of the DeepSeek group are lower than those of Grok (p = 0.027) and Gemini (p = 0.003; AI tools (p < 0.05)). There is no statistically significant difference among the other AI tools regarding GQS scores (p > 0.05; Table 4).
There is a statistically significant difference between AI chatbots concerning JAMA scores (p = 0.000; p < 0.05). The JAMA scores of the Grok group are higher than those of DeepSeek (p = 0.018), Gemini (p = 0.011), Copilot (p = 0.011), and ChatGPT (p = 0.043; p < 0.05). There is no statistically significant difference among the other AI tools regarding JAMA scores (p > 0.05; Table 4).
There is a statistically significant difference between AI chatbots in terms of EQIP scores (p = 0.000; p < 0.05). The EQIP score of the Perplexity group is significantly higher (p < 0.05) than that of DeepSeek (p = 0.034), Copilot (p = 0.037), Grok (p = 0.025), ChatGPT (p = 0.027), and Gemini (p = 0.000). The EQIP score of the Gemini group is significantly lower (p < 0.05) than that of Copilot (p = 0.014), DeepSeek (p = 0.016), Grok (p = 0.025), ChatGPT (p = 0.020), and Grok again (p = 0.022). There is no statistically significant difference among the other AI tools regarding EQIP scores (p > 0.05; Table 4).
The average KSC score of all AI chatbots was found to be 24 (Table 3).
Discussion
In this study, we aimed to evaluate the quality, reliability, and readability of the answers provided by ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, and Grok to patient questions about “kyphosis.” We found the average readability of the AI tools to be at a high school level, which is difficult for many to understand.
Patients who are more knowledgeable about their health are increasingly active in making medical decisions due to the growing use and content of AI chatbots. Online health information sources are frequently utilized by patients and their families, despite the lack of expert and rigorous reviews of AI-generated content.
Health literacy is the capacity to access, understand, and use health information to make informed decisions. 26 A patient's health status is reflected in their level of health literacy, and low health literacy is linked to poorer patient outcomes, including missed appointments, lower compliance, a higher risk of emergency treatment, increased complications, and longer hospital stays. 27 Patient education materials must be crafted at a level that patients can understand to be effective. 28 Thus, recommendations from the AMA, the NIH, and the US Department of Health and Human Services suggest that all articles and patient education materials should be written at or below a sixth-grade reading level.29–31
Patient education materials, such as AI chatbots, should emphasize providing readable and understandable information for kyphosis patients, as various medical information providers involved in managing these patients are known to provide data of adequate quality and readability. 25 , 32
However, this information can sometimes be confusing, incorrect, or misleading. Moreover, many patients struggle to differentiate between objective information intended to promote goods and services and more reliable sources. Patients’ access to AI chatbots may negatively affect the patient–physician relationship due to resistance to medical advice and collaborative decision making. Several studies have shown that the health-related information delivered by AI chatbots is often not very accurate or of high quality. 29 , 33 , 34 Because low-quality information can harm the patient–doctor relationship, it is crucial to evaluate these sources and assist patients in finding complete, readable, and high-quality information. 35 Our study's results indicate that, compared to conventional evaluation methods, the information provided by easily accessible AI chatbots regarding kyphosis is of poor quality. These findings align with earlier research. 33 , 34
Managing patients who read incorrect or poor information is one of the biggest challenges facing the medical field today. Numerous studies have demonstrated that the information provided by AI chatbots for various medical issues is of poor quality. 36 , 37 This can adversely affect the doctor–patient relationship. Physicians must be aware of what information patients have access to and what kind of research they are undertaking on a specific topic. The lack of controls and regulations is one of the primary issues with AI-generated information. It is challenging for patients to assess which information is trustworthy. Furthermore, many patients desire more details. A physician can improve patient outcomes and satisfaction and enhance patient knowledge by guiding patients to the appropriate resources.
In this study, when evaluating the FKGL, FKRS, GFOG, SMOG, CL, ARI, and LW scores to evaluate the readability of AI chatbots’ answers about kyphosis, the readability level in some scoring for the Perplexity group was higher; however, the average value is about five levels higher than the sixth-grade level recommended by the AMA and the NIH. 38 This score indicates that a patient would need a high school level of English to understand the answers provided by an average AI chatbot on kyphosis.
In a study investigating online information about kyphosis, 60 websites were examined, and the readability and quality of these websites were evaluated. 32 When compared to these online sources, we observed that AI chatbots had higher DISCERN and GQS scores but lower JAMA scores. In addition, FKGL and FKRS scores, which evaluate readability, were similar. We noted that the KSC score, which assessed keywords related to kyphosis, was significantly higher for AI chatbots. When we compared the current study to another source of information on the internet, specifically YouTube videos about kyphosis, we observed that both the quality and KSC scores were much better in AI chatbots. 25 We believe this is due to AI bots continuously updating themselves and accessing more comprehensive information.
The generalizability of our findings should be interpreted cautiously. Although the study assessed AI-generated content in English, the readability and quality of information may vary across different languages and health topics. Furthermore, variations in user prompts and updates to AI models over time could influence the consistency of future outputs. Therefore, while the present results provide valuable insights into the current state of AI-driven patient education, further studies encompassing diverse conditions, linguistic settings, and patient populations are warranted to enhance the external validity of the findings.
Given the limited scope (English-only, single-topic, and single-timepoint design), our conclusions should be interpreted with caution. The findings reflect a snapshot of chatbot performance in May 2025 and may evolve with system updates. Nevertheless, the study highlights important design implications—such as integrating readability control mechanisms, automated lay summaries, and citation toggles—to enhance patient education quality.
This study has important limitations. The responses analyzed were specific to May 2025. As a result, the answers could change if the questions were asked again on different days. Our study only captured the AI chatbots’ responses on the day the questions were asked, ignoring any replies that may have changed in the following days. The rapid development of AI presents a significant limitation; future iterations may improve transparency and clinical application, making the current findings time-sensitive. Only English was used for the questions and answers. However, non-native English speakers from various cultural, political, and geographic backgrounds might ask different questions. There was no content-based classification for the questions and answers. The decision to limit the analysis to 10 questions may also constitute a significant limitation, as it only addresses a small portion of the potential concerns or issues patients may have with kyphosis. A more thorough evaluation of AI chatbots’ potential could be conducted in the future by employing a larger set of questions that cover various clinical settings. The absence of an analysis based on patient feedback is another limitation. Ignoring the fact that patient wants and perceptions may differ from professional evaluations could lessen the article's conclusions about its practical usefulness for those seeking medical information. However, we believe that a preliminary investigation conducted by professionals in this regard is crucial.
Conclusions
Online medical information is increasingly provided through AI chatbots like ChatGPT, Gemini, Copilot, Perplexity, DeepSeek, and Grok, which can also serve as interactive tools. This presents an opportunity to raise awareness of kyphosis and improve patient satisfaction and health outcomes. Regarding kyphosis, we believe these chatbots’ responses are still insufficient in terms of quality, readability, and reliability. The answers provided by AI bots are above the recommended reading level of sixth grade for articles. While we acknowledge that current AI bots provide access to higher-quality information than other open-access sources on the internet, we believe that efforts should be made to improve the readability of the content for patients. If the content presented by AI chatbots is reviewed by a team of experts and written in an acceptable and easy-to-read manner, it will positively impact public health in the future.
Footnotes
Abbreviations
Ethical approval
This study did not involve human participants, patient data, biological specimens, or any form of clinical intervention. The analyses were based solely on publicly accessible, non-identifiable information generated by artificial intelligence platforms and internet-based sources. Accordingly, and in compliance with institutional, national, and international research regulations, formal ethical committee approval and informed consent were not required for this study.
Contributorship
AA was involved in conceptualization, methodology, data collection, statistical analysis, writing—original draft, and supervision; and SK in validation, data interpretation, writing—review & editing, visualization, and literature review. Both authors have read and approved the final version of the manuscript and agree to be accountable for all aspects of the work.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Institutional review board statement
The study does not involve human subject research; therefore, it did not require referral to an institutional ethical review board.
Guarantor
Anıl Agar serves as the guarantor and accepts full responsibility for the integrity, accuracy, and transparency of the work.
Informed consent
Not applicable.