
Abstract
Objective
This study aimed to systematically evaluate the performance of three advanced Chinese large language models (LLMs)—DeepSeek-R1, GPT-4o, and Claude-Sonnet-4—in supporting patient education during post-cardiac surgery rehabilitation.
Methods
A total of 35 patient-centered questions were developed based on clinical guidelines, covering five core domains: postoperative care, medication and diet, mental health, complication prevention, and physical activity. Each model was prompted with the same questions five times. Responses were independently assessed by clinical experts for accuracy, completeness, readability (using FRE and FKGL), and reproducibility under repeated prompting. Statistical analyses were conducted using analysis of variance and post-hoc least significant difference (LSD) tests.
Results
DeepSeek-R1 demonstrated the highest overall performance in terms of accuracy (mean score: 4.64) and completeness (4.20), and achieved the highest response stability (85.7%). GPT-4o outperformed the others in readability (FRE: 53.19) and linguistic fluency but showed lower reproducibility (62.9%). Claude-Sonnet-4 showed moderate and variable performance, with limitations in clinical detail. All observed differences were statistically significant (P < 0.05).
Conclusion
DeepSeek-R1 is most suitable for structured, guideline-based rehabilitation education. GPT-4o may be preferable in emotionally supportive or patient-facing scenarios due to its superior readability. Claude-Sonnet-4, while less consistent, may offer stylistic balance in diverse communication settings. Overall, LLMs show promising potential in digital cardiac rehabilitation, but task-specific model alignment remains essential.
Introduction
Artificial intelligence (AI) is increasingly becoming a driving force in transforming and optimizing healthcare systems, with wide applications in disease management, health services, and clinical decision support.1–4 Among its various branches, large language models (LLMs) have begun to reshape how clinical knowledge is accessed, patient communication is conducted, and medical information is disseminated. Built on deep neural network architectures and trained on large-scale medical corpora, LLMs can generate coherent, context-aware, and medically relevant responses in diverse scenarios such as diagnostic dialogues, health consultations, and clinical documentation.5–8 As such, they offer a powerful technological foundation for advancing digital health services.
Recent systematic evaluations have demonstrated both the promise and challenges of LLMs in patient-focused communication. A scoping review by Aydin et al. identified six key themes in LLM applications for patient education, including generating educational materials, interpreting medical information, and providing lifestyle recommendations, with studies showing that LLMs could accurately answer health-related questions over 90% of the time in certain domains. 9 However, domain-specific performance varies considerably—for instance, Zeljkovic et al. found that while ChatGPT-4 achieved perfect scores in lifestyle adjustment queries for atrial fibrillation patients, it struggled with complex medical queries requiring in-depth clinical judgment, highlighting the importance of task-specific evaluation and the need for careful implementation in specialized medical contexts. 10
Among the current state-of-the-art models, Claude-Sonnet-4, GPT-4o, and DeepSeek-R1 stand out for their advanced capabilities and distinct design goals. Claude-Sonnet-4, released by Anthropic on 22 May 2025, represents a significant upgrade to Claude 3.7. 11 It features enhanced reasoning ability and alignment with safety protocols, making it well-suited for high-complexity clinical reasoning and patient-facing tasks. Its improvements in structured decision-making and instruction-following also support clinical utility. GPT-4o, unveiled by OpenAI on 13 May 2024, is the first native multimodal LLM capable of interpreting and generating text, images, and audio simultaneously. Optimized for seamless human-like interactions, GPT-4o facilitates cross-modal and multilingual healthcare communication, making it valuable in diverse care settings.12,13 DeepSeek-R1, launched by DeepSeek AI on 20 January 2025, is a high-performing bilingual (Chinese–English) model designed for both cloud-based and offline deployment. This flexibility enhances its applicability in privacy-sensitive or infrastructure-limited environments. 14 Notably, DeepSeek-R1 achieves GPT-4-level performance in biomedical QA and math reasoning benchmarks and supports private deployment for research and clinical integration.15–17 Its publicly available chatbot, DeepThink, further expands access to cutting-edge LLM technology across user groups. The DeepSeek-R1 model integrates chain-of-thought technology, 18 significantly enhancing the interpretability of its reasoning processes. Interpretability refers to humans’ ability to understand the model's internal mechanisms and output results. 19 This technique enables the model to systematically decompose complex problems, dynamically adjust reasoning strategies, and provide complete thought processes as output, thereby demonstrating enhanced adaptive capabilities and traceability when handling multi-step tasks.
As digital health tools proliferate, approximately two-thirds of U.S. adults now search for health-related information online, with many increasingly turning to AI-driven chatbots for assistance.20,21 In cardiology, a high-stakes field, ensuring the reliability of LLMs is crucial. Preliminary studies show that ChatGPT can correctly answer around 60% of U.S. Medical Licensing Examination questions, meeting the passing threshold. 22 GPT-4o, similarly, has performed well in the 2023 American Society of Nuclear Cardiology board exams. 23 DeepSeek-R1's robust reasoning capabilities further underscore its potential in diagnostic support and clinical decision-making, comparable to OpenAI's top-tier models. Beyond exams, LLMs are now being used to write clinical notes, produce patient education materials, and streamline medical workflows.24,25
LLMs like ChatGPT are also transforming patient education by enabling more personalized, interactive experiences. These models can simulate clinical dialogues, support training through role-play, and adapt to learner needs, thus enhancing communication skills and medical reasoning.26,27 Internationally, the combination of generative AI and virtual reality (VR) is gaining traction in immersive clinical simulations that foster interdisciplinary collaboration.28,29 Recent studies further highlight LLMs’ capabilities in disease triage, with reported accuracy rates generally between 80% and 90%. For instance, ChatGPT has been tested in ophthalmology-related scenarios. In a comparative study involving 80 anonymized ophthalmic case summaries—including anterior segment, glaucoma, pediatric ophthalmology, neuro-ophthalmology, oculoplastic, and retinal disorders—two LLMs, GPT-4 and Bard, were assessed for their triage and diagnostic accuracy based on textual symptom descriptions. 30 Three ophthalmologists independently rated the outputs. GPT-4 achieved a triage accuracy of 96.3%, outperforming Bard's 83.8%. Additionally, GPT-4's responses received significantly higher satisfaction scores from the expert reviewers (81.3% vs 55.0%).
While these findings underscore the practical promise of LLMs in clinical settings, limitations remain. Chief among these are hallucinations—plausible but incorrect outputs—stemming from the self-supervised training of LLMs on large-scale internet data. 31 These hallucinations can be categorized into functional hallucinations (logical but incorrect reasoning) and input hallucinations (fact fabrication). Documented cases include incorrect dosing, outdated treatments, and fabricated citations, which present safety risks. 32 To mitigate these issues, researchers have proposed integrating validated medical knowledge bases, incorporating expert-driven reinforcement learning, and maintaining human oversight. Fine-tuning on high-quality, domain-specific corpora may also enhance reliability in clinical practice.
Cardiovascular diseases (CVD) remain the leading cause of death worldwide. Although the immediate public health impact of the COVID-19 pandemic has abated, cardiovascular mortality—which had declined for years—reversed course in 2020 and remained elevated through 2022. This regression resulted in over 228,000 excess CVD-related deaths, representing a substantial loss of nearly a decade of public health gains. 33 According to the American Heart Association, more than 1.5 million patients undergo cardiac surgery annually in the United States alone. 34 Rehabilitation following surgery is a critical yet complex process that involves medication adherence, lifestyle changes, and regular monitoring. Among postoperative complications, arrhythmias are particularly common and can significantly influence recovery trajectories. 35 Timely detection and management are vital for optimizing outcomes. Moreover, psychological health plays a pivotal role in recovery. Depression not only increases the risk of developing CVD but also adversely affects recovery and long-term prognosis. 36 Despite its significance, access to mental health services remains limited, emphasizing the potential of AI-based interventions in cardiac rehabilitation.
This study aims to evaluate and compare the performance of Claude-Sonnet-4, GPT-4o, and DeepSeek-R1 in five key domains relevant to post-cardiac surgery rehabilitation: postoperative care, medication and diet, mental health, complication prevention, and physical activity. By assessing each model's accuracy, completeness, readability, and repeatability, this cross-sectional study contributes to the growing evidence base on LLMs in real-world clinical and patient-centered applications.
Methods
This study employed a cross-sectional, comparative evaluation design to systematically assess the performance of three LLMs—DeepSeek-R1, GPT-4o, and Claude-Sonnet-4—in providing patient-centered information for post-cardiac surgery rehabilitation. The primary objective was to evaluate these models’ accuracy, completeness, readability, and reproducibility when responding to clinically relevant questions spanning five key domains of cardiac rehabilitation.
Ethics consideration
As this study did not involve direct patient participation or the use of identifiable personal data, ethical approval from the institutional ethics committee was deemed unnecessary.
Question development and scope
A total of 35 patient-centered questions were developed to evaluate the models’ performance in post-cardiac surgery rehabilitation. These questions spanned five clinically relevant domains: postoperative care (n = 8), medication and diet (n = 8), mental health (n = 7), complication prevention (n = 6), and physical activity/exercise (n = 6) (Table 1). The question development process drew upon published rehabilitation guidelines, expert consultation, and frequently asked questions from patient forums and online health platforms. All questions were carefully phrased in accessible, conversational language to reflect the real-world concerns of post-operative cardiac patients and their caregivers, ensuring patient relevance and minimizing technical bias.
List of questions asked to chatbots.
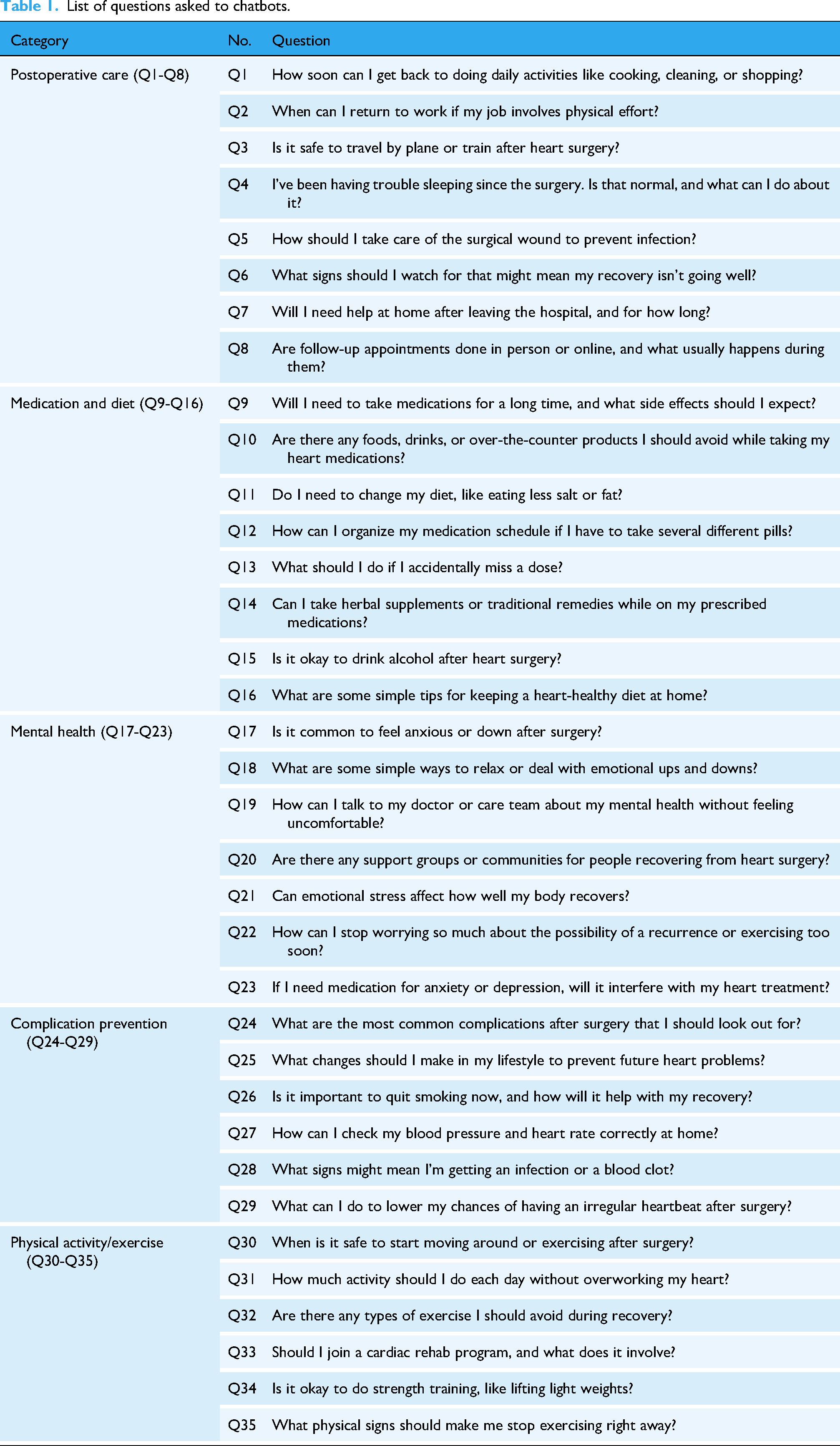
List of questions asked to chatbots.
Model setup and prompting procedure
To ensure reproducibility and standardization, all models were accessed through their official web-based interfaces without the use of APIs, scripts, or plugins.
– Claude-Sonnet-4: Accessed through Claude-Sonnet-4's official web interface at https://www.anthropic.com/claude/sonnet. – GPT-4o: Accessed through ChatGPT's official web interface at https://chat.openai.com. – DeepSeek-R1: Accessed through DeepSeek's official web interface at https://chat.deepseek.com.
All sessions were conducted in private/incognito mode, with cookies cleared prior to each session. The default language was set to English, and all responses were generated using platform-specific default settings without adjusting decoding parameters. A standardized initial prompt (“I just had heart surgery and want to ask some questions.”) was used to simulate a clinical scenario. To evaluate reproducibility, each question was independently submitted to each LLM five times between 15 June and 20 June 2025, under identical parameter configurations.
Response sampling and reproducibility testing
Each of the 35 questions was asked five times per model, yielding multiple responses for consistency analysis. All responses were anonymized, uniformly formatted, and stripped of any model-identifying information12–16 before evaluation. To reduce bias, evaluations were conducted in a blinded manner, with assessors unaware of the response sources.
Evaluation framework
Evaluations were performed in quiet, non-clinical environments to ensure focused judgment without external distractions or time pressure. A total of six clinical experts independently rated the accuracy and completeness of each response. The expert panel included two cardiovascular surgeons, two cardiologists, one cardiac rehabilitation and preventive cardiology specialist, and one clinical psychologist with expertise in postoperative psychological care. All evaluators were actively engaged in clinical practice at tertiary care hospitals, ensuring that their assessments reflected real-world applicability and the demands of high-pressure clinical settings. Ratings were based on clinical applicability, scientific validity, and the comprehensiveness of the information provided. The expert panel rated the accuracy and completeness of each response using a five-point Likert scale (Figure 1). Additionally, two study authors independently assessed readability and reproducibility metrics.

Likert scales for the accuracy and completeness of LLMs’ responses.
Evaluation criteria
Accuracy was defined as the factual correctness of the AI-generated response, reflecting alignment with current medical knowledge and clinical guidelines. Completeness assessed whether the response addressed all key aspects of the question. Reproducibility and stability were assessed independently by two reviewers with clinical backgrounds. For each model, five responses per question were evaluated for content similarity. Responses were categorized as follows: “Basically the same” if at least three out of five responses shared ≥75% overlapping content; “Not exactly the same” if content overlap was <75%; “Incorrect” if any of the responses included factual inaccuracies or lacked key information relevant to the question. Readability was evaluated using the Flesch Reading Ease (FRE) and Flesch-Kincaid Grade Level (FKGL). Higher FRE scores indicate easier readability, while lower FKGL scores suggest simpler language. By integrating expert evaluations, readability metrics, and reproducibility measures, the study aimed to comprehensively assess LLM performance in patient-facing rehabilitation contexts. The study adhered to the Strengthening the Reporting of Cohort, Cross-Sectional and Case–Control Studies in Surgery (STROCSS) guidelines. 37 The study procedure is illustrated in Figure 2.
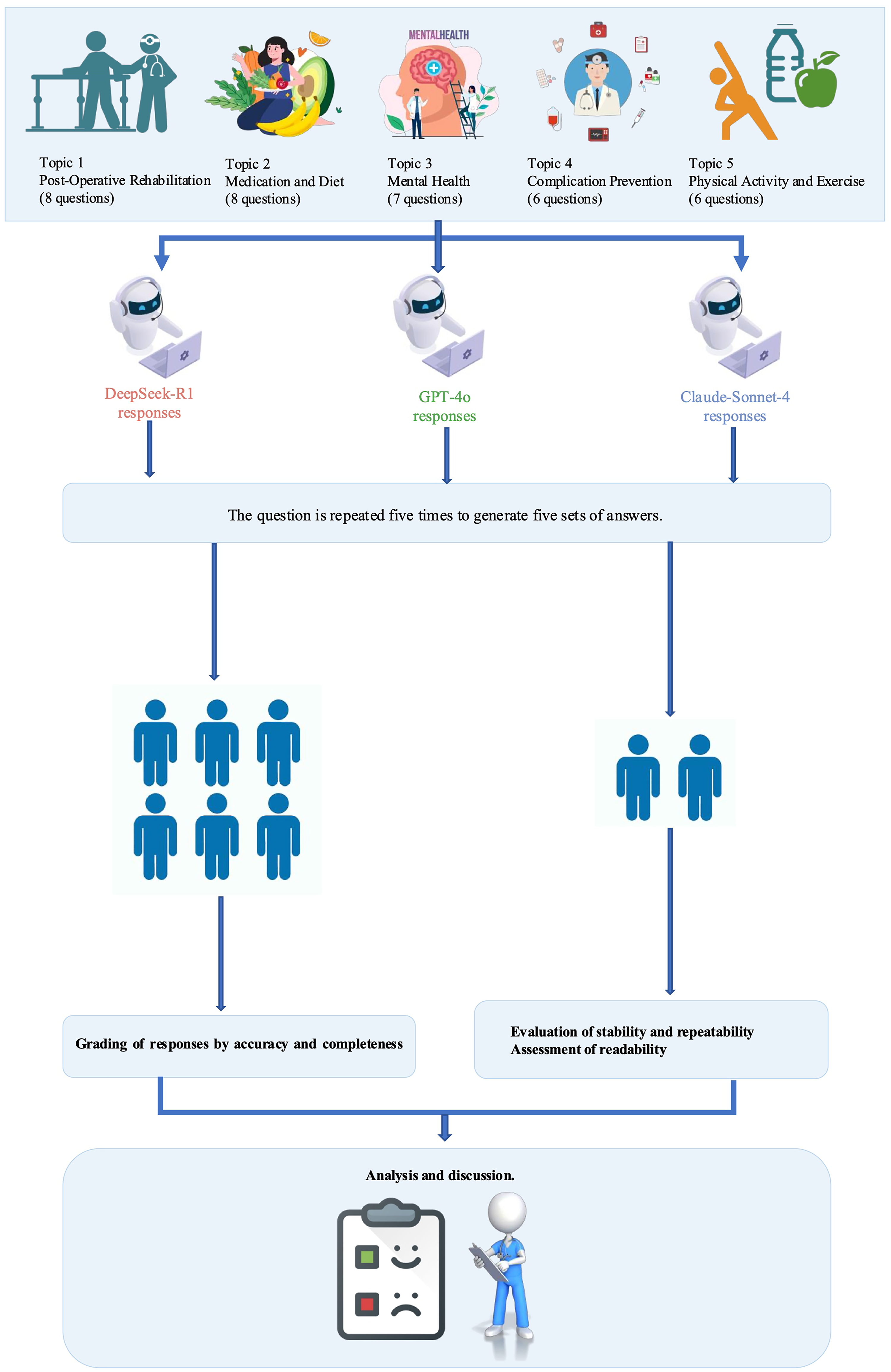
Flowchart of overall study design.
Statistical analysis
Continuous variables were expressed as mean ± standard deviation (SD). Comparisons among multiple groups were performed using one-way analysis of variance (ANOVA), with a threshold of P < 0.05 considered statistically significant. Kendall's coefficient of concordance was calculated to assess the agreement among six experts on the Likert scale ratings. All statistical analyses were conducted using SPSS version 21.0 (IBM Corp.).
Results
Evaluation of accuracy
Table 2 summarizes the accuracy scores of responses generated by each language model. Among the three LLMs, DeepSeek-R1 achieved the highest overall accuracy, with a mean Likert score of 4.64 (SD = 0.60). In the domain-specific analysis, DeepSeek-R1 consistently scored the highest across all five clinical areas. ANOVA analysis indicated that the differences in accuracy scores among the three models were statistically significant both overall and within each domain (P < 0.05). Post-hoc least significant difference (LSD) tests further confirmed that DeepSeek-R1's accuracy was significantly higher than that of both Claude-Sonnet-4 and ChatGPT-4o.
Comparison of accuracy scores among DeepSeek-R1, GPT-4o, and Claude-Sonnet-4.

Evaluation of completeness
As shown in Table 3, DeepSeek-R1 achieved the highest overall score for response completeness (4.20 ± 0.58), followed by ChatGPT-4o (3.97 ± 0.53) and Claude-Sonnet-4 (3.81 ± 0.63). The differences were statistically significant (F = 22.886, P < 0.001), with post-hoc analyses confirming the same ranking order: Claude-Sonnet-4 < ChatGPT-4o < DeepSeek-R1. In subgroup analyses by clinical domain, DeepSeek-R1 achieved the highest scores in four out of five domains. Notably, in the domain of postoperative care, ChatGPT-4o scored significantly higher than DeepSeek-R1 (4.17 ± 0.43 vs 3.90 ± 0.47, P = 0.003). In contrast, DeepSeek-R1 led significantly in the mental health (4.17 ± 0.58), complication prevention (4.53 ± 0.51), and physical activity/exercise (4.33 ± 0.72) domains.
Comparison of completeness scores among DeepSeek-R1, GPT-4o, and Claude-Sonnet-4.

Evaluation of readability
Table 4 presents the readability characteristics of responses. ChatGPT-4o generated the longest responses (357.91 ± 138.27 words), followed by DeepSeek-R1 (340.80 ± 81.01) and Claude-Sonnet-4 (289.11 ± 133.94). ANOVA analysis showed a marginal difference in word count across models (P = 0.050) (F = 3.09, P = 0.050). For the FRE score, ChatGPT-4o scored significantly higher (53.19 ± 10.40) than both Claude-Sonnet-4 (50.39 ± 11.73) and DeepSeek-R1 (50.15 ± 9.12) (P = 0.001), indicating a higher level of textual ease. No significant differences were found in FKGL among the models (P = 0.404), although DeepSeek-R1 had the lowest mean grade level (7.83 ± 1.27).
Readability evaluation of responses generated by each model.

As shown in Table 5, DeepSeek-R1 demonstrated the highest response stability under repeated prompting, with 85.7% of its responses rated as “essentially identical.” This was notably higher than Claude-Sonnet-4 (68.6%) and ChatGPT-4o (62.9%). DeepSeek-R1 also had the lowest proportion of “not exactly the same” (11.4%) and “incorrect” responses (2.9%). In contrast, ChatGPT-4o exhibited the lowest repeatability, with only 62.9% of responses rated as consistent and a relatively higher rate of partial inconsistency (28.6%). However, it maintained a lower error rate (8.6%) compared to Claude-Sonnet-4 (11.4%).
Stability and consistency of model outputs under repeated queries.

Discussion
This study offers an early comparative analysis of three advanced LLMs—DeepSeek-R1, GPT-4o, and Claude-Sonnet-4—within the context of post-cardiac surgery rehabilitation. By analyzing 35 patient-centered questions spanning five clinical domains, we systematically evaluated each model's performance in terms of accuracy, completeness, readability, and consistency. The results shed light on how different LLM architectures may align with the needs of digital health communication, particularly when delivering reliable and patient-appropriate information.
Comparative performance of LLMs in post-cardiac surgery rehabilitation
Among the models tested, DeepSeek-R1 emerged as the most reliable overall, excelling in both factual correctness and informational depth. Its answers were frequently aligned with current clinical recommendations and often included critical elements such as dosage specifics, monitoring timelines, and practical follow-up steps. In domains requiring clinical reasoning—like postoperative care and medication guidance—it consistently outperformed GPT-4o and Claude-Sonnet-4. Furthermore, its reproducibility across repeated prompts (85.7%) suggests a high degree of internal stability, making it a promising candidate for deployment in standardized digital rehabilitation workflows, particularly where guideline-based uniformity is essential. This superior repeatability likely stems from DeepSeek-R1's chain-of-thought architecture, which provides structured reasoning pathways and systematic problem decomposition, thereby reducing output variability compared to models optimized for creative expression.
GPT-4o, while moderately accurate, distinguished itself through its superior readability and conversational clarity. This made it particularly effective in domains like mental health and physical activity, where empathetic tone and accessible language are crucial for patient engagement. Despite occasional fluctuations in factual consistency, its responses were more emotionally attuned and linguistically approachable, which could enhance patient trust, comprehension, and adherence in educational or supportive care platforms. However, its lower reproducibility (62.9%) indicates potential unpredictability in iterative deployments. This variability reflects the stochastic sampling mechanisms inherent in modern LLMs, which introduce controlled randomness to generate more natural responses—a characteristic that could be problematic in clinical settings requiring standardized information delivery.
Notably, while GPT-4o achieved the highest readability scores among the three models (FRE: 53.19), this level still represents “fairly difficult” reading, requiring high school to college-level comprehension skills. This is concerning given that health literacy studies show the average patient reads at an 8th-grade level, with recommended patient education materials maintaining FRE scores above 60–70. At an FRE of 53, many adults are likely to find the content challenging to understand—posing a meaningful barrier for cardiac rehabilitation patients, who may also face cognitive burdens from medications, stress, or age. This complexity likely reflects the models’ training on academic medical literature, causing them to default to technical language even for patient-oriented questions. This finding aligns with cognitive load theory, 38 where responses rich in specialized medical terms increase intrinsic cognitive load—the mental effort required due to the complexity of the learning material. While such terminology enhances the text's professional depth and clinical precision, it also demands greater cognitive resources from readers without a medical background. The disconnect between even the best-performing model's readability and patient health literacy levels suggests that current LLMs require either explicit simplification prompting or post-processing to achieve truly accessible patient education materials.
Claude-Sonnet-4 demonstrated variable performance, ranking between the other two models across most evaluation metrics. Its language was generally clear and well-modulated, but its outputs sometimes lacked essential clinical information or offered overly generalized suggestions—especially in questions concerning complication prevention and psychological well-being. Its moderate repeatability (68.6%) falls between DeepSeek-R1's consistency and GPT-4o's variability, reflecting a balance between structured output and conversational diversity. This inconsistency may limit its use in high-precision clinical contexts. Nonetheless, its neutral tone and balanced phrasing may be useful in culturally sensitive communications or in ensemble systems that require stylistic diversity.
In sum, each model presents distinct advantages tailored to different digital health scenarios. DeepSeek-R1 appears best suited for clinically precise, structured communication, such as automated guidance in postoperative care. GPT-4o may be preferable for patient-facing tools that prioritize clarity, tone, and empathy, especially in psychosocial or behavioral domains. Claude-Sonnet-4, while less consistent, may serve as a complementary tool in applications requiring moderated phrasing or multilingual adaptability. These findings emphasize the importance of aligning model selection with the specific needs and risks of individual healthcare tasks.
Methodological strengths and a multidimensional evaluation framework
To the best of our knowledge, this study is the first to systematically evaluate Claude-Sonnet-4 within a structured, clinically oriented benchmark for post-cardiac surgery rehabilitation. Unlike previous research that relied heavily on synthetic datasets or single-domain queries, our study utilized 35 real-world, patient-centered questions derived from authoritative clinical guidelines. These questions spanned five key domains—postoperative care, medication and diet, mental health, complication prevention, and physical activity—ensuring both thematic breadth and clinical depth.
To strengthen the internal and external validity of our findings, we implemented several methodological safeguards. A standardized input procedure was applied, with all prompts submitted under identical conditions by the same investigator, minimizing variability and input-related bias. Each question was repeated five times per model, enabling us to assess response consistency as a proxy for reproducibility—an often overlooked yet clinically relevant dimension. All outputs were independently rated by experienced cardiac rehabilitation clinicians using predefined criteria, while readability was quantified with validated tools (FRE, FKGL), ensuring objectivity and real-world applicability.
An important contribution of our study lies in its multidimensional evaluation framework. Beyond accuracy and completeness, we evaluated reproducibility and readability—two crucial but frequently underexplored aspects that directly influence patient comprehension, trust, and adherence. By comparing three representative LLMs—a state-of-the-art multimodal model (GPT-4o), an open-source model (DeepSeek-R1), and a newly released instruction-tuned model (Claude-Sonnet-4)—we offer nuanced insights into the comparative strengths, limitations, and clinical suitability of current-generation LLMs in digital rehabilitation contexts.
Limitations
Nonetheless, our study has several limitations. First, while the questions were grounded in clinical guidelines, they were implemented in a simulated single-turn Q&A format. This format cannot fully replicate the complexity of real-world interactions, including emotional nuances, evolving patient needs, and cultural context. Second, although clinician ratings using Likert scales introduced a degree of structure, they inevitably carry some subjectivity, and the absence of universal benchmarks for clinical LLM evaluation limits cross-study comparability. Third, our analysis did not address multilingual capabilities or real-time conversational fluency—critical factors for broader adoption in diverse healthcare settings.
Future research directions
Future research should prioritize evaluating LLMs in real-world clinical settings, enabling direct interaction with patients and healthcare providers. Such studies will better capture the complexity of clinical communication, including emotional dynamics, adaptive dialogue, and culturally sensitive interactions. Task designs should be expanded to include voice-based conversations, multi-turn dialogues, and multimodal communication (e.g. text, audio, and visual elements), which more accurately reflect actual patient education scenarios. The development of standardized, medically validated evaluation frameworks—particularly those that are hallucination-aware and capable of automated scoring—will be essential to enhance transparency, replicability, and clinical safety. Beyond technical performance, future studies should assess patient acceptance, satisfaction, and trust in LLM-mediated education, especially across diverse populations and health literacy levels. Longitudinal studies are also needed to explore the impact of LLM-assisted interventions on clinical outcomes, behavioral adherence, and rehabilitation success over time. Moreover, tools that assess the cultural and linguistic adaptability of LLMs should be introduced to ensure equitable patient engagement across sociocultural contexts. Finally, as AI continues to permeate clinical workflows, regulatory and ethical frameworks must evolve in parallel to address data privacy, liability, and the delineation of decision-making authority between humans and machines. If these challenges can be addressed, LLMs may become a valuable adjunct in the delivery of patient-centered, scalable, and personalized cardiac rehabilitation.
Conclusion
In summary, this study systematically evaluated the performance of DeepSeek-R1, GPT-4o, and Claude-Sonnet-4 in post-cardiac surgery rehabilitation tasks. DeepSeek-R1 outperformed the others in accuracy, completeness, and reproducibility, while GPT-4o excelled in readability and conversational clarity. Claude-Sonnet-4 showed moderate and balanced performance but lacked clinical precision in some domains. All three models demonstrate potential in supporting digital rehabilitation, though their strengths vary by task type and communication style.
Footnotes
Acknowledgements
The authors would like to sincerely thank the seven specialists for their invaluable contributions to this research. Their expertise and insights were instrumental in evaluating the responses provided by the large language models.
Ethical approval
Approval from the ethics committee was not required since no patients were involved in our study.
Author contributions
W.L.: writing—original draft preparation; Q.L.: writing—review and editing and data collection.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Guarantor
Qiujie Li.
Disclosure of AI tool use
We acknowledge that parts of the results in this article were generated with DeepSeek-R1, GPT-4o, and Claude-Sonnet-4 (accessed via their official web interfaces), but all outputs were reviewed and confirmed by the authors.