
Abstract
Introduction
Artificial intelligence (AI)-powered chatbots, such as ChatGPT-4 and DeepSeek, are increasingly utilized in providing medical information. However, their accuracy, comprehensiveness, and reliability, particularly in specialized fields such as colorectal cancer, remain under-evaluated. This study aimed to compare the performance of ChatGPT-4 and DeepSeek in responding to both community- and expert-oriented questions related to colorectal cancer.
Materials and methods
A total of 30 questions were formulated based on clinical experience, including 15 community-focused and 15 expert-oriented questions. On February 13, 2025, ChatGPT-4 (OpenAI, version 4.0) and DeepSeek-R1 (initial January 2025 release) were queried simultaneously in a single session. Responses were independently evaluated by four colorectal surgery experts for appropriateness (0-100), comprehensiveness (0-100), and reference provision (yes/no). Statistical analyses included Mann-Whitney U and chi-square tests, with significance set at p < 0.05.
Results
ChatGPT-4 and DeepSeek demonstrated comparable appropriateness scores (94.0 vs. 92.25, p > 0.05). In community-oriented questions, ChatGPT-4 showed significantly higher comprehensiveness (median 95.0, interquartile range (IQR) 92-98 vs. 90.0, interquartile range 85-94; p = 0.044). Neither chatbot provided scientific references. Inter-rater agreement ranged from good to moderate, with slightly higher consistency observed for DeepSeek (appropriateness ICC 0.83 vs. 0.81).
Discussion
Both chatbots exhibited distinct strengths and limitations. ChatGPT-4 demonstrated superior comprehensiveness in community-oriented responses, whereas DeepSeek provided slightly more consistent evaluations. The absence of scientific references represents a major limitation, restricting clinical applicability and reliability. Enhancing reference support and response consistency is essential before AI-powered chatbots can be safely integrated into colorectal cancer-related clinical decision-making.
Keywords
Introduction
Artificial intelligence (AI)-supported information systems (chatbots), especially large-language models such as ChatGPT, are rapidly becoming widespread in the field of medical information. Although these models are seen as a potential source of information for patients and health professionals, there is insufficient research on important issues such as the accuracy, comprehensiveness, and citation of their answers.1–3 The contribution of AI-powered chatbots to health information provision is increasing, and models such as ChatGPT-4 and DeepSeek stand out as important tools that aim to facilitate access to medical information for both patients and healthcare professionals.4–8 However, especially in specialized medical fields such as colorectal cancer, the adequacy of these models in terms of important criteria such as accuracy, comprehensiveness, and reference support is still limited.9–11
Given the high prevalence and clinical complexity of colorectal cancer, evaluating how effectively AI chatbots can convey accurate and comprehensible information in this field is particularly relevant. Colon and rectal cancer is one of the most common malignancies in both men and women. 12 Providing accurate and comprehensive information is critical for both patients and healthcare providers to make informed decisions. Incorrect or incomplete information can lead to misunderstandings, increased anxiety, and poor clinical outcomes. Therefore, it is of great importance to evaluate the performance of AI-powered chatbots in providing reliable and detailed information. 13 Although some previous studies have compared the performance of AI chatbots in different medical subjects, there is limited data in the field of colorectal cancer.14–16 In addition, the fact that chatbots provide verifiable sources in their responses and the appropriateness of their content are decisive factors in terms of reliability. Understanding the extent to which these criteria are met can contribute to optimizing these models for clinical use. In this context, key evaluation metrics such as appropriateness (the factual accuracy and contextual relevance of responses) and comprehensiveness (the breadth and depth of information provided) were considered essential for assessing chatbot performance.
Recent years have witnessed a surge in the use of AI chatbots for oncological purposes, including patient education, symptom triage, emotional support, and general information delivery. Multiple platforms—such as ChatGPT, Perplexity, Bing AI, and DeepSeek—have demonstrated promising results in answering common cancer-related queries with relatively low rates of misinformation and satisfactory DISCERN (a standardized instrument for judging the quality of written consumer health information on treatment choices) scores.17–19 However, when tasked with more complex clinical duties—such as generating chemotherapy regimens or making treatment recommendations—the performance of these tools markedly declines. For instance, a comparative evaluation showed that ChatGPT and Bing provided correct chemotherapy suggestions in only 5/9 and 4/9 cases, respectively. 20
Beyond accuracy, chatbots vary considerably in terms of comprehensibility, actionability, and tone. Studies have revealed that many chatbot outputs are composed at a college reading level,17–19 potentially limiting accessibility for the general public. Moreover, although platforms like Claude AI have been rated highly for empathy and clarity in patient forums, 21 their actionability remains limited, with Patient Education Materials Assessment Tool scores for practical advice often falling below 40%. These limitations raise concerns about the equitable and safe deployment of such tools in clinical settings. Furthermore, the “black-box” nature of large-language models makes it difficult to verify the sources or logic behind their outputs, and bias in training datasets may perpetuate health disparities.22,23
In this study, we compared the responses of two different chatbots, ChatGPT-4 and DeepSeek, to patient (community) and expert questions about colorectal cancer. Our aim is to evaluate the ability of these models to provide medical information and to identify aspects that need to be improved to increase their reliability. 24 Comparison will be based on key performance measures, including relevance, comprehensiveness, and referencing, across both patient-oriented and professional-level questions. The aim of this study is to evaluate the reliability of AI tools in colorectal cancer information delivery. To our knowledge, this is the first study to directly compare ChatGPT-4 and DeepSeek in colorectal cancer within a dual-audience framework, highlighting their differential performance in patient education and clinical decision support.
Materials and methods
This study was designed to compare the responses generated by two large-language model-based chatbots, ChatGPT-4 (OpenAI, version 4.0) and DeepSeek-R1 (initial release January 2025), to community-oriented (patient) and expert-level questions related to colorectal cancer. All chatbot queries were performed on February 13, 2025, during a single session. The primary aim of the study was to evaluate and compare the quality of medical information provided by these models in terms of appropriateness, comprehensiveness, and reference provision.
Within the scope of the study, a total of 30 questions were developed based on clinical experience, including 15 community-oriented (patient-focused) questions and 15 expert-level (professional) questions. The questions were formulated by two colorectal surgery experts. Community-oriented questions addressed basic informational topics frequently asked by the general public, whereas expert-level questions focused on complex issues relevant to clinical decision-making.
Sample size calculation
Prior to study initiation, a prospective power analysis was conducted. Based on the effect sizes observed in similar comparative studies of AI chatbots, a total sample size of 30 questions (15 per group) was determined to be sufficient to achieve 80% statistical power with an alpha level of 0.05.
Question formulation
Community-oriented questions were simulated to reflect common patient concerns, such as “If I have a family history of colorectal cancer, is my risk increased?” and “When and how should colorectal cancer screening be performed?” Expert-level questions addressed complex clinical topics relevant to specialist decision-making, including “What is the prognostic and predictive value of microsatellite instability (MSI) and mismatch repair (MMR) defects in colorectal cancer?” and “What is the current evidence on the use of microRNAs as diagnostic and prognostic markers in colorectal cancer?” The questions were not derived from real patient encounters but were developed based on the clinical knowledge and experience of colorectal surgery experts.
All questions were directed to both chatbots (ChatGPT-4, OpenAI, version 4.0; and DeepSeek-R1, initial release January 2025) in the same format. The queries were performed on February 13, 2025, in a single session, and the responses were then coded for evaluation. The text responses received from the chatbots were directly presented for evaluation without any editing. Chatbot responses were evaluated by four experienced colorectal surgery experts. The evaluation was blinded; the experts did not know which answer belonged to which chatbot.
Evaluation protocol and blinding
Chatbot responses were evaluated by four experienced colorectal surgery experts. To minimize bias, all chatbot outputs were anonymized by removing identifiers such as chatbot names, timestamps, and formatting differences, and were subsequently randomized. Responses were presented in a shuffled order, preventing side-by-side comparison. Evaluators were blinded to the identity of the chatbot generating each response and were instructed to focus solely on content quality using predefined criteria. Each response was scored using a 0–100 numerical rating scale, where 0 indicated completely irrelevant or incomplete content and 100 indicated fully appropriate and comprehensive responses, with intermediate scores reflecting expert judgment. Inter-rater reliability for appropriateness and comprehensiveness scores was assessed using the intraclass correlation coefficient (ICC) with a two-way random-effects model for absolute agreement; ICC values were interpreted as <0.50 (poor), 0.50–0.75 (moderate), 0.75–0.90 (good), and >0.90 (excellent).
Consistency in this study refers exclusively to inter-rater agreement among the evaluators, measured using the ICC. We did not evaluate within-model response reproducibility across repeated queries.
The evaluation was based on three main criteria:
Appropriateness (0–100)
Appropriateness measured how accurately and directly the chatbot's response addressed the question, considering factual correctness, clinical relevance, clarity and consistency of terminology, and suitability for the intended audience (community or expert). Higher scores indicated responses that were accurate, contextually appropriate, and free from misleading or hallucinated information.
Comprehensiveness (0–100)
Comprehensiveness assessed the breadth and depth of information provided in each response. Higher scores were assigned to answers that covered multiple relevant aspects of the question, included sufficient explanations or examples, and demonstrated an appropriate level of detail according to the question type (community or expert).
Reference provision (yes/no)
Reference provision was recorded as a binary outcome indicating whether the chatbot response included any scientific citation, clinical guideline, or verifiable source.
The distribution of continuous data was assessed using the Shapiro–Wilk test. Appropriateness and comprehensiveness scores were compared between chatbots using a Mann–Whitney U test. Reference provision, recorded as a binary outcome (Yes/No), was analyzed using a chi-square test or Fisher's exact test, as appropriate. Inter-rater reliability for appropriateness and comprehensiveness scores was assessed using the ICC with a two-way random-effects model for absolute agreement. All statistical analyses were performed using SPSS (version 29.0), and statistical significance was defined as p < 0.05. Additional methodological details and supplementary analyses are provided in the Supplemental Material.
Results
Primary outcomes: appropriateness and comprehensiveness
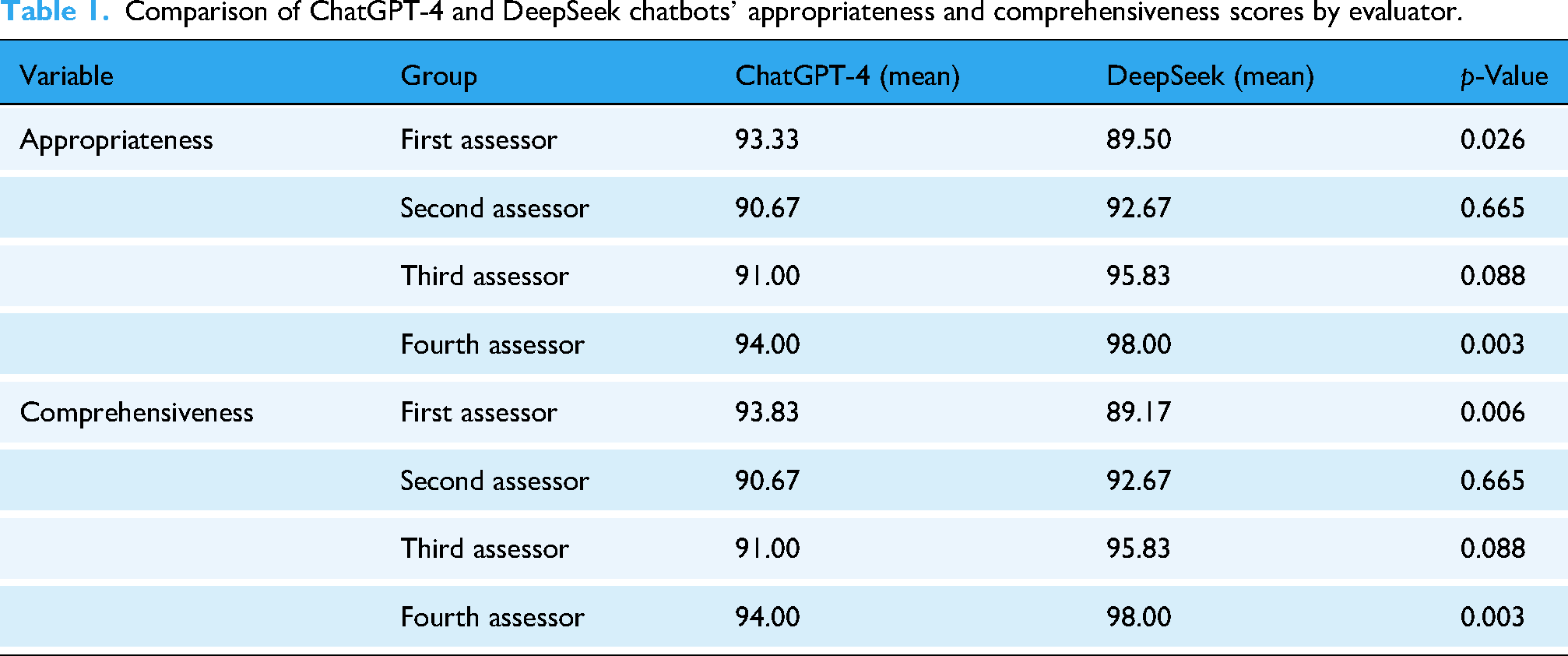
Based on overall average scores, ChatGPT-4 and DeepSeek demonstrated comparable performance in terms of appropriateness (92.25 vs. 94.0, respectively; p > 0.05), indicating no statistically significant difference between the two models. Similarly, no significant difference was observed between ChatGPT-4 and DeepSeek with respect to overall comprehensiveness scores. A comparison of mean appropriateness and comprehensiveness scores for both chatbots is presented in Figure 1. Individual assessor-based comparisons of appropriateness and comprehensiveness scores are summarized in Table 1.

Comparison of appropriateness and comprehensiveness scores of ChatGPT-4 and DeepSeek chatbots.
Comparison of ChatGPT-4 and DeepSeek chatbots’ appropriateness and comprehensiveness scores by evaluator.
Comprehensiveness in community-oriented questions
When analyses were restricted to community-oriented questions, ChatGPT-4 demonstrated significantly higher comprehensiveness scores compared with DeepSeek (p = 0.044). The distribution of comprehensiveness scores for community questions is illustrated using a boxplot in Figure 2, while Figure 3 presents a violin plot depicting score distributions for both chatbots, highlighting differences in score density and dispersion within this subgroup.
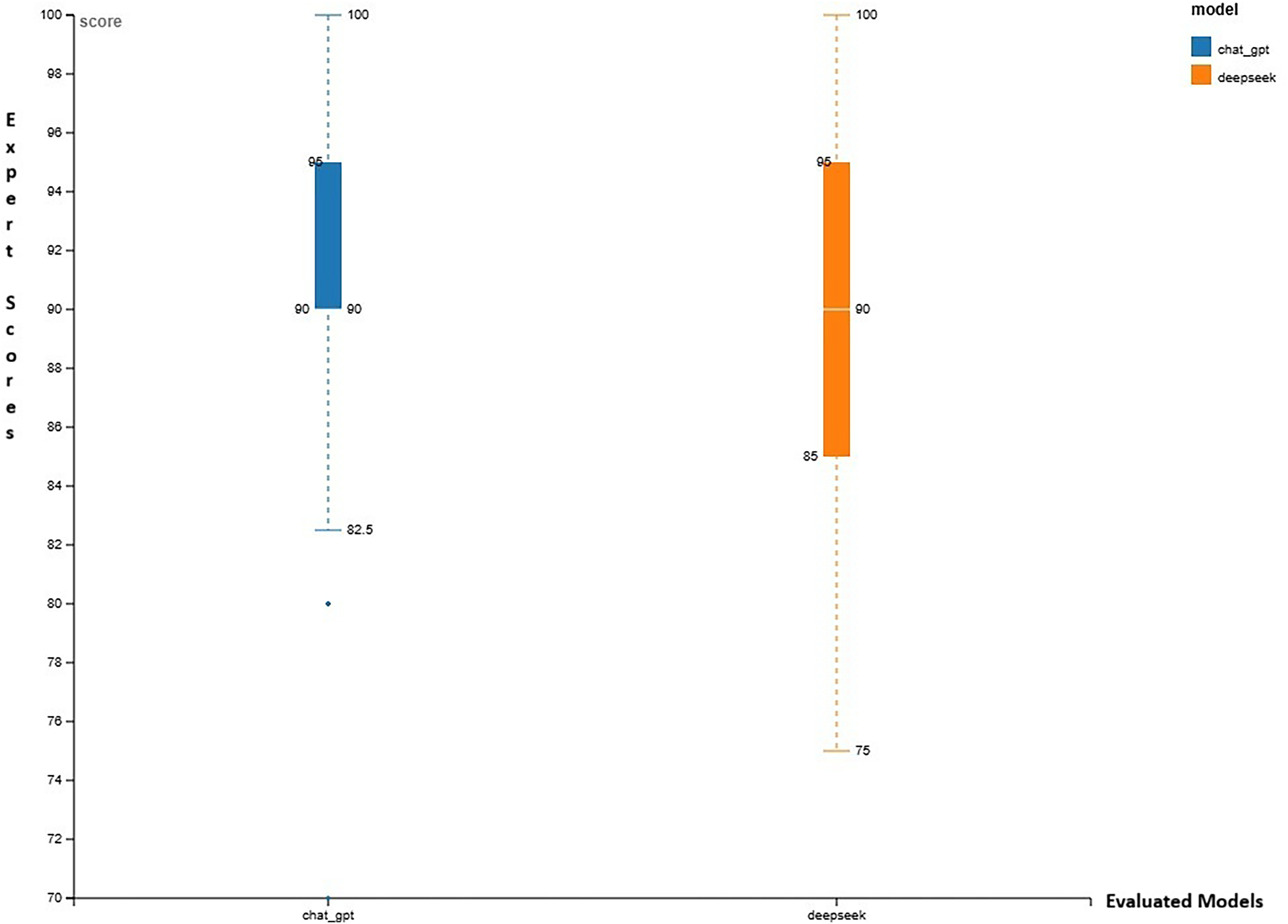
Boxplot comparing the comprehensiveness scores of ChatGPT-4 and DeepSeek chatbots for community-oriented questions. A statistically significant difference was observed between the two models (p = 0.044).

Violin plot showing the distribution of the comprehensiveness scores of ChatGPT-4 and DeepSeek chatbots for community-oriented questions.
Reference provision
Neither ChatGPT-4 nor DeepSeek provided any scientific references, clinical guidelines, or verifiable sources in their responses across all evaluated questions.
Inter-rater reliability
Inter-rater reliability was assessed using the ICC with a two-way random-effects model for absolute agreement. As shown in Table 2, ChatGPT-4 demonstrated good reliability for community-oriented questions (appropriateness: ICC = 0.812, 95% confidence interval (CI) [0.735–0.871]; comprehensiveness: ICC = 0.743, 95% CI [0.648–0.818]) and moderate reliability for professional-level questions (appropriateness: ICC = 0.751, 95% CI [0.659–0.823]; comprehensiveness: ICC = 0.652, 95% CI [0.543–0.742]). DeepSeek showed slightly higher reliability overall, with good agreement for community questions (appropriateness: ICC = 0.831, 95% CI [0.759–0.885]; comprehensiveness: ICC = 0.769, 95% CI [0.678–0.839]) and good to moderate agreement for professional questions (appropriateness: ICC = 0.772, 95% CI [0.683–0.841]; comprehensiveness: ICC = 0.684, 95% CI [0.579–0.769]). All ICC values were statistically significant (p < 0.001), indicating consistent agreement among evaluators across both chatbots and question types.
Inter-rater reliability results based on intraclass correlation coefficient (ICC) for both chatbots (ChatGPT-4 and DeepSeek) and question types (community and professional).

CI: confidence interval.
The ICC values were computed separately for appropriateness and comprehensiveness scores. All ICCs indicate good to moderate agreement among the four expert raters, with higher consistency observed in community-type questions across both chatbot models.
Discussion
This study provides a direct comparison of ChatGPT-4 and DeepSeek in responding to colorectal cancer-related questions addressed to both community (patient) and professional (expert) audiences. Overall, the findings demonstrate that both chatbots are capable of generating generally relevant information, with comparable performance in appropriateness, while differences were observed in comprehensiveness depending on the target audience. These results contribute to the growing literature on the role of large-language models in oncology-related medical information delivery and extend prior work by directly comparing two distinct models within a cancer-specific context.25–28
The inclusion of both patient-oriented and clinician-level questions offers insight into chatbot performance across different levels of informational complexity. This dual-audience approach allows for a more comprehensive evaluation of how AI-generated responses align with the needs of diverse users, an aspect that has been less frequently addressed in previous chatbot assessments.
Inter-rater reliability analysis demonstrated good to moderate agreement among evaluators for both chatbots, supporting the consistency of the expert assessments. Higher agreement was observed for community-oriented questions compared with professional-level questions, indicating greater consistency in evaluating patient-directed information than responses addressing specialized clinical topics. Across all conditions, appropriateness scores showed higher agreement than comprehensiveness scores, suggesting that evaluators more consistently agreed on whether responses were suitable for the question than on the extent to which all relevant aspects were covered.
From a clinical perspective, these findings suggest that AI-powered chatbots may have potential utility as supplementary tools for patient education and general informational support. The higher consistency observed in community-oriented responses supports their possible role in patient-facing contexts, where clarity and consistency are essential. In contrast, the lower agreement observed for professional-level comprehensiveness underscores the current limitations of chatbot outputs in supporting complex clinical discussions without additional validation or oversight.
Although DeepSeek achieved slightly higher reliability coefficients across most evaluation conditions, overall appropriateness scores did not differ significantly between the two models. This indicates that both chatbots perform at a similar level in terms of relevance and contextual suitability of information. Differences in comprehensiveness were more pronounced at the community level, where ChatGPT-4 demonstrated significantly higher scores. This finding aligns with prior reports suggesting that ChatGPT models tend to provide more detailed responses for lay audiences.29,30
A critical finding of this study is the complete absence of scientific references in chatbot responses. The lack of verifiable source attribution substantially limits the transparency and clinical reliability of the information provided. As emphasized in previous studies, reference-supported responses are essential for ensuring trustworthiness and safe use of AI-generated medical content.1,27,30,31 Without such support, chatbot outputs cannot be reliably integrated into clinical decision-making processes. Previous studies have similarly reported that even when citations are provided, they are often generic, incomplete, or unverifiable, limiting transparency and clinical trustworthiness of chatbot-generated content.32,33
Taken together, these findings highlight both the potential and the current constraints of large-language models in colorectal cancer information delivery. While AI chatbots can generate relevant and, in some contexts, comprehensive responses, significant challenges remain regarding reliability, transparency, and suitability for professional-level use. Addressing these issues will be essential for the responsible advancement of AI applications in healthcare.
Limitations of the study
Several limitations of this study should be acknowledged. First, the question set was developed by two colorectal surgery experts based on clinical experience rather than derived from validated patient questionnaires or standardized guideline-based frameworks. Although this approach reflects real-world practice, it may introduce selection bias and limit the generalizability of the findings. Future studies should consider incorporating validated patient FAQs or guideline-based question sets to improve external validity.
Second, the relatively limited number of questions and the evaluation of only two chatbot models restrict the scope of inference, and the results may not be generalizable to other AI systems. In addition, chatbot responses may vary over time and across different sessions. To minimize temporal variability and ensure identical testing conditions, all queries were intentionally conducted within a single standardized session; however, this approach does not capture potential longitudinal variability in chatbot performance.
Third, the evaluation relied on expert judgment, which inherently involves a degree of subjectivity. Although explicit scoring anchors were defined (0 = completely irrelevant/incomplete; 100 = fully appropriate/comprehensive), no validated rubric currently exists for assessing AI-generated medical content. To mitigate this limitation, multiple blinded evaluators were employed, and inter-rater reliability was assessed using the ICC; nevertheless, some degree of interpretative variability remains unavoidable.
Finally, additional dimensions such as readability level, linguistic complexity, and the influence of language and regional clinical guidelines were not systematically evaluated. Differences between guideline frameworks, such as National Comprehensive Cancer Network (NCCN) and European Society for Medical Oncology (ESMO) recommendations, may affect the accuracy and applicability of AI-generated medical information across healthcare settings. 34 Future studies addressing these factors may provide a more comprehensive evaluation of chatbot performance.
Conclusion
In conclusion, this study demonstrates that AI-powered chatbots such as ChatGPT-4 and DeepSeek are capable of generating relevant and generally appropriate information on colorectal cancer. However, their current utility is fundamentally limited by the complete absence of verifiable scientific references, which compromises the transparency and reliability of their outputs. While ChatGPT-4 provided more informative and detailed responses for community-oriented questions, this increased informativeness was not accompanied by source verification. Conversely, although DeepSeek demonstrated slightly higher internal consistency, it did not overcome the lack of evidence-based referencing. Together, these findings highlight a persistent and unresolved trade-off between informativeness, consistency, and verifiability in current large-language models. The integration of evidence-based medical databases—such as PubMed, UpToDate, and clinical guideline repositories—through structured API connections should be prioritized in future development to enable transparent, reproducible, and clinically trustworthy AI-generated medical information for both patients and clinicians.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076261425149 - Supplemental material for Comparative informative capacity of artificial intelligence (AI)-powered chatbots in colorectal cancer: ChatGPT-4 versus DeepSeek
Supplemental material, sj-docx-1-dhj-10.1177_20552076261425149 for Comparative informative capacity of artificial intelligence (AI)-powered chatbots in colorectal cancer: ChatGPT-4 versus DeepSeek by Nurhilal Kızıltoprak, Ömer Faruk Özkan, Fevzi Cengiz, Erdinç Kamer and İlker Sücüllü in DIGITAL HEALTH
Footnotes
Ethical approval
No patient data were used in this study, and therefore ethical approval was not required. The study was conducted in accordance with the ethical principles outlined in the Declaration of Helsinki.
Author contributions
Nurhilal Kızıltoprak: study design, data collection, analysis, manuscript writing, and final approval.
Erdinç Kamer: data collection.
Ömer Faruk Özkan: data collection, statistical analysis, and final approval.
Fevzi Cengiz: data collection.
İlker Sücüllü: data collection.
An artificial intelligence-based language model was used during literature review and drafting, but all final decisions were made by the authors.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Availability of data and materials
The data used in this study are securely stored in compliance with ethical guidelines. Since no patient data were used, confidentiality regulations were not applicable. Relevant data can be shared with authorized institutions upon reasonable request. At certain stages of this study, an artificial intelligence-based language model was used to support the literature review and writing process. However, the final evaluation and content approval was carried out by the researchers.
Guarantor
Nurhilal Kızıltoprak.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.