
Abstract
Background
Artificial intelligence (AI)-based language models such as ChatGPT show promise in generating medical documentation. However, their effectiveness in occupational therapy (OT) documentation—particularly in terms of perceived quality and empathy—remains underexplored.
Objective
This study aimed to compare the quality and empathy of clinical documentation generated by licensed occupational therapists versus ChatGPT-3.5, using standardized OT case scenarios.
Methods
Fifteen standardized OT cases were used to generate human- and AI-written assessment and plan sections. Five occupational therapists and five patients or caregivers independently evaluated the documentation using 5-point Likert scales across three quality subdomains (completeness, correctness, concordance) and three empathy dimensions (cognitive, affective, behavioral). Inter-rater reliability and correlations between quality and empathy were also analyzed.
Results
Artificial intelligence-generated documentation received significantly higher ratings across all quality and empathy dimensions than human-generated documentation (all p < 0.001). However, human-generated documentation demonstrated stronger correlations between quality and empathy, and higher inter-rater reliability, indicating greater consistency among evaluators. These findings suggest that while AI can produce responses perceived as more complete and empathetic, its outputs may vary more widely in interpretation.
Conclusion
Artificial intelligence-based tools may help reduce documentation burdens for therapists by generating high-quality, empathetic notes. However, human-authored documentation remains more consistent across evaluators. These results underscore the potential and limitations of AI in clinical documentation, highlighting the need for further development to enhance contextual sensitivity, communication coherence, and evaluator reliability. Future research should examine AI performance in real-world OT practice settings.
Introduction
Occupational therapy (OT) plays a crucial role in patient rehabilitation, addressing various conditions that impact daily functioning and overall quality of life by enhancing independence and facilitating engagement in meaningful activities. 1 While OT documentation, particularly the assessment and plan (A/P) section, is essential for tracking patient progress, guiding interventions, and ensuring continuity of care across healthcare providers, 2 the process is also time-consuming and significantly contributes to the administrative burden faced by healthcare professionals.3,4
The recent emergence of artificial intelligence (AI)-based large language models, such as ChatGPT, presents an opportunity to streamline documentation processes.5,6 These models have demonstrated promising capabilities in generating medical text across various healthcare domains. 6 Previous research on AI-generated medical documentation, typically involving the automated generation of clinical notes or specific documentation sections, has focused on fields such as nursing care and internal medicine,6,7 yet empirical evidence on AI-generated OT documentation, especially regarding the A/P sections, remains limited. Given the complexity of OT practice—which requires patient-centered, context-specific assessments and sound clinical reasoning—it is important to examine whether AI-generated A/P documentation can match the quality and empathy of human-generated notes. 8 Moreover, whether AI can effectively interpret and synthesize subjective and objective (S/O) patient information remains uncertain.
A previous study found that AI-generated responses received higher ratings in quality and empathy than human-generated responses. 6 However, these findings are subject to important limitations. First, a prior study has generally assessed quality and empathy as single-component constructs, which may not fully capture the complexities of these attributes. Notably, quality was not assessed with an accuracy component, thereby failing to evaluate potential fabrication in AI-generated responses. Second, empathy was exclusively rated by physicians, limiting insight from the patient perspective. Third, the reliability and validity of Likert scales used in a previous study remained unverified, as only physicians conducted an evaluation using Likert scales.
To address these limitations, this study employed structured virtual OT clinical cases, in which both human- and AI-generated A/P documentation. Building on prior research, this study assessed a key gap by adopting a multicomponent framework to enable more comprehensive evaluation. Specifically, quality was evaluated across three dimensions—completeness, correctness, and concordance—based on prior frameworks used in evaluating healthcare documentation, which emphasize comprehensive content coverage, clinical accuracy, and alignment with professional standards.11,12 Empathy was assessed through cognitive, affective, and behavioral components, derived from validated theoretical models such as the Consultation and Relational Empathy (CARE) Measure and the Jefferson Scale of Physician Empathy.13,14 Furthermore, both occupational therapists and patients or caregivers were included in the evaluation process to capture both clinical and patient-centered perspectives. Including both rater groups not only enriches the assessment of documentation but also aligns with prior research emphasizing the multidimensional and subjective nature of empathy in healthcare communication.14,15
Therefore, this study aimed to compare the quality and empathy of AI-generated and human-generated OT documentation using standardized clinical case scenarios. Specifically, it sought to evaluate whether documentation generated by ChatGPT-3.5 can match human-generated documentation in terms of quality and empathy.
Methods
This study employed a blinded, comparative, cross-sectional design to evaluate the quality and empathy of OT documentation generated by licensed occupational therapists and the AI model (ChatGPT-3.5). The assessment focused on the A/P sections of the documentation, using standardized case simulations to ensure uniformity across conditions.
Fifteen individuals participated in the study. Five licensed occupational therapists were recruited through purposive sampling and invited to generate A/P documentation based on fictional clinical scenarios. Another five therapists were recruited to evaluate the quality and empathy of these documents, along with five patients or caregivers with relevant lived experience. All participation was voluntary and anonymous, and no personal information was collected. The recruitment was conducted via professional networks and patient advocacy channels.
This study was reviewed and granted exempt status by the Institutional Review Board of Soonchunhyang University, in accordance with institutional guidelines for research involving minimal risk and no identifiable personal data. The study involved licensed occupational therapists who generated A/P documentation based on predeveloped, anonymized educational case scenarios. Additionally, other therapists and patient representatives evaluated these responses using Likert-scale ratings for quality and empathy. While these data were human-generated, they did not contain any personal or clinical identifiers. No demographic or identifying information about participants was collected, stored, or analyzed at any stage of the study.
A visual flowchart was included to enhance clarity and transparency of the study design. As shown in Figure 1, the process involved case selection, documentation generation by both occupational therapists and AI, followed by blinded evaluations from occupational therapists and patients or caregivers using multidimensional criteria for quality and empathy (Figure 1).

Flowchart of the study design and analytical workflow.
To ensure ethical compliance, identifiable patient information would have needed to be removed from the original case materials. However, removing such details could have altered the clinical context and negatively impacted the comparability between the A/P sections written by occupational therapists and those generated by ChatGPT-3.5. 9 Thus, while open-access online data would have been an ideal alternative, obtaining appropriate clinical cases from online sources proved challenging.
Instead, this study utilized cases from a published casebook publicly accessible in South Korea. This casebook provides a structured and standardized dataset, comprising clinical scenarios categorized by diagnostic domains such as neurological and musculoskeletal conditions, and including S/O sections. 10 These cases were developed by experienced occupational therapy professionals, including the authors of this study as the casebook contains anonymized, standardized educational scenarios with no identifiable patient data, no additional permission was required for academic use. Importantly, the original casebook content was not reproduced or disclosed in the manuscript; the material was used solely for structured documentation analysis. Fifteen cases were randomly selected from the casebook, referencing previous research findings and assuming 80% power to detect a 40 percentage point difference between human and AI-generated responses (70% vs. 30%). 7 These cases represented four major clinical domains: musculoskeletal disorders (n = 11), developmental disorders (n = 10), neurological disorders (n = 10), and psychosocial disorders (n = 6). Each case includes detailed and structured S/O sections to simulate real-world patient encounters.
Occupational therapists were licensed professionals with clinical experience in their respective domains. Each was assigned a case within their respective specialty and instructed to generate an A/P section following standard documentation guidelines. To generate AI-based documentation, identical case data were entered into separate ChatGPT sessions on April 28 and 29, 2025, ensuring that no previous interactions influenced the output. The AI was prompted to generate an A/P section using the same standard documentation guidelines (Supplementary Material 1). The ChatGPT responses were then saved. Both human- and AI-generated documentation were limited to approximately half an A4 page, formatted in a 12-point font within a Word document (Microsoft Word). To eliminate biases, all responses underwent a standardization process to remove stylistic differences, ensure consistent terminology usage, and anonymize identifying elements.
The anonymized responses were then randomly assigned for evaluation by two independent assessment groups: 1) Five licensed occupational therapists and 2) Five patients or caregivers. Quality and empathy were evaluated by two groups. If patients were too young or had cognitive impairment preventing independent evaluation, their caregivers completed the evaluation on their behalf; otherwise, patients self-assessed their experience. This approach ensured a diverse assessment of perceived interpersonal responsiveness.
Two variables—quality and empathy—were assessed using 5-point Likert scales. To improve the dimensionality of evaluation and address prior research limitations, 7 quality was assessed across three subdomains (very poor, poor, acceptable, good, or very good): completeness, correctness, and concordance, following established frameworks for evaluating healthcare documentation.11,12 Completeness measured the extent to which responses included all relevant information, correctness evaluated factual and clinical accuracy, and concordance assessed alignment with professional OT practice standards.11,12 Similarly, empathy was evaluated across three structured criteria—cognitive, affective, and behavioral empathy—rated on a 5-point Likert scale (not empathetic, slightly empathetic, moderately empathetic, empathetic, very empathetic). Cognitive empathy refers to a comprehensive understanding of the patient's condition, affective empathy involves the demonstration of a compassionate and positive attitude, and behavioral empathy reflects clear and responsive communication. These dimensions—cognitive, affective, and behavioral empathy—were informed by validated frameworks such as the CARE Measure and the Jefferson Scale of Physician Empathy.13,14 While these tools were originally developed for evaluating empathy in face-to-face interactions, they provided a theoretical basis for assessing perceived empathy in medical documentation. Brief explanations were included for each subdomain and dimension to help clarify how raters interpreted within the occupational therapy documentation context.
Descriptive statistics (means and standard deviations) were used to summarize quality and empathy scores for both OT- and AI-generated documentation. To compare group differences, paired t-tests were performed to evaluate the mean difference in quality and empathy between the two documentation types. To examine the associations between quality and empathy ratings, Pearson correlation coefficients were calculated within each group. Inter-rater reliability for the Likert-scale ratings was assessed using the two-way random effects intraclass correlation coefficient (ICC), focusing on absolute agreement across raters (occupational therapists vs. patients/caregivers). A two-tailed significance threshold of p < 0.05 was applied for all inferential analyses. All statistical analyses were conducted using IBM SPSS Statistics for Windows, version 22.0 (IBM Corp., Armonk, NY, USA).
Results
Clinical cases and documentation
Occupational therapy documentation generated by both humans and AI was created for 15 clinical cases and analyzed. Summaries of example clinical cases and documentation are shown in Supplementary Material 2.
Quality ratings of human-generated vs. AI-generated documentation
Across all three subdomains of quality (completeness, correctness, concordance), both occupational therapists and patients/caregivers rated AI-generated documentation significantly higher than human-generated documentation (p < 0.001). Mean scores for AI outputs consistently exceeded the “good” threshold (≥4), while human-generated documentation remained within the “acceptable” range (3–3.9). For instance, occupational therapists rated AI-generated documentation with means of 4.17–4.18 versus 3.43–3.54 for human-generated versions; similar patterns were found among patient raters. While the proportion of low-quality responses (<3) was similar across groups, AI-generated documentation was 2.7–2.8 times more likely to be rated as good or very good across all subdomains (Figure 2).
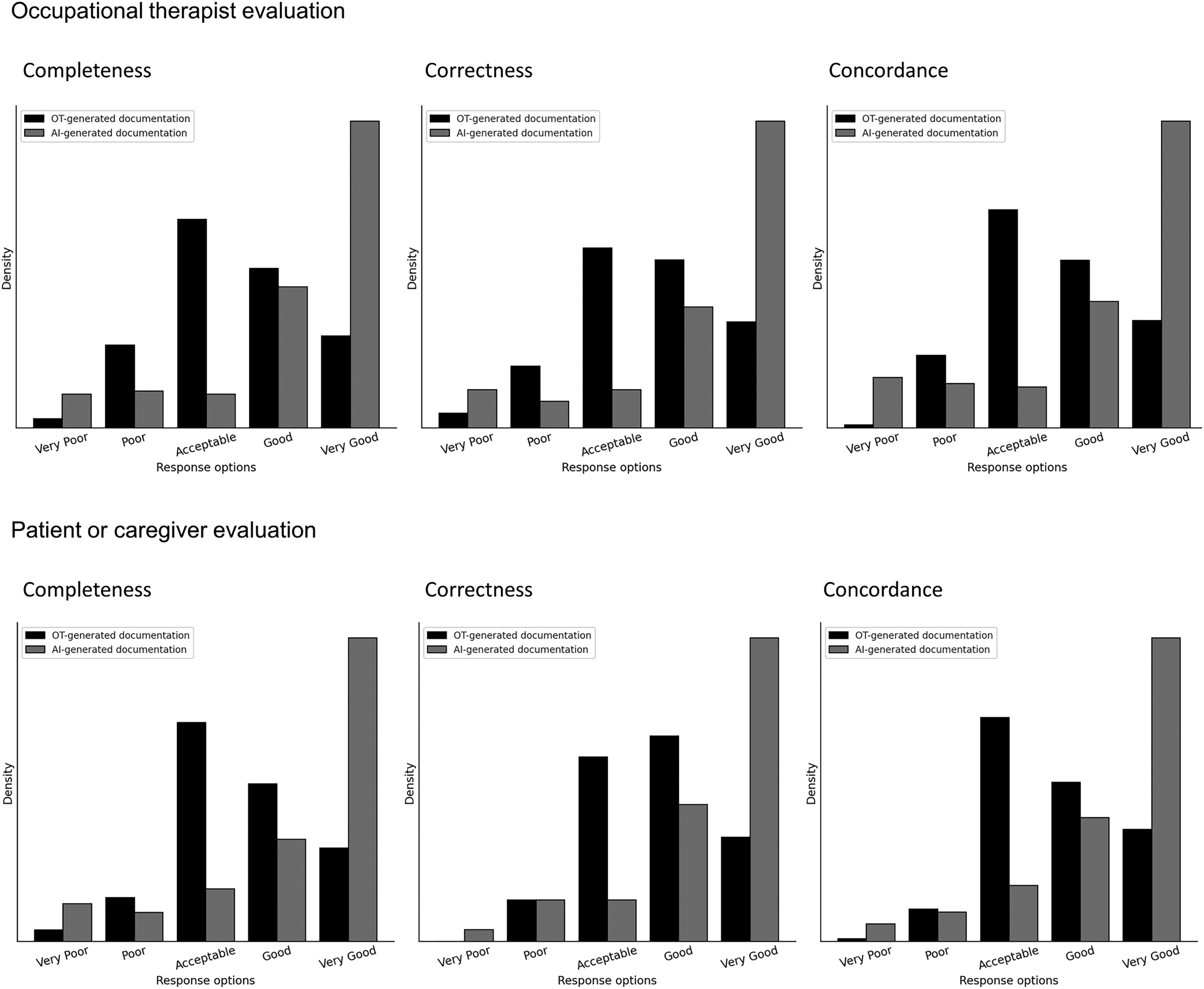
Quality ratings for documentation generated by human and artificial intelligence (AI).
Empathy ratings of human-generated vs. AI-generated documentation
AI-generated documentation also received significantly higher empathy ratings in cognitive, affective, and behavioral dimensions from both occupational therapists and patients/caregivers (p < 0.001). Mean empathy scores for AI documentation consistently exceeded 4.0, while human-generated versions averaged around 3.6. The proportion of low-empathy ratings (<3) remained comparable, but the proportion of empathetic or very empathetic responses (≥4) was markedly higher for AI-generated documentation—2.6 to 3 times more frequent than for human-generated notes (Figure 3).

Empathy ratings for documentation generated by human and artificial intelligence (AI).
Correlation between quality and empathy
Quality and empathy scores were significantly correlated in human-generated documentation (p < 0.001), indicating that higher quality was associated with greater empathy. In contrast, this association was generally absent in AI-generated documentation, with the exception of a weak but significant correlation between correctness and affective empathy (r = 0.148, p = 0.005). These patterns held consistently across both occupational therapist and patient/caregiver evaluations (Table 1).
Correlation between quality and empathy in human-generated and AI-generated documentation.

**p < 0.01, ***p < 0.001.
AI: artificial intelligence.
Inter-rater reliability of human-generated vs. AI-generated documentation
Inter-rater reliability was generally moderate to high across all domains for both human- and AI-generated documentation (p < 0.001). For human-generated responses, ICC values ranged from 0.580 (concordance) to 0.754 (affective empathy), indicating more consistent agreement among raters.
Artificial intelligence-generated documentation showed slightly lower agreement overall, with ICCs ranging from 0.527 (correctness) to 0.743 (concordance). Notably, inter-rater reliability for AI documentation was comparable or higher in concordance, but tended to be lower in correctness and affective/behavioral empathy, suggesting greater variability in how raters interpreted AI outputs (Table 2).
Evaluator agreement for quality and empathy ratings in human vs. AI-generated documentation.
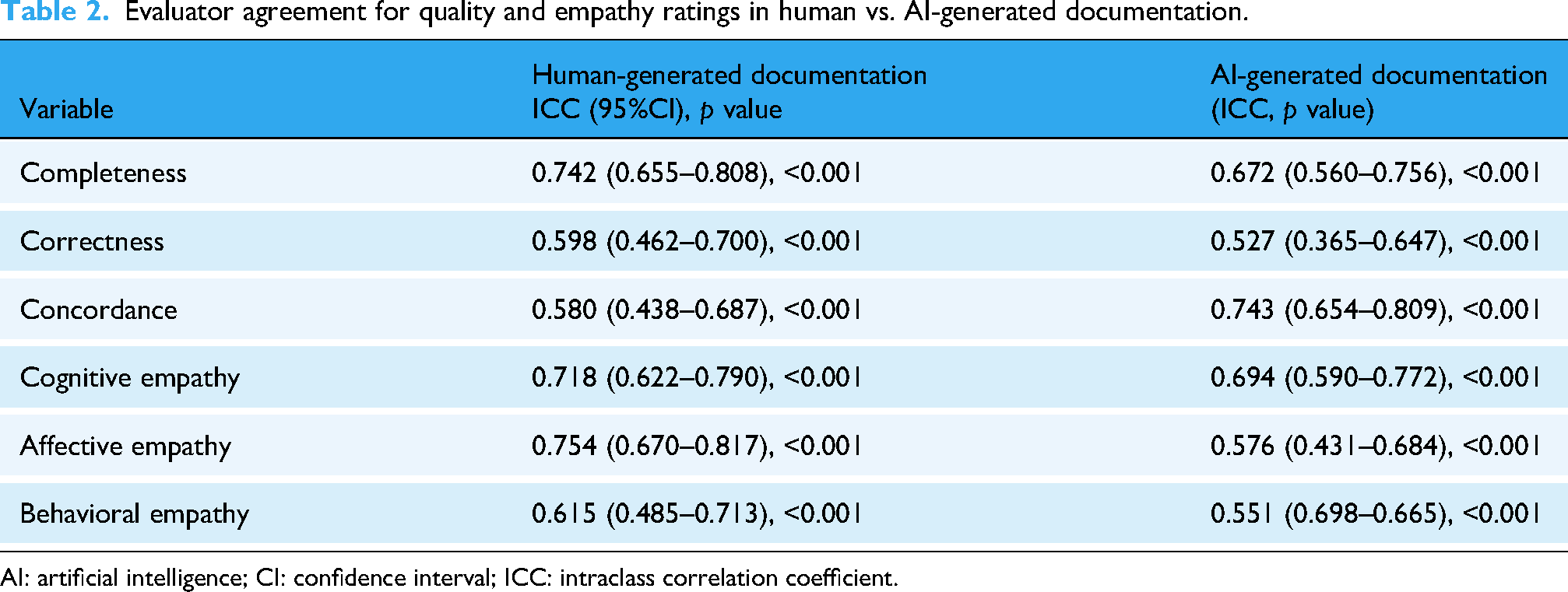
AI: artificial intelligence; CI: confidence interval; ICC: intraclass correlation coefficient.
Discussion
The aim of this study was to investigate the effectiveness of AI-generated documentation in OT. The results demonstrated that, within the context of standardized clinical case scenarios, AI-generated OT documentation outperformed human-generated responses in both quality and empathy ratings. Quality was assessed across completeness, correctness, and concordance, while empathy was evaluated across cognitive, affective, and behavioral empathy. Notably, while AI-generated OT documentation received higher mean ratings, human-generated documentation exhibited higher inter-rater reliability, suggesting more consistent perceptions among evaluators. Furthermore, AI-generated documentation showed a weak correlation between quality and empathy, in contrast to a stronger association found in human-generated content.
These findings align with prior research on AI-generated medical responses,6,7 which demonstrated that AI-generated OT documentation outperformed human-generated OT documentation in both quality and empathy. Specifically, a previous study reported that AI-generated responses to patient inquiries on an online platform were rated higher than physician responses in both quality and empathy. However, this study extends prior work by focusing on discipline-specific documentation in OT, applying a multi-component evaluation framework, and incorporating assessment from both clinicians and patients/caregivers.
In contrast to previous research that used single-component metrics, 7 this study included completeness, correctness, and concordance, whereas a prior study primarily focused on a general quality rating. Notably, a prior study overlooked accuracy, making it unclear whether AI-generated responses contained fabricated information. In contrast, by incorporating correctness into the quality assessment, this study could provide a more rigorous assessment of response validity.
In addition, this study emphasized the importance of a multidimensional approach to empathy evaluation by assessing cognitive, affective, and behavioral empathy. On the other hand, a previous study relied solely on physician evaluations of responses. 7 While physician evaluations provide valuable clinical insights, empathy is inherently subjective and may be better assessed from the perspective of patients or caregivers.14,15 To address this limitation, this study included both OT and patient or caregiver evaluators, ensuring a balanced assessment that captures both professionals and patient-centered perspective. This aligns with research indicating that patient-reported empathy scores may be more predictive of healthcare outcomes than clinician evaluations.16,17
A previous study has also reported higher quality and empathy ratings for AI-generated responses, 7 which supports the findings of this study. However, a critical distinction is that a previous study primarily analyzed responses to general medical inquiries on a public forum, whereas this study examined structured OT case documentation, which required greater contextual understanding, clinical reasoning, and patient-centered care. The higher ratings for AI-generated OT documentation suggest that AI may be particularly effective at generating structured, comprehensive responses that align with documentation standards. This finding aligns with previous research showing that AI models excel at synthesizing and summarizing complex information while maintaining clarity and coherence.6,18–20
One prior study reported a significant correlation between quality and empathy in physician-generated responses, whereas AI-generated responses exhibited a much weaker correlation. 7 Similarly, in this study, human-generated documentation exhibited a stronger correlation between quality and empathy, compared to AI-generated documentation. Although one statistically significant association was observed in AI responses, this correlation was weak and unlikely to hold clinical relevance. The finding should therefore be interpreted cautiously, as statistical significance does not necessarily imply practical or clinical significance. This finding suggests that human professionals naturally integrate empathetic language when producing high-quality documentation, while AI-generated documentation, though technically proficient, may lack the intuitive depth and contextual awareness that shape human communication. This interpretation is consistent with previous research indicating that empathy in clinician communication is influenced by experience, intuition, and real-world patient interactions—elements that AI currently struggles to replicate.20,21
Despite the superiority of AI-generated documentation in terms of quality and empathy, inter-rater reliability analysis revealed that human-generated documentation exhibited greater consistency among evaluators. This contrasts with a prior study where AI-generated responses were primarily evaluated by a single professional group (e.g., physicians), without assessing variability across different evaluator backgrounds. This discrepancy highlights a potential limitation of AI-generated documentation—while AI responses may appear high-quality, their interpretation and perceived reliability may vary among evaluators. This suggests that AI-generated medical text may introduce variability in user interpretation, emphasizing the need for standardization in AI-generated clinical documentation.
A key strength of this study lies in its multi-component and rigorous evaluation approach. By decomposing quality and empathy into three core subdomains each, this study offers a more granular understanding of AI performance. Including both occupational therapists and patients/caregivers as evaluators enhanced the ecological validity of the empathy assessments. The use of standardized clinical cases allowed for controlled comparisons, ensuring that all evaluators assessed identical content. Moreover, inter-rater reliability analysis contributed to the methodological robustness of the findings of this study.
The findings of this study have important clinical implications. First, AI-based tools may contribute to enhancing the quality of OT documentation. The consistently higher ratings for quality and empathy suggest that AI-generated drafts could serve as a useful starting point for therapists, potentially supporting collaborative documentation processes. This aligns with prior suggestions that AI can assist clinicians by generating preliminary drafts, 7 which can be reviewed and edited for clinical accuracy and contextual relevance. Second, the variability in inter-rater reliability suggests that AI-generated documentation may require additional standardization. Future AI development should focus on enhancing contextual adaptation, individualized patient reasoning, and tailored language models to improve reliability and alignment with professional documentation standards.
While this study provides valuable insights, several limitations should be acknowledged. First, standardized OT case scenarios were used instead of real-world patient encounters. While this approach ensured controlled comparisons, it could not fully capture the complexities of live clinical interactions. Future research should investigate how AI-generated documentation performs in dynamic clinical settings where patient conditions and responses vary. Second, documentation quality and empathy were assessed using Likert-scale evaluations. However, no standardized tools currently exist to assess empathy and quality in written documentation outside face-to-face contexts. Developing and validating such tools should be a priority for future studies to improve the reliability and applicability of AI-generated documentation evaluations. Third, documentation length was controlled to minimize bias, ensuring that response length would not unduly influence quality and empathy ratings. However, this might not fully reflect real-world documentation practices, where content length and detail can vary significantly based on clinical needs. Fourth, the generalizability of these findings to other healthcare domains remains uncertain. Since OT documentation involves distinct considerations, such as goal-setting, functional assessments, and interdisciplinary collaboration, future research should explore whether similar AI performance trends are observed in other fields, including nursing, physical therapy, or speech therapy. Fifth, although this study incorporated a blinded and structured rating process, the number of evaluators (n = 5 per group) was relatively small. This limited rater pool may introduce bias and restrict the generalizability of the inter-rater reliability findings. Although 95% confidence intervals were reported to indicate the precision of ICC estimates, further research involving a larger and more diverse sample of raters would help further validate and strengthen the reliability of these results. Finally, this study utilized ChatGPT-3.5, a publicly available AI model, to ensure generalizability. However, since ChatGPT-3.5 was not specifically designed for answering medical questions, unlike Med-PaLM and other medically fine-tuned LLMs, the results may vary depending on the type of LLM used.
Conclusion
This study contributes to the growing body of research on AI-generated medical documentation by demonstrating that, in the context of standardized case simulations, AI-generated OT documentation was rated higher in perceived quality and empathy than human-generated documentation. However, human-generated documentation exhibited greater inter-rater reliability, suggesting that AI-generated text may be interpreted inconsistently by different evaluators. These findings highlight both the potential benefits and limitations of AI in clinical documentation, emphasizing the importance of human oversight, contextual adaptation, and further refinement of AI models. As the findings are based on controlled scenarios, they may not fully generalize to real-world clinical settings. Further research is needed to examine the applicability and effectiveness of AI-assisted documentation in routine occupational therapy practice. Future research should explore strategies to enhance the reliability, patient-centeredness, and real-world applicability of AI-generated documentation in clinical practice.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251386657 - Supplemental material for Artificial intelligence in occupational therapy documentation: Chatbot vs. Occupational Therapists
Supplemental material, sj-docx-1-dhj-10.1177_20552076251386657 for Artificial intelligence in occupational therapy documentation: Chatbot vs. Occupational Therapists by Si-An Lee and Jin-Hyuck Park in DIGITAL HEALTH
Supplemental Material
sj-docx-2-dhj-10.1177_20552076251386657 - Supplemental material for Artificial intelligence in occupational therapy documentation: Chatbot vs. Occupational Therapists
Supplemental material, sj-docx-2-dhj-10.1177_20552076251386657 for Artificial intelligence in occupational therapy documentation: Chatbot vs. Occupational Therapists by Si-An Lee and Jin-Hyuck Park in DIGITAL HEALTH
Footnotes
Acknowledgements
The authors would like to thank occupational therapists who wrote documentation or rated.
Consent statement
Not applicable as this study is neither a clinical trial nor a human trial.
Contributorship
S-A.L. drafted the original manuscript. S-A.L. and J-H.P. conceptualized the study, designed the methodology, conducted the investigation, and curated the data. Both authors contributed to reviewing and editing the manuscript. J-H.P. supervised the overall research process. All authors have read and approved the final version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Research Foundation of Korea (grant number 2021R1I1A3041487) and Soonchunhyang University.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Data collected and used in this study can be requested from the corresponding author.
Guarantor
J-HP.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.