
Abstract
Objective
This study introduces LiteFallNet, a lightweight and interpretable deep learning model for real-time fall detection using only inertial sensor data. It aims to overcome key limitations in current systems, including high computational demands, latency, and privacy concerns, while delivering accurate and reliable performance.
Methods
LiteFallNet integrates a Gated Recurrent Unit (GRU) layer, a Temporal Convolutional Network (TCN) block, depthwise separable convolutions, and a Squeeze-and-Excitation (SE) block to efficiently extract temporal features from tri-axial accelerometer, gyroscope, and magnetometer signals. The model was trained and evaluated on the FallAllD and the UMAFall datasets. To enhance transparency, one-dimensional gradient-weighted class activation mapping (1D Grad-CAM) and local interpretable model-agnostic explanations (LIME) were used to interpret how the model made its predictions.
Results
The model on the FallAllD dataset achieved an accuracy of 97.81%, a recall of 98.55%, and an F1-score of 97.88%, with an area under the receiver operating characteristic curve of 99.33%. With a size of just 0.312 MB and an inference time of 7.07 ms, LiteFallNet combines strong performance with efficiency. These attributes make it highly suitable for deployment in real-time, resource-constrained environments.
Conclusion
LiteFallNet offers a privacy-preserving and real-time solution for fall detection. Its accuracy, transparency, and lightweight design make it suitable for smart homes, eldercare facilities, and wearable health technologies.
Introduction
Falls are a significant concern in public health, particularly among older adults and individuals with limited mobility.1,2 They represent one of the leading causes of injury-related morbidity and mortality in older adults, with far-reaching physical, psychological, and economic consequences.1–4 Approximately 37.3 million falls annually require medical attention, many of which result in life-altering injuries such as hip fractures and traumatic brain injuries.5,6
In older adults, even minor falls can be catastrophic. Approximately 30% to 50% of falls result in minor injuries, and around 10% cause serious harm.5,7 Notably, about 1% of falls among the elderly lead to hip fractures, which are strongly associated with postfall complications, increased dependency, and mortality.7,8 Beyond physical harm, falls also impose psychological burdens such as fear of falling again, 9 which often leads to reduced activity levels, social isolation, and diminished quality of life. 10 Additionally, prolonged isolation can contribute to depression and anxiety, further discouraging activity. 11 This fear-driven inactivity contributes to a cycle of muscular atrophy, impaired balance, and greater fall risk.12,13 Economically, fall-related injuries place a significant strain on healthcare systems due to emergency care, hospitalizations, rehabilitation, and long-term support,4,14 especially for individuals with chronic conditions like diabetes and arthritis.15,16
The interplay of physical decline, psychological distress, and financial hardship creates a vicious cycle of fear-induced inactivity and restriction of access to essential healthcare remedies.17,18 These challenges underscore the critical need for efficient fall detection systems that provide timely alerts and interventions to reduce injuries and enhance quality of life.
Timely and accurate fall detection systems are crucial to reducing medical complications associated with falls and facilitating emergency response. Early systems relied on wearable push-button alerts, which were ineffective if the user was unconscious or unable to activate the device. 19 This limitation led to the development of threshold-based algorithms that use motion parameters like acceleration and angular velocity. While improvements in smartphone-based systems have enhanced signal capture, especially when devices are worn on the hip, 20 threshold-based models struggle to adapt to varied user behavior, sensor positions, and environmental conditions,21,22 often leading to high false alarm rates or missed falls.
Recently, machine learning and deep learning have opened the door to more reliable detection methods. Classical ML techniques like Support Vector Machines (SVM), Random Forests, and K-Nearest Neighbors have shown better performance by learning from labeled datasets.23,24 However, their performance relies heavily on dataset diversity and is computationally inefficient, especially on edge devices.22,25
In contrast, deep learning architectures such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and their hybrids have shown strong potential in modeling complex spatiotemporal patterns in raw sensor data.26,27 These models offer higher accuracy and adaptability21,28 but often have increased computational requirements. Vision-based deep learning models, while accurate, introduce privacy risks due to continuous video monitoring, even when techniques like skeletonization are used.21,29–31 This constant surveillance can feel intrusive, especially in sensitive environments like bedrooms, bathrooms, or elderly care facilities. In addition, vision-based fall detection systems often rely on cloud computing, resulting in latency and security concerns. 32 Some state-of-the-art models require millions of parameters and specialized hardware, making them impractical for real-time use in resource-constrained settings.
High-performing video-based models often come with significant computational demands. Many of them require complex deep learning architectures, such as hybrid CNN-RNN models, which are not optimized for edge deployment. For example, Dutt et al.'s CNN-based video fall detection model achieved a high accuracy of 98% but required real-time processing at 60 frames per second on a GPU, making it unsuitable for deployment on low-power edge devices. 33 Similarly, state-of-the-art models such as SDES-YOLO by Huang et al. and LFD-YOLO by Wang et al., despite their strong detection performance, require 2.9 million and 5.67 million parameters, respectively.34,35
Sensor-based fall detection using Inertial Measurement Units (IMUs) offers a more privacy-preserving and efficient alternative. IMUs record only motion-related data, such as acceleration, angular velocity, and magnetic field strength, without capturing identifiable personal information. 36 Moreover, these systems can operate entirely on-device, enabling real-time responsiveness without cloud connectivity. This local processing also enhances user privacy by avoiding external data transmission and allows low latency for timely emergency responses. 37 However, existing sensor-based deep learning models still face tradeoffs between accuracy, model complexity, and computational generalizability. For instance, CNNs are good at capturing local spatial features but less effective at modeling temporal dependencies. RNNs like Long Short-Term Memory models (LSTMs) and GRUs excel in temporal modeling but are computationally intensive.33,38
To address these limitations, this study introduces LiteFallNet, a novel lightweight deep learning model designed for real-time fall detection using only IMU sensor data. LiteFallNet addresses four significant challenges: (1) reducing computational complexity to enable real-time processing on edge devices; (2) eliminating privacy concerns associated with visual data collection; (3) maintaining high classification accuracy and model interpretability; and (4) maintaining a low latency to support real-time responsiveness.
LiteFallNet combines Gated Recurrent Units (GRUs) for short-term temporal modeling, Temporal Convolutional Network (TCN) block for capturing long-range dependencies, Depthwise Separable Convolutions to minimize parameter count, and Squeeze-and-Excitation (SE) blocks for channel-wise feature recalibration. To promote interpretability, we used one-dimensional gradient-weighted class activation mapping (1D Grad-CAM) and local interpretable model-agnostic explanations (LIME) to visualize sensor contributions during classification.
This article presents a comprehensive evaluation of LiteFallNet, including training on the FallAllD dataset, architectural robustness testing on the UMAFall dataset, and ablation studies to quantify the contribution of each architectural component. We demonstrate that LiteFallNet achieves high accuracy with low latency and memory footprint, making it suitable for deployment in smart homes, eldercare facilities, and wearable devices.
Methodology
LiteFallNet is a lightweight deep learning model capable of real-time fall detection, developed, and evaluated on two public inertial sensor datasets: FallAllD and UMAFall. FallAllD served as the primary dataset for model training and validation, while UMAFall was used to examine further the architectural robustness of LiteFallNet across different activity profiles. The model captures temporal and spatial patterns from tri-axial accelerometer, gyroscope, and magnetometer signals. The development pipeline included four stages: dataset acquisition, data preprocessing, model design, and evaluation, as outlined in Figure 1.

Model pipeline.
Study design
This retrospective study was conducted between January and March 2025 at the Kwame Nkrumah University of Science and Technology, Ghana, to develop and evaluate the performance of LiteFallNet using publicly available datasets. Model development and training were performed in Python 3.10 with the TensorFlow 2.11 framework. All experiments were executed on a local machine (Intel Core i7, 16 GB RAM) and a cloud environment (Kaggle GPU: T4 x2, 29 GB RAM).
Data description
FallAllD dataset
The FallAllD dataset, obtained from the IEEE DataPort website, 39 was the primary dataset. It contains 6605 labeled instances across 23 activities, including diverse fall types and activities of daily living (ADLs), collected from 15 participants using wearable sensors at the neck, wrist, and waist. Table 1 summarizes the activity instances, showing that FallAllD is unbalanced.
Number of instances per activity.

Despite the relatively small sample size of 15 participants, the dataset captures a wide range of activities, sensor placements, and environmental settings (both indoor and outdoor). This level of diversity reduces the risk of overfitting and promotes the development of models that generalize well across different real-world scenarios. Table 2 provides a summary of the FallAllD dataset characteristics.
Summary description of the FallAllD dataset. 39

UMAFall dataset
The UMAFall 40 dataset is a publicly available benchmark developed by the University of Málaga for human activity recognition and fall detection research. It comprises inertial data collected from 17 subjects (11 males and 6 females) aged between 18 and 60 years, who performed 11 types of activities, including 5 types of falls and 6 ADLs. A total of 728 fall instances and 2184 ADL instances were recorded using a waist-worn Shimmer3 device, which collected synchronized signals from a tri-axial accelerometer, gyroscope, and magnetometer. All signals were sampled at 20 Hz, providing a reliable temporal resolution for detecting dynamic motion patterns.
UMAFall was selected as a secondary dataset to test the architectural robustness of the model due to its high-quality annotations, consistent sampling rate, and sensor configuration, which align with the modalities used in the FallAllD dataset. Its inclusion in this study enabled a robust evaluation of LiteFallNet's reproducibility and architectural stability.
Data preprocessing
In the FallAllD dataset, tri-axial accelerometer, gyroscope, and magnetometer recordings were used for analysis, while barometric pressure signals were excluded because they do not capture motion-related information relevant to fall detection and may introduce inconsistencies in temporal alignment across modalities. No corrupted or incomplete recordings were identified during exploratory data analysis. Magnetometer recordings were upsampled to 238 from 80 Hz using linear interpolation to match the sampling rate of accelerometer and gyroscope data. Each instance was standardized to 4760 time-steps per 20 seconds by zero-padding for shorter sequences or truncation for sequences longer than 4760 time-steps.
All signal values were scaled by a factor of 1/10000 to normalize their wide dynamic range and stabilize the training process. Final inputs, stored as NumPy arrays, had a shape of (N, 4760, 9), where N is the number of instances, and 9 refers to tri-axial signals from the three sensor types. Class labels were then binarized: ADLs were labeled as 0, and falls as 1.
Regarding the UMAFall dataset, all available inertial signals (accelerometer, gyroscope, and magnetometer) were retained, after which the data was normalized and the input sequence length was adjusted to 400 time-steps to reflect a 20Hz sampling rate over a 20-second window.
Data augmentation and balancing
A data-level augmentation was used to address the class imbalance in the FallAllD dataset. Gaussian jittering, 41 a time-series augmentation technique, was applied to the original fall samples by adding Gaussian noise (σ = 0.01). Each original fall instance was used to generate two augmented versions, effectively tripling the number of fall instances. After this augmentation, the final class distribution was nearly balanced, with 5166 fall samples and 4883 ADL samples.
Gaussian jittering (σ = 0.01) was also applied to rectify the class imbalance in the UMAFall dataset, obtaining a nearly balanced dataset of 2184 fall samples and 1733 ADL samples.
Datasets partitioning
The two augmented datasets were each partitioned independently into 60% training, 20% validation, and 20% test sets. A stratified splitting strategy was employed at the instance level to preserve the original class distribution (fall vs. ADL) across all subsets. Notably, the test set remained completely blind until the final evaluation after model development.
Table 3 presents the number of samples in each partition of the augmented FallAllD dataset.
Number of samples for training, validation, and test datasets.

Model architecture
Model overview
LiteFallNet is a modular, multistage architecture consisting of:
Temporal Feature Extraction: Batch normalization, a Gated Recurrent Unit (GRU), and a Temporal Convolutional Network (TCN) layer to capture short-term and long-range temporal dependencies. Feature Enhancement: A SE block for channel recalibration, depthwise separable convolutions, and max pooling for compact and informative representations. Pooling Aggregation: Global average and max pooling are applied along the temporal dimension and concatenated to form a fixed-length embedding. Classification: A fully connected layer followed by a sigmoid activation for binary fall or ADL prediction.
Figure 2 presents the model architecture of LiteFallNet, including its detailed layers and components.

Model architecture of LiteFallNet.
Feature extraction
The model input is a time-series signal 
In LiteFallNet, the learnable parameters
Following batch normalization, the normalized signal
At each time step t, the GRU receives as input the current feature vector 
The GRU employs two gating mechanisms, the update gate and the reset gate, that regulate how past information and new input are combined. The first gating mechanism, the update gate, determines how much of the previous hidden state should be preserved versus replaced by the candidate state: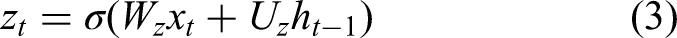
The second gating mechanism, the reset gate 
The candidate hidden state 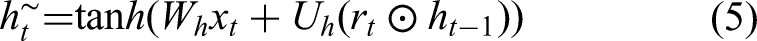
Together, the update and reset gates allow the GRU to strike a balance between retaining past information and incorporating new input. When the update gate
After temporal encoding by the GRU, the resulting sequence,
The TCN employed in LiteFallNet uses 1D convolutional layers with 32 filters, a kernel size of 3, and a dilation rate of 2. These causal convolutions ensure that the outputs depend on the current, t, and past time-steps, t’, where t’ ≤t. By using dilation, the receptive field of the convolutional filters expands without requiring additional layers or parameters, allowing the model to “look back” farther in time while remaining computationally efficient. Mathematically, the dilation causal convolution at time t for a given output channel is expressed as:

The final output of the feature extraction block is given by:
Feature enhancement
This stage is designed to refine and selectively amplify informative features by integrating an SE mechanism, a depthwise separable convolutional layer, and a max pooling operation. The enhancement process begins with the SE module, which recalibrates channel-wise features based on global temporal context. To achieve this, a global average pooling operation is applied across the temporal axis of each feature map. For a given feature f 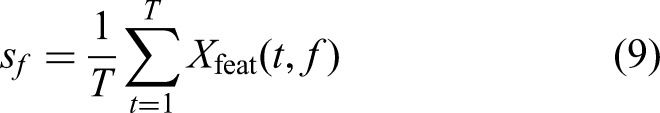
The channel descriptor vector 

This result in a recalibrated tensor
The output tensor
The final stage in the enhancement block is temporal downsampling via max pooling, which reduces the temporal resolution from T to T’ while preserving dominant local patterns. A max pooling operation does this with a stride and kernel size of 2, which is applied to 
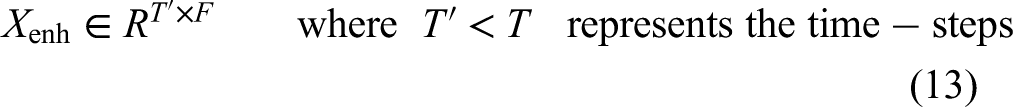
The final output,
Pooling aggregation block
An additional batch normalization layer is applied to the output of the enhancement block to prevent scale shifts across the channels, ensuring stable and balanced inputs for the subsequent pooling operations. This stabilized representation is then passed to the pooling aggregation stage, which is designed to generate a compact, fixed-length embedding of the temporal sequence. LiteFallNet employs a dual pooling strategy that combines global max pooling and global average pooling along the temporal axis to ensure that peak activations and overall trends are conserved, offering a rich and discriminative representation of temporal dynamics.
For a given feature f 
This operation results in a vector
Subsequently, global average pooling summarizes the overall activity in each feature channel by taking the mean activation across time, thus capturing long-term trends or smoother activity patterns. The average for feature f is given by:
The operation output yields a vector avg 
By combining both the most salient activations (from max pooling) and the overall trends (from average pooling), the resulting embedding Z preserves both short bursts of activity and longer-duration context. This dual perspective is critical in fall detection, where fall events often appear as abrupt spikes superimposed on more gradual activity patterns. The rich embedding Z is then passed into the classifier block, where it is further processed for final binary classification between fall and ADL instances.
Classifier block
The classifier block takes the information-rich embedding Z
First, Z is passed through a dense (fully connected) layer with 64 neurons. This layer learns nonlinear interactions among the pooled features, thereby projecting the input Z into a higher-level latent space. The transformation is mathematically defined as:

Model training
The model was trained over 30 epochs using the Adam optimizer with a learning rate of 0.0001 and a batch size of 32. Adam was chosen for its adaptive learning capabilities and reliable convergence, particularly in deep learning tasks. A batch size of 32 provided a good balance between computational efficiency and stable gradient updates. The binary cross-entropy loss function was employed for the binary classification task, as it effectively captures differences in predicted probabilities and yields well-calibrated confidence scores.
Model performance evaluation
We conducted independent training and evaluation on FallAllD and UMAFall. The model was trained and tested exclusively on the FallAllD dataset in the first phase. The same architecture was retrained from scratch in the second phase and evaluated on the UMAFall dataset under similar preprocessing, class balance, and temporal windowing settings. This dual-phase evaluation allowed us to examine whether LiteFallNet consistently retains strong performance across datasets with comparable activity categories and sensor configurations, demonstrating its reproducibility and robustness to dataset-specific variations such as UMAFall.
Model performance was evaluated on both datasets using accuracy, precision, recall (sensitivity), specificity, F1-score, area under the receiver operating characteristic curve (AUC), and inference latency. Additionally, a confusion matrix was constructed for each experiment, detailing the distribution of true or false positives and negatives to visualize class-wise prediction behavior. Inference time was measured on a laptop (Intel Core i7, 16 GB RAM) using a batch of test samples.
Ablation studies
An ablation study investigated the contribution of each architectural component in LiteFallNet on the FallAllD dataset by systematically removing or modifying individual modules within the network. Five model variants were created by excluding one key component at a time: the GRU layer, the TCN block, the SE mechanism, and the depthwise separable convolutional layers (replaced with standard Conv1D layers). The complete LiteFallNet architecture served as the baseline.
Each model variant was trained and evaluated under identical conditions: consistent training, validation, test splits, optimizer configuration, learning rate, batch size, number of epochs, and evaluation metrics. Each configuration was run three times using different dataset seeds to ensure reproducibility and prevent stochastic effects. After training, metrics across the three runs were averaged for a statistically robust comparison. The average of each evaluation metric was computed, and paired t-tests were conducted to assess the statistical significance of performance differences between each ablated variant and the complete LiteFallNet model.
Explainability
To enhance the interpretability of LiteFallNet's fall and ADL classifications, we employed both LIME 42 and 1D Grad-CAM 43 to provide local and temporal explanations. These methods brought transparency to the model's decision-making process by highlighting which features and time intervals most influenced each prediction.
LIME was used to generate local, post hoc explanations for individual predictions. Given LiteFallNet's multivariate input time-series data, each input window was flattened into a 1D vector. LIME created perturbed instances by selectively masking or altering short temporal patches within specific sensor axes to simulate minor motion variations. A custom wrapper function then reshaped these perturbed inputs into their original format before being passed to the model for inference. The LIME explainer was trained using the flattened training set, with each time-step and channel combination represented as a unique feature. The L2 norm was computed across all channels to facilitate visualization, producing a univariate motion signal. Feature importance weights were aggregated across sensor channels and overlaid as spans on the L2 signal to accentuate critical regions contributing to each classification.
1D Grad-CAM was applied to identify salient temporal regions that influenced model outputs. Gradients were computed with respect to the final convolutional layer, where channel-wise gradients were globally averaged and weighted against the corresponding activation maps to construct a temporal importance map. This map was passed through a ReLU activation function, normalized, and upsampled to match the original input length of the data (4760 time-steps for FallAllD and 400 time-steps for UMAFall). The resulting heatmap was overlaid on the mean signal across all sensor channels, visually emphasizing the time intervals most influential in LiteFallNet's prediction process.
Statistical analysis
Bootstrapping (1000 iterations) was used to compute 95% confidence intervals (CIs) for accuracy, precision, recall, F1-score, and AUC on the test set. This nonparametric approach allowed for robust estimation of metric variability without assuming normality, making it well-suited for evaluating model performance across resampled test distributions. Additionally, paired t-tests were conducted to establish the statistical significance of the ablation studies. All computations were performed using NumPy (v1.26.4), scikit-learn (v1.2.2), and scipy-stats (v1.15.2), with fixed random seeds to ensure reproducibility.
Results
This section presents the results of our evaluation of LiteFallNet, including classification performance, explainability insights, efficiency metrics, and architectural robustness testing across datasets. The model was first tested on the FallAllD dataset, followed by further training and testing on the UMAFall dataset to assess LiteFallNet's robustness.
Performance of model on FallAllD dataset
LiteFallNet achieved strong classification performance on the FallAllD test set when evaluated using the performance metrics of accuracy, precision, recall (sensitivity), F1-score, specificity, and AUC. Table 4 presents the performance of LiteFallNet on the test set of the FallAllD dataset.
Performance metrics of LiteFallNet on FallAllD dataset.

AUC: area under the receiver operating characteristic curve.
To assess the stability of these results, we conducted a 1000-sample bootstrap resampling procedure. The resulting 95% confidence intervals (CIs) for the key metrics were narrow, indicating that performance variations were minimal. Specifically, the model achieved a mean test accuracy of 97.81% (95% CI: 97.16%–98.41%), precision of 97.24% (95% CI: 96.25%–98.21%), recall of 98.54% (95% CI: 97.75%–99.22%), F1-score of 97.89% (95% CI: 97.25%–98.53%), specificity of 97.03% (95% CI: 95.91%–98.04%), and AUC of 99.33% (95% CI: 99.01%–99.68%). These results confirm LiteFallNet's reliability and effectiveness across varying data distributions.
Training and validation curves showed early convergence, with accuracy stabilizing around 98% and a consistent decline in loss. Precision and recall remained closely aligned and stabilized at 97.23% and 98.54%, respectively. The AUC scores consistently reached 99%, indicating strong differentiation between fall and ADL instances. Figure 3 provides a detailed visualization of these performance trends.

Graphs showing the performance metrics over epochs.
The confusion matrix is shown in Figure 4. It revealed that 1018 out of 1033 (1.45% false negatives) fall instances in the test set were correctly identified by LiteFallNet. For the ADLs, 948 out of 977 (2.97% false positives) were correctly identified. These low error rates demonstrate the model's reliability in distinguishing between falls and ADLs.

Confusion matrix of LiteFallNet on the test set.
Model efficiency
LiteFallNet demonstrated high efficiency in both memory usage and processing speed, with 17,751 trainable parameters, a model size of 0.312 MB (TensorFlow format, including architecture metadata and training configuration), 69.34 KB of memory use at inference, a computational cost of 71 KFLOPS, and an inference time of 7.07 ms per sample. These results demonstrate the computational efficiency of LiteFallNet and confirm its suitability for deployment on real-time, resource-constrained edge devices such as wearables or embedded systems.
Ablation studies
We conducted an ablation study to evaluate each architectural component's contribution. Five LiteFallNet variants were created by removing or replacing key modules. Table 5 summarizes the average test performance across three random seeds on the FallAllD dataset, rounded to four decimal places for the whole model and its ablated variants.
Ablation study of LiteFallNet components.
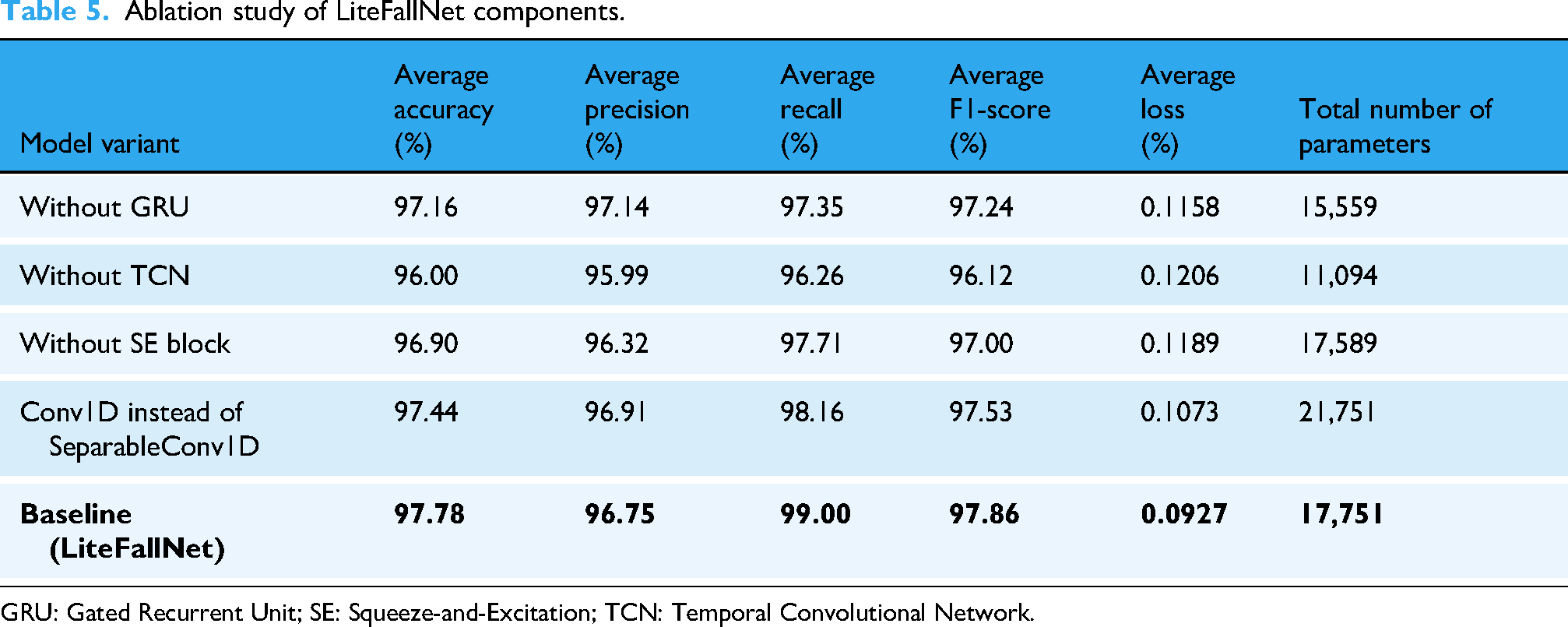
GRU: Gated Recurrent Unit; SE: Squeeze-and-Excitation; TCN: Temporal Convolutional Network.
When the GRU layer was removed, a slight reduction in recall and F1-score was observed. The TCN block was found to be the most critical component. Its removal caused the most significant performance drop, particularly in the recall by 2.74% and the F1-score by 1.74%. The decrease was statistically significant for accuracy, recall, and F1-score (p < 0.005). This observation was supported by a paired-sample t-test analysis across the three random seeds. The removal of the TCN block resulted in statistically significant declines in accuracy (t = 7.22, p = 0.0186), recall (t = 12.05, p = 0.0068), and F1-score (t = 7.84, p = 0.0159), confirming the TCN's critical role in modeling long-range dependencies. Replacing SeparableConv1D with a standard Conv1D, and singly removing the GRU and SE modules from the base model, also produced minor effects that led to performance degradation, but this was not statistically significant (p > 0.05). Removing the SE block caused moderate declines in recall and F1-score, while replacing the SeparableConv1D layer with a standard Conv1D introduced slight degradation in the F1-score and a small increase in test loss.
A table of t-statistics and p-values for all ablations is provided in Supplemental Table 2. These results reflect the additive contribution of each component to LiteFallNet's performance and computational behavior.
Architectural robustness testing on UMAFall dataset
To assess the robustness of LiteFallNet, it was retrained and evaluated on the UMAFall dataset. The model maintained excellent performance despite differences in sampling rates and activity sets. Table 6 presents the test performance metrics.
Test performance of liteFallNet on the UMAFall dataset.

AUC: area under the receiver operating characteristic curve.
The confusion matrix in Figure 5 further confirmed the model's discriminative strength, with only 8 misclassifications out of 784 test samples. The training and validation curves for loss, accuracy, precision, recall, and F1-score are shown in Figure 6. These curves reflect consistent convergence and minimal overfitting.

Confusion matrix of LiteFallNet on the UMAFall test set.

Graphs showing LiteFallNet's performance on the UMAFall dataset.
These results demonstrate LiteFallNet's ability to generalize effectively across heterogeneous fall detection datasets with varying sampling rates and activity profiles. Its consistent high performance underlines its robustness and practical applicability in real-world sensor-based fall detection scenarios.
Explainability
This study used Grad-CAM 1D and LIME to gain insights into LiteFallNet's decision logic across FallAllD and UMAFall datasets.
Grad-CAM 1D visualizations showed strong activation around abrupt motion spikes in fall signals (Figure 7b) and smooth distributions in ADL cases (Figure 7a), confirming that the model focuses on meaningful patterns. Red overlays indicate the most influential temporal segments contributing to each prediction. However, their patterns and alignment with the signal characteristics differed.
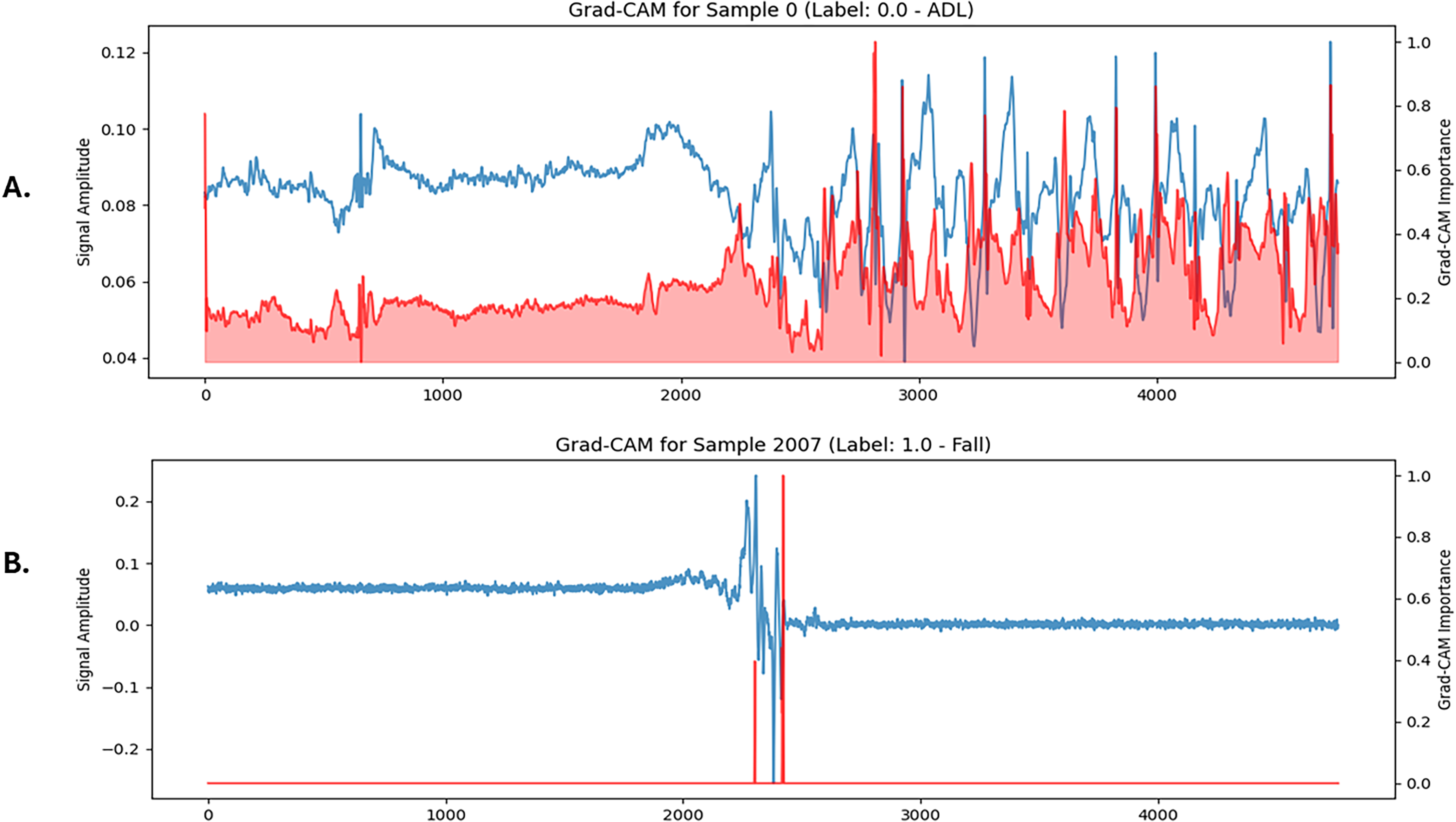
Grad-CAM 1D visualizations of LiteFallNet prediction on FallAllD dataset. (a) ADL sample showing diffuse importance across periodic signals. (b) Fall sample with focused attention on abrupt signal changes. ADL: activities of daily living.
The LIME-generated explanations are presented in Figure 8, where Figure 8a corresponds to a fall instance and Figure 8b to an ADL instance. LIME provided localized insights by identifying time-steps with high positive (green) or negative (red) contributions. Fall samples consistently displayed green highlights near signal peaks, while ADL samples exhibited red segments across steady regions. The overlaid bands are mapped onto the univariate motion-intensity signal derived from the original sensor data.

LIME explanations of LiteFallNet predictions on FallAllD dataset. (A) Fall sample with localized contributions around motion spikes. (B) ADL sample showing broader, dispersed contributions. ADL: activities of daily living; LIME: local interpretable model-agnostic explanations.
When applied to the UMAFall dataset, Grad-CAM 1D yielded activation patterns that were qualitatively consistent with those observed on the FallAllD dataset (Figure 9a and b). In fall instances, the model consistently exhibited strong activations around rapid signal transitions—particularly near sharp peaks in acceleration or angular velocity—indicating its sensitivity to abrupt, high-intensity motion typical of fall events. Conversely, ADL instances showed more diffuse and low-magnitude activations, primarily concentrated around stable signal regions, aligning with the smoother nature of routine activities.

Grad-CAM 1D visualizations of LiteFallNet prediction on UMAFall dataset. (A) ADL sample showing diffuse importance across periodic signals. (B) Fall sample with focused attention on abrupt signal changes. ADL: activities of daily living.
LIME explanations demonstrated a similarly stable pattern across datasets. As illustrated in Figure 10a and b, time-steps corresponding to high-motion bursts in fall sequences were consistently highlighted with strong positive contributions (green), whereas steady or low-motion segments in ADL sequences were marked with negative contributions (red).

LIME explanations of LiteFallNet predictions on UMAFall dataset. (A) Fall sample with localized contributions around motion spikes. (B) ADL sample showing broader, dispersed contributions. ADL: activities of daily living; LIME: local interpretable model-agnostic explanations.
These explainability tools confirm that LiteFallNet's decisions are grounded in intuitive, clinically relevant signal patterns.
Discussion
This study introduced LiteFallNet, a lightweight and interpretable deep learning model for real-time fall detection using only inertial measurement unit (IMU) data. LiteFallNet addresses three critical challenges in fall detection: computational inefficiency, privacy concerns, and latency in real-time systems. The model demonstrated strong performance across multiple datasets while maintaining a compact footprint, making it suitable for edge deployment.
LiteFallNet's architecture was designed to balance temporal modeling capacity with computational efficiency, leveraging the complementary strengths of GRUs, TCNs, SE blocks, and depthwise separable convolutions. Firstly, GRU effectively captures short-term temporal dynamics without the computational overhead of traditional RNNs or LSTMs, allowing it to recognize rapid or transient fall indicators. Next, TCNs, using dilated and causal convolutions, model long-range temporal dependencies crucial for detecting gradual or multiphase falls, such as slips, loss of balance, and descent, in the time-series input signal. The SE blocks recalibrate channel-wise feature importance, enhancing signal discrimination and noise suppression. Finally, the depthwise separable convolutions reduce the model's parameter count and computational load without compromising classification accuracy.
Ablation studies empirically confirmed the additive value of each component (Table 5). Removing the TCN block caused the most significant degradation: 1.81% in accuracy, 2.77% in recall, and 1.78% in F1-score. A paired t-test further confirmed that these reductions were statistically significant across accuracy (p = 0.00186), recall (p = 0.0068), and F1-score (p = 0.0159), emphasizing the importance of TCNs in capturing extended sequential features critical to fall detection and overall performance of LiteFallNet (see Supplementary file for more details). In comparison, the removal of the GRU layer led to a 1.66% drop in recall and 0.63% in F1-score, effects that, while statistically insignificant (p > 0.05), still reflect the importance of GRU's short-term temporal memory encoding in detecting quick transitions or subtle movements typical in falls, especially in borderline cases. Similarly, eliminating the SE block yielded a 0.88% decrease in F1-score, reinforcing the role of adaptive feature recalibration in refining signal discrimination, leading to LiteFallNet's precision and overall classification quality. Replacing SeparableConv1D with standard Conv1D incurred only a marginal 0.34% decline in F1-score. Still, it substantially increased computational load, confirming that depthwise separable convolutions are key to LiteFallNet's efficiency-performance tradeoff (high-performance, low parameter count). Though not all effects were statistically significant (p < 0.05), their combined effects suggest a meaningful contribution to the model's overall performance. While TCNs emerged as the most critical to performance, the other architectural elements each contributed meaningful, complementary functions. Their integration enables LiteFallNet to achieve a robust balance between high classification performance and computational efficiency, attaining an overall accuracy of 97.81%, a precision of 97.23%, a recall of 98.55%, an F1-score of 97.88%, and an AUC of 99.41%.
The comparative analysis presented in Table 7 demonstrates the strong real-world competitiveness of LiteFallNet against several state-of-the-art fall detection models trained on the same IMU-based datasets. When evaluating models trained on the FallAllD dataset, LiteFallNet consistently outperforms the Multilayer Mobile Edge Computing with Knowledge Distillation (MECKD) 44 model, which reported an accuracy of approximately 93.89% and an F1-score of 92.99% despite relying on a heavyweight architecture with approximately 14.64 million parameters. Compared to the MECKD model, LiteFallNet demonstrates a more favorable balance between performance and computational efficiency. Other models achieved comparable performance only on specific metrics. For example, the LSTM-based LSTM-Based Convolutional Variant Autoencoder (CVAE) 45 recorded high precision (97.61%) but fell short in accuracy (93.42%) and recall (91.96%). The discrepancies in precision, accuracy, and recall are suggestive that the model was cautious in predicting falls by reducing false positives, but at the cost of missing many true fall events. Such scenarios are often linked to the tendency of models to focus on the majority class, making them less responsive to rare but critical events like falls. Missing falls could lead to delayed interventions or undetected incidents in clinical settings, potentially putting individuals at risk. Similarly, the Coarse-Fine CNN-GRU 46 ensemble model achieved a relatively high accuracy of 97.95% but a low recall of 92.54% and a precision of 96.13%. This 4% gap between recall and precision suggests the model prioritizes minimizing false positives over capturing true falls. Such a prioritization bias mainly occurs when models are trained on imbalanced datasets without architectural compensation. In contrast, the performance metrics of LiteFallNet are well balanced with 97.81% accuracy, 98.54% recall, and 97.89% F1-score while maintaining a compact model size (0.312 MB) and inference time of 7.07 ms.
Comparison of LiteFallNet with state-of-the-art models.

CNN: Convolutional Neural Networks; CVAE: LSTM-Based Convolutional Variant Autoencoder; DSCS: Dual-Stream Convolutional Neural Network Self-attention model; GRU: Gated Recurrent Unit; LSTM: Long Short-Term Memory model; MECKD: Multilayer Mobile Edge Computing with Knowledge Distillation.
SeqTCN, 47 trained on the UMAFall dataset, achieved an accuracy of 92.00% and a recall of 85.00%, indicating limited sensitivity in detecting actual fall events. While the model may appear reasonably accurate overall, its low recall suggests a high rate of missed falls, significantly undermining its reliability in clinical settings where identifying true fall incidents are paramount. In contrast, LiteFallNet performed excellently when retrained on the same dataset (see Table 6). It achieved a 98.85% accuracy, 99.08% recall, and 99.91% AUC, considerably higher than SeqTCN's performance. These results showcase LiteFallNet's adaptability to new datasets without overfitting or losing performance.
PreFallKD, 38 which was trained on the Kfall dataset, achieved a slightly higher accuracy of 98.05% than LiteFallNet (when trained on the FallAllD dataset). However, its precision (90.62%) and recall (94.79%) were lower, indicative that PreFallKD could be more prone to false alarms and missed falls. The moderately lower recall of PreFallKD also suggests a limited sensitivity to actual fall events. Compared to the PreFallKD model, LiteFallNet demonstrates a more balanced performance across all metrics, which enhances its robustness and reliability. Furthermore, LiteFallNet uses only 17,751 parameters, substantially fewer than PreFallKD's 59,557, underscoring its computational efficiency and suitability for deployment on edge devices with limited processing resources.
From Table 7, LiteFallNet holds a competitive position even when compared to high-performing models trained on other datasets such as UP Fall, 48 SisFall, 49 and MobiFall. 50 The 1D-FCN 51 model, trained on the UP-Fall dataset, reported superior accuracy (99.52%) and specificity (99.65%) compared to LiteFallNet's performance on FallAllD (97.81% accuracy and 97.03% specificity). However, it is worth noting that the UP-Fall dataset lacks magnetometer data, which LiteFallNet utilizes to improve spatial awareness and detect orientation-based fall dynamics, further enhancing its real-world utility. LiteFallNet performed better in three evaluation metrics when trained and tested on the UMAFall dataset. LiteFallNet recorded 99.08% recall, 98.86% precision, and a 98.97% F1-score on UMAFall, outperforming 1D-FCN's respective scores of 98.70%, 98.14%, and 98.38%. These results suggest that LiteFallNet offers a better balance between sensitivity and reliability, especially in fall-critical contexts where false negatives and false positives could have detrimental effects. LiteFallNet's compactness and efficiency stem from its architecture, which combines a GRU layer, TCNs, an SE block, and depthwise separable convolutions to effectively extract temporal and spatial features. These components enable high performance with just 17,751 parameters, making LiteFallNet suited for deployment on resource-constrained edge devices. In contrast, 1-Dimensional Fully Connected Network (1D-FCN) lacks temporal and attention mechanisms, relying on stacked convolutions and requiring over 59,170 parameters to achieve comparable or lower results. While 1D-FCN achieves a slightly faster inference time (5 vs. 7.07ms), LiteFallNet compensates by offering stronger overall performance with a much smaller parameter budget. It provides a more favorable balance between architectural efficiency, computational speed, and predictive accuracy, underscoring its suitability for real-world deployment. Among the models compared, only the 1D-FCN study reported inference time, while the remaining works did not report such runtime metrics. Therefore, we emphasized parameter count alongside the main performance metrics to demonstrate LiteFallNet's efficiency.
Similarly, the Dual-Stream Convolutional Neural Network Self-attention model (DSCS) 52 model, evaluated on SisFall and MobiFall, reported high accuracy (99.32% and 99.65%) and perfect recall (100%) on MobiFall. However, LiteFallNet surpassed DSCS in precision on both datasets (98.86% vs. 98.58% on SisFall and 98.86% vs. 98.39% on MobiFall) when evaluated on the UMAFall dataset. This higher precision indicates LiteFallNet's stronger ability to avoid false alarms, which is crucial in clinical or home settings. Additionally, while DSCS is described as lightweight and embeddable, the paper provides no explicit parameter count or model size, making it challenging to compare deployment feasibility objectively. Conversely, LiteFallNet has just 17,751 parameters and a compact size of 0.312 MB, making it scalable across diverse sensor-rich deployment scenarios.
Explainability remains a critical factor in clinical AI applications. This study used Grad-CAM 1D and LIME to unpack the model's decision-making process. Grad-CAM 1D visualizations offered crucial insight into the interpretability of LiteFallNet by revealing the temporal regions most influential in the model's decision making. In fall samples, the attention represented by red overlays was sharply concentrated around abrupt spikes in the mean sensor signal, aligning with the sudden, high-magnitude changes typically observed during real fall events. This focused activation suggests that the model has effectively internalized physiologically meaningful cues associated with fall dynamics. Conversely, in ADL sequences, the attention was more diffusely distributed or centered on smoother signal segments, indicating that the model recognized the steady and continuous nature typical of nonfall activities. These visual patterns highlight that LiteFallNet is not reacting randomly to signal changes but is instead attentive to consistent features that reflect how normal human movements unfold over time. The alignment between the model's attention and the expected behavioral signatures of falls versus ADL strengthens confidence in its reasoning process. It bolsters its acceptability for deployment in real-world, safety-critical environments. LIME explanations also reinforced LiteFallNet's interpretability by identifying specific time steps that contributed most significantly to the model's predictions. For fall sequences, LIME consistently highlighted clusters of green bars representing strong positive contributions, particularly around segments with high signal intensity, short bursts, or sharp spikes. These patterns indicate that the model associated these abrupt transitions with fall events and was confident in its predictions based on those localized signal features. In contrast, ADL samples exhibited predominantly red bars scattered throughout the signal, signifying negative contributions to the fall class and reflecting the model's recognition of smooth, nontransitional movements as evidence against a fall. The distinct contrast in LIME outputs, green dominating in falls and red in ADLs, mirrors the Grad-CAM results and underscores the model's precision in differentiating falls from ADLs over time. The LIME outputs confirm that LiteFallNet's predictions are reliable and grounded in behaviorally and physiologically meaningful features.
The architectural design of LiteFallNet reflects a deliberate response to the operational demands of real-world fall detection, particularly in settings characterized by privacy sensitivity, constrained connectivity, and limited computational resources. The model overcomes the infrastructural and ethical concerns associated with vision-based systems by leveraging inertial sensor data and supporting rapid on-device inference. Its lightweight architecture and efficient temporal data handling enable continuous monitoring on embedded devices, such as wearables and ambient IoT sensors, without cloud connectivity or high-bandwidth networks. These strengths make LiteFallNet a practical solution for real-world deployment in environments where autonomy, energy efficiency, and real-time responsiveness are non-negotiable, such as smart homes, eldercare settings, and mobile health applications.
In addition to technical feasibility, LiteFallNet can be scalable across heterogeneous deployment environments. Its modular design supports seamless integration into existing edge-based health monitoring infrastructures, particularly in resource-limited settings where computational and financial constraints often preclude using more complex models. The alignment between the model's internal representations and domain-relevant motion patterns further supports its clinical transparency and regulatory plausibility. LiteFallNet can potentially serve as a deployable system capable of addressing the increasing need for reliable, cost-effective fall detection in aging populations across diverse care settings by coupling high model fidelity with architectural efficiency.
Despite its strengths, LiteFallNet has some limitations. Both datasets used in this study were collected under semicontrolled conditions and involved a relatively small number of participants. Although the datasets included relatively few participants, they provided thousands of labeled activity instances across diverse activities, sensor placements, and environments. This diversity reduces overfitting risks and improves the model's robustness. Although LiteFallNet provided consistent performance across the two distinct datasets, the relatively small number of participants in the datasets limits the generalizability of our findings. Nonetheless, future studies using larger and more heterogeneous participant populations are needed to confirm external validity and improve generalizability. Larger-scale, real-world datasets from hospitals, nursing homes, or community settings would offer a more rigorous test of the model's robustness. Future work could also explore multisensor fusion strategies, such as combining IMUs from different body parts or integrating environmental sensors, to improve detection under more complex conditions. Investigating domain adaptation techniques could also help the model generalize across diverse user populations and sensor configurations.
Conclusion
LiteFallNet is a compact, interpretable deep learning model optimized for fall detection using only inertial sensor data. It delivers both speed and accuracy. It works in real time, protects user privacy, and requires very little computing power, making it ideal for wearable and smart home systems.
The model performed consistently across two public datasets and demonstrated strong robustness and low latency. It also offers transparent decision making, helping users and clinicians trust how and why it works. With its balance of performance, simplicity, and explainability, LiteFallNet is a strong candidate for real-world deployment in next-generation digital health solutions.
Supplemental Material
sj-docx-1-dhj-10.1177_20552076251386698 - Supplemental material for LiteFallNet: A lightweight deep learning model for efficient real-time fall detection
Supplemental material, sj-docx-1-dhj-10.1177_20552076251386698 for LiteFallNet: A lightweight deep learning model for efficient real-time fall detection by Emmanuel Owusu, Isaac Acquah, Michael Asiedu Asare and Benjamin Appiah Yeboah in DIGITAL HEALTH
Footnotes
Acknowledgments
The authors acknowledge the use of Grammarly software to assist with language editing. All scientific content, analysis, and interpretations were performed by the authors, who carefully reviewed and edited the text and take full responsibility for the final version of this manuscript.
Ethical approval
The datasets used in this study were obtained from publicly available Kaggle repositories that had been ethically sourced and verified by expert clinicians. Although these datasets were de-identified and openly accessible, we obtained ethical approval from the Committee on Human Research, Publication, and Ethics of Kwame Nkrumah University of Science and Technology (CHRPE/AP/372/25) to ensure compliance with institutional standards and to reinforce our commitment to the responsible use of human-related data.
Author contribution
EO, IA, MAA, and BY was involved in conceptualization, formal analysis, and investigation; EO and MAA in methodology; ; EO, IA, and MAA writing—original draft preparation; IA and BY in writing—review and editing; and IA in supervision.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability
The FallAllD dataset used in this research to train and test the developed model is publicly available at https://ieee-dataport.org/open-access/fallalld-comprehensive-dataset-human-falls-and-activities-daily-living. The UMAFall dataset used in this research to train and test the developed model is publicly available at ![]() . We do not own these data.
. We do not own these data.
Guarantor
IA.
Informed consent
Not applicable.
Peer review
This article was peer-reviewed by external and independent referees. The journal's editorial team managed the review process, and all reviewer comments were addressed by the authors before final acceptance.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.