
Abstract
Objective
To address the complexities of distinguishing truth from falsehood in the context of the COVID-19 infodemic, this paper focuses on utilizing deep learning models for infodemic ternary classification detection.
Methods
Eight commonly used deep learning models are employed to categorize collected records as true, false, or uncertain. These models include fastText, three models based on recurrent neural networks, two models based on convolutional neural networks, and two transformer-based models.
Results
Precision, recall, and F1-score metrics for each category, along with overall accuracy, are presented to establish benchmark results. Additionally, a comprehensive analysis of the confusion matrix is conducted to provide insights into the models’ performance.
Conclusion
Given the limited availability of infodemic records and the relatively modest size of the two tested data sets, models with pretrained embeddings or simpler architectures tend to outperform their more complex counterparts. This highlights the potential efficiency of pretrained or simpler models for ternary classification in COVID-19 infodemic detection and underscores the need for further research in this area.
Introduction
The term “infodemic” is a portmanteau combining “information” and “epidemic.” Coined by David J. Rothkopf in 2003 during the SARS outbreak, an infodemic refers to the rapid and extensive spread of both accurate and inaccurate information, often exacerbated by digital communication technologies. 1 The World Health Organization formally recognized the term during the COVID-19 pandemic to describe an overwhelming amount of information in both digital and physical environments during a disease outbreak. 2 Some scholars argue that continuous discussions about infodemics can heighten public anxiety, potentially eroding trust in authoritative sources, and increasing skepticism toward official information channels. Conversely, other scholars contend that information control and censorship measures aimed at combating infodemics may infringe upon freedom of expression and limit access to diverse sources of information. Thus, effectively addressing infodemics presents a complex challenge. 3
The onset of the COVID-19 pandemic witnessed a significant upsurge in the infodemic phenomenon. Misinformation during this period spanned from false cures and prevention methods to conspiracy theories regarding the virus's origins. This surge in misleading information presented considerable challenges for public health efforts, as inaccuracies had the potential to undermine official guidelines, 4 fuel panic, 5 and even induce harmful behaviors. 6 Effectively managing an infodemic requires active measures to promote accurate information and counter misinformation. However, there are inherent challenges associated with distinguishing truth from falsehood in the context of specific information during the outbreak. Some theories, such as the mode of transmission of COVID-19 7 and the characteristics of the virus, 8 are still in flux. Additionally, it is difficult to draw direct conclusions about certain events from reports. 9 Therefore, it is crucial to consider infodemic detection as a ternary classification, where one group contains records requiring further checking and those without a certain conclusion at that time.
Currently, misinformation detection heavily relies on manual monitoring, where suspected cases are forwarded to experts for verification. This approach is time-consuming and cannot keep up with the rapid spread of infodemic, especially as social media accelerates its dissemination. Moreover, detecting misinformation on social media becomes even more challenging when considering the poor quality of user-generated content, the complex semantics of natural language, and the high dimensionality of textual data, especially when malicious entities can frequently manipulate and change their writing style to mimic trustworthy content. 10 Hence, we suggest it is imperative to develop automated techniques for misinformation detection to address the infodemic more efficiently.
Several approaches have been employed to automatically combat misinformation, and deep learning algorithms have proven superior to traditional methods in most cases. 11 Nonetheless, these algorithms become less accurate at detecting COVID-19 fake news due to their lack of specific knowledge about the incidents. After the outbreak, methods dedicated to detecting COVID-19 fake news have emerged. However, all these approaches center on misinformation detection as a binary classification problem, neglecting the inherent challenge of distinguishing the truth from falsehood. Recognizing the challenges associated with identifying misinformation through manual monitoring in certain cases, it is advisable to consider infodemic detection as a ternary classification, categorizing information into true, false, and uncertain. 12
Therefore, this paper is driven by the need to improve the accuracy and efficiency of detecting true, false, and uncertain information in the context of an infodemic. It is a preliminary study that employs deep learning models for infodemic ternary classification detection and evaluates their performance using two open-source data sets. The main contributions of our work are summarized as follows:
Eight frequently used deep learning models are employed for COVID-19 infodemic ternary classification, categorizing records into three groups: true, false, and uncertain. Precision, recall, and F1-score for each group, along with the overall accuracy, are presented for the eight models on the English data set and the Chinese data set, establishing a benchmark result. An analysis of the confusion matrix for eight models on two data sets is conducted to gain a deeper understanding of their performance across the three groups.
Related works
Misinformation on the Internet is generally treated as fake news or rumors. 13 Many deep learning-based misinformation detection methods have been proposed and attracted significant attention recently. Zhang et al. 14 studied a graph attention network-based model that combined both sentiment and external knowledge comparison to meet the needs of fake news classification. Liu et al. 15 displayed a framework for detecting fake news by leveraging a graph neural network to jointly model the content, emotional information, and propagation structure of news conversations. Xie et al. 16 studied a social network fake news detection method by introducing the concept of gatekeepers into social network fake news detection and presenting a recurrent neural network (RNN)-based gatekeeping behavior model. Shrestha et al. 17 studied a role-relational graph convolutional network to exploit inter-relationships between stories, sources, and final users for jointly estimating the credibility degree of each entity and detecting fake news. Yang et al. 18 proposed a multimodal relationship-aware attention network for fake news detection where the captured text and image representations were input into the relationship-aware attention network. Chen et al. 19 developed a deep semantic-aware graph convolutional network for Cantonese rumor detection in social networks, which integrated the global structural information and the local semantic features. Chen et al. 20 presented a syntactic multilevel interaction network model that incorporated syntactic dependency relationships and a multilevel interaction network for rumor detection. Luvembe et al. 21 displayed a unified complementary attention fusion with an optimized deep neural network that captured subtle cross-modal relationships for multimodal fake news detection.
Misinformation around the COVID-19 is considered as the first social media infodemic. 22 Therefore, it has drawn the attention of deep learning models specifically designed for categorizing the COVID-19 infodemic as either true or false. Bangyal et al. 23 constructed a semantic model and applied it along with eight machine-learning algorithms and four deep-learning algorithms to identify COVID-19-related fake news, concluding that bidirectional long short-term memory (BiLSTM) and convolutional neural network (CNN) exhibited the best performance. Paka et al. 24 introduced a cross-stitch-based semi-supervised end-to-end neural attention model for COVID-19 fake news detection, which demonstrated partial generalization to emerging fake news by incorporating relevant external knowledge into its learning process. Malla et al. 25 proposed a fusion technique-based ensemble deep learning model to detect fraudulent tweets during the COVID-19 epidemic where the fusion vector multiplication was designed to enhance the model's effectiveness. Chen et al. 26 used multiple deep learning model frameworks to detect misinformation in Chinese and English, comparing them based on different text feature selections, with BiLSTM producing the best detection results for COVID-19 fake news. Alghamdi et al. 27 evaluated various downstream neural network approaches for COVID-19 fake news detection where CT-BERT + BiGRU outperformed others with its effectiveness in capturing context and generating informative representations for downstream tasks. Xia et al. 28 studied a hybrid CNN-BiLSTM-AM model with an outlier knowledge management framework of generation–spread–identification–refutation for detecting COVID-19 fake news.
To the best of our knowledge, all deep learning models specifically developed for detecting COVID-19 infodemic have treated it as a binary classification problem. This choice is rooted in the fact that the majority of collected records used in the analysis and detection of the infodemic phenomenon are typically labeled as either true or false. 29 However, a few studies have taken a different approach, classifying these records into three to five groups to achieve a more comprehensive understanding of the COVID-19 infodemic and its impact with greater granularity. Haouari et al. 30 introduced an Arabic COVID-19 Twitter data set, wherein each tweet was labeled as either true, false, or categorized as other. Cheng et al. 31 assembled an English COVID-19 rumor data set by gathering news and tweets, which were then manually labeled as true, false, or unverified. Kim et al. 32 produced a data set comprising English claims and associated tweets, categorized into four groups: COVID true, COVID fake, non-COVID true, and non-COVID fake. Luo et al. 33 gathered widely spread Chinese infodemic content during the COVID-19 outbreak from Weibo and WeChat, classifying each record as true, false, or questionable after a four-time adjustment. Dharawat et al. 34 published a data set for assessing health risks associated with COVID-19-related social media posts, consisting of English tweets and tokens. Each entry in the data set was classified into one of five categories: real news/claims, not severe, possibly severe, highly severe, or refutes/rebuts misinformation. Luo et al. 35 released two balanced infodemic data sets by refining previously collected social media textual data with annotations from healthcare workers where all records were categorized into three distinct groups: true, false, and uncertain.
The summary of misinformation detection in the literature is presented in Table 1. It is evident that numerous deep learning-based misinformation detection methods have been proposed and have garnered considerable interest. While the infodemic gained public attention following the COVID-19 pandemic, it has also drawn the focus of deep learning models specifically designed for infodemic detection. However, these models are limited in categorizing the COVID-19 infodemic as either true or false. Given the complexity of the infodemic, it is crucial to approach it as a multiclass classification problem. The above-mentioned data sets, which classify COVID-19 infodemic records into three to five groups, provide a starting point for research in this domain. Therefore, this paper aims to employ deep learning models for infodemic ternary classification, categorizing information into true, false, and uncertain. It specifically focuses on English and Chinese, as they are recognized as the two most common languages used on the Internet. 36
Summary of misinformation detection in the literature.

Methodology
This study centers on numerical analysis, specifically utilizing publicly available data sets in English and Chinese languages. The English data set was published on October 1, 2020 37 sourced from public fact-verification websites, Twitter API, and online tools.38,39 The Chinese data set consists of records collected until April 10, 2020 33 sourced from manually verified Weibo posts, WeChat mini-program “Jiaozhen,” and authoritative sources.40,41,42 All experiments are conducted on a MacBookPro equipped with a Dual-Core Intel Core i5 processor, using PyTorch, an open-source machine learning library.
Data preparation
The two balanced data sets proposed in Luo et al. 35 are used in this research, as balanced data sets can significantly reduce bias in deep learning models. For model tuning, 10% of each data set is randomly selected, while the remaining 90% is randomly divided in a 3:1 ratio for training and testing. The details are presented in Table 2.
Statistics of the COVID-19 infodemic ternary classification detection data sets.

The English data originate from the training set published by Patwa et al. 37 Three healthcare workers were engaged to manually classify these records into three categories: true, false, and uncertain. Their evaluations relied solely on their own judgment, without reference to external sources, and the assigned label for each record was determined by a majority vote. To address the limited number of instances in the true category (830 records), an equal number of 830 records was selected from both the false and uncertain categories.
The Chinese data are sourced from Luo et al., 33 where all instances are classified as either strongly related health records or weakly related health records based on their content. The strongly related health records are further subdivided into categories such as prevention measures, general virus knowledge, and treatment information. The weakly related health records are further subdivided into categories such as local measures, national measures, patient information, and others. By examining the properties of the collected records, the initially imbalanced data set was adjusted over four rounds, resulting in 435 records labeled as questionable, 281 as false, and 339 as true. The final labels achieved high intercoder reliability with healthcare workers’ annotations. Therefore, the classification results were retained, with the label questionable being replaced by uncertain.
Research models
Eight commonly used deep learning models are employed for the ternary classification of the COVID-19 infodemic in this research. These include fastText, three models based on RNNs, two models based on CNNs, and two transformer-based models. The dropout rate and early stopping criteria for each model are determined through experimentation and observation to achieve the optimal balance between preventing overfitting and maintaining high performance.
FastText
43
: It is a library for learning word embeddings and text classification, representing each word as a bag of character n-grams. To enhance the solution's quality, the concatenation of the standard unigram average with bigram and trigram vector averages is employed. In this study, the number of hidden units in the hidden layer is set to a fixed value of 64. TextRNN
44
: The BiLSTM is selected for TextRNN. The LSTM is a widely utilized RNN architecture while the bidirectional structure enables the network to incorporate both backward and forward information at every time step. In this study, the size of the hidden units in the BiLSTM is set to a fixed value of 64, and the number of hidden layers is fixed at 4. TextRNN_Att
45
: This model is an extension of TextRNN with a neural attention mechanism where an attention layer is introduced after the BiLSTM layer. The attention layer produces a weight vector, which is then utilized to merge word-level features from each time step into a sentence-level feature vector by multiplication. TextRCNN
46
: This model is an extension of TextRNN with a max-pooling layer, which is applied after computing representations for all words. The representation of each word is formed by concatenating the left-side context vector, the word embedding, and the right-side context vector where the BiLSTM is employed to capture both the left and right contexts of a word. TextCNN
47
: This model employs convolutional operations on input text sequences to capture local patterns and features. It consists of a single convolutional layer followed by a max-pooling layer. In this study, the filter sizes are configured as 2, 3, and 4, with 64 filters for each size. DPCNN
48
: This model is an extension of TextCNN by increasing the depth of the network. It iteratively alternates between a convolution block and a down-sampling layer. Therefore, the size of internal data diminishes in a pyramid shape and the final layer aggregates internal data for each record into a single vector. Transformer
49
: This model relies solely on attention mechanisms, specifically self-attention and multihead attention, allowing it to capture long-range dependencies in input sequences efficiently. In this study, it is configured with a hidden size of 768, an intermediate size of 3072, 12 attention heads, and 12 hidden layers. BERT
50
: This model is an extension of the transformer, specifically the bidirectional encoder representations from transformers. In this study, the BERT-Base, cased version is applied for COVID-19 infodemic ternary classification detection in English, while the BERT-Base, Chinese version is used for processing Chinese records.
Evaluation metrics
Precision, recall, F1-score, and accuracy are used as evaluation metrics to assess the performance of eight deep learning models. Additionally, the confusion matrix is utilized to visualize the model's actual classifications. In the ternary classification prediction task, the classifications are labeled as 0, 1, and 2, representing uncertain, false, and true, respectively.
Precision: Precision for class i is the ratio of correctly predicted instances of class i to the total instances predicted as class i. It is formulated as Recall: Recall for class i is the ratio of correctly predicted instances of class i to the total instances that actually belong to class i. It is formulated as F1-score: It is the harmonic mean of precision and recall, providing a balance between the two metrics, which is formulated as Accuracy: It is the ratio of correctly predicted instances to the total number of instances which is formulated as

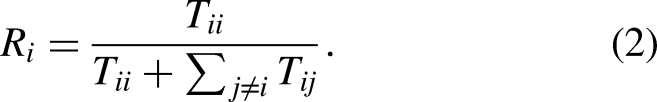


Statistical analysis
The test results for COVID-19 infodemic ternary classification detection in English are presented in Table 3, while the test results for Chinese records are displayed in Table 4. The confusion matrix for English records is presented in Figure 1, while the confusion matrix for Chinese records is displayed in Figure 2.

Confusion matrix of eight deep learning models for ternary classification of COVID-19 infodemic in English.

Confusion matrix of eight deep learning models for ternary classification of COVID-19 infodemic in Chinese.
Test results for COVID-19 infodemic ternary classification detection in English.

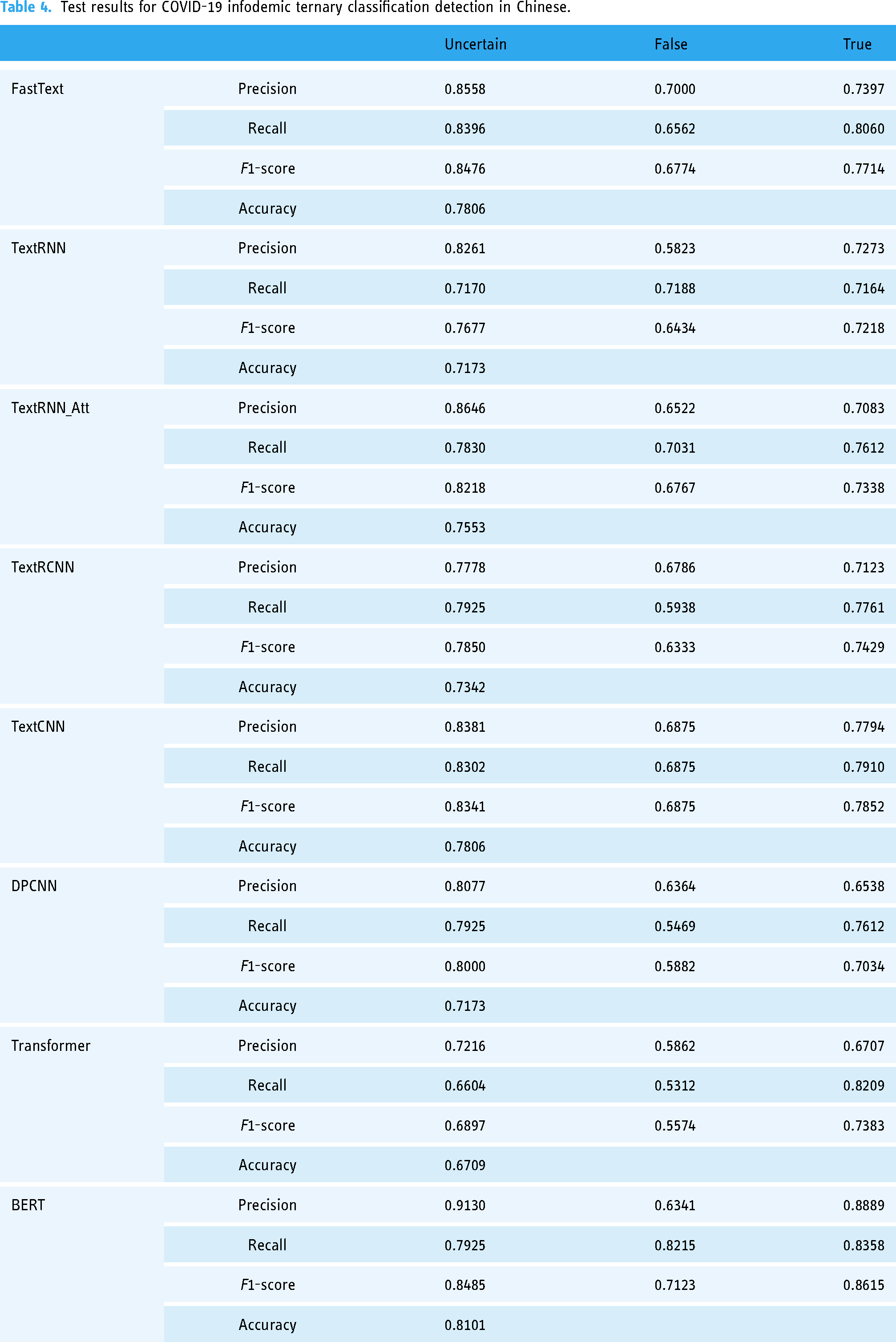
Test results for COVID-19 infodemic ternary classification detection in Chinese.
Regarding the test results for English records, the accuracy of fastText, TextRNN, TextRNN_Att, TextRCNN, and TextCNN is ∼65%, indicating a similar level of performance. However, the accuracy of DPCNN and transformer is low at 61.43% and 55.00%, respectively. Notably, BERT achieves the highest accuracy at 75.71%. For records labeled as uncertain, the F1-score is low for TextRCNN and transformer at 49.36% and 47.16%, respectively, while it is high for TextCNN and BERT at 61.12% and 64.94%, respectively. For records labeled as false, the F1-score is low for TextCNN, DPCNN, and transformer at 64.27%, 60.70%, and 55.68%, respectively, while it is high for BERT at 76.88%. For records labeled as true, the F1-score is low for TextRNN, DPCNN, and transformer at 65.25%, 65.87%, and 60.72%, respectively, while it is high for BERT at 82.61%.
Concerning the test results for Chinese records, the accuracy of TextRNN, TextRNN_Att, TextRCNN, and DPCNN ranges from 71% to 76%. The accuracy of transformer is low at 67.09%, while fastText, TextCNN, and BERT are high at 78.06%, 78.06%, and 81.01%, respectively. For records labeled as uncertain, the F1-score is low for transformer at 68.97%, while it is high for fastText, TextRNN_Att, TextCNN, DPCNN, and BERT at 84.76%, 82.18%, 83.41%, 80.00%, and 84.85%, respectively. For records labeled as false, the F1-score is low for DPCNN and transformer at 58.82% and 55.74%, respectively, while it is high for BERT at 71.23%. For records labeled as true, the F1-score is low for TextRNN, TextRNN_Att, TextRCNN, DPCNN, and transformer at 72.18%, 73.38%, 74.29%, 70.34%, and 73.83%, while it is high for BERT at 86.15%.
Regarding the confusion matrix for English records, the overall performance of the eight models is best for records labeled as true, followed by those labeled as false, and worst for records labeled as uncertain. In detail, BERT achieves the best performance for records labeled as true, while TextRNN performs the worst. BERT achieves the best performance for records labeled as false, while transformer performs the worst. TextCNN achieves the best performance for records labeled as uncertain, while TextRCNN performs the worst. Moreover, more records are misclassified as uncertain than misclassified as false in the true group in most cases, and more records are misclassified as false than misclassified as true in the uncertain group in most cases. This tendency is not obvious in the false group.
Concerning the confusion matrix for Chinese records, the overall performance of the eight models is best for records labeled as uncertain, followed by those labeled as true, and worst for records labeled as false. In detail, fastText achieves the best performance for records labeled as uncertain, while transformer performs the worst. BERT achieves the best performance for records labeled as true, while TextRNN performs the worst. BERT achieves the best performance for records labeled as false, while transformer performs the worst. Moreover, more records are misclassified as false than misclassified as true in the uncertain group in most cases, and more records are misclassified as false than misclassified as uncertain in the true group in most cases. This tendency is not obvious in the false group.
Discussions
The overall performance of deep learning models for infodemic ternary classification detection is better on the Chinese data set than on the English data set. BERT achieves the highest accuracy and consistently obtains high F1-scores across all categories. This indicates BERT's robustness in understanding and classifying complex linguistic patterns and contexts related to infodemic content. On the opposite, transformer has the lowest accuracy on both data sets underscoring the need for language-specific model tuning or selection. Surprisingly, fastText demonstrates unexpectedly good performance just after BERT. Among the three RNN-based models, there is a similar level of performance, with TextRNN achieving the best on the English data set and TextRNN_Att excelling on the Chinese data set. Regarding the two CNN-based models, the shallow TextCNN outperforms the deep DPCNN on both data sets.
The tested deep learning models exhibit a greater proficiency in learning the features for records labeled as false and true on the English data set. In contrast, the tested models display a higher capability in learning the features for records labeled as uncertain and true on the Chinese data set. This discrepancy may stem from linguistic or contextual variations between the two languages, impacting the models’ ability to generalize features effectively. Furthermore, BERT consistently achieves the best performance in most cases, while TextCNN and fastText also perform well in specific instances. Given the limited availability of infodemic records and the relatively modest size of the two tested data sets, models with pretrained embeddings or simpler architectures tend to outperform more complex counterparts.
Some limitations of this study cannot be overlooked. Firstly, the limited availability and modest size of the tested infodemic data sets are highlighted. Such constraints affect the robustness of the findings and may impact the models’ performance when applied to larger or more diverse data sets. Secondly, models demonstrate different capabilities across English and Chinese data sets. It is challenging to discern whether this performance discrepancy arises from linguistic and contextual variations or from the models themselves. Thirdly, only the efficiency metrics of the models are discussed, while their effectiveness is not considered. Finally, a specific set of deep learning models is evaluated. There may be other models or techniques that could perform better but are not included in this study.
Conclusions
The infodemic has gained significant public attention in the wake of the COVID-19 pandemic. Given its complexity, it is crucial to address infodemic detection as a multiclass classification problem. This paper focused on the application of deep learning models for infodemic ternary classification, categorizing information into true, false, and uncertain. Firstly, eight commonly used models, including fastText, RNN-based models, CNN-based models, and transformer-based models, were tested on collected English and Chinese records. Secondly, precision, recall, and F1-score metrics for each category, along with overall accuracy, were presented to establish a benchmark. BERT demonstrated its robustness in understanding and classifying the complex linguistic patterns and contexts related to infodemic content. Thirdly, a comprehensive analysis of the confusion matrix was conducted to provide insights into the models’ performance. In these evaluations, BERT consistently achieved the best results in most cases, while TextCNN and fastText also performed well in specific instances. Finally, a discussion highlighted the potential efficiency of pretrained or simpler models for infodemic ternary classification detection due to the limited availability of infodemic records.
Footnotes
Author's note
Lei Shi is also affiliated with Key Laboratory of Ethnic Language Intelligent Analysis and Security Governance of MOE, Minzu University of China, Beijing, China, and Key Laboratory of Education Informatization for Nationalities (Yunnan Normal University), Ministry of Education, Kunming, China.
Contributorship
Jia Luo initiated the idea, addressed the whole issues in the manuscript, and wrote the manuscript. Didier El Baz revised and polished the final edition of the manuscript. Lei Shi conducted the numerical experiments.
Data availability
Data will be made available on request.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 72104016), the Natural Science Foundation of Chongqing, China (Grant No. CSTB2023NSCQ-MSX0391), Beijing Natural Science Foundation (Grant No. 9242003), the R&D Program of the Beijing Municipal Education Commission (Grant No. SM202110005011), the Key Laboratory of Ethnic Language Intelligent Analysis and Security Governance of MOE (Grant No. 202306) and the Foundation of Key Laboratory of Education Informatization for Nationalities (Yunnan Normal University), Ministry of Education(Grant No. EIN2024C006).