
Abstract
Objective
This study aims to establish a real-time dynamic monitoring system for silent aspiration (SA) to provide evidence for the early diagnosis of and precise intervention for SA after stroke.
Methods
Multisource signals, including sound, nasal airflow, electromyographic, pressure and acceleration signals, will be obtained by multisource sensors during swallowing events. The extracted signals will be labeled according to videofluoroscopic swallowing studies (VFSSs) and input into a special dataset. Then, a real-time dynamic monitoring model for SA will be built and trained based on semisupervised deep learning. Model optimization will be performed based on the mapping relationship between multisource signals and insula-centered cerebral cortex–brainstem functional connectivity through resting-state functional magnetic resonance imaging. Finally, a real-time dynamic monitoring system for SA will be established, of which the sensitivity and specificity will be improved by clinical application.
Results
Multisource signals will be stably extracted by multisource sensors. Data from a total of 3200 swallows will be obtained from patients with SA, including 1200 labeled swallows from the nonaspiration category from VFSSs and 2000 unlabeled swallows. A significant difference in the multisource signals is expected to be found between the SA and nonaspiration groups. The features of labeled and pseudolabeled multisource signals will be extracted through semisupervised deep learning to establish a dynamic monitoring model for SA. Moreover, strong correlations are expected to be found between the Granger causality analysis (GCA) value (from the left middle frontal gyrus to the right anterior insula) and the laryngeal rise time (LRT). Finally, a dynamic monitoring system will be established based on the former model, by which SA can be identified precisely.
Conclusion
The study will establish a real-time dynamic monitoring system for SA with high sensitivity, specificity, accuracy and F1 score.
Keywords
Introduction
Aspiration, one of the leading clinical manifestations of poststroke dysphagia (PSD), is characterized by the misdirected inflow of oropharyngeal or gastric contents from the larynx or stomach into the respiratory tract. 1 Aspiration can be classified as silent aspiration (SA) or overt aspiration (OA). Among PSD patients, SA is frequently ignored or misdiagnosed due to the absence of overt symptoms, 2 with an estimated incidence rate between 51% and 73%. 3 Aspiration pneumonia (AP) is a serious complication of SA that can have extremely poor prognoses. 4 It has been reported that the incidence rate of AP among patients with SA is at least three times as high as the incidence among those with OA and 13 times as high as the incidence among nonaspiration patients.3,4 Therefore, SA has been considered an independent risk factor for AP and should be worthy of attention.4–6
The current assessment for SA mainly includes bedside screening tools, clinical evaluations and instrument examinations. 5 However, some notable shortcomings of these methods should not be ignored. First, low screening sensitivity and specificity limit the application of bedside screening tools in the diagnosis of SA. Second, clinical evaluations heavily rely on well-trained physiotherapists and cannot be applied to achieve real-time dynamic monitoring for SA. Third, although a videofluoroscopic swallowing study (VFSS) is recognized as the gold standard for SA assessment, it still carries the unknown cumulative risk of radiation exposure. 7
Recently, wearable, noninvasive, convenient, and nonradiative sensors have been applied in clinical assessments of swallowing function. For example, flexible miniature high-precision sensors and biaxial accelerometers have been used to identify aspiration by recording acceleration signals during swallowing.8,9 High-resolution cervical auscultation (HRCA) combining a triaxial accelerometer with a high-resolution microphone can precisely measure acceleration and sound signals. 10 In addition, some other important signals, such as airflow, acceleration, sound and electromyography (EMG), can be simultaneously collected and analyzed by a set of combined sensors.11,12 However, these methods still have some potential disadvantages: vibration signals from flexible miniature high-precision sensors are still extracted from a single location, which inevitably leads to a lack of multisource information;8,9 HRCA cannot accurately identify SA due to its single-source data acquisition approach; 10 and the combined sensors fail to effectively diagnose SA due to the limitations of data analysis and processing.11,12
To improve the accuracy of SA diagnosis, several machine learning-based dynamic monitoring methods have been proposed in some recent studies. Traditional mode recognition methods utilize prior knowledge of swallowing, breathing and handcrafted features, which may lead to bias and cannot achieve optimal efficacy in real applications. 12 In contrast, machine learning-based methods extract practical features from swallowing data samples and then establish models based on machine learning algorithms, which can serve as effective diagnostic methods for SA. The strong association between some HRCA signal characteristics and penetration aspiration has been verified by building SA detection models with features extracted from the time, frequency and time-frequency domains and various classifiers (including support vector machine and naive Bayes classifiers). 13 In addition, surface EMG improves the performance of automatic classification models for dysphagia detection.14–17
Dynamic monitoring models based on deep learning (a mainstream method in machine learning) have been used in the evaluation of swallowing function in recent years. 18 For example, a deep belief network was adopted to classify swallowing signals and showed promising results, indicating that this network has outstanding classification capability for this purpose and can be used to evaluate dysphagia. 19 In addition, thanks to the capacity of modeling sequential events and temporal dependencies in biomedical signals, recurrent neural networks (RNNs) have also been applied in automatic detection and diagnosis for dysphagia, such as acceleration signal detection during swallowing, including hyoid movement, upper esophageal sphincter opening and laryngeal vestibular closure.20,21 Thus, the machine learning-based dynamic monitoring technique is without doubt an essential method in the assessment of SA.
Most importantly, the regulatory mechanism of SA can be further explored with optimized real-time dynamic monitoring models. The occurrence of SA is thought to be associated with swallowing–breathing incoordination, 22 which is regulated by the swallowing–breathing coordination center located in the medulla oblongata of the brainstem and other cortical/subcortical neural networks, including the insular cortex, sensorimotor cortex, prefrontal lobe and thalamus.23–25 Among these brain areas, the insular cortex may play an important role since it has been observed to be significantly activated during swallowing tasks.26–28 The insular cortex may exert its modulating effect on swallowing function by accepting projection fibers from the thalamic nucleus and integrating sensory–motor information. 29 Furthermore, the insular cortex is involved in respiratory function regulation as well. For example, Trevizan-Baú et al. once adopted cholera toxin subunit B (CT-B) in the retrograde tracing of neural regulation for breathing. Finally, the authors found plenty of CT-B neurons in the insular cortex. 30 In another study, the authors inoculated pseudorabies virus (PRV) in the thyroarytenoid muscle, which participates in swallowing–breathing coordination, and found that the PRV was transferred from the periphery to the swallowing central pattern generator, respiratory swallowing central pattern generator, hypothalamus and finally to the insular cortex. 31 Therefore, insula-centered cerebral cortex–brainstem functional connectivity may be involved in the occurrence of SA through the regulation of swallowing–breathing coordination. 32 However, more powerful evidence is still urgently needed.
Currently, little research has been conducted on the mapping relationship between insula-centered cerebral cortex–brainstem functional connectivity and multisource signals (such as airflow, acceleration, sound and EMG signals) related to SA. In this protocol, we plan to develop a novel real-time dynamic monitoring system for SA based on deep learning that can elucidate this mapping relationship and increase the weight of the signals with the strongest correlation. Some issues associated with the regulatory mechanism of swallowing function may also be solved with the use of the optimized models from this system.
Objective
This study aims to establish a real-time dynamic SA monitoring system based on the mapping relationship for SA between insula-centered cerebral cortex–brainstem functional connectivity and multisource signals. First, multisource signals, including sound, nasal airflow, EMG, pressure and acceleration signals, will be extracted by multisource sensors, including EMG, nasal airflow, microphone, pressure and triaxial accelerometer sensors, during swallowing events. The extracted signals will then be labeled according to a VFSS to form a dataset. Next, a real-time dynamic SA monitoring model will be constructed and trained based on semisupervised deep learning. Model optimization will be performed based on the mapping relationship between the multisource signals and insula-centered cerebral cortex–brainstem functional connectivity through resting-state functional magnetic resonance imaging (rsfMRI). Finally, a real-time dynamic monitoring system of SA will be established, and its improved sensitivity and specificity will be demonstrated through clinical applications, thus providing more evidence for precise intervention in SA patients after stroke and improving prevention efficacy in clinical settings.
Method
Trial design
The trial is a single-center, nonrandomized, open-label cohort study. The study was approved by the Medical Ethics Committee of the Third Affiliated Hospital of Sun Yat-Sen University (No. 02-192-01) and registered at ClinicalTrials.gov (No. ChiCTR2300068908). The first patient will be included on 1 December 2023. The planned end date of the study is 1 December 2025.
Patients
Individuals with PSD will be voluntarily enrolled after providing informed consent. Then, the individuals will undergo VFSS examinations, multisource signal acquisition, and rsfMRI. Patients will be recruited from the Rehabilitation Department of the Third Affiliated Hospital of Sun Yat-Sen University.
Inclusion and exclusion criteria
The inclusion criteria are defined as follows: (a) age > 18 years; (b) stroke confirmed by MRI/CT; (c) PSD first evaluated by the volume–viscosity swallow test (V-VST) and manifesting as impaired efficacy and/or safety during oropharyngeal swallowing; (d) no cognitive impairment (Montreal Cognitive Assessment Scale ≥ 26 and mini-mental state examination ≥ 27),33,34 no pathological changes in the head and neck, metallic implants in the neck or tracheotomy; (e) the ability to cooperate with the multisource signal extraction and clinical evaluation procedures; and (f) agreement with the research terms and signed informed consent. The exclusion criteria are defined as follows: (a) cognitive impairment; (b) tracheotomy; (c) hypoxemia; (d) serious illness, including pneumonia, active infection and intractable epilepsy; and (f) inability to cooperate with the signal extraction and clinical evaluation procedures.
Outcomes
Sound signals
Sound signals, including swallowing and cough sounds, will be collected by a microphone (ECM-LZ1UBMP, Sony, Tokyo, Japan, sample rate: 48 kHz, sensitivity: −31.0 dB ± 3.0 dB; frequency response: 60 Hz–8 kHz; noise ratio: 68 dB) (Fig. 1A). The microphone will be placed on a point that is on the left of the intersection point between the anterior arch of the cricoid cartilage and midline (the distance is 1 cm).
10
To prevent noisy or mixed signals, the data will be collected in the room used to conduct the VFSS with no murmurs except for the sound of the mechanical operation (Fig. 1B). The extracted sound signals will be saved as wav audio files (sampling rate of 48 kHz, approximately 16 bits per sample, monovocal tract). Then, the audio files

Extraction of multisource signals synchronized with VFSS data. (a–c) Individual with multisource sensors, including those from EMG, nasal airflow, the microphone, pressure and triaxial accelerometer sensors, to extract multisource signals. Example multisource signals: airflow (d), sound (e), EMG signals (f) and acceleration signals (g).
Nasal airflow signals
A nasal airflow sensor (AFM3000-200, Guangzhou Aosong Electronics Co. Ltd., China, sample rate: 100 Hz) with a dead-space nasal mask over the nose will be applied to collect the nasal airflow signals, which reflect the respiratory waveform, frequency, rhythm and apnea duration (Fig.1D, E). Baseline data extraction will be performed prior to the swallowing tasks and consisted of respiratory cycle information, including exhale duration, inhale duration, apnea duration and breathing–swallowing patterns. The same data will be extracted from patients with SA.
EMG signals
An EMG sensor (LE3100, Shenzhen Dongdixin Technology Co. Ltd., China, sample rate: 8 kHz, resolving power: 0.1 µV, accuracy: ± 2 µV) will be used to extract EMG signals from the submental muscles (Fig. 1A, F), and the surface electrodes will be fixed around the center of the surface of the submental muscle to detect contractions during swallowing. 11
Pressure and acceleration signals
A pressure sensor (PVDF, Analog Devices Inc., MA, USA, sample rate: 8 kHz) will be utilized to collect pressure signals from the thyroid cartilage, which is located at the anterior midline between the thyroid and cricoid cartilage. 35 The thyroid cartilage retracts during each swallowing movement and returns to its original position after swallowing. These movements cause the pressure on the pressure sensors to change (Fig. 1A–C). 35 A triaxial accelerometer sensor (ADXL, Analog Devices Inc., MA, USA, sample rate: 100 Hz, resolving power: 78 µg/LSB) will be utilized to extract acceleration signals from the cricoid cartilage and will be positioned at the anterior midline overlying the arch of the cricoid cartilage (Fig. 1A–C, G). 10
VFSS
The VFSS will be accomplished with a Lanmage dynamic digital radiography machine (Athena Plus 7500; Shenzhen Lanmage Medical Technology Co. Ltd.; Shenzhen, China) during swallowing image acquisition, and the multisource signals will be collected at the same time (Fig. 1C). Each subject will receive 3 ml, 5 ml, or 10 ml of thickened and diluted barium liquid (contrast media: 60% w/v barium sulfate suspension). The viscosity of the liquid will be divided into four levels: lower than 50 mPa.s, in the range of 51–350 mPa.s, in the range of 351–1750 mPa.s, and above 1750 mPa·s. 36 A 10-ml injector will be used for bolus administration. The patients will be required to swallow all different volumes and viscosities of boluses, and the specific steps will be performed according to the modified Logemann protocol. 37 The VFSS data will be digitally recorded as a video in .avi format using a VFSS acquisition and analysis system (Longest Inc., Guangzhou, China) at 30 frames/s.
rsfMRI
rsfMRI will be adopted to evaluate the mapping relationship between insula-centered functional brain network properties and the different signals. rsfMRI will be conducted with a Siemens Verio 3.0 T scanner (Siemens, Erlangen, Germany) using a 64-channel coil. The T1-weighted magnetization-prepared rapid gradient-echo (MP-RAGE) scan for structural image acquisition will use the following parameters: repetition time (TR) = 2530 ms, echo time (TE) = 2.27 ms, flip angle (FA) = 90°, field of view (FOV) = 256 × 256 mm, matrix = 256 × 256, and slice thickness = 1 mm. Functional echo planar images (EPIs) will be acquired in interval sections spanning the entire brain with a gradient–echo sequence with the following parameters: TR = 2000 ms, TE = 30 ms, FOV = 256 × 256 ms, slice thickness = 3 mm, voxel size = 3 mm × 3 mm, and FA = 90°.
Sample size
In this prospective study, the sample size refers to the number of swallows. According to previous studies, a total of 3144 swallows from 248 patients with suspected dysphagia are needed. 21 Each individual repeatedly swallows during the VFSS examination. Early termination of the VFSS will be performed to prevent AP if aspiration (penetration–aspiration scale > 5) occurs, which may result in the loss of 20% to 30% of swallowing samples. Therefore, the study is designed to recruit 350 patients, with 200 subjects in the SA group and 150 subjects in the nonaspiration group.
The sample distribution is defined as follows: (1) A total of 150 individuals are needed in the dataset establishment phase to provide high-quality labeled signals. (2) A total of 50 SA patients are needed in the model optimization phase. (3) A total of 150 individuals are needed in the clinical application phase, with 100 individuals in the SA group and 50 individuals in the nonaspiration group.
Study procedures
Multisource signal extraction and synchronization
Multisource sensors, including microphone, nasal airflow, EMG, pressure and triaxial accelerometer sensors, are flexible and integrable with high sensitivity and high resolving power. These sensors will be applied to collect sound, nasal airflow, EMG, pressure, and acceleration signals during swallowing events. The signal extraction methods are described in Section 4.
To synchronize the multimodal signals, these multisource sensors will be connected to a Raspberry Pi device (4B, Broadcom Corporation). The Raspberry Pi device is a single-board computer based on the Advanced RISC Machine (ARM) architecture. The multiple GPIO (general purpose input/output) pins of the Raspberry Pi are programmed to read the signals from the connected sensors and record the timestamps. During the signal collection, the Raspberry Pi sends the recorded data and timestamps to a computer in real time over the local area network.
High-quality labeling of multisource signals synchronized with the VFSS
First, the interval of effective multisource signals will be determined by the VFSS. The signals will then be labeled by two well-trained speech–language therapists with at least 5 years of clinical experience and imaging technicians according to the VFSS results. The time points of the oral phase and pharyngeal phase will be labeled in the VFSS video, which will be played back frame by frame at a speed of 30 frames/s by ImageJ open-source software (version 1.42, National Institutes of Health, Bethesda, Maryland). The oral phase refers to the time when the bolus is being processed in the oral cavity to when the bolus is passing the ramus of the mandible, and the pharyngeal phase refers to the time when the bolus is passing the ramus of the mandible to when upper esophageal sphincter relaxation occurs. 38 Finally, the multisource signals will be segmented according to the labeled time points. The established dataset includes labeled and unlabeled multisource signals.
Establishment of a real-time dynamic Sa monitoring model based on semisupervised deep learning
Input data preprocessing
Multisource signals are vulnerable to extensive noise interference from internal and external environments, including head motions and large artery pulsations. Therefore, the first step in the signal preprocessing procedure will be to whiten the signals with a finite impulse response (FIR) filter to reinforce decorrelations in the data. The plan is to model the noise for each sensor using an autoregressive model with an order of 10. The order of the autoregressive model will be determined using the Bayesian information criterion. Based on the coefficients of the autoregressive model, a FIR filter will be created. The inverse of the FIR filter will be applied to the collected data to eliminate noise. Next, the acceleration and EMG signals will be denoised. To remove unwanted noise from the acceleration signal, a bandpass filter with a frequency range of 0.1 Hz to 3 kHz will be applied. The acceleration signal will consist of three channels corresponding to the x-, y- and z-axes, with a sampling rate of 200 Hz for the x- and y-axes and a sampling rate of 1600 Hz for the z-axis accelerations. 39
The sampling rate of EMG signals will be 2 kHz, and a bandpass filter will be implemented with a cutoff frequency between 20 and 500 Hz. The optimal parameters for the EMG will be as follows: mother wavelet db5, five decomposition levels, soft thresholding and minimax rule for threshold selection. 17
Considering the influence of concurrent events, the input signal will be downsampled to 4 kHz. Furthermore, the amplitudes and frequencies of all the signals will be normalized to eliminate the influence of the signal magnitude.
Location and identification of the swallowing cycle based on an attention mechanism
After the input data are preprocessed, the weight of each source signal will be dynamically learned with an attention mechanism. The acquired timing signal will be divided into frames to obtain the initial signal sequence


The temporal boundaries of swallowing events will be determined with a multiscale sliding window. Based on the swallowing recognition result G, a window of length d will be selected, with the t-th frame chosen as the starting point in the signal sequence; thus, the class probability corresponding to the window is
Training and testing of a real-time dynamic SA monitoring model based on semisupervised deep learning
The establishment of a real-time dynamic SA monitoring model is based on the feature fusion of multisource signals and the swallowing cycle location. To address the problems caused by the limited labeled data and class imbalances, a semisupervised deep learning method with pseudolabel generation will be applied to develop the real-time dynamic SA monitoring model.
First, a small number of labeled samples will be sent to a high-performance classifier for training. The classifier is then used to extract SA features to improve the signal recognition accuracy. If unlabeled samples exist, the samples are predicted by the trained high-performance classifier and sorted according to the predicted probability. High-probability samples will then be considered to be reliably labeled and added to the training set. This procedure will be repeated until the number of labeled samples meets the iterative requirements. The new integrated dataset will be used to train a convolutional RNN with stronger classification capability, which finally outputs the SA detection results.
To validate the performance of the proposed method, a 10-fold subject cross-validation will be performed on the collected swallowing samples. The subjects will be first randomly divided into 10 groups, each consisting of approximately 10% of the total samples. In each fold of the cross-validation, one of the 10 groups will be selected as the testing set, while the remaining samples are utilized for training. This process will be repeated 10 times, with each group serving as the validation set once (Fig. 2).

Framework of the SA monitoring model based on semisupervised learning.
Model optimization based on mapping relationships in functional brain networks
rsfMRI analyses
MATLAB (MathWorks, version 7.14) and RESTPLUS in SPM 12.0 will be used for rsfMRI data preprocessing.
Amplitude of low-frequency fluctuation (ALFF): After the preprocessed data are bandpass filtered (0.01-0.08 Hz), RESTPLUS software (http://www.restfmri.net/forum/REST-GCA) will be used to calculate the ALFF of each voxel in the whole brain, and anatomical automatic labeling (AAL) will be used to mark the bilateral insula on the template as seed points. Then, analyses of differences in the ALFF values in the insular region of interest (ROI) between the SA and nonaspiration groups will be performed to determine the relationship between this brain region and SA.
Granger causality analysis (GCA): GCA will be used to calculate the direction and strength of functional connections between cortical regions and the insular cortex. Using the bilateral insula in the AAL template as seed points for GCA, voxel-level bidirectional GCA analyses of the whole brain will be implemented via RESTPLUS software. The signed path coefficients will be used to characterize the strength and direction of connections between voxels in the whole brain and those in the insular cortex. In addition, other cortical or subcortical regions, including the sensorimotor cortex, prefrontal lobe, thalamus, laryngeal motor cortex and sensory cortex, will be investigated.
Mapping relationship analyses between the insula-centered cerebral cortex–brainstem functional connectivity and multisource timing signals will be performed as follows. First, the point coordinates of brain regions with strong functional connections will be obtained according to the previous steps and used as centers to draw spherical ROIs. RESTPLUS software was used to extract the GCA values of all samples in the y–x direction for correlation analyses. Then, continuous variables, including multisource timing signals and GCA values, will be evaluated for normality with Kolmogorov‒Smirnov tests. Pearson chi-square tests or Spearman correlation analyses (as appropriate) will be applied to clarify the relationship between the multisource timing signals and brain functional connectivity, which provides prior knowledge for model optimization.
Model optimization
The mapping relationship between the multisource signals and insula-centered cerebral cortex–brainstem functional connectivity explores the weight of different multisource signals and will be used as prior knowledge for model optimization.
The association between various physiological signals and swallowing disorders can be reflected by the actual clinical manifestation. This encompasses the significance of different physiological signals and the characteristic parameters that are pivotal in monitoring malabsorption. All these elements can serve as prior knowledge to guide the optimization of the model. Incorporating prior knowledge in the signal feature fusion stage further improves the feature fusion performance and optimizes the proposed aspiration monitoring model.
The first step will be to assign different initial weights to different signals according to the a priori distribution before feature fusion. Specifically, based on the importance weights of the a priori five meta-signals


Clinical application
The real-time dynamic monitoring system for SA will have been established when the accuracy, precision and recall rate meet the standard criteria. Then, the improved sensitivity and specificity of the system will be demonstrated through clinical applications. Precise patient interventions can be adopted according to the real-time dynamic monitoring results, and a VFSS can be applied simultaneously to test the accuracy of the system.
Statistical analyses
Multisource signal analyses
Apnea time: The nasal airflow signals will be labeled by the VFSS, with points i and j marked in one respiratory cycle. k is an arbitrary integer

The frequency domain sound signal features (including the bandwidth and spectral centroid) will be extracted by short-time Fourier transforms. The bandwidth of a signal refers to the range of frequencies that the signal occupies. It is calculated as the difference between the upper and lower frequencies of the signal. The spectral centroid is the mean of the frequencies weighted according to the energy and is an important parameter that reflects the frequency and energy distribution of sound signals.
EMG signals: After filtering, the resulting EMG signals will be split into several smaller data segments as data windows. It will be assumed that the total number of windows of interest is N. The EMG signals will be analyzed in the time and frequency domains. For the time domain, the root mean square (RMS) will be calculated by taking the mean of the squared EMG samples over a window of interest and then taking the square root of the resulting value. The RMS can be written as follows:


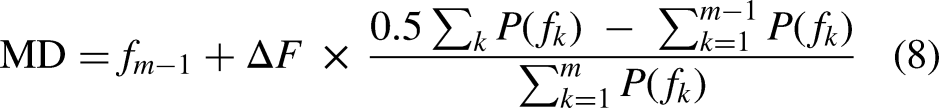
Pressure signals: Pressure signals are used to evaluate laryngeal motion (LM). The original LM signal will be transformed into the integrated LM (iLM) involving the calculation of the area under the receiver-operating characteristic (ROC) curve (AUC) of the LM waveform. The AUC value can be obtained by integrating the absolute value of the LM signal over time. The equation for calculating the integrated LM can be written as follows:

To match the pressure signals with the thyroid cartilage motion, the laryngeal rise time (LRT) and laryngeal activation duration (LAD) will be calculated based on the iLM. The calculation steps for these two parameters are as follows: (1) Within each determined swallowing cycle, the time point (P) where the sensor's raw output (LM) reaches its peak is searched for first. Due to the different characteristics of the pressure impedance sensor, this corresponds to the situation where the speed of the laryngeal elevation reaches its maximum. (2) Then, the data are searched backward from P for the zero-crossing point. If iLM has a positive value at this zero-crossing point, the search is continued forward until the local minimum of iLM with a negative value is found, which indicates the starting point (T1) of LRT. (3) A search is performed forward from P to the first zero-crossing point M. M is the time point when the larynx reaches its maximum height. (4) A search is performed backward from M for the zero-crossing point. If iLM has a positive value at this zero-crossing point, the search is continued forward until the local minimum of iLM with a negative value is found, which indicates the ending point (T2) of LAD. In conclusion, LRT represents the duration between time T1 and M, while LAD represents the duration between time P and T2 (Fig. 3).

Calculation of the LRT and LAD. LRT, laryngeal rise time; LAD, laryngeal activation duration.
Accelerometry signals: The feature set in the time domain comprises statistical metrics, such as the mean and standard deviation. In addition, other features, such as the difference between the minimum and maximum values, zero-crossings, peak to average ratio (PAR), signal magnitude area (SMA), signal vector magnitude and differential signal vector magnitude (DSVM), will be computed. 40
The feature set in the frequency domain will be calculated by the fast Fourier transform (FFT) algorithm. The FFT algorithm will be used to convert the time series data of each component into the frequency domain. The resulting features in the frequency domain include energy and entropy metrics. 41 Spectral energy in certain frequencies refers to the amount of energy or power that is present in a specific frequency range within the signal's frequency spectrum. The Fourier transform decomposes the signal into its component frequencies. Entropy is a statistical measure of the amount of uncertainty or randomness in the signal. It can be used to analyze the complexity or irregularity of the signal's frequency distribution.
Ethics and dissemination
The trial protocol was approved by the Medical Ethics Committee of the Third Hospital of Sun Yat-Sen University (2022-02-192-01). The study will be conducted according to good clinical practice guidelines suggested by researchers in the neurorehabilitation, artificial intelligence, and neuroimaging fields. The investigators will obtain written informed consent from all individuals by the investigators. The study's findings will be published in high-ranking peer-reviewed international journals and communicated to the (inter)national scientific community.
Serious adverse events
Safety risks for participants are minimal, as real-time dynamic monitoring is noninvasive. Moreover, VFSSs are conventional examinations in clinical applications and are conducted by well-trained physiotherapists to reduce complications. Furthermore, fMRI does not include the unknown cumulative risk of radiation exposure.
Expected results
Multisource signals will be stably extracted by multisource sensors. The events of the swallowing cycle, including the oral phase and pharyngeal phase, will be consistent with the time series VFSS results. A total of 3200 swallows will be obtained from patients with SA, with 1200 swallows with nonaspiration labeled by the VFSS and 2000 unlabeled swallows. The dataset will include swallowing data.
A significant difference in the multisource signals is expected to be found between the SA and nonaspiration groups. The sound signals will show differences in the variance, skewness, kurtosis, bandwidth and spectral centroid. The nasal airflow data will indicate that the apnea time in the SA group is shorter than that in the nonaspiration group, and the breathing–swallowing patterns will differ between the SA and nonaspiration groups (mainly manifesting as inhaling directly after swallowing in the SA group). Moreover, the EMG signals are expected to show differences in the time domain (including in the iEMG and RMS) and the frequency domain (including in the MPF and MF). Furthermore, the pressure signal analyses will show that the LM displacement is shorter and the LRT is longer in the SA group than in the nonaspiration group.
The features of labeled and pseudolabeled multisource signals will be extracted based on semisupervised deep learning to establish a dynamic SA monitoring model. Moreover, strong correlations will be found between the GCA value (from the left middle frontal gyrus to the right anterior insula) and the LRT. Therefore, the dynamic SA recognition model will be optimized by increasing the LRT weight. The results will demonstrate that the accuracy, precision and recall of the model meet the desired requirements. Finally, a dynamic SA monitoring system will be established for clinical applications to assess the occurrence of SA in routine daily practice.
Discussion
The present study establishes a real-time dynamic monitoring system for SA in stroke patients by extracting multisource signals during aspiration and verifies the central regulatory mechanism of SA. This system can be an early warning system of SA both in inpatient and outpatient rehabilitation. It was reported that AP is closely related to SA4–6; therefore, the system may decrease the occurrence of AP, which may increase the quality of life of SA patients.
Current swallowing aspiration detection models mostly use supervised deep learning methods, 21 but the effectiveness of the models is limited due to the limited clinical annotated samples. In this study, a semisupervised deep learning method will be used, which integrates labeled and unlabeled samples for feature learning and addresses the problem of an insufficient number of labeled samples by generating pseudolabels. Furthermore, with more signal sources than other studies,8–12 the model can learn high-level representations simultaneously from raw signals and have substantial expressive power.
In addition, precise interventions will be applied in SA patients according to our results. The optimal treatment strategy for aspiration includes swallowing exercises (such as the Mendelsohn maneuver, supraglottal swallowing, shaker exercises and effort pitch glide), neuromuscular electrical stimulation and noninvasive brain stimulation (NIBS).42–44 The present study will explore the mapping relationship between multisource signals and brain function and find the most relevant brain region of SA, which provides a feasible method for choosing the central target of NIBS. Furthermore, trying to intervene at the peripheral level by evaluating the characteristics of multisource signals of SA provides a precise way to treat SA.
There are some limitations in this protocol. First, the VFSS carries the unknown cumulative risk of radiation exposure. Second, injector use to induce swallowing is not representative of natural swallowing conditions, which may lead to potential bias. Third, we used rsfMRI to explore the mapping relationship between the functional connectivity of neural networks and multisource signals, which is indirect. Fourth, simultaneous multiple-data acquisition from PSD patients using excessive multiple sensors may cause discomfort.
Conclusion
The study will establish a real-time dynamic monitoring system for SA in PSD patients based on semisupervised deep learning by extracting multisource signals during SA, with high sensitivity, specificity, accuracy and F1 score.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China, Science and Technology Program of Guangzhou, China (grant numbers 82272617 and 2023B03J1234).