
Abstract
Objective
To compare the performance of ChatGPT-5.0, DeepSeek-R1, and Gemini-2.5 Pro in real-world outpatient prescription counseling and evaluate their applicability across clinical contexts.
Methods
Fifty authentic prescriptions from four departments were submitted to the three models using standardized Chinese prompts. Responses were independently rated by three associate chief pharmacists across five dimensions—accuracy, relevance, clarity, practicality, and completeness—on a 5-point Likert scale. Rank-based non-parametric tests were applied for overall and subgroup analyses.
Results
Significant inter-model differences were observed in most dimensions (P < 0.05). DeepSeek excelled in clarity and practicality, ChatGPT achieved the highest accuracy and completeness, while Gemini consistently scored lower. Department-specific analyses revealed distinct contextual advantages. All models exhibited high response stability.
Conclusions
LLMs demonstrate promising yet heterogeneous performance in outpatient medication counseling. DeepSeek and ChatGPT showed superior overall quality, supporting their potential as assistive “AI pharmacists” under professional supervision. However, several limitations should be acknowledged, including a modest sample size, reliance on expert evaluation rather than patient feedback, and context-specific findings that may limit generalizability.
Keywords
1. Introduction
Outpatient medication counseling represents a critical component of clinical pharmacy practice, directly influencing patients’ adherence, understanding of therapy, and medication safety.1,2 In real-world outpatient settings, pharmacists are frequently required to perform prescription review, dispensing, and patient education under strict time constraints. With the growing complexity of therapeutic regimens and the increasing prevalence of chronic diseases and polypharmacy, providing individualized, clear, and complete medication guidance for every patient has become increasingly difficult. 3 This tension between workload and service quality has prompted exploration of intelligent tools that can extend pharmacists’ capacity without compromising safety or professionalism.
In parallel, large language models (LLMs) have rapidly advanced in their ability to process natural language and to generate contextually coherent responses. Among currently available large language models, ChatGPT, DeepSeek, and Gemini represent three prominent systems with distinct development paradigms and application focuses. ChatGPT, developed by OpenAI, is based on the Generative Pre-trained Transformer architecture and has demonstrated strong performance in medical question answering, clinical reasoning, and patient-oriented communication due to its extensive multilingual training corpus and alignment optimization. 4 DeepSeek, developed in China, has shown advantages in structured reasoning and Chinese-language semantic processing, with particular strength in generating coherent and context-aware responses in clinical and technical domains. 5 Gemini, developed by Google DeepMind, integrates multimodal capabilities and real-time information retrieval, enabling dynamic interaction with up-to-date knowledge sources 6 ; however, its performance in domain-specific medical tasks has shown greater variability across studies. Their applications in medicine—ranging from clinical decision support and patient education to information retrieval—have attracted widespread attention.7,8 Compared with traditional rule-based or template-driven systems, LLMs demonstrate greater flexibility in understanding colloquial expressions, integrating background context, and producing fluent human-like explanations. 9 These features position them as potential assistants in patient counseling tasks, particularly in environments where pharmacist resources are limited. Recent studies have further demonstrated that large language models can assist in generating patient-specific clinical guidance and treatment plans with moderate agreement with expert recommendations, particularly in rehabilitation and patient communication contexts. 10 However, despite their promising capabilities, these models may exhibit limitations in detailed clinical reasoning and require professional oversight to ensure safety and accuracy. 6
Nevertheless, the clinical use of LLM-generated information presents both opportunities and risks. Although their linguistic fluency is impressive, their factual accuracy and contextual appropriateness are not guaranteed. Differences in training corpora, alignment strategies, and update cycles lead to substantial variation across models. 11 Inconsistent performance raises concerns regarding reliability, safety, and trust, especially in medication-related communication, where errors may directly endanger patient outcomes.12–14 Therefore, systematic and quantitative evaluations of different LLMs in authentic pharmaceutical service scenarios are essential to clarify their strengths, limitations, and boundaries of use. 15
Previous studies have attempted to assess the utility of individual models for drug counseling or medical question answering. However, most existing work is confined to English-language datasets or standardized test questions, and few have incorporated real Chinese outpatient prescription contexts.16–18 Moreover, prior research has largely emphasized technical correctness—such as accuracy or medical validity—while neglecting patient-centered aspects including clarity, practicality, and informational completeness. 19 Comparative studies across different departments or disease types are also rare, and little evidence exists on the stability and reproducibility of model outputs, an issue that is crucial for clinical reliability and patient trust.
To address these gaps, the present study conducted a multidimensional comparison of three representative LLMs—ChatGPT-5.0, DeepSeek-R1, and Gemini-2.5 Pro—using real outpatient prescriptions from diverse clinical departments. By assessing model-generated counseling responses across five key dimensions (accuracy, relevance, clarity, practicality, and completeness), this study aims to elucidate performance variability among models and clinical contexts, providing empirical evidence for their potential integration into human–AI collaborative pharmaceutical services.
2. Methods
2.1. Study design
This study employed a cross-sectional comparative design to evaluate the performance of three large language models—ChatGPT-5.0, DeepSeek-R1, and Gemini-2.5 Pro—in outpatient medication counseling. The research process included four key stages: (1) prescription selection, (2) standardized model prompting and response collection, (3) expert evaluation of LLM outputs, and (4) statistical comparison across models and clinical contexts. The overall workflow is illustrated in Figure 1. Flowchart of the study design.
Distribution of prescribing departments and categories of medications.

2.2. Model query and response collection
From September 1 to 3, 2025, each prescription was submitted independently to three large language models via their official web interfaces: ChatGPT-5.0 (OpenAI, USA), DeepSeek-R1 (DeepSeek Inc., China), and Gemini-2.5 Pro (Google DeepMind, USA). All interactions were conducted through publicly accessible web-based platforms rather than application programming interfaces (APIs). To minimize bias and carryover effects, a new conversation was initiated for every input. The standardized Chinese prompt was as follows:
“You are a senior clinical pharmacist at a tertiary hospital with ten years of experience in patient counseling. Please provide medication instructions for this outpatient prescription.”
Each prescription was queried once per day for three consecutive days under identical conditions, yielding 150 response sets. The first-day responses were used for primary analysis, and all three-day results were analyzed for response stability. Model settings, including temperature and conversation reset, followed the default configuration of each platform, and no additional parameter tuning was applied. Because large language models are continuously updated and do not provide fixed version identifiers or static model snapshots, exact reproducibility cannot be fully guaranteed. Although all interactions were conducted within a defined time window using standardized prompts and independent sessions, several sources of variability may still affect the outputs. First, inherent stochasticity in model generation may lead to response variability even under identical inputs. Second, the use of publicly accessible web interfaces, rather than controlled API environments, may introduce additional variability due to backend updates and undisclosed system-level optimizations. Third, model performance may change over time as providers continuously update training data and alignment strategies. To mitigate these limitations, we implemented strict standardization procedures, including identical prompts, independent sessions, and repeated queries across three consecutive days. Nevertheless, the findings should be interpreted as representative of model performance within the specific evaluation window rather than as fully reproducible results across different time points or system versions.
2.3. Expert evaluation and scoring framework
Three associate chief pharmacists, each with more than 10 years of clinical pharmacy experience, independently evaluated the LLM-generated counseling responses. All evaluators were affiliated with the Department of Pharmacy, The First Affiliated Hospital of Guangxi Medical University. They were not involved in the study design, data collection, statistical analysis, or manuscript preparation, and were invited solely for independent evaluation.
To minimize potential evaluation bias, several safeguards were implemented. First, all model outputs were anonymized, and any identifiers related to model origin (e.g., model name, interface characteristics) were removed before scoring, ensuring that evaluators were blinded to model identity. Second, the order of responses was randomized prior to assessment to prevent sequence effects. Third, evaluators conducted scoring independently without communication with each other during the evaluation process.
All evaluators declared no financial or non-financial conflicts of interest related to this study.
A five-dimension, five-point Likert scale was used, encompassing: Accuracy – consistency with current medical evidence and pharmaceutical guidelines; Relevance – alignment with the patient’s prescription question; Clarity – linguistic comprehensibility and logical organization; Practicality – usability and applicability to patient education; Completeness – inclusion of all essential medication details. Scores ranged from 1 (seriously inadequate) to 5 (fully compliant). Before scoring, evaluators participated in a calibration session to standardize judgment criteria. For each prescription and evaluation dimension, the final score was calculated as the mean of the three raters’ scores. Inter-rater reliability was assessed using the intraclass correlation coefficient (ICC) based on a two-way random-effects model with absolute agreement.
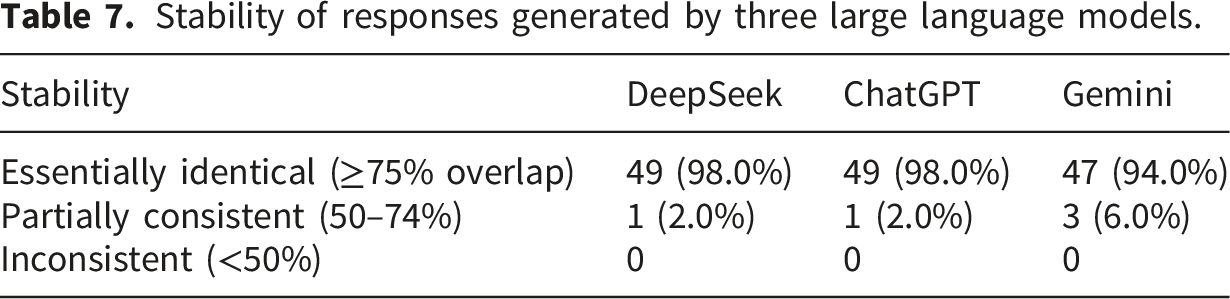
For stability analysis, responses generated on three different days were compared for textual similarity. Outputs with ≥75% overlapping content were classified as “essentially identical”, 50–74% as “partially consistent”, and <50% as “inconsistent. 20 ”
2.4. Statistical analysis
All quantitative data were managed in Excel 2019 and analyzed using SPSS 26.0. As Likert scores are ordinal variables and most dimensions did not meet normality assumptions (Shapiro–Wilk test), non-parametric tests were adopted. The Kruskal–Wallis H test was used to compare score distributions among the three models, followed by Bonferroni-adjusted Mann–Whitney U tests for pairwise comparisons. The significance threshold was set at α = 0.05 (two-tailed).
2.5. Data security and ethics
All prescription data were fully anonymized prior to analysis. Specifically, all direct and indirect identifiers were removed, including patient name, identification number, contact information, address, visit date, and any other information that could potentially enable re-identification.
The study was conducted in accordance with the Declaration of Helsinki and approved by the Ethics Committee of the First Affiliated Hospital of Guangxi Medical University (Approval No. 2025-E0542). Data handling complied with institutional policies on patient data protection and privacy.
When interacting with large language models, only de-identified prescription content was entered. No personally identifiable information was provided to any external platform. In addition, potential data retention risks associated with third-party LLM interfaces were considered. To mitigate such risks, all inputs were strictly limited to anonymized clinical information, and no sensitive personal data were included at any stage of the study.
This study was reported in accordance with the STROBE guidelines for cross-sectional studies.
3. Results
Inter-rater reliability analysis demonstrated moderate agreement among the three pharmacists (ICC = 0.58, 95% CI: 0.53–0.63), indicating an acceptable level of consistency in scoring.
3.1. Overall comparison among the three models
Overall comparison of three large language models in outpatient prescription counseling.
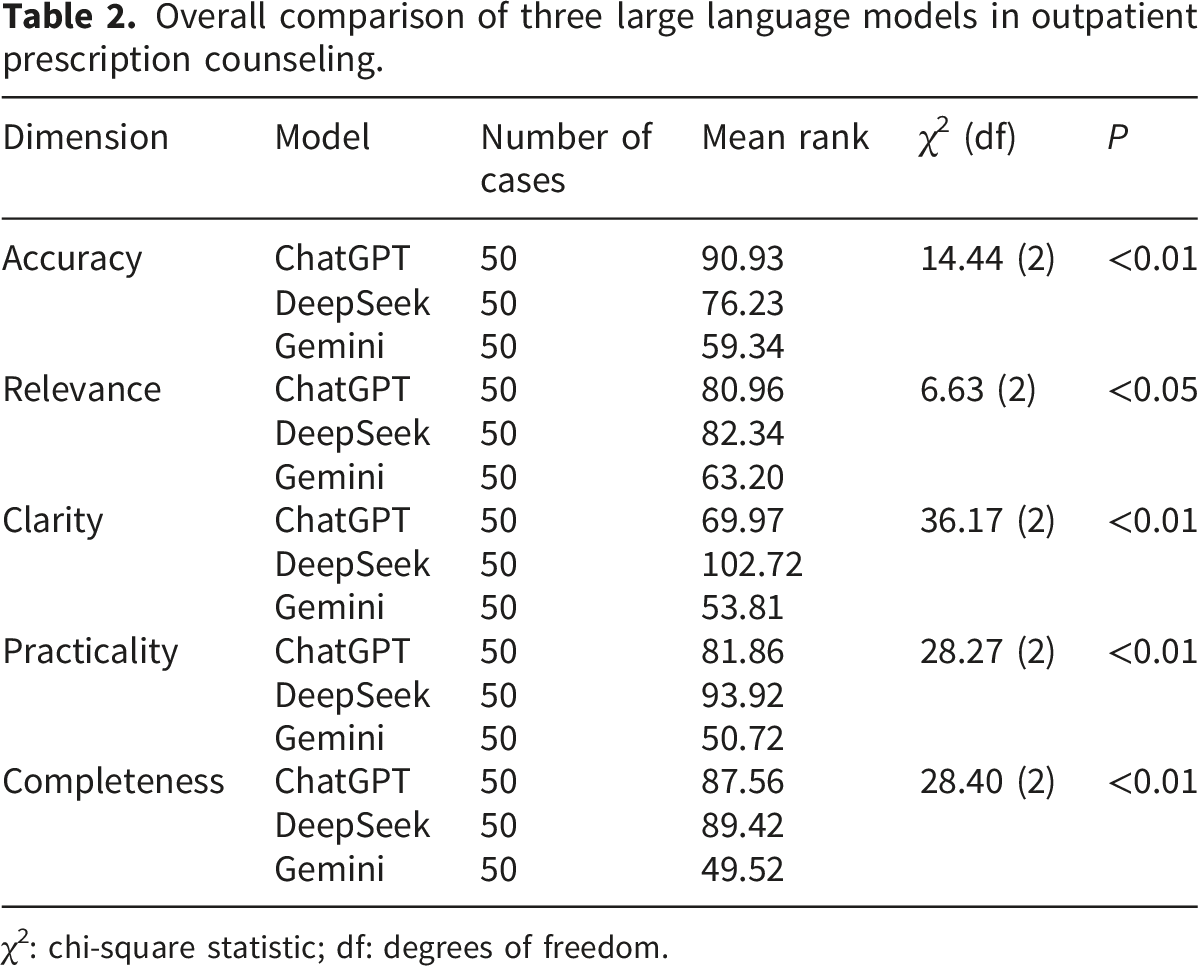
χ2: chi-square statistic; df: degrees of freedom.

Scoring analysis of the three LLMs in medication counseling across different scenarios: (a) overall; (b) obstetrics, gynecology, and pediatrics; (c) emergency department; (d) chronic disease; (e) oncology (*P < 0.01, **P < 0.05).
These results suggest that both ChatGPT and DeepSeek provide more precise and patient-friendly medication explanations than Gemini, with DeepSeek’s responses generally being more structured and fluent.
3.2. Departmental subgroup analyses
3.2.1. Obstetrics, gynecology, and pediatrics
Scoring analysis of the three LLMs in medication counseling for obstetrics, gynecology, and pediatrics prescriptions.

χ2: chi-square statistic; df: degrees of freedom.
3.2.2. Emergency department
Scoring analysis of the three LLMs in medication counseling for emergency department prescriptions.

χ2: chi-square statistic; df: degrees of freedom.
3.2.3. Chronic disease management
Scoring analysis of the three LLMs in medication counseling for chronic disease prescriptions.

χ2: chi-square statistic; df: degrees of freedom.
3.2.4. Oncology prescriptions
Scoring analysis of the three LLMs in medication counseling for oncology department prescriptions.

χ2: chi-square statistic; df: degrees of freedom.
3.3. Stability evaluation
Stability of responses generated by three large language models.
4. Discussion
4.1. Overall performance and key findings
This study provided a real-world, multidimensional comparison of three large language models—ChatGPT-5.0, DeepSeek-R1, and Gemini-2.5 Pro—applied to outpatient medication counseling. All models generated medication explanations that met minimum professional standards, yet their performance varied considerably across evaluation dimensions. DeepSeek and ChatGPT consistently achieved higher overall scores, while Gemini showed weaker and less consistent output quality. These findings confirm that LLMs differ significantly in reasoning depth, linguistic organization, and factual reliability, indicating that they cannot be regarded as equivalent in clinical pharmacy applications.21,22
Across the five evaluated dimensions, accuracy and relevance were generally high, but greater divergence occurred in clarity, practicality, and completeness. DeepSeek performed best in clarity and practicality, likely due to its emphasis on Chinese semantic optimization and contextual generation. ChatGPT maintained superior accuracy and completeness, reflecting its extensive multilingual medical corpus and alignment optimization. Gemini’s weaker performance—particularly in completeness—may be related to its limited domain-specific training data and less mature contextual reasoning mechanisms. 23 Together, these results illustrate that corpus diversity and alignment strategies critically influence LLM behavior in pharmacy-related tasks.
4.2. Model variation across prescription types
Significant context-dependent differences were observed among departments. In obstetrics, gynecology, and pediatrics, ChatGPT and DeepSeek outperformed Gemini in accuracy and practicality, suggesting stronger competence in identifying high-risk drug warnings for special populations such as children and pregnant women. In the emergency department, DeepSeek achieved the best clarity and completeness, implying that structured reasoning facilitates accurate communication in urgent and complex prescriptions. In chronic disease management, DeepSeek again led in clarity, relevance, and practicality, while ChatGPT maintained the highest accuracy. These results align with prior findings that conversational coherence improves comprehension and adherence among long-term patients. For oncology prescriptions, only clarity showed a significant difference, with DeepSeek ranking highest, possibly due to sample heterogeneity and complex regimens.
Overall, these outcomes emphasize that model applicability is context-specific. Rather than a uniform approach, selection should consider department characteristics, medication complexity, and patient literacy. 24 Such differentiation ensures safer and more efficient use of LLMs in clinical counseling workflows.
4.3. Implications for pharmacy practice
The findings suggest that LLMs can serve as assistive tools for outpatient counseling but cannot replace pharmacists’ professional judgment. When incorporated into structured service models, LLMs may generate preliminary drafts of counseling texts based on standardized prompts. Pharmacists can then verify and refine these drafts, reducing repetitive workload while maintaining professional oversight. 25 Models demonstrating superior clarity and practicality—such as DeepSeek—may be particularly useful in chronic disease management, where written summaries can enhance patients’ medication understanding and recall. 26
However, potential risks should be carefully considered. Some generated content omitted clinically critical safety information, including contraindications and drug–drug interaction (DDI) details. 12 For example, several responses failed to provide warnings for pregnancy or lactation when teratogenic medications were involved, did not adequately address dose adjustments in patients with renal or hepatic impairment, and occasionally overlooked common DDIs such as interactions between anticoagulants and antibiotics or between antihypertensive agents and nonsteroidal anti-inflammatory drugs. 27
These omissions are clinically significant, as they may directly compromise patient safety, lead to inappropriate medication use, and reduce adherence due to insufficient risk communication. In real-world pharmacy practice, such missing information could result in preventable adverse drug events, particularly among vulnerable populations such as elderly patients or those with polypharmacy.
These findings are consistent with previous research demonstrating that large language models show variable and often incomplete performance in identifying drug–drug interactions, with limited reliability for standalone clinical decision-making. The inconsistency in detecting DDIs highlights a fundamental limitation of current LLMs in handling complex, context-dependent pharmacological safety information. 28
Therefore, pharmacist oversight remains essential when integrating LLMs into medication counseling workflows. To mitigate these risks, several strategies can be considered. First, structured prompting approaches that explicitly request safety-related information (e.g., contraindications, DDIs, dose adjustments, and special population considerations) may improve output completeness. Second, integrating LLMs with validated drug interaction databases or clinical decision support systems could enhance accuracy and reliability. Third, implementing standardized safety checklists during pharmacist review may help identify and correct omissions before patient-facing use.
4.4. Strengths, limitations, and future directions
Nevertheless, several limitations should be acknowledged. First, the relatively small sample size, particularly in subgroup analyses (e.g., oncology prescriptions, n = 9), may have reduced statistical power and increased the risk of Type II error, potentially leading to false-negative findings and obscuring true differences among models. Second, this study was conducted using data from a single institution, which may limit the generalizability of the findings to other clinical settings, healthcare systems, or patient populations. Third, although the study focused on “patient counseling,” all evaluations were performed by clinical pharmacists rather than patients. Therefore, the results primarily reflect professional judgment of response quality and may not fully capture patient comprehension, readability, or real-world usability. Finally, this study did not specifically examine high-risk clinical scenarios, such as polypharmacy, major drug–drug interactions, or high-alert medications. These situations may present additional challenges for large language models and should be addressed in future research.
Future research should extend evaluation beyond expert scoring to include patient-reported outcomes, such as comprehension, satisfaction, and adherence. Studies focusing on high-risk scenarios—including polypharmacy, major drug–drug interactions, and high-alert medications—are also needed to assess safety under more complex conditions. In addition, multicenter studies across diverse clinical settings would improve generalizability. Integrating LLMs with clinical decision support systems may further enhance reliability in practice.
5. Conclusion
This study demonstrates that current mainstream large language models show promising yet heterogeneous performance in outpatient medication counseling. DeepSeek-R1 and ChatGPT-5.0 achieved superior overall performance, while Gemini-2.5 Pro showed relatively lower completeness and stability. These findings support the potential role of LLMs as assistive tools in clinical pharmacy practice under professional supervision. Future integration should emphasize structured prompting, pharmacist oversight, and system-level safeguards to ensure safety and reliability.
Supplemental material
Supplemental Material - Comparative evaluation of ChatGPT-5.0, DeepSeek-R1, and Gemini-2.5 pro in real-world outpatient prescription counseling: A multidimensional analysis
Supplemental Material for Comparative evaluation of ChatGPT-5.0, DeepSeek-R1, and Gemini-2.5 pro in real-world outpatient prescription counseling: A multidimensional analysis by Quanyuan Huang, Wuchang Zhu, Huizhen Mo, Bingxiu Huang, Zuming Liao, Xiao Lu and Hongliang Zhang in Digital Health.
Footnotes
Acknowledgments
The authors would like to thank the clinical pharmacists from the Department of Pharmacy, the First Affiliated Hospital of Guangxi Medical University, who served as independent evaluators in this study. They were not involved in study design, data analysis, or manuscript preparation. We also appreciate the constructive feedback from anonymous reviewers, which greatly improved the quality of this work.
Ethical considerations
This study was conducted in accordance with the ethical principles of the Declaration of Helsinki. The use of anonymized outpatient prescription data was approved by the Ethics Committee of the First Affiliated Hospital of Guangxi Medical University (Approval No. 2025-E0542).
Author contributions
Quanyuan Huang and Hongliang Zhang conceived and designed the study, supervised the research progress, and provided critical revisions to the manuscript. Wuchang Zhu, Huizhen Mo, Bingxiu Huang, Zuming Liao and Xiao Lu collected and anonymized the real-world outpatient prescriptions, conducted the model evaluation, and performed the statistical analysis. Quanyuan Huang drafted the initial version of the manuscript. Quanyuan Huang, Wuchang Zhu, Huizhen Mo, Bingxiu Huang, Zuming Liao and Xiao Lu contributed to data interpretation and visualization. All authors participated in reviewing and refining the paper, approved the final version for publication, and agreed to be accountable for all aspects of the work.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research project is supported by the Medical Quality (Evidence-based) Management Research Project of the National Health Commission Hospital Management Research Institute (No. YLZLXZ23K004) and The Self-funded Scientific Research Project of the Guangxi Zhuang Autonomous Region Administration of Traditional Chinese Medicine (No. GXZYA20250316).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.