
Abstract
This article deals with the recovery flight problem of flapping-wing micro-aerial vehicles under extreme attitude by using a reinforcement learning approach. First, the reinforcement learning-based control policy is proposed to enable the flapping-wing micro-aerial vehicles to be recovery flight rapidly and keep the angular acceleration as small as possible. Then, a hybrid control approach is designed to significantly improve the flight stability by combining the reinforcement learning-based control approach with the proportional-derivative control approach. Finally, simulation results show the effectiveness of the reinforcement learning-based method and the hybrid control method for the flapping-wing micro-aerial vehicles under extreme attitudes.
Introduction
Recently, flapping-wing micro-aerial vehicles (FWMAVs) have attracted much attention from researchers and engineers due to their exceptional stealth, excellent aerodynamic efficiency, and maneuverability.1–5 Compared with traditional fixed-wing or rotary-wing aerial vehicles, the FWMAVs can efficiently complete agile flight skills such that the FWMAVs are widely applied in some special scenarios.6,7 For example, according to Han et al., 2 an eagle-like flapping-wing robot with a vision system and a flight control system was designed for environmental monitoring. According to Wu et al., 7 a servo-driven bird-like flapping-wing robot was proposed to conduct an outdoor airdrop mission.
It is worth mentioning that the FWMAVs are studied from two aspects. One aspect is to study the structure design8,9 while the other aspect focuses on the controller design.10,11 The structure design involves wing motion mode, wing structure, torque generation structure, and so on.12,13,8,9 For example, according to Wang et al., 8 a bat-inspired flapping-wing aircraft model that combines the flexible wing and tail design of a bat was presented. The advantages of this model over conventional rigid-wing aircraft were its higher maneuverability and flight efficiency, especially in dynamic environments. According to Hou et al., 9 a bio-inspired smart-winged microlight based on a wing mimicking a scarab beetle’s wing was designed, which integrates aerodynamics, sensory functions, and power generation for environmental monitoring. According to Ishiguro et al., 12 an optimal wing size for soft wings in flapping microlights was investigated. It was found that the use of chord-directed wing veins produces more force than wingspan wing veins. However, it is hard to achieve stable flight only by designing structure. One possible solution is to design the attitude controller of the FWMAVs.14–20 For example, according to Guo et al., 16 the proportional–integral–derivative (PID) algorithm was employed to stabilize the attitude within small range. According to Nian et al., 18 a cascaded proportional–integral (PI) controller was proposed based on wing-tail interaction and aerodynamic-dynamic coupling so as to further enhance the control performance in complex flight tasks. However, the PID algorithm is sensitive to parameter changes and can be significantly influenced by the disturbance variations. Some improved approaches have been proposed. 20 For example, according to Ferdaus et al., 20 a neuro-fuzzy controller was introduced to deal with the problem of parameter changes.
It should be pointed out that, there are two main limitations in using traditional algorithms to realize complex flight skills of FWMAVs. One limitation is that traditional control algorithms rely on real-time and efficient control reference updates. Moreover, complex flight trajectories are often difficult to plan, and in some cases, the special flight state is prone to violate the control requirements of traditional control algorithm. In this case, the algorithm is liable to accumulate errors from the control reference, and finally, the situation is out of control. The second limitation is that, for the model-based traditional control algorithm, part of the dynamic parameters of the FWMAVs are generally obtained by fitting the data under specific conditions, such as the quasi-steady-state model. When the state of FWMAVs deviates from this specific situation in the complex flight process, the dynamic parameters will change. As a result, the obtained simplified model is difficult to predict and control the state of the FWMAVs.
To address the aforementioned limitations, the model-free reinforcement learning (RL) method can be introduced, 21 which represents an end-to-end strategy optimization and does not rely on the model of FWMAVs. RL uses trial and error methods to obtain the action that can improve the future long-term return at a certain state, instead of selecting actions following to the control reference. In addition, the RL method with data-driven allows the policy to ignore the influence of the dynamic parameter changes. Hence, the RL-based method can be applied in the FWMAVs to deal with the two limitations.
In fact, there are some research efforts on the RL-based policy for the agile movement of unmanned aerial vehicles (UAVs).22–26 For example, a control strategy based on proximal policy optimization (PPO) was utilized to map Kalman filter data to output control commandin, where the data from real world is used to train the PPO algorithm in order to mitigate discrepancies. 24 By combining a DDPG algorithm with a no-dominated sorting approach, a new approach was proposed to achieve planar quadcopters flight vertically for the first time in a simulation environment. 25 The PPO approach was extended to enable rapid escape maneuvers of FWMVAs within short time, which effectively avoid the challenges posed by acrobatic flight under the constraints of model errors. 26 Thus, the RL-based method for the UAVs can be referred for controller design of the FWMAVs.
Notice that, extreme attitude is a special case where the FMWAV has a large pitch angle and random velocities. This case often occurs in hand-held throwing, strong winds, or collision conditions. For the FWMAVs, the large attitude angles and angular velocities in extreme attitudes make it difficult to be effectively controlled by traditional controllers. Moreover, the aerodynamic characteristics under extreme attitudes change significantly, which increases the model uncertainty and the difficulty of control. In addition, there is a high demand for fast control, and the FWMAV needs to make attitude corrections in a very short time, otherwise it may lead to loss of control. Therefore, how to design the RL-based policy for recovery flight of the FWMAVs under extreme attitudes to deal with the issues mentioned above motivates the current study.
In this article, we design the RL-based control approach for the recovery flight of the FWMAVs under extreme attitudes, and develop the hybrid control strategy to improve the control stability after attitude recovery. The contributions are summarized as follows.
An RL-based control approach is designed to solve the recovery flight issue of the FWMAVs under extreme attitudes. The proposed control approach has the ability to adjust attitudes under 1.5 s. A hybrid control approach combining reinforcement learning and PD control approach is proposed, which can keep the stable flight after attitude recovery. The two approaches are validated by simulation results, where one can see that the proposed control approaches can control the FWMAV to finish the recovery flight under extreme attitudes and keep the sustained flight.
This article is organized in the following. The “Preliminaries” section describes the dynamics model of FWMAVs. The “RL based controller” section presents the RL-based control policy and proposes a hybrid control approach. In the “Simulation results and discussion” section, the control effectiveness of the RL-based control policy for recovery flight under the extreme attitudes is discussed. And the effectiveness of the hybrid control approach for the sustained flight is also validated. Finally, the last “Conclusion” section concludes this work.
Preliminaries
In this section, we briefly describe the dynamics of FWMAVs, which is used in the following simulations. The configuration scheme is similar to the “Nimble,” 27 shown in Figure 1, which can flap the left and right wings, separately. The “Nimble” shows the strong maneuverability due to the capability of achieving stability without tail-wing.

Flapping-wing micro-aerial vehicle (FWMAV) platform “Nimble.”
Dynamics of wing-actuator
In the longitudinal dynamics plane, only thrust and pitching torque can produce control effects. The corresponding actuators are the wing flutter and the dihedral angle actuator. By considering the actual performance limitations of the actuators, the wing flutter is modeled as the first-order system as follows:


The dynamics of the dihedral angle actuator is given by the following equation:


Force and torque modeling
The “Nimble” generates pitch torque by varying the position offset of the force produced by its two-sided wings. Moreover, the magnitude of the produced thrust can be altered by adjusting the flapping amplitude. The

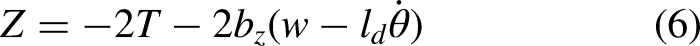

Longitudinal dynamics of the FWMAV
In this article, according to the control objective of recovering flight under extreme initial pitch attitude, a simplified longitudinal dynamics model is formulated by the following equation:


RL-based controller
This section introduces the RL-based controller for arbitrarily initial attitudes based on the model-free PPO algorithm. Then, the hybrid control approach is proposed by combining the RL-based controller and the PD controller for subsequent stable flight, where both persistence and stability have been significantly enhanced.
Task statement
In this work, our aim is to keep recovery flight with extreme conditions within a restricted area for the FWMAVs. The FWMAV initially flies with a pitch angle in
RL-based controller
Proximal policy optimization (PPO): In RL, the agent chooses the next action relying on the current state and policy. Then, the environment rewards the agent and updates the state with a transition model. The continuous interactions between the agent and environment can be formulated as a Markov decision process (MDP) PPO is a policy iteration algorithm (see Hoang et al.
23
and the reference therein). Traditional policy gradient optimization algorithms may suffer from aggressive policy updates, which leads to dramatic performance fluctuations. To mitigate this issue of policy update oscillations, PPO employs two separate policy networks to represent the current and previous policies. Note that importance sampling is introduced to calculate the ratio To further limit the magnitude of policy updates, the clipped objective function is obtained by the following equation: PPO updates policy by maximizing the objective function (13) with multiple steps stochastic gradient descent (SGD). In the practical training, the PPO algorithm uses the actor-critic (AC) theory for iterative updates. The AC neural network is illustrated in Figure 2. The Actor NN selects and carries out actions State and action: Here, we assume that the state of the FWMAV It should be noted that the state space does not exactly correspond to the observable state of the FWMAV mentioned above. As a part of the inputs vector to the actor and Critic NN in the PPO algorithm, the state space has a significant influence on the understanding of complex rules for policy. The article focuses on stabilizing flight of the FWMAV within a confined area. Therefore, the state The action is Reward Function: In this article, the reward function uses a straightforward design principle that is to minimize ambiguity as much as possible. The reward function is given by the following equation:
It is worth mentioning that the reward function needs to be able to accurately reflect the attitude deviation, energy consumption, and flight stability of the vehicle such that the FWMAV can quickly keep a stable flight state under the extreme attitude. For this reason, the reward function contains a penalty term

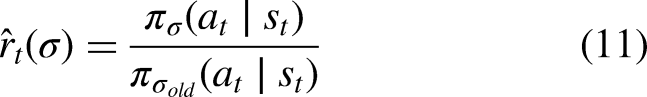





The neural networks of the proximal policy optimization (PPO) algorithm.
Hybrid control approach
The FWMAV completes the attitude recovery flight within a restricted area based on the RL-based controller. However, the FWMAV is prone to states that exceed restricted areas during flight such that the RL-based controller may choose the bad actions at the state that outside of the training state distribution. Thus, undesirable control can be generated due to lacking the enough information in the training process. To enhance the performance of the FWMAV in some particular scenarios with limited training data, the hybrid control approach is designed by combining the RL-based controller with the PD controller, as shown in Figure 3.

The hybrid control framework, where the PD controller is employed when the FWMAV finishes the recovery task. PD: proportional-derivative; FWMAV: flapping-wing micro-aerial vehicle.
In this figure, dynamics module estimates the state after RL strategy choosing the action. Then PD controller gets the error between the estimated state and the target state to calculate the control output
Simulation results and discussion
In this section, we illustrate the test results of the RL-based control strategy for the recovery flight problem of the FWMAV under extreme attitudes. To highlight the performance, we compare the performance capabilities of the proposed control strategy with a traditional PID controller in two different scenarios. Finally, we tests the proposed hybrid control approach to show its effectiveness for subsequent flight tasks.
Simulation environment
In the following simulations, we employed the interface provided by OpenAI Gym to build the RL training environment, where the bullet is used to render and evaluate the policy.
In the training process, the minimal longitudinal dynamics model is used to update the state information of the FWMAV. The control policy updating frequency is set as 200 Hz, which ensures the consensus with real physical platform. The model parameters of the FWMAV are presented in Table 1. From this table, one can see that the mass of the FWMAV is set as
Model parameters of the flapping-wing micro-aerial vehicle (FWMAV).

In order to enhance the diversity of samples and prevent the policy from getting stuck in local optima, the initial state of the FWMAV is randomized
The parameters setting of the PPO algorithm are listed in Table 2. From this table, one can see that the learning rate is 0.0003, the batch size is 64, the total timestep is
Hyper-parameters for reinforcement learning.

It is pointed out that model nonlinearities, model uncertainties, external disturbances, and input constraints are simulated by adding random values to actions and states in the simulation environment. This allows us to simulate a range of possible real-world scenarios and test the robustness of our proposed method under varying conditions. PID control approach is used as comparison algorithm.
Recovery flight
In Figure 4, the comparison results of the RL-based controller and the PID controller are shown for the recovery flight of the FWMAV with under the same initial pitch angle of

The results of the FWMAV by comparing the RL-based controller (blue line) with the PID controller (red line) under the same initial condition. (a) The movement trajectories of the FWMAV at the
In order to understand the impact of different situations on extreme attitude recovery, Figures 5 to 7 show the success rates for FWMAV controlled by the RL-based controller for different the velocities at the x-axis, the velocities at the z-axis, and the angular velocities, respectively. It is worth mentioning that, if the FWMAV can still remain in the restricted flying area within 2 seconds, the task of recovery flight is considered to be successful. Note that, the range of initial velocity values is set as [

Success rates for the different pitch angles and velocities at the x-axis.

Success rates for the different pitch angles and velocities at the z-axis.

Success rates for the different pitch angles and angular velocities.
Figure 8 shows the FWMAV’s attitude recovery under pitch angles of

Recovery flight trajectories under different initial pitch angles
Sustained flight
As shown in Figure 9, the RL-based controller does not perform excellently in the sustained flight tasks because the training objective is only to stabilize the attitude to 



After the recovery flight, the sustained flight trajectories for the RL-based control approach and hybrid control approach.
Evaluation results for sustained flight.

RL: reinforcement learning.
Bold values indices that the corresponding method is the best for the current performance metric.
Discussion
It is worth mentioning that, if the proposed approach is applied to the real FWMAV, the flight effect in a short time can be consistent with the simulation results. However, due to the limitation of the hardware manufacturing process of the experimental prototype, when the motor of the FWMAV maintains a higher speed, it will bring about a violent vibration of the flap structure, which may cause the gear box to be offset. And the FWMAV rotates about the fuselage axis as time goes by, which can lead to the inconsistency between the actual flight results and the simulation results. In addition, when collecting the dataset, due to the limitation of the manufacturing process, it is impossible to ensure that the dimensional parameters of the experimental prototype are the same each time, which makes it difficult to obtain the dynamics model with high prediction accuracy. However, the simulation results can illustrate that the proposed RL-based method still has certain potential and advantages.
From the aforementioned results, the proposed RL-based approach can quickly finish recovery flight under extreme attitudes compared with traditional control methods such as PID control. This method does not rely on environmental models and can ignore the influence of dynamic parameter changes such that the proposed RL-based approach is effective in complex environments. Moreover, this method has strong robustness and is suitable for different flight mission requirements, with high flexibility and adaptability. However, the proposed RL-based approach requires a large amount of environmental interaction data. And long-term flight training consumes a significant amount of computing resources. Due to the limited payload capacity, the FWMAV relies on wireless transmission of control commands, which introduces the potential impact of signal interference. At the same time, a large amount of training data is required to ensure the effectiveness of the proposed RL-based approach. For specific scenarios of recovery flight under extreme attitudes, specialized data collection and processing are needed, which increases the complexity and cost of the experiments.
Conclusion
The problem of recovery flight under the extreme attitudes has been addressed. First, we have designed the RL-based controller to guide the FWMAV to implement the recovery flight. Second, in order to keep sustain flight after the recovery flight, we have developed the hybrid control approach by combining the RL-based control approach with the PD control approach. Finally, we have illustrated the effectiveness of the proposed RL-based control approach and the hybrid control approach. In future, we will use the real FWMAV to test the effectiveness of the proposed RL-based control approach and the hybrid control approach.
Footnotes
Data availability
The simulation data can be obtained by contacting the corresponding author.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the Zhejiang Provincial Natural Science Foundation under Grant LZ23F030004, the National Natural Science Foundation of China under Grant 62073108, and the Fundamental Research Funds for the Provincial Universities of Zhejiang under Grant GK229909299001-004.
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.