
Abstract
To achieve high accuracy in indoor positioning using a smartphone, there are two limitations: (1) limited computational and memory resources of the smartphone and (2) the human walking in large buildings. To address these issues, we propose a new feature descriptor by deeply combining histogram of oriented gradients and local phase quantization. This feature is a local phase quantization of a salient histogram of oriented gradient visualizing image, which is robust in indoor scenarios. Moreover, we introduce a base station–based indoor positioning system for assisting to reduce the image matching at runtime. The experimental results show that accurate and efficient indoor location positioning is achieved.
Keywords
Introduction
Indoor positioning is considered an enabler for a variety of applications, such as guidance of passengers on airports, conference attendees, visitors in shopping malls, and for many novel context-aware services, which can play a significant role for monetarization. The demand for an indoor positioning service or indoor location-based services (iLBS) has also accelerated given that people spend the majority of their time indoors. 1 Over the last decade, researchers have studied many indoor positioning techniques. 2 In addition, with the development of the integrated circuit technology, multi-sensors, for example, camera, Earths magnetic field, WiFi, Bluetooth, inertial module, have been integrated in smartphones. Therefore, smartphones are becoming powerful platforms for location awareness.
The traditionally used outdoor localization method, Global Navigation Satellite System (GNSS), is not available in indoor environments, even though navigation tasks on street level are very precise. A catalog of alternative localization techniques has been investigated, such as infrared-, 3 sensor-,3,4 wireless-,5,6 communication basestation–based technologies, 7 pseudolite 8 or visual markers. 9 However, most of these technologies, relying on wireless technology, face issues in the presence of radio frequency interference (RFI) and interference of non-line of sight (NLOS) caused by dense forests, urban canyons, and terrain. 1 Moreover, some of these technologies work in a limited area such as inertial sensor–based approaches or some need a particular environmental infrastructure and augmentation such as Locata, that is, a pseudolite positioning system. 8 Therefore, smartphone camera–based indoor positioning is a promising approach for accurate indoor positioning without the need for expensive infrastructure such as access points or beacons.
The key method of camera-based localization is image matching. Images taken by a smartphone camera are matched to previously acquired reference images with known position and orientation. The matching of smartphone recordings with a database of geo-referenced images allows for meter accurate infrastructure-free localization. 10 According to the matched reference image, the location of the smartphone is calculated. In mobile indoor scenarios that are shown by Figure 2, users usually walk during positioning and navigation procedure. Therefore, the captured images by smartphone cameras are scaled, rotated, and even blurred because of hands shaking. Moreover, most of the researchers recently focus on invariant feature extraction. Ravi et al. 11 extracted color histograms, wavelet decomposition, and image shape for image matching to locate a user’s position. Kim and Jun 12 proposed a method based on image color histogram feature for positioning using augmented reality tool. However, the positioning accuracy of those two methods would work inefficiently in the varying light and crowded scenarios. In order to extract the invariant features, SIFT and its improved algorithms are widely used for image-based indoor localization. Kawaji et al. used principal component analysis-scale invariant feature transform (PCA-SIFT) feature for railway museum indoor positioning. Werner et al. 13 proposed a camera-based indoor positioning using speeded up robust features (SURF) feature for speeding up the image matching. Li and Wang 14 introduced affine-scale invariant feature transform (A-SIFT) feature for image matching achieved by random sample consensus (RANSAC), which increased the matching accuracy. Heikkilä et al. 15 proposed a similar method 14 for indoor positioning.
However, those two complex computational methods are not suitable for smartphone-based indoor positioning. This is because the limited computational resources of mobile devices 16 extracted the edge-based features from the visual tag image, and those features are fused with inertial information for indoor navigation. Kim and Jun 12 used the Sobel filter integrating mean structural similarity index for estimating the arrival of angle and height during the indoor localization. However, these two methods need additional visual marks for assisting smartphone camera for detecting features, which increases the indoor positioning cost. Meanwhile, all of these research works mainly focus on improving image-matching accuracy. Some of these algorithms are, however, quite demanding in terms of their computational complexity and therefore not suited to run on mobile devices, which need smartphones with high hardware configuration. Although smartphones are inexpensive, they have even more limited performance than Tablet and PCs. Phones are embedded systems with severe limitations in both the computational facilities and memory bandwidth. Therefore, natural feature extraction and matching on phones have largely been considered prohibitive and have not been successfully demonstrated to date. 17 To address these issues, Van Opdenbosch et al. 10 used the improved vector of locally aggregated descriptors’ (VLAD) image signature and emerging binary feature descriptor binary robust independent elementary features (BRIEF) to achieve the smartphone camera-based indoor positioning. Besides, in order to reduce the overall computational complexity, they proposed a scalable streaming approach for loading the reference images to the phones. Different with their method, this article proposed an efficient feature descriptor named Turbo Fusing Histogram of oriented gradients (HOG) and Local phase quantization (LPQ) Salient feature (TFHLS). The TFHLS features are extracted from the partial image which are salient image regions, and they are invariant to the illumination, scale, rotation, and blur caused by camera shaking. Moreover, a wireless-based indoor positioning system time&code division-orthogonal frequency division multiplexing (TC-OFDM) is introduced to calculate the coarse positions for supporting the floor number to the smartphone, which would reduce the number of images which are downloaded to the smartphones. Using this approach, our camera-based indoor positioning algorithm results in the reduction in computational complexity, hardware requirement, and network latency.
This article is organized as follows to achieve our investigations. First of all, we discuss the related work on HOG and LPQ feature extraction in section “Related work.” Then, we introduce our image feature extraction based on fusing HOG and LPQ in section “Proposed smartphone camera-based indoor positioning.” After that, we test the proposed algorithm on the Technische Universität München (TUM) indoor dataset 18 and the Beijing University of Posts and Telecommunications (BUPT) indoor dataset collected by our lab, and the evolution of our algorithm is also shown in this section. Finally, in Section “Conclusion,” we conclude the article and provide a future work on possible extensions.
Related work
Finding efficient and discriminative descriptors is crucial for indoor complex scenarios. HOG descriptor was proposed by Dalal and Triggs 19 for human detection. The main idea behind HOG is based on the local edge information. 15 Because of its efficient performance, HOG feature are widely used in human detection,20,21 face recognition,22,23 and image searching. 24 All of these applications show that HOG feature is invariant to the illumination. According to our experiment, HOG feature is not robust when the humans are crowded and the images are blurred. Wang et al. 25 combined the HOG and local binary pattern (LBP) features for human detection. However, they concluded that their detector cannot handle the articulated deformation of people. Our visualizations reveal that the world that features see is slightly different from the world that the human eye perceives.
Recently, LPQ is insensitive to image blurring, and it has proven to be a very efficient descriptor in face recognition from blurred and sharp images.15,26 LPQ was originally designed by Ojansivu and Heikkila similar to the LBP methodology as a texture descriptor. 27 In our opinion, robust and efficient image matching requires several different kinds of appearance information to be taken into account, suggesting the use of heterogeneous feature sets. In our proposed algorithm, the HOG features are extracted from the salient regions, and LPQ features are extracted from the HOG visualizing image. Therefore, the HOG and LPQ are integrated for building an efficient feature, that is, TFHLS for indoor image matching.
Proposed smartphone camera-based indoor positioning
The smartphone camera-based indoor positioning procedure using TFHLS feature is shown in Figure 1.

Flowchart of smartphone camera-based indoor positioning.
Study materials
In order to test and evaluate the proposed algorithm, two databases are used. The first one is supported by TUM. 28 In TUM dataset, there are 54,896 reference views, which covers 3431 positions with 1-m accuracy. Another dataset is collected by our lab which captured 1000 indoor images using smartphone cameras in BUPT campus. Different with TUM dataset in calculating the reference positions, a static measurement system based on TC-OFDM and BeiDou real-time kinematic is introduced. The scalable locations with positioning accuracy 0.1–1 m are obtained. The BUPT dataset covers four buildings and results in a total of 2189 positions.
Superpixel-based, sparsifying, high-resolution image
Inspired by the human vision system (HVS), the features extracted from salient regions are invariant to viewpoint change, insensitivity to image perturbations and repeatability under intra-class variation. 29 These features are extracted from some regions of the image, but not the whole image. This procedure is called sparsifying image in this article. Therefore, the salient region is introduced for the image matching. In this article, a superpixel-based approach, simple linear iterative clustering (SLIC), proposed by Achanta et al. 30 is used to pre-segment an image. SLIC method generates superpixels by clustering pixels based on their combined five-dimensional similarity and proximity in the image plane which is shown by the following functions
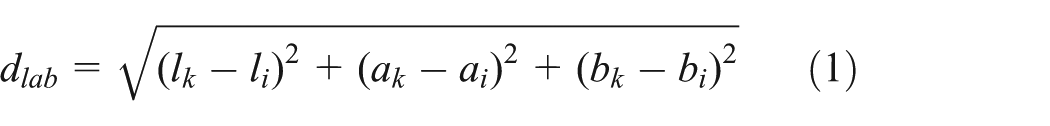


where

where ℜ is the candidate salient region,

where

where
TFHLS feature extraction approach
HOG feature extraction
HOG descriptors are invariant to two-dimensional (2D) rotation which has been used in many different problems in computer vision, such as pedestrian detection. Compared to the original HOG, the integrated HOG feature proposed by Zhu et al.
21
without trilinear interpolation is easier and faster to be computed. However, the HOG’s performance would be worse than the original HOG. Therefore, we introduced a constrained trilinear interpolation approach to replace the general trilinear interpolation. Moreover, it should be noted that both Wang et al.
25
and Li et al.
31
proposed a


Moreover, in order to reduce the space complexity of the integral image method, the kernel in equation (8) is convoluted with the salient rectangle but not the whole original image, which decreased the computational complexity.
HOG feature visualization
In this article, we introduced a HOG visualizing method proposed by Vondrick et al. 32 Different with their complex method, a more simple method based on equation (9) is proposed

where
LPQ feature extraction from HOG visualization image
After inverting HOG features into an image

where

The final LPQ features are used as feature vectors to represent an indoor sub-image.
TFHLS feature matching
The main advantage of the binarization, apart from a reduced memory footprint, is a very fast matching process using the normalized Hamming distance by equation (12)

where
Experimental results
Query dataset and setup description
We recorded a query set of 128 images captured by an iPhone 6 with manually annotated position information. The images are approximately 5 megapixels in size and are taken using the default settings of the iPhone 6 camera application. Furthermore, the images consist of landscape photos either taken head-on in front of a building or at a slanted angle of approximately

Exemplary queries for all classes from TUM: (a) low textures, (b) high textures, (c) blurred image, (d) building hall, (e) hallway, and (f) Illumination change.

Exemplary queries for all classes from BUPT: (a) low textures, (b) high textures, (c) blurred image, (d) building hall, (e) hallway, and (f) illumination change.
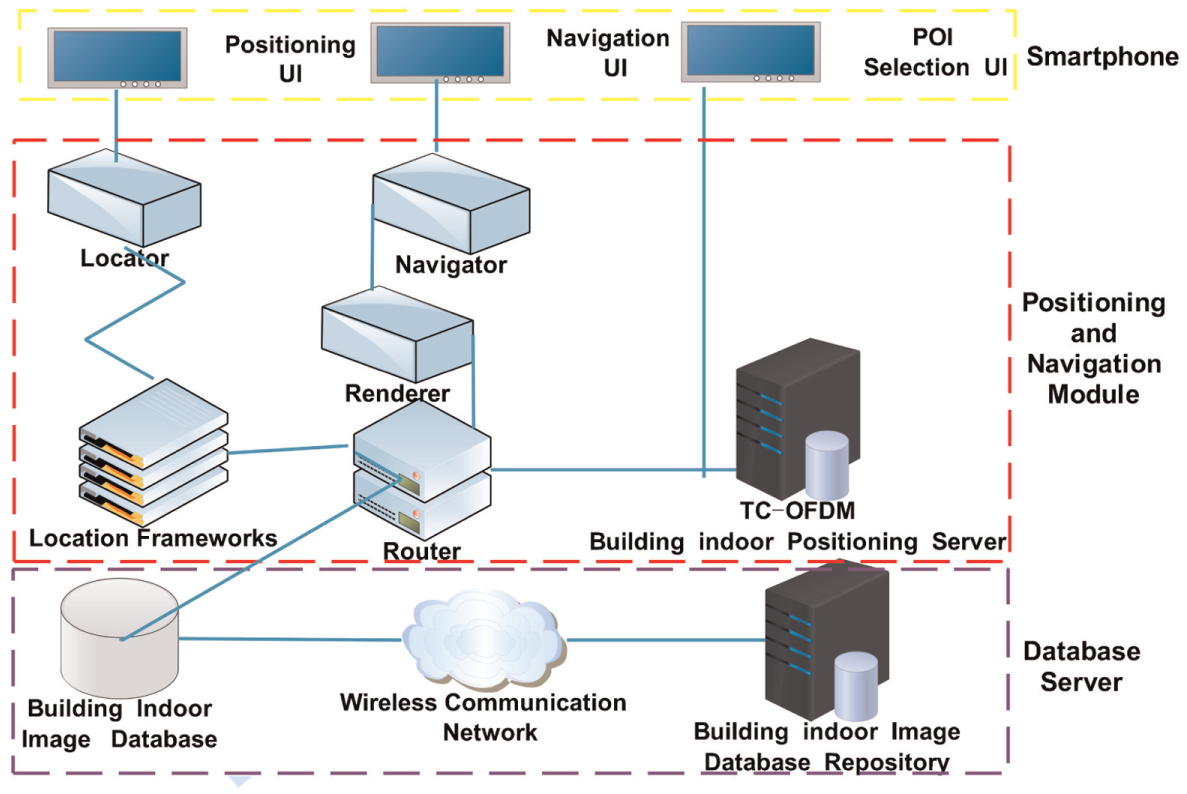
The module of navigation and positioning system.
Our method was implemented using MATLAB 2015a, and this method was programmed by integrating C# and MATLAB code. The hardware configuration of our experimental platform where our method ran is shown in Table 1.
Hardware configuration

It is noted that the camera-based positioning method proposed by Ravi et al. 11 is used to compare with our proposed method, and both the test data and the MATLAB code of that method are supported by Opdenbosch.
Evaluation of high-resolution image sparsifying
Figure 5 shows a qualitative result for the image sparsifying by detecting salient regions based on superpixels. From the second row of Figure 5 obtained by the proposed HVS-based approach for a variety of images from the TUM and BUPT database. Preserve the salient regions in each image while remaining compact and uniform in size of objects. Moreover, the salient superpixels that are detected include sparse features, which can be achieved to reduce the computation of indoor positioning.

Exemplary queries for salient region detection and HOG feature visualization: (a) Indoor of Our Lab, (b) Hall of Our Research Building, (c) Corridor of a Building in TMU, (d) Corridor of Our Research Building, (e) Salient Map of Figure 5(a), (f) Salient Map of Figure 5(b), (g) Salient Map of Figure 5(c), (h) Salient Map of Figure 5(d), (i) HOG Feature Visualization of Figure 5(e), (j) HOG Feature Visualization of Figure 5(f), (k) HOG Feature Visualization of Figure 5(g), and (l) HOG Feature Visualization of Figure 5(h).
According to Figure 5, we can find that salient regions are detected even when the image is blurred, which is shown by three images in the second column of Figure 5.
According to our statistics, the number of TFHLS features in Figure 6(b) is 69% less than that in Figure 6(a). It is noted that features in Figure 6(b) are extracted from the salient regions of an image, which shows that our salient region detection approach is efficient and powerful. Therefore, less features are used for image matching, which speeds up the process of the image matching and remains high matching ration according to Table 2.

TFHLS features matching for BUPT images: (a) TFHLS feature extraction with high density and (b) TFHLS features sparsing.
Matching result of different image features.

Qualitative evaluation of HOG visualization
The third row of Figure 5 shows the HOG feature visualization results under different indoor scenarios. These result visualizations allow us to analyze object from the view of HOG detector, which is a new approach and gain new insight into the detectors failures, which is different with the human salient vision. From the first and third row of Figure 5, the high-frequency details in original images have high contrast in HOG visualization images. Paired dictionary learning tends to produce the best visualization for HOG descriptors. Although HOG does not explicitly describe the color, we found that the paired dictionary is able to recover color from HOG descriptors. Therefore, by visualizing feature spaces, we can obtain a more intuitive understanding of recognition systems.
Evaluation of TFHLS feature extraction and matching
In order to identify optimal parameters for the approach described above, several experiments are conducted with varying settings. Figure 7 summarizes the performance of comparing the TFHLS feature matching to the method proposed by Van Opdenbosch et al. 10 A smartphone running Andriod OS 4.4 was used to implementing the positioning methods which were used in this article.

TFHLS features matching for BUPT images: (a) TFHLS features matching for high-texture image, (b) TFHLS features matching for blurred image, (c) TFHLS features matching for low-texture image, and (d) TFHLS features matching for indoor image.
Qualitative results
Figure 7 shows the TFHLS features matching results in four different scenarios. As shown in Figure 7(a), successful retrieval usually involves matching of object textures in both query and database images. According to Figure 7(b), we can find that our proposed TFHLS feature is efficient to match the blurred images.
Quantitative results
Table 2 shows that we successfully match 113 of 128 images to achieve a retrieval rate of 93%, where LS means linear search and LSH means locality sensitive hashing. Moreover, as shown in Table 2, the proposed method achieves to match the images of TUM database with the highest success in 13.2 ms for each image. Figure 8 shows the performance comparison in miss rate between our proposed method and other two LBP-based methods.
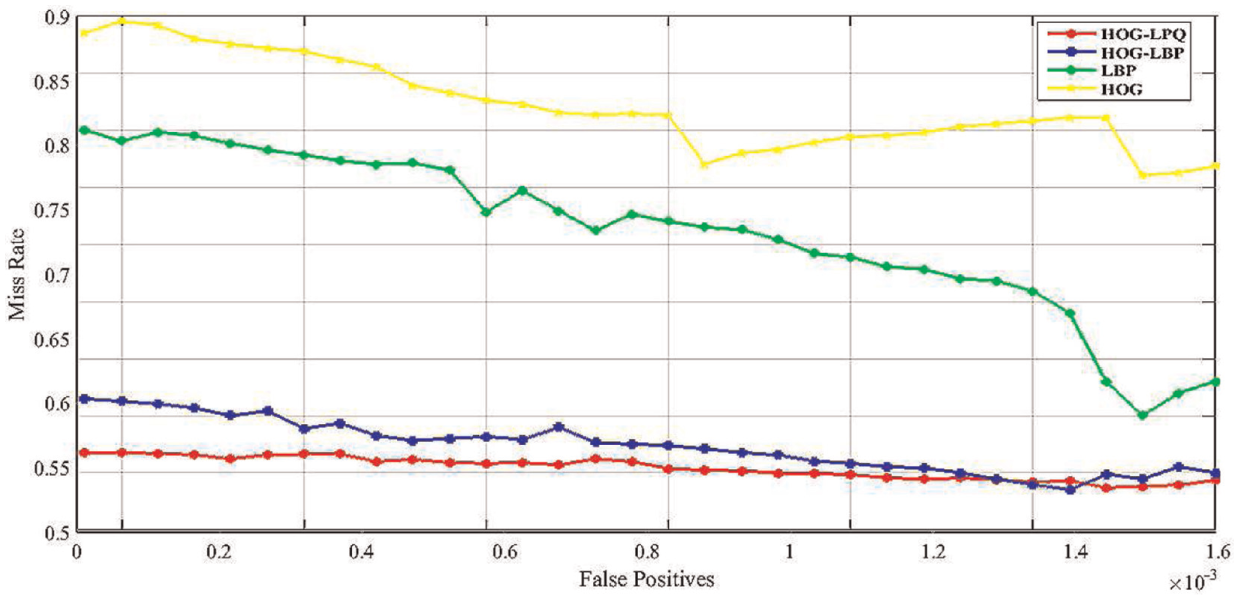
The performance comparison between the proposed human detectors and the state-of-the-art detectors on BUPT database.
Positioning result evaluation
Figure 9 summarizes the performance of the location information estimation and the comparison result. From Figure 9(a) and (b), we can localize the position to within sub-meter level of accuracy for over 56% of the query images. Furthermore, 85% of the query images are successfully localized to within 2 m of the ground’s truth position. As seen in Figure 7(a), when the location error is less than 1 m, the TFHLS features of the corresponding corridor signs present in both query and database images matched together. Moreover, we find that the TFHLS detector extracted more features, 10 even though the images are blurred, which is shown in Figure 9(b). As shown in Figure 10(a) and (b), we plot the estimated and ground-truth locations in the horizontal and vertical directions. Besides, Figure 10(c) shows the comparing locations of the query images onto the New Research Buildings 2D floor plan. As seen from Figure 10, there is a close agreement between the ground truth and TFHLS-based results. The root mean square error (RMSE) between the estimated and the ground-truth positioning results is 1.253 m.

The module of smartphone camera-based indoor positioning: (a) positioning result based on TUM dataset and (b) positioning result based on BUPT dataset.

The location comparison result: (a) positioning result in horizontal direction, (b) positioning result in vertical direction, and (c) locations on the 2D floor plan.
Figure 11 shows the indoor positioning comparison performance in RMSE. From this figure, we can find that the proposed approach can achieve high-accuracy indoor locations than VLAD- and TC-OFDM-based methods. Most of the VLAD and TC-OFDM indoor positioning results are more than 3 m, while the positioning results based on our method is less than 1.5 m. Moreover, the proposed method is robust because its RMSE curve is smooth, which shows that our method can get stable results. The performance gap between the ground truth and estimations in both Figures 9 and 11 suggests that the TFHLS-based method can be adaptive to the illumination and the dense multipath indoor environments which result in obtaining a higher indoor positioning accuracy.

Performance comparison between the proposed indoor positioning and the state-of-the-art positioning methods.
Conclusion
We presented a scalable and efficient mobile camera-based localization system. To this end, we built a modified model of a feature that deeply combined HOG and LPQ, and jointly addressed the problem of limited computational capacity, as well as the required memory footprint. Moreover, we employed TC-OFDM indoor positioning system for supporting the coarse positioning knowledge related to the camera location. According to our test on the TUM and BUPT database, the indoor positioning based on the proposed algorithm is less than 1.5 m. Furthermore, the RMSE between estimated and ground-truth positioning results up to 1.25 m, which shows that our smartphone camera-based indoor positioning algorithm is precise and accuracy. In the future work, we will study the sub-meter indoor positioning algorithms based on the fusion of image and wireless signals.
Footnotes
Academic Editor: Gang Wang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was sponsored by the National Key Research and Development Program (no. 2016YFB0502002), the National High Technology Research and Development Program of China (no. 2015AA124103), the National Natural Science Foundation of China (no. 61401040), and Beijing University of Posts and Telecommunications Young Special Scientific Research Innovation Plan (2016RC13).